
Region-Specific Remote-Sensing Models for Predicting Burn Severity, Basal Area Change, and Canopy Cover Change following Fire in the Southwestern United States

 ,
,
Abstract
:1. Introduction
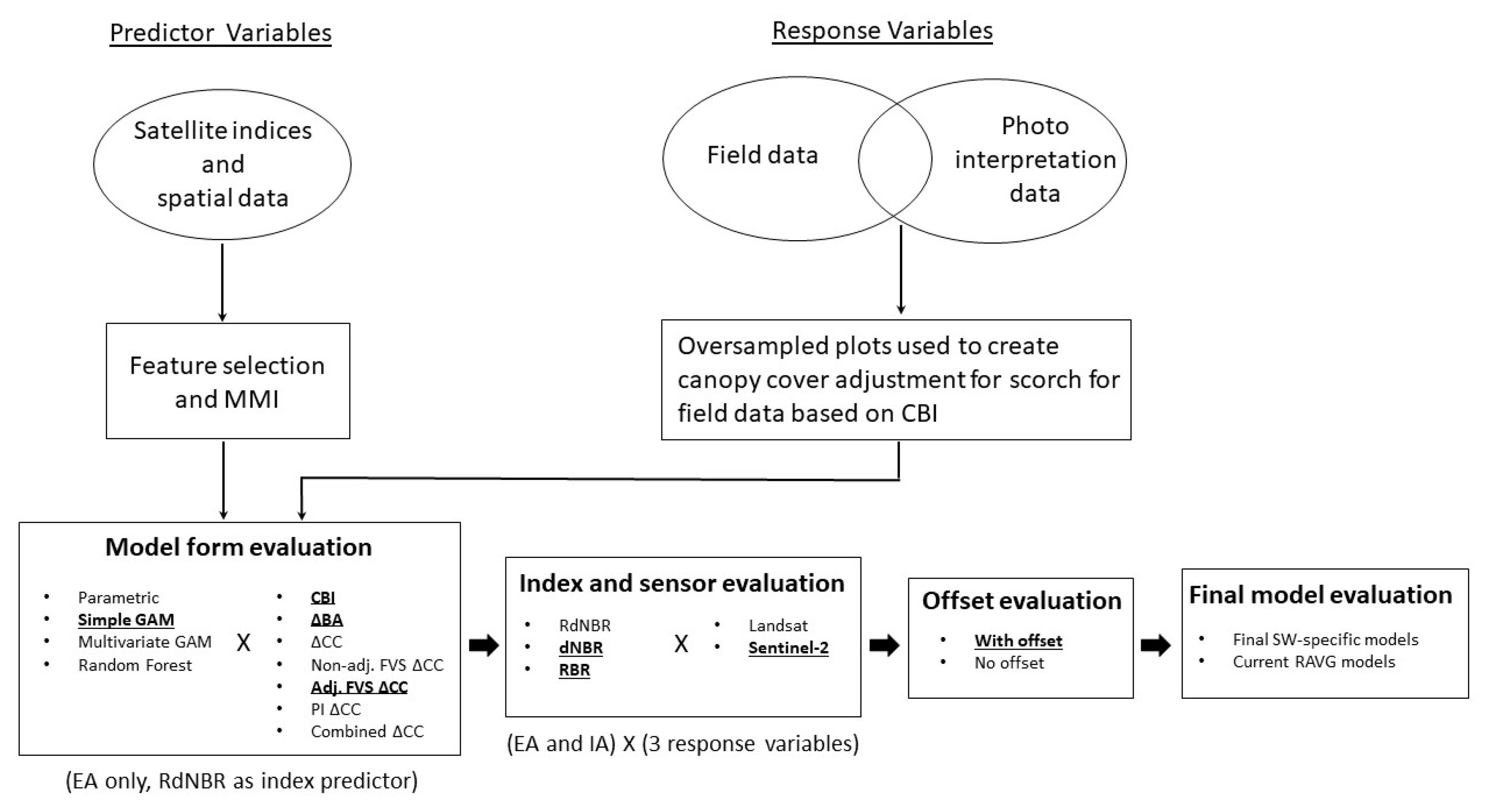
2. Methods
2.1. Site Locations
2.2. Field Sampling
2.3. Derivation of Satellite Imagery Indices
2.4. Photo-Interpretation Sampling
2.5. Accounting for Canopy Reduction due to Fire
2.6. Model Development
3. Results
3.1. Model Development Process
3.2. Final Models
4. Discussion
4.1. Efficacy of Region-Specific Models in Assessing Post-Wildfire Change
4.2. Influence of Forest Change Measurements on Error
4.3. Implications and Directions for Future Research
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Model Development Methods and Intermediate Results
Appendix A.1.1. Model Evaluation Metrics and Feature Selection
Appendix A.1.2. Non-Parametric Modelling Methods
Appendix A.1.3. Canopy Cover Estimation Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Min | 1st Quartile | Median | Mean | 3d Quartile | Max | Standard Deviation |
|---|---|---|---|---|---|---|---|
| Pre-Fire | |||||||
| FVS (Extremely Uniform) | 38.7 | 80.3 | 87.7 | 84.6 | 92.6 | 100.0 | 11.5 |
| FVS (Very Uniform) | 24.0 | 59.7 | 69.1 | 67.2 | 76.7 | 99.2 | 14.2 |
| FVS (Moderately Uniform) | 17.9 | 48.0 | 57.1 | 56.1 | 65.0 | 96.8 | 14.3 |
| FVS (Somewhat Uniform) | 13.9 | 39.1 | 47.3 | 47.0 | 54.8 | 92.6 | 13.7 |
| FVS (Random) | 12.2 | 35.0 | 42.7 | 42.6 | 49.9 | 89.5 | 13.2 |
| Photo interpretation (PI) | 22.0 | 57.0 | 70.0 | 67.6 | 79.5 | 100.0 | 18.9 |
| Post-Fire | |||||||
| FVS (Extremely Uniform) | 0 | 45.2 | 75.2 | 62.3 | 86.7 | 100.0 | 33.4 |
| FVS (Very Uniform) | 0 | 28.8 | 54.2 | 47.4 | 67.8 | 99.2 | 27.5 |
| FVS (Moderately Uniform) | 0 | 21.7 | 43.0 | 38.8 | 55.7 | 96.8 | 23.6 |
| FVS (Somewhat Uniform) | 0 | 17.0 | 34.6 | 32.0 | 46.0 | 92.6 | 20.3 |
| FVS (Random) | 0 | 14.9 | 30.9 | 28.9 | 41.5 | 89.5 | 18.7 |
| Photo interpretation (PI) | 0 | 11.0 | 35.0 | 36.3 | 59.0 | 92.0 | 27.6 |
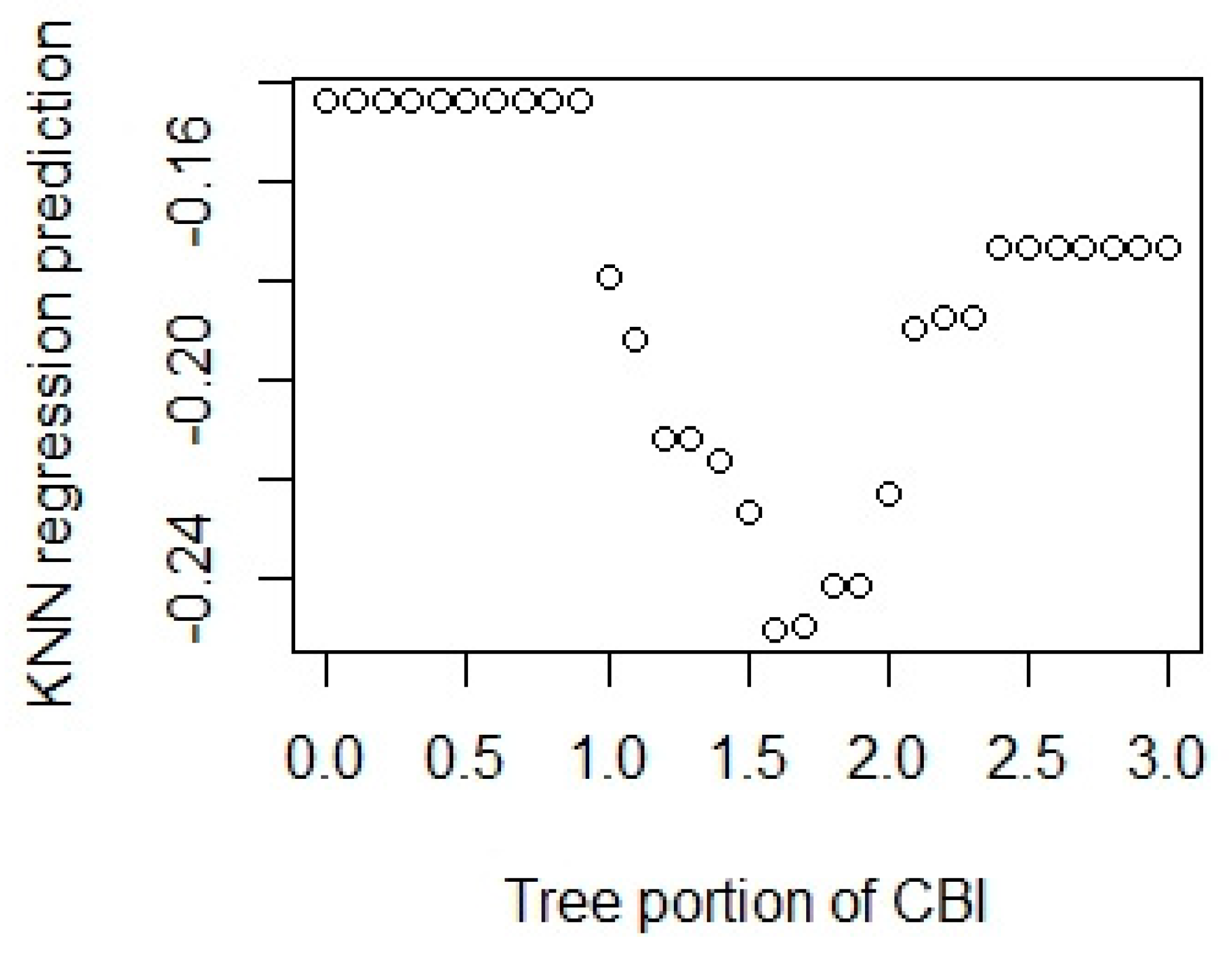

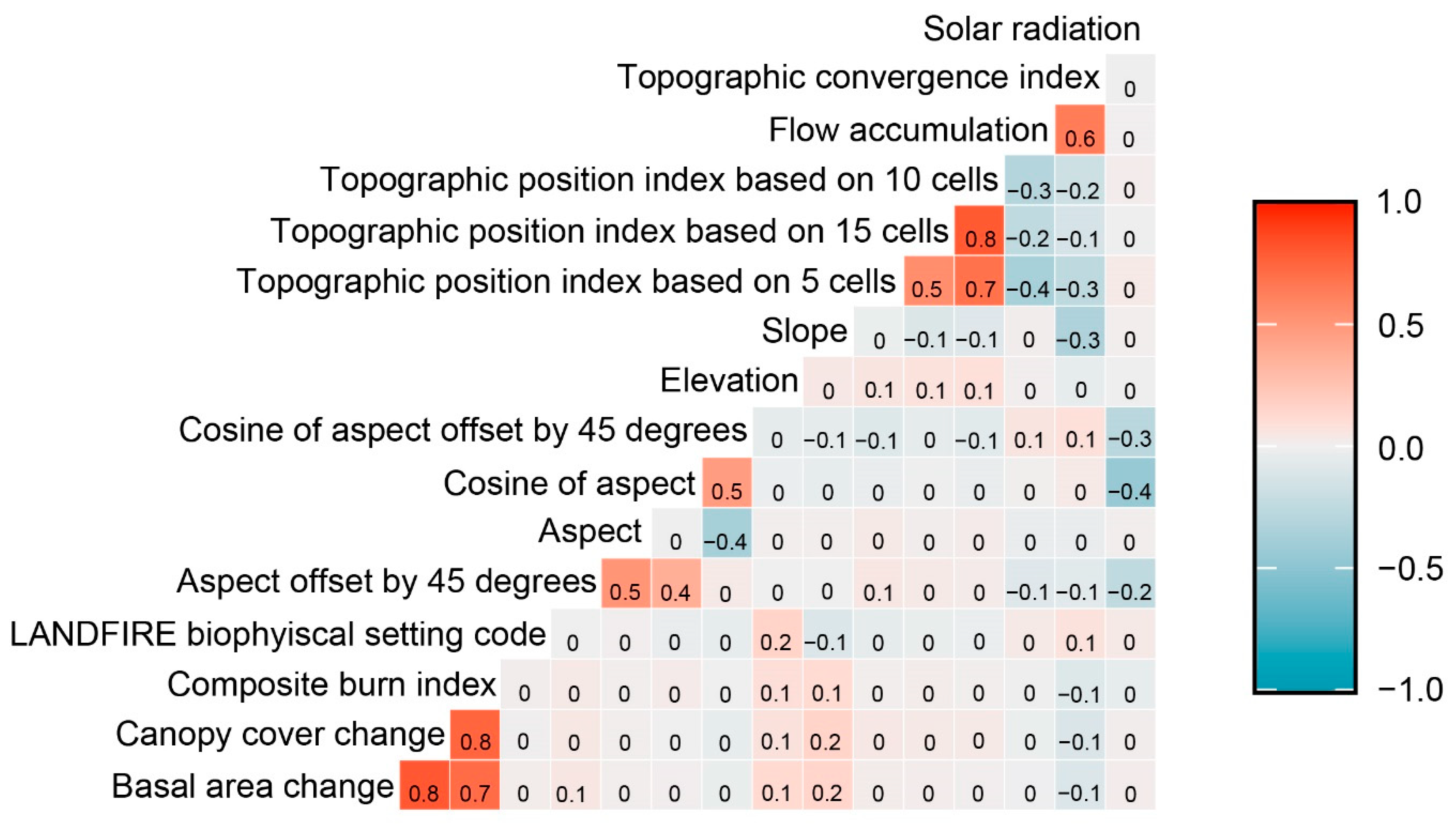
Appendix A.1.4. Feature Selection Results
| Relative (Predictor) Variable Importance for the “Best” Models | |||||
|---|---|---|---|---|---|
| Response Variable | RdNBR *** | Elevation | TCI | Slope | BPS Code |
| CBI | 1 | 0.66 | 0.44 | 0.35 | |
| ∆BA | 1 | 0.44 | 0.50 | 0.33 | |
| FVS ∆CC * | 1 | 0.43 | 0.50 | 0.36 | |
| PI ∆CC ** | 1 | 0.38 | 0.79 | 0.39 | 0.04 |
Appendix A.1.5. Model Form Evaluation Results
| Parametric | Simple GAM | Multivariate GAM | Random Forest | |
|---|---|---|---|---|
| CBI | 0.2486(0.0289) | 0.0273(0.0032) | 0.0267(0.0033) | 0.2657(0.0247) |
| ΔBA | 0.0504(0.0085) | 0.0483(0.0104) | 0.0473(0.0101) | 0.0518(0.0040) |
| Non-adj. FVS ΔCC | 0.0511(0.0081) | 0.0484(0.0102) | 0.0474(0.0094) | 0.0518(0.0040) |
| Adj. FVS ΔCC | 0.0392(0.0065) | 0.0397(0.0072) | 0.0390(0.0070) | 0.0440(0.0048) |
