1. Introduction
In today’s digital era, individuals and organizations increasingly rely on technology to carry out everyday tasks. However, this dependence exposes users to a wide spectrum of cyber threats, with malicious actors exploiting digital platforms to deceive victims and extract valuable information [
1]. Email phishing remains particularly concerning among the various forms of cyberattacks, as email continues to be a primary mode of communication. These attacks often serve as an entry point for more severe security breaches, including theft of sensitive data, system compromise, and significant financial or reputational damage [
2]. Phishing schemes exploit human error, manipulate users by revealing login credentials, financial details, or unknowingly downloading malware that can disrupt systems. As attackers continually refine their methods, distinguishing legitimate from deceptive content has become increasingly difficult. Therefore, developing robust defenses against such threats is essential [
1].
An increasingly sophisticated tactic is zero-face phishing, an emerging email-based technique that manipulates text visibility by embedding characters styled with a font size of zero. These invisible characters bypass human detection while remaining visible to email filters, allowing attackers to evade conventional spam and phishing detection systems. This approach is often combined with other tactics, such as spear phishing or clone phishing, to increase the probability of deceiving the recipient [
3].
This research aims to investigate the Zero-Font phishing technique within the broader landscape of phishing attacks. It compares the effectiveness of Zero-Font phishing with traditional methods and evaluates the shortcomings of current detection tools. To address these challenges, the study proposes a phishing detection tool capable of identifying both conventional and Zero-Font-based attacks. The framework integrates multiple analytical layers to improve detection accuracy and reduce risk. By addressing both established and emerging phishing strategies, this work contributes a practical solution to strengthening email security and advancing the field of cybersecurity.
The remainder of this paper is organized as follows:
Section 2 outlines the motivation for this work, explores various phishing techniques and attack vectors, and reviews relevant research on phishing detection.
Section 4 compares existing detection approaches.
Section 5 describes the proposed methodology.
Section 6 presents the experimental results, and
Section 7 concludes the paper.
2. Background
2.1. Motivation
Phishing remains one of the most prevalent and damaging forms of cyberattacks, with increasingly sophisticated techniques that challenge traditional detection systems. Although several phishing detection tools are currently in use, many struggle to detect advanced tactics such as Zero-Font phishing and other obfuscation-based methods. Traditional filters, which are highly dependent on static rules or superficial content analysis, often fail to capture the nuanced and deceptive strategies employed by modern attackers. These limitations create vulnerabilities that expose users to data breaches, financial losses, and a growing erosion of trust in digital communication.
In this context, machine learning presents a powerful solution for enhancing phishing detection. Unlike conventional tools, machine learning algorithms—such as Random Forest, Decision Trees, and Support Vector Machines—can process large datasets to identify subtle patterns and features indicative of malicious behavior. These models learn from historical data, adapt to evolving threats, and offer real-time classification of phishing emails with high accuracy. By leveraging techniques like feature extraction and pattern recognition, machine learning significantly improves detection speed, accuracy, and resilience against emerging attack vectors.
Integrating machine learning into phishing detection frameworks not only addresses the limitations of traditional methods but also enables more proactive defense strategies. As cyber threats continue to evolve, machine learning becomes increasingly vital for protecting sensitive information and maintaining trust in digital ecosystems. Its adoption is not only advantageous; it is essential to build robust and adaptive cybersecurity defenses.
2.2. Phishing Techniques and Attack Vectors
2.2.1. Spear Phishing
Spear phishing is a targeted form of phishing targeted at specific individuals or groups. It often includes malicious attachments or links to compromised websites within the email content [
4]. Although spear phishing is more resource intensive than mass phishing, its effectiveness lies in the use of personalized information to craft highly tailored and convincing messages [
5].
Human factors play a significant role in the success of these attacks. Research has shown that individual behaviors—such as impulsivity, risk-taking, sociability, compliance, and anxiety—can be exploited by attackers to increase susceptibility [
6].
Due to their personalized and persuasive nature, spear phishing attacks are notoriously difficult to detect [
7]. Addressing them requires a combination of technical defenses and human-centered strategies. Cybersecurity training and awareness programs are crucial to minimizing user error, which is responsible for approximately 60% of data breaches. In 2019 alone, phishing-related incidents caused an estimated SAR 3.5 millionin financial losses [
8].
2.2.2. Business Email Compromise (BEC)
Business Email Compromise is a targeted phishing technique that uses social engineering to defraud organizations engaged in routine financial transactions. In BEC attacks, cybercriminals impersonate trusted figures, often senior executives or business partners, to manipulate employees into revealing sensitive information or transferring funds to fraudulent accounts [
9,
10]. One common variant is CEO fraud, where attackers pose as an executive requesting urgent or confidential actions.
BEC incidents have grown rapidly in recent years, especially during the COVID-19 pandemic, leading to significant financial losses. These emails are particularly difficult to detect because they often lack obvious malicious payloads and instead rely on psychological manipulation. As a result, conventional defenses, such as email filters and static content analysis, are frequently ineffective.
