Abstract
Semantic folding theory (SFT) is an emerging cognitive science theory that aims to explain how the human brain processes and organizes semantic information. The distribution of text into semantic grids is key to SFT. We propose a sentence-level semantic division baseline with 100 grids (SSDB-100), the only dataset we are currently aware of that performs a relevant validation of the sentence-level SFT algorithm, to evaluate the validity of text distribution in semantic grids and divide it using classical division algorithms on SSDB-100. In this article, we describe the construction of SSDB-100. First, a semantic division questionnaire with broad coverage was generated by limiting the uncertainty range of the topics and corpus. Subsequently, through an expert survey, 11 human experts provided feedback. Finally, we analyzed and processed the feedback; the average consistency index for the used feedback was 0.856 after eliminating the invalid feedback. SSDB-100 has 100 semantic grids with clear distinctions between the grids, allowing the dataset to be extended using semantic methods.
1. Introduction
Human language has been considered a very complex domain for decades [1], and its actual representation in the brain is crucial for performing language-processing tasks [2]. To date, the human brain is the only known system capable of processing language correctly. A crucial issue in this domain is the representation of language (data) in the brain [3]. Hierarchical Temporal Memory (HTM) [4] mimics the structure and operation of the neocortex and is an online learning system. A third-generation model of Biological and Machine Intelligence (BaMI) is currently representative [5]. The input data in HTM are encoded to generate a Sparse Distribution Representation (SDR) [6,7], a representation expressed as sparse 0- and 1-valued vectors or matrices of thousands of dimensions, bringing excellent robustness to the simplicity of operations in the learning system. Ahmad et al. [8,9] demonstrated that the SDR can solve many complex problems using Boolean operators and generic similarity functions similar to the Euclidean distance. Each bit in the actual representation contains part of the semantics, and semantically similar data representations are more similar in their presentation.
The semantic folding theory (SFT) [10] is a computational theoretical approach developed for linguistic data processing to produce SDR encodings that can be used directly by the HTM. This works by composing one or more sentences into a text fragment and treating this text fragment as the context of each word contained within it. A grid map of text clusters with different topics was eventually formed by clustering semantically similar contexts close to each other and dissimilar contexts distant from each other. Each grid in the semantic grid corresponds to a bit in the SDR; when the vocabulary appears in this grid, the corresponding bit of this grid is marked as bit 1, and otherwise, it is 0. For each grid on the 128 × 128 map, as implemented in the SFT white paper [10], many text fragments can be found to collectively represent semantic topics that overlap in semantic information but are not identical in meaning. However, the distribution of a corpus among the two-dimensional grids using different methods has different effects. There is no standard validation dataset for evaluating various types of semantic folding methods, which makes it difficult to measure the accuracy of other classification methods and promote their application in HTM models. In this study, we constructed a validation set called “SSDB-100,” which specialized in evaluating the segmentation effect of semantic lattices constructed based on the SFT segmentation algorithm. By carefully collecting the corpus, restricting the semantic scope of the lattices, and constructing a high-quality baseline validation set with expert knowledge, we provide a good evaluation standard for the SFT-based process that can promote the popularization and application of the SFT.
The remainder of this paper is organized as follows. Section 2 presents related work. Section 3 describes the preparation of the raw data and expert questionnaire. Section 4 describes the analysis and processing of the feedback and the generation of the SSDB-100. Section 5 presents conclusions and future perspectives.
2. Related Work
The key step in the semantic folding theory is the processing of context, which divides semantically similar contexts into identical or similar sentences. Where context is the semantic granularity of the processing and determines the ability to generate semantic associations of encodings, context can be composed of a varying number of sentences. Khan et al. [11] utilized SFT to encode Internet text and employed HTM models for online anomaly detection. Within the scope of our research, we observed that only Webber et al. [10] constructed a semantic grid and effectively applied its encoding in commercial applications of natural language processing.
Constructing a semantic map essential for SFT involves the utilization of semantic segmentation datasets, which can be further divided into textual semantic classification datasets [12] and text semantic clustering datasets [13,14], depending on the specific experimental algorithms employed. The datasets were categorized based on whether they were single-label or multi-label, as well as general or non-general semantic segmentation datasets, depending on the criteria guiding the segmentation process. Each semantic segmentation dataset was carefully crafted, emphasizing distinct elements such as segmentation criteria, cluster quantity, and segmentation quality, making them adaptable to different scenarios and providing valuable insights into specific semantic segmentation objectives.
