
Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions

 ,
,
Abstract
1. Introduction
- We aimed to explore and analyze current advanced approaches used in video-based fire detection and their associated systems. We discuss the challenges and opportunities in designing and developing deep learning approaches for fire detection, focusing on recognition, object detection, and segmentation;
- We present the most-widely used public datasets for the fire-recognition, fire-object-detection, and fire-segmentation tasks;
- We discuss various challenges and potential research directions in this field.
2. Background and Related Work
- (1)
- Fire recognition:Fire recognition refers to determining whether there is the presence of smoke or flames in an image. It is also known as global fire recognition and represents the coarsest-grained recognition task in fire detection.
- (2)
- Fire object detection:Fire object detection is an extension of fire recognition in fire-detection tasks. Its main objective is to detect fire or smoke objects in a given image. The core functionality of this task is to roughly locate fire instances in the image and bounding box estimation. These bounding boxes provide localization information for the targets and serve finer-grained tasks in fire detection.
- (3)
- Fire segmentation:Fire segmentation involves accurately classifying every pixel in the image, separating the fire objects and their detailed boundaries from the image. It represents a comprehensive task encompassing fire classification, localization, and boundary delineation. Image segmentation can effectively identify and track fire events. When a fire occurs, image segmentation can use surveillance cameras in open areas to capture the distribution of flames and make relatively accurate predictions about the spread of the fire, enabling quick localization of specific areas and appropriate responses. Smoke segmentation typically outputs masks with detailed boundaries involving object classification, localization, and boundary description.
3. Datasets and Evaluation Metrics
3.1. Datasets
- VisiFire dataset [29]:The VisiFire dataset is a widely used public video dataset for fire and smoke detection. It consists of four categories of videos: flame, smoke, other, and forest smoke. The fire set comprises 13 videos, the smoke set 21 videos, the forest smoke set 21 videos, and the other video set 2 videos. Dharmawan et al. [30] selected 12 commonly used videos from the VisiFire dataset for frame-by-frame segmentation annotation, resulting in 2684 annotated frames.
- BoWFire dataset [31]:The BoWFire dataset comprises 226 images of varying resolutions, with 119 images depicting fires and 107 representing non-fire scenes. The fire images encompass different scenarios of urgent fire events, such as building fires, industrial fires, accidents, and riots. The non-fire images include fire-like objects in red or yellow hues and sunset scenes. Additionally, a training set consisting of 240 images with a resolution of 50 × 50 px is provided, comprising 80 fire images and 160 non-fire images.
- Corsican Fire Database [32]:The Corsican Fire Database is a comprehensive dataset containing multi-modal wildfire images and videos. It includes 500 visible images, 100 multi-modal fire images incorporating visible light and near-infrared spectra, and 5 multi-modal sequences depicting fire propagation. The Corsican Fire Database encompasses annotations regarding fire and background attribute categories, describing visual information related to fires, such as flame color, smoke color, fire distance, percentage of smoke obscuring flames, background brightness, vegetation conditions, and weather conditions. Each image in this dataset is accompanied by its corresponding segmentation mask, which can be utilized for fire-segmentation research.
- FESB MLID dataset [33]:The FESB MLID dataset comprises 400 natural Mediterranean landscape images and their corresponding semantic segmentation. These images are segmented into 11 semantic categories, including smoke, clouds and fog, sunlight, sky, water surface, and distant views, among others. Additionally, an unknown region category is added, resulting in 12 defined classes. This dataset contains several challenging samples, where many smoke features are small-scale or distant smoke instances.
- Smoke100k [34]:Due to the hazy edges and translucent nature of smoke, the manual annotation of smoke objects can be challenging. The Smoke100k dataset provides a large-scale synthetic smoke image dataset for training smoke-detection models. The dataset includes three subsets: Smoke100k-L, Smoke100k-M, and Smoke100k-H, with 33 k, 36 k, and 33 k images, respectively. Each subset comprises synthetic smoke images, background images, smoke masks, and ground-truth bounding box positions. The Smoke100k dataset generates three different smoke masks based on smoke density to simulate the dynamic motion of rising smoke, blending pure smoke images with background images to generate synthetic smoke scene images.
- Video Smoke Detection Dataset [35]:The Video Smoke Detection Dataset (VSD) consists of three smoke videos, three non-smoke videos, and four sets of smoke and non-smoke image datasets. The image datasets are referred to as Set 1, Set 2, Set 3, and Set 4. Set 1 comprises 552 smoke images and 831 non-smoke images. Set 2 comprises 668 smoke images and 817 non-smoke images. Set 3 consists of 2201 smoke images and 8511 non-smoke images. Set 4 contains 2254 smoke images and 8363 non-smoke images. The non-smoke images exhibit many similarities to the smoke images in color, shape, and texture.
- FLAME dataset [36]:The Fire Luminosity Air-Based Machine Learning Evaluation (FLAME) provides aerial images and videos of burning piled detritus in the Northern Arizona forests, collected using two unmanned aerial vehicles (UAVs). The dataset includes four photographic modes captured with conventional and thermal imaging cameras: normal, Fusion, WhiteHot, and GreenHot. The fire-recognition task comprises 48,010 RGB aerial images, divided into 30,155 fire images and 17,855 non-fire images, curated explicitly for wildfire recognition. The dataset includes 2003 segmentation masks with pixel-level annotations for the fire-segmentation task. This dataset serves as a valuable resource for fire recognition, segmentation methods, and further development of visual-based fire spread models.
- Flame and Smoke Detection Dataset [37]:The Flame and Smoke Detection Dataset (FASDD) is a large-scale dataset containing 100,000-level flame and smoke images from various sources, including surveillance cameras, drones, multi-source remote sensing satellite images, and computer graphics paintings depicting fire scenes. Moreover, the FASDD dataset encompasses a significant number of small-scale flame and smoke objects, posing challenges for deep learning research on small object detection. It consists of two subsets: FASDD_CV, which includes 95,314 samples captured from surveillance cameras, lookout towers, and drones, and FASDD_RS, comprising 5773 remote sensing image samples. Additionally, FASDD provides annotation files in three different formats.
