
Optimal Topology of Vision Transformer for Real-Time Video Action Recognition in an End-To-End Cloud Solution

Abstract
:1. Introduction
2. Related Work
2.1. Transformers in Computer Vision
2.2. Cloud-Based Solution for Real-Time Computer Vision Applications
3. Materials and Methods
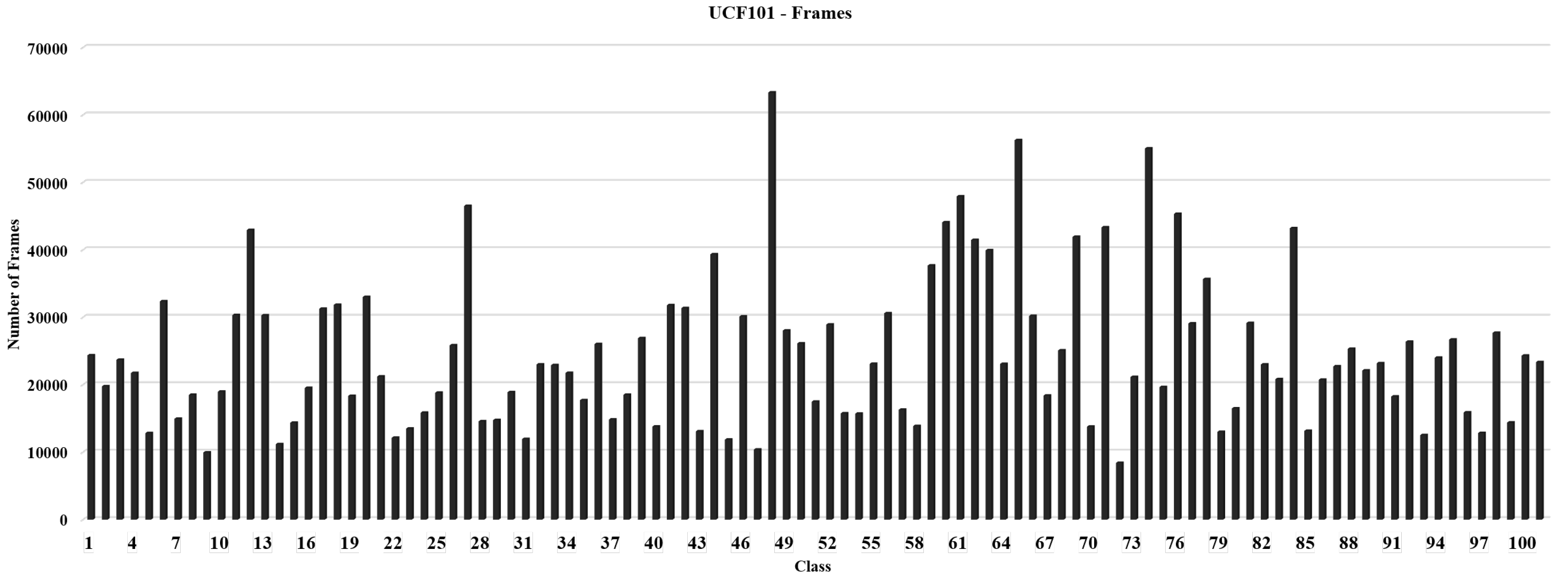
3.1. Dataset
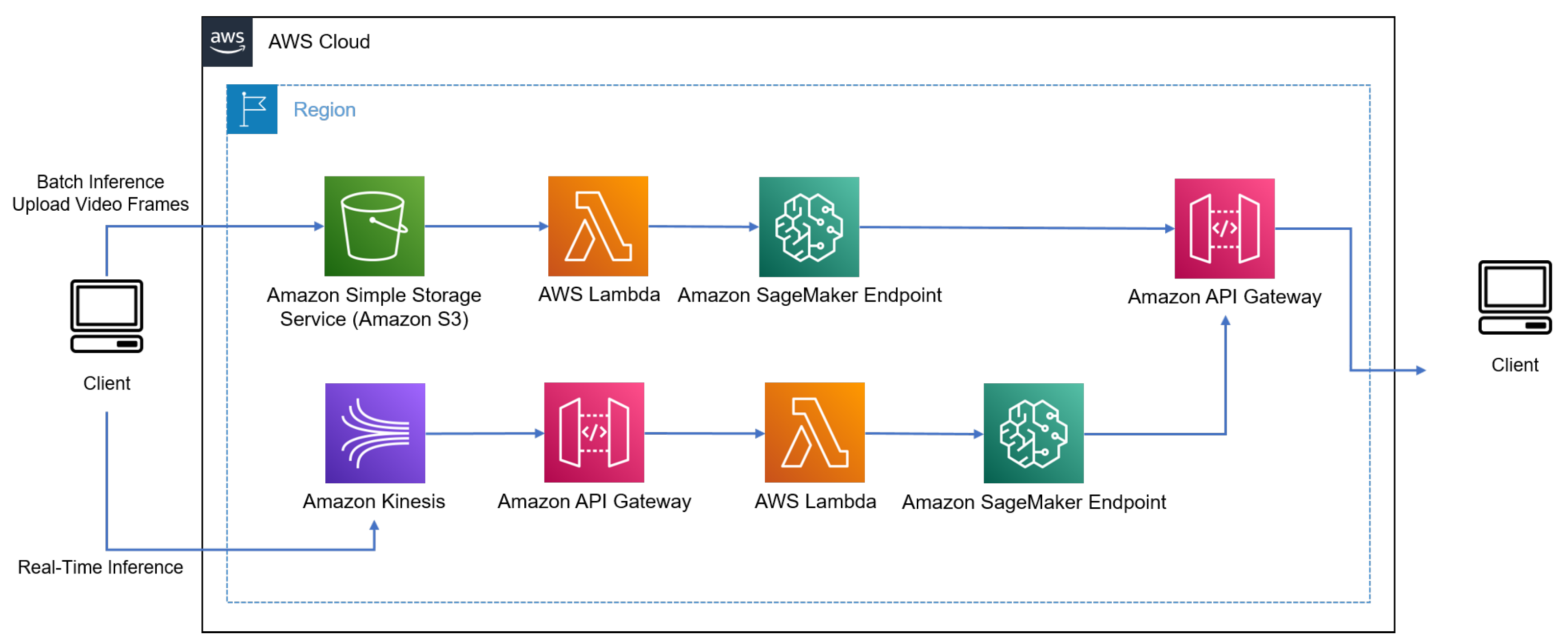
3.2. Machine Learning/Computer Vision Pipeline
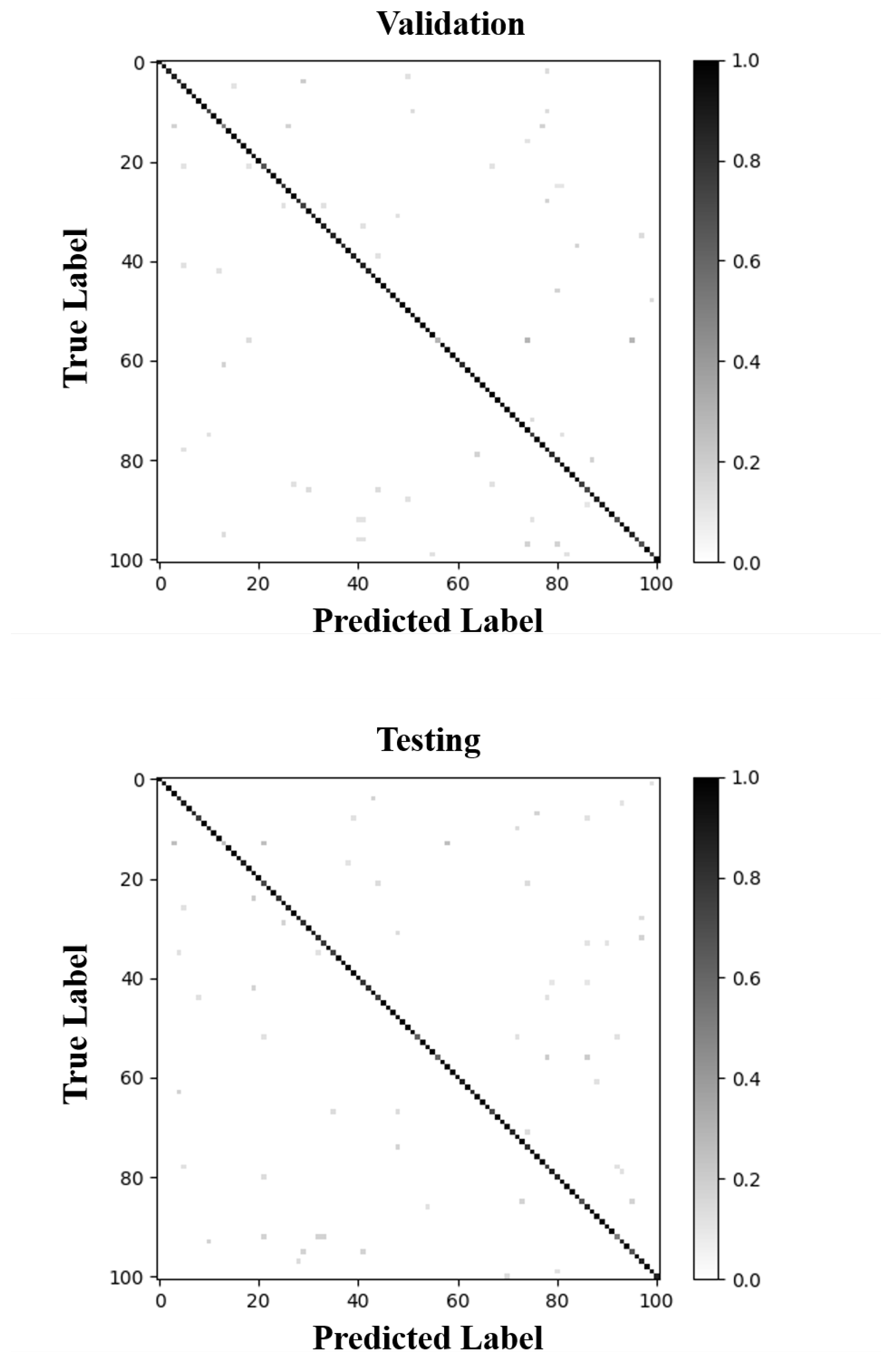
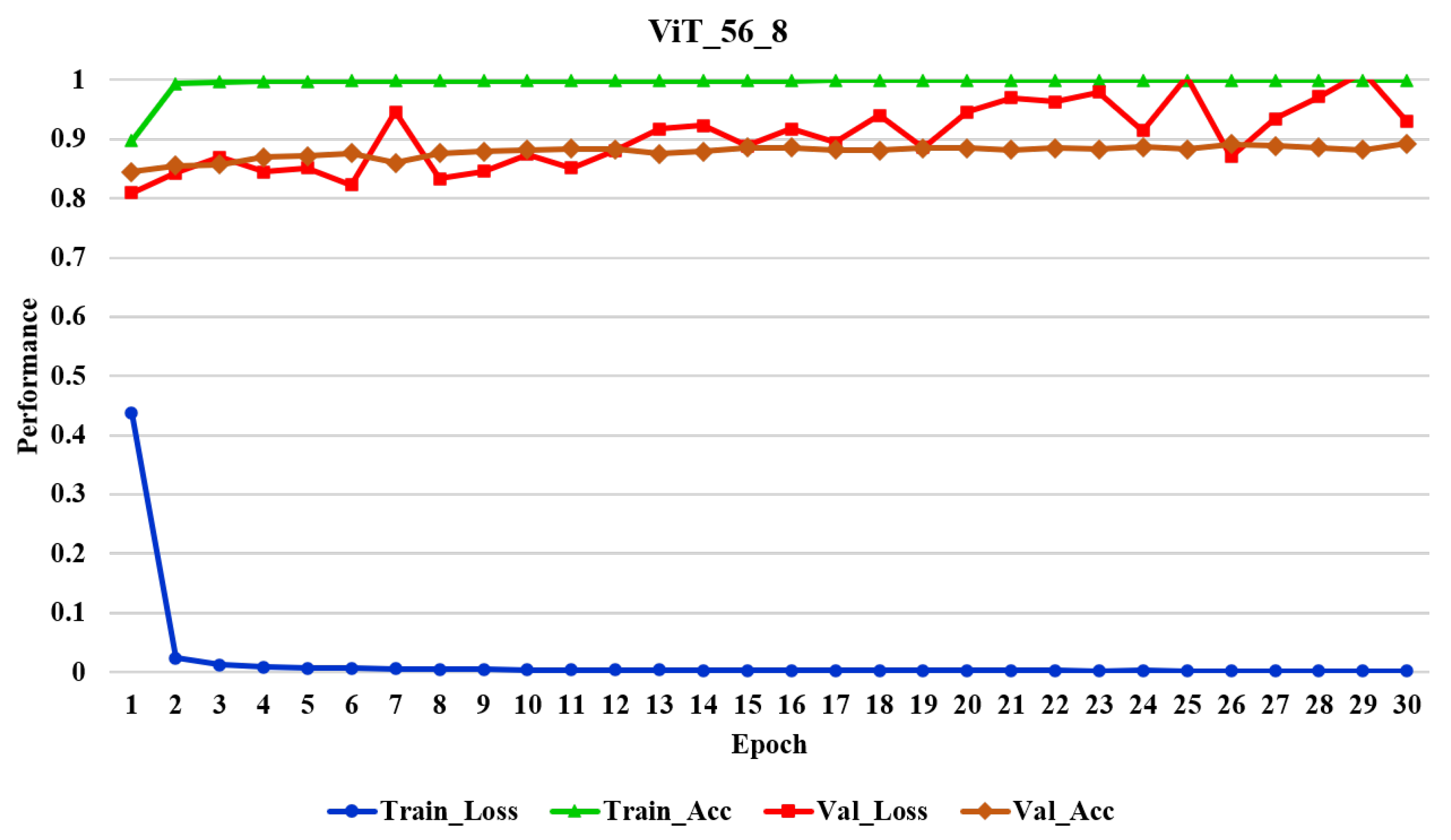
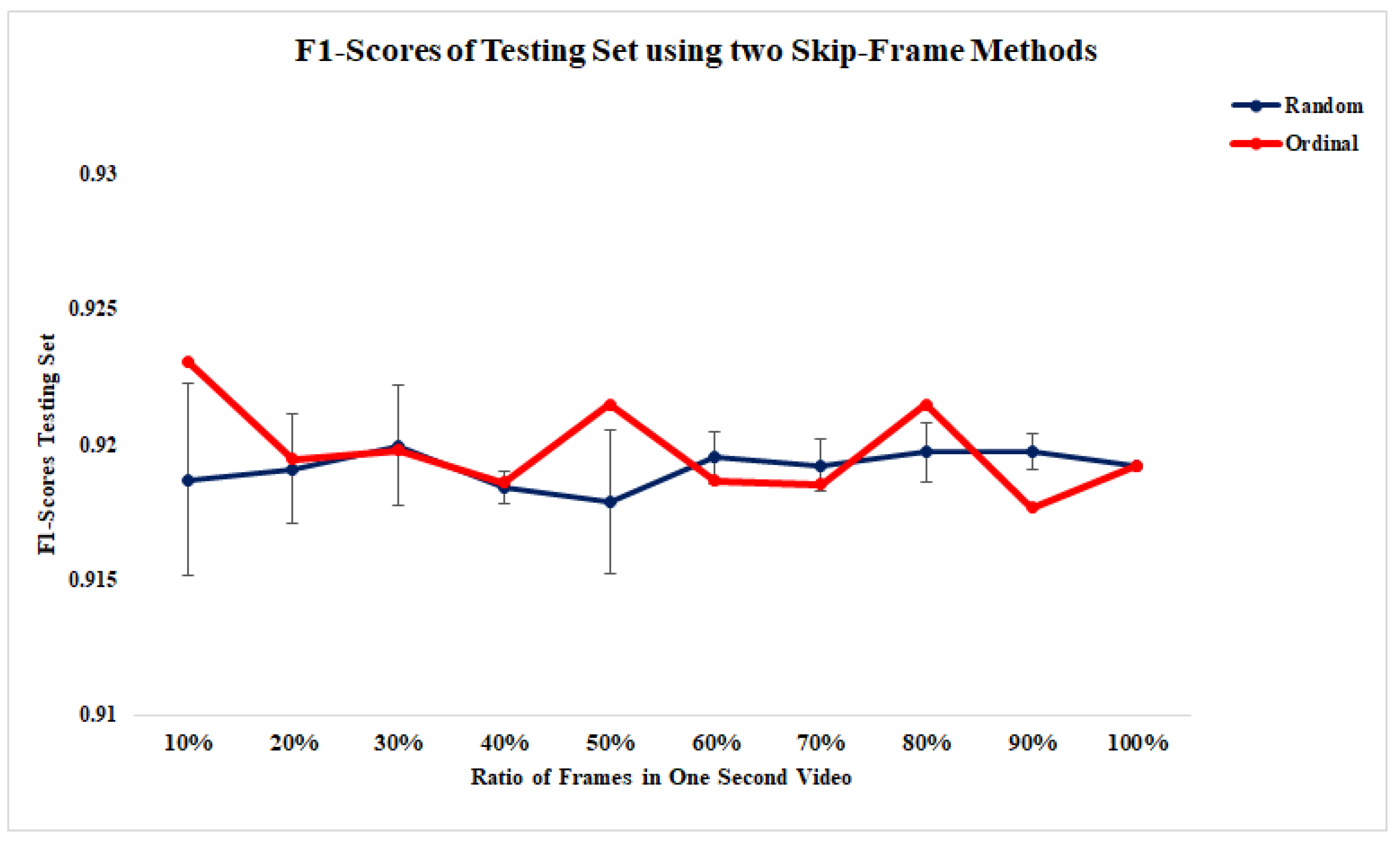
4. Results
5. Discussion
6. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Precision | Recall | Recall | F1 Score | F1 Score | Support |
|---|---|---|---|---|---|---|---|---|
| MA. | WA. | MA. | WA. | M.A. | W.A. | |||
| ViT_224_16_test | 0.92406 | 0.91014 | 0.9303 | 0.90779 | 0.92406 | 0.9038 | 0.92344 | 168631 |
| ViT_224_16_val | 0.9236 | 0.91243 | 0.92668 | 0.90819 | 0.9236 | 0.9059 | 0.92167 | 168890 |
| ViT_224_8_test | 0.92561 | 0.91287 | 0.93024 | 0.91162 | 0.92561 | 0.90838 | 0.92503 | 168631 |
| ViT_224_8_val | 0.92574 | 0.91191 | 0.93025 | 0.91245 | 0.92574 | 0.90837 | 0.92527 | 168890 |
| ViT_112_16_test | 0.91277 | 0.89425 | 0.91914 | 0.89688 | 0.91277 | 0.89142 | 0.91306 | 168631 |
| ViT_112_16_val | 0.91599 | 0.89986 | 0.91962 | 0.90056 | 0.91599 | 0.89577 | 0.91454 | 168890 |
| ViT_112_8_test | 0.91181 | 0.896 | 0.91706 | 0.89369 | 0.91181 | 0.89059 | 0.91121 | 168631 |
| ViT_112_8_val | 0.91229 | 0.89606 | 0.91667 | 0.89547 | 0.91229 | 0.89164 | 0.91156 | 168890 |
