1. Introduction
Fire accidents, defined as disasters resulting from uncontrolled fires in terms of time or space, present a significant threat to public safety and social progress. Currently, in the realm of automatic fire extinguishing, large-area sprinkling systems dominate as the principal technology for indoor fire suppression. Nevertheless, this approach often leads to extensive activation for small-scale fires within a monitored environment, causing considerable and sometimes immeasurable damages. Consequently, the development of pinpoint fire-extinguishing methods has emerged as a key area of research.
The current research in fire localization primarily revolves around scanning and search-based localization techniques using infrared and ultraviolet fire detectors, as well as GPS-based technologies. However, these methods are not well suited for environments with special structures, such as the shelving systems found in large-span spaces. This inadequacy underscores the urgent need for innovative solutions specifically designed for such challenging environments.
Computer vision-based techniques are increasingly gaining traction in the field of fire safety due to their intuitive nature, rapid response time, and cost-effectiveness. The application of computer vision theory for the automatic localization of fire holds significant practical value. It enables the precise identification of a fire’s location when it occurs, thereby enhancing the effectiveness of fire monitoring systems. Storage racks, characterized by their distinct and rigid row-and-column structure, are particularly well suited for edge detection in computer vision. By applying edge detection methods, we can accurately segment the storage rack into rows and columns. This segmentation is crucial in laying the groundwork for precise fire localization within these structures.
Edge detection is a fundamental problem in the field of computer vision. Initially, the primary objective of edge detection was to identify abrupt changes in color and intensity within an image. However, this approach often lacked semantic understanding, leading to suboptimal performance in complex backgrounds. To address these challenges, researchers have increasingly incorporated convolutional neural networks (CNNs) into edge detection methodologies. In recent years, CNN-based approaches have come to dominate the landscape of edge detection. These methods boast impressive hierarchical feature extraction capabilities. Notably, some of these CNN-based techniques have achieved performance levels that surpass human capabilities. Expanding on this, the integration of CNNs in edge detection represents a significant shift towards more intelligent and context-aware systems. Unlike traditional methods that rely on simple gradient-based techniques, CNNs can learn and identify more nuanced and complex patterns in images. This makes them particularly effective in environments with varying lighting conditions, textures, and other visual complexities. Moreover, the development of deeper and more sophisticated CNN architectures has further enhanced the accuracy and reliability of edge detection. These advanced networks can extract and process multiple layers of features, from simple edges to more complex shapes and patterns. This layered approach mimics the way the human visual system processes visual information, leading to more natural and accurate interpretations of scenes. The potential applications of these advanced edge detection systems are vast. They can be used in various fields such as autonomous driving [
1], medical imaging [
2], and surveillance systems [
3]. In each of these applications, the ability to accurately detect and interpret edges can be crucial for the system’s overall performance and reliability. However, the application of edge detection in fire safety is rare, and we believe that edge detection can help address related issues in this field.
The attention mechanism is another fundamental method in visual information processing, drawing inspiration from the study of human vision. In cognitive science, due to the bottleneck in information processing, humans tend to focus on a portion of the available information while neglecting other visible data. This selective process of focusing on specific information is commonly referred to as the attention mechanism. In CNNs, an attention module often serves as a complementary neural network architecture. It is designed to select specific segments of the input or assign varying weight values to different parts of the input. In environments with large spaces, where the background is complex and filled with many irrelevant pieces of information, this challenge can be particularly pronounced. To address this, we propose the integration of an attention module into our edge detection methodology. The inclusion of an attention module in edge detection for complex environments like large-span spaces enhances the system’s ability to discern relevant information from a cluttered background. This module can effectively prioritize areas of the input image that are more likely to contain critical information, such as the edges of shelves, while downplaying less relevant areas. The attention mechanism can adapt dynamically to different scenarios. For instance, in a changing environment where the lighting conditions or the positioning of objects vary, the attention module can adjust its focus accordingly. This adaptability is crucial for maintaining high accuracy in edge detection under varying conditions.
To this end, we propose a CNN-based edge detection approach for extracting the rows and columns of storage racks in a warehouse. When a fire breaks out, our method can output the coordinates of the fire points. By using this method, we are able to accurately locate the fire point. The main contributions of our work can be summarized as follows:
We propose a novel edge detection approach and apply this method to successfully locate the flame of storage racks in a warehouse.
We introduce an attention module to filter invalid information.
The proposed method is accurate for fire location and has good real-time performance, which can reach 0.188 s per image.
To the extent of our knowledge, this is the first paper to achieve fire localization by edge detection.
The structure of this paper is as follows.
Section 2 introduces the related work.
Section 3 elaborates our approach.