- D-Fire dataset [38]:The D-Fire dataset is a collection of fire and smoke images specifically designed for object-detection-method development. Considering the diverse morphology of smoke and flame, the dataset incorporates data from the Internet, fire simulations, surveillance cameras, and artificially synthesized images where artificial smoke is composited with green landscape backgrounds using computer software. The D-Fire dataset consists of 21,527 images annotated with YOLO format labels, amounting to 26,557 bounding boxes. Among these, 1164 images depict fire, 5867 images solely smoke, 4658 images fire and smoke, and 9838 images as negative examples.
- DSDF [39]:The dataset for smoke detection in foggy environments (DSDF) is designed for studying smoke detection in foggy conditions. It comprises over 18,413 real-world images collected in both normal and foggy weather conditions. These images are annotated with four distinct categories, namely: non-smoke without fog (nSnF), smoke without fog (SnF), non-smoke with fog (nSF), and smoke with fog (SF). The dataset consists of 6528 images for nSnF, 6907 for SnF, 1518 for nSF, and 3460 for SF. DSDF covers a wide range of smoke variations in terms of color, size, shape, and density. Additionally, the samples in the dataset provide rich background information, which contributes to enhancing the detection model’s generalization capability in real-world scenarios.
- DFS [40]:The Dataset for Fire and Smoke Detection (DFS) contains 9462 fire images collected from real-world scenes. The images are categorized based on the proportion of the flame area in the image, including Large Flame, Medium Flame, and Small Flame, with 3357, 4722, and 349 images, respectively. In addition to the annotations for “Flame” and “Smoke”, the DFS includes a new category called “Other” to label objects such as vehicle lights, streetlights, sunlight, and metal lamps, comprising a total of 1034 images. This “Other” category is included to reduce false positives caused by misclassification.
3.2. Evaluation Metrics
3.2.1. Evaluation Metrics for Fire Recognition
3.2.2. Evaluation Metrics for Fire Object Detection and Segmentation
4. Deep-Learning-Based Approaches for Videos Fire Detection
4.1. Fire Recognition Methods
4.2. Fire-Object-Detection Methods
4.3. Fire-Segmentation Methods
5. Discussion
- (1)
- Establishing a high-quality fire dataset:In the domain of fire-detection research, the significant improvement of fire-detection models relies on the construction of a large-scale dataset comprising high-dimensional images. Such a dataset enables the models to extract diverse and rich features. However, the field currently faces challenges such as limited samples, sample imbalance, and a lack of diversity in the background, resulting in the absence of an authoritative standard dataset. The limited availability of publicly accessible fire videos and image datasets further restricts the models’ generalization capabilities. It is recommended that researchers construct a high-quality dataset encompassing a wide range of scenes, including public buildings, forests, and industrial areas. This dataset should incorporate various modalities of data, such as visible light and infrared, while considering different environmental conditions such as indoor settings, haze, and nighttime scenarios. To address the aforementioned issues, the utilization of generative adversarial networks (GANs) can aid in generating realistic fire images. Moreover, 3D computer graphics software can simulate highly controlled smoke and flame effects, integrating them with existing background image datasets to create synthetic data. By expanding the dataset, not only can the issue of sample imbalance be effectively alleviated, but it can also enhance the detection performance of fire-detection methods. Hence, it is advisable to prioritize the construction of high-quality fire datasets in video fire detection research, enabling a comprehensive exploration and evaluation of fire detection algorithms’ performance and application capabilities.
- (2)
- Exploring information fusion and utilization with multiple features:In the context of fire detection in various scenarios, such as chemical industrial parks, forests, and urban buildings, the morphology of smoke and flames exhibits diversity, accompanied by a wide range of scale variations and significant feature changes. Deep-learning-based video-fire-detection models still have room for improvement in effectively extracting the essential characteristics of fires. Furthermore, in video-based fire detection, limited research addresses the utilization of information between consecutive video frames to capture the correlation between static features and dynamic changes. Therefore, it is recommended that researchers fully exploit the color, texture, flicker, and other characteristics of flames and smoke. Additionally, it is essential to consider the temporal and spatial information within the video sequence to effectively reduce the false negative and false positive rates of fire detection models.
- (3)
- Building lightweight models for edge computing devices:In recent years, deep learning has achieved significant success in fire detection. However, the inference process of deep learning models heavily relies on high-performance computing devices, particularly in complex environments where long-distance data transmission and centralized processing negatively impact efficiency. As a distributed computing architecture, edge computing places computational capabilities closer to the end devices to meet the high computational and low-latency requirements of deep learning [104]. Due to edge computing devices’ limited computing and storage capacities, real-time performance is compromised for deep learning models with large network parameters and computational complexity. Thus, immature challenges persist in combining deep-learning-based fire-detection methods with low-power small-scale edge computing devices. To adapt to the resource limitations and real-time requirements of edge computing devices, it is recommended that researchers focus on studying lightweight fire-detection methods to enhance the detection efficiency of the models. Research on model compression primarily focuses on techniques such as quantization, pruning, and knowledge distillation. These methods compress the model’s size and computational load by reducing the data precision, parameter compression, and knowledge transfer [105]. Additionally, designing efficient and lightweight backbone network architectures is an important research direction.
- (4)
- Conducting research on fire scene reconstruction and propagation trends based on video:By utilizing surveillance devices installed in the vicinity of fire scenes, such as buildings and lookout towers, we can gather abundant information about the fire. This fire-related information can be utilized to infer the physical parameters of the fire and assess the trends in fire spread. This provides vital auxiliary support for fire management and emergency response, including fire propagation prediction, intelligent graded response, and handling accidents and disasters. However, the current research in this field, specifically deep learning methods based on fire scene video data, remains inadequate. It is recommended that researchers combine theoretical models from fire dynamics and heat transfer and utilize a vast amount of real fire data from various scenarios for their studies. Through the analysis of fire scene video data, it is possible to infer the physical parameters of the fire, such as the fire size and flame heat release rate (HRR). Furthermore, it is essential to investigate fire situation analysis based on video features and the actual conditions of the hazard-formative environment and the hazard-affected bodies to infer the fire’s propagation trends. This will significantly contribute to enabling emergency rescue personnel to conduct rescue operations based on the fire situation. Therefore, it is advisable to carry out research on fire scene reconstruction and propagation trends based on video in order to provide more-effective decision support for fire management and emergency response.