| ViT_56_16_test | 0.89653 | 0.87922 | 0.9011 | 0.87842 | 0.89653 | 0.87521 | 0.89612 | 168631 |
| ViT_56_16_val | 0.89541 | 0.87908 | 0.89915 | 0.87414 | 0.89541 | 0.87191 | 0.89397 | 168890 |
| ViT_56_8_test | 0.89516 | 0.87321 | 0.89695 | 0.87512 | 0.89516 | 0.8715 | 0.89411 | 168631 |
| ViT_56_8_val | 0.89312 | 0.87408 | 0.89781 | 0.87235 | 0.89312 | 0.86837 | 0.89208 | 168890 |
| ResNet101_test | 0.94119 | 0.92764 | 0.94566 | 0.92693 | 0.94119 | 0.92412 | 0.94091 | 168631 |
| ResNet101_val | 0.9429 | 0.93211 | 0.94742 | 0.93141 | 0.9429 | 0.92829 | 0.94264 | 168890 |
| ResNet18_test | 0.95343 | 0.9413 | 0.95546 | 0.94159 | 0.95343 | 0.93891 | 0.95283 | 168631 |
| ResNet18_val | 0.94915 | 0.94355 | 0.95212 | 0.93969 | 0.94915 | 0.93889 | 0.94852 | 168890 |
| ResNet50_test | 0.94518 | 0.93282 | 0.94718 | 0.93126 | 0.94518 | 0.92892 | 0.94393 | 168631 |
| ResNet50_val | 0.94115 | 0.9304 | 0.94383 | 0.92689 | 0.94115 | 0.92606 | 0.94057 | 168890 |
| Inception_v3_test | 0.89637 | 0.8845 | 0.90527 | 0.88079 | 0.89637 | 0.87737 | 0.89653 | 168631 |
| Inception_v3_val | 0.89762 | 0.89083 | 0.9113 | 0.88162 | 0.89762 | 0.87914 | 0.89884 | 168890 |
| VGG_16_test | 0.90065 | 0.88897 | 0.90662 | 0.88417 | 0.90065 | 0.88147 | 0.89972 | 168631 |
| VGG_16_val | 0.90009 | 0.88997 | 0.90706 | 0.88288 | 0.90009 | 0.88224 | 0.90026 | 168890 |
| Model | Accuracy | Precision MA. | Precision WA. | Recall MA. | Recall WA. | F1 Score M.A. | F1 Score W.A. | Support |
