1. Introduction
Air quality monitoring is important for the sustainable growth of cities, mitigating the risks that may affect human health. According to the American Environmental Protection Agency [
1], particle pollution includes inhalable particles of 2.5 (PM
) and 10 (PM
) microns or smaller, the source of which could be construction sites, unpaved roads, and forest fires, to name a few. When inhaled, these particles may cause serious health problems [
2,
3,
4]. There is a correlation between air pollution exposure and severe health concerns such as the incidence of respiratory and cardio-respiratory diseases [
5] and even deaths. Thus, PM
concentrations are measured constantly in the main cities to determine whether they are under the national permissible limit [
6,
7,
8]. To be prepared for the next extreme event, it is essential to forecast the intensity of the pollution levels, since air pollutant concentrations are influenced by emission levels, meteorological conditions, and geography.
Accurately predicting the level of pollution is of great importance. However, it is also challenging because the time series of PM
exhibit non-linear time-varying behavior with sudden events [
9]. Therefore, different approaches have been used to address this challenge, such as statistical methods [
10,
11], machine learning algorithms [
12], artificial neural networks (ANNs) [
13,
14,
15], deep learning algorithms in general [
16,
17], and other hybrid methods [
18,
19,
20]. In particular, ANNs have had great influence and wide applicability as a non-linear tool in the forecasting of time series [
21,
22], where different architectures have been used: a feed-forward neural network (FFNN) [
23], an Elman neural network [
24], a recursive neural network [
25], and adaptive neuro-fuzzy inference systems [
26]. These methods successfully model PM
and other pollution levels, generating accurate forecasts given their non-linear mapping and learning capabilities. Deep learning methods have been successfully applied to predict PM
concentrations [
27]. For instance, attention-based LSTM [
17] and convolutional neural network (CNN)–LSTM models [
16,
28] have been used for improving the performance of PM
forecasting using data from multiple monitoring locations. Even though predicting the average PM
concentrations is a problem reasonably addressed in the literature with various techniques, approaches that can also address the forecasting of pollution peaks are still challenging.
We consider extreme events as those observations in a sample that are unusually high or low and are, therefore, considered to occur in the tails of a probability distribution. To address problems such as forecasting and identifying trends in extreme levels of air pollution, understanding environmental extremes and forecasting extreme values is challenging and has paramount importance in weather and climate [
29]. Although extreme values can be momentary in time, they have the potential to recirculate within an urban area and, therefore, move around and affect other nearby locations, having significant adverse health implications [
30]. Extreme value data may often exhibit excess kurtosis and/or prominent right tails. Therefore, their exposure impact increases and is much more difficult to predict.
Several authors have proposed statistical methods to analyze and forecast environmental extremes. For instance, Zhang et al. [
31] analyzed the 95th percentile of historical data to study the relationship between the extreme concentration of ozone and PM
events, together with meteorological variables, such as the maximum daily temperature, the minimum relative humidity, and minimum wind speed. Bougoudis et al. [
32] presented a low-cost, rapid forecasting hybrid system that makes it possible to predict extreme values of atmospheric pollutants. Mijić et al. [
33] studied the daily average pollutant concentrations by fitting an exponential distribution. Zhou et al. [
4] applied the extreme value theory using the generalized Pareto distribution to model the return pollution levels at different periods, where the authors used the GPD to fit the PM
, NO
, and SO
in Changsha, China. Zhou et al. [
4] and Ercelebi et al. [
34] reported that the distribution might vary at different stations due to specific factors and conditions.
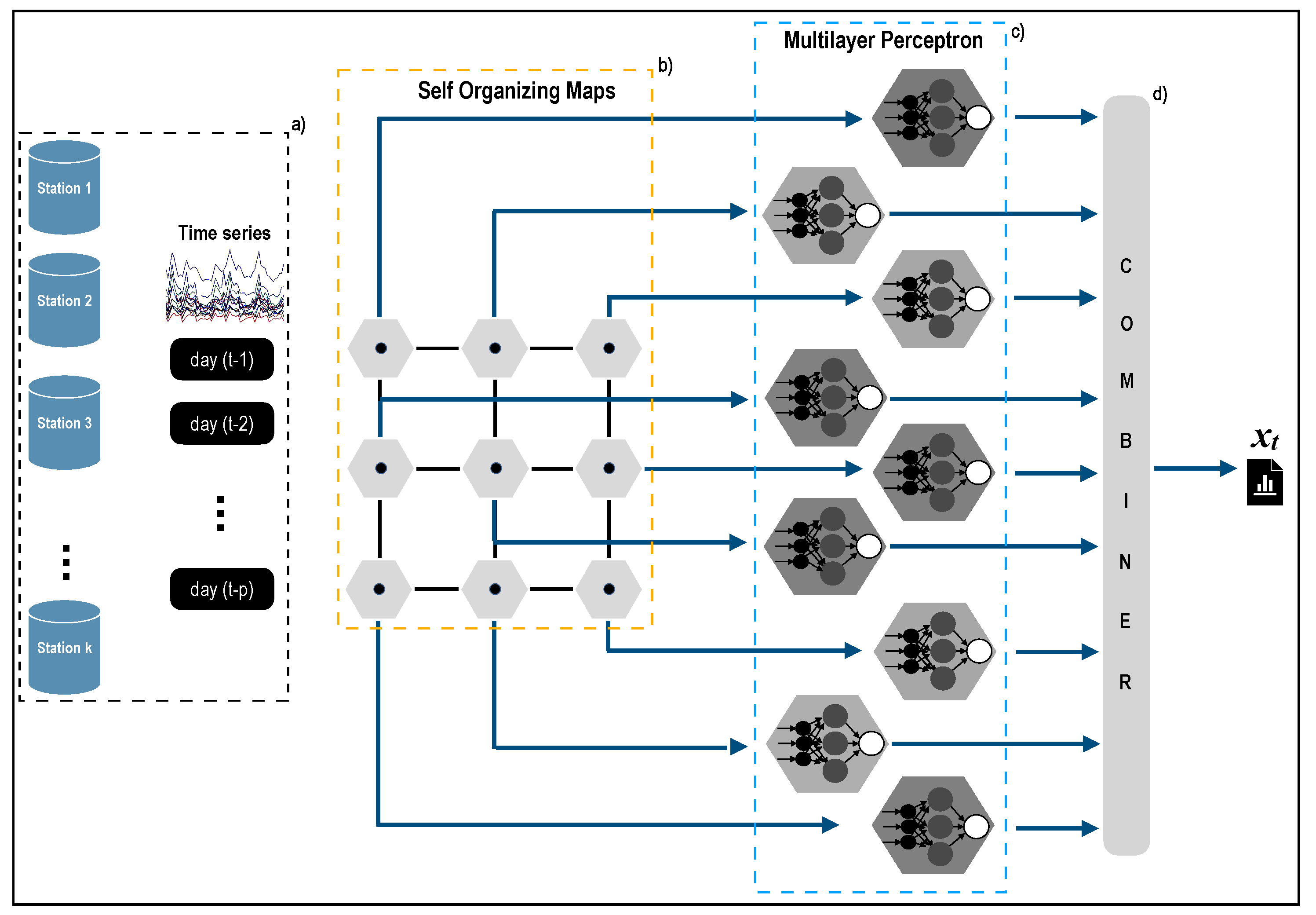
In this work, we propose a new hybrid method based on machine learning to predict extreme daily events of PM
pollution concentration. Without loss of generality, in this study, we consider extreme events to be the highest daily levels, particularly in the 75th and 90th percentiles. Predicting these excessive daily levels is complex because their behavior is not regular, and they are prone to environmental and urban factors. The proposed hybrid method combines the unsupervised learning self-organizing maps (SOM) [
35,
36] with the supervised Multilayer Perceptron (MLP) [
37] for time series forecasting. For this reason, the hybrid method is called Self-Organizing Topological Multilayer Perceptron (
SOM-MLP). The main idea behind the model is to identify temporal patterns of extreme daily pollution found at different monitoring stations. First, a self-organizing map is applied to cluster time series segments that present similar behaviors to accomplish this task. Second, a non-linear auto-regressive model is constructed using a multilayer perceptron for each cluster. The method is used for predicting the daily extreme values of PM
concentration depending on the pattern of the historical time series data obtained from several monitoring stations in the metropolitan area of Santiago, Chile. Lastly, a gate function is applied to aggregate the predictions of each model.
