Semi-Supervised Adversarial Variational Autoencoder


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Our approach perfectly combines the two models, i.e., GAN and VAE, and thus improves the generation and reconstruction performance of the VAE.
- The VAE training is done in two steps, which allows to dissociate the constraints used for the construction of the latent space on the one hand, and those used for the training of the decoder.
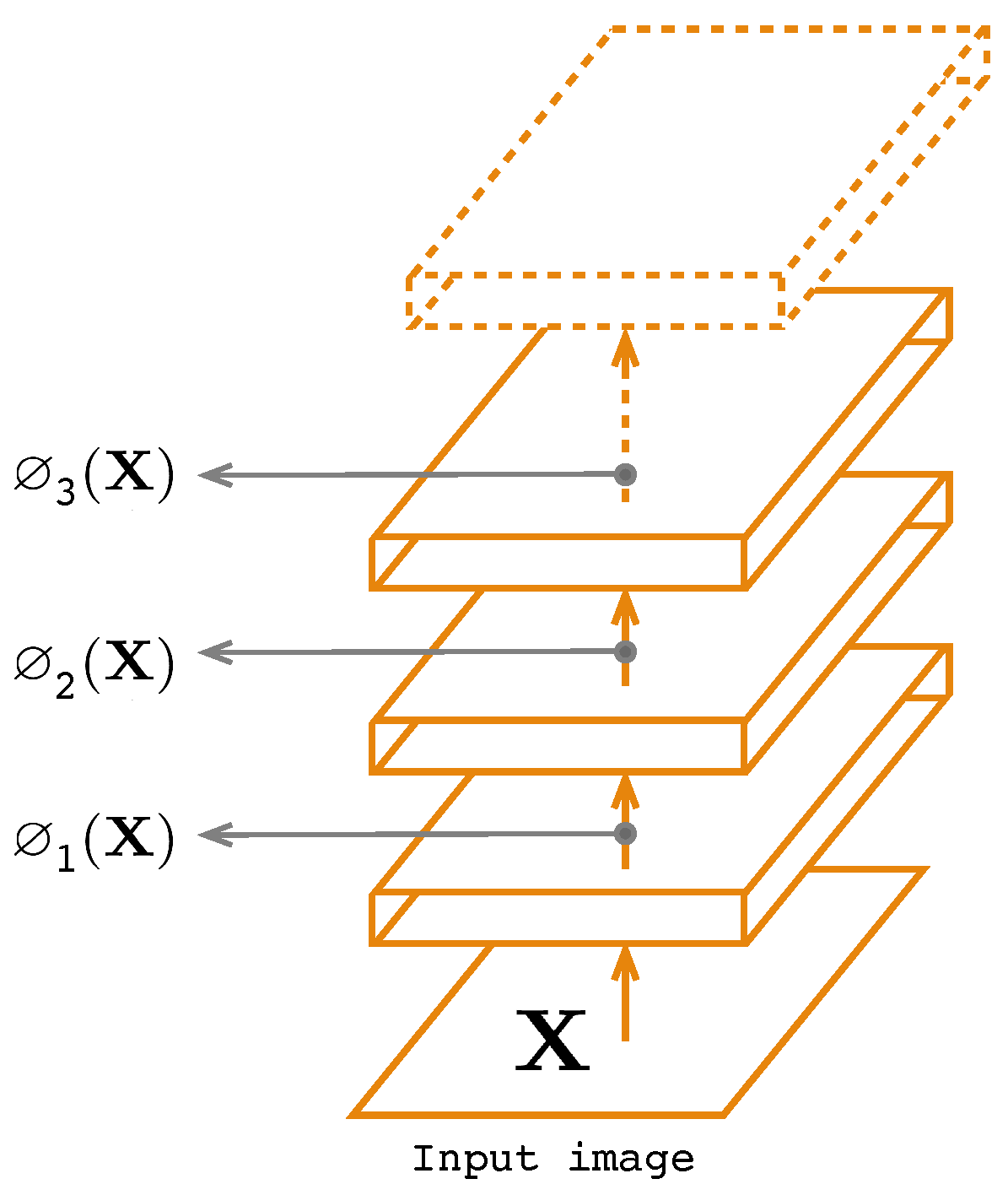
- The encoder is used for the consistency principle for deep features extracted from the hidden layers.
