

Efficient Visual-Aware Fashion Recommendation Using Compressed Node Features and Graph-Based Learning



Abstract
1. Introduction
- We introduce the VAGCN, which utilizes enhanced visual features in the graph-based learning process to improve the model’s understanding of complex product relationships.
- We develop a sophisticated graph-based model that leverages compressed node features via a deep-stacked autoencoder. This approach reduces computational load while integrating latent visual data, enabling a comprehensive analysis of fashion item compatibility.
- We optimize the GCN architecture by decreasing hidden units across layers, balancing efficiency and accuracy.
- We investigate the impact of neighborhood size on the effectiveness of graph-based learning, providing evidence to optimize the balance between accuracy and computational efficiency.
- We demonstrate the effectiveness of the VAGCN through rigorous validation across various fashion categories, comparing its performance with existing methods.
2. Related Work
2.1. Content-Based Fashion Recommenders
2.2. Graph-Based Learning
2.3. Predicting Visual Compatibility in Fashion
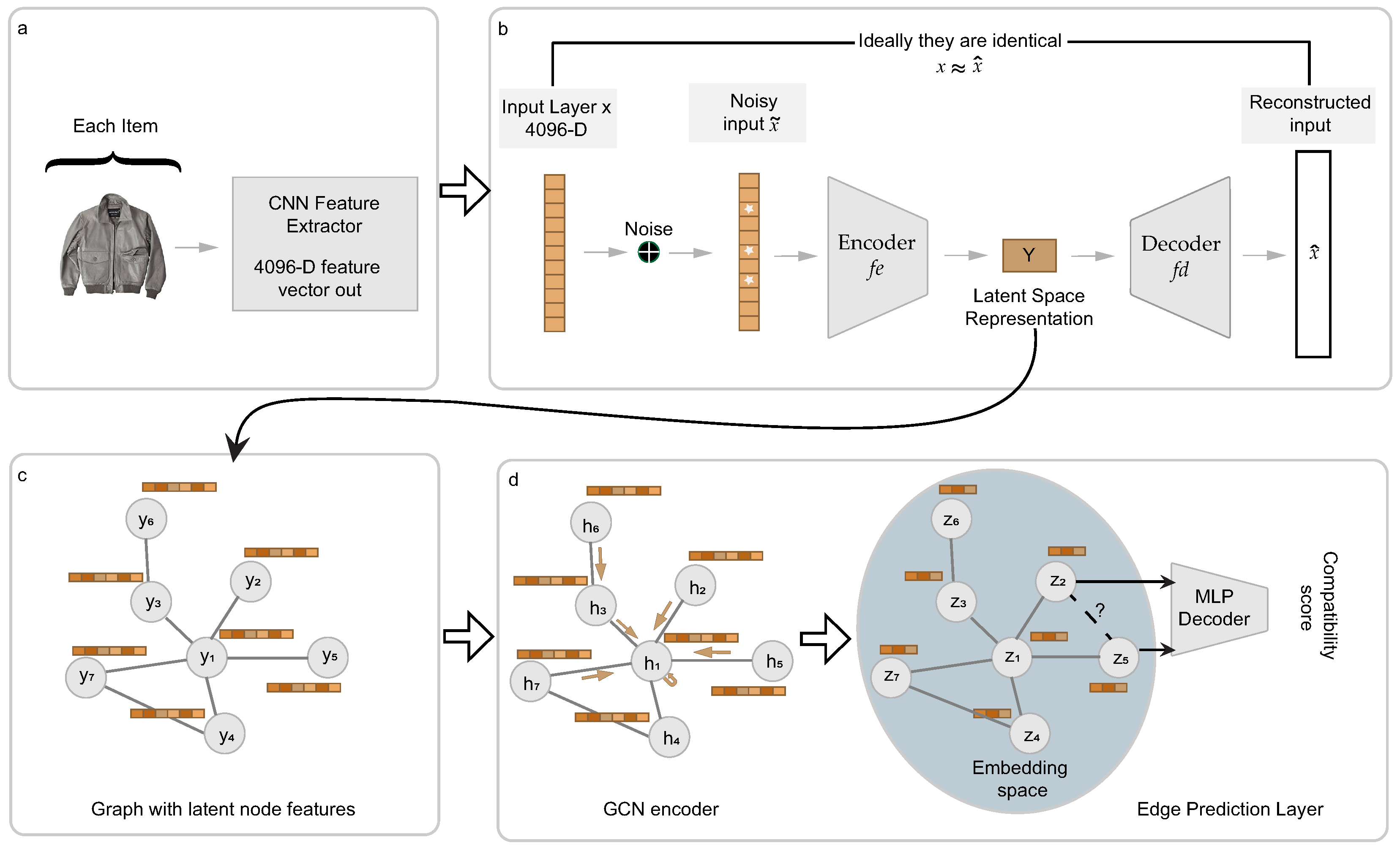
3. Method
3.1. Enhanced Data Representation via Autoencoders
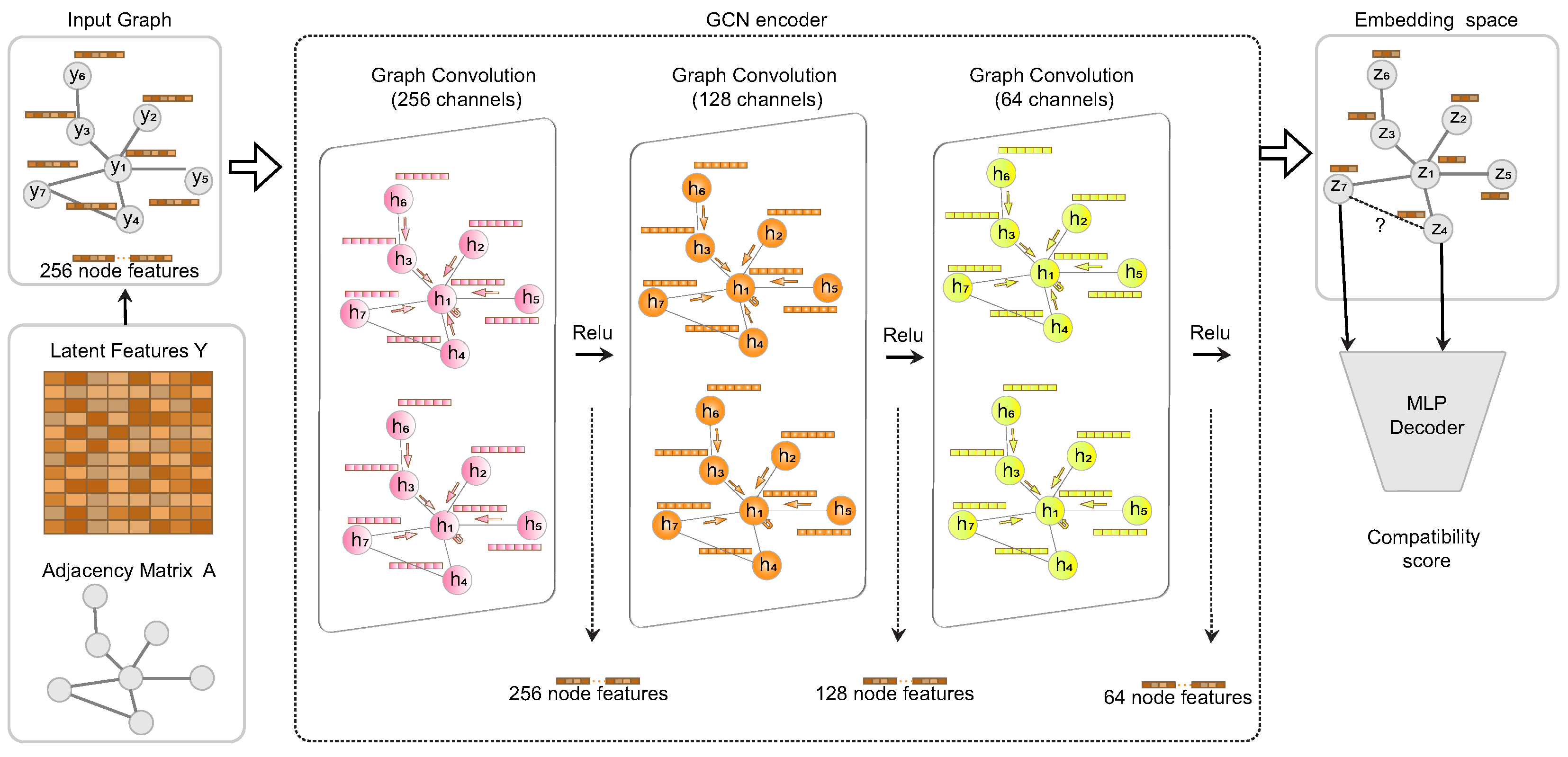
3.2. GCN Encoder
3.3. Edge Prediction Layer
| Algorithm 1 VAGCN Model for Predictive Compatibility Scoring |
|
3.4. Computational Complexity
4. Experimental Implementation
4.1. Dataset
4.2. Feature Extraction and Graph Construction
4.3. Model Training
4.4. Baseline Models
- Category Tree (CT): This method directly utilizes Amazon’s intricate category tree, exploiting the structured hierarchies inherent in the platform’s product categories. The CT approach acts as a benchmark to gauge the upper-performance limit of an image-based classification model, particularly in its ability to discern category-specific distinctions.