| PI ΔCC | 0.0514(0.0028) | 0.0523(0.0035) | 0.0530(0.0038) | 0.0607(0.0050) |
| Combined ΔCC | 0.0457(0.0015) | 0.0481(0.0041) | 0.0724(0.0032) | 0.0492(0.0027) |
| Variable Name | Data |
|---|---|
| L_EA_rdnbr_with | EA Landsat RdNBR with offset |
| LEA_preN_f | EA Landsat pre-fire NBR |
| elev | Elevation |
| slope | Slope |
| TCI | Topographic convergence index |
| CBI.B | Overall CBI rescaled to 0-1 |
| pdBA | Pre- to post-fire percent change in BA |
| pdFVSVU | Pre- to post-fire percent change in non-scorch-adjusted FVS canopy cover |
| adj.lim.pdFVSVU | Pre- to post-fire percent change in scorch-adjusted FVS canopy cover |
| pdTreeCCloss | Pre- to post-fire percent change in PI-derived canopy cover change |
| pdCC | adj.lim.pdFVSVU and pdTreeCCloss datasets combined |
| Variable Name | Data |
|---|---|
| L_EA_rdnbr_with | EA Landsat RdNBR with offset |
| pdBA | Pre- to post-fire percent change in BA |
| BPScode | Landfire Biophysical Setting Code |
| asp_N45 | Aspect shifted to the north by 45 degrees |
| aspect | Aspect |
| cos_aspect | Cosine of aspect |
| cosasp_N45 | Cosine of aspect shifted to the north by 45 degrees |
| Elev | Elevation |
| slope | Slope |
| TPI_5cell | Topographic position index calculated across 5 cells |
| TPI_10cell | Topographic position index calculated across 10 cells |
| TPI_15cell | Topographic position index calculated across 15 cells |
| FlowAcc | Flow accumulation intermediate calculation from TPI |
| SolarRad | Solar radiation |
| TCI | Topographic convergence index |
| LEA_preN_f | EA Landsat pre-fire NBR |
Appendix A.1.6. Index and Sensor Evaluation
| RdNBR | dNBR | RBR | ||||
|---|---|---|---|---|---|---|
| Landsat | Sentinel-2 | Landsat | Sentinel-2 | Landsat | Sentinel-2 | |
| CBI | 0.0273 (0.0032) | 0.0275 (0.0033) | 0.0260 (0.0021) | 0.0256 (0.0018) | 0.0244 (0.0020) | 0.0240 (0.0018) |
| ΔBA | 0.0483 (0.0104) | 0.0455 (0.0087) | 0.0495 (0.0062) | 0.0465 (0.0052) | 0.0450 (0.0070) | 0.0416 (0.0059) |
| Adj. FVS ΔCC | 0.0397 (0.0072) | 0.0363 (0.0056) | 0.0412 (0.0042) | 0.0378 (0.0032) | 0.0378 (0.0048) | 0.0340 (0.0039) |
| RdNBR | dNBR | RBR | ||||
|---|---|---|---|---|---|---|
| Landsat | Sentinel-2 | Landsat | Sentinel-2 | Landsat | Sentinel-2 | |
| CBI | 0.0333 (0.0022) | 0.0273 (0.0018) | 0.0215 (0.0021) | 0.0185 (0.0020) | 0.0227 (0.0021) | 0.0193 (0.0021) |
| ΔBA | 0.0710 (0.0092) | 0.0642 (0.0103) | 0.0440 (0.0052) | 0.0416 (0.0069) | 0.0454 (0.0057) | 0.0424 (0.0079) |
| Adj. FVS ΔCC | 0.0605 (0.0060) | 0.0524 (0.0065) | 0.0377 (0.0031) | 0.0351 (0.0045) | 0.0399 (0.0034) | 0.0360 (0.0056) |
| Sentinel-2 IA dNBR | Sentinel-2 EA RBR | |||
|---|---|---|---|---|
| With Offset | No Offset | With Offset | No Offset | |
| CBI | 0.0185 (0.0020) | 0.0193 (0.0018) | 0.0240 (0.0018) | 0.0253 (0.0019) |
| ΔBA | 0.0416 (0.0069) | 0.0428 (0.0065) | 0.0416 (0.0059) | 0.0443 (0.0064) |