2. Generative Networks and Adversarial Learning
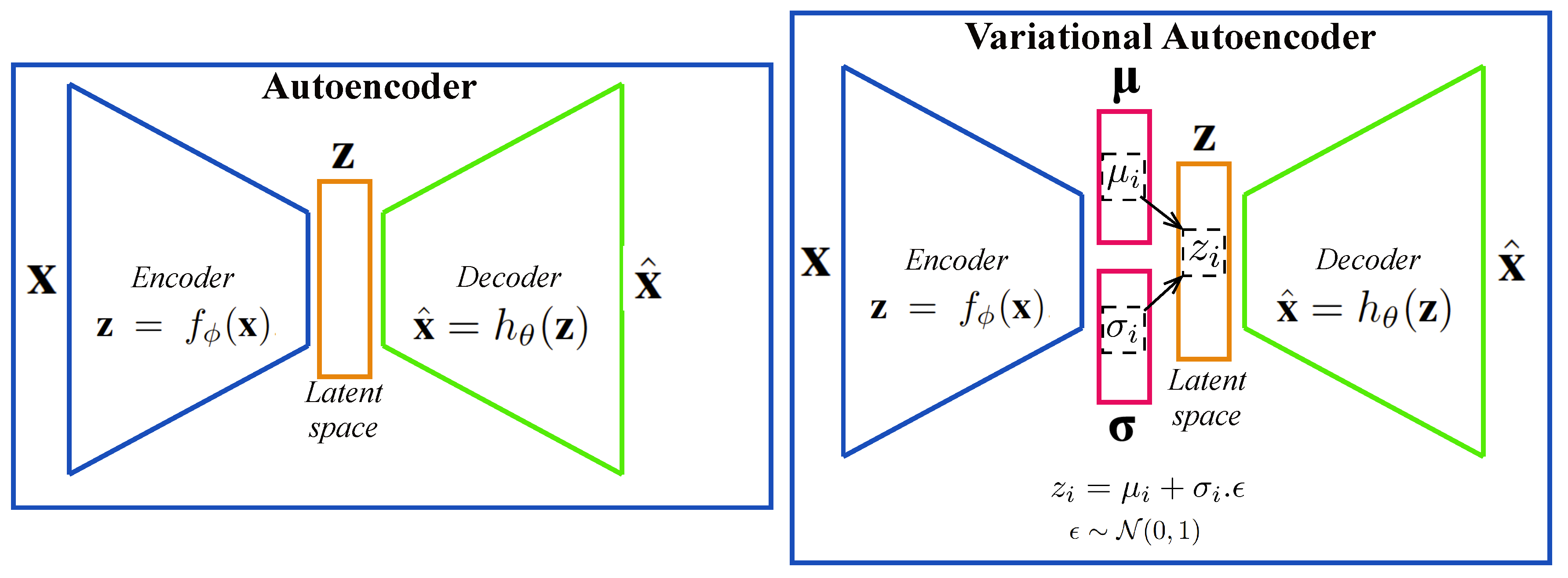
2.1. Autoencoder and the Variational Form
2.2. Adversarial Learning
3. Proposed Method
3.1. Method Overview
- A reconstruction loss function ()
- An adversarial loss function ()
- A latent space loss function ()
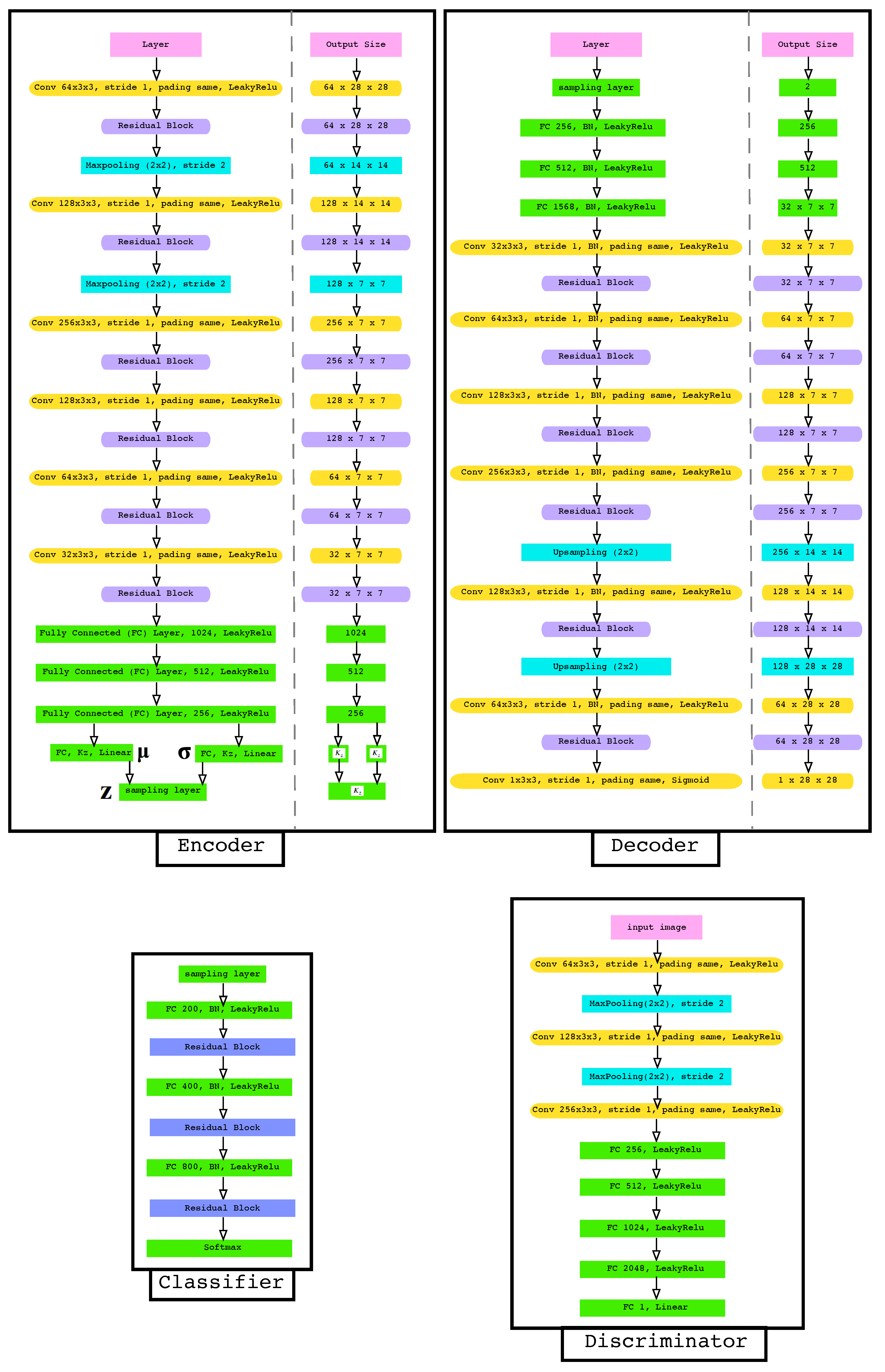
3.2. First Step: Training the Variational Encoder Classifier
| Algorithm 1 Training the VEC Model |
 |
