3.1. Datasets
The experimentally measured cross-sectional profiles and features furnish two datasets. The image dataset is implemented by dividing the original profiles of the processed material into smaller images. These cropped images are subsequently divided into separate datasets for training, validation, and testing. In this study, a total of 6400 image segments are used, with 5113 randomly chosen for training, 1279 allocated for validation, and the rest assigned to the test set. As explained further below, k-fold cross-validation is also conducted to ensure the reliability of the findings. In addition to the images, a numerical dataset is also established, which contains information on the localization and number of passes associated with the material.
These datasets are fed to neural networks of two main types: CNN and MLP. The CNN branch receives the image data as input and classifies them through convolutional, pooling, batch normalization, dropout, flattening, and dense layers. The final output of the classification is a four-element array that carries the information on the mechanical properties. In the first and second rows of
Figure 2, eight randomly cropped images utilized for the training set are displayed. The features of interest include the process parameters and measured mechanical properties, which are pegged to four different values of tensile strength. The numerical dataset consists of information on the location and number of passes, which are stored as binary and integer variables. The MLP branch’s input is the numerical dataset, a two-element array containing the process parameters of the underlying cross-sectional profiles. The data are processed via dense and dropout layers, leading to a four-element output representing the tensile strength associated with the cross-sectional surface.
3.3. Network Architecture and Calibration Process
The model calibration is performed to determine favorable specifications. As an illustration, the primary focus is on the hybrid CNN-MLP model. Employing a similar strategy, this process is performed for the remaining models when it is applies.
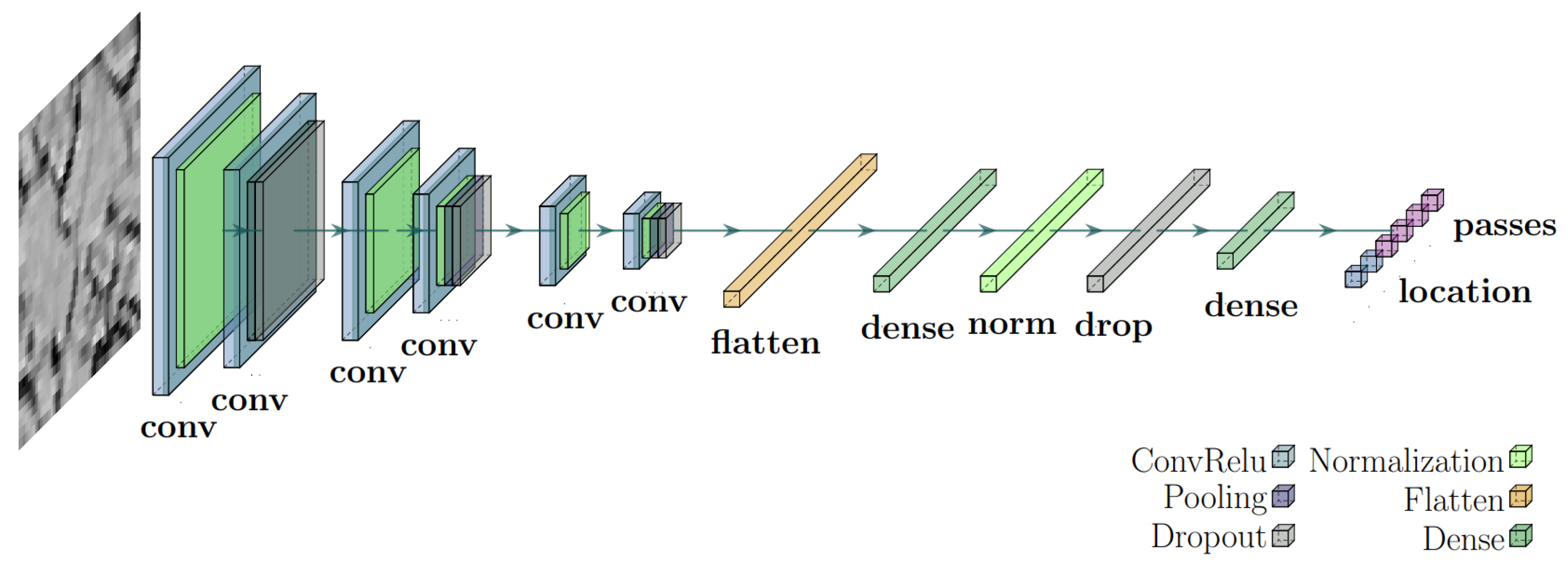
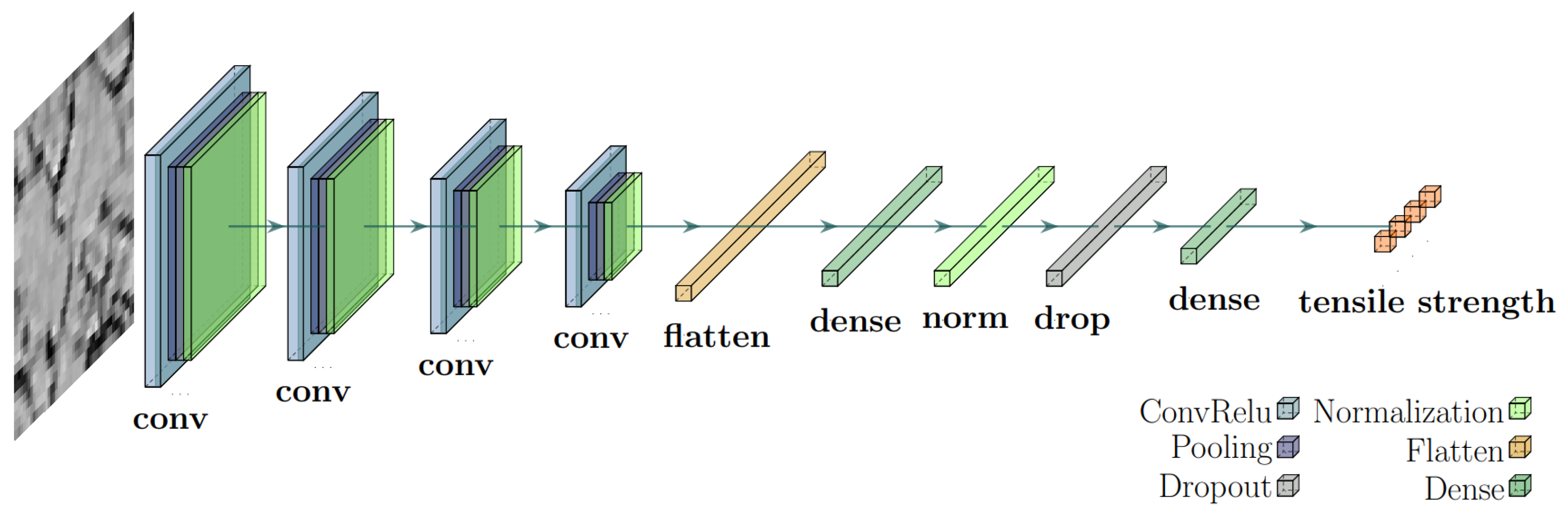
The architectures of the models are presented in
