
Addressing Disparities in the Propensity Score Distributions for Treatment Comparisons from Observational Studies

Abstract
:1. Introduction
2. Causal Estimands
- Positivity: Each subject has a positive probability of being assigned to either treatment of interest. The assumption is violated when there exists neighborhoods in the covariate space where all subjects are assigned the same treatment.
- Ignorable treatment assignment: : Treatment assignment is independent of the potential outcomes, given the observed covariates.
2.1. ATE
2.2. TATE
2.3. ATM
2.4. ATO
3. Causal Estimators
3.1. IPTW
3.2. AIPTW
3.3. PENCOMP
4. Simulation
4.1. Study Design
4.2. Results
5. Application
5.1. Multicenter AIDS Cohort Study (MACS)
5.2. Right Heart Catheterization (RHC)
6. Discussion
7. Disclaimer
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Supplementary Results from Applications

{kind=link}
| Before Adjusting | After Adjusting | |||||
|---|---|---|---|---|---|---|
| Covariates | Mean | Mean | Standardized | T Stats | Standardized | T Stats |
| Treated | Control | Mean Difference | Mean Difference | |||
| CD4 visit 12 | 17.15 | 23.97 | −1.13 | 17.32 | 0.0086 | −0.13 |
| CD4 visit 13 | 17.01 | 23.65 | −0.99 | 15.09 | −0.0072 | 0.11 |
| CD8 visit 12 | 30.46 | 31.16 | −0.094 | 1.43 | −0.015 | 0.23 |
| CD8 visit 13 | 29.53 | 30.34 | −0.11 | 1.61 | −0.012 | 0.18 |
| WBC visit 12 | 67.03 | 74.33 | −0.68 | 10.38 | 0.00013 | −0.0020 |
| WBC visit 13 | 65.61 | 72.18 | −0.59 | 8.94 | −0.030 | 0.46 |
| RBC visit 12 | 1.99 | 2.18 | −1.30 | 19.45 | 0.012 | −0.18 |
| RBC visit 13 | 1.93 | 2.18 | −1.96 | 29.65 | −0.018 | 0.28 |
| Platelet visit 12 | 14.76 | 15.03 | −0.12 | 1.75 | −0.0044 | 0.067 |
| Platelet visit 13 | 14.57 | 14.69 | −0.054 | 0.82 | −0.019 | 0.28 |
| age | 39.78 | 38.11 | 0.24 | −3.65 | 0.00062 | −0.0095 |
| white | 0.94 | 0.85 | 0.28 | −4.33 | 0.011 | −0.17 |
References
- Imbens, G.W.; Rubin, D.B. Causal Inference in Statistics, Social, and Biomedical Sciences; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar]
- Rosenbaum, P.R.; Rubin, D.B. The Central Role of the Propensity Score in Observational Studies for Causal Effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. Reducing Bias in Observational Studies Using Subclassification on the Propensity Score. J. Am. Stat. Assoc. 1984, 79, 516–524. [Google Scholar] [CrossRef]