- (5)
- Research on fire detection methods for unmanned emergency rescue equipment:In recent years, the development of unmanned emergency rescue equipment has emerged as a prominent focus within the field of emergency response. When confronted with complex and extreme emergency scenarios, the utilization of unmanned rescue equipment enhances the efficiency and safety of fire rescue operations, thereby reducing casualties and property losses. Consequently, the study of fire-detection methods holds paramount importance in researching unmanned emergency rescue equipment, serving as a crucial technology for achieving equipment control and decision autonomy. For instance, the application of unmanned aerial drones in firefighting and rescue operations can encompass a wide range of emergency inspection tasks, thereby facilitating precise fire scene management. Unmanned drones equipped with visible light and infrared sensors can detect potential fire hazards day and night, thus enhancing real-time situational awareness for firefighting and rescue efforts. Furthermore, by integrating fire-detection methods with intelligent firefighting and rescue equipment, coupled with the utilization of unmanned automated firefighting vehicles, it becomes possible to identify areas affected by flames and to automatically respond by implementing appropriate extinguishing measures. Consequently, it is recommended to conduct research on fire-detection methods tailored explicitly for unmanned emergency rescue equipment, thereby promoting the intelligent and integrated development of such equipment and enhancing the efficiency of emergency response operations.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- National Fire and Rescue Administration of China’s Ministry of Emergency Management. The National Police Situation and Fire Situation in 2022. 2023. Available online: https://www.119.gov.cn/qmxfxw/xfyw/2023/36210.shtml (accessed on 3 August 2023).
- Ministry of Emergency Management of the People’s Republic of China. Basic Situation of National Natural Disasters in 2022. 2023. Available online: https://www.mem.gov.cn/xw/yjglbgzdt/202301/t20230113_440478.shtml (accessed on 3 August 2023).
- Quintiere, J.G. Principles of Fire Behavior, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar] [CrossRef]
- Çetin, A.E.; Dimitropoulos, K.; Gouverneur, B.; Grammalidis, N.; Günay, O.; Habiboǧlu, Y.H.; Töreyin, B.U.; Verstockt, S. Video fire detection—Review. Digit. Signal Process. 2013, 23, 1827–1843. [Google Scholar] [CrossRef]
- Wooster, M.J.; Roberts, G.J.; Giglio, L.; Roy, D.P.; Freeborn, P.H.; Boschetti, L.; Justice, C.; Ichoku, C.; Schroeder, W.; Davies, D. Satellite remote sensing of active fires: History and current status, applications and future requirements. Remote Sens. Environ. 2021, 267, 112694. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire-detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Kaku, K. Satellite remote sensing for disaster management support: A holistic and staged approach based on case studies in Sentinel Asia. Int. J. Disaster Risk Reduct. 2019, 33, 417–432. [Google Scholar] [CrossRef]
- Wani, J.A.; Sharma, S.; Muzamil, M.; Ahmed, S.; Sharma, S.; Singh, S. Machine learning and deep learning based computational techniques in automatic agricultural diseases detection: Methodologies, applications, and challenges. Arch. Comput. Methods Eng. 2022, 29, 641–677. [Google Scholar] [CrossRef]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A systematic literature review on crop yield prediction with deep learning and remote sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Thirunavukarasu, R.; Gnanasambandan, R.; Gopikrishnan, M.; Palanisamy, V. Towards computational solutions for precision medicine based big data healthcare system using deep learning models: A review. Comput. Biol. Med. 2022, 149, 106020. [Google Scholar] [CrossRef]
- Khalil, R.A.; Saeed, N.; Masood, M.; Fard, Y.M.; Alouini, M.S.; Al-Naffouri, T.Y. Deep learning in the industrial internet of things: Potentials, challenges, and emerging applications. IEEE Internet Things J. 2021, 8, 11016–11040. [Google Scholar] [CrossRef]
- Younan, M.; Houssein, E.H.; Elhoseny, M.; Ali, A.A. Challenges and recommended technologies for the industrial internet of things: A comprehensive review. Measurement 2020, 151, 107198. [Google Scholar] [CrossRef]
- Peng, S.; Cao, L.; Zhou, Y.; Ouyang, Z.; Yang, A.; Li, X.; Jia, W.; Yu, S. A survey on deep learning for textual emotion analysis in social networks. Digit. Commun. Netw. 2022, 8, 745–762. [Google Scholar] [CrossRef]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Cambria, E. Recent advances in deep learning based dialogue systems: A systematic survey. Artif. Intell. Rev. 2023, 56, 3055–3155. [Google Scholar] [CrossRef]
- Geetha, S.; Abhishek, C.; Akshayanat, C. Machine vision based fire detection techniques: A survey. Fire Technol. 2021, 57, 591–623. [Google Scholar] [CrossRef]
- Kong, S.G.; Jin, D.; Li, S.; Kim, H. Fast fire flame detection in surveillance video using logistic regression and temporal smoothing. Fire Saf. J. 2016, 79, 37–43. [Google Scholar] [CrossRef]
- Filonenko, A.; Hernandez, D.C.; Wahyono; Jo, K.H. Smoke detection for surveillance cameras based on color, motion, and shape. In Proceedings of the 2016 IEEE 14th International Conference on Industrial Informatics (INDIN), Poitiers, France, 19–21 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary results from a wildfire-detection system using deep learning on remote camera images. Remote Sens. 2020, 12, 166. [Google Scholar] [CrossRef]
- Ye, S.; Bai, Z.; Chen, H.; Bohush, R.; Ablameyko, S. An effective algorithm to detect both smoke and flame using color and wavelet analysis. Pattern Recognit. Image Anal. 2017, 27, 131–138. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Zhang, Q.; Jia, Y.; Xu, G.; Wang, J. Smoke detection in video sequences based on dynamic texture using volume local binary patterns. KSII Trans. Internet Inf. Syst. 2017, 11, 5522–5536. [Google Scholar]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Hassan Ahmed, S.; Wook Baik, S. Efficient Fire Detection for Uncertain Surveillance Environment. IEEE Trans. Ind. Inform. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire sensing technologies: A review. IEEE Sensors J. 2019, 19, 3191–3202. [Google Scholar] [CrossRef]
- Xue, X.; Feiniu, Y.; Lin, Z.; Longzhen, Y.; Jinting, S. From traditional methods to deep ones: Review of visual smoke recognition, detection, and segmentation. J. Image Graph. 2019, 24, 1627–1647. [Google Scholar]
- Bu, F.; Gharajeh, M.S. Intelligent and vision-based fire-detection systems: A survey. Image Vis. Comput. 2019, 91, 103803. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Khanna, P.; Ojha, A. A survey on vision-based outdoor smoke detection techniques for environmental safety. ISPRS J. Photogramm. Remote Sens. 2022, 185, 158–187. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechida, A. A review on early wildfire detection from unmanned aerial vehicles using deep-learning-based computer vision algorithms. Signal Process. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A. Deep Learning Approaches for Wildland Fires Remote Sensing: Classification, Detection, and Segmentation. Remote Sens. 2023, 15, 1821. [Google Scholar] [CrossRef]
- Cetin, A.E. Computer Vision Based Fire Detection Dataset. 2014. Available online: http://signal.ee.bilkent.edu.tr/VisiFire/ (accessed on 3 August 2023).