Figure 3,
Figure 4,
Figure 5 and
Figure 6. The multi-output CNN was employed in [
27] to explore the process parameters, such as the number of passes applied to the material. As shown in
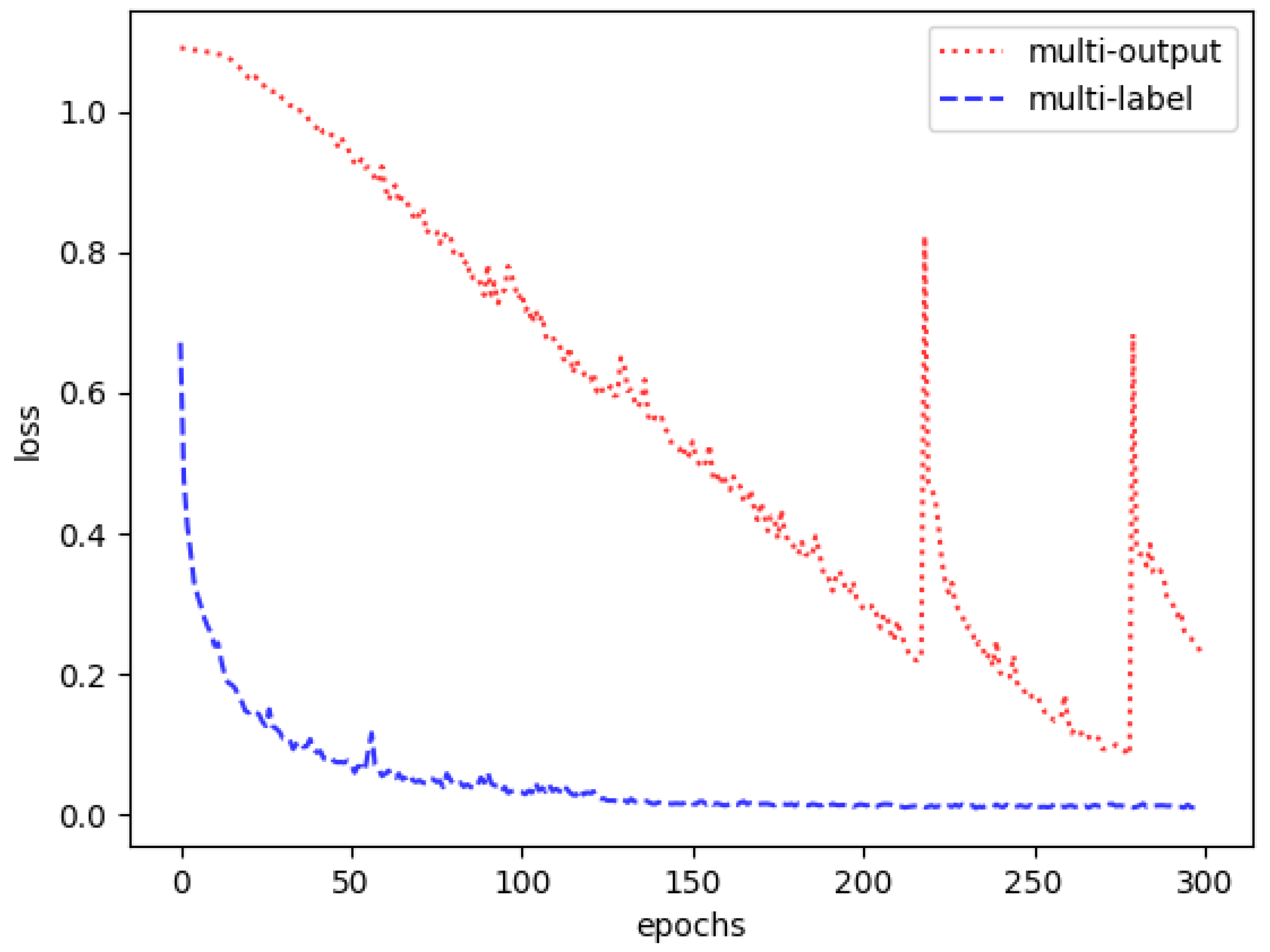
Figure 3, it consists of largely independent networks, individually dedicated to distinct features. The multi-label CNN is closely related and is often an alternative approach to the multi-output architecture. The main difficulty of employing the multi-label architecture for such a task is that a few different features are mutually exclusive. Therefore, a straightforward application of the multi-label network is not feasible as it might cause the network to predict some properties that are not physically plausible simultaneously. To circumvent such a difficulty, a filter layer is added at the network’s output that guarantees that only one feature out of a collection of mutually exclusive ones is selected based on its “rank”. A schematic layout of the multi-label CNN is given in
Figure 4. A more detailed comparison between the multi-output and multi-label CNNs is developed further in
Section 4.1.