Combating BEC requires a multifaceted strategy. Employee and leadership training programs are essential to raise awareness and improve recognition of these threats. Preventive measures such as multifactor authentication, robust access controls, anti-malware systems, and digital email signing have proven effective in reducing organizational risk. Together, these defenses improve overall resilience and reduce vulnerability to BEC attacks.
2.2.3. Clone Phishing Attacks
Clone phishing is a sophisticated attack in which a legitimate email previously delivered is replicated and altered to include malicious attachments or links [
11]. The spoofed message is then sent from an address that closely mimics the original sender, increasing its perceived authenticity. The objective is to deceive the recipient into disclosing sensitive information or installing malware.
These attacks have been used against both individuals and organizations. A notable campaign aimed at users of Google Docs and Microsoft Office 365 [
12]. The phishing emails closely resembled official service notifications and directed recipients to fake login pages under the pretense of a password change. Once both old and new credentials were entered, the attackers gained unauthorized access. This example underscores the need for greater user vigilance, stronger authentication methods, and broader cybersecurity education to defend against clone phishing.
2.2.4. Zero-Font Phishing Attacks
Zero-Font phishing is a sophisticated and increasingly recognized email-based attack that exploits font rendering to bypass security mechanisms. It involves inserting text styled with a font size of zero, rendering it invisible to recipients while still being parsed by email scanners. This technique allows attackers to obscure malicious content from users while manipulating filters to misclassify the message as legitimate (“ham”) [
3]. The deceptive design of such attacks makes them particularly effective for delivering malware or conducting scams.
This tactic typically involves the use of HTML or CSS to embed invisible text. Attackers may style sections of text with zero font size to evade detection while still being flagged by email-processing systems. In addition, research has shown that malicious fonts can subtly alter the way content is displayed in a browser without modifying the underlying HTML or CSS [
3,
13]. These strategies highlight how attackers exploit visual presentation to mislead users and circumvent detection.
As reported by GBHackers [
14], even advanced filters such as those in Microsoft Outlook can be fooled by Zero-Font techniques. Outlook’s Natural Language Processing (NLP) engine scans for key phrases to flag phishing attempts. For example, it may look for “© 2018 Microsoft Corporation. All rights reserved” and verify the sender. However, by inserting invisible characters between words (e.g., “2018 Microsoft Corporation” with font size zero), attackers can alter the text enough to evade detection while preserving its visual appearance. This manipulation can trick the NLP engine into treating malicious content as legitimate as shown in
Figure 1 and
Figure 2.
These examples underscore the pressing need for more advanced filtering technologies and greater user awareness to counter Zero-Font phishing threats effectively.
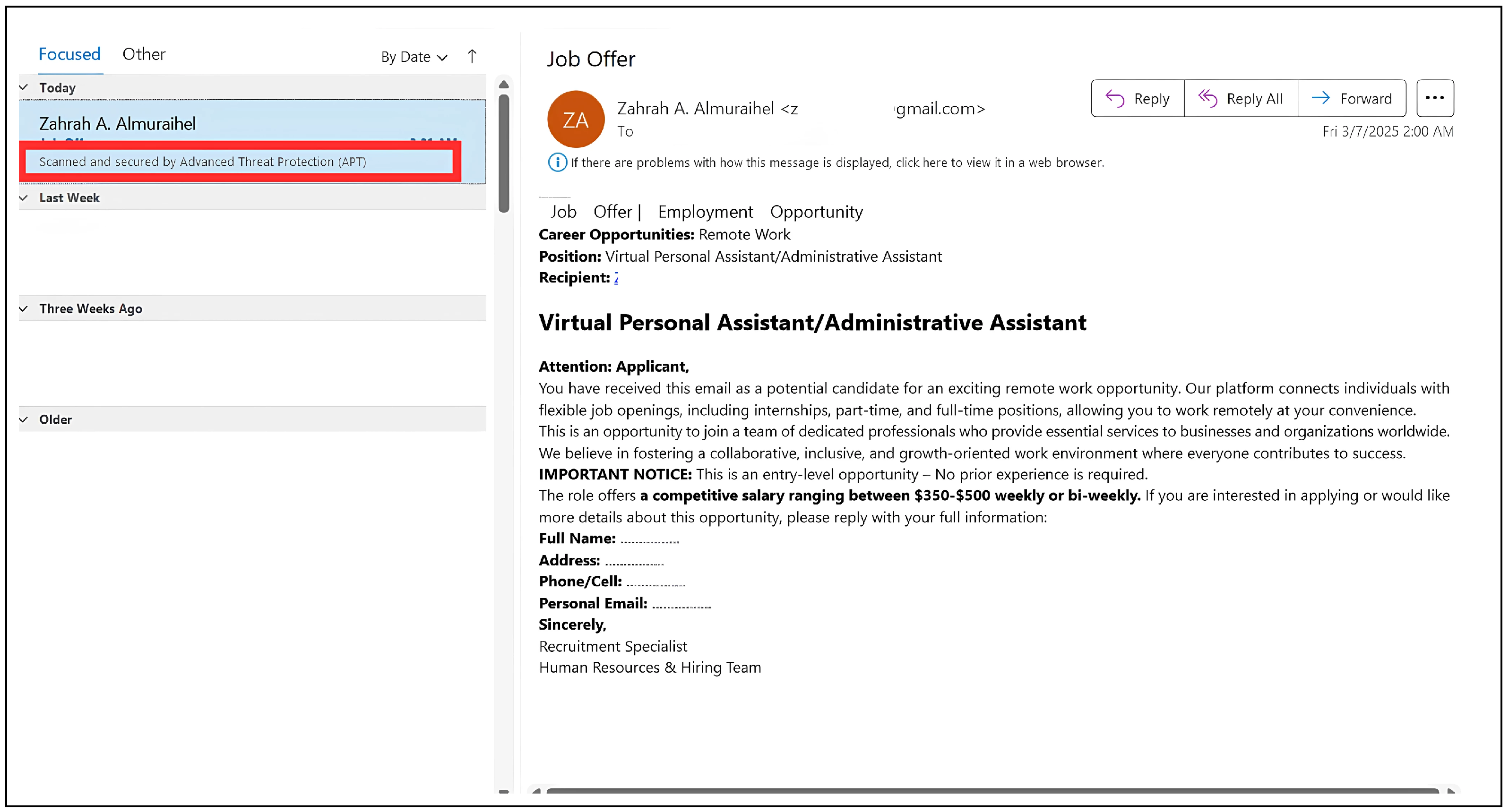
Another variation of this tactic is discussed by ISC SANS [
15]. An example of this Zero-Font phishing technique is represented in
Figure 3. Here, attackers attempt to make the email appear scanned and approved by inserting hidden text into the
<span> HTML element (e.g.,
<span style="FONT-SIZE: 0px">) as shown in
Figure 4. Although the font is set to zero, the content may still be visible in the email listing pane due to quirks in how Microsoft Outlook renders messages. This highlights another vulnerability that attackers can exploit. As threat actors continue to combine various evasion techniques in a single phishing campaign, it becomes imperative that both individuals and organizations remain informed and adopt layered security measures.