- Dharmawan, A.; Harjoko, A.; Adhinata, F.D. Region-based annotation data of fire images for intelligent surveillance system. Data Brief 2022, 41, 107925. [Google Scholar]
- Chino, D.Y.; Avalhais, L.P.; Rodrigues, J.F.; Traina, A.J. Bowfire: Detection of fire in still images by integrating pixel color and texture analysis. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 95–102. [Google Scholar]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef]
- Braović, M.; Stipaničev, D.; Krstinić, D. FESB MLID Dataset. 2018. Available online: http://wildfire.fesb.hr/index.php?option=com_content&view=article&id=66%20&Itemid=76 (accessed on 3 August 2023).
- Cheng, H.Y.; Yin, J.L.; Chen, B.H.; Yu, Z.M. Smoke 100k: A Database for Smoke Detection. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 596–597. [Google Scholar]
- Yuan, F. Video Smoke Detection Dataset. 2020. Available online: http://staff.ustc.edu.cn/~yfn/vsd.html (accessed on 3 August 2023).
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Wang, M.; Jiang, L.; Yue, P.; Yu, D.; Tuo, T. FASDD: An Open-access 100,000-level Flame and Smoke Detection Dataset for Deep Learning in Fire Detection. Earth Syst. Sci. Data Discuss. 2023. published online. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.; Lisboa, A.C.; Barbosa, A.V. An automatic fire-detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Gong, X.; Hu, H.; Wu, Z.; He, L.; Yang, L.; Li, F. Dark-channel based attention and classifier retraining for smoke detection in foggy environments. Digit. Signal Process. 2022, 123, 103454. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, X.; Liu, R.; Li, B. A dataset for fire and smoke object detection. Multimed. Tools Appl. 2023, 82, 6707–6726. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Wan, B.; Xia, X.; Shi, J. Convolutional neural networks based on multi-scale additive merging layers for visual smoke recognition. Mach. Vis. Appl. 2019, 30, 345–358. [Google Scholar] [CrossRef]
- Khudayberdiev, O.; Zhang, J.; Abdullahi, S.M.; Zhang, S. Light-FireNet: An efficient lightweight network for fire detection in diverse environments. Multimed. Tools Appl. 2022, 81, 24553–24572. [Google Scholar] [CrossRef]
- Zheng, S.; Gao, P.; Wang, W.; Zou, X. A Highly Accurate Forest Fire Prediction Model Based on an Improved Dynamic Convolutional Neural Network. Appl. Sci. 2022, 12, 6721. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q. An adaptive frame selection network with enhanced dilated convolution for video smoke recognition. Expert Syst. Appl. 2023, 215, 119371. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, F.U.M.; Gupta, S.K.; Lee, M.Y.; Baik, S.W. Randomly Initialized CNN with Densely Connected Stacked Autoencoder for Efficient Fire Detection. Eng. Appl. Artif. Intell. 2022, 116, 105403. [Google Scholar] [CrossRef]
- Huang, L.; Liu, G.; Wang, Y.; Yuan, H.; Chen, T. Fire detection in video surveillances using convolutional neural networks and wavelet transform. Eng. Appl. Artif. Intell. 2022, 110, 104737. [Google Scholar] [CrossRef]
- Kwak, D.K.; Ryu, J.K. A Study on Fire Detection Using Deep Learning and Image Filtering Based on Characteristics of Flame and Smoke. J. Electr. Eng. Technol. 2023. published online. [Google Scholar] [CrossRef]
- Hu, C.; Tang, P.; Jin, W.; He, Z.; Li, W. Real-Time Fire Detection Based on Deep Convolutional Long-Recurrent Networks and Optical Flow Method. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Ghosh, R.; Kumar, A. A hybrid deep learning model by combining convolutional neural network and recurrent neural network to detect forest fire. Multimed. Tools Appl. 2022, 81, 38643–38660. [Google Scholar] [CrossRef]
