
An Attention-Based ConvLSTM Autoencoder with Dynamic Thresholding for Unsupervised Anomaly Detection in Multivariate Time Series


Abstract
:1. Introduction
- A novel framework that consists of pre-processing and enriching the multivariate time series, constructing feature images, and an attention-based ConvLSTM network autoencoder to reconstruct the feature image input. Moreover, the framework consists of a dynamic thresholding mechanism to detect anomalies and identify anomalies’ root cause in multivariate time series.
- A generic, unsupervised learning framework that utilizes state-of-the-art DL algorithms and can be applied for various different multivariate time series use cases in SM.
- An attention-based, time-distributed ConvLSTM encoder–decoder model that is capable of sustaining constant performance as the rate of input time series sequences from the manufacturing operations increases.
- A nonparametric and dynamic thresholding mechanism for evaluating reconstruction errors that addresses non-stationarity, noise, and diversity issues in the data.
- A robust framework evaluated on a real-life public manufacturing data set, where results demonstrate its performance strengths over state-of-the-art methods under various experimental settings.
2. Motivation and Related Work
3. Technical Preliminaries
3.1. Convolutional Neural Network (CNN)
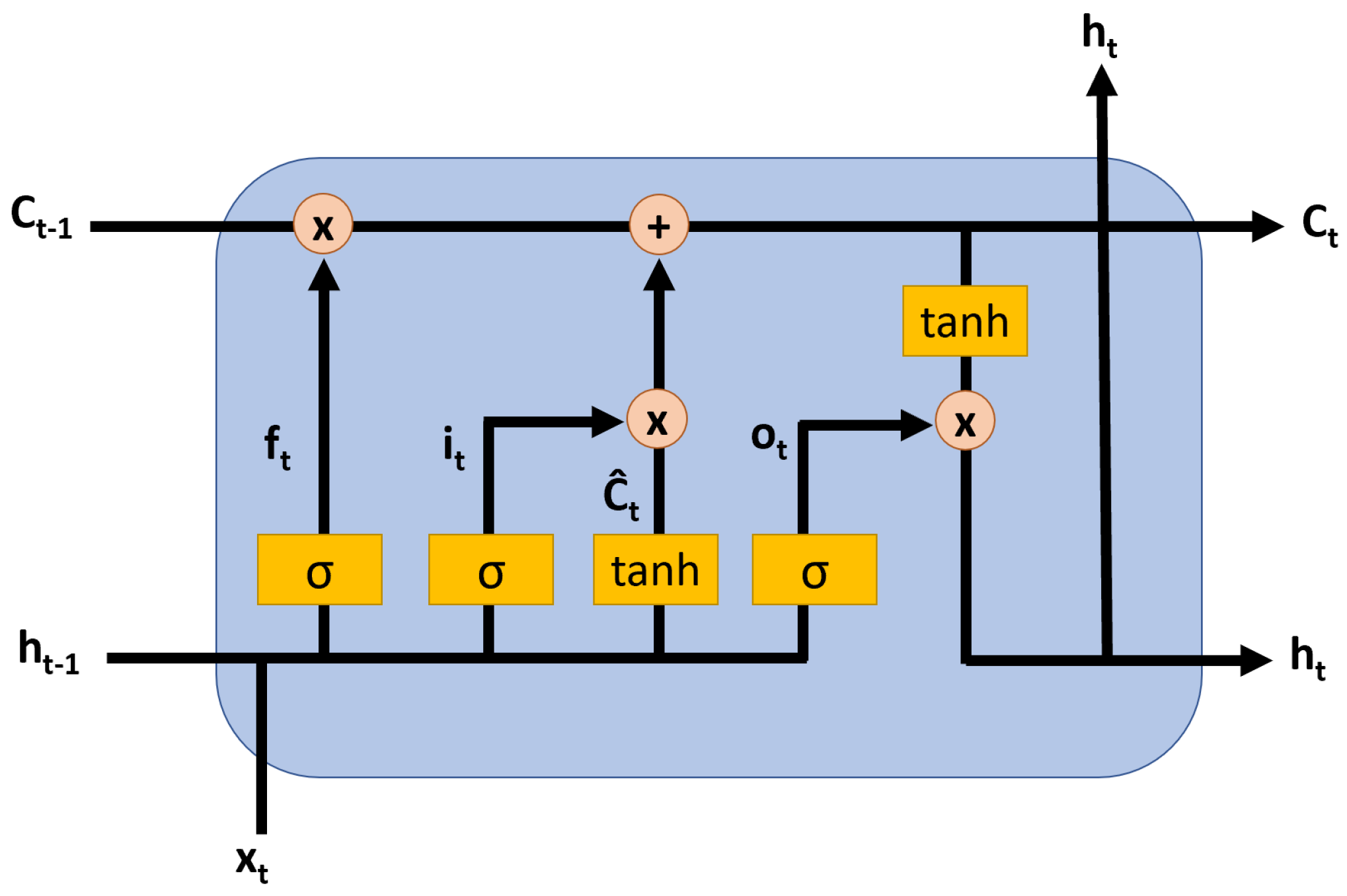
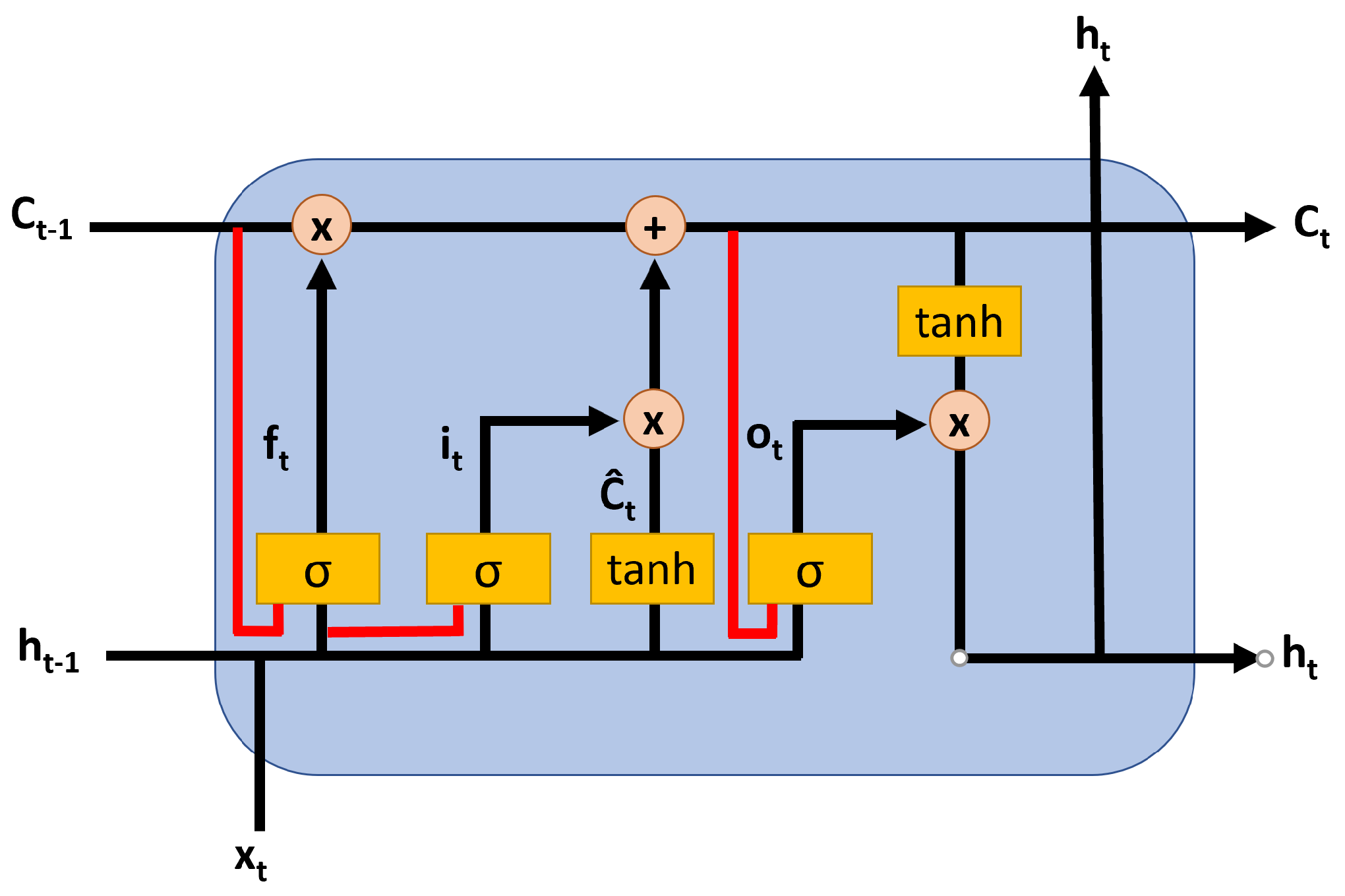
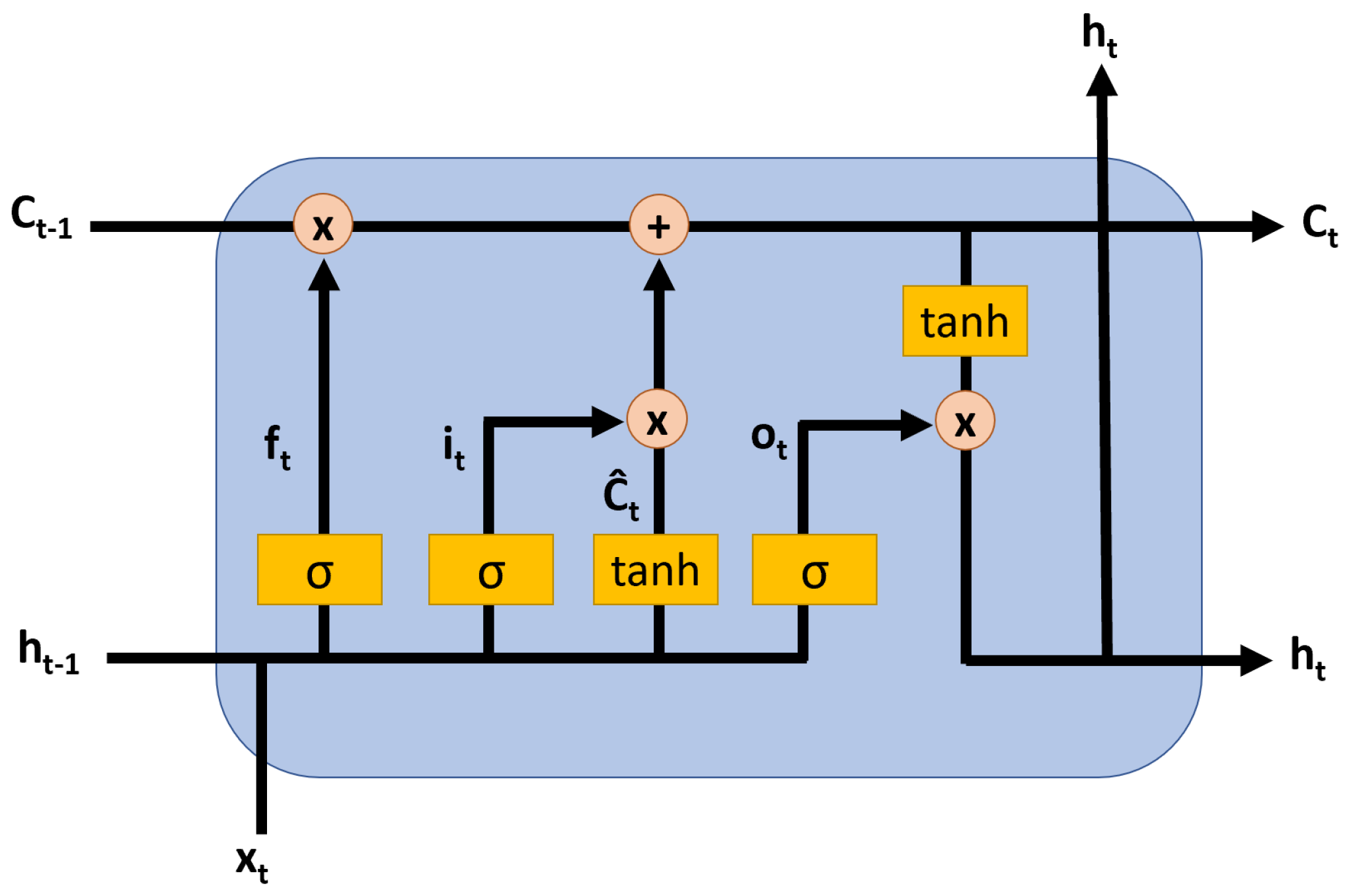
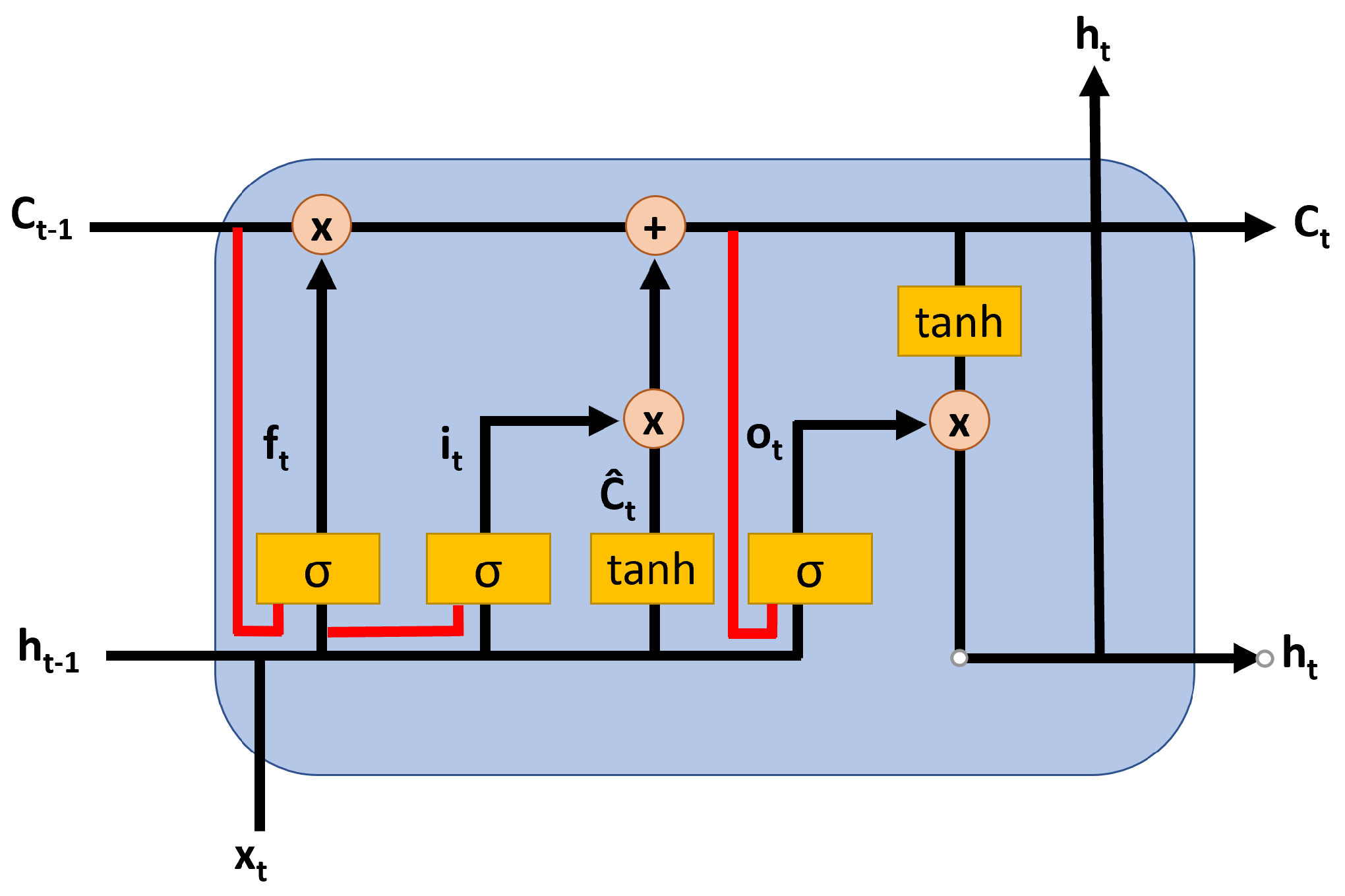
3.2. Long Short-Term Memory (LSTM) Neural Network