3.3. Second Step: Training the Decoder
| Algorithm 2 Training the Decoder Model |
 |
3.3.1. Feature Reconstruction Loss
3.3.2. Adversarial Loss
3.3.3. Latent Loss
4. Experiments
4.1. Dataset Description
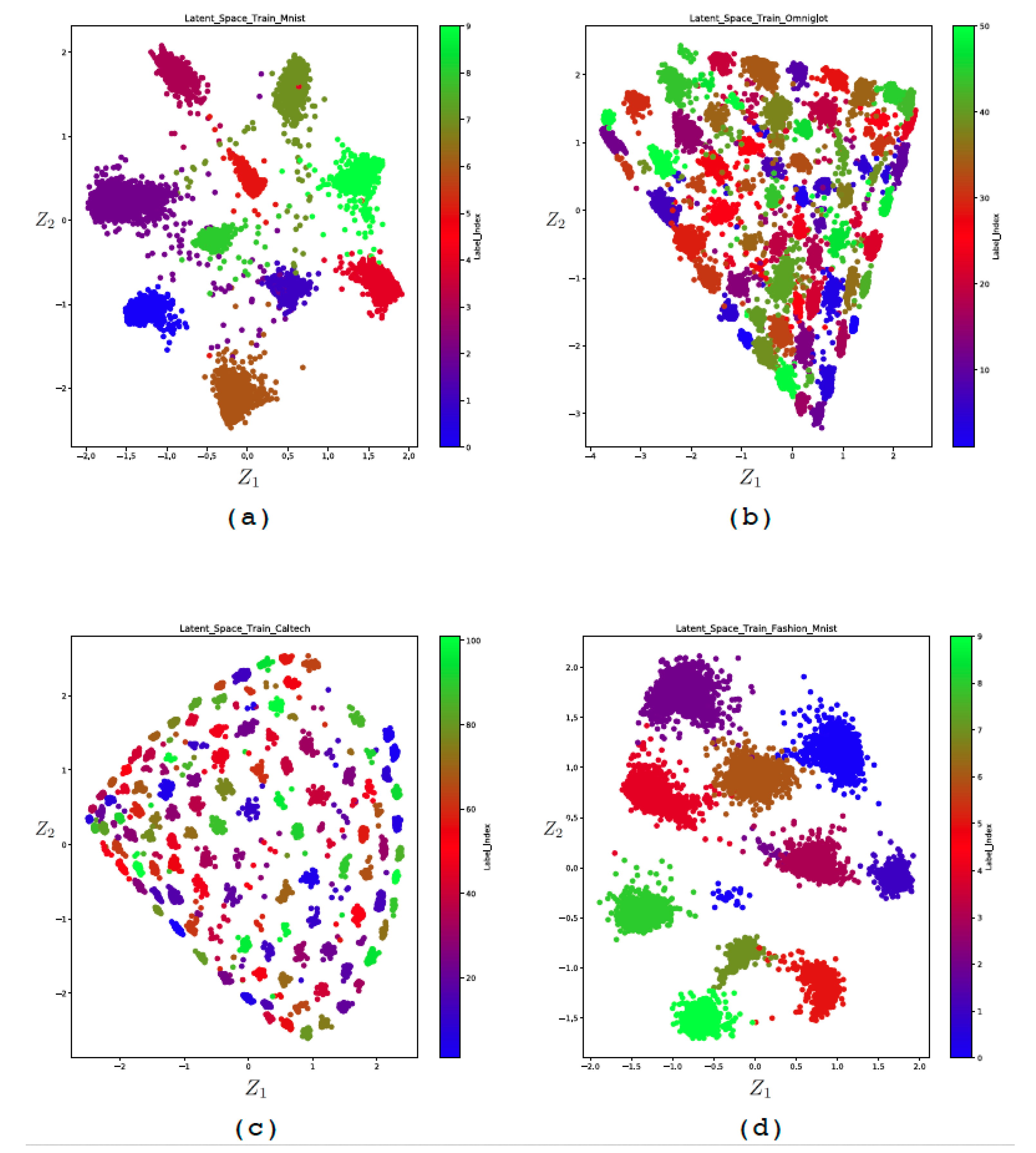
- The MNIST [67] is a standard database that contains images of ten handwritten digits (0 to 9) and is split into 60,000 samples for training and 10,000 for the test.
- The Omniglot dataset [68] contains images of handwritten characters from many world alphabets representing 50 classes, which is split into 24,345 training and 8070 test images.
- The Caltech 101 Silhouettes dataset [69] is composed of images representing object silhouettes of 101 classes and is split into 6364 samples for training and 2307 for the test.
- Fashion-MNIST [70] contains images of fashion products from 10 categories and is split in 60,000 samples for training and 10,000 for the test.
