1. Introduction
Cardiovascular diseases (CVDs) are among the greatest concerns for public health and humanity. The World Health Organization (WHO) reported that 17.9 million people died due to CVDs in 2019, meaning 32% of all global deaths [
1]. Electrocardiogram (ECG) analysis is a powerful method for analyzing cardiac health. It can be an ally to saving many lives by rapid and accurate identification of CVDs, like arrhythmias, for example, [
2].
The ECG signal is the electrical activity of different cardiac tissues obtained from a patient’s skin, providing a graphic pattern that represents the heart muscle’s function [
3]. Sequential waves represent the cardiac cycle. Each wave part is associated with one physiological heart activity [
4]. It is a powerful non-invasive method, and analyses of them can determine cardiac health [
5]. The signal amplitude and intervals, defined by fiducial points, supply the most helpful information [
5,
6]. The main feature of arrhythmia detection is an accurate R-peak detection, which is critical for heart rate measurement. Different ventricular arrhythmias can be classified by detecting and examining QRS complexes and determining the R–R interval [
7,
8].
Different works in the literature have presented several automated algorithms for QRS and R-peak detection techniques [
9]. However, implementations of the proposed algorithms are still challenging for ECG signal analysis in the real world [
3,
6]. Some proposed ECG detectors have very high accuracy but use several complex steps under specific conditions [
3,
10,
11]. Undoubtedly, a computational technique to analyze the ECG signal with higher accuracy in streaming applications is still required. Since data flows continuously from data streams at high speed, traditional data management systems do not support the continuous queries required by streaming applications [
10]. Instead, new techniques must be defined, or adapted methods should appear for ECG streaming settings [
12,
13].
Applications of medical services in healthcare in the Internet of Medical Things (IOMT) context will increase greatly in the coming years. Traditional methods cannot collect, analyze, query and store data within a reasonable time frame [