Section 4 shows the experiment results. The last part is the conclusion of our work in
Section 5.
2. Related Work
In this section, we present previous studies in terms of three aspects: fire spatial localization, edge detection, and the attention mechanism.
Fire spatial localization: The research on image-based spatial localization methods has a history of more than thirty years and has gradually formed distinctive theories and methods [
4]. According to the number of viewpoints, these methods can be divided into two major directions: monocular and binocular. Based on the existing research on image-based spatial localization methods, Chen et al. [
5] used a single CCD camera, fixed it on a fire hose, and took pictures of the same scene at different positions, forming stereo image pairs, and then mapped the flame images to three-dimensional space, realizing the three-dimensional spatial localization of the flame. However, this method does not conform to the characteristics of indoor cameras being single and fixed. Ouyang et al. [
6] used an improved SURF algorithm to identify the fire area, which required two cameras to simultaneously acquire images, forming stereo image pairs. Although it could achieve accurate distance measurement, the matching time of the stereo image pairs was long, the process was cumbersome, and it could not achieve real-time results. Gao et al. [
7] used a thermal imager to extract the flame characteristics, detected the flame area in the image, and then used a binocular vision image localization method in the flame localization stage. Although this method could accurately identify and locate the flame, it required a thermal imager in the image processing stage, which was not suitable for daily life. Feng et al. [
8] used an adaptive threshold method in the flame area stage and, on this basis, used a left-right view mismatch method to perform stereo matching, restoring the three-dimensional information of the space and obtaining the depth information of the flame area. However, this method was prone to misjudgment or omission in flame detection and had poor universality. Moreover, the above-mentioned flame localization methods based on binocular vision do not conform to the characteristics of cameras being single and fixed and are not suitable for the fire localization of storage racks in large-span spaces.
Edge detection: Traditional edge detection algorithms include the Sobel detector [
9], the Canny detector [
10], and other methods. The Canny detector has been widely used in the past few years. However, these traditional detectors primarily focus on sharp changes in color, brightness, and other low-level features, making them less suitable for more complex scenes. Subsequently, some researchers began to employ data-driven methods to learn how to combine features such as color, brightness, and gradient for edge detection. They proposed some popular methods such as Pb [
11] and gPb [
12]. Despite achieving considerable performance improvements over traditional methods, these approaches still rely on human-designed features, which ultimately limits their potential for further improvement. With the rapid development of deep learning, recent edge detection methods have been primarily based on CNNs. HED [
13], the first end-to-end edge detector built on a fully convolutional neural network, can directly produce an edge map from an input image. RCF [
14] improves the structure of the decoder in HED by fusing each convolutional feature of the VGG network, resulting in enhanced performance. HCF [
15] employs an auxiliary loss function and integrates hybrid convolutional features from different levels of the VGG network to generate high-quality edge maps. DRC [
16] proposes a novel network architecture by stacking refinement modules. All these CNN-based edge detection methods outperform non-deep-learning methods, offering broader potential for application.
Attention mechanism: In the past years, the development and application of attention mechanisms in the field of deep learning have made significant strides. The introduction of the Transformer [
17] marks a major breakthrough in self-attention mechanisms. This model, leveraging attention mechanisms to capture long-range dependencies, significantly improves performance across various natural language processing (NLP) tasks. Subsequently, Transformer-based models like BERT [
18] set new records in a range of NLP benchmarks. Beyond language processing, attention mechanisms have also gained prominence in computer vision. Vision Transformer (ViT) [
19] demonstrates the effectiveness of self-attention in image classification. Additionally, attention mechanisms have been integrated into CNN architectures to improve feature representation. For instance, the Squeeze-and-Excitation (SE) network [
20] employs channel-wise attention to recalibrate feature maps, enhancing the representational power of CNNs. Similarly, the Convolutional Block Attention Module (CBAM) [
21] combines spatial and channel attention to refine feature maps for better performance in various vision tasks. These developments highlight the versatility and effectiveness of attention mechanisms across different deep learning architectures and applications.
Our edge detection method, inspired by HED, utilizes a CNN-based architecture. This method can be effectively applied to storage rack structures in large-span warehouses, making it a beneficial supplement to the field of fire safety.
3. Methodology
The proposed method is designed to extract rows and columns of storage racks. Once a fire breaks out on a rack, the system will output the flame’s position in two-dimensional coordinates. In this section, we describe the proposed method in detail.