3.3. Convolutional LSTM (ConvLSTM)
3.4. Autoencoder
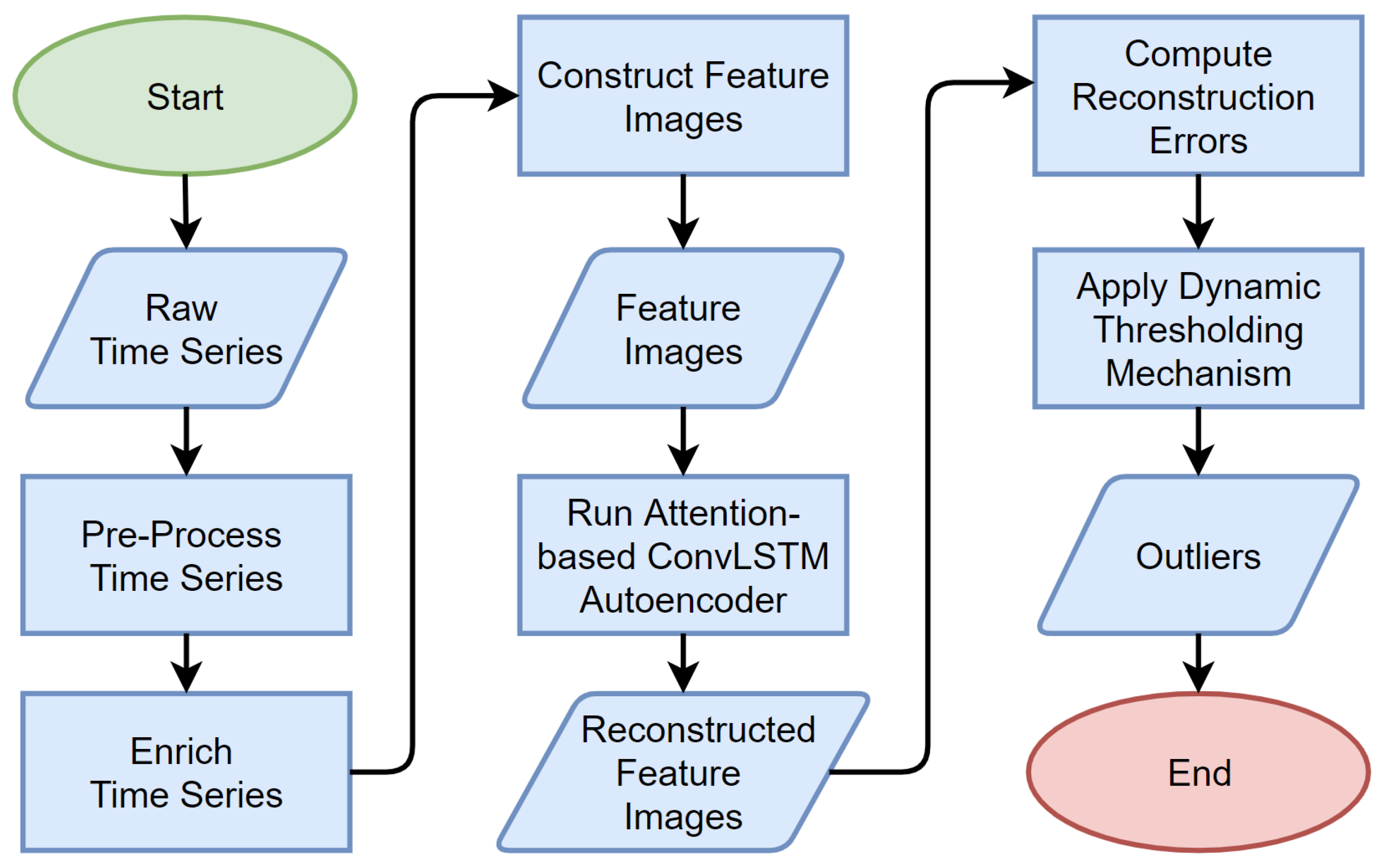
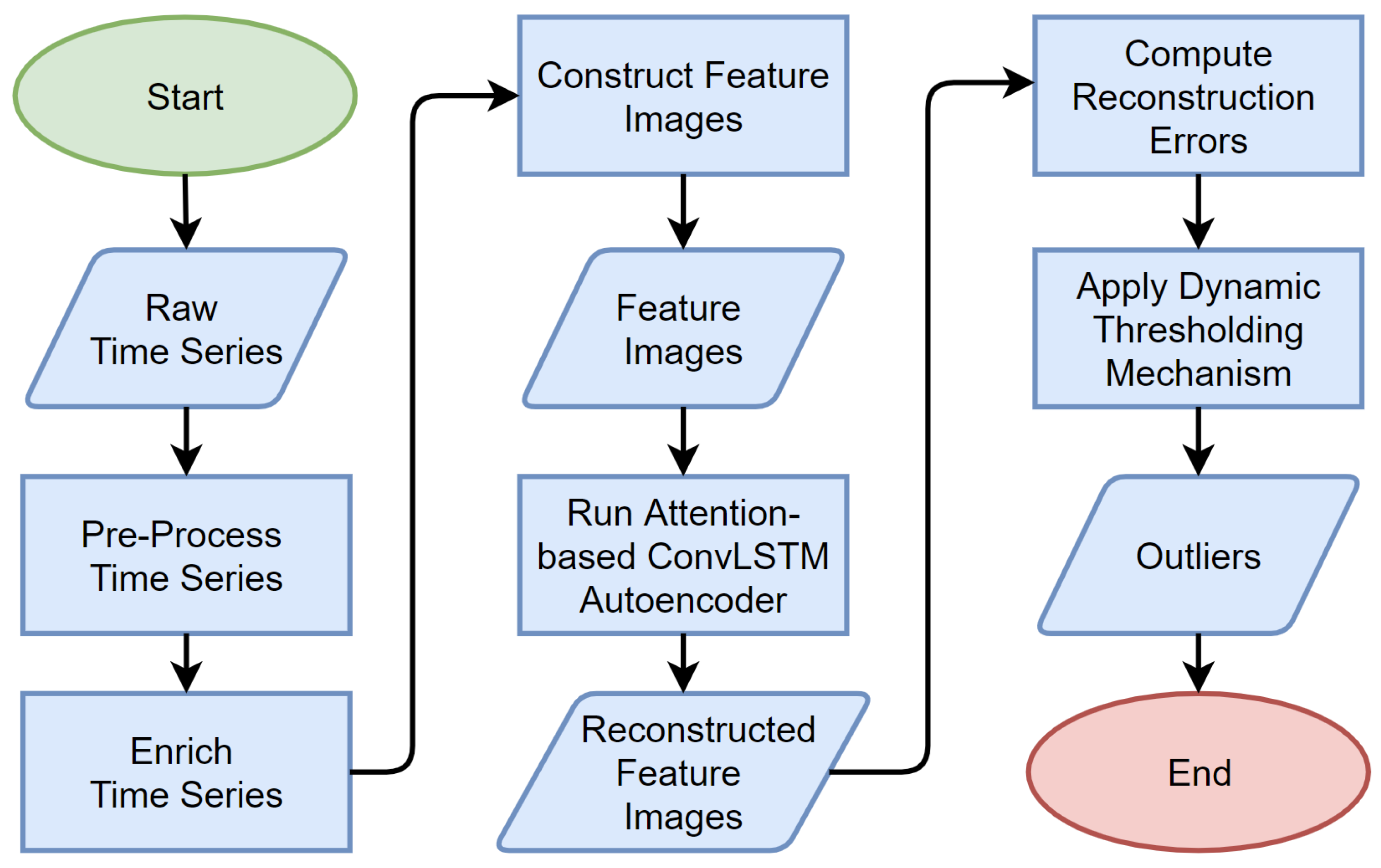
4. ACLAE-DT Framework
4.1. Problem Statement
4.2. Pre-Process Time Series
4.3. Enrich Time Series
4.3.1. Utilizing Sliding Windows
4.3.2. Embedding Contextual Information
4.4. Construct Feature Images
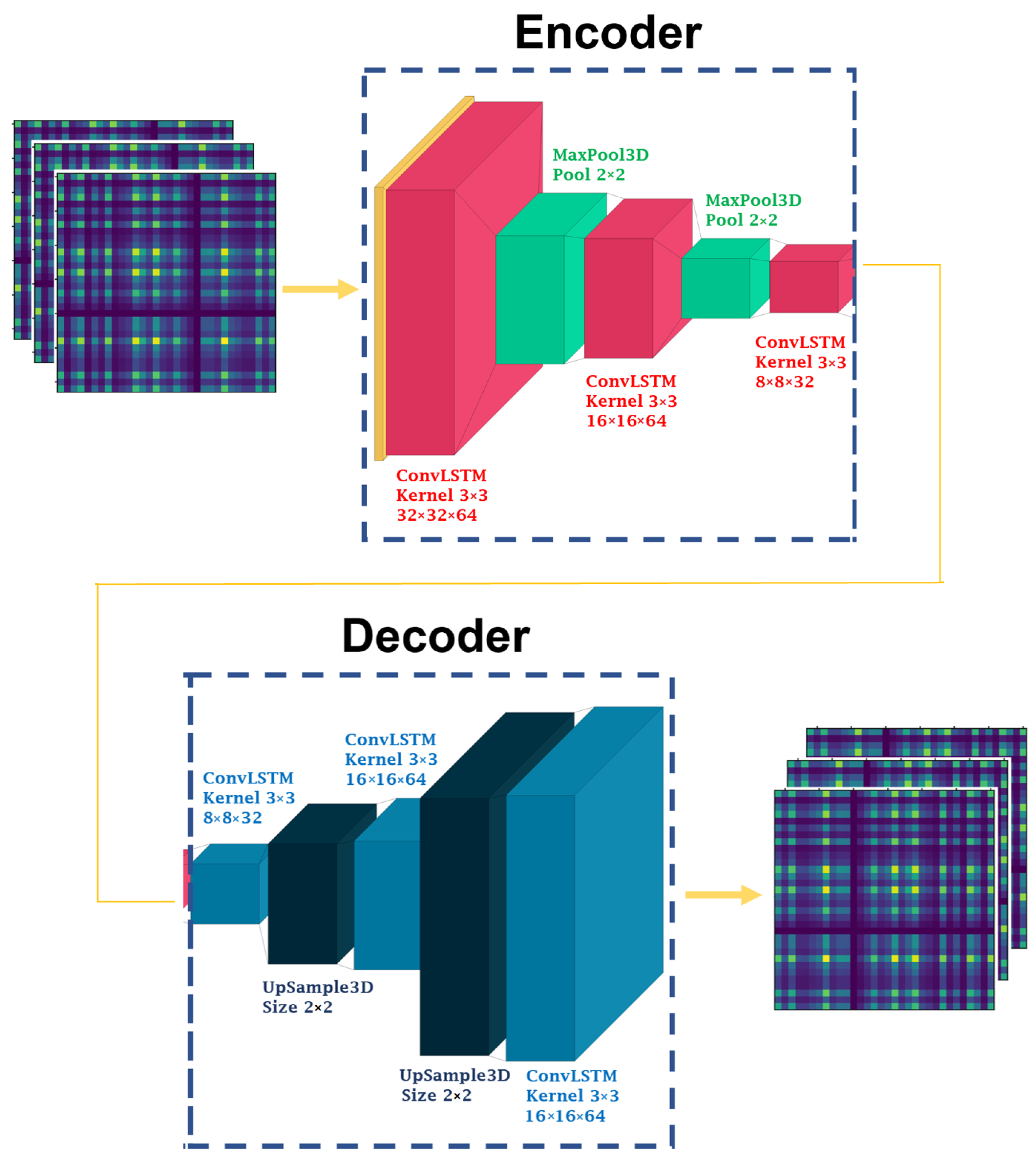
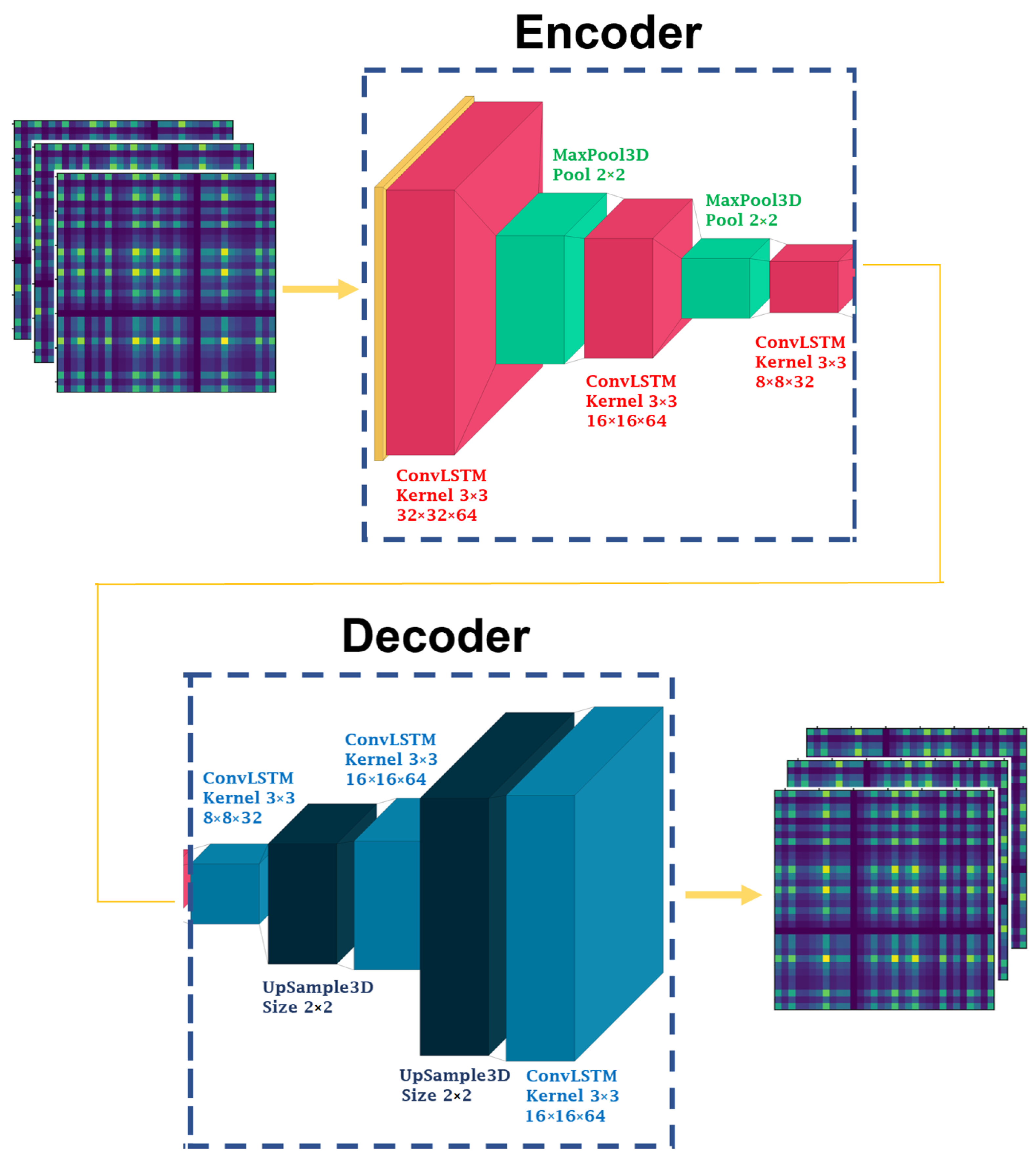
4.5. Attention-Based ConvLSTM Autoencoder Model
4.6. Model’s Hyperparameter Optimization
4.7. Compute Reconstruction Errors
4.8. Dynamic Thresholding Mechanism
5. Experiments
- SVM: An ML method that classifies whether a test data point is an anomaly or not based on the learned decision function from the training data.
- Auto-Regressive Integrated Moving Average (ARIMA): A classical prediction model that captures the temporal dependencies in the training data to forecast the predicted values of the testing data.
- LSTM Autoencoder: A DL method that utilizes LSTM networks in both the encoder and decoder.
- ConvLSTM-LSTM Autoencoder: A DL method that utilizes ConvLSTM networks in the encoder and LSTM networks in the decoder.
- CNN-LSTM Autoencoder: A DL method that utilizes CNN-LSTM networks in both the encoder and decoder.
- ACLAE-DT Shallow: An ACLAE-DT variant that utilizes ACLAE-DT’s model without the last MaxPool3D and ConvLSTM encoder components and without the first UpSample3D and ConvLSTM decoder components.
- ACLAE-DT No-Attention: An ACLAE-DT variant that utilizes ACLAE-DT’s model without attention.
