1. Introduction
Generalized linear models are proposed by Nelder and Wedderburn [
1],
; for a detail review, we refer the readers to McCullagh and Nelder [
2]; it consists of a random component and systematic component. GLMs assume the responses come from the exponential dispersion model family. They extend linear models to allow the relationship between the predictors and the function of the mean of continuous or discrete response through a canonical link function. These models encounter problems such as the canonical link function is sometimes unknown, the link between response and predictors can be complex as well as the plague of dimension reduction. To address these problems, several approaches have been developed. Hastie and Tibshirani [
3] propose the GAMs models, in which the linear predictor depends linearly on smooth of predictor variables, one of the criticisms of these models is that they do not take into consideration the interactions between covariates. The manuscripts of Wood [
4] and Dunn, Peter, Smyth, Gordon [
5] are the latest references dealing with these two models.
The single index model had been employed to reduce the dimensionality of data, and avoid the “curse of dimensionality” while maintaining the advantages of non-parametric smoothing in multivariate regression cases over the last few decades, see for example the work of Lai et al. [
6].
The single index aggregates the influence of the observed values of the explanatory variables into one number.
Examples of economic index include the following: a stock index, inflation index, cost-of-living index, and price index.
Furthermore, this idea had first been extended to the functional setting by Ferraty, Vieu et al. [
7] for functional regression problems, which led to the functional single index regression model (FSIRM). The functional index acts as a filter permitting the extraction of the part of explaining the scalar response Y, and plays an important role in a such model.
The predictor is not generally linear, but is complex, which prompted Caroll et al. [
8] to propose their model GPLSIM by applying the local-quasi-likelihood function and the kernel type of smoothing by approximating the function
using local linear methods
. A GPLSIM was proposed by Chin-Shang Li et al. [
9], in which the unknown smooth function of single index was approximated by a spline function that can be expressed as a linear combination of B-spline basis function considered as follows
using a modified Fisher-scoring method. Moreover, Wang and Cao [
10], have studied the GPLSIM model by applying the quasi-likelihood and polynomial spline smoothing
.
In recent years, the analysis of functional data has made considerable progress in several areas, including image processing, biomedical studies, environmental sciences, public health, etc. Several researchers have focused their efforts on studying this type of data. We mention the work of Aneiros-Pérez and Vieu [
11], and for more details, we refer to the books of Horváth Kokoszka [
12], Ferraty and Vieu [
7], Aneiros-Pérez and Vieu [
13], and Ramsay and Silverman [
14]. Yu, Du and Zhang [
15] have proposed the SIPFLM model combining the single-index model (SIM) and the FLM model by optimizing the sum of the least squares using the B-Spline basis
. Jiang Du et al. [
16] proposed the GFPLM model using the functional principal component analysis
. Rachdi, Alahiane, Ouassou and Vieu presented a book chapter on the generalization of the GPLSIM model in the Iwfos 2020 conference, see Rachdi et al. [
17]. Our objective is to combine the GPLSIM with the SIPFLM and consider the following generalized partially functional single-index model called PLGSIMF using B-Spline expansion and the quasi-likelihood function
in order to remedy the interaction effects, the dimension scourge and to take into account the functional random variables.
The paper is organized as follows. In
Section 1 and
Section 2, we localize our model in the literature, and we present the Fisher-scoring update algorithm used to estimate our single-index vector, the parametric function and the slope function. In
Section 3, we investigate an asymptotic study of the estimators presented in the paper. Numerical simulation in the Gaussian case as in the logistic case is presented in
Section 4. The proofs of the results are developed in
Section 6 and in the
Appendix A for the different technical lemmas necessary to develop our asymptotic study both for the non-parametric function, for the single-index vector and for the slope function.
Let
H be a separable Hilbert space, which is endowed with the scalar product
and the norm
. Let
Y be a scalar response variable and
be the predictor vector where
and
Z to be a functional random variable that is valued in
H. For a fixed
, we assume that the conditional density function of the response
Y given
belongs to the following canonical exponential family:
where
B and
C are two known functions that are defined from
into
, and
is the parameter in the generalized parametric linear model, which is linked to the dependent variable
where
denotes the first derivative of the function
B. In what follows, we consider the function
as a generalized single-index partially functional linear model:
where
is the
d-dimensional single-index coefficient vector,
is the coefficient function in the functional component, and
is the unknown single-index link function which will be assumed to be sufficiently smooth.