14] for processing real-time data streams. In this new paradigm, a large amount of multimodal information comes from multiple resources, sensors, or other biomedical acquisition systems. The IOMT system needs low power consumption, low memory usage, and low CPU resource usage to deal with the continuous data volume from all the other streaming frames to maintain performance [
15].
We can find in the literature a constant search for novel and more efficient ways to reduce computing costs so that the technique can be implementable in practice [
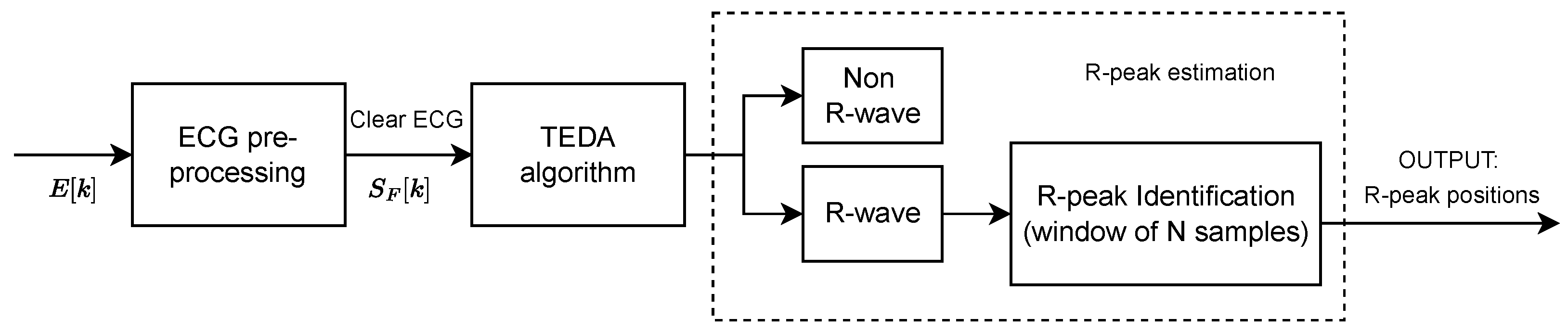
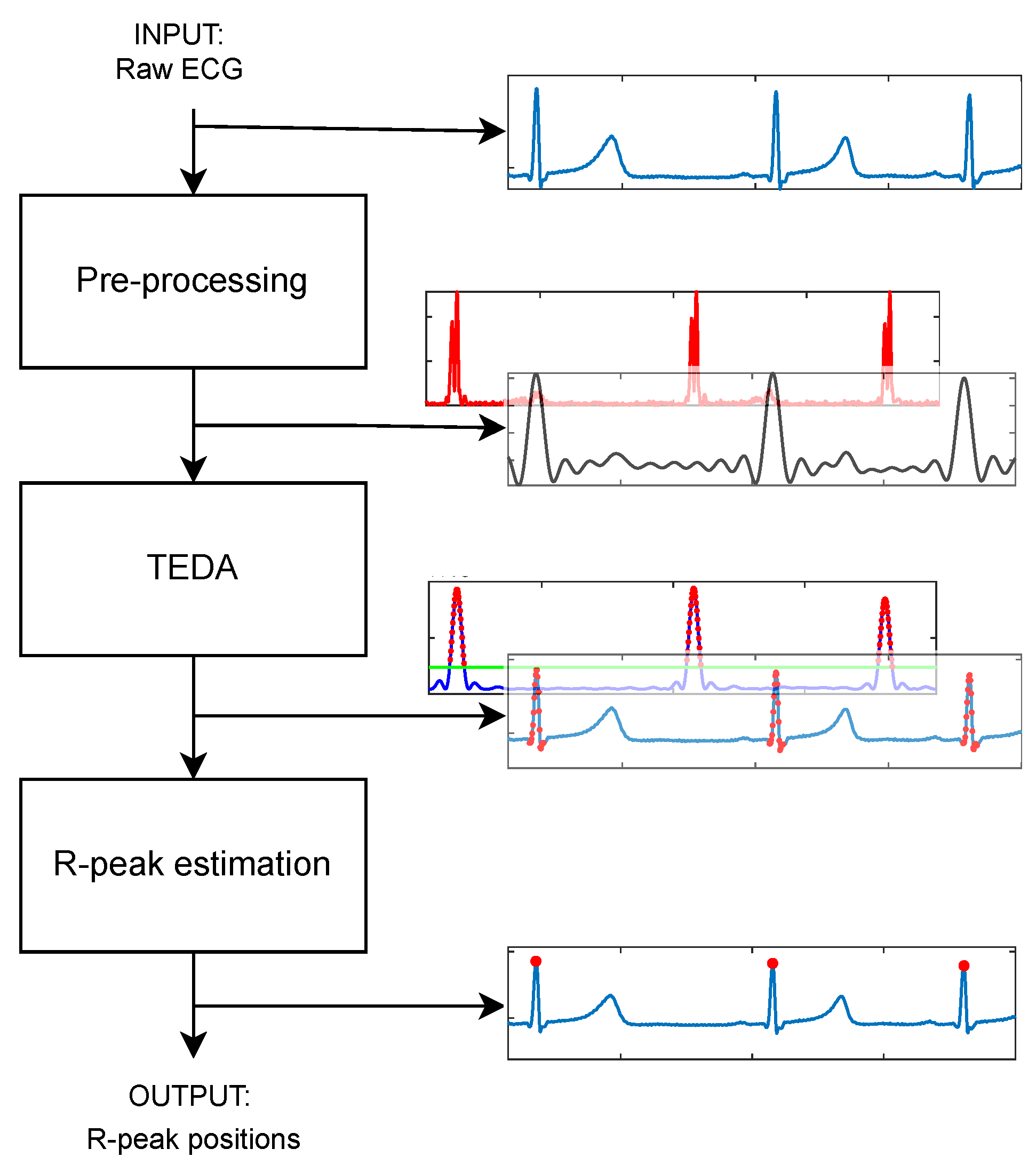
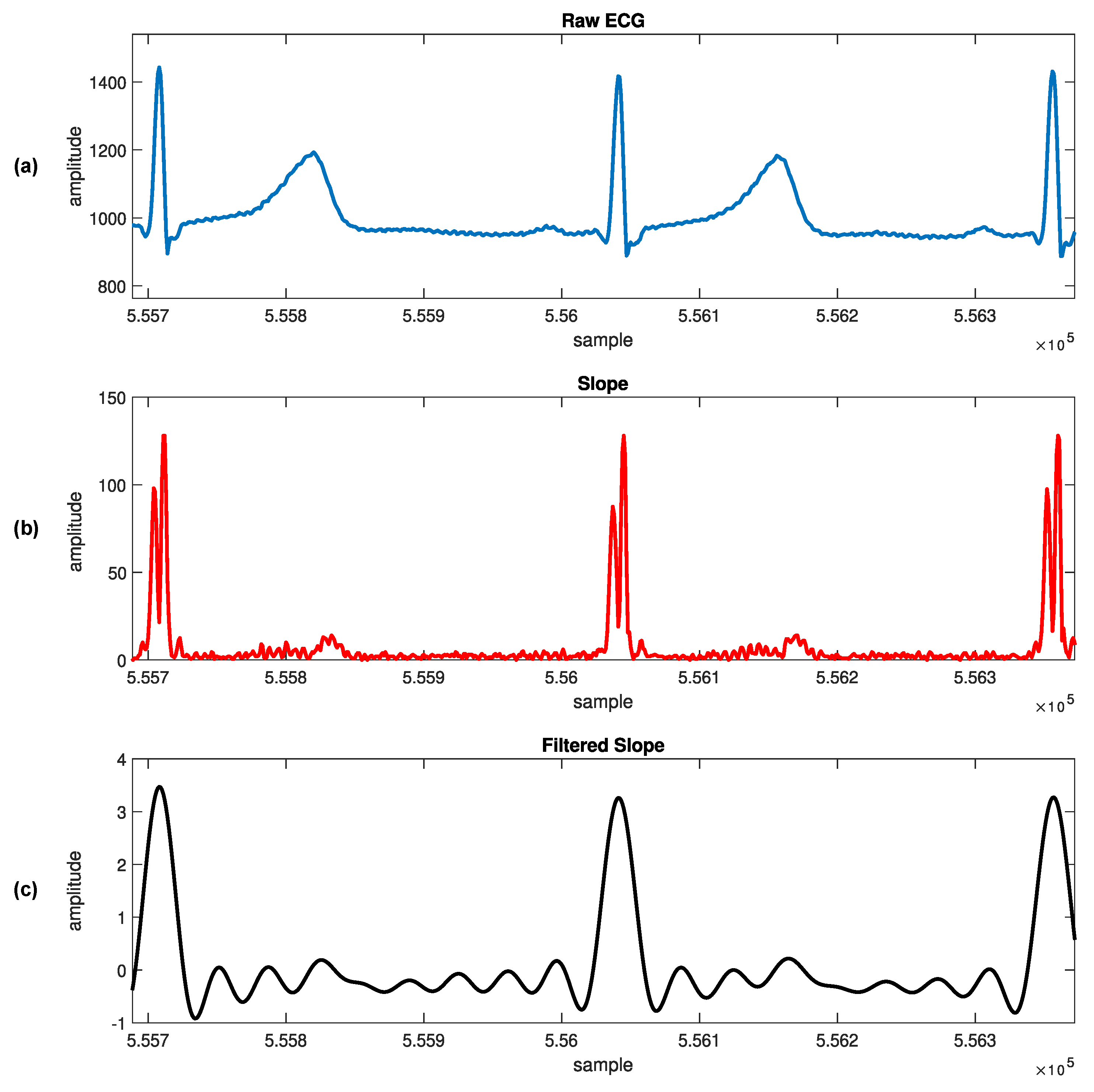
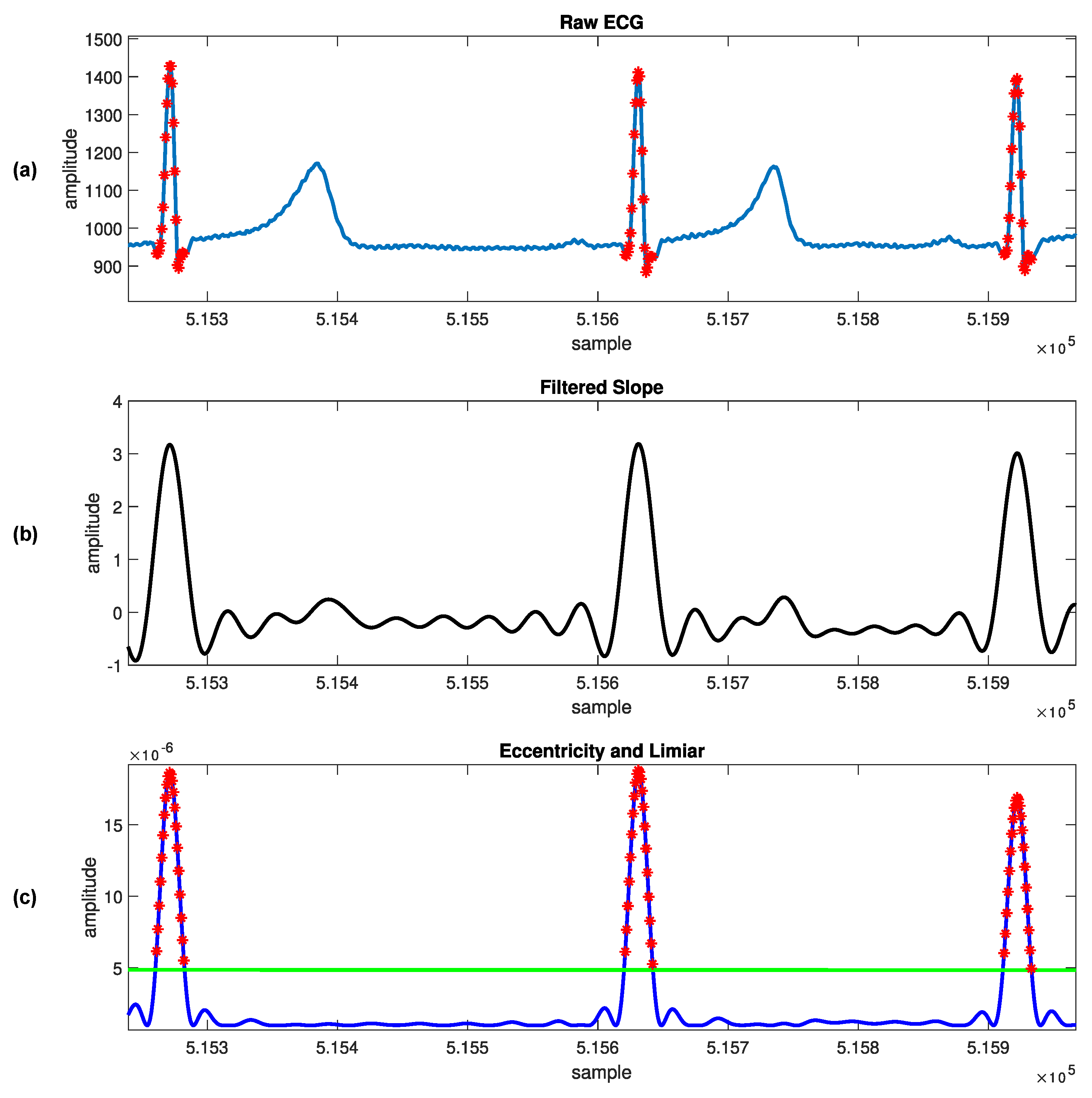
16]. Our approach uses the typicality eccentricity detection anomaly (TEDA) algorithm recursively to minimize storage and time consumption, so that agents with lower computational complexity, such as portable and smart devices, could use it. TEDA is a recursive method designed to detect industrial signal anomalies in streaming applications. The R-peak wave portion is interpreted as an anomaly by TEDA because it is a very eccentric portion when compared to the rest of the ECG wave. Because of this, we infer the position of the R peak. In the literature, few algorithms are recursive in their analysis of the ECG signal.
TEDA can be an alternative to a statistical framework. New metrics are the TEDA’s foundation, all based on the similarity/proximity of data in the data space, not on density or entropy, as per traditional methods. TEDA is suitable for data streams because it is lightweight and recursive, so signals can be analyzed as they are generated and it can interpret large amounts of data, such as physiological data recorded continuously in an ICU. ECG signals are streaming data, and detections are needed continuously to aid in diagnosing heart disease, for example. An accurate streaming ECG analysis approach requires continuous adaptation. However, streaming data can be infinite, so algorithms that store the entire data for analysis are unsuitable. Instead, detectors should process data in real time and constantly update the model directly from the input stream [
10,
17].
