
Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy



Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants and Recruitment
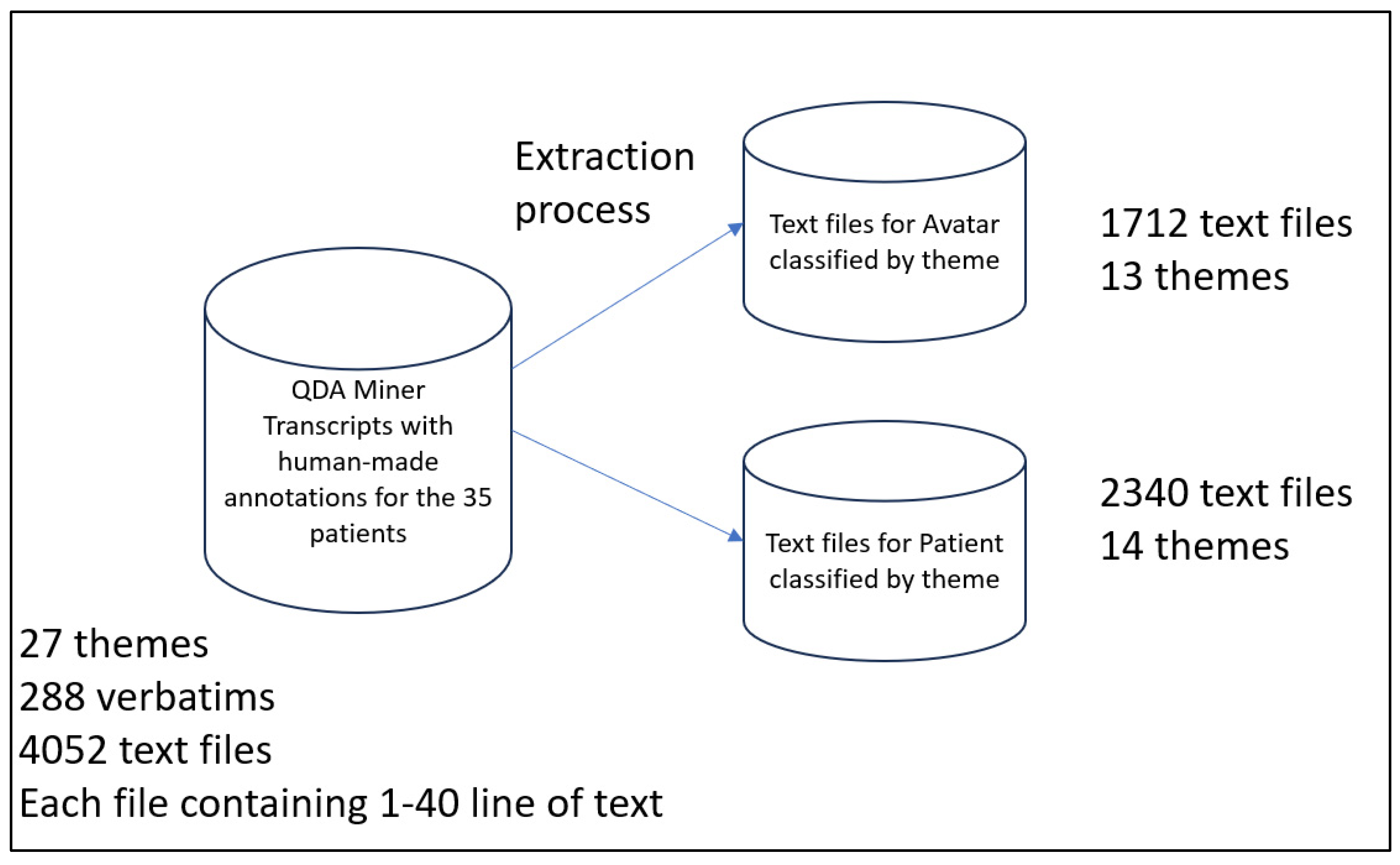
2.2. Dataset: Corpus of Avatar Therapy and Features
2.3. Machine Learning Algorithms
2.3.1. Support Vector Classifier (SVC)
2.3.2. Linear Support Vector Classifier (Linear SVC)
2.3.3. Multinomial Naïve Bayes Classifier (Multinomial NB)
2.3.4. Decision Tree Classifier (DT)
2.3.5. Multi-Layer Perceptron Classifier (MLP)
2.4. Data Analysis and Validation
3. Results
3.1. Sample Characteristics
3.2. Performance of Machine Learning Algorithms
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Charlson, F.J.; Ferrari, A.J.; Santomauro, D.F.; Diminic, S.; Stockings, E.; Scott, J.G.; McGrath, J.J.; Whiteford, H.A. Global Epidemiology and Burden of Schizophrenia: Findings from the Global Burden of Disease Study 2016. Schizophr. Bull. 2018, 44, 1195–1203. [Google Scholar] [CrossRef]
- Cloutier, M.; Aigbogun, M.S.; Guerin, A.; Nitulescu, R.; Ramanakumar, A.V.; Kamat, S.A.; DeLucia, M.; Duffy, R.; Legacy, S.N.; Henderson, C.; et al. The Economic Burden of Schizophrenia in the United States in 2013. J. Clin. Psychiatry 2016, 77, 5379. [Google Scholar] [CrossRef]
- Habtewold, T.D.; Hao, J.; Liemburg, E.J.; Baştürk, N.; Bruggeman, R.; Alizadeh, B.Z. Deep Clinical Phenotyping of Schizophrenia Spectrum Disorders Using Data-Driven Methods: Marching towards Precision Psychiatry. J. Pers. Med. 2023, 13, 954. [Google Scholar] [CrossRef] [PubMed]
- Huhn, M.; Nikolakopoulou, A.; Schneider-Thoma, J.; Krause, M.; Samara, M.; Peter, N.; Arndt, T.; Bäckers, L.; Rothe, P.; Cipriani, A.; et al. Comparative efficacy and tolerability of 32 oral antipsychotics for the acute treatment of adults with multi-episode schizophrenia: A systematic review and network meta-analysis. Lancet 2019, 394, 939–951. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Merinder, L.B.; Belgamwar, M.R. Psychoeducation for schizophrenia. In Cochrane Database of Systematic Reviews; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; p. Cd002831. [Google Scholar]
- Lally, J.; Gaughran, F.; Timms, P.; Curran, S.R. Treatment-resistant schizophrenia: Current insights on the pharmacogenomics of antipsychotics. Pharmacogenomics Pers. Med. 2016, 9, 117–129. [Google Scholar] [CrossRef]