4.2. Neural Network Architecture
4.3. Experimental Focus
4.3.1. Impact of the Dimension Size of the Latent Space
4.3.2. Impact of Weighting Parameters and
4.4. Results and Discussion
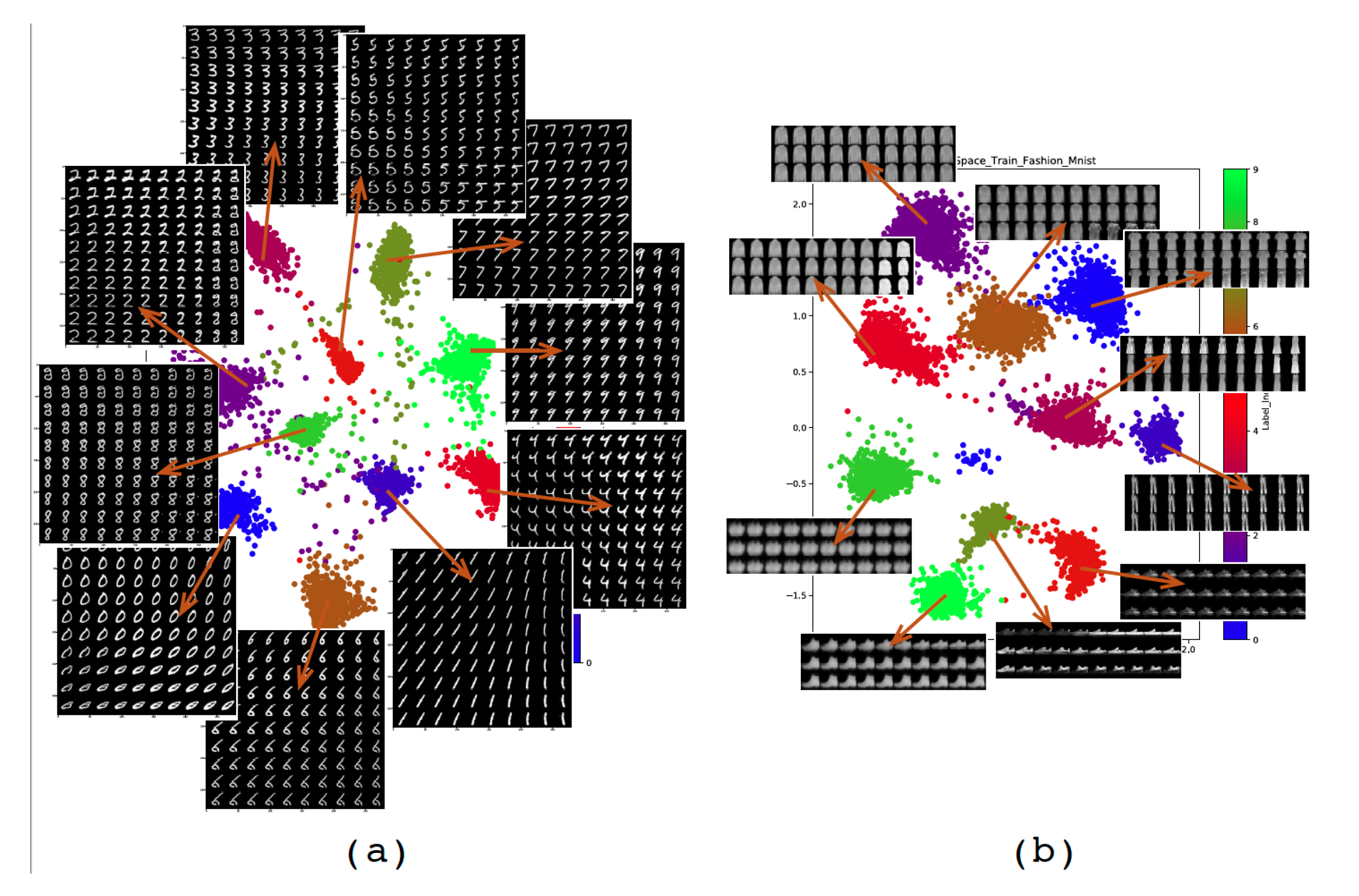
4.4.1. Supervised 2D-Latent Space
4.4.2. Image Reconstruction and Generation
- dominant reconstruction effect with blurred images.
