1. Introduction
Wildfires are among the most devastating natural disasters, causing significant loss of life and property worldwide. The escalating frequency and intensity of wildfires, a phenomenon attributable in large part to climate change, has led to a heightened demand for effective wildfire detection and response systems [
1,
2]. The capacity to detect and respond to wildfires in their nascent stages is of paramount importance in minimizing damage [
3].
Current wildfire detection systems primarily rely on sensor-based technologies that identify direct fire signals, such as smoke and flames. While these systems demonstrate a high degree of accuracy, they often face challenges in detecting subtle smoke and flames during the initial stages of a fire. Moreover, these systems are susceptible to false alarms triggered by non-fire factors, such as fog/haze in humid conditions or chimney smoke in forested areas [
4,
5,
6]. To address these challenges, recent research has focused on integrating Fourth Industrial Revolution technologies into wildfire detection systems [
7]. Specifically, deep learning-based object detection techniques have emerged as a pivotal area of interest for enhancing wildfire detection performance [
8,
9,
10].
A variety of approaches have been investigated in previous studies to improve the effectiveness of deep learning-based wildfire detection models. Pu Li et al. [
11] developed a vision-based fire detection model using Faster R-CNN, R-FCN, SSD, and YOLOv3 and evaluated its performance in diverse environments, such as indoor settings, mountainous areas, and industrial sites. Their experimental findings indicated that the YOLOv3-based model attained the highest detection accuracy (83.7%) and FPS (28). In a similar vein, Zhao et al. [
12] proposed Fire-YOLO, a system that integrates EfficientNet and YOLOv3. This integration yielded enhanced detection of small-scale fires in comparison to existing YOLOv3 and Faster R-CNN models. However, their model exhibited limitations in detecting large-scale fires and adapting to diverse environments, resulting in diminished performance in distinguishing between fire and non-fire scenarios. In contrast, Shen et al. [
13] introduced FireViT, a novel model that integrates a deformable vision transformer as the backbone with a YOLOv8 head. While FireViT achieved a lightweight structure with high efficiency and accuracy compared to traditional convolutional neural network (CNN) models, it still struggled to capture fine-grained features of early-stage fires. Additionally, research considering non-fire factors, such as clouds, fog/haze, and chimney smoke in forested areas, remains insufficient.
In response to these challenges, the present study proposes an integration of the swintransformer into the Faster R-CNN model backbone to enhance the detection of subtle smoke and flames during the initial stages of a wildfire. Furthermore, incorporating non-fire classes such as clouds, fog/haze, and chimney smoke enables the evaluation of the model’s capacity to accurately differentiate between fire and non-fire events.
The main contributions of this study are as follows:
Unlike existing wildfire datasets, we constructed a dataset that includes initial flames and smoke as well as non-fire events (clouds, fog/haze, and chimney smoke).
This is the first study to focus on early fire and non-fire events that can be mistaken for fire, rather than typical wildfire detection models.
The new application of the swintransformer as the backbone of the Faster R-CNN model improves the detection performance of initial flames, smoke, and non-fire events.
2. Related Work
Recent advancements in deep learning have led to substantial improvements in the performance and reliability of wildfire detection systems. A methodological categorization of research endeavors in this domain reveals two primary approaches: (1) classification-based methods and (2) object detection-based methods. This section provides a structured review of the recent literature in both areas, highlighting the methodologies employed, their core contributions, and limitations, while also establishing the research gap addressed by the present study.
2.1. Classification-Based Methods
Classification-based methods are primarily developed to discriminate between fire and non-fire scenes without providing explicit spatial localization of the fire region. These approaches commonly utilize CNN or transfer learning with lightweight architectures to maintain computational efficiency and enable real-time deployment. The findings of earlier forest fire detection studies that employed classification-based methodologies are presented in
Table 1. Reis and Turk [
14] applied DenseNet121 and InceptionV3 architectures to UAV-acquired wildfire imagery from the FLAME dataset. Their study demonstrated that transfer learning significantly enhances classification accuracy, achieving up to 99.32% in distinguishing fire from non-fire scenes. Khan et al. [
15] proposed FireNet, a lightweight classification framework based on MobileNetV2, designed for efficient operation in smart city environments. Their model, evaluated on a public forest fire image dataset, achieved an accuracy of 98.42%, along with a precision of 97.42% and a recall of 99.47%. Seydi and Hasanlou [
16] developed Fire-Net, a deep learning framework incorporating residual and separable convolutional layers for active wildfire detection using multispectral Landsat-8 satellite imagery. Their model reported a classification accuracy of 97.35% across diverse fire-prone regions, including the Amazon, Central Africa, and parts of Australia. Zhou et al. [
17] addressed temporal variability in video-based fire detection by integrating EfficientNetB0 with a long short-term memory (LSTM) network. Their method exhibited improved temporal consistency and robustness in detecting fire events from surveillance video streams.
Despite the evident benefits of classification-based approaches in terms of computational simplicity and deployment feasibility, their inability to localize fire regions or manage multi-class scenarios imposes significant limitations on their practical application in dynamic, real-world environments characterized by complex fire signatures and ambiguous visual cues.
2.2. Object Detection-Based Methods
Object detection-based approaches are utilized to localize and classify fire-related elements, such as flames or smoke, within visual scenes. These approaches employ advanced architectures, including YOLOv5–v8, RetinaNet, and transformer-based models, to achieve high precision in object detection.
