Emerging Scientific Field Detection Using Citation Networks and Topic Models—A Case Study of the Nanocarbon Field


Abstract
:1. Introduction
1.1. Literature Review
1.2. Purpose and Contribution
2. Method Development
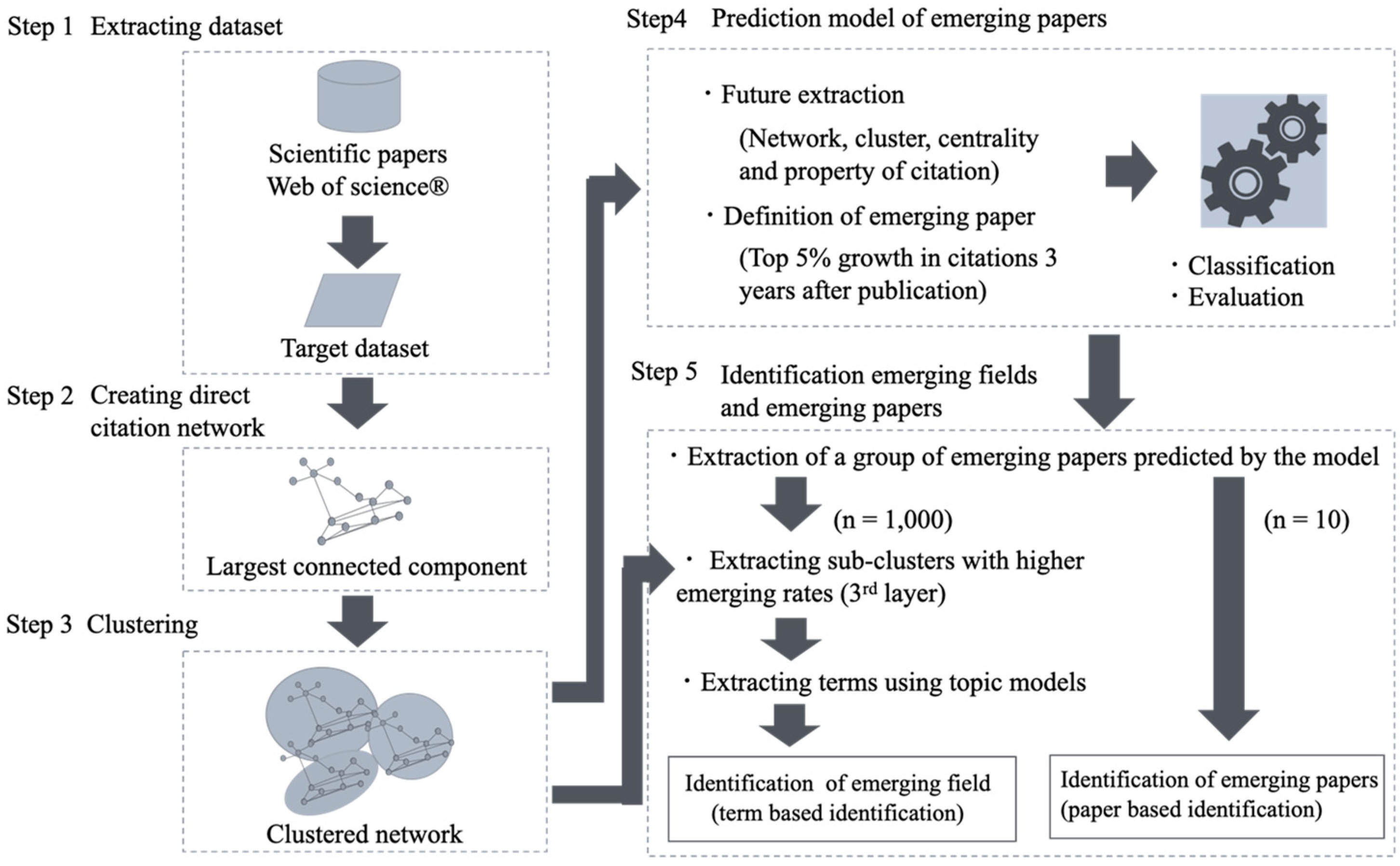
2.1. Overview
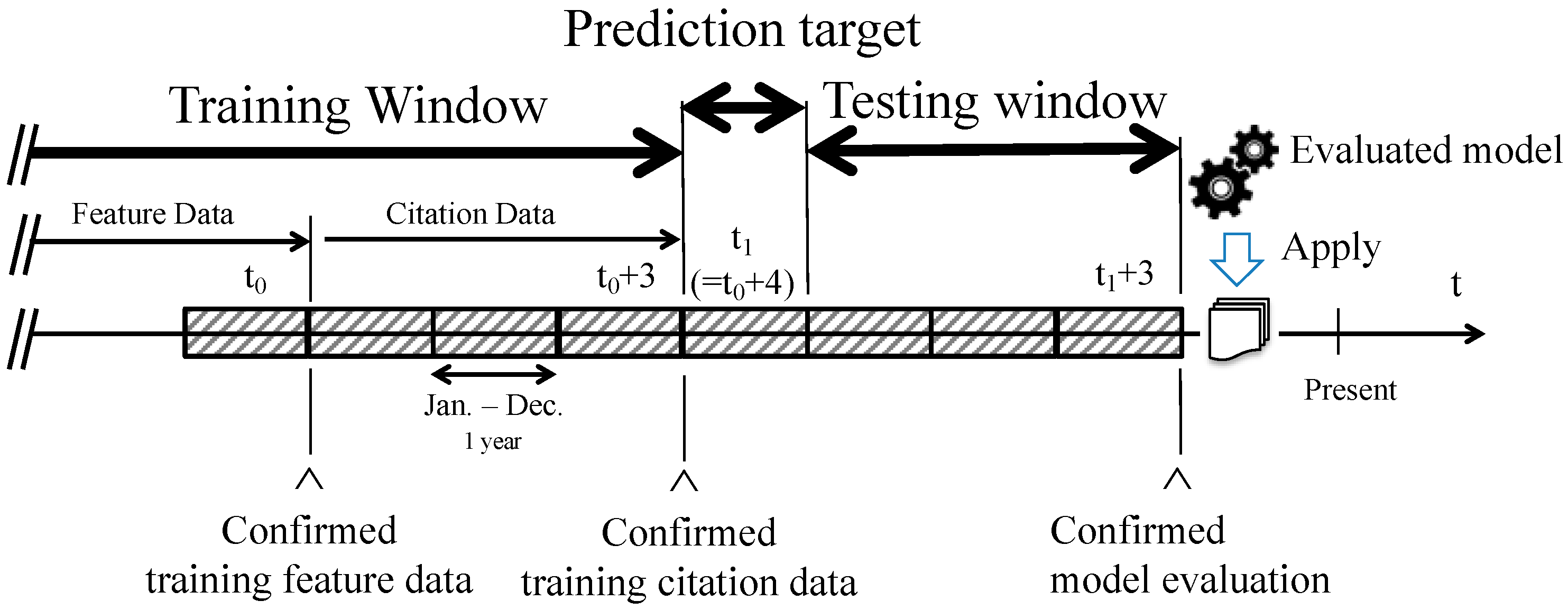
2.2. Feature Extraction
2.3. Task Definition
2.4. Evaluation
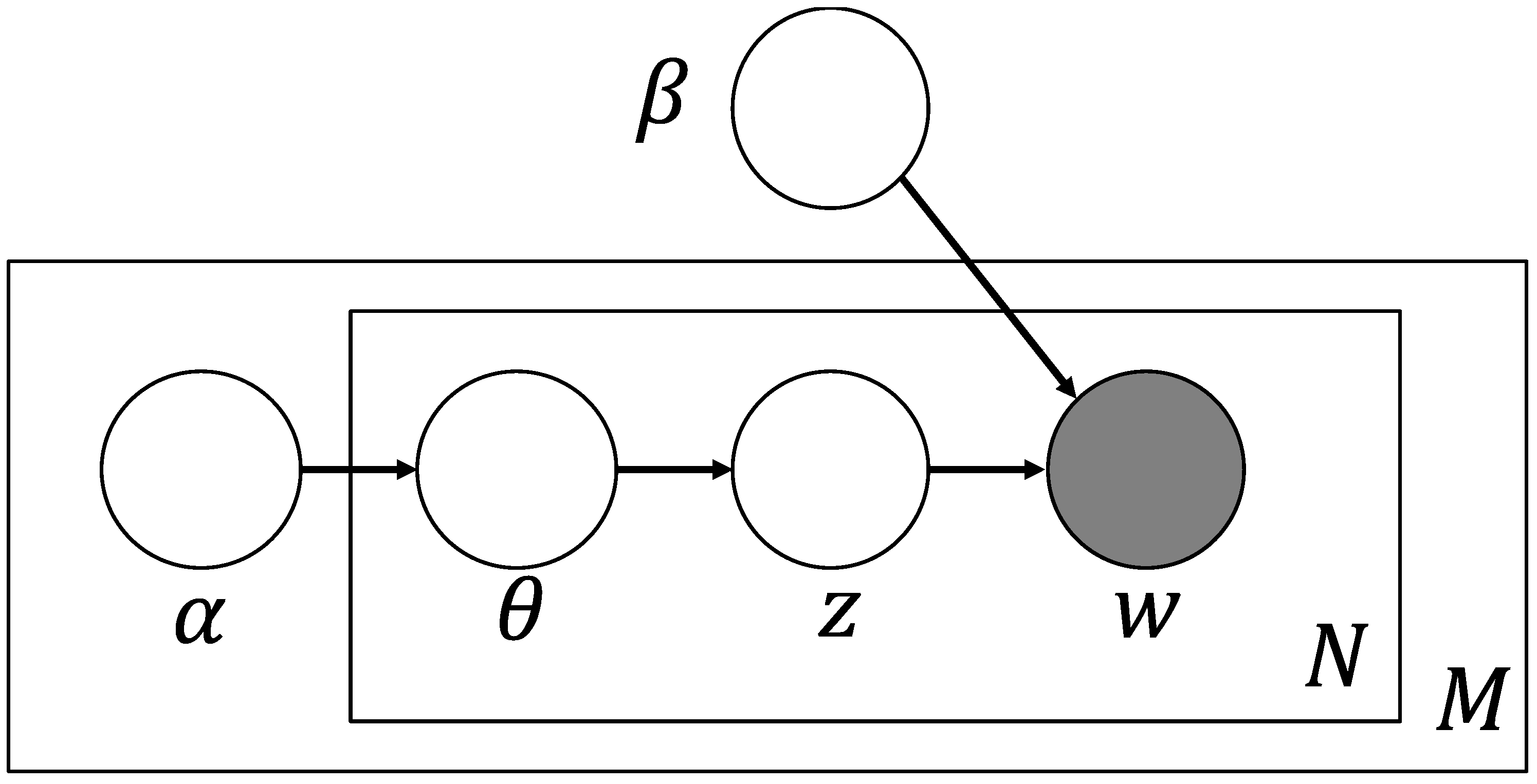
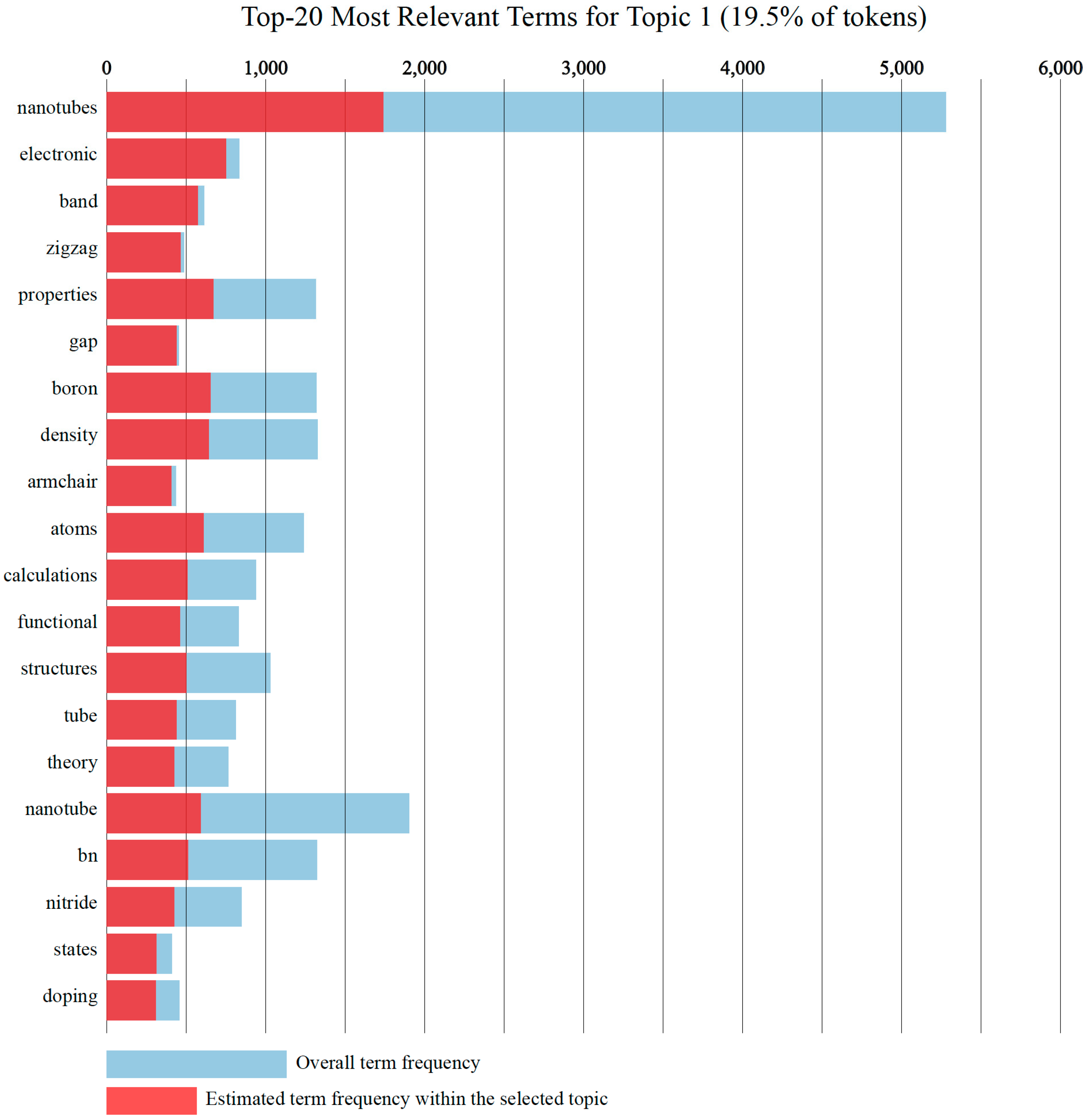
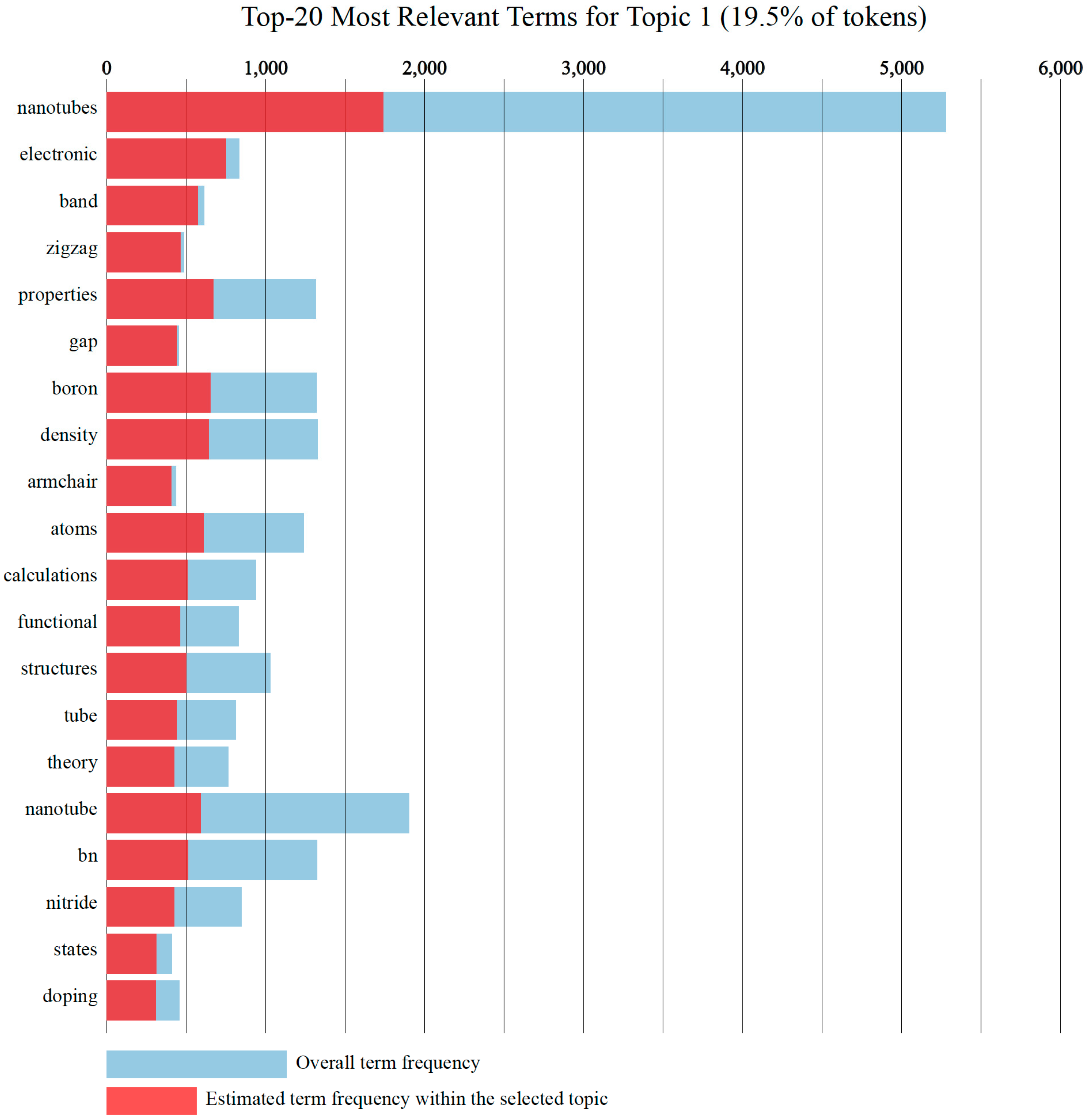
2.5. Topic Extraction from Each Cluster
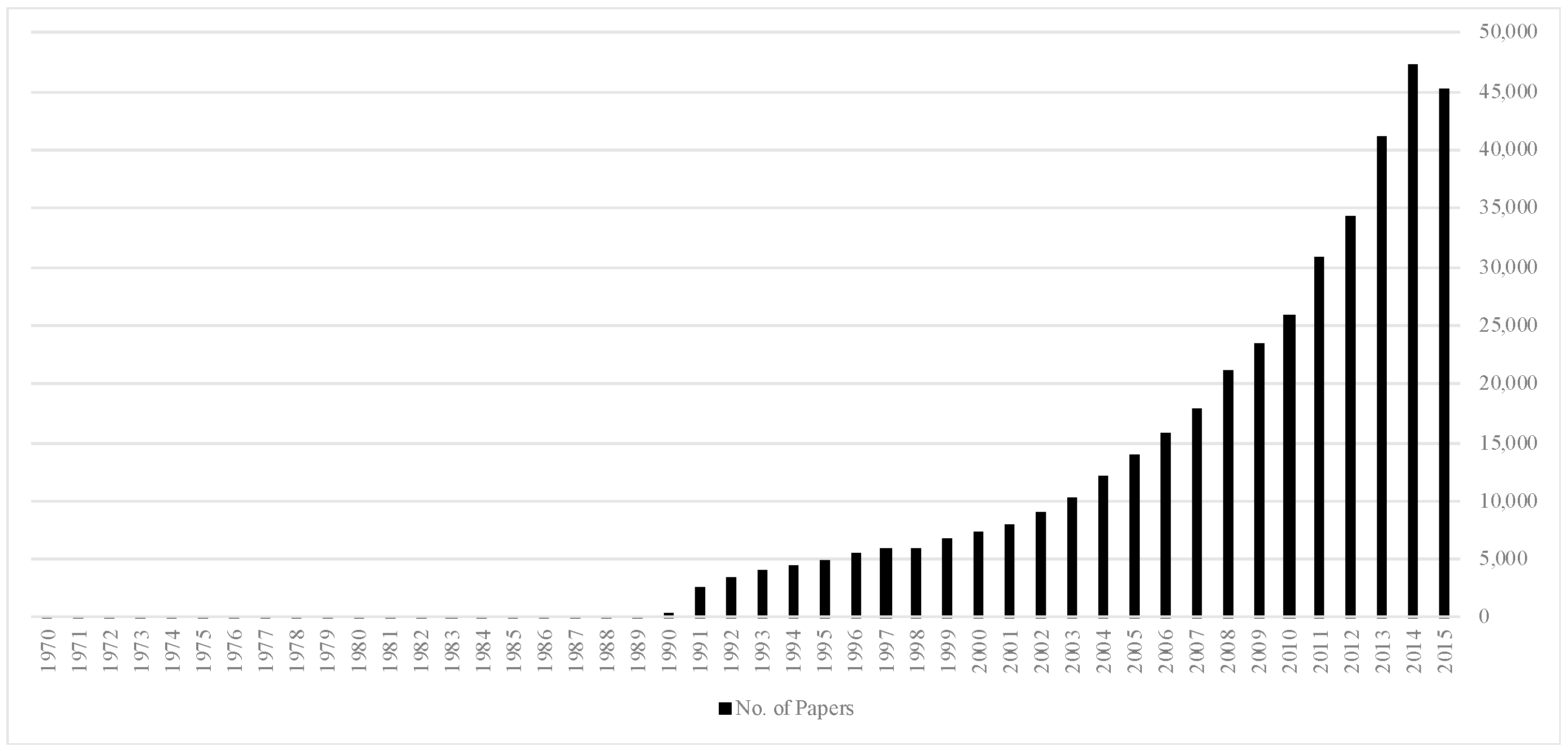
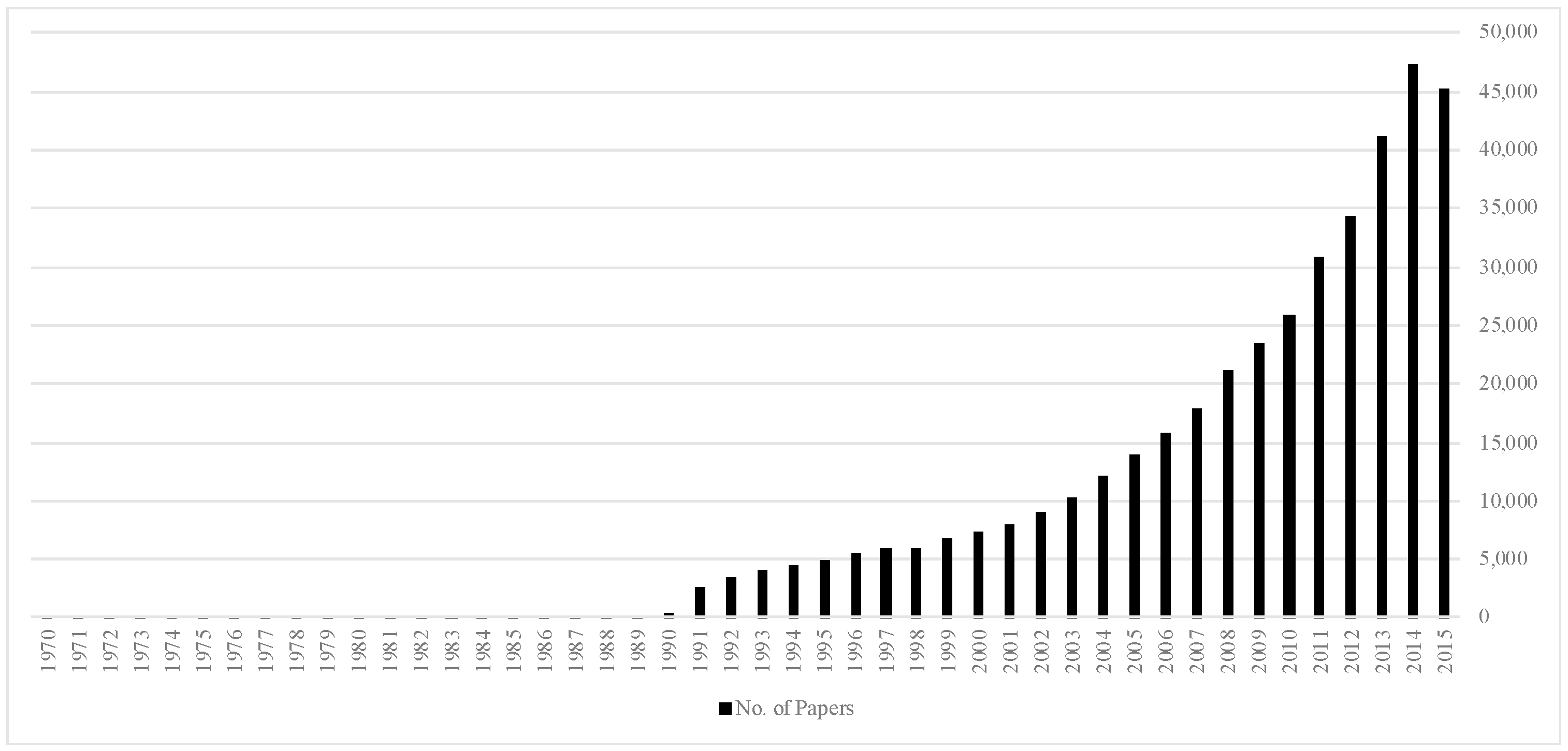
3. Dataset
4. Results
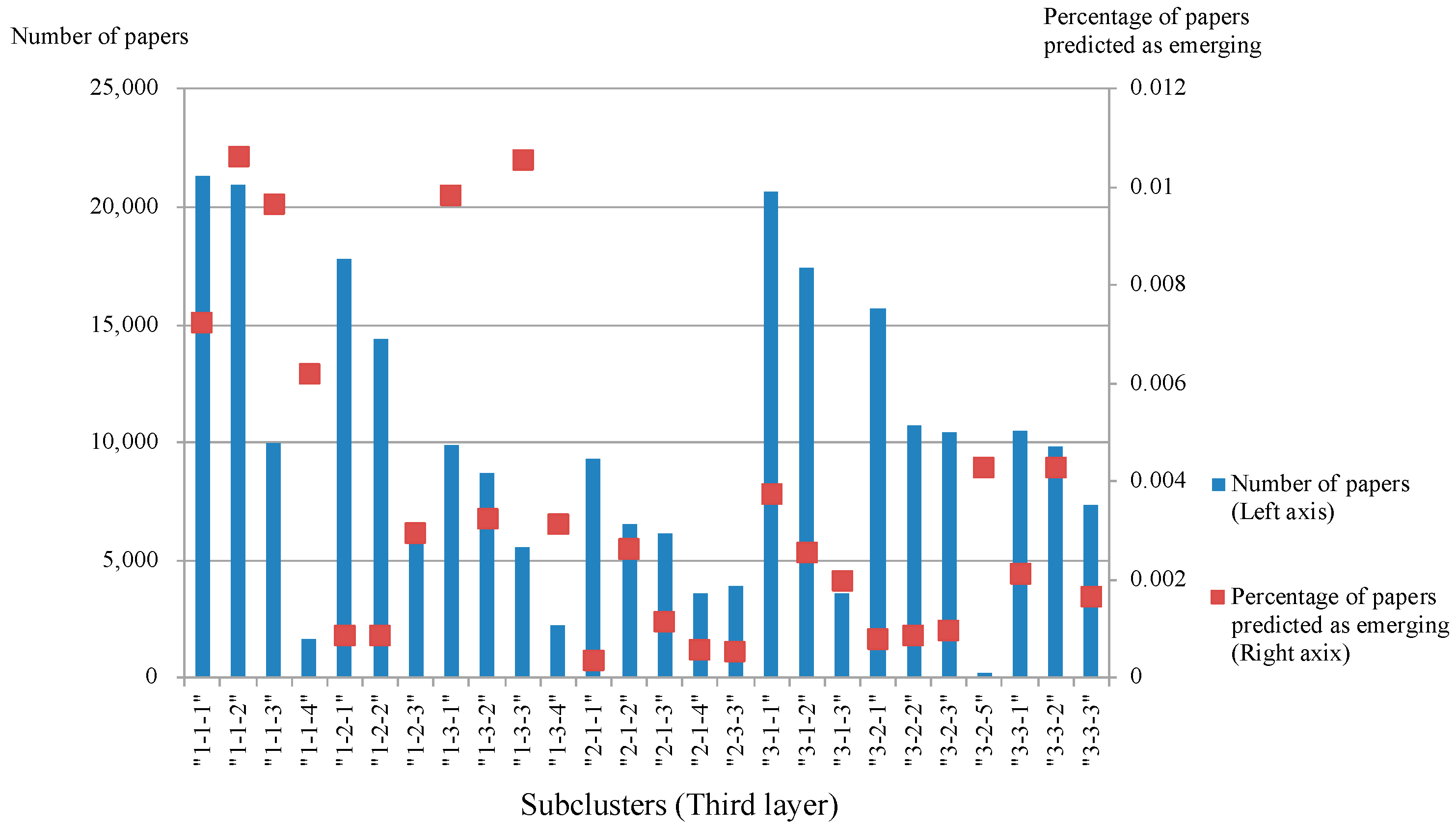
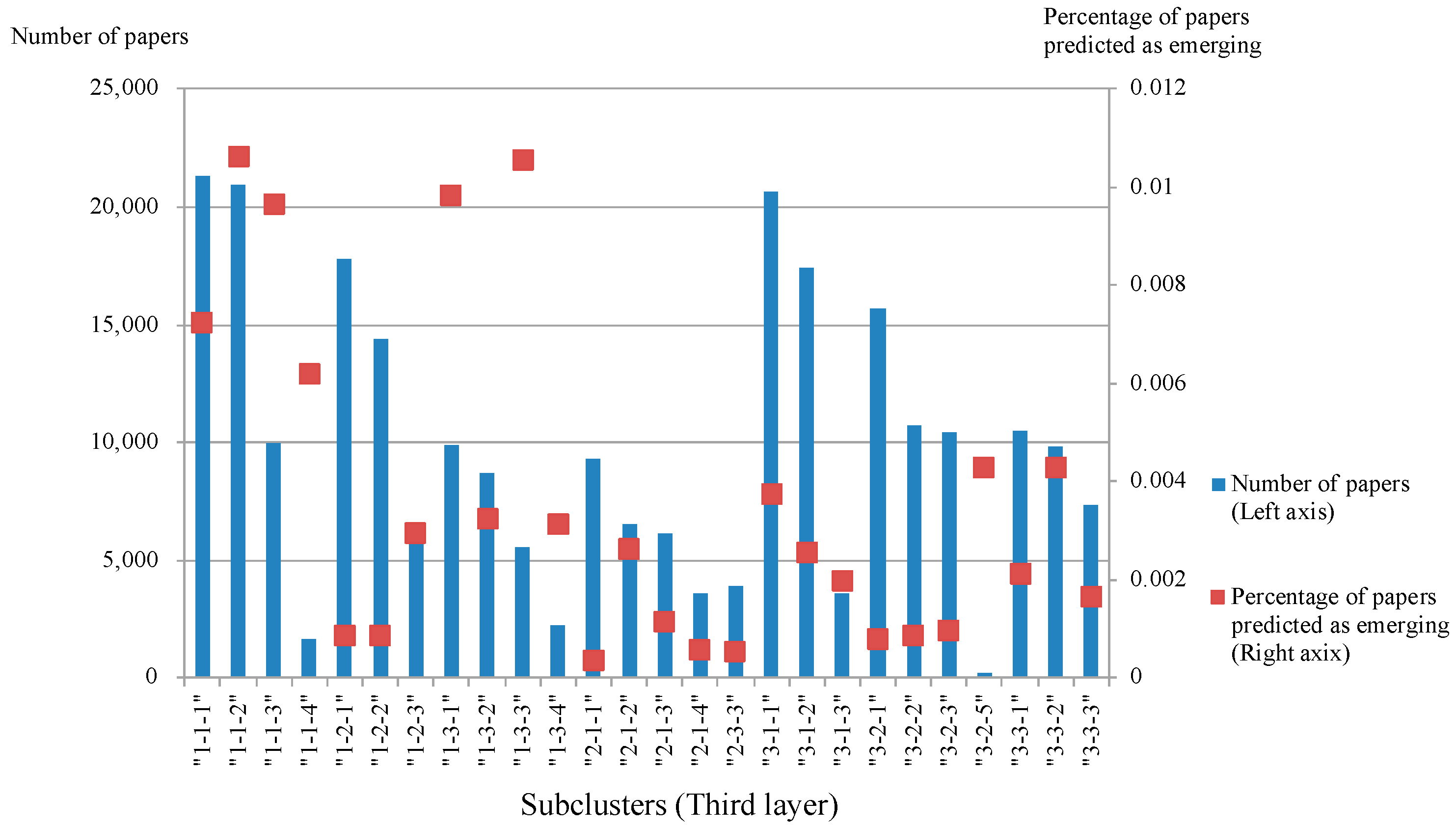
4.1. Result of the Network Model
4.2. Result of Topic Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Beretta, R. A critical review of the Delphi technique. Nurse Res. 1996, 3, 79–89. [Google Scholar] [CrossRef] [PubMed]
- Kajikawa, Y.; Yoshikawa, J.; Takeda, Y.; Matsushima, K. Tracking emerging technologies in energy research: Toward a roadmap for sustainable energy. Technol. Forecast. Soc. Chang. 2008, 75, 771–782. [Google Scholar] [CrossRef]