- Weighted Nearest Neighbor (WNN): The WNN method applies a classification paradigm that utilizes weighted distances between data points. This approach emphasizes the importance of each neighbor’s contribution to the classification decision, enhancing prediction accuracy.
- Compatibility Metric on CNN-Extracted Features (McAuley et al.): This technique, originally described by McAuley et al. [24], focuses on visual compatibility prediction. It is based on a compatibility metric that utilizes features extracted from CNNs. This metric, reliant on the distance within the feature embedding space, offers insights into the compatibility between product pairs.
4.5. Model Evaluation Matrices
- Loss Analysis: To track the model’s performance during training and validation, we use a cross-entropy loss function, as defined in [51]. The loss function is expressed as:where represents the actual label, and is the predicted value before applying the sigmoid function, , which converts it into a probability. The first term, , penalizes the model when the true label is 1, and the prediction is incorrect (i.e., is close to 0). The second term, , penalizes the model when the true label is 0, and the prediction incorrectly suggests a positive outcome (i.e., is close to 1). By summing these penalties across all N samples, the function provides a measure of how well the model’s predictions match the actual labels. This balanced approach ensures the model learns effectively, helping prevent overfitting and improving its ability to generalize to new data.
- Accuracy Measurement: Accuracy metrics quantify the model’s ability to align predictions with actual labels. This is calculated as:where the round function maps the sigmoid output to the nearest integer.
