
FireNet-KD: Swin Transformer-Based Wildfire Detection with Multi-Source Knowledge Distillation



Abstract
1. Introduction
Key Contributions
- 1.
- FireNet-KD with Adaptive Fusion
- 2.
- Confidence-Aware Detection and Imbalance Mitigation
2. Related Works
2.1. Early and Accurate Forest Fire Detection
2.2. Deep Learning Methods and Model Optimization for Fire Detection
2.3. Comparison with Other Similar Knowledge Distillation Techniques
3. Methodology
3.1. Data Collection and Processing
3.2. FireNet-KD Arcitecture
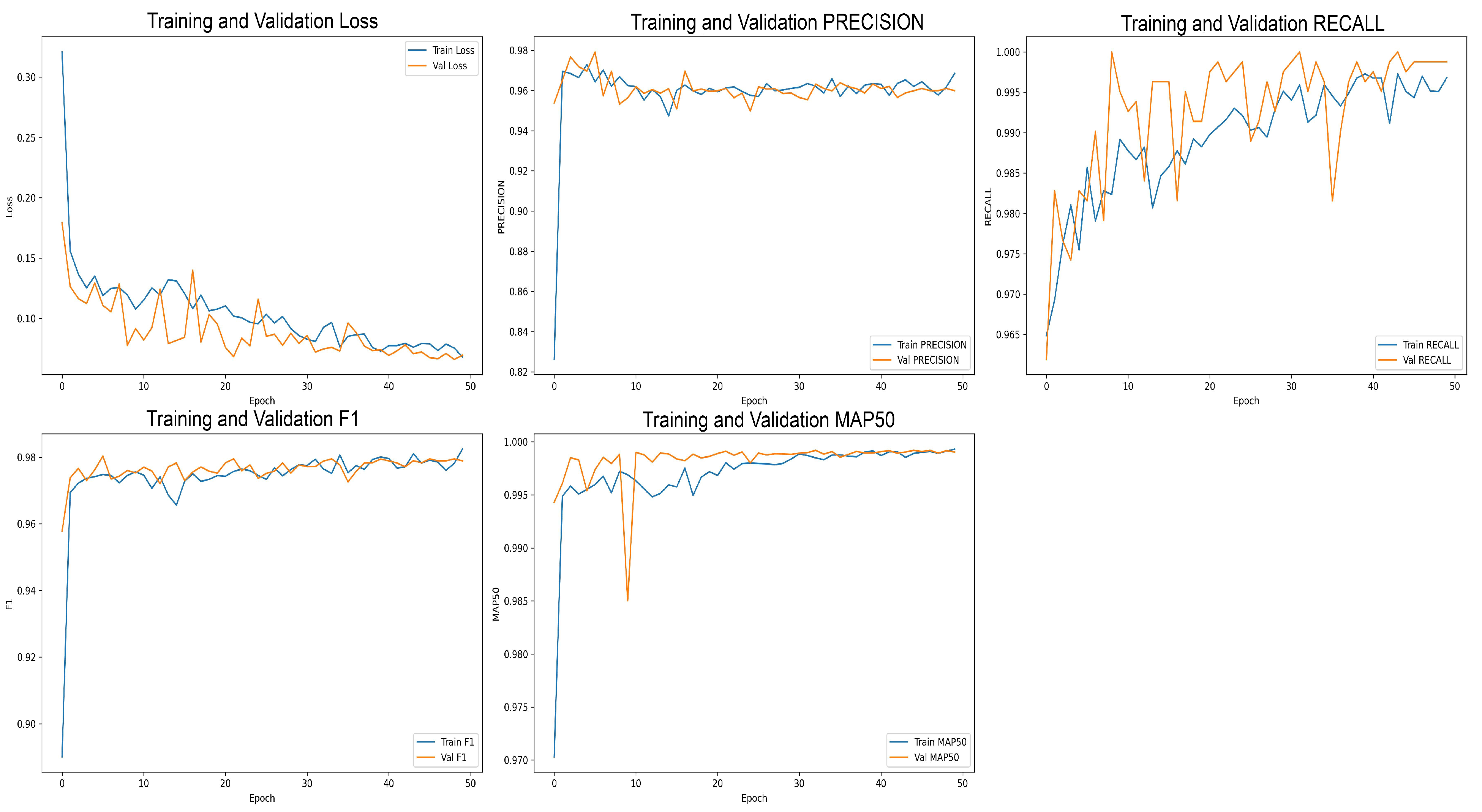
3.3. Training Protocol and Loss Functions
3.4. Multi-Scale Inference Pipeline
3.5. Evaluation Metrics
3.6. Precision: The Accuracy of Positive Predictions
3.7. Recall: Comprehensive Fire Detection Capability
3.8. F1-Score: Balanced Performance Metric
3.9. mAP@0.5: Localization Accuracy Evaluation
3.10. Computational Environment
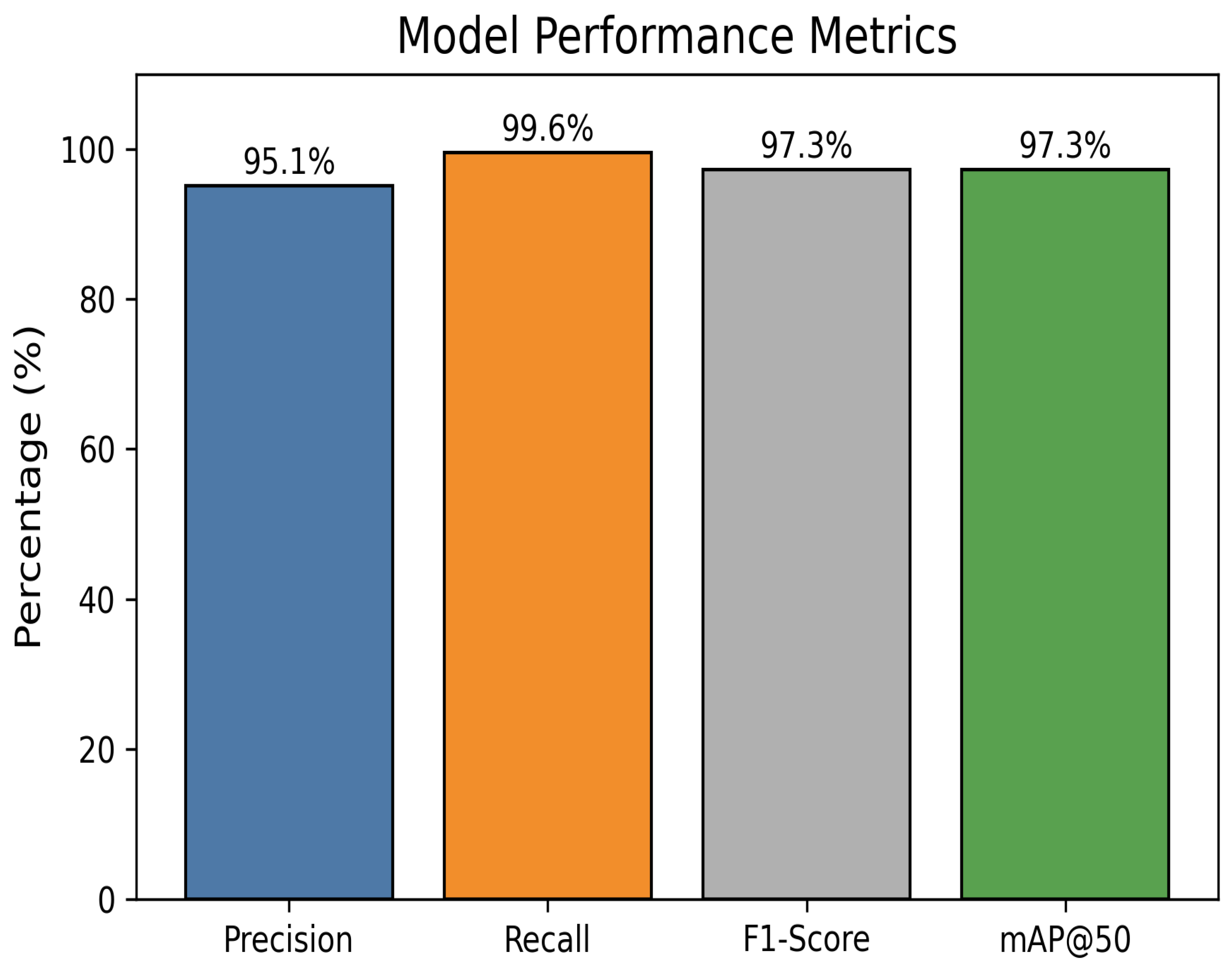
4. Results and Discussions
5. Ablation Study