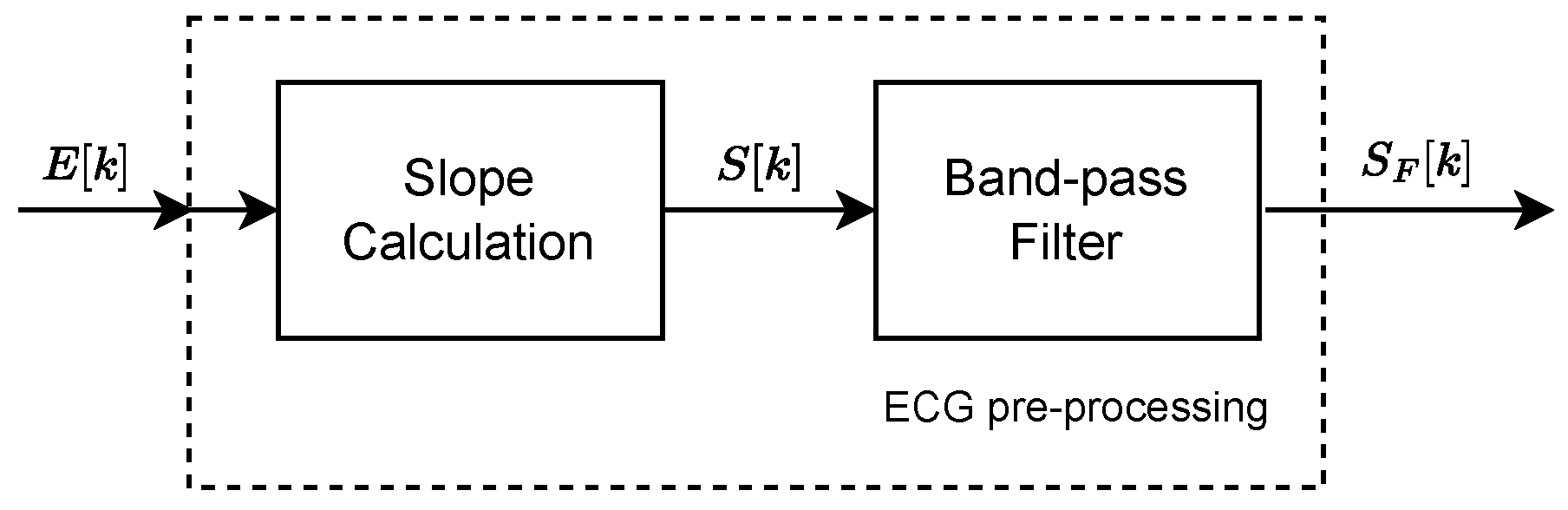
This work proposes a novel automated ECG feature extraction algorithm based on the TEDA algorithm with a light preprocessing step, designed to detect R peaks by verifying their eccentricity in relation to the other waveform points. Its simplicity and low computational complexity make it a potential candidate for real-time and streaming ECG applications.
The highlights of this study can be summarized as follows:
The proposed method is much lighter in terms of computational complexity.
For the first time, the approach uses the TEDA algorithm for physiological signals, more specifically, for electrocardiogram signals.
The method achieves a sensitivity (Se), positive predictivity (+P), and accuracy (ACC) of , , and for a 100 ms tolerance (TOL).
The proposed technique can be performed online without pre-setting.
The method shows a reduced and efficient pipeline compared to other studies in the literature.
3. Results
To demonstrate the effectiveness of the proposed method, we carried out a set of tests.
Table 1 presents the evaluation results for each ECG record in terms of sensitivity (Se in %), positive predictivity (+P in %), and accuracy (ACC in %).
Identifying a type of wave in an ECG sequence does not mean that the identified points should appear at the exact annotation or particular time. Instead, the difference in timing between the identified point and the annotation should be inferior to a TOL.
Table 1 presents results for a 100 ms TOL. Traditional values adopted for TOL are 150, 70, or 40 ms [
24].
Aside from the Se, +P, and ACC, we calculated the averaged timing difference
and the associated standard deviation
of the correctly labeled points concerning the annotation. Equations (
8) and (
9) illustrate the averaged timing difference
and the associated standard deviation
, respectively.
where
N is the number of samples labeled correctly as an R peak within the tolerance TOL, and
and
n are the time stamps of the detected peak inferred by this approach and annotated by specialists, respectively.
Table 2 presents the averaged timing difference and the associated standard deviation or different TOLs. We also verify the proposal’s effectiveness by presenting typical metrics used to validate classification performance, such as positive prediction, sensitivity, F1 score, and accuracy.
4. Discussion
The literature on ECG delineation algorithms has been increasing over the last decades. R-peak detection applications use methods ranging from traditional processing methods to machine learning and its subbranches, such as deep learning [
2]. The conventionally used methods often focus on the frequency aspect, using complex mathematical functions, transforms, and optimization techniques that need substantial computational resources [
12].