Talaat and ZainEldin [
18] proposed a YOLOv8-based smart fire detection system (SFDS), achieving a high precision of 97.1% on a custom smart city dataset and demonstrating real-time performance optimized for urban environments. Cao et al. [
19] introduced YOLO-SF, a segmentation-based detection model that integrates MobileViTv2 and CBAM attention modules. Evaluated on a fire segmentation dataset (FSD), the model outperformed YOLOv7-Tiny, improving Box and Mask mAPs by 4% and 6%, respectively. Guede-Fernández et al. [
20] developed a deep learning-based smoke detection system that was evaluated using the HPWREN dataset. Their most advanced model, Faster R-CNN, attained a smoke detection rate of 90% and an F1-score of approximately 80%. In a related study, Casas, E et al. [
21] employed a stereo vision-enhanced YOLO-NAS framework for UAV-based wildfire localization, achieving an mAP 0.5 of 0.71 on a wildfire image dataset. Xu et al. [
22] proposed a lightweight fire detection model, Light-YOLOv5, which was designed to improve detection speed and accuracy in complex fire scenarios. The model’s integration of a separable vision transformer (SepViT), a lightweight bi-directional feature pyramid network (Light-BiFPN), and a global attention module (GAM) has been shown to significantly enhance multiscale feature extraction. Experimental results demonstrated an mAP of 0.5 at 70.9%, surpassing the baseline YOLOv5n by 3.3% while achieving real-time performance at 91.1 FPS. These enhancements underscore the model’s aptitude for implementation on resource-constrained platforms and its resilience under challenging fire conditions.
Table 2 presents a comparative overview of recent object detection-based wildfire detection systems, encompassing models, evaluation metrics, datasets, and performance.
The present study offers a distinctive contribution by integrating the swintransformer as the backbone within the Faster R-CNN framework. This architectural enhancement introduces hierarchical attention and multiscale feature representation, which significantly improve the model’s capacity to detect small, dynamic, and visually ambiguous fire-related phenomena, such as fog, chimney smoke, and early-stage flames. These elements have traditionally challenged conventional CNN-based detectors. A notable distinction of this study is its utilization of ground-level visual data collected from controlled early-stage wildfire scenarios in mountainous forest regions of the Republic of Korea. This approach stands in contrast to previous studies that primarily relied on satellite or UAV imagery, often depicting fully developed wildfire events at a macroscopic scale. This unique dataset, characterized by low-visibility conditions and multi-class environments, serves as a more realistic benchmark for evaluating fire detection systems in their intended operational context. The integration of a vision transformer backbone with a region-based detection strategy has been demonstrated to enhance the model’s accuracy and robustness, particularly in scenarios involving diverse object scales and complex scenes. The empirical results presented in this study substantiate the proposed model’s superior performance, particularly under conditions that resemble the actual constraints of early wildfire detection and response in field deployments.
3. Material and Methods
The following section is dedicated to providing the theoretical background on the Faster R-CNN and swintransformer that was utilized in this study. Additionally, this section describes the wildfire image dataset, the experimental conditions, and the object detection evaluation metrics that were employed in this study.
3.1. Faster R-CNN
Faster R-CNN represents a cutting-edge deep learning algorithm that was developed for the purpose of identifying the location and category of objects within real-time imagery. As illustrated in
Figure 1 [
23], the Faster R-CNN architecture operates in a series of sequential stages. In the initial stage, the backbone network employs a CNN-based residual network (ResNet) algorithm to extract diverse features from the input image, resulting in the generation of a feature map. Subsequently, the region proposal network (RPN) employs the aforementioned feature map to identify potential object areas within each box by utilizing anchor boxes of varied sizes and proportions. The third stage, ROI Pooling, processes each object region identified by the RPN to extract a fixed-size feature vector, which is then transmitted to the head stage. In the final stage, the head employs ROI Align to classify each object based on the extracted features and to ascertain its precise location. In this phase, the data are passed through fully connected layers (FC Layers), where the functions for class classification and bounding box prediction are established.
3.2. Swintransformer
The transformer model, which was initially developed for natural language processing, has exhibited remarkable efficiency in acquiring contextual information through a self-attention mechanism that processes all input data concurrently [
24]. The adaptation of this algorithm for visual tasks resulted in the creation of the vision transformer (ViT), which employs a method of segmenting images into patches and processing each patch in a manner analogous to that of a word, thereby achieving notable performance gains in computer vision [
25]. However, as the input image size increases, ViT begins to encounter computational challenges. To address this issue, the swintransformer was introduced as a means of enhancing the computational efficiency of ViT. This enhancement is achieved by partitioning the image into smaller windows and calculating self-attention within these windows. The swintransformer employs a shifted window technique, which facilitates inter-window information exchange, and has been successfully applied across a range of visual domains, including classification, object detection, and segmentation. This success can be attributed to the hierarchical architecture of the model [
26].
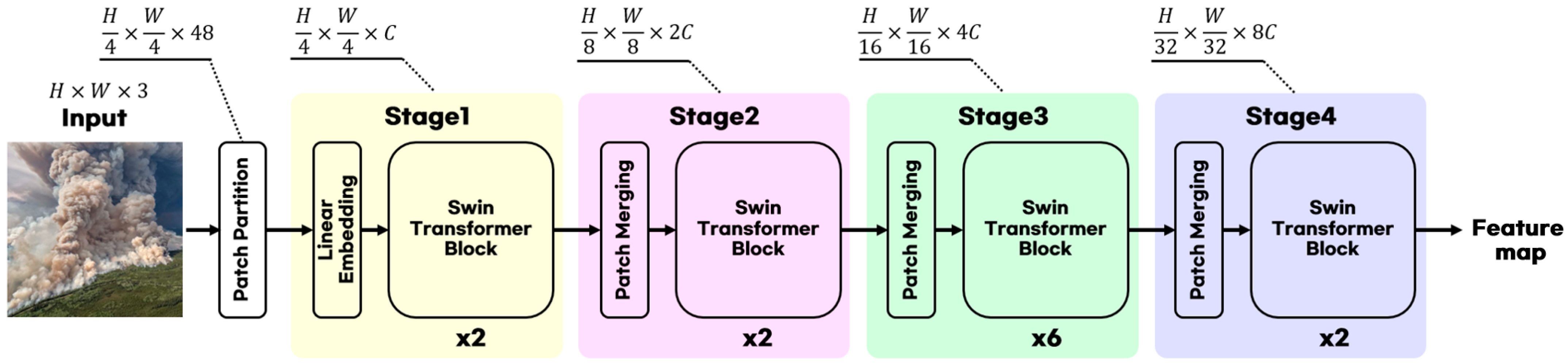
The comprehensive structure of the swintransformer is depicted in
Figure 2 [
25]. The model divides the input image into discrete sections, each of which is treated as a unit of information that encapsulates features from the RGB channels. The image is partitioned into patches of size H × W × 3 through the patch partition method, which are subsequently subdivided into 4 × 4 × 3 sub-patches. Each sub-patch, with a size of 4 × 4 × 3 = 48, is subjected to linear embedding in order to facilitate its transition into the feature space. Subsequently, the swintransformer block employs an analysis of inter-patch relationships to extract the distinctive characteristics of the overall image. During the patch merging phase, adjacent patches are combined to derive features at a larger scale, thereby facilitating the consideration of a broader visual context. The merged patches generate a novel feature map of dimensions
, which is then reintegrated into the patch merging process, continuing through repeated iterations of the swintransformer block [
27].
