Modelling the Influence of Soil Properties on Crop Yields Using a Non-Linear NFIR Model and Laboratory Data





Abstract
1. Introduction
2. Materials and Methods
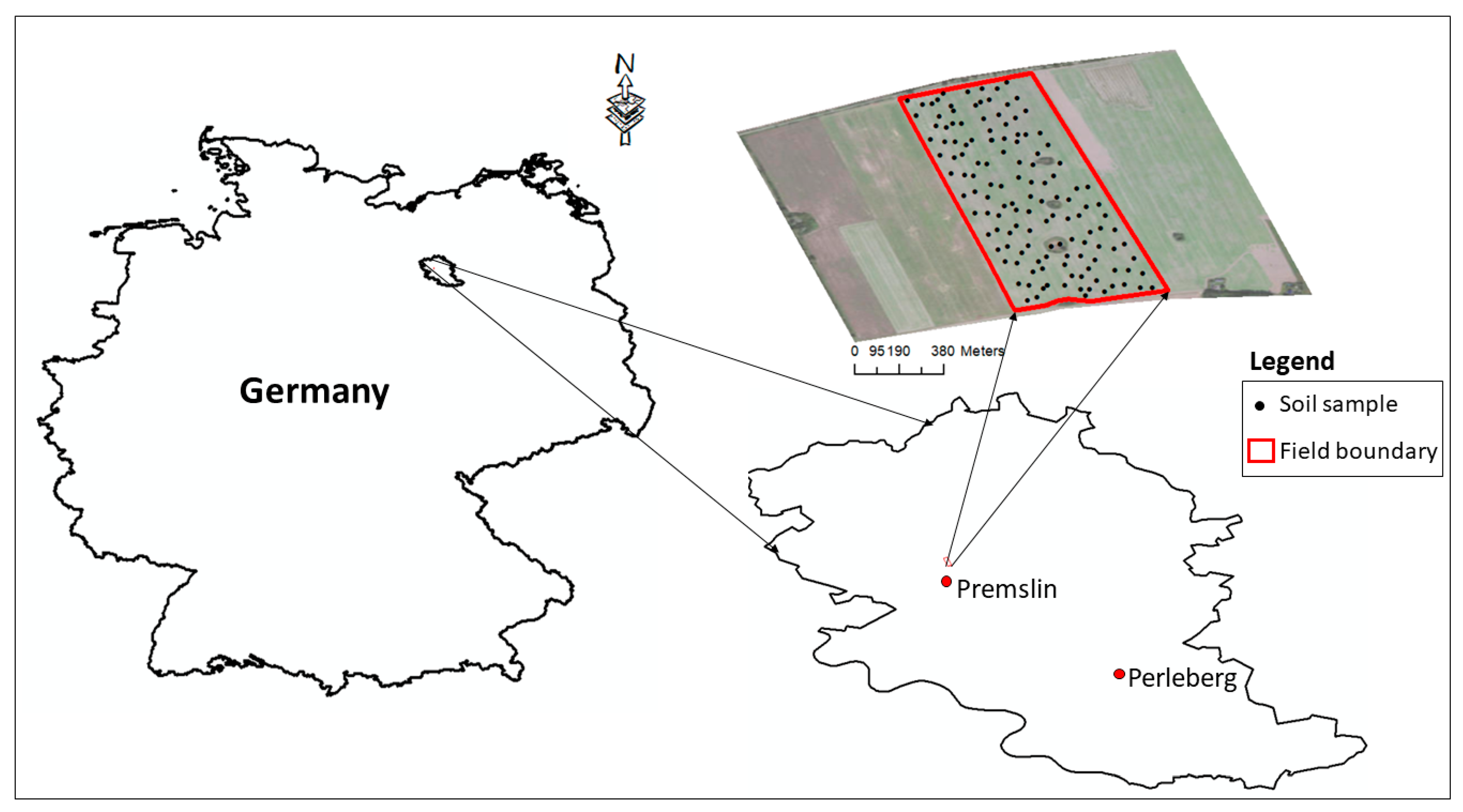
2.1. Study Site and Data Collection
2.2. Laboratory Analysis and Development of Calibration Models of the Soil Properties
2.3. Data Processing
2.4. Random Forest Method
- (1)
- Sample the calibration set with replacement to generate bootstrap resamples
- (2)
- For each resample , grow a regression tree .
