

Is Anonymization Through Discretization Reliable? Modeling Latent Probability Distributions for Ordinal Data as a Solution to the Small Sample Size Problem


Abstract
1. Introduction
2. De-Anonymization of Metric Data
2.1. Introduction to the Method
2.2. Process of Discretization
2.3. Theoretical Formulation
2.4. Features and Model Definition
2.4.1. Linear Regression
2.4.2. Bayesian Linear Regression
2.5. Evaluation Metrics
3. Explanatory Application Example
3.1. Application Example Design
3.2. Input Features
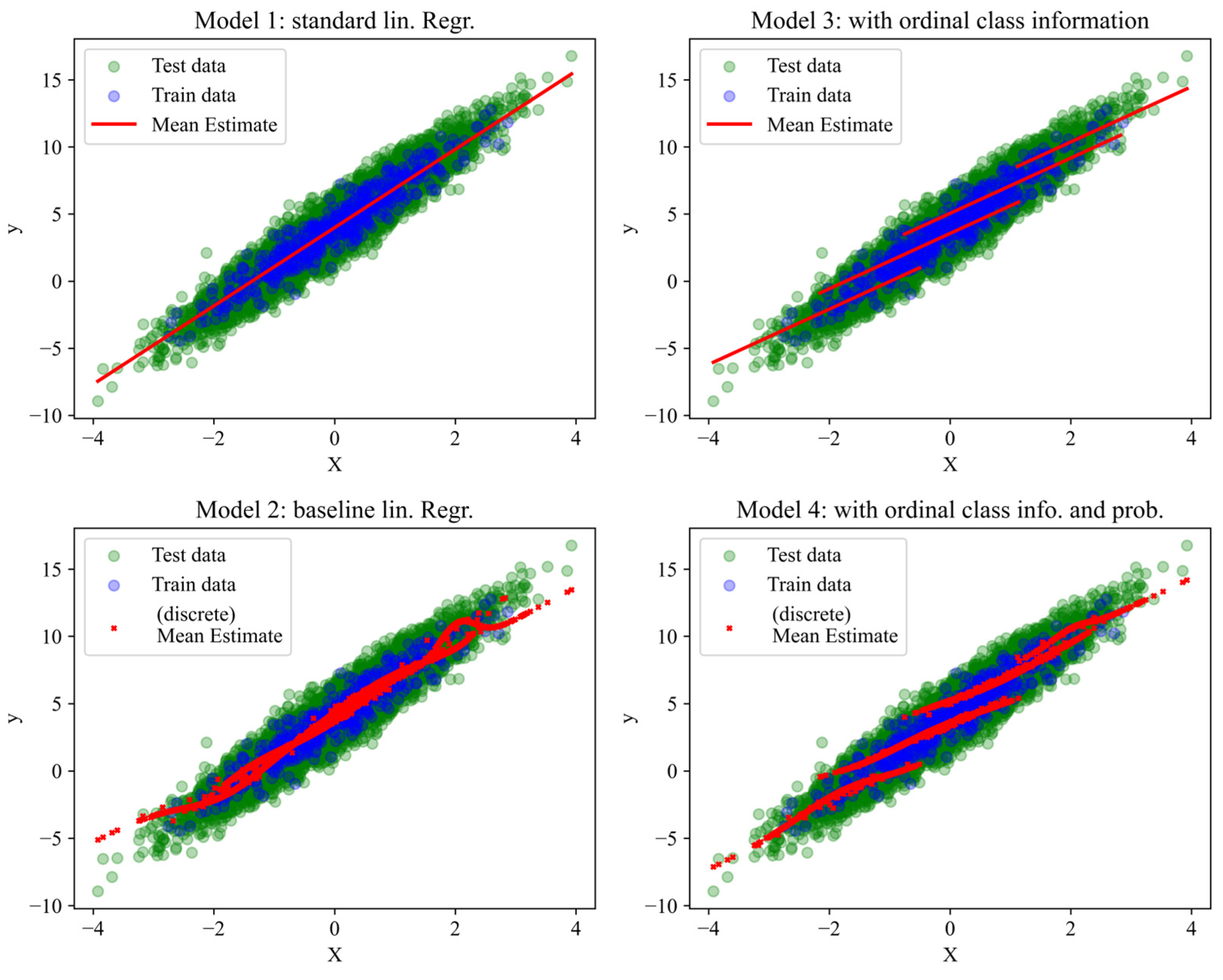
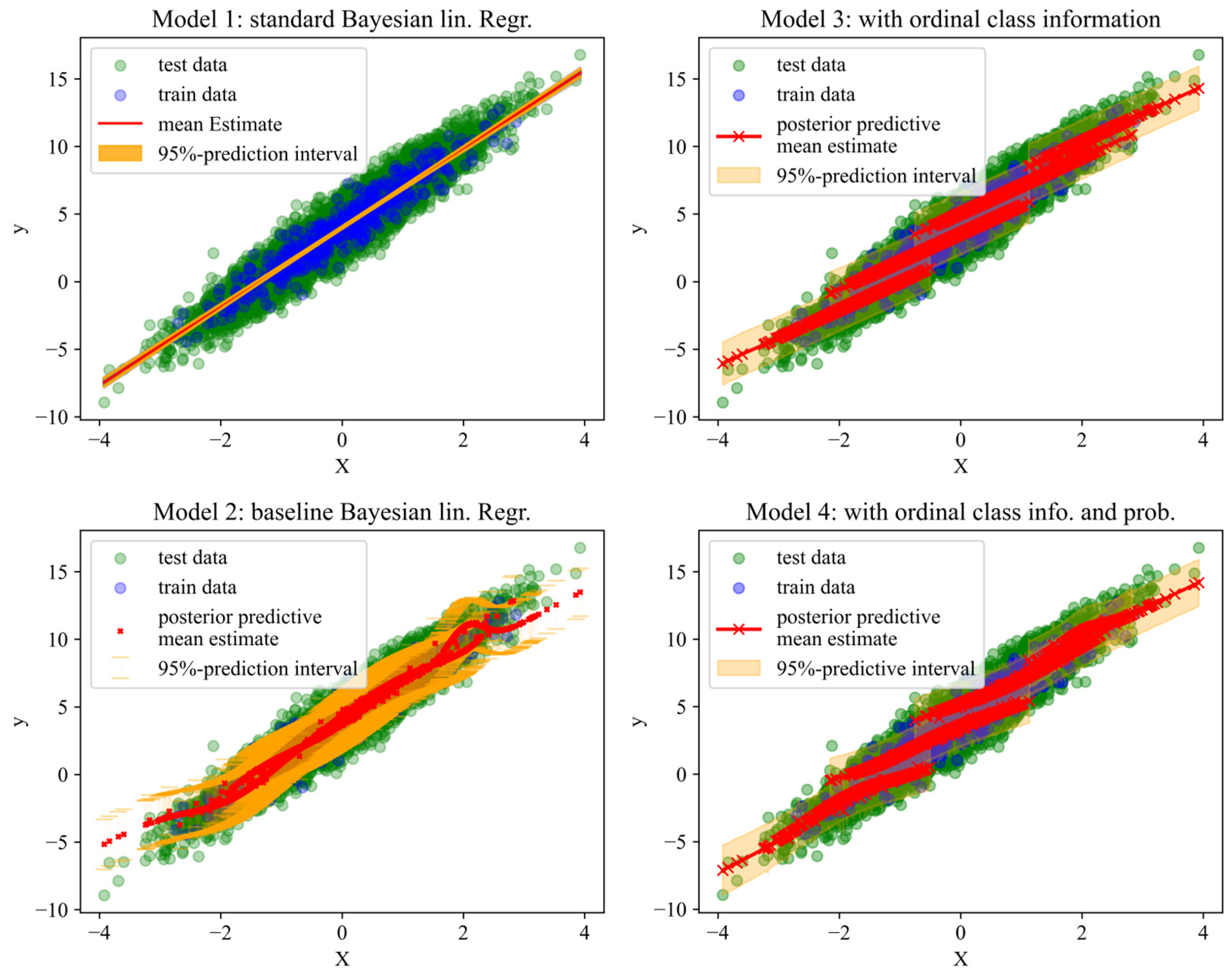
3.3. Models to Compare
| Model | 1 (Standard) | 2 (Baseline) | 3 | 4 |
| X* | X1 | X2 | X3 | X4 |
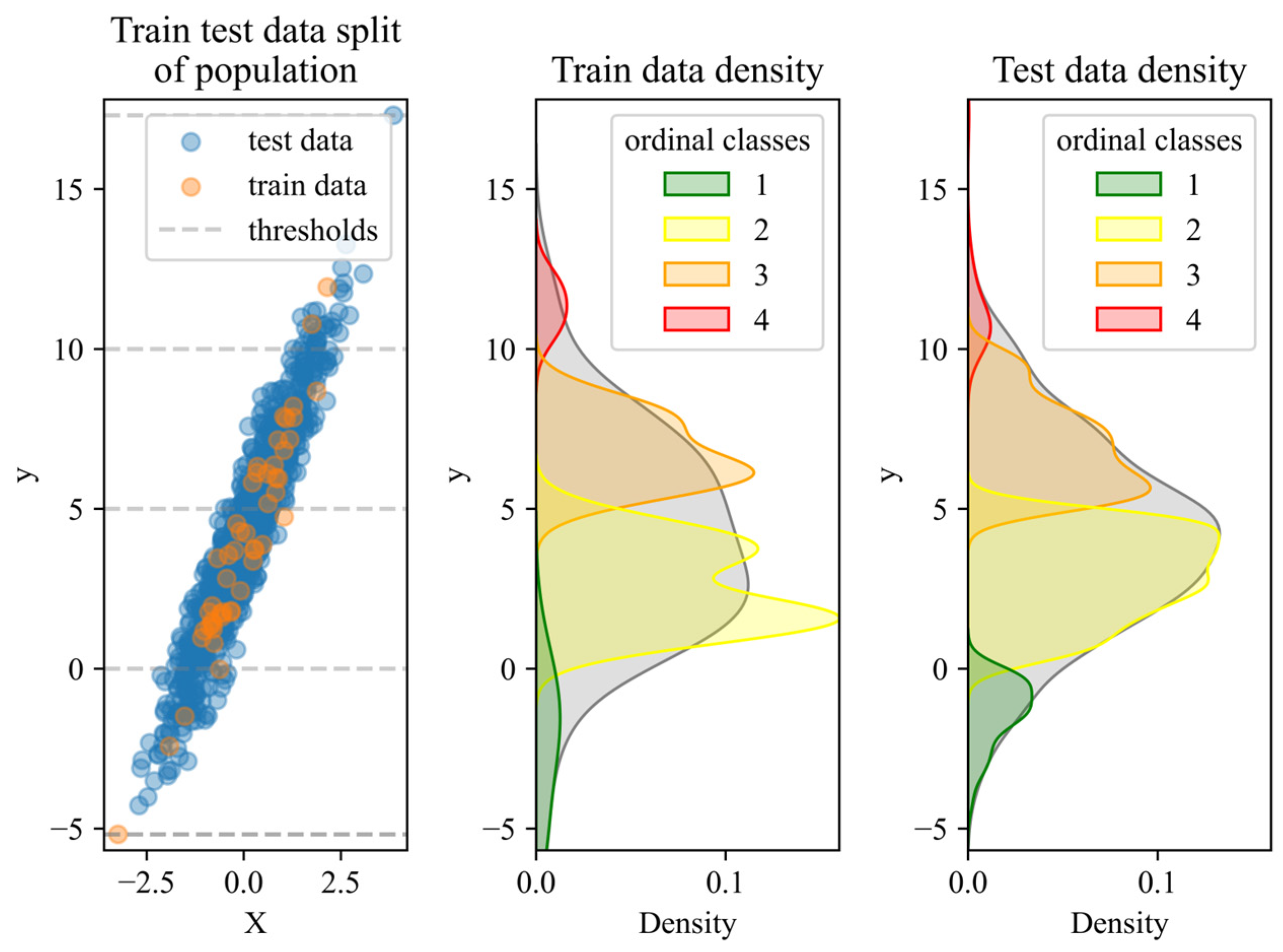
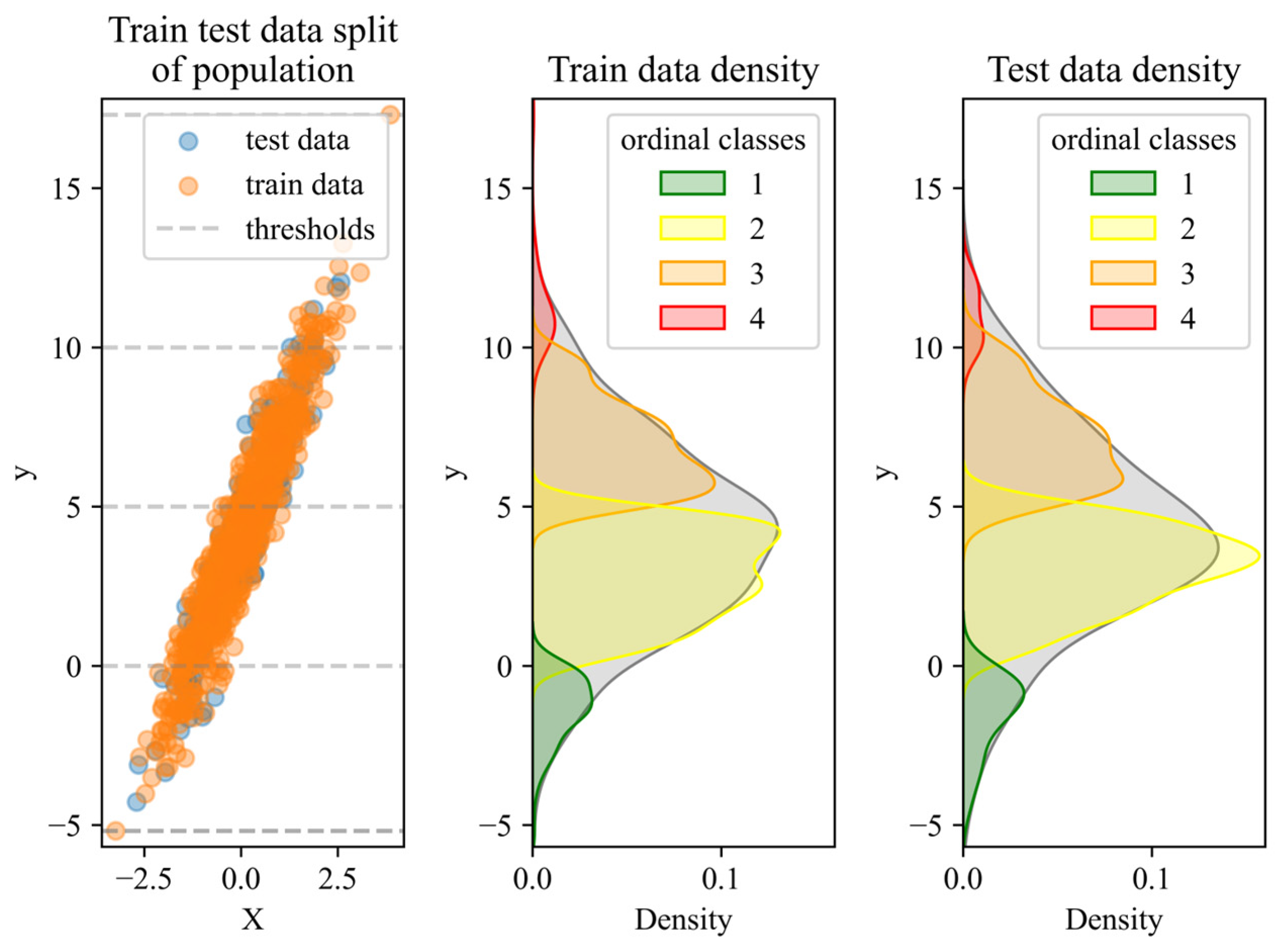
3.4. Descriptive Statistics
3.5. Analysis and Evaluation
4. Simulation Study
4.1. Simulation Design
4.2. Simulation Results
5. Benchmarking
5.1. Datasets
5.2. Evaluation
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lubarsky, B. Re-Identification of “Anonymized Data”. Georg. Law Technol. Rev. 2010. Available online: https://www.georgetownlawtechreview.org/re-identification-of-anonymized-data/GLTR-04-2017 (accessed on 10 September 2021).
- Porter, C.C. De-Identified Data and Third Party Data Mining: The Risk of Re-Identification of Personal Information. Shidler JL Com. Tech. 2008, 5, 1. [Google Scholar]
- Senavirathne, N.; Torra, V. On the Role of Data Anonymization in Machine Learning Privacy. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 664–675. [Google Scholar]
- Ercikan, K. Limitations in Sample-to-Population Generalizing. In Generalizing from Educational Research; Routledge: Abingdon, UK, 2008; ISBN 978-0-203-88537-6. [Google Scholar]
- Hertzog, M.A. Considerations in Determining Sample Size for Pilot Studies. Res. Nurs. Health 2008, 31, 180–191. [Google Scholar] [CrossRef]
- Li, T.; Li, N.; Zhang, J. Modeling and Integrating Background Knowledge in Data Anonymization. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 6–17. [Google Scholar]
