


Show Me Once: A Transformer-Based Approach for an Assisted-Driving System



Abstract
1. Introduction
1.1. Motivation
1.2. Related Works
1.2.1. Deep Reinforcement Learning and Its Challenges
1.2.2. A New Avenue: Transformers
1.3. Main Contributions
- Fine-tuning the model, achieving up to 29% of the goal-reaching time reduction with respect to the foundational model on the collected dataset;
- Designing a retrieval mechanism to perform a language-based image search;
- The deployment and evaluation of performances on an embedded device.
2. Simulation Environment and Setup
2.1. DRL-Based Driving Assistance
2.2. System Definition
2.3. Setup
3. Show Me Once System Architecture
3.1. Workflow
| Algorithm 1 Pseudo-code for SMOS workflow. |
|
3.2. Insights
3.3. Fine-Tuning
3.4. Waypoints Generations
3.5. Software Infrastructure
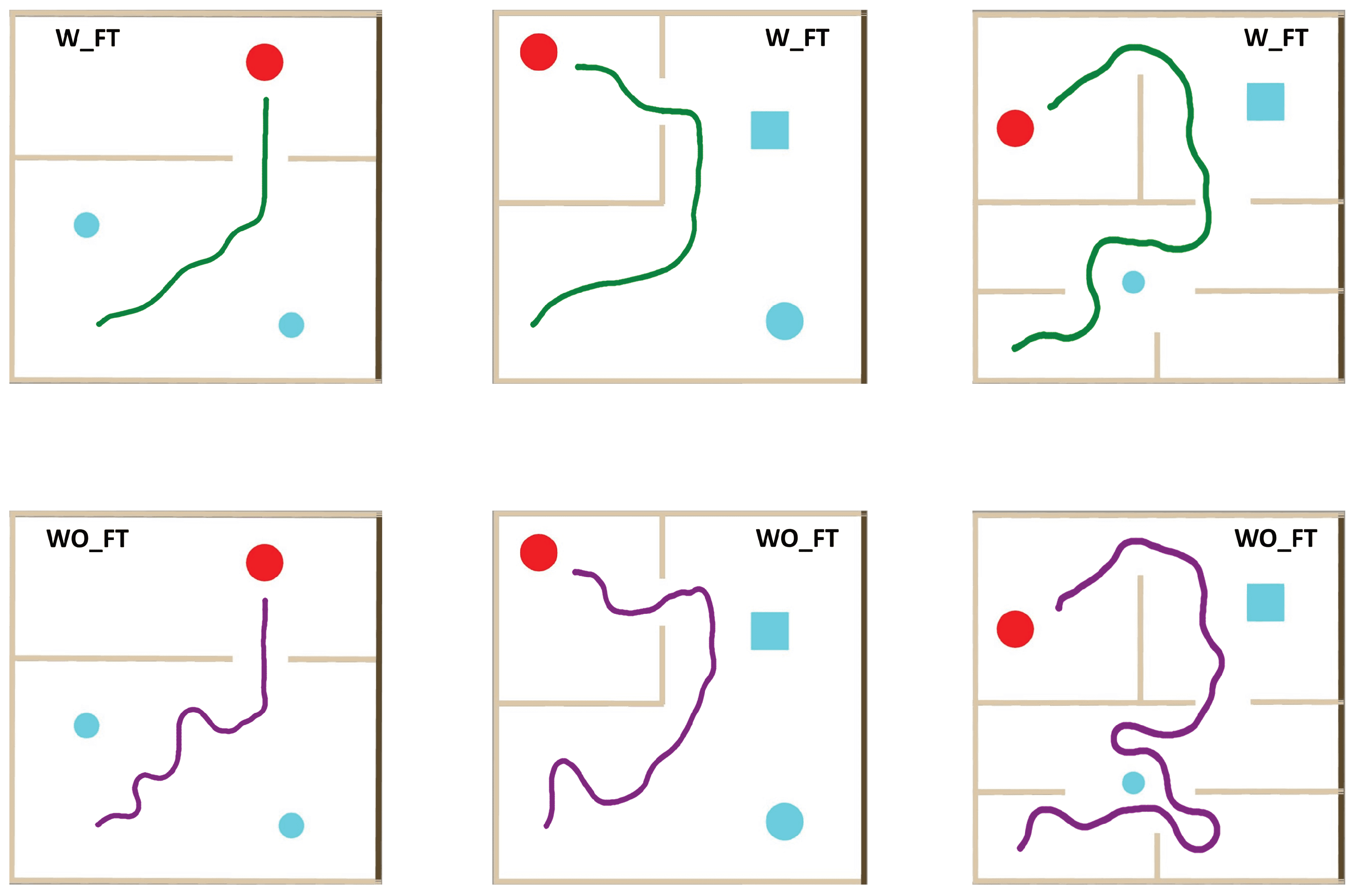
4. Simulations
- Goal-reaching time—the time needed from the instant in which the system receives the goal image till the instant in which the wheelchair reaches the goal;
- Collision risk—the number of occurred collisions.