3. Related Work
Phishing detection has been extensively studied, with recent approaches leveraging machine learning and deep learning to enhance detection accuracy and adaptability. This section reviews and categorizes key techniques into supervised learning, unsupervised learning, and other hybrid or specialized methods. The review highlights the notable contributions, datasets used, detection performance, and remaining limitations, motivating the need for improved and robust phishing detection systems.
3.1. Supervised Learning Algorithms
Supervised learning remains the dominant approach in phishing detection due to the availability of labeled datasets. Naïve Bayes, Support Vector Machines (SVMs), Random Forests, and neural networks have been widely adopted. For example, Ref. [
16] evaluated multiple classifiers in the Kaggle and Sklearn datasets and found that Nave Bayes achieved the best performance for spam detection tasks.
Based on feature diversity, Ref. [
17] integrated domain-based, stylometric, and structural features with a Random Forest classifier to address traditional and spear phishing attacks. Their system also introduced a verifiable secret-sharing protocol for internal sender authentication. However, the lack of publicly available spear-phishing datasets limited practical evaluation.
Feature optimization has also been explored. In [
18], a hybrid Cuckoo Search–SVM (CS-SVM) model was proposed to tune the RBF kernel parameters. The model, trained on emails from MillerSmiles, Enron, and the Naser Abdullah Alam and Amith Khandakar corpus, achieved 99.52% accuracy—outperforming standard SVM configurations.
Deep learning approaches have shown strong potential, particularly for semantic feature extraction. Ref. [
19] combined word embedding with neural architectures such as CNN, RNN, LSTM, and MLP to detect phishing emails. The system achieved a 10-fold cross-validation accuracy of 0.991 using the IWSPA-AP 2018 dataset.
Other studies have focused on semantic cues and text structure. SEAHound [
20] employed NLP and semantic analysis to detect patterns of social engineering in email text. It reduces false positives compared to commercial tools but remains limited to text-only attacks, excluding image-based or mixed-content phishing.
Lightweight frameworks have also been proposed. Ref. [
21] utilized feature selection and neural networks to detect phishing emails in real time. Their model, trained in domain and content features, achieved an accuracy of 93. 9% and included a blacklist for repeated threats.
Convolutional architectures have been effective in learning complex patterns from raw text. CNNPD, developed by [
22], achieved 99. 42% precision in PhishingCorpus and SpamAssassin datasets using an embedding layer and convolutional filters without manual feature engineering.
3.2. Unsupervised Learning Algorithms
Unsupervised learning approaches have gained traction for their scalability and ability to detect unknown threats. HOLMES [
23] exemplifies this trend by focusing on email header anomalies using word embeddings and novelty detection. The model learned from SMTP traffic and visualized attack patterns using graph analytics. It outperformed several commercial anti-spam systems.
URL-based detection has also been applied in unsupervised settings. Ref. [
24] developed a model using logistic regression and neural networks to classify emails based on URL characteristics. Although the system achieved 93% accuracy, it suffered occasional false positives due to limited representation of characteristics, particularly when tested on small samples.
3.3. Other Techniques
Beyond conventional machine learning, hybrid and content-aware methods have been explored. Ref. [
25] proposed a semantic filtering model that combines creative computing and fuzzy logic. Although this approach improved contextual understanding, its dependency on manual category definition posed scalability challenges.