- Martín-Martín, A.; Orduna-Malea, E.; Ayllón, J.M.; López-Cózar, E.D. Un panorama académico de dos caras: Retrato de los documentos altamente citados en google scholar (1950–2013). Rev. Esp. Doc. Cient. 2016, 39, e149. [Google Scholar] [CrossRef]
- Hashimoto, M.; Sakata, I.; Kajikawa, Y.; Takeda, Y.; Matsushima, K. Academic landscape of innovation research and innovation policy by network science. Hitotsubashi Bus. Rev. 2009, 56, 194–211. [Google Scholar] [CrossRef]
- Takeda, Y.; Kajikawa, Y. Optics: A bibliometric approach to detect emerging research domains and intellectual bases. Scientometrics 2009, 78, 543–558. [Google Scholar] [CrossRef]
- Börner, K.; Chen, C.; Boyack, K.W. Visualizing knowledge domains. Annu. Rev. Inf. Sci. Technol. 2003, 37, 179–255. [Google Scholar] [CrossRef]
- Kostoff, R.N.; Toothman, D.R.; Eberhart, H.J.; Humenik, J.A. Text mining using database tomography and bibliometrics: A review. Technol. Forecast. Soc. Chang. 2001, 68, 223–253. [Google Scholar] [CrossRef]
- Boyack, K.W.; Wylie, B.N.; Davidson, G.S. Domain visualization using VxInsight® for science and technology management. J. Am. Soc. Inf. Sci. Technol. 2002, 53, 764–774. [Google Scholar] [CrossRef]