- Zhou, T.; Elliott, M.R.; Little, R.J.A. Penalized Spline of Propensity Methods for Treatment Comparison. J. Am. Stat. Assoc. 2019, 114, 1–19. [Google Scholar] [CrossRef]
- Gutman, R.; Rubin, D. Robust Estimation of Causal Effects of Binary Treatments in Unconfounded Studies with Dichotomous Outcomes. Stat. Med. 2013, 32, 1795–1814. [Google Scholar] [CrossRef]
- Cochran, W.; Rubin, D. Controlling Bias in Observational Studies: A Review. Indian J. Stat. 1973, 35, 417–446. [Google Scholar]
- Dehejia, R.; Wahba, S. Causal Effects in Nonexperimental Studies: Reevaluating the Evalutation of Training Programs. J. Am. Stat. Assoc. 1999, 94, 1053–1062. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Optimal Matching of an Optimally Chosen Subset in Observational Studies. J. Comput. Graph. Stat. 2012, 21, 57–71. [Google Scholar] [CrossRef]
- Ho, D.E.; Imai, K.; King, G.; Stuart, E.A. Matching As Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference. Political Anal. 2007, 15, 199–236. [Google Scholar] [CrossRef] [Green Version]
- Crump, R.; Hotz, V.; Imbens, G.; Mitnik, O. Dealing with Limited Overlap in Estimation of Average Treatment Effects. Biometrika 2009, 96, 187–199. [Google Scholar] [CrossRef] [Green Version]
- Yoshida, K.; Solomon, D.H.; Haneuse, S.; Kim, S.C.; Patorno, E.; Tedeschi, S.K.; Lyu, H.; Franklin, J.M.; Stürmer, T.; Hernández-Díaz, S.; et al. Multinomial Extension of Propensity Score Trimming Methods: A Simulation Study. Am. J. Epidemiol. 2019, 188, 609–616. [Google Scholar] [CrossRef]
- Li, F.; Morgan, K.; Zaslavsky, A. Balancing Covariates via Propensity Score Weighting. J. Am. Stat. Assoc. 2017, 113–521, 390–400. [Google Scholar] [CrossRef]
- Li, F.; Thomas, L.E.; Li, F. Addressing Extreme Propensity Scores via The Overlap Weights. Am. J. Epidemiol. 2019, 188, 250–257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, L.; Greene, T. A Weighting Analogue to Pair Matching in Propensity Score Analysis. Int. J. Biostat. 2013, 9, 215–234. [Google Scholar] [CrossRef] [PubMed]
- Mao, H.; Li, L.; Greene, T. Propensity Score Weighting Analysis and Treatment Effect Discovery. Stat. Methods Med. Res. 2018, 28, 2439–2454. [Google Scholar] [CrossRef] [PubMed]