With increasing requirements for semantic granularity, number of topics, and data quality, it has become increasingly challenging to construct a generalized semantic text delineation dataset, which is often constructed by algorithmic delineation, manual correction, crowdsourcing, expert knowledge, etc., and the quality of the constructed dataset usually increases gradually. Wang et al. [15] used symmetric matrix decomposition to group semantically similar sentences to construct a dataset, but the division process is not subject to human intervention, resulting in a limited practical reference value. Zha et al. [16] constructed a dataset with the idea that the corpus of the same paragraph has a certain semantic relationship, which serves as a quality control criterion. However, a paragraph of text may be very long, and it cannot be guaranteed that all the content within the paragraph will be related to each other. Geiss et al. [17] clustered the sentences in DUC 2005 using the method of expert research, but there were significant differences in semantic alignment and integration because several experts carried out the construction of topic clusters and the delineation of sentences by themselves. Consequently, this method used a high-quality method for constructing the expert research, while at the same time intervention control was applied to the topic clusters and ranges.
In contrast to the delineation of generic semantic divisions, the construction of text semantic delineation datasets suitable for specific tasks is guided by criteria that are commonly used for functions such as sentiment analysis and news classification. Sentiment analysis datasets are represented by simple coarse-grained datasets, such as Yelp [18] and IMDB [19], and fine-grained datasets such as SST [20] and Amazon [21], which are used to identify and classify the sentiments contained in text semantics. Similarly, 20-newsgroups [22] are news collections evenly distributed over 20 different topics, of which the most popular version contains 18,821 news documents. Reuters-21578 [23] is one of the most widely used multi-categorization datasets in text division, collected in 1987 by the Reuters Financial Newswire service. It not only provides a large corpus but also has a multi-label feature, where most documents have only one or two labels and a maximum of 15 labels exist. The news division dataset above typically uses the whole text or paragraphs of the text as the corpus. Researchers often use it to develop new datasets. For example, Seno et al. [24] segmented 20 news articles into sentences and created a sentence-clustering dataset consisting of 1153 sentences using the news topic as the division center.
There are a few generic semantic divisions, with many clusters among the existing semantic division datasets. Non-generic semantic partitioning datasets usually have fewer partitioning clusters and cannot be used in SFT experiments. Neither of the two division datasets consider the task features of the SFT, such as forming a semantic grid and then using grids to generate encoding. With the continuous development and application of SFT, there is an urgent need to build a benchmark dataset using SFT to generate semantic grids for evaluating and comparing the effectiveness and reliability of this method. Our study combines the construction of a semantic text-division dataset with SFT encoding. It focuses on controlling ambiguity during construction to form a scalable, general, and semantic text-division dataset with many clusters.
3. Sentence-Level Semantic Division Baseline
3.1. General Idea
To construct the dataset, sentences in each semantic topic grid must be divided. While the current society produces a huge amount of natural language text data, if the division of topics and corpora is chosen arbitrarily, the quality of the dataset cannot be assured. By considering various aspects, such as SFT principles, corpus acquisition, and applicable tasks, we propose a dataset construction method.
First, contexts are conducted by limiting the range of uncertainties, such as topics and corpus sources; then, the experts generate a topic database based on the contextual corpus selected within the range interval, and volunteers search for and match contexts in the database. We then created a semantic division questionnaire with a wide range of topics and manual division data obtained by investigating experts and scholars in various fields. Finally, we checked the consistency of the collected feedback, eliminated invalid feedback, analyzed the survey results to ensure the validity of the data, and dealt with the dispute data to generate the dataset. We simulated the properties of similar meshes close together and dissimilar meshes far apart using relatively independent subject cells. Figure 1 illustrates the basic concept of building a dataset.
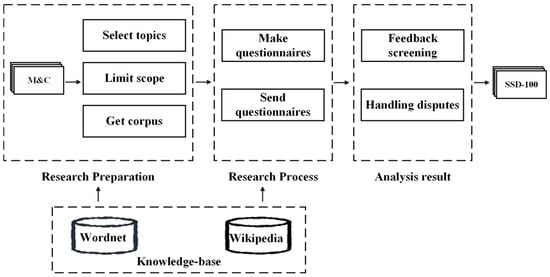
Figure 1.