- Stickland, M.; Li, J.D.-Y.; Tarman, T.D.; Swiler, L.P. Uncertainty Quantification in Cyber Experimentation; Sandia National Lab. (SNL-NM): Albuquerque, NM, USA, 2021. [Google Scholar]
- Oertel, H.; Laurien, E. Diskretisierung. In Numerische Strömungsmechanik; Vieweg+Teubner Verlag: Wiesbaden, Germany, 2003; pp. 126–214. ISBN 978-3-528-03936-3. [Google Scholar]
- Senavirathne, N.; Torra, V. Rounding Based Continuous Data Discretization for Statistical Disclosure Control. J. Ambient Intell. Humaniz. Comput. 2023, 14, 15139–15157. [Google Scholar] [CrossRef]
- Inan, A.; Kantarcioglu, M.; Bertino, E. Using Anonymized Data for Classification. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 429–440. [Google Scholar]
- Pors, S.J. Using Discretization and Resampling for Privacy Preserving Data Analysis: An Experimental Evaluation. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2018. [Google Scholar]
- Milani, M.; Huang, Y.; Chiang, F. Data Anonymization with Diversity Constraints. IEEE Trans. Knowl. Data Eng. 2021, 35, 3603–3618. [Google Scholar] [CrossRef]
- Bayardo, R.J.; Agrawal, R. Data Privacy through Optimal K-Anonymization. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar]
- Robitzsch, A. Why Ordinal Variables Can (Almost) Always Be Treated as Continuous Variables: Clarifying Assumptions of Robust Continuous and Ordinal Factor Analysis Estimation Methods. Front. Educ. 2020, 5, 589965. [Google Scholar] [CrossRef]
- Zouinina, S.; Bennani, Y.; Rogovschi, N.; Lyhyaoui, A. A Two-Levels Data Anonymization Approach. In Artificial Intelligence Applications and Innovations; Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; IFIP Advances in Information and Communication Technology; Springer International Publishing: Cham, Switzerland, 2020; Volume 583, pp. 85–95. ISBN 978-3-030-49160-4. [Google Scholar]
- Xin, G.; Xiao, Y.; You, H. Discretization of Continuous Interval-Valued Attributes in Rough Set Theory and Its Application. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; Volume 7, pp. 3682–3686. [Google Scholar]