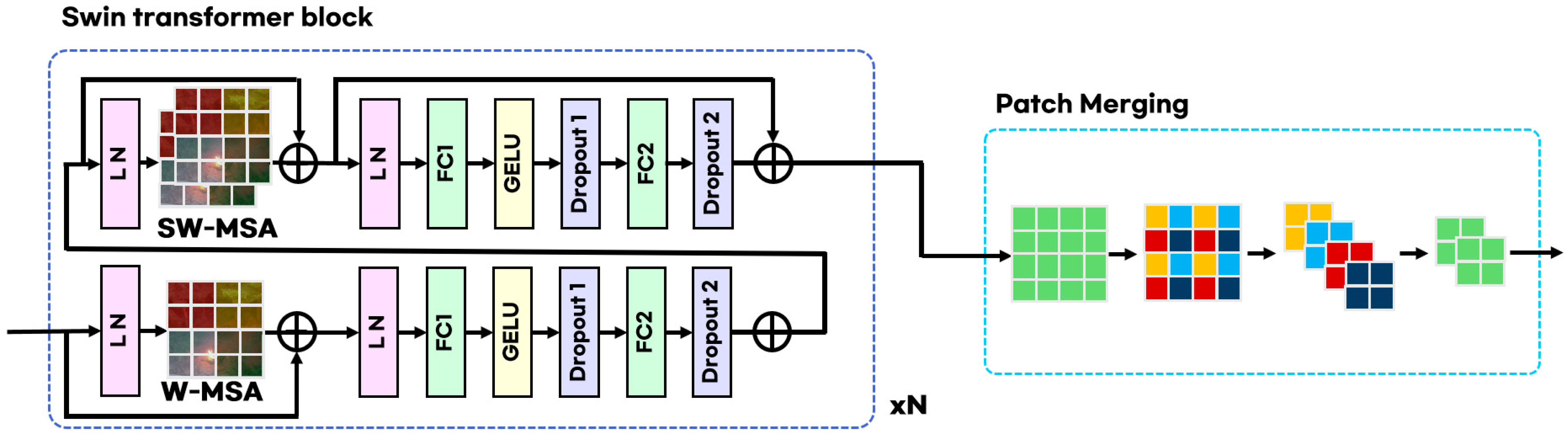
As illustrated in
Figure 3, the swintransformer block possesses an intricate internal architecture that meticulously processes images into discrete, fine-grained patches, thereby facilitating efficient computational operations. The block implements two distinct attention mechanisms, namely: window multi-head self-attention (W-MSA) and shifted window multi-head self-attention (SW-MSA). W-MSA enhances computational efficiency by confining the scope of attention computations to a predefined window. Conversely, SW-MSA modifies the positioning of the window, thereby reducing the potential for information loss at the window boundaries.
Each phase within the swintransformer block is composed of two sequential layers. The initial layer performs layer normalization (LN) and subsequently executes self-attention computation using either W-MSA or SW-MSA. The subsequent layer further processes the information post-LN through two linear transformations (FC1 and FC2), incorporating a GELU activation function and dropout to refine the output. Following this, the patch merging process combines neighboring patches. This process leads to a systematic reduction in resolution while concurrently augmenting the dimensionality of the feature representation. Consequently, each patch captures a more extensive array of information, thereby enhancing the network’s capacity for abstraction and feature discernment [
28].
The computational complexity of the traditional transformer is illustrated in Equation (1), while the computational complexity utilized in the swintransformer is depicted in Equation (2) [
29].
The computational complexity of multi-head self-attention (MSA) in the standard attention model is influenced by quadratic scaling with the feature map size. Specifically, the computational burden increases with the height and width,
h and
w, of the feature map, as the operations involve two terms: The first, 4
hwC2, accounts for the computation required to generate and combine the query, key, and value vectors. The second term, 2(
hw)
2C, corresponds to the calculations needed to compute the self-attention scores across the entire feature map.
In the window-based W-MSA mechanism, computational complexity is reduced compared to the global self-attention mechanism. Specifically, the complexity becomes
, where the calculations are confined to windows within the input feature map [
30].
Given that MSA computes the self-attention for the entire input, the computational complexity increases squared with the size of the input. Conversely, the W-MSA operation shown in Equation (2) divides the entire input into multiple small windows and computes the self-attention only within each window. As a result, the computational complexity remains constant even when the size of the input image increases [
31]. Consequently, W-MSA was shown to significantly reduce computational complexity in comparison to MSA.
In this study, the swintransformer structure was implemented on the existing Faster R-CNN backbone layer to assess the efficacy of forest fire detection for initial fire and non-fire reports. The performance of this approach was then compared with that of the existing forest fire detection model. The proposed model architecture is illustrated in
Figure 4.
3.3. Experimental Methods and Conditions
In the following section, we proceed to delineate the methodologies employed in the collection of data, the experimental environment and its concomitant conditions, and the model metrics that were utilized.
3.3.1. Data Collection
The development of the swintransformer-based wildfire detection model, as outlined in this study, involved the collection of wildfire-related image data. The dataset was meticulously categorized into five distinct classes: early-stage flames, early-stage smoke, clouds, fog/haze, and chimney smoke. This categorization aimed to encompass both fire and non-fire scenarios, thereby ensuring a comprehensive representation of the complexities inherent in wildfire detection. The dataset was constructed using the “Large-Scale AI Database for Disaster Safety and Wildfire Prevention” provided by AI-Hub [
32].
