1. Introduction
The flexible job shop scheduling problem (FJSP) is an important challenge widely faced in manufacturing industries. In contrast to the classic scheduling problem (JSP), operations in FJSP can be processed on a set of eligible machines. Additionally, the job precedence constraint (JPC) is another practical feature that often exists in various types of production scenarios. More specifically, the JPC indicates that some jobs can start processing after one or several other jobs have been completed. That is, the precedence relationship exists not only among operations in the job as in classic job shop scheduling, but also among different jobs.
An example of the JPC is shown in
Figure 1. In this figure, each job (rectangle) represents an item, which could be either a product or a component, and each operation (circle) corresponds to a manufacturing process for that item. Edges indicate precedence relationships between operations or jobs. In this example,
is the final product, and operation
represents its final assembly. The components of
include
,
, and
, while
itself is composed of parts
and
. These hierarchical assembly relationships form a strict tree-like structure among the jobs, similar to a Bill of Materials (BOM).
Several methodologies have been proposed to solve FJSP [
1]. One of the most important is mathematical programming, including mixed integer linear programming (MILP) [
2,
3] and constraint programming [
4]. Yet, due to the NP-hardness of FJSP, the direct solving of these models tends to be difficult even for medium-scale instances [
5]. Recent works for FJSP have focused on meta-heuristic algorithms, including genetic algorithm [
6], Grey Wolf Algorithm [
7], particle swarm optimization [
8], etc. Li and Gao [
9] proposed a method combining the population-based global search of genetic algorithm with the local improvement of tabu search, achieving a higher solution performance and shorter computational time for FJSP. Xie et al. [
10] proposed a hybrid algorithm for the distributed FJSP that combines the global search capability of genetic algorithms with the local search strength of tabu search. He et al. [
11] developed a method based on the ant colony optimization algorithm, incorporating heuristic rules to address both scheduling and transportation tasks in the FJSP.
Although traditional operations research methods can generally produce promising results, they often involve complex and time-consuming processes. Their computational burden grows rapidly with problem size, making them less suitable for dynamic environments where quick decision-making is essential. To balance computational cost and solution quality, recent research in JSP and FJSP has increasingly shifted toward artificial intelligence approaches, including reinforcement learning (RL) [
12] and deep reinforcement learning (DRL) [
13]. DRL, in particular, leverages neural networks to map environmental information to optimal decision actions [
14]. Johnson et al. [
15] proposed a multi-agent reinforcement learning (MARL) method for solving real-time FJSP in robotic assembly cells, demonstrating high flexibility and efficiency in dynamic environments. Luo et al. [
16] introduced a hierarchical multi-agent method based on proximal policy optimization (PPO), tailored for real-time scheduling in discrete flexible manufacturing systems. Du et al. [
17] studied a multi-objective FJSP with crane transportation and preparation time constraints. They developed a double deep Q-network algorithm with a specialized network architecture to minimize both makespan and total energy consumption. Han and Yang [
18] proposed an end-to-end DRL framework based on the 3D disjunctive graph and an improved pointer network, which integrates both static and dynamic features for FJSP. Xu et al. [
19] developed a scheduling framework based on the transformer and PPO for FJSP, which captures the relationships between state features and enhances performance through composite dispatching rules and a dense reward function.
These DRL methods rely on manually designed environmental features, which may overlook important information and struggle to handle the complex constraint relationships between operations and machines. To address this limitation, Graph Neural Networks (GNNs) have gradually been applied to FJSP. By representing operations, machines, and constraints as a graph structure, GNNs can effectively capture the structural characteristics of scheduling problems [
20]. Park et al. [
21] proposed a GNN-PPO framework for solving JSP, which models the problem structure using graphs and demonstrates strong generalization capabilities across untrained datasets of varying sizes. Song et al. [
22] developed an end-to-end approach based on GNN and PPO for FJSP, employing a heterogeneous graph to capture the complex relationships between operations and machines. Wang et al. [
23] proposed a DRL framework based on a dual attention network and PPO for FJSP. It constructs attention blocks for operation messages and machine messages to accurately represent their interconnections and performs well on large-scale instances. Lei et al. [
24] introduced an end-to-end DRL framework for FJSP, utilizing disjunctive graphs to represent the local system state and designing a multi-action PPO algorithm that learns job and machine action policies, effectively handling instances of various sizes.