Among the different techniques developed for ECG analysis, time-domain analysis, frequency-domain analysis, and wavelet transform are the predominant approaches. Many ECG R-peak detection methods utilizing transforms [
25] primarily use Hilbert (HT) [
26,
27,
28], Pan–Tompkins (PT) [
29,
30], and wavelet transforms [
31,
32,
33]. Transform-based methods often require buffering of multiple samples before detection. In contrast, streaming algorithms like TEDA perform detection sample by sample. Transform-based techniques often require multiple preprocessing steps and complex signal processing operations.
The work presented in [
5] introduces a P, QRS, and T-peaks detector that utilizes adaptive thresholding and a template waveform. In the initial stage, an adaptive thresholding process is employed for QRS complex detection, followed by threshold initialization. Additionally, false-positive QRS complexes are effectively removed using kurtosis coefficient computation. The method further includes the detection of Q and S points through clustering and the identification of P and T peaks using min–max techniques. Detailed explanations of the detection of Q, S, P, and T points are beyond the scope of our study. Their proposed technique for R-peak detection offers reduced computational complexity compared to conventional methods, as it relies on simple decision rules rather than heuristic or optimization approaches. However, it involves a multi-step process flow. The method involves preprocessing the ECG, employing adaptive thresholding to detect R peaks, and applying post-processing based on the kurtosis coefficient to eliminate false R peaks and enhance accuracy. To initialize the threshold, baseline estimation and RMS value calculation of the ECG from a 3-second buffer are required. This is in contrast to our proposed approach, where classification is performed sample by sample without pre-setting.
The work presented in [
6] employed hierarchical clustering and discrete wavelet transform (DWT) for ECG analysis. They initially identified a template of the single ECG beat and then detected all R peaks using hierarchical clustering. Subsequently, T-wave boundaries were delineated based on template morphology. The T-wave peaks were determined using modulus maxima analysis (MMA) of the DWT coefficients. Throughout the analysis, a sliding window of 1.2 s was utilized at each step.
Our work shares similarities with this approach. We also perform preprocessing and utilize similarity-based metrics to classify the R wave. In their work, the signals are preprocessed through filtering and normalization. Next, hierarchical clustering with the linkage algorithm and Euclidean distance is applied to determine R-clusters and non-R-clusters. Once the R-wave clusters are identified, the corresponding R-wave ECG sample sequences are extracted. In addition, a post-processing step is incorporated to remove false R peaks. Although the subsequent stages of their method involve T-wave peak detection, we will not discuss the methods employed for this step in our work.
It is relevant to note that the aforementioned approach involves signal windowing and relies on prior knowledge of the signal. For instance, their proposed preprocessing step of signal normalization requires prior knowledge of the signal, which implies a pre-setting requirement. This limitation could restrict the applicability of their technique in streaming applications. In contrast, our proposed approach performs classification sample by sample, without any pre-setting requirements.
Overall, our approach aligns with certain aspects of the work presented in [
6], but it distinguishes itself by enabling sample-by-sample classification without the need for pre-setting and avoiding signal windowing. These characteristics make our approach particularly suitable for streaming applications.
The study presented in [
24] proposes a refined post-processing ECG delineation method that classifies each sample point in the ECG recording using 1D-UNet and determines the boundaries of the waveforms. The ECG signals are divided into segments of a single heartbeat cycle before being inputted into 1D-UNet. These segments allow the network to accurately extract the characteristics of different waveforms. A post-processing algorithm, utilizing the morphological information, eliminates the influence of misclassified data points. Tests conducted on public ECG databases demonstrate satisfactory delineation performance with sensitivities of 99.88% and 99.48%, respectively. However, the 1D-UNet, due to its 1D convolutional operations along the temporal axis, coupled with the post-processing, is computationally complex and not suitable for online real-time performance.
Although some studies have achieved slightly higher accuracy, their complex nature and computational demands limit their practical use. In comparison, our method offers a simplified and efficient R-peak detection approach suitable for streaming applications. It is important to note that the calculation of eccentricity in the TEDA algorithm involves summing the geometric distances between current and past samples, enhancing the algorithm’s ability to identify samples with high eccentricity and low typicality as R peaks. This methodology efficiently separates R peaks from noise and other components of the ECG waveform without requiring the complete dataset for analysis, allowing detectors to process data directly from the input stream in real time. The adaptability and efficiency of TEDA in handling noise significantly improve the accuracy and reliability of R-peak detection, making it a robust solution for continuous ECG monitoring and analysis in various clinical contexts.