6. Conclusions and Future Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Köhl, M.; Lasco, R.; Cifuentes, M.; Jonsson, Ö.; Korhonen, K.T.; Mundhenk, P.; de Jesus Navar, J.; Stinson, G. Changes in forest production, biomass and carbon: Results from the 2015 UN FAO Global Forest Resource Assessment. For. Ecol. Manag. 2015, 352, 21–34. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Balch, J.K.; Artaxo, P.; Bond, W.J.; Carlson, J.M.; Cochrane, M.A.; d’Antonio, C.M.; DeFries, R.S.; Doyle, J.C.; Harrison, S.P.; et al. Fire in the Earth system. Science 2009, 324, 481–484. [Google Scholar] [CrossRef]
- Westerling, A.L.; Hidalgo, H.G.; Cayan, D.R.; Swetnam, T.W. Warming and earlier spring increase western US forest wildfire activity. Science 2006, 313, 940–943. [Google Scholar] [CrossRef] [PubMed]
- Abatzoglou, J.T.; Williams, A.P. Impact of anthropogenic climate change on wildfire across western US forests. Proc. Natl. Acad. Sci. USA 2016, 113, 11770–11775. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, S.; Gonçalves, A.; Zêzere, J.L. Reassessing wildfire susceptibility and hazard for mainland Portugal. Sci. Total Environ. 2021, 762, 143121. [Google Scholar] [CrossRef]
