1. Introduction
Statistics show an unprecedented increase in the size, intensity, and effects of wildfire events relative to historical records [
1,
2]. In 2018, the deadliest fire in California history, the Camp Fire, resulted in 85 casualties and destroyed nearly 14,000 homes and more than 500 commercial structures [
2]. Exacerbated by climate change, extreme wildfires are projected by the United Nations Environment Program to further increase globally on the order of 30% by 2050 and 50% by the end of the century [
3]. Wildfires are continuing to grow into a substantial threat to the well-being of communities and infrastructure despite technological and theoretical advancements in fire science. The unprecedented size and complexity of this problem call for multi-disciplinary and data-informed research on wildfire risk management (assessment, mitigation, and response).
Efficient wildfire risk management relies on accurate wildfire spread simulations. Such simulations can substantially improve the effectiveness of pre-event mitigation, as well as evacuation, rescue, and fire suppression efforts [
4,
5]. A key input to wildfire simulations is robust estimates of fuels that carry wildfires. Fuels are mainly categorized into the three layers of ground (litter, duff, and coarse woody debris), surface (grass, forb, shrubs, large logs), and canopy fuels (trees and snags) [
6]. Although surface fuels are the primary drivers of the initiation and spread of forest fires, research in this area has matured slowly with the Anderson 13-category standard fire models [
7], which served as the primary input for point-based and spread simulations until the inclusion of the 40 Scott and Burgan standard fire behavior models introduced in 2005 [
8]. Surface fuel characterization methods were developed as generalizations, which did not capture the full range of temporal variability and spatial non-conformity that are inherent in surface fuel beds [
6]. Therefore, input data into modern fire behavior models bear uncertainties in describing the dynamic processes that are missed in traditional fuel inventories [
9]. A review of the state of the art in surface fuel mapping research indicates that most of the past research efforts were focused on site-specific semi-manual expert systems or traditional machine learning methods (e.g., decision trees and random forests) at regional scales. These systems have limited capability in leveraging big data analytics, which can be exploited to learn from spatial and spectral continuities and provide consistency of vegetation and fuels across a given landscape. As a result, such systems are difficult to generalize to large problem domains.
At the national scale, the LANDFIRE program has created comprehensive and consistent geospatial fuel products that incorporate remote sensing with machine learning, expert-driven rulesets, and quality control [
10]. Although these products have created a valuable foundation for fire spread simulation efforts based on years of collective experience and domain expertise, large-scale modeling techniques are needed that deliver near-real-time on-demand fuel mapping based on georeferenced fuel data and do not rely on experience-driven expert rulesets and localized vegetation models [
11]. Such models could improve the frequency and reduce the latency of fuel data, which are currently at a multi-year level. Furthermore, new techniques could allow for a comprehensive and systematic accuracy assessment using independent validation datasets, which are currently unavailable for LANDFIRE fuel maps.
To build on the success of the LANDFIRE products as a baseline and improve their capabilities, this paper describes a deep-learning-based framework that ingests multimodal—i.e., hyperspectral satellite, high-resolution aerial image, and biophysical climate and terrain—data. This framework relies on a deep network of layers of learnable weights that are trained using large amounts of georeferenced labeled data that guide the formation of the data extraction pipeline.
Background. Most past efforts to map surface fuels for wildfire spread simulations utilize
fire behavior fuel models, which are abstract categorizations of fuels that are used as input in fire spread simulations. The most widely adopted model in the United States was developed by Scott and Burgan, which has 40 fuel categories [
8]. Most of the past work on fuel identification and mapping focused on classifying the pixels of a georeferenced map into one of the fire behavior fuel model categories. A review of the fuel identification and mapping literature shows a variety of approaches leveraging remote sensing and biophysical data.
Table 1 summarizes the major studies on surface fuel identification and mapping. We note here that our paper focuses only on surface fuels. Therefore, the term fuel will be used hereafter to refer to
surface fuels only.
The studies listed in
Table 1 mostly use spectral signatures from satellite or airborne imagers, lidar data, biophysical data, or a combination thereof to identify and map fuels. In most cases, the area of interest is less than a few hundred square kilometers, and the labeled training data comprise only small numbers of points. This means that the resulting fuel identification models are localized and site-specific. The closest work to large-scale fuel identification is that of Pickel et al. [
12], wherein the utility of an Artificial Neural Network model for fuel mapping was explored. They used a three-layer neural network to estimate 9 fuel types based on the Canadian Fire Behavior Prediction System for a 200 × 200 km
2 area in British Columbia, using a vector of 24 spectral, terrain, and climate inputs. For the target fuel labels, their work used a sample of pixels from the Canadian fuel product. The results of the study demonstrated that an overall accuracy of 60–70% could be achieved after regrouping the less-frequent fuel types.
The review of the literature in
Table 1 also shows that, while different sources of imagery have been used to extract multispectral information at the points of interest, high-resolution images have not been used yet as an independent input to identify fuels. In the cases where high-resolution aerial or satellite optical images (e.g., NAIP and Quickbird imagery) have been used ([
18,
23,
27]), only RGB pixel values were collected as scalar inputs similar to other spectral or biophysical features. In Mutlu et al. [
20]—while bands of 2.5-m resolution Quickbird images were used to create composite images with lidar-generated bands of height bins, variance, and canopy cover—per-pixel classification using decision rules essentially resulted in the treatment of pixels in isolation, rather than within the landscape context. Therefore, an investigation of the application of high-resolution images as distinct inputs for fuel identification is lacking and would be useful.
The literature review also reveals that none of the previous approaches provide a measure of fuel identification uncertainty. Such uncertainty is well-recognized to exist within any identification task and can be a result of a variety of sources, including randomness in the data, models, and sensors, as well as environmental noise. Knowledge of the uncertainty in the identified fuels is important as it provides a means to account for wildfire simulation uncertainties, which can be helpful in risk assessment and uncertainty-aware decision-making [
28]. Furthermore, knowledge of the confidence with which fuels are predicted can be a useful tool for model diagnostics and quality control. In other words, increased uncertainty in the identification can point to underlying problems in the data and, thus, to methods that can be used to improve their accuracy. Specifically, the active learning framework in machine learning aims to improve model performance while reducing the costs associated with large-scale data labeling by actively querying ground truth labels for data points with the highest uncertainty. Providing fuel identification uncertainties would enable the use of active learning to improve fuel identification efforts in the future.
Research Significance. To overcome the current limitations in fuel mapping using remote sensing, this paper leverages emerging deep learning technology to examine the feasibility of creating surface fuel maps at a much larger scale than the existing fuel mapping capabilities, while quantifying fuel map uncertainty. To that end, we use a data fusion scheme to integrate spectral and biophysical features with high-resolution imagery and identify surface fuels using a single end-to-end model for the State of California. To train the model, fuel pseudo-labels are generated using a geospatial sampling of the LANDFIRE fuel maps. This information is then coupled with multimodal input data sourced from various data repositories and geospatial data products, including multispectral satellite data (bands of Landsat surface reflectance), spectral indices (e.g., Normalized Difference Vegetation Index (NDVI)), topography and terrain data (from the U.S. Geological Survey (USGS) Digital Elevation Model), and high-resolution aerial imagery from the NAIP. The proposed approach presents the following technical contributions and benefits with respect to the existing literature:
Creating fuel identification models that are applicable at large spatial scales (e.g., state and national levels) while integrating spectral and biophysical information with high-resolution imagery and providing a measure of model uncertainty;
Creating a method for anomaly detection in the existing surface fuel mapping systems (specifically the LANDFIRE products) by comparing the predicted fuels with the existing fuel labels and using the discrepancies as a starting point for quality control;
Providing a means to interpolate fuels for the intermediate years when fuel maps are not available within the LANDFIRE database.
A detailed analysis of the effect of the individual components of the model, the proposed stochastic ensemble approach, and the size of the dataset utilized for model training is presented in the discussions. It should be noted that the use of pseudo-labels sampled from the LANDFIRE products is to demonstrate the proof-of-concept and examine the feasibility of developing large-scale fuel identification models. However, the proposed framework is readily applicable to large collections of field data from national data collection campaigns, such as the Forest Inventory and Analysis (FIA) program of the United States Forest Service, which is not publicly available at this time [
29].
