
A Smoothed Three-Part Redescending M-Estimator


Abstract
1. Introduction
2. Materials and Methods
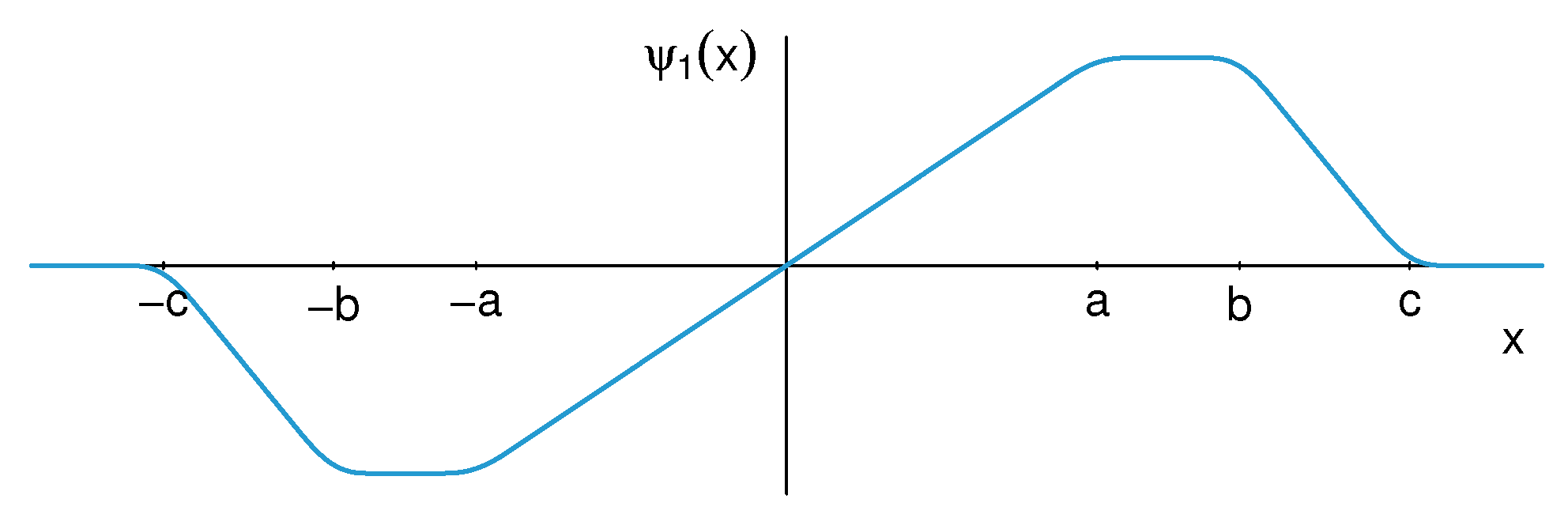
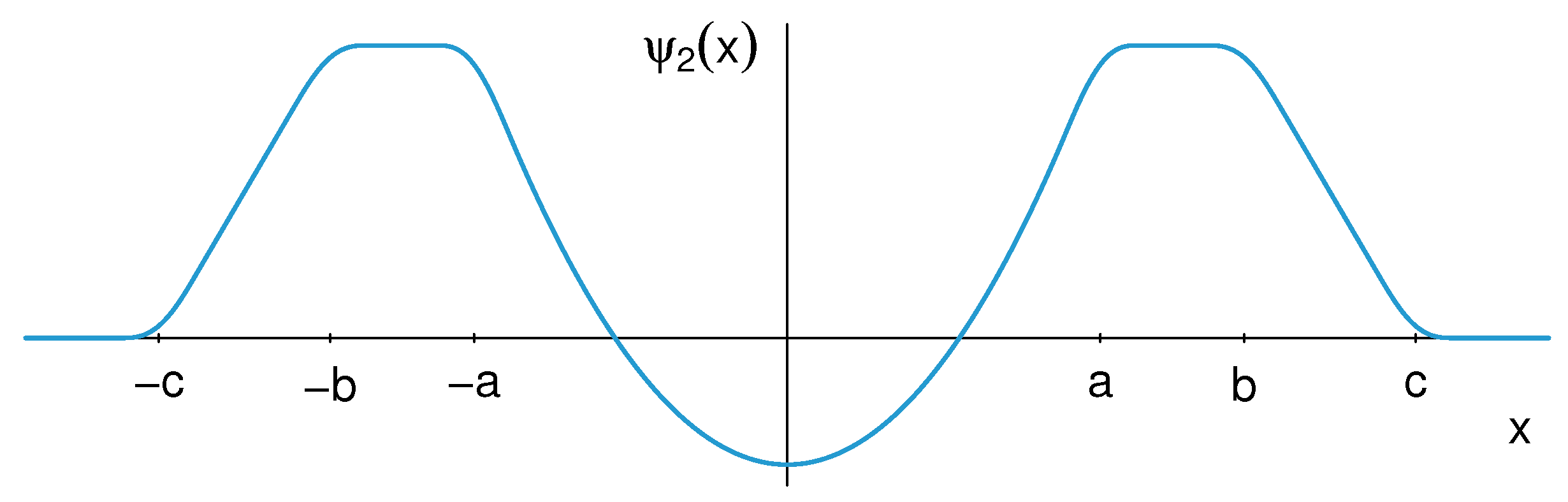
2.1. A Smoothed Three-Part Redescender