- reconstruction effect with clearer and more realistic images.
- generative effect is dominant.
- Up to , the reconstruction effect is dominant with blurred images.
- For the images are clearer and more realistic.
- The generative effect becomes dominant for where most of the resulting images do not match the original ones. These cases are highlighted in red.
4.5. Test on Cifar 10
5. Conclusions
Funding
Conflicts of Interest
References
- Martin, G.S.; Droguett, E.L.; Meruane, V.; das Chagas Moura, M. Deep variational auto-encoders: A promising tool for dimensionality reduction and ball bearing elements fault diagnosis. Struct. Health Monit. 2018. [Google Scholar] [CrossRef]
- Canchumuni, S.W.; Emerick, A.A.; Pacheco, M.A.C. Towards a robust parameterization for conditioning facies models using deep variational autoencoders and ensemble smoother. Comput. Geosci. 2019, 128, 87–102. [Google Scholar] [CrossRef]
- Lee, S.; Kwak, M.; Tsui, K.L.; Kim, S.B. Process monitoring using variational autoencoder for high-dimensional nonlinear processes. Eng. Appl. Artif. Intell. 2019, 83, 13–27. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, T.; Zhan, C.; Yang, Y. Gaussian feature learning based on variational autoencoder for improving nonlinear process monitoring. J. Process. Control. 2019, 75, 136–155. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2014; pp. 2672–2680. [Google Scholar]
- Yan, S.; Smith, J.S.; Lu, W.; Zhang, B. Abnormal Event Detection from Videos using a Two-stream Recurrent Variational Autoencoder. IEEE Trans. Cogn. Dev. Syst. 2018, 12, 30–42. [Google Scholar] [CrossRef]
- Wang, T.; Qiao, M.; Lin, Z.; Li, C.; Snoussi, H.; Liu, Z.; Choi, C. Generative Neural Networks for Anomaly Detection in Crowded Scenes. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1390–1399. [Google Scholar] [CrossRef]
- Sun, J.; Wang, X.; Xiong, N.; Shao, J. Learning Sparse Representation With Variational Auto-Encoder for Anomaly Detection. IEEE Access 2018, 6, 33353–33361. [Google Scholar] [CrossRef]
- He, M.; Meng, Q.; Zhang, S. Collaborative Additional Variational Autoencoder for Top-N Recommender Systems. IEEE Access 2019, 7, 5707–5713. [Google Scholar] [CrossRef]
- Xu, W.; Tan, Y. Semisupervised Text Classification by Variational Autoencoder. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 295–308. [Google Scholar] [CrossRef]
- Song, T.; Sun, J.; Chen, B.; Peng, W.; Song, J. Latent Space Expanded Variational Autoencoder for Sentence Generation. IEEE Access 2019, 7, 144618–144627. [Google Scholar] [CrossRef]
- Wang, X.; Takaki, S.; Yamagishi, J.; King, S.; Tokuda, K. A Vector Quantized Variational Autoencoder (VQ-VAE) Autoregressive Neural F0 Model for Statistical Parametric Speech Synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 157–170. [Google Scholar] [CrossRef]
- Agrawal, P.; Ganapathy, S. Modulation Filter Learning Using Deep Variational Networks for Robust Speech Recognition. IEEE J. Sel. Top. Signal Process. 2019, 13, 244–253. [Google Scholar] [CrossRef]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. ACVAE-VC: Non-Parallel Voice Conversion With Auxiliary Classifier Variational Autoencoder. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1432–1443. [Google Scholar] [CrossRef]
- Khodayar, M.; Mohammadi, S.; Khodayar, M.E.; Wang, J.; Liu, G. Convolutional Graph Autoencoder: A Generative Deep Neural Network for Probabilistic Spatio-temporal Solar Irradiance Forecasting. IEEE Trans. Sustain. Energy 2019, 11, 571–583. [Google Scholar] [CrossRef]
- Deng, X.; Huangfu, F. Collaborative Variational Deep Learning for Healthcare Recommendation. IEEE Access 2019, 7, 55679–55688. [Google Scholar] [CrossRef]
- Han, K.; Wen, H.; Shi, J.; Lu, K.H.; Zhang, Y.; Fu, D.; Liu, Z. Variational autoencoder: An unsupervised model for encoding and decoding fMRI activity in visual cortex. NeuroImage 2019, 198, 125–136. [Google Scholar] [CrossRef]
