Prediction by Empirical Similarity via Categorical Regressors



Abstract
1. Introduction
2. Preliminaries
Empirical Similarity Model
3. Prediction Based on Empirical Similarity with Categorical Regressors
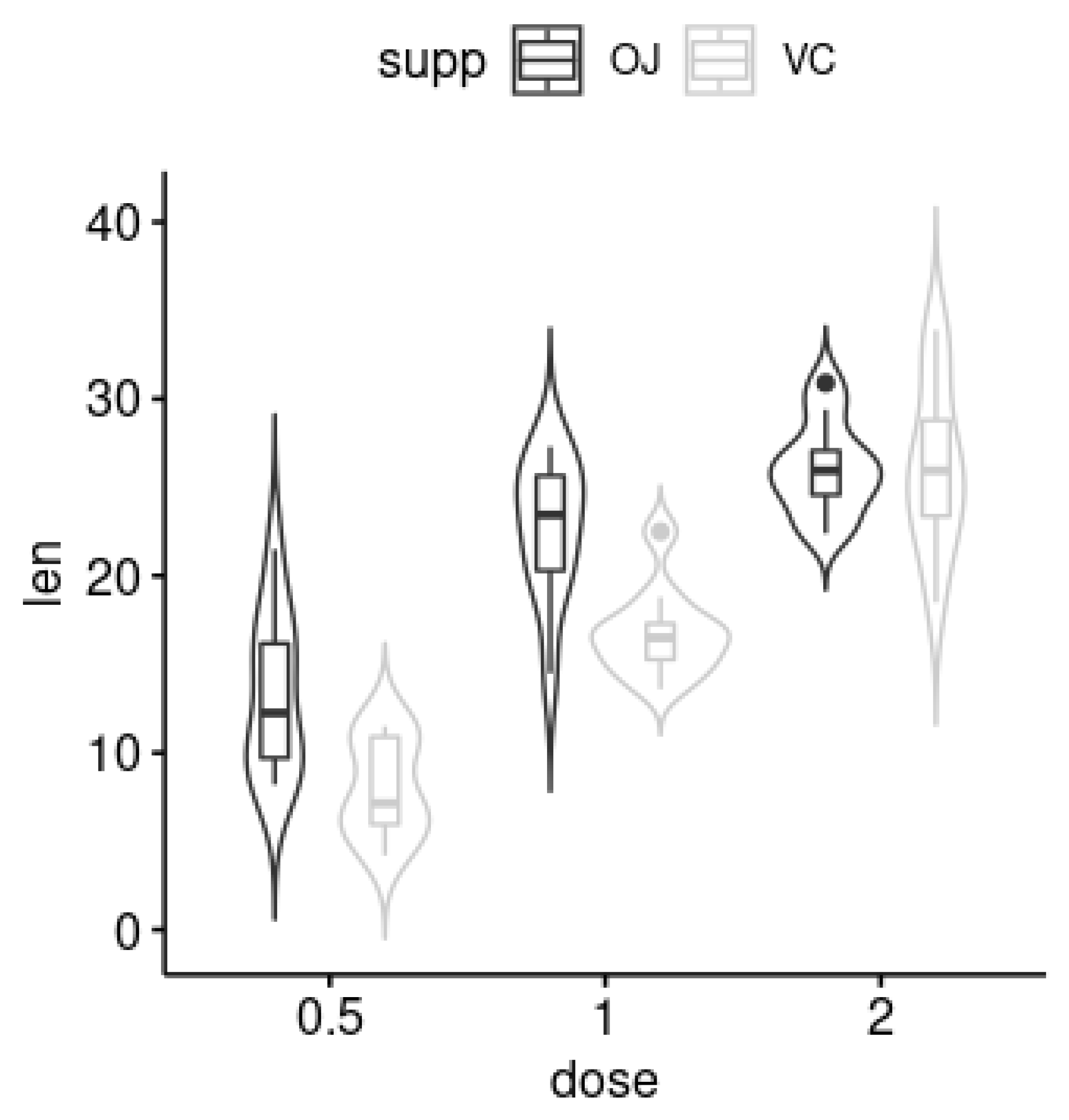
4. Application
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties; Technical Report 4; Project Number 21-49-004; USAF School of Aviation Medicine: Randolph Field, TX, USA, 1951. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory Analysis: Samall Sample Performance; Technical Report 21-49-004; USAF School of Aviation Medicine: Randolph Field, TX, USA, 1952. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Devroye, L.; Gyorfy, L.; Lugosi, G. A probabilistic Theory of Pattern Recognition; Springer: New York, NY, USA, 1996. [Google Scholar]
- Akaike, H. An approximation to the density function. Ann. Inst. Stat. Math. 1954, 6, 127–132. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On the Estimation of a Probability Density Function and the Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall: London, UK, 1986. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice and Visualization; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Gilboa, I.; Lieberman, O.; David, S. Empirical Similarity. Rev. Econ. Stat. 2006, 88, 433–444. [Google Scholar] [CrossRef]
- Gilboa, I.; Schmeidler, D. Case-based decision theory. Q. J. Econ. 1995, 110, 605–639. [Google Scholar] [CrossRef]
- Gilboa, I.; Schmeidler, D. A Theory of Case-Based Decisions; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Gilboa, I.; Schmeidler, D. Inductive inference: An axiomatic approach. Econometrica 2003, 71, 1–26. [Google Scholar] [CrossRef]
- Gayer, G.; Gilboa, I.; Lieberman, O. Rule-Based and Case-Based Reasoning in Housing Prices. BE J. Theor. Econ. 2007, 7. [Google Scholar] [CrossRef]
- Gilboa, I.; Lieberman, O.; Schmeidler, D. A similarity-based approach to prediction. J. Econ. 2011, 162, 124–131. [Google Scholar] [CrossRef]
- Lieberman, O. Asymptotic Theory for Empirical Similarity Models. Econ. Theory 2010, 4, 1032–1059. [Google Scholar] [CrossRef]
- Lieberman, O. A Similarity-Based Approach to Time-Varying Coefficient Non-Stationary Autoregression. J. Time Ser. Anal. 2012, 33, 484–502. [Google Scholar] [CrossRef]
- Davison, A.C. Statistical Models; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Wassermann, L. All of Nonparametric Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Billot, A.; Gilboa, I.; Samet, D.; Schmeidler, D. Probabilities as similarity-weighted frequencies. Econometrica 2005, 73, 1125–1136. [Google Scholar] [CrossRef]
- Billot, A.; Gilboa, I.; Schmeidler, D. Axiomatization of an exponential similarity function. Math. Soc. Sci. 2008, 55, 107–115. [Google Scholar] [CrossRef]
- Gilboa, I.; Lieberman, O.; Schmeidler, D. On the definition of objective probabilities by empirical similarity. Synthese 2010, 172, 79–95. [Google Scholar] [CrossRef]