2.1.1. Smoothed Three-Part Redescender for Location
2.1.2. Smoothed Three-Part Redescender for Scale
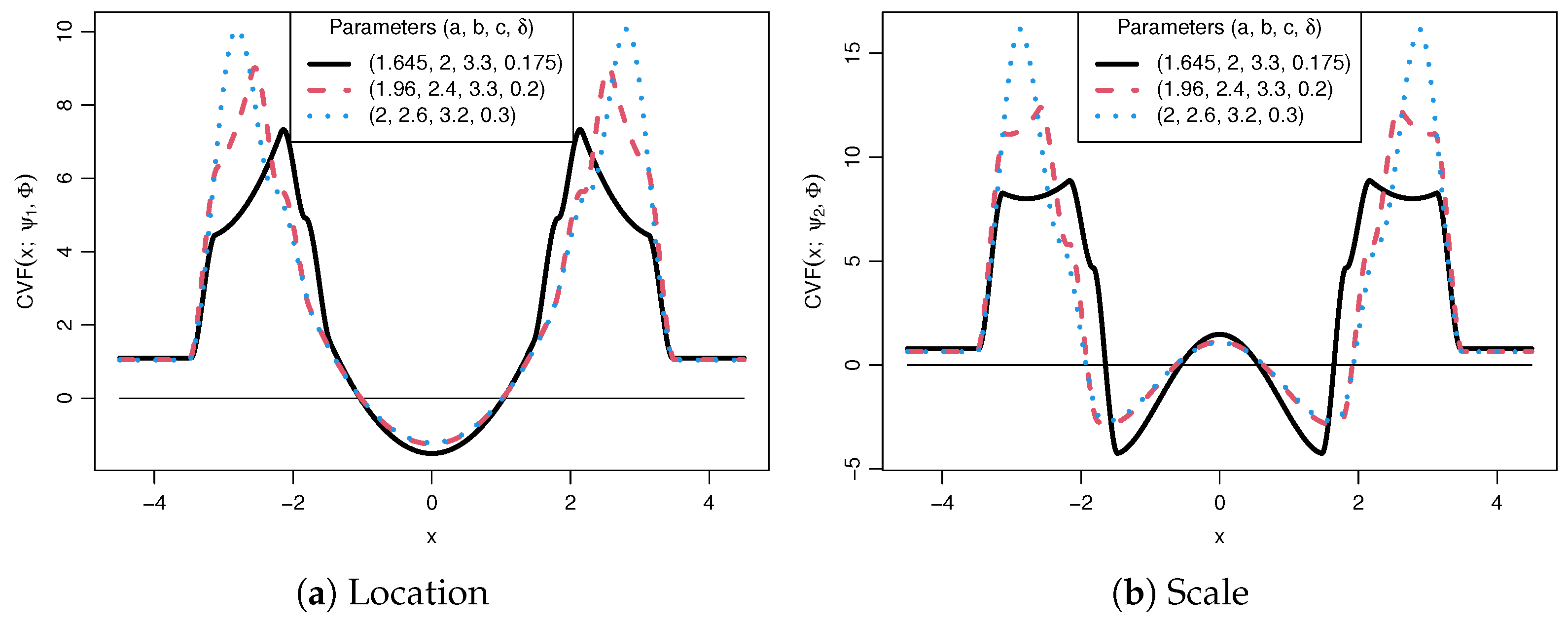
2.2. The Influence Function and Fréchet Derivative
- Conditions
- :
- .