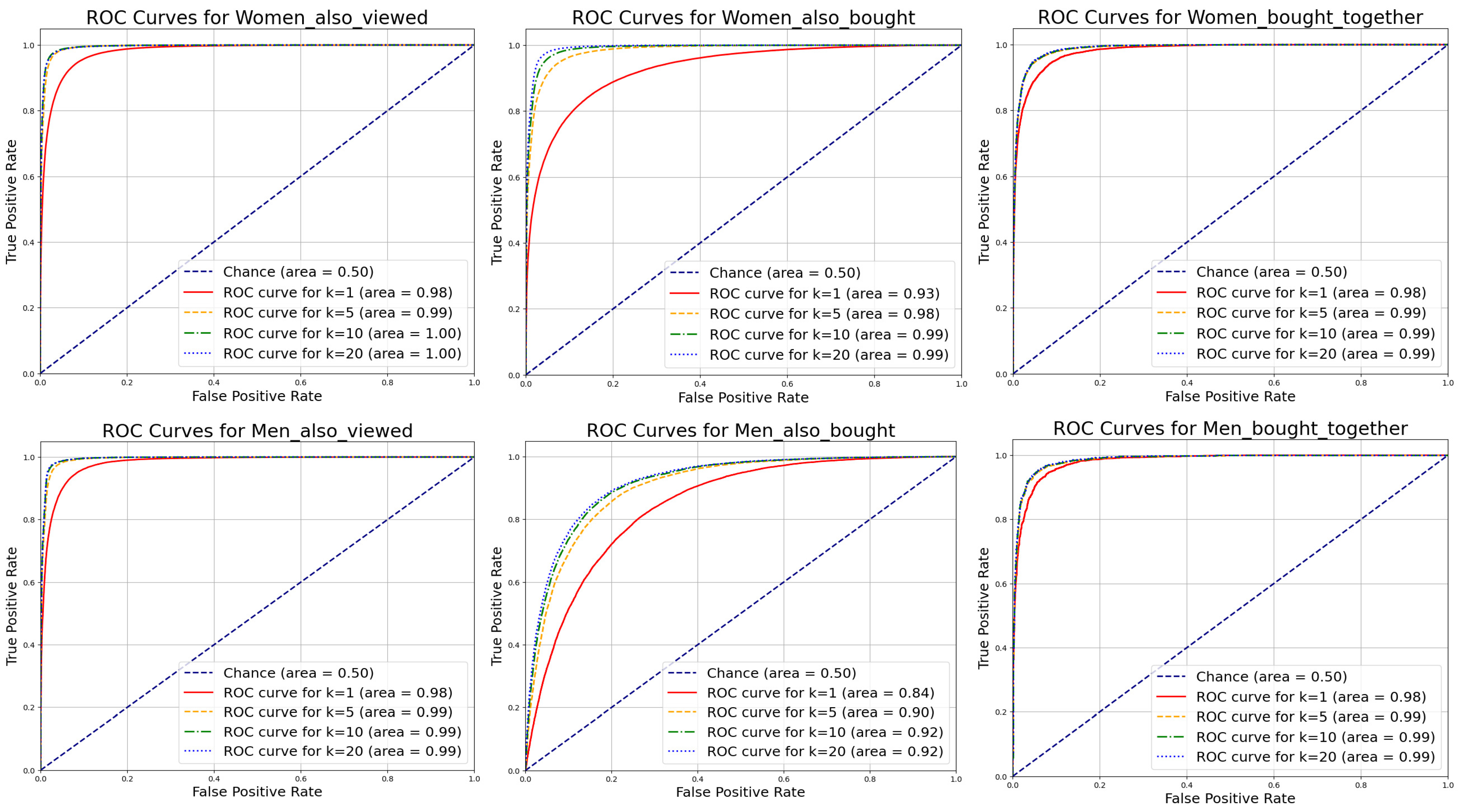
- Area under the ROC Curve (AUC) Evaluation: We compute the area under the Receiver Operating Characteristic Curve (AUC-ROC) to assess the model’s ability to distinguish between compatible and incompatible item pairs, which is indicative of model performance [52]. The AUC is calculated as:where t is the threshold for classifying predicted probabilities as positive or negative.
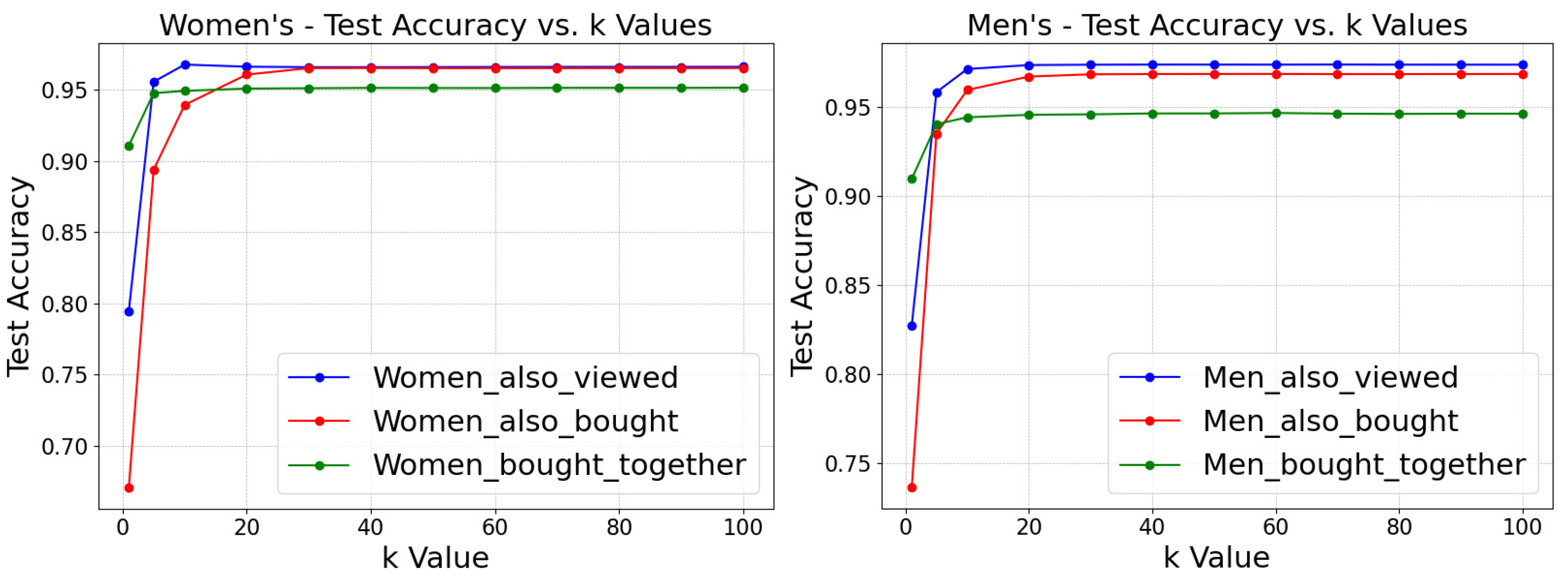
- Neighborhood-Based Evaluation: In the fashion industry, understanding outfit compatibility extends beyond analyzing individual items. Insights from neighboring nodes can provide a comprehensive view, particularly when integrating the visual attributes of multiple nodes. In our model, the k-neighborhood of a node i in the relational graph is defined by the set of k nodes accessible through a layered traversal method akin to ‘breadth-first-search’. During the testing phase, each dataset encompasses the primary items and their associated K-neighborhoods. This allows for systematically evaluating our model’s performance as the value of k is varied. For , the model focuses on the features directly linked to the outfit’s node. However, as k increases, the item embeddings begin to utilize knowledge from a wider array of neighboring nodes. This expanded neighborhood evaluation method is employed explicitly during the testing phase. Detailed results for varying k values are presented in subsequent sections.