Besides the aforementioned studies, relatively few works have addressed the FJSP with job precedence constraints. Xiong et al. [
25] proposed novel scheduling rules that account for job tardiness in addressing dynamic job shop scheduling problems with job batch releases and extended technological precedence constraints. Zhu and Zhou [
26] investigated a job shop scheduling problem with job precedence constraints for bicycle assembly and proposed a multi-micro-swarm leadership hierarchy-based optimization algorithm to address this problem. Zhang et al. [
27] studied the FJSP with multi-level assembly structures and proposed a distributed ant colony optimization algorithm to optimize makespan and total tardiness. Lin et al. [
28] introduced the FJSP with job precedence constraints accommodating both machining and assembly operations, designing a genetic algorithm with an innovative two-dimensional encoding method to solve it.
Table 1 summarizes some recent works mentioned above on the job shop scheduling problem and compares the differences between our method and them. In summary, most current methods for the FJSP-JPC are based on mathematical programming and metaheuristic algorithms, which may struggle to adapt to dynamic scenarios due to their relatively long computational times. DRL-based methods, on the other hand, demonstrate significant potential for improving the resolution efficiency while maintaining the solution quality. However, to the best of our knowledge, no DRL-based approach has yet been proposed for FJSP-JPC. To fill this gap, this paper investigates the FJSP-JPC with the objective of minimizing makespan. The main contributions of this paper are as follows:
- 1.
We formulate the FJSP-JPC as a MILP model and develop a heterogeneous disjunctive graph model for improving problem representation.
- 2.
We propose a DRL-based approach to solve the FJSP-JPC, which outperforms traditional priority dispatching rules (PDRs) as well as a state-of-the-art DRL-based method.
- 3.
We analyze the impact of various factors in the proposed DRL framework, such as node embeddings, information diffusion range, and action space selection, on the algorithm performance.
The remainder of this paper is organized as follows.
Section 2 provides the definition and mathematical model of FJSP-JPC.
Section 3 introduces the proposed method.
Section 4 reports the experimental results.
Section 6 concludes this paper.
3. Methodology
FJSP-JPC involves two types of decisions: assigning an operation to one of its eligible machines, and sequencing the operations on the same machine. Though FJSP-JPC is a combinatorial optimization problem, the schedule construction can be viewed as a sequential decision-making procedure. This allows for the possibility to formulate the schedule procedure as a Markov decision process (MDP), where the optimal policy can be estimated by RL algorithms. In this section, the details of our proposed approach are presented. Firstly, we explain the scheduling environment for FJSP-JPC. Then, the definitions of state, action, reward function, and state transition logic are described, along with several improvement strategies we propose.
3.1. MDP Formulation of the Scheduling Problem
At the first scheduling step (), the system clock is initialized to , with all machines idle and all operations unscheduled. Let denote the current system state. Based on , the agent takes an action , which involves selecting an unscheduled operation and scheduling its start time on one of its eligible machines. This action transitions the system to a new state , and the environment provides a reward .
Typically, only a subset of operations can be scheduled at time
T, such as those whose predecessors have been completed [
23]. However, the definition of this subset is not unique. If no such operations are available, or all machines that can process these operations are busy, the system clock advances to the earliest time at which a machine completes a scheduled operation. An operation is considered completed once its scheduled completion time is earlier than the system clock. This process continues until all operations have been scheduled and completed.
3.2. State
The state representation of FJSP typically summarizes the environment information at time
T. Traditional methods often use manually crafted features, such as job completion rate and machine load rate, as state descriptors [
13]. The advantage of this approach lies in its ability to abstract information into fixed-size feature vectors, making it applicable to systems of different scales and allowing the agent a certain degree of generalization capability. However, the limitations of this method are also evident. In principle, the state representation provided to the agent should comprehensively capture all of the relevant information about the environment at time
T. In practice, the complexity of manufacturing systems makes it difficult for manually designed features to include all critical aspects. Important factors such as job precedence constraints and machine-operation compatibility may be overlooked. To address this issue and better capture the complex characteristics of the environment, we propose a state representation method based on a heterogeneous disjunctive graph, combined with a multi-head graph attention network (GAT), to learn rich and structured features automatically.
3.2.1. Heterogeneous Disjunctive Graph
The disjunctive graph is a graph model used to represent the scheduling process of JSP [
29]. The typical disjunctive graph is a directed acyclic graph written as
. Here,
is the set of nodes consisting of all operations and two dummy operations representing the start and end of processing.
is the set of directed conjunctive arcs, representing the precedence relationship between operations.
is the set of disjunctive arcs connecting the operations that can be processed on the same machine
. Solving JSP involves fixing the direction of each disjunctive arc and, thus, arranging the sequence of operations on the same machine.