- Bi, L.; Zhang, J.; Lian, J. EEG-Based Adaptive Driver-Vehicle Interface Using Variational Autoencoder and PI-TSVM. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2025–2033. [Google Scholar] [CrossRef]
- Wang, D.; Gu, J. VASC: Dimension Reduction and Visualization of Single-cell RNA-seq Data by Deep Variational Autoencoder. Genom. Proteom. Bioinform. 2018, 16, 320–331, Bioinformatics Commons (II). [Google Scholar] [CrossRef]
- Zemouri, R.; Lévesque, M.; Amyot, N.; Hudon, C.; Kokoko, O.; Tahan, S.A. Deep Convolutional Variational Autoencoder as a 2D-Visualization Tool for Partial Discharge Source Classification in Hydrogenerators. IEEE Access 2020, 8, 5438–5454. [Google Scholar] [CrossRef]
- Na, J.; Jeon, K.; Lee, W.B. Toxic gas release modeling for real-time analysis using variational autoencoder with convolutional neural networks. Chem. Eng. Sci. 2018, 181, 68–78. [Google Scholar] [CrossRef]
- Li, H.; Misra, S. Prediction of Subsurface NMR T2 Distributions in a Shale Petroleum System Using Variational Autoencoder-Based Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2395–2397. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, C.; Huang, C. Motor Fault Detection and Feature Extraction Using RNN-Based Variational Autoencoder. IEEE Access 2019, 7, 139086–139096. [Google Scholar] [CrossRef]
- Wang, K.; Forbes, M.G.; Gopaluni, B.; Chen, J.; Song, Z. Systematic Development of a New Variational Autoencoder Model Based on Uncertain Data for Monitoring Nonlinear Processes. IEEE Access 2019, 7, 22554–22565. [Google Scholar] [CrossRef]
- Cheng, F.; He, Q.P.; Zhao, J. A novel process monitoring approach based on variational recurrent autoencoder. Comput. Chem. Eng. 2019, 129, 106515. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Zemouri, R.; Zerhouni, N.; Racoceanu, D. Deep Learning in the Biomedical Applications: Recent and Future Status. Appl. Sci. 2019, 9, 1526. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wang, Y. An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 2018, 310, 213–222. [Google Scholar] [CrossRef]
- Wang, X.; Huang, H.; Hu, Y.; Yang, Y. Partial Discharge Pattern Recognition with Data Augmentation based on Generative Adversarial Networks. In Proceedings of the 2018 Condition Monitoring and Diagnosis (CMD), Perth, WA, Australia, 23–26 September 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Xu, Y.; Zheng, Y.; Peng, X.; Jiang, W. Unsupervised fault diagnosis of rolling bearings using a deep neural network based on generative adversarial networks. Neurocomputing 2018, 315, 412–424. [Google Scholar] [CrossRef]
- Mao, W.; Liu, Y.; Ding, L.; Li, Y. Imbalanced Fault Diagnosis of Rolling Bearing Based on Generative Adversarial Network: A Comparative Study. IEEE Access 2019, 7, 9515–9530. [Google Scholar] [CrossRef]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl. Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Alam, M.; Vidyaratne, L.; Iftekharuddin, K. Novel deep generative simultaneous recurrent model for efficient representation learning. Neural Netw. 2018, 107, 12–22, Special issue on deep reinforcement learning. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. arXiv 2016, arXiv:stat.ML/1610.09585. [Google Scholar]
- Odena, A. Semi-Supervised Learning with Generative Adversarial Networks. arXiv 2016, arXiv:stat.ML/1606.01583. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:cs.LG/1411.1784. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. arXiv 2016, arXiv:cs.CV/1611.04076. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled Generative Adversarial Networks. arXiv 2016, arXiv:cs.CV/1606.07536. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. arXiv 2016, arXiv:cs.CV/1609.04802. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. arXiv 2017, arXiv:cs.CV/1703.05192. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2016, arXiv:cs.CV/1611.07004. [Google Scholar]