The basic idea of building the dataset.
3.2. Survey Preparation
The smallest unit of the corpus used in the SFT is called context, and its fragment size directly affects the associative power of encoding. When using contexts with smaller specifications, “gem” and “women” will be associated together. In contrast, “women” can also be associated with “crime” when using larger specifications. During the practice of specific tasks, the context scale was set according to the task.
To construct this dataset, sentences containing certain semantic information were selected as the context. On the one hand, using sentences containing complete semantic information not only satisfies the needs of the task but also does not require inference based on the background; therefore, semantic understanding is simpler. On the other hand, at present, Wikipedia [25], English-Corpora [26], and other real corpora hold a large amount of the sentence text corpus, and the relevant corpus can be retrieved quickly by setting the retrieval rules to facilitate the acquisition of sentences. In the SFT, the context distribution is closely related to the generation of codes, and the code of words is obtained by mapping a grid. To limit the scope of corpus acquisition and to conduct future research on vocabulary coding, we focused on the retrieval of relevant words from the Miller–Charles (M&C) dataset [27] (a benchmark set containing 30 word pairs for word similarity and relatedness), and with the expansion and improvement of the dataset corpus, this dataset can be used for sentence division, and then the study of SFT vocabulary coding can begin.
We selected the Wikipedia corpus as the data search source to ensure the authenticity of the data and build efficiency. The Wikipedia corpus contains the full text of Wikipedia, which currently contains over 5.7 million English-language articles. Many natural language-processing tasks use it as a data source, providing both full and incremental data downloads. The entire corpus can be conveniently obtained for custom processing; in this study, the corpus was cut into sentence units to facilitate local extension operations. If there is only one word in the corpus representing one semantic meaning, this will seriously affect the effectiveness of the segmentation algorithm and the final encoding generated. Therefore, we started with the vocabulary of the M&Cs and used WordNet [28] (a large database of English words) to obtain their different expressions to form a candidate keyword database, and we treated each word and its derivatives as a lexical unit. Using WordNet to obtain different expressions may result in different semantic interpretations within a lexical unit due to the existence of polysemous words. However, we contend that the presence of polysemy is permissible, as in SFT, and the similarity of encoding between two lexical encodings is reflected through semantic relationships in contexts. The presence of polysemy allows the encoding of “board” to encompass diverse meanings (e.g., business board, embarking on a ship or plane, a thin flat piece of wood, or residing and receiving regular meals in exchange for payment or services). This diversity lays the groundwork for subsequent studies in encoding, facilitating a nuanced exploration of semantic relationships. Lexical units were randomly searched in the corpus to match sentences within 10–30 words in length. The sentence length limit ensures that the retrieved sentences contain certain semantic information and keeps the context fragments within the range of everyday sentences for further processing.
In a corpus of the same magnitude, the frequency of lexical units appearing is different, such as “car” and “oracle”. The former appears much more frequently than the latter. We randomly selected ten million sentences from the corpus as candidates and sequentially tested whether they matched a certain lexical unit. The lexical unit was removed when the number of retrieved sentences reached 100, and retrieval was stopped when the total number of sentences reached 2000. We set the threshold at which each lexical unit should match at least 20 sentences to ensure that the set of sentences generated at this stage covered the lexical units, and finally 2041 sentences were obtained as the corpus for subsequent topic selection. Throughout the matching retrieval process, the volunteer judged whether the resulting sentence contained basic semantics and proceeded to the next sentence retrieval match. We used the above strategy to simulate the situation in which high-frequency lexical units occur more frequently than low-frequency lexical units and to ensure coverage of each lexical unit. However, the simulation of lexical frequency was not the core issue we considered; therefore, it was not guaranteed that the distribution would be strictly according to lexical frequency.
To strengthen the connection between the dataset and vocabulary in M&C, we did not select topics arbitrarily but generated topics from a corpus covering the lexical units in M&C. Topic selection was performed by experts who analyzed the 2041 sentences in turn, using the selection tool to generate new topics or select existing topics, and 113 candidate topics were finally obtained. To control the number of topics and simulate a rectangular grid, we constructed a 10 × 10 grid that kept 100 topics at random and 427 sentences related to the topics. The experts followed the following principles for selecting themes:
- (a)
- Topics can be distinguished from each other and are not allowed to have highly related or inclusive relationships. For example, theft and burglary are considered highly related and need to be removed or fused.
