Abstract
Detecting events in videos is a complex task, and many different approaches, aimed at a large variety of use-cases, have been proposed in the literature. Most approaches, however, are unimodal and only consider the visual information in the videos. This paper presents and evaluates different approaches based on neural networks where we combine visual features with audio features to detect (spot) and classify events in soccer videos. We employ model fusion to combine different modalities such as video and audio, and test these combinations against different state-of-the-art models on the SoccerNet dataset. The results show that a multimodal approach is beneficial. We also analyze how the tolerance for delays in classification and spotting time, and the tolerance for prediction accuracy, influence the results. Our experiments show that using multiple modalities improves event detection performance for certain types of events.
Keywords:
audio; video; multimodality; event classification; event detection; machine learning; soccer 1. Introduction
The generation of video summaries and highlights from sports games is of tremendous interest for broadcasters as a large percent of audiences prefer to view only the main events in a game. Having worked closely with and observed soccer domain experts for a decade, and lately been part of building a soccer tagging operation center used in the Norwegian and Swedish elite leagues, we see the need for high-performance automatic event detection systems in soccer. The current manual annotation process, where a group of people annotates video segments as they are aired during a live broadcast, is tedious and expensive. The “holy grail” of event annotation has long been anticipated to be a fully automated event extraction system. Such a system needs to be timely and accurate, and must capture events in near real-time.
One of the key components of such a comprehensive pipeline is the detection and classification of significant events in real-time. Existing approaches for this task need significant improvement in terms of detection and classification accuracy. Much work has been done on using visual information to detect events in soccer videos, and promising examples with a good detection performance [1,2,3,4] are available. However, in order to be usable in practice, the detection performance must be high, and for events such as goals in soccer, 100% (perfect) detection is required for any method to be considered for deployment as an official tool.
In this paper, we aim to develop an intelligent soccer event detection and classification system using machine learning (ML). In particular, we explore the potential in the data itself to improve the performance of both event detection (also called spotting), and event classification. Typically, a data stream contains several types of data. For example, a sports broadcast might be composed of several video and audio streams. The final broadcast consumed by the viewers typically consists of a video stream created from various camera views and an audio stream containing, for example, the commentators’ voices with the background audio from the audience in the stadium. However, research on detecting particular events has traditionally focused solely on the visual modality of the video. Even in multimedia venues, researchers have for a long time presented work based on video only. Thus, our objective in this study is to evaluate whether the narrow focus of existing multimedia research limits the potential for high-performance event detection, by not utilizing all available modalities.
Using the SoccerNet dataset [1], from which a number of samples are presented in Figure 1, we evaluate two previous unimodal approaches focusing on video [2,4] and experiment with different parameters, showing the trade-offs between accuracy and latency. Subsequently, we evaluate the performance of an audio model, where the audio is sampled and transformed into a Log-Mel spectrogram [5], which is analyzed using a 2D-ResNet model. Following this single-modality event analysis, we fuse the models using softmax predictions. Our results show the various trade-offs between different requirements, but more importantly, that existing state-of-the-art visual models achieve increased performance when a causally related audio analysis is added. Hence, we prove the importance of multimedia analysis in future event detection systems. The main contributions of this work are as follows:

Figure 1.
Sample frames from the SoccerNet dataset [1] for three different event types. The middle frame is at the annotated time for the event.
- We implement, configure, and test two state-of-the-art visual models [2,4] built on the ResNet model and assess their detection performance of various soccer events, such as cards, substitutions, and goals, using the SoccerNet dataset [1]. As expected, adding higher tolerance (enabling the models to use more data) improves the performance, trading off event processing delay for event detection (spotting) accuracy.
- We implement a Log-Mel spectrogram-based audio model, testing different audio sample windows and assessing the model’s event detection and classification performance. The results show that using the audio model alone gives poor performance compared to using the visual models.
- We combine the visual and audio models, proving that utilizing all the potential of the data (multiple modalities) improves the performance. We observe a performance increase for various events under different configurations. In particular, for events such as goals, the multimodal approach is superior. For other events such as cards and substitutions, the gain depends more on the tolerances, and in some cases, adding audio information can be detrimental to the performance.
The rest of the paper is structured as follows. In Section 2, we provide an overview of related work. We present our ML models in Section 3 and show how we combine them to achieve a multimodal system for soccer event classification in Section 4. In Section 5, we present our experiments and discuss various aspects in Section 6. We summarize our results and conclude the paper in Section 7.
2. Related Work
This section briefly introduces relevant research on action detection and, more specifically, the automatic detection of events from soccer videos.
2.1. Action Detection and Localization
Computer vision has been an active field of research for many decades. One of the most important areas of computer vision is video understanding. There are several interesting subareas of video understanding, but the two most relevant in our context are action recognition and action detection, i.e., aiming to find what actions occur and at what time, in videos.
Several different approaches have been proposed for the task of action recognition. In earlier works, features such as histogram of oriented gradients (HOG), histogram of flow (HOF), motion boundary histograms (MBH) [6], and dense trajectories [7,8] have shown promising results. More recently, proposed approaches have started to use some variant of neural networks. For example, Karpathy et al. [9] provided an empirical evaluation of convolutional neural networks (CNNs) on large-scale video classification using a dataset of 1 million YouTube videos belonging to 487 classes. Multiple CNN architectures were studied to find an approach that combines information across the time domain. The CNN architecture was modified to process two streams to improve runtime performance, a context stream and a fovea stream. Moreover, the stream was cropped at the center of the image and down-sampled. The runtime performance was increased by up to , and the accuracy of classification was increased by about 60–64% compared to the 2014 state-of-the-art. The learned features generalized to a different smaller dataset, showing benefits of transfer learning. Simonyan and Zisserman [10] also used a two-stream convolutional network, related to the two-streams hypothesis [11], and their performance exceeded the previous works using deep neural networks, by a large margin. They used two separate CNNs, with a spatial CNN [12] pre-trained on ImageNet [13] using RGB input by sampling frames from video, and the temporal stream using optical flow fields as input.
Tran et al. [14] proposed 3-dimensional convolutional networks (3D-CNNs) and found out that 3D CNNs are more suitable for spatio-temporal feature learning than 2D CNNs, also having compact features. Later, Tran et al. [15] introduced a new spatiotemporal convolutional block R(2+1)D, which is based on (2+1)D convolutions separating the 3D convolution into two steps. The idea is that it may be easier for the network to learn spatial and temporal features separately. Furthermore, Feichtenhofer et al. [16] have introduced the SlowFast architecture. The model is based on the use of two different frame rates as input, where the idea is to have a high-capacity slow pathway that sub-samples the input heavily, and a fast pathway that has less capacity but significantly higher frame rate.
Carreira and Zisserman [17] introduced an inflated 3D-CNN (I3D) that is expanded from the 2D CNN inflation, using both 3D convolution and the inception architecture [18]. I3D works much like the two-stream networks, using one network for the RGB stream input and one for the optical flow. To enable 3D convolution, they inflated filters on a pre-trained 2D CNN, i.e., they used transfer learning to initialize the 3D filters. Feichtenhofer et al. [19] explored the fusion process with 3D convolution and 3D pooling. The two-stream architecture is also extended with ST-ResNet [20], which adds residual connections [21] in both streams and from the motion stream to the spatial stream. Research into a combination of hand-crafted features and deep-learned features has also shown promising results [22]. Wang et al. [23,24] proposed temporal segment networks (TSNs), arguing that existing models mostly focused on short-term motion rather than on long-range temporal structures. TSN takes a video input, separates it into multiple snippets, and makes a prediction using two-stream networks for each snippet. C3D [14] explored learning spatio-temporal features with 3D convolutional networks. When compared to existing 2D convolution solutions, 3D convolution indeed proves beneficial by adding temporal information such as motion.