- :
- is a vector function on and has continuous partial derivatives on , where is some non-degenerate compact interval containing in its interior and for which the scale is bounded away from zero.
- :
- , are bounded above in Euclidean norm by a constant.
- :
- The matrix , given by (12), is nonsingular.
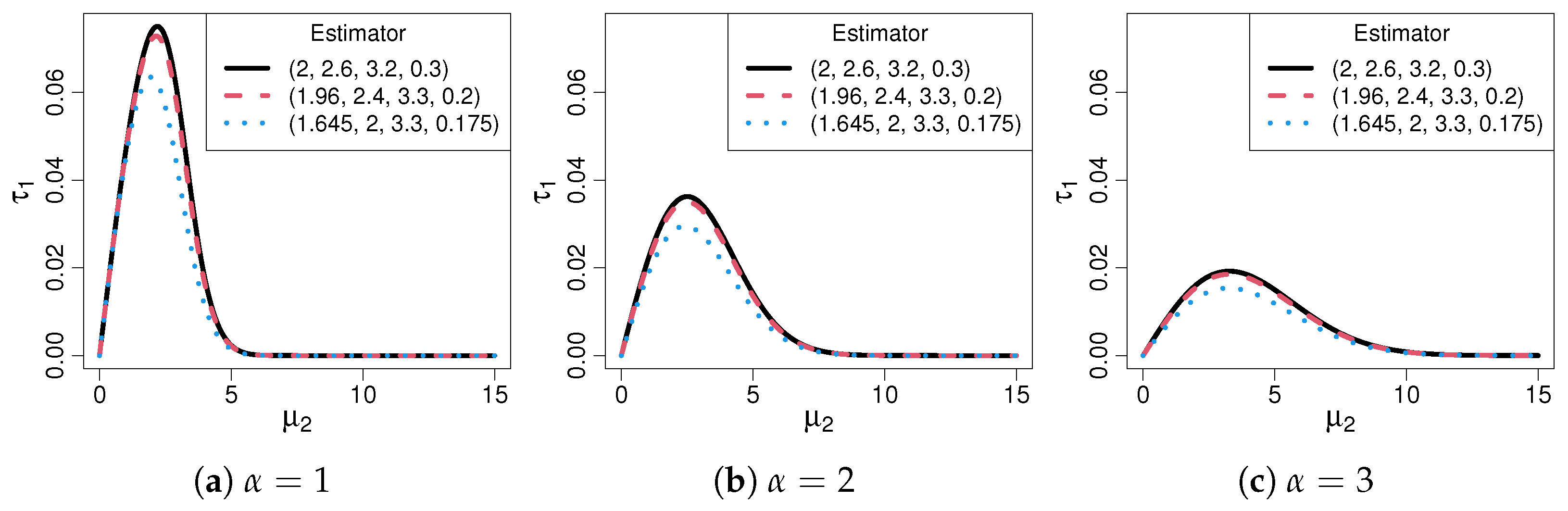
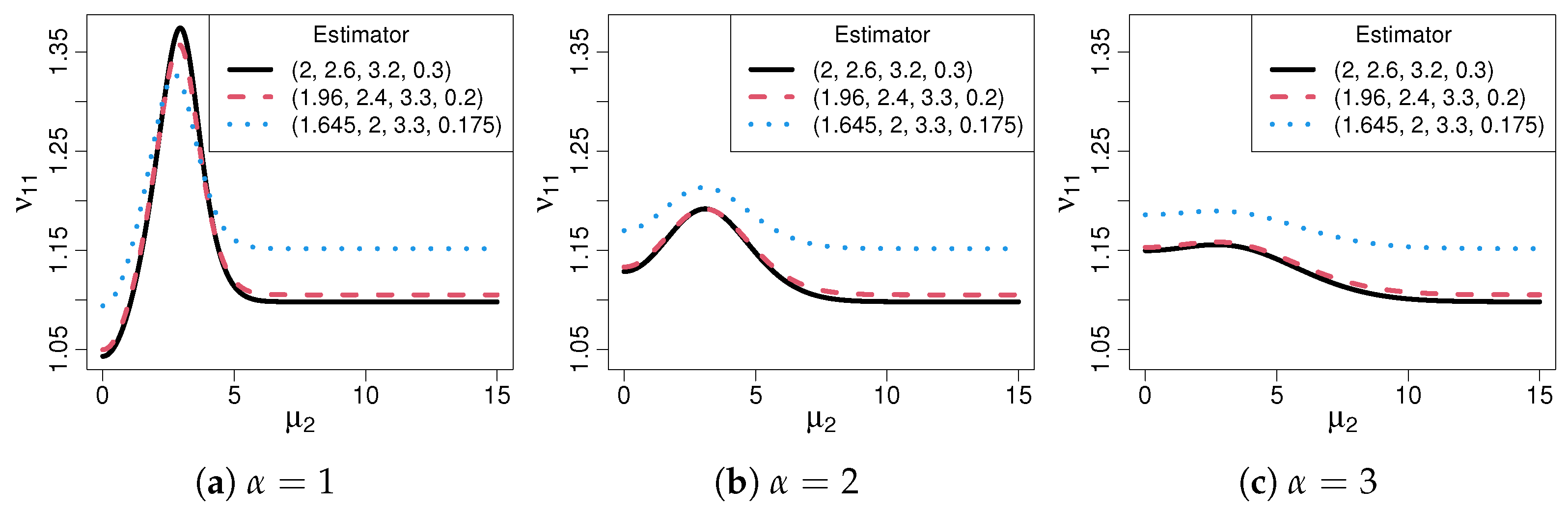
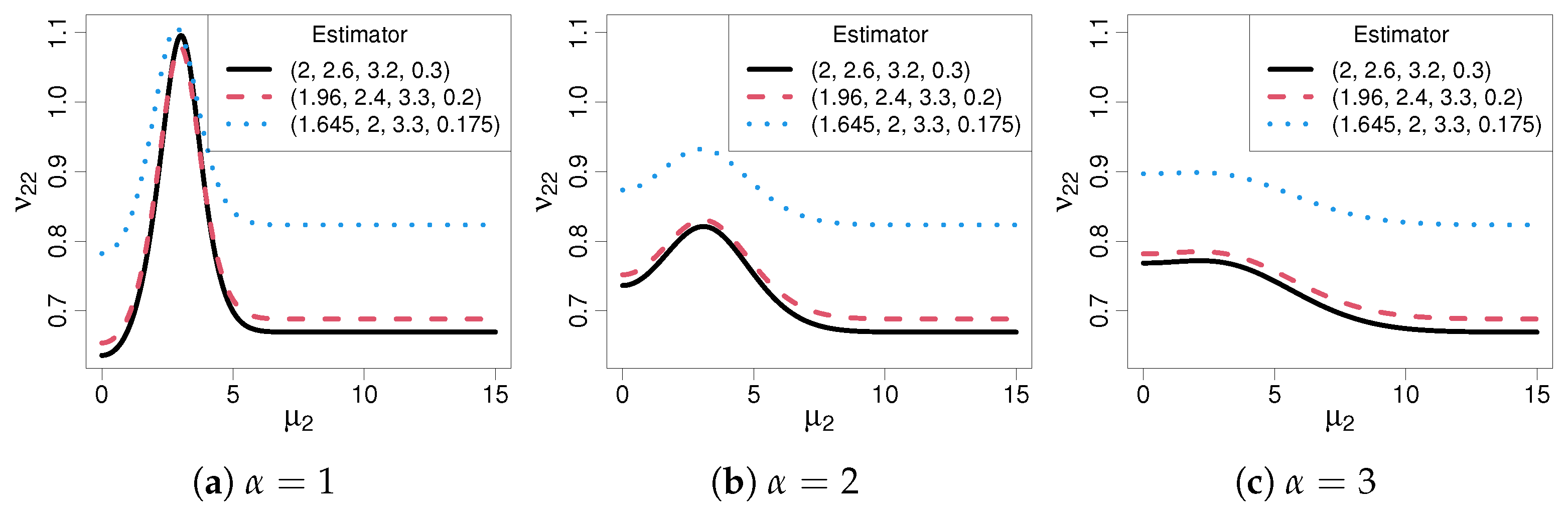
2.3. Quantifiable Measures of Robustness
3. Results
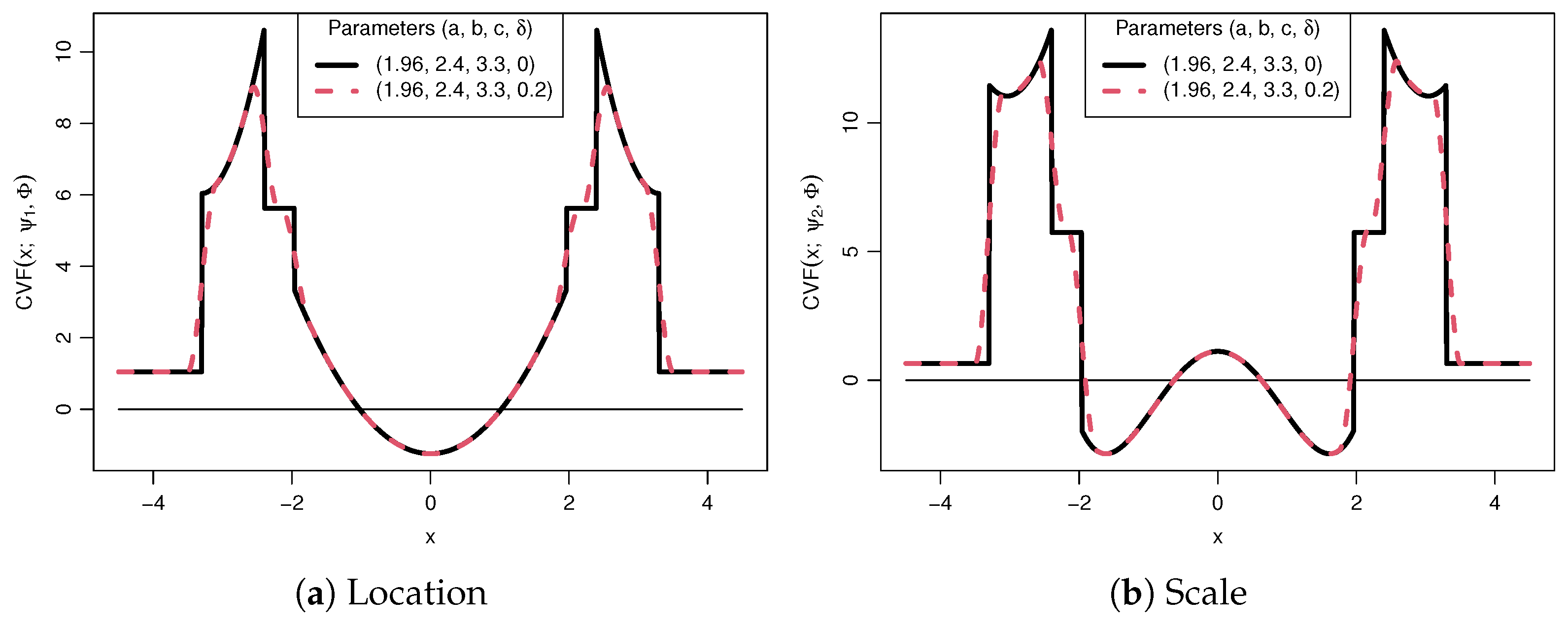
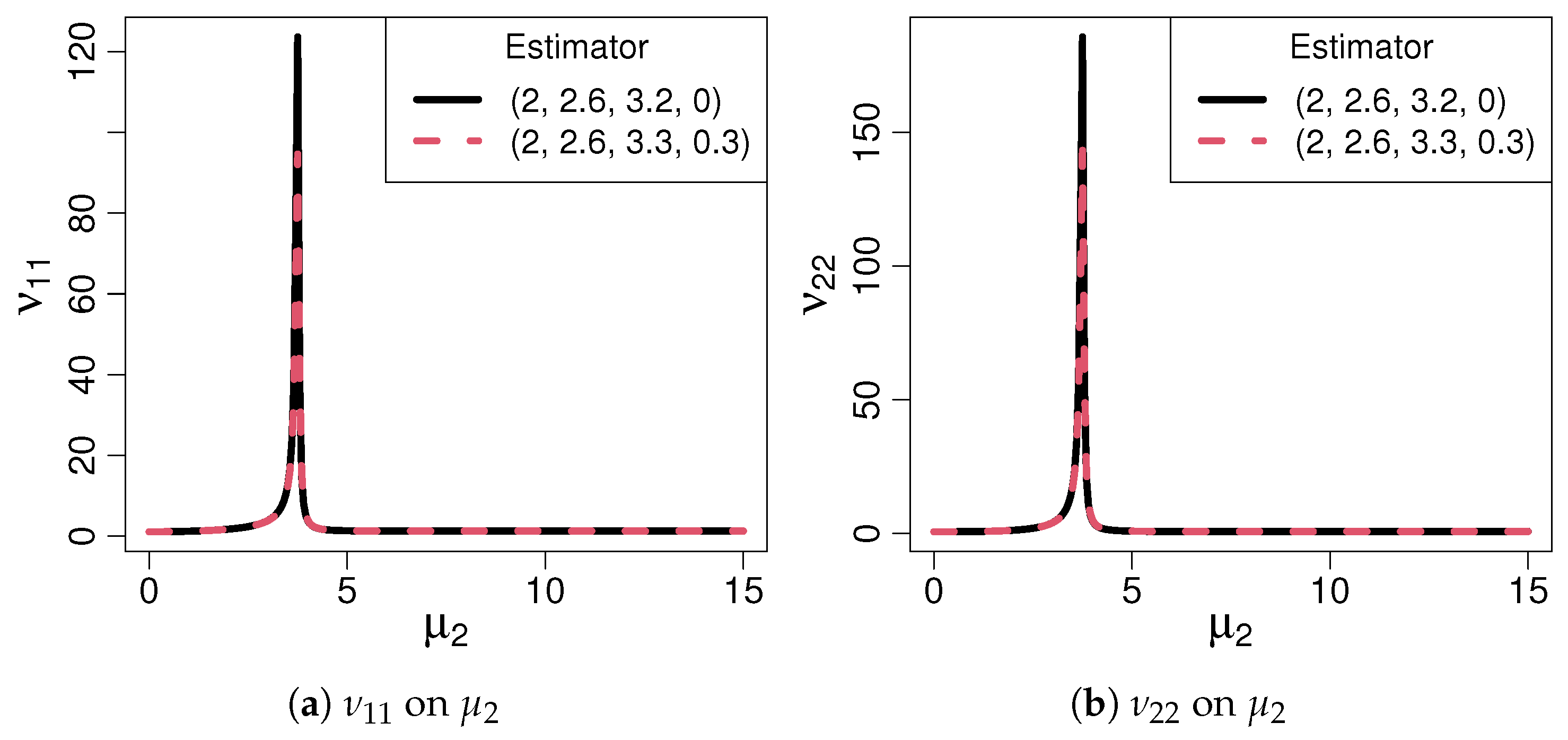
3.1. Smoothed and Non-Smoothed Estimator Comparison
3.2. Contaminated Distribution Asymptotics
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAD | median of absolute deviations |
| MADN | normalised median of absolute deviations |
Appendix A. Proof of Theorem 1
Appendix B. Description of Proof of Theorem 2
References
- Hampel, F.R. The influence curve and its role in robust estimation. J. Am. Stat. Assoc. 1974, 69, 383–393. [Google Scholar] [CrossRef]
- Bednarski, T.; Zontek, S. Robust estimation of parameters in a mixed unbalanced model. Ann. Stat. 1996, 24, 1493–1510. [Google Scholar] [CrossRef]
