All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
This article presents a new methodology called Deep Theory of Functional Connections (TFC) that estimates the solutions of partial differential equations (PDEs) by combining neural networks with the TFC. The TFC is used to transform PDEs into unconstrained optimization problems by analytically embedding the PDE’s constraints into a “constrained expression” containing a free function. In this research, the free function is chosen to be a neural network, which is used to solve the now unconstrained optimization problem. This optimization problem consists of minimizing a loss function that is chosen to be the square of the residuals of the PDE. The neural network is trained in an unsupervised manner to minimize this loss function. This methodology has two major differences when compared with popular methods used to estimate the solutions of PDEs. First, this methodology does not need to discretize the domain into a grid, rather, this methodology can randomly sample points from the domain during the training phase. Second, after training, this methodology produces an accurate analytical approximation of the solution throughout the entire training domain. Because the methodology produces an analytical solution, it is straightforward to obtain the solution at any point within the domain and to perform further manipulation if needed, such as differentiation. In contrast, other popular methods require extra numerical techniques if the estimated solution is desired at points that do not lie on the discretized grid, or if further manipulation to the estimated solution must be performed.
Partial differential equations (PDEs) are a powerful mathematical tool that is used to model physical phenomena, and their solutions are used to simulate, design, and verify the design of a variety of systems. PDEs are used in multiple fields including environmental science, engineering, finance, medical science, and physics, to name a few. Many methods exist to approximate the solutions of PDEs. The most famous of these methods is the finite element method (FEM) [1,2,3]. FEM has been incredibly successful in approximating the solution to PDEs in a variety of fields including structures, fluids, and acoustics. However, FEM does have some drawbacks.
FEM discretizes the domain into elements. This works well for low-dimensional cases, but the number of elements grows exponentially with the number of dimensions. Therefore, the discretization becomes prohibitive as the number of dimensions increases. Another issue is that FEM solves the PDE at discrete nodes, but if the solution is needed at locations other than these nodes, an interpolation scheme must be used. Moreover, extra numerical techniques are needed to perform further manipulation of the FEM solution.
Reference [4] explored the use of neural networks to solve PDEs, and showed that the use of neural networks avoids these problems. Rather than discretizing the entire domain into a number of elements that grows exponentially with the dimension, neural networks can sample points randomly from the domain. Moreover, once the neural network is trained, it represents an analytical approximation of the PDE. Consequently, no interpolation scheme is needed when estimating the solution at points that did not appear during training, and further analytical manipulation of the solution can be done with ease. Furthermore, Ref. [4] compared the neural network method with FEM on a set of test points that did not appear during training (i.e., points that were not the nodes in the FEM solution), and showed that the solution obtained by the neural network generalized well to points outside of the training data. In fact, the maximum error on the test set of data was never more than the maximum error on the training set of data. In contrast, the FEM had more error on the test set than on the training set. In one case, the test set had approximately three orders of magnitude more error than the training set. In short, Ref. [4] presents strong evidence that neural networks are useful for solving PDEs.
However, what was presented in Ref. [4] can still be improved. In Ref. [4] the boundary constraints are managed by adding extra terms to the loss function. An alternative method is to encapsulate the boundary conditions, by posing the solution in such a way that the boundary conditions must be satisfied, regardless of the values of the training parameters in the neural network. References [5,6] manage boundary constraints in this way when solving PDEs with neural networks by using a method similar to the Coons’ patch [7] to satisfy the boundary constraints exactly.
Exact boundary constraint satisfaction is of interest for a variety of problems, particularly when confidence in the constraint information is high. This is especially important for physics informed problems. Moreover, embedding the boundary conditions in this way means that the neural network needs to sample points from the interior of the domain only, not the domain and the boundary. While the methods presented in [5,6] work well for low-dimensional PDEs with simple boundary constraints, they lack a mechanized framework for generating expressions that embed higher-dimensional or more complex constraints while maintaining a neural network with free-to-choose parameters. For example, the fourth problem in the results section cannot be solved using the solution forms shown in Ref. [5,6]. Luckily, a framework that can embed higher-dimensional or more complex constraints has already been invented: The Theory of Functional Connections (TFC) [8,9]. In Ref. [10], TFC was used to embed constraints into support vector machines, but left embedding constraints into neural networks to future work. This research shows how to embed constraints into neural networks with the TFC, and leverages this technique to numerically estimate the solutions of PDEs. Although the focus of this article is a new technique for numerically estimating the solutions of PDEs, the article’s contribution to the machine learning community is farther reaching, as the ability to embed constraints into neural networks has the potential to improve performance when solving any problem that has constraints, not just differential equations, with neural networks.
TFC is a framework that is able to satisfy many types of boundary conditions while maintaining a function that can be freely chosen. This free function can be chosen, for example, to minimize the residual of a differential equation. TFC has already been used to solve ordinary differential equations with initial value constraints, boundary value constraints, relative constraints, integral constraints, and linear combinations of constraints [8,11,12,13]. Recently, the framework was extended to n-dimensions [9] for constraints on the value and arbitrary order derivative of -dimensional manifolds. This means the TFC framework can now generate constrained expressions that satisfy the boundary constraints of multidimensional PDEs [14].
2. Theory of Functional Connections
The Theory of Functional Connections (TFC) is a mathematical framework designed to turn constrained problems into unconstrained problems. This is accomplished through the use of constrained expressions, which are functionals that represent the family of all possible functions that satisfy the problem’s constraints. This technique is especially useful when solving PDEs, as it reduces the space of solutions to just those that satisfy the problem’s constraints. TFC has two major steps: (1) Embed the boundary conditions of the problem into the constrained expression; (2) solve the now unconstrained optimization problem. The paragraphs that follow will explain these steps in more detail.
The TFC framework is easiest to understand when explained via an example, like a simple harmonic oscillator. Equation (1) gives an example of a simple harmonic oscillator problem.
where the subscript in denotes a derivative of y with respect to .
Based on the univariate TFC framework presented in Ref. [8], the constrained expression is represented by the functional,
where the are a set of mutually linearly independent functions, called support functions, and are coefficient functions that are computed by imposing the constraints. For this example, let’s choose the support functions to be the first two monomials, and . Hence, the constrained expression becomes,
The coefficient functions, and , are solved by substituting the constraints into the constrained expression and solving the resultant set of equations. For the simple harmonic oscillator this yields the set of equations given by Equations (3) and (4).
Solving Equation (3) results in , and solving Equation (4) yields . Substituting and into Equation (3) we obtain,
which is an expression satisfying the constraints, no matter what the free function, , is. In other words, this equation is able to reduce the solution space to just the space of functions satisfying the constraints, because for any function , the boundary conditions will always be satisfied exactly. Therefore, using constrained expressions transforms differential equations into unconstrained optimization problems.
This unconstrained optimization problem could be cast in the following way. Let the function to be minimized, , be equal to the square of the residual of the differential equation,
This function is to be minimized by varying the function . One way to do this is to choose as a linear combination of a set of basis functions, and calculate the coefficients of the linear combination via least-squares or some other optimization technique. Examples of this methodology using Chebyshev orthogonal polynomials to obtain least-squares solutions of linear and nonlinear ordinary differential equations (ODEs) can be found in Refs. [11,12], respectively.
2.1. n-Dimensional Constrained Expressions
The previous example derived the constrained expression by creating and solving a series of simultaneous algebraic equations. This technique works well for constrained expressions in one dimension; however, it can become needlessly complicated when deriving these expression in n dimensions for constraints on the value and arbitrary order derivative of dimensional manifolds [9]. Fortunately, a different, more mechanized formalism exists that is useful for this case. The constrained expression presented earlier consists of two parts; the first part is a function that satisfies the boundary constraints, and the second part projects the free-function, , onto the hyper-surface of functions that are equal to zero at the boundaries. Rearranging Equation (2) highlights these two parts,
where satisfies the boundary constraints and is a functional projecting the free-function onto the hyper-surface of functions that are equal to zero at the boundaries.