- Rhemtulla, M.; Brosseau-Liard, P.É.; Savalei, V. When Can Categorical Variables Be Treated as Continuous? A Comparison of Robust Continuous and Categorical SEM Estimation Methods under Suboptimal Conditions. Psychol. Methods 2012, 17, 354. [Google Scholar] [CrossRef]
- Jorgensen, T.D.; Johnson, A.R. How to derive expected values of structural equation model parameters when treating discrete data as continuous. Struct. Equ. Model. A Multidiscip. J. 2022, 29, 639–650. Available online: https://scholar.google.de/scholar?hl=de&as_sdt=0%2C5&q=Jorgensen%2C+T.D.%3B+Johnson%2C+A.R.+How+to+Derive+Expected+Values+of+Structural+Equation+Model+Parameters+When+Treating+Discrete+Data+as+Continuous.&btnG= (accessed on 10 October 2024). [CrossRef]
- Zhou, B.; Pei, J.; Luk, W. A Brief Survey on Anonymization Techniques for Privacy Preserving Publishing of Social Network Data. ACM Sigkdd Explor. Newsl. 2008, 10, 12–22. [Google Scholar] [CrossRef]
- Murthy, S.; Bakar, A.A.; Rahim, F.A.; Ramli, R. A Comparative Study of Data Anonymization Techniques. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; pp. 306–309. [Google Scholar]
- Mogre, N.V.; Agarwal, G.; Patil, P. A Review on Data Anonymization Technique for Data Publishing. Int. J. Eng. Res. Technol. IJERT 2012, 1, 1–5. [Google Scholar]
- Kaur, P.C.; Ghorpade, T.; Mane, V. Analysis of Data Security by Using Anonymization Techniques. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 287–293. [Google Scholar]
- Martinelli, F.; SheikhAlishahi, M. Distributed Data Anonymization. In Proceedings of the 2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 580–586. [Google Scholar]
- Marques, J.F.; Bernardino, J. Analysis of Data Anonymization Techniques. In Proceedings of the KEOD 2020—12th International Conference on Knowledge Engineering and Ontology Development, Online Streaming, 2–4 November 2020; pp. 235–241. [Google Scholar]
- Abd Razak, S.; Nazari, N.H.M.; Al-Dhaqm, A. Data Anonymization Using Pseudonym System to Preserve Data Privacy. IEEE Access 2020, 8, 43256–43264. [Google Scholar] [CrossRef]