Donahue et al. [25] used long-term recurrent convolutional networks and models combining CNN as a feature extractor, and they fed the features to a long short-term memory (LSTM) model. This approach produced comparable results to Simonyan and Zisserman’s two-stream approach on the UCF101 dataset [26]. Qiu et al. [27] presented Local and Global Diffusion (LGD) networks. That is a novel architecture for the learning of spatio-temporal representations capturing long-range dependencies. LGD networks have two paths: a local and a global path for each spatio-temporal location. The local path describes local variation, and the global path describes holistic appearance. The LGD network outperformed several state-of-the-art models at the time on benchmarks, including UCF101 [26], where it reached an accuracy of %. Kalfaoglu et al. [28] combined 3D convolution with late temporal modeling. With the use of bidirectional encoder representations from transformers (BERT) instead of temporal global average pooling (TGAP), they increased performance for 3D convolution, achieving an accuracy of % and % for the HMDB51 [29] and UCF101 datasets, respectively.
Action detection aims to find the time interval in a video where a specific action occurs and to return these time tags along with a classification of the action. The task can be divided into two parts: generating temporal region proposals (also referred to as temporal action localization) and classifying the type of action taking place within the proposed time frame. In many studies, these two aspects are considered separately [23,30,31,32], but they are also adressed jointly with a single model in other works [33,34]. Some success has been observed with sliding window approaches [35]. However, this is computationally expensive and lacks flexibility due to fixed window sizes. Some works have focused on generating the temporal proposals, which can then be used with a classifier [36,37]. Inspired by Faster R-CNN [38], Xu et al. [39] created an end-to-end model for temporal action detection that generates temporal region proposals, followed by classification. There are two approaches to the proposal generation task: top down and bottom up. The top down approach has been used more frequently in previous works [31,40,41] and involves pre-defined intervals and lengths. This has the problems of boundary precision and the lack of flexibility in duration. Some methods have used the bottom up approach, like TAG [31] and BSN [37]. The drawback for them is the lack of ability to generate sufficient confidence scores for retrieving proposals. Recently, Lin et al. [37] addressed this challenge by introducing boundary-matching network (BMN), which generates proposals with more precise temporal boundaries and more reliable confidence scores. Combined with an existing action classifier, they reported state-of-the-art performance for temporal action localization.
In this work, we focus on action detection in the context of sports, and, more specifically, soccer videos. We refer to this task as event detection (also called spotting), which serves the purpose of identifying actions of interest in soccer games such as goals, player substitutions, and yellow/red cards (bookings).
2.2. Event Detection in Soccer Videos
Researchers have worked on capturing and analyzing soccer events for a long time, for various applications ranging from the verification of goals through goal-line technology [42], to player and ball tracking for segmentation and analysis [43,44,45], and the automatic control of camera movements for following the gameplay [46]. Events have also been extracted offline using metadata from news and media [47]. In this work, we are interested in the extraction of game happenings such as goals, cards, and substitutions in real-time (from live video streams), and in this context, the detection of events in soccer videos is not a new concept. Earlier approaches for the automated detection of selected events have employed probabilistic models such as Bayesian Networks [48,49], and hidden Markov model (HMM) [50,51,52,53,54]. With the rise of machine learning, there has been growing interest in using support vector machine (SVM) [55,56,57,58,59,60] and deep learning [45,61,62,63,64,65] due to their relatively higher performance (detection accuracy) and the availability of more advanced computing infrastructures.
After the release of SoccerNet by Giancola et al. [1], works on action detection in soccer videos through neural networks have gained prominence over solutions based on SVMs. SoccerNet was released with a baseline model reaching a mean average precision (mAP) of % for tolerances ranging from 5 to 60 s for the task of spotting, which has been defined by the authors as finding the temporal anchors of soccer events in a video. Giancola et al. proposed a sliding window approach at s stride, using C3D [14], I3D [17], and ResNet [21] as fixed feature extractors. Rongved et al. [2,3] used a ResNet 3D model pre-trained on the Kinetics-400 dataset [66] and reported an average-mAP of 51%, which is an increase from the baseline provided in Giancola et al. [1]. Rongved et al. further showed that the model generalized to datasets containing clips from the Norwegian soccer league Eliteserien and the Swedish soccer league Allsvenskan. The results showed that, in clips containing goals, they could classify 87% of the samples from Allsvenskan and 95% of the samples from Eliteserien, with a threshold of . Cioppa et al. [4] introduced a novel loss function that considers the temporal context present around the actions. They addressed the spotting task by using the introduced contextual loss function in a temporal segmentation module, and a YOLO [67]-like loss for an action spotting module creating the spotting predictions. This approach increased the average-mAP for the spotting task to % and is currently considered the state-of-the-art for the SoccerNet spotting task. Another approach to the SoccerNet spotting task was studied in Vats et al. [68], where the authors introduced a multi-tower temporal convolutional network architecture. 1D CNNs of varying kernel sizes and receptive fields were used, and the class-probabilities were obtained by merging the information from the parallel 1D CNNs. They reported an average-mAP of %, which has a difference of % from Cioppa et al. [4] with a simpler approach using a cross-entropy loss function. More recently, Zhou et al. [69] presented a solution where they fine-tune multiple action recognition models on soccer data to extract high-level semantic features, and design a transformer-based temporal detection module to locate the target events. They achieve good results in the SoccerNet-v2 spotting challenge with an average-mAP of about 75%.
In this work, we focus on the solutions presented by Cioppa et al. [4] and Rongved et al. [2,3] as representatives of state-of-the-art models and attempt to augment them using a multimodal context that includes both video and audio information.
2.3. Multimodality
The idea of a multimodal analysis of video content goes back at least 20 years. For example, Sadlier et al. [70] performed audio and visual analysis separately, then combined the statistics of the two approaches afterwards, showing the potential of multimodal analysis. Wang et al. [48] extracted audio and visual features from sport videos to generate keyword sequences, where a traditional SVM classifier was used to group the features, and an HMM classifier automatically found the temporal change character of the event instead of rule based heuristic modeling, to map certain keyword sequences into events.
Recently, newer approaches using deep neural networks have also been presented for use cases other than soccer. Ortega et al. [71] combined audio, video, and textual features by first separately using fully connected layers, followed by concatenation. SlowFast [72] used video frames as input at different sample rates and combined these with an audio stream that takes Log-Mel spectrograms as input, with lateral connections and a special training method to avoid overfitting.
In the context of our own research (event detection and classification in soccer videos), AudioVid [73] used a pre-trained audio model to extract features and combine them with the baseline model NetVLAD [1] at different points through concatenation. They found that audio generally increased the performance, and achieved a mAP of % for an action classification task and % for an action spotting task using SoccerNet. Gao et al. [74] used a new dataset including video (460 soccer game broadcasts) and audio information (commentator voice for 160 of the games, categorized as “excited” and “not-excited”) to benchmark existing methods such as I3D [17], I3D-NL [75], ECO [76], and pySlowFast [16], on detecting events (“celebrate”, “goal/shoot”, “card”, and “pass”) and found that I3D-NL achieves the best result. However, despite having a real-world deployment, the dataset from this work is not open.
In this work, we apply the idea of using multiple modalities for event detection in soccer videos, which has more frequently been demonstrated for HMMs and SVM, using deep learning models. More specifically, we focus on the state-of-the-art models from [2,4] (which improve upon the baseline model used by [73]) and augment these with a Log-Mel spectrogram-based audio model. We quantify the performance benefits for different event classes using the same SoccerNet dataset as our benchmark and point out when multimodality might be helpful and when it might actually be detrimental.