- He, L.; Gong, X.; Zhang, S.; Wang, L.; Li, F. Efficient attention based deep fusion CNN for smoke detection in fog environment. Neurocomputing 2021, 434, 224–238. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Zhang, Q.x.; Lin, G.h.; Zhang, Y.m.; Xu, G.; Wang, J.j. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Pan, J.; Ou, X.; Xu, L. A collaborative region detection and grading framework for forest fire smoke using weakly supervised fine segmentation and lightweight faster-RCNN. Forests 2021, 12, 768. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire detection from images using faster R-CNN and multidimensional texture analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8301–8305. [Google Scholar]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster r-cnn. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Zhang, J.; Shi, R.; Yang, Y.; Huang, W. A robust fire-detection model via convolution neural networks for intelligent robot vision sensing. Sensors 2022, 22, 2929. [Google Scholar] [CrossRef]
- Chen, C.; Yu, J.; Lin, Y.; Lai, F.; Zheng, G.; Lin, Y. Fire detection based on improved PP-YOLO. Signal Image Video Process. 2023, 17, 1061–1067. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Zhou, H.; Li, Z.; Gao, Y.; Bai, D.; Xu, R.; Lin, H. Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s. Forests 2023, 14, 315. [Google Scholar] [CrossRef]
- Kristiani, E.; Chen, Y.C.; Yang, C.T.; Li, C.H. Flame and smoke recognition on smart edge using deep learning. J. Supercomput. 2023, 79, 5552–5575. [Google Scholar] [CrossRef]
- Wu, Z.; Xue, R.; Li, H. Real-Time Video Fire Detection via Modified YOLOv5 Network Model. Fire Technol. 2022, 58, 2377–2403. [Google Scholar] [CrossRef]
- Yin, H.; Chen, M.; Fan, W.; Jin, Y.; Hassan, S.G.; Liu, S. Efficient Smoke Detection Based on YOLO v5s. Mathematics 2022, 10, 3493. [Google Scholar] [CrossRef]
- Yan, C.; Wang, Q.; Zhao, Y.; Zhang, X. YOLOv5-CSF: An improved deep convolutional neural network for flame detection. Soft Comput. 2023. published online. [Google Scholar] [CrossRef]
- Huo, Y.; Zhang, Q.; Jia, Y.; Liu, D.; Guan, J.; Lin, G.; Zhang, Y. A deep separable convolutional neural network for multiscale image-based smoke detection. Fire Technol. 2022, 58, 1445–1468. [Google Scholar] [CrossRef]
- Wu, H.; Wu, D.; Zhao, J. An intelligent fire-detection approach through cameras based on computer vision methods. Process Saf. Environ. Prot. 2019, 127, 245–256. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.; Campos, R.J.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. A hybrid method for fire detection based on spatial and temporal patterns. Neural Comput. Appl. 2023, 35, 9349–9361. [Google Scholar] [CrossRef]
- Li, C.; Cheng, D.; Li, Y. Research on fire detection algorithm based on deep learning. In Proceedings of the International Conference on Cloud Computing, Performance Computing, and Deep Learning (CCPCDL 2022), Wuhan, China, 11–13 March 2022; SPIE: Cergy, France, 2022; Volume 12287, pp. 510–514. [Google Scholar]
- Jandhyala, S.S.; Jalleda, R.R.; Ravuri, D.M. Forest Fire Classification and Detection in Aerial Images using Inception-V3 and SSD Models. In Proceedings of the 2023 International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), Bengaluru, India, 5–7 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 320–325. [Google Scholar]
- Li, S.; Yan, Q.; Liu, P. An Efficient Fire Detection Method Based on Multiscale Feature Extraction, Implicit Deep Supervision and Channel Attention Mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient video fire detection exploiting motion-flicker-based dynamic features and deep static features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Huo, Y.; Zhang, Q.; Zhang, Y.; Zhu, J.; Wang, J. 3DVSD: An end-to-end 3D convolutional object detection network for video smoke detection. Fire Saf. J. 2022, 134, 103690. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Yang, C.; Pan, Y.; Cao, Y.; Lu, X. CNN-Transformer Hybrid Architecture for Early Fire Detection. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2022: 31st International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; Part IV. Springer: Berlin, Germany, 2022; pp. 570–581. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Choi, H.S.; Jeon, M.; Song, K.; Kang, M. Semantic Fire Segmentation Model Based on Convolutional Neural Network for Outdoor Image. Fire Technol. 2021, 57, 3005–3019. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3431–3440. [Google Scholar]
