1. Introduction
The technology world is continually changing and developing to advance the current technologies with new services and features that make people’s lives easier, faster, and better. As an advancement of 4G, 5G technology opens up the horizon to improve many other services and technologies, owing to its superior bandwidth and download speeds [
1]. The number of subscribers of 5G technology is predicted to increase 10 times by 2025 and reach 1.7 billion [
2]. Many technologies will be improved by utilizing the features of 5G, such as Voice Over Internet Protocol (VoIP).
VoIP is promising technology that brings substantial benefits for subscribers. VoIP allows subscribers to communicate to anyone around the world freely by using smartphones or any other smart devices. This condition is because the VoIP data move in IP packets over the data connection. The number of mobile VoIP users is expected to be more than 3 billion. The Internet transported more than 156 petabytes of VoIP traffic every month in 2015 [
3,
4]. Mobile VoIP technology necessitates minimal latency in data transmission. Accordingly, one of the services that will remarkably improve when working with 5G technology is VoIP. VoIP systems are anticipated to wholeheartedly embrace 5G technology. VoIP will benefit from the high speed of 5G to enhance the call quality up to user satisfaction. VoIP will also benefit from the high bandwidth of 5G to tremendously maximize the call capacity [
5,
6].
Despite these possible benefits, VoIP is wasting a considerable share of the 5G technology bandwidth with no valuable use. This condition is due to the lengthy header of the VoIP packet compared with its payload [
7,
8]. For instance, the G.728 codec produces 10-byte digital voice data (packet payload). In the case of IPv4, the header of the VoIP packet, which consists of 40-byte RTP/UDP/IPv4 (12-byte RTP, 8-byte UDP, and 20-byte IPv4), wastes up to 80% of the bandwidth specified for a VoIP call. The problem even worsens when it comes to IPv6. Specifically, the header of the VoIP packet, which consists of 60-byte RTP/UDP/IPv6 (40-byte IPv6), wasted up to around 85.7% of the bandwidth specified for a VoIP call. This consumption is a huge waste of bandwidth resources.
Table 1 shows the apportioned bandwidth of different voice codes [
9,
10,
11]. A huge amount of wasted bandwidth is evident with all the codecs. Theoretically, this process also consumes the same percentage of transmission time of the 5G networks.
The propagation of the IPv6 protocol has increased year after year. IPv6 has emerged from the “Innovators” and “Early Adoption” stages of deployment and is now in the “Early Majority” phase [
12]. According to the authors of [
12], the rate of global adoption of IPv6 increased from 2.8% in 2014 to 23.48% as of 2018. The worldwide adoption of IPv6 has been growing intensely at an average of more than 51% each year [
13]. The integration of VoIP and IPv6 over 5G networks is inevitable. Therefore, the above problem of wasting the resources of 5G networks should be considered and carefully investigated. VoIP developers have developed many solutions to the lengthy header of VoIP. These solutions include combining the VoIP packet in one header, compacting the packet’s header, replacing the VoIP header protocols with new VoIP-specific protocols, and utilizing the header’s superfluous fields to carry the voice data of the packet [
11,
14,
15].
The main advantage of the last solution of utilizing the superfluous header’s fields is that many of the proposed methods under it are compatible with the existing standards and equipment. Thus, they are workable in the current environment without major changes. However, none of these methods have been developed for VoIP when using IPv6, specifically over 5G networks. In this article, a new method is proposed to enhance the bandwidth utilization of 5G networks when running VoIP on IPv6. The proposed method uses the superfluous fields of the IPv6 protocol to carry the digital voice data of the packet.
Accordingly, the proposed method reduces the payload size or makes it zero. This condition enhances the bandwidth utilization of the used networks, such as 5G networks. The occupied airtime to transmit the VoIP packet over 5G networks is reduced. This condition indirectly affects the voice connection quality due to the decrease in the packet loss and delay.
The rest of this paper is organized as follows.
Section 2 introduces the main solutions that handle the bandwidth problem of VoIP.
Section 3 presents the proposed method, including its core idea of handling the bandwidth issue using the IPv6 protocol fields to carry the packet payload.
Section 4 discusses the performance of the proposed method versus other comparable methods.
Section 5 summarizes the findings of this study.