- Muthukumarana, S.; Swartz, T.B. Bayesian Analysis of Ordinal Survey Data Using the Dirichlet Process to Account for Respondent Personality Traits. Commun. Stat.-Simul. Comput. 2014, 43, 82–98. [Google Scholar] [CrossRef]
- Sha, N.; Dechi, B.O. A Bayes Inference for Ordinal Response with Latent Variable Approach. Stats 2019, 2, 321–331. [Google Scholar] [CrossRef]
- Cox, D.R. Note on Grouping. J. Am. Stat. Assoc. 1957, 52, 543–547. [Google Scholar] [CrossRef]
- Fang, K.-T.; Pan, J. A Review of Representative Points of Statistical Distributions and Their Applications. Mathematics 2023, 11, 2930. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Data Proportion [in %] | Model | MSE | R2 [%] | CT [s] | ||
|---|---|---|---|---|---|---|
| in * | out ** | in * | out ** | |||
| 5 | 1 | 0.876 | 1.001 | 89.47 | 89.39 | 1.27 |
| 2 | 0.646 | 0.893 | 92.24 | 90.53 | 1.39 | |
| 3 | 0.499 | 0.594 | 94.00 | 93.71 | 1.90 | |
| 4 | 0.427 | 0.527 | 94.86 | 94.41 | 1.99 | |
| 20 | 1 | 1.011 | 0.991 | 88.41 | 89.62 | 1.50 |
| 2 | 0.724 | 0.873 | 91.70 | 90.85 | 1.66 | |
| 3 | 0.527 | 0.544 | 93.95 | 94.30 | 1.45 | |
| 4 | 0.459 | 0.501 | 94.73 | 94.75 | 1.47 | |
| 50 | 1 | 1.066 | 0.921 | 88.19 | 90.54 | 1.22 |
| 2 | 0.739 | 0.864 | 91.82 | 91.11 | 1.23 | |
| 3 | 0.465 | 0.594 | 94.85 | 93.89 | 1.25 | |
| 4 | 0.426 | 0.547 | 95.28 | 94.38 | 1.14 | |
| 80 | 1 | 0.998 | 0.977 | 89.09 | 90.52 | 1.08 |
| 2 | 0.730 | 0.987 | 92.02 | 90.42 | 0.95 | |
| 3 | 0.485 | 0.691 | 94.69 | 93.30 | 0.87 | |
| 4 | 0.467 | 0.616 | 94.89 | 94.02 | 0.91 | |
| Train Data Proportion [in %] | Input Feature Settings | Pl Metrics | CT [s] | ||
|---|---|---|---|---|---|
| Cov. Rate [in %] | PI Width | Ratio [in %] | |||
| 5 | 1 | 31.68 | 1.31 | 24.25 | 53.94 |
| 2 | 53.89 | 3.75 | 14.38 | 56.27 | |
| 3 | 96.21 | 3.25 | 29.61 | 78.09 | |
| 4 | 97.89 | 3.43 | 28.55 | 97.43 | |
| 20 | 1 | 15.13 | 0.56 | 27.14 | 50.89 |
| 2 | 24.63 | 1.57 | 15.66 | 55.21 | |
| 3 | 96.00 | 2.96 | 32.49 | 96.06 | |
| 4 | 95.63 | 2.83 | 33.78 | 138.68 | |
| 50 | 1 | 9.80 | 0.40 | 24.79 | 50.48 |