- Mseddi, W.S.; Ghali, R.; Jmal, M.; Attia, R. Fire detection and segmentation using YOLOv5 and U-net. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: Piscatway, NJ, USA, 2021; pp. 741–745. [Google Scholar]
- Zhang, J.; Zhu, H.; Wang, P.; Ling, X. ATT squeeze U-Net: A lightweight network for forest fire detection and recognition. IEEE Access 2021, 9, 10858–10870. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, P.; Liang, H.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. Semantic segmentation and analysis on sensitive parameters of forest fire smoke using smoke-unet and landsat-8 imagery. Remote Sens. 2022, 14, 45. [Google Scholar] [CrossRef]
- Harkat, H.; Nascimento, J.; Bernardino, A. Fire segmentation using a DeepLabv3+ architecture. In Proceedings of the Image and Signal Processing for Remote Sensing XXVI, Online, 21–25 September 2020; SPIE: Cergy, France, 2020; Volume 11533, pp. 134–145. [Google Scholar]
- Barmpoutis, P.; Stathaki, T.; Dimitropoulos, K.; Grammalidis, N. Early Fire Detection Based on Aerial 360-Degree Sensors, Deep Convolution Neural Networks and Exploitation of Fire Dynamic Textures. Remote Sens. 2020, 12, 3177. [Google Scholar] [CrossRef]
- Khan, S.; Muhammad, K.; Hussain, T.; Del Ser, J.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H.C. Deepsmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A gated recurrent network with dual classification assistance for smoke semantic segmentation. IEEE Trans. Image Process. 2021, 30, 4409–4422. [Google Scholar] [CrossRef] [PubMed]
- Shahid, M.; Virtusio, J.J.; Wu, Y.H.; Chen, Y.Y.; Tanveer, M.; Muhammad, K.; Hua, K.L. Spatio-Temporal Self-Attention Network for Fire Detection and Segmentation in Video Surveillance. IEEE Access 2021, 10, 1259–1275. [Google Scholar] [CrossRef]
- Yuan, F.; Dong, Z.; Zhang, L.; Xia, X.; Shi, J. Cubic-cross convolutional attention and count prior embedding for smoke segmentation. Pattern Recognit. 2022, 131, 108902. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Shao, X. A lightweight network for real-time smoke semantic segmentation based on dual paths. Neurocomputing 2022, 501, 258–269. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Song, K.; Choi, H.S.; Kang, M. Squeezed fire binary segmentation model using convolutional neural network for outdoor images on embedded device. Mach. Vis. Appl. 2021, 32, 120. [Google Scholar] [CrossRef]
- Yuan, F.; Li, K.; Wang, C.; Fang, Z. A Lightweight Network for Smoke Semantic Segmentation. Pattern Recognit. 2023, 137, 109289. [Google Scholar] [CrossRef]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2020, 149, 1–16. [Google Scholar] [CrossRef]
- Guan, Z.; Miao, X.; Mu, Y.; Sun, Q.; Ye, Q.; Gao, D. Forest fire segmentation from Aerial Imagery data Using an improved instance segmentation model. Remote Sens. 2022, 14, 3159. [Google Scholar] [CrossRef]
- Perrolas, G.; Niknejad, M.; Ribeiro, R.; Bernardino, A. Scalable fire and smoke segmentation from aerial images using convolutional neural networks and quad-tree search. Sensors 2022, 22, 1701. [Google Scholar] [CrossRef] [PubMed]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep learning and transformer approaches for UAV-based wildfire detection and segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Kamath, V.; Renuka, A. Deep Learning Based Object Detection for Resource Constrained Devices-Systematic Review, Future Trends and Challenges Ahead. Neurocomputing 2023, 531, 34–60. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
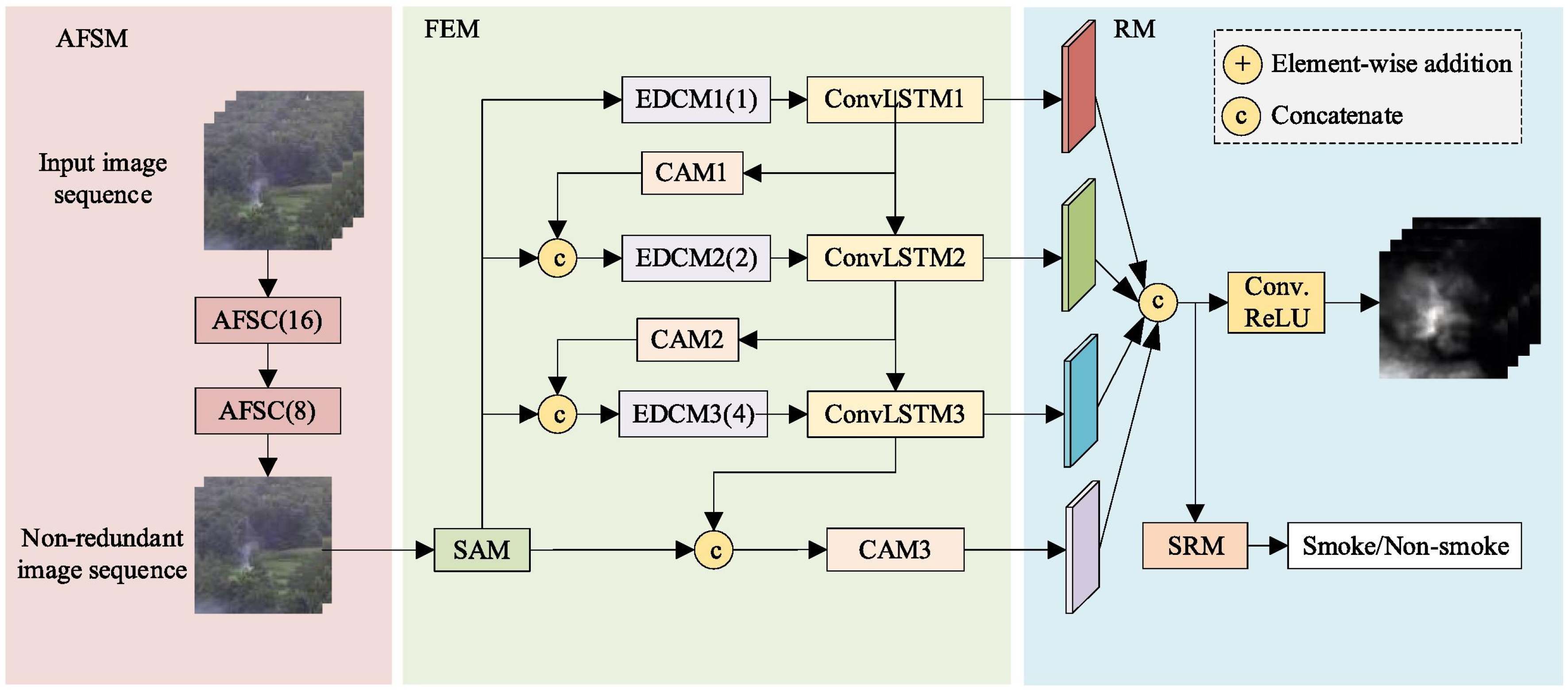{kind=link}
{kind=link}
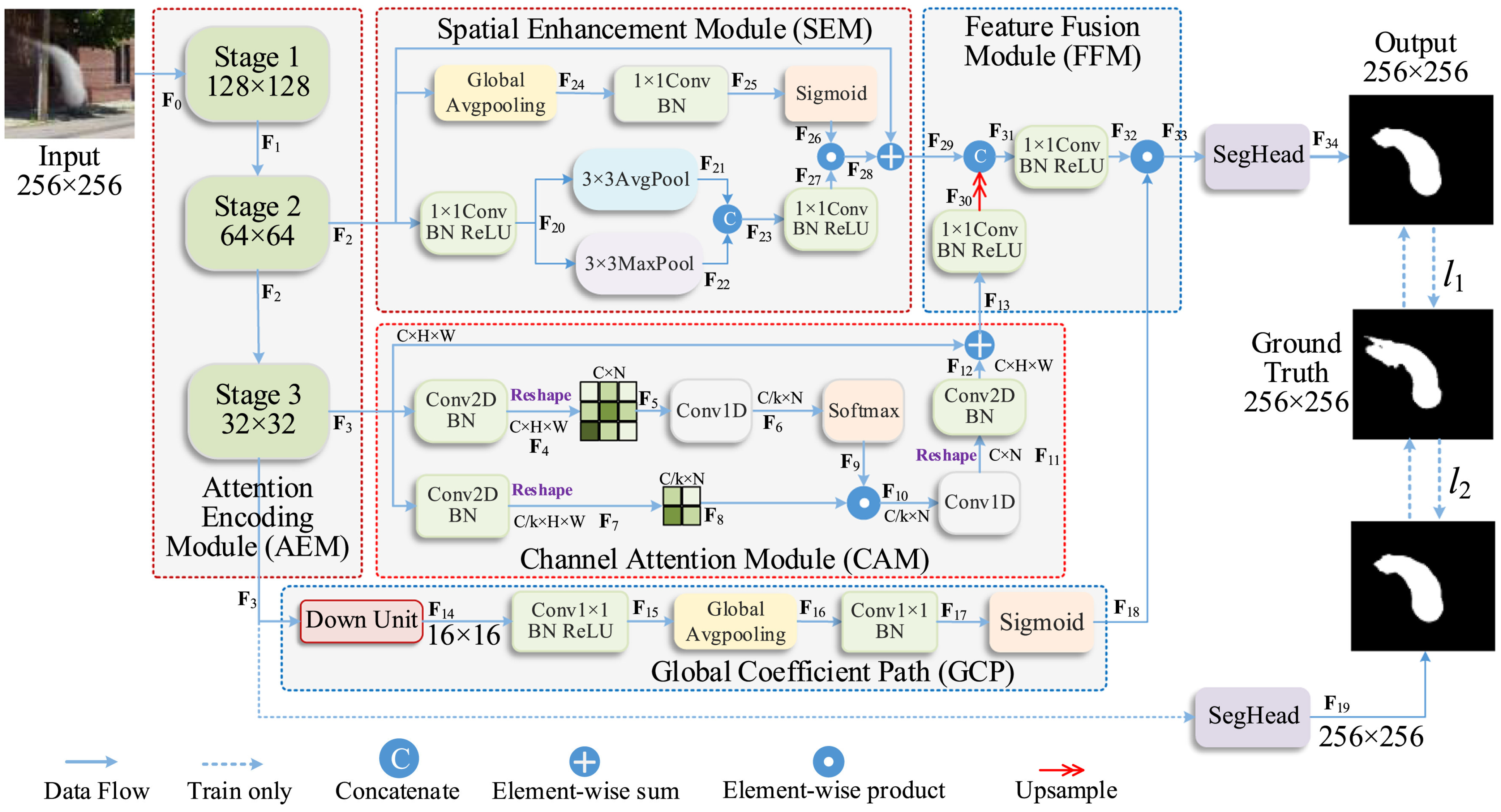{kind=link}
| Author | Year | Scenes | Key Notes |
|---|---|---|---|
| Gaur et al. [22] | 2019 | Building | This work discussed the advancements in fire-sensing technology and highlights the disparities between hardware and method development. |
