Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches

 ,
, 
 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
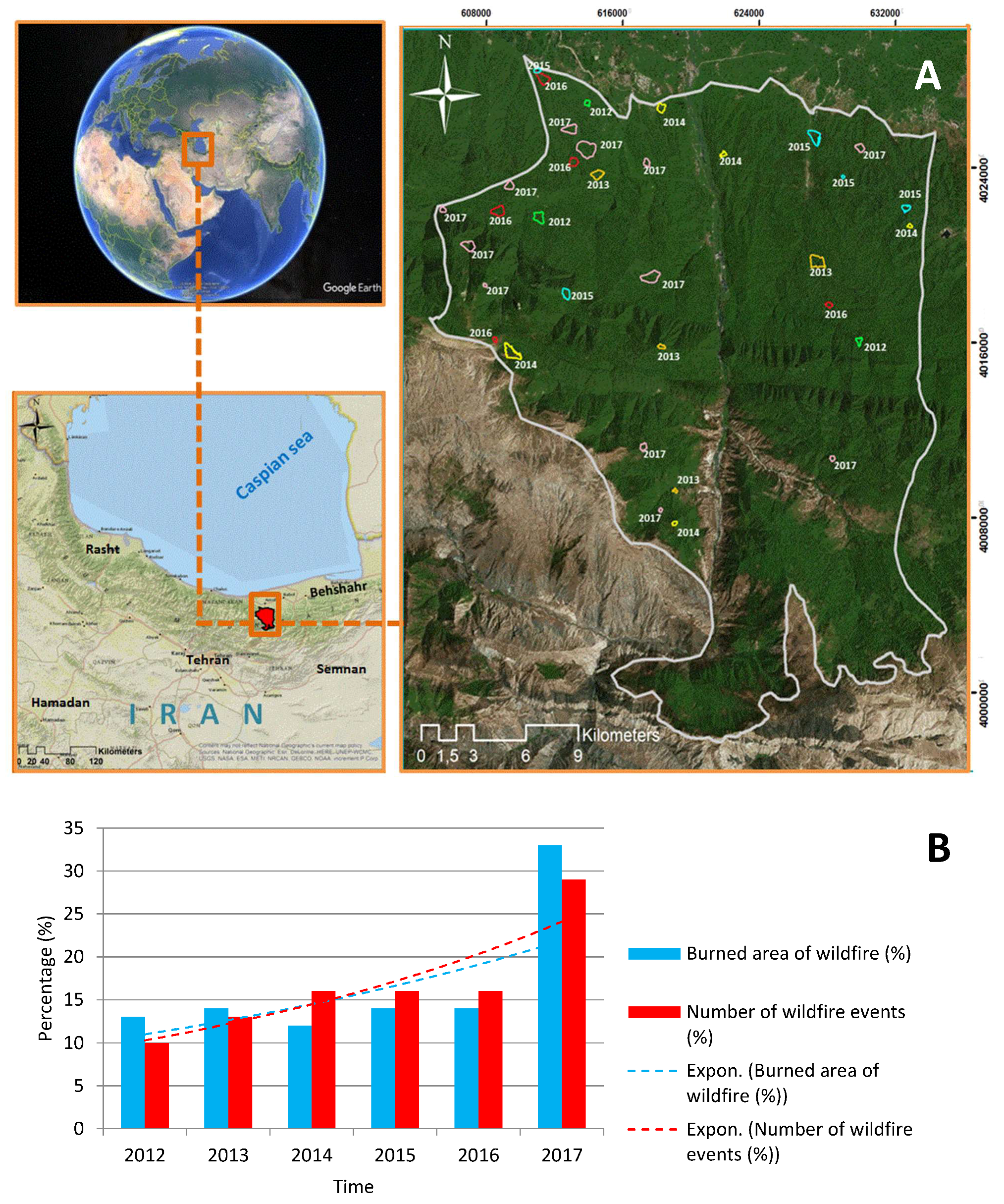
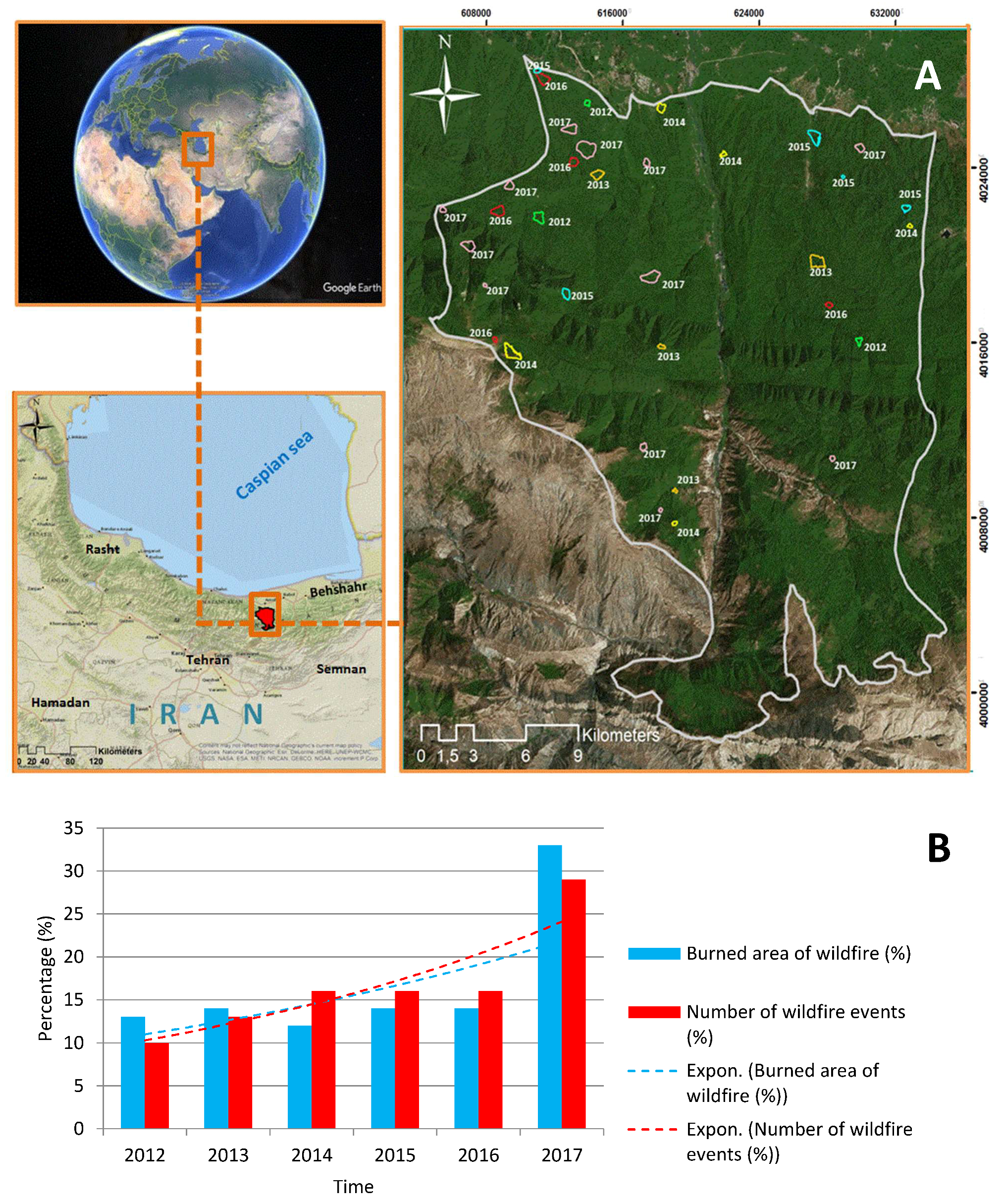
2. Overview of the Study Area
3. Materials
3.1. Conditioning Factors
3.2. Generating a Wildfire Inventory Dataset
3.2.1. Data Source
3.2.2. Dataset Organization
4. Methods
4.1. Overall Methodology
- ▪
- Preparing the conditioning factors based on five main factors, namely topographic, meteorological, anthropological, vegetation, and hydrological.
- ▪
- Generating a wildfire inventory dataset from the hotspots of MODIS data-enhanced using field survey GPS data.
- ▪
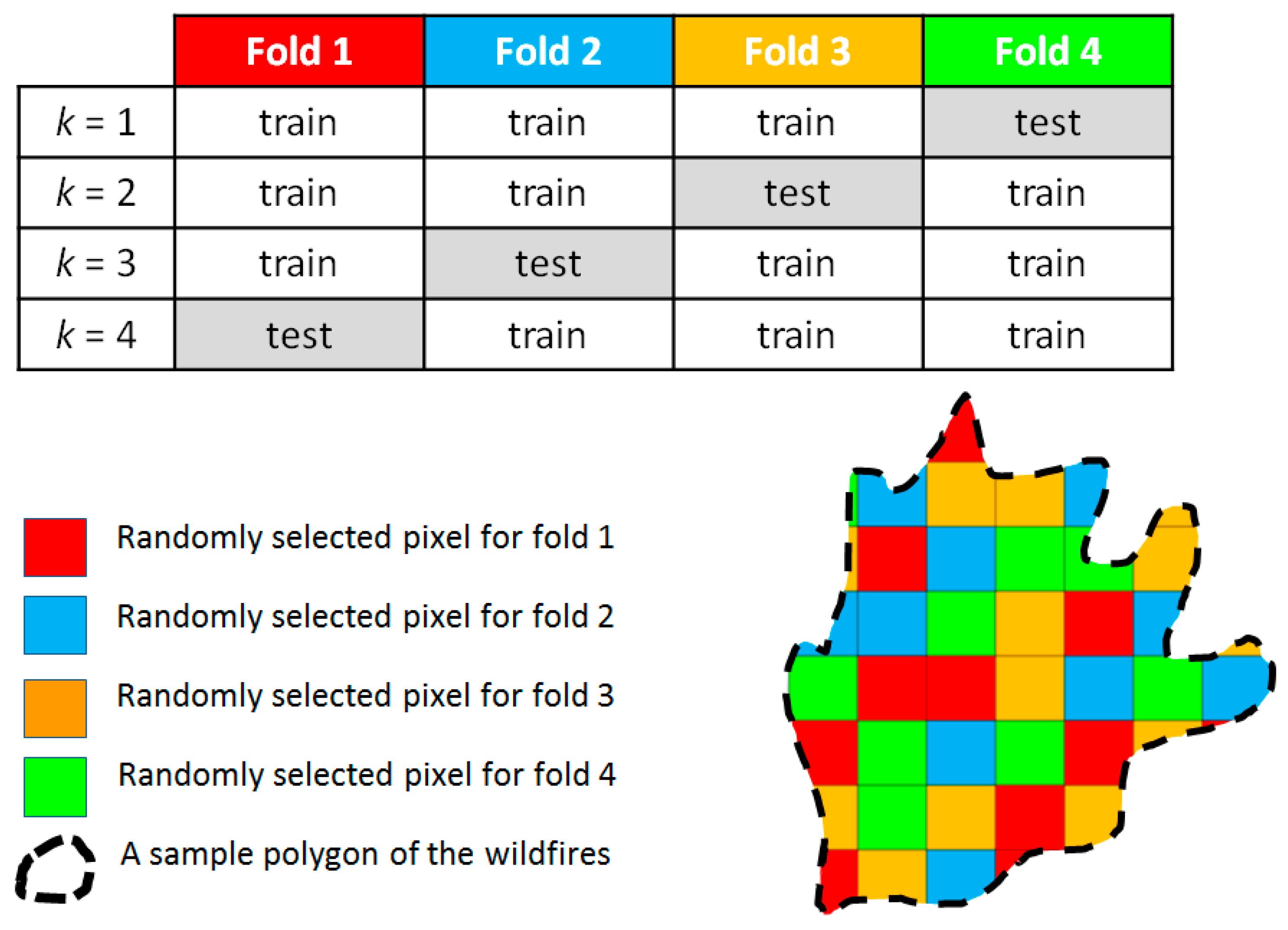
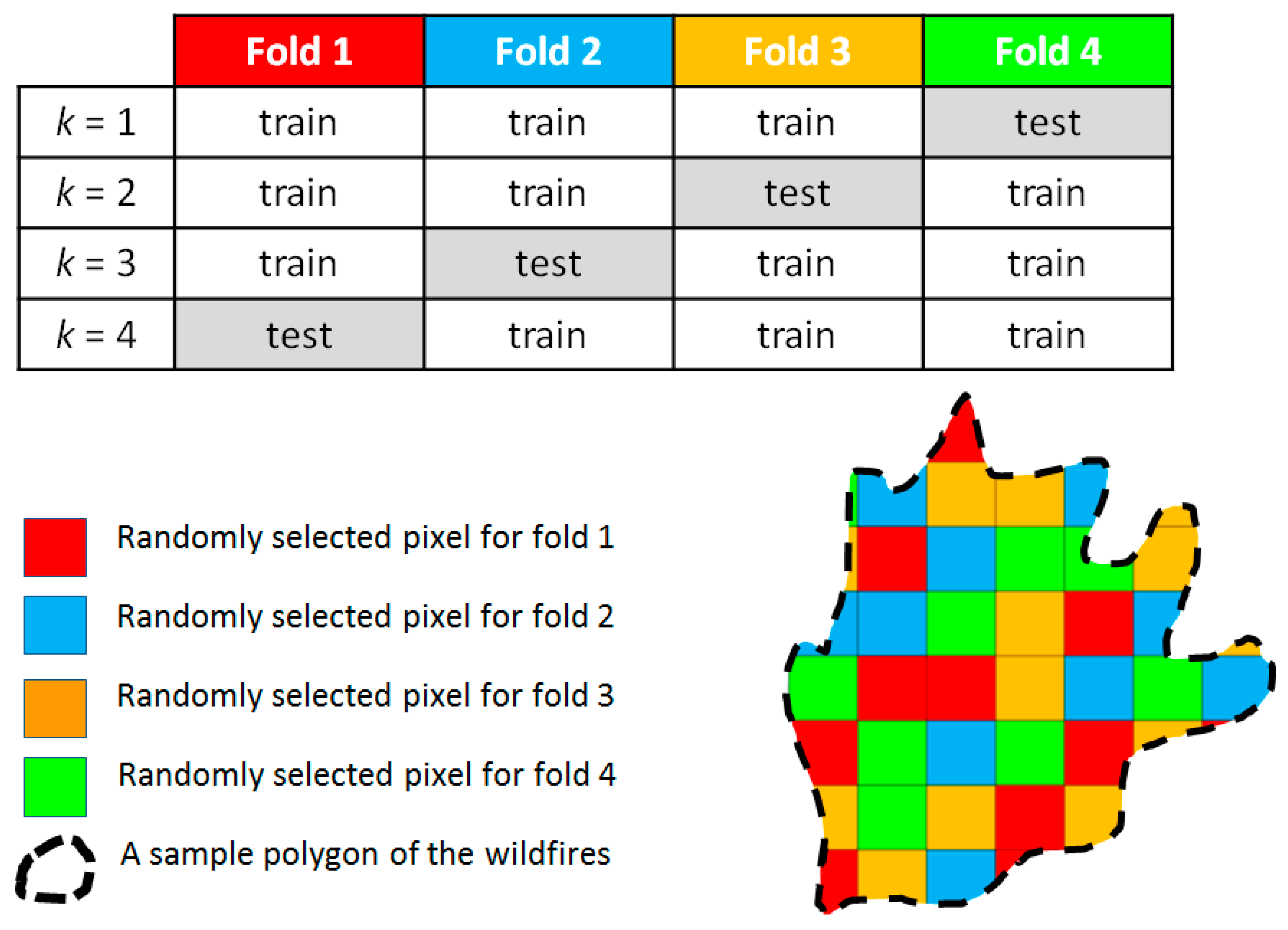
- Using a four-fold CV and dividing the inventory dataset into four different equal-sized folds.