Unlike JSP, each operation in FJSP can have more than one eligible machines. To better represent this relationship between operations and machines, a heterogeneous disjunctive graph
is designed. As shown in
Figure 2a, the graph retains operation nodes
and directed conjunctive arcs
, while introducing a new type of node, i.e., machine nodes
, to represent the machines. The disjunctive arcs
build connections between the operations and their eligible machines.
The scheduling process involves selecting one disjunctive arc for each operation node, converting it into a conjunctive arc, and determining the operation start time, which is stored in the node features. A possible solution is illustrated in
Figure 2b. The detailed step-by-step scheduling procedure can be found in
Appendix A.
We embed a set of features into the graph to represent scheduling information.
Table 2 reports the features for each operation node in
, machine node in
, and undirected arc in
. Most of these features are identical to those used in [
23] for FJSP; we modify a subset of them to accommodate the JPC characteristics of our problem.
More specifically, compared to those proposed in Wang et al. [
23], the newly designed features are (o2), (o8), (o9), and (a3). These features are specifically adapted to the tree-like JPC in our problem. More specifically, when computing the estimated completion time of operation
in (o2), we consider all operations related to
through JPC across the entire graph. Instead of assuming
, we determine the estimated starting time of
by Equation (
20). Similarly, when calculating the number of remaining operations (o8) and the remaining work (o9), we account for all operations connected to
via JPC, i.e., all unscheduled operations along the directed path from
to
End. On the other hand, the calculation of feature (a3) differs from that in Wang et al. [