| Adj. FVS ΔCC | 0.0351 (0.0045) | 0.03670 (0.0041) | 0.0340 (0.0039) | 0.0368 (0.0042) |
Appendix B
Appendix B.1. Final Models
Appendix B.1.1. Final Model Coefficients and Equations
Appendix B.1.2. Final Model Confusion Matrices
| Reference | ||||||
|---|---|---|---|---|---|---|
| Prediction | 0–<0.1 | 0.1–<1.25 | 1.25–<2.25 | 2.25–3 | Total | User’s Accuracy (%) |
| 0–<0.1 | 9 | 3 | 0 | 0 | 12 | 75.0 |
| 0.1–<1.25 | 52 | 73 | 16 | 1 | 142 | 51.4 |
| 1.25–<2.25 | 1 | 29 | 67 | 24 | 121 | 55.4 |
| 2.25–3 | 0 | 0 | 4 | 58 | 62 | 93.5 |
| Total | 62 | 105 | 87 | 83 | 337 | |
| Producer’s accuracy (%) | 14.5 | 69.5 | 77.0 | 69.9 | 61.4 | |
| Reference | ||||||
|---|---|---|---|---|---|---|
| Prediction | 0–<0.1 | 0.1–<1.25 | 1.25–<2.25 | 2.25–3 | Total | User’s Accuracy (%) |
| 0–<0.1 | 61 | 87 | 39 | 1 | 188 | 32.4 |
| 0.1–<1.25 | 1 | 5 | 9 | 3 | 18 | 27.8 |
| 1.25–<2.25 | 0 | 11 | 36 | 23 | 70 | 51.4 |
| 2.25–3 | 0 | 2 | 3 | 56 | 61 | 91.8 |
| Total | 62 | 105 | 87 | 83 | 337 | |
| Producer’s accuracy (%) | 98.4 | 4.8 | 41.4 | 67.5 | 46.9 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 118 | 13 | 2 | 1 | 0 | 0 | 134 | 88.1 |
| 10–<25% | 50 | 9 | 3 | 2 | 0 | 4 | 68 | 13.2 |
| 25–<50% | 17 | 9 | 12 | 11 | 5 | 3 | 57 | 21.1 |
| 50–<75% | 0 | 6 | 3 | 2 | 1 | 14 | 26 | 7.7 |
| 75–<90% | 0 | 0 | 0 | 2 | 2 | 12 | 16 | 12.5 |
| 90–<100% | 0 | 0 | 0 | 1 | 2 | 33 | 36 | 91.7 |
| Total | 185 | 37 | 20 | 19 | 10 | 66 | 337 | |
| Producer’s accuracy (%) | 63.8 | 24.3 | 60.0 | 10.5 | 20.0 | 50.0 | 52.2 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 167 | 21 | 9 | 2 | 0 | 2 | 201 | 83.1 |
| 10–<25% | 10 | 2 | 4 | 1 | 1 | 3 | 21 | 9.5 |
| 25–<50% | 3 | 6 | 3 | 6 | 3 | 3 | 24 | 12.5 |
| 50–<75% | 2 | 3 | 1 | 5 | 3 | 4 | 18 | 27.8 |
| 75–<90% | 0 | 5 | 2 | 1 | 0 | 4 | 12 | 0.0 |
| 90–<100% | 3 | 0 | 1 | 4 | 3 | 50 | 61 | 82.0 |
| Total | 185 | 37 | 20 | 19 | 10 | 66 | 337 | |
| Producer’s accuracy (%) | 90.3 | 5.4 | 15.0 | 26.3 | 0.0 | 75.8 | 67.4 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 69 | 13 | 4 | 0 | 0 | 0 | 86 | 80.2 |
| 10–<25% | 26 | 23 | 16 | 3 | 0 | 0 | 68 | 33.8 |
| 25–<50% | 8 | 27 | 31 | 7 | 4 | 8 | 85 | 36.5 |
| 50–<75% | 0 | 4 | 10 | 2 | 3 | 8 | 27 | 7.4 |
| 75–<90% | 0 | 1 | 4 | 3 | 1 | 12 | 21 | 4.8 |
| 90–<100% | 0 | 0 | 0 | 1 | 4 | 45 | 50 | 90.0 |
| Total | 103 | 68 | 65 | 16 | 12 | 73 | 337 | |
| Producer’s accuracy (%) | 67.0 | 33.8 | 47.7 | 12.5 | 8.3 | 61.6 | 50.7 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 98 | 40 | 15 | 1 | 0 | 0 | 154 | 63.6 |
| 10–<25% | 1 | 8 | 8 | 3 | 0 | 1 | 21 | 38.1 |
| 25–<50% | 2 | 10 | 15 | 2 | 0 | 2 | 31 | 48.4 |
| 50–<75% | 2 | 4 | 13 | 3 | 2 | 8 | 32 | 9.4 |
| 75–<90% | 0 | 1 | 5 | 5 | 3 | 4 | 18 | 16.7 |
| 90–<100% | 0 | 5 | 9 | 2 | 7 | 58 | 81 | 71.6 |
| Total | 103 | 68 | 65 | 16 | 12 | 73 | 337 | |
| Producer’s accuracy (%) | 95.1 | 11.8 | 23.1 | 18.8 | 25.0 | 79.5 | 54.9 | |
| Reference | ||||||
|---|---|---|---|---|---|---|