- ▪
- Applying the ANN, SVM and RF models for the spatial prediction of wildfire susceptibility, based on each fold of the training dataset.
- ▪
- Validating the performances of each ML approach using the receiver operating characteristics (ROC) curve.
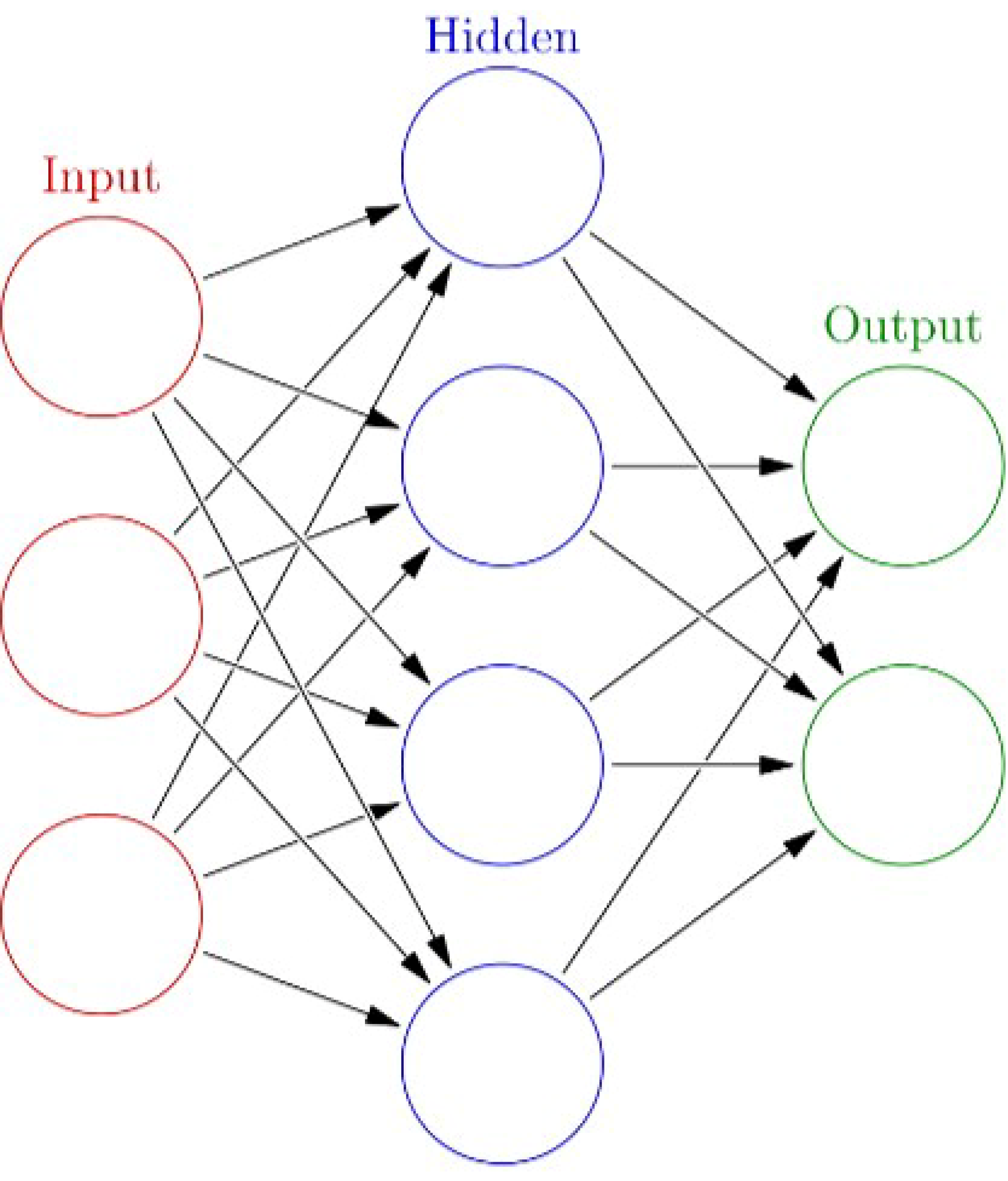