3. Tested Models
In this section, we describe the models we have experimented with for both visual and audio information. For the visual analysis, we used the model introduced by Cioppa et al. [4], the model presented by Rongved et al. [2], and a basic 2D CNN model. As mentioned in Section 2.2, the approach proposed in Cioppa et al. is currently considered the state-of-the-art for the SoccerNet spotting task, and Rongved et al. have shown that their model could generalize to multiple datasets. Thus, these can be considered as representative approaches of existing work. The 2D CNN model serves as a baseline. For the audio analysis, we have created another ResNet-based model by transforming audio signals into Log-Mel spectrograms and analyzing these.
3.1. Visual Model: CALF
As mentioned above, Cioppa et al. [4] introduced a loss function that considers the temporal context present around the actions, called context-aware loss function (CALF). Their model consists of a base convolution, a segmentation module that uses their novel loss function, and a spotting module. In the context of this work, we refer to this model as “CALF”. Our implementation follows the description provided in the original paper. The inputs to the model are the ResNet [21] features provided with the SoccerNet dataset [1] (see Section 5.1 for details).
3.2. Visual Model: 3D-CNN
Based on the model presented by Rongved et al. [2], we use an 18-layered 3D-ResNet on the video frame inputs. The model is composed of several residual blocks that contain 3D convolutions, with batch-normalization and ReLU. A visual representation of the pipeline is shown in Figure 2. Additionally, the model has been pre-trained on the Kinetics-400 [66] dataset.
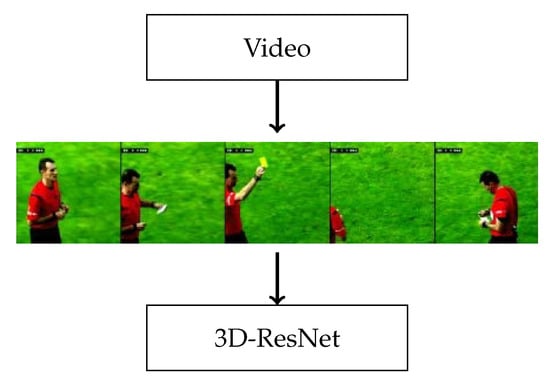
Figure 2.
Illustration of the pipeline used by the video-based 3D-ResNet model.
3.3. Visual Model: 2D-CNN
We use a 2D-CNN model that uses the pre-extracted ResNet features provided by SoccerNet. A visual representation of the overall pipeline is shown in Figure 3, and further details of the model are depicted in Figure 4. The model takes in features, where W is the window size used for sampling in seconds and . Inspired by the approach in SoccerNet [1], we first use a 2D convolution with a kernel . This is followed by batch-normalization and another 2D convolution that has a kernel of , such that it has a temporal receptive field of . Finally, we have two fully connected layers and an output layer.
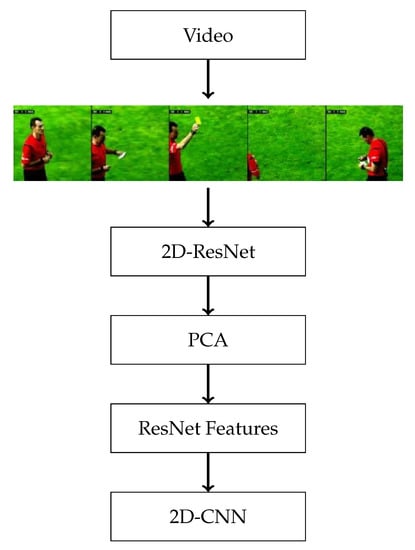
Figure 3.
Illustration of the pipeline used by the video-based 2D-CNN model. A pre-trained ResNet is used to extract features from video, followed by PCA [1]. The features can then be used to train a network for action detection tasks.

Figure 4.
Detailed workflow for the 2D-CNN model. This model uses a pre-computed set of features and is tested with both visual and audio-visual (visual augmented with audio) features in our study.
3.4. Audio Model
Our audio model is based on transforming the audio into Log-Mel spectrograms [5]. Figure 5 shows the pipeline for the audio model. First, audio is extracted from video in wave-form, which again is used to generate Log-Mel spectrograms. As several other approaches using Log-Mel spectrograms, we then use a CNN as a classifier, i.e., an 18-layered 2D-ResNet [21], in the same way as we train our visual models. We also test with different window sizes over which the spectrograms are generated, representing the temporal extent of the input used.
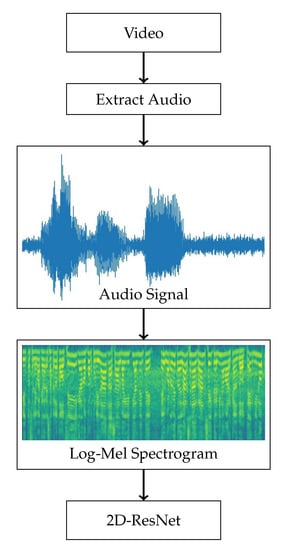
Figure 5.
Illustration of the pipeline used by the audio-based model. First, audio is extracted from the video. The audio is used to compute Log-Mel spectrograms, which are then used as inputs to a 2D-ResNet.
4. Model Fusion
In order to use multiple modalities such as video and audio, different models need to be combined. There are multiple ways of fusing models. We focus on two different approaches, which are detailed below.
4.1. Early Fusion through Concatenated Features
Early fusion, also referred to as data-level fusion or input-level fusion, is a traditional way of fusing data before conducting an analysis [77]. Within the context of our work, this approach translates to generating concatenated audio-visual features (i.e., generating audio features and concatenating them with existing visual ResNet features), which can then be used for training. We use the ResNet features supplied in SoccerNet [1] as our visual features. For our audio features, we first train an audio model using Log-Mel spectrograms on . Next, we remove the last layer, resulting in a 512-dimensional feature vector. These features are calculated 2 times per second, and we concatenate them such that we align them over time, resulting in a 1024-dimensional feature vector, 2 times per second. We illustrate this process of concatenated feature generation in Figure 6.
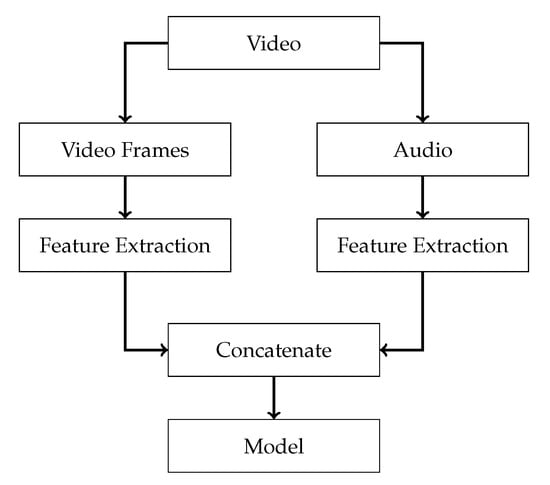
Figure 6.
Early fusion. Illustration of how audio-visual features can be created. A ResNet is used to compute visual features based on single frames. For the audio, a Log-Mel spectrogram is used to train a 2D-ResNet and further used as a feature extractor by removing the output layer. These features are then concatenated.
4.2. Late Fusion through Softmax Average and Max
In late fusion, also referred to as decision-level fusion, data sources are used independently until fusion at a decision-making stage. This method might be simpler than early fusion, particularly when the data sources are significantly varied from each other in terms of sampling rate, data dimensionality, and unit of measurement [77].
Within the context of our work, this approach translates to fusing independently built video and audio models by taking the softmax average or max of their predictions at test time. The intuition behind this approach is that, in cases where the video model might make a strong prediction that an event has occurred, the audio model might have weaker and made more uniform predictions, or vice versa. For softmax average fusion, we use the audio and video models, which have been trained on their respective inputs. For each sample, we take the average softmax prediction between the two models. For softmax max fusion, we calculate it similarly to softmax average, except that instead of average, we use the maximum softmax prediction between the two models. The process is illustrated in Figure 7.