If the conditional variance
, where
V is an unknown positive function, then the estimation of the mean function
may be obtained by replacing the log-likelihood
given by (
1), by the quasi-likelihood
given by
for any real numbers
u and
v, which may be written as
.
2. Estimation Methodology
Let
be a sequence of independent and identically distributed (i.i.d.) as
and, for each
,
We assume that the function is supported within the interval where and .
We introduce a sequence of knots in the interval , with J interior knots, such that , where is a sequence of integers which increases with the sample size n. Now, let be the number of knots, be the B-spline basis functions of order r, and be the distance between the neighbors knots.
Let
be the space of polynomial splines on
of order
. By De Boor [
18], we can approximate
assumed in
(which will be defined in
Section 3) by a function
. So, we can write
where
is the spline basis and
is the spline coefficient vector.
We introduce a new knots sequence
of
. Then, there exists
functions in the B-splines basis which are normalized and of order
r, such that
By setting
and
w and
are defined accordingly to (
5), the mean function estimator
is then given by the evaluation of the parameter
and by inverting the following equation
Notice that the parameter
is determined by maximizing the following quasi-likelihood rule
where
, with
where
with
,
,
,
,
denoting the true values, respectively, of
,
,
,
and
.
To overcome the constraint
and
of the
d-dimensional index
, we proceed by a re-parameterization, which is similar to Yu and Ruppert [
19]
The true value of , must satisfy . Then, we assume that . The jacobian matrix of of dimension is . Notice that is unconstrained and is one dimension lower than .
Finally, let
the jacobian matrix of
, which is of dimension
. Let
Denote
and
where
. Note that
is a
-dimensional parameter, while
is a
-dimensional one. Let
and denote
The score vector is then
where
The expectation of the Hessian matrix is
The Fisher Scoring update equations
, becomes
where
, for
and
.
It follows that
where
, and
is the estimator of the single-index coefficient vector of the PLGSIMF model.
3. Some Asymptotics
We present asymptotic properties of the estimators for the non-parametric components, the functional component, the single-index coefficient vector and the slope function of the PLGSIMF model. For this aim, we will need some assumptions.
3.1. Some Additional Notions and Assumptions
Let
,
and
be measurable functions on
. We define the empirical inner product
and its corresponding norm
as follows
If
,
and
are
-integrable, we define the theoretical inner product and its corresponding norm as follows
Let
and
such that
. We denote by
the collection of functions
g, which are defined on
whose
v-th order derivative,
, exists and satisfies the following
e-th order Lipschitz condition
Let where .
(C1) The single-index link function , where is defined as above.
(C2) For all and for all y in the range of the response variable Y, the function is strictly negative, and for , there exist some positive constants and such that
(C3) The marginal density function of is continuous and bounded away from zero and is infinite on its support . The v-th order partial derivatives of the joint density function of X satisfy the Lipschitz condition of order ().
(C4) For any vector
, there exist positive constants
and
, such that
where
and
.
(C5) The number of knots satisfy , for .
(C6) The fourth order moment of the random variable Z is finite, i.e., , where C denotes a generic positive constant.
(C7) The covariance function is positive definite.
(C8) The slope function is a r-th order continuously differentiable function, i.e.,
(C9) For some finite positive constants
,
and
(C10) For some finite positive constants
,
and
, the link function
g, in the model (
3), satisfies:
and, for all
,
(C11) It exists a positive constant , such that .
3.2. Estimators Consistencies
Next we formulate several assertions on the considered estimators.
3.3. Estimation of the Nonparametric Component
The following theorem states the convergence, with rates, of the estimator
Theorem 1. Under assumptions , we havewhere denotes a “grand O of Landau” in probability. Proof of Theorem 1.
The proof of the previous theorem is given in the
Appendix A. □
3.4. Estimation of the Slope Function
Theorem 2. Under assumptions , and , we have Proof of Theorem 2.