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| P | 5 |
| H | 5 |
| 2 | |
| 2 | |
| 4 | |
| −3 | |
| 3 | |
| 0.5 |

Appendix B
References
- World Health Organization; World Bank. World Report on Disability 2011; World Health Organization, World Bank: Geneva, Switzerland, 2011. [Google Scholar]
- Mars, L.; Arroyo, R.; Ruiz, T. Mobility and wellbeing during the COVID-19 lockdown. Evidence from Spain. Transp. Res. Part A Policy Pract. 2022, 161, 107–129. [Google Scholar] [CrossRef] [PubMed]
- Freedman, V.A.; Carr, D.; Cornman, J.C.; Lucas, R.E. Aging, mobility impairments and subjective wellbeing. Disabil. Health J. 2017, 10, 525–531. [Google Scholar] [CrossRef] [PubMed]
- Arroyo, R.; Mars, L.; Ruiz, T. Activity Participation and wellbeing during the covid-19 lockdown in Spain. Int. J. Urban Sci. 2021, 25, 386–415. [Google Scholar] [CrossRef]
- Comai, S.; De Bernardi, E.; Matteucci, M.; Salice, F. Maps for Easy Paths (MEP): Enriching Maps with Accessible Paths Using MEP Traces. In Proceedings of the Smart Objects and Technologies for Social Good, Venice, Italy, 30 November–1 December 2017; pp. 254–263. [Google Scholar]
- Pacini, F.; Dini, P.; Fanucci, L. Cooperative Driver Assistance for Electric Wheelchair. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society; Springer: Berlin/Heidelberg, Germany, 2023; pp. 109–116. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Chen, L.; Hu, X.; Tang, B.; Cheng, Y. Conditional DQN-based motion planning with fuzzy logic for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2966–2977. [Google Scholar] [CrossRef]
- Li, J.; Chen, Y.; Zhao, X.; Huang, J. An improved DQN path planning algorithm. J. Supercomput. 2022, 78, 616–639. [Google Scholar] [CrossRef]
- Okuyama, T.; Gonsalves, T.; Upadhay, J. Autonomous driving system based on deep q learnig. In Proceedings of the 2018 IEEE International conference on intelligent autonomous systems (ICoIAS), Singapore, 1–3 March 2018; pp. 201–205. [Google Scholar]
- Zhang, W.; Gai, J.; Zhang, Z.; Tang, L.; Liao, Q.; Ding, Y. Double-DQN based path smoothing and tracking control method for robotic vehicle navigation. Comput. Electron. Agric. 2019, 166, 104985. [Google Scholar] [CrossRef]
- Wu, K.; Wang, H.; Esfahani, M.A.; Yuan, S. Bnd*-ddqn: Learn to steer autonomously through deep reinforcement learning. IEEE Trans. Cogn. Dev. Syst. 2019, 13, 249–261. [Google Scholar] [CrossRef]
- Xue, X.; Li, Z.; Zhang, D.; Yan, Y. A deep reinforcement learning method for mobile robot collision avoidance based on double dqn. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; pp. 2131–2136. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Pacini, F.; Dini, P.; Fanucci, L. Design of an Assisted Driving System for Obstacle Avoidance Based on Reinforcement Learning Applied to Electrified Wheelchairs. Electronics 2024, 13, 1507. [Google Scholar] [CrossRef]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to train your robot with deep reinforcement learning: Lessons we have learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 9 September 2024).