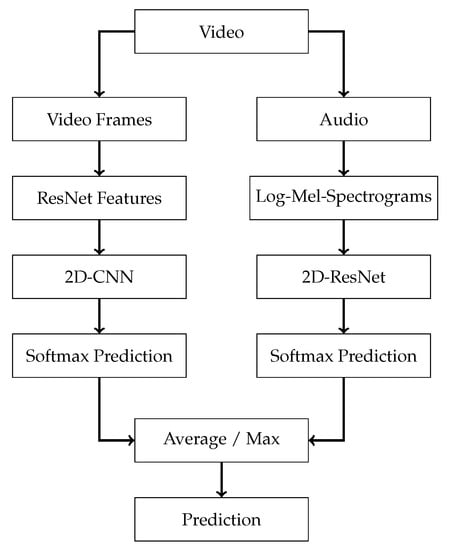
Figure 7.
Late fusion. Visualization of how two seperate models can be fused through softmax average: a visual pathway that uses a feature extractor with a 2D-CNN, and an audio pathway that uses Log-Mel spectrograms with a 2D-ResNet. These models are trained individually, and the output predictions are fused by softmax (average or max).
5. Experiments and Results
We have performed several experiments to evaluate the performance of different models, using the SoccerNet dataset for both spotting and classification tasks.
5.1. Dataset
We used the soccer-specific SoccerNet [1] dataset released in 2018. This is a dataset containing 500 soccer games from 2014 to 2017 with games from six European elite leagues. It has a total duration of 764 h and includes 6637 annotations of the event types goal, (yellow/red) card, and substitution. This gives a frequency of an event happening every min on average. Along with the three classes above, we follow the example in Rongved et al. [2] and add a background class by sampling in between events. If the time distance between two consecutive events is larger than 180 s, then a new background sample is added in the center, such that a background sample will never be within 90 s of another event.
In Table 1, we present the distribution of different events and how we have divided the dataset into training, validation, and test splits. The training, validation, and test splits are the same as in Giancola et al. [1], where the authors use 300 games for the training split, 100 games for the validation split, and 100 games for the test split. The augmented dataset containing the added background class is used for the classification task, for which the results are presented in Section 5.4 and Section 5.5, while only the original three classes are used by the CALF model for the spotting task, for which the results are presented in Section 5.6.

Table 1.
The number of samples per class in our dataset.
The SoccerNet dataset also comes with extracted visual ResNet features [1]. The features have been extracted from the videos by using a ResNet-152 [21] image classifier pre-trained on ImageNet [13]. Features are extracted from single video frames at a rate of 2 times per second. Subsequently, principal component analysis (PCA) is used to reduce the feature dimension to 512. These features are used in our experiments, as illustrated in Figure 3.
In addition to the visual ResNet features provided by SoccerNet, we also extract information from the video and audio streams in the dataset directly. In Table 2, we give an overview of which type of data is used with which combination of models.
Table 2.
Overview of which combination of models use which type of data, indicated by a checkmark. ResNet features are the visual features extracted using the ResNet model accompanying the SoccerNet dataset. Video is the 3D-ResNet extracted features using video frames from the games in SoccerNet. Audio is the Log-Mel spectrograms generated from the audio of the games in SoccerNet.
5.2. Training and Implementation Details
We implemented the classification models in PyTorch [78], and trained on an Nvidia DGX-2, which consists of 16 Nvidia Tesla V100 graphics processing units (GPUs) and has a total memory capacity of 512 Gigabytes. For the CALF model, we used the implementation from the original paper [4].
Both the 3D-CNN described in Section 3.2 and the 2D-ResNet described in Section 3.4 have similar architectures, with a global average pool (GAP) layer at the end. Due to the GAP layer, varying input dimensions will not have an effect on the number of weights for each model. For both the CALF and 2D-CNN models, described in Section 3.1 and Section 3.3, respectively, the models are generated based on input dimensions. This results in a greater number of weights when the input dimensions increase.
5.2.1. Classification Task
For the classification task, we use a minibatch size of 32 for all models, an initial learning rate of , and momentum of . We use a scheduler that reduces the learning rate by a multiplicative factor of every 10 epochs. During training, we saved the model that had the best accuracy on the validation set and evaluate its performance on the test set.
The 3D-CNN is described in Section 3.2. This approach takes video frames as input. First, due to high memory cost, we use a sample interval of 5, meaning that we reduce each second of video from 25 frames to five frames. Additionally, we downscale the resolution from to . During training, we randomly flip all frames in a sample horizontally, with probability. In both training and testing, the samples are normalized. We initialize the model with pre-trained weights, previously trained on the Kinetics-400 dataset [66], and fine-tune the model on the SoccerNet dataset over 12 epochs.
For the audio model, we first generate Log-Mel spectrograms, after which we train on a 2D-ResNet as described in Section 3.4. We use ResNet features to create a 2D-CNN as described in Section 3.3. For both the audio model and for the 2D-CNN on ResNet features, we train for 25 epochs.
5.2.2. Spotting Task
For the spotting task, we use the CALF model and features from the audio model described in Section 3.4 for . We experiment with ResNet features, audio features, and concatenated features that combine the ResNet features and audio features. Our testing is based on the implementation provided by Cioppa et al. [4].
The model takes as input chunks of frames, and the chosen chunk size in the original CALF model covers 120 s of gameplay, with a receptive field of 40. We vary the chunk size and temporal receptive field as they might affect the results for lower tolerances and for when audio features are used. In this paper, we use the models that achieve the best results on the validation, i.e., chunk sizes 120 and 60, with receptive fields of 40, 20, and 5. These three configurations are referred to as “CALF-120-40”, “CALF-60-20”, and “CALF-60-5”.
We use a learning rate of for all variations. For our tests with only ResNet features, we train CALF for 300 epochs, validating every 20 epochs. Due to instabilities while training with audio and concatenated features, we train for 30 epochs on audio features and 50 epochs on concatenated features, and validate every 2 epochs.
5.3. Metrics
We use standard metrics like accuracy, precision, recall, and F1-score in our multi-class classification experiments. The task can be interpreted as a one-vs.-all binary classification problem for each class, where a prediction is considered to be a True Positive (TP) when the model predicts the correct class, a False Positive (FP) when a class is incorrectly predicted, a True Negative (TN) when a class is correctly rejected, and a False Negative (FN) when a class is incorrectly rejected. Based on these, accuracy is defined as the number of correct predictions over the total number of predictions:
Precision, also called Positive Predictive Value (PPV), is the ratio of samples that are correctly identified as positive over all samples that are identified as positive:
Recall is the ratio of samples that are correctly identified as positive over all positive samples:
Finally, the F1 score is the harmonic mean of precision and recall:
For spotting, we additionally use average-mAP, which is a metric introduced by Giancola et al. [1], and is expressed as the area under the mAP curve with tolerances ranging from 5 to 60 s. We regard each class separately as a one-vs.-all binary problem and consider a positive prediction as a possible True Positive (TP) if it is within a tolerance of the ground truth event with a confidence equal to or higher than our threshold. Formally, we use the condition in Equation (5):
where is a ground truth spot and is a predicted spot in seconds. We take predictions that match the criteria in Equation (5) and create unique pairs of predicted spots and ground truth spots. These are matched in a greedy fashion, where each ground truth spot is matched with the closest prediction. Predicted spots that have no match are considered a False Positive (FP). For a given , when no predictions are made where this condition holds, we consider it a False Negative (FN). We use the condition in Equation (5) to calculate the average precision (AP) for each class:
where and are the recall and precision at the n’th threshold, respectively. AP is related to precision-recall and can be calculated as the area under the curve. This is useful as it reduces the PR-curve to a single numerical value. Subsequently, we calculate the mAP:
where is AP calculated for the i’th class for C classes and mAP is the mean AP calculated over all classes. This is then calculated for tolerances ranging between 5 and 60 s. Finally, we use the mAP scores calculated for different to calculate the area under the ROC curve (AUC) and the average-mAP score, which provides some insight into the model’s overall performance in the range of 5–60 s.