|---|---|---|---|---|---|---|---|---|
| ViT_224_16_test | 0.94273 | 0.94935 | 0.95087 | 0.93892 | 0.94273 | 0.93838 | 0.94152 | 908 |
| ViT_224_16_val | 0.94053 | 0.94920 | 0.94937 | 0.93688 | 0.94053 | 0.93721 | 0.93971 | 908 |
| ViT_224_8_test | 0.93943 | 0.94383 | 0.94493 | 0.93647 | 0.93943 | 0.93605 | 0.93818 | 908 |
| ViT_224_8_val | 0.94934 | 0.95250 | 0.95389 | 0.94615 | 0.94934 | 0.94652 | 0.94899 | 908 |
| ViT_112_16_test | 0.93172 | 0.93804 | 0.94039 | 0.92838 | 0.93172 | 0.92837 | 0.93144 | 908 |
| ViT_112_16_val | 0.92952 | 0.93339 | 0.93572 | 0.92459 | 0.92952 | 0.92394 | 0.92805 | 908 |
| ViT_112_8_test | 0.92952 | 0.93530 | 0.93703 | 0.92470 | 0.92952 | 0.92436 | 0.92797 | 908 |
| ViT_112_8_val | 0.93502 | 0.93951 | 0.94165 | 0.93124 | 0.93502 | 0.93059 | 0.93400 | 908 |
| ViT_56_16_test | 0.92511 | 0.93299 | 0.93386 | 0.92160 | 0.92511 | 0.92166 | 0.92419 | 908 |
| ViT_56_16_val | 0.91740 | 0.92264 | 0.92434 | 0.91182 | 0.91740 | 0.91051 | 0.91490 | 908 |
| ViT_56_8_test | 0.91630 | 0.92018 | 0.92173 | 0.91263 | 0.91630 | 0.91223 | 0.91497 | 908 |
| ViT_56_8_val | 0.90969 | 0.91827 | 0.92007 | 0.90580 | 0.90969 | 0.90506 | 0.90870 | 908 |
| ResNet101_test | 0.94383 | 0.94689 | 0.94900 | 0.94037 | 0.94383 | 0.93972 | 0.94261 | 908 |
| ResNet101_val | 0.94824 | 0.94979 | 0.95327 | 0.94511 | 0.94824 | 0.94430 | 0.94776 | 908 |
| ResNet18_test | 0.95815 | 0.96032 | 0.96200 | 0.95593 | 0.95815 | 0.95539 | 0.95749 | 908 |
| ResNet18_val | 0.95705 | 0.95977 | 0.96071 | 0.95459 | 0.95705 | 0.95472 | 0.95653 | 908 |