| Prediction | 0–<0.1 | 0.1–<1.25 | 1.25–<2.25 | 2.25–3 | Total | User’s Accuracy (%) |
| 0–<0.1 | 1 | 0 | 0 | 0 | 1 | 100 |
| 0.1–<1.25 | 61 | 87 | 26 | 1 | 175 | 49.7 |
| 1.25–<2.25 | 0 | 18 | 56 | 17 | 91 | 61.5 |
| 2.25–3 | 0 | 0 | 5 | 65 | 70 | 92.9 |
| Total | 62 | 105 | 87 | 83 | 337 | |
| Producer’s accuracy (%) | 1.6 | 82.9 | 64.4 | 78.3 | 62.0 | |
| Reference | ||||||
|---|---|---|---|---|---|---|
| Prediction | 0–<0.1 | 0.1–<1.25 | 1.25–<2.25 | 2.25–3 | Total | User’s Accuracy (%) |
| 0–<0.1 | 60 | 83 | 28 | 1 | 172 | 34.9 |
| 0.1–<1.25 | 2 | 8 | 15 | 2 | 27 | 29.6 |
| 1.25–<2.25 | 0 | 10 | 37 | 16 | 63 | 58.7 |
| 2.25–3 | 0 | 4 | 7 | 64 | 75 | 85.3 |
| Total | 62 | 105 | 87 | 83 | 337 | |
| Producer’s accuracy (%) | 96.8 | 7.6 | 42.5 | 77.1 | 50.1 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 131 | 13 | 1 | 0 | 0 | 0 | 145 | 90.3 |
| 10–<25% | 39 | 7 | 5 | 2 | 0 | 4 | 57 | 12.3 |
| 25–<50% | 12 | 11 | 10 | 6 | 5 | 4 | 48 | 20.8 |
| 50–<75% | 3 | 3 | 3 | 8 | 0 | 14 | 31 | 25.8 |
| 75–<90% | 0 | 3 | 1 | 1 | 3 | 14 | 22 | 13.6 |
| 90–<100% | 0 | 0 | 0 | 2 | 2 | 30 | 34 | 88.2 |
| Total | 185 | 37 | 20 | 19 | 10 | 66 | 337 | |
| Producer’s accuracy (%) | 70.8 | 18.9 | 50.0 | 42.1 | 30.0 | 45.5 | 56.1 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 142 | 10 | 3 | 0 | 0 | 0 | 155 | 91.6 |
| 10–<25% | 9 | 8 | 2 | 2 | 0 | 1 | 22 | 36.4 |
| 25–<50% | 20 | 3 | 5 | 0 | 1 | 1 | 30 | 16.7 |
| 50–<75% | 7 | 7 | 5 | 4 | 3 | 5 | 31 | 12.9 |
| 75–<90% | 3 | 2 | 2 | 6 | 1 | 4 | 18 | 5.6 |
| 90–<100% | 4 | 7 | 3 | 7 | 5 | 55 | 81 | 67.9 |
| Total | 185 | 37 | 20 | 19 | 10 | 66 | 337 | |
| Producer’s accuracy (%) | 76.8 | 21.6 | 25.0 | 21.1 | 10.0 | 83.3 | 63.8 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 80 | 17 | 4 | 0 | 0 | 0 | 100 | 80.0 |
| 10–<25% | 21 | 29 | 23 | 1 | 0 | 1 | 74 | 39.2 |
| 25–<50% | 2 | 17 | 24 | 6 | 2 | 5 | 56 | 42.9 |
| 50–<75% | 0 | 5 | 11 | 3 | 4 | 11 | 34 | 8.8 |
| 75–<90% | 0 | 0 | 3 | 5 | 1 | 13 | 22 | 4.5 |
| 90–<100% | 0 | 0 | 0 | 1 | 5 | 43 | 51 | 84.3 |
| Total | 103 | 68 | 65 | 16 | 12 | 73 | 337 | |
| Producer’s accuracy (%) | 77.7 | 42.6 | 36.9 | 18.8 | 8.3 | 58.9 | 53.4 | |
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| Prediction | 0–<10% | 10–<25% | 25–<50% | 50–<75% | 75–<90% | 90–<100% | Total | User’s Accuracy (%) |
| 0–<10% | 98 | 40 | 15 | 1 | 0 | 0 | 154 | 63.6 |
| 10–<25% | 1 | 8 | 8 | 3 | 0 | 1 | 21 | 38.1 |
| 25–<50% | 2 | 10 | 15 | 2 | 0 | 2 | 31 | 48.4 |
| 50–<75% | 2 | 4 | 13 | 3 | 2 | 8 | 32 | 9.4 |
| 75–<90% | 0 | 1 | 5 | 5 | 3 | 4 | 18 | 16.7 |
| 90–<100% | 0 | 5 | 9 | 2 | 7 | 58 | 81 | 71.6 |
| Total | 103 | 68 | 65 | 16 | 12 | 73 | 337 | |
| Producer’s accuracy (%) | 95.1 | 11.8 | 23.1 | 18.8 | 25.0 | 79.5 | 54.9 | |
References
- National Interagency Coordination Center. Wildland Fire Summary and Statistics Annual Report 2021. 2021. Available online: https://www.predictiveservices.nifc.gov/intelligence/2021_statssumm/annual_report_2021.pdf (accessed on 24 August 2022).
