
Comparison of Imputation Methods for Missing Rate of Perceived Exertion Data in Rugby


Abstract
:1. Introduction
2. Materials and Methods
3. Results
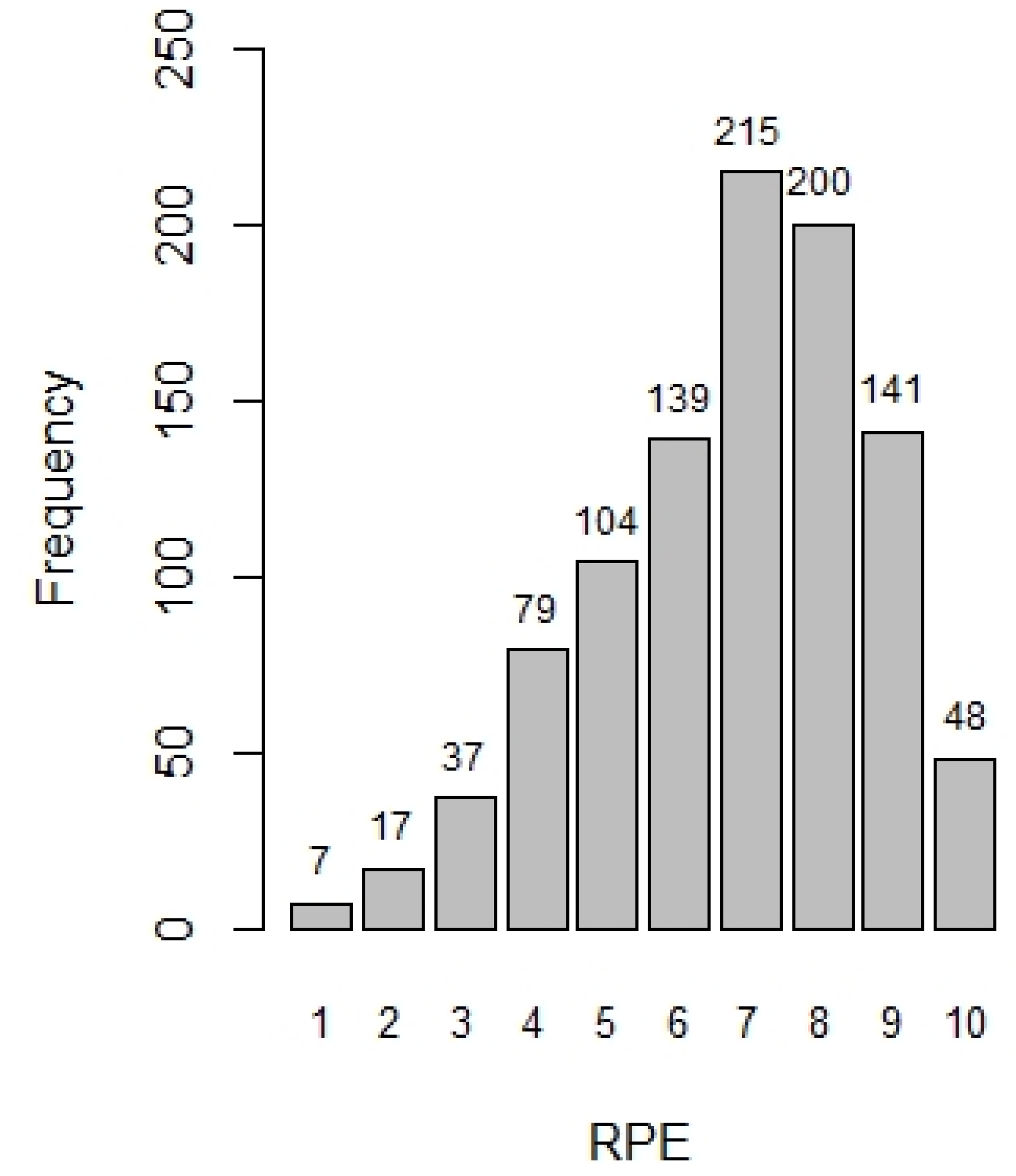
3.1. Description of Data
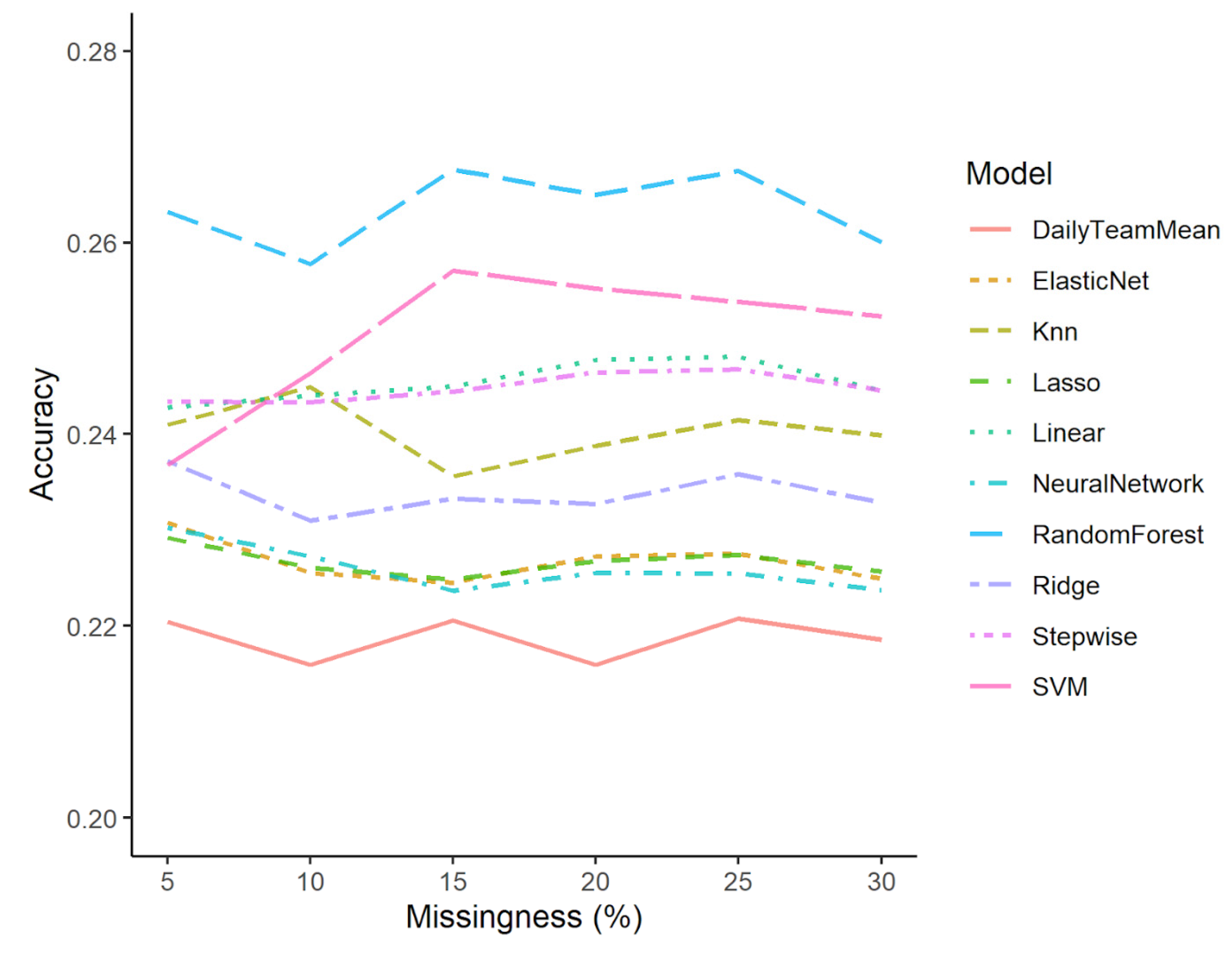
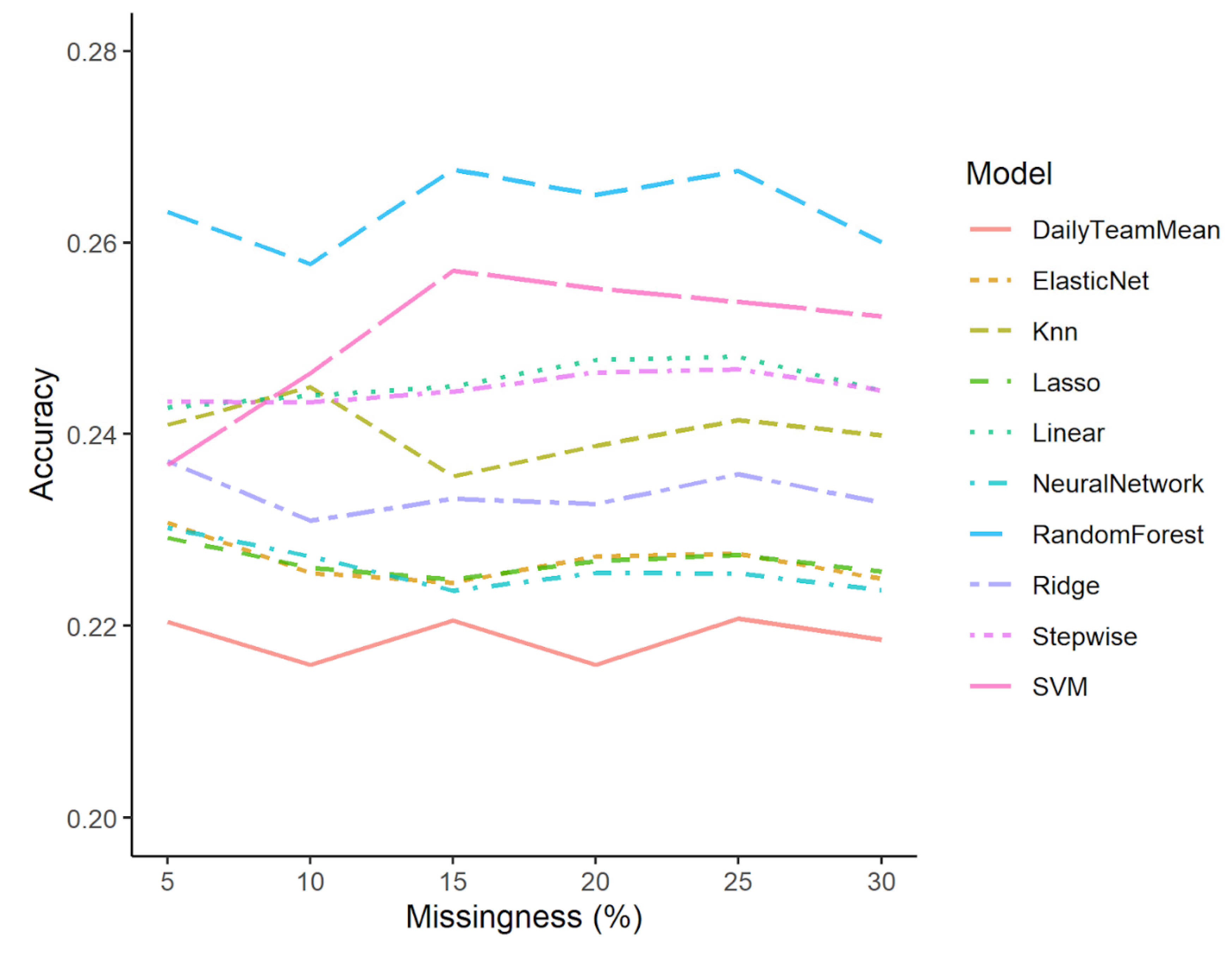
3.2. Model Performance
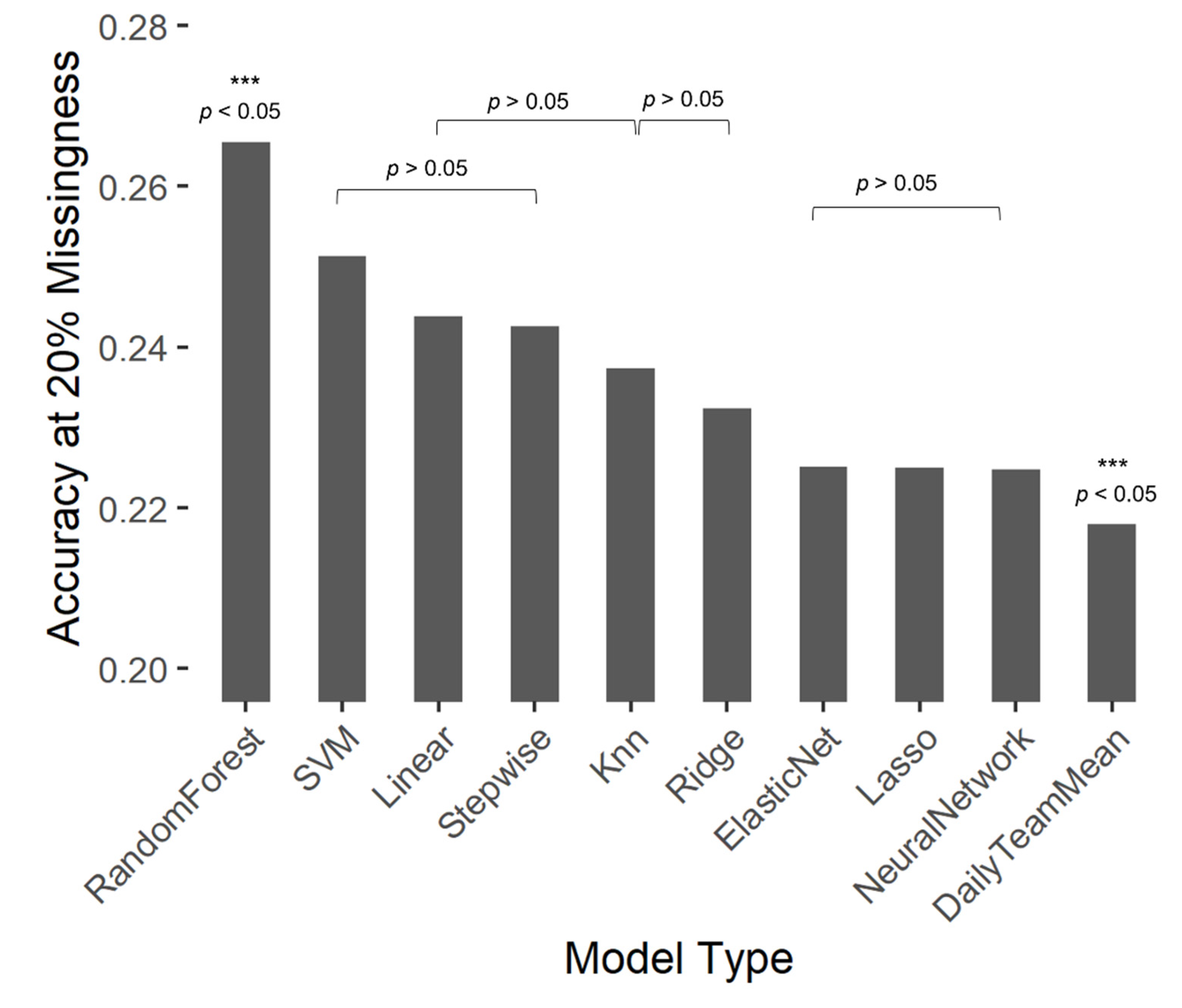
3.3. Comparison of Models
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haddad, M.; Stylianides, G.; Djaoui, L.; Dellal, A.; Chamari, K. Session-RPE method for training load monitoring: Validity, ecological usefulness, and influencing factors. Front. Neurosci. 2017, 11, 612. [Google Scholar] [CrossRef]
- Benson, L.C.; Stilling, C.; Owoeye, O.B.A.; Emery, C.A. Evaluating methods for imputing missing data from longitudinal monitoring of athlete workload. J. Sports Sci. Med. 2021, 20, 188–196. [Google Scholar] [CrossRef]
- Griffin, A.; Kenny, I.C.; Comyns, T.M.; Purtill, H.; Tiernan, C.; O’Shaughnessy, E.; Lyons, M. Training load monitoring in team sports: A practical approach to addressing missing data. J. Sports Sci. 2021, 39, 2161–2171. [Google Scholar] [CrossRef]