- Bachmaier, M. Consistency of completely outlier-adjusted simultaneous redescending M-estimators of location and scale. Adv. Stat. Anal. 2007, 91, 197–219. [Google Scholar] [CrossRef]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Hampel, F.R.; Ronchetti, E.M.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics, the Approach Based on Influence Functions; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Clarke, B.R. Robustness Theory and Application; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Andrews, D.F.; Bickel, P.J.; Hampel, F.R.; Huber, P.J.; Rogers, W.H.; Tukey, J.W. Robust Estimates of Location: Survey and Advances; Princeton University Press: Princeton, NJ, USA, 1972. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Statist. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Huber, P.J. Robust regression: Asymptotics, conjectures and Monte Carlo. Ann. Statist. 1973, 1, 799–821. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistics, 1st ed.; John Wiley & Sons: New York, NY, USA, 1981. [Google Scholar]
- Arachchige, C.N.P.G.; Prendergast, L.A. Confidence intervals for median absolute deviations. Commun. Stat. Simul. Comput. 2024, 52, 1–10. [Google Scholar] [CrossRef]
- Clarke, B.R.; Milne, C.J. A small sample bias correction and implications for inference. In Proceedings of the 59th ISI World Statistics Congress, Hong Kong, China, 25–30 August 2013. [Google Scholar]
- Hearn, D.; Baker, M.P. Computer Graphics, 2nd ed.; Prentice Hall, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Rousseeuw, P.J.; Croux, C. Alternatives to the median absolute deviation. J. Am. Stat. Assoc. 1993, 88, 1273–1283. [Google Scholar] [CrossRef]
- Hampel, F.R. Contributions to the Theory Of Robust Estimation. Ph.D. Thesis, University of California, Berkeley, CA, USA, 1968. [Google Scholar]
- Huber, P.J. Robust Statistical Procedures, 2nd ed.; CBMS-NSF Regional Conference Series in Applied Mathematics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1996. [Google Scholar]
- Bednarski, T. Fréchet differentiability and robust estimation. In Asymptotic Statistics, Proceedings of the Fifth Prague Symposium 1994; Mandl, P., Hušková, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1993; pp. 49–58. [Google Scholar]