- Swetnam, T.W.; Baisan, C.H. Historical fire regime patterns in the southwestern United States since AD 1700. In Fire Effects in Southwestern Forest: Proceedings of the 2nd La Mesa Fire Symposium, Los Alamos, NM, USA, 29–31 March 1994; Allen, C.D., Ed.; USDA Forest Service General Technical Report RM-GTR-286; RMRS: Fort Collins, CO, USA, 1996; pp. 11–32. [Google Scholar]
- Swetnam, T.W.; Brown, P.M. Climatic inferences from dendroecological reconstructions. In Dendroclimatology; Hughes, M., Swetnam, T., Diaz, H., Eds.; Developments in Paleoenvironmental Research; Springer: Berlin/Heidelberg, Germany, 2011; Volume 11. [Google Scholar]
- Hurteau, M.D.; Bradford, J.B.; Fule, P.Z.; Taylor, A.H.; Martin, K.L. Climate change, fire management, and ecological services in the southwestern U.S. For. Ecol. Manag. 2014, 327, 280–289. [Google Scholar] [CrossRef]
- Stefanidis, S.; Alexandridis, V.; Spalevic, V.; Mincato, R.L. Wildfire Effects on Soil Erosion Dynamics: The Case of 2021 Megafires in Greece. Agric. For. 2022, 68, 49–63. [Google Scholar]
- Wilder, B.J.; Lancaster, J.T.; Cafferata, P.H.; Coe, D.B.; Swanson, B.J.; Lindsay, D.N.; Short, W.R.; Kinoshita, A.M. An analytical solution for rapidly predicting post-fire peak streamflow for small watersheds in southern California. Hydrol. Process. 2021, 35, e13976. [Google Scholar] [CrossRef]
- Morgan, P.; Keane, R.E.; Dillon, G.K.; Jain, T.B.; Hudak, A.T.; Karau, E.C.; Sikkink, P.G.; Holden, Z.A.; Strand, E.K. Challenges of assessing fire and burn severity using field measures, remote sensing and modelling. Int. J. Wildland Fire 2014, 23, 1045. [Google Scholar] [CrossRef]
- Agee, J.K. Fire Ecology of Pacific Northwest Forests; Island Press: Washington, DC, USA, 1993. [Google Scholar]
- Lentile, L.B.; Smith, F.W.; Shepperd, W.D. Influence of topography and forest structure on patterns of mixed severity fire in ponderosa pine forests of the South Dakota Black Hills, USA. Int. J. Wildland Fire 2006, 15, 557–566. [Google Scholar] [CrossRef]
- Dillon, G.K.; Panunto, M.F.; Davis, B.; Morgan, P.; Birch, D.S.; Jolly, W.M. Development of a Severe Fire Potential Map for the Contiguous United States; General Technical Report RMRS-GTR-415; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2020; 107p. [Google Scholar]
- Miesel, J.; Reiner, A.; Ewell, C.; Maestrini, B.; Dickinson, M. Quantifying changes in total and pyrogenic Carbon stocks across burn severity gradients using active wildland fire incidents. Front. Earth Sci. 2018, 6, 41. [Google Scholar] [CrossRef]
- Key, C.H.; Benson, N.C. 2006. Landscape Assessment: Sampling and Analysis Methods. In FIREMON: Fire Effects Monitoring and Inventory System; Lutes, D.C., Keane, R.E., Caratti, J.F., Key, C.H., Benson, N.C., Sutherland, S., Gangi, L.J., Eds.; USDA Forest Service General Technical Report RMRS-GTR-164-CD; RMRS: Ogden, UT, USA; p. LA 1–51.