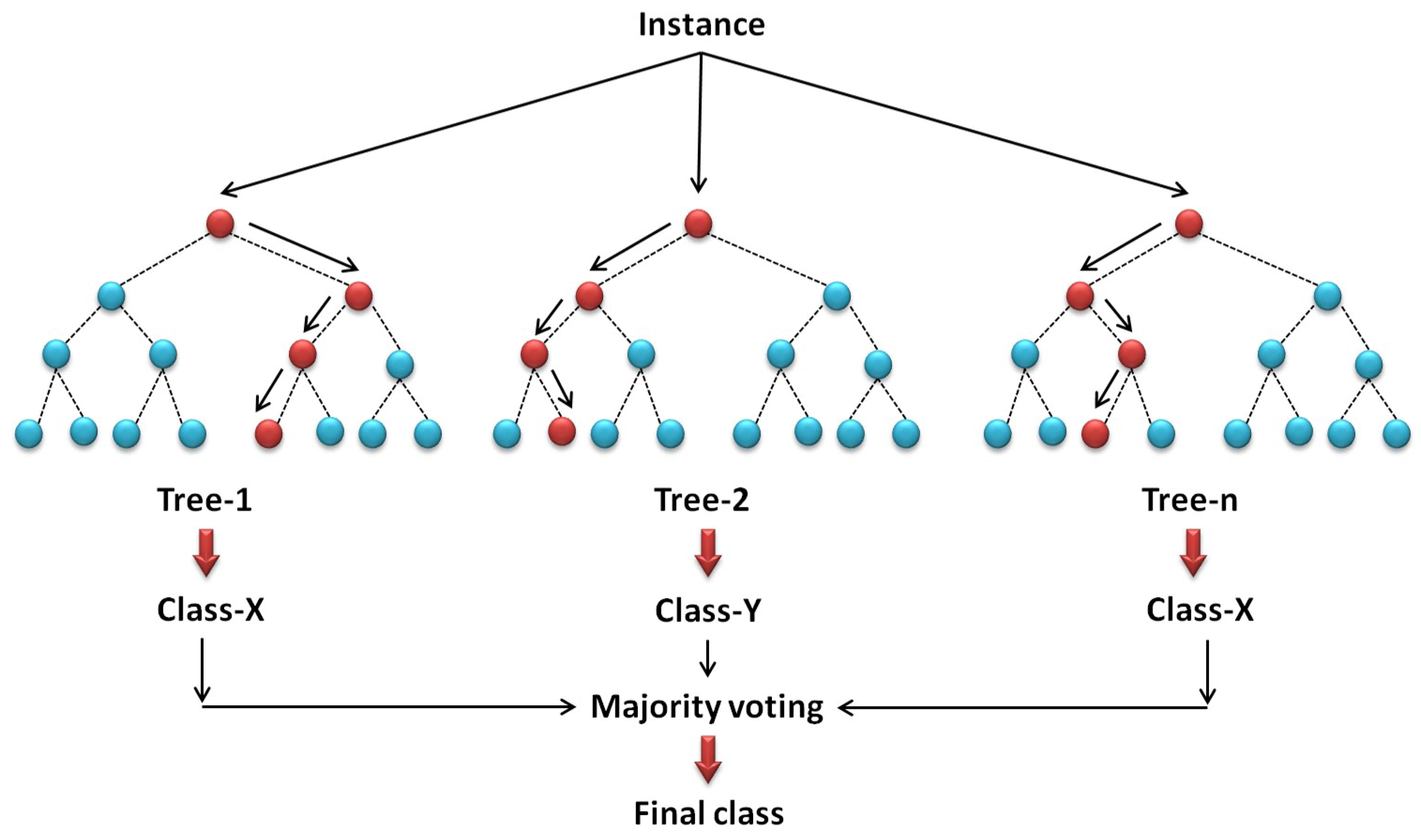
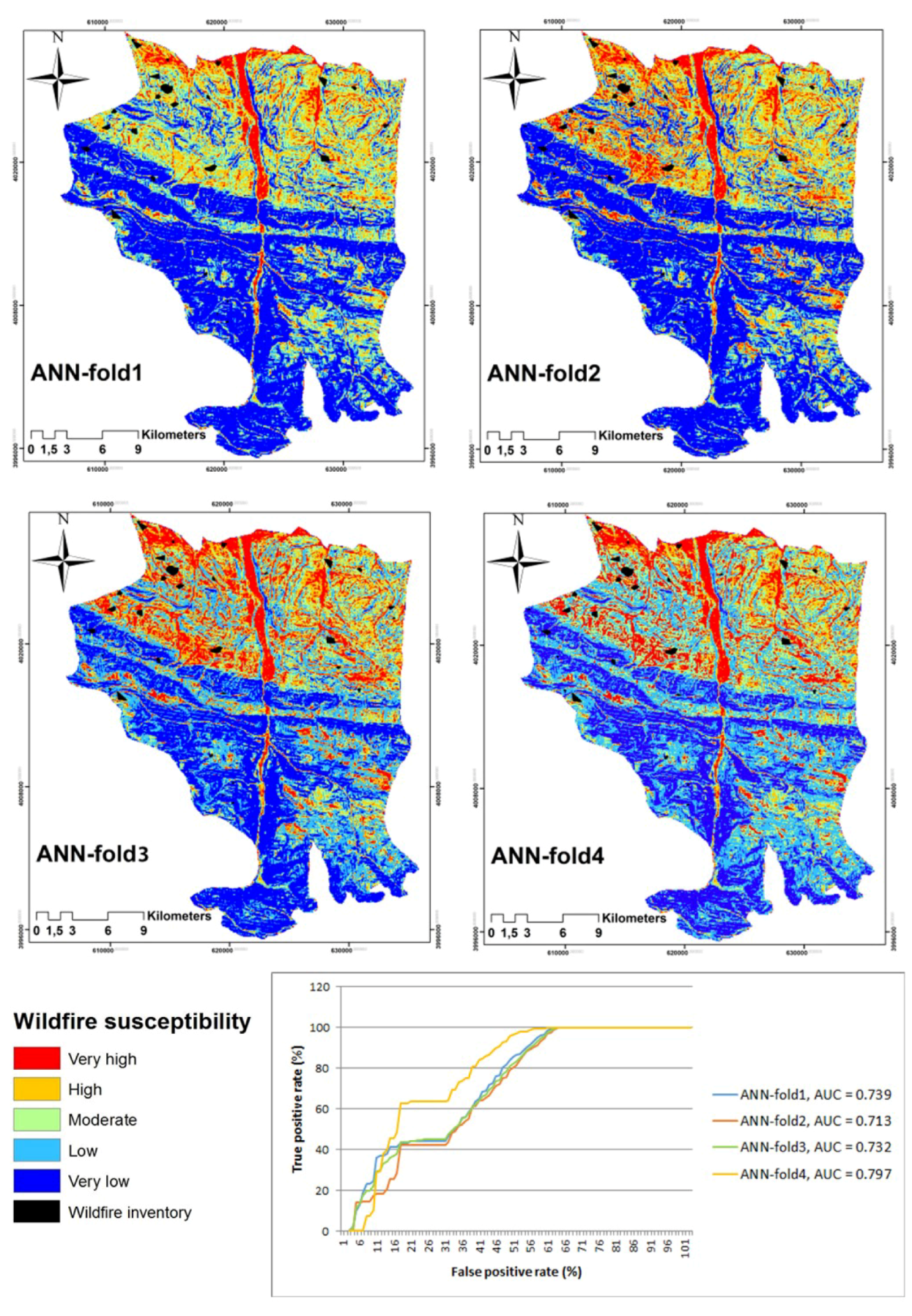
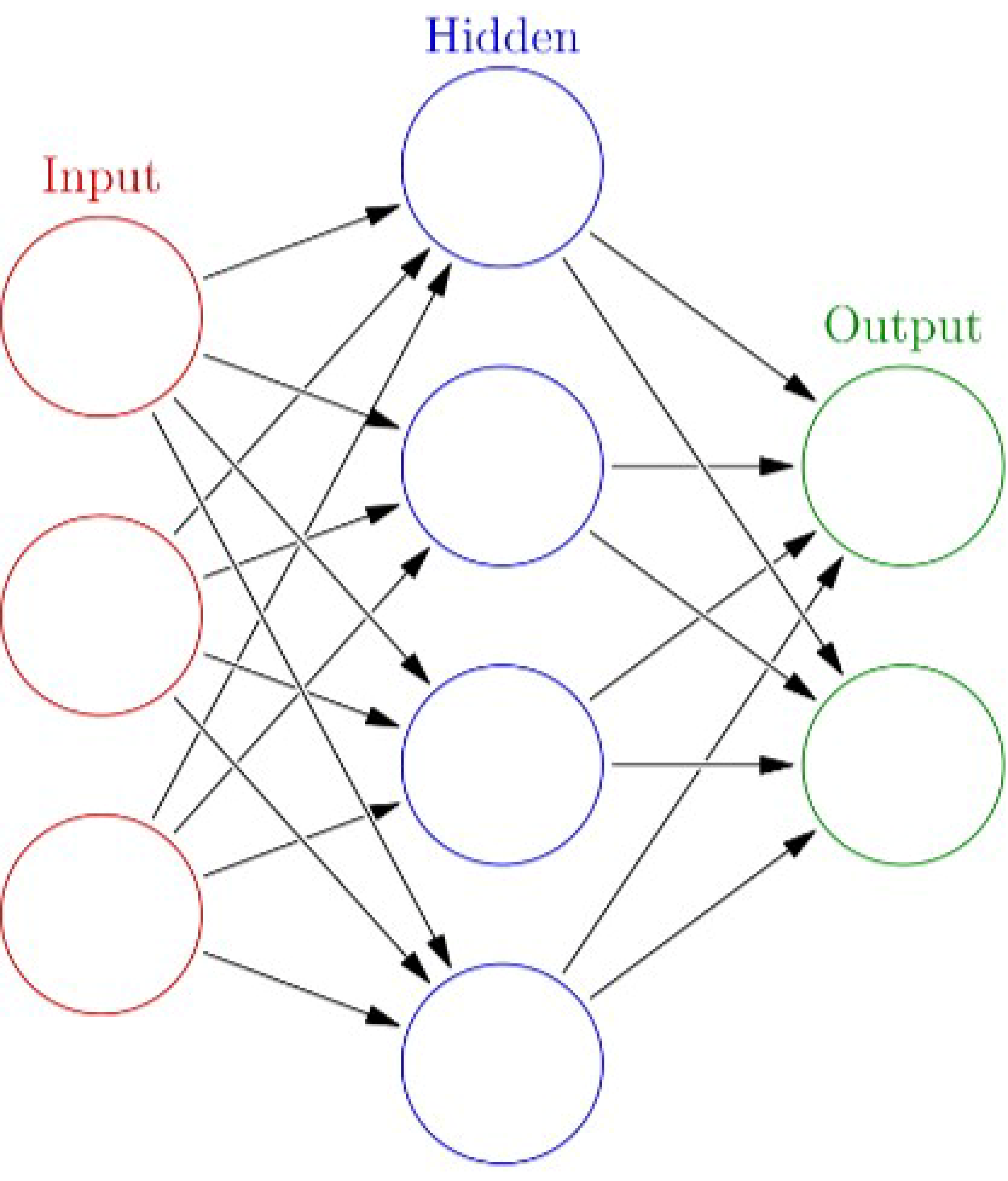
4.2. Artificial Neural Network (ANN)
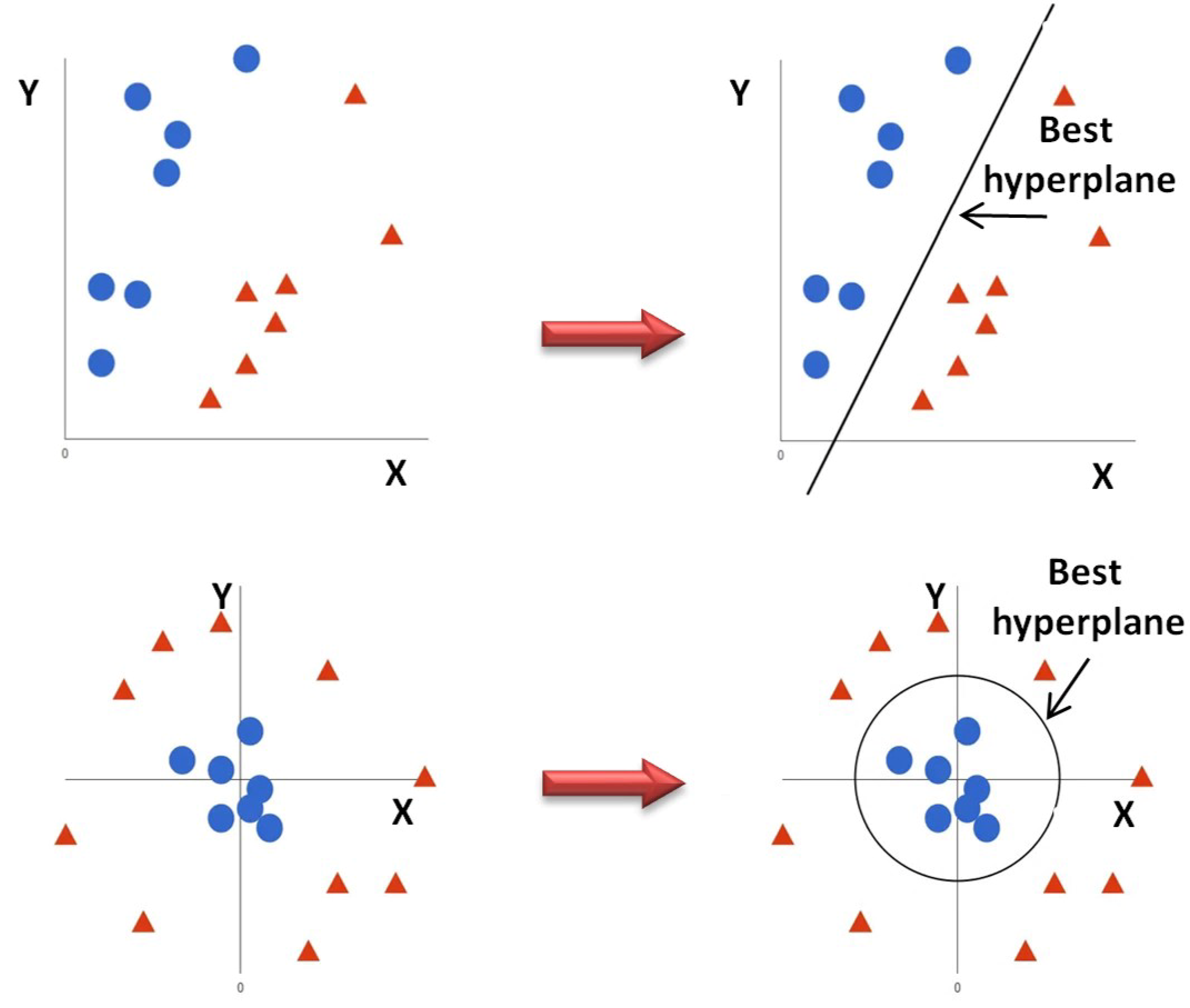
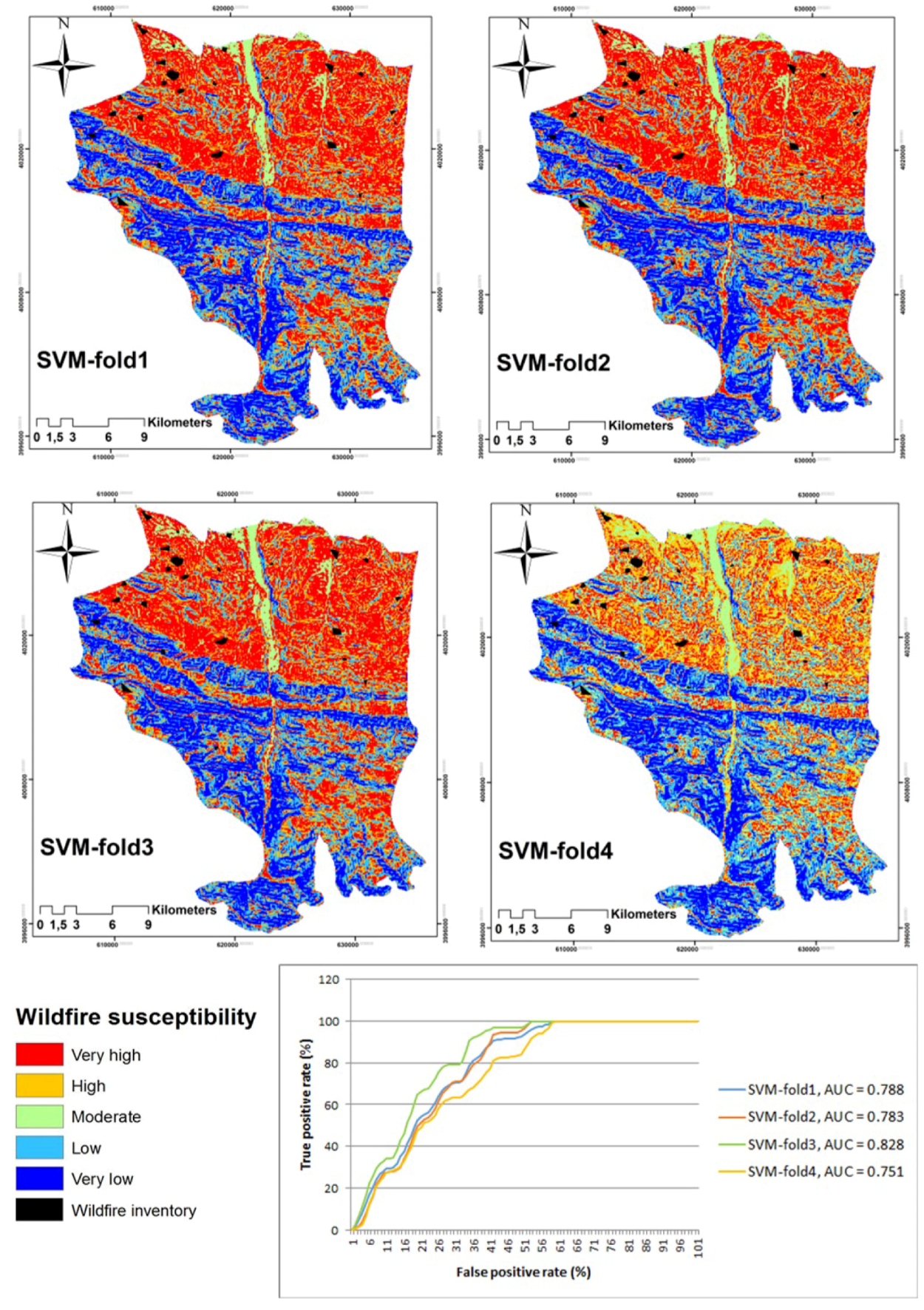
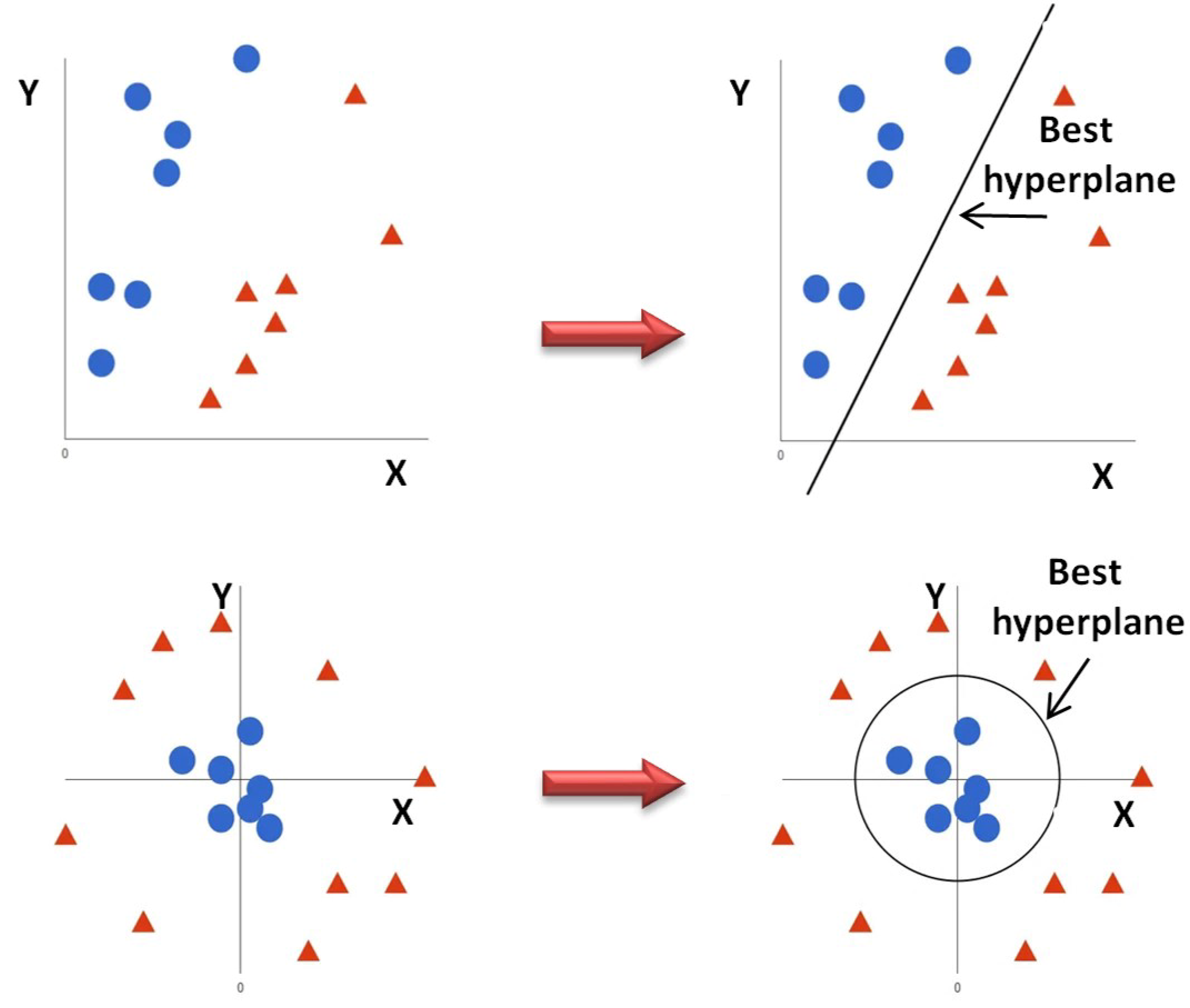
4.3. Support Vector Machines (SVM)
- (a).