- Chen, C.; Cribbin, T.; Macredie, R.; Morar, S. Visualizing and tracking the growth of competing paradigms: Two case studies. J. Am. Soc. Inf. Sci. Technol. 2002, 53, 678–689. [Google Scholar] [CrossRef] [Green Version]
- Small, H. Tracking and predicting growth areas in science. Scientometrics 2006, 68, 595–610. [Google Scholar] [CrossRef] [Green Version]
- Shibata, N.; Kajikawa, Y.; Takeda, Y.; Matsushima, K. Detecting emerging research fronts based on topological measures in citation networks of scientific publications. Technovation 2008, 28, 758–775. [Google Scholar] [CrossRef]
- Glänzel, W. Bibliometric methods for detecting and analysing emerging research topics. Prof. Inf. 2012, 21, 194–201. [Google Scholar] [CrossRef]
- Winnink, J.J.; Tijssen, R.J.W. Early stage identification of breakthroughs at the interface of science and technology: Lessons drawn from a landmark publication. Scientometrics 2015, 102, 113–134. [Google Scholar] [CrossRef]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Disc. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Bauhofer, W.; Kovacs, J.Z. A review and analysis of electrical percolation in carbon nanotube polymer composites. Compos. Sci. Technol. 2009, 69, 1486–1498. [Google Scholar] [CrossRef]
