1. Introduction
Unit root testing is a central problem of time series and econometric analysis. For example, the presence (or not) of a unit root in time series data has huge repercussions in forecasting applications. In econometric analyses, unit roots render the data to be highly sensitive to shocks; while stationary processes tend to revert to the mean in the presence of shocks, random walks tend to diverge.
The primary approaches to unit root testing include the augmented Dickey-Fuller (henceforth referred to as ADF) test [
1], and the Phillips-Perron (PP) test [
2]. Extensive literature including the work of Schwert (1989) [
3], Perron and Ng (1996) [
4] as well as Davidson and MacKinnon (2004) [
5] point to evidence that PP tests underperform with respect to size in finite samples compared to ADF tests since PP tests are highly reliant on asymptotic results; additionally PP tests suffer from severe size distortions in the presence of negative moving average errors. However, the ADF test may suffer from reduced power; see Paparoditis and Politis (2018) [
6] and references therein.
The ADF test examines the presence of a unit root in a stretch of time series data
by focusing on the Ordinary Least Squares (OLS) estimate
of
in the regression equation
fitted to the observed data. In the above equation, we use the notation
. Additionally, note that the number of lagged differences (denoted by
q) is allowed to vary with the sample size
n, and thus
q is an abbreviated notation for
. The null and alternative hypotheses for the ADF testing framework are as follows.
A typical assumption in the above is that
, where the
are autoregressive (AR) coefficients, and
is a sequence of independent, identically distributed (i.i.d.) mean zero random variables with finite (and nonzero) variance, denoted by
; however, the i.i.d. assumption on
can be relaxed as discussed in
Section 2. To elaborate, the hypotheses are essentially that under the null, the series
is obtained by integrating an infinite order autoregressive process, while the alternative is that the series is a
de facto infinite order autoregressive process. The process
can be guaranteed to be stationary and causal by imposing conditions on its coefficients, namely
for some
and that
for all
.
In their seminal work on the topic, Dickey and Fuller (1979) [
1] suggested the studentized statistic
with
used to denote the estimated standard deviation of the OLS estimator of
. We explicitly denote the importance of the lag length
q by using the notation
to denote the ADF test statistic as opposed to
. The distribution of this studentized statistic under the null is non-standard/non-normal; however, it is free of unknown parameters, and has been promulgated in econometric and statistics literature. Assumptions under which this distribution is valid have been progressively relaxed since Dickey and Fuller’s original work in 1979; see [
6] for a chronological account.
The ADF test has been demonstrated to have less than ideal size and power performance in real world applications. It is well examined in literature [
3,
7] that the presence of negative MA coefficients in the data generating process causes severe size distortions, while the work of Paparoditis and Politis [
6] offers a concrete real world example wherein the power performance is poor. The latter work also provides evidence of the asymptotic collinearity problem in the ADF regression; the collinearity becomes more prominent for large
q, in which case loss of power ensues. The issue is then how to work with a moderate value of
q while still achieving a (close to) nominal size of the ADF test.
A succinct summary justifying the choice of adopting the prepivoting framework for the ADF test comes from
Section 3 of Beran (1988) [
8], where the author demonstrates that (under regularity conditions
and in the case where the asymptotic null distribution of the test statistic is independent of the unknown parameters) prepivoted tests have smaller order errors in rejection probability than that of the asymptotic theory test. Since the asymptotic null distribution of the OLS estimate
from the ADF regression is independent of
, the ADF test belongs to the category of hypothesis tests that stand to benefit from the prepivoting framework.
The remainder of this paper is organized as follows.
Section 2 reviews the asymptotic properties of the ADF test statistic, along with conditions on
for good size and power. We also demonstrate that the AR-sieve bootstrap of Paparoditis and Politis [
9] is a prepivoted test in the sense of Beran [
8].
Section 3 highlights the consistency of the prepivoted ADF test against fixed and local alternatives.
Section 4 details the results of numerical experiments wherein we study the empirical performance of the prepivoted ADF test for different lag length specifications.
Section 5 introduces a novel bootstrap-based tuning parameter selection algorithm and its application to the prepivoted ADF test, along with numerical experiments that demonstrate its efficacy with respect to both size and power.
2. Asymptotic Properties of the ADF Test
The asymptotic properties of the ADF test primarily hinge upon the convergence results of the test statistic
under the null and the alternative, as well as the conditions governing the underlying stationary process
. In what follows, we proffer a brief summary of the relaxations to assumptions under which the convergence result of the test statistic
under the null. Dickey and Fuller [
1] initially derived the non-standard null distribution of the statistic under the assumption that the underlying process is autoregressive with
known and finite order. The result was consequently extended in 1984 by Said and Dickey [
10] to the setup where the innovation process
is an invertible ARMA process; the latter can be expressed as an AR
process with exponentially decaying coefficients. Further relaxations to conditions have been examined in literature with Chang and Park (2002) [
11] considering the case that
is a martingale difference sequence and in 2018, Paparoditis and Politis [
6] showed the convergence under the sole provision that the innovation process
has a continuous spectral density that is strictly positive; this is can also be stated in the equivalent form that the process
has a Wold-type AR representation with respect to just white noise errors, allowing for a much larger class of time series versus hitherto linear AR
processes with i.i.d. or martingale difference innovations. The following subsections review the two main asymptotic results of the ADF test statistic from the work of Paparoditis and Politis (2018) [
6].