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. Adv. Neural Inf. Process. Syst. 2021, 34, 15084–15097. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J.; et al. Rt-1: Robotics transformer for real-world control at scale. arXiv 2022, arXiv:2212.06817. [Google Scholar]
- Shah, D.; Sridhar, A.; Dashora, N.; Stachowicz, K.; Black, K.; Hirose, N.; Levine, S. Vint: A foundation model for visual navigation. arXiv 2023, arXiv:2306.14846. [Google Scholar]
- Pacini, F.; Di Matteo, S.; Dini, P.; Fanucci, L.; Bucchi, F. Innovative Plug-and-Play System for Electrification of Wheel-Chairs. IEEE Access 2023, 11, 89038–89051. [Google Scholar] [CrossRef]
- Cosimi, F.; Dini, P.; Giannetti, S.; Petrelli, M.; Saponara, S. Analysis and design of a non-linear MPC algorithm for vehicle trajectory tracking and obstacle avoidance. In Proceedings of the Applications in Electronics Pervading Industry, Environment and Society: APPLEPIES 2020 8; Springer: Berlin/Heidelberg, Germany, 2021; pp. 229–234. [Google Scholar]
- Dini, P.; Saponara, S. Processor-in-the-Loop Validation of a Gradient Descent-Based Model Predictive Control for Assisted Driving and Obstacles Avoidance Applications. IEEE Access 2022, 10, 67958–67975. [Google Scholar] [CrossRef]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Saponara, S. Co-simulation and verification of a non-linear control system for cogging torque reduction in brushless motors. In Proceedings of the Software Engineering and Formal Methods: SEFM 2019 Collocated Workshops: CoSim-CPS, ASYDE, CIFMA, and FOCLASA, Oslo, Norway, 16–20 September 2019; Revised Selected Papers 17. Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–19. [Google Scholar]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Palmieri, M.; Saponara, S. Formal verification and co-simulation in the design of a synchronous motor control algorithm. Energies 2020, 13, 4057. [Google Scholar] [CrossRef]
- NVIDIA Teslta T4 Datasheet. Available online: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet-951643.pdf (accessed on 23 May 2024).
- AMD Epyc Server CPU Family. Available online: https://www.amd.com/en/processors/epyc-server-cpu-family (accessed on 23 May 2024).