5. Results & Discussion
5.1. VAGCN Performance and Comparisons
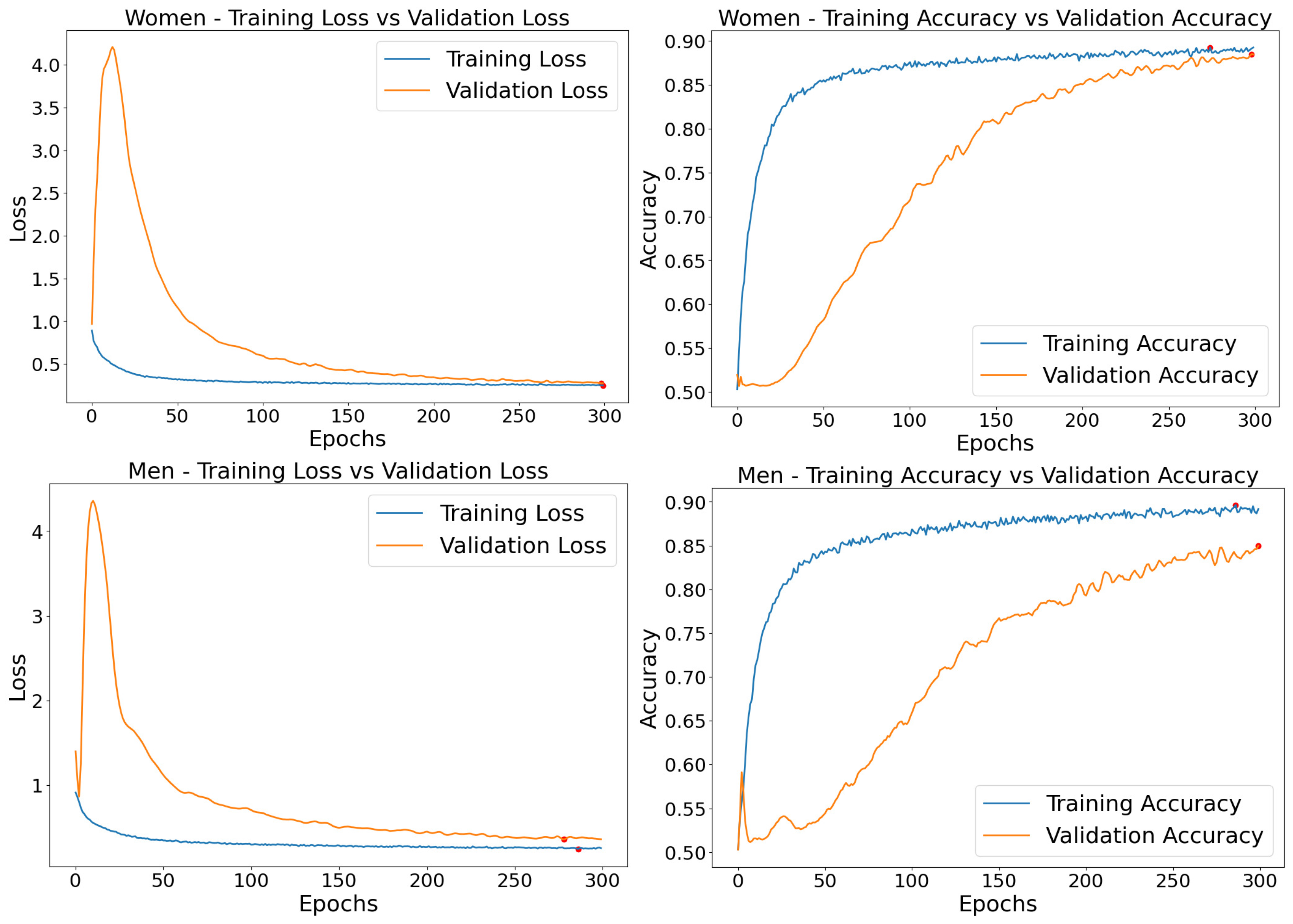
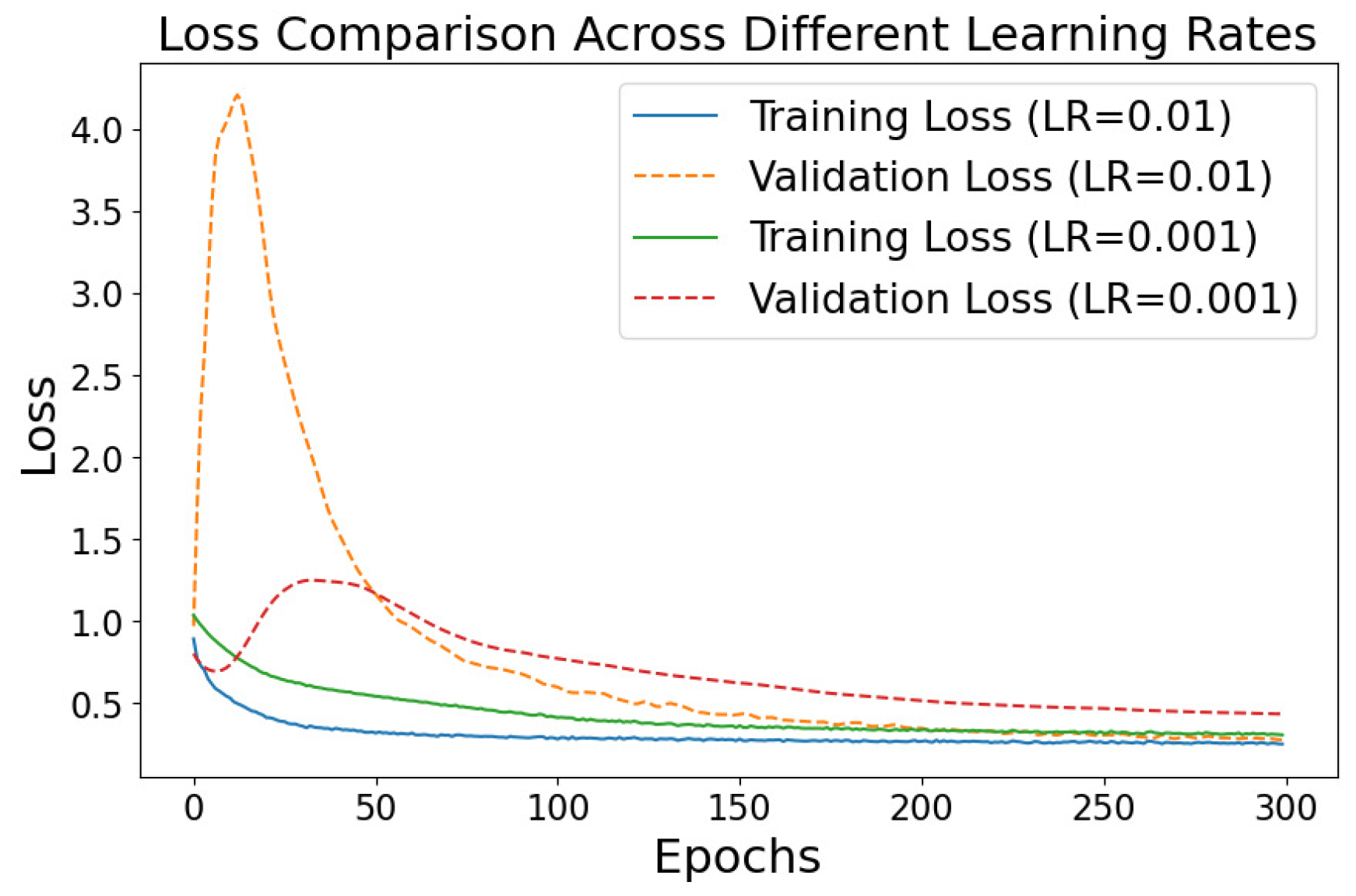
5.2. Loss Analysis
5.3. Impact of Neighborhood Size
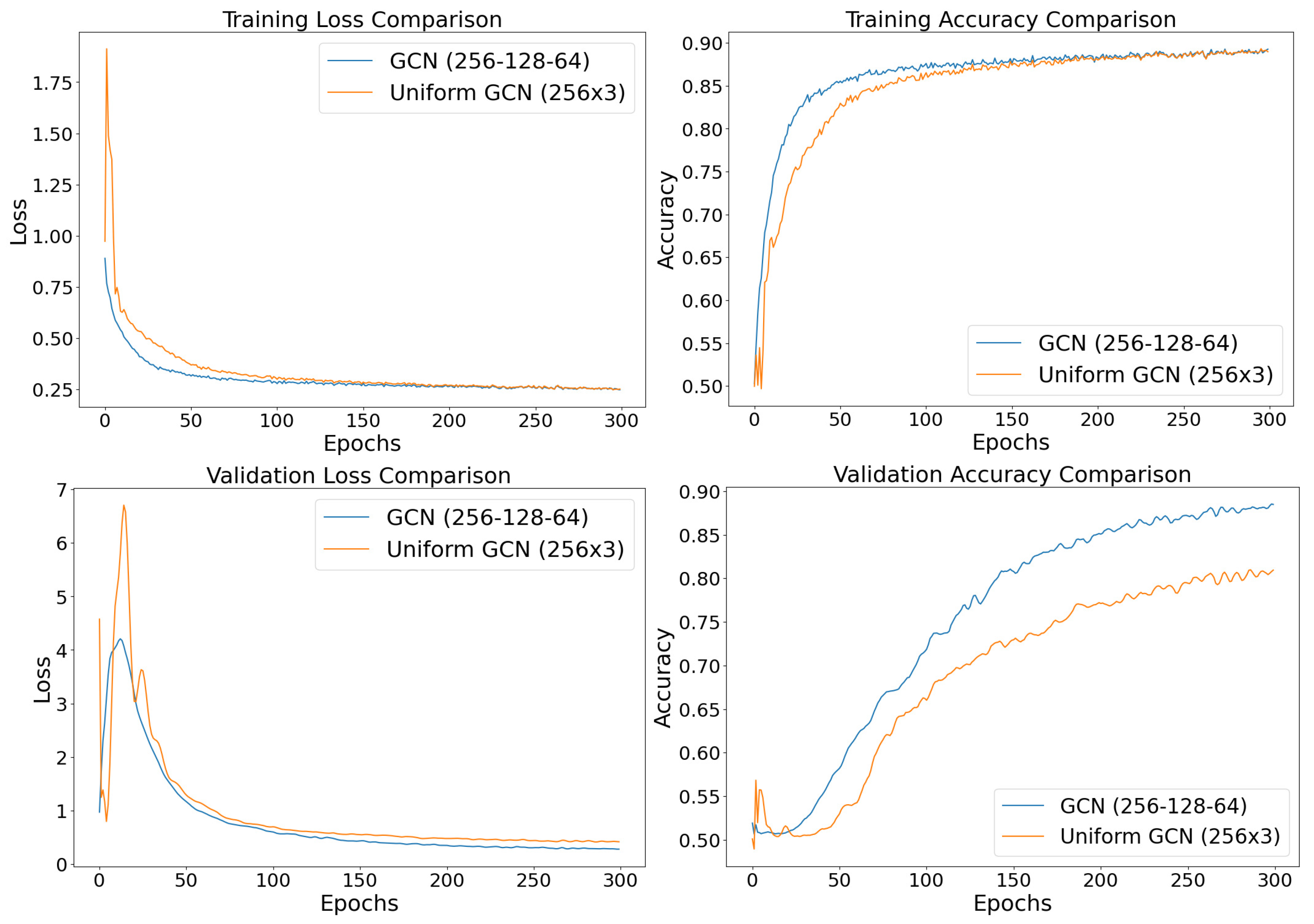
5.4. Parameter Evaluations
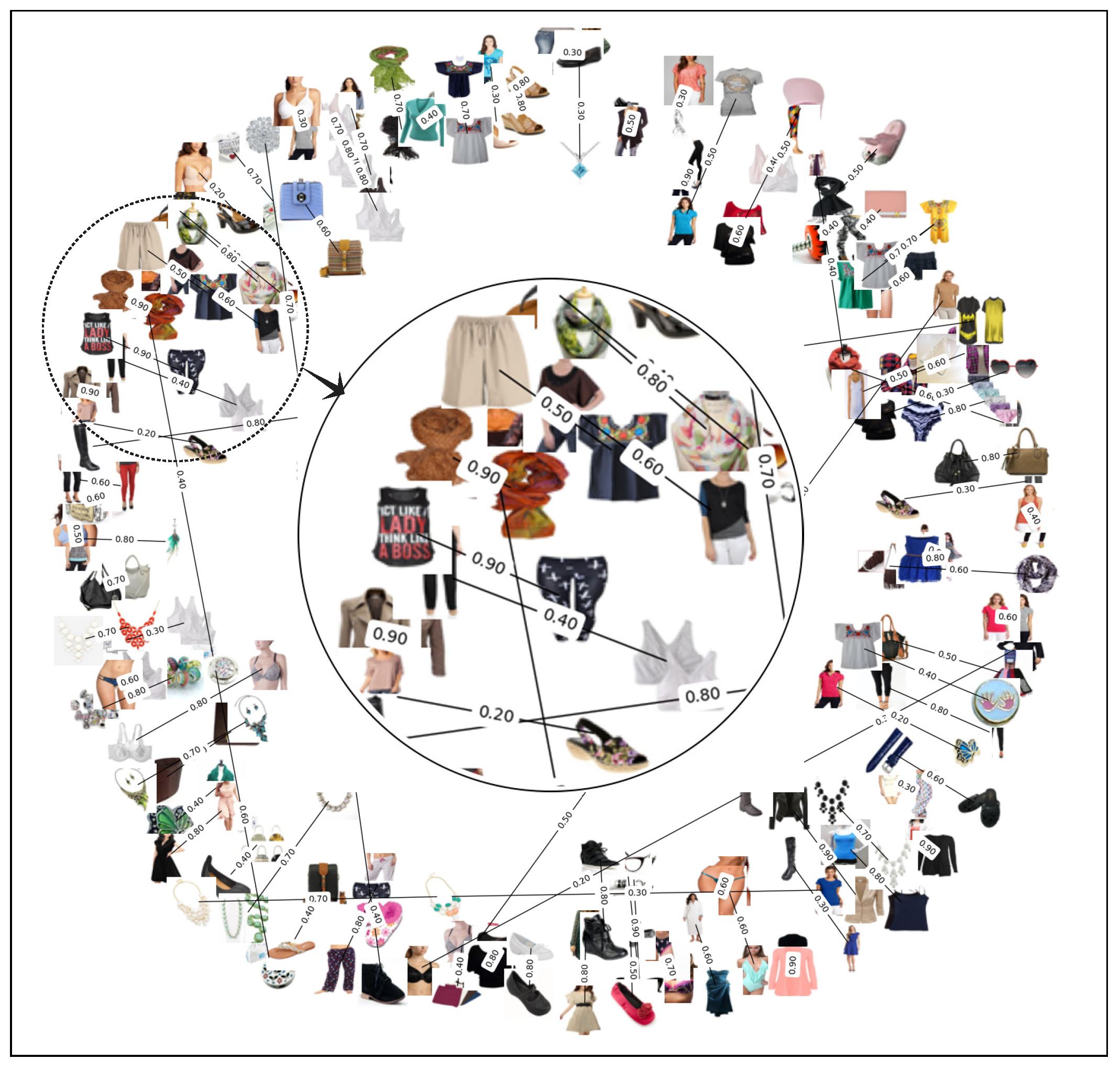
5.5. Visualization of Compatibility Score
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, H.J.; Shuai, H.H.; Cheng, W.H. A survey of artificial intelligence in fashion. IEEE Signal Process. Mag. 2023, 40, 64–73. [Google Scholar] [CrossRef]
- Hidayati, S.C.; Goh, T.W.; Chan, J.S.G.; Hsu, C.C.; See, J.; Wong, L.K.; Hua, K.L.; Tsao, Y.; Cheng, W.H. Dress with style: Learning style from joint deep embedding of clothing styles and body shapes. IEEE Trans. Multimed. 2020, 23, 365–377. [Google Scholar] [CrossRef]
- Ding, Y.; Lai, Z.; Mok, P.; Chua, T.S. Computational Technologies for Fashion Recommendation: A Survey. ACM Comput. Surv. 2023, 56, 121. [Google Scholar] [CrossRef]
- Zanker, M.; Rook, L.; Jannach, D. Measuring the impact of online personalisation: Past, present and future. Int. J. Hum.-Comput. Stud. 2019, 131, 160–168. [Google Scholar] [CrossRef]
- Markchom, T.; Liang, H.; Ferryman, J. Scalable and explainable visually-aware recommender systems. Knowl.-Based Syst. 2023, 263, 110258. [Google Scholar] [CrossRef]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 3. [Google Scholar] [CrossRef]
- Wang, L.; Guo, D.; Liu, X. Research on Intelligent Recommendation Technology for Complex Tasks. In Proceedings of the 2023 4th IEEE International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 7–9 April 2023; pp. 353–360. [Google Scholar]
- Dossena, M.; Irwin, C.; Portinale, L. Graph-based recommendation using graph neural networks. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; pp. 1769–1774. [Google Scholar]
- Zzh; Zhang, W.; Wentao. Industrial Solution in Fashion-Domain Recommendation by an Efficient Pipeline Using GNN and Lightgbm. In Proceedings of the Recommender Systems Challenge, Seattle, WA, USA, 18–23 September 2022; pp. 45–49. [Google Scholar]
- Vasileva, M.I.; Plummer, B.A.; Dusad, K.; Rajpal, S.; Kumar, R.; Forsyth, D. Learning type-aware embeddings for fashion compatibility. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 390–405. [Google Scholar]
- Kuang, Z.; Gao, Y.; Li, G.; Luo, P.; Chen, Y.; Lin, L.; Zhang, W. Fashion retrieval via graph reasoning networks on a similarity pyramid. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3066–3075. [Google Scholar]