- Miller, J.D.; Thode, A.E. Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR). Remote Sens. Environ. 2007, 109, 66–80. [Google Scholar] [CrossRef]
- Key, C.H. Ecological and sampling constraints on defining landscape burn severity. Fire Ecol. 2006, 2, 34–59. [Google Scholar] [CrossRef]
- Parks, S.A. Mapping day-of-burning with coarse-resolution satellite fire-detection data. Int. J. Wildland Fire 2014, 23, 215–223. [Google Scholar] [CrossRef]
- Parks, S.A.; Holsinger, L.M.; Voss, M.A.; Loehman, R.A.; Robinson, N.P. Mean composite fire severity metrics computed with Google Earth Engine offer improved accuracy and expanded mapping potential. Remote Sens. 2018, 10, 879. [Google Scholar] [CrossRef]
- Miller, J.D.; Knapp, E.E.; Key, C.H.; Skinner, C.N.; Isbell, C.J.; Creasy, R.M.; Sherlock, J.W. Calibration and validation of the relative differenced Normalized Burn Ratio (RdNBR) to three measures of fire severity in the Sierra Nevada and Klamath Mountains, California, USA. Remote Sens. Environ. 2009, 113, 645–656. [Google Scholar] [CrossRef]
- Kolden, C.A.; Smith, A.M.S.; Abatzoglou, J.T. Limitations and utilisation of Monitoring Trends in Burn Severity products for assessing wildfire severity in the USA. Int. J. Wildland Fire 2015, 24, 1023–1028. [Google Scholar] [CrossRef]
- Huffman, D.W.; Zegler, T.J.; Fule, P.Z. Fire history of a mixed conifer forest on the Mogollon Rim, northern Arizona, USA. Int. J. Wildland Fire 2015, 24, 680–689. [Google Scholar] [CrossRef]
- O’Connor, C.D.; Falk, D.A.; Lynch, A.M.; Swetnam, T.W. Fire severity, size and climatic associations diverge from historical precedent along an ecological gradient in the Pinaleño Mountains, Arizona, USA. Int. J. Wildland Fire 2014, 329, 264–278. [Google Scholar]
- Miller, J.D.; Skinner, C.; Safford, H.D.; Knapp, E.E.; Ramirez, C.M. Trends and causes of severity, size, and number of fires in northwestern California, USA. Ecol. Appl. 2012, 22, 184–203. [Google Scholar] [CrossRef]
- Sheppard, P.R.; Comrie, A.C.; Packin, G.D.; Angersbach, K.; Hughes, M.K. The climate of the US southwest. Clim. Res. 2002, 21, 219–238. [Google Scholar] [CrossRef]
- Alexandrov, G.A.; Ames, D.; Bellocchi, G.; Bruen, M.; Crout, N.; Erechtchoukova, M.; Hildebrandt, A.; Hoffman, F.; Jackisch, C.; Khaiter, P.; et al. Technical assessment and evaluation of environmental models and software: Letter to the Editor. Environ. Model. Softw. 2011, 26, 328–336. [Google Scholar] [CrossRef]
- Saberi, J.S. Quantifying Burn Severity in Forests of the Interior Pacific Northwest: From Field Measurements to Satellite Spectral Indices. Master’s Thesis, University of Washington, Seattle, WA, USA, 2019. [Google Scholar]
- Flora of North America Editorial Committee (Ed.) Flora of North America North of Mexico; Flora of North America Editorial Committee: New York, NY, USA; Oxford, MI, USA, 1993; Volume 22, Available online: http://beta.floranorthamerica.org (accessed on 1 May 2021).
- Schrader, D.K.; Min, B.C.; Matson, E.T.; Dietz, J.E. Real-time averaging of position data from multiple GPS receivers. Measurement 2016, 90, 329–337. [Google Scholar] [CrossRef]
- Parks, S.A.; Holsinger, L.M.; Koontz, M.J.; Collins, L.; Whitman, E.; Parisien, M.; Loehman, R.A.; Barnes, J.L.; Bourdon, J.F.; Boucher, J.; et al. Giving ecological meaning to satellite-derived fire severity metrics across North American forests. Remote Sens. 2019, 11, 1735. [Google Scholar] [CrossRef]
- Harvey, B.J.; Donato, D.C.; Romme, W.H.; Turner, M.G. Influence of recent bark beetle outbreak on burn severity and postfire tree regeneration in Montane Douglas-fir forests. Ecology 2013, 94, 2475–2486. [Google Scholar] [CrossRef]
- Forest Vegetation Simulator (FVS) Software, 2019.11.01 version. Available online: https://www.fs.usda.gov/fvs/index.shtml (accessed on 16 September 2019).
- Dixon, G.E. Essential FVS: A User’s Guide to the Forest Vegetation Simulator; Internal Report; Department of Agriculture, Forest Service: Fort Collings, CO, USA, 2002. [Google Scholar]
- Harvey, B.J.; Andrus, R.A.; Anderson, R.A. Incorporating biophysical gradients and uncertainty into burn severity maps in a temperate fire-prone forested region. Ecosphere 2019, 10, e02600. [Google Scholar] [CrossRef]
- Crookston, N.L.; Stage, A.R. Percent Canopy Cover and Stand Structure Statistics from the Forest Vegetation Simulator; General Technical Report, RMRS-GTR-24; Department of Agriculture, Forest Service, Rocky Mountain Research Station: Ogden, UT, USA, 1999; 15p. [Google Scholar]
- Jenkins, J.C.; Chojnacky, D.C.; Heath, L.S.; Birdsey, R.A. National-scale biomass estimators for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Christopher, T.A.; Goodburn, J.M. The effects of spatial patterns on the accuracy of Forest Vegetation Simulator (FVS) estimates of forest canopy cover. West. J. Appl. For. 2008, 23, 5–11. [Google Scholar] [CrossRef] [Green Version]
- Copernicus Sentinel Data; Retrieved from ASF DAAC [April 2019]; ESA: Paris, France, 2019.
- Coulston, J.W.; Moisen, G.G.; Wilson, B.T.; Finco, M.V.; Cohen, W.B.; Brewer, C.K. Modeling Percent Tree Canopy Cover: A Pilot Study. Photogramm. Eng. Remote Sens. 2012, 78, 715–727. [Google Scholar] [CrossRef]
- Toney, C.; Liknes, G.; Lister, A.; Meneguzzo, D. Assessing alternative measures of tree canopy cover: Photo-interpreted NAIP and ground-based estimates. In Monitoring Across Borders: 2010 Joint Meeting of the Forest Inventory and Analysis (FIA) Symposium and the Southern Mensurationists; McWilliams, W., Roesch, F.A., Eds.; e-General Technical Report SRS-157; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2012; pp. 209–215. [Google Scholar]
- Falkowski, M.J.; Evans, J.S.; Naugle, D.E.; Hagen, C.A.; Carleton, S.A.; Maestas, J.D.; Khalyani, A.H.; Poznanovic, A.J.; Lawrence, A.J. Mapping tree canopy cover in support of proactive Prairie Grouse conservation in western North America. Rangel. Ecol. Manag. 2017, 70, 15–24. [Google Scholar] [CrossRef]
- U.S. Geological Survey. USGS 30 Meter Resolution, One-Sixtieth Degree National Elevation Dataset for CONUS, Alaska, Hawaii, Puerto Rico, and the U.S. Virgin Island; U.S. Geological Survey: Reston, VA, USA, 1999. [Google Scholar]
- Holden, Z.; Morgan, P.; Evans, J.S. A predictive model of burn severity based on 20-year satellite-inferred burn severity data in a large southwestern US wilderness area. For. Ecol. Manag. 2009, 258, 2399–2406. [Google Scholar] [CrossRef]
- Dillon, G.K.; Holden, Z.A.; Morgan, P.; Crimmins, M.A.; Heyerdahl, E.K.; Luce, C.H. Both topography and climate affected forest and woodland burn severity in two regions of the western US, 1984 to 2006. Ecosphere 2011, 2, 130. [Google Scholar] [CrossRef]
- Parks, S.A.; Holsinger, L.M.; Panunto, M.H.; Jolly, W.M.; Dobrowski, S.Z.; Dillon, G.K. High-severity fire: Evaluating its key drivers and mapping its probability across western US forests. Environ. Res. Lett. 2018, 13, 044037. [Google Scholar] [CrossRef]
- Dilts, T.E. Topography Tools for ArcGIS 10.1. University of Nevada Reno. 2015. Available online: http://www.arcgis.com/home/item.html?id=b13b3b40fa3c43d4a23a1a09c5fe96b9 (accessed on 16 September 2019).