2. Related Work
The bandwidth obstacle has slowed the propagation of VoIP for some time. Many solutions have been proposed to overcome this obstacle and accelerate the adoption of VoIP. One of the first solutions suggested is collecting the packets sharing the same path and encapsulating them in one header, known as the packet or frame aggregation standard. Some of these methods have been designed to aggregate the frames at layer two in one header, whereas others have been designed to aggregate the packets at layer three in one header. Performing the aggregation at layer two accomplishes better bandwidth utilization. Maximizing the number of aggregated packets, which is based on the parameters of the environment, saves more bandwidth [
3,
16]. Seytnazarov et al. presented one of the best aggregation methods in 2018. Seytnazarov’s method works in the IEEE 802.11n wireless networks. At the transmitter, several layer two frames (i.e., multiplexing MAC protocol data units (MPDUs)) are grouped in one aggregation (A-MPDU). If one of the grouped MPDUs is spoiled, then it causes the resending of only that MPDU. The frames in the suggested method are split into three groups: voice, video, and streaming groups with priority queuing (PQ), which assumes scheduling. The A-MPDU’s allowable length fluctuations adapt in accordance with the urgency delay (UD), which is the remaining period to dequeue the frame. The frame with the minimal UD is the first frame added to the A-MPDU. The allowable aggregation time of the A-MPDU is set on the basis of the remaining UD of this frame. In addition to frame aggregation, a new scheduling mechanism is suggested to handle the drawbacks of the PQ scheduler under saturated conditions. The analysis of the suggested technique showed a more advanced throughput rate with minor delay and packet loss than the other comparable methods [
16].
Another established solution for the bandwidth snag is compacting the header of the packet, known as header compression, by eliminating some of the header’s fields. The other end of the call can obtain their values by using simple derivations because they are following certain patterns. The header is compacted up to two bytes when using IPv4, which greatly conserves the bandwidth. William A. Flanagan designed one of the recent compression methods in 2020, which was named “Session Bridging”. This method is a new customization of header compression that reduces bandwidth poverty. It splits the links into end chunks marked by distinct protocol instances using standard headers. A chunk segment between them conveys voice data with compressed headers. This method takes the benefit of multiprotocol label switching and virtual Ethernet connections in current networks. The analysis of certain networks proves that session bridging is viable for latency-sensitive applications (e.g., VoIP and gaming) [
17].
Some VoIP developers have suggested creating other VoIP-specific protocols, such as the Inter-Asterisk Exchange (IAX) protocol. Although IAX can carry all types of streaming media, it is mainly developed for voice calls over IP commuter networks. IAX uses its 4-byte mini-header to carry the digital voice data and replace the 12-byte RTP protocol, which saves good bandwidth. The IAX protocol supports trunking, in which voice data from several sessions are combined in one stream of packets. This condition saves a huge share of bandwidth consumed by the IP header without extra delay [
18].
One of the recently considered solutions is to utilize the header’s superfluous fields to carry the voice data of the packet. This solution is based on the assumption that the VoIP packet header protocol transfers various types of application data. Therefore, some of the fields in these protocols are necessary with some applications, but they are not with some other applications. The latter are burdening the bandwidth without valuable use. These fields are called the superfluous fields [
14,
15]. This last solution to the bandwidth problem uses the superfluous fields to carry the voice data of the packet, thereby reducing or eliminating the payload and saving bandwidth. One of the best methods under this solution was proposed by Abualhaj et al., and it is named short voice frame (SVF). The SVF method successfully utilizes the seven superfluous fields of the packet header on the basis of certain assumptions. These fields manage to save 17 bytes of each VoIP packet, which is typically between 50 and 70 bytes. The analysis results proved that the saved bandwidth can reach around 29% in some instances [
14]. Another method called zero size payload (ZSP) is developed to utilize superfluous fields. The ZSP method uses different assumptions compared with the SVF method. Therefore, it manages to utilize the 10 superfluous fields with 19 bytes. The analysis results confirmed that the saved bandwidth can reach around 32% in some instances [
15].