- Marcuzzo, M.; Zangari, A.; Albarelli, A.; Gasparetto, A. Recommendation systems: An insight into current development and future research challenges. IEEE Access 2022, 10, 86578–86623. [Google Scholar] [CrossRef]
- Ferreira, D.; Silva, S.; Abelha, A.; Machado, J. Recommendation system using autoencoders. Appl. Sci. 2020, 10, 5510. [Google Scholar] [CrossRef]
- Xie, Y.; Yao, C.; Gong, M.; Chen, C.; Qin, A.K. Graph convolutional networks with multi-level coarsening for graph classification. Knowl.-Based Syst. 2020, 194, 105578. [Google Scholar] [CrossRef]
- Papadakis, H.; Papagrigoriou, A.; Panagiotakis, C.; Kosmas, E.; Fragopoulou, P. Collaborative filtering recommender systems taxonomy. Knowl. Inf. Syst. 2022, 64, 35–74. [Google Scholar] [CrossRef]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1616–1637. [Google Scholar] [CrossRef]
- Georgiou, T.; Liu, Y.; Chen, W.; Lew, M. A survey of traditional and deep learning-based feature descriptors for high dimensional data in computer vision. Int. J. Multimed. Inf. Retr. 2020, 9, 135–170. [Google Scholar] [CrossRef]
- Jing, L.; Vincent, P.; LeCun, Y.; Tian, Y. Understanding dimensional collapse in contrastive self-supervised learning. In Proceedings of the 10th International Conference on Learning Representations, ICLR 2022, Virtual, 25–29 April 2022. [Google Scholar]
- Tao, Y.; Guo, K.; Zheng, Y.; Pan, S.; Cao, X.; Chang, Y. Breaking the curse of dimensional collapse in graph contrastive learning: A whitening perspective. Inf. Sci. 2024, 657, 119952. [Google Scholar] [CrossRef]
- Tran, B.; Tran, D.; Nguyen, H.; Ro, S.; Nguyen, T. scCAN: Single-cell clustering using autoencoder and network fusion. Sci. Rep. 2022, 12, 10267. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Malhi, U.S.; Huang, Y.; Tao, R. Unsupervised deep clustering for fashion images. In Proceedings of the Knowledge Management in Organizations: 14th International Conference, KMO 2019, Zamora, Spain, 15–18 July 2019; Proceedings 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 85–96. [Google Scholar]
- Malhi, U.S.; Zhou, J.; Yan, C.; Rasool, A.; Siddeeq, S.; Du, M. Unsupervised Deep Embedded Clustering for High-Dimensional Visual Features of Fashion Images. Appl. Sci. 2023, 13, 2828. [Google Scholar] [CrossRef]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Sarkar, R.; Bodla, N.; Vasileva, M.; Lin, Y.L.; Beniwal, A.; Lu, A.; Medioni, G. Outfittransformer: Outfit representations for fashion recommendation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2263–2267. [Google Scholar]
