1. Introduction
Hypothesis testing is a central method in scientific research [
1]. Traditional null hypothesis testing (henceforth called precise hypothesis testing) is considered with a precise null hypothesis
and its set complement
in the parameter space
, which, in the Bayesian approach, is typically a Borel space
with
-algebra
, and in the frequentist approach, it is simply a set [
2]:
where
. However, various authors have criticized that precise null hypothesis testing is inadequate in a variety of research situations, questioning the usefulness of this approach. One of the main critiques of precise hypothesis testing based on equality constraints is that such constraints are often not plausible for the context of research. Small violations of these equality constraints nearly always exist [
3,
4]. Concerning the questionable scientific standard of precise hypothesis testing in fields like medicine or cognitive science, Berger, Boukai, and Wang [
5] noted the following:
“The decision whether or not to formulate an inference problem as one of testing a precise null hypothesis centers on assessing the plausibility of such an hypothesis. Sometimes this is easy, as in testing for the presence of extrasensory perception, or testing that a proposed law of physics holds. Often it is less clear. In medical testing scenarios, for instance, it is often argued that any treatment will have some effect, even if only a very small effect, and so exact equality of effects (between, say, a treatment and a placebo) will never occur.” Berger et al. [
6] (p. 145)
Examples where the appropriateness of precise hypotheses may be questioned include exploratory research, measurements that include a non-negligible amount of error, and general complex phenomena in which simple statistical models at best can be interpreted as approximations to reality [
5,
7,
8]. As exact equality of effects is unplausible in a variety of research contexts, interval hypotheses present an appealing alternative to precise hypotheses, at least in a variety of research settings in the medical, cognitive, and social sciences [
7]. In contrast to precise null hypotheses, an interval hypothesis and its alternative are formalized as follows:
for some
, where often
. In the above,
is the parameter of interest and
is the null value of the precise null hypothesis
. In contrast to precise hypotheses, an interval hypothesis consists of an interval of parameter values, where
is determined from the available research context, domain-specific knowledge, or the available measurement precision, which is always finite. As a sidenote, in the vast majority of clinical phase II trials that aim to demonstrate the efficacy of a novel drug or treatment, a one-sided test for the binary variable success is of interest (where a success can have different interpretations, e.g., reduction of tumor volume [
9,
10]), see Zhou et al. [
11] and Kelter and Schnurr [
12]. While such a hypothesis often is formulated as
for an efficacy threshold
, in the majority of cases, values of
close to 1 are deemed unrealistic a priori. Note that such cases also represent an interval hypothesis, which can be modeled with the region of practical equivalence (see next section).
The core idea behind an interval hypothesis is, therefore, that equality constraints can be tested only up to a limited precision.
Research Problem and Outline
In the Bayesian paradigm, two popular approaches exist: The first is the region of practical equivalence (ROPE), which has become increasingly popular in the cognitive sciences. The second is the Bayes factor for interval null hypotheses, which was proposed by Morey et al. [
13]. However, while the ROPE is conceptually appealing, it lacks a clear decision-theoretic foundation like the Bayes factor. In this paper, a decision-theoretic justification for the ROPE procedure is derived for the first time, which shows that the Bayes risk of a decision rule is asymptotically minimized for increasing sample size.
Therefore, details on Bayesian approaches to interval hypothesis testing, including the ROPE and interval Bayes factors, are provided in
Section 2. Then, in
Section 3, a specific loss function is introduced for the ROPE. Then, the main result is provided by using this loss function. The main result gives an important decision-theoretic justification for testing interval hypotheses in the Bayesian approach via the ROPE.
Section 4 reports the results of a simulation study, which yields recommendations for application of the results in practical settings.
Section 5 provides a discussion of the result and concludes this paper.
3. Decision-Theoretic Foundation of the ROPE
In this section, the main result is presented. Although the ROPE has appealing practical properties like its robustness to the prior selection and wide applicability, it lacks a decision-theoretic justification. In contrast, the Bayes factor can be motivated from a decision-theoretic perspective as a formal Bayes rule, as shown in the previous section. The main result of this paper is given in Theorem 1 and shows that the decision rule based on the ROPE and HPD asymptotically minimizes the Bayes risk and can thus be called an asymptotic Bayes rule.
