1. Introduction
A Bayesian network (BN) is a probabilistic graphical model that can model complex and nonlinear relationships between variables [
1,
2,
3,
4]. It is composed of a directed acyclic graph (DAG) and conditional probabilities tables (CPTs) that are used to quantify the dependence relationships between random variables defined as nodes [
1,
5,
6,
7]. BNs have been applied to a variety of research fields, including water quality [
3], medical problems [
2], network traffic prediction [
8], and risk assessment [
9].
To learn the BN model from data, the DAG (also called structure) must first be learned from it [
10]. BN structure learning is challenging because the search space has a super-exponential character [
11,
12]. This characteristic makes the structural learning of BN an NP-hard [
13] problem [
11]. Three different kinds of methods can achieve structural learning: constraint-based (CB) methods, search and score methods (also called score-based (SB)), and hybrid methods, that combine the two previous methods [
10,
14,
15]. The CB methods are based on applying conditional independence (CI) tests to the data. In contrast, the SB methods are based on a search throughout the space of possible structures using a score function to determine the fit of the structures to the data [
10,
15].
There are recent papers that tackle BN structural learning methods. In [
16], a review of 74 algorithms, including CB and SB methods, was performed. It described these algorithms, including state-of-the-art, well-established, and prototypical approaches, and discussed how they were evaluated and compared. In addition to that, it also discussed approaches to deal with data noise and approaches on how to include expert knowledge in structural learning.
Complementing this work, in [
14], 15 structural learning algorithms were investigated, and their performance was compared. Four CB algorithms were tested (PC-Stable, FCI, Inter-IAMB, and GS), six SB algorithms (FGES, HC, TABU, ILP, WINASOBS, and NOTEARS), and five hybrid methods (GFCI, RFCI-BSC, MMHC, H2PC, and SaiyanH). The experiments showed that HC and TABU were the algorithms that performed the best in most of the tests made. Hill climbing (HC) is a gradient ascent algorithm that searches the space of DAGs by adding, removing, or inverting edges [
14,
17]. The TABU algorithm is an improved version of HC in which candidates considered on previous iterations are not considered again to search new regions [
14,
17].
Recent works have also proposed new algorithms to perform BN structural learning. A discrete firefly optimization algorithm is proposed in [
18]. The firefly algorithm imitates the behavior of fireflies being attracted to light [
18]. In [
19], a Prufer-leaf coding genetic algorithm was proposed. This algorithm prioritizes connection to nodes with high mutual information [
19]. Finally, in [
20], the adaptive genetic algorithm with varying population size (AGAVaPS) is proposed. In this algorithm, each solution has its own mutation rate and number of iterations that will be a part of the population. This algorithm was tested for different applications and performed well in problems with huge search spaces. A preliminary test on BN structural learning was also carried out and showed that it could be a good algorithm to be used on it [
20].
In this paper, a deeper analysis of the application of AGAVaPS in BN structural learning is carried out. A small-scale analysis of different algorithm parameters was performed. Finally, AGAVaPS was compared to HC and TABU, considering datasets from the literature with different sizes. In this comparison, the score value, F1 score, structural Hamming distance (SHD), balanced scoring function (BSF) and execution time were considered. Thirty executions for each algorithm were performed, and the algorithms’ performance was compared.
2. Materials and Methods
This section describes the algorithms used and the tests and analysis performed.
2.1. Algorithms
For the comparison, three algorithms were considered: AGAVaPS, the algorithm under analysis, and HC and TABU, which are used for comparison. These two algorithms were chosen based on the results of [
14] that showed that HC and TABU were the best-performing algorithms overall in the tests.
2.1.1. Genetic Algorithm Terminology
In genetic algorithms (GAs), a population of possible solutions is evolved to perform a search over the problem search space. A solution in the population can be named an individual. At each iteration, solutions are selected to create new solutions. These solutions can be named parents. The parents undergo crossover or reproduction to generate some new solutions. These new solutions can be named descendants or children. The children undergo mutation, a process that changes a part of these solutions to increase the randomness of the search. Then, these new solutions and the current population are combined, creating a new population. A more extensive explanation of these terminologies and an example can be found in [
21].