23]. Since we use a different action space, the set of candidate operations that a machine, say
, can process at a given time
T is larger than that in the original version.
3.2.2. Multi-Head GAT
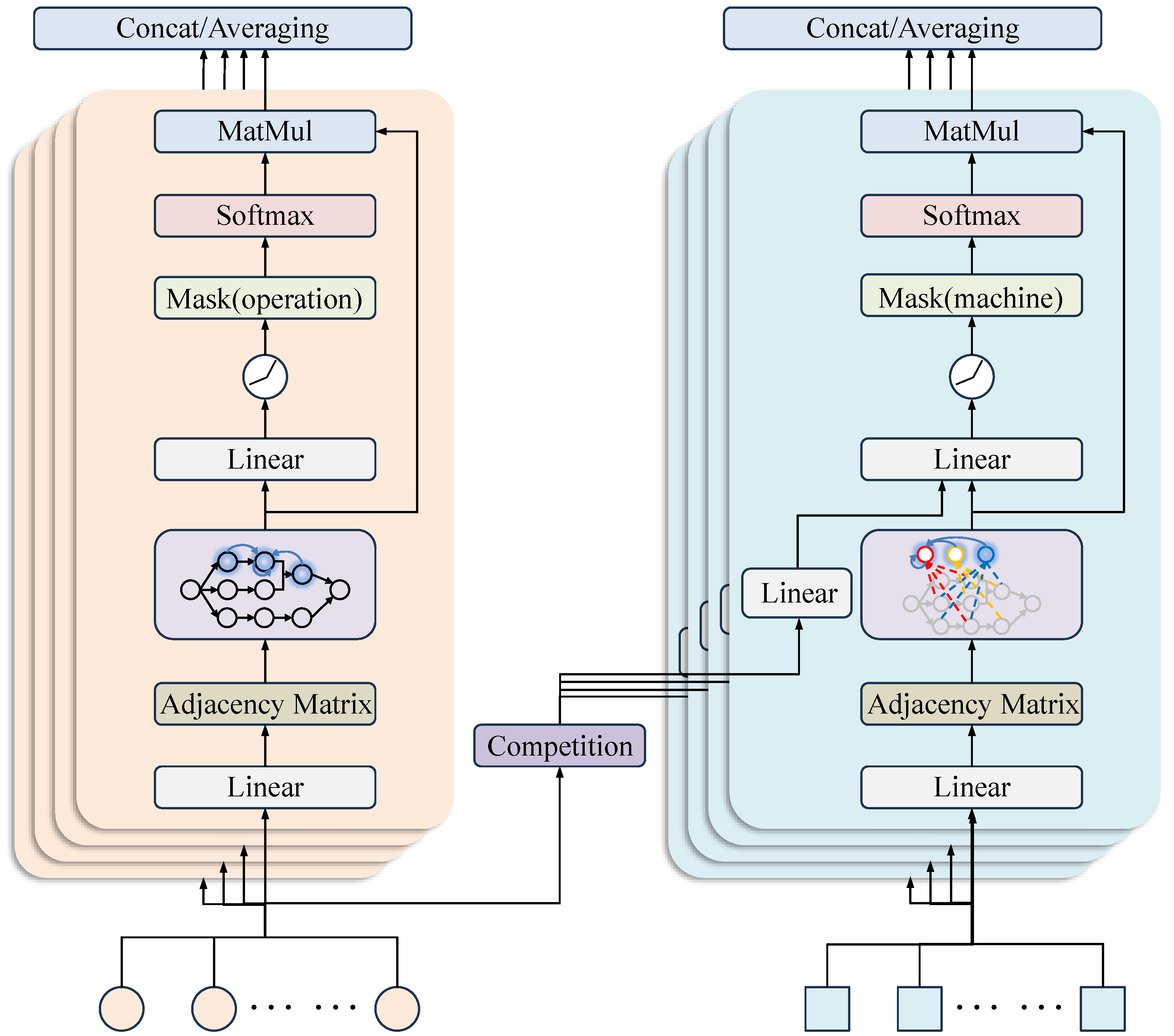
Traditional neural network architectures, such as the multi-layer perceptron (MLP), can only process inputs with fixed-size dimensions. However, in FJSP-JPC, the size of the graph structures representing the states varies between instances. To tackle this difficulty, we utilize a multi-head GAT to process the graph features. The multi-head GAT uses a graph of arbitrary size as input and outputs a graph of the same topology with updated feature vectors in each node and arc. The GAT assigns different attention weights to neighboring nodes, allowing it to focus more on important neighbors during the feature aggregation process. Meanwhile, the graph attention layer utilizes attention mechanism to learn critical structural features of the graph during the embedding process and places greater emphasis on the local information by applying attention masks. The attention mechanism is described in the following subsection.
3.2.3. Attention Mechanism
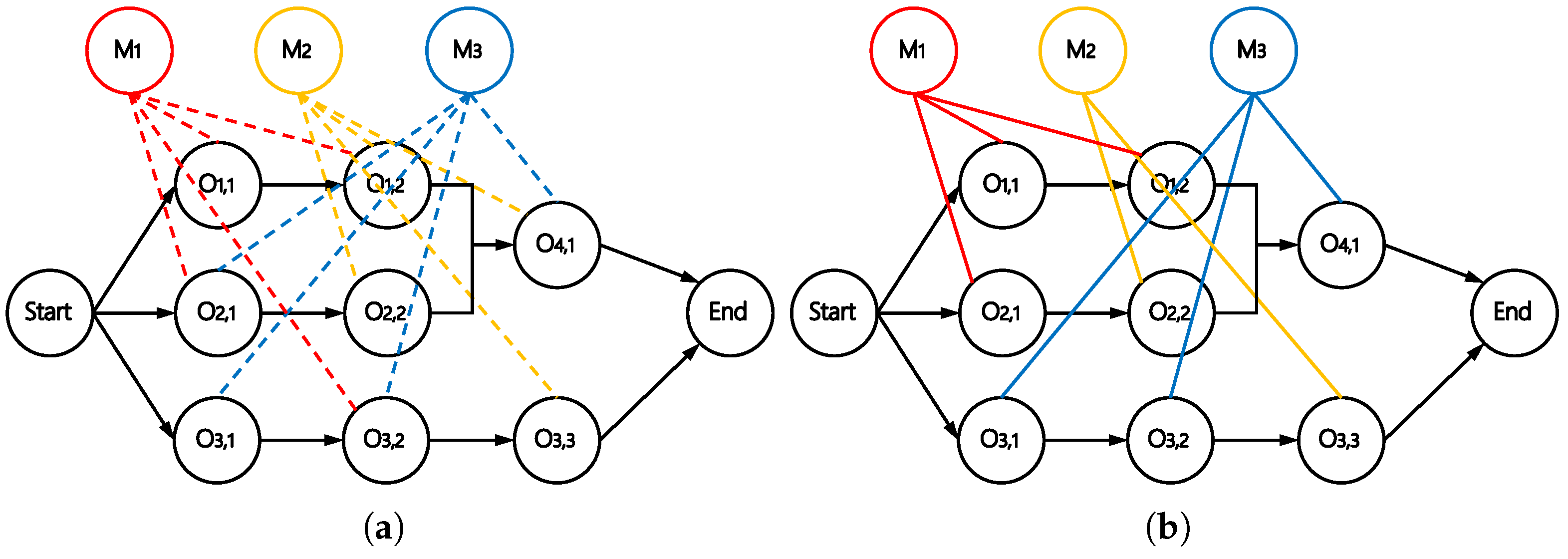
The heterogeneous disjunctive graph can essentially be viewed as a superposition of two distinct subgraphs, i.e., the operation relationship graph and the machine relationship graph. Hence, two separate attention blocks are employed in the model to embed the features of operations and machines, respectively. This design facilitates the learning of complex connections both between operation nodes and between operation nodes and machine nodes. While the two attention blocks share similar structural designs, they have different dimensions and parameters.