- Kumar, M.; Ando, Y. Chemical vapor deposition of carbon nanotubes: A review on growth mechanism and mass production. J. Nanosci. Nanotechnol. 2010, 10, 3739–3758. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.M.; Huang, Z.D.; Oh, S.W.; Zhang, B.; Ma, P.C.; Yuen, M.M.F.; Kim, J.K. Carbon nanotube (CNT)-based composites as electrode material for rechargeable Li-ion batteries: A review. Compos. Sci. Technol. 2012, 72, 121–144. [Google Scholar] [CrossRef]
- Tomczak, S.K.; Staszkiewicz, P. Cross-Country Application of Manufacturing Failure Models. J. Risk Financ. Manag. 2020, 13, 34. [Google Scholar] [CrossRef] [Green Version]
- Staszkiewicz, P. The application of citation count regression to identify important papers in the literature on non-audit fees. Manag. Audit. J. 2019, 34, 96–115. [Google Scholar] [CrossRef]
- Staszkiewicz, P. Search for Measure of the Value of Baltic Sustainability Development: A Meta-Review. Sustainability 2019, 11, 6640. [Google Scholar] [CrossRef] [Green Version]
- Watts, R.J.; Porter, A.L. R&D cluster quality measures and technology maturity. Technol. Forecast. Soc. Chang. 2003, 70, 735–758. [Google Scholar] [CrossRef]