The following notation is used: A decision rule
maps the observed sample data
, where
x is an element of a measure space
with
-algebra
onto an action space
, which is a measure space with
-algebra
:
A loss function
is then introduced, where
, which takes a parameter
and a decision (or action)
and returns the incurred loss
when deciding for
when
is true. In the Bayesian interpretation,
is another measure space, the parameter space. The loss function
depends on the decision made, which itself depends on the decision rule
, which itself depends on the observed data
. To account for the uncertainty in the decision rule
, the risk function
is introduced, where
is the set of all (randomized) decision functions
:
In the above, the inner integral
is the loss incurred when using the decision rule
for all possible decisions
for the fixed parameter value
and fixed sample
. The outer integral over
with respect to the measure
, which is
, accounts for the variability when observing
. That is,
is a probability measure on the sample space
of the (identifiable parameterized, compare [
39]) statistical model
, which is assumed to represent the true data generating process (which is a family of probability measures in most situations). The outer integral averages the incurred loss over the sample space
in the sense that it computes the incurred loss for all observable
.
A Bayesian will argue that he does not know which value
has, so although Equation (
14) accounts for the uncertainty in observing
, it remains unclear for which parameter value (
14) should be computed. Phrased differently, Equation (
14) accounts for the randomness of the observed data
and the randomness of the action
, but it does not account for the randomness of the parameter
. Therefore, the Bayesian statistician selects a prior distribution
, where
is the set of all probability measures on the parameter space
and averages the risk over the prior distribution:
which is called the
Bayes risk of decision rule
with respect to the prior
. Substituting (
14) into (
15),
can also be written as as follows:
A decision rule
is called a Bayes rule if it minimizes the Bayes risk, which is formalized as follows:
A decision rule
is called an asymptotic Bayes rule if it minimizes the Bayes risk asymptotically, which is formalized as follows:
where
n denotes the sample size of the observed data
.
In the following, a decision rule and a loss function are introduced, for which the asymptotic Bayes risk is zero; that is, . This presents a decision-theoretic justification for the ROPE + HPD procedure for testing interval hypotheses.
The ROPE + HPD decision rule allows us only to accept or reject the null value or to make no decision. This implies that , where means accept for practical purposes, means reject for practical purposes, and means make no decision. Acceptance of the null value is interpreted as acceptance of the interval hypothesis specified by the ROPE , as noted above, and rejection of the null value as rejection of the interval hypothesis .
The decision rule based on the HPD and ROPE is now defined as follows:
Definition 1 (ROPE decision rule).
Let , with and . The ROPE decision rule is given aswhere is the ROPE (e.g., for some , where often, ) and , where a and b are the boundaries of the α% HPD based on the posterior density based on the observed data .
The loss function is then defined as follows:
Definition 2 (ROPE loss function).
Let with . The ROPE loss function is given as follows:where are penalties associated with the parameter not being located inside the HPD, accepting the null hypothesis when the HPD is not located entirely inside the ROPE R, rejecting the null hypothesis when the HPD is located entirely inside the ROPE R, and with making no decision. In all cases, the HPD width and the cost of the parameter not being inside the HPD contribute to the loss. If , the null value is rejected, and the additionally incurred loss is ; that is, the constant if the HPD is located entirely inside the ROPE R (then, ). This situation occurs if the HPD is in the ROPE, but the parameter is still excluded from the HPD. This situation occurs when the consistency of the posterior distribution causes the HPD to be already located inside the ROPE, but the parameter is still excluded from the HPD, possibly due to a not sufficiently large sample size.
If , one accepts the null value . The additional costs are ; that is, the constant if the HPD is located entirely outside the ROPE R (then, ). Such a case could occur when the posterior concentrates outside the ROPE R, but one still accepts the null value included in the ROPE (or the interval hypothesis described by the ROPE, see the first section).
If , no decision is made, and the additional costs are when the HPD partially overlaps with the ROPE and with the complement of the ROPE (then, ).