- (3)
- For predicting the test case with covariate , the predicted value by the whole RF is obtained by combining the results given by individual trees. Let denote the prediction of by mth tree, the RF prediction for regression problems can then be written as
- (4)
- Parallel to the calibration step, RF performs an internal cross-validation by dividing the calibration set into in-bag (2/3 of the data) and the reaming is assigned to out-of-bag (OOB) sets. The number of variables per level (mtry = 1), size of the nodes (nodesize = 20), and the number of trees (ntree = 500) parameters are optimised by minimising the aggregate error rate of the OOB set (RMSE_OOB) [20,21]. The accuracy of a random forest’s prediction can be estimated from these OOB data, by using the following equation:where is the average prediction for the ith observation from all trees, for which this observation has been OOB [22].
2.5. Parametric Modelling
3. Results and Discussion
3.1. Soil and Yield Data Analysis
3.2. Linear Correlation
3.3. Random Forest Model
3.4. Parametric Models
3.5. Parametric Models versus Random Forest Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hole, D.; Perkins, A.; Wilson, J.; Alexander, I.; Grice, P.; Evans, A. Does organic farming benefit biodiversity? Biol. Conserv. 2005, 122, 113–130. [Google Scholar] [CrossRef]
- Hahn, H. Actual pathogen detection: Sensors and algorithms—A review. Algorithms 2009, 2, 301–338. [Google Scholar] [CrossRef]
- Thorp, K.R.; Ale, S.; Bange, M.P.; Barnes, E.M.; Hoogenboom, G.; Lascano, R.J.; McCarthy, A.C.; Nair, S.; Paz, J.O.; Rajan, N.; et al. Development and application of process-based simulation models for cotton pro-duction: A review of past, present, and future directions. J. Cotton Sci. 2014, 8, 10–47. [Google Scholar]
- Fourcaud, T.; Zhang, X.; Stokes, A.; Lambers, H.; Körner, C. Plant Growth Modelling and Applications: The Increasing Importance of Plant Architecture in Growth Models. Ann. Bot. 2007, 101, 1053–1063. [Google Scholar] [CrossRef]
- Pantazi, X.-E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Mouazen, A. Wheat yield prediction using machine learning and advanced sensing technologies. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Ajami, M.; Heidari, A.; Khormali, F.; Zeraatpisheh, M.; Gorji, M.; Ayoubi, S. Spatial Variability of Rainfed Wheat Production Under the Influence of Topography and Soil Properties in Loess-Derived Soils, Northern Iran. Int. J. Plant Prod. 2020, 14, 597–608. [Google Scholar] [CrossRef]
- Peralta, N.R.; Costa, J.L.; Balzarini, M.; Franco, M.C.; Córdoba, M.; Bullock, D. Delineation of management zones to im-prove nitrogen management of wheat. Comput. Electron. Agric. 2015, 110, 103–113. [Google Scholar] [CrossRef]
- Palm, R. Les modèles de prévision statistique: Cas du modèle Eurostat-Agromet. In Estimation de la Production Agricole à une Échelle Régionale; Tychon, B., Tonnard, V., Eds.; Official Publications of the EU: Luxembourg, 1997; pp. 85–108. [Google Scholar]
- Gommes, R. Non-parametric crop yield forecasting, a didactic case study for Zimbabwe. Proc. ISPRS Arch. 2016, 8, W48. [Google Scholar]
- Billings, S.; Chen, S.; Korenberg, M.J. Identification of MIMO nonlinear systems using a forward regression orthogonal estimator. Int. J. Control 1989, 49, 2157–2189. [Google Scholar] [CrossRef]