2.1. Behaviour of the Test Statistic Under the Null
We now describe the convergence behavior of the test statistic
. We adopt the general framework of Paparoditis and Politis [
6], and assume that
is a mean zero weakly stationary process with autocovariance function
that is absolutely summable; hence, the spectral density
is well-defined. We also assume that the logarithm of the spectral density
is integrable, and therefore
admits the Wold representation
where
and
is a white noise, i.e., a weakly stationary process with zero mean, common variance and
for
; see Brockwell and Davis [
12].
If we further assume that
for all
w, then
also admits the Wold-type AR representation:
where
is the same white noise process as above, and the coefficients
are absolutely summable. Additionally,
for
; see [
6] for details. The assumption of positive spectral density of the underlying innovation process is a sine qua non for an AR(
∞) approximation to the spectral density to be consistent; this assumption has been used by Paparoditis and Politis (2018) [
6] and Kreiss, Paparoditis and Politis (2011) [
13] and has not been found to be a limitation for practical applications and has not been found to be a limitation for practical applications.
Under all the above assumptions, and recalling the ADF regression (1) used to test unit root hypothesis
, the following result is true. To state it, we require an extra assumption on the white noise process appearing in (4), namely:
where
,
is the
-field generated by
for
, and the norm
is the
norm with
.
Theorem 1 (Paparoditis and Politis (2018) [
6])
. Assume for all w, and Equations (4) and (5). If as such that , thenwhen is true; here is the standard Wiener process on , and denotes convergence in distribution. The level ADF test therefore rejects the null whenever the test statistic is smaller than where is the lower percentile of the above distribution.
Theorem 1 can be further extended to the cases wherein (1) is modified to include an affine time trend; the same limit result except that the standard Wiener process is replaced by
For a case by case analysis of intercept/trend inclusion, the reader is referred to the book of Hamilton [
14].
2.2. Behaviour Under the Alternative
The limiting distribution of the test statistic
under the alternative is more straightforward; the limiting distribution is normal albeit dependent on the true
in (1). The work of Paparoditis and Politis [
6] establishes this limiting behavior even under their relaxed requirement where the underlying innovation process is just assumed to possess a continuous spectral density which is strictly positive; they also discuss the problem of asymptotic collinearity in the ADF regression where increasing the number of lagged differences leads to a reduction in power. In essence, as the chosen number of lags
q increases, the regressors in the ADF regression (1) become asymptotically collinear, leading to slow rate of convergence of the estimator
. This directly leads to a loss of power of the ADF test. We comment on this behaviour of the prepivoted ADF test further in the following sections.
Under the same assumptions on the innovation process used in Theorem 1 the limiting behaviour of the test statistic under the alternative hypothesis is as follows.
Theorem 2 (Paparoditis and Politis (2018) [
6])
. Assume is true with such that for all w, and Equations (4) and (5). Let as in such a way that and . Then, as - 1.
in probability
- 2.
.
3. Power of the Prepivoted Test
Prepivoting, as introduced by Beran [
8], is the mapping of the test statistic
to a new test statistic
, where
is a consistent estimator of the distribution function of
computed from the data
; typically,
will be based on some kind of bootstrap procedure. We will adopt the residual AR bootstrap of Paparoditis and Politis [
9] to generate the
ith bootstrap sample denoted by
where
. Applying the ADF regression(1) to each of these
B samples, we obtain
B bootstrap ADF statistics
; this allows us to compute the bootstrap estimate of the CDF, denoted by
. Thus, the prepivoted test statistic is
. The prepivoted ADF test rejects the null hypothesis if
, the nominal level of the test.
In this section, we briefly discuss the power of the prepivoted ADF test. In particular, we show that it is consistent against the alternative hypothesis . We build upon the result of Theorem 2 and obtain the following novel result.
Theorem 3. If as such that and , then the prepivoted ADF test is consistent where the alternative is that ρ is any fixed value less than 1.
Proof. From Theorem 2 we have that
. Observe that the ADF test statistic can be written as
The power of the prepivoted test is given by the probability of correct rejection of the test, i.e., where is the bootstrap estimate of the CDF of . Let be an quantile of .
Now since
and using consistency of bootstrap quantiles (cf. Lemma 1.2.1 of Politis, Romano and Wolf [
15]) and the continuous mapping theorem, we have
where
is the
quantile of the Dickey-Fuller distribution. Observe therefore, that the power of the prepivoted test tends to 1 as
.