- Deldjoo, Y.; Nazary, F.; Ramisa, A.; Mcauley, J.; Pellegrini, G.; Bellogin, A.; Noia, T.D. A review of modern fashion recommender systems. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Cardoso, Â.; Daolio, F.; Vargas, S. Product characterisation towards personalisation: Learning attributes from unstructured data to recommend fashion products. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 80–89. [Google Scholar]
- Hong, W.; Li, S.; Hu, Z.; Rasool, A.; Jiang, Q.; Weng, Y. Improving relation extraction by knowledge representation learning. In Proceedings of the 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), Washington, DC, USA, 1–3 November 2021; pp. 1211–1215. [Google Scholar]
- Jagadeesh, V.; Piramuthu, R.; Bhardwaj, A.; Di, W.; Sundaresan, N. Large scale visual recommendations from street fashion images. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1925–1934. [Google Scholar]
- Deldjoo, Y.; Di Noia, T.; Malitesta, D.; Merra, F.A. A study on the relative importance of convolutional neural networks in visually-aware recommender systems. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3961–3967. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L. Deepstyle: Learning user preferences for visual recommendation. In Proceedings of the 40th International Acm Sigir Conference on Research and Development in Information Retrieval, Shinjuku, Japan, 7–11 August 2017; pp. 841–844. [Google Scholar]
- Yan, C.; Chen, Y.; Zhou, L. Differentiated fashion recommendation using knowledge graph and data augmentation. IEEE Access 2019, 7, 102239–102248. [Google Scholar] [CrossRef]
- Yu, W.; He, X.; Pei, J.; Chen, X.; Xiong, L.; Liu, J.; Qin, Z. Visually aware recommendation with aesthetic features. VLDB J. 2021, 30, 495–513. [Google Scholar] [CrossRef]
- Dong, M.; Zeng, X.; Koehl, L.; Zhang, J. An interactive knowledge-based recommender system for fashion product design in the big data environment. Inf. Sci. 2020, 540, 469–488. [Google Scholar] [CrossRef]
- Li, Y.; Cao, L.; Zhu, J.; Luo, J. Mining fashion outfit composition using an end-to-end deep learning approach on set data. IEEE Trans. Multimed. 2017, 19, 1946–1955. [Google Scholar] [CrossRef]
- Liu, L.; Du, X.; Zhu, L.; Shen, F.; Huang, Z. Learning discrete hashing towards efficient fashion recommendation. Data Sci. Eng. 2018, 3, 307–322. [Google Scholar] [CrossRef]
- Cohen-Shapira, N.; Rokach, L. Learning dataset representation for automatic machine learning algorithm selection. Knowl. Inf. Syst. 2022, 64, 2599–2635. [Google Scholar] [CrossRef]
- Yi, J.; Chen, Z. Multi-modal variational graph auto-encoder for recommendation systems. IEEE Trans. Multimed. 2021, 24, 1067–1079. [Google Scholar] [CrossRef]