The multivariate extension of this form for problems with boundary and derivative constraints in n-dimensions can be written compactly using Equation (5).
where is a vector of the n independent variables, is an n-th order tensor containing the boundary conditions , the are vectors whose elements are functions of the independent variables, is the free-function that can be chosen to be any function that is defined at the constraints, and is the constrained expression. The first term, , analytically satisfies the boundary conditions, and the term, , projects the free-function, , onto the space of functions that vanish at the constraints. A mathematical proof that this form of the constrained expression satisfies the boundary constraints is given in Ref. [9]. The remainder of this section discusses how to construct the n-th order tensor and the vectors shown in Equation (5).
Before discussing how to build the tensor and vectors, let’s introduce some mathematical notation. Let be an index used to denote the k-th dimension. Let be the constraint specified by taking the d-th derivative of the constraint function, , evaluated at the hyperplane. Further, let be the vector of constraints defined at the hyperplanes with derivative orders of , where and . In addition, let’s define a boundary condition operator that takes the d-th derivative with respect to of a function, and then evaluates that function at the hyperplane. Mathematically,
This mathematical notation will be used to introduce a step-by-step method for building the tensor. This step-by-step process will be be illustrated via a 3-dimensional example that has Dirichlet boundary conditions in and initial conditions in and on the domain . The tensor is constructed using the following three rules.
The element .
The first order sub-tensor of specified by keeping one dimension’s index free and setting all other dimension’s indices to 1 consists of the value 0 and the boundary conditions for that dimension. Mathematically,
Using the example boundary conditions,
The remaining elements of the tensor are those with at least two indices different than one. These elements are the geometric intersection of the boundary condition elements of the first order tensors given in Equation (6), plus a sign (+ or −) that is determined by the number of elements being intersected. Mathematically this can be written as,
where m is the number of indices different than one. Using the example boundary conditions we give three examples:
A simple procedure also exists for constructing the vectors. The vectors have a standard form:
where are linearly independent functions. The simplest set of linearly independent functions, and those most often used in the TFC constrained expressions, are monomials, . The coefficients, , can be computed by matrix inversion,
Using the example boundary conditions, let’s derive the vector using the linearly independent functions and .
For more examples and a mathematical proof that these procedures for generating the tensor and the vectors form a valid constrained expression see Ref. [9].
2.2. Two-Dimensional Example
This subsection will give an in depth example for a two-dimensional TFC case. The example is originally from problem 5 of Ref. [5], and is one of the PDE problems analyzed in this article. The problem is shown in Equation (7).
Following the step-by-step procedure given in the previous section we will construct the tensor:
The first element is .
The first order sub-tensors of are:
The remaining elements of are the geometric intersection of elements from the first order sub-tensors.
Hence, the tensor is,
Following the step-by-step procedure given in the previous section we will construct the vectors. For , let’s choose the linearly independent functions and .
For let’s choose the linearly indpendent functions and .
Now, we use the constrained expression form given in Equation (5) to finish building the constrained expression.
Notice, that Equation (8) will always satisfy the boundary conditions of the problem regardless of the value of . Thus, the problem has been transformed into an unconstrained optimization problem where the cost function, , is the square of the residual of the PDE,
For ODEs, the minimization of the cost function was accomplished by choosing g to be a linear combination of orthogonal polynomials with unknown coefficients, and performing least-squares or some other optimization technique to find the unknown coefficients. For two dimensions, one could make the product of two linear combinations of these orthogonal polynomials, calculate all of the cross-terms, and then solve for the coefficients that multiply all terms and cross-terms using least-squares or non-linear least-squares. However, this will become computationally prohibitive as the dimension increases. Even at two dimensions, the number of basis functions needed, and thus the size of the matrix to invert in the least-squares, becomes large. An alternative solution, and the one explored in this article, is to make the free function, , a neural network.
3. PDE Solution Methodology
Similar to the last section, the easiest way to describe the methodology is with an example. The example used throughout this section will be the PDE given in Equation (7).
As mentioned previously, Deep TFC approximates solutions to PDEs by finding the constrained expression for the PDE and choosing a neural network as the free function. For all of the problems analyzed in this article, a simple, fully connected neural network was used. Each layer of a fully connected neural network consists of non-linear activation functions composed with affine transformations of the form , where W is a matrix of the neuron weights, is a vector of the neuron biases, and is a vector of inputs from the previous layer (or the inputs to the neural network if it is the first layer). Then, each layer is composed to form the entire network. For the fully connected neural networks used in this paper, the last layer is simply a linear output layer. For example, a neural network with three hidden layers that each use the non-linear activation function can be written mathematically as,
where is the symbol used for the neural network, is the vector of inputs, are the weight matrices, are the bias vectors, and is a symbol that represents all trainable parameters of the neural network; the weights and biases of each layer constitute the trainable parameters. Note that the notation is also used in this paper for independent variables and trainable parameters .
Thus, the constrained expression, given originally in Equation (8), now has the form given in Equation (9).
In order to estimate the solution to the PDE, the parameters of the neural network have to be optimized to minimize the loss function, which is taken to be the square of the residual of the PDE. For this example,
The attentive reader will notice that training the neural network will require, for this example, taking two second order partial derivatives of to calculate , and then taking gradients of with respect to the neural network parameters, , in order to train the neural network.
To take these higher order derivatives, TensorFlow’s™ gradients function was used [15]. This function uses automatic differentiation [16] to compute these derivatives. However, one must be conscientious when using the gradients function to ensure they get the desired gradients.
When taking the gradient of a vector, , with respect to another vector, , TensorFlow™ computes,
where is a vector of the same size as . The only example where it is not immediately obvious that this gradient function will give the desired gradient is when computing . The desired output of this calculation is the following vector,
where has the same size as and is the point used to generate . TensorFlow’s™ gradients function will compute the following vector,
However, because only depends on the point and the derivative operator commutes with the sum operator, TensorFlow’s™ gradients function will compute the desired vector (i.e., ). Moreover, the size of the output vector will be correct, because the input vectors, and , have the same size as .
Training the Neural Network
Three methods were tested when optimizing the parameters of the neural networks:
Adam optimizer [17]: A variant of stochastic gradient descent (SGD) that combines the advantages of two other popular SGD variants: AdaGrad [18] and RMSProp [19].
Broyden–Fletcher–Goldfarb–Shanno [20] (BFGS): A quasi-Newton method designed for solving unconstrained, non-linear optimization problems. This method was chosen based on its performance when optimizing neural network parameters to estimate PDE solutions in Ref. [5].
Hybrid method: Combines the first two methods by applying them in series.
For all four problems shown in this article, the solution error when using the BFGS optimizer was lower than with the other two methods. Thus, in the following section, the results shown use the BFGS optimizer.
The BFGS optimizer is a local optimizer, and the weights and biases of the neural networks are initialized randomly. Therefore, the solution error when numerically estimating PDEs will be different each time. However, Deep TFC guarantees that the boundary conditions are satisfied, and the loss function is the square of the residual of the PDE. Therefore, the loss function indicates how well Deep TFC is estimating the solution of the PDE at the training points. Moreover, because Deep TFC produces an analytical approximation of the solution, the loss function can be calculated at any point. Therefore, after training, one can calculate the loss function at a set of test points to determine whether the approximate solution generalizes well or has over fit the training points.
Due to the inherit stochasticity of the method, each Deep TFC solution presented in the results section that follows is the solution with the lowest mean absolute error of 10 trials. In other words, for each problem, the Deep TFC methodology was performed 10 times, and the best solution of those 10 trials is presented. Moreover, to show the variability in the Deep TFC method, problem 1 contains a histogram of the maximum solution error on a test set for 100 Monte Carlo trials.
4. Results
This section compares the estimated solution found using Deep TFC with with the analytical solution. Four PDE problems are analyzed. The first is the example PDE given in Equation (7), and the second is the wave equation. The third and fourth PDEs are simple solutions to the incompressible Navier–Stokes equations.
4.1. Problem 1
The first problem analyzed was the PDE given by Equation (7), copied below for the reader’s convenience.