- Sarrigiannis, P.G.; Zhao, Y.; Wei, H.-L.; Billings, S.A.; Fotheringham, J.; Hadjivassiliou, M. Quantitative EEG analysis us-ing error reduction ratio-causality test; validation on simulated and real EEG data. Clin. Neurophysiol. 2014, 125, 32–46. [Google Scholar] [CrossRef]
- Zhao, Y.; Billings, S.A.; Wei, H.; Sarrigiannis, P.G. Tracking time-varying causality and directionality of information flow using an error reduction ratio test with applications to electroencephalography data. Phys. Rev. E 2012, 86, 051919. [Google Scholar] [CrossRef] [PubMed]
- Bigg, G.R.; Wei, H.L.; Wilton, D.J.; Zhao, Y.; Billings, S.A.; Hanna, E.; Kadirkamanathan, V. A century of variation in the dependence of Greenland iceberg calving on ice sheet surface mass balance and regional climate change. Proc. R. Soc. A Math. Phys. Eng. Sci. 2014, 470, 20130662. [Google Scholar] [CrossRef]
- Zhao, Y.; Bigg, G.R.; Billings, S.A.; Hanna, E.; Sole, A.J.; Wei, H.; Wilton, D.J. Inferring the variation of climatic and glaci-ological contributions to West Greenland iceberg discharge in the twentieth century. Cold Reg. Sci. Technol. 2016, 21, 167–178. [Google Scholar] [CrossRef]
- YZhao JMehnen ASirikham, R.R.o.y. A novel defect depth measurement method based on Nonlinear System Identi-fication for pulsed thermographic inspection. Mech. Syst. Signal Process. 2017, 85, 382–395. [Google Scholar]
- Chapman, H. Methods of Soil Analysis: Part 2 Chemical and Microbiological Properties; American Society of Agronomy: Madison, WI, USA, 1965. [Google Scholar]
- Frogbrook, Z.L.; Oliver, M.A. Identifying management zones in agricultural fields using spatially constrained classifica-tion of soil and ancillary data. Soil Use Manag. 2007, 23, 40–51. [Google Scholar] [CrossRef]
- Khosla, R.; Inman, D.; Westfall, D.G.; Reich, R.M.; Frasier, M.; Mzuku, M.; Koch, B.; Hornung, A. A synthesis of mul-ti-disciplinary research in precision agriculture: Site-specific management zones in the semi-arid Western Great Plains of the USA. Precis. Agric. 2008, 9, 85–100. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Manual on Setting Up, Using, and Understanding Random Forests V3.1; Statistics Department, University of California: Berkeley, CA, USA, 2002. [Google Scholar]
- Xin, N.; Gu, X.-F.; Wu, H.; Hu, Y.-Z.; Yang, Z.-L. Discrimination of raw and processed Dipsacus asperoides by near infra-red spectroscopy combined with least squares-support vector machine and random forests. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2012, 89, 18–24. [Google Scholar] [CrossRef]
- Grömping, U. Variable Importance Assessment in Regression: Linear Regression versus Random Forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Ishwaran, H. Variable importance in binary regression trees and forests. Electron. J. Stat. 2007, 1, 519–537. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.-M.; Tuleau, C. Random forests: Some methodological insights. Research Report Institut Na-tional de Recherche en Informatique et en Automatique. arXiv 2008, arXiv:0811.3619. [Google Scholar]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression. R Package Version n 4.6. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 15 February 2021).