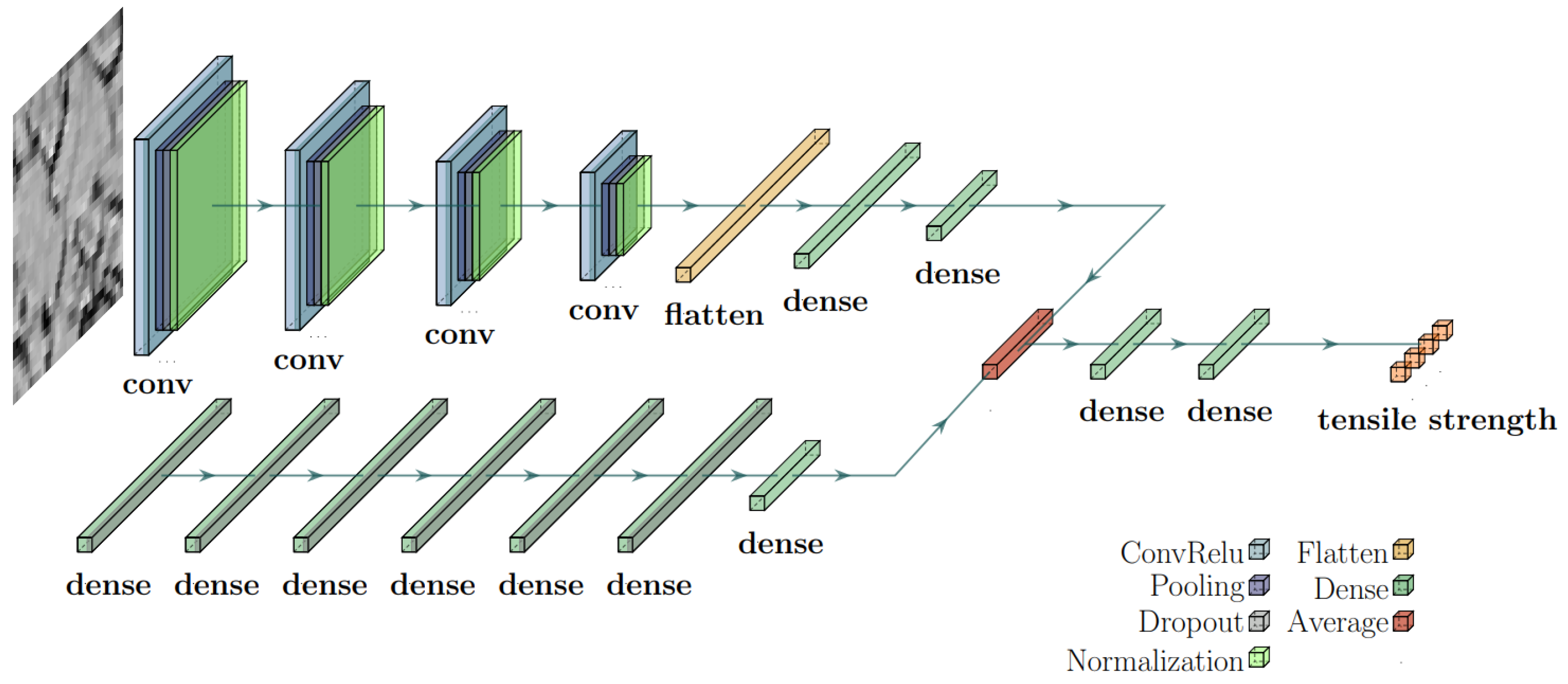
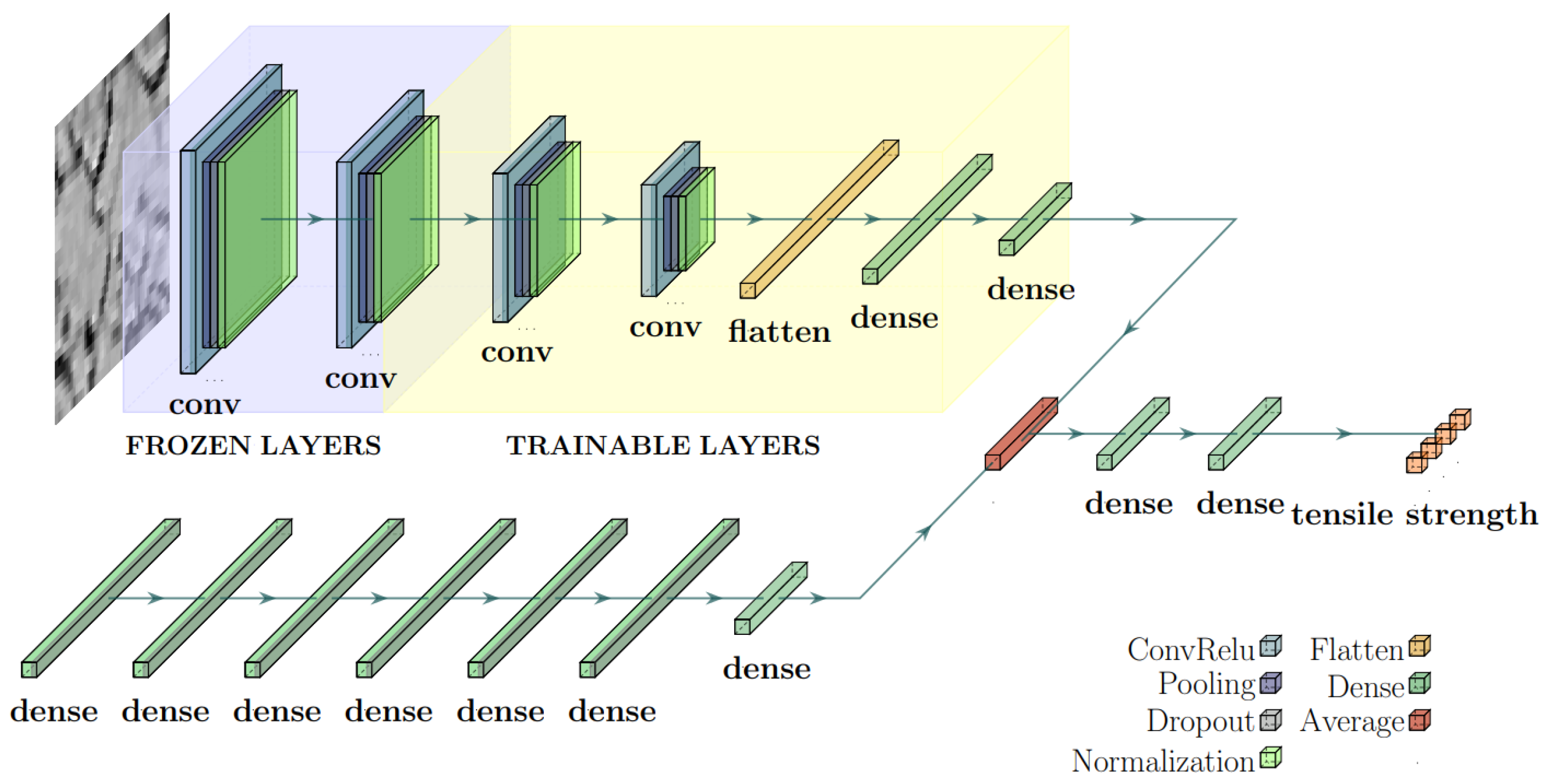
The hybrid model proposed in [
38] was applied, which combines a CNN with a long short-term memory (LSTM) network, a recurrent neural network variant. However, this approach is designed for processing temporal or sequential data, which is unsuitable since the input comprises process parameters that are fundamentally different in nature from ordered sequences. To address this, the LSTM is replaced with an MLP. This neural network’s input constitutes both image and numerical data. The image input is identical to the multi-output and multi-label CNNs described above. The numerical input consists of some of the material’s features that are seemingly irrelevant to the features of interest. The CNN’s architecture primarily consists of a few intercalated dense and convolutional layers, followed by a few flattening and dense layers, which are to be determined by the calibration process. A couple of dense layers furnish the MLP. The two networks are then merged by averaging before passing through two dense layers. The schematic architecture of the hybrid model is shown in
Figure 5. Lastly, this study also utilizes a multi-class CNN model, which possesses primarily identical architecture to the CNN sector of the hybrid model. As discussed in
Section 4.3, it is introduced to compare the effectiveness between different models.