- Ma, M.; Na, S.; Wang, H. AEGCN: An autoencoder-constrained graph convolutional network. Neurocomputing 2021, 432, 21–31. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Veit, A.; Kovacs, B.; Bell, S.; McAuley, J.; Bala, K.; Belongie, S. Learning visual clothing style with heterogeneous dyadic co-occurrences. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4642–4650. [Google Scholar]
- Yin, R.; Li, K.; Lu, J.; Zhang, G. Enhancing fashion recommendation with visual compatibility relationship. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3434–3440. [Google Scholar]
- Borges, R.; Stefanidis, K. Feature-blind fairness in collaborative filtering recommender systems. Knowl. Inf. Syst. 2022, 64, 943–962. [Google Scholar] [CrossRef]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Jiang, B.; Zhang, Z.; Lin, D.; Tang, J.; Luo, B. Semi-supervised learning with graph learning-convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11313–11320. [Google Scholar]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2017, arXiv:1711.04043. [Google Scholar]
- Xiao, Z.; Deng, Y. Graph embedding-based novel protein interaction prediction via higher-order graph convolutional network. PLoS ONE 2020, 15, e0238915. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hisano, R. Semi-supervised graph embedding approach to dynamic link prediction. In Complex Networks IX: Proceedings of the 9th Conference on Complex Networks CompleNet 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 109–121. [Google Scholar]
- Janssens, A.C.J.; Martens, F.K. Reflection on modern methods: Revisiting the area under the ROC Curve. Int. J. Epidemiol. 2020, 49, 1397–1403. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| x | Original input data |
| Noisy version of input data | |
| Y | Latent representation of data |
| Reconstructed version of original input data | |
| Weight matrices represent the encoder and decoder, respectively. | |
| Vectors represent the bias vectors for the encoder and decoder, respectively. | |
| The activation functions for the encoder and decoder, respectively | |
| Graph contains nodes V and edges E | |
| X | Node feature matrix |
| d | Dimensionality of feature vector |
| Node representation after l graph convolutional layers | |
| Normalized Laplacian matrix | |
| Predicted probability of an edge between nodes i and j | |
| Representations of nodes i and j at the L-th layer, respectively | |
| P | Probability matrix indicating the likelihood of edges between nodes. |
| A | Adjacency matrix of the graph |
| Category | Relation | # Nodes | # Edges | Avg. Degree |
|---|---|---|---|---|
| Men | also_viewed | 105,462 | 787,048 | 13.80 |