3.1. Network Architecture
The architecture of our method is shown in
Figure 1. We adopt VGG-16 [
22] as the backbone, which is split into 5 stages by max-pooling layers. Unlike the original VGG-16 network architecture, we add a block in stage 1 and stage 2. Therefore, each stage consists of three
blocks. Such improvements can enhance the feature extraction capability of the model. Additionally, we remove all three fully connected layers and the max-pooling layer of stage 5, making the entire backbone into a fully convolutional network, as it has been demonstrated to be effective in pixel-level classification tasks [
23]. Furthermore, we insert a Squeeze-and-Excitation (SE) [
20] channel attention module into each stage of our modified backbone. Incorporating this attention module into our network significantly enhances its performance by explicitly modeling the interdependencies between channels. This module operates by adaptively recalibrating channel-wise feature responses, thus allowing the network to emphasize informative features while suppressing less useful ones. By squeezing global spatial information into a channel descriptor, the SE module captures the global distribution of features, which is then used to excite channel-wise feature maps through a simple gating mechanism. This process enables the network to focus on the edge features while suppressing the background information. The integration of the SE module can improve the representational power of the network without introducing substantial computational complexity. The experiment results show that such a simple change achieves better performance. The last
block in each stage is linked to a
convolutional layer, which we name the side-output layer. Each side-output layer compresses the number of channels in the feature map to 1. Finally, we concatenate all the feature maps from the upsampling layers and employ a
convolution to merge different feature maps to obtain the final edge maps. It is necessary to note that we remove the deep supervision mechanism that is introduced in HED; we only calculate the loss based on the final prediction, which also results in a reduction in training time.
We choose the VGG-16 as our base model. The reason is that, although other models like ResNet [
24] have higher performance, they are more complex and have slower inference speeds. On the other hand, lightweight models like MobileNet [
25], despite being faster, lack sufficient detection accuracy. Therefore, VGG-16 strikes a better balance between inference speed and detection performance. Specifically, we adopt the VGG-16 pre-trained on the ImageNet [
26] dataset to accelerate the network’s convergence speed.
3.2. Attention Module: Squeeze-and-Excitation Block
In the actual environment, we found that there are a lot of boxes on the storage rack in the warehouse, which can cause interference to the network. To suppress the background information as much as possible and generate clearer edge maps, we insert the Squeeze-and-Excitation (SE) attention module into all Conv-BN-ReLU layers in each stage.
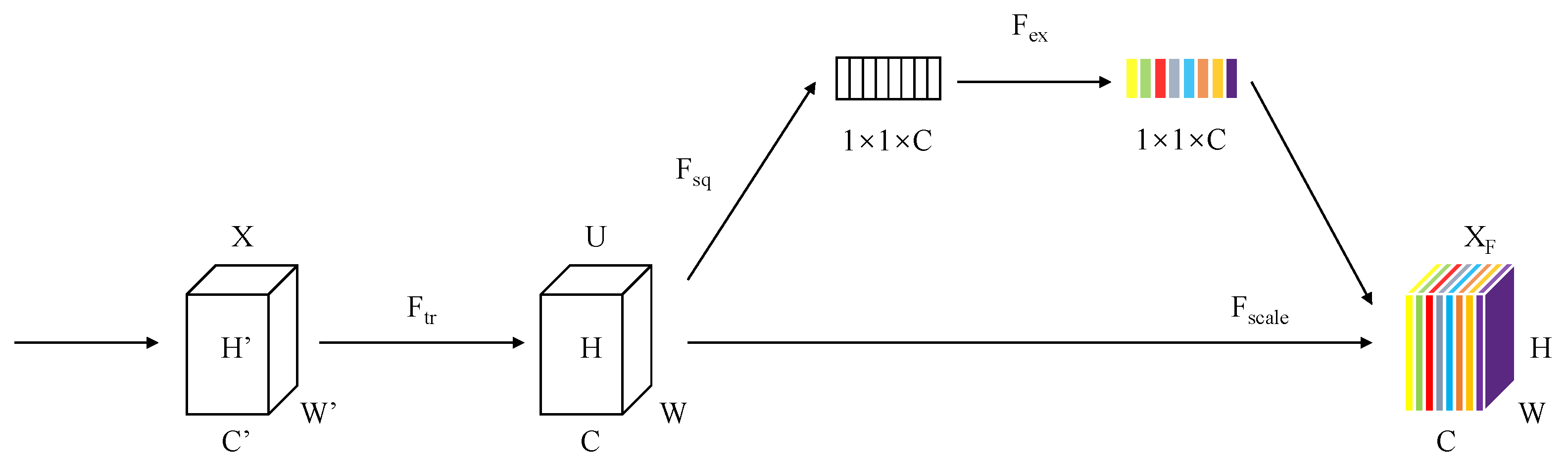
The structure of the SE block is depicted in
Figure 2. A SE block can be seen as a computational unit, which is constructed upon a transformation
such as a convolution operation mapping an input image
X to an output feature map
U. This computational unit can be divided into two operations:
Squeeze and
Excitation.