In this process, many parameters are used, such as reproduction rate, which affects the reproduction process, mutation rate, which affects the mutation process, and the initial population size. Some of these parameters are selected to improve the search in a specific problem, and some are determined from the project to result in an algorithm behavior. The specific parameters for AGAVaPS, their meaning, and how many of them were chosen can be seen in [
20], the article where AGAVaPS was proposed.
2.1.2. Adaptive Genetic Algorithm with Varying Population Size (AGAVaPS)
AGAVaPS was proposed in [
20], and a detailed explanation of its procedure and parameters can be seen in this work. A shorter description of the algorithm and details of how it was used in this article can be seen below.
On AGAVaPS, each individual has its own mutation rate; there is a slight possibility that an individual will undergo mutation twice, and each individual has a life parameter that determines the number of iterations that the individual will undergo in the population.
The mutation rate for each individual is sampled from a normal distribution with mean
and standard deviation
, with the mutation rate being in the interval
.
is updated every iteration considering the last value of
and
, the mean mutation rate of the current population. The update follows the equation:
is a sampling of a uniform distribution between 0.1 and 0.3. This variation enables the algorithm to balance between exploration and exploitation.
The mutation procedure is performed considering Equation (
2). There is a 15% chance of an individual undergoing mutation twice. This double mutation increases the exploration capacity of the algorithm. This procedure is performed by sampling a value
r from
and following Equation (
2).
Regarding the life parameter, its value is obtained by
where
is a sampling of a normal distribution with
and
, and life
. At the end of each iteration, the life of the individuals is decremented by one. The best 10% of individuals are spared from the decrement. All individuals that reach a zero value of life are removed from the population. Because of this life parameter, the population size is not constant.
For this application, the multi-objective version of AGAVaPS was used. For this, for each parent selection, one of the objectives is randomly chosen to be used. The protection of the best 10% of individuals was achieved by equally dividing this protection between the objectives being used in the search. The parent selection was achieved using a tournament of size 3, with two parents generating one individual. The reproduction rate () controls the number of new individuals that are generated at each iteration.
The mutation was performed by randomly adding, removing or inverting an edge. Meanwhile, reproduction was performed by obtaining the common edges between the parents and adding a random number of the different edges while keeping the structure a DAG. Also, the first population was created by selecting a random number of edges and adding them to an empty structure as long as it did not create a cycle. When randomly selecting edges for adding in the first population and in the mutation procedure, the mutual information (MI) between the variables was used as the weight for the sampling.
One of the objectives used was the Bayesian information criterion (BIC). This score is based on the Schwarz information criterion. Its objective is to minimize the conditional entropy of the variables considering their parents [
22]. This score is a maximization score of negative values. The other objective used was the number of edges. This objective was used to make the algorithm search smaller structures, since structures with a higher number of edges tend to have better scores. However, structures with fewer edges often have very close scores to those with more straightforward and more desirable structures.
A small-scale analysis of different algorithm parameters was performed. In this analysis,
and
were varied, and ten executions were performed for the datasets used in the analysis. The mean score was used to rank the performance of each parameter configuration for each dataset. Then, a mean rank was also employed to evaluate which parameters were best for the algorithm comparison.
Table 1 shows the values tested for each parameter.
2.1.3. Hill Climbing (HC)
HC is a gradient ascent algorithm that tests all possible changes considering adding, removing, or inverting an edge. The change that brings the most significant increase in the objective function is selected. The search is halted when all possible changes to the DAG currently under analysis would only decrease the value of the objective function compared to the current DAG score. The HC algorithm is often used for performing BN structural learning [
7,
14]. The pgmpy implementation HillClimbing was used for the tests with
[
23]. The score used was also BIC for consistency of comparison.