The fire-related classes encompassed images of flames and smoke in their nascent stages, as opposed to those of fully developed wildfires. This differentiation was intended to evaluate the model’s capability to detect early-stage wildfire scenarios, which have received less emphasis in prior studies. These non-fire classes encompassed a variety of images, such as clouds on sunny and cloudy days, fog/haze under different weather conditions, and chimney smoke from factories and residential areas. The collected images are displayed in
Figure 5. To build a robust early wildfire detection model, we utilized a large-scale image dataset collected through actual field recordings rather than simulations. The data were gathered in forest regions administered by the Gangneung City government, where real-world scenarios were recorded using flame sources, smoke bombs, and artificial smoke devices under supervised conditions. These efforts were part of a public project aiming to support AI-based wildfire monitoring and response systems in mountainous areas.
For the purpose of model training, 3000 images were manually selected for each of the five classes. To ensure balanced exposure to diverse lighting conditions, the selection process followed the original dataset’s temporal distribution. This includes images captured during the morning (06–10), midday (11–13), afternoon (14–18), and nighttime (19–05), each accounting for approximately 25% of the dataset. As such, nighttime and low-light condition images are included across all classes, enabling the model to be trained on a variety of illumination scenarios relevant to real-world deployment.
The dataset was composed of 15,000 images in total, with 3000 images per class across five classes: cloud, fog/haze, chimney smoke, smoke, and flame. All images were randomly shuffled prior to dataset splitting to avoid ordering bias. Subsequently, the dataset was divided into three subsets following a fixed ratio: 70% for training (2100 images per class), 20% for validation (600 images per class), and 10% for testing (300 images per class). This ensured equal class distribution in each subset, facilitating balanced multi-class learning. Moreover, to establish reproducibility, the random sampling process was executed using a fixed random seed, enabling identical dataset reconstruction for model re-training and performance validation.
3.3.2. Experimental Environment and Model Evaluation Metrics
In this study, the swintransformer was utilized as the primary network architecture within the Faster R-CNN framework. To this end, a series of model training and validation experiments was conducted. Comparative experiments with the original Faster R-CNN model were also performed. It is noteworthy that all experiments were conducted in identical hardware and software environments, ensuring a controlled and replicable experimental setting. Detailed hardware specifications and hyperparameters utilized for network training are enumerated in
Table 3.
The training process was executed over 100 epochs with a learning rate (LR) set to 0.01. The AdamW stochastic gradient descent optimizer was employed, and the batch size was set to 20, which allowed the researcher’s NVIDIA V100 GPU to efficiently process a total of 3000 input images.
In order to assess and contrast the performance of the model, metrics such as precision, recall, and mean average precision (mAP) were employed. In addition, confusion matrix analysis was conducted to visualize the model’s performance. True positive (TP), true negative (TN), false positive (FP), and false negative (FN) values were measured for the images to calculate precision and recall. These calculations were further used to derive average precision (AP) and mAP, which were employed to evaluate the detection performance of the five fire and non-fire classes. The calculation process is detailed in Equations (3)–(6) [
33]. Beyond the general mAP evaluation, detailed metrics such as mAP Small, mAP Medium, and mAP Large were used to quantitatively assess the detection performance for small, medium, and large objects. Specifically, mAP Small represents the performance for small objects with bounding box areas smaller than 1024 pixels; mAP Medium corresponds to medium-sized objects with bounding box areas between 1024 pixels (32 × 32) and 9216 pixels (96 × 96); and mAP Large represents large objects with bounding box areas exceeding 9216 pixels (96 × 96). These metrics enabled a more granular analysis of the detection performance for both fire and non-fire events.
In Equation (5), p(r) represents the maximum precision at a given recall, while C in Equation (6) denotes the total number of classes.
4. Results
This section outlines the outcomes derived from training and evaluating wildfire detection models that incorporate various backbone architectures. To examine the detection capabilities of the proposed model, based on the integration of the swintransformer into the Faster R-CNN framework, a comparative study was carried out against conventional ResNet-based models. Key performance indicators such as mAP50, mAP Small, mAP Medium, and mAP Large were utilized to measure the effectiveness of each model across training and testing phases. In addition to quantitative metrics, qualitative assessments including visual inference comparisons, confusion matrix analysis, and precision–recall curve evaluations were conducted to further explore the models’ proficiency in identifying both fire-related and non-fire objects under challenging and diverse conditions.