- Stürmer, T.; Rothman, K.; Avorn, J.; Glynn, R.J. Treatment Effects in the Presence of Unmeasured Confounding: Dealing with Observations in the Tails of the Propensity Score Distribution—A Simulation Study. Am. J. Epidemiol. 2010, 172, 843–854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imbens, G.W.; Wooldridge, J.M. Recent Developments in the Econometrics of Program Evaluation. J. Econ. Lit. 2009, 47, 5–86. [Google Scholar] [CrossRef] [Green Version]
- Angrist, J.D.; Imbens, G.W.; Rubin, D.B. Identification of Causal Effects Using Instrumental Variables. J. Am. Stat. Assoc. 1996, 91, 444–455. [Google Scholar] [CrossRef]
- Rubin, D.B. Discussion of “Randomization Analysis of Experimental Data: The Fisher Randomization Test” by D. Basu. J. Am. Stat. Assoc. 1980, 75, 591–593. [Google Scholar]
- Imai, K.; King, G.; Stuart, E. Misunderstandings between Experimentalists and Observationalists about Causal Inference. J. R. Stat. Soc. Ser. B (Stat. Soc.) 2008, 171, 481–502. [Google Scholar] [CrossRef] [Green Version]
- Samuels, L.R. Aspects of Causal Inference within the Evenly Matchable Population: The Average Treatment Effect on the Evenly Matchable Units, Visually Guided Cohort Selection, and Bagged One-to-One Matching; Vanderbilt University: Nashville, TN, USA, 2017. [Google Scholar]
- Kang, J.; Schafer, J. Demystifying Double Robustness: A Comparison of Alternative Strategies for Estimating a Population Mean from Incomplete Data. Stat. Sci. 2007, 22, 523–539. [Google Scholar]
- Zhou, T.; Elliott, M.R.; Little, R.J.A. Robust Causal Estimation from Observational Studies Using Penalized Spline of Propensity Score for Treatment Comparison. Stats 2021, 4, 529–549. [Google Scholar] [CrossRef]
- Little, R.J.A.; An, H. Robust Likelihood-Based Analysis of Multivariate Data with Missing Values. Stat. Sin. 2004, 14, 949–968. [Google Scholar]
- Zhang, G.; Little, R.J.A. Extensions of the Penalized Spline of Propensity Prediction Method of Imputation. Biometrics 2009, 65, 911–918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elliott, M.R.; Little, R.J.A. Discussion of on Bayesian Estimation of Marginal Structural Models. Biometrics 2015, 71, 288–291. [Google Scholar] [CrossRef]
- Elliott, M.R.; Little, R.J.A. Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies. J. Educ. Psychol. 1974, 66, 688–701. [Google Scholar]
