
Satellite Image Cloud Automatic Annotator with Uncertainty Estimation


Abstract
1. Introduction
- Convex hull selection method: The convex hull selection method has lower selection complexity for irregular cloud regions. It is worth noting that this process does not require the involvement of professional annotators, thus greatly reducing labor costs.
- Minimal annotation requirements: CloudAUE achieves excellent results on using one to two annotations, which significantly reduces labor and time consumption.
- Objective evaluation criteria: CloudAUE introduces an uncertainty estimation mechanism. This novel approach establishes a criterion for terminating annotations that does not rely on human judgment, ensuring a more objective evaluation process.
- Validation of the reliability of labeled datasets: Two publicly labeled satellite image datasets are utilized to verify the effectiveness and accuracy of our proposed method. Compared with deep learning cloud detection methods, CloudAUE achieves better or competitive results without any labels.
- Extension capability in various fields: The desired results are achieved on an unlabeled forest fire dataset.
2. Materials and Methods
2.1. Sample Selection by Convex Hull
2.2. KD-Tree Classifier
2.3. Uncertainty Estimation Mechanism
3. Experimental Settings
3.1. Dataset
3.2. Experimental Settings
3.3. Evaluation Metrics
4. Results
4.1. Results on the HRC Dataset
4.2. Results of Landsat 8 Dataset
4.3. Results on Self-Built Google Earth Dataset
4.4. Expanding Capabilities to Forest Fire Dataset
5. Discussion
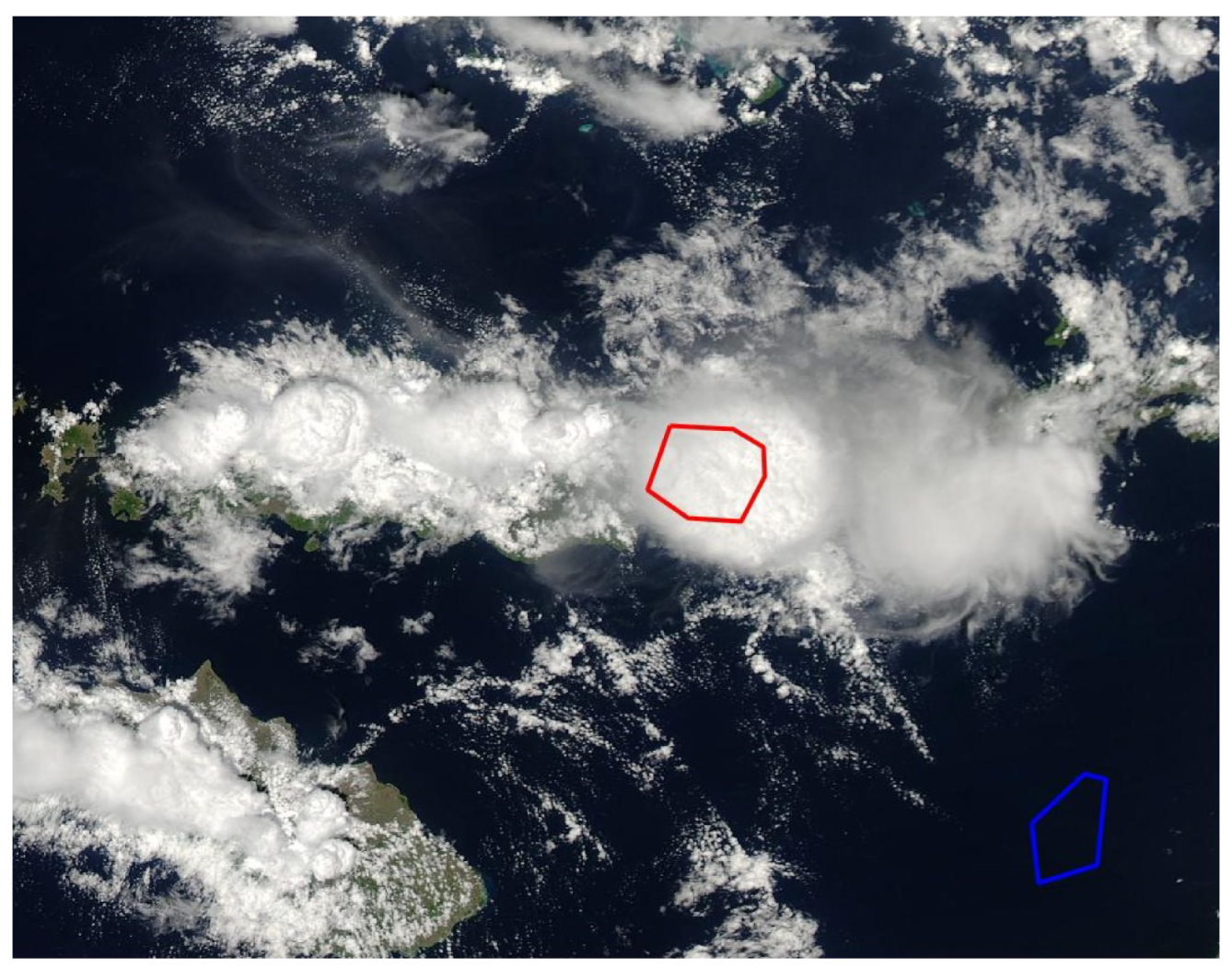
5.1. Selection of Annotation Areas
- Red polygon (cloud regions):
- *
- Optimal choices for thick cloud regions;
- *
- Avoid thin cloud regions to ensure accurate delineation of cloud regions.
- Blue polygon (non-cloud regions):
- *
- Ensure that annotation areas chosen are distinctly different from cloud regions;
- *
- When dealing with backgrounds comprising two types, consider selecting areas that represent the intersection of both background types. This strategy ensures that the annotated areas capture the common characteristics shared by both background types.
5.2. Number of Annotations
5.3. The Distribution of Confidence Values
5.4. The Balance between Performance and the Number of Annotations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sawaya, K.E.; Olmanson, L.G.; Heinert, N.J.; Brezonik, P.L.; Bauer, M.E. Extending satellite remote sensing to local scales: Land and water resource monitoring using high-resolution imagery. Remote Sens. Environ. 2003, 88, 144–156. [Google Scholar] [CrossRef]
- Shao, M.; Zou, Y. Multi-spectral cloud detection based on a multi-dimensional and multi-grained dense cascade forest. J. Appl. Remote Sens. 2021, 15, 028507. [Google Scholar] [CrossRef]