- It allows classifying linearly separable data.
- (b).
- If it is not linearly separable, it is possible to use the kernel trick to make it work.
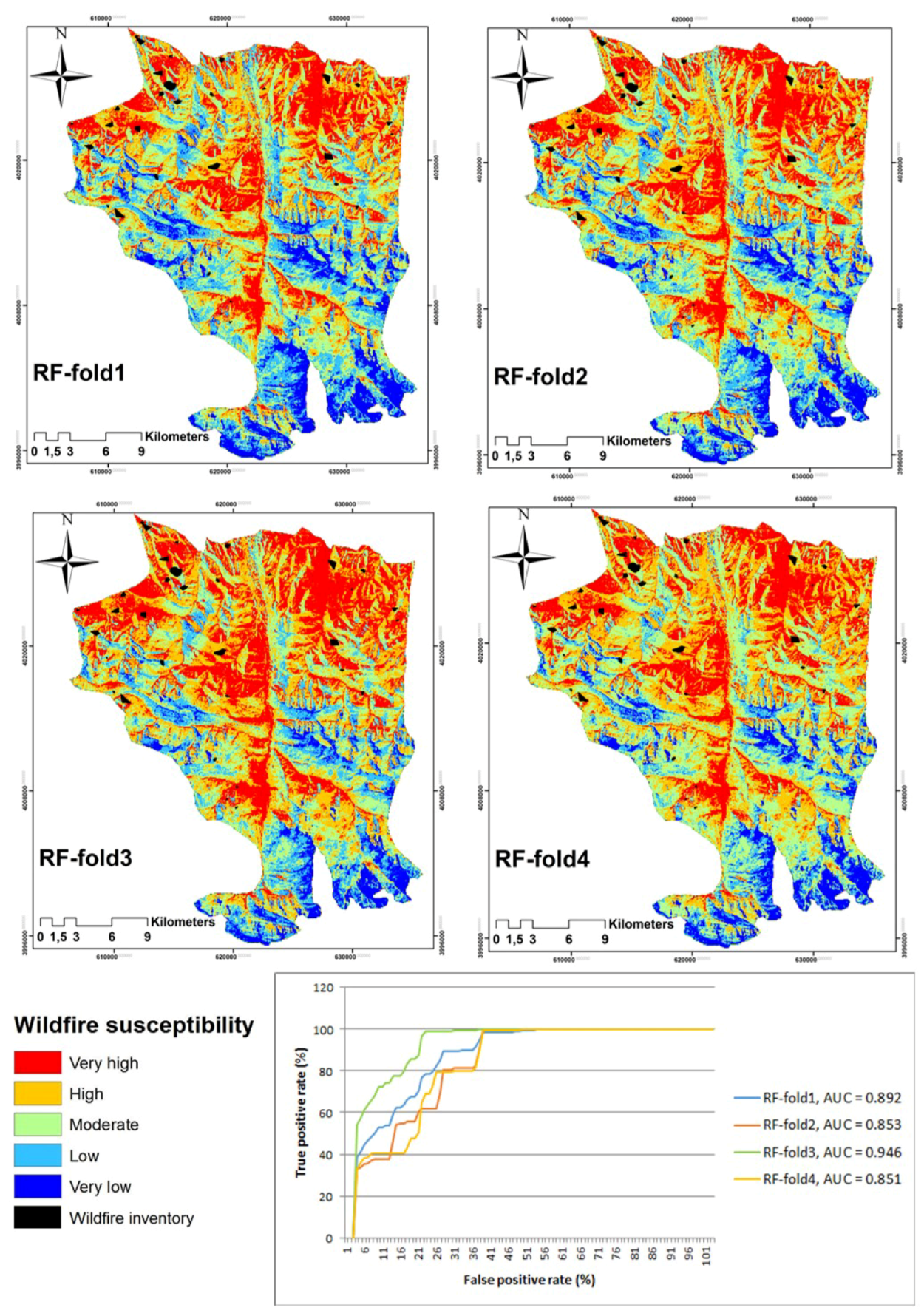
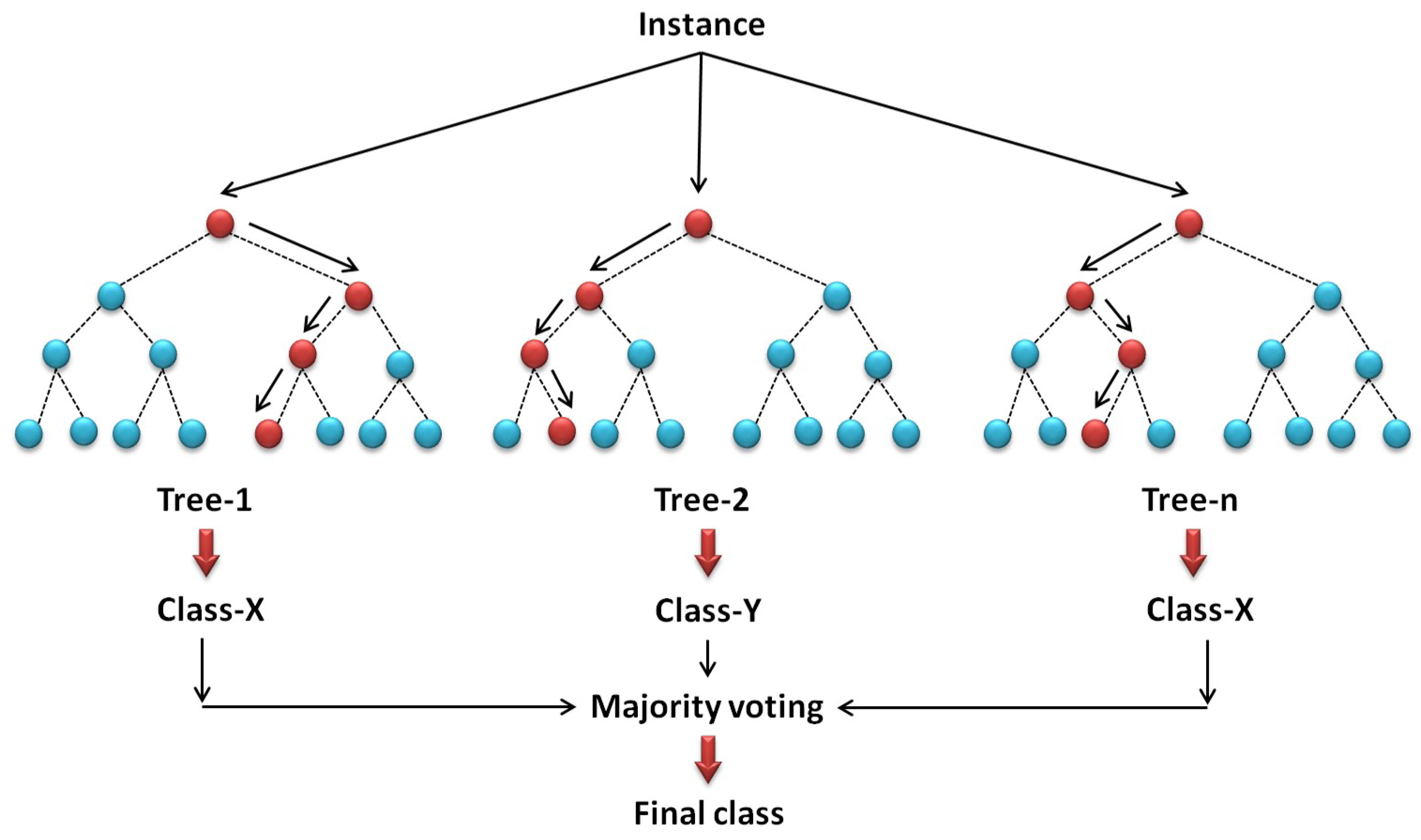
4.4. Random Forest (RF)
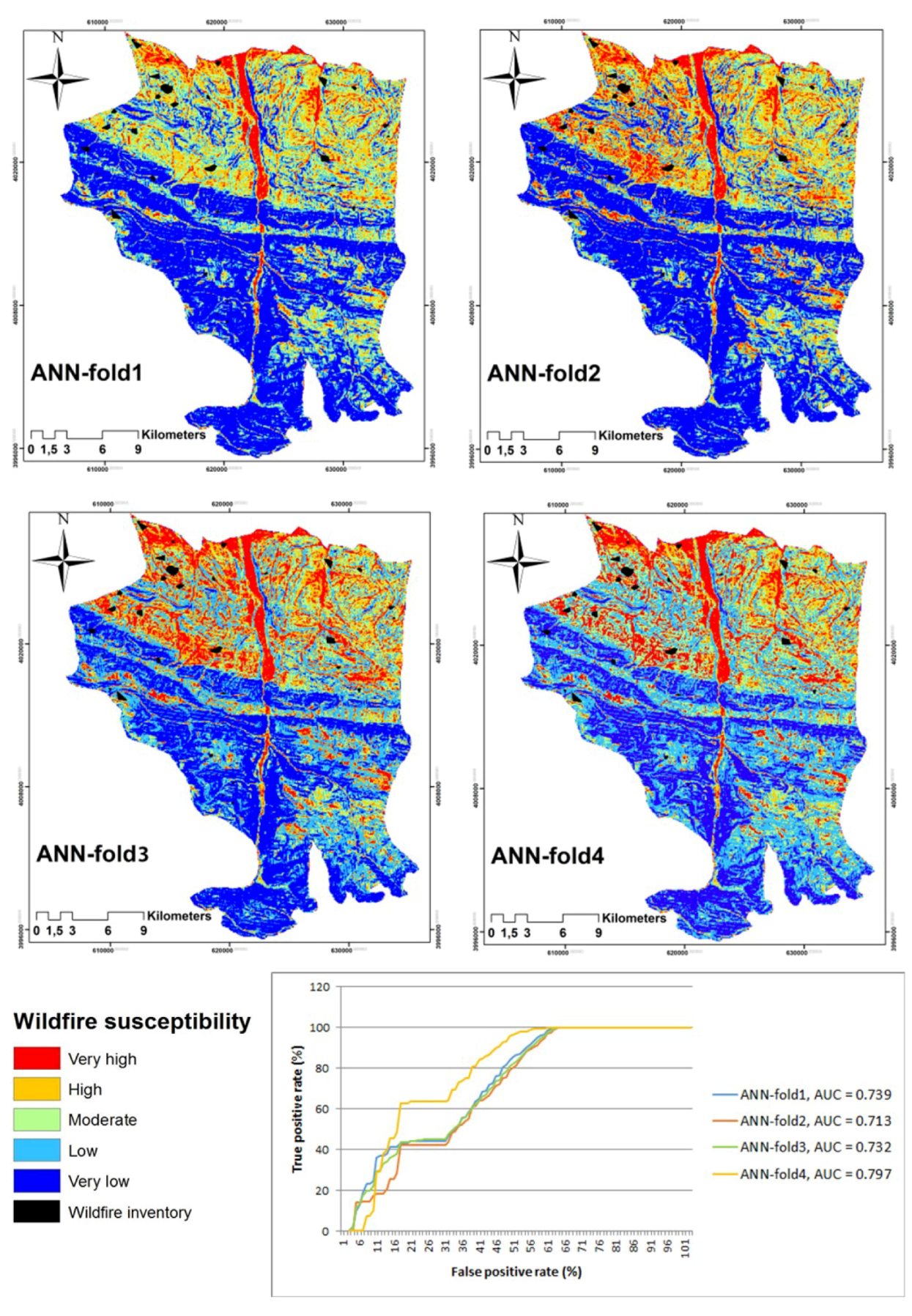
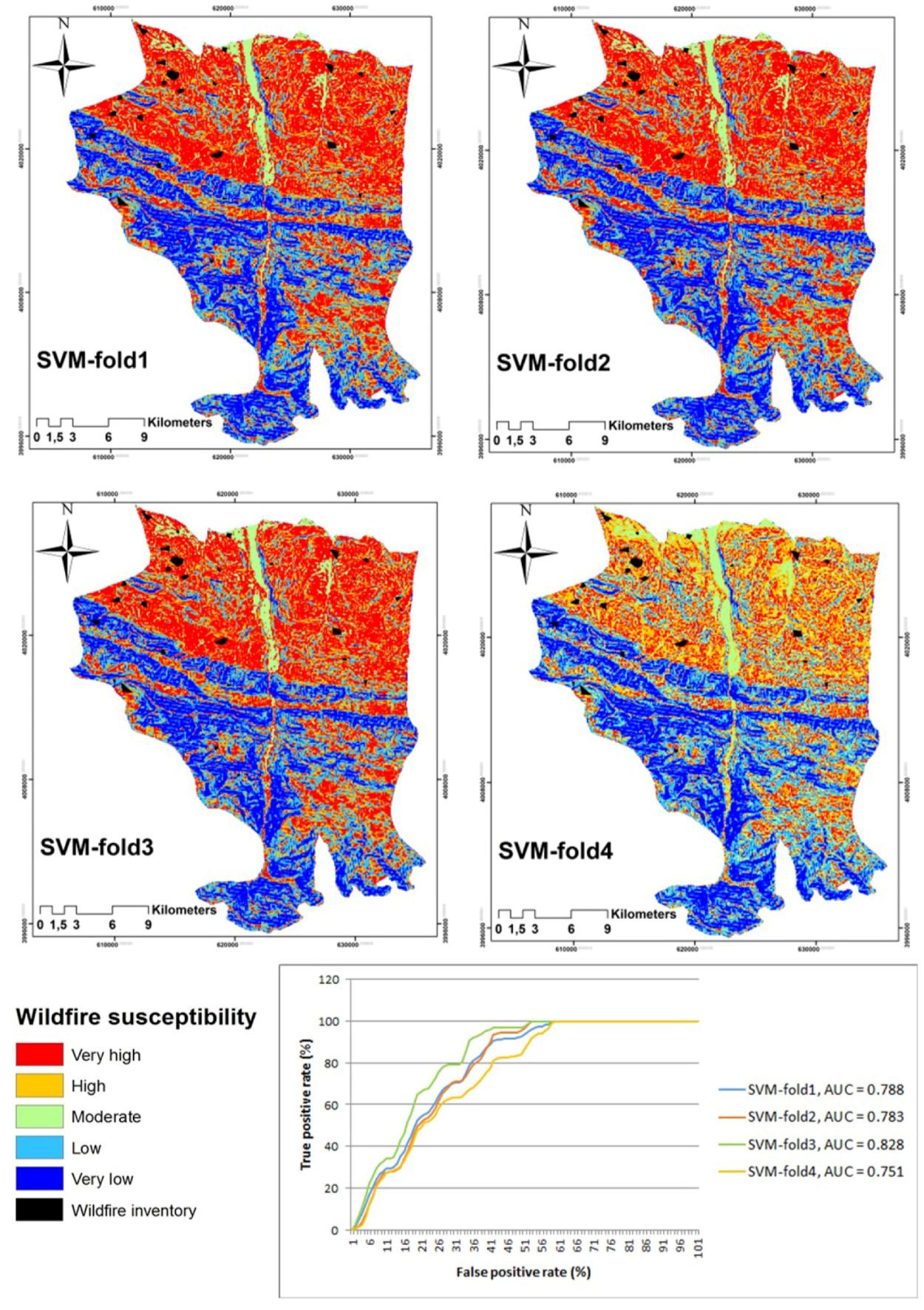
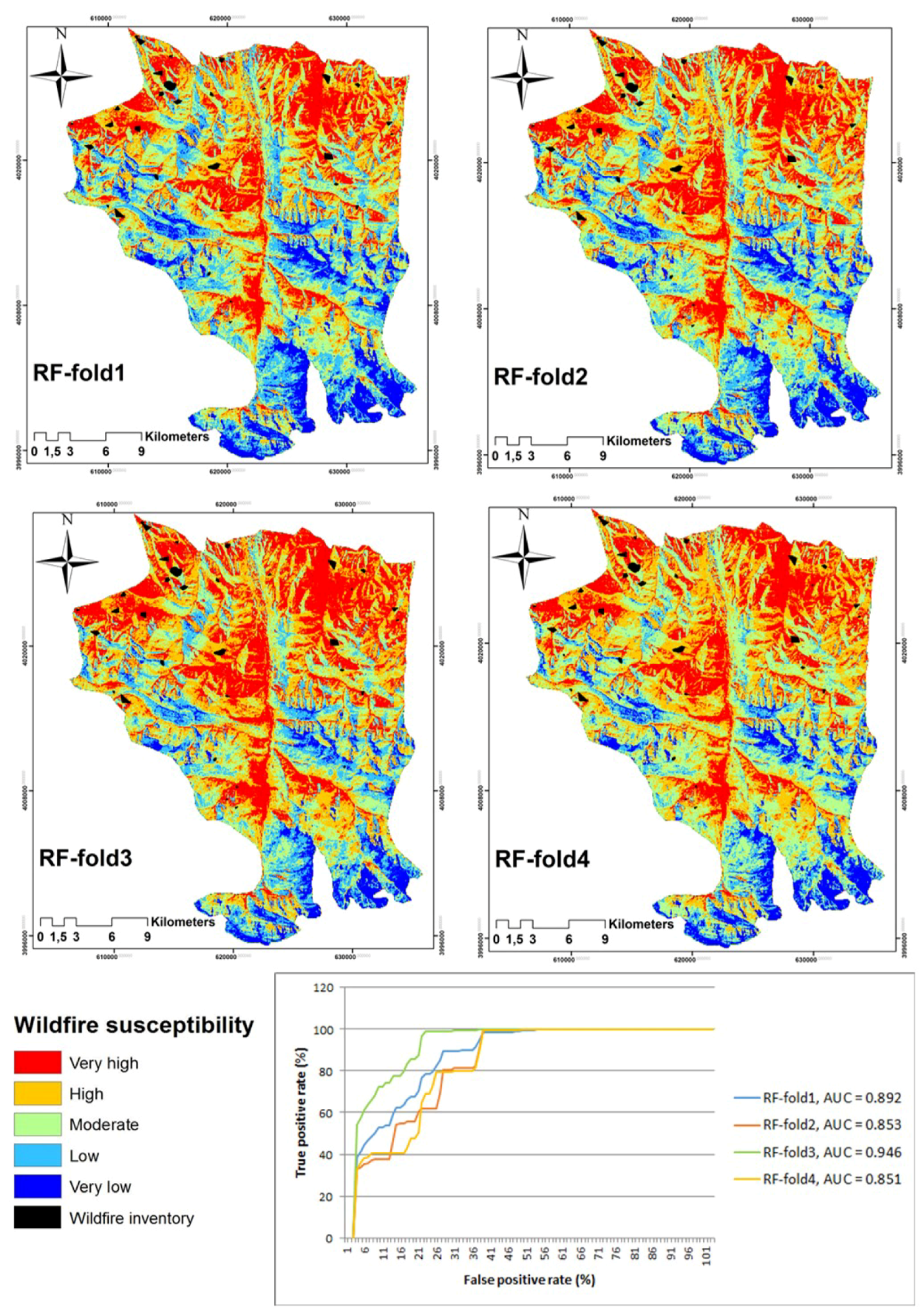
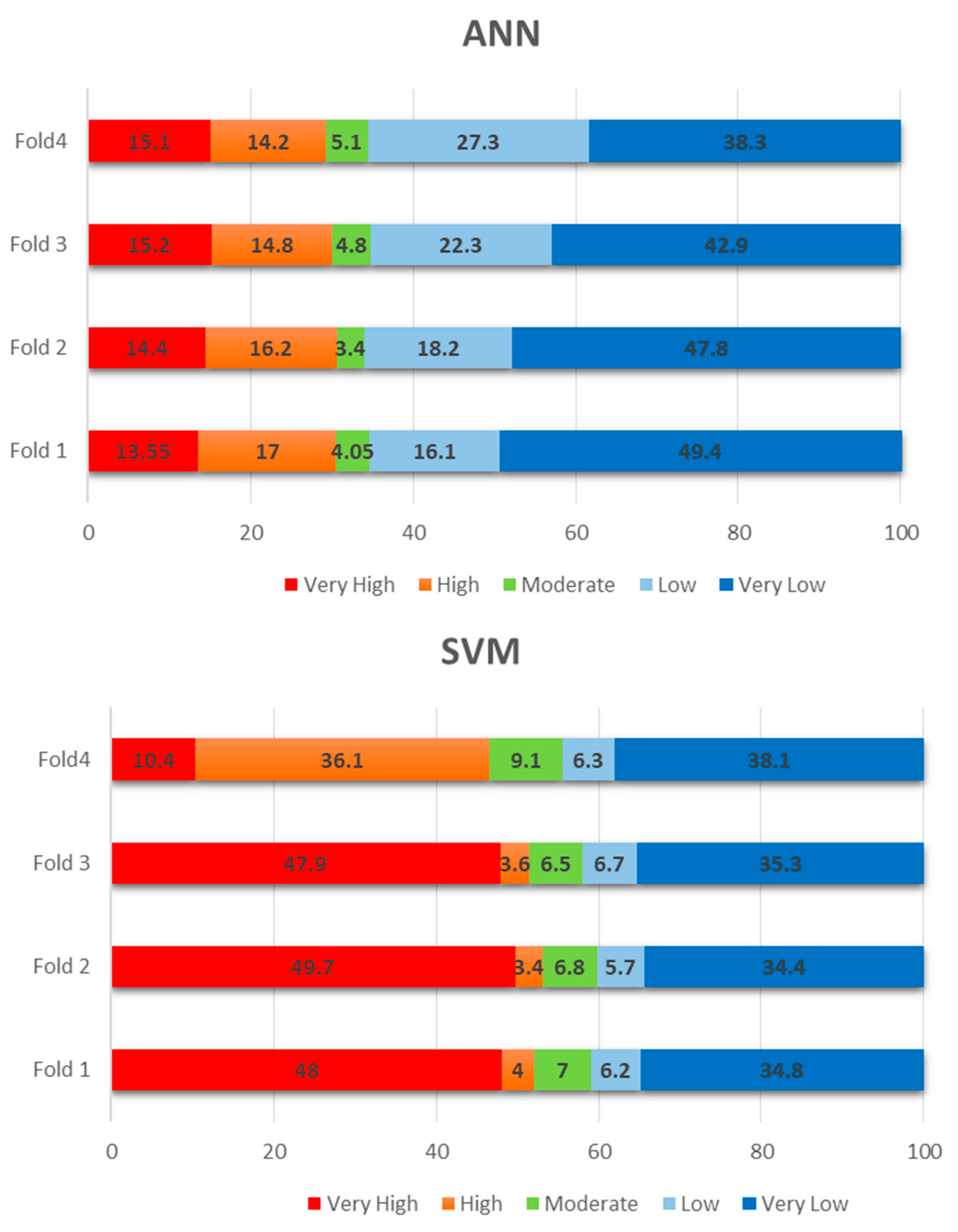
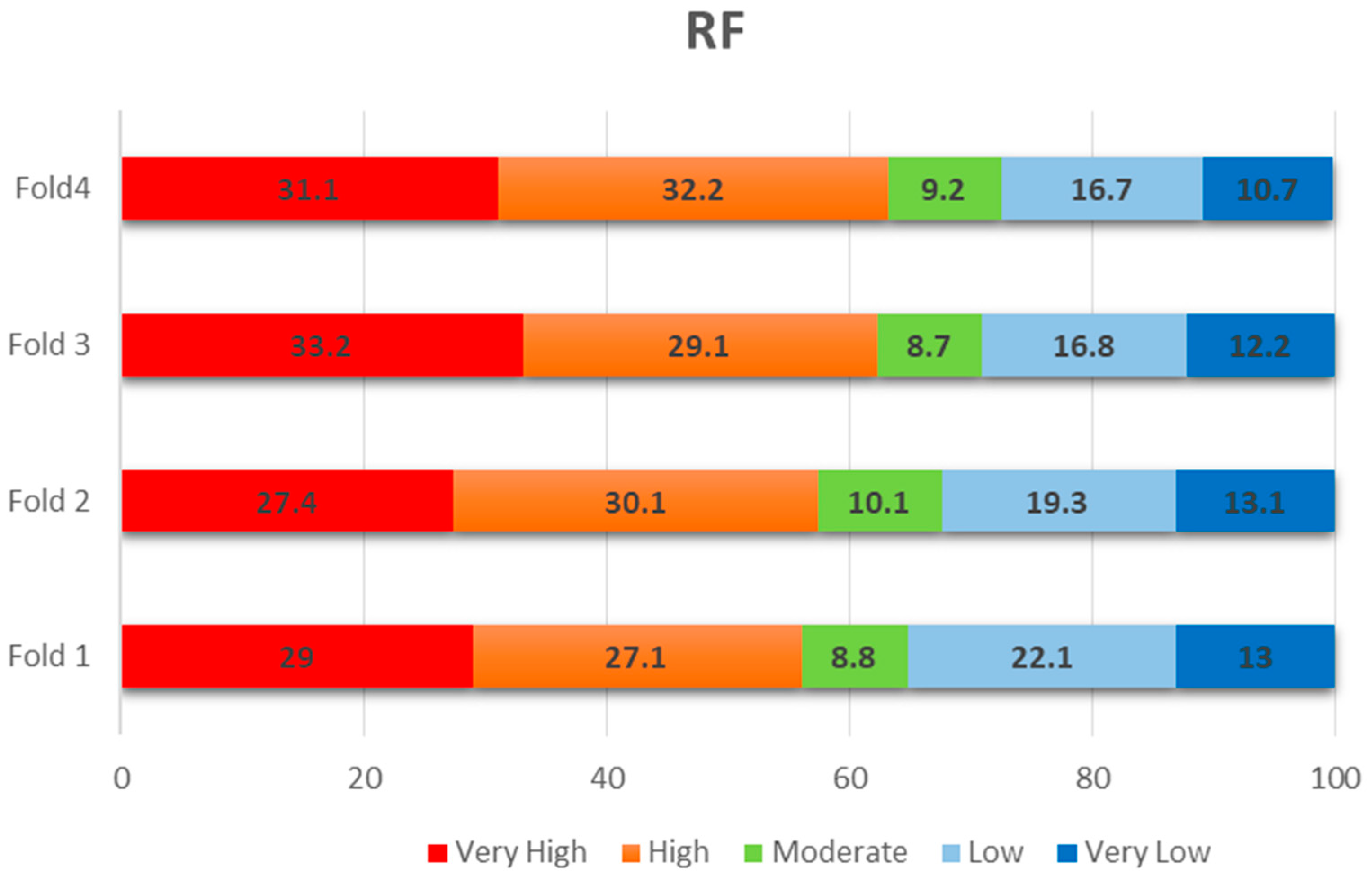
5. Results
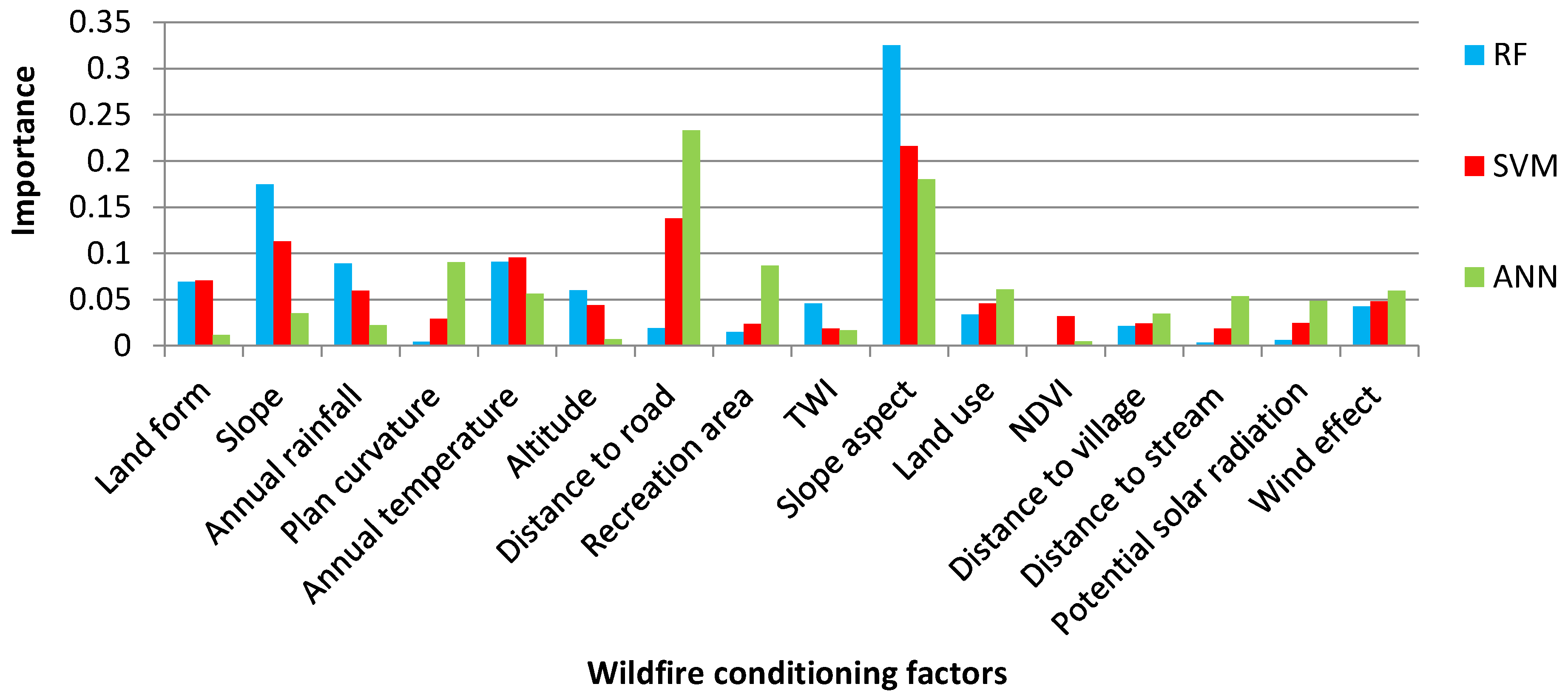
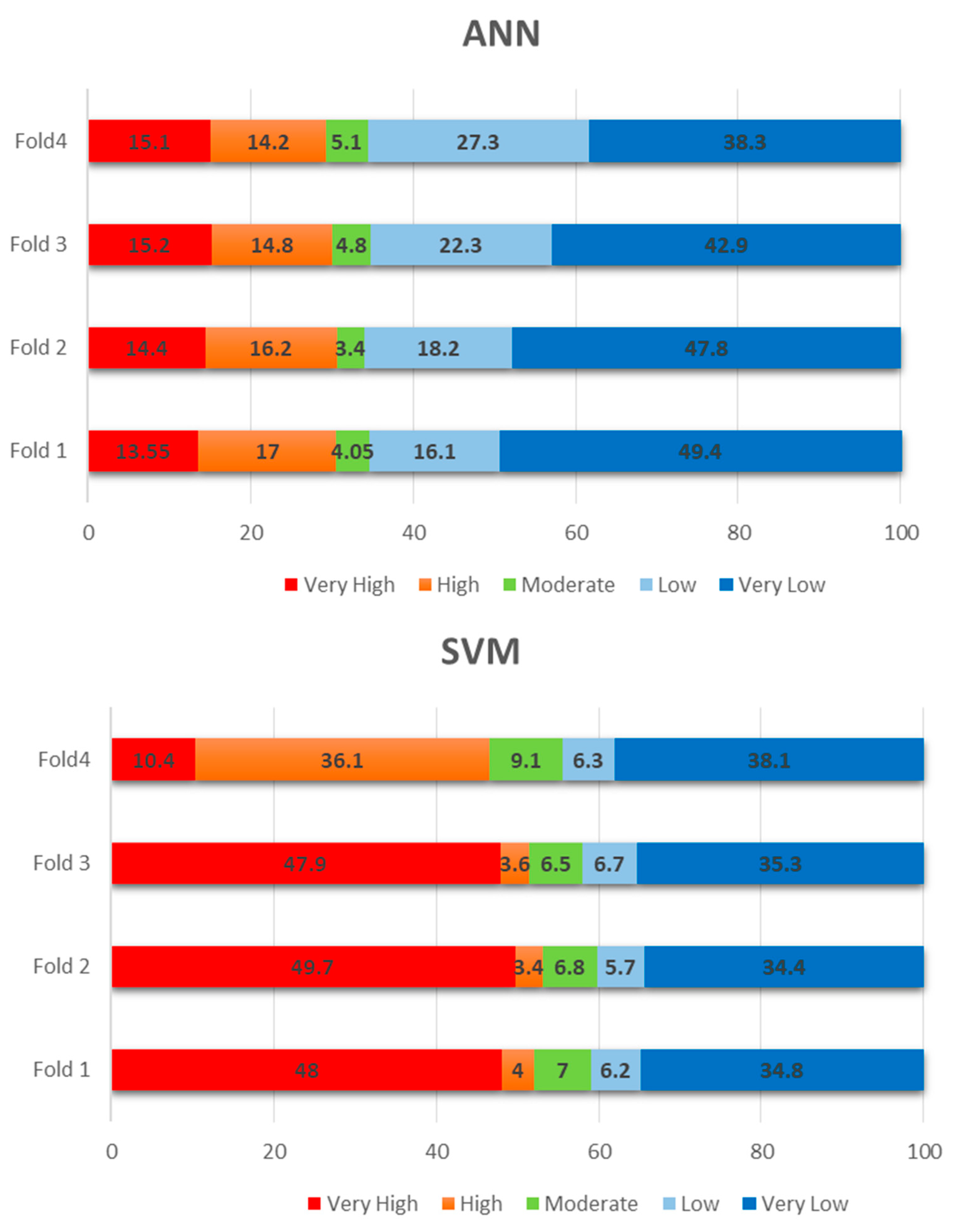
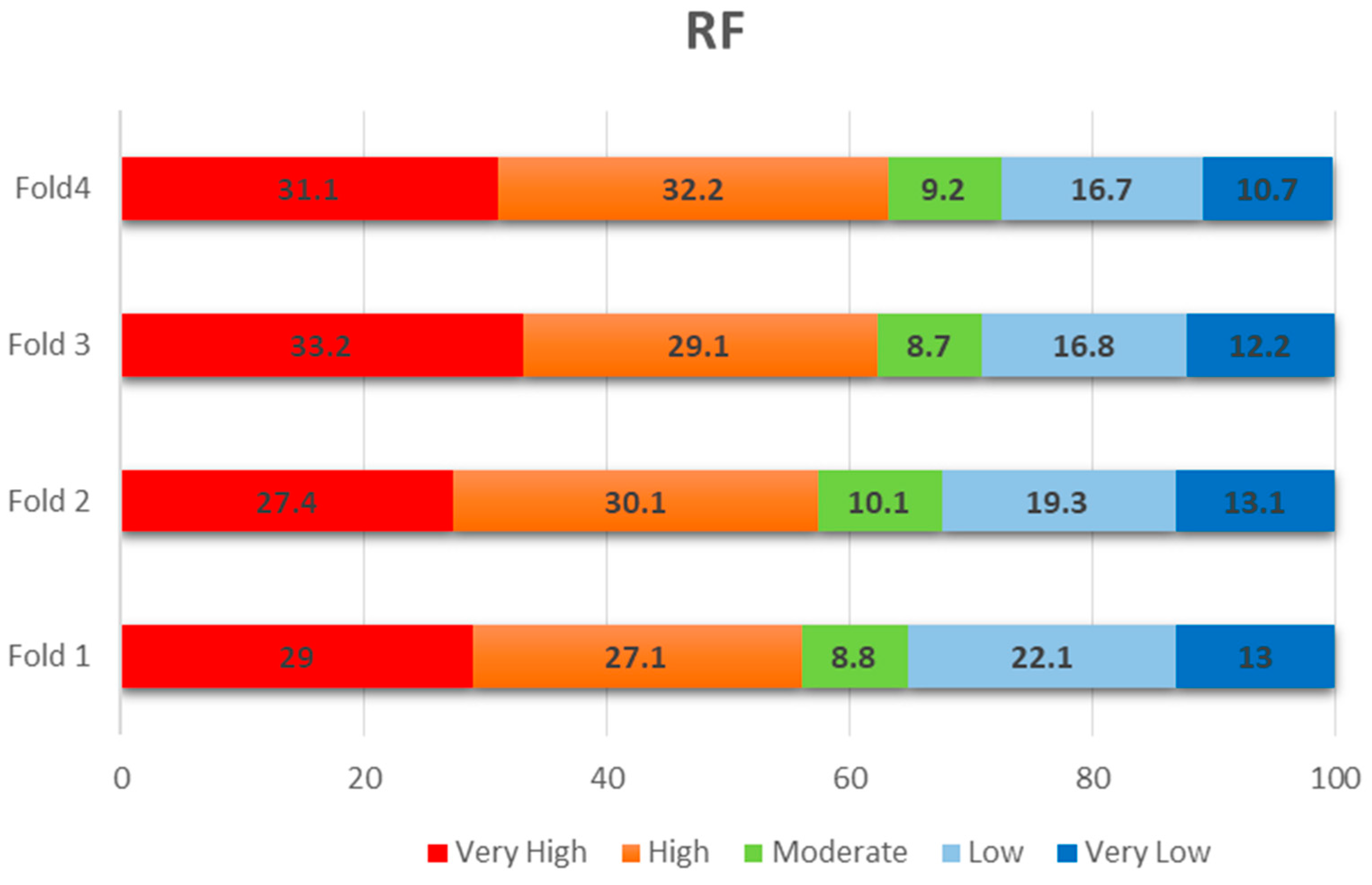
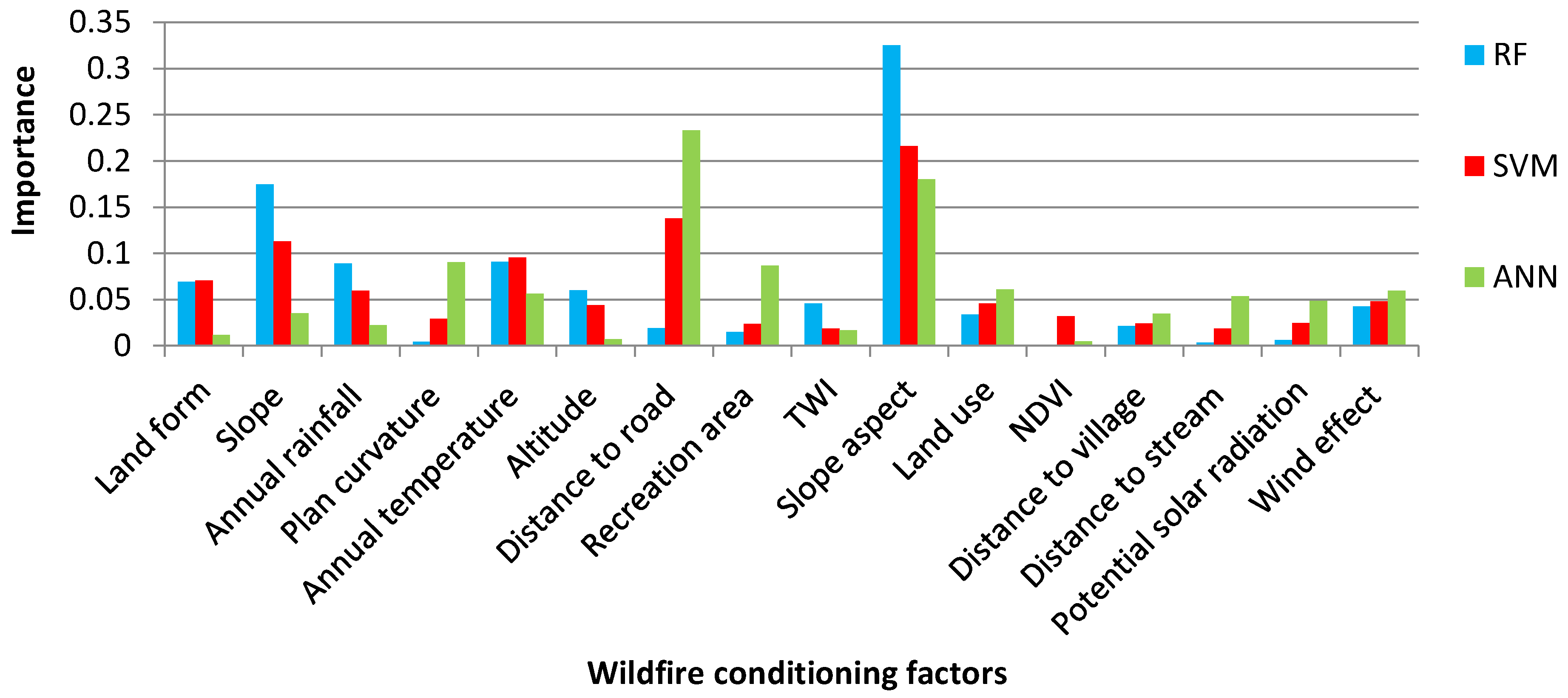
Validation and Sensitivity Analyses
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mohd Razali, S.; Marin Atucha, A.A.; Nuruddin, A.A.; Abdul Hamid, H.; Mohd Shafri, H.Z. Monitoring vegetation drought using modis remote sensing indices for natural forest and plantation areas. J. Spat. Sci. 2016, 61, 157–172. [Google Scholar] [CrossRef]
- Ndalila, M.N.; Williamson, G.J.; Bowman, D.M.J.S. Geographic patterns of fire severity following an extreme eucalyptus forest fire in southern Australia: 2013 Forcett-dunalley fire. Fire 2018, 1, 40. [Google Scholar] [CrossRef]
- Sakellariou, S.; Tampekis, S.; Samara, F.; Sfougaris, A.; Christopoulou, O. Review of state-of-the-art decision support systems (DSSS) for prevention and suppression of forest fires. J. For. Res. 2017, 28, 1107–1117. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Rossi, M. Forest fire susceptibility mapping in the minudasht forests, golestan province, Iran. Environ. Earth Sci. 2015, 73, 1515–1533. [Google Scholar] [CrossRef]
- Kim, S.; Lim, C.-H.; Kim, G.; Lee, J.; Geiger, T.; Rahmati, O.; Son, Y.; Lee, W.-K. Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sens. 2019, 11, 86. [Google Scholar] [CrossRef]
- Edwards, L.J.; Williamson, G.; Williams, S.A.; Veitch, M.G.K.; Salimi, F.; Johnston, F.H. Did fine particulate matter from the summer 2016 landscape fires in Tasmania increase emergency ambulance dispatches? A case crossover analysis. Fire 2018, 1, 26. [Google Scholar] [CrossRef]
- Berger, F.; Rey, F. Mountain protection forests against natural hazards and risks: New french developments by integrating forests in risk zoning. Nat. Hazards 2004, 33, 395–404. [Google Scholar] [CrossRef]
- Agee, J.K. Fire Ecology of Pacific Northwest Forests; Island Press: Washington, DC, USA, 1996. [Google Scholar]
- Lee, H.; Lim, S.; Paik, H. An assessment of fire-damaged forest using spatial analysis techniques. J. Spat. Sci. 2010, 55, 289–301. [Google Scholar] [CrossRef]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Darvishsefat, A.; Mostafavi, M.; Etemad, V.; Jahdi, R. Wind effect on wildfire and simulation of its spread (case study: Siahkal forest in northern Iran). J. Agric. Sci. Technol. 2018, 16, 1109–1121. [Google Scholar]
- Ghorbanzadeh, O.; Blaschke, T. Wildfire susceptibility evaluation by integrating an analytical network process approach into GIS-based analyses. Int. J. Adv. Sci. Eng. Technol. 2018, 6, 48–53. [Google Scholar]
- Akyürek, Z.; Taşel, E. Wildfire simulation modeling using RS and GIS integration for marmaris-çetibeli wildfire. In Proceedings of the 24th EARSel Symposium, Dubrovnik, Croatia, 25–27 May 2004; pp. 69–79. [Google Scholar]