The proof of the previous theorem is given in the
Appendix A. □
3.5. Estimation of the Parametric Components
The next theorem shows that the maximum quasi-likelihood estimator is root-
n consistent and is asymptotically normal, although the convergence rate of the non-parametric component
is slower than root-
n. Before enouncing the theorem, let us denote
Theorem 3. Under assumptions , the constrained quasi-likelihood estimators and with are jointly asymptotically normally distributed, i.e.,where denotes the convergence in distribution, andand Proof of Theorem 3.
The proof of the previous theorem is given in the
Appendix A. □
4. A Numerical Study
We conduct a simulation study in order to show our results’ effectiveness. We will treat two main cases of link functions: the identity and the logit link functions.
Recall that if the density of
Y given
and
is
then the link fuction
4.1. Case 1: Identity Link Function
We consider the case where the link function is the identity and the model
The responses
are simulated according to the Equation (
6),
are taken uniformly over the interval
, whereas the errors are normally distributed with mean 0 and variance
,
. Moreover, we take the following coefficients
The function
and
are given by
where
,
and
.
The knots are selected according to the formula
where
(Like in Wang and Cao [
10]). We chose
and we made 300 replications with samples of sizes
and
.
Computations of the bias, the standard deviation (SD) and the Mean Squared Error (MSE) with respect to (i) the parameter
, (ii) the parameter
and (iii) the parameter
are summarized, for
(respectively,
), in the following
Table 1,
Table 2 and
Table 3 (respectively, in the
Table 4,
Table 5 and
Table 6).
4.2. Case 2: Logit Link Function
By taking a logit link function, data are generated from the model
for which we have kept the same parameters and the variables as for the identity link function. Then, similarly to the identity link function case, computations of the bias, SD and the MSE with respect to the parameters
,
and then
are summarized, for
(respectively,
), in the
Table 7,
Table 8 and
Table 9 (respectively, in the
Table 10,
Table 11 and
Table 12).
It is obviously seen that the quality of the estimators are illustrated via simulations. The method performs quite well. The Bias, SD and MSE are reasonably small in general. The parametric and nonparametric components, the single-index and also the slope function are computed by the procedure given in this paper.
Both tables correspondingly indicate the consistency of
and
as the bias, SD and MSE decrease as the sample size increasing. The knots selection with formula
by using
like in Li Wang and Guanqun CAO [
10], we have chosen
.