6. Performance Evaluation
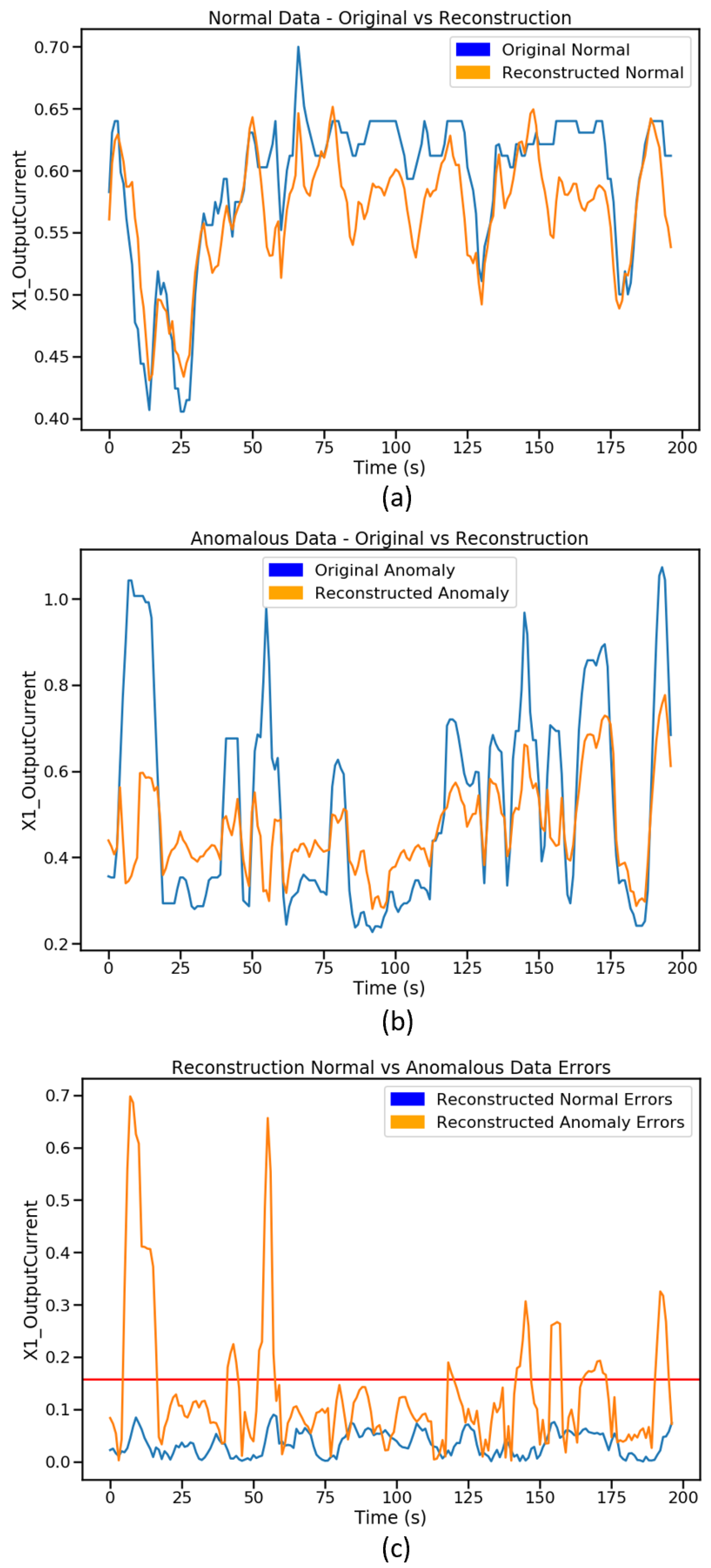
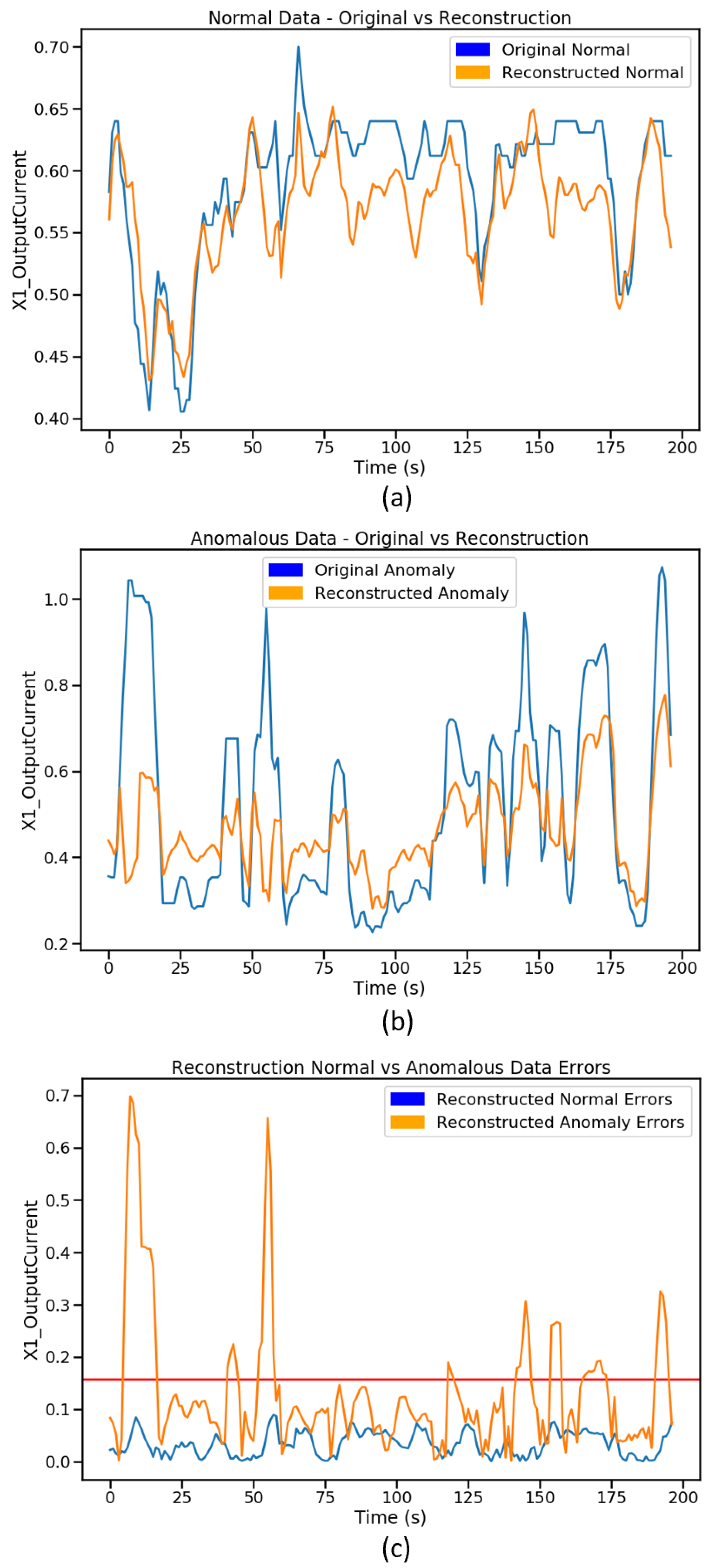
6.1. Anomaly Detection Results
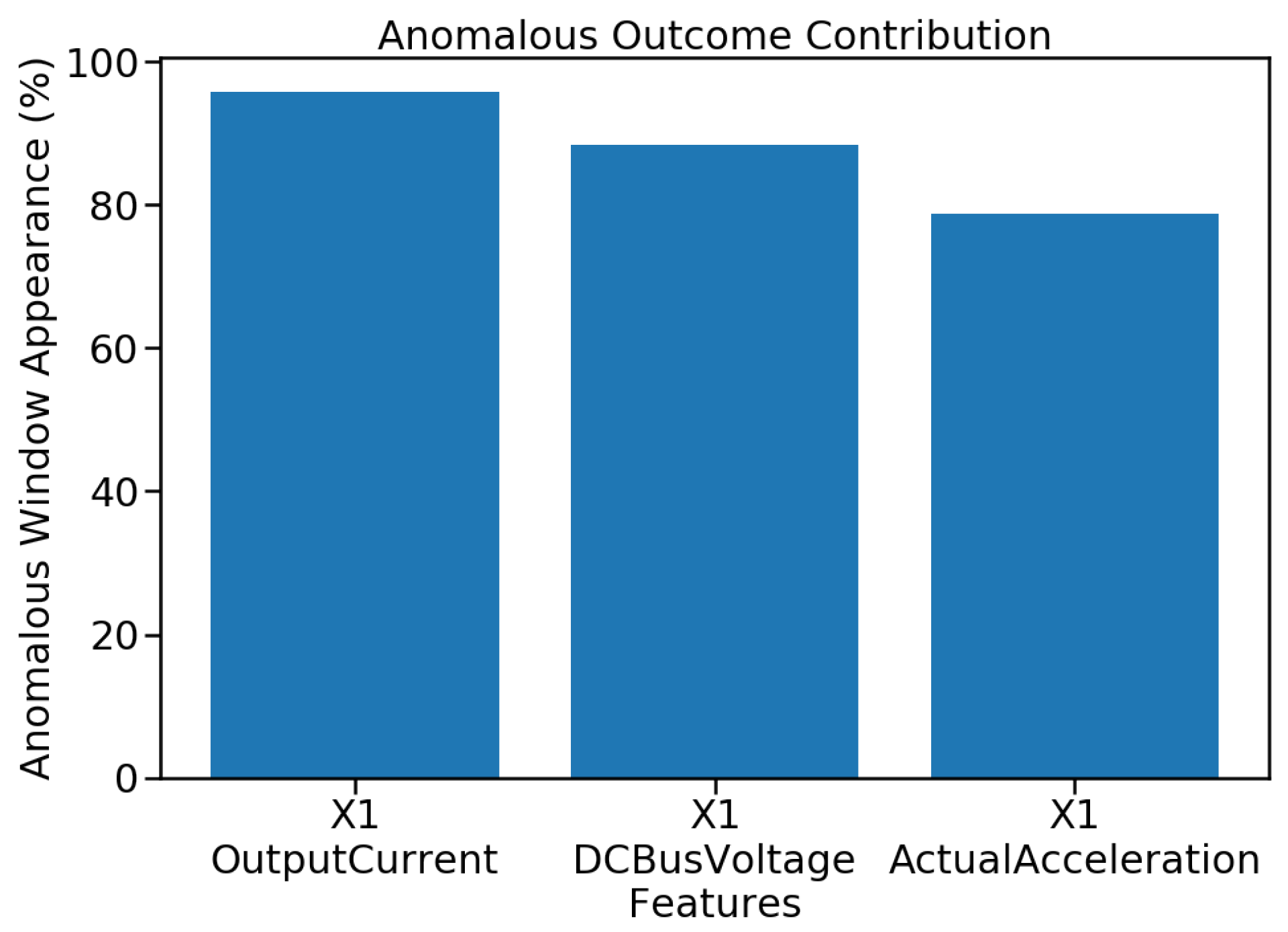
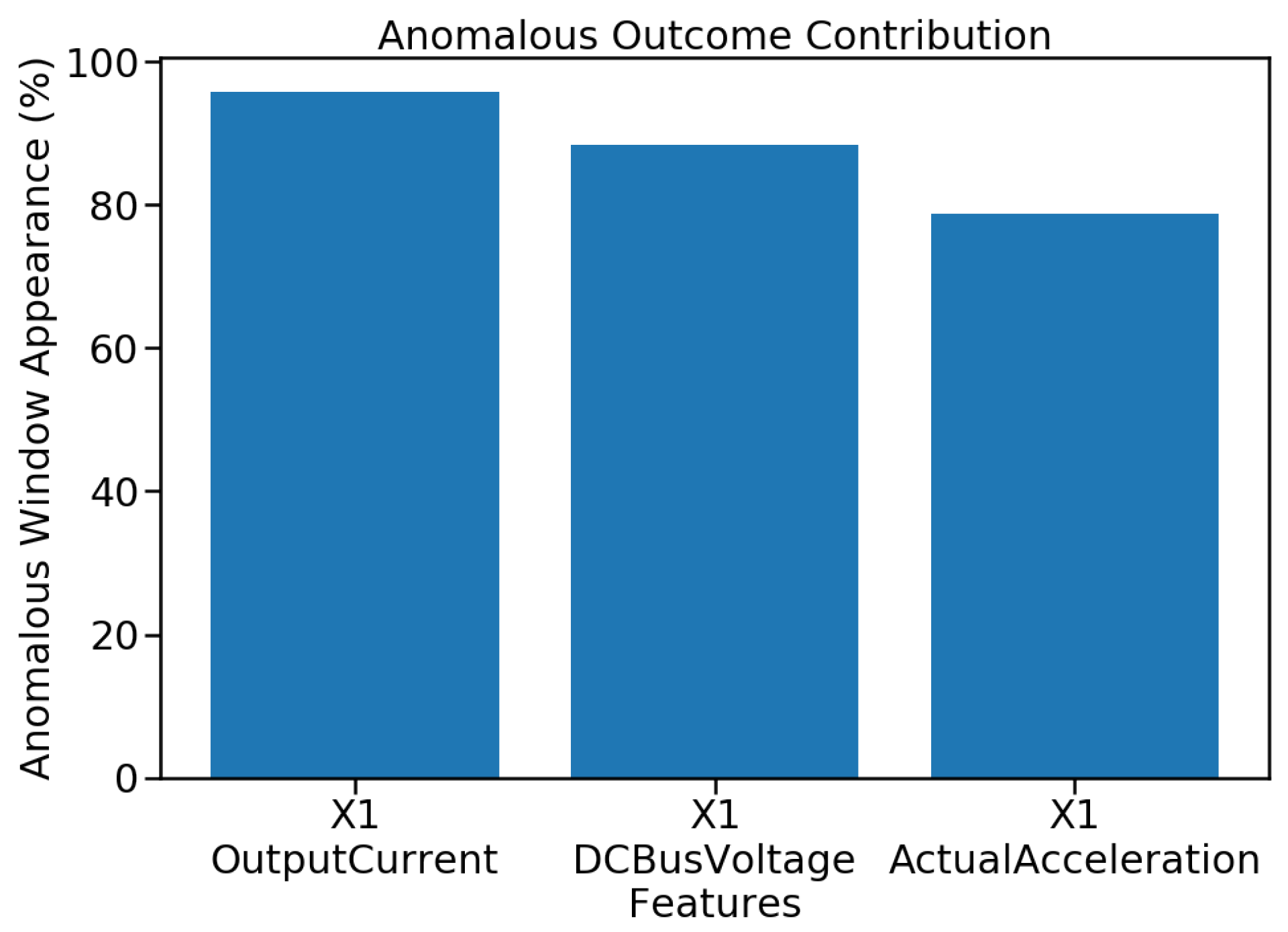
6.2. Anomaly Root Cause Identification Results
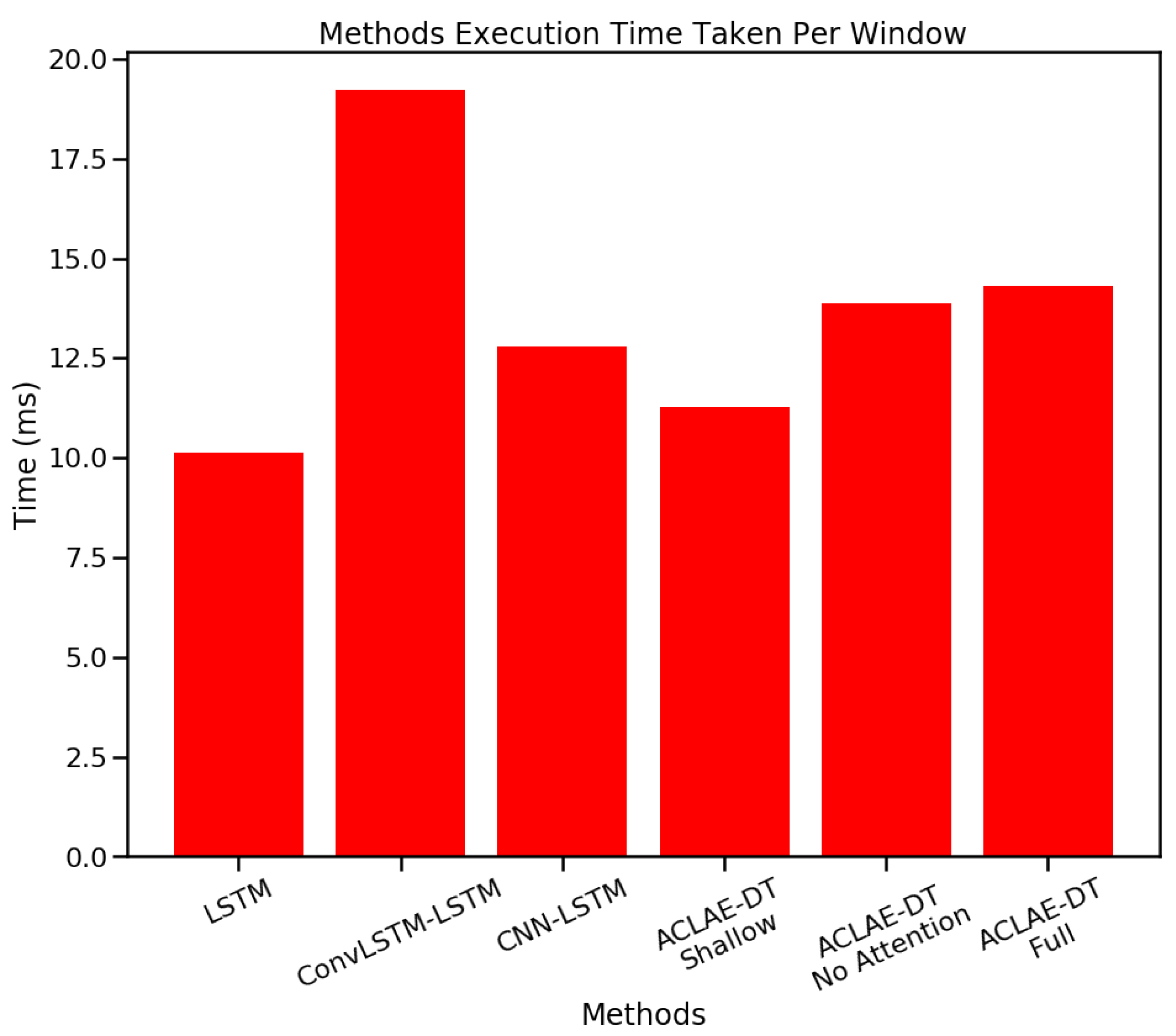
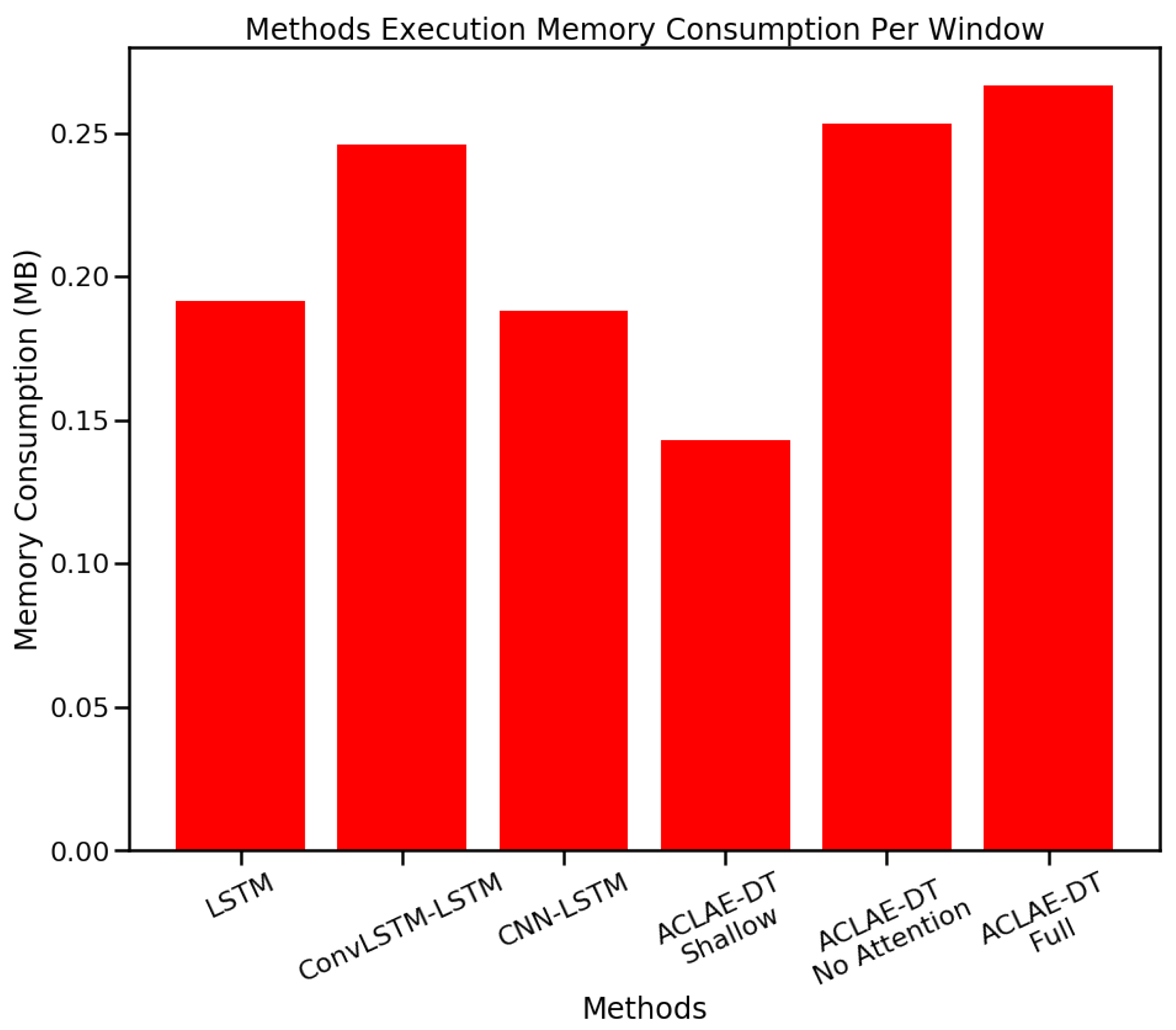
6.3. Execution Time and Memory Requirements
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ARIMA | Auto-Regressive Integrated Moving Average |
| CNC | Computer Numerical Control |
| CNN | Convolutional Neural Network |
| ConvLSTM | Convolutional Long Short-Term Memory |
| DL | Deep Learning |
| ELU | Exponential Linear Units |
| IIoT | Industrial Internet of Things |
| IoT | Internet of Things |
| K-NN | K-Nearest Neighbor |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| ReLU | Rectified Linear Units |
| RMSE | Root Mean Squared Error |
| RNN | Recurrent Neural Network |
| SELU | Scaled Exponential Linear Units |
| SGD | Stochastic Gradient Descent |
| SMART | System-level Manufacturing and Automation Research Testbed |
| SVM | Support Vector Machine |
References
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Multi-stage optimized machine learning framework for network intrusion detection. IEEE Trans. Netw. Serv. Manag. 2020, 18, 1803–1816. [Google Scholar] [CrossRef]
- Moubayed, A.; Aqeeli, E.; Shami, A. Ensemble-based feature selection and classification model for dns typo-squatting detection. In Proceedings of the 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), London, ON, Canada, 30 August–2 September 2020; pp. 1–6. [Google Scholar]
- Salo, F.; Injadat, M.; Nassif, A.B.; Shami, A.; Essex, A. Data mining techniques in intrusion detection systems: A systematic literature review. IEEE Access 2018, 6, 56046–56058. [Google Scholar] [CrossRef]
- Injadat, M.; Salo, F.; Nassif, A.B.; Essex, A.; Shami, A. Bayesian optimization with machine learning algorithms towards anomaly detection. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Moubayed, A.; Injadat, M.; Shami, A.; Lutfiyya, H. Dns typo-squatting domain detection: A data analytics & machine learning based approach. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Yu, T.; Wang, X.; Shami, A. Recursive principal component analysis-based data outlier detection and sensor data aggregation in IoT systems. IEEE Internet Things J. 2017, 4, 2207–2216. [Google Scholar] [CrossRef]
- Liu, J.; Guo, J.; Orlik, P.; Shibata, M.; Nakahara, D.; Mii, S.; Takáč, M. Anomaly detection in manufacturing systems using structured neural networks. In Proceedings of the 2018 13th World Congress on Intelligent Control and Automation (WCICA), Changsha, China, 4–8 July 2018; pp. 175–180. [Google Scholar]
- Thakur, N.; Han, C.Y. An ambient intelligence-based human behavior monitoring framework for ubiquitous environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Kusiak, A. Smart manufacturing. Int. J. Prod. Res 2018, 56, 508–517. [Google Scholar] [CrossRef]
- Kang, H.S.; Lee, J.Y.; Choi, S.; Kim, H.; Park, J.H.; Son, J.Y.; Kim, B.H.; Do Noh, S. Smart manufacturing: Past research, present findings, and future directions. Int. J. Precis. Eng. Manuf.-Green Technol. 2016, 3, 111–128. [Google Scholar] [CrossRef]
- Russo, I.; Confente, I.; Gligor, D.M.; Cobelli, N. The combined effect of product returns experience and switching costs on B2B customer re-purchase intent. J. Bus. Ind. Mark. 2017, 32, 664–676. [Google Scholar] [CrossRef]