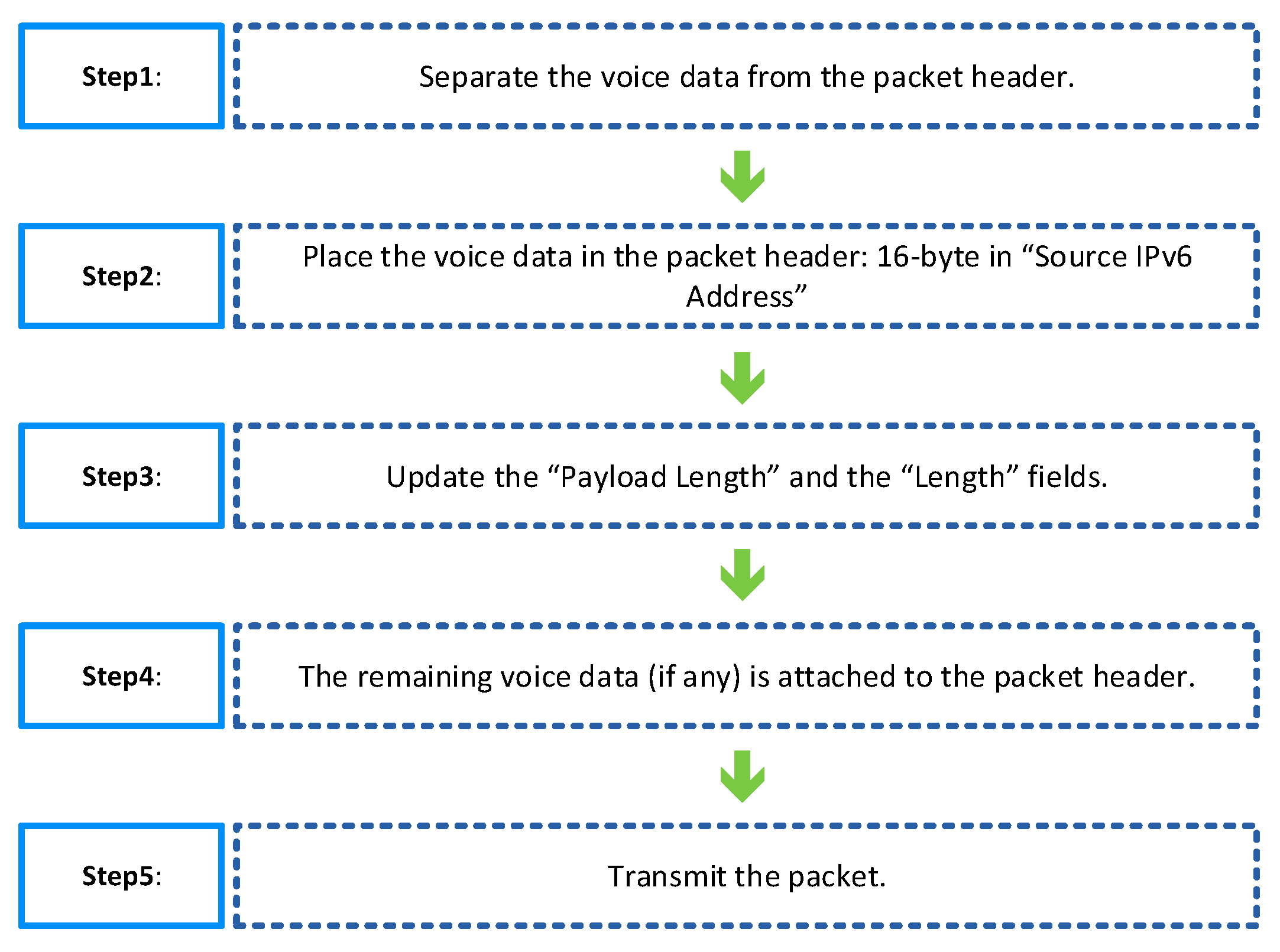
Developers have exerted great efforts to save bandwidth when running VoIP. The bandwidth issue becomes difficult when integrating the VoIP and IPv6 protocol, owing to the large size of the IPv6 header. However, the bandwidth problem of the VoIP and IPv6 protocol is not addressed, especially with 5G wireless networks. In this study, a new method is designed to solve this problem using the superfluous fields in the VoIP packet header. The proposed method uses the source IPv6 address to carry the digital voice data of the VoIP packet. This process minimizes the VoIP packet payload size or makes it zero; thus, the designed method is called the Zeroize (zero sizes) method. The Zeroize method enhances bandwidth utilization and improves the quality of the calls.
4. Zeroize Method Performance Analysis
This section analyzes the proposed Zeroize method. Although intended for 5G networks, the Zeroize method applies to many other wireless technologies (e.g., IEEE 802.11). The proposed method is analyzed on the basis of the layer three header and above because the layer two header changes depending on the used technology. The Zeroize method is tested and analyzed versus the standard RTP (S-RTP method) method of transferring the VoIP packets, the SVF method proposed in [
14], and the ZSP method proposed in [
15]. The SVF and ZSP methods were selected because they are similar to the proposed Zeroize method. The SVF and ZSP methods share the same primary objective as the Zeroize method, conserving the network bandwidth when using VoIP applications. The SVF and ZSP methods use the same main concept to save bandwidth: carrying the voice data in the superfluous fields of the packet header. However, the SVF and ZSP methods work over IPv4 networks and are intended only for point-to-point calls. The proposed Zeroize method was tested versus the other methods in terms of channel capacity and apportioned bandwidth reduction. The LPC, G.726, and G.723.1 codecs were assumed for the comparison.
Network Simulation 3 (NS3) was used to simulate the proposed Zeroize method. After simulating the Zeroize method, a network topology using NS3 was designed to evaluate the Zeroize method and compared with the SVF and ZSP methods. The simulation topology included two components of the Zeroize method, which were situated at the sender and receiver sides, as discussed in
Section 3. Each component utilized a buffer with a maximum size of five. The connection between the two components was mimicked as a first-in-first-out buffer. A constant bit rate traffic generator was attached to each end.