Operation attention block. The inputs to this block are the features of the operation nodes. The precedence constraints between operation nodes are represented by an adjacency matrix, which is used to propagate information between nodes with strong correlations. Specifically, each operation
is associated with an input feature
. Let
denote the set of direct predecessor and successor nodes that are less than one edge away from
, including
itself. Notably,
may also include cross-job operations that do not belong to the same job as
. For example, in
Figure 3a, the operation node
aggregates information from two of its predecessors in different jobs, namely
and
. This mechanism enables information to diffuse across the graph, enhancing overall performance.
The methodology for computing the attention coefficient between
and
is as follows:
where
is a linear transformation that projects the node features
and
into a higher-dimensional space. The transformed features are concatenated and then passed through a single-layer feedforward neural network with a
activation function. The network weights are denoted by
. Afterwards, we normalize attention coefficients by the softmax function as follows:
where
represents the set of completed and dummy operation nodes whose effect on the scheduling process is not considered. Having the attention coefficients, we update the features for each operation node by
where
is the exponential linear unit nonlinear activation function.
This approach updates the node embeddings by aggregating information from their neighbors. Let represent the node embedding after passing through l attention layers. By doing so, incorporates information from a broader range of nodes, thereby expanding the receptive field.
Machine attention block. The attention block for machines is similar to that for operations; the difference is in the consideration of neighbors. In FJSP, machines are related to each other due to the competition of unscheduled operations. More specifically, if an unscheduled operation can be processed by two machines, say
and
, there can be a competitive relationship between them. As shown in
Figure 3b,
is related to
through the competition for
, while it is related to
by the competition for
and
. Let
be the set of operations that
and
compete for, and
be the set of machines competing with machine
(including
itself). The parameter that measures the competitive intensity between
and
can be defined as follows:
Then, the attention coefficient between machines
and
can be computed by
where
is a linear transformation scaling up the machine features vectors, and
is a matrix evaluating the influence of a competitive intensity on non-self-attention. Specifically, if
is empty,
and
do not affect each other, and the attention coefficients between them are set to zero by a mask. Finally, we update the machine features
by
3.2.4. Multi-Head Attention
According to Vaswani et al. [
30], the expressive power of the attention mechanism can be enhanced by capturing information across different dimensions using multiple independent attention heads. To leverage this, we employ
attention heads within both the operation and machine attention block. More specifically, each head uses the same raw features of operation nodes (or machine nodes) as inputs, while the attention coefficients
s (or
s) are computed in parallel and independently. Then, the outputs of each head are combined by an aggregation operator. Following GAT, we use concatenation except for the last attention layer, which is combined by an averaging operator.
3.2.5. Global Average Pooling
Besides the node features, we apply an average pooling on all the active nodes to obtain a global feature vector
describing the overall state of the graph, which is given by
3.2.6. The Overall Architecture
The overall architecture of the multi-head GAT is illustrated in
Figure 4. The input consists of features of nodes and operation–machine arcs. After passing through the attention layers, the node features are updated. The output is a graph with the same structure but with updated features, which serve as the state to guide scheduling decisions.
3.3. Action
In prior studies on DRL-based FJSP [
13], priority dispatching rules (PDRs) are often employed as actions for decision-making. However, this action space, derived from human experience, while capable of quickly generating suboptimal solutions, fails to fully encompass all feasible actions in
, potentially resulting in performance limitations.
To maintain the degree of exploration, we define the action set
as all feasible operation–machine pairs that can be selected at step
t. A similar approach is adopted in [
31]. More specifically, an operation–machine pair
is feasible at step
t when
is unscheduled and all its predecessors are completed or being processed at time
. Note that this action space is different from the classic one used in prior studies (e.g., [
23]), which only considers operations whose predecessors are completed. This results in a non-delay schedule and may lose the coverage of the optimal schedule. Our scheme generates a semi-active schedule, as the machines are allowed to stay idle while an operation is waiting for processing. The benefit of this scheme is illustrated by numerical results.