| 2 | 20.80 | 0.89 | 23.45 | 53.81 | |
| 3 | 94.00 | 2.71 | 34.66 | 118.48 | |
| 4 | 93.2 | 2.62 | 35.55 | 191.8 | |
| 80 | 1 | 7.50 | 0.31 | 24.34 | 49.81 |
| 2 | 15.00 | 0.62 | 24.10 | 54.81 | |
| 3 | 94.00 | 2.75 | 34.15 | 154.44 | |
| 4 | 93.50 | 2.72 | 34.37 | 215.88 | |
| Dataset | Train Data Proportion | Model | MSE | R2 | ||
|---|---|---|---|---|---|---|
| in * | out ** | in * | out ** | |||
| 1 (# 3000) | 5 | 1 | 0.00246 | 0.00358 | 84.97 | 80.85 |
| 2 | 0.00050 | 0.00118 | 96.97 | 93.72 | ||
| 3 | 0.00055 | 0.00113 | 96.65 | 93.97 | ||
| 4 | 0.00048 | 0.00130 | 97.06 | 93.03 | ||
| 10 | 1 | 0.00366 | 0.00352 | 80.16 | 81.09 | |
| 2 | 0.00111 | 0.00098 | 93.98 | 94.73 | ||
| 3 | 0.00104 | 0.00098 | 94.39 | 94.71 | ||
| 4 | 0.00092 | 0.00102 | 95.00 | 94.51 | ||
| 20 | 1 | 0.00342 | 0.00354 | 80.17 | 81.30 | |
| 2 | 0.00104 | 0.00108 | 93.95 | 94.30 | ||
| 3 | 0.00099 | 0.00099 | 94.27 | 94.75 | ||
| 4 | 0.00094 | 0.00093 | 94.56 | 95.07 | ||
| 2 (# 3000) | 5 | 1 | 0.00488 | 0.00528 | 66.18 | 65.13 |
| 2 | 0.00054 | 0.00121 | 96.25 | 92.00 | ||
| 3 | 0.00059 | 0.00114 | 95.92 | 92.49 | ||
| 4 | 0.00053 | 0.00113 | 96.32 | 92.54 | ||
| 10 | 1 | 0.00474 | 0.00534 | 66.99 | 64.89 | |
| 2 | 0.00087 | 0.00119 | 93.92 | 92.20 | ||
| 3 | 0.00093 | 0.00109 | 93.55 | 92.84 | ||
| 4 | 0.00084 | 0.00110 | 94.15 | 92.80 | ||
| 20 | 1 | 0.00517 | 0.00523 | 66.32 | 65.31 | |
| 2 | 0.00084 | 0.00138 | 94.51 | 90.84 | ||
| 3 | 0.00095 | 0.00109 | 93.78 | 92.75 | ||
| 4 | 0.00083 | 0.00130 | 94.59 | 91.37 | ||
| 3 (# 5000) | 5 | 1 | 0.00311 | 0.00285 | 80.75 | 81.05 |
| 2 | 0.00107 | 0.00093 | 93.41 | 93.86 | ||
| 3 | 0.00086 | 0.00081 | 94.71 | 94.59 | ||
| 4 | 0.00073 | 0.00074 | 95.46 | 95.10 | ||
| 10 | 1 | 0.00297 | 0.00287 | 80.54 | 81.02 | |
| 2 | 0.00085 | 0.00082 | 94.40 | 94.56 | ||
| 3 | 0.00090 | 0.00080 | 94.13 | 94.72 | ||
| 4 | 0.00083 | 0.00075 | 94.58 | 95.01 | ||
| 20 | 1 | 0.00316 | 0.00278 | 80.19 | 81.32 | |
| 2 | 0.00124 | 0.00080 | 92.20 | 94.64 | ||
| 3 | 0.00104 | 0.00074 | 93.50 | 95.02 | ||