Behavioral modeling using deep learning was explored in [
26], where CNNs and Keras word embeddings processed both raw text and metadata. Despite operating on imbalanced datasets, their system achieved 96.8% and 94.2% accuracy in two experiments involving emails with and without headers.
In comparative studies, Ref. [
27] evaluated Naïve Bayes and Hidden Markov Models (HMMs) under various pre-processing configurations of NLP. HMM consistently outperformed Nave Bayes, with precisions of 84. 46% and 74. 86%, respectively.
Furthermore, Ref. [
28] explored active learning for spam detection using TF-IDF weighting and multiple classifiers, including SVM and SGD. The system achieved up to 88% accuracy but required several days for manual labeling, suggesting limited real-time applicability.
For image-based spam detection, Ref. [
29] proposed a SpamAssassin plugin that used multifractal analysis and SVM classification. The system processed up to 100,000 emails daily and achieved 92% detection with fewer than 1% false positives.
Although these studies demonstrate substantial progress in phishing detection, most existing solutions are not designed to address emerging obfuscation techniques such as Zero-Font phishing. These attacks exploit font-level manipulation to bypass user scrutiny and traditional spam filters. Furthermore, many detection systems operate in silos, focusing exclusively on header analysis, email body content, or URL inspection, thus limiting their ability to detect more sophisticated and multifaceted threats. This fragmentation creates vulnerabilities that can be exploited by attackers using layered deception strategies.
4. Comparison and Analysis
This section presents a comparative analysis of the phishing detection techniques reviewed in
Section 3. The comparison focuses on key evaluation criteria relevant to designing a robust detection framework, including model performance, feature coverage, real-time detection capabilities, and support for emerging attack vectors such as Zero-Font phishing, see
Table 1,
Table 2 and
Table 3.
The comparison tables above synthesize a broad spectrum of phishing detection approaches across supervised, unsupervised, and hybrid techniques. They provide insights into the trade-offs between accuracy, real-time performance, and detection granularity. Key considerations include dataset diversity, feature scope, and the presence or absence of support for novel obfuscation techniques such as Zero-Font phishing.
Supervised learning approaches—particularly Random Forest, Decision Trees, and SVM—consistently demonstrate high accuracy and are widely adopted due to their robustness. Popular datasets such as Kaggle, Enron, and SpamAssassin serve as standard benchmarks in evaluating model performance. However, limitations persist. Most notably, no surveyed method addresses Zero-Font phishing, an increasingly prevalent and evasive tactic. Additionally, many systems are optimized for either structural, semantic, or URL-based analysis, without integrating these dimensions into a cohesive, multi-layered defense.
These findings underscore a key research gap and inform the design objectives of our proposed framework, which explicitly targets Zero-Font phishing while combining structural inspection, semantic analysis, and machine learning-based classification to enhance adaptability and resilience against sophisticated attacks.
5. Methodology
The phishing detection tool proposed in this study adopts a multi-layered architecture as illustrated in
Figure 5. Each layer plays a specific role in the overall detection process, which is explained in detail in the following subsections.
5.1. Temporary Email Isolation Mechanism
To minimize user exposure to potentially malicious content, the system initially places incoming emails in a temporary isolation zone. This step ensures that every email undergoes a full inspection across all detection layers before being delivered to the user. Isolation acts as a protective buffer, allowing for complete verification.
5.2. HTML Code Scanning Layer (1st Layer)
The first security layer of the tool examines the HTML code within the email body to detect instances of Zero-Font attributes. If any of these attributes are identified, or a combination of them, as listed in
Table 4, they are removed before the email is passed to the next layer. This removal is essential because Zero-Font attributes can serve legitimate formatting purposes, which often leads traditional filters to overlook them.
5.3. Header Analysis Layer (2nd Layer)
The second layer inspects critical fields in the email header, including DMARC, SPF, and DKIM records, to evaluate whether the email aligns with the sender’s domain policies. These indicators assist in verifying the sender’s authenticity and detecting spoofing attempts.
5.4. URL Analysis Layer (3rd Layer)
This layer focuses on evaluating URLs embedded in the email body. All hyperlinks are extracted and assessed using external threat intelligence services. This step helps identify malicious links that may redirect users to phishing sites.
5.5. Machine Learning Classifier (4th Layer)
The fourth layer employs a machine learning classifier for email body analysis. This section covers the dataset used, data pre-processing, feature extraction, and model evaluation.
5.5.1. Dataset Description
The dataset consists of 4053 emails: 3039 legitimate (ham) and 1014 phishing. These emails were sourced from two repositories:
Phishing emails: Collected by Naser Abdullah Alam and Amith Khandakar from the Phishing Corpus [
30], spanning 2015–2023.
Ham emails: Provided by Cyber Cop in the Phishing Email Detection dataset [
31], published in 2023.
These emails were combined into a single dataset and then divided into 80% for training and 20% for validation. The details of the dataset split are summarized in the
Table 5 below:
This split ensures a balanced representation of ham and phishing emails in the training and validation sets.