The paper is structured as follows. In
Section 2, we describe the theoretical framework of the multilayer perceptron and self-organizing map artificial neural networks. We introduce our proposed hybrid model in
Section 3. In
Section 4 and
Section 5, we show the simulation results and comparative analysis. Discussion is presented in
Section 6, and in
Section 7, we offer concluding remarks and some future challenges.
2. Theoretical Framework
2.1. Time Series Forecasting
A time series is a sequence of observed values
recorded at specific times
t [
38]. It represents the evolution of a stochastic process, which is a sequence of random variables indexed by time
. A time series model provides a specification of the joint distributions of these random variables
, capturing the underlying patterns and dependencies in the data.
Although many traditional models for analyzing and forecasting time series require the series to be stationary, non-stationary time series are commonly encountered in real-world data. Non-stationarity arises when the statistical properties of the series change over time, such as trends, seasonality, or shifts in mean and variance. Dealing with non-stationary time series poses challenges as standard techniques assume stationarity.
To handle non-stationary time series, various methods have been developed. One approach is to transform the series to achieve stationarity, such as differencing to remove trends or applying logarithmic or power transformations to stabilize the variance. Another approach is to explicitly model and account for non-stationarity, such as incorporating trend or seasonal components into the models.
In recent years, advanced techniques have been proposed to handle non-stationary time series effectively. These include proposals, adaptations, transformations, and generalizations of classical parametric and non-parametric methods, and modern machine and deep learning approaches. Neural networks, including multilayer perceptron (MLP) and self-organizing maps (SOM), have been applied with success because they can capture complex patterns and dependencies in non-stationary data, offering promising results.
In time series forecasting, MLPs can be trained to predict future values based on past observations. The network takes into account the temporal dependencies present in the data and learns to approximate the underlying mapping between input sequences and output forecasts. Various training algorithms, such as backpropagation, can be used to optimize the network’s weights and biases. Similarly, SOMs can be employed to discover patterns and structure within time series data. By projecting high-dimensional time series onto a 2D grid, SOMs reveal clusters and similarities between different sequences. This can assist in identifying distinct patterns, understanding data dynamics, and providing insights for further analysis.
Both MLPs and SOMs offer valuable tools for time series analysis, with MLPs focused on prediction and forecasting tasks, while SOMs excel in visualization and clustering. Their application in time series analysis depends on the specific problem, dataset characteristics, and objectives of the analysis. In the next subsections, we briefly describe both MLP and SOM neural networks.
2.2. Artificial Neural Networks
Artificial Neural Networks have received significant attention in engineering and science. Inspired by the study of brain architecture, ANN represents a class of non-linear models capable of learning from data [
39]. Some of the most popular models are the multilayer perceptron and the self-organizing maps. The essential features of an ANN are the basic processing elements referred to as neurons or nodes, the network architecture describing the connections between nodes, and the training algorithm used to estimate values of the network parameters. Researchers see ANNs as either highly parameterized models or semiparametric structures [
39]. ANNs can be considered as hypotheses of the parametric form
, where hypothesis
h is indexed by the vector of parameters
. The learning process consists of estimating the value of the vector of parameters
to adapt learner
h to perform a particular task.
2.2.1. Multilayer Perceptron
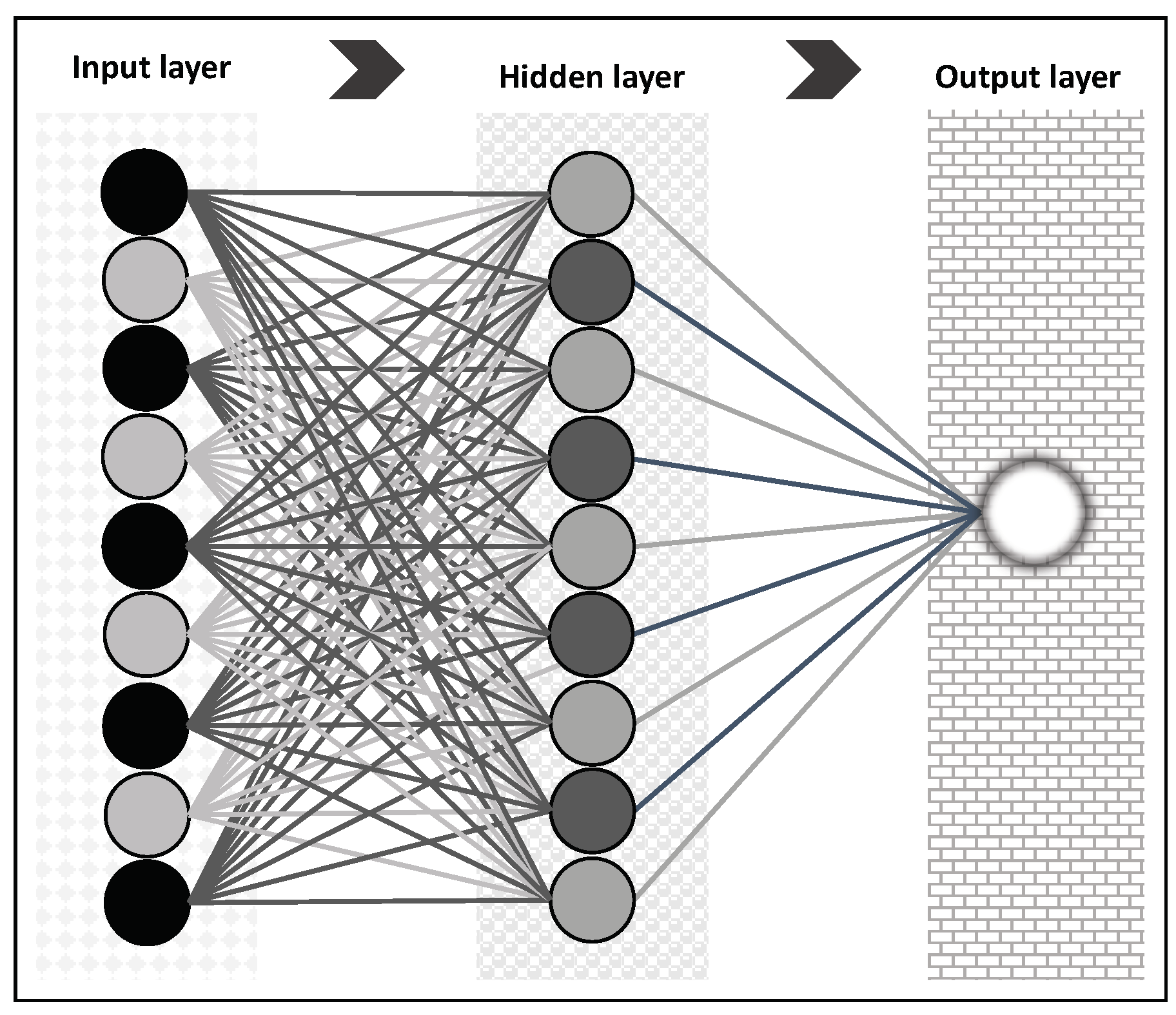
The multilayer perceptron (MLP) model consists of a set of elementary processing elements called neurons [
23,
40,
41,
42,
43]. These units are organized in architecture with three layers: the input, the hidden, and the output layers. The neurons corresponding to one layer are linked to the neurons of the subsequent layer.
