
Forest Fire Object Detection Analysis Based on Knowledge Distillation

Abstract
:1. Introduction
2. Background and Related Work
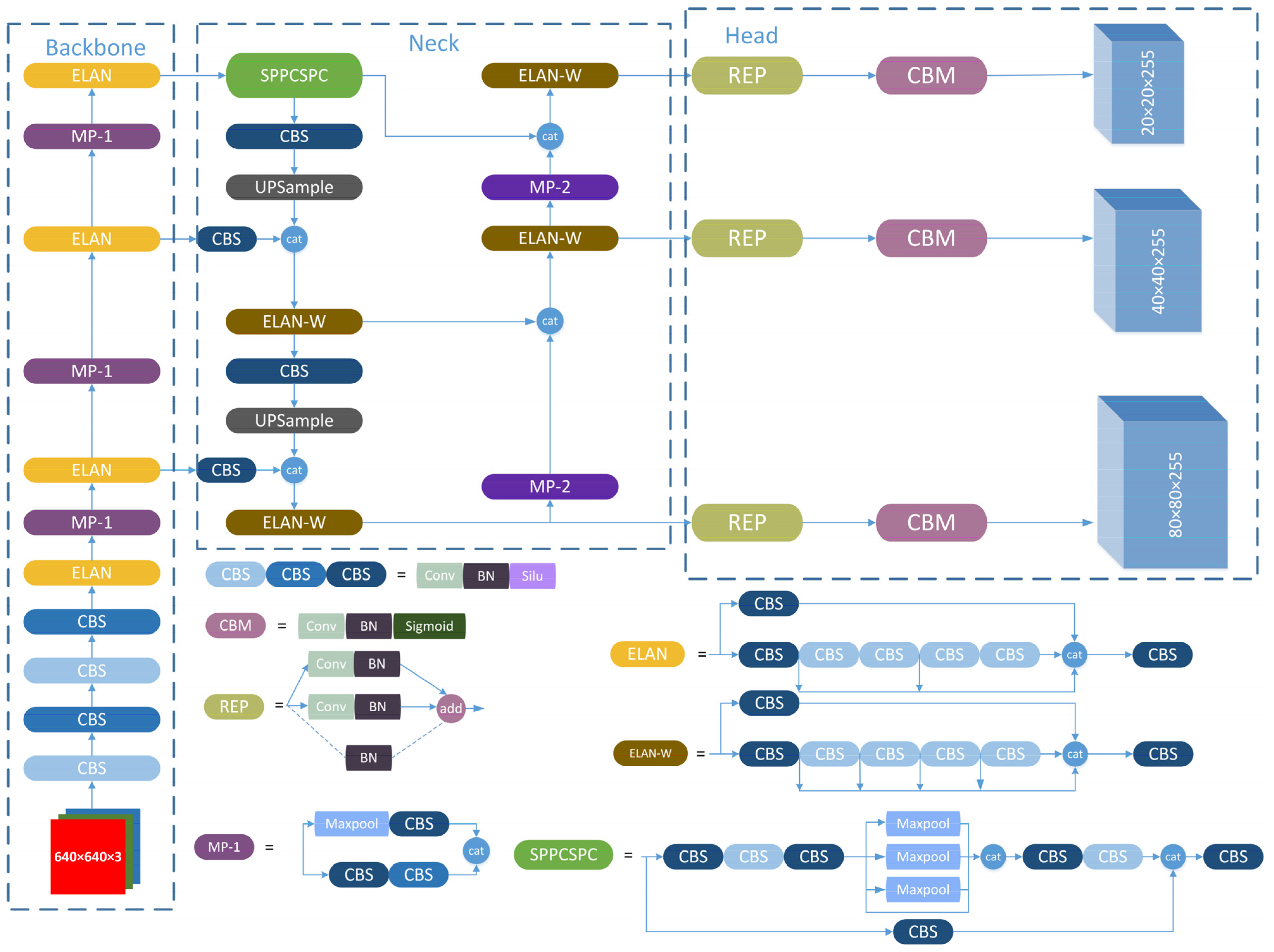
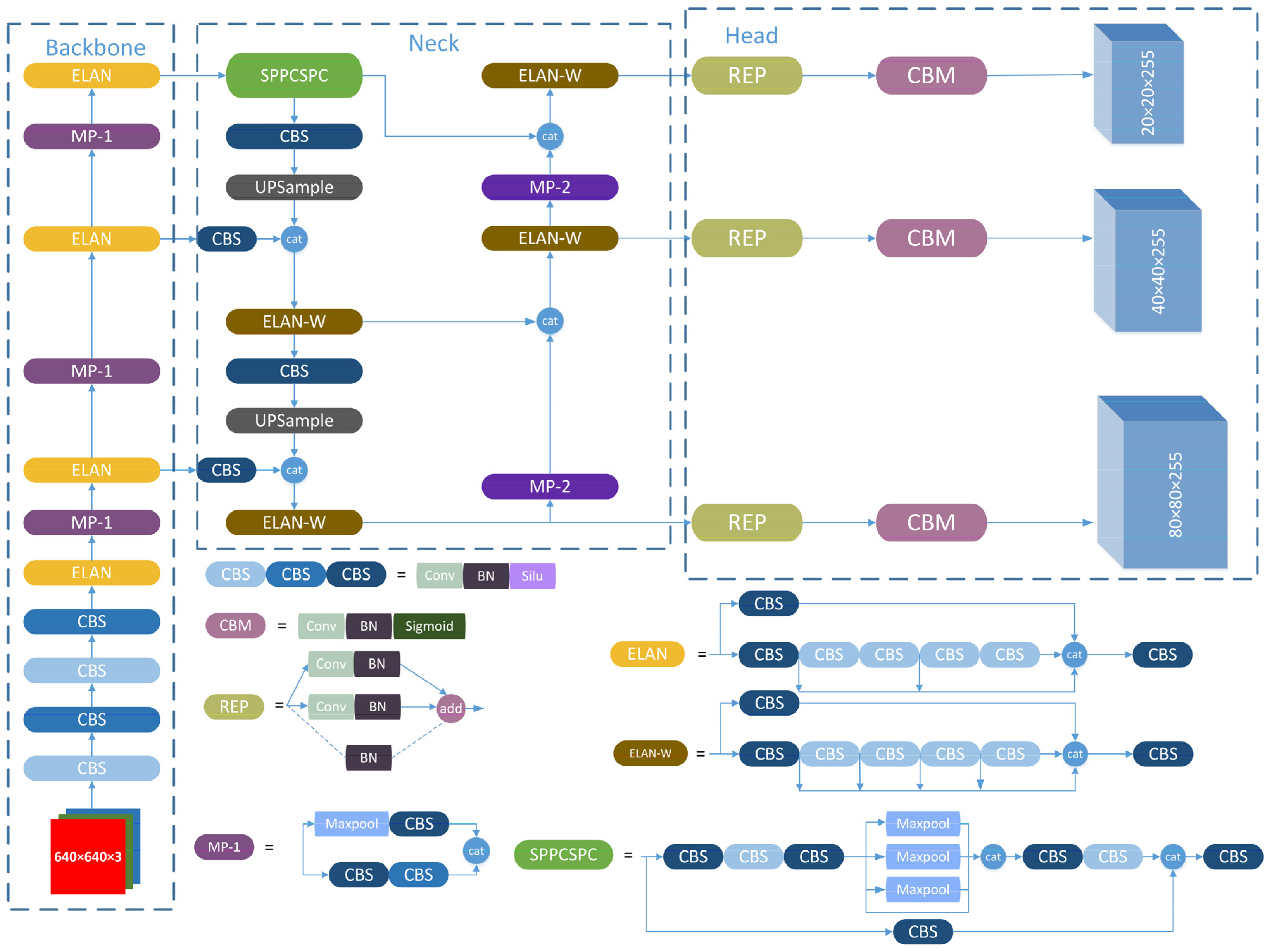
YOLOv7 Architecture
3. Materials and Methods
3.1. Knowledge Distillation
3.2. Flow of Solution Procedure (FSP) Matrix
3.3. Loss Function
4. Experiments
4.1. Dataset
4.2. Experimental Configuration and Environment
4.3. Evaluation of the Model
4.4. Comparison of Experimental Results
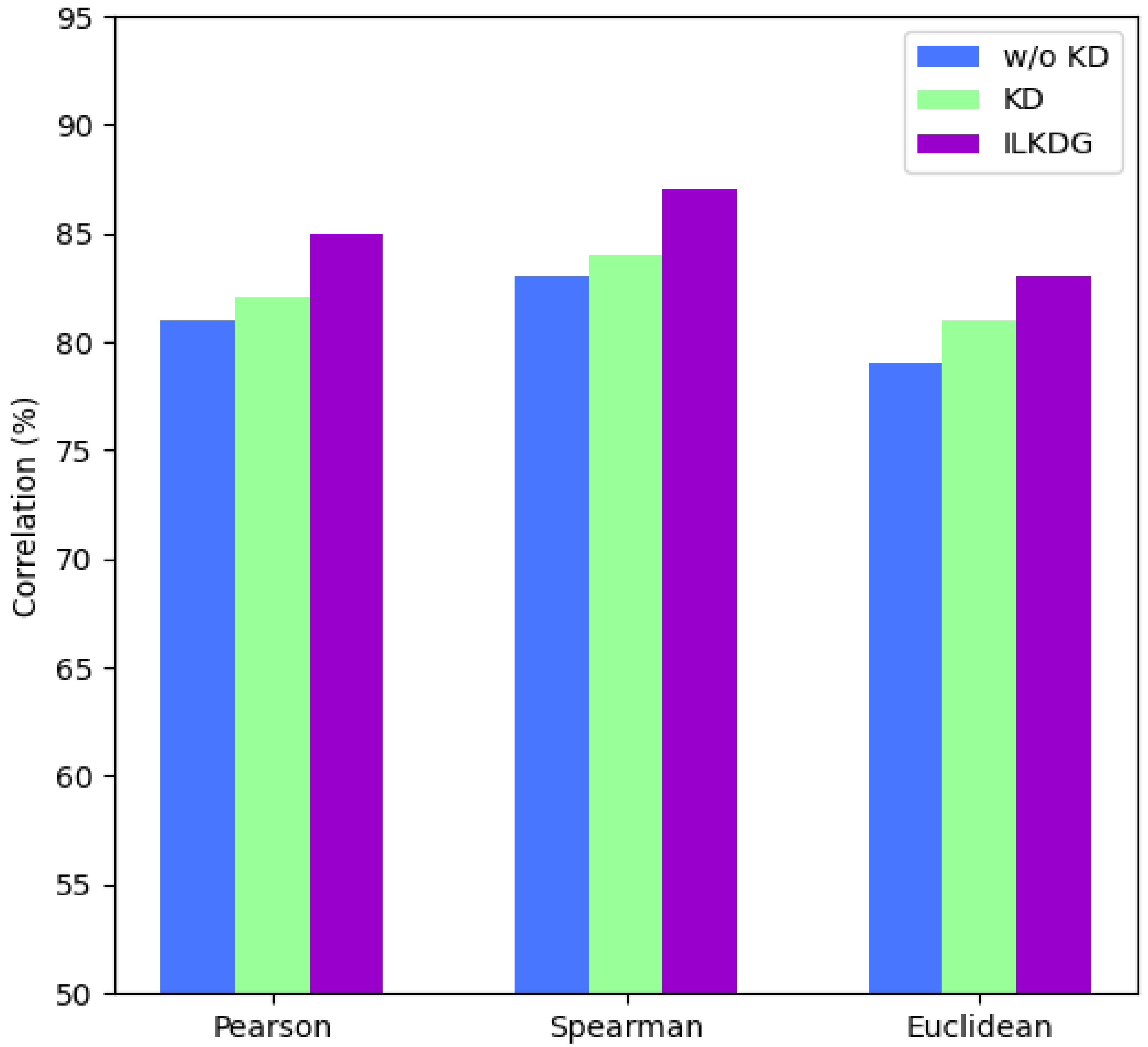
4.5. Ablation Study
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abid, F. A survey of machine learning algorithms based forest fires prediction and detection systems. Fire Technol. 2021, 57, 559–590. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N.J. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 8, 1935–1944. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Yu, L.; Wang, N.; Meng, X. Real-time forest fire detection with wireless sensor networks. In Proceedings of the 2005 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 26 September 2005; pp. 1214–1217. [Google Scholar]
- Vipin, V.A. Image processing based forest fire detection. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 87–95. [Google Scholar]
- Benzekri, W.; El Moussati, A.; Moussaoui, O.; Berrajaa, M. Early forest fire detection system using wireless sensor network and deep learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 496–503. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Islam, B.M.S.; Nasimov, R.; Mukhiddinov, M.; Whangbo, T.K. An improved forest fire detection method based on the detectron2 model and a deep learning approach. Sensors 2023, 23, 1512. [Google Scholar] [CrossRef]