4.1. Training Results of the Wildfire Detection Model
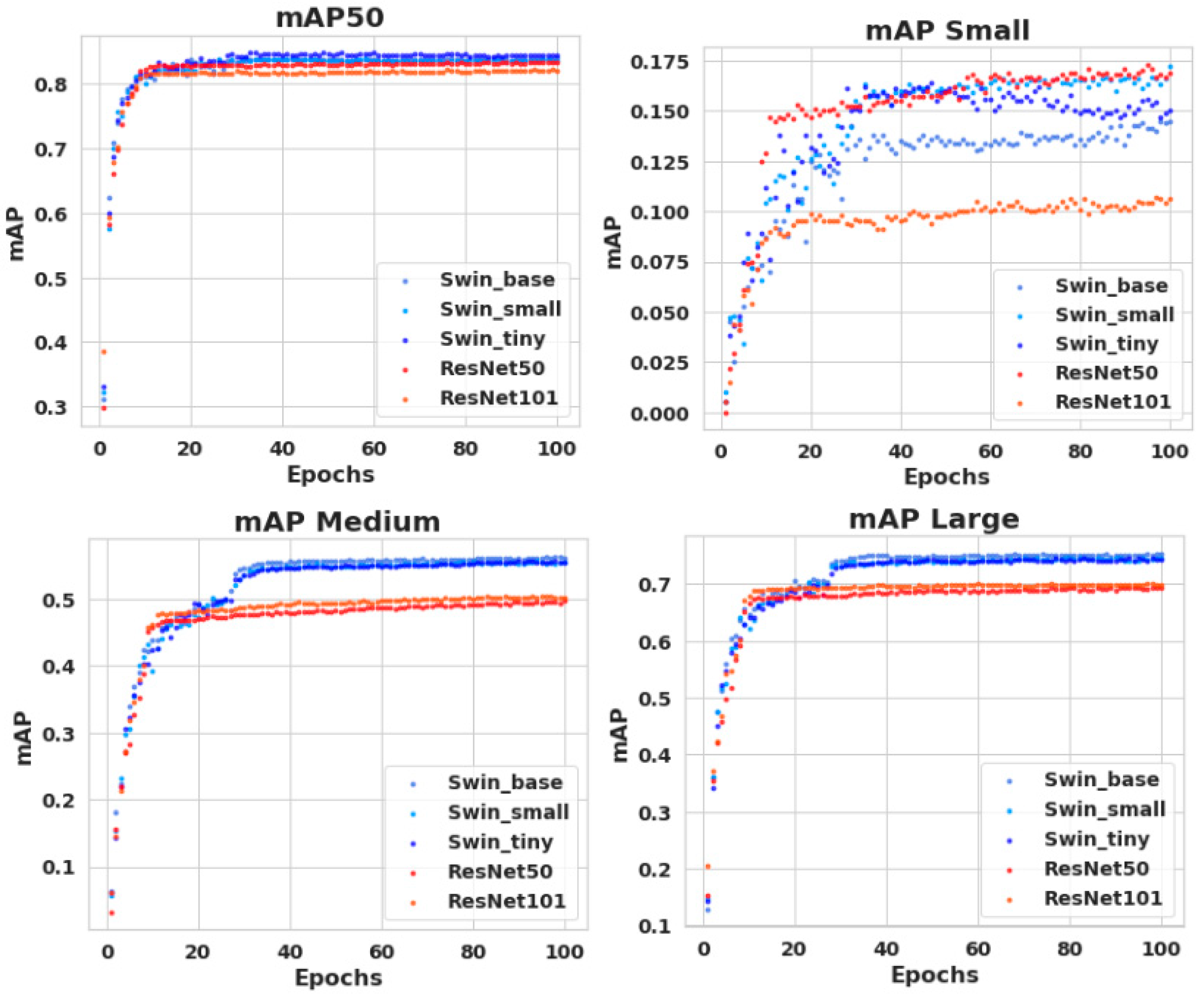
As illustrated in
Figure 6, the training results of swintransformer-based models (swin_base, swin_small, and swin_tiny) and ResNet-based models (ResNet50 and ResNet101) are presented. The training was conducted over 100 epochs to ensure sufficient learning, and the performance of each model was analyzed in detail using the mAP50, mAP Small, mAP Medium, and mAP Large metrics.
The analysis revealed that swintransformer-based models exhibited superior performance across all evaluation metrics when compared to ResNet-based models. Of particular note is the swin_base model, which exhibited high performance and converged more rapidly, with mAP50 and mAP Large both exceeding 0.8. The swin_small and swin_tiny models also exhibited superior performance in comparison to ResNet-based models, particularly in the detection of small objects (mAP Small) and medium-sized objects (mAP Medium). While ResNet-based models initially demonstrated comparatively lower performance, they converged to stable results with increased epochs. However, further investigation into a novel test dataset was undertaken to explore the enhanced performance of ResNet50 in mAP Small.
4.2. Test Dataset-Based Wild Fire Detection Model Evaluation Results
As illustrated in
Table 4, a performance comparison of swintransformer-based and ResNet-based models is presented, utilizing the test dataset. The evaluation metrics encompass mAP50, mAP Small, mAP Medium, and mAP Large for each class. The analysis reveals that swintransformer-based models consistently demonstrate superior performance in comparison to ResNet models. The swin_base model demonstrated the highest mAP50 of 0.841, particularly excelling in the cloud and fog/haze classes with mAP50 values of 0.954 and 0.968, respectively. These findings suggest that the swintransformer model is highly effective in detecting complex environments and dynamic objects.
In contrast, ResNet models demonstrated higher performance in the flame class, with ResNet50 achieving an mAP50 of 0.725, which was comparable to or slightly better than the performance of swintransformer models. However, ResNet models exhibited lower performance for small and dynamic objects, such as smoke and fog/fog/haze/fog/haze. While the swin_small and swin_tiny models exhibited slightly lower performance compared to swin_base, they demonstrated consistent performance for small objects, as evidenced by mAP Small. This finding underscores the reliability of swintransformer models in detecting objects of various sizes and shapes.
Figure 7 provides a visual comparison of the inference results of swintransformer-based and ResNet-based models for the smoke, flame, and chimney smoke classes. A comparative analysis of mAP Small from
Table 2 was conducted to assess the performance of the swin_small and ResNet50 models in detecting small objects. The swin_small model exhibited high confidence and accuracy in detecting dynamic objects, such as smoke and chimney smoke, achieving confidence scores between 0.93 and 1.00 for smoke images. Conversely, ResNet50 exhibited lower confidence or failed to detect specific objects within the same class.
For the flame class, both models exhibited similar performance; however, the swin_small model demonstrated slightly more stable detection. While ResNet50 demonstrated competence in static environments, it exhibited misclassification and lower confidence in certain flame objects. In the chimney smoke class, the swintransformer model attained a perfect confidence score of 1.00, surpassing the performance of ResNet models and showcasing its capacity to maintain high discrimination even in complex backgrounds.