- Potkin, S.G.; Kane, J.M.; Correll, C.U.; Lindenmayer, J.P.; Agid, O.; Marder, S.R.; Olfson, M.; Howes, O.D. The neurobiology of treatment-resistant schizophrenia: Paths to antipsychotic resistance and a roadmap for future research. NPJ Schizophr. 2020, 6, 1. [Google Scholar] [CrossRef] [PubMed]
- Stępnicki, P.; Kondej, M.; Kaczor, A.A. Current Concepts and Treatments of Schizophrenia. Molecules 2018, 23, 2087. [Google Scholar] [CrossRef]
- Guaiana, G.; Abbatecola, M.; Aali, G.; Tarantino, F.; Ebuenyi, I.D.; Lucarini, V.; Li, W.; Zhang, C.; Pinto, A. Cognitive behavioural therapy (group) for schizophrenia. Cochrane Database Syst. Rev. 2022, 7, Cd009608. [Google Scholar]
- Aali, G.; Kariotis, T.; Shokraneh, F. Avatar Therapy for people with schizophrenia or related disorders. Cochrane Database Syst. Rev. 2020, 5, Cd011898. [Google Scholar]
- Dellazizzo, L.; Potvin, S.; Phraxayavong, K.; Lalonde, P.; Dumais, A. Avatar Therapy for Persistent Auditory Verbal Hallucinations in an Ultra-Resistant Schizophrenia Patient: A Case Report. Front. Psychiatry 2018, 9, 131. [Google Scholar] [CrossRef]
- Leff, J.; Williams, G.; Huckvale, M.; Arbuthnot, M.; Leff, A.P. Avatar therapy for persecutory auditory hallucinations: What is it and how does it work? Psychosis 2014, 6, 166–176. [Google Scholar] [PubMed]
- Leff, J.; Williams, G.; Huckvale, M.A.; Arbuthnot, M.; Leff, A.P. Computer-assisted therapy for medication-resistant auditory hallucinations: Proof-of-concept study. Br. J. Psychiatry 2013, 202, 428–433. [Google Scholar] [CrossRef] [PubMed]
- Craig, T.K.; Rus-Calafell, M.; Ward, T.; Leff, J.P.; Huckvale, M.; Howarth, E.; Emsley, R.; Garety, P.A. AVATAR therapy for auditory verbal hallucinations in people with psychosis: A single-blind, randomised controlled trial. Lancet Psychiatry 2018, 5, 31–40. [Google Scholar] [CrossRef]
- Dellazizzo, L.; Potvin, S.; Phraxayavong, K.; Dumais, A. One-year randomized trial comparing virtual reality-assisted therapy to cognitive-behavioral therapy for patients with treatment-resistant schizophrenia. NPJ Schizophr. 2021, 7, 9. [Google Scholar] [CrossRef]
- Chai, H.H.; Gao, S.S.; Chen, K.J.; Duangthip, D.; Lo, E.C.M.; Chu, C.H. A Concise Review on Qualitative Research in Dentistry. Int. J. Environ. Res. Public Health 2021, 18, 942. [Google Scholar] [CrossRef]