| 4 | 0.00098 | 0.00072 | 93.88 | 95.19 | ||
| 4 (# 5000) | 5 | 1 | 0.00501 | 0.00497 | 67.83 | 66.18 |
| 2 | 0.00096 | 0.00107 | 93.86 | 92.69 | ||
| 3 | 0.00105 | 0.00103 | 93.24 | 92.97 | ||
| 4 | 0.00095 | 0.00107 | 93.87 | 92.70 | ||
| 10 | 1 | 0.00403 | 0.00502 | 70.46 | 66.24 | |
| 2 | 0.00052 | 0.00113 | 96.17 | 92.40 | ||
| 3 | 0.00062 | 0.00108 | 95.46 | 92.76 | ||
| 4 | 0.00051 | 0.00111 | 96.28 | 92.54 | ||
| 20 | 1 | 0.00480 | 0.00492 | 66.17 | 66.91 | |
| 2 | 0.00117 | 0.00116 | 91.76 | 92.24 | ||
| 3 | 0.00095 | 0.00100 | 93.32 | 93.30 | ||
| 4 | 0.00089 | 0.00094 | 93.76 | 93.69 | ||
| Descriptive Analysis of the Target | Class Size | Class Thresholds | |||
|---|---|---|---|---|---|
| Min | Mean | Max | |||
| AutoMPG | 9 | 23.52 | 46.6 | 4 | [8, 16, 24, 32.5, 48] |
| Boston Housing | 5 | 22.53 | 50 | 4 | [4, 15, 25, 35, 51] |
| Student Performance | 0 | 11.91 | 19 | 4 | [−1, 9, 12, 15, 20] |
| Automobile * | - | - | - | 2 | [−3.5, 1, 3.5] |
| California Housing | 14,999 | 206,855 | 500,001 | 4 | [14,998, 136,249, 257,500, 378,751, 500,002] |
| Bike Sharing | 1 | 189.46 | 977 | 4 | [0, 150, 350, 500, 1000] |
| Samples Size | Features Size | Sample/ Feature- Ratio | Target | Target Unit | Target Mean | Target IQR | |
|---|---|---|---|---|---|---|---|
| AutoMPG | 398 | 8 | 49.8 | MPG | 0.3860 | 0.3059 | |
| Boston Housing | 506 | 14 | 36.1 | MEDV | [1k USD] | 0.3896 | 0.1772 |
| Student Performance | 649 | 57 | 11.4 | G3 | Points | 0.6266 | 0.2105 |
| Automobile | 205 | 69 | 3.0 | Risk | Level | 0.5668 | 0.4000 |
| California Housing | 20,640 | 14 | 1474.3 | MHV | [USD] | 0.3956 | 0.2992 |
| Bike Sharing | 17,379 | 14 | 1241.4 | Count | Bikes | 0.1931 | 0.2469 |
| Dataset | Train Data Proportion | Model | MSE | R2 | ||
|---|---|---|---|---|---|---|
| in * | out ** | in * | out ** | |||
| AutoMPG | 5 | 1 | 0.00273 | 0.01178 | 92.92 | 72.77 |
| 2 | 0.00079 | 0.00975 | 97.96 | 77.47 | ||
| 3 | 0.00087 | 0.00507 | 97.75 | 88.28 | ||
| 4 | 0.00041 | 0.03101 | 98.93 | 28.36 | ||
| 10 | 1 | 0.00642 | 0.00938 | 85.46 | 78.14 | |