4.3. Advanced Analysis of Detection Models
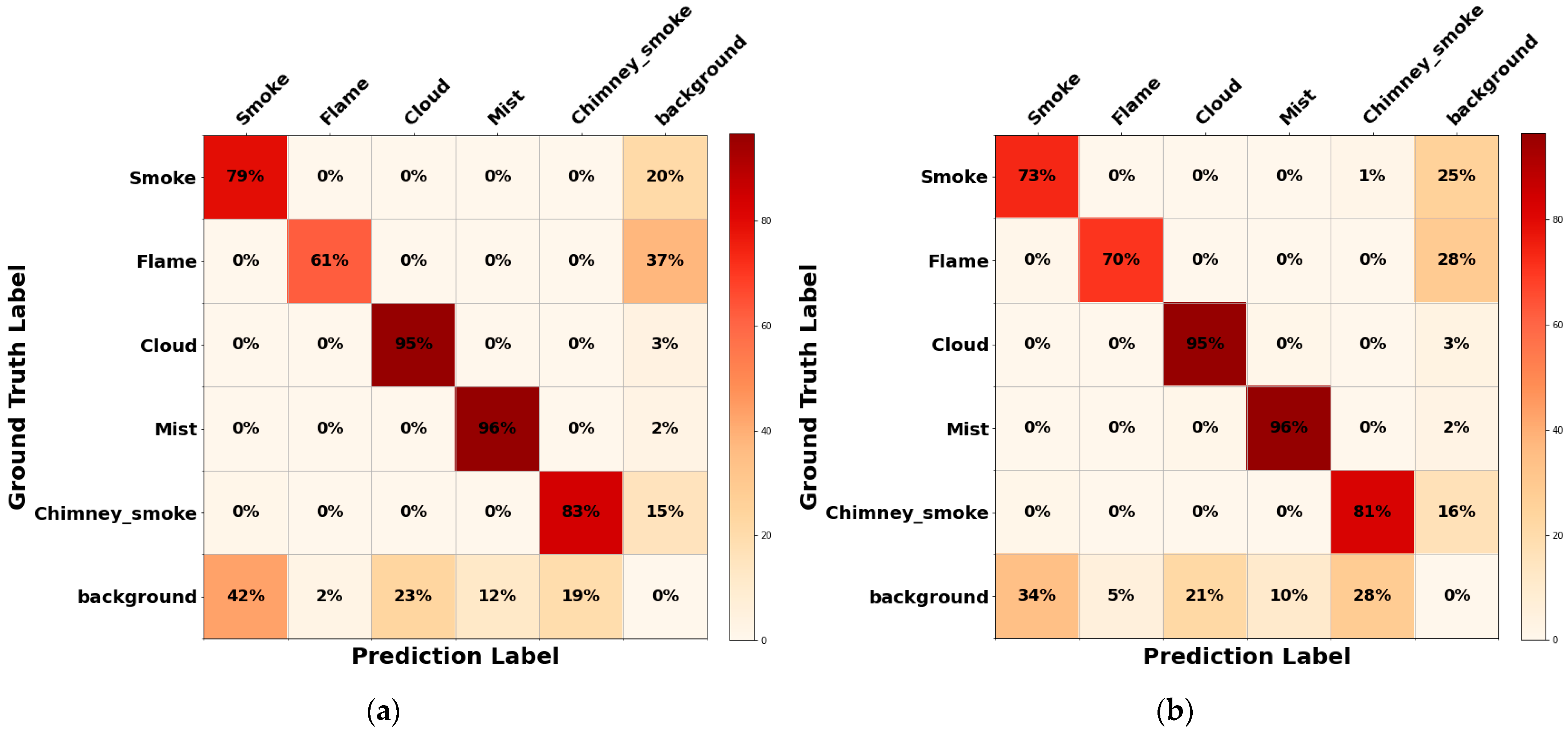
As illustrated by the confusion matrix in
Figure 8, the efficacy of the models in handling inter-class confusion varies significantly. Swintransformer-based models demonstrated a substantial reduction in misclassification between classes with analogous characteristics, such as smoke and chimney smoke. The swin_small model attained 79% accuracy for the smoke class and 83% for the chimney smoke class, surpassing the performance of ResNet50, which recorded 73% and 81%, respectively. In contrast, ResNet models exhibited higher accuracy in the flame class but performed less well in the cloud and fog/haze classes compared to swintransformer models.
For the background class, swintransformer models exhibited a misclassification rate of less than 40%, which was similar to the performance of ResNet models (34–35%). This finding suggests that swintransformer models are more adept at delineating inter-class boundaries.
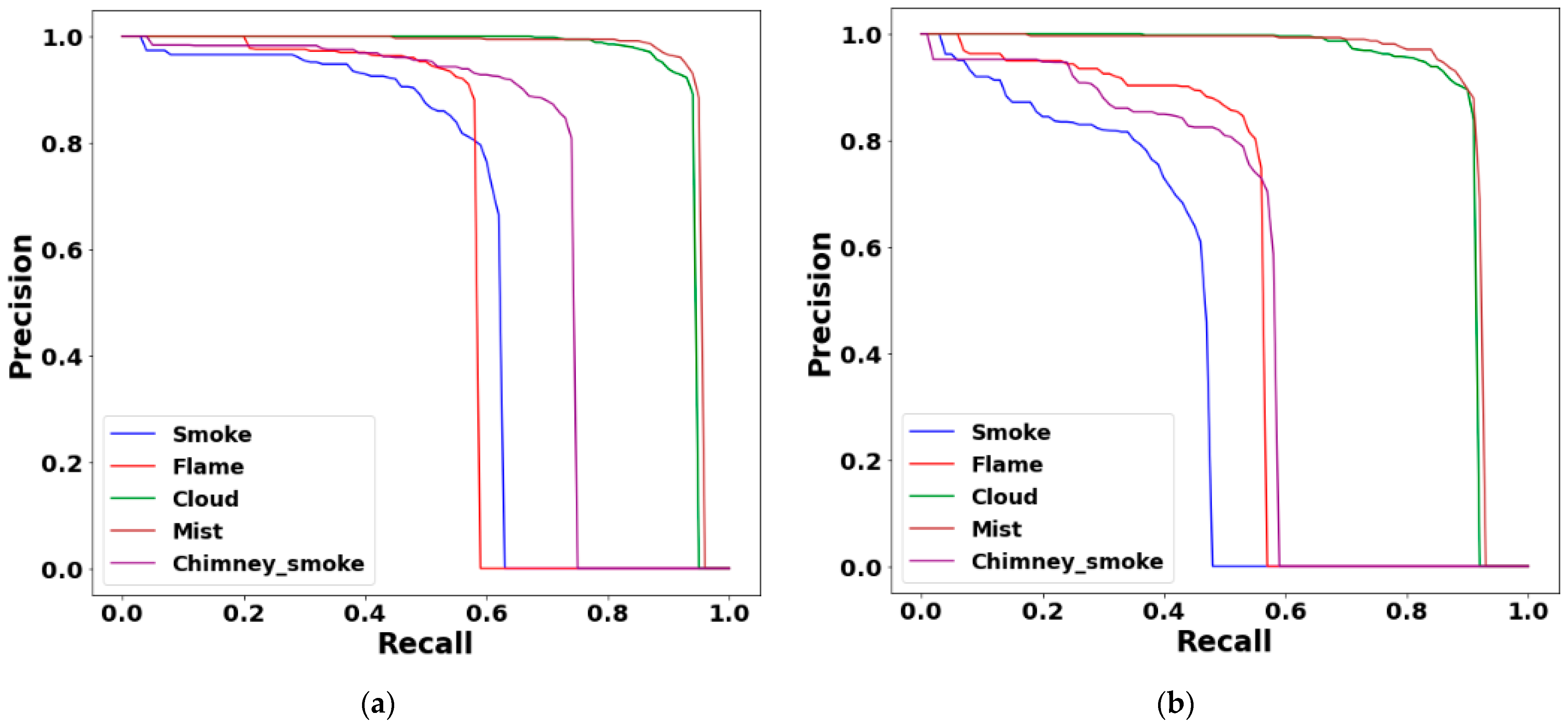
Figure 9 provides a quantitative comparison of the performance of swintransformer and ResNet50 models using precision–recall curves. Swintransformer models demonstrated consistent high precision and recall across various classes, including cloud, fog/haze, and chimney smoke, indicating their superior performance. Of particular note are the results for the cloud and fog/haze classes, where swintransformer models achieved nearly perfect precision and recall values, indicating a substantial advantage over ResNet50 models.
