Business Process Automation: A Workflow Incorporating Optical Character Recognition and Approximate String and Pattern Matching for Solving Practical Industry Problems

Abstract
:1. Introduction
2. Related Work
2.1. OCR Tools
2.2. Combining OCR and ASM
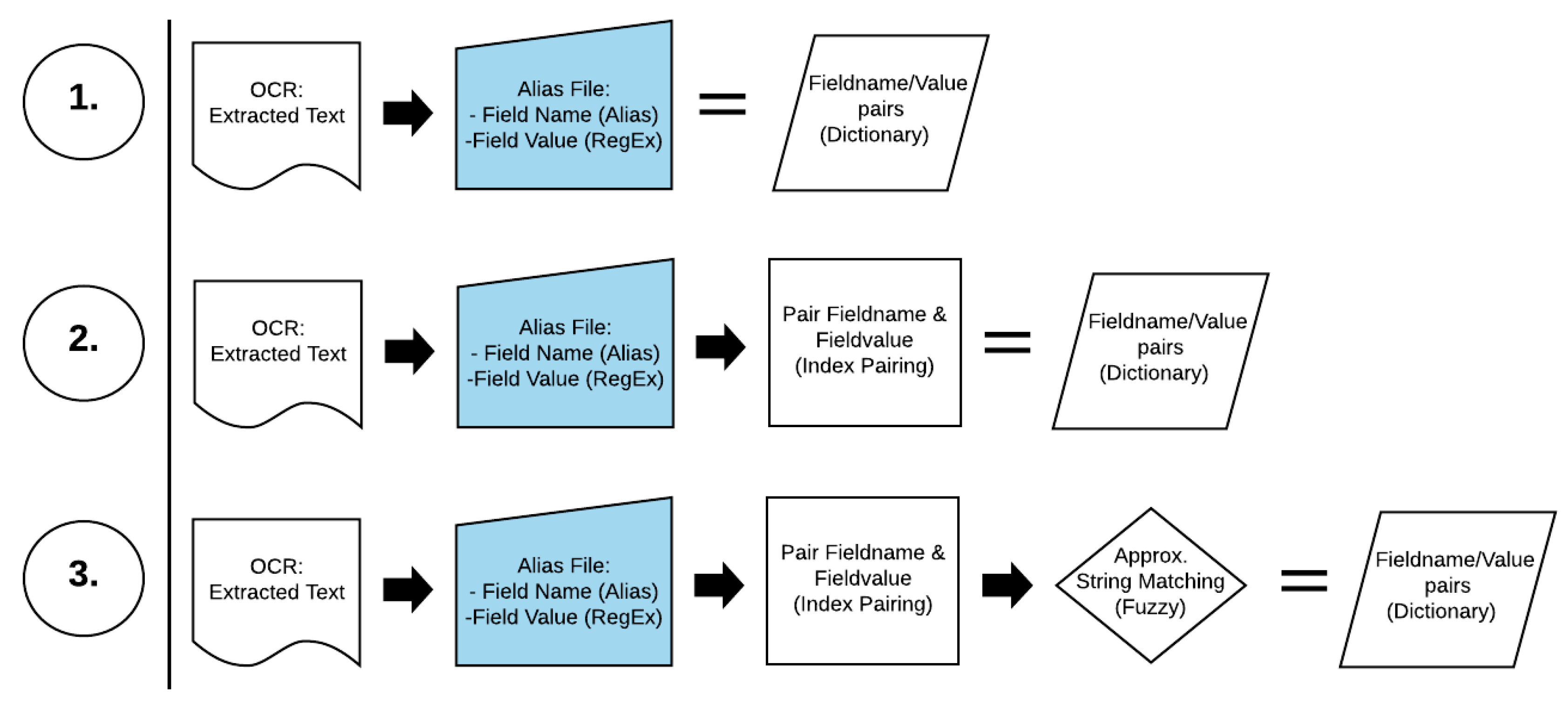
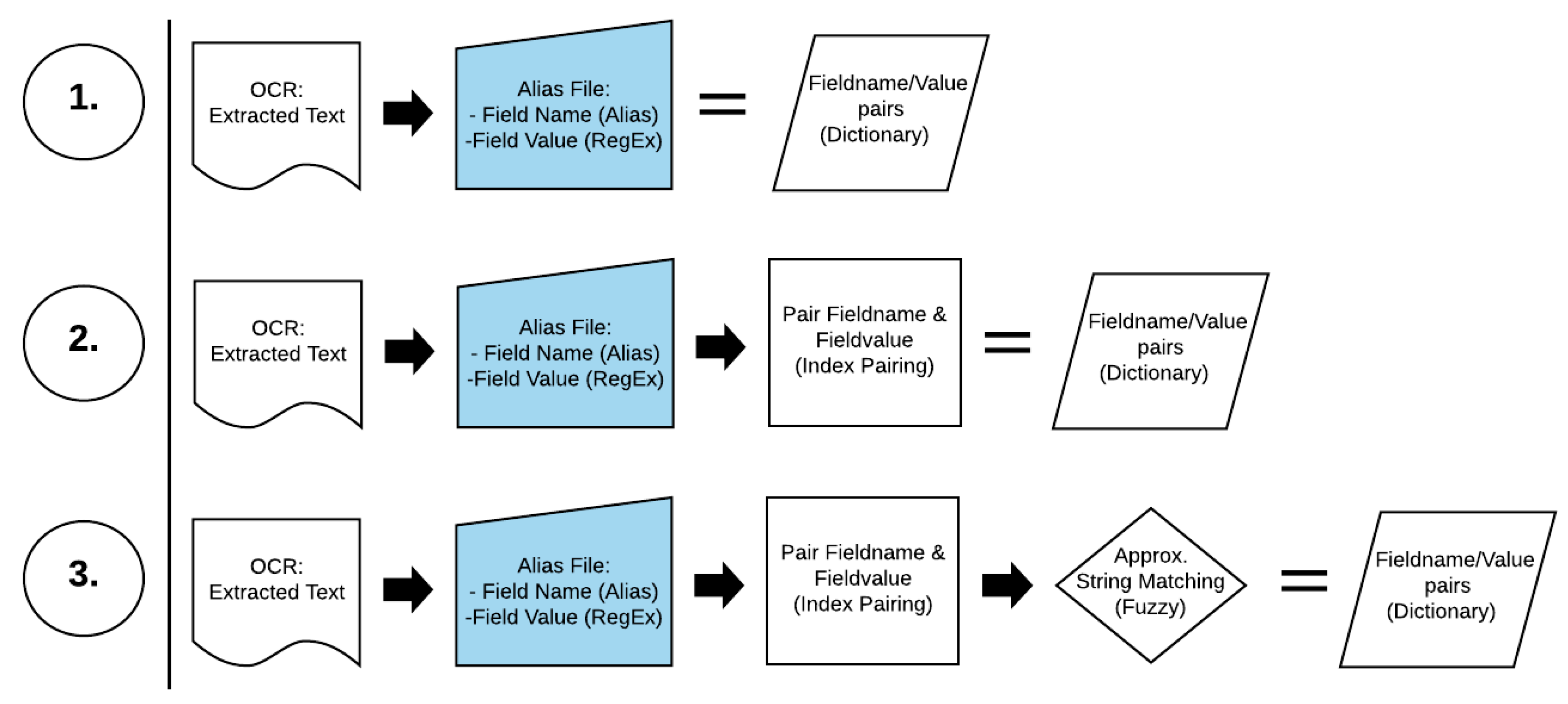
2.3. Combining OCR and Text Processing (Index Pairing)
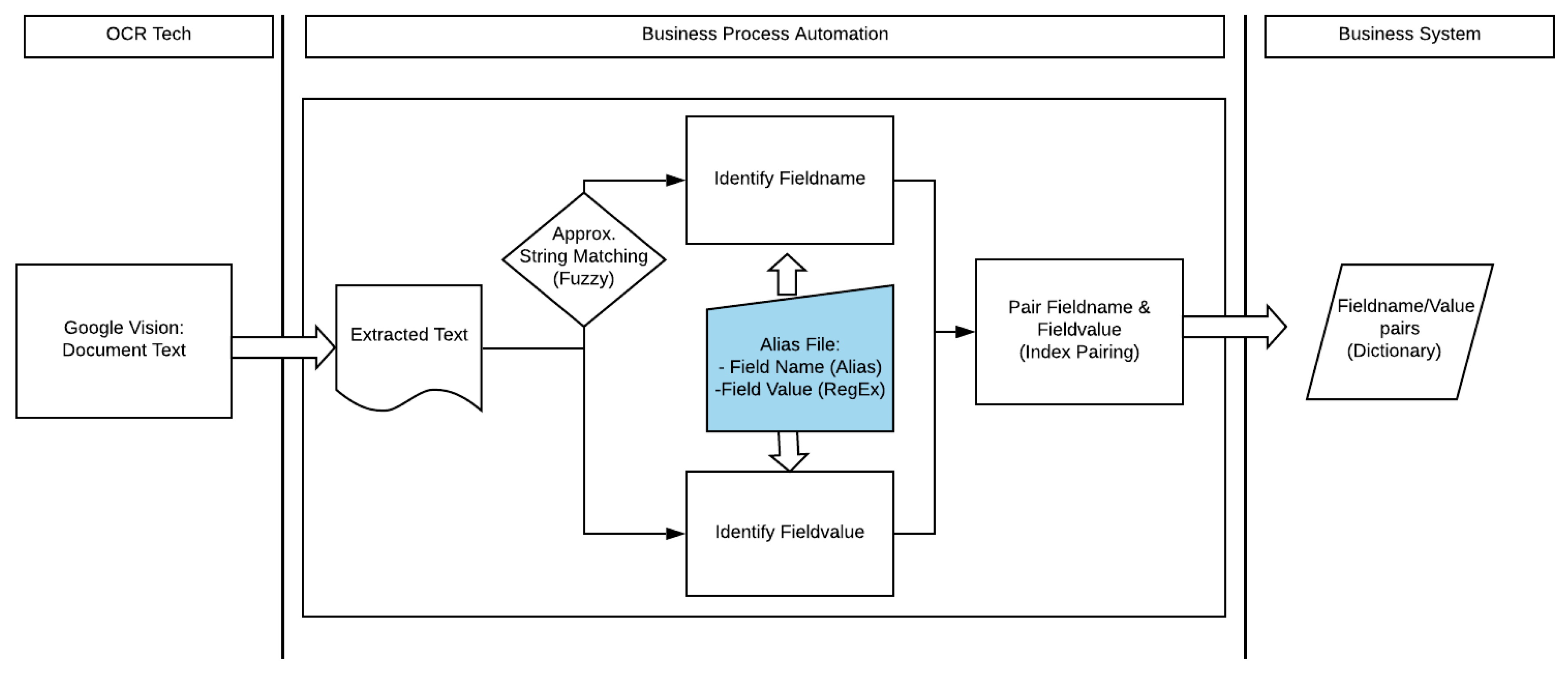
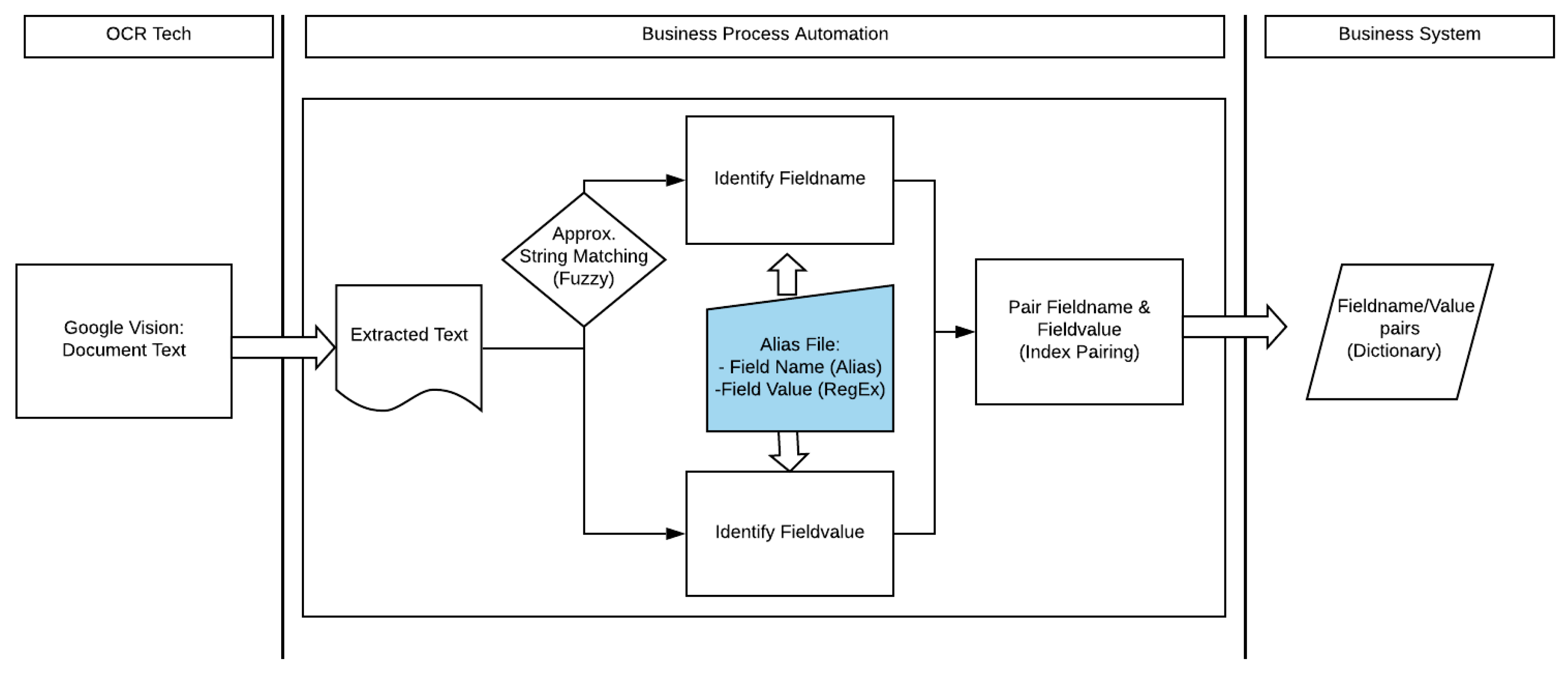
3. Description of the Approach
3.1. OCR Tools
3.2. Approximate String Matching
3.3. Regular Expressions
4. Implementation Details
4.1. Project Input Files (Dataset)
4.2. Project Approach
5. Evaluation Approach
Project Metrics