| 2 | 0.00249 | 0.00398 | 94.37 | 90.73 | ||
| 3 | 0.00231 | 0.00362 | 94.76 | 91.57 | ||
| 4 | 0.00202 | 0.00528 | 95.42 | 87.71 | ||
| 20 | 1 | 0.00625 | 0.00852 | 86.02 | 80.04 | |
| 2 | 0.00155 | 0.00439 | 96.52 | 89.71 | ||
| 3 | 0.00167 | 0.00380 | 96.27 | 91.10 | ||
| 4 | 0.00130 | 0.00424 | 97.10 | 90.08 | ||
| Boston Housing | 5 | 1 | 0.00318 | 0.01769 | 92.32 | 57.55 |
| 2 | 0.00216 | >1 | 94.79 | |||
| 3 | 0.00057 | 0.01033 | 98.63 | 75.21 | ||
| 4 | 0.00037 | 0.01878 | 99.11 | 54.95 | ||
| 10 | 1 | 0.00349 | 0.02233 | 88.87 | 47.85 | |
| 2 | 0.00147 | 0.01741 | 95.32 | 59.35 | ||
| 3 | 0.00122 | 0.00656 | 96.11 | 84.69 | ||
| 4 | 0.00093 | 5.82780 | 97.03 | |||
| 20 | 1 | 0.00653 | 0.01684 | 83.81 | 59.93 | |
| 2 | 0.00258 | 0.00642 | 93.59 | 84.72 | ||
| 3 | 0.00185 | 0.00329 | 95.40 | 92.18 | ||
| 4 | 0.00165 | 0.00373 | 95.91 | 91.12 | ||
| Automobile | 5 | 1 | 0.07078 | 100.00 | −12.98 | |
| 2 | 0.07211 | 100.00 | −15.10 | |||
| 3 | 0.06992 | 100.00 | −11.61 | |||
| 4 | 0.07121 | 100.00 | −13.66 | |||
| 10 | 1 | 0.08464 | 100.00 | −36.34 | ||
| 2 | 0.08549 | 100.00 | −37.70 | |||
| 3 | 0.05165 | 100.00 | 16.80 | |||
| 4 | 0.05027 | 100.00 | 19.04 | |||
| 20 | 1 | 0.17308 | 100.00 | −181.87 | ||
| 2 | 0.14112 | 100.00 | −129.83 | |||
| 3 | 0.16912 | 100.00 | −175.43 | |||
| 4 | 0.14078 | 100.00 | −129.27 | |||
| Student Performance | 5 | 1 | 0.08539 | 100.00 | −197.44 | |
| 2 | 0.07496 | 100.00 | −161.09 | |||
| 3 | 0.02395 | 100.00 | 16.56 | |||
| 4 | 0.02728 | 100.00 | 4.99 | |||
| 10 | 1 | 0.00910 | 0.07507 | 66.09 | −158.08 | |
| 2 | 0.00186 | 0.03561 | 93.05 | −22.41 | ||
| 3 | 0.00151 | 0.01194 | 94.37 | 58.95 | ||
| 4 | 0.00100 | 0.02383 | 96.27 | 18.07 | ||
| 20 | 1 | 0.01423 | 0.03304 | 47.32 | −12.67 | |
| 2 | 0.00403 | 0.01178 | 85.06 | 59.82 | ||
| 3 | 0.00312 | 0.00659 | 88.43 | 77.53 | ||
| 4 | 0.00305 | 0.00676 | 88.70 | 76.95 | ||
| California Housing | 5 | 1 | 0.01949 | 0.02040 | 65.61 | 63.96 |
| 2 | 0.00497 | 0.00532 | 91.23 | 90.60 | ||
| 3 | 0.00382 | 0.00389 | 93.27 | 93.12 | ||