- Fernández-Guisuraga, J.M.; Martins, S.; Fernandes, P.M. Characterization of biophysical contexts leading to severe wildfires in Portugal and their environmental controls. Sci. Total Environ. 2023, 875, 162575. [Google Scholar] [CrossRef]
- World Resources Institute. Tree Cover Loss from Fires Reached Record High in 2022; World Resources Institute: Washington, DC, USA, 2023; Available online: https://www.wri.org/ (accessed on 20 May 2025).
- California Department of Forestry and Fire Protection (CAL FIRE). 2020 Fire Season Summary; CAL FIRE: Sacramento, CA, USA, 2020. Available online: https://www.fire.ca.gov/incidents/2020/ (accessed on 20 May 2025).
- Natural Resources Canada. Canada’s 2023 Wildfire Season—A Record Year; Government of Canada: Ottawa, ON, Canada, 2023. Available online: https://natural-resources.canada.ca/ (accessed on 20 May 2025).
- Geetha, S.; Abhishek, C.S.; Akshayanat, C.S. Machine vision based fire detection techniques: A survey. Fire Technol. 2021, 57, 591–623. [Google Scholar] [CrossRef]
- Giglio, L.; Boschetti, L.; Roy, D.; Hoffmann, A.A.; Humber, M.; Hall, J.V. Collection 6 Modis Burned Area Product User’s Guide Version 1.0; NASA EOSDIS Land Processes DAAC: Sioux Falls, SD, USA, 2016; pp. 11–27.