5.5.2. Data Pre-Processing
To ensure the dataset is reliable and suitable for analysis, the cleaning process is carried out in three key phases. The first phase involves deduplication, which preserves data integrity and ensures efficient processing. The second phase focuses on the removal of null or empty cells, as these gaps can distort the analysis and lead to inaccurate results. In the third phase, the dataset is further refined by eliminating stop words and non-alphabetic characters, enhancing the overall quality of the data for processing. Effective dataset cleaning is crucial, as it not only improves the accuracy of the analysis but also improves the overall efficiency of the data processing.
5.5.3. Features Extraction
The initial stage of developing a machine learning system to detect phishing emails involved a comprehensive research phase to identify effective features. The 10 characteristics listed in
Table 6 were selected based on their prevalence and effectiveness as demonstrated in multiple sources, including scientific articles, technical reports, and the widely recognized literature.
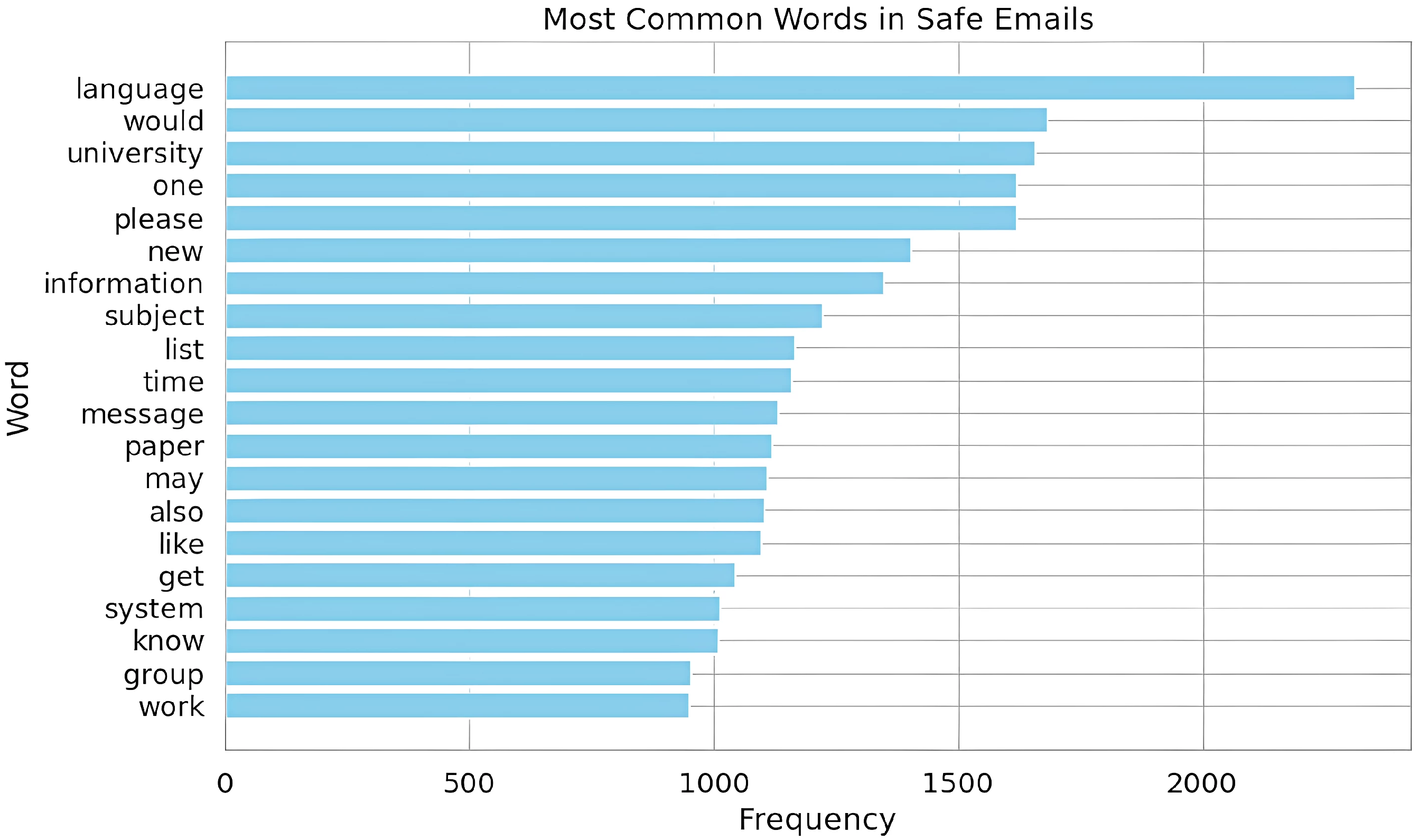
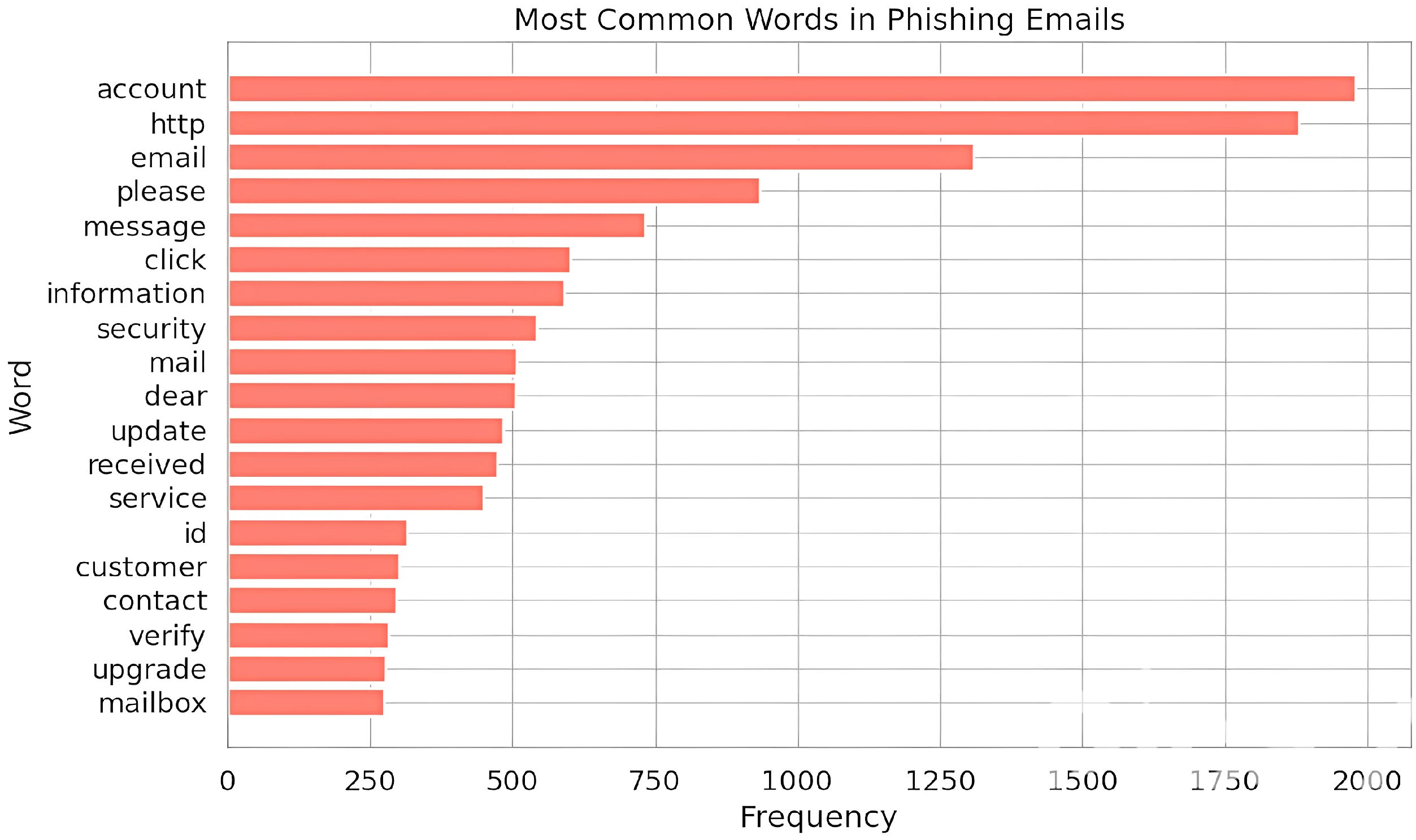
In particular, the presence of phishing keywords and the features of safe keyword presence were derived through a combination of word frequency analysis (through word clouds) and manual refinement using domain expertise. Only frequently occurring and semantically relevant terms, those commonly associated with phishing intent (e.g., urgency, threats, and log-in prompts) or legitimate communication were retained. This ensured statistical significance and contextual validity in the final set of keywords.
In
phishing_keyword_presence and