2.1.4. Tabu Search (TABU)
TABU is a variant of HC where a
k number of the last structures evaluated are not re-evaluated. This restriction is to increase the search for new regions. For the tests, the pgmpy implementation HillClimbing was used with
[
23]. The score used was also BIC for consistency of comparison.
2.2. Datasets
The datasets used in the tests are from the bnlearn library and its Bayesian Network Repository [
24]. The details of the datasets can be seen in
Table 2.
2.3. Test Procedure
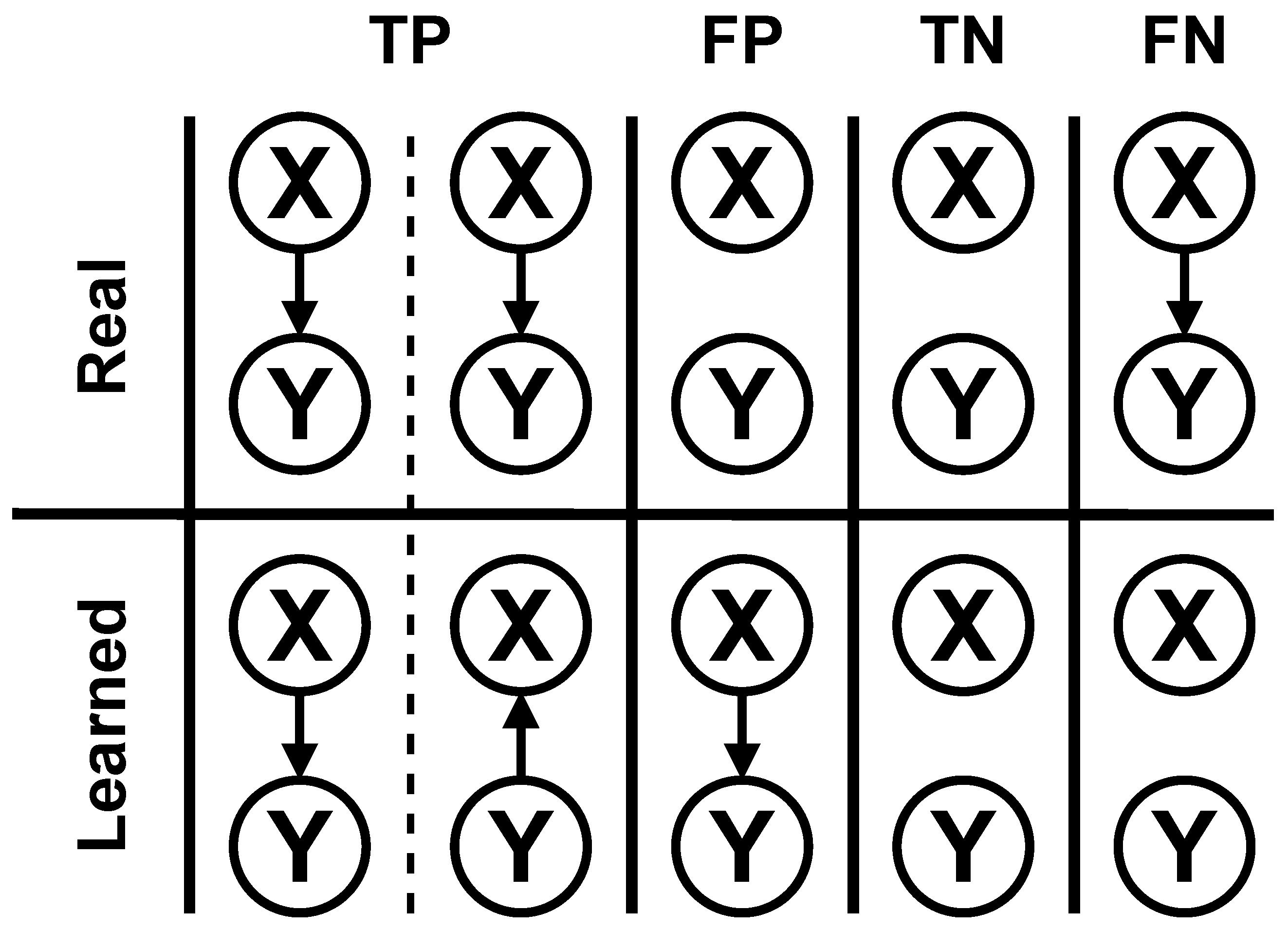
All three algorithms were executed for all the datasets thirty times for the test. For each execution, five metrics were measured and saved to compare the algorithms. These metrics were the BIC score of the best structure found, execution time, F1 score, structural Hamming distance (SHD), and balanced scoring function (BSF). F1, SHD, and BSF use the concepts of true positives (TPs), false positives (FPs), true negatives (TNs) and false negatives (FNs). An example of how these concepts are considered in BN structure learning can be seen in
Figure 1. For the AGAVaPS, which is multi-objective, all the solutions in the final Pareto set were measured for the metrics, and the highest value was used for comparison. This decision was made because when a multi-objective algorithm is used, the user can choose whichever solution in the Pareto set it thinks is the best.