- Guo, H.; Weingart, S.; Börner, K. Mixed-indicators model for identifying emerging research areas. Scientometrics 2011, 89, 421–435. [Google Scholar] [CrossRef]
- Dong, Y.; Johnson, R.A.; Chawla, N.V. Will this paper increase your h-index? Scientific impact prediction. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining—WSDM’15, Shanghai, China, 2–6 February 2015; ACM: New York, NY, USA; pp. 149–158. [Google Scholar]
- Chakraborty, T.; Kumar, S.; Goyal, P.; Ganguly, N.; Mukherjee, A. Towards a stratified learning approach to predict future citation counts. In Proceedings of the 14th ACM/IEEE-CS Joint Conference on Digital Libraries, London, UK, 8–12 September 2014; IEEE: London, UK; pp. 351–360. [Google Scholar]
- Wang, D.; Song, C.; Barabási, A.-L. Quantifying long-term scientific impact. Science 2013, 342, 127–132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adams, J. Early citation counts correlate with accumulated impact. Scientometrics 2005, 63, 567–581. [Google Scholar] [CrossRef]
- Li, L.; Tong, H. The child is father of the man: Foresee the success at the early stage. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD’15, Sydney, Australia, 10–13 August 2015; ACM: New York, NY, USA; pp. 655–664. [Google Scholar]
- Boyack, K.W.; Klavans, R.; Small, H.; Ungar, L. Characterizing the emergence of two nanotechnology topics using a contemporaneous global micro-model of science. J. Eng. Technol. Manag. 2014, 32, 147–159. [Google Scholar] [CrossRef]
- Kuusi, O.; Meyer, M. Anticipating technological breakthroughs: Using bibliographic coupling to explore the nanotubes paradigm. Scientometrics 2007, 70, 759–777. [Google Scholar] [CrossRef]
- Garfield, E.; Sher, I.H.; Torpie, R.J. The Use of Citation Data in Writing the History of Science; Institute for Scientific Information Inc.: Philadelphia, PA, USA, 1964. [Google Scholar]
- Scharnhorst, A.; Garfield, E. Tracing scientific influence. arXiv 2010, arXiv:1010.3525. [Google Scholar]
- Davletov, F.; Aydin, A.S.; Cakmak, A. High impact academic paper prediction using temporal and topological features. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management—CIKM’14, Shanghai, China, 3–7 November 2014; ACM: New York, NY, USA; pp. 491–498. [Google Scholar]
- Arxiv. arxiv.org, March. 2020. Available online: http://arxiv.org (accessed on 1 September 2020).