| Xia et al. [23] | 2019 | Outdoor | This work comprehensively reviewed recent research results in smoke recognition, detection, and pixelwise smoke segmentation from both traditional and deep learning perspectives. |
| Bu et al. [24] | 2019 | Multi-scene environment | This endeavor entailed conducting a thorough examination of the visual-based intelligent fire-detection system, dividing it into two distinct categories: forest fires and all of the environment. |
| Gaur et al. [25] | 2020 | Indoor, Outdoor | This work focused on the discussion of the handcrafted rules and classifiers method and the deep learning method used for fire flame and smoke detection. |
| Chaturvedi et al. [26] | 2022 | Outdoor | This work primarily discussed the research progress in smoke detection focused on outdoor environmental scenes using visual technology. It comprehensively presented three research directions in smoke detection: classification, segmentation, and bounding box estimation. |
| Bouguettaya et al. [27] | 2022 | Forest, wildland | This work primarily focused on the comparative analysis of utilizing unmanned aerial vehicles (UAVs) and remote sensing technology based on deep learning approaches for the early detection of wildfires in forested and barren terrains. |
| Ghali et al. [28] | 2023 | Forest, wildland | This work conducted a comprehensive literature review on deep learning approaches for the classification, detection, and segmentation of wildland fires and introduced popular wildfire datasets in this field. |
| Method | Technique | Application Scenario | Dataset | Evaluate |
|---|---|---|---|---|
| Muhammad et al. [47] | SqueezeNet, feature map selection | Fire detection in monitoring scenarios | BoWFire Dataset | PR (%) = 86; F-m (%) = 91 |
| Yuan et al. [48] | Deep multi-scale convolutional | Multi-scene smoke detection | The datasets of smoke images | DR (%) = 98.55; AR (%) = 99.14; FAR (%) = 0.36 |
| Khudayberdiev et al. [49] | Hard Swish | Multi-scene fire detection | 55,500 images, including fire and non-fire | AR(%) = 97.83; PR (%) = 98.37 F-m (%) = 99.18 |
| Zheng et al. [50] | Dynamic CNN, PCA reconstruction techniques | Forest fire smoke detection | More than 4000 forest fire risk images | AR (%) = 98.3; FNR (%) = 0.13 |
| Majid et al. [51] | EfficientNet-B0, attention mechanism, Grad-CAM | Multi-scene fire detection | 7977 images, including fire and non-fire | AR (%) = 95.40; DR (%) = 97.61; FNR (%) = 94.76 |
| Tao et al. [52] | Adaptive frame-selection convolution, dilated convolution | Smoke detection in surveillance video scenes | SRSet | DR (%) = 96.73; FAR (%) = 3.16; F-m (%) = 96.57 |
| Khan et al. [53] | EfficientNet, autoencoder, weights’ randomization | Fire detection in surveillance video scenes | Foggia Dataset [59] | AR (%) = 97.20; FAR (%) = 0.042; FNR (%) = 0.034 |
| Huang et al. [54] | Haar wavelet transform, Faster R-CNN | Fire detection in surveillance video scenes | 5667 images, including fire and non-fire | PR (%) = 89.0; F-m (%) = 94.0 |
| Kwak et al. [55] | Dark channel prior, Lucas–Kanade method, Inception-V4 | Multi-scene fire detection | 8000 images, including flame, smoke, and non-fire | AR-flame (%) = 97.0; AR-smoke (%) = 94.0 |
| Hu et al. [56] | Deep LSTM, optical flow method | Open space fire detection | The video dataset includes 100 fire videos and 110 non-fire videos | AR (%) = 93.3; F-m (%) = 90.0 |
| Ghosh et al. [57] | Combination of CNN and RNN networks for feature extraction | Forest fire smoke detection | Mivia Dataset | AR (%) = 99.54; DR (%) = 99.75 |
| He et al. [58] | Spatial and channel attention mechanism, FPN | Smoke detection in fog scenes | Fog smoke dataset for 33,666 images | AR (%) = 92.3088; F-m (%) = 92.3833 |
| Gong et al. [39] | Dark-channel-based mixed attention, two-stage training strategy | Smoke detection in fog scenes | DSDF | AR (%) = 87.33; F-m (%) = 87.22 |
| Method | Technique | Application Scenario | Dataset | Evaluate |
|---|---|---|---|---|
| Barmpoutis et al. [62] | Faster R-CNN, linear dynamical systems, Grassmannian VLAD encoding | Multi-scene fire detection | Corsican Fire Database | F-m (%) = 99.7 |