We developed our algorithm in both cases: the identity link function and the logistic link function. Simulations show that the PLGSIMF algorithm works well in both cases.
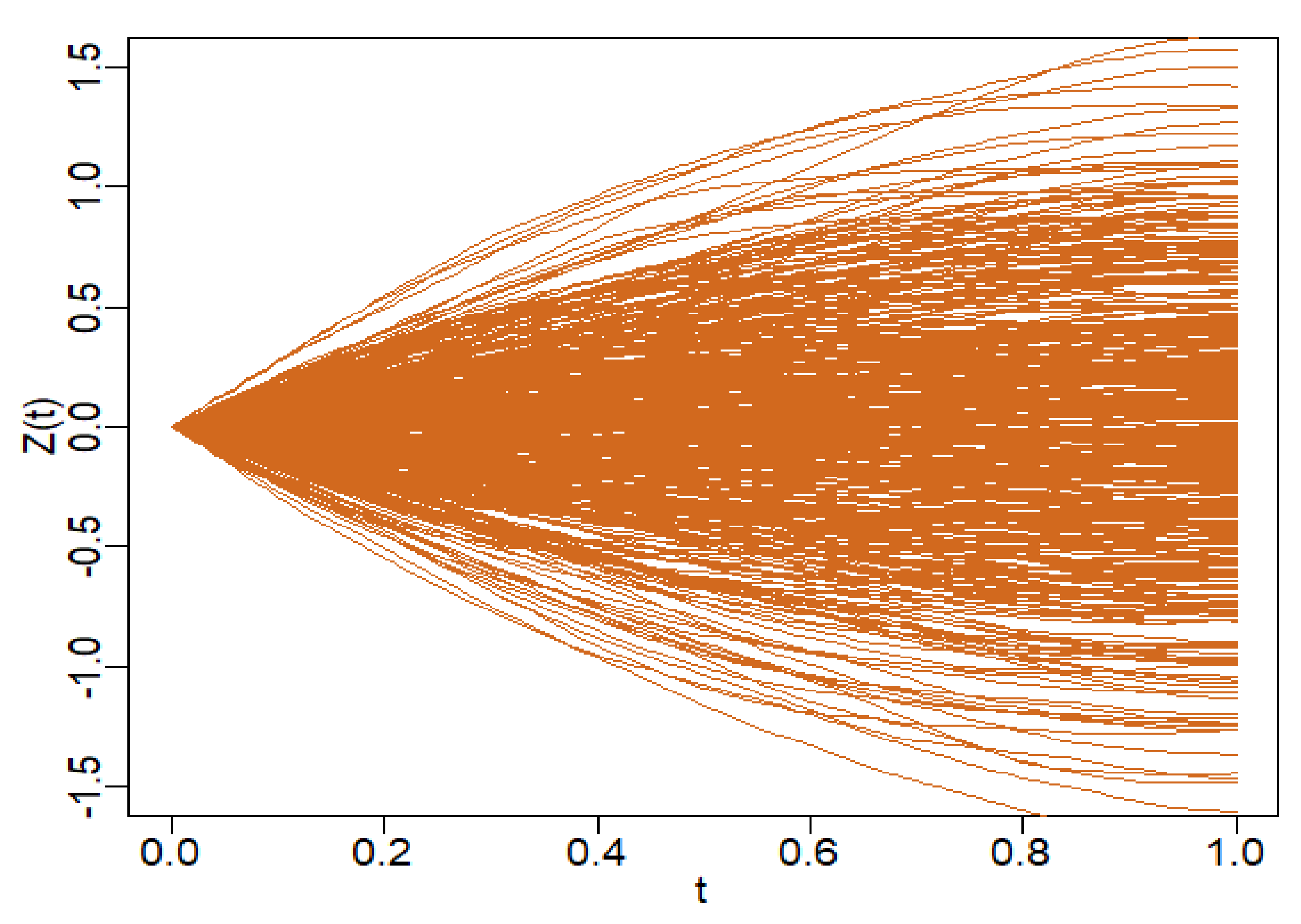
In the figure below (
Figure 1), we illustrate 500 realizations of the functional random variable Z.
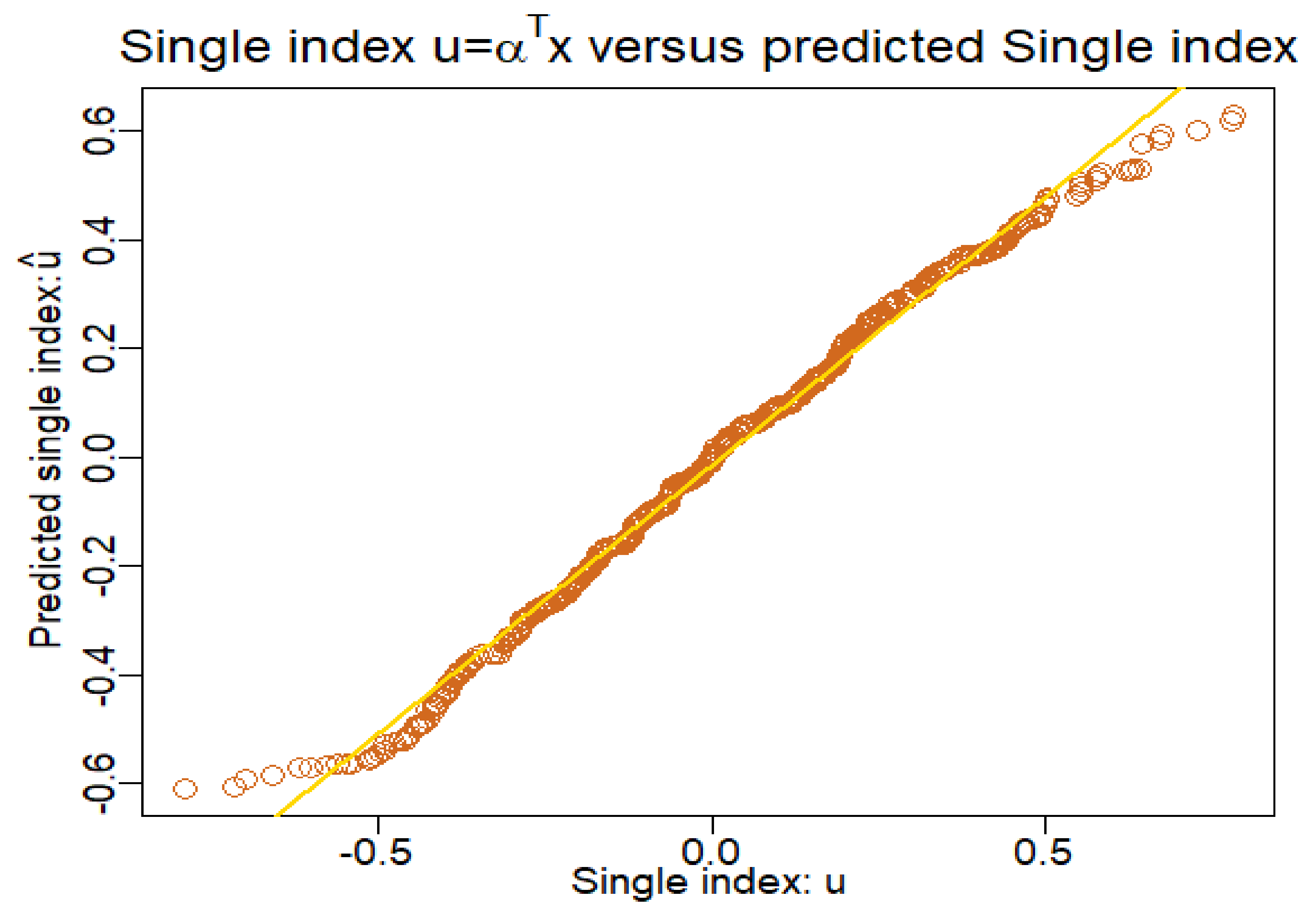
In the following figure (
Figure 2), we observe the almost linearity of the single-index
and its estimate
In the figure below (
Figure 3), we plot the slope function
and its estimator
Our model approximates well the slope function .
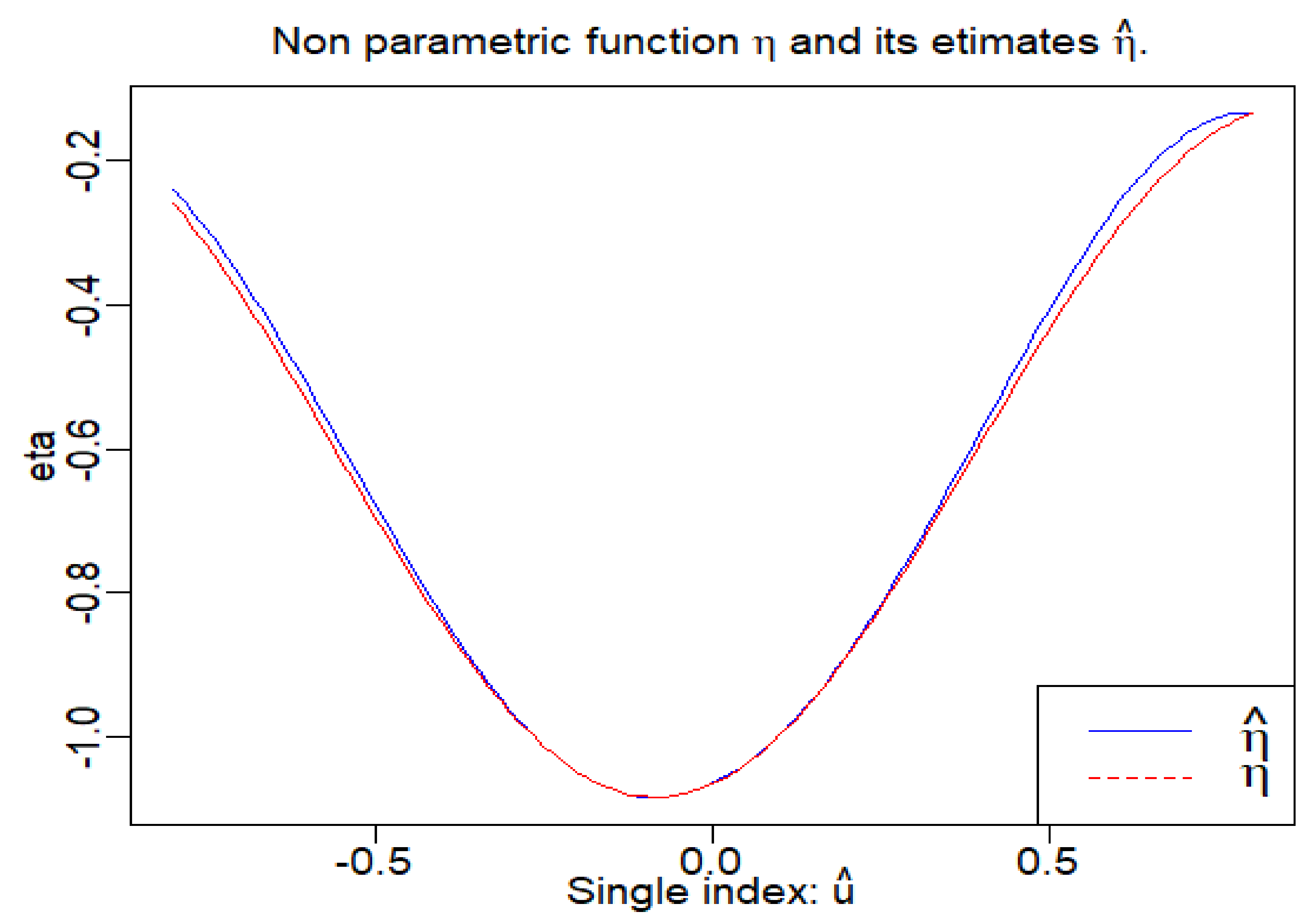
The following figure (
Figure 4) shows us the comparison between the non-parametric function
and its estimator
We consider that our model approximated to the best the non-parametric function
To study the performance of our estimation for non-parametric function
and slope function, respectively, we will use the square root of average square errors criterion (RASE, see Peng et al. [
20]):
The following tables (
Table 13 amd
Table 14) summarize the sample means, medians and variances of the RASE
(
) with different sample sizes in the Gaussian case.
For the case , we get
Table 13.
The RASE criterion with the non-parametric function and slope function for the case .
Table 13.
The RASE criterion with the non-parametric function and slope function for the case .
| Gaussian Cases | Mean | Median | Var |