| ResNet50_test | 0.94383 | 0.94932 | 0.94923 | 0.94123 | 0.94383 | 0.94039 | 0.94206 | 908 |
| ResNet50_val | 0.94273 | 0.94390 | 0.94744 | 0.93946 | 0.94273 | 0.93849 | 0.94206 | 908 |
| Inception_v3_test | 0.92731 | 0.93923 | 0.94104 | 0.92461 | 0.92731 | 0.92501 | 0.92762 | 908 |
| Inception_v3_val | 0.92841 | 0.94126 | 0.94231 | 0.92586 | 0.92841 | 0.92772 | 0.92975 | 908 |
| VGG_16_test | 0.93833 | 0.94885 | 0.94887 | 0.93611 | 0.93833 | 0.93636 | 0.93759 | 908 |
| VGG_16_val | 0.93282 | 0.93872 | 0.94062 | 0.93020 | 0.93282 | 0.93018 | 0.93249 | 908 |
| Model | Head | Input Size | p3.16xlarge | p3.8xlarge | p3.2xlarge |
|---|---|---|---|---|---|
| ViT_224_16 | 16 | 224 | 1474.0831 | 1434.5108 | 1420.8712 |
| ViT_224_8 | 8 | 224 | 1343.1789 | 1300.7208 | 1304.822 |
| ViT_112_16 | 16 | 112 | 1016.7971 | 1279.6002 | 1241.0731 |
| ViT_112_8 | 8 | 112 | 995.6327 | 977.1326 | 962.3076 |
| ViT_56_16 | 16 | 56 | 861.1608 | 859.4907 | 862.2177 |
| ViT_56_8 | 8 | 56 | 856.8517 | 853.8936 | 851.4978 |
References
- Rahmani, H.; Bennamoun, M.; Ke, Q. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 3200–3225. [Google Scholar] [CrossRef]
- Pareek, P.; Thakkar, A. A survey on video-based Human Action Recognition: Recent updates, datasets, challenges, and applications. Artif. Intell. Rev. 2020, 54, 2259–2322. [Google Scholar] [CrossRef]
- Ahn, D.; Kim, S.; Hong, H.; Ko, B.C. STAR-Transformer: A Spatio-temporal Cross Attention Transformer for Human Action Recognition. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023. [Google Scholar] [CrossRef]