- Pourghasemi, H.R.; Beheshtirad, M.; Pradhan, B. A comparative assessment of prediction capabilities of modified analytical hierarchy process (m-AHP) and mamdani fuzzy logic models using netcad-GIS for forest fire susceptibility mapping. Geomat. Nat. Hazards Risk 2016, 7, 861–885. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Feizizadeh, B.; Blaschke, T. Multi-criteria risk evaluation by integrating an analytical network process approach into GIS-based sensitivity and uncertainty analyses. Geomat. Nat. Hazards Risk 2018, 9, 127–151. [Google Scholar] [CrossRef]
- Kamran, K.V.; Omrani, K.; Khosroshahi, S.S. Forest fire risk assessment using multi-criteria analysis: A case study Kaleybar forest. In Proceedings of the International Conference on Agriculture, Environment and Biological Sciences, Antalya, Turkey, 4–5 June 2014; pp. 30–33. [Google Scholar]
- Dutta, R.; Das, A.; Aryal, J. Big data integration shows Australian bush-fire frequency is increasing significantly. R. Soc. Open Sci. 2016, 3, 150241. [Google Scholar] [CrossRef] [PubMed]
- Yu, X. Disaster prediction model based on support vector machine for regression and improved differential evolution. Nat. Hazards 2017, 85, 959–976. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G.; Wejinya, U.C. Artificial intelligence for forest fire prediction. In Proceedings of the 2010 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Montreal, QC, Canada, 6–9 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1311–1316. [Google Scholar]
- Abdollahi, S.; Pourghasemi, H.R.; Ghanbarian, G.A.; Safaeian, R. Prioritization of effective factors in the occurrence of land subsidence and its susceptibility mapping using an SVM model and their different kernel functions. Bull. Eng. Geol. Environ. 2018, 1–18. [Google Scholar] [CrossRef]
- Valdez, M.C.; Chang, K.-T.; Chen, C.-F.; Chiang, S.-H.; Santos, J.L. Modelling the spatial variability of wildfire susceptibility in honduras using remote sensing and geographical information systems. Geomat. Nat. Hazards Risk 2017, 8, 876–892. [Google Scholar] [CrossRef]
- Arpaci, A.; Malowerschnig, B.; Sass, O.; Vacik, H. Using multi variate data mining techniques for estimating fire susceptibility of Tyrolean forests. Appl. Geogr. 2014, 53, 258–270. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Rostamzadeh, H.; Blaschke, T.; Gholaminia, K.; Aryal, J. A new GIS-based data mining technique using an adaptive neuro-fuzzy inference system (anfis) and k-fold cross-validation approach for land subsidence susceptibility mapping. Nat. Hazards 2018, 94, 497–517. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266, 198–207. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F.; Martínez-Álvarez, F.; Bui, D.T. A novel ensemble modeling approach for the spatial prediction of tropical forest fire susceptibility using logitboost machine learning classifier and multi-source geospatial data. Theor. Appl. Climatol. 2018, 137, 637–653. [Google Scholar] [CrossRef]
- Ebel, B.A. Simulated unsaturated flow processes after wildfire and interactions with slope aspect. Water Resour. Res. 2013, 49, 8090–8107. [Google Scholar] [CrossRef]