The known analytical solution for this problem is,
The neural network used to estimate the solution to this PDE was a fully connected neural network with 6 hidden layers, 15 neurons per layer, and 1 linear output layer. The non-linear activation function used in the hidden layers was the hyperbolic tangent. Other fully connected neural networks with various sizes and non-linear activation functions were tested, but this combination of size and activation function performed the best in terms of solution error. The biases of the neural network were all initialized as zero, and the weights were initialized using TensorFlow’s™ implementation of the Xavier initialization with uniform random initialization [21]. One hundred training points, , evenly distributed throughout the domain were used to train the neural network.
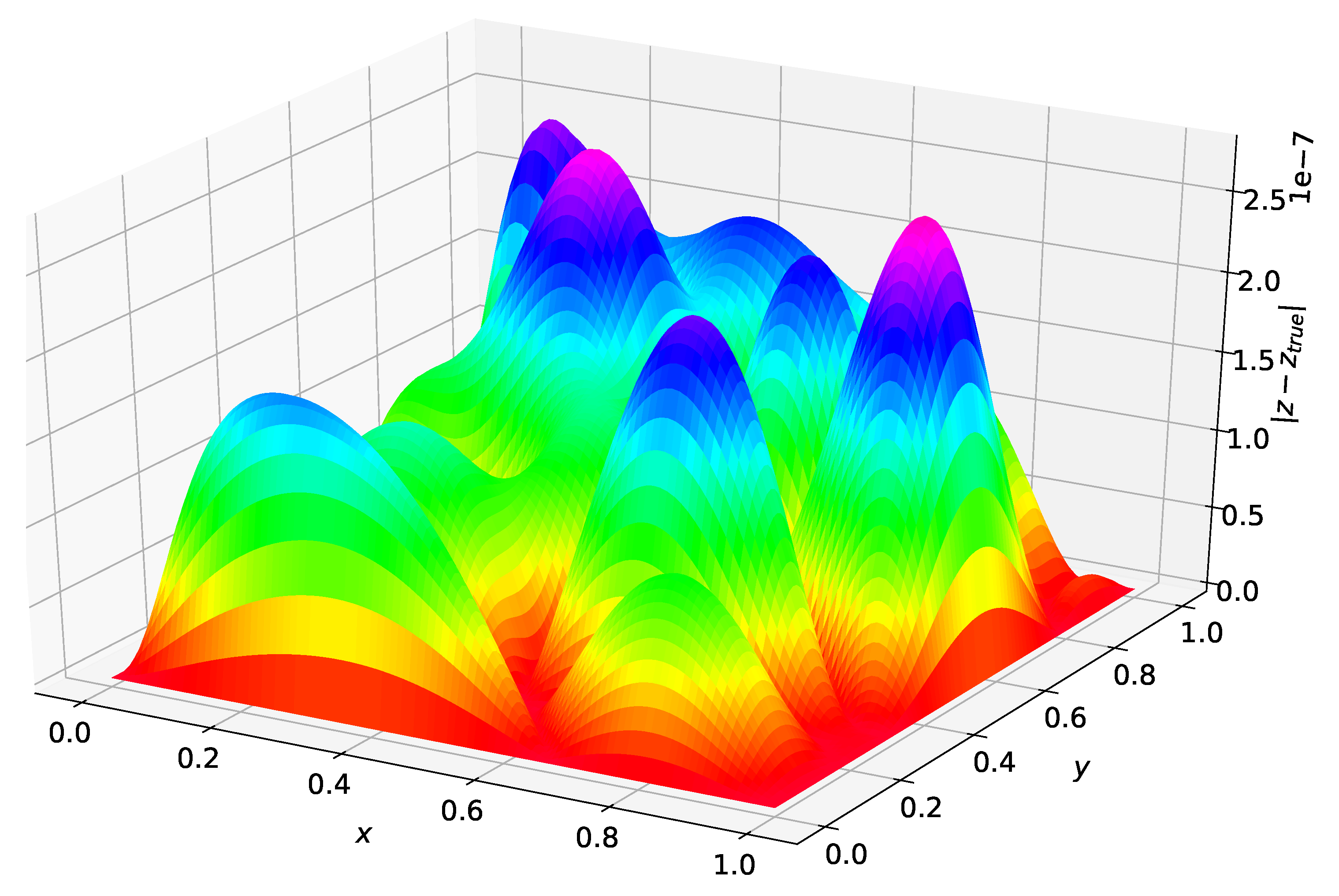
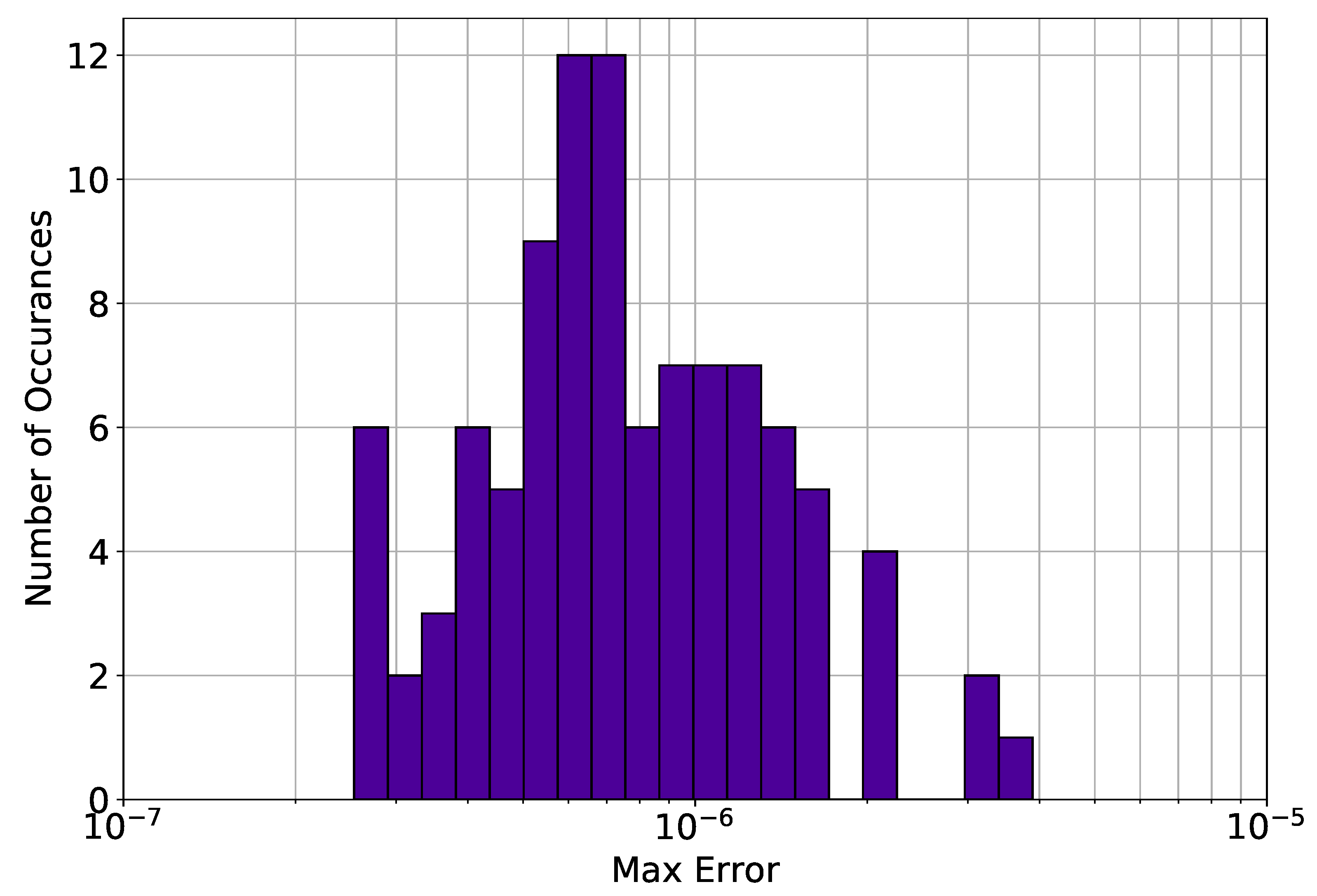
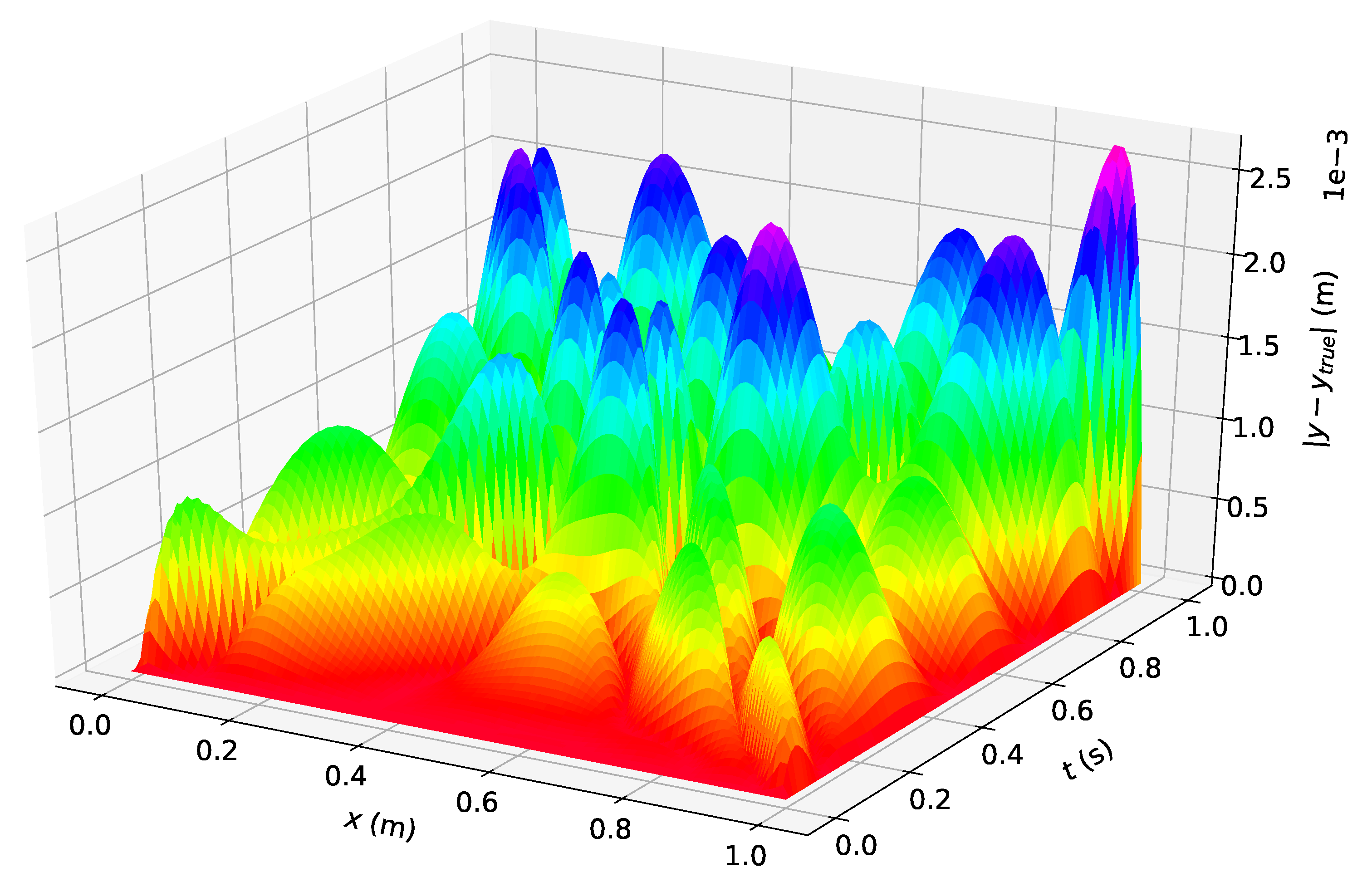
Figure 1 shows the difference between the analytical solution and the estimated solution using Deep TFC on a grid of 10,000 evenly distributed points. This grid represents the test set. Figure 2 shows a histogram of the maximum solution error on the test set for 100 Monte Carlo trials.
The maximum error on the test set shown in Figure 1 was and the average error was . Figure 2 shows that Deep TFC produces a solution at least as accurate as the solution in Figure 1 approximately 10% of the time. The remaining 90% of the time the solution error will be larger. Moreover, Figure 2 shows that the Deep TFC method is consistent. The maximum solution error in the 100 Monte Carlo tests was , approximately an order of magnitude larger than the maximum solution error shown in Figure 1. The maximum error from Figure 1 is relatively low, six orders of magnitude lower than the solution values, which are on the order of . Table 1 compares the maximum error on the test and training sets obtained with Deep TFC with the method used in Ref. [5] and FEM. Note, the FEM data was obtained from Table 1 of Ref. [5].