- Hampel, F.R. A general qualitative definition of robustness. Ann. Math. Statist. 1971, 42, 1887–1896. [Google Scholar] [CrossRef]
- Clarke, B.R. Nonsmooth analysis and Fréchet differentiability of M-functionals. Probab. Theory Relat. Fields 1986, 73, 197–209. [Google Scholar] [CrossRef]
- Varadarajan, V.S. On the convergence of probability distributions. Sankhy A 1958, 19, 23–26. [Google Scholar]
- Prohorov, Y.V. Convergence of random processes and limit theorems in probability. Theory Probab. Appl. 1956, 1, 157–214. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. A new infinitesimal approach to robust estimation. Z. Wahrsch. Verw. Geb. 1981, 56, 127–132. [Google Scholar] [CrossRef]
- Rousseeuw, P. New Infinitesimal Methods in Robust Statistics. Ph.D. Thesis, Vrije Universiteit Brussel, Brussells, Belgium, 1981. [Google Scholar]
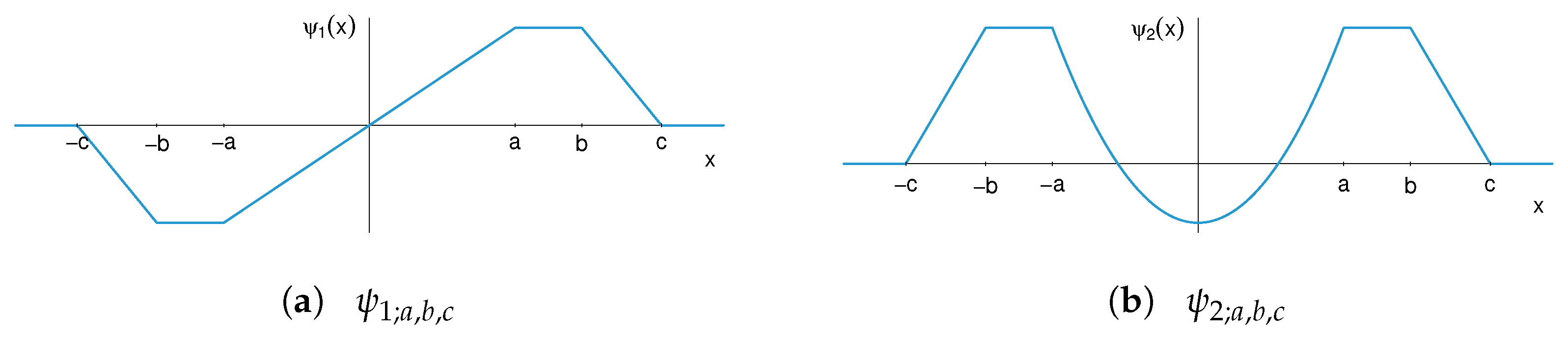


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Smoothed | Non-Smoothed | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | P | P | |||||
| 1.285 | 1.96 | 2.575 | −0.35516 | 0.3075 | 1.2164 | 1.1292 | −0.34505 | 1.2182 | 1.1493 |