- Chen, S.; Billings, S.A. Representation of non-linear systems: The NARMAX model. Int. J. Control 1989, 49, 1013–1032. [Google Scholar] [CrossRef]
- Wei, H.; Billings, S.; Liu, J. International Journal of Control. Term Var. Sel. Nonlinear Syst. Identif. 2004, 77, 86–110. [Google Scholar]
- Zhao, Y.; Billings, S.A.; Wei, H.; He, F.; Sarrigiannis, P.G. A new NARX-based Granger linear and nonlinear casual in-fluence detection method with applications to EEG data. J. Neurosci. Methods 2013, 212, 79–86. [Google Scholar] [CrossRef] [PubMed]
- DEFRA. The analysis of agriculture materials. In Refrence Book 427; Stationary Office: London, UK, 2000. [Google Scholar]
- Murrmann, R.P.; Peech, M. Effect of pH on Labile and Soluble Phosphate in Soils. Soil Sci. Soc. Am. J. 1969, 33, 205–210. [Google Scholar] [CrossRef]
- Cambardella, C.A.; Moorman, T.B.; Novak, J.M.; Parkin, T.B.; Karlen, D.L.; Turco, R.F.; Konopka, A.E. Field-Scale Variability of Soil Properties in Central Iowa Soils. Soil Sci. Soc. Am. J. 1994, 58, 1501–1511. [Google Scholar] [CrossRef]
- Chang, D.; Zhang, J.; Zhu, L.; Ge, S.-H.; Li, P.-Y.; Liu, G.-S. Delineation of management zones using an active canopy sensor for a tobacco field. Comput. Electron. Agric. 2014, 109, 172–178. [Google Scholar] [CrossRef]
- Carlyle, J. Carbon in forested sandy soils: Properties, processes, and the impact of forest management. N. Z. J. For. Sci. 1993, 23, 390–402. [Google Scholar]
- Kuang, B.; Mouazen, A. Calibration of a visible and near infrared spectroscopy for soil analysis at field scales across three European farms. Eur. J. Soil Sci. 2011, 62, 629–636. [Google Scholar] [CrossRef]
- Hazelton, P.A.; Murphy, B.W. Interpreting Soil Test Results: What Do All the Numbers Mean Australia; CSIRO Publisher: Clayton, Australia, 2007. [Google Scholar]
- Roberts, M.J.; Schlenker, W.; Eyer, J. Agronomic Weather Measures in Econometric Models of Crop Yield with Implications for Climate Change. Am. J. Agric. Econ. 2012, 95, 236–243. [Google Scholar] [CrossRef]
- Lobell, D.B.; Roberts, M.J.; Schlenker, W.; Braun, N.; Little, B.B.; Rejesus, R.M.; Hammer, G.L. Greater Sensitivity to Drought Accompanies Maize Yield Increase in the U.S. Midwest. Science 2014, 344, 516–519. [Google Scholar] [CrossRef]
- Paveley, N.; Blake, J.; Gladders, P.; Cockerell, V. Wheat Disease Management Guide; HGCA: Warwickshire, UK, 2012. [Google Scholar]
- Agegnehu, G.; Nelson, P.N.; Bird, M.I. Crop yield, plant nutrient uptake and soil physicochemical properties under organic soil amendments and nitrogen fertilization on Nitisols. Soil Tillage Res. 2016, 160, 1–13. [Google Scholar] [CrossRef]