- Justice, C.O.; Townshend, J.R.G.; Vermote, E.F.; Masuoka, E.; Wolfe, R.E.; Saleous, N.; Roy, D.P.; Morisette, J.T. An overview of MODIS Land data processing and product status. Remote Sens. Environ. 2002, 83, 3–15. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, W.; Wu, S.; Liu, C.; Yan, H. Fire monitoring algorithm and its application on the geo-kompsat-2A geostationary meteorological satellite. Remote Sens. 2022, 14, 2655. [Google Scholar] [CrossRef]
- Schroeder, W.; Oliva, P.; Giglio, L.; Csiszar, I.A. The New VIIRS 375 m active fire detection data product: Algorithm description and initial assessment. Remote Sens. Environ. 2014, 143, 85–96. [Google Scholar] [CrossRef]
- Fu, Y.; Li, R.; Wang, X.; Bergeron, Y.; Valeria, O.; Chavardès, R.D.; Wang, Y.; Hu, J. Fire detection and fire radiative power in forests and low-biomass lands in Northeast Asia: MODIS versus VIIRS Fire Products. Remote Sens. 2020, 12, 2870. [Google Scholar] [CrossRef]
- Lloret, J.; Garcia, M.; Bri, D.; Sendra, S. A wireless sensor network deployment for rural and forest fire detection and verification. Sensors 2009, 9, 8722–8747. [Google Scholar] [CrossRef] [PubMed]
- Haque, A.; Soliman, H. A Transformer-Based Autoencoder with Isolation Forest and XGBoost for Malfunction and Intrusion Detection in Wireless Sensor Networks for Forest Fire Prediction. Future Internet 2025, 17, 164. [Google Scholar] [CrossRef]
- Ramadan, M.N.A.; Basmaji, T.; Gad, A.; Hamdan, H.; Akgün, B.T.; Ali, M.A.H.; Alkhedher, M.; Ghazal, M. Towards early forest fire detection and prevention using AI-powered drones and the IoT. Internet Things 2024, 27, 101248. [Google Scholar] [CrossRef]
- Radhi, A.A.; Ibrahim, A.A. Forest Fire Detection Techniques Based on IoT Technology. In Proceedings of the 2023 1st IEEE International Conference on Smart Technology (ICE-SMARTec), Bandung, Indonesia, 17–19 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 128–133. [Google Scholar]
- Nikhilesh Krishna, C.; Rauniyar, A.; Bharadwaj, N.K.S.; Raj, S.B.; Valsan, V.; Suresh, K.; Pandi, V.R.; Sathyan, S. ECO-Guard: An Integrated AI Sensor System for Monitoring Wildlife and Sustainable Forest Management. In Proceedings of the International Conference on Information and Communication Technology for Competitive Strategies, Jaipur, India, 8–9 December 2023; Springer Nature: Singapore, 2023; pp. 409–419. [Google Scholar]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2020, 149, 1–16. [Google Scholar] [CrossRef]
- Gao, Y.; Hao, M.; Wang, Y.; Dang, L.; Guo, Y. Multi-scale coal fire detection based on an improved active contour model from Landsat-8 Satellite and UAV images. ISPRS Int. J. Geo-Inf. 2021, 10, 449. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral imaging: A review on UAV-based sensors, data processing and applications for agriculture and forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- Liu, W.; Lyu, S.-K.; Liu, T.; Wu, Y.-T.; Qin, Z. Multi-target optimization strategy for unmanned aerial vehicle formation in forest fire monitoring based on deep Q-network algorithm. Drones 2024, 8, 201. [Google Scholar] [CrossRef]