- Ospina, R.; Ferrari, S.L.P. A general class of zero-or-one inflated beta regression models. Comput. Stat. Data Anal. 2012, 56, 1609–1623. [Google Scholar] [CrossRef]
- Miller, J.D.; Quayle, B. Calibration and validation of immediate post-fire satellite-derived data to three severity metrics. Fire Ecol. 2015, 11, 12–30. [Google Scholar] [CrossRef]
- Cansler, A.C.; McKenzie, D. How robust are burn severity indices when applied in a new region? Evaluation of alternate field-based and remote-sensing methods. Remote Sens. 2012, 4, 456–483. [Google Scholar] [CrossRef]
- Van Wagtendonk, J.; Root, R.R.; Key, C.K. Comparison of AVIRIS and Landsat ETM+ detection capabilities for bur severity. Remote Sens. Environ. 2004, 92, 397–408. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach; Spring Science & Business Media: New York, NY, USA, 2002; 512p. [Google Scholar]
- Smith, A.M.S.; Falkowski, M.J.; Hudak, A.T.; Evans, J.S.; Robinson, A.P.; Steele, C.M. A cross-comparison of field, spectral, and lidar estimates of forest canopy cover. Can. J. Remote Sens. 2009, 35, 447–459. [Google Scholar] [CrossRef]
- McCarley, T.R.; Hudak, A.T.; Sparks, A.M.; Vaillant, N.M.; Meddens, A.J.H.; Trader, L.; Mauro, F.; Kreitler, J.; Boschetti, L. Estimating wildfire fuel consumption with multitemporal airborne laser scanning data and deomonstrating linkage with MODIS-derived fire radiative energy. Remote Sens. Environ. 2020, 251, 112114. [Google Scholar] [CrossRef]
- Li, F.; Zhang, X.; Kondragunta, S.; Csiszar, E. Comparison of fire radiative power estimates from VIIRS and MODIS observations. J. Geophys. Res. Atmos. 2018, 123, 4545–4563. [Google Scholar] [CrossRef]
- Lentile, L.B.; Holden, Z.A.; Smith, A.M.S.; Falkowski, M.J.; Hudak, A.T.; Morgan, P.; Lewis, S.A.; Gessler, P.E.; Benson, N.C. Remote sensing techniques to assess active fire characteristics and post-fire effects. Int. J. Wildland Fire 2006, 15, 319. [Google Scholar] [CrossRef]
- Smith, A.M.S.; Sparks, A.M.; Kolden, C.A.; Abatzoglou, J.T.; Talhelm, A.F.; Johnson, D.M.; Boschetti, L.; Lutz, J.A.; Apostol, K.G.; Yedinak, K.M.; et al. Towards a new paradigm in fire severity research using dose-response experiments. Int. J. Wildland Fire 2016, 25, 158–166. [Google Scholar] [CrossRef]
- Ferri, C.; Hernandez-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Delgado RTibau, X. Why Cohen’s Kappa should be avoided as a performance measure in classification. PLoS ONE 2019, 14, e0sss916. [Google Scholar] [CrossRef] [PubMed]
- Welch, K.R.; Safford, H.D.; Young, T.P. Predicting conifer establishment post wildfire in mixed conifer forests of the North American Mediterranean-climate zone. Ecosphere 2016, 7, e01609. [Google Scholar] [CrossRef]
- Kendall, M. A New Measure of Rank Correlation. Biometricka 1938, 30, 81–89. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Cao, H.; Xiong, M.; Shugart, Y.Y.; Jin, L. Efficient test for nonlinear dependence of two continuous variables. BMC Bioinform. 2015, 16, 260. [Google Scholar] [CrossRef]
- Barton, K. MuMin: Multi-Model Inference. R Package. Version 4.0.5. Available online: https://cran.r-project.org/web/packages/MuMIn/index.html (accessed on 1 June 2020).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–23. [Google Scholar] [CrossRef] [Green Version]
- R core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- R Documentation. Gamlss.dist R Package (version 5.3-2). https://www.rdocumentation.org/packages/gamlss.dist/versions/5.3-2. (accessed on 1 May 2021). BEINF: The Beta Inflated Distribution for Fitting a GAMLSS. Available online: https://www.rdocumentation.org/packages/gamlss.dist/versions/6.0-5/topics/BEINF (accessed on 1 May 2021).
- Stasinopoulos, M.; Rigby, B.; Voudouris, V.; Heller, G.; De Bastiani, F. Flexible Regression and Smoothing: The GAMLSS Packages in R. July 23, 2017; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- LANDFIRE Program. Available online: https://landfire.gov/cbd.php (accessed on 1 September 2019).