- Schiffer, R.A.; Rossow, W.B. The International Satellite Cloud Climatology Project (ISCCP): The first project of the world climate research programme. Bull. Am. Meteorol. Soc. 1983, 64, 779–784. [Google Scholar] [CrossRef]
- Schmit, T.J.; Lindstrom, S.S.; Gerth, J.J.; Gunshor, M.M. Applications of the 16 spectral bands on the Advanced Baseline Imager (ABI). J. Oper. Meteorol. 2018, 6, 33–46. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Shang, H.; Letu, H.; Xu, R.; Wei, L.; Wu, L.; Shao, J.; Nagao, T.M.; Nakajima, T.Y.; Riedi, J.; He, J.; et al. A hybrid cloud detection and cloud phase classification algorithm using classic threshold-based tests and extra randomized tree model. Remote Sens. Environ. 2024, 302, 113957. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wang, M.; Liu, M.; Zhang, D. A survey on deep learning for neuroimaging-based brain disorder analysis. Front. Neurosci. 2020, 14, 779. [Google Scholar] [CrossRef]
- Fang, Y.; Ye, Q.; Sun, L.; Zheng, Y.; Wu, Z. Multi-attention joint convolution feature representation with lightweight transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–14. [Google Scholar]
- Li, L.; Li, X.; Jiang, L.; Su, X.; Chen, F. A review on deep learning techniques for cloud detection methodologies and challenges. Signal Image Video Process. 2021, 15, 1527–1535. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Francis, A.; Sidiropoulos, P.; Muller, J.P. CloudFCN: Accurate and robust cloud detection for satellite imagery with deep learning. Remote Sens. 2019, 11, 2312. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July 2019–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1029–1032. [Google Scholar]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Cloud detection for satellite imagery using attention-based U-Net convolutional neural network. Symmetry 2020, 12, 1056. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, J.; Yang, X.; Jiang, R.; Ye, Q. Improving deep learning-based cloud detection for satellite images with attention mechanism. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ge, W.; Yang, X.; Jiang, R.; Shao, W.; Zhang, L. CD-CTFM: A Lightweight CNN-Transformer Network for Remote Sensing Cloud Detection Fusing Multiscale Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2024, 17, 4538–4551. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Li, Y.; Wan, Y.; Yao, Y. CloudViT: A lightweight vision transformer network for remote sensing cloud detection. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Tymchenko, B.; Marchenko, P.; Spodarets, D. Segmentation of cloud organization patterns from satellite images using deep neural networks. Her. Adv. Inf. Technol. 2020, 1, 352–361. [Google Scholar] [CrossRef]
- Iglovikov, V.; Mushinskiy, S.; Osin, V. Satellite imagery feature detection using deep convolutional neural network: A kaggle competition. arXiv 2017, arXiv:1706.06169. [Google Scholar]