| Chaoxia et al. [63] | Faster R-CNN, color-guided anchoring strategy, global information network | Multi-scene fire detection | 3719 images, including fire and non-fire | AR (%) = 93.36 F-m (%) = 94 |
| Chen et al. [67] | YOLOv5s, CoT, CA, BiFPN | Multi-scene fire detection | 2976 images including BowFire and forest fire | mAP@0.5(%) = 87.7 |
| Yan et al. [71] | YOLOv5, CA, ASFF Swin transformer | Multi-scene fire detection | 2059 flame images | mAP@0.5 (%) = 66.8 mAP@[0.5:0.95] (%) = 33.8 |
| Huo et al. [72] | YOLOv4, SPP, Depthwise-separable convolution | Multi-scene fire detection | 9270 images, including smoke and non-smoke | AR (%) = 97.8 FAR (%) = 1.7 F-m (%) = 97.9 |
| Wu et al. [73] | YOLO, background subtraction | Multi-scene fire detection | 5075 flame images | mAP@0.5 (%) = 60.4 |
| Venâncio et al. [74] | YOLOv5, TPT, AVT | Multi-scene fire detection | D-Fire Dataset | mAP@0.5 (%) = 79.10 ± 0.36 (%) = 85.88 ± 0.35 (%) = 72.32 ± 0.52 |
| Huo et al. [79] | YOLO layer, 3D convolutional, SPP | Multi-scene fire detection | 14,700 images, including smoke and non-smoke | AR (%) = 99.54 FAR (%) = 1.11 FNR (%) = 0.14 |
| Li et al. [81] | DETR, NAM | Multi-scene fire detection | 26,060 images including fire, smoke and two-object with both smoke and fire | (%) = 76.0 (%) = 81.7 |
| Yang et al. [83] | MobileViT, SPP, BiFPN, YOLO Head | Multi-scene fire detection | 3717 images of the early stages of the fire | mAP@0.5(%) = 80.71 |
| Method | Technique | Application Scenario | Dataset | Evaluate |
|---|---|---|---|---|
| Khan et al. [92] | EfficientNet, DeepLabv3+ | Smoke detection in fog scenes | Fog smoke dataset for 252 images | mAR (%) = 93.33 mIoU (%) = 77.86 F-m (%) = 50.76 |
| Yuan et al. [93] | Xception, GRU, CCL, PPM | Smoke detection in complex scenes | Synthetic smoke image dataset and a real smoke image dataset | mIoU (%) = 82.18 mMSE = 0.2212 |
| Shahid et al. [94] | 3D convolution, UNet++, self-attention | Fire detection in surveillance video scenes | 1033 videos of which 559 contain fire and 434 contain normal scenes | F-m (%) = 84.80 |
| Yuan et al. [95] | Cubic-cross-convolution, PPM, CPA | Multi-scene smoke detection | A synthetic smoke dataset consisting of 70,632 images | mIoU (%) = 76.01 |
| Li et al. [96] | BiSeNet, PPM, ECA | Multi-scene smoke detection | 8280 actual scenes of smoke images | AR (%) = 98.0 mIoU (%) = 80.9 |
| Song et al. [98] | FusionNet, depthwise-separable convolution | Multi-scene fire detection | Corsican Fire Database | mIoU (%) = 90.76 |
| Yuan et al. [99] | CSSAM, CA, SE | Multi-scene smoke detection | A synthetic smoke dataset consisting of 70,632 images | mIoU (%) = 74.2 |
| Barmpoutis et al. [91] | DeepLab V3+, post-validation adaptive | Forest fire smoke detection | Fire detection 360-degree dataset | mIoU (%) = 77.1 F-m (%) = 94.6 |
| Guan et al. [101] | MS R-CNN, UNet, FPN | Forest fire smoke detection | FLAME | mIoU (%) = 82.31 F-m (%) = 90.30 |
| Perrolas et al. [102] | SqueezeNet, Deeplabv3+, Quadtree search, | Forest fire smoke detection | Corsican Fire Database | F-m (%) = 90.30 mIoU-fire (%) = 88.51 |
| Ghali et al. [103] | EfficientSeg, Transformer | Forest fire smoke detection | FLAME | F-m (%) = 99.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, C.; Wang, T.; Alhusaini, N.; Zhao, S.; Liu, H.; Xu, K.; Zhang, J. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire 2023, 6, 315. https://doi.org/10.3390/fire6080315
Jin C, Wang T, Alhusaini N, Zhao S, Liu H, Xu K, Zhang J. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire. 2023; 6(8):315. https://doi.org/10.3390/fire6080315
Chicago/Turabian StyleJin, Chengtuo, Tao Wang, Naji Alhusaini, Shenghui Zhao, Huilin Liu, Kun Xu, and Jin Zhang. 2023. "Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions" Fire 6, no. 8: 315. https://doi.org/10.3390/fire6080315
APA StyleJin, C., Wang, T., Alhusaini, N., Zhao, S., Liu, H., Xu, K., & Zhang, J. (2023). Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire, 6(8), 315. https://doi.org/10.3390/fire6080315