|---|
| RASE | 0.039 | 0.038 | 0.003 |
| RASE | 0.123 | 0.122 | 0.020 |
For the case , we get
Table 14.
The RASE criterion with the non-parametric function and slope function for the case .
Table 14.
The RASE criterion with the non-parametric function and slope function for the case .
| Gaussian Cases | Mean | Median | Var |
|---|
| RASE | 0.016 | 0.016 | 0.001 |
| RASE | 0.027 | 0.125 | 0.006 |
The following tables (
Table 15 and
Table 16) summarize the sample means, medians and variances of the RASE
(
) with different sample sizes in the Logistic case.
For the case , we get
Table 15.
The RASE criterion with the non-parametric function and slope function for the case .
Table 15.
The RASE criterion with the non-parametric function and slope function for the case .
| Logistic Cases | Mean | Median | Var |
|---|
| RASE | 0.045 | 0.044 | 0.023 |
| RASE | 0.133 | 0.103 | 0.0120 |
For the case where , we get
Table 16.
The RASE criterion with the nonparametric function and slope function for the case where .
Table 16.
The RASE criterion with the nonparametric function and slope function for the case where .
| Logistic Cases | Mean | Median | Var |
|---|
| RASE | 0.028 | 0.026 | 0.014 |
| RASE | 0.124 | 0.121 | 0.002 |
We conclude that as the sample size n increases from 500 to 1000, the sample mean, median and variance of RASE (i = 1, 2) decrease.