- Cummins, C.; Orr, R.; O’Connor, H.; West, C. Global positioning systems (GPS) and microtechnology sensors in team sports: A systematic review. Sports Med. 2013, 43, 1025–1042. [Google Scholar] [CrossRef]
- El-Masri, M.M.; Fox-Wasylyshyn, S.M. Missing data: An introductory conceptual overview for the novice researcher. Can. J. Nurs. Res. 2005, 37, 156–171. [Google Scholar]
- Windt, J.; Ardern, C.L.; Gabbett, T.J.; Khan, K.M.; Cook, C.E.; Sporer, B.C.; Zumbo, B.D. Getting the most out of intensive longitudinal data: A methodological review of workload–injury studies. BMJ Open 2018, 8, e022626. [Google Scholar] [CrossRef]
- Gabbett, T.J. The training-injury prevention paradox: Should athletes be training smarter and harder? Br. J. Sports Med. 2016, 50, 273–280. [Google Scholar]
- Clarke, A.C.; Anson, J.M.; Pyne, D.B. Physiologically based GPS speed zones for evaluating running demands in women’s rugby sevens. J. Sports Sci. 2015, 33, 1101–1108. [Google Scholar] [PubMed]
- Clarke, A.C.; Anson, J.M.; Pyne, D.B. Proof of concept of automated collision detection technology in rugby sevens. J. Strength Cond. Res. 2017, 31, 1116–1120. [Google Scholar]
- Carey, D.; Ong, K.; Morris, M.; Crow, J.; Crossley, K. Predicting ratings of perceived exertion in Australian football players: Methods for live estimation. Int. J. Comput. Sci. Sport 2016, 15, 64–77. [Google Scholar] [CrossRef]
- Musil, C.M.; Warner, C.B.; Yobas, P.K.; Jones, S.L. A comparison of imputation techniques for handling missing data. West. J. Nurs. Res. 2002, 24, 815–829. [Google Scholar] [CrossRef]
- Schmitt, P.; Mandel, J.; Guedj, M. A comparison of six methods for missing data imputation. J. Biomet. Biostat. 2015, 6, 1–6. [Google Scholar] [CrossRef]
- Waljee, A.K.; Mukherjee, A.; Singal, A.G.; Zhang, Y.; Warren, J.; Balis, U.; Marrero, J.; Zhu, J.; Higgins, P.D. Comparison of imputation methods for missing laboratory data in medicine. BMJ Open 2013, 3, e002847. [Google Scholar] [CrossRef]
- Celton, M.; Malpertuy, A.; Lelandais, G.; de Brevern, A.G. Comparative analysis of missing value imputation methods to improve clustering and interpretation of microarray experiments. BMC Genom. 2010, 11, 15. [Google Scholar] [CrossRef]