Thus, the proposed loss function consists of three main components: A loss that occurs when accepting the null value (or the associated interval hypothesis) although the HPD is not in the ROPE R, a loss of rejecting it when the HPD is in R, and a loss for making no decision. All three components seem reasonable.
From a second perspective, the loss function increases the loss gradually: First, the HPD width is smaller for larger sample sizes and thus vanishes to zero due to the posteriors consistency [
39]. The cost of the parameter not being inside the HPD indicates that a second step is needed. In this case, the HPD is off in some way, meaning that due to randomness in the data, the HPD has not sufficiently captured the characteristics of the true data generating processes. The last and third step is the one described in the previous paragraph.
The main result in this paper shows that the decision rule
specified in Definition 1 minimizes the Bayes risk
in Equation (
15) asymptotically under the loss function
specified in Definition 2.
Theorem 1. The decision rule , as specified in Definition 1, minimizes the asymptotic Bayes risk with respect to any proper prior under the loss function in Definition 2. That is, and consequently, for any other decision rule , we have asymptotically in probability for .
The above result has a drawback, however. The loss function of Definition 1 includes the width of the HPD interval as a constant loss in any case, whether the action , or is made (accept, reject, or stay neutral about the hypothesis specified by the ROPE R). However, for small to moderate amounts of data, the width of the HPD interval can be substantial, depending on the statistical model and its parameter space of interest. Thus, a less debatable decision rule would consist solely of the following:
- ▸
the loss for the parameter not being inside the HPD due to randomness in the observed sample ,
- ▸
the loss associated with accepting a hypothesis when the HPD is not inside R, the loss of rejecting a hypothesis when the HPD is inside R, and the loss of making no decision at all, respectively.
The first point is an inherent problem that can occur in small to moderately sized samples . The second point is the natural cost one would associate with making an obviously wrong decision when the (consistent) posterior distribution shows that the ROPE does not include the true parameter , but one rejects or accepts the hypothesis circumscribed by the ROPE R. Note that these two losses are the second and third summands in the loss function of Definition 1.
We will now extend Theorem 1 and show that even when omitting the width
of the
-HPD interval from it, it still remains an asymptotic Bayes rule. The important consequence is that as the width
vanishes only for unrealistically large sample sizes
, this renders the loss function of Definition 1 and Theorem 1 a much more practically relevant result. This is due to the fact that while the width
vanishes for only extremely large
, the convergence speed in Equations (
A5) and () is
much faster. Therefore, even in situations where the HPD width might be substantial due to using only a moderate or small amount of data, the decision-theoretic justification of the ROPE, as stated in Theorem 1, holds.
Definition 3 (Simplified ROPE loss function).
Let with . The simplified ROPE loss function is given as follows:where are penalties associated with the parameter not being located inside the HPD, accepting the null hypothesis when the HPD is not located entirely inside the ROPE R, rejecting the null hypothesis when the HPD is located entirely inside the ROPE R, and with making no decision.
Now, given this simplified loss function, Theorem 1 still holds.
Theorem 2. The decision rule , as specified in Definition 1, minimizes the asymptotic Bayes risk with respect to any proper prior under the loss function in Definition 3. That is, , and consequently, for any other decision rule , we have asymptotically in probability for .
In closing this section, note that Theorems 1 and 2 do not contradict each other. Theorem 1 holds, but for the loss function in Definition 3, the inequality asymptotically in probability for , as ascertained in Theorem 1, becomes an equality. For a finite sample size , the Bayes risk of the simplified ROPE loss function in Definition 3 is smaller then for the one given in Definition 2, particularly when the sample size of the observed data is small (and the HPD width in turn might be substantial).
4. Simulation Study
The result presented above provides a decision-theoretic justification of the ROPE for interval hypothesis testing, but it offers little guidance regarding how to make use of it in practical settings. While the result holds to any parametric statistical model and therefore is quite general, when the sample size is moderate, the key question is which of the costs
dominates the total costs. In most realistic settings, it will be difficult if not even impossible to determine precise or even vague values for the costs
. Still, some comments can be made even without simulations: First, the costs
associated with the parameter not being located inside the HPD are independent of the decision made and indicate that the sample size is too small to capture the true parameter. The latter must happen eventually for large enough sample sizes due to the consistency of the posterior distribution [
2]. As a consequence, the cost parameter
will influence the total costs when the sample size is moderate or small. Second, it is well known from other research that the ROPE is slow, in the sense that it requires more samples than other Bayesian testing approaches to accept or reject a hypothesis [
23,
24,
40]. As a consequence, for moderate sample sizes, the costs of no decision
will dominate the total costs. In that case, the HPD partially overlaps with the ROPE, but is neither located entirely inside or outside of it.