Conversely, ResNet50 demonstrated comparable or marginally superior precision for the flame class, likely attributable to the relatively static and well-defined structural characteristics of this class. However, for dynamic objects such as smoke and chimney smoke, swintransformer models demonstrated superior performance in both precision and recall, thereby substantiating their efficacy in detecting challenging scenarios.
5. Discussion
This study proposed the integration of the swintransformer as a backbone within the Faster R-CNN architecture to enhance the accuracy of wildfire detection, particularly in its early stages. The efficacy of this approach can be ascribed to the distinct architectural characteristics of the swintransformer, which differ fundamentally from those of conventional CNN-based backbones, such as ResNet. The swintransformer employs a hierarchical feature extraction scheme, in conjunction with a shifted window-based self-attention mechanism. This configuration facilitates localized attention computation within non-overlapping windows while enabling information exchange across windows, thereby preserving both local and global feature relationships. In the context of wildfire detection, where distinguishing fine-grained patterns like thin smoke, subtle flames, and visually similar non-fire elements (e.g., fog or chimney smoke) is crucial, this architecture proves especially beneficial. The comparative results presented in
Table 5 demonstrate that swin-transformer-based models outperform ResNet-based models across various metrics, particularly in mAP Small and mAP Medium. This enhancement can be attributed to the swintransformer’s capacity to preserve spatial resolution and model long-range dependencies without a substantial increase in computational cost. Furthermore, the integration of patch merging and embedding layers within the swintransformer framework facilitates multiscale representation, thereby enhancing its sensitivity to both small and large object features within complex environments.
6. Conclusions
This study introduced a wildfire detection model that integrates the swintransformer into the Faster R-CNN backbone, effectively improving the detection of early-stage fires and distinguishing non-fire events. The proposed model, incorporating the flame, smoke, fog/haze, cloud, chimney smoke classes, outperformed ResNet-based Faster R-CNN models across all classes. The shifted window self-attention mechanism and hierarchical structure of the swintransformer enabled the model to achieve high mAP50 values for objects of various sizes, demonstrating exceptional performance in early wildfire detection and non-fire event differentiation.
The confusion matrix and precision–recall curve analyses highlighted the swintransformer-based model’s capability to reduce misclassification between challenging classes such as smoke and chimney smoke while maintaining high precision and recall in non-fire classes like cloud and fog/haze. However, limitations were observed, including relatively lower recall for certain classes, higher misclassification in the background class, and lower FPS compared to ResNet models, indicating areas for future improvement.
Future work will explore the real-world applicability of the proposed swintransformer-based wildfire detection system by testing it under diverse and unpredictable environmental settings. Practical trials will be arranged in multiple locations to examine the system’s ability to distinguish wildfires from similar non-fire occurrences, such as fog, haze, and chimney smoke. Efforts will also be directed toward refining the model for real-time use, with particular attention to lowering its computational requirements and enhancing its processing efficiency on edge devices. Additionally, further studies will consider technical issues including sensor data fusion, communication delays, and the control of false alarms to support reliable implementation in operational wildfire monitoring contexts.
Author Contributions
Conceptualization, H.J.; methodology, S.C.; software, S.C.; validation, S.K. and H.J.; formal analysis, S.C.; investigation, S.C.; data curation, S.K.; writing—original draft preparation, S.C.; writing—review and editing, S.K. and H.J.; supervision, S.K. and H.J.; project administration, H.J.; funding acquisition, S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This study is supported by the Korea Agency for Infrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (Grant 202102220002). This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (NRF: 2021R1G1A1014385).