- Pourghasemi, H.R. GIS-based forest fire susceptibility mapping in Iran: A comparison between evidential belief function and binary logistic regression models. Scand. J. For. Res. 2016, 31, 80–98. [Google Scholar] [CrossRef]
- Koutsias, N.; Allgöwer, B.; Conedera, M. What is common in wildland fire occurrence in greece and switzerland?—Statistics to study fire occurrence pattern. In Proceedings of the 4th International Conference on Forest Fire Research, Coimbra, Portugal, 18–23 November 2002; pp. 18–23. [Google Scholar]
- Ganteaume, A.; Camia, A.; Jappiot, M.; San-Miguel-Ayanz, J.; Long-Fournel, M.; Lampin, C. A review of the main driving factors of forest fire ignition over Europe. Environ. Manag. 2013, 51, 651–662. [Google Scholar] [CrossRef]
- Baltar, M. County-Level Analysis of the Impact of Temperature and Population Increases on California Wildfire Data; UCLA: Los Angeles, CA, USA, 2015. [Google Scholar]
- Vasilakos, C.; Kalabokidis, K.; Hatzopoulos, J.; Matsinos, I. Identifying wildland fire ignition factors through sensitivity analysis of a neural network. Nat. Hazards 2009, 50, 125–143. [Google Scholar] [CrossRef]
- Tanskanen, H.; Venäläinen, A.; Puttonen, P.; Granström, A. Impact of stand structure on surface fire ignition potential in picea abies and pinus sylvestris forests in Southern Finland. Can. J. For. Res. 2005, 35, 410–420. [Google Scholar] [CrossRef]
- Fovell, R.G.; Gallagher, A. Winds and gusts during the thomas fire. Fire 2018, 1, 47. [Google Scholar] [CrossRef]
- Hilton, J.; Miller, C.; Sharples, J.; Sullivan, A. Curvature effects in the dynamic propagation of wildfires. Int. J. Wildland Fire 2017, 25, 1238–1251. [Google Scholar] [CrossRef]
- Porensky, L.M.; Derner, J.D.; Pellatz, D.W. Plant community responses to historical wildfire in a shrubland–grassland ecotone reveal hybrid disturbance response. Ecosphere 2018, 9, e02363. [Google Scholar] [CrossRef]
- Cantarello, E.; Newton, A.C.; Hill, R.A.; Tejedor-Garavito, N.; Williams-Linera, G.; López-Barrera, F.; Manson, R.H.; Golicher, D.J. Simulating the potential for ecological restoration of dryland forests in Mexico under different disturbance regimes. Ecol. Model. 2011, 222, 1112–1128. [Google Scholar] [CrossRef]
- Verbesselt, J.; Somers, B.; van Aardt, J.; Jonckheere, I.; Coppin, P. Monitoring herbaceous biomass and water content with spot vegetation time-series to improve fire risk assessment in savanna ecosystems. Remote Sens. Environ. 2006, 101, 399–414. [Google Scholar] [CrossRef]
- Razali, S.M.; Nuruddin, A.A.; Malek, I.A.; Patah, N.A. Forest fire hazard rating assessment in peat swamp forest using landsat thematic mapper image. J. Appl. Remote Sens. 2010, 4, 043531. [Google Scholar] [CrossRef]
- Stephens, S.L. Forest fire causes and extent on United States forest service lands. Int. J. Wildland Fire 2005, 14, 213–222. [Google Scholar] [CrossRef]
- Keeley, J.; Fotheringham, C. Impact of past, present, and future fire regimes on North American mediterranean shrublands. In Fire and Climate Change in Temperate Ecosystems of the Western Americas; Veblen, T.T., Baker, W.L., Montenegro, G., Swetnam, T.W., Eds.; Springer-Verlag: New York, NY, USA, 2003. [Google Scholar]