- Morshed, M.G.; Sultana, T.; Alam, A.; Lee, Y.K. Human Action Recognition: A Taxonomy-Based Survey, Updates, and Opportunities. Sensors 2023, 23, 2182. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A Comprehensive Survey of Vision-Based Human Action Recognition Methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Johnson, W.R.; Mian, A.; Donnelly, C.J.; Lloyd, D.; Alderson, J. Predicting athlete ground reaction forces and moments from motion capture. Med. Biol. Eng. Comput. 2018, 56, 1781–1792. [Google Scholar] [CrossRef]
- Lee, E.J.; Kim, Y.H.; Kim, N.; Kang, D.W. Deep into the Brain: Artificial Intelligence in Stroke Imaging. J. Stroke 2017, 19, 277–285. [Google Scholar] [CrossRef]
- Yu, M.; Huang, Q.; Qin, H.; Scheele, C.; Yang, C. Deep learning for real-time social media text classification for situation awareness—Using Hurricanes Sandy, Harvey, and Irma as case studies. Int. J. Digit. Earth 2019, 12, 1230–1247. [Google Scholar] [CrossRef]
- Jayakodi, N.K.; Chatterjee, A.; Choi, W.; Doppa, J.R.; Pande, P.P. Trading-Off Accuracy and Energy of Deep Inference on Embedded Systems: A Co-Design Approach. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 2881–2893. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, T.; Li, M. Efficient Deep Learning Inference on Edge Devices. 2018. Available online: https://www.amazon.science/publications/efficient-deep-learning-inference-on-edge-devices (accessed on 30 August 2023).