- (b)
- A topic cannot be just a word in M&C, which would affect the associative power of the grid. For example, a car cannot be a topic because it is a word in M&C, but our results allow a car accident to be a topic in the grid.
- (c)
- To be considered valid, the semantics of a candidate topic must be contained in at least two sentences.
Similar to the generation of lexical units, we generated topic units containing synonymous expressions and then combined topic units with lexical units to search the corpus. Considering that there is a certain degree of distinction between topics and that each sentence may be related to more than one topic unit, volunteers added relevant topic tags to the sentences and finally obtained 3220 sentences, which may contain the semantic information of more than one unit at the same time or may contain only the attention information of the topic unit.
For example, “His wrecked and burned car had been found later with a body inside, which had been burned beyond recognition.” is straightforward; “traffic accident” and “incineration” can be found among the candidate themes. In another example, “But the fact that the Anglo-Australian miner is weighing a bid at all suggests it has emerged from its post-Alcan funk.” is not a direct option among the candidates; we adopted a simple inference in the process of marking instead of arbitrarily discarding the sentence. In simple inference, “company acquisition, the aluminum era of panic” with “economic properties in the financial crisis” and “miners and aluminum” with “metals in metal refining” have a particular connection. In reality, a computer may prefer these two tags in the calculation; therefore, it also uses them as tags for sentences. For each sentence, we selected the best-matching theme from a pool of 100 topics. Consequently, not all sentence labels perfectly encapsulate the semantic essence of the sentences. For example, in the sentence “It suffered severe damage during the Peninsula War in the Napoleonic era, and the monks were dispersed”, volunteers associated it with the themes “Buddhism” and “War” from the set of 100 topics. However, “Buddhism” may not be the most fitting semantic theme for the sentence. It is through these contextual snippets that the semantic linkage between Buddhism and war is reinforced during the SFT encoding process. Of course, there are a certain number of sentences with three or more related tags, as shown in Table 1. Please note that label assignments reflect the views and opinions of the volunteers and experts that participated in the process, while alternative assignments could be possible.

Table 1.
Volunteer-generated sentence-tag relationship correspondence table.
3.3. Survey Process
The quality of a dataset related to the semantics of human language must be measured by examining how well it fits common sense. However, it may not be objective in some ways because of human factors. To obtain a high-quality semantic division dataset, we created a questionnaire with topic tags and communicated it to experts in the field of natural language. To facilitate division by experts, we considered sentences that could match fewer topics on the topic base. The number of semantic tags carried by each sentence was expanded to five by volunteers, and the subsequently added topic tags may not have a strong semantic relevance to the sentence. Finally, the expert questionnaire comprised 3220 sentences with six corresponding options (A–E are five candidate topic options, and option F represents no suitable option among them). We sent surveys via email to 61 experts, whose research interests included natural language processing, knowledge graphs, semantic association, data mining, and knowledge representation. The order of sentences and corresponding options were randomly determined for each questionnaire. The experts were given a task description and questionnaire to be completed. They were asked to select the most semantically relevant topic among the candidates for each of the 3220 sentences from among the six corresponding options. To ensure the quality of the questionnaire, an objective consulting fee was paid to experts who completed qualified questionnaires.
We provided the experts with the following requirements for completion:
- (a)
- Only one most relevant topic should be selected for all sentences.
- (b)
- Do not use too much inference.
- (b)
- If a sentence contained multiple components with differences, then the most important part of the topic was selected.
- (d)
- When filling out the questionnaire, there was no concern about the impact of the different statements.
- (e)
- If you find no option that matches the requirements, please choose option F, which means that no subject among the candidates matches.
4. Evaluation
We received 11 expert questionnaire responses (11 experts, including 10 associate researchers and 1 university lecturer), each completing all questions. In Section 4.1, we evaluate the feedback, remove unreliable feedback, and use the remaining feedback as a source of evaluation for dataset production. In Section 4.2, controversial questions are analyzed and processed to generate the SSDB-100. In Section 4.3, we describe the segmentation of SSDB-100 using common segmentation algorithms.