Institutional Review Board Statement
Not applicable
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Acknowledgments
This research was supported by the Research Grant of Jeonju University in 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mansoor, S.; Farooq, I.; Kachroo, M.M.; Mahmoud, A.E.D.; Fawzy, M.; Popescu, S.M.; Ahmad, P. Elevation in wildfire frequencies with respect to the climate change. J. Environ. Manag. 2022, 301, 113769. [Google Scholar] [CrossRef]
- Thornberry, T.D.; Gao, R.S.; Ciciora, S.J.; Watts, L.A.; McLaughlin, R.J.; Leonardi, A.; Zucker, M. A lightweight remote sensing payload for wildfire detection and fire radiative power measurements. Sensors 2023, 23, 3514. [Google Scholar] [CrossRef] [PubMed]
- Lourenço, M.; Oliveira, L.B.; Oliveira, J.P.; Mora, A.; Oliveira, H.; Santos, R. An integrated decision support system for improving wildfire suppression management. ISPRS Int. J. Geo-Inf. 2021, 10, 497. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Sulthana, S.F.; Wise, C.T.A.; Ravikumar, C.V.; Anbazhagan, R.; Idayachandran, G.; Pau, G. Review study on recent developments in fire sensing methods. IEEE Access 2023, 11, 90269–90282. [Google Scholar] [CrossRef]
- Yu, M.; Yuan, H.; Li, K.; Wang, J. Research on multi-detector real-time fire alarm technology based on signal similarity. Fire Saf. J. 2023, 136, 103724. [Google Scholar] [CrossRef]
- El-Madafri, I.; Peña, M.; Olmssesseedo-Torre, N. The Wildfire Dataset: Enhancing deep learning-based forest fire detection with a diverse evolving open-source datsaset focused on data representativeness and a novel multi-task learning approach. Forests 2023, 14, 1697. [Google Scholar] [CrossRef]
- Hong, Z.; Hamdan, E.; Zhao, Y.; Ye, T.; Pan, H.; Cetin, A.E. Wildfire detection via transfer learning: A survey. Signal Image Video Process. 2024, 18, 207–214. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A. Deep learning approaches for wildland fires remote sensing: Classification, detection, and segmentation. Remote Sens. 2023, 15, 1821. [Google Scholar] [CrossRef]
- Yandouzi, M.I.; Grari, M.; Idrissi, I.; Moussaoui, O.; Azizi, M.; Ghoumid, K.; Elmiad, A. Review on forest fires detection and prediction using deep learning and drones. J. Theor. Appl. Inf. Technol. 2022, 100, 4565–4576. [Google Scholar]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Shen, P.; Sun, N.; Hu, K.; Ye, X.; Wang, P.; Xia, Q.; Wei, C. FireViT: An adaptive lightweight backbone network for fire detection. Forests 2023, 14, 2158. [Google Scholar] [CrossRef]
- Reis, H.C.; Turk, V. Detection of forest fire using deep convolutional neural networks with transfer learning approach. Appl. Soft Comput. 2023, 143, 110362. [Google Scholar] [CrossRef]
- Khan, S.; Khan, A. Ffirenet: Deep learning based forest fire classification and detection in smart cities. Symmetry 2022, 14, 2155. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M. Fire-Net: A deep learning framework for active forest fire detection. J. Sens. 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Zhou, J.; Sathishkumar, V.E.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An Improved Fire Detection Approach Based on YOLO-v8 for Smart Cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for Fire Segmentation Detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Martins, L.; de Almeida, R.V.; Gamboa, H.; Vieira, P. A Deep Learning Based Object Identification System for Forest Fire Detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Casas, E.; Ramos, L.; Bendek, E.; Rivas-Echeverría, F. Assessing the Effectiveness of YOLO Architectures for Smoke and Wildfire Detection. IEEE Access 2023, 11, 96554–96569. [Google Scholar] [CrossRef]
- Xu, H.; Li, B.; Zhong, F. Light-YOLOv5: A Lightweight Algorithm for Improved YOLOv5 in Complex Fire Scenarios. Appl. Sci. 2022, 12, 12312. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tao, D. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swintransformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Zeng, C.; Kwong, S.; Ip, H. Dual swin-transformer based mutual interactive network for RGB-D salient object detection. Neurocomputing 2023, 559, 126779. [Google Scholar] [CrossRef]
- Xiao, X.; Guo, W.; Chen, R.; Hui, Y.; Wang, J.; Zhao, H. A Swintransformer-based encoding booster integrated in U-shaped network for building extraction. Remote Sens. 2022, 14, 2611. [Google Scholar] [CrossRef]
- Mahaadevan, V.C.; Narayanamoorthi, R.; Gono, R.; Moldrik, P. Automatic identifier of socket for electrical vehicles using SWIN-transformer and SimAM attention mechanism-based EVS YOLO. IEEE Access 2023, 11, 111238–111254. [Google Scholar] [CrossRef]
- Lu, S.; Liu, X.; He, Z.; Zhang, X.; Liu, W.; Karkee, M. Swin-Transformer-YOLOv5 for real-time wine grape bunch detection. Remote Sens. 2022, 14, 5853. [Google Scholar] [CrossRef]
- Luo, H.; Li, J.; Cai, L.; Wu, M. STrans-YOLOX: Fusing Swintransformer and YOLOX for automatic pavement crack detection. Appl. Sci. 2023, 13, 1999. [Google Scholar] [CrossRef]
- Artificial Intelligence Hub (AI-Hub). Large-Scale AI Database for Disaster Safety and Wildfire Prevention. Available online: https://www.aihub.or.kr (accessed on 17 March 2025).
- Samal, S.; Zhang, Y.D.; Gadekallu, T.R.; Balabantaray, B.K. ASYv3: Attention-enabled pooling embedded Swintransformer-based YOLOv3 for obscenity detection. Expert Syst. 2023, 40, e13337. [Google Scholar] [CrossRef]
- Mamadaliev, D.; Touko, P.L.M.; Kim, J.H.; Kim, S.C. Esfd-yolov8n: Early smoke and fire detection method based on an improved yolov8n model. Fire 2024, 7, 303. [Google Scholar] [CrossRef]
- Xie, X.; Chen, K.; Guo, Y.; Tan, B.; Chen, L.; Huang, M. A flame-detection algorithm using the improved YOLOv5. Fire 2023, 6, 313. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Zhang, L.; Liu, H.; Zhang, F. CNTCB-YOLOv7: An effective forest fire detection model based on ConvNeXtV2 and CBAM. Fire 2024, 7, 54. [Google Scholar] [CrossRef]
- Liu, H.; Hu, H.; Zhou, F.; Yuan, H. Forest flame detection in unmanned aerial vehicle imagery based on YOLOv5. Fire 2023, 6, 279. [Google Scholar] [CrossRef]
- Safarov, F.; Muksimova, S.; Kamoliddin, M.; Cho, Y.I. Fire and smoke detection in complex environments. Fire 2024, 7, 389. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}