5.4. Input Window
When training on audio and/or video features, we need to consider what input works best. To that end, we investigate the effect of different temporal windows used for our classification samples, as well as the positioning of our samples relative to the events.
5.4.1. Window Size
The window size determines the temporal size of the input, for example, 1 s of audio features around a given event. Using a large window may include other events or noise, while using a small window might not capture enough relevant information. Another implication of the window size is that it can impact the buffering needed in a real-time scenario, where low latency is required. Regarding the effect the window size has on performance, we observe an improvement for larger temporal inputs across all approaches in Figure 8. Thus, for classification accuracy, a larger window is better. However, as large windows can also have drawbacks, we continue experimenting with different windows sizes in the following experiment.
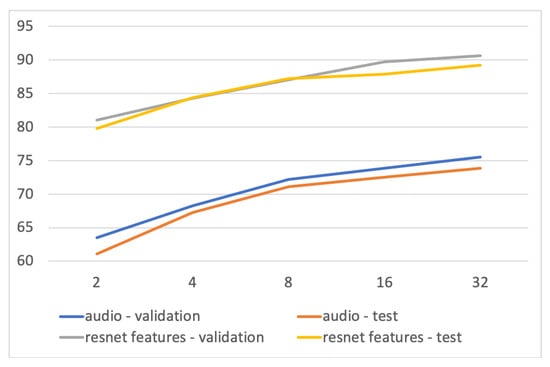
Figure 8.
Classification performance with respect to window size (2–32), using the audio model and the ResNet visual features on the validation and test sets. In general, larger windows lead to better results.
5.4.2. Window Position
The window position will impact what information we are using. We illustrate some different positions in Figure 9:
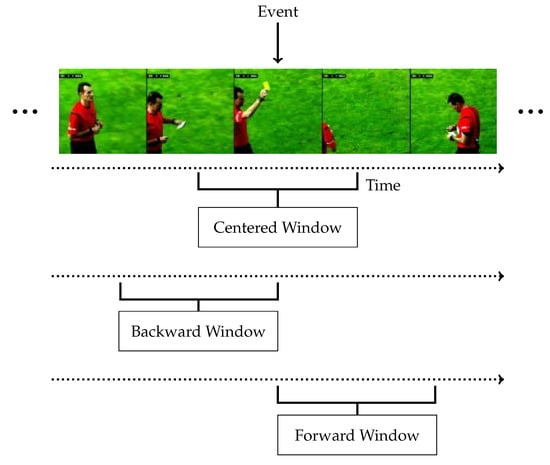
Figure 9.
Illustration of window positions relative to the event, for a given sample. A centered window uses both past and future information, while a backward or forward (shifted) window relies only on the past and future, respectively.
- Centered window: A centered window will sample locally around a given event, including both past and future information.
- Backward (shifted) window: For backward window, we only use temporal information up to the point of an event. This can be thought of as a slightly different task, where we predict what is about to occur based on information leading up to an event, rather than what has happened.
- Forward (shifted) window: Samples from just after the event anchor may contain the most relevant information, such as a soccer ball in a goal, with subsequent celebration without ambiguous prior information.
There are both theoretical and practical consequences associated with the different window positions. In real-time detection, reliance on future information requires buffering before a prediction can be made, thus introducing an undesirable delay.
From Table 3, we observe that for the audio model, using a centered window performs best at 75% accuracy on both the validation and test set. A forward shift results in a drop in performance, and a backward shift performs the worst. This may be due to the relative change in audio just before and after an event, which is only captured by the center position.
Table 3.
Comparison of the accuracy of classification for different models on the validation and test sets, with respect to window position.
The results for the visual model show that there is little difference between centered and forward shifted window positions. Backward shifted window performs worse, with close to a 13% absolute drop in accuracy. The reason for this may be that for visual features, the most interesting and discriminating information can be found after the event itself. Thus, in the following experiments, we use a centered window.
5.5. Classification Performance
To evaluate the performance of the classification task, we performed several experiments using the audio 2D-ResNet on Log-Mel spectrograms as described in Section 3.4. This is compared to and combined with the two different visual models based on the 3D-CNN ResNet described in Section 3.2 and the 2D-CNN described in Section 3.3. These models are combined by softmax average and softmax max described in Section 4. Additionally, a separate model trained on concatenated audio features and ResNet features is used.
5.5.1. Overall Performance
We have first assessed the overall results across all events. As observed in Table 4 and Table 5 for the 3D and 2D models, respectively, the audio model generally performs worse than the visual model. Evaluating the results in Table 4 for the 3D visual model, the results indicate that using visual information alone is slightly better. However, using the 2D visual model, the results in Table 5 show improvements in most cases using result concatenation. Thus, it is unclear if the multimodal approach improves performance. When combining the visual and audio models at small window sizes, we observe that the results are worse than the visual model but still competitive. However, the overall best results are present for window sizes W > 16, where the softmax average outperforms the visual-only model. It is therefore interesting to break down the performance into per-event classification to evaluate whether there are differences between event types (which should be expected as, for example, goals often have predictable audio with high sound and fans cheering, whereas events like cards and substitutions have unpredictable audio).
Table 4.
Comparison of the accuracy of classification on the validation and test sets, for different models and late fusion alternatives. The audio model is described in Section 3.4, and the video-based 3D-CNN model is described in Section 3.2. The fusion of the audio and video features is performed using either softmax average or softmax max, as described in Section 4.
Table 5.
Comparison of the accuracy (%) of classification on the validation and test sets, for different models and fusion alternatives. The audio model is described in Section 3.4, and the video-based 2D-CNN model with pre-extracted ResNet features is described in Section 3.3. The fusion of the audio and video features is performed using early fusion (concatenation) or late fusion (either softmax average or softmax max), as described in Section 4.
5.5.2. Performance per Event Type
For the per-event analysis, we used the same audio and visual models as described above, and softmax average for the fusion of features. Table 6 shows the detailed results using the 3D-CNN model, and Table 7 presents the 2D-CNN model. In Figure 10, we highlighted some of the F1 scores given in the tables. In general, we observe that for goals, combining audio information with visual information almost always improves performance. For other events, it depends a bit on the configuration, but it appears that the more audio information is included, i.e., the larger the audio window, the better the results become.
Table 6.
Comparison of precision, recall and F1-score per class (event type), for the 3D model (Section 3.2). W is the window size used for the input. The results for the combined input types are obtained using late fusion with softmax average.
Table 7.
Comparison of precision, recall, and F1-score per class (event type), for the 2D model (Section 3.3). W is the window size used for the input. The input type Combined is the combination of the Resnet and audio models. The results for the Combined input type are obtained using late fusion with softmax average.
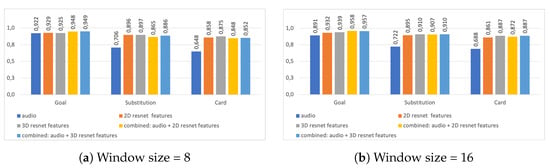
Figure 10.
Classification performance in terms of F1 score, for the 2D (Section 3.3) and the 3D (Section 3.2) models using different input types. We present the results for selected samples from Table 6 and Table 7, using window sizes of 8 and 16. The results for the combined input types are obtained using softmax average. We observe that for the Goal class, the multimodal approach always performs better.
5.6. Spotting Performance
To test how different combinations of audio and visual features affect spotting performance, i.e., detecting an event in the video stream, once again we experimented with various settings. Here, we used the CALF model described in Section 3.1 with chunk sizes 60 and 120, and receptive fields of 5, 20, and 40. We compared the performance of the models using audio features, visual ResNet features, and combined audio and ResNet features as input. The audio features were extracted from the model described in Section 3.4, and the visual ResNet features were the ResNet features supplied along with SoccerNet [1]. The combination (fusion) of audio and ResNet features was performed using the concatenation process described in Section 4.1.