| 4 | 0.00381 | 0.00389 | 93.28 | 93.13 | ||
| 10 | 1 | 0.01783 | 0.02049 | 68.19 | 63.84 | |
| 2 | 0.00455 | 0.00518 | 91.87 | 90.87 | ||
| 3 | 0.00366 | 0.00384 | 93.48 | 93.22 | ||
| 4 | 0.00363 | 0.00386 | 93.52 | 93.19 | ||
| 20 | 1 | 0.01969 | 0.02027 | 64.68 | 64.32 | |
| 2 | 0.00521 | 0.00523 | 90.65 | 90.80 | ||
| 3 | 0.00371 | 0.00381 | 93.35 | 93.29 | ||
| 4 | 0.00369 | 0.00380 | 93.37 | 93.31 | ||
| Bike Sharing | 5 | 1 | 0.02051 | 0.02143 | 40.93 | 37.93 |
| 2 | 0.00343 | 0.00339 | 90.13 | 90.17 | ||
| 3 | 0.00255 | 0.00297 | 92.65 | 91.41 | ||
| 4 | 0.00249 | 0.00296 | 92.84 | 91.43 | ||
| 10 | 1 | 0.02122 | 0.02117 | 39.20 | 38.63 | |
| 2 | 0.00333 | 0.00347 | 90.47 | 89.94 | ||
| 3 | 0.00282 | 0.00294 | 91.93 | 91.48 | ||
| 4 | 0.00280 | 0.00292 | 91.98 | 91.53 | ||
| 20 | 1 | 0.02141 | 0.02111 | 39.42 | 38.52 | |
| 2 | 0.00411 | 0.00371 | 88.36 | 89.19 | ||
| 3 | 0.00295 | 0.00291 | 91.65 | 91.54 | ||
| 4 | 0.00291 | 0.00289 | 91.78 | 91.60 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stroka, S.M.; Heumann, C. Is Anonymization Through Discretization Reliable? Modeling Latent Probability Distributions for Ordinal Data as a Solution to the Small Sample Size Problem. Stats 2024, 7, 1189-1208. https://doi.org/10.3390/stats7040070
Stroka SM, Heumann C. Is Anonymization Through Discretization Reliable? Modeling Latent Probability Distributions for Ordinal Data as a Solution to the Small Sample Size Problem. Stats. 2024; 7(4):1189-1208. https://doi.org/10.3390/stats7040070
Chicago/Turabian StyleStroka, Stefan Michael, and Christian Heumann. 2024. "Is Anonymization Through Discretization Reliable? Modeling Latent Probability Distributions for Ordinal Data as a Solution to the Small Sample Size Problem" Stats 7, no. 4: 1189-1208. https://doi.org/10.3390/stats7040070
APA StyleStroka, S. M., & Heumann, C. (2024). Is Anonymization Through Discretization Reliable? Modeling Latent Probability Distributions for Ordinal Data as a Solution to the Small Sample Size Problem. Stats, 7(4), 1189-1208. https://doi.org/10.3390/stats7040070