- Yu, Y.; Zhang, M.; Shi, X.; Caram, M.; Little, R.; Mukherjee, B. A Comparison of Parametric Propensity Score-Based Methods for Causal Inference with Multiple Treatments and a Binary Outcome. Stat. Med. 2021, 40, 1653–1667. [Google Scholar] [CrossRef]
- Eilers, P.H.C.; Marx, B.D. Flexible Smoothing with b-splines and Penalties. Stat. Sci. 1996, 11, 89–121. [Google Scholar] [CrossRef]
- Ngo, L.; Wand, M.P. Smoothing with Mixed Model Software. J. Stat. Softw. 2004, 9, 1–54. [Google Scholar] [CrossRef]
- Wand, M.P. Smoothing and mixed models. Comput. Stat. 2003, 18, 223–249. [Google Scholar] [CrossRef]
- Schafer, J.; Kang, J. Average Causal Effects from Nonrandomized Studies: A Practical Guide and Simulated Example. Psychol. Methods 2008, 13, 279. [Google Scholar] [CrossRef]
- Kaslow, R.A.; Ostrow, D.G.; Detels, R.; Phair, J.P.; Polk, B.F.; Rinaldo, C.J. The Multicenter AIDS Cohort Study: Rationale, Organization, and Selected Characteristics of the Participants. Am. J. Epidemiol. 1987, 126, 310–318. [Google Scholar] [CrossRef] [PubMed]
- Connors, A.F.; Speroff, T.; Dawson, N.V.; Thomas, C.; Harrell, F.E.; Wagner, D.; Desbiens, N.; Goldman, L.; Wu, A.W.; Califf, R.M.; et al. The Effectiveness of Right Heart Catheterization in the Initial Care of Critically Ill Patients. J. Am. Med. Assoc. 2001, 276, 889–897. [Google Scholar] [CrossRef]
- Hirano, K.; Imbens, G. Estimation of Causal Effects Using Propensity Score Weighting: An Application to Data on Right Heart Catheterization. Health Serv. Outcomes Res. Methodol. 2001, 2, 259–278. [Google Scholar] [CrossRef]
- Traskin, M.; Small, D. Defining the Study Population for an Observational Study to Ensure Sufficient Overlap: A Tree Approach. Stat. Biosci. 2011, 3, 94–118. [Google Scholar] [CrossRef]
- Rubin, D.B. The Design Versus the Analysis of Observational Studies for Causal Effects: Parallels with the Design of Randomized Trials. Stat. Med. 2007, 26, 20–36. [Google Scholar] [CrossRef] [PubMed]
- Brookhart, M.A.; Schneeweiss, S.; Rothman, K.J.; Glynn, R.J.; Avorn, J.; Stürmer, T. Variable Selection for Propensity Score Models. Am. J. Epidemiol. 1992, 163, 1149–1156. [Google Scholar] [CrossRef]
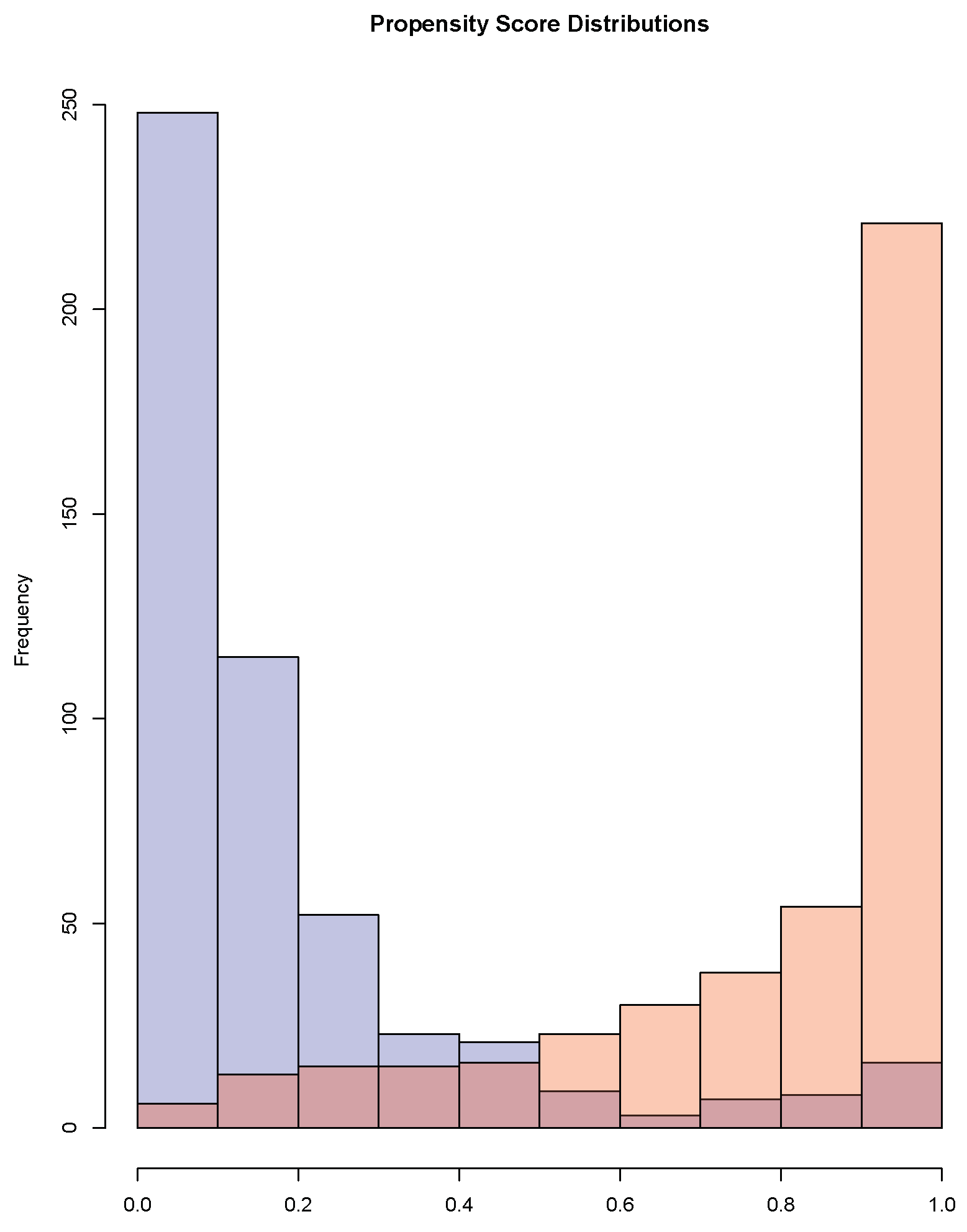
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 750 | 555 | 74 | 112 | 41.4 |
| ATE | AIPTW | 750 | 3 | 0 | 26 | 9.2 |
| ATE | PENCOMP | 750 | 6 | 1 | 20 | 2.2 |