Table 1 shows that Deep TFC is slightly more accurate than the method from Ref. [5]. Moreover, in consonance with the findings from Ref. [5], the FEM solution performs better on the training set than Deep TFC, but worse on the solution set. Note also “that the accuracy of the finite element method decreases as the grid becomes coarser, and that the neural approach considers a mesh of points while in the finite element case a mesh was employed” [5].
The neural network used in this article is more complicated than the network used in Ref. [5], even though the two solution methods produce similarly accurate solutions. The constrained expression, , created using TFC, which is used as the assumed solution form, is more complex both in the number of terms and the number of times the neural network appears than the assumed solution form in Ref. [5]. For the reader’s reference, the assumed solution form for problem 1 from Ref. [5] is shown in Equation (10). Equation (10) was copied from Ref. [5], but the notation used has been transformed to match that of this paper; furthermore, a typo in the assumed solution form from Ref. [5] has been corrected here.
To investigate how the assumed solution form affects the accuracy of the estimated solution, a comparison was made between the solution form from Ref. [5] and the solution form created using TFC in this article, while keeping all other variables constant. Furthermore, in this comparison, the neural network architecture used is identical to the neural network architecture given in Ref. [5] for this problem: one hidden layer with 10 neurons that uses a sigmoid non-linear activation function and a linear output layer. Each network was trained using the BFGS optimizer. The training points used were 100 evenly distributed points throughout the domain.