F1 is the harmonic mean between precision and recall and is given by Equation (
4) [
25]. It ranges from 0 to 1, where 1 is the highest score and 0 is the lowest.
The SHD score compares the structure learned to the real networks. It penalizes having extra edges, inverted edges, and not having edges from the real network [
26]. The SHD is given by Equation (
5) [
27]. The best score for the SHD is 0.
The BSF score is a score that removes the bias of the SHD score and is given by Equation (
6), where
a is the number of edges of the real network, and
i is the independence of the real network that is calculated using Equation (
7), where
is the number of variables [
27]. The BSF score ranges from −1 to 1, where 1 is the highest score and −1 is the lowest.
All the executions were performed on a computer running on Ubuntu 22.04.3 LTS with processor Intel Core i7-8750H and 12 GB of RAM. For the datasets Asia, Coronary, and Sachs, the value of 10,000 evaluations for the AGAVaPS was kept for this test. Meanwhile, the number of evaluations was increased for the Alarm, Hailfinder, and Insurance datasets, which have much bigger search spaces (bigger than
possible DAGs). The number of evaluations for the AGAVaPS for each dataset can be seen in
Table 3.
Table 3 shows the max in-degree used in the structural learning. The max in-degree limit is used to limit the CPT size, which can cause memory overflow if not limited. This limitation is effective by limiting the number of parents a variable can have (in-degree) as the CPT size is given by
where
is the number of states of the variable,
p is the number of parents of the variable, and
are the number of states of the parent variables [
28]. These maximum in-degree values were used for all the algorithms.
The results were compared pairwise using the Wilcoxon signed-rank test with a significance level 0.05. The Wilcoxon test tests if two observations from different populations have a median difference between them equal to zero [
29]. This test was used to group the algorithms by performance and rank them. If the Wilcoxon test indicated that the algorithms had the same performance, the algorithms received the same rank. The mean rank for each algorithm in all test cases was also calculated and used to compare the performance of the algorithms.
3. Results and Discussion
In this section, the results obtained are presented and discussed. The results of the AGAVaPS parameter analysis can be seen in
Table 4 and
Table 5.
Table 4 shows the mean BIC score of each parameter combination for the datasets tested, considering the highest BIC score of the structures included in the Pareto set.
Table 5 shows the ranks of each parameter combination for the datasets tested considering the values from
Table 4. From the results, it can be seen that in many of the cases, the difference between them was minimal. The best combination was
and
, performing best for four test cases. Thus,
and
are the parametrizations used for the comparison test with the other algorithms.
The results of the comparison between the algorithms can be seen in
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. In
Table 6,
Table 7 and
Table 8, the mean, standard deviation, and rank of the F1, SHD, and BSF metrics can be seen. In
Table 9 and
Table 10, the mean, standard deviation, and rank of the BIC score and execution time can be seen. For each dataset and metric, the best value obtained is highlighted, and in the row “Mean Rank” the mean rank for the algorithm for all test cases is shown.