As an illustration, the calibration process of the hybrid model, which emphasizes the CNN sector, is discussed in the following. The architecture is denoted as a ratio of the shape and weight of the convolutional layer’s output to the number of convolutional kernel instances, represented as “(size, weight)/no. kernel”. The intermediate pooling and fully connected layers are assumed to be present but not specifically quantified. In particular, the CNN sector’s architecture within the model is denoted as
where
N is the total number of convolutional layers. The following aspects are analyzed: batch size, data augmentation “fill mode”, architecture in terms of the number of dense and convolutional layers, optimizer schemes, and the ReduceLROnPlateau callback application and its inherent parameters. Unless specified, the calculations are carried out by using the following given CNN layout:
Table 3 displays the results for both training and validation datasets regarding different options of batch sizes. Calculations are carried out for a given layout shown in Equation (
2) with 100 epochs with different batch sizes of 16, 32, 64, and 128. As shown below, the 64-batch size produces the best results among the options tested; it gives the highest accuracies while showing reasonably consistent values for the training and validation results.
Various data augmentation techniques are utilized, as shown in the third row of
Figure 2. An analysis of the effects of various options related to the fill mode are shown in
Table 4, which determines the specific recipe used to top up the excess space in an image after the augmentation. Although it might seem that the “constant”, “nearest”, or “reflect” modes have little impact on the texture information of the profiles, practical results show otherwise. Specifically, the “constant” mode provides marginally improved performance in terms of training and validation accuracies for the model, as evidenced in
Table 4.
The architecture of the hybrid model is analyzed and presented in
Table 5 and
Table 6. The CNN sector shows the resultant accuracies by exploring different architectures in terms of different numbers of convolutional and dense layers. Specifically, the following three different layouts are explored:
These architectures utilize alternating filter sizes of
and
pixels and are trained over 100 epochs with a batch size of
and an “Adam” optimizer.
Table 5 illustrates how the network’s sensitivity varies with the number of convolutional layers across different architectures. Generally, increasing the number of layers enhances performance, though the improvement is incremental. A network with just three layers and a well-designed architecture can still achieve decent precision. When more advanced architectures are used, training and validation accuracies tend to stabilize, showing marginal gains.
Regarding the MLP sector, in
Table 6, the results for different architectures are presented. The calculations use two, four, and six dense layers while keeping intact the CNN’s architecture shown in Equation (
2). It is noted that a reasonable number of dense layers is already sufficient. As the number of layers increases further, the network performance increases slightly. The above calibration determines the architecture of the CNN-MLP model, whose detailed layout is presented in