2. Materials and Methods
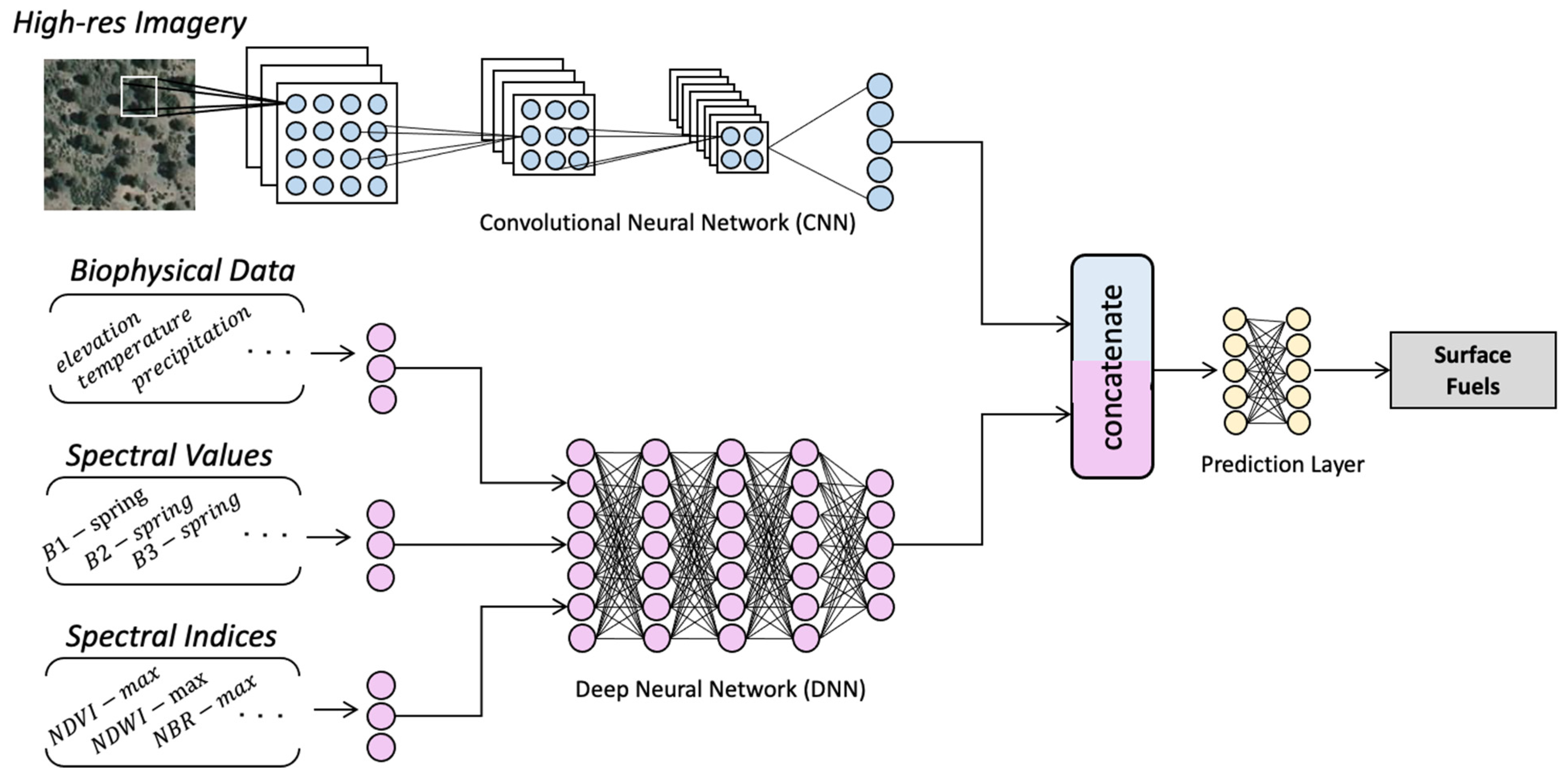
Proposed System. This paper investigates the use of deep learning for large-scale surface fuel mapping.
Figure 1 provides a schematic of the proposed identification model where two types of neural networks are used to extract information from different modalities of input data in a way that facilitates their fusion and end-to-end training on labeled data. For tabular data—such as biophysical metadata (e.g., terrain and climate features), seasonal spectral values (e.g., bands of Landsat multispectral imagery), and statistics of spectral indices (e.g., NDVI), a multi-layer artificial neural network (ANN) consisting of multiple fully connected neural layers is used. For image-based contextual data (i.e., high-resolution imagery), a convolutional neural network (CNN) is used, which leverages a deep hierarchy of stacked convolutional filters that constitute layers of increasingly meaningful visual representations. The number, arrangement, and characteristics of these layers can be designed for each specific task. Alternatively, a variety of state-of-the-art CNN architectures exist that can be utilized as backbones and outfitted with custom dense output layers. Examples of these architectures include VGGNet [
30], ResNet [
31], DenseNet [
32], Inception [
33], and InceptionResNet [
34]. These architectures have been used in several remote sensing applications with different degrees of success [
35], and the selection of the optimal architecture is known to be dependent on the characteristics of the specific task at hand. In this work, an array of architectures is trained and compared with each other to maximize fuel identification performance. To speed up and improve the learning process, a learning mode called transfer learning can be used, wherein the extracted features in state-of-the-art CNN architectures that have been pre-trained on generic large-scale computer vision datasets are repurposed and fine-tuned to the existing task. This is built upon the widely known observation that the intermediate visual features extracted in visual recognition tasks are not entirely task-specific, except for the final classification layer [
36,
37]. Even in cases with a large distance between the source and target tasks, transferring features from networks pre-trained on large datasets is better than random initialization [
36]. This has been shown to be applicable to various remote sensing problems involving RGB imagery [
38,
39,
40]. In remote sensing applications involving spatial data other than RGB imagery (e.g., multi/hyper-spectral data, lidar, and radar images), the number and nature of input bands are usually not consistent with such pre-trained networks. However, in the proposed approach, the application of the CNN backbone on high-resolution RGB imagery allows for the use of transfer learning. As a result, the weights of the CNN backbone are initialized from those pre-trained on the generic computer vision ImageNet dataset [
41], which are then fine-tuned using the high-resolution fuel imagery herein.
At the conclusion of each neural network branch, the computed features are concatenated before the final prediction layer to fuse the multimodal data. The optimal share of the branches in the data fusion will be determined through training in terms of the weights of the prediction layers. This end-to-end architecture is shown in
Figure 1, which is built upon the established notion that different modalities of sensing the same subject usually provide complementary information, enabling deep learning methods to produce more reliable predictions. Details on the network and data fusion design are presented in a later section.
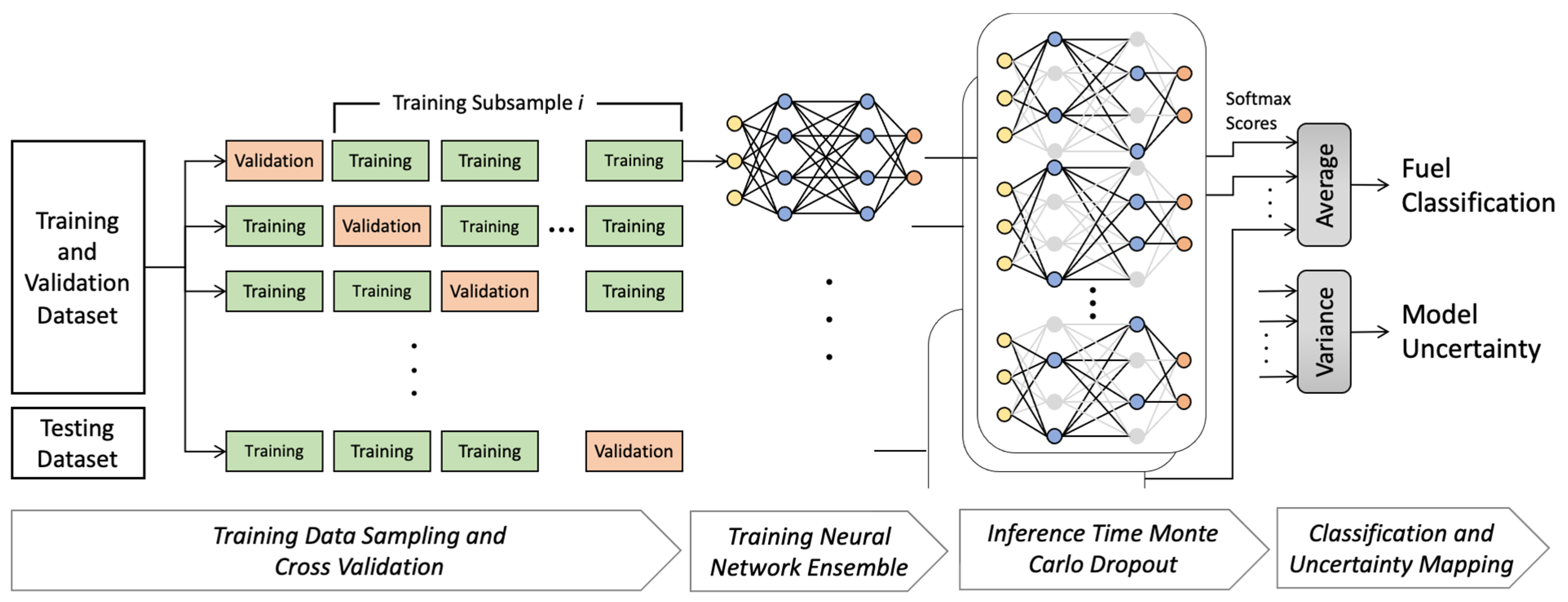
Training the same machine learning model on different sets of observations from the same population has been shown to result in a degree of variance in the resulting models [
42]. Furthermore, aside from the CNN backbone that is initialized from pre-trained weights according to transfer learning, all other neural network layers are randomly initialized, resulting in slightly different models, some of which may not provide optimal fuel identification results. To improve the accuracy and robustness of the model in response to variations in observation subsets and training randomness, and to provide a measure of model uncertainty, a stochastic ensemble of models was created, which is depicted in
Figure 2.