Figure 1 illustrates the architecture of this artificial neural network with one hidden layer. The non-linear function
represents the output of the model, where
is the input signal and
is its parameter vector. For a three-layer ANN (one hidden layer), the
kth output computation is given by the following equation:
where
is the number of hidden neurons. An important factor in the specification of neural network models is the choice of the activation function (one of the most used functions is the sigmoid). These can be non-linear functions as long as they are continuous, bounded, and differentiable. The transfer function of hidden neurons
should be nonlinear, while for the output neurons, function
could be a linear or a nonlinear function.
The MLP operates as follows. The input layer neurons receive the input signal. These neurons propagate the signal to the first hidden layer and do not conduct any processing. The first hidden layer processes the signal and transfers it to the subsequent layer; the second hidden layer propagates the signal to the third, and so on. When the output layer receives and processes the signal, it generates a response. The MLP learns the mapping between input space and output space by adjusting the connection strengths between neurons called weights. Several techniques have been created to estimate the weights, the most popular being the backpropagation learning algorithm.
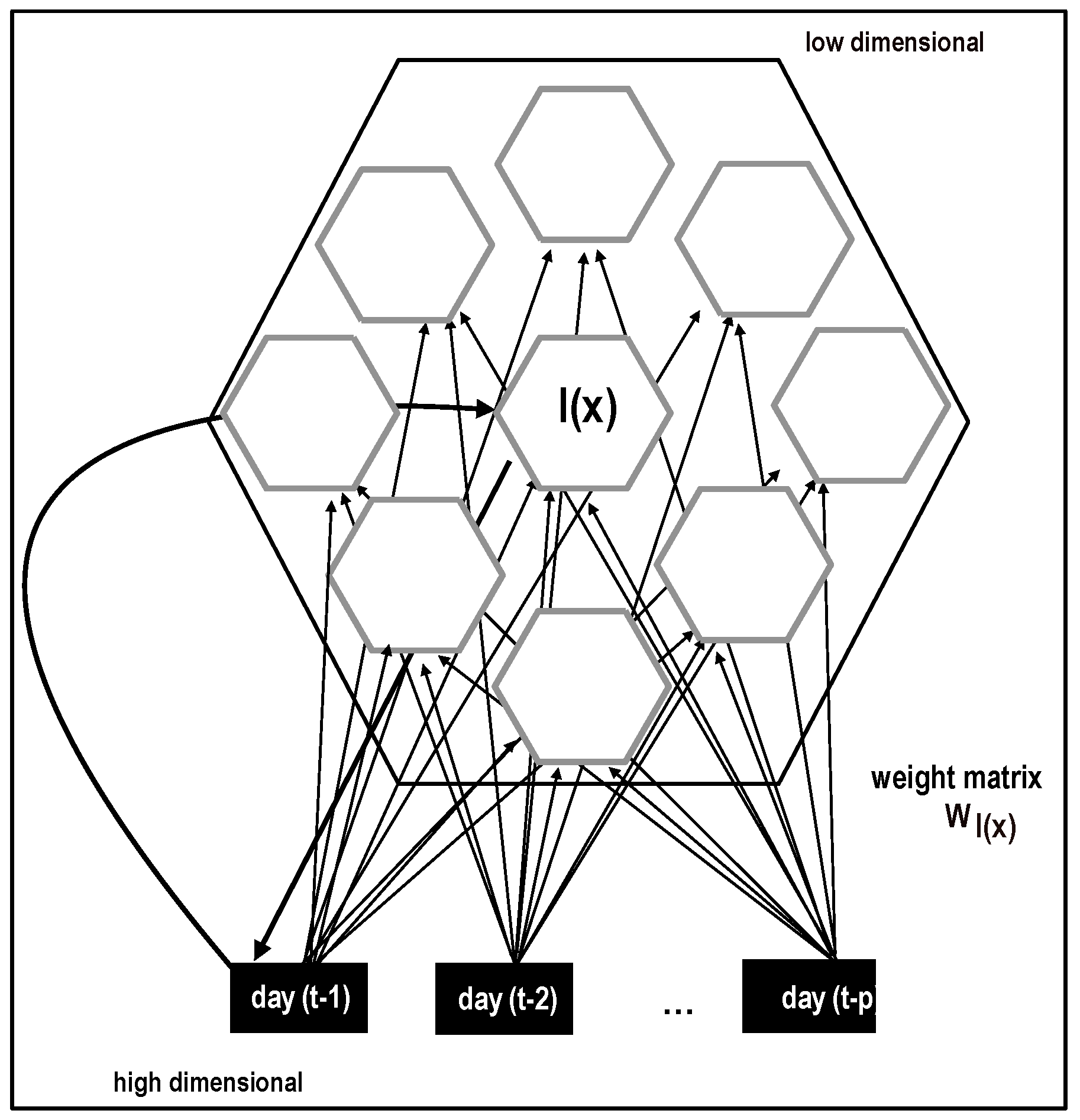
2.2.2. Self-Organizing Maps
The SOM, introduced by T. Kohonen [
35], is an artificial neural network with unsupervised learning. The model projects the topology mapping from the high-dimensional input space into a low-dimensional display (see
Figure 2). This model and its variants have been successfully applied in several areas [
44].