Squeeze: We supposed
, where
c represents the number of channels. Our purpose is to obtain a channel representation by squeezing global spatial information; to achieve this goal, we employ the global average pooling operation to produce channel-wise statistics. The original size is
, and after the Squeeze operation, the size is
. The whole process can be elaborated by the following formula:
where
H and
W represent the height and width of a feature map, respectively.
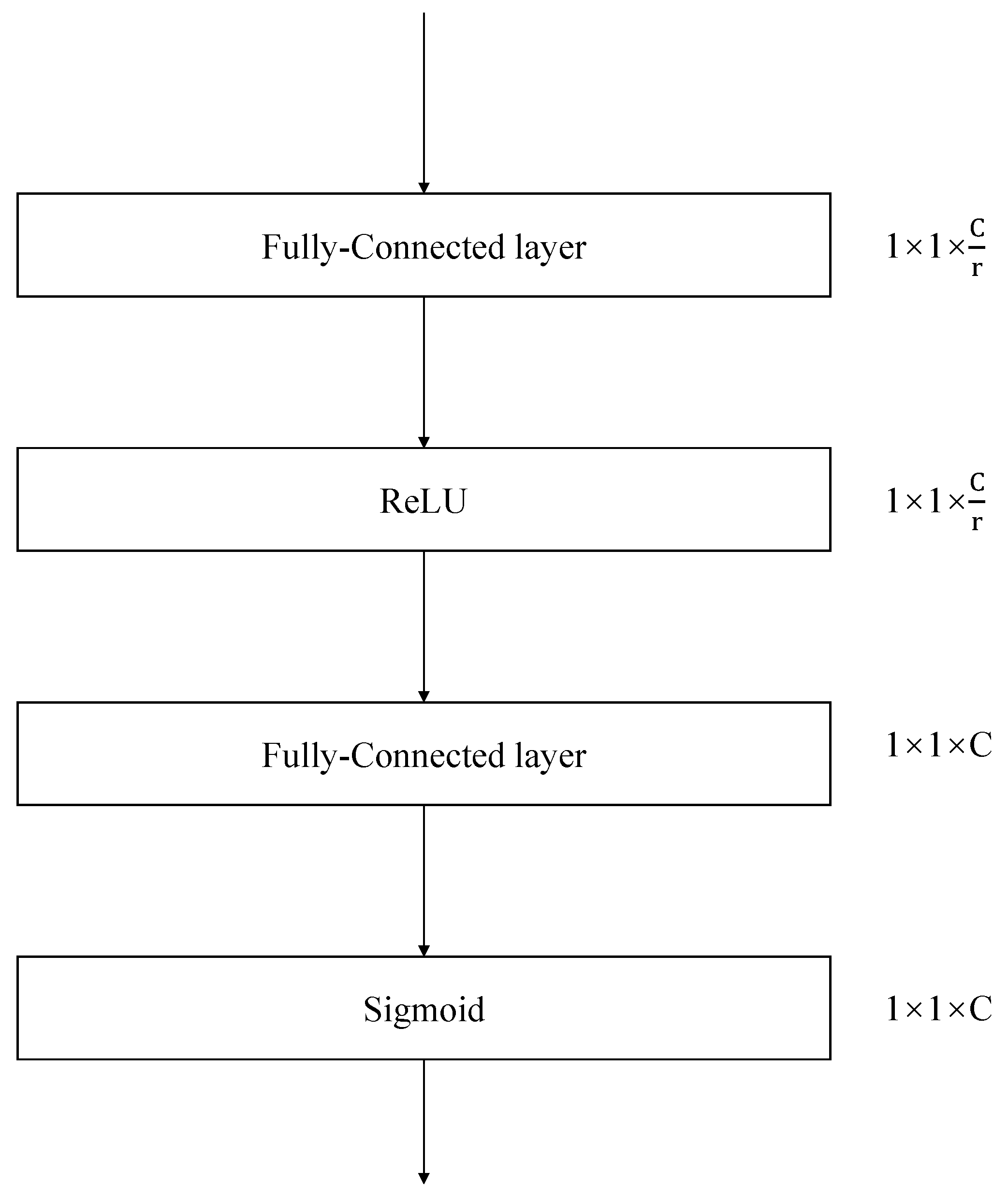
Excitation: After the Squeeze operation, the Excitation operation is employed, whose purpose is to capture channel-wise dependencies. This operation consists of two fully connected layers, one ReLU activation function, and one Sigmoid activation function. The whole process can be described by the following equation:
where
and
represent Sigmoid and ReLU, respectively.
and
are the parameters of two fully connected layers
and
, respectively. The details of the Excitation operation can be seen in
Figure 3.