| ATM | IPTW | 750 | 0 | 0 | 14 | 5.0 |
| ATM | AIPTW | 750 | 2 | 0 | 14 | 4.2 |
| ATM | PENCOMP | 750 | 3 | 0 | 14 | 2.4 |
| ATO | IPTW | 750 | 4 | 1 | 14 | 5.4 |
| ATO | AIPTW | 750 | 4 | 1 | 14 | 5.2 |
| ATO | PENCOMP | 750 | 3 | 0 | 14 | 4.0 |
| TATE0.01 | IPTW | 750 | 92 | 12 | 45 | 10.0 |
| TATE0.01 | AIPTW | 750 | 13 | 2 | 21 | 8.8 |
| TATE0.01 | PENCOMP | 750 | 5 | 1 | 16 | 4.0 |
| TATE0.05 | IPTW | 750 | 22 | 3 | 22 | 4.8 |
| TATE0.05 | AIPTW | 750 | 12 | 2 | 17 | 4.2 |
| TATE0.05 | PENCOMP | 750 | 5 | 1 | 14 | 4.4 |
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 750 | 555 | 74 | 112 | 41.4 |
| ATE | AIPTW | 750 | 229 | 31 | 63 | 30.8 |
| ATE | PENCOMP | 750 | 44 | 6 | 22 | 2.0 |
| ATE | PENCOMP* | 750 | 23 | 3 | 22 | 1.2 |
| ATM | IPTW | 750 | 0 | 0 | 14 | 5.0 |
| ATM | AIPTW | 750 | 3 | 0 | 15 | 4.6 |
| ATM | PENCOMP | 750 | 29 | 4 | 14 | 1.8 |
| ATM | PENCOMP* | 750 | 47 | 6 | 15 | 1.2 |
| ATO | IPTW | 750 | 4 | 1 | 14 | 5.4 |
| ATO | AIPTW | 750 | 6 | 1 | 14 | 5.4 |
| ATO | PENCOMP | 750 | 19 | 3 | 14 | 3.4 |
| ATO | PENCOMP* | 750 | 37 | 5 | 14 | 2.6 |
| TATE0.01 | IPTW | 750 | 92 | 12 | 45 | 10.0 |
| TATE0.01 | AIPTW | 750 | 49 | 7 | 35 | 11.0 |
| TATE0.01 | PENCOMP | 750 | 20 | 3 | 16 | 2.8 |
| TATE0.01 | PENCOMP* | 750 | 30 | 4 | 16 | 2.2 |
| TATE0.05 | IPTW | 750 | 22 | 3 | 22 | 4.8 |
| TATE0.05 | AIPTW | 750 | 16 | 2 | 21 | 3.6 |
| TATE0.05 | PENCOMP | 750 | 17 | 2 | 14 | 3.4 |
| TATE0.05 | PENCOMP* | 750 | 36 | 5 | 15 | 2.2 |
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 750 | 963 | 128 | 127 | 62.2 |
| ATE | AIPTW | 750 | 9 | 1 | 24 | 8.0 |
| ATE | PENCOMP | 750 | 0 | 0 | 20 | 2.8 |
| ATM | IPTW | 750 | 435 | 58 | 46 | 74.8 |
| ATM | AIPTW | 750 | 2 | 0 | 14 | 5.0 |
| ATM | PENCOMP | 750 | 2 | 0 | 14 | 2.6 |
| ATO | IPTW | 750 | 439 | 59 | 47 | 78.0 |
| ATO | AIPTW | 750 | 3 | 0 | 14 | 6.0 |
| ATO | PENCOMP | 750 | 2 | 0 | 14 | 4.4 |
| TATE0.01 | IPTW | 750 | 552 | 74 | 69 | 39.0 |
| TATE0.01 | AIPTW | 750 | 1 | 0 | 20 | 8.2 |
| TATE0.01 | PENCOMP | 750 | 1 | 0 | 16 | 5.2 |
| TATE0.05 | IPTW | 750 | 461 | 61 | 51 | 54.8 |
| TATE0.05 | AIPTW | 750 | 0 | 0 | 16 | 5.2 |
| TATE0.05 | PENCOMP | 750 | 2 | 0 | 14 | 4.4 |
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 144 | 33.07 | 22.90 | 8.8 | 19.8 |
| ATE | AIPTW | 144 | 2.02 | 1.40 | 2.7 | 3.8 |