An illustration of this phenomenon is given by simulating one of the most common testing problems, the two-sample
t-test. We make use of the Bayesian
t-test given by Rouder et al. [
41] and four simulation scenarios: (1)
, so the null hypothesis
holds. Here, we draw on the results of a large-scale meta-analysis of effect size magnitudes in medical research, comparing [
42] to determine the ROPE boundaries
and
. (2)
, which equals a small effect size according to Cohen [
43], (3)
, which equals a medium effect size according to Cohen [
43], and (4)
, which equals a large effect size according to Cohen [
43]. Most relevant here are the results under no effect, a small effect, and a medium effect size, because these are much more realistic in applied research; compare [
42]. We provide the percentage of the posterior probability inside the ROPE
for sample sizes
, which are common sample sizes per group in the cognitive and medical sciences. For each scenario, 10,000 datasets were simulated to compute the (1) mean posterior probability inside the ROPE and (2) the probability of the parameter being inside the HPD.
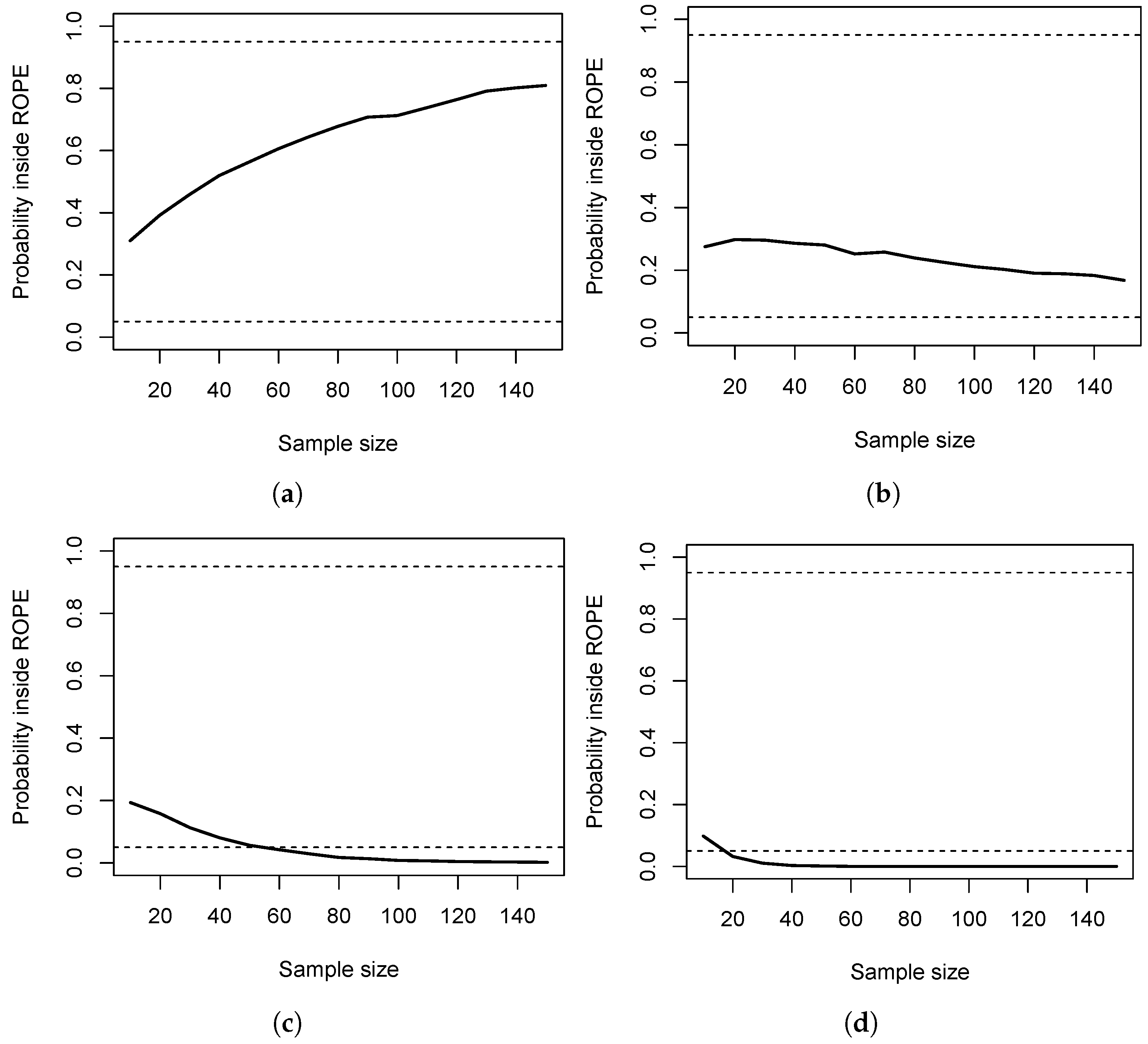
Figure 1 shows the results, and
Figure 1a provides the results under
, so
holds. The dashed horizontal lines show the values
to accept
and
to reject it (in that case, 95% of the posterior probability is located inside
, indicating to accept
). As can be seen, for all sample sizes, the situation remains indecisive, and there is a partial overlap between the ROPE and 95% HPD. As a consequence, the costs
for making no decision fully dominate the entire costs in that scenario, that is, when
holds.