- Tiessen, H.; Cuevas, E.; Chacon, P. The role of soil organic matter in sustaining soil fertility. Nat. Cell Biol. 1994, 371, 783–785. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, M.; Sun, N.; Xiong, W.; Huang, S.; Wu, L. Modelling and predicting crop yield, soil carbon and nitrogen stocks under climate change scenarios with fertiliser management in the North China Plain. Geoderma 2016, 265, 176–186. [Google Scholar] [CrossRef]
- Lorenz, K.; Lal, R.; Preston, C.M.; Nierop, K.G. Strengthening the soil organic carbon pool by increasing contributions from recalcitrant aliphatic bio(macro)molecules. Geoderma 2007, 142, 1–10. [Google Scholar] [CrossRef]
- Lal, R. Sequestering carbon in soils of agro-ecosystems. Food Policy 2011, 36, S33–S39. [Google Scholar] [CrossRef]
- Fan, M.; Cao, J.; Wei, W.; Zhang, F.; Su, Y. Managing soil organic carbon for advancing food security and strengthening ecosystem services in China. In Ecosystem Services and Carbon Sequestration in the Biosphere; Lal, R., Lorenz, K., Hüttl, R.F., Schneider, B., von Braun, J., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 419–429. [Google Scholar]
- Murrell, T.S.; Logsdon, S.; Clay, D.; Moore, D.; Tsegaye, T. Measuring Nutrient Removal, Calculating Nutrient Budgets. In Guidelines for Analysis and Description of Soil and Regolith Thin Sections; American Society of Agronomy and Soil Science Society of America: Madison, WI, USA, 2015; pp. 159–182. [Google Scholar]
- Renouf, M.A.; Wegener, M.K.; Pagan, R.J. Life cycle assessment of Australian sugarcane production with a focus on sugarcane growing. Int. J. Life Cycle Assess. 2010, 15, 927–937. [Google Scholar] [CrossRef]
- Boone, L.; de Meester, S.; Vandecasteele, B.; Muylle, H.; Roldán-Ruiz, I.; Nemecek, T.; Dewulf, J. Environmental life cycle assessment of grain maize production: An analysis of factors causing variability. Sci. Total Environ. 2016, 553, 551–564. [Google Scholar] [CrossRef]
- Eberhart, S.A.; Russell, W.A. Stability Parameters for Comparing Varieties. Crop. Sci. 1966, 6, 36–40. [Google Scholar] [CrossRef]
- Baligar, V.; Fageria, N.; He, Z. Nutrient use efficiency in plants. Commun. Soil Sci. Plant Anal. 2001, 32, 921–950. [Google Scholar] [CrossRef]
- Wakeel, A. Potassium–sodium interactions in soil and plant under saline-sodic conditions. J. Plant Nutr. Soil Sci. 2013, 176, 344–354. [Google Scholar] [CrossRef]
- Perrenoud, S. Potassium and Plant Health, 2nd ed.; IPI Research Topics No. 3; International Potash Institute: Bern, Switzerland, 1990. [Google Scholar]
- Reeves, D. The role of soil organic matter in maintaining soil quality incontinuous cropping systems. Soil Tillage Res. 1997, 43, 131–167. [Google Scholar] [CrossRef]
- Shukla, M.; Lal, R.; Ebinger, M. Determining soil quality indicators by factoranalysis. Soil Tillage Res. 2006, 87, 194–204. [Google Scholar] [CrossRef]
- D’Hose, T.; Cougnon, M.; De Vliegher, A.; Vandecasteele, B.; Viaene, N.; Cornelis, W.; Van Bockstaele, E.; Reheul, D. The positive relationship between soil quality and crop production: A case study on the effect of farm compost application. Appl. Soil Ecol. 2014, 75, 189–198. [Google Scholar] [CrossRef]