5.6.1. Overall Performance
From Table 8, we observe that for 2 out of 3 tested configurations (“CALF-60-20” and “CALF-120-40”), using ResNet features alone achieves the highest average-mAP. The only configuration that has an increase in average-mAP for input type of ResNet + audio is the model with the smallest chunk size and receptive field (“CALF-60-5”). This may imply that the benefits of concatenating audio and ResNet features compared to using ResNet features alone are higher for smaller receptive fields.
Table 8.
Performance of the CALF [4] model with different configurations, tested on the test set. The mAP values indicate the Average Precision values averaged over all event types. The Combined input type is the integration of the ResNet and the audio models.
The highest average-mAP among all the tested CALF configurations is achieved by the one that uses ResNet features only, with a chunk size of 120 and receptive field 40 (“CALF-120-40”). With respect to average-mAP, we observe that the configuration that performs best with the ResNet + audio input type (“CALF-60-5”) does not outperform either of the configurations which perform best with ResNet features alone, overall.
It should also be noted that for some configurations, using audio features alone did not allow one to identify any events correctly. There might be several reasons for this, but still, we see examples where the combination of audio and visual information improves the results. As Table 8 depicts the combined results over all 3 event types (Card, Goal, and Substitution classes), we next look at the spotting performance for each individual class, similar to the classification performance analysis in Section 5.5.
5.6.2. Performance per Event Type
Inspecting the performance indicators in Figure 11 and Table 9, we observe a clear distinction between different classes (event types). While the performance for Card and Substitution events drops for two of the configurations, there is a significant increase in the Average-AP for all three configurations for Goal events. Averaged across all three, the increase is at nearly 7%. This may imply that some events are inherently easier to recognize through audio than others, due to the nature of the event. It is easy to imagine that a goal might be easier to recognize based on sound than cards and substitutions, due to the loud celebration that often follows a goal.
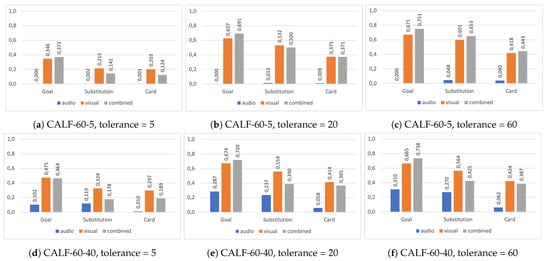
Figure 11.
Spotting performance in terms of Average Precision per event type, for the CALF-60-5 and CALF-60-20 models over the tolerances 5, 20, and 60. In general, we can observe that for goals, adding audio information almost always improves performance. For other events, it depends on the configuration, but it seems like the more audio information is included, the better the results get.
Table 9.
Comparison of precision, recall, and F1-score per class (event type), for the CALF [4] model with different configurations. Highlighted cells indicate the best Average Precision score in each individual experiment. The Combined input type is the integration of the ResNet and the audio models.
Since we observed that the performance has declined for card and substitution events, where it has increased for goal events, it could be interesting to train a model using different modalities for different events. If one could identify events that benefit from concatenated features and only use these features for the given events, the overall performance of the ensemble model could be improved. As an example, if we combine the results from the concatenated features for goals, and the ResNet features for cards and substitutions, we increase the average-mAP by over 2%.
6. Discussion
In this work, our main aim is not to develop a completely novel model that yields a performance surpassing the state-of-the-art but rather to assess the potential of using multiple modalities, for event detection in soccer videos. We evaluate different model and modality combinations from the state-of-the-art using different configurations, in order to derive insights. In this respect, as also described in Section 2.3, the use of multiple modalities is not a new idea, but the amount of work on deep neural networks is limited. In this paper, we used two existing state-of-the-art visual models based on CNN and assessed the effect of adding audio information on the detection accuracy, for different types of events.
In general, our experimental results show that the benefit of analyzing audio information alone, or in addition to the visual information, is dependent on the context or the type of event. As shown in Table 7 and Table 9, there are many events where the combined modalities have a positive effect on detection and classification performance. Still, the improvement is much more profound for events such as goals, which tend to be followed by a more predictable type of sound (e.g., high volume audio with excited commentator or a cheering crowd). This finding is in line with existing works focusing solely on audio information, which typically focus on events where commentator and audience responses to the action are distinguishable. For instance, Xu et al. [55] create seven audio keywords for detecting potential events: long-whistling, double-whistling, multiwhistling, exciting commentator speech, plain commentator speech, exciting audience sound, and plain audience sound, with the justification that these have strong ties to certain types of events. Islam et al. [79] propose an approach to extract audio features using Empirical Mode Decomposition (EMD) that can filter out noises. They conduct a set of experiments on four soccer videos and show that the proposed method can detect goal events with 96% accuracy. Albeit successful, this approach might not be generalizable to different types of events as a standalone solution and is tested on a relatively small scale. However, this is a very interesting area for research. Our results show that, overall, multimodality has a more inconclusive effect on events without any particular audio pattern. Thus, the choice of modalities should be based on the target event. However, this does not discourage the use of finer-tuned and event-specific audio models, which can be used together with visual models conditionally (depending on context).
The visual CNN models we have experimented with are meant as examples of state-of-the-art models. New models are currently being developed and tested. For example, in the SoccerNet-v2 challenge [80], the best dataset benchmark models, CALF [4], AudioVid [73] and NetVLAD [1], have achieved average-mAP values of 72.2%, %, and % for goal events, respectively. Moreover, Zhou et al. [69] also achieved good results in the SoccerNet-v2 spotting challenge as the winning team, with an overall average-mAP of about 75% (the authors do not provide event-specific numbers). However, these numbers are lower than our AP of 84% for goal events, achieved by the combined model as shown in Table 9.
Another issue observed both in our results and in various SoccerNet papers (e.g., [1,4,73,80]) is that the input window greatly affects performance. A larger window yields more data to analyze and delays inference prediction in any live event scenario as one must wait for the window to be available and processed. For example, our approach in [2] relies on a small temporal window of 8 s after post-processing, and the values calculated for tolerances can therefore be misleading. The average-mAP metric uses a range of tolerances from 5 to 60 s, and since our model relies on local information rather than long-range contextual information regarding events, it is expected that higher tolerances will only result in finding spots that are false positives. However, in a real-time setting, it may be important to have as little delay in predictions as possible. For our approach, a live prediction will have a delay of about 4 s (for tolerances ). This includes buffering future frames and computation. The baseline model would have about 10 s of delay, while the current state-of-the-art [4] would have about 100 s. It seems that long-range contextual features can boost performance, and there is a trade-off between delay and the practical ability to buffer future video frames.
7. Summary and Conclusions
In this paper, we present our research on detecting events in soccer videos, where we evaluate the use of visual, audio, and the combination of visual and audio features. In particular, we focus on three types of events (cards, substitutions, and goals), implement and experiment with existing state-of-the-art visual models based on the ResNet model, using the SoccerNet dataset containing 500 games and a total of 6637 annotated events belonging to the above classes. Additionally, we develop an audio-based model using Log-Mel spectrograms and similarly experiment with this model under different configurations. Finally, we use a multimodal approach where we combine the video and audio models, using both early fusion (feature concatenation) and late fusion (averaging/maxing the softmax prediction values from independent models).
Our experimental results demonstrate the potential of using multiple modalities as the performance of detecting events increases in many of the selected configurations when features are combined. However, we have also seen that there is a difference in the benefits gained from the multimodal approach with respect to different event types. More specifically, the combination of audio and visual features proved more beneficial for the Goal events than for Card and Substitution events. This yields insights into a potential new research direction, where we could decide on the use of multiple modalities based on targeted event categories since different events have different “associated” audio (e.g., for goals, it is usually some predictable high volume cheering, whereas for substitutions and cards, we do not have the same predictable audio). In summary, an ML-based event detection component utilizing several available data modalities can be an important component of future intelligent video processing and analysis systems.