In the proposed model, the dataset is first randomly split into multiple subsets for training and validation, following the widely used
k-fold cross-validation scheme. A separate randomly initialized model is trained on each of the training subsamples to capture the variance from the randomness in the observations. Subsequently, each of these
k models is further randomized in inference mode using a process called Monte Carlo dropout [
43]. Dropout refers to a regularization technique in neural networks that was originally proposed to combat overfitting by applying a binary mask drawn from a Bernoulli distribution, which has the effect of randomly dropping some of the nodes in the network during training [
44]. This, in turn, is known to prevent complex co-adaptation between nodes and can result in improved robustness of trained models [
44].
Monte Carlo dropout [
43] has been proposed as a mechanism specific to neural networks that aims to quantify machine learning model uncertainties and improve their robustness. In this process, dropout layers embedded before every dense layer in the network are activated at testing time, and the model is applied
m times on each observation resulting in
m different neural network models where a fraction of the nodes are deactivated at random, hence creating a stochastic ensemble of many slightly perturbed models. Gal and Ghahramani [
43] demonstrated that using the mentioned dropout scheme at the testing time provides an approximation of Bayesian inference over the neural network weights that is computationally efficient. This technique has been successfully utilized to derive model uncertainty in visual scene understanding [
45], medical imaging [
46], robotics, and autonomous driving [
47]. However, aside from a few recent applications in road segmentation from synthetic aperture radar [
48], ocean hydrographic profiles [
49], lunar crater detection [
50], and urban image segmentation [
51], its applications in remote sensing and especially in wildfires have been limited.
To account for the variations from observation subsets and training randomness by means of the stochastic model ensemble proposed in this work, an overall array of
softmax scores are created for each data point. Lastly, the average of the softmax scores is used to arrive at the final fuel identification, and the variance of the probability scores provides a measure of model uncertainty.
Figure 2 depicts this process and its components schematically. In this figure, the arrows at the conclusion of the process denote the softmax scores from each one of the individual models acting on each pixel’s inputs, whose average and variance determine the fuel type classification and its uncertainty, respectively.
Area of Study. To investigate the feasibility of creating a large-scale fuel identification model using deep learning, the state of California was selected as the area of study for data extraction and model training. To train the system, fuel labels were generated by a random geospatial sampling of the 2016 LANDFIRE Scott and Burgan 40 fuel model. An initial sample of 40,000 points was generated to provide a large training and validation dataset to test the feasibility of training large-scale deep learning models. However, smaller subsets of data were also later created to study the effects of the number of training samples on the performance of the model. This dataset is then divided into training and validation subsets for cross-validation as previously described.
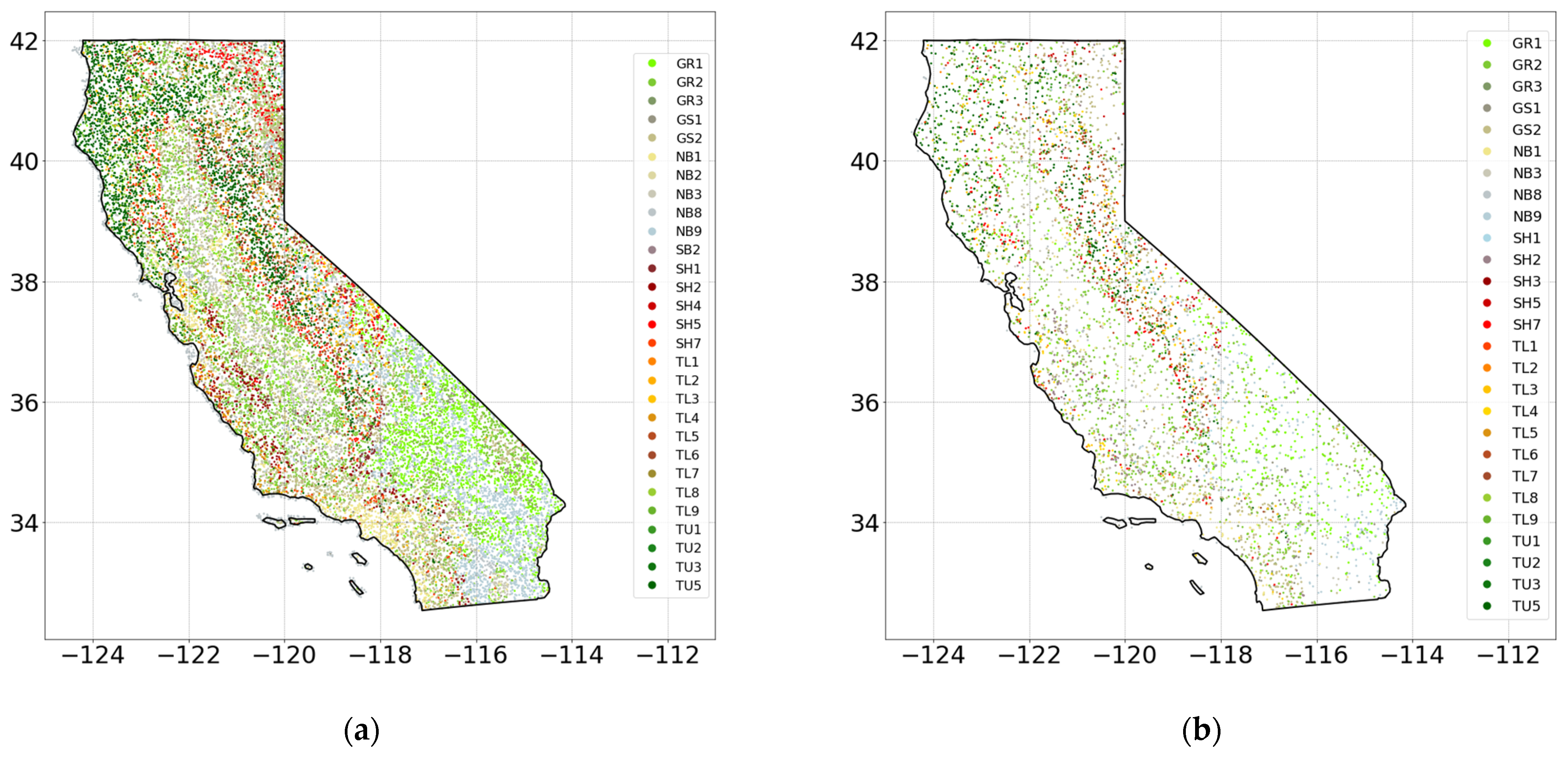
Figure 3a depicts the spatial distribution of the collected training samples. To create a means for evaluating the developed models, a random test set was also independently generated. To avoid the proximity and correlation of training and testing samples that could affect the generalizability of the testing results, a minimum distance of 1 mile was enforced between the training and testing samples. This eliminates the possibility of very similar points ending up in both the training and testing sets, which can lead to overly optimistic results. An initial sample of 5000 points was selected for testing (
Figure 3b). Fuel type labels in
Figure 3 are based on the Scott and Burgan fuel models [
8], as presented in
Table 2.