- Li, Y.; Han, Z.; Zhang, Q.; Li, Z.; Tan, H. Automating Cloud Deployment for Deep Learning Inference of Real-time Online Services. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020. [Google Scholar] [CrossRef]
- Cipriani, G.; Bottin, M.; Rosati, G. Applications of Learning Algorithms to Industrial Robotics. In Mechanisms and Machine Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 260–268. [Google Scholar] [CrossRef]
- Gheisari, M.; Wang, G.; Bhuiyan, M.Z.A. A Survey on Deep Learning in Big Data. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017. [Google Scholar] [CrossRef]
- Aslam, A.; Curry, E. A Survey on Object Detection for the Internet of Multimedia Things (IoMT) using Deep Learning and Event-based Middleware: Approaches, Challenges, and Future Directions. Image Vis. Comput. 2021, 106, 104095. [Google Scholar] [CrossRef]
- Sarraf, S.; Tofighi, G. Deep learning-based pipeline to recognize Alzheimer’s disease using fMRI data. In Proceedings of the 2016 Future Technologies Conference (FTC), San Francisco, CA, USA, 6–7 December 2016; pp. 816–820. [Google Scholar]
- Sarraf, S.; DeSouza, D.D.; Anderson, J.; Tofighi, G. DeepAD: Alzheimer’s Disease Classification via Deep Convolutional Neural Networks using MRI and fMRI. BioRxiv 2016. [Google Scholar] [CrossRef]
- Sarraf, S.; Desouza, D.D.; Anderson, J.A.E.; Saverino, C. MCADNNet: Recognizing Stages of Cognitive Impairment Through Efficient Convolutional fMRI and MRI Neural Network Topology Models. IEEE Access 2019, 7, 155584–155600. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Bellemare, M.G.; Menick, J.; Munos, R.; Kavukcuoglu, K. Automated curriculum learning for neural networks. In Proceedings of the International Conference on Machine Learning. Pmlr, Sydney, NSW, Australia, 6–11 August 2017; pp. 1311–1320. [Google Scholar]
- Sun, X.; Lu, W. Understanding Attention for Text Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020. [Google Scholar] [CrossRef]
- Zanca, D.; Gori, M.; Melacci, S.; Rufa, A. Gravitational models explain shifts on human visual attention. Sci. Rep. 2020, 10, 16335. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Bahsoon, R.; Ali, N.; Heisel, M.; Maxim, B.; Mistrik, I. Introduction. Software Architecture for Cloud and Big Data: An Open Quest for the Architecturally Significant Requirements. In Software Architecture for Big Data and the Cloud; Elsevier: Amsterdam, The Netherlands, 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Seda, P.; Masek, P.; Sedova, J.; Seda, M.; Krejci, J.; Hosek, J. Efficient Architecture Design for Software as a Service in Cloud Environments. In Proceedings of the 2018 10th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 5–9 November 2018. [Google Scholar] [CrossRef]
- Vikash; Mishra, L.; Varma, S. Performance evaluation of real-time stream processing systems for Internet of Things applications. Future Gener. Comput. Syst. 2020, 113, 207–217. [Google Scholar] [CrossRef]
- Needham, C.J.; Boyle, R.D. Performance Evaluation Metrics and Statistics for Positional Tracker Evaluation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 278–289. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Srinivasan, M.; Khapra, M.M. Efficient Video Classification Using Fewer Frames. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Hu, D.; Krishnamachari, B. Fast and Accurate Streaming CNN Inference via Communication Compression on the Edge. In Proceedings of the 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), Sydney, Australia, 21–24 April 2020. [Google Scholar] [CrossRef]
- Geva, R.; Zivan, M.; Warsha, A.; Olchik, D. Alerting, orienting or executive attention networks: Differential patters of pupil dilations. Front. Behav. Neurosci. 2013, 7, 145. [Google Scholar] [CrossRef] [PubMed]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order Boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1–9. [Google Scholar]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Gosmann, J.; Voelker, A.; Eliasmith, C. A Spiking Independent Accumulator Model for Winner-Take-All Computation. In Proceedings of the CogSci, London, UK, 26–29 July 2017. [Google Scholar]