4.1. Screening Feedback
To avoid invalid feedback, expert questionnaires were screened to ensure data quality. Our questionnaire contains 3220 questions, each with six options (the same question in different questionnaires with the same number of options but in a different order). To assess the consistency of feedback, it is necessary to compare multiple individuals’ responses to the same question and determine whether they are consistent. The option consistency problem among feedback is essentially a multi-categorization problem, in which the results are consistent with the actual categorization results. This involves the problem of categorizing multiple categories using multiple individuals. We calculated the mean of the common multicategory indicators between any two types of feedback as consistency indicators, such as , , , and .
Accuracy is a common and straightforward classification metric. Its value is the number of positive samples divided by the total number of samples. In our calculation, we assume that each feedback item is the correct sample when compared with other feedback. The coefficient is an indicator used for consistency testing and can also be used to measure the effect of classification, with a value between −1 and 1, and is considered highly consistent when it is higher than 0.8. The formula for calculating the coefficient based on the confusion matrix is shown in Equations (1)–(3).
where is the accuracy, which is also the sum of the diagonal elements of the confusion matrix divided by the total number of matrix elements, and is the sum of the products of the actual number of categories corresponding to all classes and the predicted number of that category divided by the square of the number of sample elements.
The is a measure of the accuracy of a classification model with unbalanced data, considering both precision and recall, and takes values between zero and one. In multi-classification problems, , , and are common methods for calculating the of a model. The effects of all categories on the results were considered, but the calculation methods were different. The was calculated with the same weight for each class, and the precision and recall were averaged over all classes, which increased the image of unbalanced samples. The had the same weight for each class, and the of each class was first calculated and then averaged to reduce the impact of unbalanced samples. The formula for calculating the is shown in Equation (4):
We took the feedback as a positive sample and averaged the indicators obtained through analysis with other feedback, which was used as the reliability score of the feedback’s reliability score (RS). Equation (5), the RS of this model, was used to verify the consistency of the results of the questionnaire completed by the experts.
To ensure the high reliability of the questionnaire results, we set a threshold value of 0.8 for RS and numbered the 11 feedback items from 1 to 11. The RS of 10 feedback items exceeded the threshold value, whereas the RS of feedback-10 was 0.752; therefore, it was discarded. Each feedback item affected the RS of the other feedback items, and the RS calculated for each was considered to be a set. In Figure 2, the distribution of the RS set is shown. The median score of feedback-10 was significantly lower than that of the other types of feedback. After removing the influence of feedback-10, the remaining 10 feedback items had RS values between 0.8 and 0.9. The total mean value was 0.856, which exceeded the threshold, indicating high consistency among the 10 selected feedback items. Table 2 shows the consistency index of each feedback item, where RS(10) represents the RS generated by the remaining 10 feedback items after removing 10-feedback.
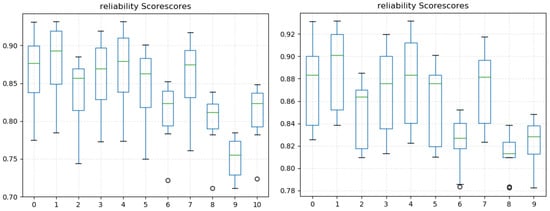
Figure 2.
Inter-feedback reliability scores. The box plot shows the distribution of RS. For each pooled value, the minimum, 25% quartile, median, 75%, and maximum values of RS are shown. The ‘-’ in the middle of the set represents the mean.
Table 2.
Table of consistency indices for each type of feedback.
4.2. Generating SSDB-100
Among the ten selected valid feedback items, we found that 1394 of the 3220 sentences were divided in a way not unanimously agreed upon by all ten experts: there were 1120 sentences with two controversial options, 254 sentences with three controversial options, and 20 sentences with four controversial options among these contentious divisions, as shown in Table 3, with the number of sentences divided under different controversial options.
Table 3.
Number of sentence divisions under different dispute options.
Each of these sentences was divided by ten experts. For example, in the sentence “The CFP limits how long a boat can be at sea and sets quotas for how much it can catch and of what.”, two experts chose “about ships” as the topic, while eight experts thought the fishing theme was more representative; we define this example as the a:b case. In Figure 3, the ratio of disputed options shows the ratio of the number of options contained in the disputed sentences. Among the disputed sentences, controversial cases such as 1:9, 2:8, 1:1:8, and 1:1:1:7 accounted for the majority. Because of the large number of sentences to be divided into one questionnaire, the appearance of these controversial cases is somewhat contingent. We believe that such extreme options cannot represent the results and should be regarded as uncontroversial divisions.