When considering the F1 score, the algorithms showed a tied performance for half of the test cases. Despite that, AGAVaPS performed better for the other half of the test cases and ranked first for all the tests. Interestingly, HC and TABU performed the same for all tests, with no improvement observed when using the tabu list.
When considering the SHD metric, AGAVaPS was again the best-performing algorithm, ranking first for all the test cases. The algorithms were all tied in rank for Coronary, the smallest test case, with six nodes. In addition to that, HC and TABU were tied for all test cases.
When considering the BSF metric, all algorithms were tied in the overall mean rank. Again, HC and TABU were tied for all the test cases. Moreover, AGAVaPS outperformed the other algorithms for three test cases (Asia, Sachs, and Sachs 2 ), and they were all tied for the first rank for Coronary. These results indicate that AGAVaPS deals better with datasets with fewer nodes when considering the BSF. Meanwhile, HC and TABU performed better in the datasets that had a higher number of variables.
When considering the BIC score, it can be seen that AGAVaPS performed better than the other two algorithms for four test cases (Asia, Coronary, Sachs, and Sachs 2 ), and all algorithms were tied for Insurance. The datasets for which AGAVaPS performed best all have 27 nodes or less, indicating that AGAVaPS could have performed better for datasets with more variables. However, this may be a result of AGAVaPS not evaluating enough structures; this is especially true for the Hailfinder dataset, where the execution time of AGAVaPS is closer to the execution time of HC and TABU than in other test cases and where the search space is much bigger than the other datasets. Also, again, HC and TABU had the same ranks for all the test cases.
When looking at the execution time, TABU was faster for all datasets. However, it was tied with HC in five of seven test cases. This result was expected since the HC and TABU are much simpler search algorithms than AGAVaPS.
4. Conclusions
From the parameter test, it was indicated that and was the best overall parameter combination to be used when performing BN structural learning. From the comparative test between HC, TABU, and AGAVaPS, it was seen that for basically all metrics, HC and TABU performed the same, having a difference in only one of the execution times. This result means no relevant difference between HC and TABU was seen in this work. Looking at the proposed method, AGAVaPS performed better for the F1 score, SHD, and BIC score.
For the F1 score and SHD, AGAVaPS was ranked first for all test cases, tying with other algorithms for some of the tests. For the BIC score, AGAVaPS was ranked first in test cases with 27 nodes or less, showing that it could not beat HC and TABU for the bigger test cases. However, there may be a need to let the algorithm evaluate enough structures, especially for the Hailfinder dataset, where the execution of AGAVaPS was relatively close to the execution time of HC and TABU compared to other test cases. For BSF, all algorithms were tied as the best-performing algorithms. AGAVaPS performed the best for test cases with a smaller number of nodes.
This better performance of the AGAVaPS over HC and TABU can be associated with the strong diversity preservation mechanism that AGAVaPS has, and that is something necessary to search complex spaces and escape local optima. The high capacity for coverage of the search space of the AGAVaPS was seen and better analyzed in [
20]. In [
20], it was also seen that the AGAVaPS has a behavior of changing between global and local search according to what is achieving better results. This behavior could be one of the reasons that AGAVaPS obtained better results than HC and TABU for datasets with a smaller number of nodes.
When considering the execution time, the results were that HC and TABU were the quickest. This result was expected, as HC and TABU are much simpler algorithms. Although AGAVaPS takes longer, since the BN structural learning is only performed once in most cases, taking more time to learn a better structure can be considered when modeling a system. AGAVaPS performed very well, being the best-performing algorithm for three out of four structure quality metrics. AGAVaPS performed poorer on datasets with many variables for two of the metrics. With this in mind, future work will study how to improve AGAVaPS’s performance in this kind of dataset, exploring the form of the problem definition, reproduction, and mutation process, and parameter analysis for datasets with many variables. Another thing to explore is using parallelism in AGAVaPS to speed it up and thus obtain a better execution time.





{kind=link}