- Fox-Wasylyshyn, S.M.; El-Masri, M.M. Handling missing data in self-report measures. Res. Nurs. Health 2005, 28, 488–495. [Google Scholar] [CrossRef]
- Mujika, I. Quantification of training and competition loads in endurance sports: Methods and applications. Int. J. Sports Physiol. 2017, 12, S29–S217. [Google Scholar] [CrossRef] [PubMed]
- Eston, R. Use of ratings of perceived exertion in sports. Int. J. Sports Physiol. Perform. 2012, 7, 175–182. [Google Scholar]
- Comyns, T.; Flanagan, E.P. Applications of the session rating of perceived exertion system in professional rugby union. Strength Cond. J. 2013, 35, 78–85. [Google Scholar]
- Gabbett, T.; Kelly, J. Does fast defensive line speed influence tackling proficiency in collision sport athletes? Int. J. Sports Sci. Coach. 2007, 2, 467–472. [Google Scholar]
- Gabbett, T.; Kelly, J.; Pezet, T. Relationship between physical fitness and playing ability in rugby league players. J. Strength Cond. Res. 2007, 21, 1126–1133. [Google Scholar]
- King, D.; Hume, P.; Clark, T. Video analysis of tackles in professional rugby league matches by player position, tackle height and tackle location. Int. J. Perform. Anal. Sport 2010, 10, 241–254. [Google Scholar] [CrossRef]
- Wheeler, W.K.; Wiseman, R.; Lyons, K. Tactical and technical factors associated with effective ball offloading strategies during the tackle in rugby league. Int. J. Perform. Anal. 2011, 11, 392–409. [Google Scholar] [CrossRef]
- Koo, T.K.; Li, M.Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- R Core Team. The R Stats Package. Available online: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/stats-package.html (accessed on 25 August 2022).
- Ripley, B.; Venables, B.; Bates, D.M.; Hornik, K.; Gebhardt, A.; Firth, D. Package “MASS”. 2022. Available online: https://cran.r-project.org/web/packages/MASS/MASS.pdf (accessed on 25 August 2022).
- Friedman, J.; Hastie, T.; Tibshirani, R.; Narasimhan, B.; Tay, K.; Simon, N.; Qian, J.; Yang, J. Package “glmnet”. 2022. Available online: https://cran.r-project.org/web/packages/glmnet/glmnet.pdf (accessed on 25 August 2022).
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Beygelzimer, A.; Kakadet, S.; Langford, J.; Arya, S.; Mount, D.; Li, S. Package “FNN”. 2022. Available online: https://cran.r-project.org/web/packages/FNN/FNN.pdf (accessed on 25 August 2022).
- Liaw, A.; Wiener, M. Package “randomForest”. 2022. Available online: https://cran.rproject.org/web/packages/randomForest/randomForest.pdf (accessed on 25 August 2022).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.C.; Lin, C.C. Package “e1071”. 2022. Available online: https://cran.r-project.org/web/packages/e1071/e1071.pdf (accessed on 25 August 2022).
- Hsu, C.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. 2003, pp. 1396–1400. Available online: http://www.datascienceassn.org/sites/default/files/Practical%20Guide%20to%20Support%20Vector%20Classification.pdf (accessed on 25 August 2022).
- Fritsch, S.; Guenther, F.; Wright, M.N.; Suling, M.; Mueller, S.M. Package “neuralnet”. 2019. Available online: https://cran.r-project.org/web/packages/neuralnet/neuralnet.pdf (accessed on 25 August 2022).