5. Comparison with the State of the Art
The article presented in [
34] introduces an advanced method for detecting QRS complexes in ECG signals, aiming to improve the automatic diagnosis of cardiovascular diseases. The proposed technique is based on a sophisticated preprocessing process that includes band-pass filtering, differentiation, squaring, and integration, followed by peak detection and an adaptive threshold approach to identify QRS complexes accurately. This methodology demonstrates an ACC of
, Se of
, and P+ of
on the MIT-AD. The total complexity of the algorithm can be expressed by
, where
N is the number of ECG signal samples and
M is the dimension of the applied filters. The other steps add linear complexity
, leading to a total approximate complexity of
. The method involves multiple preprocessing steps, including band-pass filtering, differentiation, squaring, and integration, each contributing to the total computational load. The implementation of filters and the sequence of operations might be computationally intensive.
The article in [
5] is outlined in two main stages: initially, an FIR filter in the 5–20 Hz band is used for preprocessing, followed by a cubing operation to enhance the R peaks and adaptive thresholding for effective QRS complex detection. Subsequently, a clustering process is employed to generate a template waveform of the ECG segment between the S and Q wave points, followed by a conditional thresholding method based on the morphology of the template to detect P and T peaks. This approach demonstrates precision in detection, as validated on standard databases such as MIT-AD. Applied to the MIT-AD, the final results were an Se of
, +P of
, and an ACC of
. The size of the analysis windows mainly influences the complexity of the technique, the order of the FIR filter, and the total number of samples processed, with
being linear relative to the number of samples for operations such as filtering, normalization, and thresholding. However, despite the technique exhibiting linear complexity
, it requires multiple processing steps, including FIR filtering, cubing, adaptive thresholding, and clustering processes for
template waveform generation. The complexity of clustering processes can range significantly based on the algorithm chosen: from
for optimized DBSCAN, up to
or even
for hierarchical clustering or spectral clustering, respectively. Hence, the computational burden of the clustering step could substantially impact the method’s feasibility on devices with limited processing and storage capacities, particularly without optimizations.
The article presented in [
6] introduces a methodology for automatically detecting R and T peaks in ECG signals, combining hierarchical clustering techniques and discrete wavelet transform (DWT). The process begins with the ECG signal being filtered using a fourth-order Butterworth filter to eliminate noise, followed by the normalization of the data. The detection of R peaks is performed through hierarchical clustering, which analyzes the similarity between samples based on Euclidean distance. In contrast, T peaks are identified by analyzing the modulus maxima of the DWT coefficients. This method achieved impressive results on the MIT-AD: an Se of
, a +P of
, and an ACC of
. The complexity of hierarchical clustering varies with the specific approach used but is generally considered high compared to other clustering methods. Agglomerative hierarchical clustering, one of the most common methods, has a typical computational complexity of
in the general case. This is due to repeatedly calculating distances between all pairs of clusters, and then, combining the two closest clusters at each step.
The work presented in [
35] proposes an advanced approach for detecting the QRS complex in ECG signals. The method begins with preprocessing the ECG signal, including band-pass filtering to remove noise, differentiation to highlight rapid changes indicative of the QRS complex, and application of the Hilbert transform to form the signal envelope. The crucial step is the application of a modified adaptive threshold, using two thresholds (upper and lower) that are dynamically adjusted based on the statistical analysis of the signal within each analysis window. This process allows for accurate detection of the QRS complex, adapting to the variable characteristics of the ECG signal. The efficacy of the method was validated on 48 recordings from the MIT-AD, achieving an Se of
%, a +P of
, and an ACC of
for QRS complex detection, highlighting the precision and adaptability of the proposed approach for detecting QRS complexes under different signal conditions. The complexity of this method can be estimated by considering the primary operations described in the article, where filtering with a sixth-order Butterworth filter and differentiation have essentially linear complexities concerning the number of samples
N, implying an
complexity for these stages. However, the application of the Hilbert transform raises the overall complexity of the method to
due to the use of FFT and IFFT. The modified adaptive threshold step, though based on statistical analysis and dynamic adjustments of thresholds, likely maintains a linear complexity
, given the nature of its processing.