safe_keyword_presence, we conducted a word cloud analysis to find the most repeated words in phishing and ham emails. Then we chose the first 20 correct and meaningful words that were repeated frequently. The results of the cloud analysis are shown in
Figure 6 and
Figure 7.
Figure 6 highlights the most common words found in safe emails, while
Figure 7 displays the most common terms identified as phishing emails based on their occurrence.
The feature phishing_keyword_presence is equal to one if there are five or more phishing keywords in the same email; otherwise, it is equal to zero. The same applies to safe_keyword_presence with the presence of safe words.
5.6. Machine Learning Models Evaluation
This subsection outlines the model evaluation methodology and presents the comparative results.
5.6.1. Performance and Evaluation
The classifier was evaluated using standard metrics derived from the confusion matrix (
Table 7): accuracy, precision, recall, and F1-Score. The 80/20 training–validation split was used to assess model generalizability while preventing overfitting.
The matrix will monitor the classifier and the errors it makes in the following ways:
True Positive (TP): Correctly identified phishing email;
True Negative (TN): Correctly identified ham email;
False Positive (FP): Ham email incorrectly classified as phishing;
False Negative (FN): Phishing email incorrectly classified as ham.
5.6.2. Models’ Evaluation and Results
Three models were evaluated: Random Forest, Decision Tree, and Linear Support Vector Machine (SVM). Each model was trained and tested on the same dataset. Linear SVM outperformed the others in all evaluation metrics and was selected for deployment in the detection tool.