3.4. Reward
The reward after one step of state transition is defined by
Here,
represents the estimated makespan in step
t, which is defined as the maximum completion time among all operations. The completion times for completed and ongoing operations are known, while those for unscheduled operations are estimated by
where
is the set of predecessor operations of
.
After the scheduling process is completed and the discount factor
, the cumulative reward is given by
where
is a constant for a specific instance, and
is the actual makespan. In this formulation,
G is negatively correlated with
, which means that maximizing the cumulative reward
G is equivalent to minimizing
.
3.5. Decision-Making
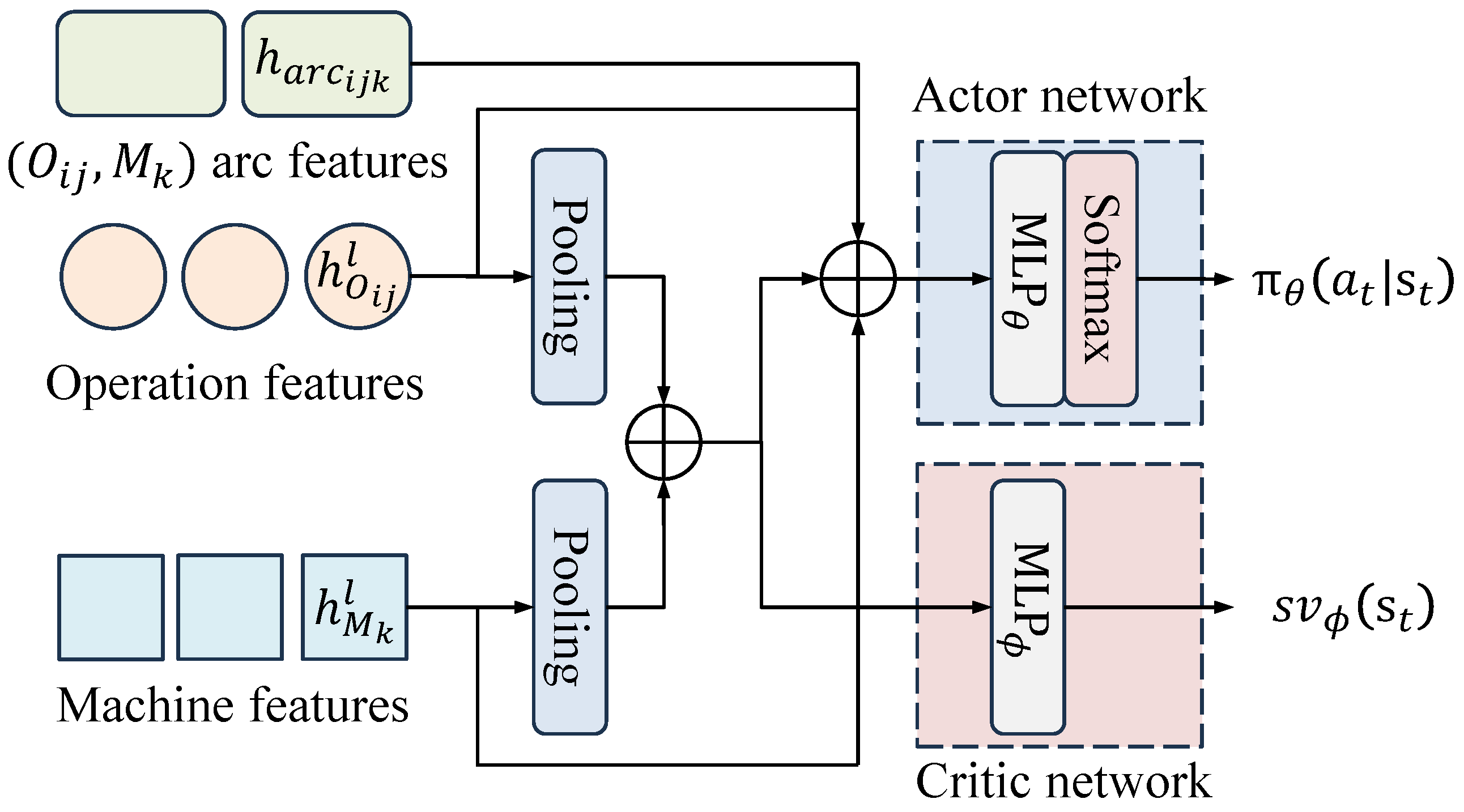
We adopt an actor–critic framework parameterized by
and
for decision-making, as shown in
Figure 5. The actor network aims to generate a policy function
for actions. More specifically, for each
in
, say
, the extracted features of
and
, the global features, and the operation–machine arc features are concatenated into a single vector and fed into the actor network, which outputs the score by
Then, the probability of selecting
is
The critic network is used to estimate the state value function. This estimation serves as a baseline to stabilize and improve the efficiency of the training process by reducing variance in the policy gradient. The state value function is estimated by
The loss function of [
32] is used, which consists of three parts: the policy loss computed by Generalized Advantage Estimation (GAE), the value loss, and the entropy loss used to encourage exploration:
3.6. Training Process
The actor–critic framework was trained using the Proximal Policy Optimization (PPO) algorithm. The pseudocode is given in Algorithm 1. To improve training stability, we used a reference action network with the same structure as the actor network with lagged parameters. Also, clipping was used to limit the update magnitude of the policy.