Figure 1b shows the results under a small effect size, and although
is true now, the same situation holds. Even for
, the sample size is not large enough to reduce the posterior probability inside the ROPE
to below 5%. The costs
entirely dominate the resulting costs. For a medium effect size,
Figure 1c shows that for
, the costs of no decision
again drive the entire costs. From
on, the correct decision is made, reducing the costs to zero.
Figure 1d shows the situation for a large effect size, and here, even
samples per group suffice to avoid any costs of making no decision
.
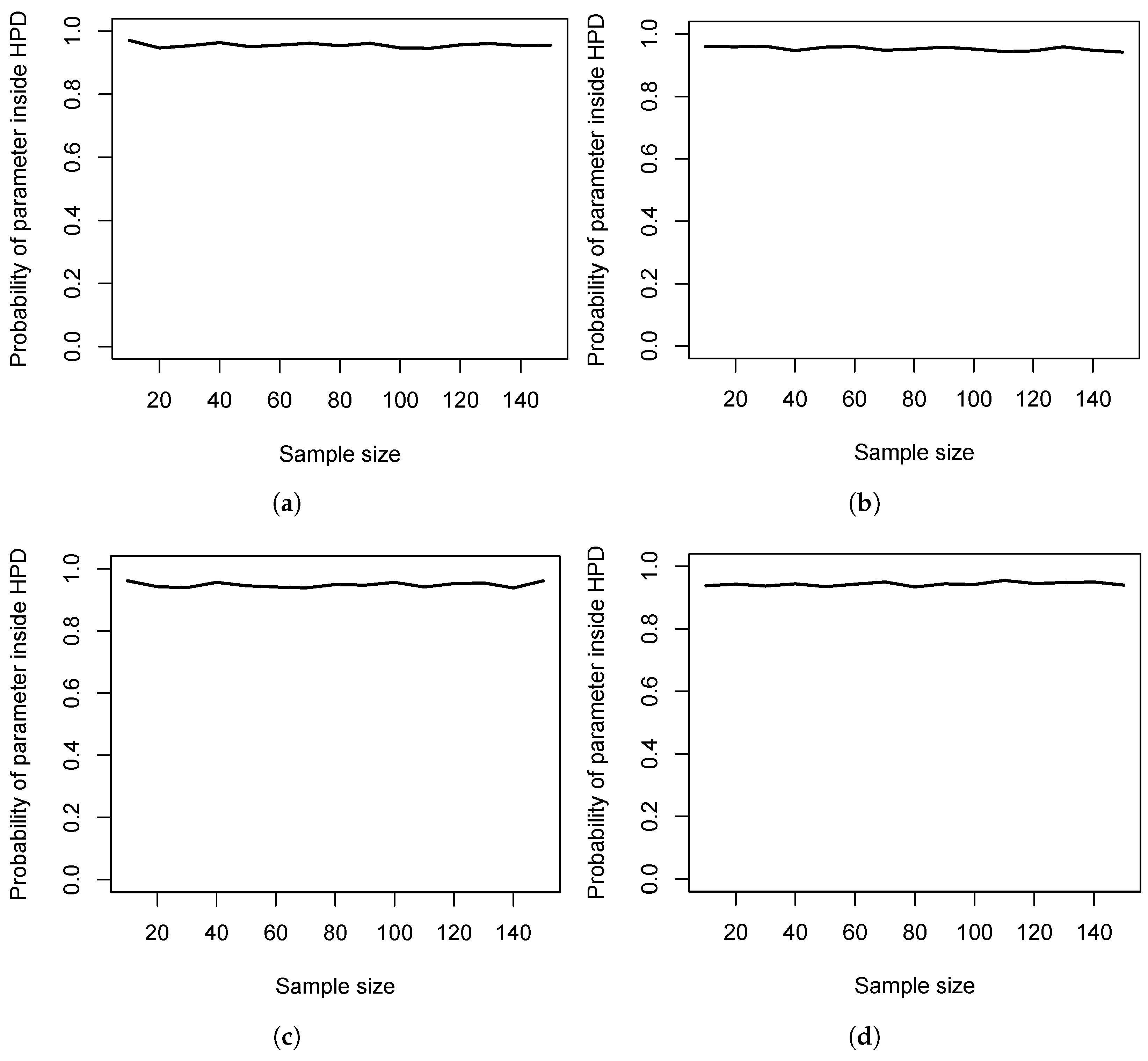
Figure 2 shows the probability of the HPD containing the true parameter
for varying sample and effect sizes. Thus, the cost parameter
is studied. In
Figure 2a, the results under
show that the true parameter
is captured by the majority of HPDs independently of the sample size. This, most probably, is due to the Cauchy prior, which is used on
in the model proposed by Rouder et al. [
41] and which is centered around
.
Figure 2b–d show that the same phenomenon holds for increasing effect size magnitude. Thus, the costs
are much less relevant in realistically attainable sample sizes than the costs
to stay indecisive.
We close this section with two comments. First, the values
and
clearly influence which costs are more relevant in a given situation. However, the probabilities in
Figure 1 and
Figure 2 show that the probability of staying indecisive is much larger than the probability of obtaining a HPD that does not cover the true parameter. Second, the costs
and