Table 8 and
Figure 8,
Figure 9 and
Figure 10 summarize the results.
6. Results
The proposed solution demonstrated a high degree of reliability in detecting and mitigating various phishing attacks, including the Zero-Font technique. Extensive evaluations across multiple test scenarios consistently yielded high detection accuracy, underscoring the effectiveness of the tool in protecting individuals and organizations against phishing-related threats such as data breaches, credential theft, and financial loss.
This performance is largely attributed to the multi-layered architecture of the system, which integrates heuristic-based techniques with machine learning algorithms. By analyzing subtle and often obfuscated indicators, such as metadata, headers, embedded URLs, and textual features, the system effectively identified and flagged phishing attempts. Once detected, these emails were automatically redirected to the user’s junk folder, eliminating the need for manual filtering. Furthermore, a real-time alert mechanism promptly notified users of potential threats, reducing the likelihood of engagement with malicious content and minimizing the risk of data exposure.
Importantly, the system maintained a low false positive rate, ensuring that legitimate emails were not incorrectly flagged. This balance between high detection accuracy and practical usability reinforces the suitability of the proposed solution for real-world deployment. In general, the results demonstrate that the approach provides robust and proactive defense against a wide range of phishing techniques, positioning it as a promising enhancement to existing cybersecurity systems.
Table 9 presents a comparison between the proposed method and other supervised learning algorithms. Although our solution incorporates additional layers beyond supervised learning, the classification performance of the integrated machine learning models can still be benchmarked against these established algorithms.
7. Conclusions
This study presents a robust multi-layered phishing detection system capable of identifying conventional and Zero-Font phishing attacks in real time. By integrating machine learning with layered email security strategies, the system achieves high detection accuracy while maintaining a low false-positive rate, supporting practical deployment with minimal user disruption.
Experimental results confirm the system’s ability to mitigate risks such as data breaches and financial loss by accurately identifying subtle indicators of phishing behavior, including obfuscation techniques used in Zero-Font attacks. Automated email redirection further improves operational efficiency and protects users from engaging with malicious content.
Despite these promising results, the absence of publicly available comprehensive datasets focused on Zero-Font phishing remains a key limitation. Future work should focus on collecting domain-specific datasets and investigating advanced machine learning models, such as deep neural networks and hybrid architectures, to improve the detection capabilities. Furthermore, incorporating richer evaluation metrics, such as AUC-ROC and confusion matrix heatmaps, could offer deeper insights into model behavior, especially in class-imbalanced scenarios.
In general, this research contributes to a practical and extensible framework for phishing detection. It underscores the importance of continuous innovation to address the evolving threat landscape in email-based cyberattacks.
Author Contributions
Z.A.A., R.Z.A., F.A.A. and J.M.A.: conceptualization, software, methodology, and writing—original draft preparation, N.A.S., S.A.A. and S.C.: supervision, writing—review and editing reviewing, supervision and formal analysis. D.A. and D.A.A.K.: methodology, and data curation, A.A.A.: resources, and funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the SAUDI ARAMCO Cybersecurity Chair, Imam Abdulrahman Bin Faisal University, Dammam, KSA.
Data Availability Statement
The original contributions are detailed in the article; additional information can be requested from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alkhalil, Z.; Hewage, C.; Nawaf, L.; Khan, I. Phishing attacks: A recent comprehensive study and a new anatomy. Front. Comput. Sci. 2021, 3, 563060. [Google Scholar] [CrossRef]
- Atkins, C. Phishing Attacks: Advanced Attack Techniques; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2018; ISBN 1984093975. [Google Scholar]
- Jaiswal, R.; Marshal, R.; Rao, V.V.; Singh, K.P. AI Phishing Detection Framework for Businesses with Limited Resources. In Proceedings of the 2024 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhir, Bahrain, 17–19 November 2024; pp. 399–404. [Google Scholar]
- Mon, E.E.; Kham, N.S.M. Studying Email Filtering Approach to Identify Spear Phishing Attacks. In Proceedings of the International Conference on Computer Applications, Denver, CO, USA, 26–28 September 2016. [Google Scholar]
- Zhao, M.; An, B.; Kiekintveld, C. Optimizing personalized email filtering thresholds to mitigate sequential spear phishing attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Eftimie, S.; Moinescu, R.; Răcuciu, C. Spear-phishing susceptibility stemming from personality traits. IEEE Access 2022, 10, 73548–73561. [Google Scholar] [CrossRef]
- Chen, T.; Henry, P. A Review of: “Phishing and Countermeasures: Understanding the Increasing Problem of Electronic Identity Theft. By Markus Jakobsson and Steven Myers, Editors”; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bhardwaj, A.; Sapra, V.; Kumar, A.; Kumar, N.; Arthi, S. Why is phishing still successful? Comput. Fraud. Secur. 2020, 2020, 15–19. [Google Scholar] [CrossRef]
- Atlam, H.F.; Oluwatimilehin, O. Business email compromise phishing detection based on machine learning: A systematic literature review. Electronics 2022, 12, 42. [Google Scholar] [CrossRef]
- Al-Musib, N.S.; Al-Serhani, F.M.; Humayun, M.; Jhanjhi, N. Business email compromise (BEC) attacks. Mater. Today Proc. 2023, 81, 497–503. [Google Scholar] [CrossRef]
- Bhavsar, V.; Kadlak, A.; Sharma, S. Study on phishing attacks. Int. J. Comput. Appl. 2018, 182, 27–29. [Google Scholar] [CrossRef]
- Chaudhuri, A. Clone Phishing: Attacks and Defenses. Int. J. Sci. Res. Publ. 2023, 13, 13626. [Google Scholar] [CrossRef]
- Mueller, T.; Klotzsche, D.; Herrmann, D.; Federrath, H. Dangers and prevalence of unprotected web fonts. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–5. [Google Scholar]
- Eswar. ZeroFont Phishing—Hackers Manipulate Font Size to Bypass Office. 2023. Available online: https://gbhackers.com/zerofont-phishing/ (accessed on 22 February 2025).
