We remark that Statcast data is “big data”. For every pitch that is thrown, Statcast records over 30 variables related to defensive, offensive and pitching outcomes. With 30 teams in MLB, 162 matches in a season and roughly 150 pitches per game, this leads to over 10 million data values collected per season.
2.1. Using 2015 Data and Predictions
As Statcast is a relatively new tracking system, we began by investigating aspects of its reliability. Each case (each thrown ball) in the Statcast dataset has many associated variables including the identification of the batter, the identification of the pitcher and the properties of the thrown ball. We used the event variable in the Statcast dataset to determine the outcome of each at-bat (e.g., fielding error, strikeout, double play, etc.) In doing so, we used the resultant outcomes to calculate the batting average for batters during the 2015 regular season. We then compared the batting averages and the number of bats for five randomly selected players with the reported values from
www.baseball-reference.com. The five players were Aramis Ramirez, Troy Tulowitzki, Trevor Plouffe, Omar Infante, and Bobby Wilson. In each case, both their number of at-bats and the number of hits matched exactly.
Our first decision in the data analysis was to restrict the prediction of batting averages to players for whom we had adequate data in the previous season. Without sufficient at-bats, there may be great variation in the predicted batting averages. Therefore, for the 2015 regular season, we only considered players who had at least 200 at-bats. We were left with 334 players who met the threshold. Consequently, we used 84.1% of all at-bats in the 2015 dataset (i.e., 140,896 of the 167,606 at-bats).
In the next step of our procedure, we want to estimate the probability of a hit based on the characteristics of the particular at-bat. The variables that we used in assessing the characteristics of an at-bat were the exit velocity (
) the launch angle (
) and the distance that the ball was hit (
). Our intuition is that these are physically meaningful variables regarding the probability of a hit. For example, we believe that the harder the ball is hit (i.e., the greater the exit velocity), the greater the chance of a hit. It also seems that the relationship between
and the three variables are not necessarily linear and that interactions may exist. We also consider two further variables that are provided by auxiliary datasets. We introduce the indicator variable
which characterizes the handedness of the batter with the idea that a left-handed batter is closer to first base than a right handed batter, and may, therefore, be advantaged in running out a ground ball. We also introduce the continuous variable
which is the footspeed of players. The variable
is obtained from the webpage
www.baseballsavant.mlb.com/sprint_speed_leaderboard where the idea again is that faster runners may be advantaged in running out a ground ball. These observations are therefore suggestive of a logistic regression model where
is regressed against covariates originating from
,
,
,
and
.
However, before proceeding with logistic regression, missing Statcast data is a concern since missingness can introduce bias. There are some batting outcomes for which covariates are systematically missing. For example, when there is a strikeout, , , and are always missing since the ball is not put into play. Therefore, in the case of strikeouts, we assigned . There were 29,713 strikeouts of the 140,896 at-bats in the restricted dataset (i.e., 21.1%).
High angled pop-outs are another case that requires special attention. Our investigation found that radar sometimes loses track of the ball, and in these instances, imputed values of
,
, and
were provided, and these imputed values cannot be deemed reliable [
16]. Although this is not the same sort of missingness as with strikeouts, almost all pop-outs result in outs. Therefore, in the case of pop-outs, we also assigned
. There were 7341 pop-outs of the 140,896 at-bats in the restricted dataset (i.e., 5.2%).
There was one more remaining case of systematic missingness that proved problematic, and it involved ground balls. With ground balls, the hit distance variable
was missing when the ball was stopped by an infielder before it could reach its true hit distance. Our solution to this problem was to take all ground balls and carry out a logistic regression of
p solely against the exit velocity variable
given by Statcast and the auxilary variables
and
. There were 50,717 ground balls of the 140,896 at-bats in the restricted dataset (i.e., 36.0%). The fitted logistic regression model was
To compare (1) versus our intuition, consider batted balls with exit velocities mph and mph. The fitted probabilities of a hit are and , respectively. As is reasonable, the ball which is hit harder has the greater probability of a hit. The AIC fit diagnostic for (1) is 57011 whereas it is 57170 for the null model with only the intercept term.
In the main logistic regression, we removed observations corresponding to strikeouts, pop-outs and ground balls. We were left with only 3280 missing values which we attribute to missing at random. The missing values constitute only 2.3% of the restricted dataset involving 140,896 at-bats. Therefore, the complete data logistic regression involves 49,845 of the 140,896 at-bats (i.e., 35.4%). We characterize these remaining observations as fly-balls. We considered all third-order covariates involving
,
, and
since there could be complex interactions between some of the covariates. For example, with launch angle
, it is intuitive that balls hit at a higher angle relative to the ground will have a greater probability of resulting in a hit. However, there is a caveat in that if the ball is a little too high, then it will provide the fielder with more time to reach the ball and make a catch. Looking ahead to Equation (
2), we indeed see that the covariate
has a negative coefficient. We did not include
(handedness)and
(footspeed) as our physical understanding of baseball suggests that these variables should not be relevant in the prediction of hits from fly-balls. Then, after removing covariates with correlations exceeding
, we carried out stepwise regression on the remaining variables. We obtained the fitted logistic regression model
where all included variables are highly significant. We note that each of the estimated parameters of the first order terms have signs that correspond to our intuition. The AIC fit diagnostic for (1) is 54587 whereas it is 68801 for the null model with only the intercept term.