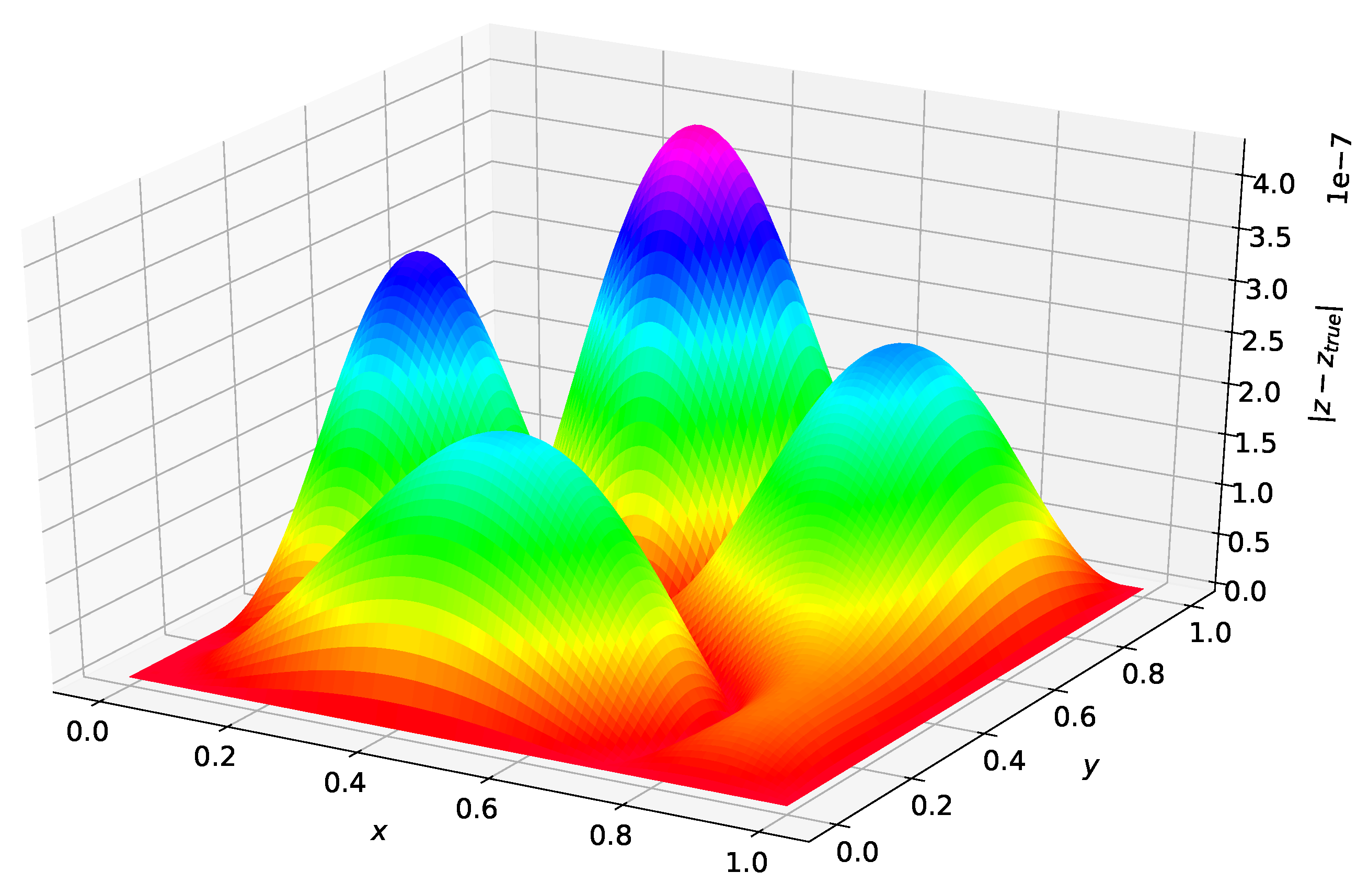
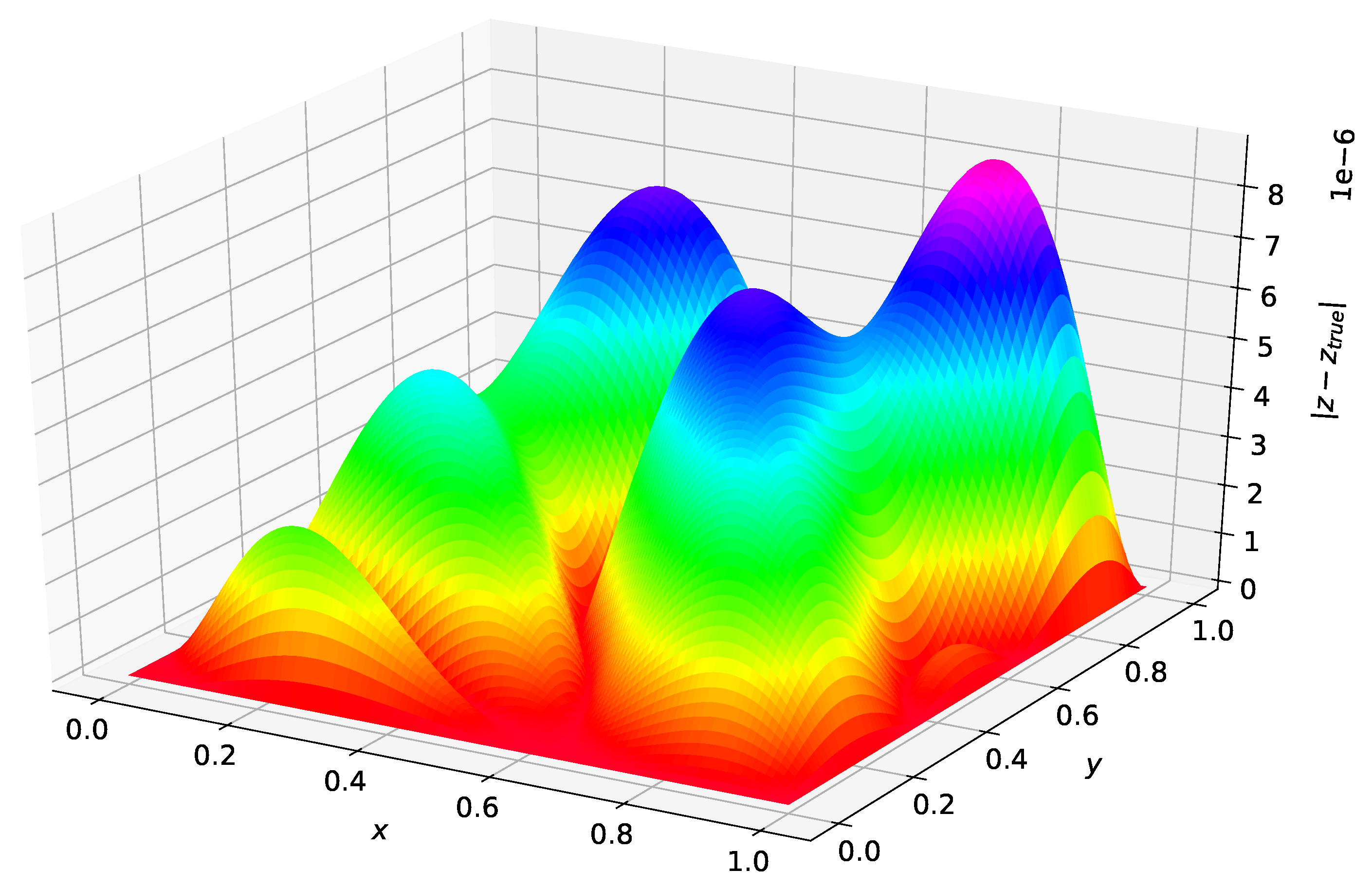
Figure 3 was created using the solution form posed in [5]. The maximum error on the test set was and the average error on the test set was . Figure 4 was created using the Deep TFC solution form. The maximum error on the test set was and the average error on the test set was .
Comparing Figure 3 and Figure 4 shows that the solution form from [5] gives an estimated solution that is approximately an order of magnitude lower in terms of average error and maximum error for this problem. Hence, the more complex TFC solution form requires a more complex neural network to achieve the same accuracy as the simpler solution form from Ref. [5] with a simple neural network. This results in a trade-off. The TFC constrained expressions allow for more complex boundary conditions (i.e., derivatives of arbitrary order) and can be used on n-dimensional domains, but require a more complex neural network. In contrast, the simpler solution form from Ref. [5] can achieve the same level of accuracy with a simpler neural network, but cannot be used for problems with higher order derivatives or n-dimensional domains.
4.2. Problem 2
The second problem analyzed was the wave equation, shown in Equation (11).
where the constant, . The analytical solution for this problem is,
Although the true analytical solution is an infinite series, for the purposes of making numerical comparisons, one can simply truncate this infinite series such that the error incurred by truncation falls below machine level precision. The constrained expression for this problem is shown in Equation (12).
The neural network used to estimate the solution to this PDE was a fully connected neural network with three hidden layers and 30 neurons per layer. The non-linear activation function used was the hyperbolic tangent. The biases and weights were initialized using the same method as problem 1. The training points, , were created by choosing x to be an independent and identically distributed (IID) random variable with uniform distribution in the range , and t to be an IID random variable with uniform distribution in the range . The network was trained using the BFGS method and 1000 training points.
Figure 5 shows the difference between the analytical solution and the estimated solution using Deep TFC on a grid of 10,000 evenly distributed points; this grid represents the test set.
The maximum error on the test set was m and the average error on the test set was m. The error of this solution is larger than in the problem 1, while the solution values are on the same order of magnitude, m, as in problem 1. The larger relative error in problem 2 is due to the more oscillatory nature of the solution (i.e., the surface of the true solution in problem 2 is more complex than that of problem 1).