Data Extraction. For each data point in the extracted sample, an array of input features was extracted.
Table 3 summarizes the input features used in the modeling, which was informed by the fuel mapping literature reviewed in the background section. Multispectral data are the most widely used data for wildfire fuel modeling, with the Landsat mission being one of the primary sources of open data for these applications [
52]. The atmospherically corrected and orthorectified Landsat-8 Operational Land Imager and Thermal Infrared Sensor (OLI/TIRS) surface reflectance data were used at 30-m resolution. A seasonal composite of Landsat OLI/TIRS data was computed for each sample location using the medoid compositing criterion [
53]. This criterion minimizes the sum of Euclidean distances in the multispectral space to all other observations over the time period of interest (i.e., seasons). This method selects seasonal representative values while preserving the relationships between the bands and has been shown to produce radiometrically consistent composites [
54]. The quality assessment (QA) band codes were utilized to mask pixels contaminated with cloud and cloud shadow.
In addition to the seasonal spectral values, annual statistics of well-established spectral indices were also computed using the Landsat data as shown in
Table 4. The annual median, minimum, maximum, and range of each of the spectral indices were computed for each point at 30-m resolution. Biophysical characteristics of each point of interest, including terrain properties and climate normal, were also extracted. Elevation data were collected from the 1/3 arc-second National Elevation Dataset (NED) by the USGS [
55], from which slope and aspect were calculated and added to the input data. In addition, NED-derived multi-scale topographic position index (mTPI) calculated as the elevation difference from the mean elevation within multiple neighborhoods was retrieved as a differentiator of ridge and valley landforms [
58]. Climate normal values, including temperature, precipitation, dew point, vapor pressure deficit, and horizontal, sloped, and clear sky solar radiation, were extracted from the Parameter-Elevation Regressions on Independent Slopes Model (PRISM) dataset from Oregon State University [
56].
Aerial imagery from the NAIP [
57] was used. This program of the US Department of Agriculture’s Farm Service Agency has collected high-resolution aerial imagery during the agricultural growing seasons for the conterminous United States nearly every two years since 2002 [
57]. A 1-m resolution color image centered at each sample location (120 × 120-m) was collected for 2016 representing the most recent release of LANDFIRE’s comprehensive fuel remap. In cases where an image was not found for 2016, the closest image within a one-year window was retrieved.
Figure 4 depicts sample NAIP images for fuel types under investigation in this study. Of note,
Figure 4 shows that some of the fuel types can be difficult to differentiate even for the human eye due to their close visual similarity at the scale under study (e.g., GR1, GR2, and GS1). This depicts the difficulty of the classification task and can foreshadow potential areas of misclassification even by powerful machine learning algorithms. The definitions of the fuel type labels in
Figure 4 are based on the Scott and Burgan fuel models [
8], and their characteristic differences are presented in
Table 2.
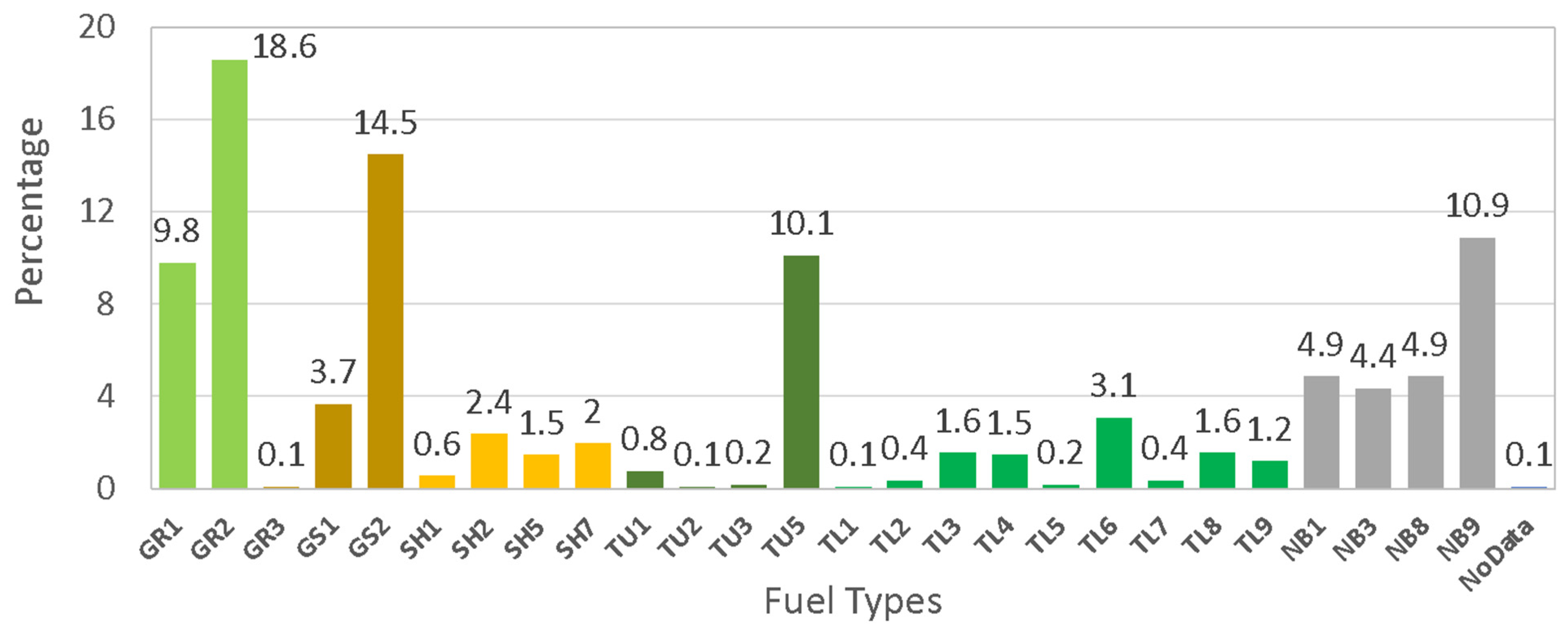
To train the model, ground truth labels describing the fuels found at each location are required. However, large-scale datasets obtained by field surveys that could be used for this purpose are not publicly available (e.g., the Forest Inventory and Analysis (FIA) Database by the United States Forest Service) and fuel model assignments may not be available as part of data collection. To demonstrate the proof of concept and feasibility of training such models, pseudo-labels using an existing fuel map were used in this work. To this end, pseudo-labels for the points of interest were retrieved by randomly sampling fuel pixels from the 2016 LANDFIRE map of standard surface fire behavior fuel models based on Scott and Burgan fuel models. As a result of the random sampling, the distribution of the extracted labels is a function of the frequency of different fuel types across California.
Figure 5 depicts a histogram of fuel types for the pixels within the 2016 LANDFIRE fuel map and shows that several fuel types are not widely represented in the fuel map within the area of study. This is important because fuel types with a small frequency of occurrence are known to be difficult for models to learn as a result of the lack of representative data and the resulting imbalance between the classes. On the other hand, mis-predicting a very small number of isolated pixels has a less pronounced effect on the overall fire spread than making errors in the prediction of large areas of dominant fuel types. As a result, identifying the most common fuel types in the study area provides a more important contribution to the effectiveness of the resulting fire spread simulations. Future sensitivity analyses to quantify the effect of individual fuel types—especially rare and small categories—on fire spread modeling are needed to evaluate these effects. To investigate the effects of class size on the fuel identification performance of the model,
Table 5 lists the fuel types larger than different minimum sizes and their cumulative coverages. For example, with a minimum class size of 4%, the model will include 8 classes that cover 78.1% of the pixels of the study area. Alternatively, by aggregating the classes of the same fuel category that are smaller than the minimum class size, models with full coverage of all pixels can be created.