Map
consists of an ordered set of
M prototypes
,
, with a neighborhood relation between these units forming a grid, where
k indexes the location of the prototype in the grid. The most commonly used lattices are the linear, the rectangular, and the hexagonal arrays of cells. In this work, we consider the hexagonal grid where
is the vectorial location of the unit
in the grid. When the data vector
is presented to model
, it is projected to a neuron position of the low dimensional grid by searching the best matching unit (
), i.e., the prototype that is closest to the input and is obtained as follows:
where
is some user-defined distance metric (e.g., the Euclidean distance).
This model’s learning process consists of moving the reference vectors toward the current input by adjusting the prototype’s location in the input space. The winning unit and its neighbors adapt to represent the input by applying the following learning rule iteratively:
where the size of the learning step of the units is controlled by both learning rate parameter
and neighborhood kernel
. Learning rate parameter function
is a monotonically decreasing function with respect to time. For example, this function could be linear,
, or exponential,
, where
is the initial learning rate (<1.0),
is the final rate (≈0.01), and
is the maximum number of iteration steps to arrive to
. The neighborhood kernel is defined as a decreasing function of the distance between unit
and
on the map lattice at time
t. A Gaussian function usually produces the kernel.
In practice, the neighborhood kernel is chosen to be wide at the beginning of the learning process to guarantee the global ordering of the map, and both their width and height decrease slowly during learning. Repeated presentations of the training data thus lead to topological order. We can start from an initial state of complete disorder, and the SOM algorithm gradually leads to an organized representation of activation patterns drawn from the input space [
45]. In the recent years, there have been some improvements to this model; for example, Salas et al. [
46] added flexibility and robustness to the SOM; also, Salas et al. [
47] proposed a combination of SOM models.
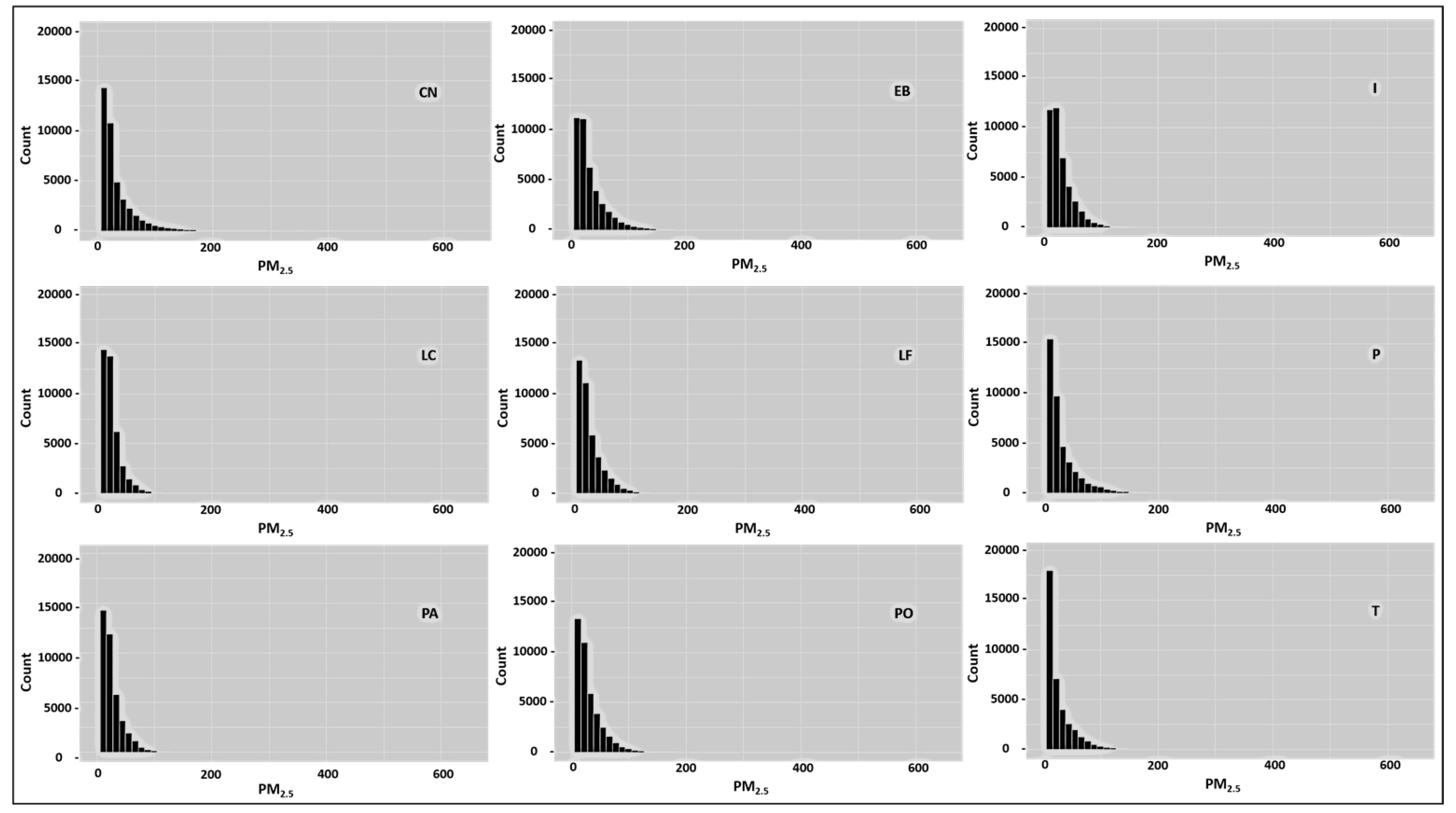
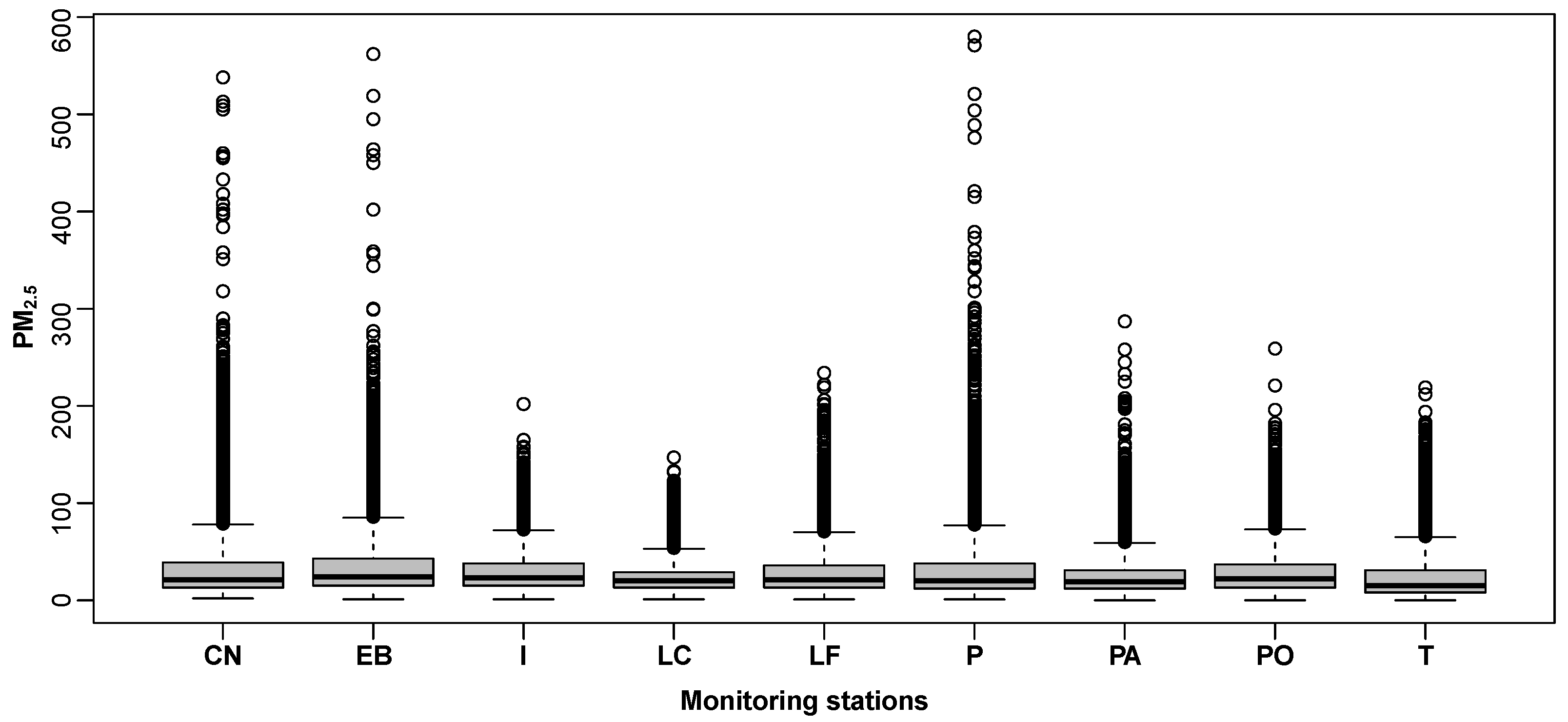
5. Performance Results
In this section, an evaluation of the performance of the proposed model SOM-MLP is carried out by comparing it with a global neural network (MLP-Global) and with neural networks obtained for each monitoring station (MLP-Station). The proposed model is applied to predict the next days’ extreme values given by the percentile 75 and 90 of that day, . The input vector is time segment constructed with day lags and . In this case, 72 neurons are used for the input layer, 96 neurons for the hidden layer, and one neuron for the output layer of the MLP models.
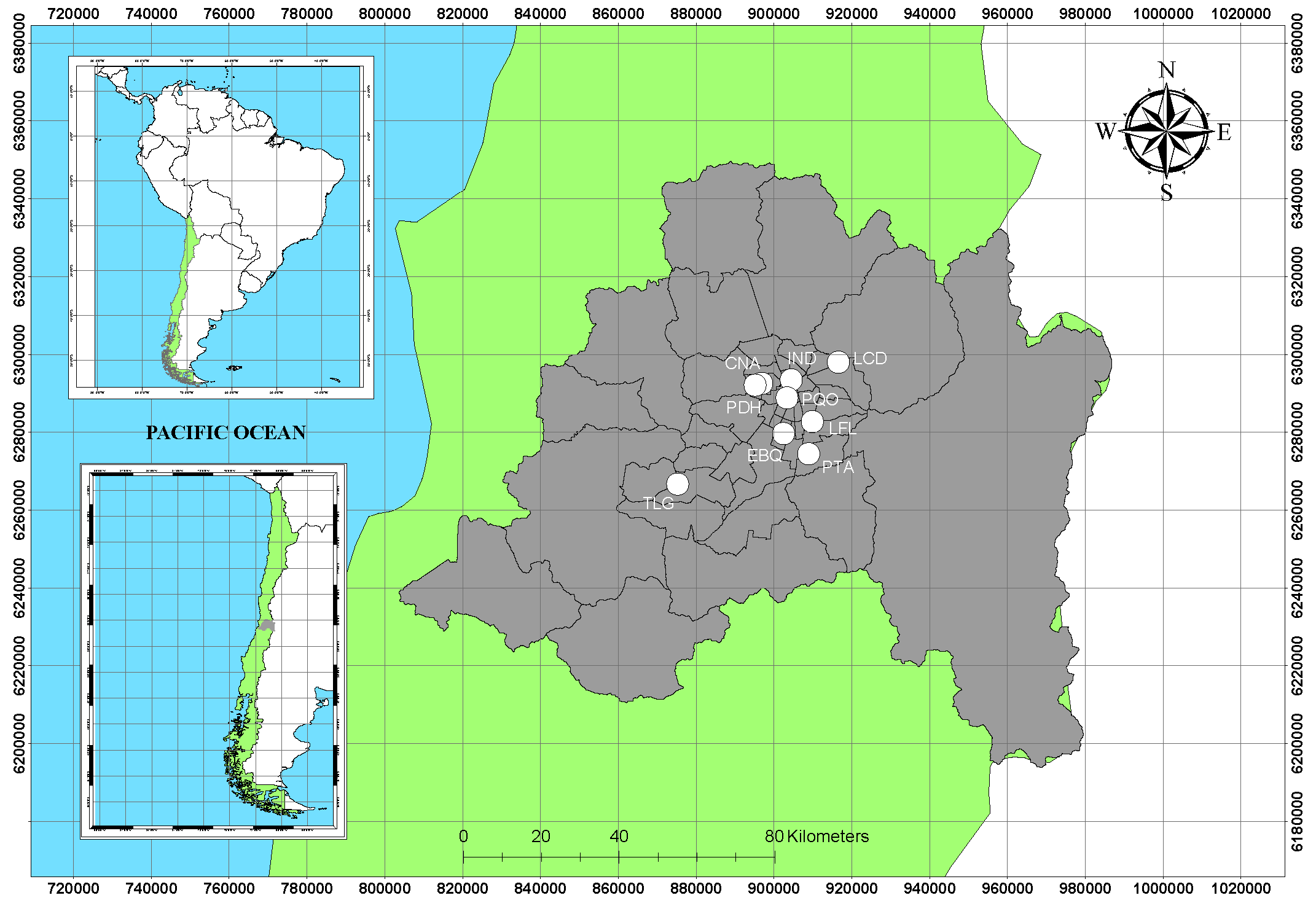
The data used in this study correspond to the concentrations of the PM
pollutant obtained on an hourly scale collected from 1 January 2015 to 30 September 2019. The data are obtained from the SINCA, where a total of nine monitoring stations are considered:
Cerro Navia (CNA),
Independencia (IND),
Las Condes (LCD),
Pudahuel (PDH),
Parque O’Higgins (POH),
La Florida (LFL),
El Bosque (EBQ),
Puente Alto (PTA) and
Talagante (TLG) (see
Figure 4).