- Peters, M.P.; Iverson, L.R.; Matthews, S.N.; Prasad, A.M. Wildfire hazard mapping: Exploring site conditions in eastern us wildland–urban interfaces. Int. J. Wildland Fire 2013, 22, 567–578. [Google Scholar] [CrossRef]
- Canu, A.; Arca, B.; Pellizzaro, G.; Valeriano Pintus, G.; Ferrara, R.; Duce, P. Wildfires and post-fire erosion risk in a coastal area under severe anthropic pressure associated with the touristic fluxes. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 23–28 April 2017; p. 9585. [Google Scholar]
- Badarinath, K.; Madhavilatha, K.; Chand, T.K.; Murthy, M. Modeling potential forest fire danger using modis data. J. Indian Soc. Remote Sens. 2004, 32, 343–350. [Google Scholar] [CrossRef]
- Cusworth, D.H.; Mickley, L.J.; Sulprizio, M.P.; Liu, T.; Marlier, M.E.; DeFries, R.S.; Guttikunda, S.K.; Gupta, P. Quantifying the influence of agricultural fires in northwest India on urban air pollution in Delhi, India. Environ. Res. Lett. 2018, 13, 044018. [Google Scholar] [CrossRef] [Green Version]
- Mead, M.; Castruccio, S.; Latif, M.; Nadzir, M.; Dominick, D.; Thota, A.; Crippa, P. Impact of the 2015 wildfires on malaysian air quality and exposure: A comparative study of observed and modeled data. Environ. Res. Lett. 2018, 13, 044023. [Google Scholar] [CrossRef]
- SWOAC. A National Project of Mazandaran Province; SWOAC: Amol, Iran, 2018. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection; IJCAI: Montreal, QC, Canada, 1995; pp. 1137–1145. [Google Scholar]
- Ghorbanzadeh, O.; Blaschke, T.; Aryal, J.; Gholaminia, K. A new GIS-based technique using an adaptive neuro-fuzzy inference system for land subsidence susceptibility mapping. J. Spat. Sci. 2018, 1–17. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Safi, Y.; Bouroumi, A. Prediction of forest fires using artificial neural networks. Appl. Math. Sci. 2013, 7, 271–286. [Google Scholar] [CrossRef]
- Park, S.; Choi, C.; Kim, B.; Kim, J. Landslide susceptibility mapping using frequency ratio, analytic hierarchy process, logistic regression, and artificial neural network methods at the Inje area, Korea. Environ. Earth Sci. 2013, 68, 1443–1464. [Google Scholar] [CrossRef]
- Mohammadi, A.; Shahabi, H.; Bin Ahmad, B. Land-cover change detection in a part of cameron highlands, malaysia using ETM+ satellite imagery and support vector machine (SVM) algorithm. EnvironmentAsia 2019, 12, 145–154. [Google Scholar]
- Janik, P.; Lobos, T. Automated classification of power-quality disturbances using svm and rbf networks. IEEE Trans. Power Deliv. 2006, 21, 1663–1669. [Google Scholar] [CrossRef]
- Ho, T.K.; Hull, J.J.; Srihari, S.N. Decision combination in multiple classifier systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 1, 66–75. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lü, Y.; Luo, Y.; Ren, Y.; Comber, A. A modified change vector approach for quantifying land cover change. Remote Sens. 2018, 10, 1578. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Petkovic, D.; Altman, R.B.; Wong, M.; Vigil, A. Improving the Explainability of Random Forest Classifier-User Centered ApproachPSBWorld Scientific: Singapore, 2018; pp. 204–215.
