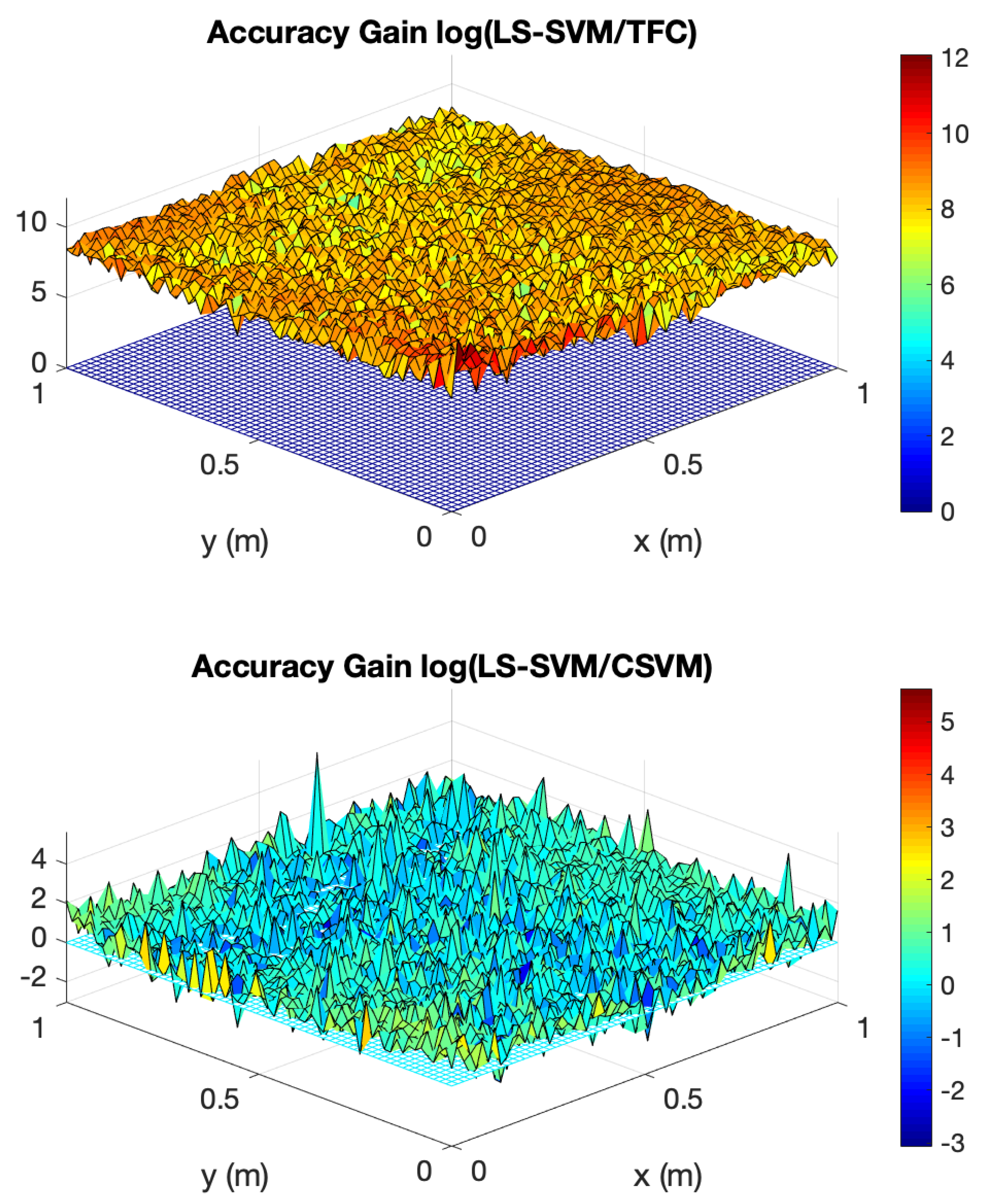
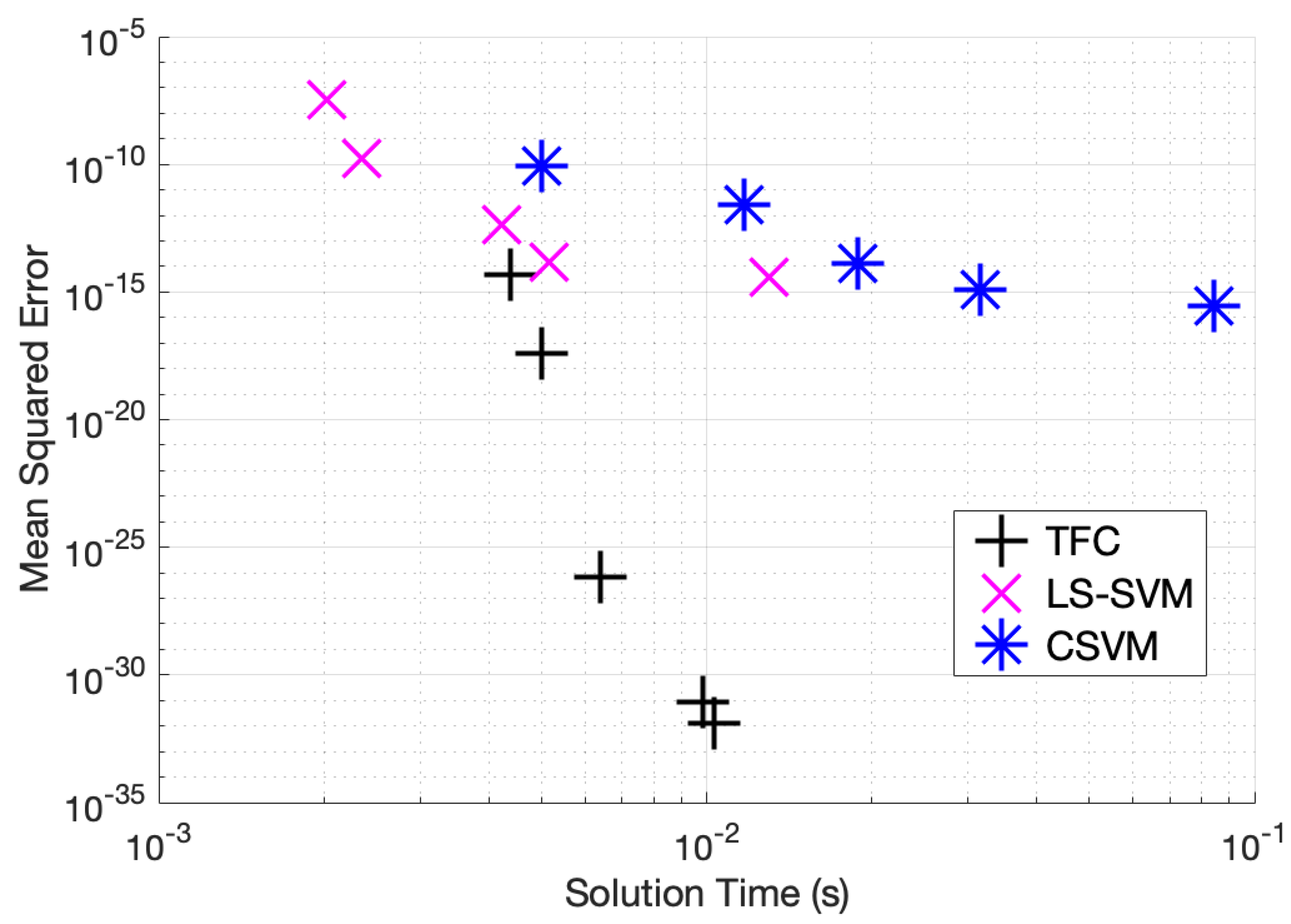
3.1. An Overview of SVMs
Support vector machines (SVMs) were originally introduced to solve classification problems [
17]. A classification problem consists of determining if a given input,
x, belongs to one of two possible classes. The proposed solution was to find a decision boundary surface that separates the two classes. The equation of the separating boundary depended only on a few input vectors called the support vectors.
The training data is assumed to be separable by a linear decision boundary. Hence, a separating hyperplane,
H, with equation
, is sought. The parameters are rescaled such that the closest training point to the hyperplane
H, let’s say
, is on a parallel hyperplane
with equation
. By using the formula for orthogonal projection, if
satisfies the equation of one of the hyperplanes, then the signed distance from the origin of the space to the corresponding hyperplane is given by
. Since
equals
for
H, and
for
, it follows that the distance between the two hyperplanes, called the “separating margin”, is
. Thus to find the largest separating margin, one needs to minimize
. The optimization problem becomes,
If a separable hyperplane does not exist, the problem is reformulated by taking into account the classification errors, or slack variables,
, and a linear or quadratic expression is added to the cost function. The optimization problem in the non-separable case is,
When solving the optimization problem by using Lagrange multipliers, the function
always shows up as a dot product with itself; thus, the kernel trick [
25] can be applied. In this research, the kernel function chosen is the radial basis function (RBF) kernel proposed in [
12]. Hence, the function
can be written using the kernel [
25],
and its partial derivatives [
12,
26],
where the Kernel bandwidth,
, is a tuning parameter that must be chosen by the user.