The data set is divided into training (80%) and test (20%) sets, where the latter has the last 365 days. The training set is used to find the parameters of the neural network models, and the test set is used to evaluate the prediction performance capabilities of the models. The three approaches and the evaluation of the SOM-MLP model performance are implemented through a hold-out validation scheme using 1360 days for training and 365 days for testing.
Table 3 shows the performance of the global MLP method (
MLP-Global) and the MLP constructed for each Station (
MLP-Station) compared to our proposed hybrid method
SOM-MLP with 4, 9 and 25 neurons. The
SOM-MLP shows a good compromise between complexity and performance and outperforms the
MLP-Global and
MLP-Station alternatives.
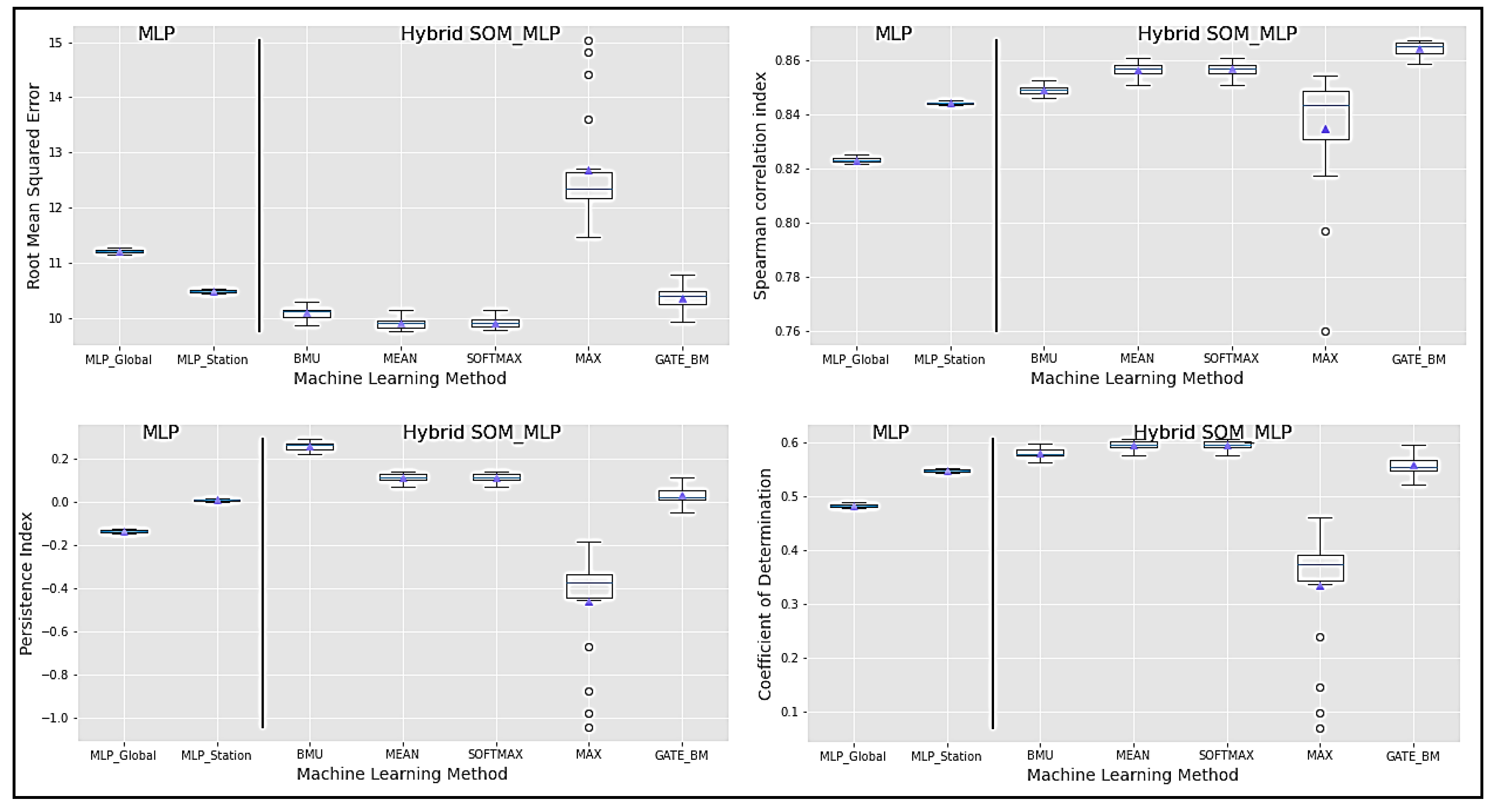
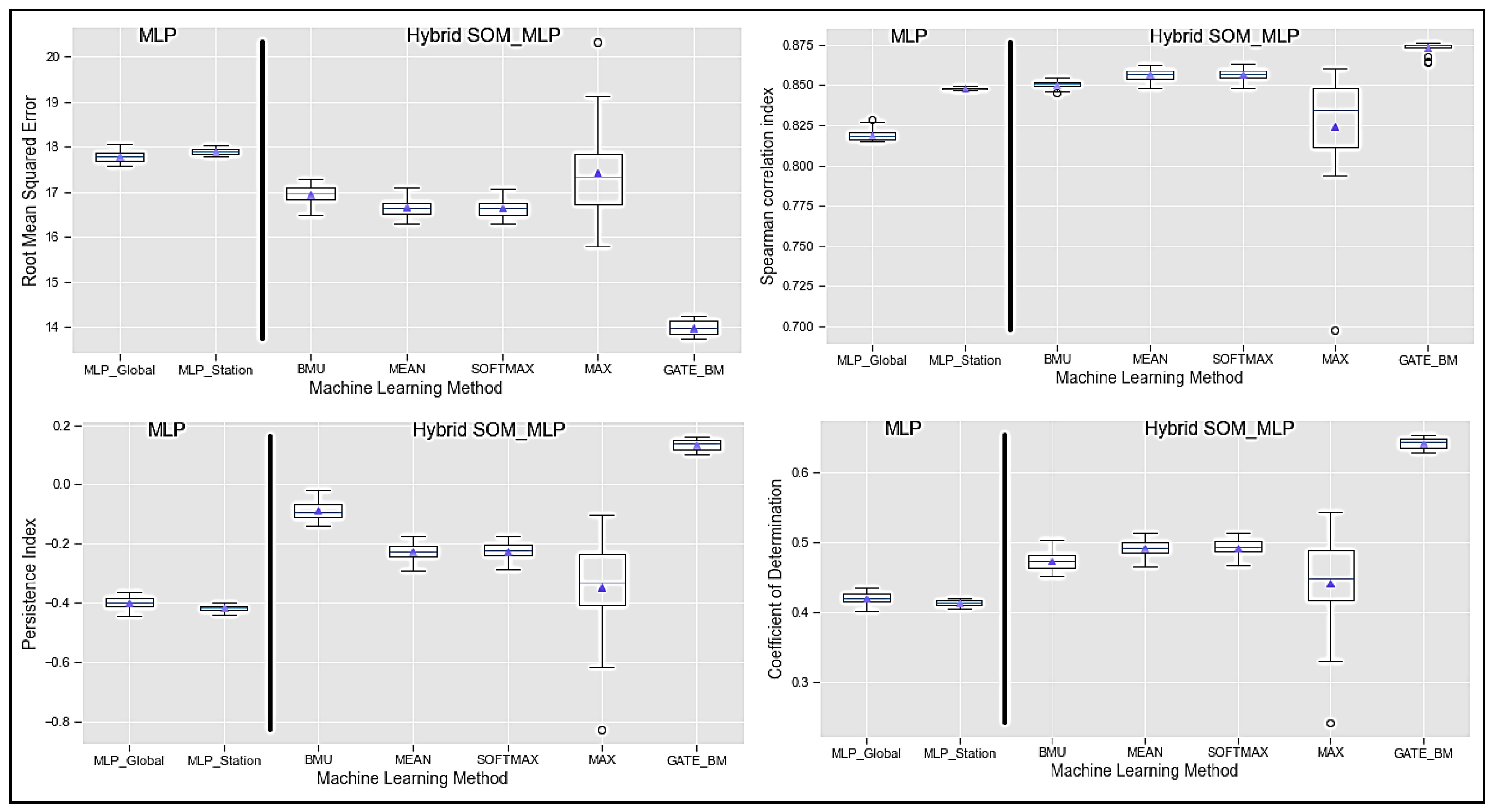
Figure 8 and
Figure 9 show the boxplots of the performance metric for each gate for the 75th and 90th percentiles, respectively. Among these are the RMSE, the Spearman correlation index, and the coefficient of determination. For the 90th percentile, it is observed that the GATE_BM is the one with the best performance. It is highlighted that, in extreme values, it is convenient to use the GATE_BM, which does not happen for the 75th percentile since other operators such as BMU, mean, and softmax are suitable in this scenario.