- Riedmiller, M. Advanced supervised learning in multi-layer perceptrons—From backpropagation to adaptive learning algorithms. Comput. Stand. Interfaces 1994, 16, 265–278. [Google Scholar] [CrossRef]
- Lakens, D.; Scheel, A.M.; Isager, P.M. Equivalence testing for psychological research: A tutorial. Adv. Methods Pract. Psychol. Sci. 2018, 1, 259–269. [Google Scholar] [CrossRef]
- Lakens, D. Equivalence tests: A practical primer for t tests, correlations, and meta-analyses. Soc. Psychol. Personal Sci. 2017, 8, 355–362. [Google Scholar] [CrossRef]
- Hawthorne, G.; Elliot, P. Imputing cross-sectional missing data: Comparison of common techniques. Aust. N. Z. J. Psychiatry 2005, 39, 583–590. [Google Scholar] [CrossRef]
- Kang, H. The prevention and handling of the missing data. Korean J. Anesthesiol. 2013, 64, 402–406. [Google Scholar] [CrossRef] [PubMed]
- Bartlett, J.D.; O’Connor, F.; Pitchford, N.; Torres-Ronda, L.; Robertson, S.J. Relationships between internal and external training load in team-sport athletes: Evidence for an individualized approach. Int. J. Sports Physiol. Perform. 2017, 12, 230–234. [Google Scholar] [CrossRef] [PubMed]
- Epp-Stobbe, A.; Tsai, M.; Morris, C.; Klimstra, M. The influence of physical contact on athlete load in international female rugby sevens. J. Strength Cond. Res. 2022. [Google Scholar] [CrossRef]
- Mujika, I. The alphabet of sport science research starts with Q. Int. J. Sports Physiol. Perform. 2013, 8, 465–466. [Google Scholar] [CrossRef] [PubMed]
- Faulkner, J.; Parfitt, G.; Eston, R. The rating of perceived exertion during competitive running scales with time. Psychophysiology 2008, 45, 977–985. [Google Scholar] [CrossRef]
- Bonacci, J.; Vleck, V.; Saunders, P.U.; Blanch, P.; Vicenzino, B. Rating of perceived exertion during cycling is associated with subsequent running economy in triathletes. J. Sci. Med. Sport 2013, 16, 49–53. [Google Scholar] [CrossRef]
- Hong, S.; Lynn, H.S. Accuracy of random-forest-based imputation of missing data in the presence of non-normality, non-linearity, and interaction. BMC Med. Res. Methodol. 2020, 20, 199. [Google Scholar] [CrossRef]
- Kokla, M.; Virtanen, J.; Kolehmainen, M.; Paananen, J.; Hanhineva, K. Random forest-based imputation outperforms other methods for imputing LC-MS metabolomics data: A comparative study. BMC Bioinform. 2019, 20, 492. [Google Scholar] [CrossRef]
- Shah, A.D.; Bartlett, J.W.; Carpenter, J.; Nicholas, O.; Hemingway, H. Comparison of random forest and parametric imputation models for imputing missing data using MICE: A CALIBER study. Am. J. Epidemiol. 2014, 179, 764–774. [Google Scholar] [CrossRef]
- Burkart, N.; Huber, M.F. A survey on the explainability of supervised machine learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Rahman, M.G.; Islam, M.Z. Missing value imputation using a fuzzy clustering-based EM approach. Knowl. Inf. Syst. 2016, 46, 389–422. [Google Scholar] [CrossRef]
- Shataee, S.; Kalbi, S.; Fallah, A.; Pelz, D. Forest attribute imputation using machine-learning methods and ASTER data: Comparison of k-NN, SVR and random forest regression algorithms. Int. J. Remote Sens. 2012, 33, 6254–6280. [Google Scholar] [CrossRef]
- Shen, X.; Mu, L.; Li, Z.; Wu, H.; Gou, J.; Chen, X. Large-scale support vector machine classification with redundant data reduction. Neurocomputing 2016, 172, 189–197. [Google Scholar] [CrossRef]
- Waldmann, P.; Mészáros, G.; Gredler, B.; Fürst, C.; Sölkner, J. Evaluation of the lasso and the elastic net in genome-wide association studies. Front. Genet. 2013, 4, 270. [Google Scholar] [CrossRef]
- Verpoort, P.C.; MacDonald, P.; Conduit, G.J. Materials data validation and imputation with an artificial neural network. Comput. Mater. Sci. 2018, 147, 176–185. [Google Scholar] [CrossRef]