- Li, S.; Zhou, M.; Luo, X.; You, Z.H. Distributed Winner-Take-All in Dynamic Networks. IEEE Trans. Autom. Control 2017, 62, 577–589. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Le, Q.; Vaswani, A.; Shlens, J. Attention Augmented Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Tay, C.P.; Roy, S.; Yap, K.H. AANet: Attribute Attention Network for Person Re-Identifications. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Zhao, T.; Wu, X. Pyramid Feature Attention Network for Saliency Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Virtual Event, 18–24 July 2021; Volume 2, p. 4. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 6824–6835. [Google Scholar]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Chen, J.; Ho, C.M. MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar] [CrossRef]
- Ma, Y.; Yuan, L.; Abdelraouf, A.; Han, K.; Gupta, R.; Li, Z.; Wang, Z. M2DAR: Multi-View Multi-Scale Driver Action Recognition with Vision Transformer. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Xing, Z.; Dai, Q.; Hu, H.; Chen, J.; Wu, Z.; Jiang, Y.G. SVFormer: Semi-supervised Video Transformer for Action Recognition. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, R. Relative-position embedding based spatially and temporally decoupled Transformer for action recognition. Pattern Recognit. 2023, 109905. [Google Scholar] [CrossRef]
- Mu, L.; Li, Z.; Xiao, W.; Zhang, R.; Wang, P.; Liu, T.; Min, G.; Li, K. A Fine-Grained End-to-End Latency Optimization Framework for Wireless Collaborative Inference. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, H.; Zhu, Y.; Zhang, R.; Cao, Y.; Zhu, C.; Wang, W.; Dong, D.; Li, X. LOCP: Latency-optimized channel pruning for CNN inference acceleration on GPUs. J. Supercomput. 2023, 79, 14313–14341. [Google Scholar] [CrossRef]
- Li, X.; Gong, X.; Wang, D.; Zhang, J.; Baker, T.; Zhou, J.; Lu, T. ABM-SpConv-SIMD: Accelerating Convolutional Neural Network Inference for Industrial IoT Applications on Edge Devices. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3071–3085. [Google Scholar] [CrossRef]
- Gannon, D.; Barga, R.; Sundaresan, N. Cloud-Native Applications. IEEE Cloud Comput. 2017, 4, 16–21. [Google Scholar] [CrossRef]
- Sether, A. Cloud Computing Benefits. SSRN Electron. J. 2016. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, M.; Wang, W.; Yan, F. {MArk}: Exploiting Cloud Services for {Cost-Effective},{SLO-Aware} Machine Learning Inference Serving. In Proceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC 19), Renton, WA, USA, 10–12 July 2019; pp. 1049–1062. [Google Scholar]
- Zhang, R. Making convolutional networks shift-invariant again. In Proceedings of the International Conference on Machine Learning (PMLR), Beach, CA, USA, 9–15 June 2019; pp. 7324–7334. [Google Scholar]
- Tsagkatakis, G.; Jaber, M.; Tsakalides, P. Goal!! Event detection in sports video. Electron. Imaging 2017, 29, 15–20. [Google Scholar] [CrossRef]
- Khan, A.; Lazzerini, B.; Calabrese, G.; Serafini, L. Soccer Event Detection. In Proceedings of the Computer Science & Information Technology (CS & IT), Dubai, UAE, 1–2 July 2018. Academy & Industry Research Collaboration Center (AIRCC), 2018. [Google Scholar] [CrossRef]
- Sarraf, S.; Noori, M. Multimodal deep learning approach for event detection in sports using Amazon SageMaker. AWS Mach. Learn. Blog 2021, 1, 1–12. [Google Scholar]
- Pandit, S.; Shukla, P.K.; Tiwari, A.; Shukla, P.K.; Maheshwari, M.; Dubey, R. Review of video compression techniques based on fractal transform function and swarm intelligence. Int. J. Mod. Phys. B 2020, 34, 2050061. [Google Scholar] [CrossRef]
- Mohammed, T.; Joe-Wong, C.; Babbar, R.; Francesco, M.D. Distributed Inference Acceleration with Adaptive DNN Partitioning and Offloading. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020. [Google Scholar] [CrossRef]
- Sengar, S.S.; Mukhopadhyay, S. Motion segmentation-based surveillance video compression using adaptive particle swarm optimization. Neural Comput. Appl. 2019, 32, 11443–11457. [Google Scholar] [CrossRef]
- Dong, F.; Wang, H.; Shen, D.; Huang, Z.; He, Q.; Zhang, J.; Wen, L.; Zhang, T. Multi-exit DNN Inference Acceleration based on Multi-Dimensional Optimization for Edge Intelligence. IEEE Trans. Mob. Comput. 2022. [Google Scholar] [CrossRef]
- Uy, W.I.T.; Hartmann, D.; Peherstorfer, B. Operator inference with roll outs for learning reduced models from scarce and low-quality data. Comput. Math. Appl. 2023, 145, 224–239. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Ma, S.; Bargal, S.A.; Zhang, J.; Sigal, L.; Sclaroff, S. Do less and achieve more: Training CNNs for action recognition utilizing action images from the Web. Pattern Recognit. 2017, 68, 334–345. [Google Scholar] [CrossRef]