- Progress. Anomaly Detection & Prediction Decoded: 6 Industries, Copious Challenges, Extraordinary Impact. 2017. Available online: https://www.progress.com/docs/default-source/datarpm/progress_datarpm_cadp_ebook_anomaly_detection_in_6_industries.pdf?sfvrsn=82a183de_2 (accessed on 8 March 2022).
- Yang, L.; Moubayed, A.; Hamieh, I.; Shami, A. Tree-based intelligent intrusion detection system in internet of vehicles. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Kieu, T.; Yang, B.; Jensen, C.S. Outlier detection for multidimensional time series using deep neural networks. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 25–28 June 2018; pp. 125–134. [Google Scholar]
- Aburakhia, S.; Tayeh, T.; Myers, R.; Shami, A. A Transfer Learning Framework for Anomaly Detection Using Model of Normality. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 55–61. [Google Scholar]
- Guo, Y.; Liao, W.; Wang, Q.; Yu, L.; Ji, T.; Li, P. Multidimensional time series anomaly detection: A gru-based gaussian mixture variational autoencoder approach. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 97–112. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 13. [Google Scholar]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Cook, A.A.; Mısırlı, G.; Fan, Z. Anomaly detection for IoT time-series data: A survey. IEEE Internet Things J. 2019, 7, 6481–6494. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Görnitz, N.; Kloft, M.; Rieck, K.; Brefeld, U. Toward supervised anomaly detection. J. Artif. Intell. Res. 2013, 46, 235–262. [Google Scholar] [CrossRef]
- Kawachi, Y.; Koizumi, Y.; Harada, N. Complementary set variational autoencoder for supervised anomaly detection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2366–2370. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montréal, QC, Canada, 11–12 December 2015; pp. 1–9. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Saci, A.; Al-Dweik, A.; Shami, A. Autocorrelation Integrated Gaussian Based Anomaly Detection using Sensory Data in Industrial Manufacturing. IEEE Sens. J. 2021, 21, 9231–9241. [Google Scholar] [CrossRef]
- Huo, W.; Wang, W.; Li, W. Anomalydetect: An online distance-based anomaly detection algorithm. In Proceedings of the International Conference on Web Services, Milan, Italy, 8–13 July 2019; pp. 63–79. [Google Scholar]
- Li, J.; Izakian, H.; Pedrycz, W.; Jamal, I. Clustering-based anomaly detection in multivariate time series data. Appl. Soft Comput. 2021, 100, 106919. [Google Scholar] [CrossRef]
- Gokcesu, K.; Kozat, S.S. Online anomaly detection with minimax optimal density estimation in nonstationary environments. IEEE Trans. Signal Process 2017, 66, 1213–1227. [Google Scholar] [CrossRef]
- Xie, M.; Hu, J.; Han, S.; Chen, H.H. Scalable hypergrid k-NN-based online anomaly detection in wireless sensor networks. Ieee Trans. Parallel Distrib. Syst. 2012, 24, 1661–1670. [Google Scholar] [CrossRef]
- Wang, Y.; Wong, J.; Miner, A. Anomaly intrusion detection using one class SVM. In Proceedings of the Proceedings from the Fifth Annual IEEE SMC Information Assurance Workshop, West Point, NY, USA, 10–11 June 2004; pp. 358–364. [Google Scholar]
- Ryan, J.; Lin, M.J.; Miikkulainen, R. Intrusion detection with neural networks. Adv. Neural Inf. Process. Syst. 1998, 10, 943–949. [Google Scholar]
- Rasheed, W.; Tang, T.B. Anomaly detection of moderate traumatic brain injury using auto-regularized multi-instance one-class SVM. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 28, 83–93. [Google Scholar] [CrossRef]
- Kusiak, A. Smart manufacturing must embrace big data. Nature 2017, 544, 23. [Google Scholar] [CrossRef] [PubMed]
- Tayeh, T.; Aburakhia, S.; Myers, R.; Shami, A. Distance-Based Anomaly Detection for Industrial Surfaces Using Triplet Networks. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 372–377. [Google Scholar]