| ATE | PENCOMP | 144 | 0.44 | 0.31 | 2.4 | 3.2 |
| ATM | IPTW | 252 | 4.67 | 1.85 | 5.1 | 5.4 |
| ATM | AIPTW | 252 | 3.95 | 1.57 | 4.7 | 3.8 |
| ATM | PENCOMP | 252 | 6.18 | 2.45 | 4.7 | 2.4 |
| ATO | IPTW | 242 | 4.57 | 1.89 | 4.8 | 4.2 |
| ATO | AIPTW | 242 | 4.17 | 1.72 | 4.3 | 3.4 |
| ATO | PENCOMP | 242 | 4.11 | 1.70 | 4.4 | 0.0 |
| TATE0.01 | IPTW | 177 | 2.94 | 1.66 | 6.0 | 5.6 |
| TATE0.01 | AIPTW | 177 | 6.46 | 3.65 | 3.5 | 2.8 |
| TATE0.01 | PENCOMP | 177 | 8.60 | 4.86 | 3.4 | 3.4 |
| TATE0.05 | IPTW | 231 | 5.59 | 2.42 | 5.3 | 4.0 |
| TATE0.05 | AIPTW | 231 | 6.42 | 2.78 | 4.4 | 3.6 |
| TATE0.05 | PENCOMP | 231 | 6.76 | 2.92 | 4.2 | 3.2 |
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 144 | 33.07 | 22.90 | 8.8 | 19.8 |
| ATE | AIPTW | 144 | 1.89 | 1.31 | 4.6 | 4.6 |
| ATE | PENCOMP | 144 | 1.02 | 0.71 | 2.4 | 2.2 |
| ATE | PENCOMP* | 144 | 1.22 | 0.84 | 2.5 | 1.8 |
| ATM | IPTW | 252 | 4.67 | 1.85 | 5.1 | 5.4 |
| ATM | AIPTW | 252 | 3.65 | 1.45 | 5.0 | 4.4 |
| ATM | PENCOMP | 252 | 2.25 | 0.89 | 4.7 | 2.0 |
| ATM | PENCOMP* | 252 | 0.67 | 0.27 | 4.7 | 1.2 |
| ATO | IPTW | 242 | 4.57 | 1.89 | 4.8 | 4.2 |
| ATO | AIPTW | 242 | 3.69 | 1.52 | 4.8 | 4.4 |
| ATO | PENCOMP | 242 | 2.22 | 0.92 | 4.3 | 0.0 |
| ATO | PENCOMP* | 242 | 1.45 | 0.60 | 4.3 | 0.0 |
| TATE0.01 | IPTW | 177 | 2.94 | 1.66 | 6.0 | 5.6 |
| TATE0.01 | AIPTW | 177 | 3.83 | 2.17 | 5.1 | 3.4 |
| TATE0.01 | PENCOMP | 177 | 6.86 | 3.88 | 3.3 | 2.0 |
| TATE0.01 | PENCOMP* | 177 | 6.76 | 3.82 | 3.3 | 1.6 |
| TATE0.05 | IPTW | 231 | 5.59 | 2.42 | 5.3 | 4.0 |
| TATE0.05 | AIPTW | 231 | 5.83 | 2.52 | 5.2 | 2.4 |
| TATE0.05 | PENCOMP | 231 | 4.93 | 2.13 | 4.1 | 2.2 |
| TATE0.05 | PENCOMP* | 231 | 4.85 | 2.10 | 4.1 | 2.0 |
| Estimand | Estimator | Truth | Absolute | Percent | RMSE | Non |
|---|---|---|---|---|---|---|
| Bias | Bias | Coverage | ||||
| ATE | IPTW | 144 | 73.89 | 51.17 | 10.8 | 41.8 |
| ATE | AIPTW | 144 | 1.03 | 0.72 | 2.8 | 5.4 |
| ATE | PENCOMP | 144 | 0.11 | 0.078 | 2.5 | 2.4 |
| ATM | IPTW | 242 | 62.99 | 26.01 | 7.9 | 24.4 |
| ATM | AIPTW | 242 | 4.57 | 1.89 | 4.4 | 4.0 |
| ATM | PENCOMP | 242 | 10.72 | 4.43 | 4.6 | 2.0 |
| ATO | IPTW | 231 | 59.58 | 25.81 | 7.6 | 23.8 |
| ATO | AIPTW | 231 | 4.59 | 1.99 | 4.0 | 3.4 |
| ATO | PENCOMP | 231 | 4.94 | 2.14 | 4.1 | 0.0 |
| TATE0.01 | IPTW | 169 | 54.94 | 32.55 | 7.9 | 22.4 |