- Mori, J.; Sakaki, T.; Kajikawa, Y.; Sakata, I. Predicting citations to detect emerging technologies using academic papers. In Proceedings of the 28th Annual Conference of the Japanese Society for Artificial Intelligence, Ehime, Japan, 12–15 May 2014. [Google Scholar]
- Sasaki, H.; Hara, T.; Sakata, I. Identifying emerging research related to solar cells field using a machine leaning approach. J. Sustain. Dev. Energy Water Environ. Syst. 2016, 4, 418–429. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Chen, Y.; Horowitz, M.; Hou, H.; Liu, Z.; Pellegrino, D. Towards an explanatory and computational theory of scientific discovery. J. Informetr. 2009, 3, 191–209. [Google Scholar] [CrossRef] [Green Version]
- Yau, C.K.; Porter, A.; Newman, N.; Suominen, A. Clustering scientific documents with topic modeling. Scientometrics 2014, 100, 767–786. [Google Scholar] [CrossRef]
- He, Q.; Chen, B.; Pei, J.; Qiu, B.; Mitra, P.; Giles, L. Detecting topic evolution in scientific literature: How can citations help? In Proceedings of the 18th ACM Conference on Information and Knowledge Management—CIKM’09, Hong Kong, China, 2–6 November 2009; ACM: New York, NY, USA; pp. 957–966. [Google Scholar]
- Liu, X.; Zhang, J.; Guo, C. Full-text citation analysis: Enhancing bibliometric and scientific publication ranking. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management—CIKM’12, Maui, HI, USA, 29 October–2 November 2012; ACM: New York, NY, USA; pp. 1975–1979. [Google Scholar]
- Jiang, H.; Qiang, M.; Lin, P. A topic modeling based bibliometric exploration of hydropower research. Renew. Sustain. Energy Rev. 2016, 57, 226–237. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Bonacich, P. Technique for analyzing overlapping memberships. Sociol. Methodol. 1972, 4, 176. [Google Scholar] [CrossRef]
- Burt, R.S. Structural holes and good ideas. Am. J. Sociol. 2004, 110, 349–399. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Guimerà, R.; Amaral, L.A.N. Functional cartography of complex metabolic networks. Nature 2005, 433, 895–900. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef] [Green Version]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; Association for Computational Linguistics: Baltimore, MD, USA; pp. 63–70. [Google Scholar]
- Deveaud, R.; SanJuan, E.; Bellot, P. Accurate and effective latent concept modeling for ad hoc information retrieval. Doc. Numér. 2014, 17, 61–84. [Google Scholar] [CrossRef] [Green Version]
- D’Souza, F.; Ito, O. Photosensitized electron transfer processes of nanocarbons applicable to solar cells. Chem. Soc. Rev. 2012, 41, 86–96. [Google Scholar] [CrossRef] [PubMed]
- Burke, A. R&D considerations for the performance and application of electrochemical capacitors. Electrochim. Acta 2007, 53, 1083–1091. [Google Scholar] [CrossRef]
- Suzuki, K.; Yamaguchi, M.; Kumagai, M.; Yanagida, S. Application of carbon nanotubes to counter electrodes of dye-sensitized solar cells. Chem. Lett. 2002, 32, 28–29. [Google Scholar] [CrossRef]
- Kasavajjula, U.; Wang, C.; Appleby, A.J. Nano- and bulk-silicon-based insertion anodes for lithium-ion secondary cells. J. Power Sources 2007, 163, 1003–1039. [Google Scholar] [CrossRef]
- Liu, C.; Li, F.; Ma, L.P.; Cheng, H.M. Advanced materials for energy storage. Adv. Mater. 2010, 22, E28–E62. [Google Scholar] [CrossRef]
- Edwards, B.C. Design and deployment of a space elevator. Acta Astronaut. 2000, 47, 735–744. [Google Scholar] [CrossRef]
- Pugno, N.M. On the strength of the carbon nanotube-based space elevator cable: From nanomechanics to megamechanics. J. Phys. Condens. Matter 2006, 18, S1971–S1990. [Google Scholar] [CrossRef]
- Pugno, N. The role of defects in the design of space elevator cable: From nanotube to megatube. Acta Mater. 2007, 55, 5269–5279. [Google Scholar] [CrossRef]
- Zhang, Q.; Huang, J.Q.; Zhao, M.Q.; Qian, W.Z.; Wei, F. Carbon nanotube mass production: Principles and processes. ChemSusChem 2011, 4, 864–889. [Google Scholar] [CrossRef]
- Lan, Y.; Wang, Y.; Ren, Z.F. Physics and applications of aligned carbon nanotubes. Adv. Phys. 2011, 60, 553–678. [Google Scholar] [CrossRef]
- Lee, S.H.; Lee, D.H.; Lee, W.J.; Kim, S.O. Tailored assembly of carbon nanotubes and graphene. Adv. Funct. Mater. 2011, 21, 1338–1354. [Google Scholar] [CrossRef]
- Sarma, S.D.; Adam, S.; Hwang, E.H.; Rossi, E. Electronic transport in two-dimensional graphene. Rev. Mod. Phys. 2011, 83, 407–470. [Google Scholar] [CrossRef] [Green Version]
- Hwang, E.H.; Adam, S.; Sarma, S.D. Carrier transport in two-dimensional graphene layers. Phys. Rev. Lett. 2007, 98, 186806. [Google Scholar] [CrossRef] [Green Version]
- Saito, R.; Hofmann, M.; Dresselhaus, G.; Jorio, A.; Dresselhaus, M.S. Raman spectroscopy of graphene and carbon nanotubes. Adv. Phys. 2011, 60, 413–550. [Google Scholar] [CrossRef]
- Li, Y.; Li, D.; Wang, G. Methane decomposition to COx-free hydrogen and nano-carbon material on group 8–10 base metal catalysts: A review. Catal. Today 2011, 162, 1–48. [Google Scholar] [CrossRef]
- Yan, L.; Zhao, F.; Li, S.; Hu, Z.; Zhao, Y. Low-toxic and safe nanomaterials by surface-chemical design, carbon nanotubes, fullerenes, metallofullerenes, and graphenes. Nanoscale 2011, 3, 362–382. [Google Scholar] [CrossRef]
- Singh, V.; Joung, D.; Zhai, L.; Das, S.; Khondaker, S.I.; Seal, S. Graphene based materials: Past, present and future. Prog. Mater. Sci. 2011, 56, 1178–1271. [Google Scholar] [CrossRef]
- Leary, R.; Westwood, A. Carbonaceous nanomaterials for the enhancement of TiO2 photocatalysis. Carbon 2011, 49, 741–772. [Google Scholar] [CrossRef]
- Dasgupta, A.; Rajukumar, L.P.; Rotella, C.; Lei, Y.; Terrones, M. Covalent three-dimensional networks of graphene and carbon nanotubes: Synthesis and environmental applications. Nano Today 2017, 12, 116–135. [Google Scholar] [CrossRef]
- Novoselov, K.S.; Geim, A.K.; Morozov, S.V.; Jiang, D.; Zhang, Y.; Dubonos, S.V.; Grigorieva, I.V.; Firsov, A.A. Electric field effect in atomically thin carbon films. Science 2004, 306, 666–669. [Google Scholar] [CrossRef] [Green Version]