- Feng, C.; Li, T.; Chana, D. Multi-level anomaly detection in industrial control systems via package signatures and LSTM networks. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Denver, CO, USA, 26–29 June 2017; pp. 261–272. [Google Scholar]
- Bayram, B.; Duman, T.B.; Ince, G. Real time detection of acoustic anomalies in industrial processes using sequential autoencoders. Expert Syst. 2021, 38, e12564. [Google Scholar] [CrossRef]
- Benkabou, S.E.; Benabdeslem, K.; Kraus, V.; Bourhis, K.; Canitia, B. Local Anomaly Detection for Multivariate Time Series by Temporal Dependency Based on Poisson Model. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Choi, T.; Lee, D.; Jung, Y.; Choi, H.J. Multivariate Time-series Anomaly Detection using SeqVAE-CNN Hybrid Model. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Korea, 12–15 January 2022; pp. 250–253. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1409–1416. [Google Scholar]
- Valueva, M.V.; Nagornov, N.; Lyakhov, P.A.; Valuev, G.V.; Chervyakov, N.I. Application of the residue number system to reduce hardware costs of the convolutional neural network implementation. Math. Comput. Simul. 2020, 177, 232–243. [Google Scholar] [CrossRef]
- Jayalakshmi, T.; Santhakumaran, A. Statistical normalization and back propagation for classification. Int. J. Comput. Sci. Appl. 2011, 3, 1793–8201. [Google Scholar]
- Yu, Y.; Zhu, Y.; Li, S.; Wan, D. Time series outlier detection based on sliding window prediction. Math. Probl. Eng. 2014, 2014, 879736. [Google Scholar] [CrossRef]
- Gupta, M.; Sharma, A.B.; Chen, H.; Jiang, G. Context-Aware Time Series Anomaly Detection for Complex Systems. In Proceedings of the SDM Workshop on Data Mining for Service and Maintenance, Austin, TX, USA, 2–4 May 2013. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Hallac, D.; Vare, S.; Boyd, S.; Leskovec, J. Toeplitz inverse covariance-based clustering of multivariate time series data. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 215–223. [Google Scholar]
- Claesen, M.; Simm, J.; Popovic, D.; Moreau, Y.; De Moor, B. Easy hyperparameter search using optunity. arXiv 2014, arXiv:1412.1114. [Google Scholar]
- Zöller, M.A.; Huber, M.F. Benchmark and survey of automated machine learning frameworks. arXiv 2019, arXiv:1904.12054. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. arXiv 2017, arXiv:1706.02515. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G.E. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. Stochastic estimation of the maximum of a regression function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Survey of anomaly detection. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Kovalenko, I.; Saez, M.; Barton, K.; Tilbury, D. SMART: A system-level manufacturing and automation research testbed. Smart Sustain. Manuf. Syst. 2017, 1. [Google Scholar] [CrossRef]
- Sun, S. CNC Mill Tool Wear. 2018. Available online: https://www.kaggle.com/shasun/tool-wear-detection-in-cnc-mill (accessed on 8 March 2022).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 8 March 2022).
- Kumar, S.; Kolekar, T.; Kotecha, K.; Patil, S.; Bongale, A. Performance evaluation for tool wear prediction based on Bi-directional, Encoder–Decoder and Hybrid Long Short-Term Memory models. Int. J. Qual. Reliab. Manag. 2022. [Google Scholar] [CrossRef]
- Bazi, R.; Benkedjouh, T.; Habbouche, H.; Rechak, S.; Zerhouni, N. A hybrid CNN-BiLSTM approach-based variational mode decomposition for tool wear monitoring. Int. J. Adv. Manuf. Technol. 2022, 119, 3803–3817. [Google Scholar] [CrossRef]