- Luboschik, M.; Schumann, H.; Cords, H. Particle-based labeling: Fast point-feature labeling without obscuring other visual features. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1237–1244. [Google Scholar] [CrossRef]
- Mingqiang, Y.; Kidiyo, K.; Joseph, R. A survey of shape feature extraction techniques. Pattern Recognit. 2008, 15, 43–90. [Google Scholar]
- Yang, X.; Chen, R.; Zhang, F.; Zhang, L.; Fan, X.; Ye, Q.; Fu, L. Pixel-level automatic annotation for forest fire image. Eng. Appl. Artif. Intell. 2021, 104, 104353. [Google Scholar] [CrossRef]
- Cariou, C.; Le Moan, S.; Chehdi, K. Improving K-nearest neighbor approaches for density-based pixel clustering in hyperspectral remote sensing images. Remote Sens. 2020, 12, 3745. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, H. Kd-tree based efficient ensemble classification algorithm for imbalanced learning. In Proceedings of the 2019 International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 8–10 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 203–207. [Google Scholar]
- Mahadik, S.M.; Kokate, S.M. A Survey on Fast nearest Neighbor Search Using KD Tree and Inverted Files. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2015, 3, 332–336. [Google Scholar]
- Maneewongvatana, S.; Mount, D.M. An empirical study of a new approach to nearest neighbor searching. In Proceedings of the Workshop on Algorithm Engineering and Experimentation, Washington, DC, USA, 5–6 January 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 172–187. [Google Scholar]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for remote sensing images by the fusion of multi-scale convolutional features. arXiv 2018, arXiv:1810.05801. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Piscataway, NJ, USA, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Kanu, S.; Khoja, R.; Lal, S.; Raghavendra, B.; Asha, C. CloudX-net: A robust encoder-decoder architecture for cloud detection from satellite remote sensing images. Remote Sens. Appl. Soc. Environ. 2020, 20, 100417. [Google Scholar] [CrossRef]
- Ogwok, D.; Ehlers, E.M. Jaccard index in ensemble image segmentation: An approach. In Proceedings of the 2022 5th International Conference on Computational Intelligence and Intelligent Systems, Quzhou, China, 4–6 November 2022; pp. 9–14. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Wang, J.; Yang, D.; Chen, S.; Zhu, X.; Wu, S.; Bogonovich, M.; Guo, Z.; Zhu, Z.; Wu, J. Automatic cloud and cloud shadow detection in tropical areas for PlanetScope satellite images. Remote Sens. Environ. 2021, 264, 112604. [Google Scholar] [CrossRef]
- Lee, Y.J.; Grauman, K. Foreground focus: Unsupervised learning from partially matching images. Int. J. Comput. Vis. 2009, 85, 143–166. [Google Scholar] [CrossRef]
- Budd, S.; Robinson, E.C.; Kainz, B. A survey on active learning and human-in-the-loop deep learning for medical image analysis. Med. Image Anal. 2021, 71, 102062. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|