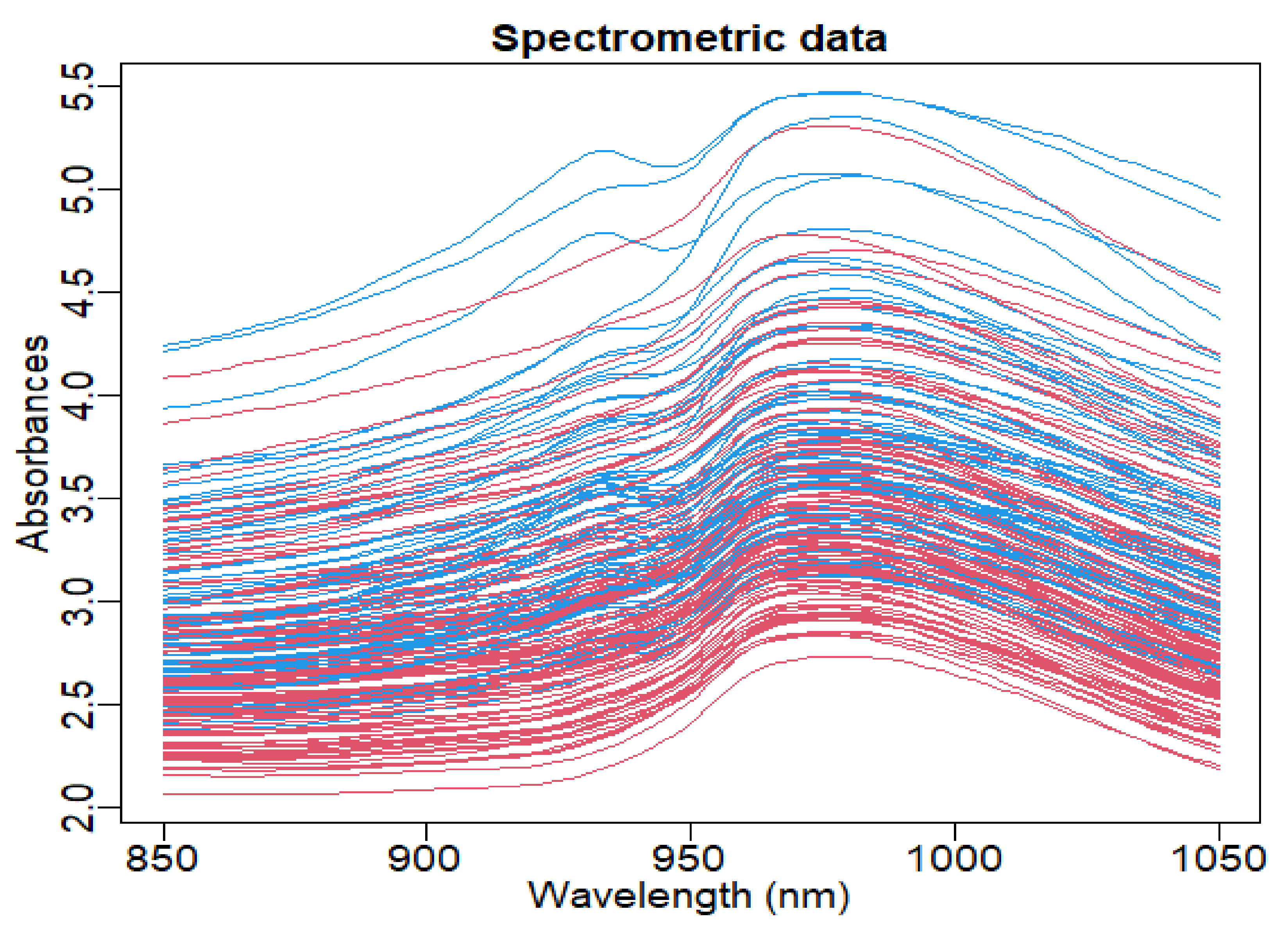
5. Application to Tecator Data
In this paragraph, we will apply the PLGSIMF model for Tecator data, popularly known in the functional data analysis. This data can be downloaded from the following link
http://lib.stat.cmu.edu/datasets/tecator (accessed on 1 August 2021). For more details, see Ferraty and Vieu [
7].
Given 215 finely chopped pieces of meat, Tecator’s data contain their corresponding fat contents (), near-infrared absorbance spectra () observed on 100 equally wavelengths in the range 850–1050 nm, the protein content and the moisture content . We are trying to predict the fat content of the finely chopped meat samples.
The following figure (
Figure 5) shows the absorbance curves.
We divide the sample randomly into two sub-samples: the training
of size 160 and the test
of size 55. The training sample is used to estimate the parameters, and the test sample is employed to verify the quality of predictions. To perform our model, we use the mean square error of prediction (MSEP) like in Aneiros-Pérez and Vieu [
11] defined as follows:
where
is the predicted value based on the training sample and
is variance of response variables’ test sample.