- Harmsen, K.; Matar, A.; Saxena, M.; Silim, S. Yield response to phosphorus fertilizer in a wheat-lentil rotation in a Medi-terranean environment. NJAS Wagening. J. Life Sci. 2001, 49, 385–403. [Google Scholar] [CrossRef]
- Sharma, K.; Grace, J.; Mandal, U.; Gajbhiye, P.; Srinivas, K.; Korwar, G.; Bindu, V.; Ramesh, V.; Ramachandran, K.; Yadav, S. Evaluation of long-termsoil management practices using key indicators and soil quality indices in asemi-arid tropical Al-fisol. Soil Res. 2008, 46, 368–377. [Google Scholar] [CrossRef]
- Walley, F.; Yates, T.; van Groenigen, J.W.; van Kessel, C. Relationships between soil nitrogen availability indices, yield, and nitrogen accumulation of wheat. Soil Sci. Soc. Am. J. 2002, 66, 1549–1561. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Bullock, D.G. Correlation of Corn and Soybean Grain Yield with Topography and Soil Properties. Semigroup Forum 2000, 92, 75. [Google Scholar] [CrossRef]
- Huber, D.M. The role of mineral nutrition in defense. In Plant Pathology an Advanced Treati; Horsfall, J.G., Cowling, E.B., Eds.; Academic Press: New York, NY, USA, 1980; pp. 381–406. [Google Scholar]
- Engelhard, A.W. (Ed.) Soil Borne. Plant Pathogens. Management of Diseases with Macro-and Microelements; The American Phytopathological Society Press: St. Paul, MN, USA, 1989. [Google Scholar]
- Fageria, K.N.; Baligar, V.C. Phosphorous—Use efficiency by corn genotypes. J. Plant Nutr. 1997, 20, 1267–1277. [Google Scholar] [CrossRef]
- Graham, R.D.; Webb, M.J. Micronutrients and disease resistance and tolerance in plants. Micronutr. Agric. 1991, 4, 329–370. [Google Scholar]


{kind=link}
| Variable | C0 | C | r (m) | (C0/C) (%) | SSE |
|---|---|---|---|---|---|
| Yield 2013 | 0.00029 | 0.00045 | 19.49 | 64.7% | 0.0000 |
| Yield 2014 | 0.00390 | 0.00900 | 40.98 | 43.1% | 0.0001 |
| TN | pH | P | OC | GMC | K+ | Mg2+ | Na+ | Ca2+ | CEC | |
|---|---|---|---|---|---|---|---|---|---|---|
| Max | 1.40 | 7.70 | 9.54 | 12.90 | 125.00 | 1.33 | 0.63 | 0.13 | 5.17 | 11.7 |
| Min | 0.50 | 5.40 | 1.34 | 5.90 | 61.50 | 0.14 | 0.13 | 0.02 | 1.47 | 6.30 |
| Mean | 0.80 | 6.63 | 2.69 | 8.30 | 81.90 | 0.50 | 0.29 | 0.06 | 2.86 | 8.45 |
| Std | 0.14 | 0.46 | 0.93 | 1.50 | 11.20 | 0.23 | 0.08 | 0.01 | 0.66 | 1.04 |
| Ca2+ | CEC | K+ | GMC | Mg2+ | Na+ | OC | P | pH | TN | Yield13 | Yield14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ca2+ | 1.000 | |||||||||||
| CEC | −0.018 | 1.000 | ||||||||||
| K+ | −0.096 | 0.187 | 1.000 | |||||||||
| GMC | 0.442 | 0.101 | 0.192 | 1.000 | ||||||||
| Mg2+ | −0.040 | 0.197 | 0.111 | 0.168 | 1.000 | |||||||
| Na+ | 0.103 | −0.052 | 0.350 | 0.235 | −0.023 | 1.000 | ||||||