- Lu, K.; Huang, J.; Li, J.; Zhou, J.; Chen, X.; Liu, Y. MTL-FFDET: A multi-task learning-based model for forest fire detection. Forests 2022, 13, 1448. [Google Scholar] [CrossRef]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W.J.S. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Wang, J.; Yu, J.; He, Z. DECA: A novel multi-scale efficient channel attention module for object detection in real-life fire images. Appl. Intell. 2022, 52, 1362–1375. [Google Scholar] [CrossRef]
- Gong, F.; Li, C.; Gong, W.; Li, X.; Yuan, X.; Ma, Y.; Song, T. A real-time fire detection method from video with multifeature fusion. Comput. Intell. Neurosci. 2019, 2019, 1939171. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Neill, J.O. An overview of neural network compression. arXiv 2020, arXiv:2006.03669. [Google Scholar]
- Sau, B.B.; Balasubramanian, V.N. Deep model compression: Distilling knowledge from noisy teachers. arXiv 2016, arXiv:1610.09650. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J.J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y.J. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Zagoruyko, S.; Komodakis, N.J. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Kim, J.; Park, S.; Kwak, N.J. Paraphrasing complex network: Network compression via factor transfer. arXiv 2018, arXiv:1802.04977. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; pp. 3779–3787. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Alkhatib, A.A. A review on forest fire detection techniques. Int. J. Distrib. Sens. Netw. 2014, 10, 597368. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M.J. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Noise Reduction in Speech Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Dufera, A.G.; Liu, T.; Xu, J.J. Regression models of Pearson correlation coefficient. Stat. Theory Relat. Fields 2023, 7, 97–106. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Soudy, M.; Afify, Y.; Badr, N. RepConv: A novel architecture for image scene classification on Intel scenes dataset. J. Intell. Comput. Inf. Sci. 2022, 22, 63–73. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K.J. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Cao, Y.; Liu, L.; Chen, X.; Man, Z.; Lin, Q.; Zeng, X.; Huang, X.J. Segmentation of lung cancer-caused metastatic lesions in bone scan images using self-defined model with deep supervision. Biomed. Signal Process. Control. 2023, 79, 104068. [Google Scholar] [CrossRef]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Hsu, Y.-C.; Hua, T.; Chang, S.; Lou, Q.; Shen, Y.; Jin, H. Language model compression with weighted low-rank factorization. arXiv 2022, arXiv:2207.00112. [Google Scholar]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks; Springer: New York, NY, USA, 2017; Volume 10, p. 51. [Google Scholar]
- Montavon, G.; Samek, W.; Müller, K.-R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Miles, R.; Mikolajczyk, K.J. A closer look at the training dynamics of knowledge distillation. arXiv 2023, arXiv:2303.11098. [Google Scholar]
- Zhao, B.; Cui, Q.; Song, R.; Qiu, Y.; Liang, J. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–18 August 2022; pp. 11953–11962. [Google Scholar]
- Chen, D.; Mei, J.-P.; Zhang, H.; Wang, C.; Feng, Y.; Chen, C. Knowledge distillation with the reused teacher classifier. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–18 August 2022; pp. 11933–11942. [Google Scholar]
- Wang, L.; Yoon, K. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Tang, R.; Chen, Y.; Yu, J.; Guo, H.; Zhang, Y. Feature generation by convolutional neural network for click-through rate prediction. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1119–1129. [Google Scholar]