4.3. Problem 3
The third problem analyzed was a known solution to the incompressible Navier–Stokes equations, called Poiseuille flow. The problem solves the flow velocity in a two-dimensional pipe in steady-state with a constant pressure gradient applied in the longitudinal axis. Equation (13) shows the associated equations and boundary conditions.
where u and v are velocities in the x and y directions respectively, H is the height of the channel, P is the pressure, is the density, and is the viscosity. For this problem, the values m, kg/m3, Pa·s, and N/m3 were chosen. The constrained expressions for the u-velocity, , and v-velocity, , are shown in Equation (14).
The neural network used to estimate the solution to this PDE was a fully connected neural network with four hidden layers and 30 neurons per layer. The non-linear activation function used was the sigmoid. The biases and weights were initialized using the same method as problem 1. The training points, , were created by sampling x, y, and t IID from a uniform distribution that spanned the range of the associated independent variable. For x, the range was . For y, the range was , and for t, the range was . The network was trained using the BFGS method on a batch size of 1000 training points. The loss function used was the sum of the squares of the residuals of the three PDEs in Equation (13).
The maximum error in the u-velocity was m per second, the average error in the u-velocity was m per second, the maximum error in the v-velocity was m per second, and the average error in the v-velocity was m per second. Despite the complexity, the maximum error and average error for this problem are six to seven orders of magnitude lower than the solution values. However, the constrained expression for this problem essentially encodes the solution, because the initial flow condition at time zero is the same as the flow condition throughout the spatial domain at any time. Thus, if the neural network outputs a value of zero for all inputs, the problem will be solved exactly. Although the neural network does output a very small value for all inputs, it is interesting to note that none of the layers have weights or biases that are at or near zero.
4.4. Problem 4
The fourth problem is another solution to the Navier–Stokes equations, and is very similar to the third. The only difference is that in this case, the fluid is not in steady state, it starts from rest. Equation (15) shows the associated equations and boundary conditions.
This problem was created to avoid encoding the solution to the problem into the constrained expression, as was the case in the previous problem. The constrained expressions for the u-velocity, , and v-velocity, , are shown in Equation (16).
The neural network used to estimate the solution to this PDE was a fully connected neural network with four hidden layers and 30 neurons per layer. The non-linear activation function used was the hyperbolic tangent. The biases and weights were initialized using the same method as problem 1. Problem 4 used 2000 training points that were selected the same way as in problem 3, except the new ranges for the independent variables were for x, for t, and for y.