- Kopriva, J. A New Spin on the ZeroFont Phishing Technique. 2023. Available online: https://isc.sans.edu/diary/30248/ (accessed on 15 February 2025).
- Kumar, N.; Sonowal, S.; Nishant. Email spam detection using machine learning algorithms. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 108–113. [Google Scholar]
- Sonowal, G.; Sharma, A.; Kharb, L. Spear-Phishing Emails Verification Method based on Verifiable Secret Sharing Scheme. J. Inf. Assur. Secur. 2021, 16, 117–124. [Google Scholar]
- Niu, W.; Zhang, X.; Yang, G.; Ma, Z.; Zhuo, Z. Phishing emails detection using CS-SVM. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 1054–1059. [Google Scholar]
- Ra, V.; HBa, B.G.; Ma, A.K.; KPa, S.; Poornachandran, P.; Verma, A. DeepAnti-PhishNet: Applying deep neural networks for phishing email detection. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM International Workshop on Security and Privacy Analytics (IWSPA), Tempe, AZ, USA, 1–11 March 2018; pp. 1–11. [Google Scholar]
- Peng, T.; Harris, I.; Sawa, Y. Detecting phishing attacks using natural language processing and machine learning. In Proceedings of the 2018 IEEE 12th international conference on semantic computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 300–301. [Google Scholar]
- Oña, D.; Zapata, L.; Fuertes, W.; Rodríguez, G.; Benavides, E.; Toulkeridis, T. Phishing attacks: Detecting and preventing infected e-mails using machine learning methods. In Proceedings of the 2019 3rd Cyber Security in Networking Conference (CSNet), Quito, Ecuador, 23–25 October 2019; pp. 161–163. [Google Scholar]
- Alotaibi, R.; Al-Turaiki, I.; Alakeel, F. Mitigating email phishing attacks using convolutional neural networks. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar]
- Wu, P.; Guo, H. Holmes: An efficient and lightweight semantic based anomalous email detector. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Haikou, China, 15–18 December 2022; pp. 1360–1367. [Google Scholar]
- Garcés, I.O.; Cazares, M.F.; Andrade, R.O. Detection of phishing attacks with machine learning techniques in cognitive security architecture. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 366–370. [Google Scholar]
- Che, H.; Liu, Q.; Zou, L.; Yang, H.; Zhou, D.; Yu, F. A content-based phishing email detection method. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Prague, Czech Republic, 25–29 July 2017; pp. 415–422. [Google Scholar]
- Hiransha, M.; Unnithan, N.A.; Vinayakumar, R.; Soman, K.; Verma, A. Deep learning based phishing e-mail detection. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM International Workshop on Security and Privacy Analytics (IWSPA), Tempe, AZ, USA, 1–11 March 2018; pp. 1–5. [Google Scholar]
- Gomes, S.R.; Saroar, S.G.; Mosfaiul, M.; Telot, A.; Khan, B.N.; Chakrabarty, A.; Mostakim, M. A comparative approach to email classification using Naive Bayes classifier and hidden Markov model. In Proceedings of the 2017 4th international conference on advances in Electrical Engineering (ICAEE), Dhaka, Bangladesh, 28–30 September 2017; pp. 482–487. [Google Scholar]
- Ahsan, M.I.; Nahian, T.; Kafi, A.A.; Hossain, M.I.; Shah, F.M. Review spam detection using active learning. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–7. [Google Scholar]
- Zhong, J.; Zhou, Y.; Deng, W. Filtering image-based Spam Using Multifractal analysis and active learning feedback-driven semi-supervised support vector machine. In Proceedings of the IEEE Conference Anthology, Chongqing, China, 20–22 August 2011; pp. 1–5. [Google Scholar]
- Alam, N.A.; Khandakar, A. Phishing Email Dataset. Available online: https://www.kaggle.com/datasets/naserabdullahalam/phishing-email-dataset (accessed on 20 May 2025).
- Cyber Cop. Phishing Email Detection Dataset. Available online: https://www.kaggle.com/datasets/subhajournal/phishingemails/data (accessed on 15 May 2025).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}