- Lieberman, O.; Phillips, P.C. Norming Rates and Limit Theory for Some Time-Varying Coefficient Autoregressions. J. Time Ser. Anal. 2014, 35, 592–623. [Google Scholar] [CrossRef]
- Hamid, A.; Heiden, M. Forecasting volatility with empirical similarity and Google Trends. J. Econ. Behav. Organ. 2015, 117, 62–81. [Google Scholar] [CrossRef]
- Gayer, G.; Lieberman, O.; Yaffe, O. Similarity-based model for ordered categorical data. Econ. Rev. 2019, 38, 263–278. [Google Scholar] [CrossRef]
- Aitchison, J.; Aitken, C.G. Multivariate binary discrimination by the kernel method. Biometrika 1976, 63, 413–420. [Google Scholar] [CrossRef]
- Delgado, M.A.; Mora, J. Nonparametric and semiparametric estimation with discrete regressors. Econom. J. Econom. Soc. 1995, 63, 1477–1484. [Google Scholar] [CrossRef]
- Chen, S.X.; Tang, C.Y. Nonparametric regression with discrete covariate and missing values. Stat. Its Interface 2011, 4, 463–474. [Google Scholar] [CrossRef]
- Nie, Z.; Racine, J.S. The crs Package: Nonparametric Regression Splines for Continuous and Categorical Predictors. R J. 2012, 4, 48–56. [Google Scholar] [CrossRef]
- Ma, S.; Racine, J.S. Additive regression splines with irrelevant categorical and continuous regressors. Stat. Sin. 2013, 23, 515–541. [Google Scholar]
- Chu, C.Y.; Henderson, D.J.; Parmeter, C.F. Plug-in bandwidth selection for kernel density estimation with discrete data. Econometrics 2015, 3, 199–214. [Google Scholar] [CrossRef]
- Guo, C.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Racine, J.; Li, Q. Nonparametric estimation of regression functions with both categorical and continuous data. J. Econ. 2004, 119, 99–130. [Google Scholar] [CrossRef]
- Li, Q.; Racine, J. Nonparametric estimation of distributions with categorical and continuous data. J. Multivar. Anal. 2003, 86, 266–292. [Google Scholar] [CrossRef]
- Li, Q.; Racine, J.S.; Wooldridge, J.M. Estimating average treatment effects with continuous and discrete covariates: The case of Swan-Ganz catheterization. Am. Econ. Rev. 2008, 98, 357–362. [Google Scholar] [CrossRef]
- Farnè, M.; Vouldis, A.T. A Methodology for Automatised Outlier Detection in High-Dimensional Datasets: An Application to Euro Area Banks’ Supervisory Data; Working Paper Series; European Central Bank: Frankfurt, Germany, 2018. [Google Scholar]
- Crampton, E.W. The growth of the odontoblasts of the incisor tooth as a criterion of the vitamin C intake of the guinea pig. J. Nutr. 1947, 33, 491–504. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Hintze, J.; Nelson, R.D. Violin Plots: A Box Plot-Density Trace Synergism. Am. Stat. 1998, 52, 181–184. [Google Scholar]
- Tutz, G.; Gertheiss, J. Regularized regression for categorical data. Stat. Model. 2016, 16, 161–200. [Google Scholar] [CrossRef]