We began by initializing the model parameters
and sampling
training instances along with
testing instances from the simulation environment. The model was then trained over
iterations, with each iteration starting by setting
. For each instance, a simulation is performed in which the agent interacts with the environment. At each decision point
t, an action is sampled from
based on the current state
, and the resulting state transition data is stored in the memory buffer
. The model parameters are updated
K times using the collected data. Additionally, the training instances are resampled every
iterations, and the policy is evaluated on the testing instances. Finally, the memory buffer is cleared at the end of each iteration. We name the proposed approach Multi-Head GAT-based PPO for FJSP-JPC (MGPPO).
| Algorithm 1 Multi-Head GAT-based PPO for FJSP-JPC |
- Input:
Mulit-Head GAT, actor network, and critic network with trainable parameters , , and ; reference behavior actor network , Memory - 1:
Sample a batch of testing instances; - 2:
Sample a batch of training instances; - 3:
for do - 4:
; - 5:
for do - 6:
Initialize state based on instance b; - 7:
while is not terminal do - 8:
Sample action ; - 9:
Receive reward and next state ; - 10:
Collect the transition () in ; - 11:
Update state ; - 12:
end while - 13:
Compute the generalized advantage estimates for each step using collected transitions; - 14:
end for - 15:
for do - 16:
Compute the total loss function with the data in ; - 17:
Update the parameters , , and ; - 18:
end for - 19:
if then - 20:
Test on testing instances; - 21:
end if - 22:
if then - 23:
Resample a batch of training instances; - 24:
end if - 25:
Empty ; - 26:
end for
|
4. Numerical Results
In this section, we first describe the experimental setup. Then, we explore the impact of several mechanisms on the scheduling performance of MGPPO. Finally, we validate the performance of MGPPO by comparing it to some benchmarks.
4.1. Experimental Setup
Test instances. Since there is no established benchmark for the FJSP-JPC, we generated test instances based on the real-world case of a hybrid bicycle assembly job shop presented in [
26]. In our formulation, the jobs making up a product are referred to as a job group, which is generated as follows:
- 1.
Each job group contains 12 operations distributed across six jobs. The number of operations per job is sampled without replacement from the set .
- 2.
There are three manufacturing stages, as illustrated in
Figure 1. Jobs
belong to the first stage and have no predecessors. Job
is in the second stage, with both predecessor and successor jobs. Job
belongs to the third stage, i.e., the final assembly stage, which starts only after all other jobs have been completed.
- 3.
Following Zhu and Zhou [
26], the processing time for each operation is randomly sampled from a uniform distribution
.
- 4.
All operations in the final assembly stage must be assigned to a designated machine. For all other operations, two available machines are randomly selected (without repetition) from the remaining machine pool.
The smallest instance includes two job groups, each consisting of six jobs and 12 operations (as illustrated in
Figure 1), and involves five machines, denoted as 2 × 12 × 5. Additionally, we consider two larger instance sizes: 3 × 12 × 5 and 4 × 12 × 5. For each size, 1000 instances are randomly generated.
Configurations. We set the training parameters as follows: training iterations , instances batches . The model parameters are updated times per iteration. The training instances are updated every iterations, and the policy is tested every iterations. The multi-head GAT module has embedding layers. There are four attention heads in both the operation attention and machine attention blocks per embedding layer. The input dimensions of each head are for the first layer and for the second layer. The output dimensions are for the first layer and for the second layer.