While it is not immediately clear from this expression, the prepivoted ADF test in fact has better power than the asymptotic ADF test. We demonstrate the same through numerical experiments in the next two sections. □
We briefly discuss the behavior of the prepivoted ADF test in the local alternative framework. We build upon the theorem of Aylar, Westerlund and Smeekes [
16], where they derive the limiting distribution of the ADF test statistic
under the local alternative
for some fixed
to demonstrate non-trivial power of the prepivoted ADF test. Their notation and assumptions are briefly reviewed as follows. The DGP under consideration is
with
. It is assumed that
is a martingale difference sequence with some filtration
with
,
and
. Assume
for all
, and
for some
. They then assume
with
, and
as
. Then, they claim that
In the above Equation (7), where is the standard Wiener process on . Additionally, , where . Given this setup, we have the following result.
Theorem 4. Under the above assumptions, the prepivoted ADF test has non-trivial power against a local alternative of the form where c is a negative constant.
Proof. Let
be the continuous CDF of the limiting distribution given in (7). Note that
for
and is an Ornstein-Uhlenbeck process that solves
with
. Let
denote the local alternative hypothesis. Then,
where the last line follows since
has infinite support. □
Remark 1. The above mentioned result of Aylar, Smeekes and Westerlund fails to capture the loss of power with increasing q. The asymptotic collinearity problem is empirically verified in Paparoditis and Politis [6] as well as the later sections of the paper at hand. Nevertheless, the result does allow us to demonstrate that the prepivoted ADF test has non-trivial power against local alternatives—which can be seen in Section 4 and Section 5, in particular Tables 3 and 4. 4. Numerical Experiments
In this section we provide the results of a numerical experiment. The setup is similar to that of Paparoditis and Politis [
6], wherein the authors consider the ARMA(1,1) model to be the data generating process i.e.,
with
. We consider six different combinations of the ARMA parameters
and
; two that yield samples under the unit root hypothesis and four that yield samples under the alternative hypothesis. For each sample size
n, we generate 10,000 time series each of length
n.
This simulation allowed us to compute the empirical rejection probabilities of the prepivoted ADF test at the nominal level . We use a ‘tuning parameter sweep’ approach to select the lag lengths for the experiment in this section: we used the formula with varying values of a. Note that the lag length used was the same for both the ADF regression on the original data as well as the ADF regression on the bootstrap samples.
The bootstrap methodology selected to generate bootstrap samples under the null is from Section 2.2 of Paparoditis and Politis [
9]. This is a bootstrap approach that is based on unrestricted residuals, and the resultant bootstrap samples are generated under the null irrespective of whether the original data obey the null or not.
Table 1 and
Table 2 correspond to the setting where
has a unit root. The resulting empirical rejection probabilities should be close to the nominal level of the test i.e.,
. The entry closest to
is presented in bold face. As opposed to [
6], the column
is omitted in all the Tables—the entries in all 6 Tables corresponding to
were very similar to those of
.
From the results of
Table 1 and
Table 2, we observe that the prepivoted ADF test yields accurate size when the lag length is large. The test has good size in the presence of the negative MA parameter
when lags are large, but suffers from severe over-rejection of the null when the lag lengths are short. The test is able to achieve accurate size for all sample sizes.
Table 3,
Table 4,
Table 5 and
Table 6 correspond to the setting where
does not have a unit root and is under the alternative hypothesis. These empirical rejection probabilities therefore represent the power of the prepivoted ADF test, and should ideally be as large as possible. The largest entries in each row are represented in boldface.
The results of
Table 3,
Table 4,
Table 5 and
Table 6 are encouraging. While the finite sample power of the prepivoted ADF test is fairly low, it is much higher than the power of the asymptotic ADF test for the same specifications. We observe that the power tends to 1 as the sample size increases—empirically verifying the theoretical consistency of the test. Unfortunately, we see that the lag length chosen to optimize size does not also optimize power—the power of the test appears to be highest when the chosen lag length is short. We also see the manifestation of the asymptotic collinearity problem from Paparoditis and Politis [
6] when the lag lengths are allowed to increase, we observe that the power of the test reduces. In the next section, we will develop a bootstrap method with the goal of choosing a lag length that optimizes power while securing a size close to nominal.
5. Bootstrap Selection of Tuning Parameters for Hypothesis Tests
In this section, we propose a state of the art tuning parameter selection algorithm for general hypothesis tests, and apply it to the case of lag length selection for the prepivoted ADF test. The general algorithm proceeds as follows. Given time series data from an assumed model, and a test statistic where a tuning parameter q is involved, the procedure is as follows:
Bootstrap Algorithm for Tuning Parameter Selection for Hypothesis Tests
Use an information-based choice of q from the sample to obtain initial parameter estimates for the assumed model.
Use the estimated parameters to compute residuals that are not restricted to be under the null.
Bootstrap the residuals to construct B stretches of bootstrap data under the null.
Compute the test statistic from each of the B bootstrap samples across the range of acceptable values of the tuning parameter. Collect the acceptance/rejections of these bootstrap tests as a matrix of 0s and 1s.