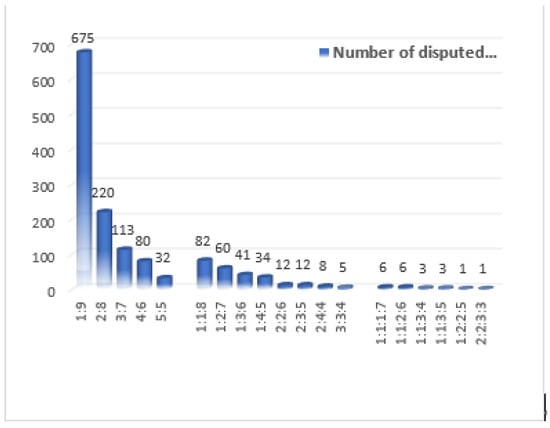
Figure 3.
The ratio of disputed options.
The division results returned by the ten experts were highly reliable. Although disputed sentences due to accidental factors, such as misfiling, have been processed, further processing of the results is required because of each expert’s different judgment criteria, such as abstraction and reasoning. We processed disputed sentences according to the disputed option ratio. For the sentence “His wrecked and burned car had been found later with a body inside which had been burned beyond recognition.”, there were controversies among topics such as “traffic accident”, “incineration”, and “murder”, with a ratio of 5:4:1. We believe that the labels recognized by most experts can represent the semantic topic of a sentence, so that we can assign more than one label for this kind of disputed sentence in a specific experiment. According to the proportion of controversial options, we retained “traffic accident” and “incineration” and discarded “murder” in the above example. To remove non-F options, and if the number of options is greater than two, all of them are valid labels for the statement (F options that experts think make it difficult to choose the most suitable option among the candidates). After the above operations, we assigned appropriate topic labels to 3215 sentences and discarded 5 sentences (F options accounted for most of the division results).
4.3. Data Division
In conducting the division experiments on SSDB-100, we first performed a series of pre-processing steps on the data, including operations such as the removal of stop words and the elimination of stop words, aimed at eradicating vocabulary that frequently appears in the text but generally lacks substantive information, such as conjunctions and prepositions. This processing step was undertaken to optimize the textual data, directing subsequent analyses towards a more focused exploration of key information. The selection of stop words was informed by domain-specific expertise and a commonly used stop-word list, ensuring the enhancement of efficiency and accuracy in subsequent model processing while retaining meaningful information. The entire pre-processing procedure involved transforming sentences into vector representations using the FastText model, thereby furnishing the experiments with a more informative input.
Subsequently, we used different partitioning methods, including hierarchical, single-pass, K-means, and DBscan, to partition SSDB-100. To evaluate the quality of such partitioning, we used common metrics such as homogeneity (verifying the consistency of the same category of data), completeness (verifying that samples from the same category are all assigned to the same cluster), and normalized mutual information (NMI) to verify the similarity between the clustering results and the real categories. Through the experiments, we observed that the overall evaluation metrics were not high because the number of grids reached 100. Considering random factors, such as the order of inputs, the average of the results of 50 iterations was used in the experiments, and the experimental results are shown in Table 4.
Table 4.
Division of the experimental results table.
Through the data after the division, we can obtain the fingerprint of the text by using the results of the division. We take the words coast and shore as an example (because the construction of the dataset starts with M&C, which contains a large amount of the corpus containing these words), and we can obtain their semantic relationship through cosine similarity, etc. The semantic fingerprints obtained from the semantic maps of coast and shore obtained after the use of the K-Means method are shown in Figure 4, where the dark color represents the presence of retrieved word in this grid
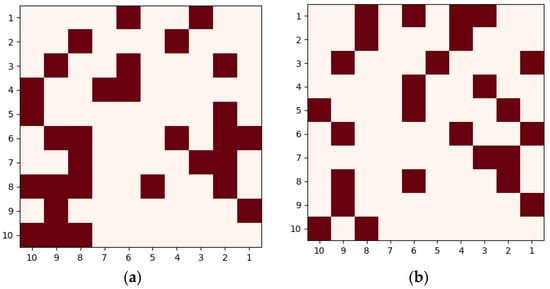
Figure 4.