As depicted in
Figure 3, the
has a reduction ratio of
r; this parameter aims to reduce the computational complexity. When the channel descriptor
is reduced to
, the
is restored to the channel dimension of
U. It is proved experimentally that the best result can be obtained when the reduction ratio
.
After the two operations mentioned above, the final result of the SE block is obtained by a channel-wise multiplication between the scalar and the feature map , which can be written as . It is worth noting that the SE block is simple yet effective in suppressing the interference information, guiding the network to draw rows and columns of shelves more precisely.
3.3. Loss Function
In an actual input image, there is a very serious imbalance in pixel distribution:
are non-edge pixels and
are edge pixels. Such an imbalanced class distribution poses significant challenges to the network’s ability to classify correctly. To tackle this issue, we adopt a weighted cross-entropy loss function to enhance the network’s accuracy in classifying different categories. We calculate the loss of each pixel concerning its label, which can be described by the following equation:
where
and
,
and
represent non-edge pixels and edge pixels in the ground truth image, respectively. The predicted value from the network and its ground truth value at pixel
p are represented by
and
.
is the Sigmoid function, and all the parameters that will be updated in our network are represented by
W. By introducing the class-balancing parameter
, we successfully address the imbalance between edge and non-edge pixels.
3.4. Flame Detection Algorithm
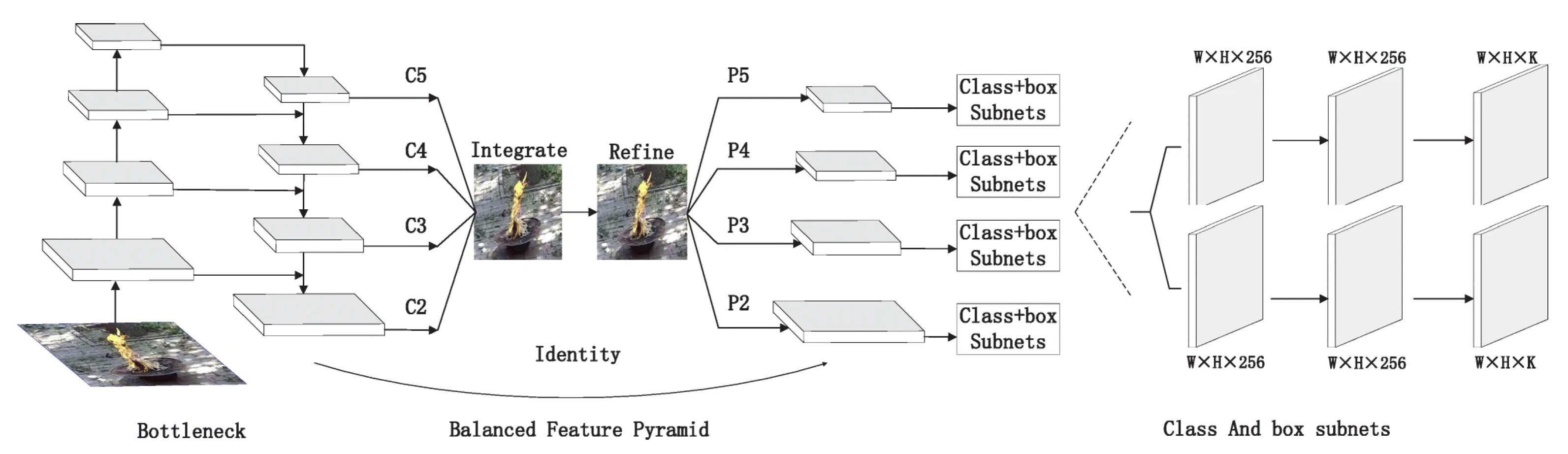
We adopt our previously proposed lightweight fire detection framework FAE-Net [
27] to accomplish flame detection. The architecture of FAE-Net is shown in
Figure 4.
The FAE-Net is based on the anchor-free structure, which consists of a backbone network responsible for feature extraction and two sub-networks for classification and frame prediction. The feature extraction backbone employs the MobileNetV3 [
25] to achieve real-time and efficient detection. Relying exclusively on a single high-level feature from the feature extraction network for subsequent classification and discrimination tasks poses a limitation, as it may hinder the accurate extraction of flame features. To address this issue, we propose enhancements to the MobileNetV3 network architecture: the average pooling layer and three
convolutional layers succeeding the final bottleneck layer are omitted. Instead, we incorporate a Balanced Feature Pyramid structure and adopt two auxiliary sub-networks for classification and boundary prediction. The Balanced Feature Pyramid reinforces the multi-scale feature representations of the flame images by leveraging the same deeply integrated balanced semantic features. The pipeline is illustrated in the middle section of
Figure 4. The other sub-networks are dedicated to predicting the object category and localizing the specific spatial regions within the image.