Select the tuning parameter that has empirical rejection probability closest to the nominal level of the test; this is essentially done by computing the column averages of the matrix generated in the previous step and selecting the index with column average closest to the nominal level. If there is more than one such choice, select the tuning parameter associated with the smallest fitted model.
The above is the optimal tuning parameter called .
The optimal tuning parameter is fed back to the original data and the hypothesis test is performed with , i.e., computing on .
Reject the null hypothesis if the p value of the test based on is less than the nominal level.
Occam’s razor postulates that if two models are equally apt in explaining a phenomenon at hand, then the smallest, i.e., least complex, model is preferable. Step 5 of the above algorithm encapsulates our preference for smaller, more parsimonious models. There are several instances in the literature of applying some form of bootstrap with the purpose of choosing a tuning parameter, see Leger and Romano [
17], Fenga and Politis [
18] and Shao [
19]. However, it is important to note that our bootstrap algorithm of
Section 5 is novel. As far as we know, no other work has proposed to generate bootstrap samples that obey the null (whether the data obey the null or not) with the purpose of choosing the smallest model order that still yields size close to nominal. In the next subsection, we will apply this algorithm to the ADF test in which case, as we have shown, using a smaller model generally leads to better power.
5.1. ADF with Bootstrap-Assisted Lag Choice
In this subsection, we apply the above general bootstrap algorithm for tuning parameter selection to the prepivoted ADF test. We perform numerical experiments to empirically verify the size and power properties of our algorithm and report the results. As per the work of Paparoditis and Politis [
6], we observe that the Akaike Information Criterion (AIC) works reasonably well with regards to both size and power of the ADF test in the case of positive MA parameters. In the case of negative MA parameters, the AIC based tests suffer from over-rejection of the null. The Modified AIC (MAIC) due to Ng and Perron [
7] was designed specifically to ameliorate the ADF test’s over-rejection of the null in the presence of negative MA parameters. Their method uses a combination of GLS detrending along with a modified information criterion to select the optimal lag length for the ADF test. The MAIC is designed to favor larger lag lengths in the presence of a negative MA parameter, but as shown by Paparoditis and Politis [
6], this can hurt the power performance of the test due to the asymptotic collinearity effect.
Our lag length selection algorithm, dubbed the ‘bootstrap-assisted lag choice’ (BALC) is given below; it uses the residual AR bootstrap of Paparoditis and Politis [
9] along with the prepivoting idea of Beran [
8] with the aim of selecting lag lengths that yield both good size and power. We performed numerical experiments using an ARMA(1,1) data generating process with six different combinations of the ARMA parameters
and
. For each ARMA(1,1) configuration and sample size
n, we generated 10,000 different time series and recorded the performance of our novel lag length selection algorithm. This allowed us to compute the empirical rejection probabilities corresponding to our algorithm at the nominal level
. We compare the results of our novel lag length selection method with prepivoted ADF tests with lag lengths selected by AIC and MAIC optimality. The experimental design is as follows:
Bootstrap Assisted Lag Choice Algorithm for the ADF Test
We are given a stretch of time series data to be tested for a possible unit root.
Run the ADF regression (1) on this data with lag length q selected by AIC. AIC minimization is done over the range 1 to . Denote the selected lag by .
Use the estimated parameters and centered residuals from the ADF regression to construct
bootstrap samples under the null, using the AR bootstrap of Paparoditis and Politis [
9].
For each of the bootstrap samples, perform a prepivoted ADF test with varying lag lengths. The bootstrap methodology for the prepivoted test also uses the AR bootstrap of Paparoditis and Politis [
9], and generates
bootstrap samples for each
q. The range of values for
q we chose was from
to
. The result of these tests is stored in a 0–1 matrix with
rows and appropriate number of columns.
The optimal is then picked by using the value of q that yields smallest type-1 error for all of the bootstrap samples i.e., the value of q that yields column average closest to the nominal level .
We then perform a prepivoted ADF test with bootstrap samples on the original data with number of lags equal to .
The unit root null hypothesis is rejected if the p-value is less than the nominal level .
5.2. Discussion of Simulation Results
The Tables below list the empirical rejection probabilities of the prepivoted ADF test with lag lengths selected by three different data dependent approaches. We list the results of our algorithm and compare them with those with lags selected by AIC, BIC and MAIC optimality. AIC optimization is carried out over lag lengths
q ranging from 1 to
, while MAIC optimization is carried out over
q ranging from 1 to
as per Schwert [
3]. For our experiments, the values of
were set to 250 and 100 respectively in the interest of computational parsimony since our simulation involved 10,000 replications; in practice, given a single dataset in hand, the values of
can easily become of the order of 1000. In terms of computational efficiency, for a single dataset, the computational complexity is entirely determined by the values of
and
and the lag length initially chosen by AIC. More specifically, the ADF regression is performed is
times. Step 4 from the algorithm is highly conducive to parallelization—the search can be run over all candidate values for
at the same time since the results from one candidate value of
are independent of those for other candidate values—thereby improving the computational efficiency and runtime of the algorithm.