| TATE0.01 | AIPTW | 169 | 4.62 | 2.74 | 3.2 | 4.2 |
| TATE0.01 | PENCOMP | 169 | 5.96 | 3.53 | 3.0 | 3.2 |
| TATE0.05 | IPTW | 214 | 56.76 | 26.49 | 7.6 | 18.6 |
| TATE0.05 | AIPTW | 214 | 5.80 | 2.71 | 4.0 | 3.2 |
| TATE0.05 | PENCOMP | 214 | 6.33 | 2.96 | 3.8 | 2.6 |
| Estimand | Estimator | Estimate | SE | 95% CI Length |
|---|---|---|---|---|
| ATE | IPTW | 3.66 | 1.78 | 6.97 |
| ATE | AIPTW | −0.18 | 0.70 | 2.75 |
| ATE | PENCOMP | −0.16 | 0.44 | 1.72 |
| ATM | IPTW | −0.10 | 0.34 | 1.34 |
| ATM | AIPTW | 0.24 | 0.32 | 1.24 |
| ATM | PENCOMP | 0.14 | 0.39 | 1.54 |
| ATO | IPTW | 0.16 | 0.30 | 1.16 |
| ATO | AIPTW | 0.20 | 0.31 | 1.20 |
| ATO | PENCOMP | 0.03 | 0.32 | 1.25 |
| TATE0.05 | IPTW | 1.67 | 1.20 | 4.68 |
| TATE0.05 | AIPTW | 0.10 | 0.52 | 2.03 |
| TATE0.05 | PENCOMP | −0.02 | 0.34 | 1.34 |
| Estimand | Estimator | Estimate | SE | 95% CI Length |
|---|---|---|---|---|
| ATE | IPTW | 5.84 | 1.69 | 6.63 |
| ATE | AIPTW | 6.51 | 1.58 | 6.21 |
| ATE | PENCOMP | 6.55 | 1.46 | 5.73 |
| ATM | IPTW | 6.52 | 1.39 | 5.44 |
| ATM | AIPTW | 6.80 | 1.39 | 5.45 |
| ATM | PENCOMP | 6.44 | 1.50 | 5.87 |
| ATO | IPTW | 6.53 | 1.36 | 5.32 |
| ATO | AIPTW | 6.72 | 1.36 | 5.34 |
| ATO | PENCOMP | 6.47 | 2.16 | 8.45 |
| TATE0.05 | IPTW | 6.26 | 1.54 | 6.05 |
| TATE0.05 | AIPTW | 6.31 | 1.49 | 5.84 |
| TATE0.05 | PENCOMP | 6.38 | 1.37 | 5.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, T.; Elliott, M.R.; Little, R.J.A. Addressing Disparities in the Propensity Score Distributions for Treatment Comparisons from Observational Studies. Stats 2022, 5, 1254-1270. https://doi.org/10.3390/stats5040076
Zhou T, Elliott MR, Little RJA. Addressing Disparities in the Propensity Score Distributions for Treatment Comparisons from Observational Studies. Stats. 2022; 5(4):1254-1270. https://doi.org/10.3390/stats5040076
Chicago/Turabian StyleZhou, Tingting, Michael R. Elliott, and Roderick J. A. Little. 2022. "Addressing Disparities in the Propensity Score Distributions for Treatment Comparisons from Observational Studies" Stats 5, no. 4: 1254-1270. https://doi.org/10.3390/stats5040076
APA StyleZhou, T., Elliott, M. R., & Little, R. J. A. (2022). Addressing Disparities in the Propensity Score Distributions for Treatment Comparisons from Observational Studies. Stats, 5(4), 1254-1270. https://doi.org/10.3390/stats5040076