The semantic fingerprints of the words “coast” and “shore”. (a) Semantic fingerprinting of the word “Coast”; (b) semantic fingerprinting of the word “Shore”.
5. Conclusions and Future Work
In this study, SSDB-100 was constructed using an expert knowledge approach based to semantic folding theory. A research questionnaire comprising 3220 single-choice questions containing six candidates was generated with experts and volunteers and sent to 61 experts via email. After analyzing the 11 complete feedback questionnaires received, the responses of 10 experts were used as evaluation data sources. The average agreement index of the 10 experts’ responses was 0.856, indicating high reliability and accuracy. We processed the disputed sentences in which the options were not fully consistent and finally retained 3215 sentences as the corpus. The benchmark validation set SSDB-100 will promote the development of class semantic folding theory and lay a solid foundation for the improvement of its practical application value. SSDB-100 has the following features and functions:
- (a)
- The 100 grid topics have different semantic granularities and can be distinguished from each other. This facilitated the expansion of the corpus into a single grid.
- (b)
- The corpus overlays the vocabulary in the lexical–semantic evaluation benchmark M&C, which is divided by humans into the most matched semantic topic grids according to semantic information.
- (c)
- The dataset is scalable, and we open-sourced the dataset so that relevant scholars can expand the thematic grid and corpus based on it.
- (d)
- Using the semantic grids obtained by SSDB-100, the corresponding SDR encoding can be obtained by the SFT, which facilitates the development of future encoding studies.
- (e)
- It is not only applicable to class semantic folding and theoretical calculations of sentence granularity, but also to text clustering tasks.
This study proposes the first dataset for an SFT with important application value and significance. However, this study is hampered by the need to invest considerable manpower in corpus screening, partitioning, and processing to construct a high-quality dataset. The current constructed dataset was a 10 × 10 grid, which could be better for validating incremental learning methods that require a large scale and still need to be expanded in terms of the grid and corpus.
In subsequent research, we opened and shared SSDB-100 (https://github.com/cks1999/SSDB-100, accessed on 1 June 2023) with the public; scholars can add or modify it to further improve the semantic coverage and data volume of the dataset. In the future, we will develop new semantic-like folding theory sentence generation methods, evaluate the effectiveness of these methods using SSDB-100, achieve the high-precision encoding of vocabulary and knowledge, and promote a better understanding and processing of natural language using brain-like neural networks.
Author Contributions
Conceptualization, K.C. and Z.C.; methodology, K.C., Z.C. and H.G.; software, K.C.; validation, K.C. and H.G.; formal analysis, K.C.; investigation, K.C.; resources, Z.C.; data curation, K.C., F.C. and H.F.; writing—original draft preparation, K.C. and Z.C.; writing—review and editing, K.C., Z.C., G.L. and J.L.; visualization, K.C.; supervision, S.W.; project administration, S.W.; funding acquisition, Z.C. and H.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China [Grant No. 42201505]; and the Natural Science Foundation of Hainan Province of China [Grant No. 622QN352]; and the National Key Research and Development Program of China [Grant No. 2021YFF070420304].
Data Availability Statement
The data presented in this study are openly available in https://github.com/cks1999/SSDB-100, accessed on 1 June 2023.
Acknowledgments
In summary, we are immensely grateful for the financial support from the China National Natural Science Foundation, as well as the invaluable data and expertise contributed by researcher Jun Xu and eleven other experts and volunteers. The success of our research would not have been possible without the collective efforts and assistance of all those involved in this endeavor.
Conflicts of Interest
All authors disclosed no relevant relationships.
References
- Fitch, W.T. Unity and diversity in human language. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2011, 366, 376–388. [Google Scholar] [CrossRef] [PubMed]
- Bhatnagar, S.C.; Mandybur, G.T.; Buckingham, H.W.; Andy, O.J. Language Representation in the Human Brain: Evidence from Cortical Mapping. Brain Lang. 2000, 74, 238–259. [Google Scholar] [CrossRef] [PubMed]
- Hagoort, P. The neurobiology of language beyond single-word processing. Science 2019, 366, 55–58. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, J. Why Can’t a Computer be more Like a Brain? IEEE Spectr. 2007, 44, 21–26. [Google Scholar] [CrossRef]
- Hawkins, J.; Ahmad, S.; Purdy, S.; Lavin, A. Biological and Machine Intelligence. Release 0.4. 2016–2020. Available online: https://numenta.com/resources/biological-and-machine-intelligence/ (accessed on 8 November 2023).