- Pannucci, C.J.; Wilkins, E.G. Identifying and Avoiding Bias in Research. Plast Reconstr. Surg. 2010, 126, 619–625. [Google Scholar] [CrossRef]
- Starks, H.; Trinidad, S.B. Choose your method: A comparison of phenomenology, discourse analysis, and grounded theory. Qual. Health Res. 2007, 17, 1372–1380. [Google Scholar] [CrossRef] [PubMed]
- Dellazizzo, L.; Percie du Sert, O.; Phraxayavong, K.; Potvin, S.; O’Connor, K.; Dumais, A. Exploration of the dialogue components in Avatar Therapy for schizophrenia patients with refractory auditory hallucinations: A content analysis. Clin. Psychol. Psychother. 2018, 25, 878–885. [Google Scholar] [CrossRef]
- Beaudoin, M.; Potvin, S.; Machalani, A.; Dellazizzo, L.; Bourguignon, L.; Phraxayavong, K.; Dumais, A. The therapeutic processes of avatar therapy: A content analysis of the dialogue between treatment-resistant patients with schizophrenia and their avatar. Clin. Psychol. Psychother. 2021, 28, 500–518. [Google Scholar] [CrossRef] [PubMed]
- Sidey-Gibbons, J.A.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef] [PubMed]
- Chekroud, A.M.; Bondar, J.; Delgadillo, J.; Doherty, G.; Wasil, A.; Fokkema, M.; Cohen, Z.; Belgrave, D.; DeRubeis, R.; Iniesta, R.; et al. The promise of machine learning in predicting treatment outcomes in psychiatry. World Psychiatry 2021, 20, 154–170. [Google Scholar] [CrossRef]
- Hudon, A.; Beaudoin, M.; Phraxayavong, K.; Dellazizzo, L.; Potvin, S.; Dumais, A. Use of Automated Thematic Annotations for Small Data Sets in a Psychotherapeutic Context: Systematic Review of Machine Learning Algorithms. JMIR Ment. Health 2021, 8, e22651. [Google Scholar] [CrossRef] [PubMed]
- Lewis, R.B.; Maas, S.M. QDA Miner 2.0: Mixed-model qualitative data analysis software. Field Methods 2007, 19, 87–108. [Google Scholar] [CrossRef]
- Paper, D.; Paper, D. Scikit-Learn Classifier Tuning from Simple Training Sets. In Hands-on Scikit-Learn for Machine Learning Applications: Data Science Fundamentals with Python; Apress: Berkeley, CA, USA, 2020; pp. 137–163. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Hyperopt-sklearn. In Automated Machine Learning: Methods, Systems, Challenges; Springer: Berlin/Heidelberg, Germany, 2019; p. 219. [Google Scholar]
- Mammone, A.; Turchi, M.; Cristianini, N. Support vector machines. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 283–289. [Google Scholar] [CrossRef]