The anchor-free paradigm eschews the use of anchor boxes within the network architecture. Instead, it employs direct keypoint detection or pixel-wise prediction mechanisms to infer the flame’s positional information and categorical identity. This methodology falls under the category of one-stage flame detection networks, exhibiting greater flexibility and computational efficiency than their anchor-based counterparts.
The FAE-Net achieves an accuracy of 90.2%, satisfying the requirements for practical deployment scenarios. Moreover, it enables early-stage fire detection, accurately identifying and reporting pixel-level localization of flame regions even before the manifestation of dense smoke or other subsequent visual interference.
3.5. Flame Localization System
The flowchart of our fire spatial localization system is shown in
Figure 5. The edge detection plays an important role in this system because the following step is based on the edge detection results. Once the quality of the edge maps we generate decreases, the localization accuracy will decrease.
To facilitate comprehensive monitoring for potential fire incidents within the localization system, we employ a multi-view camera setup encompassing four vantage points—front, back, left, and right—to achieve complete coverage of the rack area. Each camera is strategically positioned approximately 15 m from the racks, ensuring unobstructed and clear visibility of the entire rack space. When generating the edge map of the rack, we first rectify it through perspective transformation. Then, we use the Harris [
28] corner detection algorithm to detect the row and column intersections in the edge image, as shown by the red points in
Figure 5. Following that, by connecting these red points with line segments, a grid of five rows and two columns is formed.
The flame detection method outputs the coordinates of the top-left and bottom-right corners of the flame regions. Consequently, the formula for calculating the center coordinates of the flames is as follows:
where
and
are the coordinates of the top-left and bottom-right in the bounding box, respectively. Once the central coordinates of the fire point are obtained, they are mapped onto the grid rows and columns, as shown by the green point in
Figure 5. Finally, the system outputs the row and column location information of the fire point to trigger the fire extinguishing device.
4. Experiment
In this section, we describe the implementation in detail, including hyperparameters and data augmentation methods. Following that, we present the experimental results on the collected dataset and demonstrate the advantages of our method.
4.1. Implementation Details
Hyperparameters: We implement our network with the PyTorch deep learning framework and train the model by a single NVIDIA TITAN RTX GPU. The training hyperparameters are as follows: a mini-batch size of 8, an initial learning rate of
, a learning rate decay of 0.1, and 40 training epochs. Besides this, we decay the learning rate every 5 epochs to enhance the model’s generalization ability and use the Adam [
29] optimizer to optimize the parameters of the network.
Data augmentation: To alleviate the issue of insufficient data samples, we adopt the data augmentation strategy to expand the dataset. Data augmentation can be viewed as an essential technique to improve deep network performance; it can give the network the desired robustness. The main data augmentation methods we used are as follows:
Flipping: mirror the images.
Cropping: randomly select a part from the picture, then cut out this part, and then restore it to the original image size.
Rotation: rotation means rotating the image clockwise or counterclockwise.
Elastic Distortion: make the image distorted.
Through the expansion of datasets, we construct a dataset containing 1152 images, each with a resolution of
pixels. This collected dataset can help to enhance the generalization ability of our model, and the row and column edges can be extracted under different angles and lighting. Some examples of our collected dataset are shown in
Figure 6.
4.2. Experimental Results and Analysis
Comparison with some other edge detectors: To demonstrate the effectiveness of our method, we compare it with some mainstream edge detection methods, including Canny [
10], Sobel [
9], Laplacian [
30], and HED [
13]. We evaluate the accuracy of edge detection using two classical metrics: the ODS (Optimal Dataset Scale) and the OIS (Optimal Image Scale) F-score.
ODS F-score quantitatively assesses the performance of an edge detection algorithm across an entire dataset. It entails determining a singular, uniform threshold that is optimally suited for all images within the dataset. This threshold is selected to maximize the aggregate performance metric across the entire image corpus. ODS furnishes a global evaluation of the algorithm’s effectiveness, providing an overarching measure of its performance across a heterogeneous assortment of images.
Contrasting with ODS, the OIS F-score evaluates performance on the basis of individual images. For each image in the dataset, an optimal threshold is discerned that elevates the performance for that specific image to its zenith. This approach recognizes the variability across images, acknowledging that disparate images may necessitate different thresholds for optimal edge detection. The OIS score is derived from the mean of these optimal performance metrics computed for each image within the dataset. OIS thus offers insight into the algorithm’s ability to adapt to the idiosyncrasies of individual images, serving as a barometer of its local adaptability.