- Cai, W.; Zhang, W.; Hu, X.; Liu, Y. A hybrid information model based on long short-term memory network for tool condition monitoring. J. Intell. Manuf. 2020, 31, 1497–1510. [Google Scholar] [CrossRef]
- Aghazadeh, F.; Tahan, A.; Thomas, M. Tool condition monitoring using spectral subtraction and convolutional neural networks in milling process. Int. J. Adv. Manuf. Technol. 2018, 98, 3217–3227. [Google Scholar] [CrossRef]
- Martínez-Arellano, G.; Terrazas, G.; Ratchev, S. Tool wear classification using time series imaging and deep learning. Int. J. Adv. Manuf. Technol. 2019, 104, 3647–3662. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Hyperparameter | Values |
|---|---|---|
| ConvLSTM | Activation Function | ReLU, Leaky RELU, ELU, SELU |
| N/A | Learning Rate | 1 × 10, 1 × 10, 1 × 10, 1 × 10, 1 × 10 |
| N/A | Batch Size | 16, 32, 64, 128, 256 |
| N/A | Optimizer | Adam, RMSProp, ADADelta, SGD |
| N/A | Loss Function | MAE, MSE, RMSE |
| Method | Precision | Recall | F1 Score | Train Time (s) |
|---|---|---|---|---|
| SVM (Linear Kernel) | 0.15 | 0.17 | 0.16 | 14 |
| ARIMA (2,1,2) | 0.52 | 0.59 | 0.56 | 98 |
| LSTM Autoencoder | 0.83 | 0.80 | 0.82 | 13,468 |
| ConvLSTM-LSTM Autoencoder | 0.80 | 0.84 | 0.82 | 11,914 |
| CNN-LSTM Autoencoder | 0.84 | 0.84 | 0.84 | 10,136 |
| ACLAE-DT Shallow | 0.94 | 0.87 | 0.90 | 8372 |
| ACLAE-DT No Attention | 0.95 | 0.87 | 0.91 | 7574 |
| ACLAE-DT Full | 0.95 | 0.88 | 0.92 | 7812 |
| Method | Precision | Recall | F1 Score | Train Time (s) |
|---|---|---|---|---|
| SVM (Linear Kernel) | 0.15 | 0.17 | 0.16 | 14 |
| ARIMA (2,1,2) | 0.52 | 0.59 | 0.56 | 98 |
| LSTM Autoencoder | 0.82 | 0.83 | 0.83 | 15,932 |
| ConvLSTM-LSTM Autoencoder | 0.79 | 0.84 | 0.81 | 8274 |
| CNN-LSTM Autoencoder | 0.83 | 0.85 | 0.84 | 5362 |
| ACLAE-DT Shallow | 0.91 | 0.89 | 0.90 | 3388 |
| ACLAE-DT No Attention | 0.95 | 0.88 | 0.90 | 3122 |
| ACLAE-DT Full | 0.96 | 0.90 | 0.93 | 3234 |
| Method | Precision | Recall | F1 Score | Train Time (s) |
|---|---|---|---|---|
| SVM (Linear Kernel) | 0.15 | 0.17 | 0.16 | 14 |
| ARIMA (2,1,2) | 0.52 | 0.59 | 0.56 | 98 |
| LSTM Autoencoder | 0.79 | 0.83 | 0.82 | 7462 |
| ConvLSTM-LSTM Autoencoder | 0.77 | 0.82 | 0.79 | 13,496 |
| CNN-LSTM Autoencoder | 0.84 | 0.85 | 0.85 | 5152 |
| ACLAE-DT Shallow | 0.96 | 0.99 | 0.97 | 2814 |
| ACLAE-DT No Attention | 0.97 | 0.99 | 0.98 | 1638 |
| ACLAE-DT Full | 0.99 | 1.00 | 1.00 | 1736 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tayeh, T.; Aburakhia, S.; Myers, R.; Shami, A. An Attention-Based ConvLSTM Autoencoder with Dynamic Thresholding for Unsupervised Anomaly Detection in Multivariate Time Series. Mach. Learn. Knowl. Extr. 2022, 4, 350-370. https://doi.org/10.3390/make4020015
Tayeh T, Aburakhia S, Myers R, Shami A. An Attention-Based ConvLSTM Autoencoder with Dynamic Thresholding for Unsupervised Anomaly Detection in Multivariate Time Series. Machine Learning and Knowledge Extraction. 2022; 4(2):350-370. https://doi.org/10.3390/make4020015
Chicago/Turabian StyleTayeh, Tareq, Sulaiman Aburakhia, Ryan Myers, and Abdallah Shami. 2022. "An Attention-Based ConvLSTM Autoencoder with Dynamic Thresholding for Unsupervised Anomaly Detection in Multivariate Time Series" Machine Learning and Knowledge Extraction 4, no. 2: 350-370. https://doi.org/10.3390/make4020015
APA StyleTayeh, T., Aburakhia, S., Myers, R., & Shami, A. (2022). An Attention-Based ConvLSTM Autoencoder with Dynamic Thresholding for Unsupervised Anomaly Detection in Multivariate Time Series. Machine Learning and Knowledge Extraction, 4(2), 350-370. https://doi.org/10.3390/make4020015