further influence the total costs. However, assigning explicit costs to acceptance or rejection of a hypothesis seems unrealistic for almost all applied research attempting to quantify the costs of a trial without a result equal to
. We therefore recommend studying the probability of obtaining an indecisive result for the statistical model at hand under the relevant scenarios, as shown in
Figure 1. Additionally, we recommend selecting a sample size based on decision-theoretic grounds that yields a probability large enough to include the true parameter inside the HPD; compare
Figure 2. Otherwise, the whole inference can be misleading.
5. Discussion
This section discusses the main result and its limitations. First and foremost, Theorem 1 provides a decision-theoretic justification of the ROPE procedure for testing interval hypotheses in the Bayesian paradigm. The latter has gained widespread attention from areas like statistical research [
22], psychological research [
21,
23,
44], and preclinical animal research [
42]. Its simplicity and ease of application are appealing, but until now, the approach lacked a clear decision-theoretic justification. In this paper, such a justification is provided for the first time based on a decision rule that seems quite acceptable for most Bayesians.
The decision rule given in Definition 1 can be interpreted as a formalization of the ROPE method, as proposed by Kruschke [
21]. The form of the selected loss function specified in Definition 2 needs to be justified further; for example, one could easily choose the trivial loss function
, which is independent of the selected decision rule
and equals the width of the
% HPD. This motivates Definition 3 and the important extension of Theorem 1 to this loss function; see Theorem 2.