- Zhu, W.; Hu, J.; Sun, G.; Cao, X.; Qiao, Y. A Key Volume Mining Deep Framework for Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Janghel, R.; Rathore, Y. Deep convolution neural network based system for early diagnosis of Alzheimer’s disease. Irbm 2021, 42, 258–267. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Potdar, A.; Barbhaya, P.; Nagpure, S. Face Recognition for Attendance System using CNN based Liveliness Detection. In Proceedings of the 2022 International Conference on Advances in Computing, Communication and Materials (ICACCM), Dehradun, India, 10–11 November 2022. [Google Scholar] [CrossRef]
- Jin, Y.; Qian, Z.; Sun, G. A real-time multimedia streaming transmission control mechanism based on edge cloud computing and opportunistic approximation optimization. Multimed. Tools Appl. 2018, 78, 8911–8926. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, D.; Yu, D. TLSAN: Time-aware long- and short-term attention network for next-item recommendation. Neurocomputing 2021, 441, 179–191. [Google Scholar] [CrossRef]
- Duan, H.; Zhao, Y.; Xiong, Y.; Liu, W.; Lin, D. Omni-Sourced Webly Supervised Learning for Video Recognition. In Computer Vision—ECCV 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 670–688. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Ngo, C.W.; Tian, X.; Mei, T. Learning Spatio-Temporal Representation With Local and Global Diffusion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef]


| Model | ViT Vanilla | ViT Optimized | |
|---|---|---|---|
| Multi-Head Self-Attention (Number of Heads) | 16 | 8 | |
| Image Size (x, y, Channel) | 224 × 224 × 3 | 56 × 56 × 3 | |
| p3.16xlarge | Latency (sec) | 1474.0831 | 856.8517 |
| Test Samples (PNG) | 168,631 | ||
| Memory (GB) | 488 | ||
| GPU Memory (GB) | 128 | ||
| Bandwidth | 10 | ||
| Cost USD/Hour | USD24.48 | ||
| p3.8xlarge | Latency (sec) | 1434.5108 | 853.8936 |
| Test Samples (PNG) | 168,631 | ||
| Memory (GB) | 244 | ||
| GPU Memory (GB) | 64 | ||
| Bandwidth | Up to 10 | ||
| Cost USD/Hour | USD12.24 | ||
| p3.2xlarge | Latency (sec) | 1420.8712 | 851.4978 |
| Test Samples (PNG) | 168,631 | ||
| Memory (GB) | 61 | ||
| GPU Memory GB) | 16 | ||
| Bandwidth | 10 | ||
| Cost USD/Hour | USD3.06 | ||
| Model | F1 Score Macro Avg | |
|---|---|---|
| Validation | Test | |
| ViT_56_8 | 0.868368201 | 0.871495053 |
| ViT_56_16 | 0.871914203 | 0.875206396 |
| ViT_112_8 | 0.891644812 | 0.890590870 |
| ViT_112_16 | 0.895766029 | 0.891423734 |
| ViT_224_8 | 0.908368265 | 0.908376098 |
| ViT_224_16 | 0.905895462 | 0.903802112 |
| Model | F1 Score Macro Avg | |
|---|---|---|
| Validation | Test | |
| ViT_56_8 | 0.905055103 | 0.912229318 |
| ViT_56_16 | 0.910509808 | 0.921660936 |
| ViT_112_8 | 0.930591619 | 0.924362794 |
| ViT_112_16 | 0.923940036 | 0.928365605 |
| ViT_224_8 | 0.946523733 | 0.936052540 |
| ViT_224_16 | 0.937209031 | 0.938384157 |
| Model | Input | Head Layer | Memory in Training MB | Volume on Disk MB | Training Time (H:M:S) |
|---|---|---|---|---|---|
| ViT | 224 | 16 | 11,967 | 196 | 6:16:37 |
| ViT | 224 | 8 | 8703 | 148 | 6:08:14 |
| ViT | 112 | 16 | 4027 | 196 | 4:48:15 |
| ViT | 112 | 8 | 3397 | 148 | 4:23:27 |
| ViT | 56 | 16 | 2453 | 195 | 2:47:22 |
| ViT | 56 | 8 | 2125 | 147 | 2:47:07 |
| ResNet | 224 | 101 | 13,983 | 164 | 10:53:12 |
| ResNet | 224 | 50 | 10,521 | 91 | 10:12:27 |
| ResNet | 224 | 18 | 5275 | 41 | 7:09:29 |
| Inception | 224 | 48 | 13,865 | 529 | 5:11:05 |
| VGG | 224 | 16 | 13,863 | 530 | 5:12:45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarraf, S.; Kabia, M. Optimal Topology of Vision Transformer for Real-Time Video Action Recognition in an End-To-End Cloud Solution. Mach. Learn. Knowl. Extr. 2023, 5, 1320-1339. https://doi.org/10.3390/make5040067
Sarraf S, Kabia M. Optimal Topology of Vision Transformer for Real-Time Video Action Recognition in an End-To-End Cloud Solution. Machine Learning and Knowledge Extraction. 2023; 5(4):1320-1339. https://doi.org/10.3390/make5040067
Chicago/Turabian StyleSarraf, Saman, and Milton Kabia. 2023. "Optimal Topology of Vision Transformer for Real-Time Video Action Recognition in an End-To-End Cloud Solution" Machine Learning and Knowledge Extraction 5, no. 4: 1320-1339. https://doi.org/10.3390/make5040067
APA StyleSarraf, S., & Kabia, M. (2023). Optimal Topology of Vision Transformer for Real-Time Video Action Recognition in an End-To-End Cloud Solution. Machine Learning and Knowledge Extraction, 5(4), 1320-1339. https://doi.org/10.3390/make5040067