4.1. Channel Capacity (Ch-Capacity)
The Ch-Capacity of the proposed Zeroize method is presented in this section. The Ch-Capacity was analyzed for each channel bandwidth between 100 and 1000 kbps. Losing the packets designates that the channel is saturated. Hence, the Ch-Capacity of a channel equals the number of calls afore losing the packets and is measured accordingly.
Figure 4,
Figure 5 and
Figure 6 explore the Ch-Capacity for the Zeroize method in comparison to the S-RTP, SVF, and ZSP methods with G.723.1, G.726, and LPC codecs, respectively. The Ch-Capacity when using the Zeroize method outperformed (i.e., more calls) the S-RTP method. The difference in the Ch-Capacity increased with the existing bandwidth. This condition was due to eliminating the payload by utilizing the superfluous field (source IPv6 address) of the header to carry the payload. However, the Ch-Capacity when using the Zeroize method underperformed (i.e., fewer calls) the SVF and ZSP methods. This condition was because of the header of the IPv6 protocol header being twice the IPv4 protocol header and consuming more bandwidth for each call. The size of the superfluous fields of the SVF and ZSP methods was more than that of the Zeroize method. The Ch-Capacity of the SVF and ZSP methods was the same as the LPC codec. This condition was because the size of the LPC voice data was 14 bytes, which was smaller than the superfluous fields of the SVF method (17 bytes) and the ZSP method (19 bytes). Therefore, the superfluous fields of the two methods could carry the entire 14-byte voice data of the LPC codec. The extra two-byte superfluous fields of the ZSP method were not utilized when using a codec with voice data (e.g., LPC codec) smaller than the superfluous fields.
The Ch-Capacity was also calculated using mathematical equations to validate the results. The bandwidth needed by each call depends on the used codec and the packet header length. Equation (1) can be used to find the bandwidth needed by each call:
where
Cbw is the bandwidth needed by each call,
Lpld is the packet payload length,
Lh is the packet header’s length, and
Cbr is the bit rate of the used codec. For instance, assume the G.728 codec is used with a bit rate of 16 kbps, and the IPv6 protocol is in the packet header. Then, the bandwidth needed by each call when using the Zeroize method is 96 kbps. On the other hand, the bandwidth needed by each call when using the S-RTP method is 112 kbps. Therefore, the saving in the Ch-Capacity is around 14.3% when using the G.728 codec. The saving in the Ch-Capacity varies from one codec to another, based on the voice data length of each codec.
4.2. Apportioned Bandwidth Reduction
The apportioned bandwidth ratio of the proposed Zeroize method is discussed in this section. The apportioned bandwidth ratio was analyzed with 10–100 calls. The Zeroize, SVF, and ZSP methods were analyzed in comparison to the S-RTP method.
Figure 7 and
Figure 8 show the bandwidth reduction of the Zeroize, SVF, and ZSP methods in comparison to the S-RTP method. The apportioned bandwidth saving when using the Zeroize method was around 20% compared with that of the S-RTP method with the G.723.1 codec. However, the bandwidth saving when using the Zeroize method underperformed the SVF and ZSP methods. This condition was because the header of the IPv6 protocol header was twice the IPv4 protocol header and consumed more bandwidth for each call. The size of the superfluous fields of the SVF and ZSP methods was more than that of the Zeroize method.
The SVF and ZSP methods outperformed the Zeroize method in terms of Ch-Capacity and apportioned bandwidth reduction. However, the Zeroize method works over IPv6 networks, unlike the SVF and ZSP methods, which work over IPv4 networks. The SVF and ZSP methods utilize many fields as superfluous fields to carry the voice data. This condition makes them workable only in specific scenarios, which are the scenarios that they are designed for. However, the Zeroize method utilizes only the source IPv6 address field as a superfluous field to carry the voice data. This condition makes the Zeroize method a more general method that works in all scenarios. The SVF and ZSP methods burden the network compared with the Zeroize method for several reasons. The SVF and ZSP methods are designed to work at the gateway routers. Therefore, the resources of these routers are consumed, especially with the high number of calls. The Zeroize method is designed to work at the client-side without burdening the routers. The Zeroize method uses only one field (source IPv6 address) to carry the voice data without the need to set back the original value of this field. However, the SVF and ZSP methods use several fields to carry the voice data, thereby imposing more operations and calculations, such as setting back the original value of the superfluous fields at the receiver gateway, calculating the new length field value of the UDP protocol, and assigning a new value to the Internet header length field of the IP protocol. Performing these operations for every call packet consumes the routers’ resources, especially with a high number of calls. The SVF and ZSP methods burden the network compared with the Zeroize method.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}