| bought_together | 30,415 | 45,160 | 2.85 | |
| also_bought | 49,660 | 441,987 | 16.52 | |
| Women | also_viewed | 263,312 | 2,692,366 | 18.97 |
| bought_together | 93,726 | 155,344 | 3.19 | |
| also_bought | 121,963 | 1,771,173 | 26.97 | |
| Boys | also_viewed | 6695 | 24,380 | 7.04 |
| bought_together | 2306 | 2572 | 2.17 | |
| also_bought | 5897 | 22,460 | 7.42 | |
| Girls | also_viewed | 19,854 | 103,938 | 9.85 |
| bought_together | 5671 | 6962 | 2.38 | |
| also_bought | 11,962 | 63,822 | 10.15 | |
| Baby | also_viewed | 11,258 | 78,148 | 13.31 |
| bought_together | 6250 | 9681 | 3.03 | |
| also_bought | 11,148 | 113,021 | 19.66 |
| Category | Method | Also_Viewed | Also_Bought | Bought_Together |
|---|---|---|---|---|
| Men | CT | 88.2% | 78.4% | 83.6% |
| WNN | 86.9% | 78.4% | 82.3% | |
| McAuley et al. | 91.6% | 89.8% | 92.1% | |
| VAGCN (Ours) | 97.1% | 95.9% | 94.4% | |
| Women | CT | 86.8% | 79.1% | 84.3% |
| WNN | 78.8% | 76.1% | 80.0% | |
| McAuley et al. | 88.9% | 87.8% | 91.5% | |
| VAGCN (Ours) | 96.7% | 93.9% | 94.9% | |
| Boys | CT | 81.9% | 77.3% | 83.1% |
| WNN | 85.0% | 87.2% | 87.9% | |
| McAuley et al. | 94.4% | 94.1% | 93.8% | |
| VAGCN (Ours) | 96.1% | 96.0% | 94.5% | |
| Girls | CT | 83.0% | 76.2% | 78.7% |
| WNN | 83.3% | 86.0% | 84.8% | |
| McAuley et al. | 94.5% | 93.6% | 93.0% | |
| VAGCN (Ours) | 96.8% | 95.8% | 93.9% | |
| Baby | CT | 77.1% | 70.5% | 80.1% |
| WNN | 83.0% | 87.7% | 81.7% | |
| McAuley et al. | 92.2% | 92.7% | 91.5% | |
| VAGCN (Ours) | 96.7% | 95.1% | 92.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malhi, U.S.; Zhou, J.; Rasool, A.; Siddeeq, S. Efficient Visual-Aware Fashion Recommendation Using Compressed Node Features and Graph-Based Learning. Mach. Learn. Knowl. Extr. 2024, 6, 2111-2129. https://doi.org/10.3390/make6030104
Malhi US, Zhou J, Rasool A, Siddeeq S. Efficient Visual-Aware Fashion Recommendation Using Compressed Node Features and Graph-Based Learning. Machine Learning and Knowledge Extraction. 2024; 6(3):2111-2129. https://doi.org/10.3390/make6030104
Chicago/Turabian StyleMalhi, Umar Subhan, Junfeng Zhou, Abdur Rasool, and Shahbaz Siddeeq. 2024. "Efficient Visual-Aware Fashion Recommendation Using Compressed Node Features and Graph-Based Learning" Machine Learning and Knowledge Extraction 6, no. 3: 2111-2129. https://doi.org/10.3390/make6030104
APA StyleMalhi, U. S., Zhou, J., Rasool, A., & Siddeeq, S. (2024). Efficient Visual-Aware Fashion Recommendation Using Compressed Node Features and Graph-Based Learning. Machine Learning and Knowledge Extraction, 6(3), 2111-2129. https://doi.org/10.3390/make6030104