The following table (
Table 17) shows the performance of our PLGSIMF model by comparing it with other models. We can conclude that PLGSIMF is competitive one for such data.
The following figure (
Figure 6) shows us the estimator of the non-parametric function
.
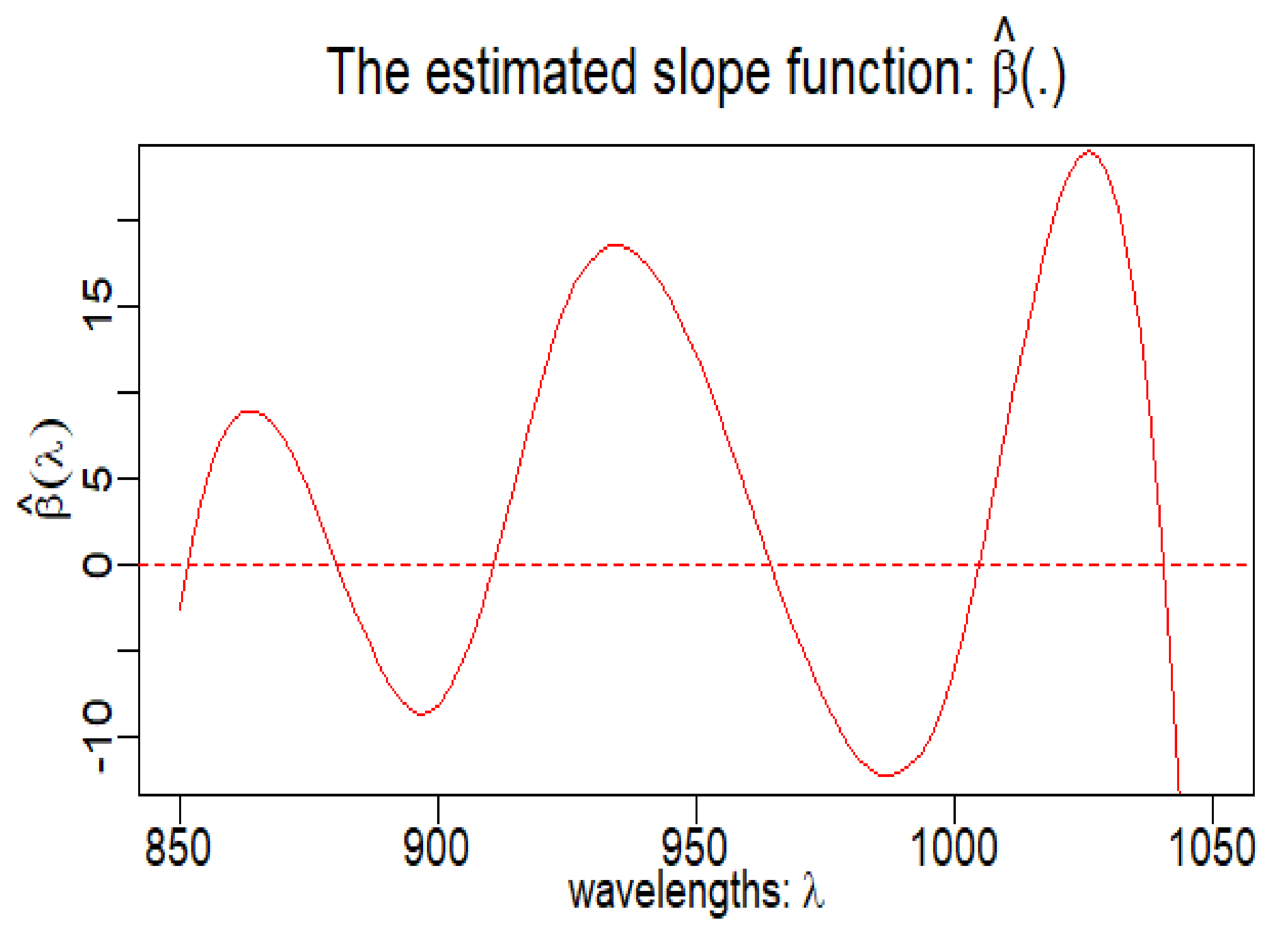
The following figure (
Figure 7) shows us the estimator of the slope function
.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}