Table 7 and
Table 8 correspond to the setting wherein the data
have a unit root. The entries therefore list the rejection probabilities under the null, and should ideally be as close to the nominal level
as possible. For each sample size in each Table, the rejection probability closest to the nominal level is presented in bold.
Putting together the results of
Table 7 and
Table 8, we see that the performance of our method is comparable to that of AIC and MAIC. It is clear from the Tables that tests achieve more accurate size for larger sample sizes. Not surprisingly, the bootstrap selection method also suffers from over-rejection of the null hypothesis in the presence of negative MA parameter.
Table 9,
Table 10,
Table 11 and
Table 12 correspond to the setting wherein the data
obey the alternative hypothesis. The entries therefore correspond to the power of the prepivoted ADF test, and should be as high as possible. For each sample size in each Table, the highest rejection probability is presented in bold.
These results allow us to draw the following conclusions. First, it appears that our method performs reasonably well with respect to finite sample power. The power of the BALC test is higher than the power of the prepivoted test with AIC or MAIC lag lengths. We also note that the method is consistent as its power approaches 1 with increasing sample size. Additionally, we observe that
Table 10,
Table 11 and
Table 12 show significant increases in the power of our method compared to the two information based criteria. What is interesting is that the biggest improvements are seen for intermediate sample sizes. In particular, we observe that our method outperforms the MAIC vis-à-vis power. This can primarily be attributed to the fact that our method is designed to favor shorter lags (provided their associated size is close to nominal), thereby avoiding the asymptotic collinearity problem under the alternative hypothesis. It appears that our proposed bootstrap-assisted lag choice (BALC) generally outperforms AIC and MAIC in the cases of size and power, with the exception that the MAIC achieves better size in the well-known problematic case of a negative MA parameter. The prepivoted test with lag length selected by BIC provides a comparable but slightly higher power in the presence of a negative MA parameter as compared to our BALC based test.
All in all, it appears that the BALC method works well at arriving at a compromise between size and power performance. Our lag selection method yields accurate size as well as improved power over the information based lag length selection criteria. The lag length selection idea along with prepivoting appears to yield appreciable improvements over the asymptotic ADF test.
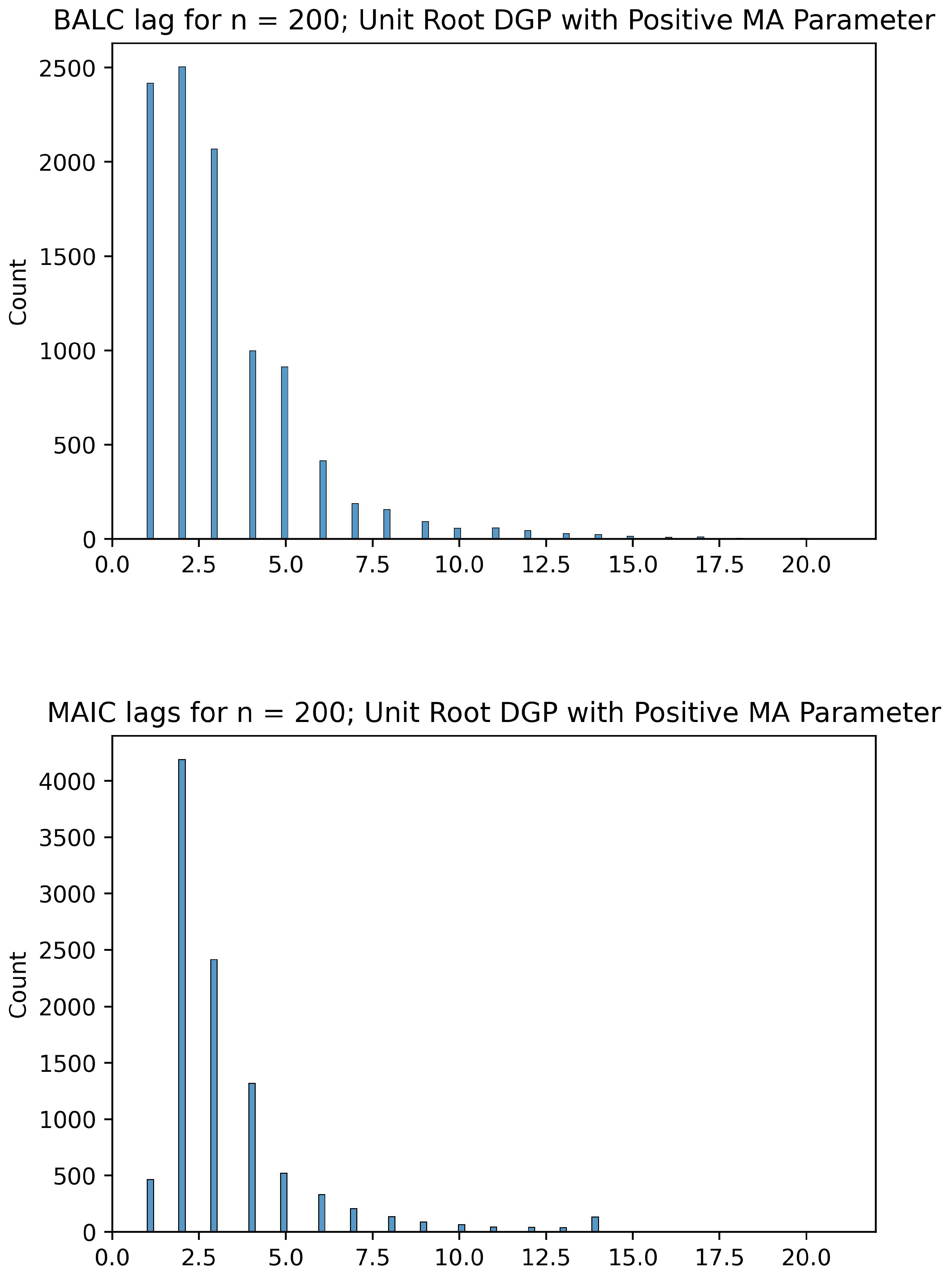
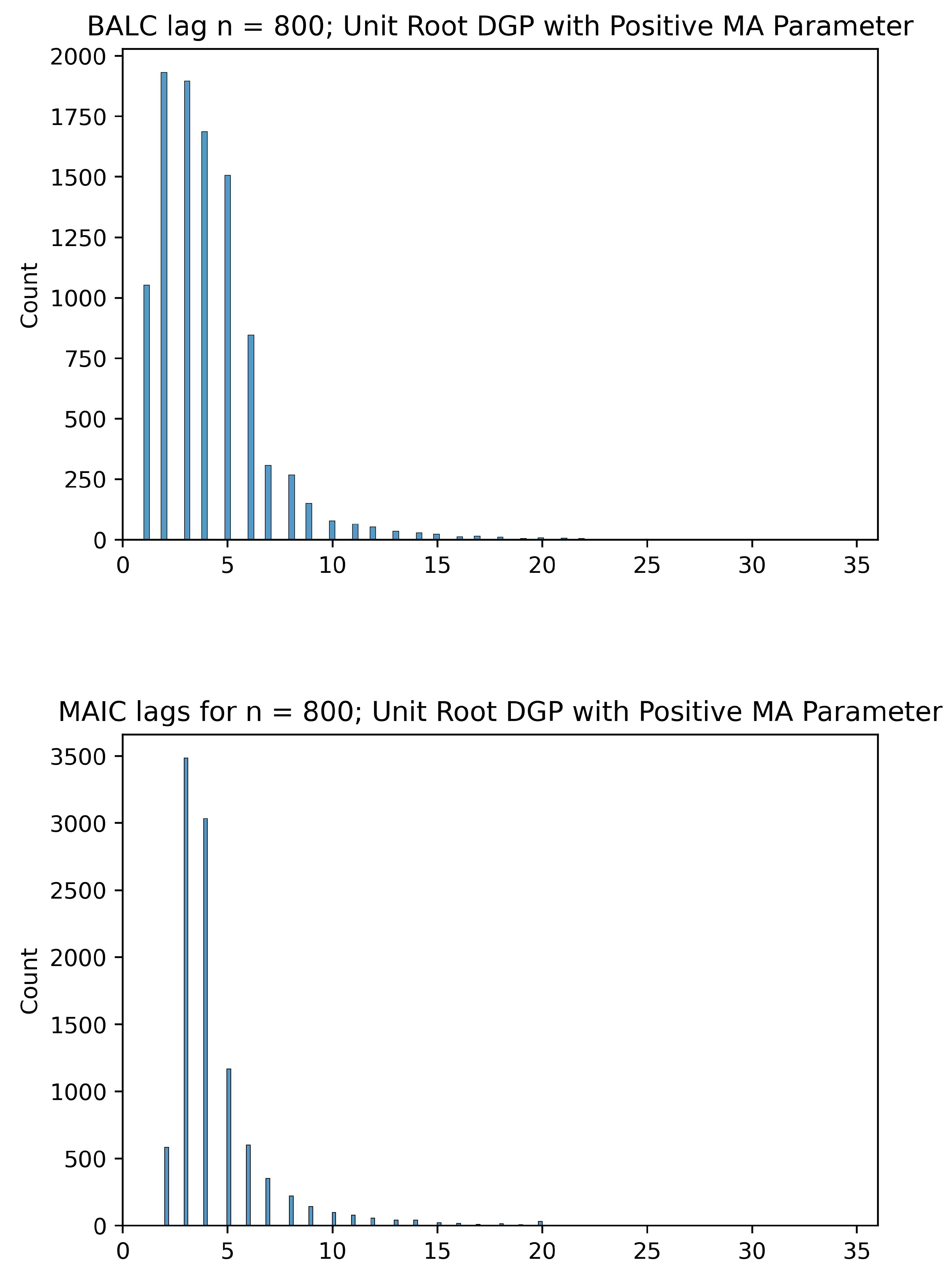
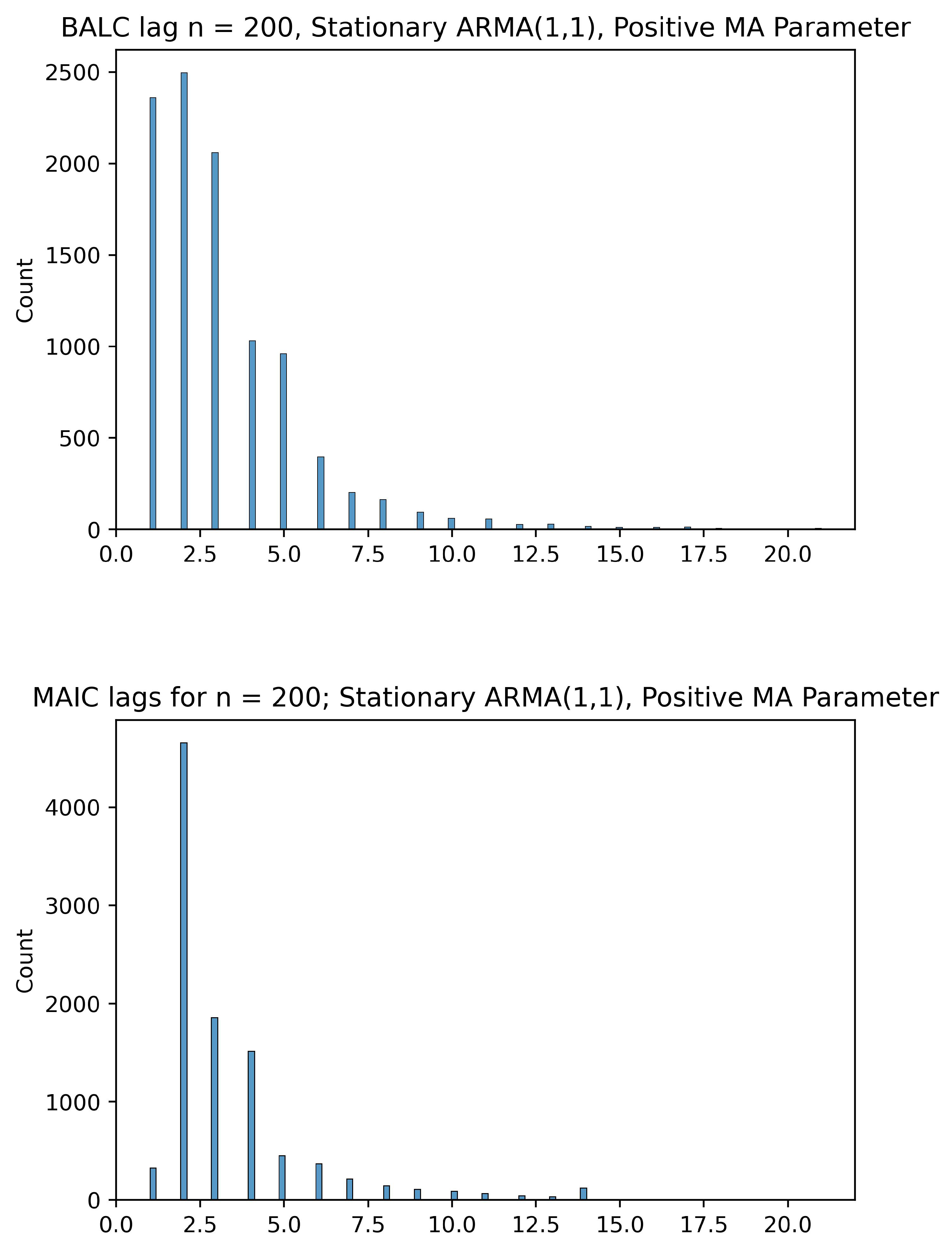