| OC | 0.507 | 0.150 | 0.004 | 0.510 | 0.189 | −0.033 | 1.000 | |||||
| P | −0.238 | 0.180 | 0.074 | −0.360 | −0.219 | 0.004 | −0.131 | 1.000 | ||||
| pH | 0.716 | −0.656 | −0.076 | 0.285 | −0.124 | 0.140 | 0.297 | −0.300 | 1.000 | |||
| TN | 0.564 | 0.216 | 0.079 | 0.559 | 0.217 | 0.006 | 0.945 | −0.130 | 0.305 | 1.000 | ||
| Yield13 | −0.058 | −0.010 | −0.037 | −0.030 | 0.059 | −0.002 | 0.239 | 0.192 | −0.043 | 0.160 | 1.000 | |
| Yield14 | 0.092 | −0.092 | −0.071 | 0.054 | −0.011 | 0.109 | −0.043 | 0.141 | 0.127 | −0.084 | 0.190 | 1.000 |
| Rank | 2013 | 2014 | ||
|---|---|---|---|---|
| Input | MSE (%) | Input | MSE (%) | |
| 1 | OC | 12.84 | TN | 11.44 |
| 2 | TN | 11.01 | OC | 7.43 |
| 3 | Ca2+ | 9.43 | P | 6.41 |
| 4 | P | 6.22 | Ca2+ | 5.20 |
| 5 | CEC | 4.73 | pH | 5.12 |
| 6 | pH | 3.91 | CEC | 3.23 |
| 7 | Na+ | 3.72 | Mg2+ | 2.82 |
| 8 | Mg2+ | 1.94 | GMC | 2.33 |
| 9 | GMC | 1.35 | Na+ | 2.03 |
| 10 | K+ | 0.82 | K+ | 0.11 |
| Total | 55.62 | 45.81 | ||
| Rank | 2013 | 2014 | ||
|---|---|---|---|---|
| Input | ERRC (%) | Input | ERRC (%) | |
| 1 | P | 12.74 | P | 8.30 |
| 2 | CEC | 12.47 | Na+ | 6.77 |
| 3 | OC | 6.44 | OC | 6.71 |
| 4 | pH | 4.91 | K+ | 5.89 |
| 5 | Ca2+ | 3.87 | pH | 5.05 |
| 6 | Na+ | 3.82 | TN | 5.01 |
| 7 | Mg2+ | 3.41 | GMC | 5.00 |
| 8 | K+ | 1.75 | Mg2+ | 4.06 |
| 9 | GMC | 1.59 | CEC | 2.79 |
| 10 | TN | 1.23 | Ca2+ | 1.08 |
| SERR | 52.23 | 50.66 | ||
| Rank | 2013 | 2014 | ||
|---|---|---|---|---|
| Input | ERRC (%) | Input | ERRC (%) | |
| 1 | P | 6.18 | P | 2.01 |
| 2 | OC | 5.73 | OC | 1.46 |
| 3 | TN | 3.94 | Na+ | 1.21 |
| 4 | Ca2+ | 1.23 | Ca2+ | 1.20 |
| 5 | pH | 1.09 | K+ | 1.13 |
| 6 | Mg2+ | 0.53 | TN | 0.88 |
| 7 | K+ | 0.17 | CEC | 0.33 |
| 8 | Na+ | 0.15 | GMC | 0.18 |
| 9 | GMC | 0.13 | Mg2+ | 0.07 |
| 10 | CEC | 0 | pH | 0.03 |
| SERR | 19.15 | 8.50 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Whetton, R.L.; Zhao, Y.; Nawar, S.; Mouazen, A.M. Modelling the Influence of Soil Properties on Crop Yields Using a Non-Linear NFIR Model and Laboratory Data. Soil Syst. 2021, 5, 12. https://doi.org/10.3390/soilsystems5010012
Whetton RL, Zhao Y, Nawar S, Mouazen AM. Modelling the Influence of Soil Properties on Crop Yields Using a Non-Linear NFIR Model and Laboratory Data. Soil Systems. 2021; 5(1):12. https://doi.org/10.3390/soilsystems5010012
Chicago/Turabian StyleWhetton, Rebecca L., Yifan Zhao, Said Nawar, and Abdul M. Mouazen. 2021. "Modelling the Influence of Soil Properties on Crop Yields Using a Non-Linear NFIR Model and Laboratory Data" Soil Systems 5, no. 1: 12. https://doi.org/10.3390/soilsystems5010012
APA StyleWhetton, R. L., Zhao, Y., Nawar, S., & Mouazen, A. M. (2021). Modelling the Influence of Soil Properties on Crop Yields Using a Non-Linear NFIR Model and Laboratory Data. Soil Systems, 5(1), 12. https://doi.org/10.3390/soilsystems5010012