- Zięba, M.; Tomczak, S.K.; Tomczak, J.M. Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction. Expert Syst. Appl. 2016, 58, 93–101. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H.; Song, Z.; Koniusz, P.; King, I. COSTA: Covariance-preserving feature augmentation for graph contrastive learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2524–2534. [Google Scholar]
- Arcos-García, Á.; Álvarez-García, J.A.; Soria-Morillo, L. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Anil, R.; Pereyra, G.; Passos, A.; Ormandi, R.; Dahl, G.E.; Hinton, G. Large scale distributed neural network training through online distillation. arXiv 2018, arXiv:1804.03235. [Google Scholar]
- Sun, R.; Tang, F.; Zhang, X.; Xiong, H.; Tian, Q.J. Distilling object detectors with task adaptive regularization. arXiv 2020, arXiv:2006.13108. [Google Scholar]
- Wang, Y.; Cheng, L.; Duan, M.; Wang, Y.; Feng, Z.; Kong, S.J. Improving Knowledge Distillation via Regularizing Feature Norm and Direction. arXiv 2023, arXiv:2305.17007. [Google Scholar]
- Dodge, Y. The Concise Encyclopedia of Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1334–1339. [Google Scholar] [CrossRef]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Chandrasegaran, K.; Tran, N.-T.; Yunqing, Z.; Cheung, N.-M. To Smooth or Not to Smooth? On Compatibility between Label Smoothing and Knowledge Distillation. 2021. Available online: https://openreview.net/forum?id=Vvmj4zGU_z3 (accessed on 15 November 2023).
- Shen, Z.; Liu, Z.; Xu, D.; Chen, Z.; Cheng, K.-T.; Savvides, M. Is label smoothing truly incompatible with knowledge distillation: An empirical study. arXiv 2021, arXiv:2104.00676. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layers | Parameters | GFLOPS | Size (MB) |
|---|---|---|---|---|
| YOLOv7 | 415 | 31189962 | 93.7 | 71.8 |