Both ODS and OIS are generally assessed via metrics such as precision, recall, and the F-measure (the harmonic mean of precision and recall). These evaluative criteria are instrumental in elucidating the balance between the detection of a maximal number of true edges (denoted by high recall) and the assurance of the veracity of the detected edges (indicated by high precision). In this work, we calculate these two metrics using EdgeBox [
31], and the results are shown in
Table 1.
As shown in
Table 1, the traditional edge detector, including Canny, Laplacian, and Sobel, shows lower performance than CNN-based methods. The Canny method, a foundational algorithm in edge detection, yields uniform scores of 0.466 for both ODS and OIS, indicating a baseline level of performance across the dataset and within individual images. The Laplacian detector shows a marginal improvement over Canny in the OIS F-score (0.480), suggesting slightly better adaptability at an individual image level. The Sobel detector demonstrates further incremental advancements, with ODS and OIS F-scores of 0.481 and 0.490, respectively, reflecting modest enhancements in detecting true positives while maintaining edge precision. HED, a CNN-based method, marks a significant leap forward, achieving ODS and OIS F-scores of 0.873 and 0.880. This substantial increase underscores the CNN-based methods’ advanced capabilities in capturing the nuances of edge information across the dataset and within specific images. However, our method outperforms the aforementioned algorithms, registering the highest OIS of 0.896 and an ODS of 0.875. This superior performance can be attributed to our method’s robustness and proficiency in generalizing edge detection across varied images while simultaneously optimizing for individual image characteristics. The OIS score, in particular, suggests that our method is exceptionally well suited for tailoring edge detection parameters to the idiosyncrasies of each image, thereby ensuring more accurate delineation of edges. This edge over competing methods signifies the effectiveness of our approach in handling the intricate demands of edge detection tasks.
The qualitative experiment results are shown in
Figure 7. The edge maps generated by Canny, Laplacian, and Sobel detectors exhibit a significant level of noise and blurring. Conversely, the edge maps generated using the HED demonstrate results that are notably closer to ours. However, even these contain some inaccuracies, as evidenced by the presence of false pixels. The experimental results indicate that, when compared with the other algorithms, our method exhibits a superior capability in extracting more comprehensive and complete edges of the shelf rows and columns. Additionally, it demonstrates exceptional proficiency in effectively suppressing noise. These attributes significantly underscore and amplify the advantages inherent in the methodology we have proposed, setting it apart in terms of performance and reliability.
Through a dual-faceted approach encompassing qualitative and quantitative comparisons, the robust performance of our method has been thoroughly demonstrated. This comprehensive validation attests to the formidable efficacy of the proposed methodology, rendering it suitable for deployment in the precise localization of fires on shelves.
The accuracy of the flame localization: We tested 1000 cases, and an example of a case is shown in
Figure 8. Each case is conducted through image acquisition via cameras. The ignition experiments employed an electronic ignition gun, which generated flames by igniting butane gas within the device. This flame was then used to ignite wooden boxes placed on the storage racks, simulating fire scenarios. To validate the accuracy of our localization algorithm, we initiated fires at various row and column positions on the storage racks. Upon accurate localization of the flame point, the alarm system would emit an auditory warning signal while simultaneously activating the corresponding high-pressure water cannon aligned with the identified row and column position, thereby precisely extinguishing the flame. To ensure comprehensive coverage of the storage racks, we deployed a network of cameras positioned at four strategic angles: front, rear, left, and right. This configuration enabled continuous monitoring of any location on the storage racks, leaving no blind spots in our surveillance system. A comprehensive statistical analysis is performed for each individual case in our experiment. The statistical results show that 927 cases accurately identified the row and column positions of the fire point on the shelves, while 73 cases failed to output the positions correctly. The accuracy reached 92.7%, which demonstrates the effectiveness of our method, and the statistical results are shown in
Table 2.
Speed analysis: Our method can achieve a rate of 29 FPS (0.188 s) on a single NVIDIA TITAN RTX GPU when the resolution of an input image is . This speed is extremely fast and meets the real-time requirements, as the proposed method is simple but effective. This expeditious performance markedly surpasses the thresholds commonly associated with real-time processing, thereby underscoring our method’s suitability for fire localization, which needs swift analytical responses.