- Hjelm, R.D.; Jacob, A.P.; Che, T.; Trischler, A.; Cho, K.; Bengio, Y. Boundary-Seeking Generative Adversarial Networks. arXiv 2017, arXiv:stat.ML/1702.08431. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:stat.ML/1701.07875. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. arXiv 2016, arXiv:cs.LG/1605.09782. [Google Scholar]
- Denton, E.; Gross, S.; Fergus, R. Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks. arXiv 2016, arXiv:cs.CV/1611.06430. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:cs.LG/1606.03657. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. arXiv 2016, arXiv:cs.CV/1612.05424. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:stat.ML/1606.00704. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2015, arXiv:cs.LG/1511.05644. [Google Scholar]
- Hou, X.; Sun, K.; Shen, L.; Qiu, G. Improving variational autoencoder with deep feature consistent and generative adversarial training. Neurocomputing 2019, 341, 183–194. [Google Scholar] [CrossRef]
- Hwang, U.; Park, J.; Jang, H.; Yoon, S.; Cho, N.I. PuVAE: A Variational Autoencoder to Purify Adversarial Examples. IEEE Access 2019, 7, 126582–126593. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, S.; Príncipe, J.C. Understanding autoencoders with information theoretic concepts. Neural Netw. 2019, 117, 104–123. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation. arXiv 2014, arXiv:1407.7906. [Google Scholar]
- Im, D.J.; Ahn, S.; Memisevic, R.; Bengio, Y. Denoising Criterion for Variational Auto-Encoding Framework. arXiv 2015, arXiv:1511.06406. [Google Scholar]
- Fan, Y.J. Autoencoder node saliency: Selecting relevant latent representations. Pattern Recognit. 2019, 88, 643–653. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Kingma, D. Variational Inference & Deep Learning: A New Synthesis. Ph.D. Thesis, Faculty of Science (FNWI), Informatics Institute (IVI), University of Amsterdam, Amsterdam, The Netherlands, 2017. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. arXiv 2016, arXiv:1601.00670. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Zemouri, R.; Devalland, C.; Valmary-Degano, S.; Zerhouni, N. Intelligence artificielle: Quel avenir en anatomie pathologique? Ann. Pathol. 2019, 39, 119–129, L’anatomopathologie augmentée. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.R.; Tenenbaum, J. One-shot learning by inverting a compositional causal process. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Lake Tahoe, NV, USA, 2013; pp. 2526–2534. [Google Scholar]
- Marlin, B.; Swersky, K.; Chen, B.; Freitas, N. Inductive Principles for Restricted Boltzmann Machine Learning. In Machine Learning Research, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; PMLR: Chia Laguna Resort; Teh, Y.W., Titterington, M., Eds.; GitHub: San Francisco, CA, USA, 2010; Volume 9, pp. 509–516. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, Department of Computer Science, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]










© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zemouri, R. Semi-Supervised Adversarial Variational Autoencoder. Mach. Learn. Knowl. Extr. 2020, 2, 361-378. https://doi.org/10.3390/make2030020
Zemouri R. Semi-Supervised Adversarial Variational Autoencoder. Machine Learning and Knowledge Extraction. 2020; 2(3):361-378. https://doi.org/10.3390/make2030020
Chicago/Turabian StyleZemouri, Ryad. 2020. "Semi-Supervised Adversarial Variational Autoencoder" Machine Learning and Knowledge Extraction 2, no. 3: 361-378. https://doi.org/10.3390/make2030020
APA StyleZemouri, R. (2020). Semi-Supervised Adversarial Variational Autoencoder. Machine Learning and Knowledge Extraction, 2(3), 361-378. https://doi.org/10.3390/make2030020