- Shao, Y.H.; Chen, W.J.; Deng, N.Y. Nonparallel hyperplane support vector machine for binary classification problems. Inf. Sci. 2014, 263, 22–35. [Google Scholar] [CrossRef]
- Xu, J.; Liu, X.; Huo, Z.; Deng, C.; Nie, F.; Huang, H. Multi-class support vector machine via maximizing multi-class margins. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI 2017), Melbourne, Australia, 19–25 August 2017; pp. 3154–3160. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Almaiah, M.A.; Almomani, O.; Alsaaidah, A.; Al-Otaibi, S.; Bani-Hani, N.; Hwaitat, A.K.A.; Al-Zahrani, A.; Lutfi, A.; Awad, A.B.; Aldhyani, T.H. Performance investigation of principal component analysis for intrusion detection system using different support vector machine kernels. Electronics 2022, 11, 3571. [Google Scholar] [CrossRef]
- Varoquaux, G.; Buitinck, L.; Louppe, G.; Grisel, O.; Pedregosa, F.; Mueller, A. Scikit-learn: Machine learning without learning the machinery. In GetMobile: Mobile Computing and Communications; Association for Computing Machinery: New York, NY, USA, 2015; Volume 19, pp. 29–33. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001. [Google Scholar]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. In Encyclopedia of Bioinformatics and Computational Biology; Elsevier: Amsterdam, The Netherlands, 2019; pp. 403–412. [Google Scholar]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Ramchoun, H.; Ghanou, Y.; Ettaouil, M.; Janati Idrissi, M.A. Multilayer perceptron: Architecture optimization and training. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 26–30. [Google Scholar] [CrossRef]
- Popescu, M.C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 relation between training and testing sets: A pedagogical explanation. Int. J. Inf. Technol. Appl. Sci. 2018, 11, 1–6. [Google Scholar]
- Bhavsar, H.; Ganatra, A. A comparative study of training algorithms for supervised machine learning. Int. J. Soft Comput. Eng. (IJSCE) 2012, 2, 2231–2307. [Google Scholar]
- Huang, X.; Jin, G.; Ruan, W. Machine Learning Basics. In Machine Learning Safety; Artificial Intelligence: Foundations, Theory, and Algorithms Book Series; Springer: Singapore, 2012; pp. 3–13. [Google Scholar]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Opitz, J.; Burst, S. Macro f1 and macro f1. arXiv 2019, arXiv:1911.03347. [Google Scholar]