The method proposed in this work includes preprocessing with slope calculation and FIR filtering, followed by the TEDA algorithm and the estimation of the R peak. The computational complexity presents essential nuances. The preprocessing step with the FIR filter has a complexity of
, where
N is the number of signal samples and
M is the order of the filter, indicating an operation that scales linearly with the size of the signal but also depends on the chosen filter order. The slope calculation and the TEDA algorithm, which analyzes each sample individually, contribute an additional linear complexity
. Finally, determining the R peak among the samples selected by TEDA maintains linear complexity
, where
M is the number of R-peak candidates. Therefore, the total complexity of the method is predominantly influenced by the FIR filtering stage and can be characterized as
, assuming that
M is not significantly large relative to
N.
Table 3 summarizes the comparison between the techniques presented here.
The comparison between different R-peak detection techniques in ECG signals reveals that, although the Se and ACC of our proposal are slightly lower than those of other methods, the P+ is significantly higher. This factor is crucial in clinical practice because it indicates a low rate of false positives, ensuring that almost all detected R peaks are accurate. This characteristic is precious in continuous monitoring applications, where reliability in identifying actual cardiac events is a priority. Even though slightly lower sensitivity and accuracy might suggest a more conservative detection of R peaks, the high predictive positivity ensures the clinical relevance of the detections, minimizing interruptions or false alarms in monitoring systems.
Our proposal also stands out for its reduced computational complexity, estimated at , making it particularly attractive for implementation in embedded systems and wearable devices. In contexts where the conservation of computational and energy resources is essential, the algorithm’s efficiency becomes critical. The lower complexity translates into lower energy consumption and processing capacity, facilitating integration into portable cardiac monitoring devices that operate continuously and autonomously. This feature allows our technique to be implemented more viably and sustainably in terms of resources compared to more complex methods, paving the way for broader applications in mobile health and remote patient monitoring.
Finally, using the TEDA algorithm in our approach offers a distinctive advantage, allowing for adaptive and intelligent analysis of ECG signals. By focusing on the eccentricity and typicality of the samples, TEDA effectively identifies QRS complexes, even under challenging signal conditions, such as in the presence of noise or pathological variations. This adaptability ensures that our proposal is technically feasible for a wide range of applications, including wearable devices and embedded systems, and robust in different clinical contexts. Thus, by balancing efficiency, precision, and adaptability, our technique represents a promising advancement in R-peak detection, promoting more reliable and accessible cardiac monitoring.
6. Conclusions
The proposed technique was performed in three steps. In the first step, the ECG signals were preprocessed, which involved slope calculation and filtering. The second step involved the application of the TEDA algorithm, where eccentricity was recursively calculated. Finally, the R-peak estimation was determined as the point with the highest eccentricity. To evaluate the effectiveness of the technique we used the traditional MIT-AD. The results demonstrated that the technique achieved an Se, +P, and ACC of , , and , respectively, with a TOL of 100 ms. One significant advantage of the proposed technique is its low computational complexity. Unlike complex traditional approaches that involve signal transformation, buffering, windowing, or complex mathematical functions, the proposed technique relies on an evolutive recursive algorithm. In conclusion, the proposed technique presents a novel approach to R-peak detection in ECG signals. The combination of preprocessing, the TEDA algorithm, and R-peak estimation results in a robust performance. Furthermore, the technique’s low computational complexity makes it well suited for real-time and streaming applications. Future research could explore the application of this technique to the analysis of other physiological signals or investigate potential enhancements to further improve its performance.
This research showed that the proposed technique exhibited an Se and ACC around on the MIT-AD, with specific experiments demonstrating values below for these metrics. This observation is not exclusive to this study; as noted in the literature, other works also report variable performances, with individual experiments showing an Se and ACC below the threshold. This highlights the inherent complexity in processing ECG signals and detecting QRS complexes, especially considering the diversity of arrhythmias and signal variations among subjects. The necessity for ongoing enhancement of the approach is recognized, and future work will involve a more detailed investigation into cases where the current technique underperformed. The focus will be on fine-tuning and adding refinement steps for specific scenarios, a prevalent strategy in existing proposals in the literature. Such endeavors aim to increase the robustness and adaptability of the method, ensuring high rates of Se and ACC generally and enhancing effectiveness in challenging conditions. This approach will contribute to further developing automatic tools for diagnosing cardiovascular diseases.
Finally, TEDA also exhibits the potential for adaptation to detecting other waves in ECG signals, such as T and P waves. Given the algorithm’s flexibility in distinguishing signal characteristics based on eccentricity and typicality, there is significant promise for exploring its application beyond R peaks in future work by adjusting its parameters to capture the nuances of these specific waves.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}