5. Conclusions
In this work, we proposed a novel edge detection approach and specifically applied it to pinpoint the precise location of fires on warehouse storage racks. By integrating an attention module into our methodology, we enhance the system’s ability to delineate the shelves’ rows and columns with greater clarity. The experiment results substantiate the suitability of our approach for this particular context. The implementation of our proposed method offers a proactive measure for early fire detection, which is instrumental in curtailing costs and effectively mitigating the damages wrought by fire incidents. Our research contributes a unique perspective to the fire location problem, specially tailored for complex environments such as warehouses. However, our method still has the limitation of extracting the edges of relatively thick storage racks, which leads to failures in some cases. Therefore, in future work, we will strive to further optimize the algorithm to enable more precise edge pixel localization, thereby improving the accuracy of flame point localization.
Author Contributions
Conceptualization, L.Z. and C.L.; methodology, L.Z., C.L. and W.Z.; software, C.L. and M.L.; validation, L.Z. and W.Z.; formal analysis, L.Z. and C.L.; investigation, Z.L. and D.Z.; resources, C.L. and W.Z.; data curation, L.Z. and C.L.; writing—original draft preparation, L.Z. and C.L.; writing—review and editing, W.Z.; visualization, L.Z. and C.L.; supervision, W.Z. and Z.L.; project administration, L.Z. and W.Z.; funding acquisition, L.Z. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Key Laboratory of Dire Protection Technology for Industry and Public Building, Ministry of Emergency Management grant number No.2022KLIB08 and special fund project for basic scientific research of Tianjin Fire Science and Technology Research Institute, Ministry of Emergency Management grant number No.2023SJ05.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to the need to protect proprietary information.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CNN | Convolutional Neural Network |
| ReLU | Rectified Linear Units |
| HED | Holistically-nested edge detection |
| RCF | Richer convolutional features for edge detection |
| HCF | Learning hybrid convolutional features for edge detection |
| DRC | Learning crisp boundaries using deep refinement network and adaptive weighting loss |
| CCD | Charge Coupled Device |
| SE | Squeeze-and-Excitation |
| CBAM | Convolutional Block Attention Module |
| ViT | Vision Transformer |
| NLP | Natural Language Processing |
| FPS | Frames Per Second |
| SURF | Speeded Up Robust Feature |
| BERT | Bidirectional Encoder Representations from Transformers |
| Pb | Probability of boundary |
| gPb | global Probability of boundary |
References
- Liang, J.; Homayounfar, N.; Ma, W.C.; Wang, S.; Urtasun, R. Convolutional Recurrent Network for Road Boundary Extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, Z.; He, X.; Qi, G.; Li, Y.; Cong, B.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Gohari, P.S.; Mohammadi, H.; Taghvaei, S. Using chaotic maps for 3D boundary surveillance by quadrotor robot. Appl. Soft Comput. 2019, 76, 68–77. [Google Scholar] [CrossRef]
- McFarland, W.D. Three-dimensional images for robot vision. In Proceedings of the Robotics and Robot Sensing Systems, San Diego, CA, USA, 23–25 August 1983; Volume 442, pp. 108–116. [Google Scholar]
- Tao, C.; Yonghong, Y.; Guofeng, S.; Binghai, L. Automatic fire location by CCD images in big space. Opt. Tech. 2003, 29, 292–294. [Google Scholar]
- Jineng, O.; Pingle, B.; Teng, W.; Zhikai, Y.; Peng, Y. Binocular vision fire location method based on improved SURF algorithm. Fire Sci. Technol. 2017, 36, 1807. [Google Scholar]
- Rong, G. Research on Infrared Stereo Vision Based Tunnel Fire Positioning System. Master’s Thesis, Chang’an University, Xi’an, China, 2015. [Google Scholar]
- Lingyun, F. Research on the method of Burning Point Localization Based on Machine Vision. Master’s Thesis, North China Electric Power University, Beijing, China, 2010. [Google Scholar]
- Sobel, I.E. Camera Models and Machine Perception; Stanford University: Stanford, CA, USA, 1970. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef] [PubMed]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Hu, X.; Liu, Y.; Wang, K.; Ren, B. Learning hybrid convolutional features for edge detection. Neurocomputing 2018, 313, 377–385. [Google Scholar] [CrossRef]
- Cao, Y.J.; Lin, C.; Li, Y.J. Learning crisp boundaries using deep refinement network and adaptive weighting loss. IEEE Trans. Multimed. 2020, 23, 761–771. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, Y.; Zhang, W.; Liu, Y.; Jin, Y. A visualized fire detection method based on convolutional neural network beyond anchor. Appl. Intell. 2022, 52, 13280–13295. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Citeseer, Manchester, UK, 15–17 September 1988; Volume 15, pp. 23.1–23.6. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 391–405. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}