- (a)
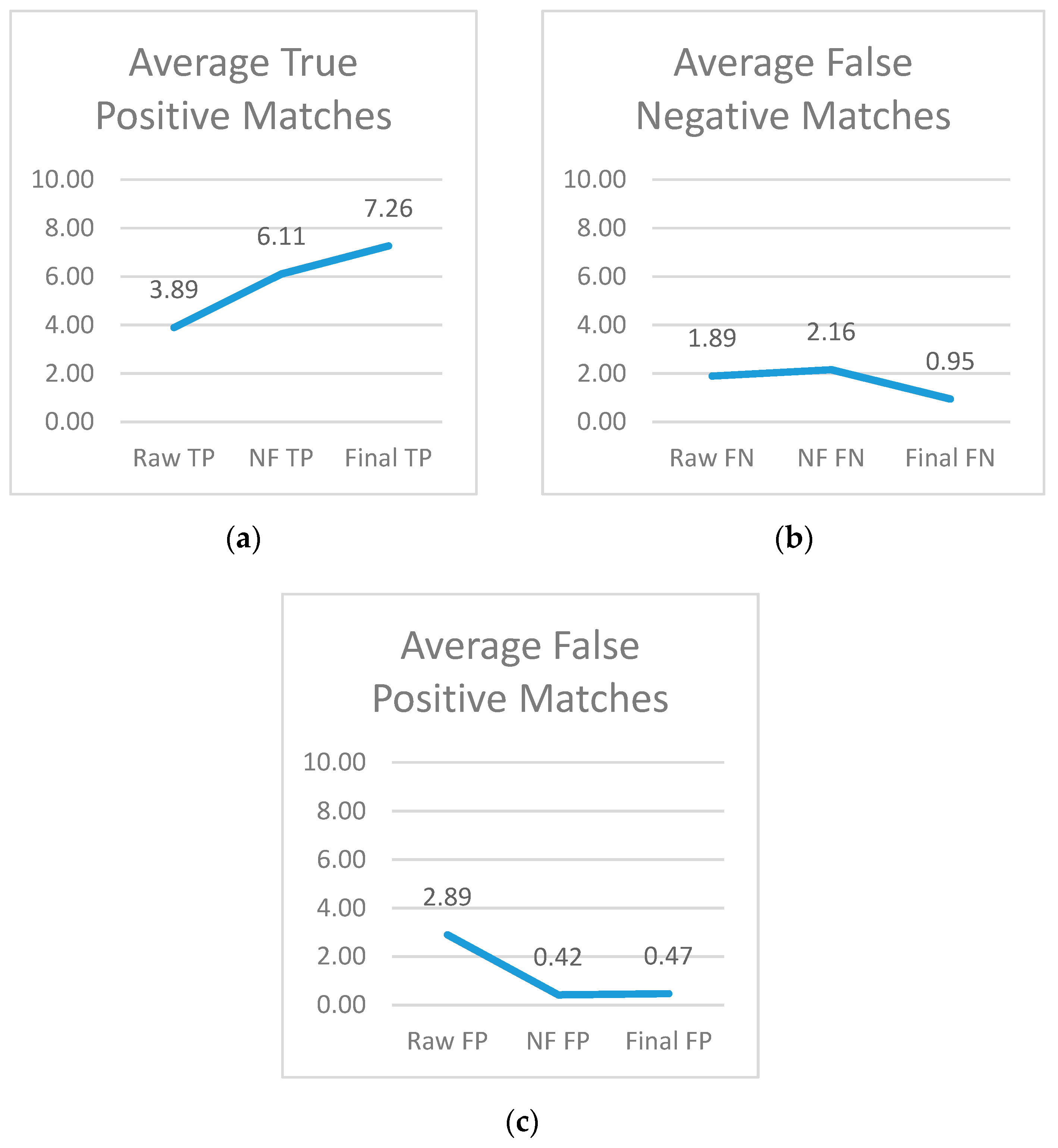
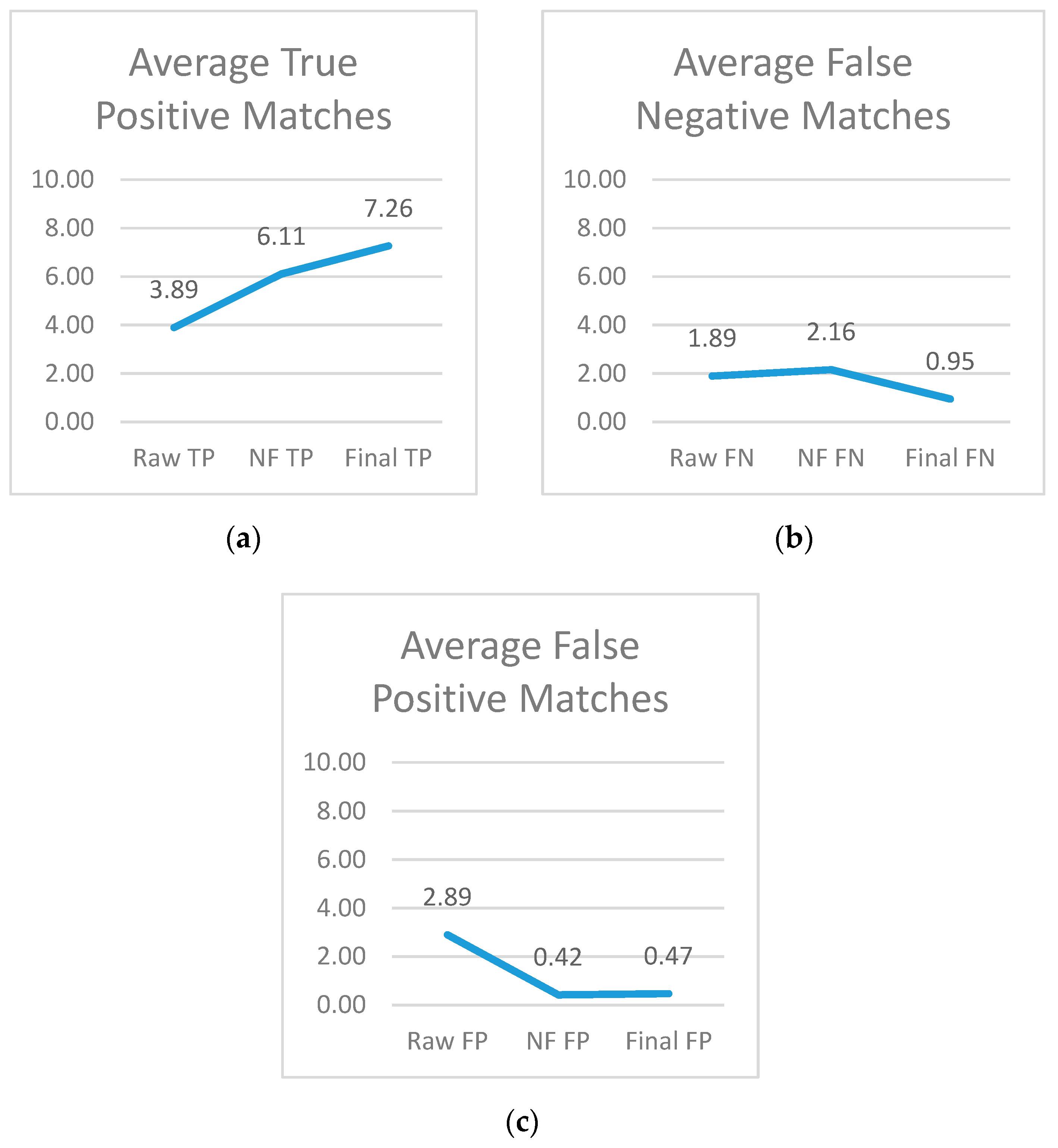
- True positive matches (TP): The number of times the system matched a key and its correct, corresponding value together.
- (b)
- False positive matches (FP): The number of times a key was matched with a value other than its actual value as found in the truth set. Reasons for this can include:
- The field name and value are present in the tax image file and the system detects the field name through the system. However, the system fails to detect the correct value for the field due to some spelling errors in the value.
- The field name and value are present in the tax image file and the system detects the field name. However, the incorrect value is paired with the field name.
- The field name has no corresponding value in the original tax document, but the system matches this field name with some value in the tax document.
- (c)
- False negative matches (FN): The amount of times a key or value was not identified. This could be due to a few different reasons:
- There is a key-value pair in the original tax document, and the system identifies the key successfully. However, it fails to identify the value from the document and so concludes that the key has no value.
- There is a key-value pair in the original tax document, but the system fails to identify the key or the value.