| YOLOv7x | 467 | 73147394 | 190.61 | 142.1 |
| Experimental Environment | Details |
|---|---|
| Programming language | Python 3.8 |
| Operating system | Windows 11 |
| Deep learning framework | PyTorch 1.13.0 |
| GPU | NVIDIA GeForce GTX 3090 |
| GPU acceleration tool | CUDA:11.3 |
| Optimization Method | Initial Learning Rate | Momentum | Weight Decay |
|---|---|---|---|
| Stochastic Gradient Descent (SGD) | 0.01 | 0.973 | 0.0001 |
| Model | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | Params (M) |
|---|---|---|---|---|---|
| Teacher (YOLOv7x) | 0.881 | 0.842 | 0.895 | 0.637 | 73.1 |
| Student (YOLOv7) | 0.833 | 0.819 | 0.846 | 0.604 | 31.1 |
| +KD | 0.844 | 0.824 | 0.859 | 0.618 | 31.1 |
| +FitNet | 0.847 | 0.822 | 0.860 | 0.611 | 31.1 |
| +FGD | 0.850 | 0.821 | 0.854 | 0.621 | 31.1 |
| +KD++ | 0.846 | 0.823 | 0.858 | 0.622 | 31.1 |
| +Proposed | 0.862 | 0.831 | 0.870 | 0.631 | 31.1 |
| Method | w/o LS | w/LS |
|---|---|---|
| Teacher | 0.892 | 0.895 |
| KD (τ = 6) | 0.850 | 0.852 |
| KD (τ = 1) | 0.853 | 0.859 |
| ILKDG (cosine) | 0.861 | 0.867 |
| ILKDG (Pearson) | 0.868 | 0.870 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, J.; Zhao, H. Forest Fire Object Detection Analysis Based on Knowledge Distillation. Fire 2023, 6, 446. https://doi.org/10.3390/fire6120446
Xie J, Zhao H. Forest Fire Object Detection Analysis Based on Knowledge Distillation. Fire. 2023; 6(12):446. https://doi.org/10.3390/fire6120446
Chicago/Turabian StyleXie, Jinzhou, and Hongmin Zhao. 2023. "Forest Fire Object Detection Analysis Based on Knowledge Distillation" Fire 6, no. 12: 446. https://doi.org/10.3390/fire6120446
APA StyleXie, J., & Zhao, H. (2023). Forest Fire Object Detection Analysis Based on Knowledge Distillation. Fire, 6(12), 446. https://doi.org/10.3390/fire6120446