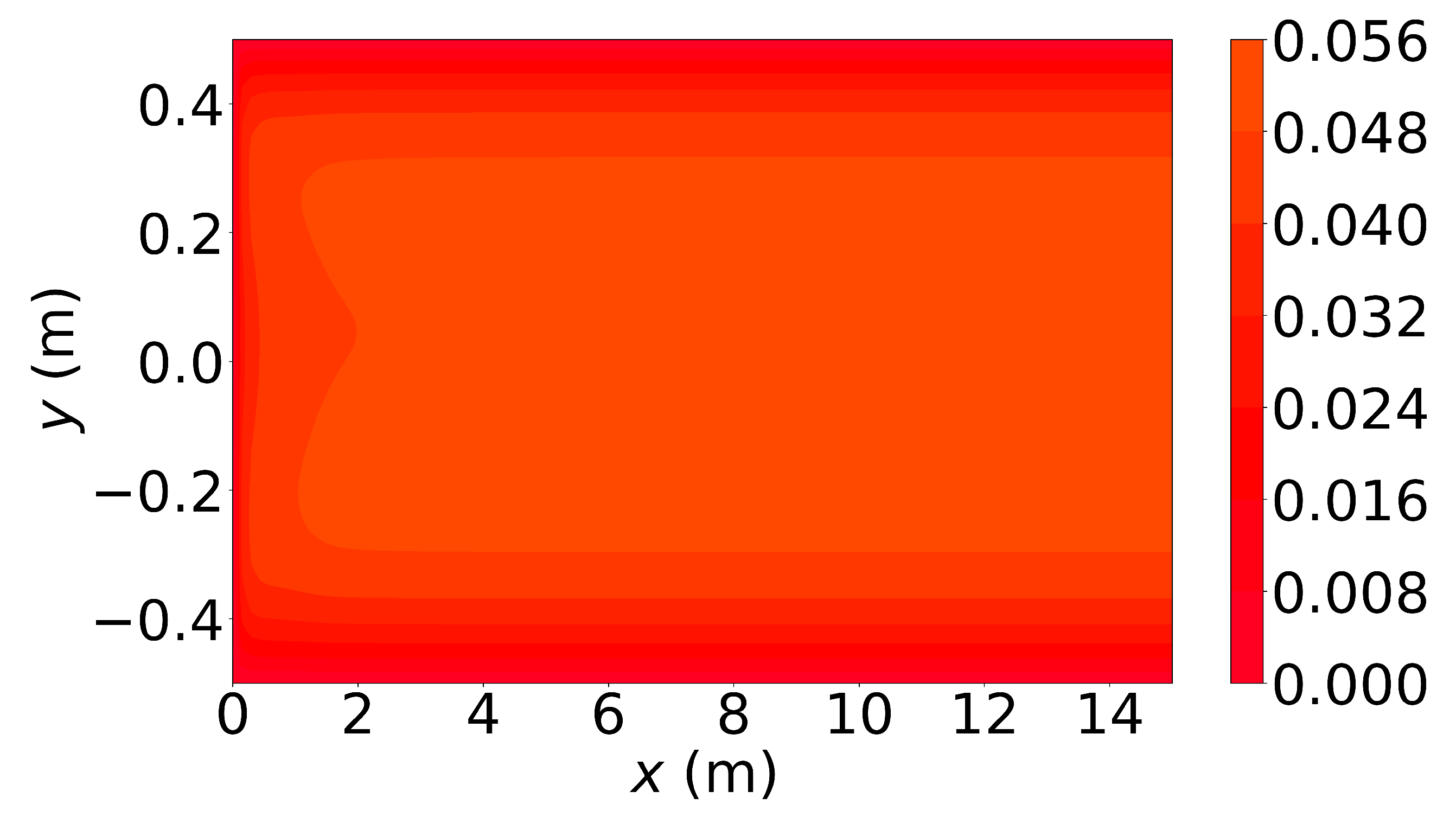
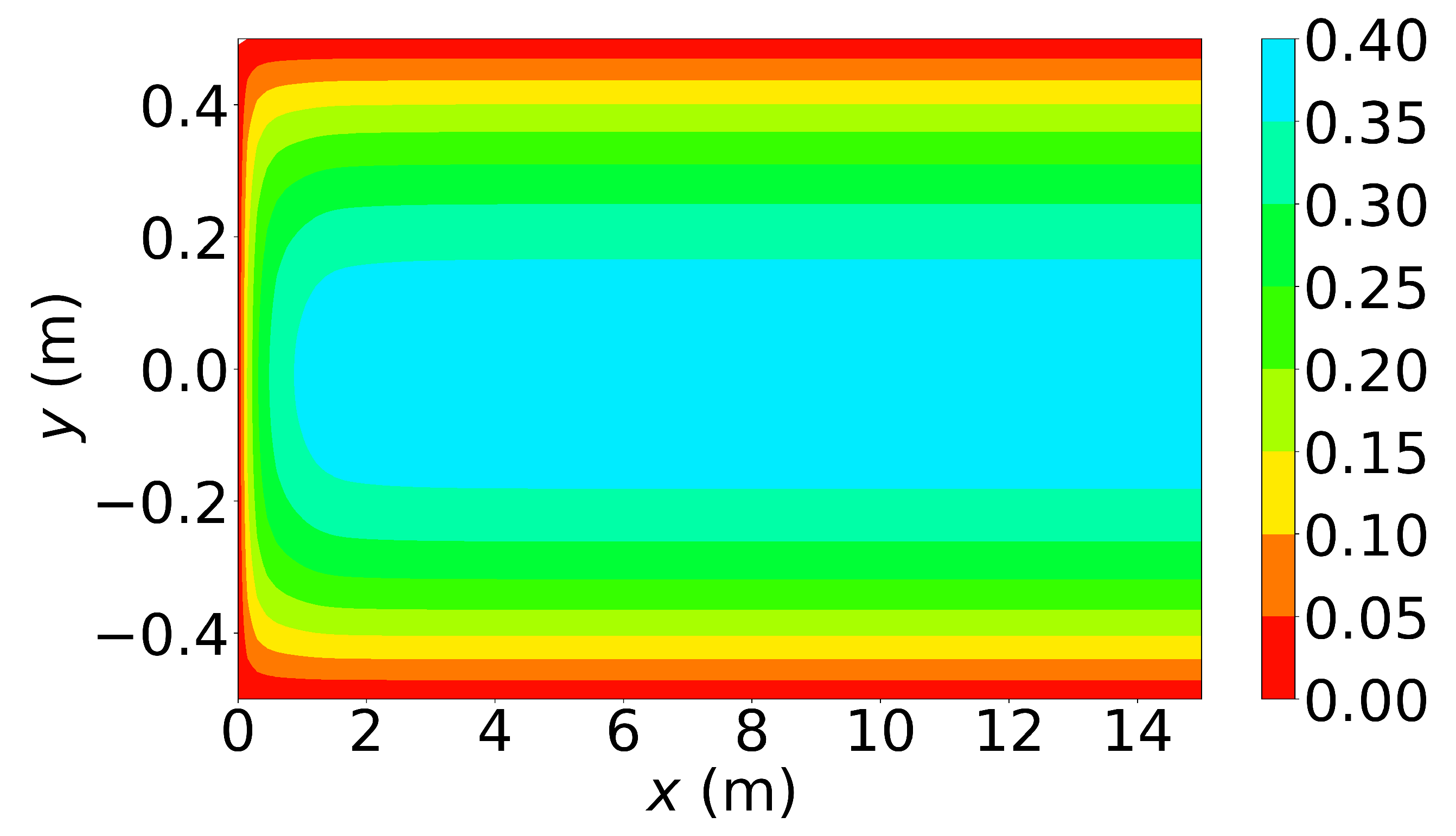
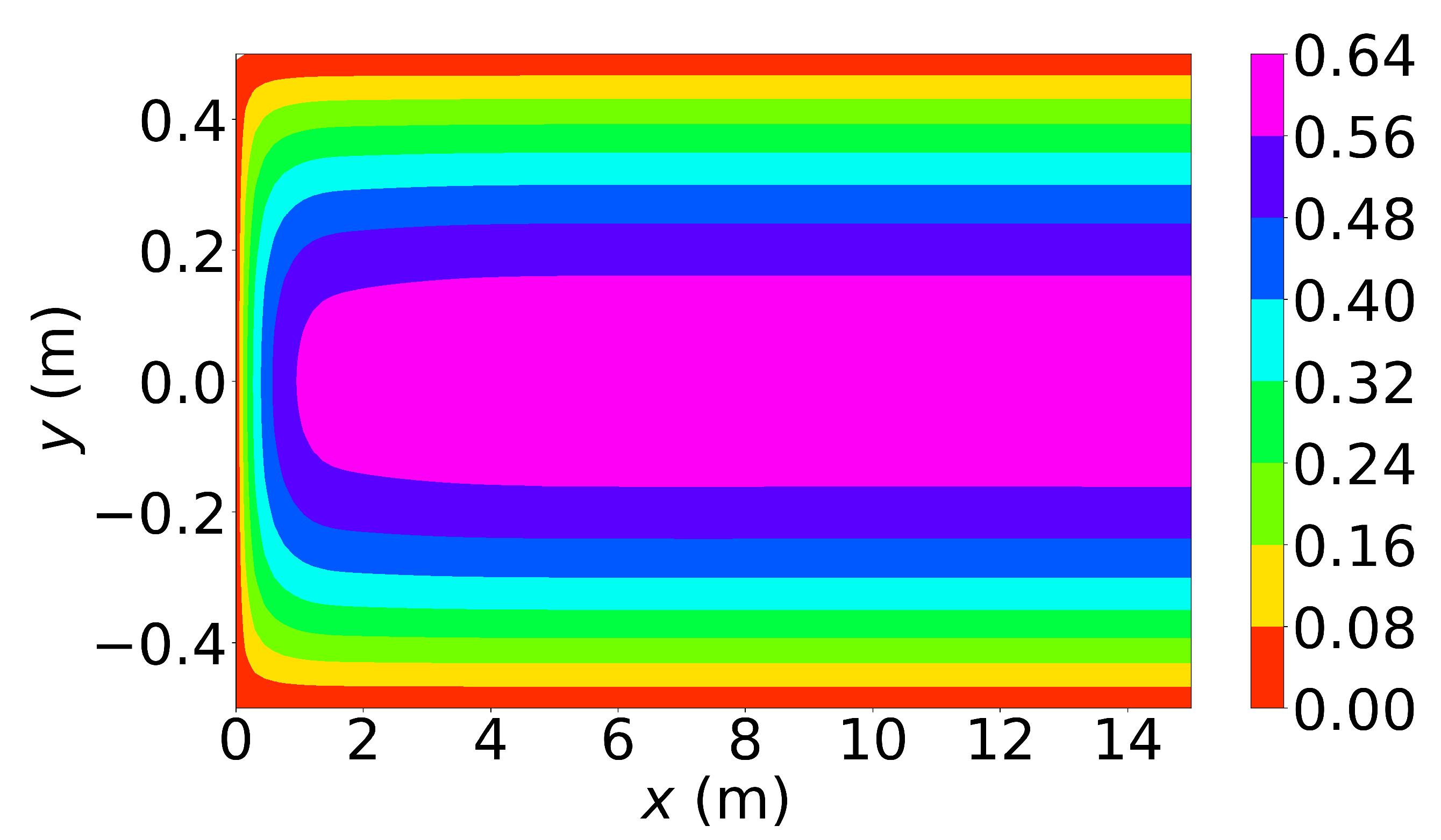
Figure 6, Figure 7 and Figure 8 show the u-velocity of the fluid throughout the domain at three different times. Qualitatively, the solution should look as follows. The solution should be symmetric about the line , and the solution should develop spatially and temporally such that after a sufficient amount of time has passed and sufficiently far from the inlet, , the u-velocity will be equal, or very nearly equal, to the steady state u-velocity of problem 3. Qualitatively, the u-velocity field looks correct in Figure 7 and Figure 8, and throughout most of the spatial domain in Figure 6. However, near the left end of Figure 6, the shape of the highest velocity contour does not match that of the other figures. This stems from the fact that none of the training points fell near this location. Other numerical estimations of this PDE were made with the exact same method, but with different sets of random training points, and in those that had training points near this location, the u-velocity matched the qualitative expectation. However, none of those estimated solutions had a quantitative u-velocity with an error as low as the one shown in Figure 6, Figure 7 and Figure 8. Quantitatively, the u-velocity at from Figure 8 was compared with the known steady state u-velocity, and had a maximum error of m per second and an average error of m per second.
5. Conclusions
This article demonstrated how to combine neural networks with the Theory of Functional Connections (TFC) into a new methodology, called Deep TFC, that was used to estimate the solutions of PDEs. Results on this methodology applied to four problems were presented that display how accurately relatively simple neural networks can approximate the solutions to some well known PDEs. The difficulty of the PDEs in these problems ranged from linear, two-dimensional PDEs to coupled, non-linear, three-dimensional PDEs. Moreover, while the focus of this article was on numerically estimating the solutions of PDEs, the capability to embed constraints into neural networks has the potential to positively impact performance when solving any problem that has constraints, not just differential equations, with a neural network.
Future work should investigate the performance of different neural network architectures on the estimated solution error. For example, Ref. [4] suggests a neural network architecture where the hidden layers contain element-wise multiplications and sums of sub-layers. The sub-layers are more standard neural network layers like the fully connected layers used in the neural networks of this article. Another architecture to investigate is that of extreme learning machines [22]. This architecture is a single layer neural network where the weights of the linear output layer are the only trainable parameters. Consequently, these architectures can ultimately be trained by linear or non-linear least squares for linear or non-linear PDEs respectively.