Model Development and Evaluation. This section presents the details of the overall deep learning framework and its design choices previously presented in
Figure 2 and
Figure 3. Extensive testing was carried out to design the optimal architecture for the proposed model via cross-validation. Pretrained CNN architectures—including VGGNet [
30], ResNet [
31], DenseNet [
32], Inception [
33], and InceptionResNet [
34]—were tested as the backbone to extract the visual features from the NAIP imagery, and the best accuracy results were achieved using the InceptionResNet_v2 backbone; hence, this architecture was used throughout the rest of the analyses. InceptionResNet_v2 is a 64-layer CNN architecture based on the Inception family of architectures that employs residual connections similar to those in the ResNet variants. The standard implementation of InceptionResNet_v2 available in the Keras library was used in this work, and further information about this architecture can be found in [
34]. Input image size was selected to be 128 × 128 pixels, where each pixel represents 1 m on the ground. Data augmentation in the form of random horizontal and vertical flipping and random rotation was applied to the images during training to increase the robustness of the training. Any transformation that could visually change the scene, such as rescaling, recoloring, or non-affine transformations, were not applied, and the original image was maintained during testing. The output of the InceptionResNet_v2 backbone was passed through an average pooling layer that reduces the last convolutional feature map by calculating the average of the feature maps. A dense layer with 128 nodes followed by a dropout layer was added to the end of the CNN branch before concatenation with the multilayer ANN outputs.
A series of DNN hidden layers and node arrangements ranging from 2 to 6 layers and 64 to 256 nodes in increments of 64 were tested to select the configuration that provides the highest accuracy on the validation sets. A substantial increase in the number of layers or nodes did not result in appreciable performance gains. The final configuration of the DNN was determined to include three dense hidden layers each with 128 nodes. Finally, the outputs of the two branches are concatenated with each other and fed to two hidden layers of 128 nodes followed by a softmax classifier (see
Figure 1). Softmax is an operator which transforms the outputs from the last layer of a neural network into class probabilities, from which the final classification is decided [
70]. Equation (1) shows the softmax operator, where
is the probability of an observation belonging to class
j, and
n_Class is equal to the number of fuel types under consideration.
A dropout layer with a dropping probability of 0.5 was used after each hidden layer throughout the network to implement the Monte Carlo dropout scheme, as shown in
Figure 2. Furthermore, a Rectified Linear Unit (ReLU) activation function in the form of
was used to provide nonlinearity in the neural network that aids the learning of complex patterns. The resulting network was then trained using the Stochastic Gradient Descent (SGD) algorithm [
70]. In this process, following every forward pass through the network, training loss is estimated via a cross-entropy loss function. This function is shown in Equation (2), where
and
represent the
i-th label and predictions, respectively, and
N denotes the size of the training set. The estimated loss in each training epoch is then used in the back-propagation process that updates the unknown parameters (i.e., weights) of the network on small subsets of training data (i.e., mini-batches). In each epoch, the gradients of loss,
L, are calculated with respect to the weights,
w, (
and a fraction (
, called learning rate) of the gradient is added to the weights from the previous step (
(Equations (3) and (4)). To improve the convergence, a term called momentum (
is added to the update. Finally, another regularization mechanism called weight decay (
is also used to discourage overfitting by imposing smaller weights [
70]. This process is iteratively repeated until convergence.
Training of the models was carried out for a maximum of 300 epochs while an early stopping criterion was applied to stop the training if validation accuracy did not improve for 30 consecutive epochs. A minibatch of 100, momentum of 0.9, weight decay of 0.0001, and learning rate of 10
−3 were used to start training, and the learning rate was reduced by 1/10 after every 15 epochs, following He et al. [
31]. Further trial-and-error with these hyperparameters did not provide appreciable accuracy improvements.
The performance of the model was evaluated using well-established classification metrics, including global accuracy, precision, recall, f-score, and Cohen’s Kappa statistic. Global accuracy (Acc) measures the ratio of total correct predictions over the entire data points. Recall (Rec) is the ratio of correct predictions of each fuel type to all predictions of that fuel type. Precision (Pre) is the ratio of correct predictions of each fuel type to all existing labels in that class. F1 score is a widely used metric that is the harmonic mean of precision and recall. Precision, recall, and F1 were computed per class, and both their macro-average (regardless of the size of each class) and their weighted average were calculated. To quantify the agreement between the fuel maps developed through the proposed method with those of LANDFIRE, Cohen’s Kappa statistic was used as a well-established agreement metric in the literature that measures the agreement between predicted and observed labels while accounting for agreement by chance.
The implementation of the deep learning procedures in this paper was carried out using the Keras neural network Application Programming Interface (API) with the TensorFlow deep learning platform as the backend. These platforms provide an array of tools compatible with the Python programming language for designing, developing, and training neural networks [
71]. Training of the models was deployed on an NVIDIA Tesla V100 GPU node with 112 GB of RAM.
3. Results
Using the proposed methodology, the models were trained for surface fuel identification.
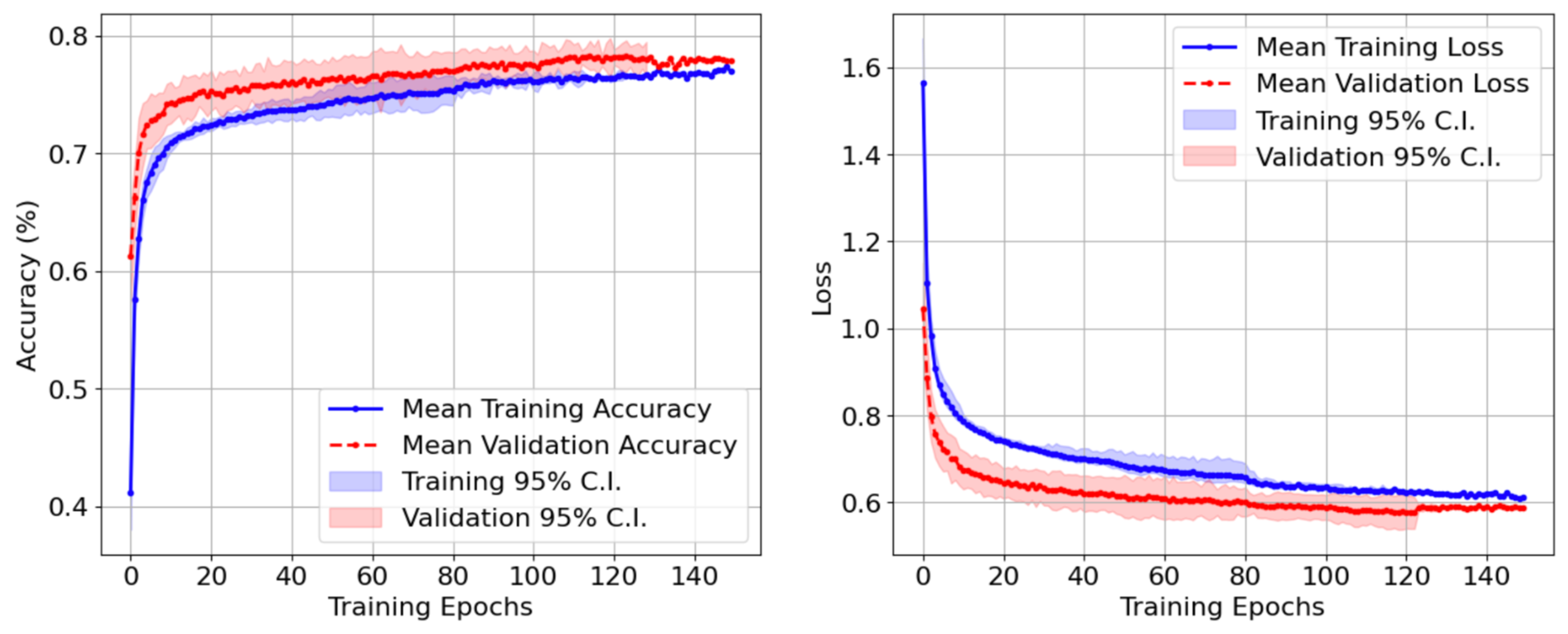
Figure 6 depicts the evolution of training and validation accuracy as well as loss during the training of the model. In this figure, solid lines show the mean of the accuracy and loss for the ensemble, and the shaded band provides the 95% confidence interval. As can be seen in this figure, the model demonstrates stable behavior with the convergence of accuracy and loss to a plateau. Furthermore, the small gap between the training and validation curves in each case demonstrates the proper training of the model with minimal effects of overfitting.