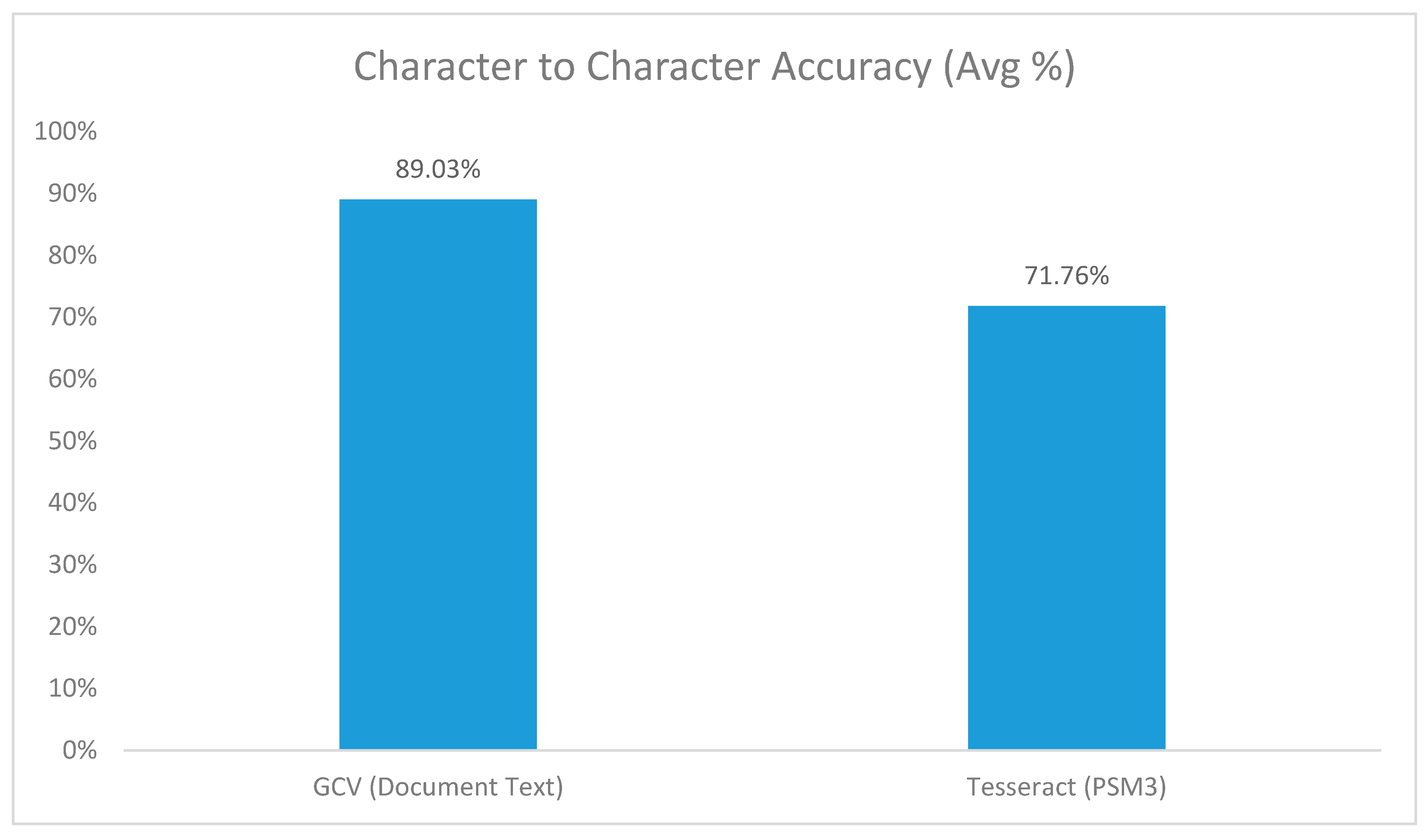
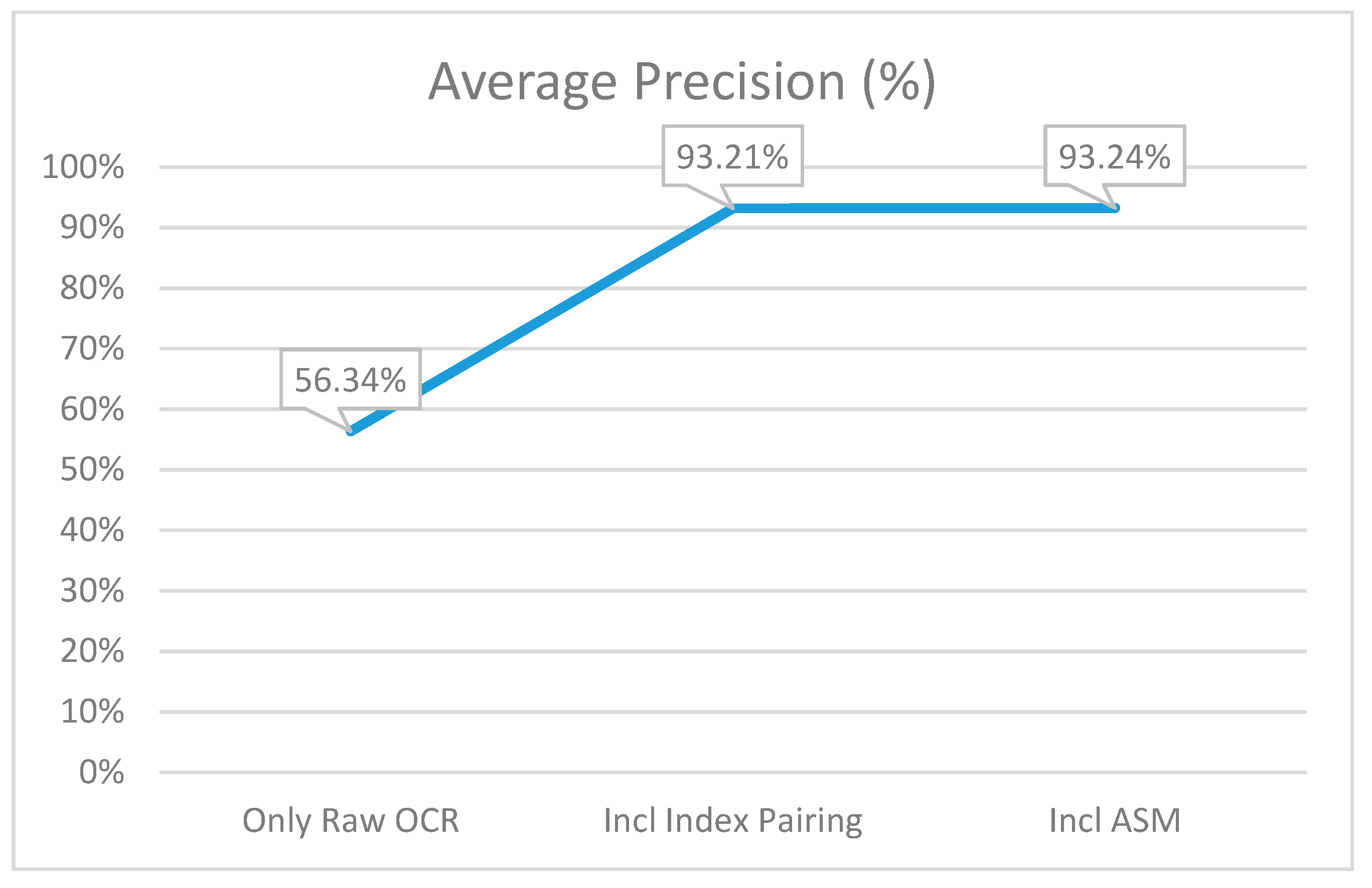
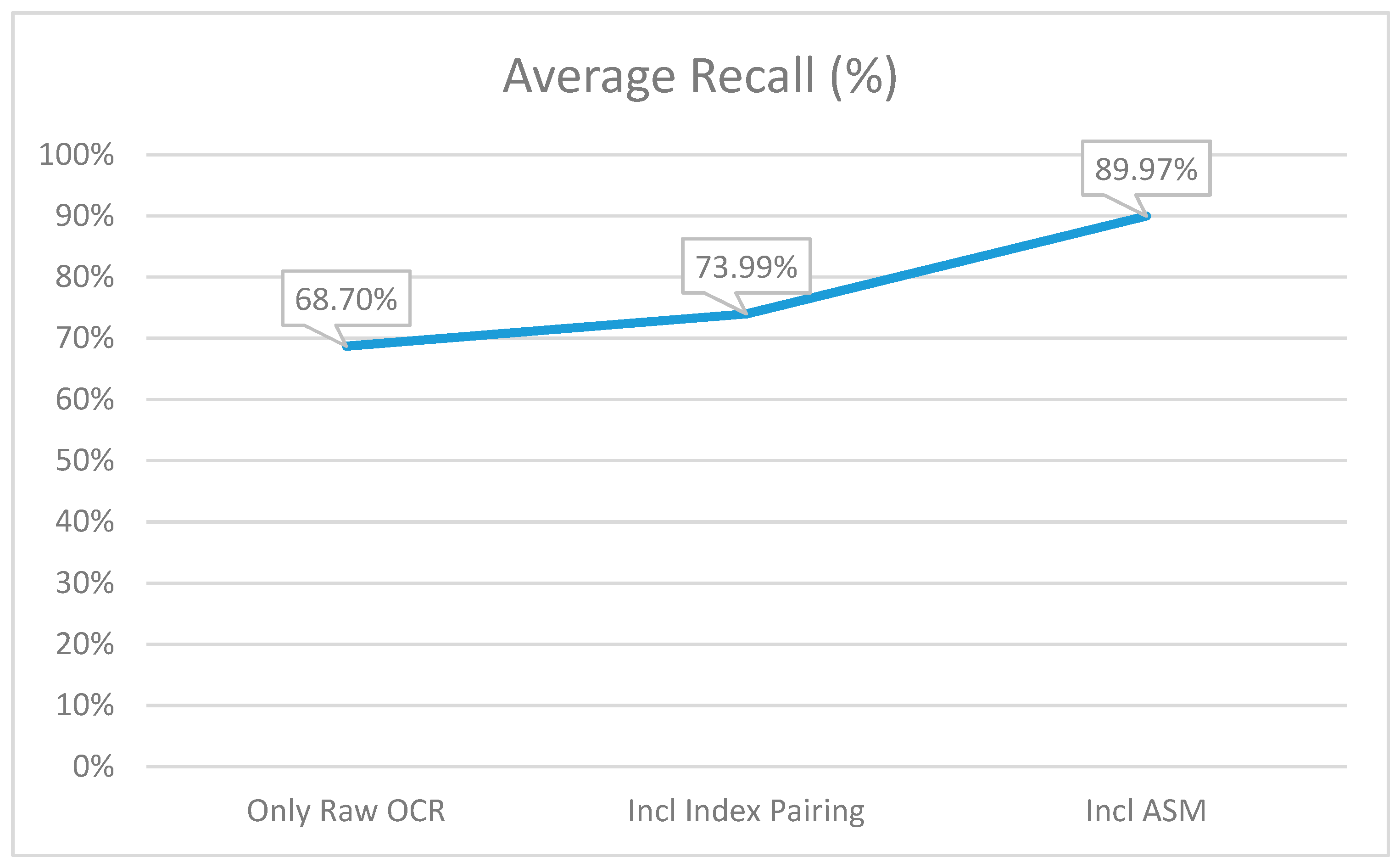
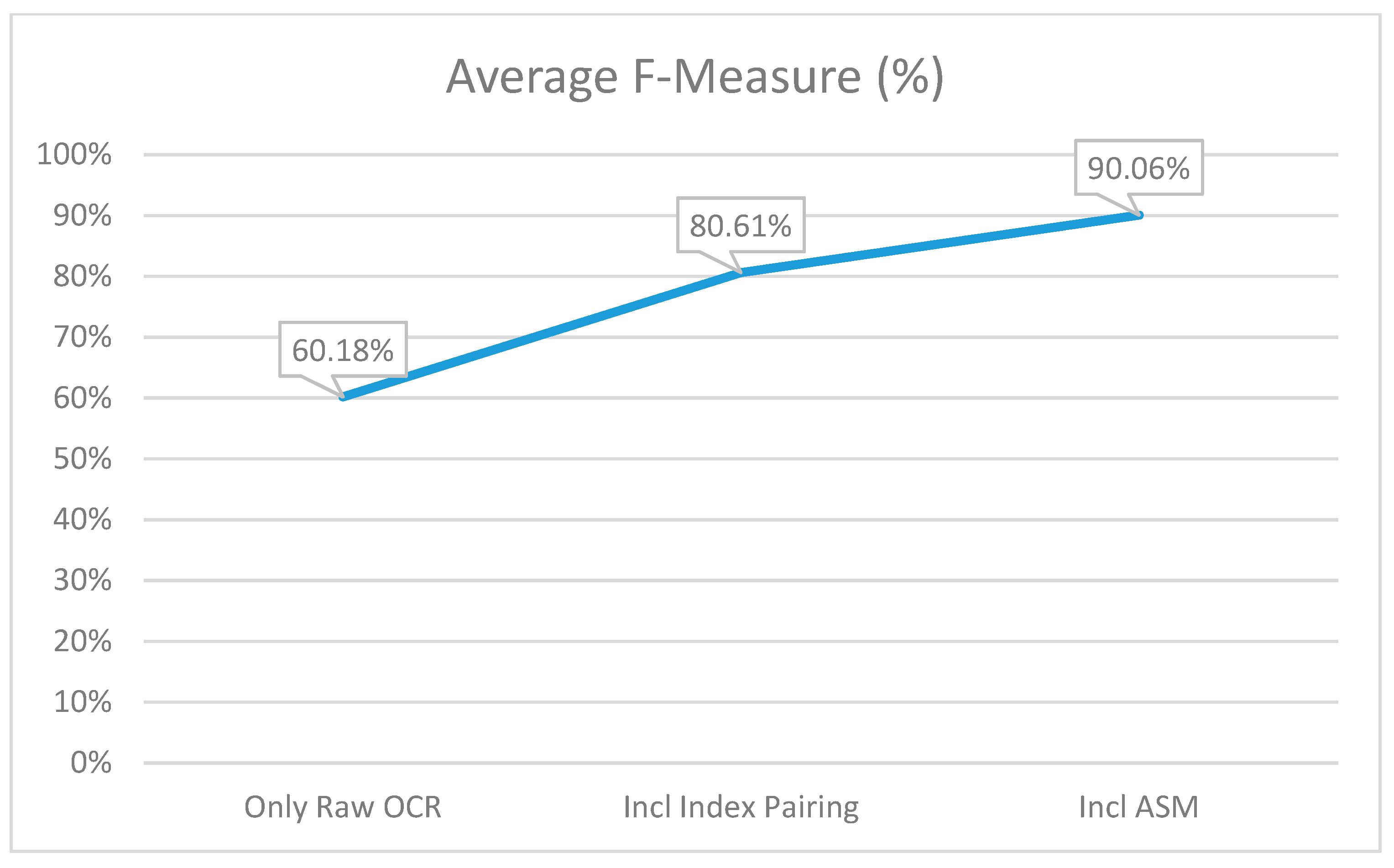
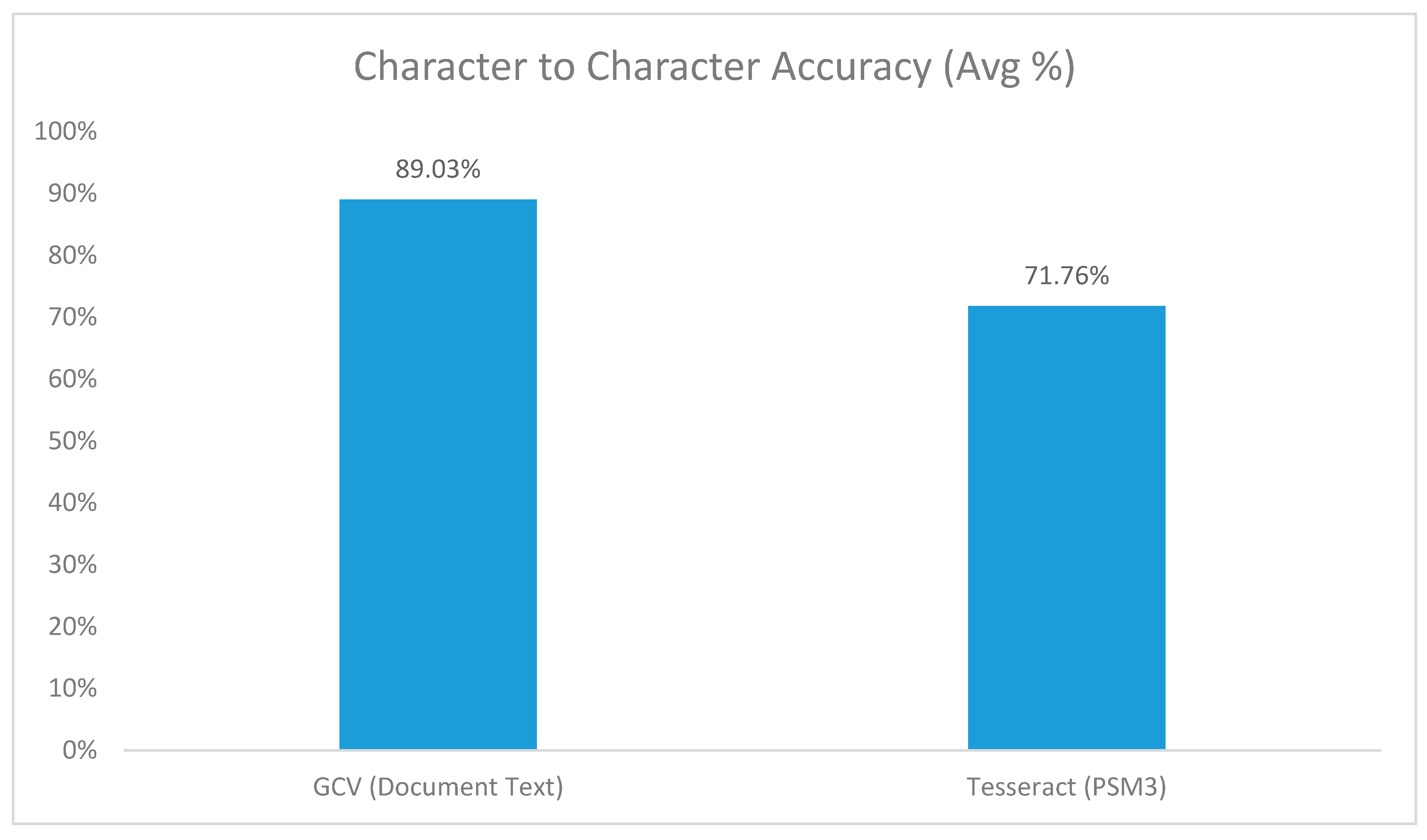
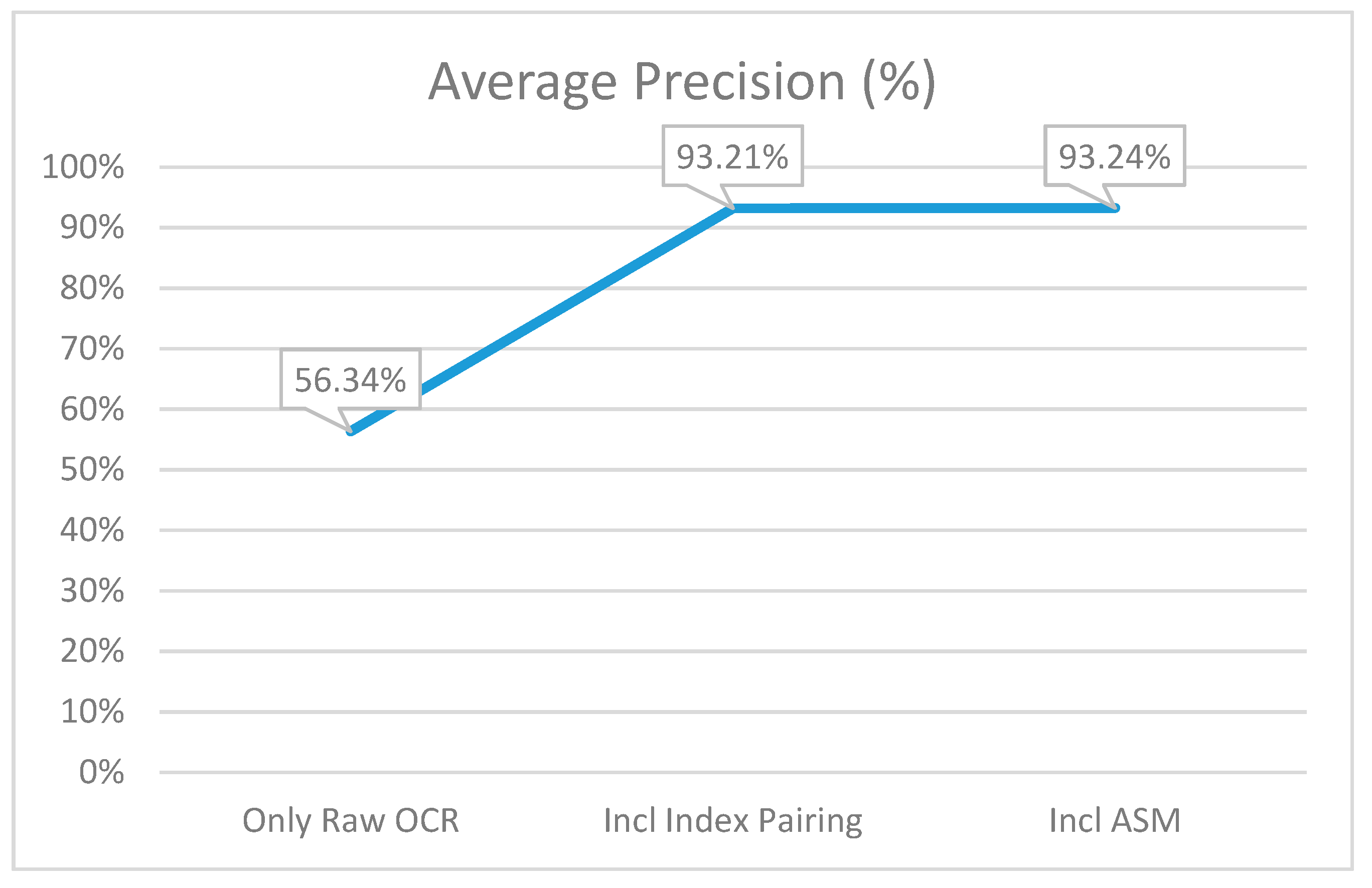
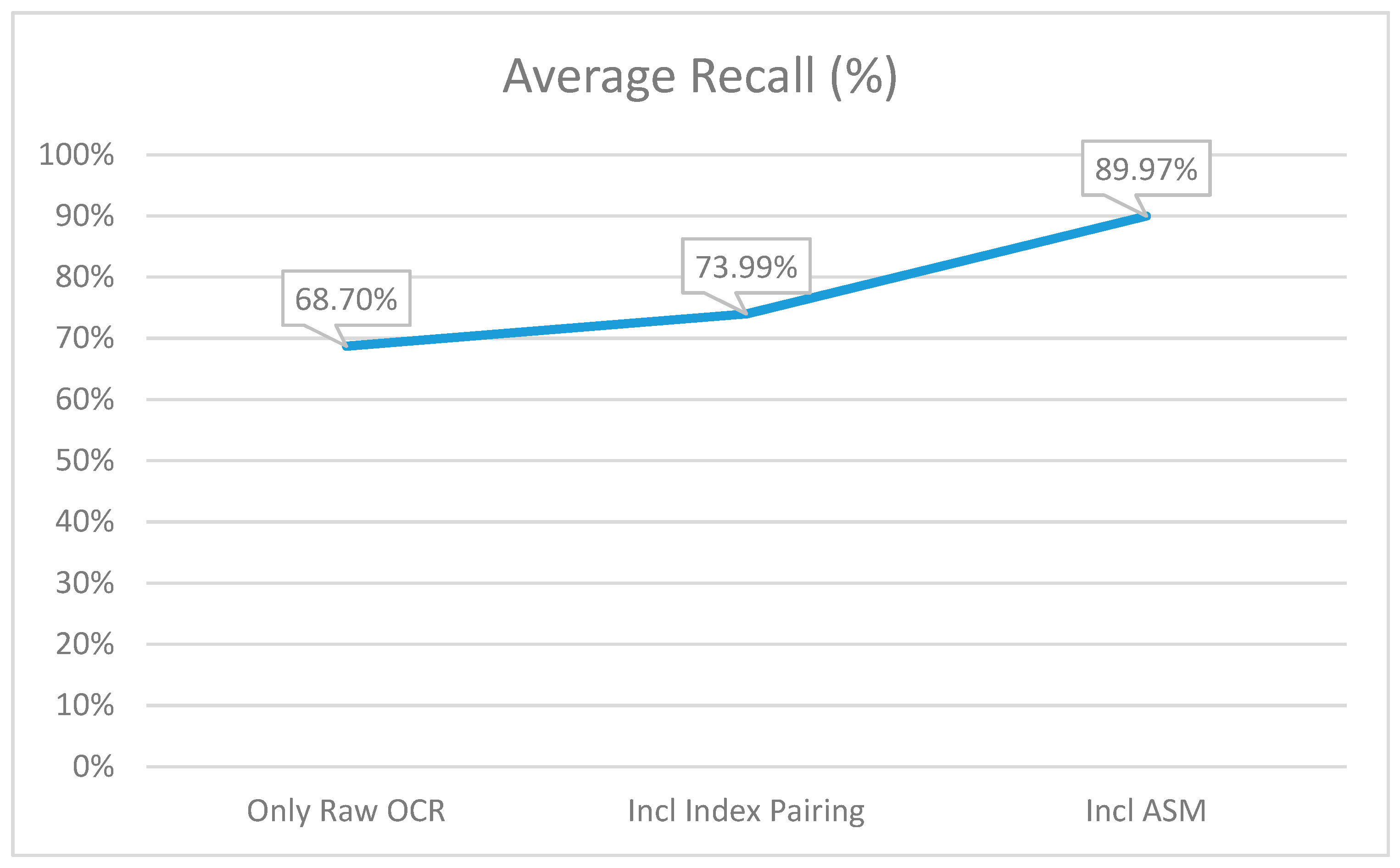
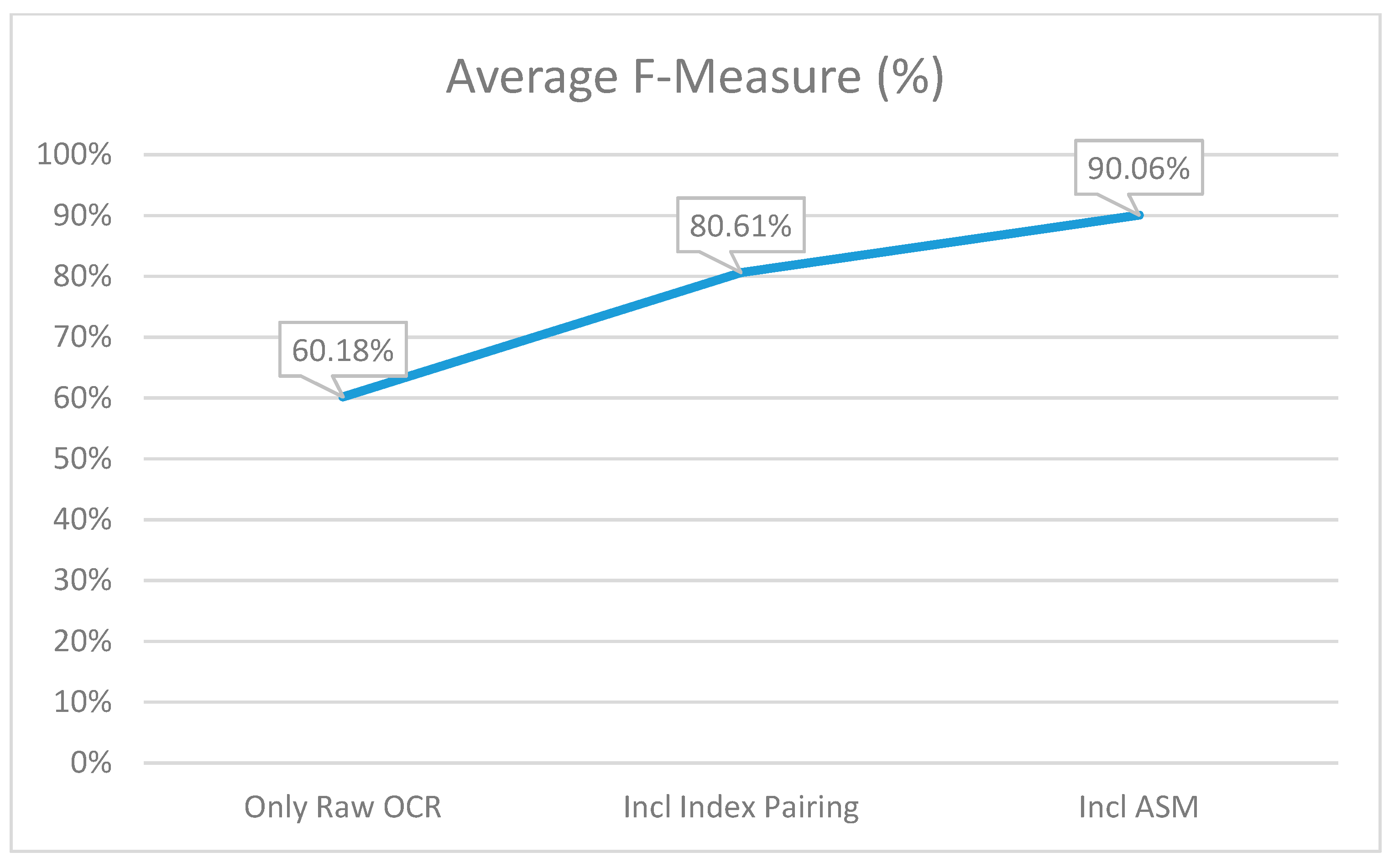
6. Results and Comparison
7. Conclusions
8. Future Improvements and Focus Areas
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Badla, S. Improving the Efficiency of Tesseract OCR Engine. Master’s Projects, San Jose State University, San Jose, CA, USA, 2014. [Google Scholar]
- Dhiman, S.; Singh, A. Tesseract vs. Gocr A Comparative Study. Int. J. Recent Technol. Eng. 2013, 2, 80. [Google Scholar]
- Talburt, J.; Zhou, Y. Entity Information Life Cycle for Big Data; Morgan Kaufmann: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Collinsdictionary.com. Digitize Definition and Meaning | Collins English Dictionary. Available online: https://www.collinsdictionary.com/dictionary/english/digitize (accessed on 15 August 2019).