- Chiquet, J.; Grandvalet, Y.; Rigaill, G. On coding effects in regularized categorical regression. Stat. Model. 2016, 16, 228–237. [Google Scholar] [CrossRef]
- Tibshirani, R.; Wainwright, M.; Hastie, T. Statistical Learning with Sparsity: The Lasso and Generalizations; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]


{kind=link}
| Binary Dist. | Euclidean Dist. | ||||
|---|---|---|---|---|---|
| Method | |||||
| Scenario 1 | LS FR | 499.59 | 14.72 | 1049.20 | 14.79 |
| LS EX | 5.28 | 2.74 | 17.09 | 2.71 | |
| MLE FR | 38.32 | 4.23 | 52.33 | 4.66 | |
| MLE EX | 3.18 | 1.62 | 6.37 | 1.55 | |
| Scenario 2 | LS FR | 113.17 | 6.67 | 170.42 | 6.94 |
| LS EX | 3.91 | 1.96 | 12.06 | 1.94 | |
| MLE FR | 23.84 | 3.57 | 32.75 | 4.00 | |
| MLE EX | 2.70 | 1.48 | 4.82 | 1.38 | |
| Method | |||||
|---|---|---|---|---|---|
| Scenario 1 | LS FR | 719.35 | 0.00 | 105.88 | 15.42 |
| LS EX | 3.79 | 0.00 | 3.56 | 2.84 | |
| MLE FR | 30.60 | 0.00 | 20.68 | 4.45 | |
| MLE EX | 2.35 | 0.00 | 2.24 | 1.68 | |
| Scenario 2 | LS FR | 86.65 | 0.00 | 46.55 | 6.94 |
| LS EX | 2.72 | 0.00 | 2.53 | 1.97 | |
| MLE FR | 25.20 | 0.00 | 7.62 | 4.04 | |
| MLE EX | 2.12 | 0.00 | 1.58 | 1.57 |
| Estimate | s.e. | p-Value | ||
|---|---|---|---|---|
| Scenario 1 | Intercept | 12.46 | 0.99 | |
| Supp. VC | −3.70 | 0.99 | <0.01 | |
| Dose 1.0 mg | 9.13 | 1.21 | <0.01 | |
| Dose 2.0 mg | 15.50 | 1.21 | <0.01 | |
| Scenario 2 | Intercept | 9.28 | 1.16 | <0.01 |
| Supp. VC | 3.76 | 1.20 | <0.01 | |
| Dose 1.0 mg | 8.52 | 1.49 | <0.01 | |
| Dose 2.0 mg | 14.26 | 1.47 | <0.01 |
| LS | MLE | ||||
|---|---|---|---|---|---|
| Method | FR | EX | FR | EX | |
| Scenario 1 | (binary) | 14.54 | 14.54 | 15.39 | 15.36 |
| (Euclidean) | 14.55 | 14.54 | 15.45 | 16.40 | |
| 14.54 | 14.51 | 15.35 | 15.19 | ||
| Regression | 13.67 | - | - | - | |
| Scenario 2 | (binary) | 14.51 | 14.88 | 18.00 | 18.41 |
| (Euclidean) | 14.40 | 14.04 | 17.54 | 18.55 | |
| 14.69 | 15.27 | 18.19 | 18.15 | ||
| Regression | 15.31 | - | - | - | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanchez, J.D.; Rêgo, L.C.; Ospina, R. Prediction by Empirical Similarity via Categorical Regressors. Mach. Learn. Knowl. Extr. 2019, 1, 641-652. https://doi.org/10.3390/make1020038
Sanchez JD, Rêgo LC, Ospina R. Prediction by Empirical Similarity via Categorical Regressors. Machine Learning and Knowledge Extraction. 2019; 1(2):641-652. https://doi.org/10.3390/make1020038
Chicago/Turabian StyleSanchez, Jeniffer Duarte, Leandro C. Rêgo, and Raydonal Ospina. 2019. "Prediction by Empirical Similarity via Categorical Regressors" Machine Learning and Knowledge Extraction 1, no. 2: 641-652. https://doi.org/10.3390/make1020038
APA StyleSanchez, J. D., Rêgo, L. C., & Ospina, R. (2019). Prediction by Empirical Similarity via Categorical Regressors. Machine Learning and Knowledge Extraction, 1(2), 641-652. https://doi.org/10.3390/make1020038