Table 4,
Table 5,
Table 6 and
Table 7 report the performances of the models. Furthermore,
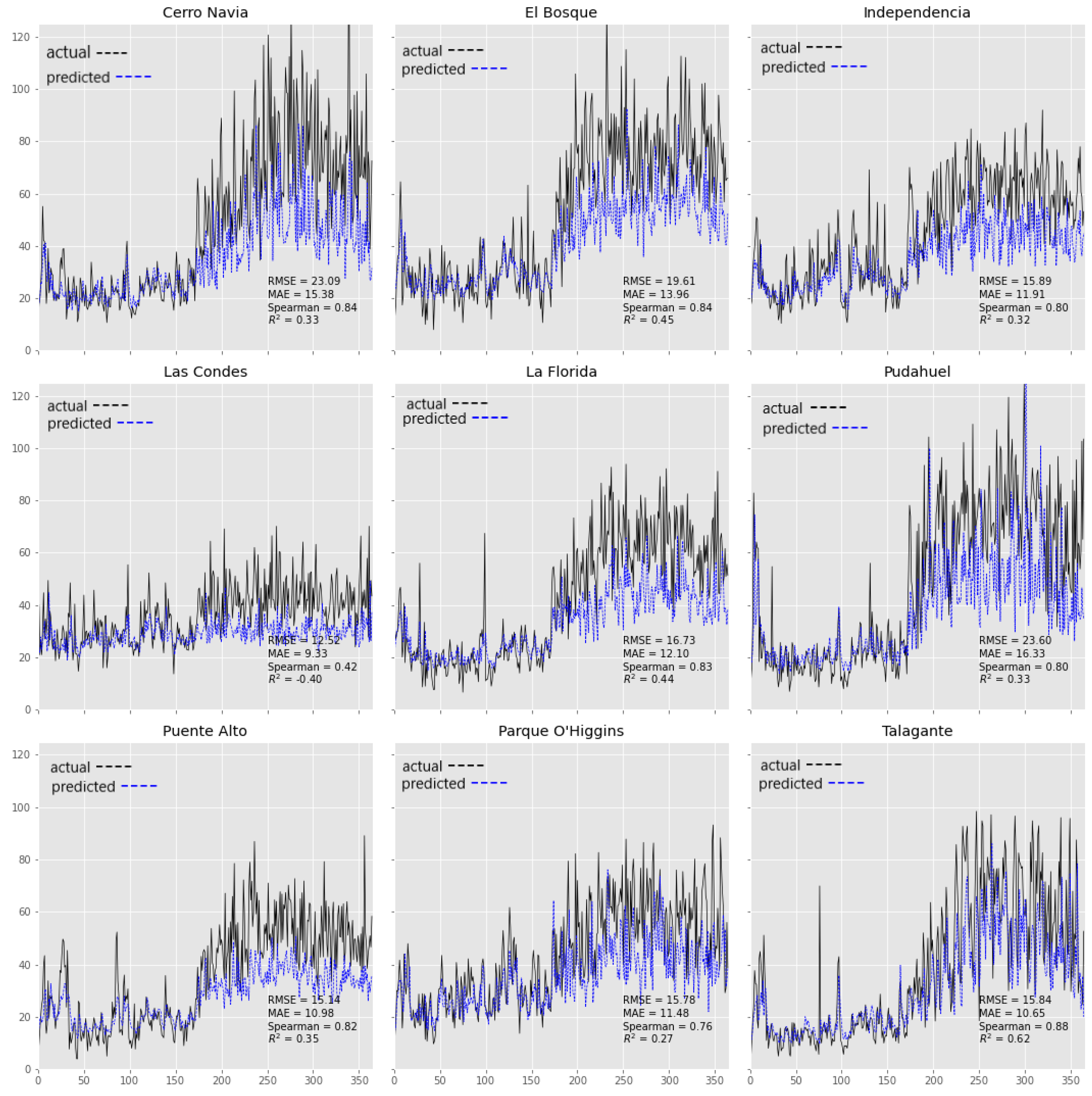
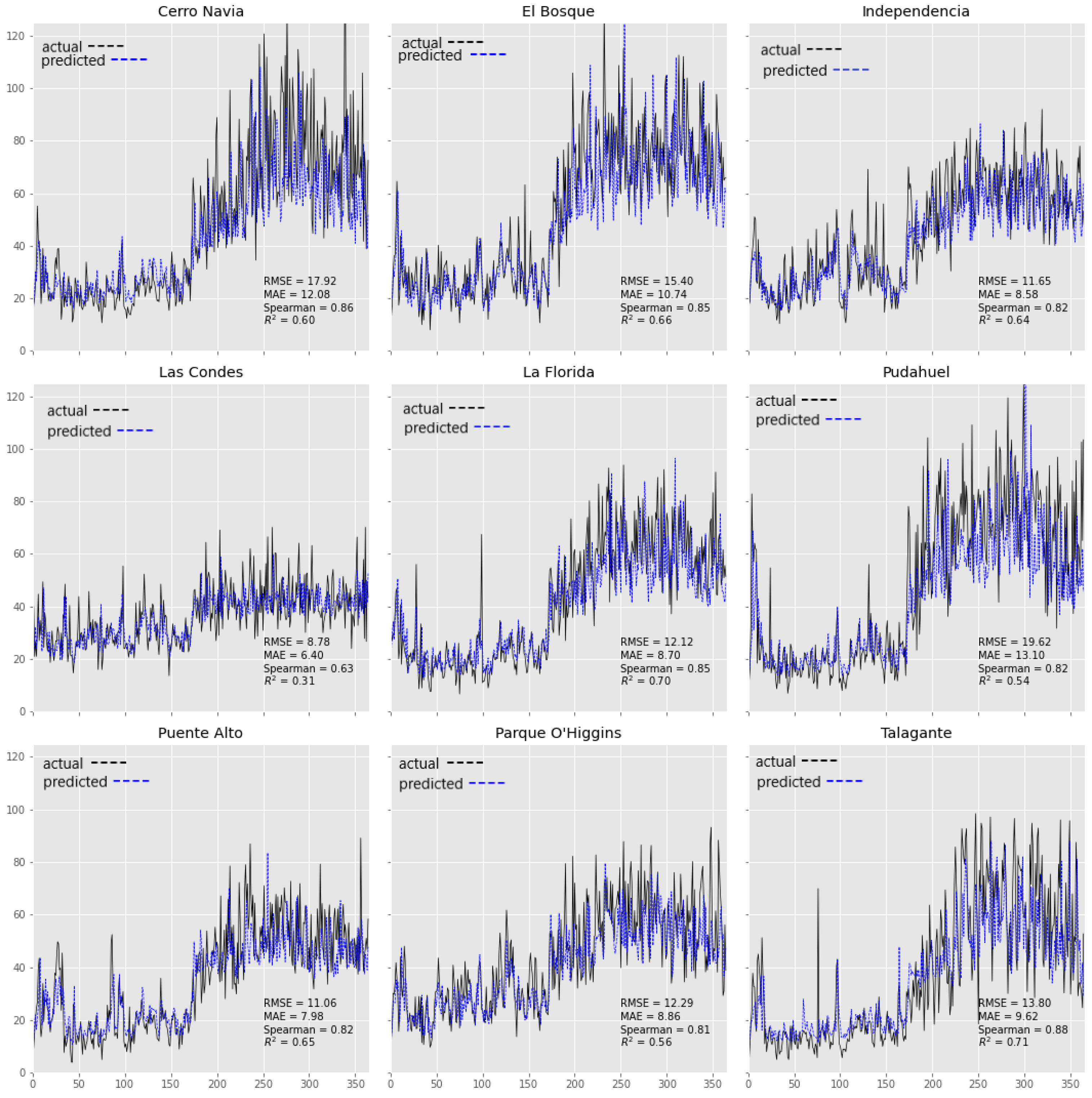
Figure 10 and
Figure 11 show the behavior of the MLP-Station and the hybrid model for each monitoring station, respectively. The highest
values of the model fit are observed at the
El Bosque,
La Florida and
Talagante monitoring stations.
6. Discussion
Extreme events in time series refer to episodes with unusually high values that can infrequently, sporadically, or frequently occur [
56]. Predicting such extreme events remains a significant challenge [
57] due to factors like limited available data, dependence on exogenous variables, or long memory dependence. Qi et al. [
57] emphasized the need for neural networks to exhibit adaptive skills in diverse statistical regimes beyond the training dataset.
To address this challenge, we propose a SOM-MLP hybrid model that segments time series into clusters of similar temporal patterns for each station. The MLP acts as a non-linear autoregressive model adapted to these patterns. Our hybrid method demonstrates improved prediction performance, as shown in
Table 3, with the SOM-MLP model consisting of nine nodes achieving the best results compared to the MLP-Global and MLP-Station models, exhibiting lower MAE and MAPE metrics.
We utilize aggregating operators for the SOM-MLP model with nine nodes to enhance computational efficiency for both the 75th and 90th percentiles. The best matching unit (BMU) operator performs well for the 75th percentile (see
Table 4 and
Table 5), while the BMU-MAX gate yields the best results for the 90th percentile (see
Table 6 and
Table 7). These operators significantly improve the prediction of extreme values, especially during periods of high magnitude and volatility.
The proposed hybrid method, SOM-MLP, effectively captures local similarities in hourly series, enhancing the next day’s 75th or 90th percentile forecasting. While estimating peak values remains challenging, particularly in volatile time series, our approach successfully captures trends and behaviors in each node’s segmented series. This highlights the potential of our proposal for improving extreme value predictions in various time series applications.
7. Conclusions
In this study, we propose a strategy to capture the essential information regarding the topological structure of PM time series. Our hybrid model demonstrates improved forecasting capabilities, particularly for extreme values. To the best of our knowledge, this is the first paper to employ this approach for predicting extreme air quality time-series events in Santiago, Chile. We observe that recognizing patterns in unique or clustered time series is essential for defining the hybrid model. The comparison of the evaluated models’ performance indicates the potential for improvement through a combined optimization of operators.