- Gibbons, C.; Richards, S.; Valderas, J.M.; Campbell, J. Supervised Machine Learning Algorithms Can Classify Open-Text Feedback of Doctor Performance with Human-Level Accuracy. J. Med. Internet Res. 2017, 19, e6533. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Machine Learning: ECML-98; Lecture Notes in Computer Science Book Series; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1389, pp. 137–142. [Google Scholar]
- Liu, Z.; Lv, X.; Liu, K.; Shi, S. Study on SVM compared with the other text classification methods. In Proceedings of the 2010 Second International Workshop on Education Technology and Computer Science, Wuhan, China, 6–7 March 2010; pp. 219–222. [Google Scholar]
- Amarappa, S.; Sathyanarayana, S.V. Data classification using Support vector Machine (SVM), a simplified approach. Int. J. Electron. Comput. Sci. Eng. 2014, 3, 435–445. [Google Scholar]
- Li, R. A Review of Machine Learning Algorithms for Text Classification; Springer Nature: Singapore, 2022. [Google Scholar]
- Harzevili, N.S.; Alizadeh, S.H. Mixture of latent multinomial naive Bayes classifier. Appl. Soft Comput. 2018, 69, 516–527. [Google Scholar] [CrossRef]
- Singh, Y.; Chauhan, A.S. Neural Networks in Data Mining. J. Theor. Appl. Inf. Technol. 2009, 5, 36–42. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Avatar Themes | Examples |
|---|---|
| Accusations | “You did this.” |
| Omnipotence | “I am all over the place.” |
| Beliefs | “I think you are crazy.” |
| Active listening, empathy | “Please relax, take your time.” |
| Incitements, orders | “You should stop doing.” |
| Coping mechanisms | “Tell me why you are sad when I say this?” |
| Threats | “I will destroy you.” |
| Negative emotions | “It’s difficult for me to realize that.” |
| Self-perceptions | “I identify myself as nothing.” |
| Positive emotions | “I am the best in the world”. |
| Provocation | “Try stopping me from making you ill.” |
| Reconciliation | “Should we make peace?” |
| Reinforcement | “Try this again.” |
| Patient Themes | Examples |
|---|---|
| Approbation | “You are right.” |
| Self-deprecation | “I can’t do this.” |
| Self-appraisal | “I am a nice person.” |
| Other beliefs | “You are the one controlling me.” |
| Counterattack | “You are the one who did this, not me!” |