- Mithe, R.; Indalkar, S.; Divekar, N. Optical Character Recognition. Int. J. Recent Technol. Eng. 2013, 72–75. [Google Scholar]
- Suitter, J.A. Accuracy of Optical Character Recognition Software Google Tesseract. Think. Matt. 2015, 46. Available online: http://digitalcommons.usm.maine.edu/thinking_matters/46 (accessed on 10 August 2019).
- Chakraborty, P.; Mallik, A. An Open Source Tesseract Based Tool for Extracting Text from Images with Application in Braille Translation for the Visually Impaired. Int. J. Comput. Appl. 2013, 68, 26–32. [Google Scholar] [CrossRef]
- Prakash Sharma, O.; Ghose, M.; Shah, K.B.; Kumar Thakur, B. Recent Trends and Tools for Feature Extraction in OCR Technology. Int. J. Soft Comput. Eng. 2013, 2, 220–223. [Google Scholar]
- Ford, G.; Hauser, S.E.; Le, D.X.; Thoma, G.R. Pattern Matching Techniques for Correcting Low-Confidence OCR Words in a Known Context. In Proceedings of the Photonics West 2001 Electron, Imaging, San Jose, CA, USA, 2–7 February 2019; 2000; Volume 4307, pp. 241–249. [Google Scholar]