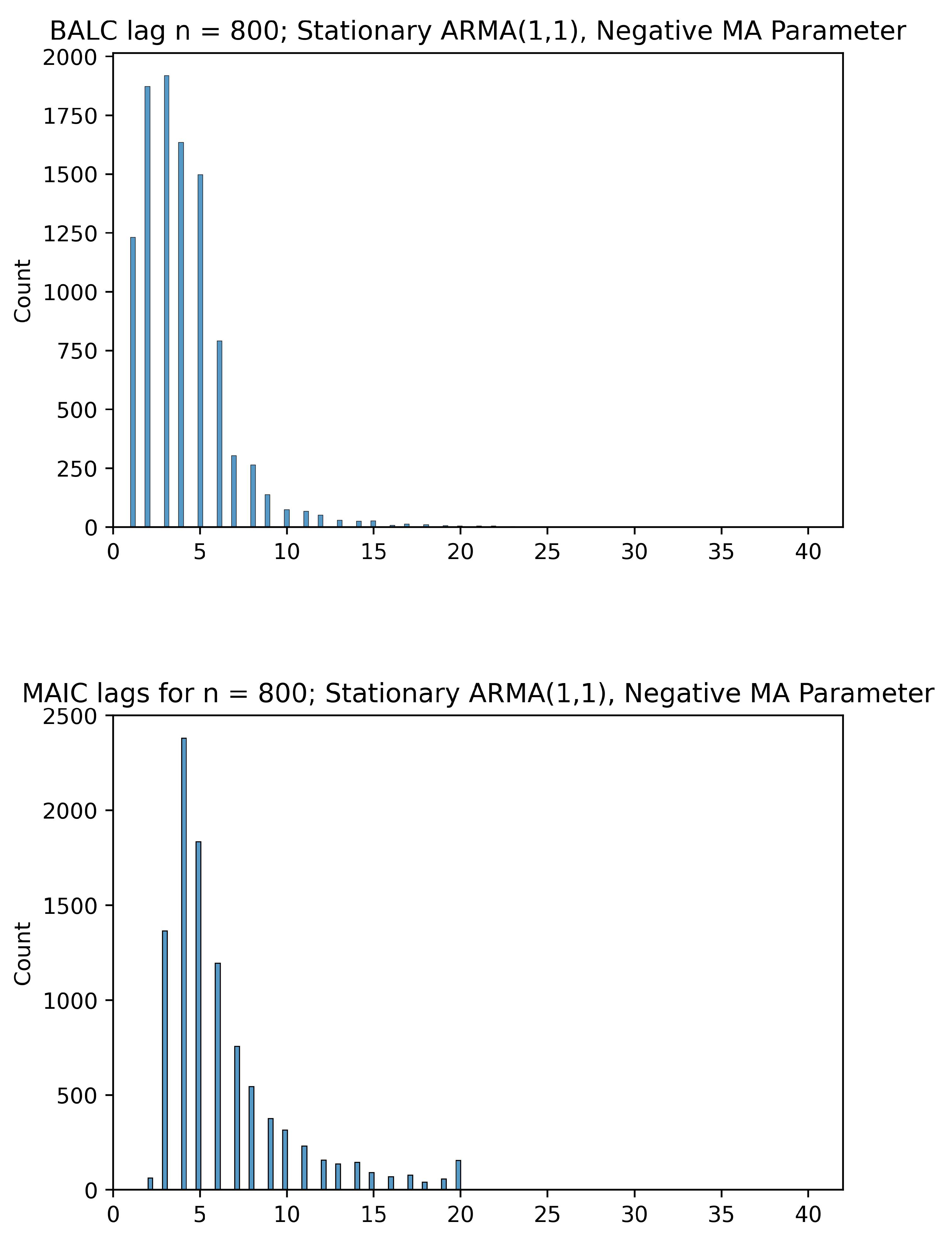
5.3. Comparing the BALC Lag Lengths to MAIC
Given below are histograms comparing the optimal lags selected by our BALC algorithm and lags selected by MAIC optimality. They serve as evidence of the fact that the BALC tends to pick lower lags than MAIC, while still searching in a range higher than the lags selected by AIC—therefore splitting the difference between AIC and MAIC. The lag lengths selected by BALC are generally shorter than those selected by MAIC. Although there is a stochastic component to the BALC framework, we observe that the choice to cut off the search for lags at
allows us to inflate the search space from just the value selected by AIC while simultaneously preventing the asymptotic collinearity problem. The asymptotic collinearity problem stems from the fact that as the number of lags q increases, the regressors in the ADF regression become asymptotically collinear—this is the reason for the loss in power of the ADF test as pointed out in Paparoditis and Politis (2018) [
6]. If a regression is collinear, then the OLS estimator is ill-conditioned/non-unique; fortunately, here we have only approximate/asymptotic collinearity (under the alternative) whose effect can be mitigated by choosing the smallest
q possible. This issue is demonstrated in
Figure 1,
Figure 2,
Figure 3 and
Figure 4 and best visualized in
Figure 5 and
Figure 6, where the MAIC picks fairly large lag lengths for a significant proportion of the 10,000 DGPs whereas the BALC algorithm avoids larger lag lengths.
5.4. A Real Data Application
Lastly, we apply our novel lag selection method to a real data example. We apply our BALC testing procedure to the dataset of
Figure 7 that is discussed in the textbook on time series analysis by Shumway and Stoffer (2017) [
20]. The dataset represents the yearly average global temperature deviations from 1880 to 2009, with the deviations measured in degrees Celsius with respect to the average temperature between 1951 and 1980. In Section 3 of Paparoditis and Politis [
6], the authors comment on the failure of the
tseries implementation of the ADF test to reject the null, as a consequence of selecting too many lags. As per their discussion and diagnostic figures, there is strong evidence that the
detrended data do not contain any strong evidence for a unit root, and therefore obeys the alternative hypothesis—evidenced by the ACF plot of the detrended data given in
Figure 8. The BALC method yields an optimal lag length of 3, compared to the
tseries ADF function’s recommendation of 5. The prepivoted ADF test with lag length
then rejects the unit root null hypothesis, which is the expected result. In contrast, the asymptotic ADF test with
(which also equals 5) fails to reject the null.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}