- Yin, M.; Vaughan, J.W.; Wallach, H. Understanding the effect of accuracy on trust in machine learning models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process. 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Joseph, T.; Johnson, B.; Battista, R.A.; Wright, G.; Dodge, C.; Porcari, J.P.; de Koning, J.J.; Foster, C. Perception of fatigue during simulated competition. Med. Sci. Sports Exerc. 2008, 40, 381–386. [Google Scholar] [CrossRef]
- Bridge, C.A.; Jones, M.A.; Drust, B. Physiological responses and perceived exertion during international taekwondo competition. Int. J. Sports Physiol. Perform. 2009, 4, 485–493. [Google Scholar] [CrossRef]
- Clarke, N.; Farthing, J.P.; Norris, S.R.; Arnold, B.E.; Lanovaz, J.L. Quantification of training load in Canadian football: Application of session-RPE in collision-based team sports. J. Strength Cond. Res. 2013, 27, 2198–2205. [Google Scholar] [CrossRef]
- Bartlett, J.D.; Drust, B. A framework for effective knowledge translation and performance delivery of Sport Scientists in professional sport. Eur. J. Sport Sci. 2021, 21, 1579–1587. [Google Scholar] [CrossRef]
- Brocherie, F.; Beard, A. All alone we go faster, together we go further: The necessary evolution of professional and elite sporting environment to bridge the gap between research and practice. Front. Sports Act. Living 2021, 2, 631147. [Google Scholar] [CrossRef]
- Coutts, A.J. Working fast and working slow: The benefits of embedding research in high performance sport. Int. J. Sports Physiol. Perform. 2016, 11, 1–2. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
| Variable | Type | Method of Data Collection |
|---|---|---|
| RPE | Integer | Athlete self-report, measured in arbitrary units |
| Match Number | Integer | Integer reflecting match order in tournament (i.e., first game played = 1, second game = 2, etc.) |
| Player | Integer | Integer used in place of name to anonymize athlete |
| Opponent | Integer | Integer used in place of name to anonymize opponent |
| Total Distance | Float | ATD, measured in meters, |
| Playing Time | Float | ATD, measured in minutes |
| Contact Count | Integer | Match footage, coded and evaluated by team analyst |
| Model | Accuracy | R2 | RMSE |
|---|---|---|---|
| Daily Team Mean Substitution | 0.216 | 0.009 | 1.832 |
| Linear Regression | 0.248 | 0.306 | 1.602 |
| Stepwise Regression | 0.247 | 0.305 | 1.603 |
| Lasso Regression | 0.227 | 0.264 | 1.651 |
| Ridge Regression | 0.233 | 0.274 | 1.650 |
| Elastic Net Regression | 0.227 | 0.265 | 1.651 |
| k-Nearest Neighbours | 0.239 | 0.268 | 1.653 |
| Random Forest | 0.265 | 0.407 | 1.480 |
| Support Vector Machine | 0.255 | 0.371 | 1.541 |
| Neural Network | 0.226 | 0.157 | 1.862 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Epp-Stobbe, A.; Tsai, M.-C.; Klimstra, M. Comparison of Imputation Methods for Missing Rate of Perceived Exertion Data in Rugby. Mach. Learn. Knowl. Extr. 2022, 4, 827-838. https://doi.org/10.3390/make4040041
Epp-Stobbe A, Tsai M-C, Klimstra M. Comparison of Imputation Methods for Missing Rate of Perceived Exertion Data in Rugby. Machine Learning and Knowledge Extraction. 2022; 4(4):827-838. https://doi.org/10.3390/make4040041
Chicago/Turabian StyleEpp-Stobbe, Amarah, Ming-Chang Tsai, and Marc Klimstra. 2022. "Comparison of Imputation Methods for Missing Rate of Perceived Exertion Data in Rugby" Machine Learning and Knowledge Extraction 4, no. 4: 827-838. https://doi.org/10.3390/make4040041
APA StyleEpp-Stobbe, A., Tsai, M.-C., & Klimstra, M. (2022). Comparison of Imputation Methods for Missing Rate of Perceived Exertion Data in Rugby. Machine Learning and Knowledge Extraction, 4(4), 827-838. https://doi.org/10.3390/make4040041