| Maliciousness of the voice | “You are trying to make this hard for all.” |
| Negative | “It is very hard.” |
| Negation | “I never did this.” |
| Omnipotence | “I am the greatest.” |
| Disappearance of the voice | “Please leave me alone!” |
| Positive | “I am feeling wonderful.” |
| Prevention | “I am trying to dismiss you.” |
| Reconciliation of the voice | “Can we work together?” |
| Self-affirmation | “I am capable of doing this.” |
| Characteristics | Value (n = 35) |
|---|---|
| Sex (number of males, number of females) | 27, 8 |
| Age (mean in years) | 41.8 ± 11.2 |
| Education (mean in years) | 13.4 ± 3.2 |
| Ethnicity (Caucasian, others) | 94.3%, 5.7% |
| % on clozapine | 45.7% |
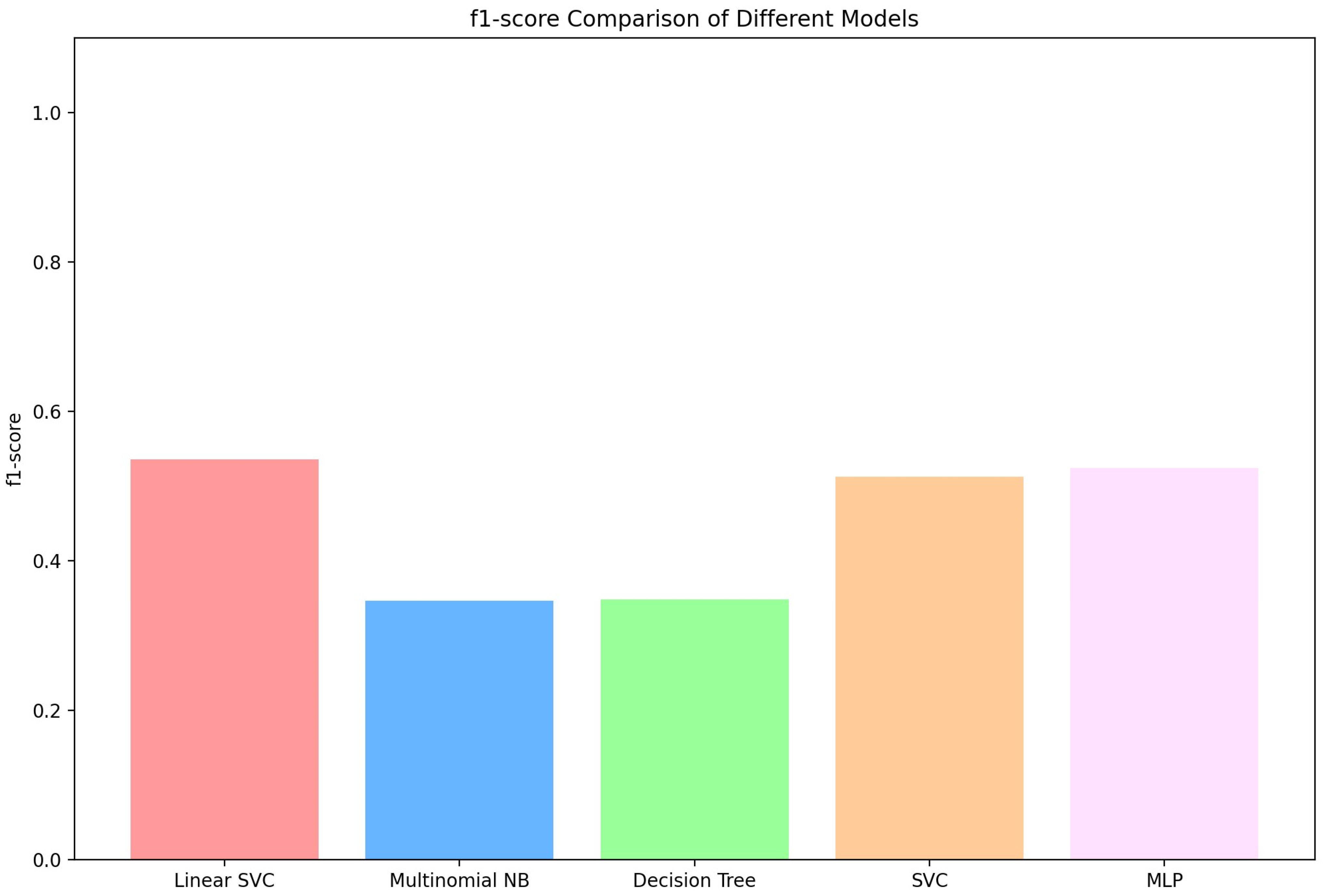
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| SVC | 0.653680 | 0.736737 | 0.636364 | 0.636396 |
| Linear SVC | 0.705628 | 0.715403 | 0.675325 | 0.674928 |
| Multinomial NB | 0.437229 | 0.540432 | 0.545455 | 0.488000 |
| Decision Tree | 0.350649 | 0.403547 | 0.389610 | 0.388143 |
| MLP | 0.662338 | 0.658041 | 0.636364 | 0.636298 |
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| SVC | 0.526842 | 0.680169 | 0.526842 | 0.552448 |
| Linear SVC | 0.571930 | 0.610126 | 0.571930 | 0.575930 |
| Multinomial NB | 0.315789 | 0.529961 | 0.315789 | 0.297080 |
| Decision Tree | 0.350877 | 0.393063 | 0.350877 | 0.359419 |
| MLP | 0.564912 | 0.578114 | 0.564912 | 0.567399 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hudon, A.; Phraxayavong, K.; Potvin, S.; Dumais, A. Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy. Mach. Learn. Knowl. Extr. 2023, 5, 1119-1131. https://doi.org/10.3390/make5030057
Hudon A, Phraxayavong K, Potvin S, Dumais A. Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy. Machine Learning and Knowledge Extraction. 2023; 5(3):1119-1131. https://doi.org/10.3390/make5030057
Chicago/Turabian StyleHudon, Alexandre, Kingsada Phraxayavong, Stéphane Potvin, and Alexandre Dumais. 2023. "Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy" Machine Learning and Knowledge Extraction 5, no. 3: 1119-1131. https://doi.org/10.3390/make5030057
APA StyleHudon, A., Phraxayavong, K., Potvin, S., & Dumais, A. (2023). Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy. Machine Learning and Knowledge Extraction, 5(3), 1119-1131. https://doi.org/10.3390/make5030057