Table 6 summarizes the overall accuracy of the model trained using different minimum class sizes ranging from 1–5%. These models were first trained on original unfiltered fuel labels obtained from LANDFIRE 2016 fuel maps, as previously described. The accuracy of the model ranged from 51.74% to 69.59% based on the minimum class size without aggregating the classes smaller than the threshold. The reduction in accuracy with the inclusion of the smaller classes is to be expected, as the model will have less information to learn about the smaller classes. Furthermore, aggregating the small classes with the most similar fuels also results in an accuracy reduction on the order of 10%, which is associated with insufficient information about the small classes as well as possible discrepancies between the aggregated classes. For a closer examination of the performance of the system,
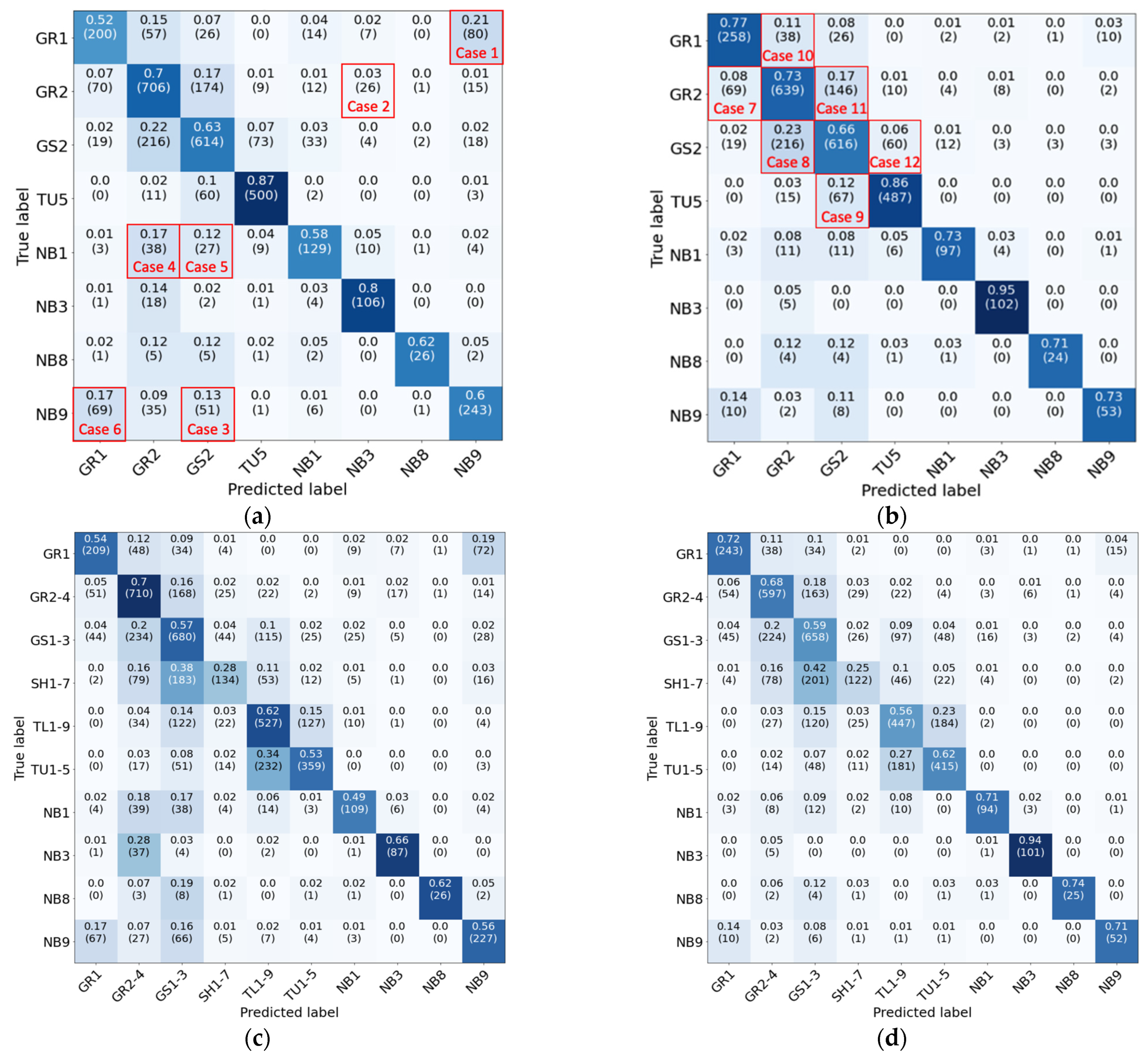
Figure 7 presents the confusion matrices for the model with a minimum class size of 4%. This case was selected for demonstration as it provides a reasonable accuracy of nearly 70% while covering nearly 80% of the fuel pixels in California.
Confusion matrices shown in
Figure 7 demonstrate a concentration of the predictions along the diagonal, which shows desirable behavior and noticeable agreement between the predicted fuel labels and the corresponding true labels. To further examine the sources of confusion, in
Figure 7a, six cases of misclassification are marked for further visual examination, as presented in
Figure 8. In
Figure 8, samples of images pertaining to each fuel type that were mistaken for a different fuel type are presented. In each case, the assumed “ground truth” labels show noticeable discrepancies with the contents of the images. For example, Case 2 includes images that are visually consistent with agricultural land cover while they have been labeled as “GR2,” and Case 5 shows mostly non-urban land cover that has been labeled as “urban.” This demonstrates that the labels suffer from a degree of impurity, which can be associated with the fact that these labels are not a direct result of field surveys by fuel experts but are instead sampled from derivative fuel maps, potentially with a level of inherent inaccuracies. Note that agricultural and urban land covers are mapped via external sources ([
72,
73]) in LANDFIRE [
74]. To demonstrate the effect of this label impurity, the models were re-trained after filtering the labels against the National Land Cover Database (NLCD) land cover map for 2016 [
73]. Because the NLCD maps do not have fuel information, any burnable fuel pixels that had a non-burnable land cover label were filtered out, and vice versa. These land cover types include developed land (open space and low- to high-intensity development), barren land (rock, clay, and sand), and cultivated crops. This resulted in the removal of 16.3% of the pixels from the training dataset. The results of this filtering are shown in
Figure 7b,d, where the severity of the off-diagonal elements has visibly decreased. This resulted in an accuracy improvement of the individual classes by more than 10% on average across all classes and a global accuracy improvement of 7.2% (from 67.11% to 74.31% in
Table 6). This demonstrates an important opportunity for the improvement of fuel maps by using the proposed method to detect the discrepancies that can highlight potential label impurities.
Figure 9 shows six of the biggest off-diagonal confusion elements highlighted in
Figure 7b after filtering the labels with the NLCD land cover maps. As can be seen, these cases are mostly concentrated adjacent to the diagonal, which implies that the model’s mistakes are mostly among the most similar fuel types. In
Figure 9, each column shows the two fuel types that have been mistaken for each other. Visual inspection of the two cases in each column shows that the differences between these classes are sometimes subtle and can be difficult to differentiate even for human annotators.
Based on the results presented in this section, the evidence suggests that the proposed model is relatively successful at identifying the surface fuel types in the test set given an assumed degree of impurity associated with the labels used for training. The level of fuel identification accuracy is dependent on the desired degree of granularity with smaller minimum class sizes, resulting in learning difficulty with less information to support the extracted patterns. Moreover, based on the confusion matrices in
Figure 7b, the non-burnable urban land cover (NB3) is the easiest to detect (class accuracy of 95.3%), which is to be expected, as this class has the most discernible features even to the untrained eye. On the other hand, the grass-shrub class (GS2) is the hardest to detect (class accuracy of 66.1%), which is associated with its close similarity to the grass fuel types.