Another topic for investigation is reducing the estimated solution error by sampling the training points based on the loss function values for the training points of the previous iteration. For example, one could create batches where half of the new batch consists of half of the points in the previous batch that had the largest loss function value and the other half are randomly sampled from the domain. This should consistently give training points that are in portions of the domain where the estimated solution is farthest from the real solution.
Finally, future work will explore extending the hybrid systems approach presented in Ref. [23] to n-dimensions. Doing so would enable Deep TFC to solve problems that involve discontinuities at interfaces. For example, consider a heat conduction problem that involves two slabs of different thermal conductivities in contact with one another. At the interface condition, the temperature is continuous but the derivative of temperature is not.
Author Contributions
Conceptualization, C.L.; Formal analysis, C.L.; Methodology, C.L.; Software, C.L.; Supervision, D.M.; Writing—original draft, C.L.; Writing—review & editing, C.L. and D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a NASA Space Technology Research Fellowship, Leake [NSTRF 2019] Grant #: 80NSSC19K1152.
Acknowledgments
The authors would like to acknowledge Jonathan Martinez for valuable advice on neural network architecture and training methods. In addition, the authors would like to acknowledge Robert Furfaro and Enrico Schiassi for suggesting extreme learning machines as a future work topic. Finally, the authors would like to acknowledge Hunter Johnston for providing computational resources.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
FEM
finite element method
IID
Independent and identically distributed
PDE
partial differential equation
TFC
Theory of Functional Connections
References
Argyris, J.; Kelsey, S. Energy Theorems and Structural Analysis: A Generalized Discourse with Applications on Energy Principles of Structural Analysis Including the Effects of Temperature and Non-Linear Stress-Strain Relations. Aircr. Eng. Aerosp. Technol.1954, 26, 347–356. [Google Scholar] [CrossRef]
Turner, M.J.; Clough, R.W.; Martin, H.C.; Topp, L.J. Stiffness and Deflection Analysis of Complex Structures. J. Aeronaut. Sci.1956, 23, 805–823. [Google Scholar] [CrossRef]
Clough, R.W. The Finite Element Method in Plane Stress Analysis; American Society of Civil Engineers: Reston, VA, USA, 1960; pp. 345–378. [Google Scholar]
Spiliopoulos, J.S.K. DGM: A deep learning algorithm for solving partial differential equations. J. Comput. Phys.2018, 1339–1364. [Google Scholar] [CrossRef]
Yadav, N.; Yadav, A.; Kumar, M. An Introduction to Neural Network Methods for Differential Equations; Springer: Dordrecht, The Netherlands, 2015. [Google Scholar] [CrossRef]
Coons, S.A. Surfaces for Computer-Aided Design of Space Forms; Technical report; Massachusetts Institute of Technology: Cambridge, MA, USA, 1967. [Google Scholar]
Mortari, D. The Theory of Connections: Connecting Points. Mathematics2017, 5, 57. [Google Scholar] [CrossRef]
Mortari, D.; Leake, C. The Multivariate Theory of Connections. Mathematics2019, 7, 296. [Google Scholar] [CrossRef]
Leake, C.; Johnston, H.; Smith, L.; Mortari, D. Analytically Embedding Differential Equation Constraints into Least Squares Support Vector Machines Using the Theory of Functional Connections. Mach. Learn. Knowl. Extr.2019, 1, 1058–1083. [Google Scholar] [CrossRef]
Mortari, D. Least-squares Solutions of Linear Differential Equations. Mathematics2017, 5, 48. [Google Scholar] [CrossRef]
Mortari, D.; Johnston, H.; Smith, L. Least-squares Solutions of Nonlinear Differential Equations. In Proceedings of the 2018 AAS/AIAA Space Flight Mechanics Meeting Conference, Kissimmee, FL, USA, 8–12 January 2018. [Google Scholar]
Johnston, H.; Mortari, D. Linear Differential Equations Subject to Relative, Integral, and Infinite Constraints. In Proceedings of the 2018 AAS/AIAA Astrodynamics Specialist Conference, Snowbird, UT, USA, 19–23 August 2018. [Google Scholar]
Leake, C.; Mortari, D. An Explanation and Implementation of Multivariate Theory of Connections via Examples. In Proceedings of the 2019 AAS/AIAA Astrodynamics Specialist Conference, AAS/AIAA, Portland, MN, USA, 11–15 August 2019. [Google Scholar]
Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 30 January 2020).
Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A. Automatic differentiation in machine learning: A survey. arXiv2015, arXiv:1502.05767. [Google Scholar]
Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv2014, arXiv:1412.6980. [Google Scholar]
Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res.2011, 12, 2121–2159. [Google Scholar]
Tieleman, T.; Hinton, G. Lecture 6.5—RMSProp, COURSERA: Neural Networks for Machine Learning; Technical report; University of Toronto: Toronto, ON, Canada, 2012. [Google Scholar]
Fletcher, R. Practical Methods of Optimization, 2nd ed.; Wiley: New York, NY, USA, 1987. [Google Scholar]
Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; PMLR: Sardinia, Italy, 2010; Volume 9, pp. 249–256. [Google Scholar]
Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing2006, 70, 489–501. [Google Scholar] [CrossRef]
Johnston, H.; Mortari, D. Least-squares solutions of boundary-value problems in hybrid systems. arXiv2019, arXiv:1911.04390. [Google Scholar]
Figure 1.
Problem 1 solution error.
Figure 1.
Problem 1 solution error.
Figure 2.
Problem 1 maximum test set solution error from 100 Monte Carlo trials.
Figure 2.
Problem 1 maximum test set solution error from 100 Monte Carlo trials.
Figure 3.
Problem 1 solution error using Ref. [5] solution form.
Figure 3.
Problem 1 solution error using Ref. [5] solution form.
Figure 4.
Problem 1 solution error using Deep TFC solution form.
Figure 4.
Problem 1 solution error using Deep TFC solution form.
Figure 5.
Problem 2 solution error.
Figure 5.
Problem 2 solution error.
Figure 6.u-velocity in meters per second at 0.01 s.
Figure 6.u-velocity in meters per second at 0.01 s.
Figure 7.u-velocity in meters per second at 0.1 s.
Figure 7.u-velocity in meters per second at 0.1 s.
Figure 8.u-velocity in meters per second at 3.0 s.
Figure 8.u-velocity in meters per second at 3.0 s.
Table 1.
Comparison of Deep TFC, Ref. [5], and finite element method (FEM).
Table 1.
Comparison of Deep TFC, Ref. [5], and finite element method (FEM).
Leake, C.; Mortari, D.
Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Mach. Learn. Knowl. Extr.2020, 2, 37-55.
https://doi.org/10.3390/make2010004
AMA Style
Leake C, Mortari D.
Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Machine Learning and Knowledge Extraction. 2020; 2(1):37-55.
https://doi.org/10.3390/make2010004
Chicago/Turabian Style
Leake, Carl, and Daniele Mortari.
2020. "Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations" Machine Learning and Knowledge Extraction 2, no. 1: 37-55.
https://doi.org/10.3390/make2010004
APA Style
Leake, C., & Mortari, D.
(2020). Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Machine Learning and Knowledge Extraction, 2(1), 37-55.
https://doi.org/10.3390/make2010004
Article Metrics
No
No
Article Access Statistics
For more information on the journal statistics, click here.
Multiple requests from the same IP address are counted as one view.
Leake, C.; Mortari, D.
Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Mach. Learn. Knowl. Extr.2020, 2, 37-55.
https://doi.org/10.3390/make2010004
AMA Style
Leake C, Mortari D.
Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Machine Learning and Knowledge Extraction. 2020; 2(1):37-55.
https://doi.org/10.3390/make2010004
Chicago/Turabian Style
Leake, Carl, and Daniele Mortari.
2020. "Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations" Machine Learning and Knowledge Extraction 2, no. 1: 37-55.
https://doi.org/10.3390/make2010004
APA Style
Leake, C., & Mortari, D.
(2020). Deep Theory of Functional Connections: A New Method for Estimating the Solutions of Partial Differential Equations. Machine Learning and Knowledge Extraction, 2(1), 37-55.
https://doi.org/10.3390/make2010004












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}