The loss function given in Definition 3 incorporates four important desiderata: First, it contains an explicit penalty whenever the hypothesis is accepted, although the % HPD is not located entirely inside the ROPE R. Second, it contains an explicit penalty whenever the hypothesis is rejected, although the % HPD is located entirely inside the ROPE R. Third, it contains an explicit penalty whenever no decision is made, which is the case when the ROPE R and the % HPD partially overlap. Fourth, in all three cases (accept , reject , make no decision), a penalty is given if the % HPD does not include the true parameter . In such cases, the decision is based on a HPD that does not include the true parameter value, and the incurred loss naturally should be larger. Consequently, the loss function given in Definition 3 is not trivial and justified from a practical point of view. Theorem 2 now guarantees that asymptotically, decisions made based on the decision rule in Definition 1 and the loss function in Definition 3 will minimize the Bayes risk.
An important limitation is that in small sample situations, little can be said about the incurred loss when following the decision rule under the loss function in Definition 2. Theorem 1 only guarantees that for large sample sizes n, the Bayes risk is minimized, but in a variety of research, only small to moderate samples can be acquired. Theorem 2 improves this situation drastically by using the simpler loss function in Definition 3, which excludes the HPD width .
However, in small sample situations, the penalty terms and influence the resulting loss and risk even more substantially. Suppose, for example, the % HPD is located entirely outside the ROPE R for a small sample size . Suppose further that the true parameter is located inside the ROPE R, so the posterior will concentrate for increasing sample size n inside the ROPE R. In this case, the resulting loss for the small sample will be based on the case for which in . Suppose now that the sample size is increased to . Then, the ROPE and % HPD may overlap, and the resulting loss for the sample based on m observations will be based on the case for which in . For growing sample size , eventually, the case is reached for which the resulting loss will be based on the case for which , but the speed of this process is not known. Consequently, when successively applying the decision rule (e.g., in the growing sample scenario outlined above), the total loss depends on the magnitudes of and . For example, if the associated costs with making no decision are tiny, it matters little if a large sample size n is required until the posterior is located entirely inside the ROPE R. On the contrary, in situations where a decision is mandatory and cannot be deferred (the costs are large), the resulting loss may be substantial when the posterior is located inside the ROPE R only after observing a sample of very large size n. However, asymptotically, Theorem 2 guarantees that the Bayes risk will be minimized for any choice of and , and a decision-theoretic justification of the popular decision rule based on the ROPE and HPD given in Definition 1 is provided.
Keeping this in mind, the result presented in this paper—as is the case with every asymptotic result, such as the laws of large numbers, the central limit theorem, or the Bernstein–von Mises-theorem—cannot provide a boundary so that for sample sizes one can be certain that the Bayes risk is minimized sufficiently. Still, it provides a decision-theoretic justification of statistical hypothesis testing based on the ROPE and HPD, which should not be understated in relevance. The reason is that the loss function in Definition 3 should be acceptable to most Bayesians, although the values of and will clearly differ from situation to situation.
Out simulation study results indicate that the costs
could drive the total incurred loss when using the ROPE substantially. This is in line with previous research [
23,
24,
40,
45], and our results provide two important recommendations for applied research. First, when sample size is moderate, we highly recommend simulating the probability inside the ROPE for varying sample sizes and different scenarios under both
and
, as in
Figure 1. Then, the costs associated with no decision can be estimated for a given
. Second, the probability that the HPD contains the true parameter is crucial for reliable inference. We recommend simulating the latter as shown in
Figure 2, also for varying sample sizes and relevant scenarios under
and
to select a minimum sample size that yields a large enough probability. This should safeguard against overconfidence and yield a Bayesian test for which Theorem 2 holds in an appealing way; that is, the total loss should be small.
Next to its robustness to the prior specification in large samples, this shows that the ROPE and HPD approach for testing interval hypotheses asymptotically minimize the Bayes risk for what seems like a natural loss function for a variety of situations. This result strengthens the justification of researchers applying interval hypothesis tests via the ROPE + HPD procedure in the Bayesian paradigm.



{kind=link}
{kind=link}