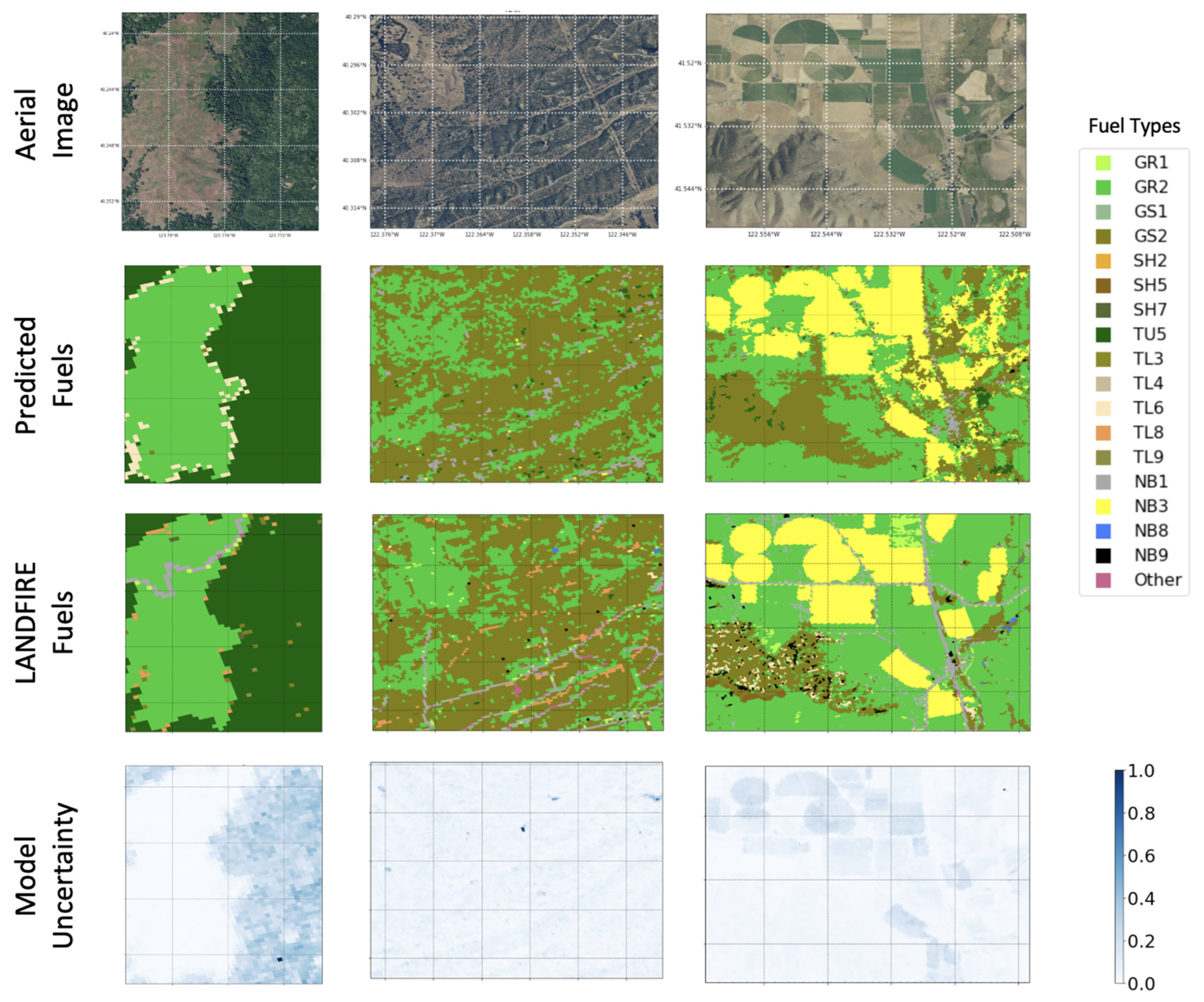
To further visualize the performance of the model outside the testing set and in mapping,
Figure 10 and
Figure 11 present samples of fuel maps generated by the proposed model together with the corresponding uncertainty maps created as previously described using the average and variance of the model probabilities. As can be seen in
Figure 10, the qualitative comparison of the predicted maps with LANDFIRE counterparts shows noticeable overall agreement, consistent with the Cohen’s Kappa values of 0.854, 0.477, and 0.475 for the three images from left to right, respectively.
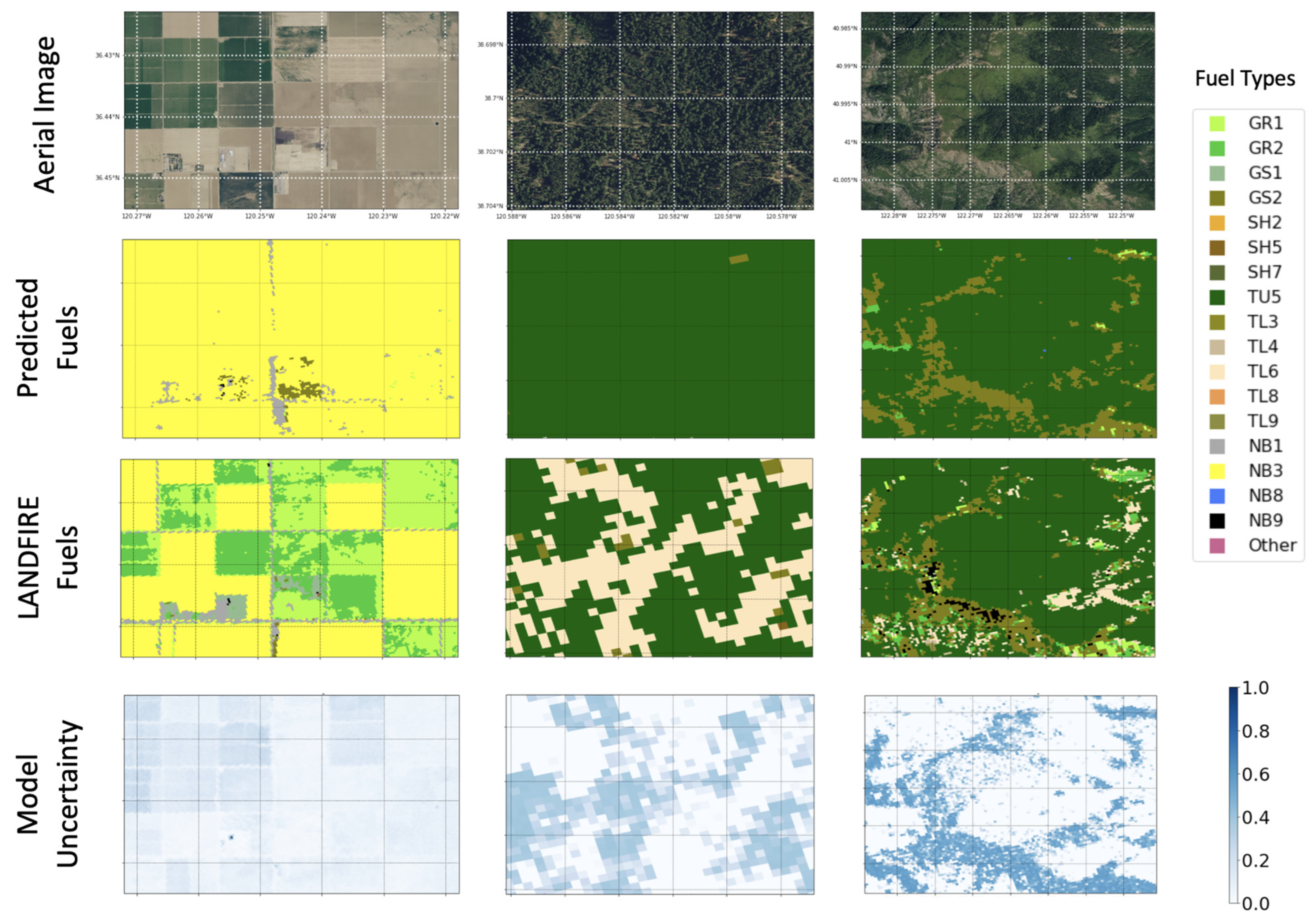
Figure 11 shows a sample of results with relatively large discrepancies between the predictions and the target labels, with Cohen’s Kappa values of 0.046, 0.016, and 0.321. Examination of the first column in this figure shows that a large portion of the GR1 and GR2 area in the target map indeed seems to be visually consistent with the predicted NB3 (agricultural). This may be pointing to a potential discrepancy in the target map (i.e., LANDFIRE) that could be used for map correction or improvement. Note that LANDFIRE uses external mapping data for agricultural lands [
72]. The second column in this figure shows that the model replaced the area covered by TL6 in the label map with TU5. In this case, the corresponding uncertainty map shows that the model has some awareness of the potentially erroneous prediction that could be accounted for in the resulting decisions. Finally, the third column shows a similar case where, despite the overall relative agreement between the maps, the predictions seem to have missed areas of NB9 (bare ground), TL6, and GR1. Similarly to the previous case, the corresponding uncertainty map may be leveraged to highlight the areas where the model has lower confidence in its predictions.