- Jiang, Y.; Kong, J.; Zhong, Y.; Zhang, Q.; Zhang, J. An Enhanced Algorithm for Active Fire Detection in Croplands Using Landsat-8 OLI Data. Land 2023, 12, 1246. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Ko, B.C.; Cheong, K.-H.; Nam, J.-Y. Fire detection based on vision sensor and support vector machines. Fire Saf. J. 2009, 44, 322–329. [Google Scholar] [CrossRef]
- Li, M.; Zhang, K.; Liu, J.; Gong, H.; Zhang, Z. Blockchain-based anomaly detection of electricity consumption in smart grids. Pattern Recognit. Lett. 2020, 138, 476–482. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Reinke, K.; Stein, A. Predicting wildfire burns from big geodata using deep learning. Saf. Sci. 2021, 140, 105276. [Google Scholar] [CrossRef]
- Yang, S.; Huang, Q.; Yu, M. Advancements in remote sensing for active fire detection: A review of datasets and methods. Sci. Total. Environ. 2024, 943, 173273. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, L.; Liu, S.; Yin, Y. Intelligent fire location detection approach for extrawide immersed tunnels. Expert Syst. Appl. 2024, 239, 122251. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; NeurIPS: San Diego, CA, USA, 2017. [Google Scholar]
- Yar, H.; Khan, Z.A.; Rida, I.; Ullah, W.; Kim, M.J.; Baik, S.W. An efficient deep learning architecture for effective fire detection in smart surveillance. Image Vis. Comput. 2024, 145, 104989. [Google Scholar] [CrossRef]
- Jin, P.; Cheng, P.; Liu, X.; Huang, Y. From smoke to fire: A forest fire early warning and risk assessment model fusing multimodal data. Eng. Appl. Artif. Intell. 2025, 152, 110848. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Yang, T.; Su, Y.; Song, W.; Li, S.; Gong, W. FF-net: A target detection method tailored for mid-to-late stages of forest fires in complex environments. Case Stud. Therm. Eng. 2025, 65, 105515. [Google Scholar] [CrossRef]
- Kong, S.; Deng, J.; Yang, L.; Liu, Y. An attention-based dual-encoding network for fire flame detection using optical remote sensing. Eng. Appl. Artif. Intell. 2024, 127, 107238. [Google Scholar] [CrossRef]
- Wang, G.; Li, H.; Xiao, Q.; Yu, P.; Ding, Z.; Wang, Z.; Xie, S. Fighting against forest fire: A lightweight real-time detection approach for forest fire based on synthetic images. Expert Syst. Appl. 2025, 262, 125620. [Google Scholar] [CrossRef]
- Wang, L.; Li, H.; Siewe, F.; Ming, W.; Li, H. Forest fire detection utilizing ghost Swin transformer with attention and auxiliary geometric loss. Digit. Signal Process. 2024, 154, 104662. [Google Scholar] [CrossRef]
- Shi, P.; Wang, X. Forest Fire Detection Method based on Improved YOLOv7. In Proceedings of the 2024 7th International Conference on Advanced Algorithms and Control Engineering (ICAACE), Shanghai, China, 1–3 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 618–622. [Google Scholar]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Lu, K.; Huang, J.; Li, J.; Zhou, J.; Chen, X.; Liu, Y. MTL-FFDET: A multi-task learning-based model for forest fire detection. Forests 2022, 13, 1448. [Google Scholar] [CrossRef]