| 1.31 | 2.039 | 2.575 | −0.33817 | 0.268 | 1.1998 | 1.0862 | −0.33063 | 1.2013 | 1.1000 |
| 1.31 | 2.039 | 4 | −0.32757 | 0.3645 | 1.0958 | 0.8542 | −0.31500 | 1.0966 | 0.8747 |
| 1.31 | 2.575 | 3.5 | −0.33002 | 0.4625 | 1.0795 | 0.8104 | −0.31035 | 1.0802 | 0.8381 |
| 1.5 | 2.5 | 3.5 | −0.24814 | 0.5 | 1.0645 | 0.7367 | −0.22728 | 1.0637 | 0.7513 |
| 1.645 | ∞ | ∞ | −0.1748 | 0.3 | 1.0259 | 0.6352 | −0.16868 | 1.0262 | 0.6402 |
| 1.645 | 2 | 3.3 | −0.19578 | 0.1775 | 1.0942 | 0.7822 | −0.19312 | 1.0943 | 0.7841 |
| 1.645 | 2.24 | 3.3 | −0.19083 | 0.2975 | 1.0754 | 0.7426 | −0.18377 | 1.0751 | 0.7461 |
| 1.645 | 2.4 | 4 | −0.18557 | 0.3775 | 1.0470 | 0.6818 | −0.17506 | 1.0466 | 0.6874 |
| 1.96 | ∞ | ∞ | −0.09117 | 0.3 | 1.0115 | 0.5692 | −0.08702 | 1.0116 | 0.5710 |
| 1.96 | 2.4 | 3.3 | −0.1069 | 0.22 | 1.0501 | 0.6537 | −0.10399 | 1.0500 | 0.6542 |
| 1.96 | 2.575 | 4 | −0.09846 | 0.3075 | 1.0263 | 0.6042 | −0.09352 | 1.0259 | 0.6050 |
| ∞ | ∞ | ∞ | - | - | - | - | 0 | 1.000 | 0.500 |
| Location | Scale | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | b | c | P | e | e | |||||||
| 1.645 | 2 | 3.3 | −0.1931 | 0 | 0.914 | 1.950 | 1.265 | 7.474 | 0.638 | 1.960 | 3.290 | 11.931 |