- Cinti, A.; Bianchi, F.M.; Martino, A.; Rizzi, A. A Novel Algorithm for Online Inexact String Matching and its FPGA Implementation. Cogn. Comput. 2019, 1–19. [Google Scholar] [CrossRef]
- Hosseinzadeh, S. A Fuzzy Inference System for Unsupervised Deblurring of Motion Blur in Electron Beam Calibration. Appl. Syst. Innov. 2018, 1, 48. [Google Scholar] [CrossRef]
- Packer, T.L.; Lutes, J.F.; Stewart, A.P.; Embley, D.W.; Ringger, E.K.; Seppi, K.D.; Jensen, L.S. Extracting Person Names from Diverse and Noisy OCR Text. In Proceedings of the Fourth Workshop on Data analytics in the Cloud–DanaC’15, Melbourne, VIC, Australia, 31 May–4 June 2015. [Google Scholar]
- OECD. Data-Driven Innovation Big Data for Growth and Well-Being (Electronic Resource); OECD Publishing: Paris, France, 2015; p. 151. [Google Scholar]
- Takahashi, H.; Itoh, N.; Amano, T.; Yamashita, A. A Spelling Correction Method and its Application to an OCR System. Pattern Recognit. 1990, 23, 363–377. [Google Scholar] [CrossRef]
- Wu, V.; Manmatha, R.; Riseman, E. Finding Text in Images. In Proceedings of the Second ACM International Conference on Digital Libraries, Philadelphia, PA, USA, 23–26 July 1997. [Google Scholar]
- Nayak, M.; Kumar, A. Odia Characters Recognition by Training Tesseract OCR Engine. Int. J. Comput. Appl. 2014, 975, 8887. [Google Scholar]
- Lasko, T.; Hauser, S. Approximate String Matching Algorithms for Limited-Vocabulary OCR Output Correction. Int. Soc. Opt. Photonics 2000, 4307, 232–240. [Google Scholar] [CrossRef]
- Hashitani. Evaluating Google Cloud Vision for OCR. Slideshare.net. Available online: https://www.slideshare.net/ShinHashitani/evaluating-google-cloud-vision-for-ocr (accessed on 12 October 2019).
- Google Cloud. Vision AI | Derive Image Insights via ML | Cloud Vision API | Google Cloud. Available online: https://cloud.google.com/vision/#industry-leading-accuracy-for-image-understanding (accessed on 10 August 2019).