Table 7.
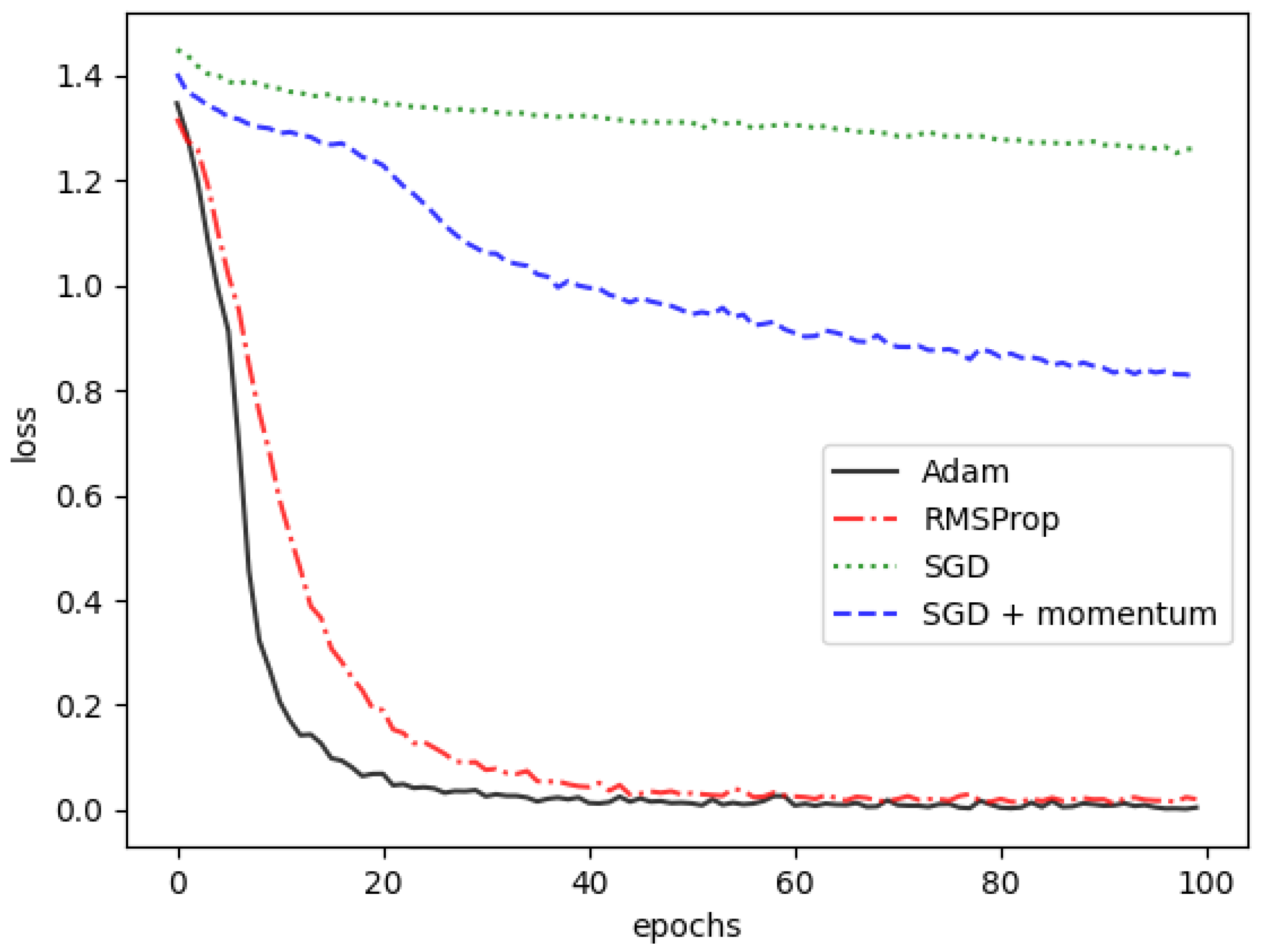
In terms of the loss function, “sparse categorical cross-entropy” was utilized, which combines a Softmax activation plus a cross-entropy loss. Several options for the optimizers were evaluated, including the adaptive learning rate optimization algorithm (Adam), root mean squared propagation (RMSprop), standard stochastic gradient descent (SGD), and a standard stochastic gradient descent with a variation in the “momentum” parameter (SGD + momentum). The outcomes of these four optimizer options are illustrated in
Figure 7 and
Table 8. A review of
Table 8 reveals that “Adam” outperforms the other optimizers. Furthermore,
Figure 7 demonstrates that “Adam” achieves quicker convergence compared to the alternatives, making it the preferred choice for the current CNN architectures.
Lastly, the outcome indicates a certain degree of overfitting, as the model performs significantly better in training than in validation. In this regard,
ReduceLROnPlateau callback was employed to minimize overfitting. The option monitors one specific quantity as a metric and reduces the learning rate when the metric stops improving. In this aspect, the validation loss values were chosen as the monitor quantity. As a result, the model’s learning rate would be reduced as the validation performance starts decreasing considerably. The callback implementation effectively decelerates the learning process and subsequently improves the model’s convergence among the train and validation datasets. In particular, a parameter of the ReduceLROnPlateau tool called “patience” plays a crucial role. This parameter is responsible for assigning the maximum number of epochs, inclusively, for the case where no improvement is observed for the monitored metric until the learning rate is reduced. As shown in
Table 9, one perceives that this parameter is vital for the calibration algorithm to detect the correct moment when the model stops learning. This allows the training and validation to converge at the highest accuracies, while the losses are essentially minimized. Moreover, the robustness of the results was confirmed through a k-fold cross-validation, which considers different separations of the training and validation datasets. The results are presented in
Table 10.
These results indicate that reasonable and consistent accuracy is achieved for the proposed model. The models utilized are robust enough to effectively detect critical patterns within the data. Although there were some cases of misidentification, the accuracy levels demonstrate the approach’s promise for real-world applications. However, it is worth noting that factors such as input data quality, task complexity, and the suitability of the model design can impact performance. Thus, while the results are promising, additional testing and fine-tuning might be required to guarantee sustained high accuracy when tackling new or more challenging datasets. Given the model calibration, the comparison of the efficiency of different network architectures and the effect of the pre-training process are discussed in the next section.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}