| 1.645 | 2 | 3.3 | −0.1957 | 0.175 | 0.914 | 1.954 | 1.265 | 6.699 | 0.639 | 1.973 | 2.940 | 11.350 |
| 1.96 | 2.4 | 3.3 | −0.1040 | 0 | 0.952 | 2.139 | 2.178 | 10.110 | 0.764 | 2.255 | 3.920 | 20.794 |
| 1.96 | 2.4 | 3.3 | −0.1064 | 0.2 | 0.952 | 2.143 | 2.178 | 8.588 | 0.765 | 2.270 | 3.520 | 18.960 |
| 2 | 2.6 | 3.2 | −0.0926 | 0 | 0.959 | 2.155 | 3.333 | 12.636 | 0.786 | 2.271 | 4.000 | 28.793 |
| 2 | 2.6 | 3.2 | −0.0976 | 0.3 | 0.958 | 2.164 | 3.333 | 9.651 | 0.786 | 2.304 | 3.400 | 25.417 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin, A.J.; Clarke, B.R. A Smoothed Three-Part Redescending M-Estimator. Stats 2025, 8, 33. https://doi.org/10.3390/stats8020033
Martin AJ, Clarke BR. A Smoothed Three-Part Redescending M-Estimator. Stats. 2025; 8(2):33. https://doi.org/10.3390/stats8020033
Chicago/Turabian StyleMartin, Alistair J., and Brenton R. Clarke. 2025. "A Smoothed Three-Part Redescending M-Estimator" Stats 8, no. 2: 33. https://doi.org/10.3390/stats8020033
APA StyleMartin, A. J., & Clarke, B. R. (2025). A Smoothed Three-Part Redescending M-Estimator. Stats, 8(2), 33. https://doi.org/10.3390/stats8020033