We follow the method of solving DEs using RBF kernels proposed in [
12]. As an example, we take a first order linear initial value problem,
to be solved on the interval
. The domain is partitioned into
N sub-intervals using grid points
, which from a machine learning perspective represents the training points. The model,
is proposed for the solution
. Note that the number of coefficients
equals the number of grid points
, and thus the system of equations used to solve for the coefficient is a square matrix. Let
be the vector of residuals obtained when using the model solution
in the DE, that is,
is the amount by which
fails to satisfy the DE,
This results in,
and for the initial condition, it is desired that,
is satisfied exactly. In order to have the model close to the exact solution, the sum of the squares of the residuals,
, is to be minimized. This expression can be viewed as a regularization term added to the objective of maximizing the margin between separating hyperplanes. The problem is formulated as an optimization problem with constraints,
Using the method of Lagrange multipliers, a loss function,
, is defined using the objective function from the optimization problem and appending the constraints with corresponding Lagrange multipliers
and
.
The values where the gradient of
is zero give candidates for the minimum.
Note that the conditions found by differentiating
with respect to
and
are simply the constraint conditions, while the remaining conditions are the standard Lagrange multiplier conditions that the gradient of the function to be minimized is a linear combination of the gradients of the constraints. Using,
we obtain a new formulation of the approximate solution
where the inner products of
can be re-written using Equations (
6) and (
7), and the parameter
in the kernal matrix is a value that is learned during the training period together with the coefficients
. The remaining gradients of
can be used to form a linear system of equations where
,
, and
b are the only unknowns. Note, that this system of equations can also be expressed using the kernal matrix and its partial derivatives rather than inner-products of
.
3.2. Constrained SVM (CSVM) Technique
In the TFC method [
7], the general constrained expression can be written for an initial value constraint as,
where
is a “freely chosen” function. In prior studies [
8,
9,
11], this free function was defined by a set of orthogonal basis functions, but this function can also be defined using SVMs,
where
becomes,
This leads to the equation,
where the initial value constraint is always satisfied regardless of the values of
and
. Through this process, the constraints only remain on the residuals and the problem becomes,
Again, using the method of Lagrange multipliers, a term is introduced for the constraint on the residuals, leading to the expression,
The values where the gradient of
is zero give candidates for the minimum,
Using,
we obtain a new formulation of the approximate solution given by Equation (
9), that can be expressed in terms of the kernel and its derivatives. Combining the three equations for the gradients of
, we can obtain a linear system with unknowns
,
The coefficient matrix is given by,
where we use the notation,
Finally, in terms of the kernel matrix, the approximate solution at the grid points is given by,
and a formula for the approximate solution at an arbitrary point
t is given by,
3.3. Nonlinear ODEs
The method for solving nonlinear, first-order ODEs with LS-SVM comes from reference [
12]. Nonlinear, first-order ODEs with initial value boundary conditions can be written generally using the form,
The solution form is again the one given in Equation (
8) and the domain is again discretized into
N sub-intervals,
(training points). Let
be the residuals for the solution
,
To minimize the error, the sum of the squares of the residuals is minimized. As in the linear case, the regularization term
is added to the expression to be minimized. Now, the problem can be formulated as an optimization problem with constraints,
The variables are introduced into the optimization problem to keep track of the nonlinear function f at the values corresponding to the grid points. The method of Lagrange multipliers is used for this optimization problem just as in the linear case. This leads to a system of equations that can be solved using a multivariate Newton’s method. As with the linear ODE case, the set of equations to be solved and the dual form of the model solution can be written in terms of the kernel matrix and its derivatives.
The solution for nonlinear ODEs when using the CSVM technique is found in a similar manner, but the primal form of the solution is based on the constraint function from TFC. Just as the linear ODE case changes to encompass this new primal form, so does the nonlinear case. A complete derivation for nonlinear ODEs using LS-SVM and CSVM is provided in
Appendix B.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