Our results demonstrate that the proposed hybrid method outperforms the application of the MLP method per station, which, in turn, exhibits superior performance compared to the Global method. Consequently, these results pave the way for future stages where optimization processes can be implemented within the MLP network structure. Additionally, it is worth exploring the use of alternative neural networks or other methods of interest to enhance the hybrid method further.
This proposal serves as a sophisticated tool for assessing air quality and formulating protective policies for the population. Moreover, the proposed model can be extended to other pollutants, with a specific emphasis on capturing their extreme values and multivariate analysis for seasons, which are often neglected. For instance, in [
58], the authors mention their developed model’s inability to predict extreme ozone values. Our proposed model can be applied to analyze this pollutant in future work. Similarly, in [
10], a visualization approach for PM
is proposed, which can be complemented by applying our hybrid method for predictive purposes. Furthermore, this study’s framework can be extrapolated to investigate PM
in the city of Lima, Peru using neural networks [
14].
It is important to highlight that the proposed methodology has some limitations. First, the technique is developed to analyze environmental pollution data based on univariate time series from various sources. Further studies are required for its validation in other contexts (for example, in data related to air quality [
59,
60,
61], solid waste [
62], also in academic performance data [
63], data related to digital marketing [
64] or those based on energy efficiency [
65,
66]). One of the methodology’s significant limitations is that it does not preserve the time series structure since it assumes an auto-regressive model with a pre-defined lag size.
The proposed approach can also be extended to support the analysis of behaviors in other pollutants in multidimensional cases. Further studies are needed to evaluate the proposed methodology when the time series is decomposed into trend, seasonal, and long-term components, which can be imputed to the model by themselves or together after removing the noise, besides considering incorporating regularization techniques such as Dropout [
67] and other strategies to avoid over-parameterization. Moreover, the models can be further improved by introducing geospatial information.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}