- Lin, J.; Lin, H.; Wang, F. A semi-supervised method for real-time forest fire detection algorithm based on adaptively spatial feature fusion. Forests 2023, 14, 361. [Google Scholar] [CrossRef]
- Xiao, Z.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Ye, Z.; Liu, W.; Zhou, W.; Xu, C. Fl-yolov7: A lightweight small object detection algorithm in forest fire detection. Forests 2023, 14, 1812. [Google Scholar] [CrossRef]
- Shi, P.; Lu, J.; Wang, Q.; Zhang, Y.; Kuang, L.; Kan, X. An efficient forest fire detection algorithm using improved YOLOv5. Forests 2023, 14, 2440. [Google Scholar] [CrossRef]
- Jin, L.; Yu, Y.; Zhou, J.; Bai, D.; Lin, H.; Zhou, H. SWVR: A lightweight deep learning algorithm for forest fire detection and recognition. Forests 2024, 15, 204. [Google Scholar] [CrossRef]
- Bai, X.; Wang, Z. Research on forest fire detection technology based on deep learning. In Proceedings of the 2021 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 24–26 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 85–90. [Google Scholar]
- Ahmad, N.; Akbar, M.; Alkhammash, E.H.; Jamjoom, M.M. CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments. Fire 2025, 8, 211. [Google Scholar] [CrossRef]
- Zhou, M.; Wu, L.; Liu, S.; Li, J. UAV forest fire detection based on lightweight YOLOv5 model. Multimed. Tools Appl. 2024, 83, 61777–61788. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, R.; Zheng, X.; Zhang, L.; Zhang, Y. A forest fire detection method based on improved YOLOv5. Signal Image Video Process. 2025, 19, 136. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, L.; Chen, Z. FFD-YOLO: A modified YOLOv8 architecture for forest fire detection. Signal Image Video Process. 2025, 19, 265. [Google Scholar] [CrossRef]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Chen, X.; Hopkins, B.; Wang, H.; O’Neill, L.; Afghah, F.; Razi, A.; Fulé, P.; Coen, J.; Rowell, E.; Watts, A. Wildland fire detection and monitoring using a drone-collected rgb/ir image dataset. IEEE Access 2022, 10, 121301–121317. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, J.; Xu, Y.; Xie, L. Mcan-YOLO: An Improved Forest Fire and Smoke Detection Model Based on YOLOv7. Forests 2024, 15, 1781. [Google Scholar] [CrossRef]
- Li, J.; Xu, R.; Liu, Y. An improved forest fire and smoke detection model based on yolov5. Forests 2023, 14, 833. [Google Scholar] [CrossRef]
- Chen, X.; Xue, Y.; Hou, Q.; Fu, Y.; Zhu, Y. RepVGG-YOLOv7: A modified YOLOv7 for fire smoke detection. Fire 2023, 6, 383. [Google Scholar] [CrossRef]
- Fan, X.; Lei, F.; Yang, K. Real-Time Detection of Smoke and Fire in the Wild Using Unmanned Aerial Vehicle Remote Sensing Imagery. Forests 2025, 16, 201. [Google Scholar] [CrossRef]
- Zheng, Y.; Tao, F.; Gao, Z.; Li, J. FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n. Forests 2024, 15, 1823. [Google Scholar] [CrossRef]
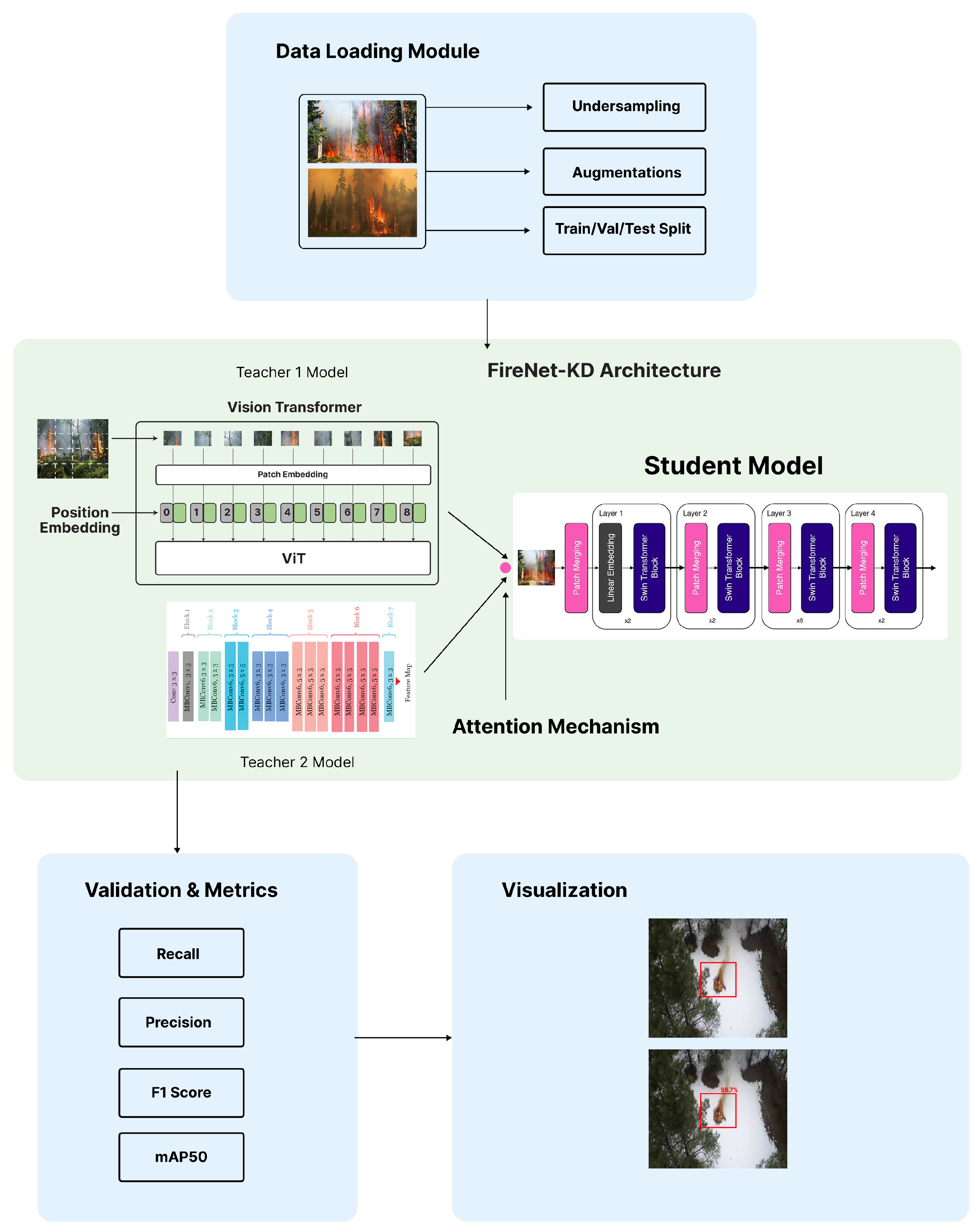