4. Discussion
Table 7 summarizes the contribution of the different components of the model by listing the per-class and overall F1 scores. As shown in
Table 7, in most cases, models made from individual components have the lowest performance, and the fusion of complementary components results in improvements with respect to individual components. Among the individual components, NAIP imagery has the highest overall performance, followed by spectral values. Although the detection of some classes (e.g., NB3, NB1) is substantially easier with imagery than spectral values, others (e.g., NB8, NB9) are easier to differentiate using spectral values. This is associated with how discernible these classes are using their spectral or visual signatures (e.g., agricultural lands may be harder to miss using their unique farm patterns than their spectral differences compared with grasslands). Furthermore, although biophysical data show weak correlations with non-vegetation classes (e.g., NB1, NB8, NB9), they provide the highest performance in the grassland classes. Of note, the addition of imagery data always results in performance improvement. This can be seen by comparing every model (single or multi-component) with its counterpart after the inclusion of imagery data. By comparing the full model with the one that includes all non-imagery data types (SV + SI + BP), all classes except NB8 (water) show accuracy improvement. This lack of improvement for NB8 can be attributed to the apparent visual similarity of some surface water image patches to simple grassland landscapes. Finally, the full model that includes the fusion of all components results in the highest detection performance, both across most individual classes and overall. This demonstrates the benefit of data fusion in improving the fuel identification performance of the system.
Table 8 compares the performance of the Monte Carlo dropout ensemble with the sub-sample ensemble (without the dropout) and the best individual model. Both ensemble models have higher performances than the best individual model, confirming that the generation of the random ensembles improves predictive performance. Monte Carlo dropout has a slightly higher performance than the sub-sample ensemble in addition to enabling the quantification of fuel identification uncertainty. In
Table 8, precision (Pre) and recall (Rec) denote the ratio of correct predictions from each fuel type to all predictions of that fuel type, and to the population of that fuel type, respectively, while the F1 score refers to the harmonic mean of precision and recall.
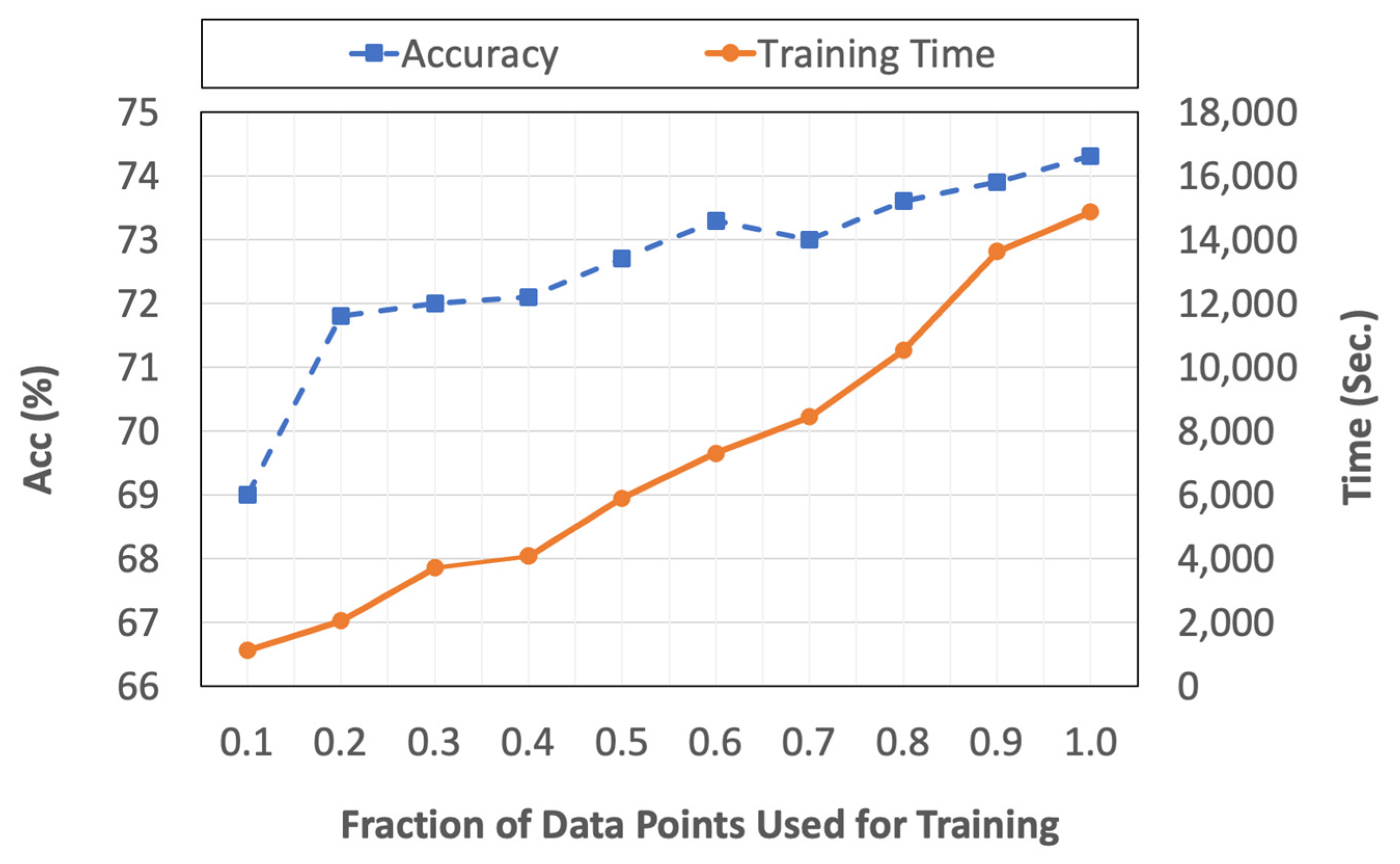
To study the effect of the size of the training set, the proposed model was trained with different fractions of the overall training set population while maintaining the relative size of the classes.
Figure 12 summarizes the accuracy of the model as well as its training time for different fractions of the training set size. Based on the figure, increasing the number of data points usually increases the accuracy, but at the cost of increased training time. For example, cutting the training set size in half results in an average of 2.2% and a maximum of 7.2% reduction in per-class accuracies while decreasing the training time from 4.13 to 1.64 h (2.5 times reduction). However, it should be noted that this is a one-time increase during training and that the size of the training set does not affect the computational complexity of the testing and model application if the same model architecture is being used with different training set populations. We also note that the reported training times are based on model deployment on an NVIDIA Tesla V100 GPU node with 112 GB of RAM. The results of this analysis demonstrate that, to create useful large-scale fuel identification models, datasets consisting of tens of thousands of fuel plots may not be required, as the model with 1/10 of the largest data size still achieves an overall accuracy within nearly 5 percent of that with 40,000 observations (
Figure 12). The proposed method can also be augmented with semi-supervised learning techniques, such as label propagation, which has been previously used in the remote sensing context to remedy the shortage of ground truth data [
75,
76].
Finally, to investigate whether the quality of the training set could be improved by avoiding sampling from isolated noisy pixels, a filter was added to the sampling such that only the points with similar fuels within their neighborhood of radius r were selected as training samples. This filter essentially ensures that only the pixels belonging to a relatively homogeneous and continuous body of similar fuel will be sampled, thus reducing the potential noise from the random sampling strategy used. Three different values of r equal to 50, 100, and 150 m were tested. Although some of the individual classes showed small improvements, the overall accuracy of the model slightly decreased with the increase in the radius. This could be attributed to the fact that increasing r resulted in a slight decrease in samples taken from smaller and naturally less prevalent fuel types, thus limiting any potential improvement from the increased sample homogeneity. More generally, enforcing homogeneity by selecting pure sample sites and filtering the minority classes can result in missed opportunities for the identification of natural discontinuities for fuel breaks and other forest management actions. However, the use of survey-based ground truth fuel labels from national data collection campaigns (e.g., FIA database), and large-scale satellite-based lidar measurements (e.g., the Global Ecosystem Dynamics Investigation -GEDI- mission) for canopy fuel modeling can address such limitations by providing high-confidence labels and can be studied in future works.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}