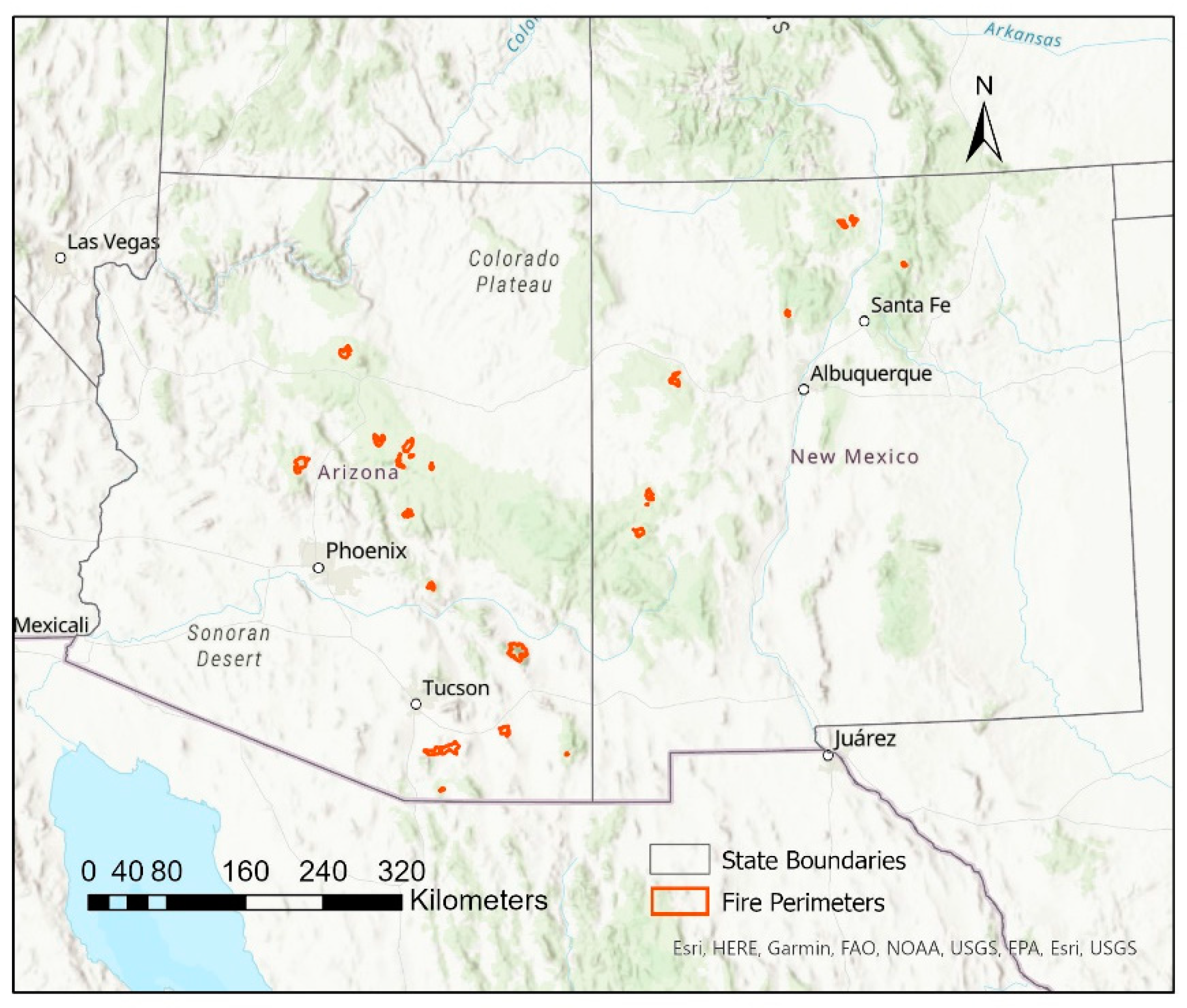
| Fire Name | National Forest | State | Ignition Date | Year Sampled | Plots |
|---|---|---|---|---|---|
| Bear | Tonto | AZ | 16 Jun 2018 | 2019 | 17 |
| Blue Water | Cibola | NM | 12 April 2018 | 2019 | 22 |
| Diener Canyon | Cibola | NM | 12 April 2018 | 2019 | 25 |
| Sardinas Canyon | Carson | NM | 24 June 2018 | 2019 | 20 |
| Tinder | Coconino | AZ | 27 April 2018 | 2019 | 25 |
| Venado | Santa Fe | NM | 20 July 2018 | 2019 | 19 |
| 33 Springs | Apache–Sitgreaves | AZ | 6 October 2017 | 2018 | 13 |
| Baca | Gila | NM | 12 May 2017 | 2018 | 23 |
| Bonita | Carson | NM | 3 June 2017 | 2018 | 27 |
| Boundary | Coconino | AZ | 1 June 2017 | 2018 | 14 |
| Flying R | Coronado | AZ | 14 June 2017 | 2018 | 15 |
| Frye | Coronado | AZ | 7 June 2017 | 2018 | 21 |
| Goodwin | Prescott | AZ | 24 June 2017 | 2018 | 11 |
| Hondito | Carson | NM | 16 May 2017 | 2018 | 7 |
| Kerr | Gila | NM | 1 May 2017 | 2018 | 14 |
| Lizard | Coronado | AZ | 7 June 2017 | 2018 | 9 |
| Pinal | Tonto | AZ | 8 May 2017 | 2018 | 9 |
| Rucker | Coronado | AZ | 7 June 2017 | 2018 | 9 |
| Sawmill | Coronado | AZ | 23 April 2017 | 2018 | 7 |
| Slim | Apache–Sitgreaves | AZ | 1 June 2017 | 2018 | 10 |
| Snake Ridge | Coconino | AZ | 19 May 2017 | 2018 | 20 |
| Total | 337 |
| Fire (National Forest) | State | Year of Fire | Year of Pre-Fire Aerial Photos | Year of Post-Fire Aerial Photos | Number of PI Plots (Number of OS Plots) |
|---|---|---|---|---|---|
| Tinder (Coconino) | AZ | 2018 | 2014 | 2018 | 35 (12) |
| Goodwin (Prescott) | AZ | 2017 | 2015 | 2017 | 13 (4) |
| Sardinas Canyon (Carson) | NM | 2018 | 2014 | 2018 | 33 (8) |
| Deiner (Cibola) | NM | 2018 | 2016 | 2018 | 29 (10) |
| Blue Water (Cibola) | NM | 2018 | 2016 | 2018 | 32 (10) |
| Pinal (Tonto) | AZ | 2017 | 2012 | 2017 | 23 (3) |
| Fires below not field sampled | |||||
| Highline (Tonto)/ Bears | AZ | 2017 | 2012 | 2017 | 19 |
| Redondo RX (Cibola) | NM | 2018 | 2016 | 2018 | 18 |
| Total | 202 (47) |
| IA SW-Specific Model (Sentinel-2 dNBR) | IA Current Model (Landsat RdNBR) | EA SW-Specific Model (Sentinel-2 RBR) | EA Current Model (Landsat RdNBR) | |||||||||
| Acc. | Kappa | Test MSE | Acc. | Kappa | Test MSE | Acc. | Kappa | Test MSE | Acc. | Kappa | Test MSE | |
| CBI | 61.4 | 46.7 | 0.0184 | 46.9 | 32.1 | 0.8753 | 62.0 | 47.0 | 0.0237 | 50.1 | 35.9 | 1.1265 |
| ΔBA | 52.2 | 33.9 | 0.0409 | 67.4 | 47.5 | 0.0547 | 56.1 | 38.1 | 0.0407 | 63.8 | 46.9 | 0.0705 |
| ΔCC | 50.7 | 38.0 | 0.0347 | 54.9 | 41.5 | 0.0886 | 53.4 | 41.2 | 0.0337 | 54.9 | 41.4 | 0.0518 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reiner, A.L.; Baker, C.; Wahlberg, M.; Rau, B.M.; Birch, J.D. Region-Specific Remote-Sensing Models for Predicting Burn Severity, Basal Area Change, and Canopy Cover Change following Fire in the Southwestern United States. Fire 2022, 5, 137. https://doi.org/10.3390/fire5050137
Reiner AL, Baker C, Wahlberg M, Rau BM, Birch JD. Region-Specific Remote-Sensing Models for Predicting Burn Severity, Basal Area Change, and Canopy Cover Change following Fire in the Southwestern United States. Fire. 2022; 5(5):137. https://doi.org/10.3390/fire5050137
Chicago/Turabian StyleReiner, Alicia L., Craig Baker, Maximillian Wahlberg, Benjamin M. Rau, and Joseph D. Birch. 2022. "Region-Specific Remote-Sensing Models for Predicting Burn Severity, Basal Area Change, and Canopy Cover Change following Fire in the Southwestern United States" Fire 5, no. 5: 137. https://doi.org/10.3390/fire5050137
APA StyleReiner, A. L., Baker, C., Wahlberg, M., Rau, B. M., & Birch, J. D. (2022). Region-Specific Remote-Sensing Models for Predicting Burn Severity, Basal Area Change, and Canopy Cover Change following Fire in the Southwestern United States. Fire, 5(5), 137. https://doi.org/10.3390/fire5050137