Our ongoing and future work include the following. Firstly, we would like to pursue the path of deciding on the deployment of multimodality based on target event type. Secondly, we would like to investigate more events that are of interest for soccer games, for instance, by using the newer SoccerNet-v2 dataset (https://soccer-net.org, accessed on 3 December 2021), which includes new categories. Thirdly, we would like to focus on the generalizability of our algorithms and findings via cross-dataset analysis, using results from multiple soccer, and, later on, other sports datasets. For instance, in addition to exploring the SoccerNet-v2 dataset, we have also been experimenting with in-house datasets we have been collecting from the Norwegian and Swedish elite soccer leagues, currently containing about 1000 annotated events. Last but not least, we would like to work on optimizing the individual models we have evaluated in this study, such as finding the right trade-offs between detection latency (as determined by input window size and position), processing overhead, and detection accuracy.
Author Contributions
Conceptualization, O.A.N.R., M.S., S.A.H., M.A.R., and P.H.; methodology, O.A.N.R., M.S., S.A.H., M.A.R., and P.H.; software, O.A.N.R. and M.S.; validation, O.A.N.R., M.S., S.A.H., M.A.R., and P.H.; investigation, all authors; resources, O.A.N.R., M.S., S.A.H., D.J., M.A.R., and P.H.; data curation, O.A.N.R., M.S., and P.H.; writing—original draft preparation, all authors; writing—review and editing, all authors; visualization, all authors; supervision, S.A.H., V.L.T., E.Z., D.J., M.A.R., and P.H.; funding acquisition, M.A.R. and P.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Norwegian Research Council, project number 327717 (AI-producer).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The SoccerNet dataset is made available by Giancola et al. [1].
Acknowledgments
The research has benefited from the Experimental Infrastructure for Exploration of Exascale Computing (eX3), which is financially supported by the Research Council of Norway under contract 270053. We also acknowledge the use of video data from Norsk Toppfotball (NTF).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Giancola, S.; Amine, M.; Dghaily, T.; Ghanem, B. SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1711–1721. [Google Scholar] [CrossRef] [Green Version]
- Rongved, O.A.N.; Hicks, S.A.; Thambawita, V.; Stensland, H.K.; Zouganeli, E.; Johansen, D.; Riegler, M.A.; Halvorsen, P. Real-Time Detection of Events in Soccer Videos using 3D Convolutional Neural Networks. In Proceedings of the SMEEE International Symposium on Multimedia (ISM), Naples, Italy, 2–4 December 2020; pp. 135–144. [Google Scholar] [CrossRef]
- Rongved, O.A.N.; Hicks, S.A.; Thambawita, V.; Stensland, H.K.; Zouganeli, E.; Johansen, D.; Midoglu, C.; Riegler, M.A.; Halvorsen, P. Using 3D Convolutional Neural Networks for Real-time Detection of Soccer Events. IEEE J. Sel. Top. Signal Process. 2021, 15, 161–187. [Google Scholar] [CrossRef]
- Cioppa, A.; Deliege, A.; Giancola, S.; Ghanem, B.; Droogenbroeck, M.; Gade, R.; Moeslund, T. A Context-Aware Loss Function for Action Spotting in Soccer Videos. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B.; Schmid, C. Human Detection Using Oriented Histograms of Flow and Appearance. In Proceedings of the ECCV, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense Trajectories and Motion Boundary Descriptors for Action Recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Schmid, C. Action Recognition with Improved Trajectories. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale Video Classification with Convolutional Neural Networks. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Goodale, M.A.; Milner, A.D. Separate visual pathways for perception and action. Trends Neurosci. 1992, 15, 20–25. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar] [CrossRef] [Green Version]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv 2018, arXiv:1705.07750. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar] [CrossRef] [Green Version]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Residual Networks for Video Action Recognition. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 3476–3484. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar] [CrossRef] [Green Version]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Qiu, Z.; Yao, T.; Ngo, C.W.; Tian, X.; Mei, T. Learning Spatio-Temporal Representation with Local and Global Diffusion. arXiv 2019, arXiv:1906.05571. [Google Scholar]
- Kalfaoglu, M.E.; Kalkan, S.; Alatan, A.A. Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition. arXiv 2020, arXiv:2008.01232. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB51: A Large Video Database for Human Motion Recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 13–16 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef] [Green Version]
- Singh, G.; Cuzzolin, F. Untrimmed Video Classification for Activity Detection: Submission to ActivityNet Challenge. arXiv 2016, arXiv:1607.01979. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal Action Detection with Structured Segment Networks. arXiv 2017, arXiv:1704.06228. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the Faster R-CNN Architecture for Temporal Action Localization. arXiv 2018, arXiv:1804.07667. [Google Scholar]
- Lin, T.; Zhao, X.; Shou, Z. Single Shot Temporal Action Detection. In Proceedings of the ACM MM, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Buch, S.; Escorcia, V.; Ghanem, B.; Fei-Fei, L.; Niebles, J.C. End-to-End, Single-Stream Temporal Action Detection in Untrimmed Videos. In Proceedings of the BMVC, London, UK, 4–7 September 2017. [Google Scholar]
- Idrees, H.; Zamir, A.R.; Jiang, Y.; Gorban, A.; Laptev, I.; Sukthankar, R.; Shah, M. The THUMOS challenge on action recognition for videos “in the wild”. Comput. Vis. Image Underst. 2017, 155, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. BMN: Boundary-Matching Network for Temporal Action Proposal Generation. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. BSN: Boundary Sensitive Network for Temporal Action Proposal Generation. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-C3D: Region Convolutional 3D Network for Temporal Activity Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Niebles, J.C. SST: Single-Stream Temporal Action Proposals. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6373–6382. [Google Scholar]
- Heilbron, F.; Niebles, J.C.; Ghanem, B. Fast Temporal Activity Proposals for Efficient Detection of Human Actions in Untrimmed Videos. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Spagnolo, P.; Leo, M.; Mazzeo, P.L.; Nitti, M.; Stella, E.; Distante, A. Non-invasive Soccer Goal Line Technology: A Real Case Study. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Portland, OR, USA, 23–28 June 2013; pp. 1011–1018. [Google Scholar] [CrossRef]
- Mazzeo, P.L.; Spagnolo, P.; Leo, M.; D’Orazio, T. Visual Players Detection and Tracking in Soccer Matches. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Santa Fe, NM, USA, 1–3 September 2008; pp. 326–333. [Google Scholar] [CrossRef]
- Stensland, H.K.; Gaddam, V.R.; Tennøe, M.; Helgedagsrud, E.; Næss, M.; Alstad, H.K.; Mortensen, A.; Langseth, R.; Ljødal, S.; Landsverk, O.; et al. Bagadus: An Integrated Real-Time System for Soccer Analytics. ACM Trans. Multimed. Comput. Commun. Appl. 2014, 10, 1–21. [Google Scholar] [CrossRef]
- Thamaraimanalan, T.; Naveena, D.; Ramya, M.; Madhubala, M. Prediction and Classification of Fouls in Soccer Game using Deep Learning. Ir. Interdiscip. J. Sci. Res. 2020, 4, 66–78. [Google Scholar]