- Ahmad, S.; Hawkins, J. Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory. arXiv 2015, arXiv:1503.07469. [Google Scholar] [CrossRef]
- Purdy, S. Encoding Data for HTM Systems. arXiv 2016, arXiv:1602.05925. [Google Scholar] [CrossRef]
- Ahmad, S.; Hawkins, J. How do neurons operate on sparse distributed representations? A mathematical theory of sparsity, neurons and active dendrites. arXiv 2016, arXiv:1601.00720. [Google Scholar] [CrossRef]
- Cui, Y.; Ahmad, S.; Hawkins, J. The HTM Spatial Pooler-A Neocortical Algorithm for Online Sparse Distributed Coding. Front. Comput. Neurosci. 2017, 11, 111. [Google Scholar] [CrossRef] [PubMed]
- Webber, F.D.S. Semantic Folding Theory—White Paper; Cortical.io: Vienna, Austria, 2015. [Google Scholar]
- Khan, H.M.; Khan, F.M.; Khan, A.; Ashgar, A.Z.; Alghazzawi, D.M. Anomalous Behavior Detection Framework Using HTM-Based Semantic Folding Technique. Comput. Math. Methods Med. 2021, 2021, 5585238. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Khasmakhi, N.N.; Asgari-Chenaghlu, M.; Gao, J. Deep Learning-based Text Classification: A Comprehensive Review. Acm Comput. Surv. 2022, 54, 1–40. [Google Scholar] [CrossRef]
- Irfan, R.; King, C.K.; Grages, D.; Ewen, S.; Khan, S.U.; Madani, S.A.; Kolodziej, J.; Wang, L.; Chen, D.; Rayes, A.; et al. A survey on text mining in social networks. Knowl. Eng. Rev. 2015, 30, 157–170. [Google Scholar] [CrossRef]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.-T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef]
- Wang, D.; Li, T.; Zhu, S.; Ding, C. Multi-document summarization via sentence-level semantic analysis and symmetric matrix factorization. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; Association for Computing Machinery: New Tork, NY, USA, 2008; pp. 307–314. [Google Scholar]
- Zha, H. Generic summarization and keyphrase extraction using mutual reinforcement principle and sentence clustering. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; Association for Computing Machinery: New Tork, NY, USA, 2002; pp. 113–120. [Google Scholar]
- Geiss, J. Creating a Gold Standard for Sentence Clustering in Multi-Document Summarization. In Proceedings of the ACL-IJCNLP 2009 Student Research Workshop, Suntec, Singapore, 4 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 96–104. [Google Scholar]
- Yelp Dataset. Available online: https://www.yelp.com/dataset (accessed on 8 November 2023).
- Large Movie Review Dataset. Available online: http://ai.stanford.edu/~amaas/data/sentiment/ (accessed on 8 November 2023).
- Richard, S.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Kaggle. Consumer Reviews of Amazon Products. Available online: https://www.kaggle.com/datasets/datafiniti/consumer-reviews-of-amazon-products (accessed on 8 November 2023).
- 20 Newsgroups. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 8 November 2023).
- Reuters. Available online: https://martin-thoma.com/nlp-reuters (accessed on 8 November 2023).
- Seno, E.R.; Nunes, M.D. Some Experiments on Clustering Similar Sentences of Texts in Portuguese. In Proceedings of the 8th International Conference on Computational Processing of the Portuguese Language, Aveiro, Portugal, 8–10 September 2008; pp. 133–142. [Google Scholar]
- Wikipedia Dataset. Available online: https://dumps.wikimedia.org/ (accessed on 8 November 2023).
- English-Corpora. Available online: https://www.english-corpora.org/ (accessed on 8 November 2023).
- Miller, G.A.; Charles, W.G. Contextual correlates of semantic similarity. Lang. Cognitive Proc. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Toral, A.; Muñoz, R.; Monachini, M. Named Entity WordNet. In Proceedings of the International Conference on Language Resources and Evaluation, Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).