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Dataset | Advantages | Limitations |
|---|---|---|---|
| FF-net | FLAME | High precision and robustness in complex scenes; handles small targets and occlusions well | Performance drops in scenes with pseudo-samples (regions resembling flames) |
| ADE-Net | FLAME | Dual encoding for spatial and semantic features; strong local and global fusion | Large model size (333.69 MB); slightly higher inference time; requires supervised data |
| DRCSPNet + Global Mixed Attention + Lite-PAN | FLAME | Lightweight and real-time (33.5 FPS); robust to lighting variations and complex backgrounds | Synthetic data may not generalize perfectly; lower mAP on real-world scenarios (58.39%) |
| GCST | FLAME | Efficient multi-scale flame and smoke feature extraction; reduced parameter count | Performance may drop in noisy real-world scenes with complex backgrounds |
| SWVR | FLAME | Bi-directional feature fusion; reduces Params and GFLOPs; suitable for edge devices | Minor reduction in semantic richness if GSConv is overused; slight speed reduction |
| CN2VF-Net | D-Fire | Handles fire scale variation, occlusions, and environmental complexity; lightweight and accurate for deployment | Limited performance on fires smaller than 16 × 16 pixels |
| SPPFP + CBAM + BiFPN | Forest fire | Detects small fire targets in long-range UAV images; overcomes traditional model limitations | Susceptible to lighting/occlusion interference; false alarms remain an issue |
| Ref | Precision | Recall | F1-Score | mAP@50 |
|---|---|---|---|---|
| Liu et al. [55] | 90.9 | 86.8 | 88.8 | 91.5 |
| Li et al. [56] | 89.2 | - | 89.9 | 89.3 |
| Chen et al. [57] | 90.8 | - | 91.8 | 91.4 |
| Fan et al. [58] | 76.7 | 75.5 | 76.1 | 79.2 |
| Zheng et al. [59] | 94.5 | 96.8 | - | 96.7 |
| Proposed | 95.1 | 99.6 | 97.3 | 97.3 |
| Model Variant | Precision (%) | Recall (%) | F1-Score (%) | mAP@50 (%) |
|---|---|---|---|---|
| Single Teacher 1 | 93.18 | 95.54 | 94.72 | 92.65 |
| Single Teacher 2 | 92.18 | 96.87 | 93.86 | 91.88 |
| Student Only | 93.58 | 97.21 | 94.89 | 94.31 |
| FireNet-KD | 95.16 | 99.61 | 97.34 | 97.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, N.; Akbar, M.; Alkhammash, E.H.; Jamjoom, M.M. FireNet-KD: Swin Transformer-Based Wildfire Detection with Multi-Source Knowledge Distillation. Fire 2025, 8, 295. https://doi.org/10.3390/fire8080295
Ahmad N, Akbar M, Alkhammash EH, Jamjoom MM. FireNet-KD: Swin Transformer-Based Wildfire Detection with Multi-Source Knowledge Distillation. Fire. 2025; 8(8):295. https://doi.org/10.3390/fire8080295
Chicago/Turabian StyleAhmad, Naveed, Mariam Akbar, Eman H. Alkhammash, and Mona M. Jamjoom. 2025. "FireNet-KD: Swin Transformer-Based Wildfire Detection with Multi-Source Knowledge Distillation" Fire 8, no. 8: 295. https://doi.org/10.3390/fire8080295
APA StyleAhmad, N., Akbar, M., Alkhammash, E. H., & Jamjoom, M. M. (2025). FireNet-KD: Swin Transformer-Based Wildfire Detection with Multi-Source Knowledge Distillation. Fire, 8(8), 295. https://doi.org/10.3390/fire8080295