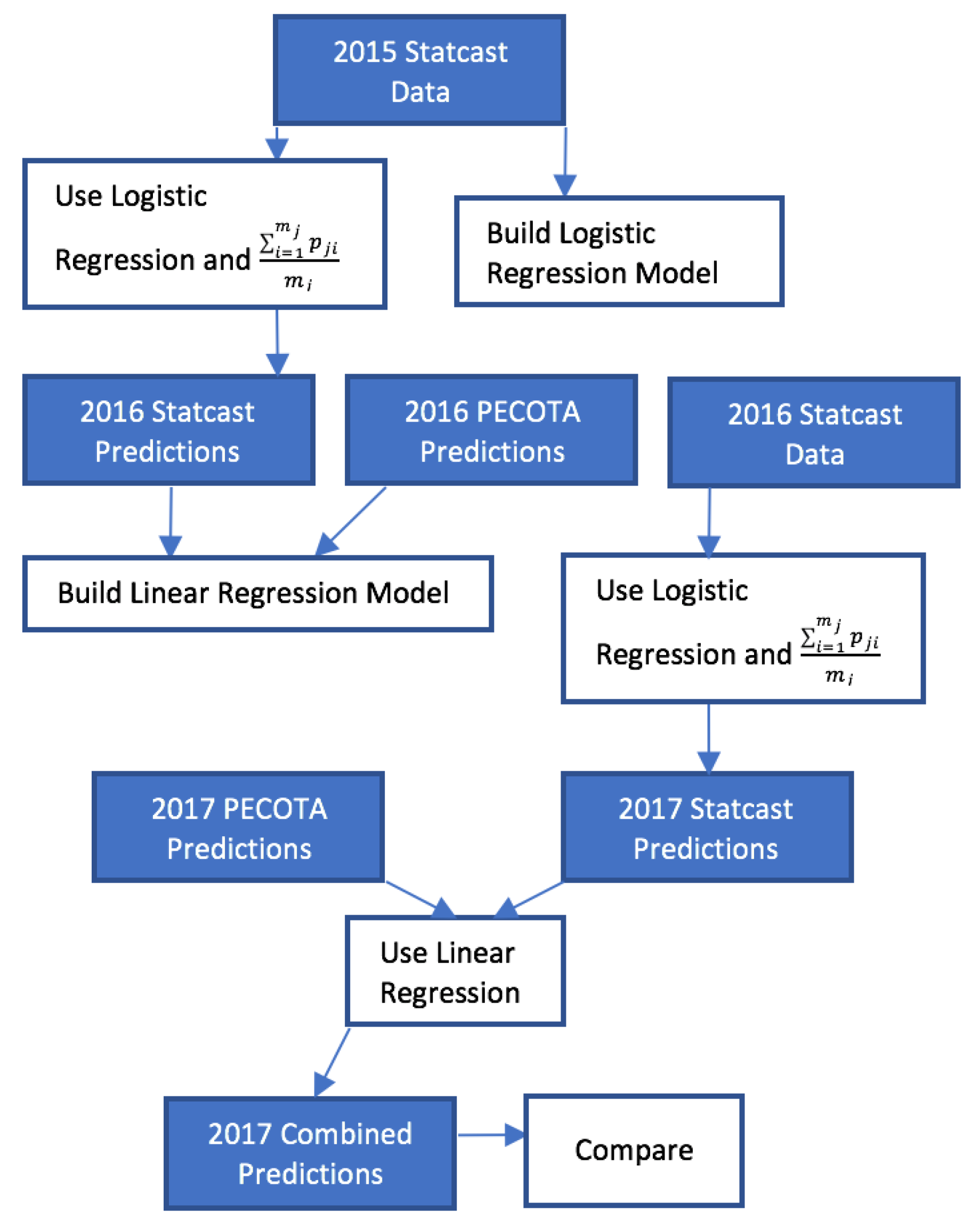
Now, the final step involving the 2015 data involves the 2016 Statcast predictions. The simple philosophy is that players will behave similarly in 2016 as they did in 2015 with the exception that their “luck” is modified. Consider the
jth player who had
at-bats in 2015. In his
ith at-bat during the 2015, we determine the probability of a hit
where
if his at-bat was either a strikeout or a pop-out,
is calculated according to (1) if his at-bat was a ground ball, and
is calculated according to (2), otherwise. Therefore, the Statcast predicted batting average for player
j in the 2016 season is given by
Figure 2 provides a scatterplot of the 2016 Statcast predictions versus the 2016 PECOTA predictions. We observe a similarity between the two sets of predictions as they appear scattered about the straight line
. We do note that the Statcast predictions are slightly more extreme as they have both larger and smaller predictions than PECOTA.
2.2. Using 2016 Data and Predictions
We recall that the Statcast 2016 predictions are not sophisticated in that they do not consider important variables such as age, injuries and player speed. However, what the Statcast 2016 forecasts do implicitly include is information concerning the luck of the player during the 2015 season. If he was lucky in 2015 (had more hits than implied by (3)), then his 2016 prediction will be less than his actual 2015 batting average. On the other hand, if he was unlucky in 2015 (had fewer hits than implied by (3)), then his 2016 prediction will be greater than his actual 2015 batting average.
There is a wisdom of the crowd philosophy (also related to model averaging) that suggests that information from various sources is often superior to information from a single source. Following these beliefs, we consider the simple linear regression model
where
is the actual batting average in 2016 for player
j,
is the 2016 Statcast prediction for player
j,
is the 2016 PECOTA prediction for player
j and
is a random error term.
The least squares fit of the simple linear regression model (4) leads to
where we refer to
as the combined predictor for player
j in 2016. In (5), we observe the fit diagnostic
. Of course, it would not be fair to assess
versus
since that would be a violation of data analytic principles where the same data are used for both model fit and model assessment. From (5), we observe that the existence of the intercept term implies that there is some bias (although small) in the Statcast and PECOTA predictors. We also observe that more weight is placed on the PECOTA predictor than on the Statcast predictor.




{kind=link}
{kind=link}
{kind=link}