- Gaddam, V.R.; Eg, R.; Langseth, R.; Griwodz, C.; Halvorsen, P. The Cameraman Operating My Virtual Camera is Artificial: Can the Machine Be as Good as a Human? ACM Trans. Multimed. Comput. Commun. Appl. 2015, 11, 1–20. [Google Scholar] [CrossRef]
- Johansen, D.; Johansen, H.; Aarflot, T.; Hurley, J.; Kvalnes, R.; Gurrin, C.; Zav, S.; Olstad, B.; Aaberg, E.; Endestad, T.; et al. DAVVI: A Prototype for the next Generation Multimedia Entertainment Platform. In Proceedings of the International Conference on Multimedia (ACM MM), Vancouver, BC, Canada, 19–24 October 2009; pp. 989–990. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Chng, E.; Tian, Q. Sports highlight detection from keyword sequences using HMM. In Proceedings of the IEEE International Conference on Multimedia Expo (ICME), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 599–602. [Google Scholar] [CrossRef]
- Dhanuja, S.P.; Waykar, S.B. A Survey on Event Recognition and Summarization in Football Videos. Int. J. Sci. Res. 2014, 3, 2365–2367. [Google Scholar]
- Xiong, Z.; Radhakrishnan, R.; Divakaran, A.; Huang, T. Audio events detection based highlights extraction from baseball, golf and soccer games in a unified framework. In Proceedings of the International Conference on Multimedia and Expo (ICME), Baltimore, MD, USA, 6–9 July 2003; Volume 3, p. III-401. [Google Scholar] [CrossRef]
- Pixi, Z.; Hongyan, L.; Wei, W. Research on Event Detection of Soccer Video Based on Hidden Markov Model. In Proceedings of the 2010 International Conference on Computational and Information Sciences, Chengdu, China, 17–19 December 2010; pp. 865–868. [Google Scholar] [CrossRef]
- Qian, X.; Liu, G.; Wang, H.; Li, Z.; Wang, Z. Soccer Video Event Detection by Fusing Middle Level Visual Semantics of an Event Clip. In Proceedings of the Advances in Multimedia Information Processing (PCM), Shanghai, China, 21–24 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 439–451. [Google Scholar]
- Qian, X.; Wang, H.; Liu, G. HMM based soccer video event detection using enhanced mid-level semantic. Multimed. Tools Appl. 2012, 60, 233–255. [Google Scholar] [CrossRef]
- Itoh, H.; Takiguchi, T.; Ariki, Y. Event Detection and Recognition Using HMM with Whistle Sounds. In Proceedings of the 2013 International Conference on Signal-Image Technology Internet-Based Systems, Kyoto, Japan, 2–5 December 2013; pp. 14–21. [Google Scholar] [CrossRef]
- Xu, M.; Maddage, N.; Xu, C.; Kankanhalli, M.; Tian, Q. Creating audio keywords for event detection in soccer video. In Proceedings of the International Conference on Multimedia and Expo (ICME), Baltimore, MD, USA, 6–9 July 2003; Volume 2, p. II-281. [Google Scholar] [CrossRef] [Green Version]
- Ye, Q.; Huang, Q.; Gao, W.; Jiang, S. Exciting Event Detection in Broadcast Soccer Video with Mid-Level Description and Incremental Learning. In Proceedings of the ACM International Conference on Multimedia (MM), Singapore, 6–11 November 2005; pp. 455–458. [Google Scholar] [CrossRef]
- Sadlier, D.; O’Connor, N. Event detection in field sports video using audio-visual features and a support vector machine. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 1225–1233. [Google Scholar] [CrossRef] [Green Version]
- Jain, N.; Chaudhury, S.; Roy, S.D.; Mukherjee, P.; Seal, K.; Talluri, K. A Novel Learning-Based Framework for Detecting Interesting Events in Soccer Videos. In Proceedings of the Indian Conference on Computer Vision, Graphics Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 119–125. [Google Scholar] [CrossRef]
- Zawbaa, H.M.; El-Bendary, N.; Hassanien, A.E.; Abraham, A. SVM-based soccer video summarization system. In Proceedings of the the World Congress on Nature and Biologically Inspired Computing, Salamanca, Spain, 19–21 October 2011; pp. 7–11. [Google Scholar] [CrossRef] [Green Version]
- Fakhar, B.; Kanan, H.; Behrad, A. Event detection in soccer videos using unsupervised learning of Spatio-temporal features based on pooled spatial pyramid model. Multimed. Tools Appl. 2019, 78, 16995–17025. [Google Scholar] [CrossRef]
- Jiang, H.; Lu, Y.; Xue, J. Automatic Soccer Video Event Detection Based on a Deep Neural Network Combined CNN and RNN. In Proceedings of the IEEE International Conference on Tools with Artificial Intelligence (ICTAI), San Jose, CA, USA, 6–8 November 2016; pp. 490–494. [Google Scholar] [CrossRef]
- Tang, K.; Bao, Y.; Zhao, Z.; Zhu, L.; Lin, Y.; Peng, Y. AutoHighlight: Automatic Highlights Detection and Segmentation in Soccer Matches. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 4619–4624. [Google Scholar] [CrossRef]
- Khan, A.; Lazzerini, B.; Calabrese, G.; Serafini, L. Soccer Event Detecion. In Proceedings of the the International Conference on Image Processing and Pattern Recognition (IPPR), Copenhagen, Denmark, 28–29 April 2018. [Google Scholar] [CrossRef]
- Hong, Y.; Ling, C.; Ye, Z. End-to-end soccer video scene and event classification with deep transfer learning. In Proceedings of the International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yu, J.; Lei, A.; Hu, Y. Soccer Video Event Detection Based on Deep Learning. In Proceedings of the MultiMedia Modeling (MMM), Thessaloniki, Greece, 8–11 January 2019; pp. 377–389. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Vats, K.; Fani, M.; Walters, P.; Clausi, D.A.; Zelek, J. Event detection in coarsely annotated sports videos via parallel multi receptive field 1D convolutions. arXiv 2020, arXiv:2004.06172. [Google Scholar]
- Zhou, X.; Kang, L.; Cheng, Z.; He, B.; Xin, J. Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection. arXiv 2021, arXiv:2106.14447. [Google Scholar]
- Sadlier, D.A.; O’Connor, N.; Marlow, S.; Murphy, N. A combined audio-visual contribution to event detection in field sports broadcast video. In Case study: Gaelic football. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Darmstadt, Germany, 17 December 2003; pp. 552–555. [Google Scholar] [CrossRef] [Green Version]
- Ortega, J.; Senoussaoui, M.; Granger, E.; Pedersoli, M.; Cardinal, P.; Koerich, A. Multimodal Fusion with Deep Neural Networks for Audio-Video Emotion Recognition. arXiv 2019, arXiv:1907.03196. [Google Scholar]
- Xiao, F.; Lee, Y.J.; Grauman, K.; Malik, J.; Feichtenhofer, C. Audiovisual SlowFast Networks for Video Recognition. arXiv 2020, arXiv:2001.08740. [Google Scholar]
- Vanderplaetse, B.; Dupont, S. Improved Soccer Action Spotting Using Both Audio and Video Streams. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Gao, X.; Liu, X.; Yang, T.; Deng, G.; Peng, H.; Zhang, Q.; Li, H.; Liu, J. Automatic Key Moment Extraction and Highlights Generation Based on Comprehensive Soccer Video Understanding. In Proceedings of the IEEE International Conference on Multimedia Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 13–18 June 2018. [Google Scholar]
- Zolfaghari, M.; Singh, K.; Brox, T. ECO: Efficient Convolutional Network for Online Video Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor Data Fusion: A Review of the State-of-the-Art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, QC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Islam, M.R.; Paul, M.; Antolovich, M.; Kabir, A. Sports Highlights Generation using Decomposed Audio Information. In Proceedings of the IEEE International Conference on Multimedia Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 579–584. [Google Scholar] [CrossRef]
- Deliège, A.; Cioppa, A.; Giancola, S.; Seikavandi, M.J.; Dueholm, J.V.; Nasrollahi, K.; Ghanem, B.; Moeslund, T.B.; Droogenbroeck, M.V. SoccerNet-v2: A Dataset and Benchmarks for Holistic Understanding of Broadcast Soccer Videos. arXiv 2021, arXiv:2011.13367. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).