- Patel, C.; Patel, A.; Patel, D. Optical Character Recognition by Open Source OCR Tool Tesseract: A Case Study. Int. J. Comput. Appl. 2012, 55, 50–56. [Google Scholar] [CrossRef]
- Levenshtein, V. Binary Codes Capable of Correcting Deletions, Insertions and Reversals. Sov. Phys.- Dokl. 1966, 10, 707–710. [Google Scholar]
- Shahbaz, M.; McMINN, P.; Stevenson, M. Automatic Generation of Valid and Invalid Test Data for String Validation Routines Using Web Searches and Regular Expressions. Sci. Comput. Program. 2015, 97, 405–425. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
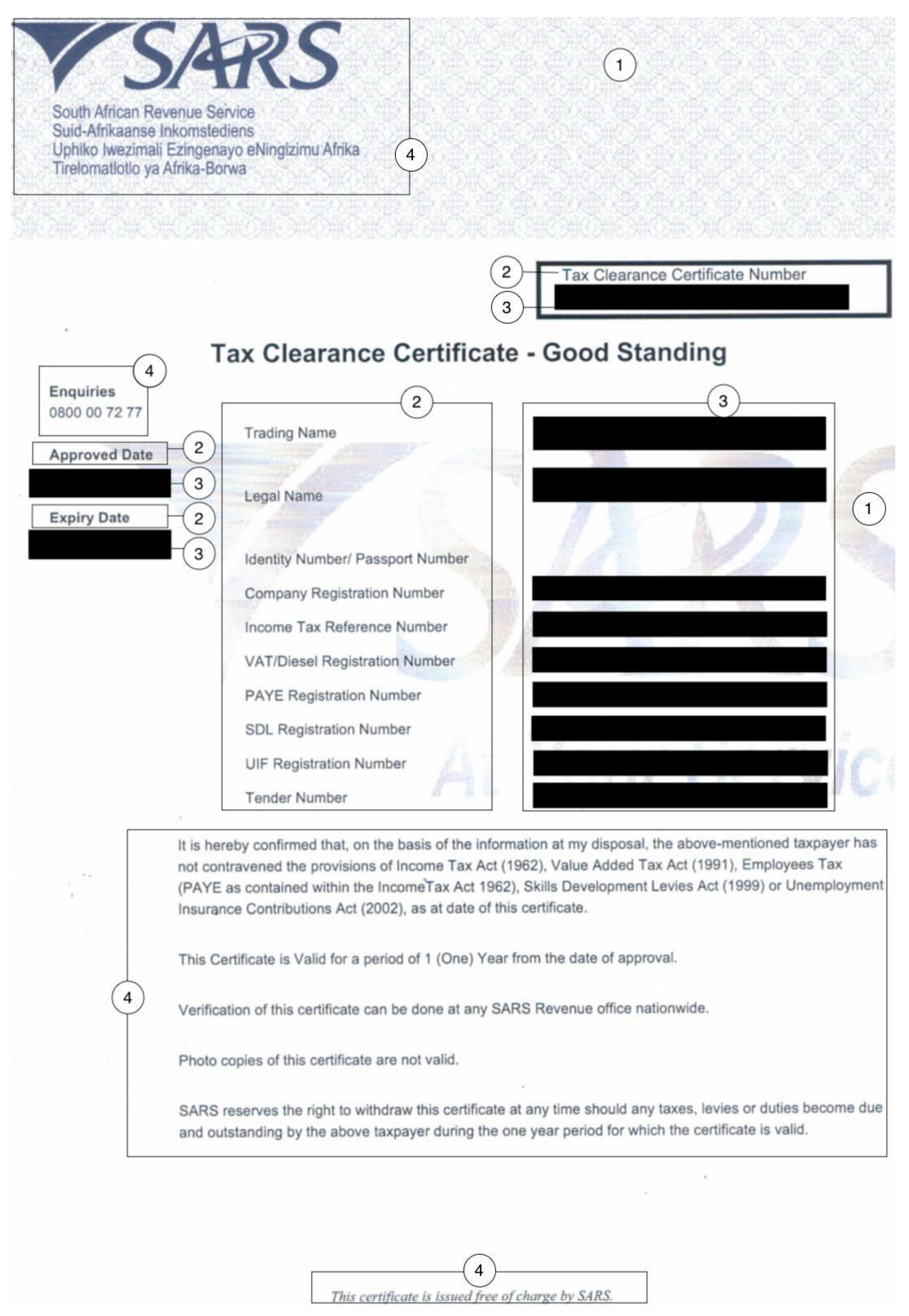
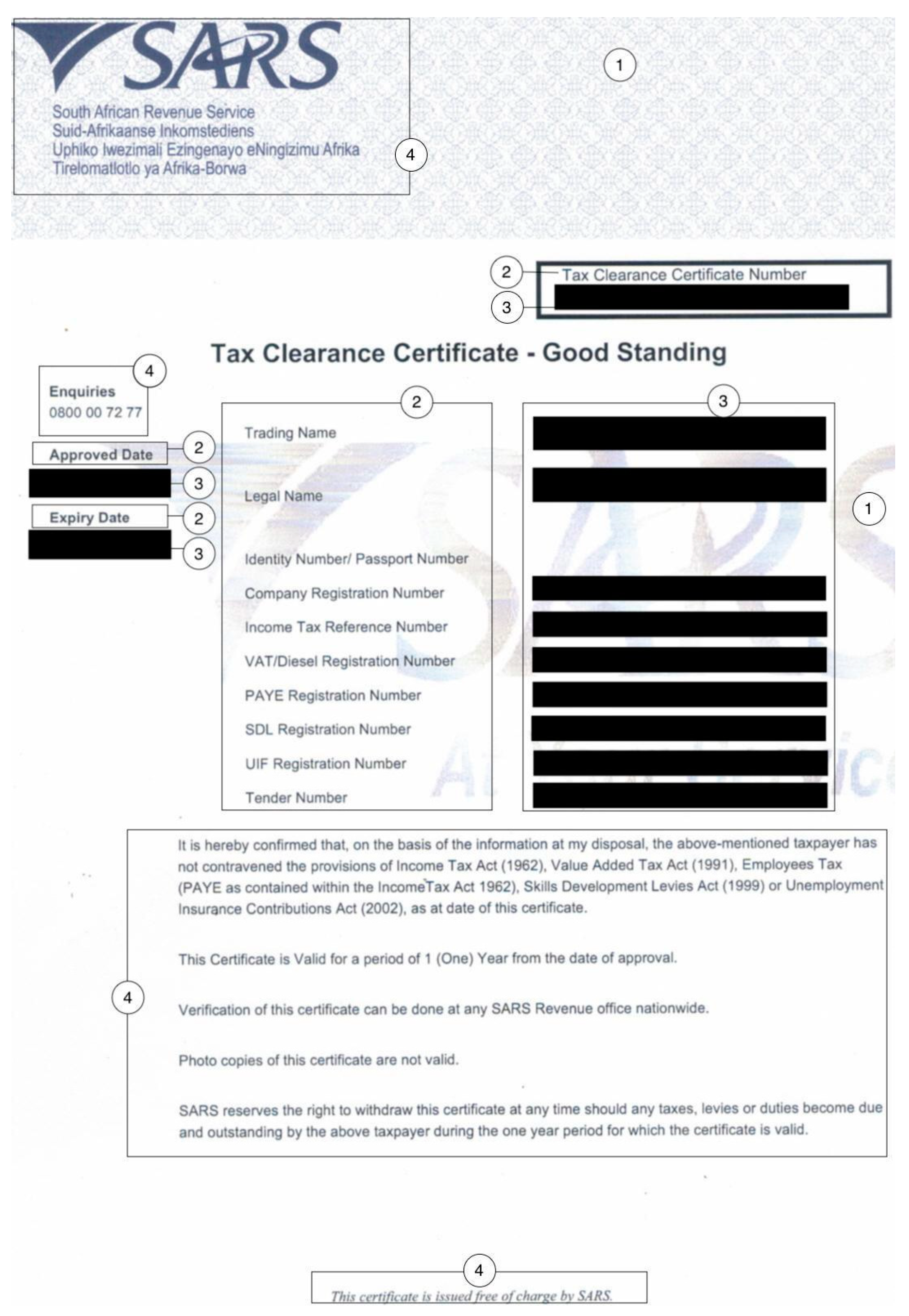
| Annotation | Description | Data Type | Relevant (Y/N) |
|---|---|---|---|
| 1 | Watermark/Background noise | String | N |
| 2 | Key/Field name | String | Y |
| 3 | Value/Field value | Numeric/String/Date | Y |
| 4 | Generic text | String | N |
| Key | Value |
|---|---|
| Tax Clearance Certificate Number | ^[0–9]{4}[/]{1}[0–9]{1}[/]{1}[0–9]{4}[/]{1}[A–Za–z0–9]{10}$ |
| Company Registration Number | [0–9]{4}[/]{1}[0–9]{6}[/]{1}[0–9]{2} |
| UIF*Registration Number | ^[U]{1}[0–9]{9} |
| SDL** Registration | ^[L]{1}[0–9]{9} |
| Metric | Calculation |
|---|---|
| Precision (P) | P = TP/(TP + FP) = TP/L |
| Recall (R) | R = TP/(TP + FN) = TP/E |
| F-Measure (F) | F = (2 × P × R)/(P + R) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Jager, C.; Nel, M. Business Process Automation: A Workflow Incorporating Optical Character Recognition and Approximate String and Pattern Matching for Solving Practical Industry Problems. Appl. Syst. Innov. 2019, 2, 33. https://doi.org/10.3390/asi2040033
de Jager C, Nel M. Business Process Automation: A Workflow Incorporating Optical Character Recognition and Approximate String and Pattern Matching for Solving Practical Industry Problems. Applied System Innovation. 2019; 2(4):33. https://doi.org/10.3390/asi2040033
Chicago/Turabian Stylede Jager, Coenrad, and Marinda Nel. 2019. "Business Process Automation: A Workflow Incorporating Optical Character Recognition and Approximate String and Pattern Matching for Solving Practical Industry Problems" Applied System Innovation 2, no. 4: 33. https://doi.org/10.3390/asi2040033
APA Stylede Jager, C., & Nel, M. (2019). Business Process Automation: A Workflow Incorporating Optical Character Recognition and Approximate String and Pattern Matching for Solving Practical Industry Problems. Applied System Innovation, 2(4), 33. https://doi.org/10.3390/asi2040033