- Dimitriadis, S.I.; Liparas, D. Alzheimer’s Disease Neuroimaging Initiative. How random is the random forest? Random forest algorithm on the service of structural imaging biomarkers for Alzheimer’s disease: From alzheimer’s disease neuroimaging initiative (ADNI) database. Neural Regen. Res. 2018, 13, 962. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Blaschke, T. Gis-multicriteria decision analysis for landslide susceptibility mapping: Comparing three methods for the Urmia lake basin, Iran. Nat. Hazards 2013, 65, 2105–2128. [Google Scholar] [CrossRef]
- Linden, A. Measuring diagnostic and predictive accuracy in disease management: An introduction to receiver operating characteristic (ROC) analysis. J. Eval. Clin. Pract. 2006, 12, 132–139. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Sameen, M.I.; Chen, W.; Xu, C. Spatial prediction of rotational landslide using geographically weighted regression, logistic regression, and support vector machine models in Xing Guo area (China). Geomat. Nat. Hazards Risk 2017, 8, 1997–2022. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, M.; de la Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Jaafari, A.; Pourghasemi, H.R. Factors influencing regional-scale wildfire probability in Iran: An application of random forest and support vector machine. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 607–619. [Google Scholar]
- Bui, D.T.; Bui, Q.-T.; Nguyen, Q.-P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar]
- Haas, J.R.; Calkin, D.E.; Thompson, M.P. A national approach for integrating wildfire simulation modeling into wildland urban interface risk assessments within the United States. Landsc. Urban Plan. 2013, 119, 44–53. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wildfire Conditioning Factors | Class | # of Pixels in the Domain | % of Domain | % of Wildfires | ||
|---|---|---|---|---|---|---|
| Slope aspect | (1) Flat | 413 | 32.66 | 0.05 | 0.23 | 0.04 |
| (2) North | 163477 | 12929.5 | 20.017 | 78.87 | 15.74 | |
| (3) Northeast | 157185 | 12431.86 | 16.25 | 74.90 | 14.95 | |
| (4) East | 111057 | 8783.56 | 13.60 | 59.27 | 11.83 | |
| (5) Southeast | 64513 | 5102.32 | 7.9 | 35.55 | 7.09 | |
| (6) South | 59425 | 4699.96 | 7.27 | 53.12 | 10.6 | |
| (7) Southwest | 69288 | 5480.03 | 8.48 | 65.06 | 12.98 | |
| (8) West | 89748 | 7098 | 10.98 | 83.87 | 16.71 | |
| (9) Northwest | 101549 | 8031.57 | 12.43 | 50.21 | 10.02 | |
| Slope (%) | ||||||
| (1) 0–5 | 52438 | 4147.35 | 6.42 | 49.13 | 9.8 | |
| (2) 5–10 | 131189 | 10375.82 | 16.06 | 129.72 | 25.89 | |
| (3) 10–15 | 165158 | 13062.45 | 20.22 | 160.07 | 31.95 | |
| (4) 15–20 | 132343 | 10467.09 | 16.20 | 68.49 | 13.67 | |
| (5) 20–30 | 172740 | 13662.11 | 21.15 | 55.58 | 11.09 | |
| (6) 30< | 162787 | 12874.92 | 19.93 | 37.93 | 7.57 | |
| Altitude (m) | ||||||
| (1) 500> | 267103 | 20609.83 | 31.76 | 272.50 | 54.39 | |
| (2) 500–1000 | 221070 | 17057.90 | 26.28 | 139.98 | 27.93 | |
| (3) 1000–1500 | 175496 | 13541.38 | 20.86 | 33.66 | 6.72 | |
| (4) 1500–2000 | 131112 | 10116.68 | 15.59 | 51.22 | 10.23 | |
| (5) 2000–2500 | 44074 | 3400.77 | 5.59 | 3.57 | 0.71 | |
| (6) 2500< | 2064 | 159.25 | 0.24 | 0 | ||
| Topographic wetness index (TWI) | ||||||
| (1) 5–10 | 89647 | 7090.23 | 10.97 | 61.82 | 12.34 | |
| (2) 10–15 | 186858 | 14778.7 | 22.8 | 117.62 | 23.48 | |
| (3) 15–20 | 113587 | 8983.66 | 13.9 | 61.22 | 12.22 | |
| (4) 20–25 | 259476 | 20522.1 | 31.7 | 174.21 | 34.72 | |
| (5) 25< | 167087 | 13215. | 20.45 | 86.07 | 17.18 | |
| Landform | ||||||
| (1) Canyon | 39975 | 3161.64 | 4.8 | 16.10 | 3.21 | |
| (2) Gentle slopes | 159331 | 12601.5 | 19.48 | 63.23 | 12.62 | |
| (3) Steep slope | 513481 | 40611.5 | 62.79 | 375.23 | 75.02 | |
| (4) Ridges | 104869 | 8294.15 | 12.825 | 45.75 | 9.13 | |
| Plan curvature (100/m) | ||||||
| (1) Concave | 153099 | 12108.7 | 18.73 | 62.9 | 12.55 | |
| (2) Flat | 499095 | 39473.7 | 61.05 | 351.45 | 70.15 | |
| (3) Convex | 165204 | 13066 | 20.21 | 86.59 | 17.28 |
| Wildfire Conditioning Factors | Class | % of Domain | % of Wildfires | ||
|---|---|---|---|---|---|
| Distance to stream (m) | |||||
| (1) 200> | 6232.1 | 9.636 | 22.56 | 4.5 | |
| (2) 200–500 | 8423.7 | 13.02 | 83.04 | 16.57 | |
| (3) 500–800 | 8397.2 | 12.985 | 97.99 | 19.57 | |
| (4) 800–1200 | 10434.9 | 16.135 | 67.93 | 13.56 | |
| (5) 1200< | 31180.93 | 48.216 | 229.43 | 45.79 | |
| Annual rainfall (mm) | |||||
| (1) 400–450 | 3186.40 | 4.92725 | 0 | 0 | |
| (2) 450–500 | 10236.4 | 15.8290 | 0 | 0 | |
| (3) 500–550 | 10955.7 | 16.9412 | 30.56 | 6.10 | |
| (4) 550–600 | 24667.2 | 38.1439 | 146.55 | 29.25 | |
| (5) 600< | 15623.0 | 24.1585 | 323.83 | 64.64 |
| Wildfire Conditioning Factors | Class | % of Domain | % of Wildfires | ||
|---|---|---|---|---|---|
| Potential solar radiation | |||||
| (1) 282.94–983.08 | 5102.61 | 7.89 | 98.04 | 19.52 | |
| (2) 983.08–1189.37 | 1711.60 | 2.646 | 1.26 | 0.002 | |
| (3) 1189.37–1339.4 | 4332.58 | 6.699 | 2.47 | 0.005 | |
| (4) 1339.4–1501.93 | 8994.4 | 13.90 | 59.65 | 11.95 | |
| (5) 1501.93–1877.01 | 44527.71 | 68.85 | 339.51 | 67.66 | |
| Annual temperature (°C) | |||||
| (1) 10> | 2425.1 | 3.75 | 0 | 0 | |
| (2) 10–12 | 15065.7 | 23.29 | 3.61 | 0.72 | |
| (3) 12–14 | 16912.3 | 26.15 | 92.93 | 18.55 | |
| (4) 14–16 | 18542 | 28.67 | 162.79 | 32.48 | |
| (5) 16< | 11723.6 | 18.1 | 241.12 | 48.25 | |
| Wind effect | |||||
| (1) 0.73–0.93 | 16100.8 | 24.9279 | 161.16 | 32.25 | |
| (2) 0.93–1.09 | 16156.7 | 25.0143 | 143.42 | 28.62 | |
| (3) 1.09–1.25 | 16211.9 | 25.0998 | 123.72 | 24.69 | |
| (4) 1.25–1.35 | 16120.2 | 24.9579 | 72.25 | 14.42 |
| Wildfire Conditioning Factors | Class | % of Domain | % of Wildfires | ||
|---|---|---|---|---|---|
| Land use | |||||
| (1) Forest | 59224.8 | 91.4729 | 491.8 | 98.03 | |
| (2) Non-forest | 4487.91 | 6.93160 | 9.87 | 1.97 | |
| (3) Farm | 839.863 | 1.29717 | 0 | 0 | |
| (4) Settlements | 193.139 | 0.29830 | 0 | 0 | |
| Distance to village (m) | |||||
| (1) 0–300 | 2623.83 | 4.05 | 0.094 | 0.018 | |
| (2) 300–600 | 2621.06 | 4.053 | 13.85 | 2.76 | |
| (3) 600–1200 | 6551.23 | 10.13 | 16.99 | 3.39 | |
| (4) 1200–2400 | 16069.71 | 24.84 | 73.72 | 14.71 | |
| (5) 2400> | 36803 | 56.9 | 396.28 | 79.1 | |
| Distance to road (m) | |||||
| (1) 0–300 | 11221.3 | 17.352 | 115.99 | 23.15 | |
| (2) 300–600 | 9248.14 | 14.30 | 107.178 | 21.49 | |
| (3) 600–1200 | 13642.5 | 21.096 | 99.06 | 19.77 | |
| (4) 1200–1800 | 10275.9 | 15.890 | 88.82 | 17.73 | |
| (5) 1800< | 20280.9 | 31.36 | 89.40 | 17.78 | |
| Recreation area (m) | |||||
| (1) 0–300 | 2689.05 | 3.881 | 13.87 | 2.77 | |
| (2) 300–700 | 5985.99 | 9.006 | 0.098 | 0.019 | |
| (3) 700< | 59830.23 | 87.021 | 468.21 | 97.20 |
| Wildfire Conditioning Factors | Class | % of Domain | % of Wildfires | ||
|---|---|---|---|---|---|
| NDVI | |||||
| (1) −0.08–0.1 | 12846.7 | 19.86 | 38.03 | 7.59 | |
| (2) 0.1–0.36 | 12121.5 | 18.74 | 72.30 | 14.44 | |
| (3) 0.36–0.41 | 12735.5 | 19.69 | 103.78 | 20.73 | |
| (4) 0.41–0.43 | 13979.9 | 21.617 | 160.03 | 31.94 | |
| (5) 0.43< | 12985.1 | 20.07 | 121.70 | 25.29 |
| No | Factors | Impacts | References |
|---|---|---|---|
| 1 | Slope aspect | North-facing slopes are colder and wetter, while south-facing slopes tend to be warmer and drier, so the risk of wildfires on south-facing slopes is higher than the other aspects. | Ebel, 2013, [28]; Oulad Sayad et al. 2019, [10]; Pourghasemi et al. 2016, [29] |
| 2 | Slope (%) | An increase in slope can increase the fire spread rate. Fire can spread more quickly up the steep areas and less quickly down the steep. | Pourtaghi et al. 2015, [4]; Sakellariou et al. 2016, [3]; Ghorbanzadeh and Blaschke, 2018, [12] |
| 3 | Altitude (m) | Altitude is an essential feature of fire danger distribution that should be considered. The wildfires that occur at higher altitudes are less severe because of the increase in moisture. | Koutsias et al. 2002, [30]; Ganteaume, et al. 2013, [31] Jaafari et al. 2019, [26] |
| 4 | Annual temperature (°C) | There is a direct relationship between temperature increase and wildfires. | Baltar et al. 2015, [32]; Oulad Sayad et al. 2019, [10] |
| 5 | Annual rainfall (mm) | The annual rainfall parameter is one of the most significant variables of wildfires; rainfall moisture influences the speed of wildfires, which makes more extension of the burned area. | Vasilakos et al. 2009, [33]; Tanskanen et al. 2005, [34] |
| 6 | Wind effect | Wind can affect the extension and direction of the wildfires immediately after their ignition. | Darvishsefat et al. 2018, [11]; Sakellariou et al. 2016, [3]; Fovell and Gallagher et al. 2018, [35] |
| 7 | Plan curvature (100/m) | The positive curvature can be considered convex, such as the top of the hills, while negative curvature is concave, which refers to features like valleys. These criteria have different effects on the dynamics of wildfires. | Hilton et al. 2016, [36]; Pourtaghi et al. 2015, [4] |
| 8 | Topographic wetness index (TWI) | Fuel moisture is directly related to the required heat of ignition occurs. The actual relationship between the TWI and wildfires differs from other ground conditions and features. | Porensky et al. 2018, [37]; Ghorbanzadeh and Blaschke, 2018, [12] |
| 9 | Landform | Areas with steep slopes usually present the highest percentage of wildfires | Cantarello et al. 2011, [38]; |
| 10 | Land use | Land use patterns based on shape and type have different impacts on wildfire risk. | Pourghasemi et al. 2016, [29] |
| 11 | NDVI | Reduction of the NDVI can cause an increase in water stress and the risk of fire. | Verbesselt et al. 2006, [39]; Pourtaghi et al. 2015, [4] |
| 12 | Distance to stream (m) | There is an indirect relationship between the distance from water sources and wildfire risk. | Razali and Sheriza 2010, [40]; Lee et al. 2010 |
| 13 | Distance to road (m) | Roads provide access to forest areas; as a result, the risk of wildfire increases. | Syphard et al. 2008 Lee et al. 2010, [9] |
| 14 | Recreation area (m) | Recreation areas are places for human gatherings; humans, intentional or unintentional, can increase the risk of wildfire. | Stephens, 2005, [41]; Keeley and Fotheringham, 2003, [42] |
| 15 | Potential solar radiation | Increasing solar radiation can cause a reduction in the soil moisture and an increase in temperature and, consequently, wildfire risk. | Peters et al. 2013, [43]; Oulad Sayad et al. 2019, [10] |
| 16 | Distance to villages (m) | Expansion of residential area can increase the risk of wildfires, mostly because of human activities. | Canu et al. 2017, [44]; Lee et al. 2010, [9] |
| ML | AUC-Fold1 | AUC-Fold2 | AUC-Fold3 | AUC-Fold4 | Cross-Validation (CV) |
|---|---|---|---|---|---|
| ANN | 0.74 | 0.71 | 0.73 | 0.79 | 0.74 |
| SVM | 0.78 | 0.78 | 0.82 | 0.75 | 0.79 |
| RF | 0.89 | 0.85 | 0.94 | 0.85 | 0.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghorbanzadeh, O.; Valizadeh Kamran, K.; Blaschke, T.; Aryal, J.; Naboureh, A.; Einali, J.; Bian, J. Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire 2019, 2, 43. https://doi.org/10.3390/fire2030043
Ghorbanzadeh O, Valizadeh Kamran K, Blaschke T, Aryal J, Naboureh A, Einali J, Bian J. Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire. 2019; 2(3):43. https://doi.org/10.3390/fire2030043
Chicago/Turabian StyleGhorbanzadeh, Omid, Khalil Valizadeh Kamran, Thomas Blaschke, Jagannath Aryal, Amin Naboureh, Jamshid Einali, and Jinhu Bian. 2019. "Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches" Fire 2, no. 3: 43. https://doi.org/10.3390/fire2030043
APA StyleGhorbanzadeh, O., Valizadeh Kamran, K., Blaschke, T., Aryal, J., Naboureh, A., Einali, J., & Bian, J. (2019). Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire, 2(3), 43. https://doi.org/10.3390/fire2030043