- Asus. Asus Rog Zephyrus GX502; Asus: Taiwan, China, 2019. [Google Scholar]
- NVIDIA. Jetson Nano 2GB Developer Kit; NVIDIA: Santa Clara, CA, USA, 2020. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Hart, P.; Nilsson, N.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Chroma Vector Database. Available online: https://www.trychroma.com/ (accessed on 5 June 2024).
- LangChain Framework. Available online: https://www.langchain.com/ (accessed on 5 June 2024).
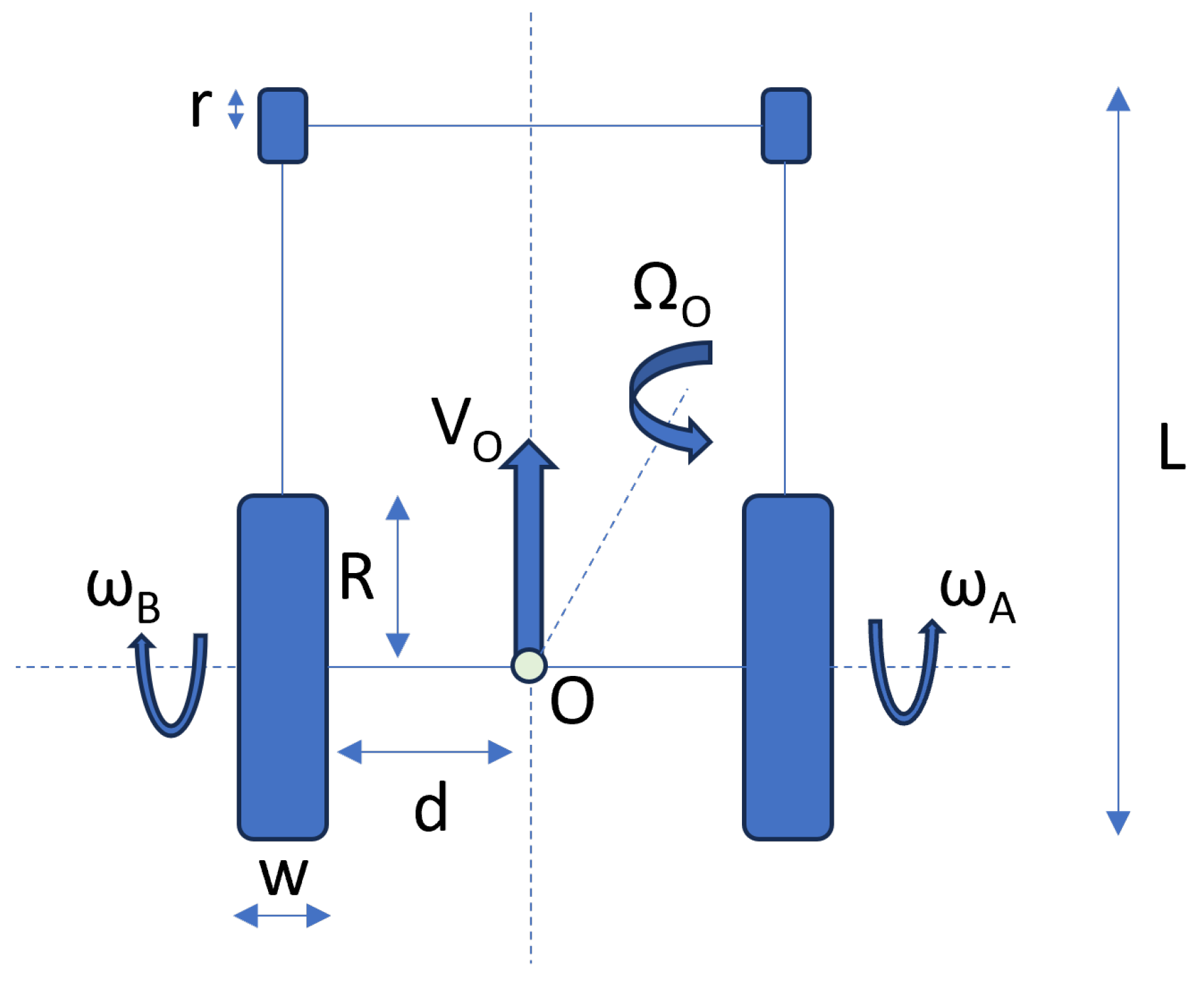







| Parameter | Value |
|---|---|
| Castor wheel radius—r | 0.17 m |
| Rear wheel width—w | 0.05 m |
| Rear wheel radius—R | 0.27 m |
| Length—L | 1.1 m |
| Width—2 × (d + w) | 0.7 m |
| Vanilla | Fine-Tuned | ||
|---|---|---|---|
| First test | Goal-reaching time [s] | 43.1 ± 2.3 | 37.6 ± 1.4 |
| Max collision | 0 | 0 | |
| Second test | Goal-reaching time [s] | 61.1 ± 3.7 | 52.1 ± 1.6 |
| Max collision | 0 | 0 | |
| Third test | Goal-reaching time [s] | 84.8 ± 6.9 | 60.3 ± 2.1 |
| Max collision | 2 | 0 |
| Computing Device | Execution Time |
|---|---|
| Laptop (with GPU) | 0.025 ± 0.015 ms |
| Jetson Nano | 0.028 ± 0.047 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pacini, F.; Dini, P.; Fanucci, L. Show Me Once: A Transformer-Based Approach for an Assisted-Driving System. Mach. Learn. Knowl. Extr. 2024, 6, 2096-2110. https://doi.org/10.3390/make6030103
Pacini F, Dini P, Fanucci L. Show Me Once: A Transformer-Based Approach for an Assisted-Driving System. Machine Learning and Knowledge Extraction. 2024; 6(3):2096-2110. https://doi.org/10.3390/make6030103
Chicago/Turabian StylePacini, Federico, Pierpaolo Dini, and Luca Fanucci. 2024. "Show Me Once: A Transformer-Based Approach for an Assisted-Driving System" Machine Learning and Knowledge Extraction 6, no. 3: 2096-2110. https://doi.org/10.3390/make6030103
APA StylePacini, F., Dini, P., & Fanucci, L. (2024). Show Me Once: A Transformer-Based Approach for an Assisted-Driving System. Machine Learning and Knowledge Extraction, 6(3), 2096-2110. https://doi.org/10.3390/make6030103