| UNet | 66.63 | 88.55 | 76.18 | 92.80 | 78.47 | 86.16 |
| Deeplabv3+ | 64.94 | 80.35 | 80.55 | 85.82 | 77.10 | 82.37 |
| Cloud-AttU | 69.83 | 86.26 | 81.43 | 90.19 | 80.34 | 87.03 |
| CloudAUE | 74.89 | 87.85 | 88.86 | 93.80 | 87.92 | 93.06 |
| Method | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|
| UNet | 87.99 | 99.49 | 88.39 | 99.82 | 93.61 | 96.54 |
| Deeplabv3+ | 84.23 | 94.05 | 88.96 | 97.74 | 91.44 | 95.22 |
| Cloud-AttU | 89.62 | 94.67 | 94.37 | 97.86 | 94.52 | 96.86 |
| CloudAUE | 90.38 | 97.83 | 92.22 | 99.18 | 94.95 | 97.19 |
| Method | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|
| UNet | 68.23 | 99.80 | 68.32 | 99.87 | 81.11 | 84.53 |
| Deeplabv3+ | 57.38 | 97.16 | 58.36 | 98.38 | 72.92 | 78.93 |
| Cloud-AttU | 78.13 | 99.83 | 78.23 | 99.87 | 87.72 | 89.35 |
| CloudAUE | 87.76 | 93.34 | 93.62 | 93.68 | 93.48 | 93.65 |
| Scene | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|
| Forest | 90.49 | 95.29 | 94.68 | 96.06 | 94.89 | 96.38 |
| Water | 76.70 | 91.30 | 82.84 | 96.17 | 86.24 | 94.66 |
| Snow | 58.36 | 67.20 | 81.81 | 87.13 | 73.06 | 86.06 |
| Barren land | 83.93 | 94.27 | 88.54 | 96.65 | 91.21 | 95.95 |
| Agriculture | 92.04 | 98.06 | 93.78 | 97.94 | 95.85 | 96.06 |
| Shrubland | 92.79 | 95.39 | 97.14 | 94.96 | 96.26 | 96.11 |
| Urban | 76.34 | 86.91 | 85.17 | 94.65 | 85.82 | 93.86 |
| Mountain | 87.53 | 94.38 | 92.47 | 92.54 | 93.30 | 92.08 |
| Method | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|
| UNet | 83.02 | 90.72 | 90.73 | 84.55 | 90.72 | 88.41 |
| Deeplabv3+ | 81.31 | 87.57 | 91.92 | 80.81 | 89.69 | 87.42 |
| Cloud-AttU | 83.26 | 90.17 | 91.58 | 84.04 | 90.87 | 88.67 |
| CloudAUE | 79.87 | 91.11 | 82.06 | 87.34 | 85.82 | 89.56 |
| Selection | Confidence | Jaccard | Precision | Recall | Specificity | F1 | Accuracy |
|---|---|---|---|---|---|---|---|
| First (Figure 11a) | 0.73 | 0.69 | 0.99 | 0.69 | 0.99 | 0.82 | 0.85 |
| Second (Figure 11c) | 0.82 | 0.89 | 0.92 | 0.96 | 0.93 | 0.94 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Shao, Y.; Jiang, R.; Yang, X.; Zhang, L. Satellite Image Cloud Automatic Annotator with Uncertainty Estimation. Fire 2024, 7, 212. https://doi.org/10.3390/fire7070212
Gao Y, Shao Y, Jiang R, Yang X, Zhang L. Satellite Image Cloud Automatic Annotator with Uncertainty Estimation. Fire. 2024; 7(7):212. https://doi.org/10.3390/fire7070212
Chicago/Turabian StyleGao, Yijiang, Yang Shao, Rui Jiang, Xubing Yang, and Li Zhang. 2024. "Satellite Image Cloud Automatic Annotator with Uncertainty Estimation" Fire 7, no. 7: 212. https://doi.org/10.3390/fire7070212
APA StyleGao, Y., Shao, Y., Jiang, R., Yang, X., & Zhang, L. (2024). Satellite Image Cloud Automatic Annotator with Uncertainty Estimation. Fire, 7(7), 212. https://doi.org/10.3390/fire7070212