- Bolotin, K.I.; Sikes, K.J.; Jiang, Z.; Klima, M.; Fudenberg, G.; Hone, J.; Kim, P.; Stormer, H.L. Ultrahigh electron mobility in suspended graphene. Solid State Commun. 2008, 146, 351–355. [Google Scholar] [CrossRef] [Green Version]
- Hitosugi, S.; Yamasaki, T.; Isobe, H. Bottom-up synthesis and thread-in-bead structures of finite (n,0)-zigzag single-wall carbon nanotubes. J. Am. Chem. Soc. 2012, 134, 12442–12445. [Google Scholar] [CrossRef] [PubMed]
- Hitosugi, S.; Nakanishi, W.; Yamasaki, T.; Isobe, H. Bottom-up synthesis of finite models of helical (n,m)-single-wall carbon nanotubes. Nat. Commun. 2011, 2, 492. [Google Scholar] [CrossRef]
- Mongeon, P.; Paul-Hus, A. The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics 2016, 106, 213–228. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class of Feature | Name of Feature | Description |
|---|---|---|
| Network | Dataset in question and feature of network in the year in question. | |
| NW_NODES | Number of papers in a network. | |
| NW_EDGES | Number of citation links in a network. | |
| NW_MAXQ | Maximum of Q-values of clusters in a network. | |
| Cluster | Feature of the cluster to which a paper belongs. | |
| CL_QMAX | Maximum of Q-values of clusters to which a paper belongs. | |
| CL_NODES | Number of nodes in the cluster to which a paper belongs. | |
| CL_RANK | Rank of the cluster to which a paper belongs. | |
| Centrality | Network centrality of a paper. | |
| CNT_DEGRE | Degree centrality. | |
| CNT_BETWE | Betweenness centrality. | |
| CNT_CLOSE | Closeness centrality. | |
| CNT_EIGEN | Eigenvector centrality. | |
| CNT_NETWO | Network constraint. | |
| CNT_CLUST | Clustering coefficient. | |
| CNT_PAGER | Page rank. | |
| CNT_HUBSC | Hub score. | |
| CNT_AUTHOR | Authority score. | |
| Property of reference | The sum of the features of paper sets that a paper cites. | |
| CITING_MAX-[feature] | Maximum of features in questions in cited paper sets that a paper cites. | |
| CITING_MIN-[feature] | Minimum of features in questions in cited paper sets that a paper cites. | |
| CITING_AVG-[feature] | Average of features in questions in cited paper sets that a paper cites. | |
| CITING_SUM-[feature] | Sum of features in questions in cited paper sets that a paper cites. | |
| Model Training Year t0 | Training Citation Data Confirmation Year t0 + 3 | Prediction Target Year t1 | Prediction Model Evaluation Year t1 + 3 |
|---|---|---|---|
| 2003 | 2006 | 2007 | 2010 |
| 2004 | 2007 | 2008 | 2011 |
| 2005 | 2008 | 2009 | 2012 |
| 2006 | 2009 | 2010 | 2013 |
| 2007 | 2010 | 2011 | 2014 |
| 2008 | 2011 | 2012 | 2015 |
| Number of Target Papers | Number of Predicted Papers | F1 Measure (Average) | ||
|---|---|---|---|---|
| 2006 | 2002 | 2990 | 1495 | 67.5 |
| 2007 | 2003 | 3598 | 1779 | 63.8 |
| 2008 | 2004 | 3990 | 1995 | 74.3 |
| 2009 | 2005 | 4664 | 2332 | 55.5 |
| 2010 | 2006 | 4994 | 2497 | 86.2 |
| 2011 | 2007 | 5830 | 2915 | 85.3 |
| 2002 Model for 2006 | 2003 Model for 2007 | 2004 Model for 2008 | |||
|---|---|---|---|---|---|
| CNT_PAGER | 20.5 | CNT_PAGER | 22.3 | CNT_PAGER | 27.1 |
| CNT_AUTHO | 9.4 | CNT_AUTHO | 10.3 | CNT_AUTHO | 11.2 |
| CITING_MAX-CNT_DEGRE | 5.3 | CNT_DEGRE | 8.0 | CNT_DEGRE | 9.0 |
| CNT_DEGRE | 5.3 | CITING_MAX-CNT_DEGRE | 5.4 | CNT_CLOSE | 5.5 |
| CITING_SUM-CL_RANK | 4.2 | CNT_CLOSE | 4.3 | CITING_AVG-CNT_CLOSE | 4.5 |
| 2005 Model for 2009 | 2006 Model for 2010 | 2007 Model for 2011 | |||
| CNT_PAGER | 23.3 | CNT_PAGER | 25.8 | CNT_PAGER | 33.1 |
| CNT_AUTHO | 9.7 | CNT_AUTHO | 18.3 | CNT_AUTHO | 14.9 |
| CNT_DEGRE | 6.1 | CNT_DEGRE | 8.2 | CNT_CLOSE | 9.3 |
| CITING_SUM-CL_RANK | 3.6 | CNT_CLOSE | 5.7 | CNT_DEGRE | 8.9 |
| CITING_SUM-CL_QMAX | 3.5 | CITING_SUM-CL_RANK | 4.6 | CITING_AVG-CNT_CLOSE | 5.2 |
| Rank | Prob. | Title | Journal | Number of Citations (2011) | Number of Citations (2014) | Ref. |
|---|---|---|---|---|---|---|
| 1 | 1 | Carbon nanotube mass production: Principles and processes | ChemSusChem | 0 | 84 | Zhang et al. [60] |
| 2 | 1 | Physics and applications of aligned carbon nanotubes | Advances in Physics | 0 | 35 | Lan et al. [61] |
| 3 | 0.99 | Tailored assembly of carbon nanotubes and graphene | Advanced Functional Materials | 6 | 82 | Lee et al. [62] |
| 4 | 0.99 | Electronic transport in two-dimensional graphene | Reviews of Modern Physics | 51 | 664 | Sarma et al. [63] |
| 5 | 0.99 | Graphene-based materials: Synthesis, characterization, properties, and applications | Small | 26 | 587 | Hwang et al. [64] |
| 6 | 0.99 | Raman spectroscopy of graphene and carbon nanotubes | Advances in Physics | 0 | 98 | Saito et al. [65] |
| 7 | 0.99 | Methane decomposition to COx-free hydrogen and nanocarbon material on group 8–10 base metal catalysts: A review | Catalysis Today | 5 | 46 | Li et al. [66] |
| 8 | 0.99 | Low-toxic and safe nanomaterials by surface-chemical design, carbon nanotubes, fullerenes, metallofullerenes, and graphenes | Nanoscale | 5 | 67 | Yan et al. [67] |
| 9 | 0.99 | Graphene-based materials: Past, present, and future | Progress in Materials Science | 7 | 506 | Singh et al. [68] |
| 10 | 0.99 | Carbonaceous nanomaterials for enhancement of TiO2 photocatalysis | Carbon | 11 | 223 | Leary and Westwood [69] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sasaki, H.; Fugetsu, B.; Sakata, I. Emerging Scientific Field Detection Using Citation Networks and Topic Models—A Case Study of the Nanocarbon Field. Appl. Syst. Innov. 2020, 3, 40. https://doi.org/10.3390/asi3030040
Sasaki H, Fugetsu B, Sakata I. Emerging Scientific Field Detection Using Citation Networks and Topic Models—A Case Study of the Nanocarbon Field. Applied System Innovation. 2020; 3(3):40. https://doi.org/10.3390/asi3030040
Chicago/Turabian StyleSasaki, Hajime, Bunshi Fugetsu, and Ichiro Sakata. 2020. "Emerging Scientific Field Detection Using Citation Networks and Topic Models—A Case Study of the Nanocarbon Field" Applied System Innovation 3, no. 3: 40. https://doi.org/10.3390/asi3030040
APA StyleSasaki, H., Fugetsu, B., & Sakata, I. (2020). Emerging Scientific Field Detection Using Citation Networks and Topic Models—A Case Study of the Nanocarbon Field. Applied System Innovation, 3(3), 40. https://doi.org/10.3390/asi3030040