In the PPO module, there are two hidden layers with dimension
and activation function tanh in both the actor and critic networks. In the loss function (
24), the coefficients are
,
,
; the clipping parameter is
. The learning rate is
, and the minibatch size is 1024.
Performance Metric. We use the results obtained by solving the MILP model with an off-the-shelf solver, Gurobi, as the benchmark. With a time limit of 1800 s, Gurobi can achieve an optimal solution for 2 × 12 × 5 instances and a near-optimal one for 3 × 12 × 5 instances. Given an algorithm, we evaluate its performance by the average relative gap between the makespan obtained by the algorithm
and the benchmark
:
4.2. Effect of Proposed Mechanisms
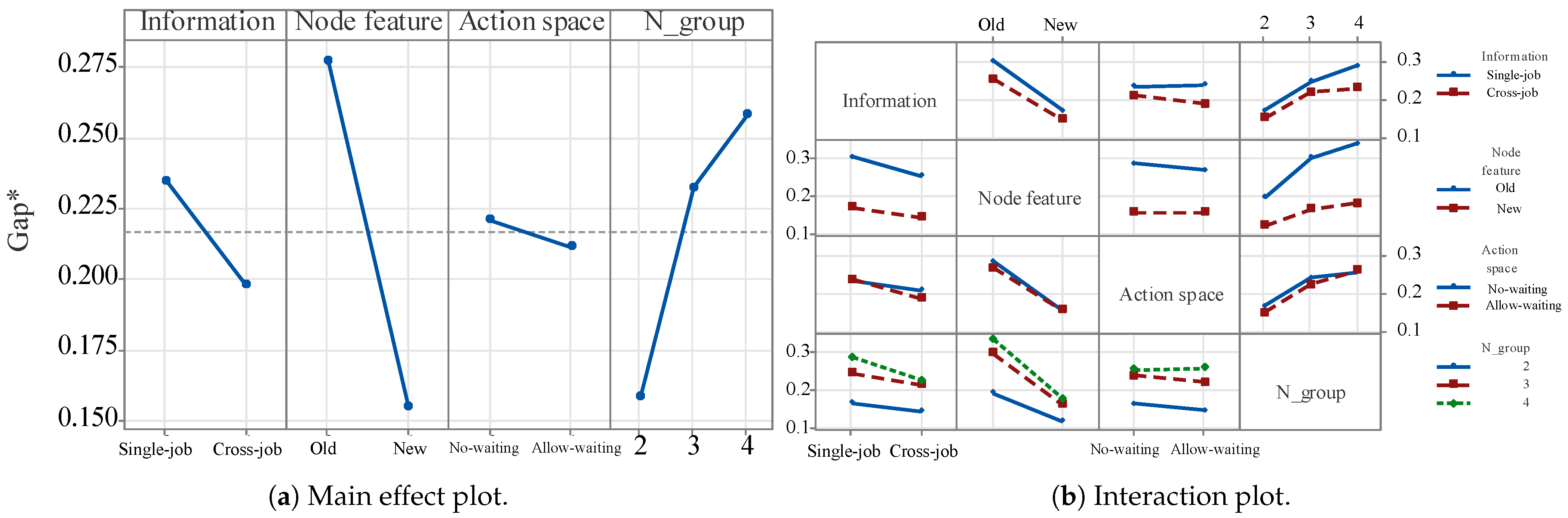
We performed a full factorial design of experiments to investigate the impacts of several proposed mechanisms on the performance of MGPPO. The factors and levels are as follows:
Information: Single-job, Cross-job;
Node feature: Old, New;
Action space: No waiting, Allow waiting;
N_group: 2,3,4.
The factor “Information” indicates whether the information diffusion is allowed to cross different jobs (cross-job) or restricted to a single job (single-job). The factor “Node feature” indicates whether the node uses features given by [
23] (old) or newly designed features (new). The factor “Action space” indicates whether operations are allowed to wait before an idle machine (allow waiting) or not (no waiting). The factor “N_group” indicates the instance size. Each experiment was run for 50 replications. In each replication, the model was first trained and then tested on 1000 instances of the specified size. The gap defined in (
25) was used as the response.
The main effect plot is shown in
Figure 6a. As shown, all the three modifications led to obvious improvements on the performance. Among them, introducing new node features is the most significant, followed by allowing cross-job information diffusion and allowing operation waiting. From
Figure 6b, we observe that allowing operation waiting is more beneficial for small- and medium-sized instances (i.e., 2 × 12 × 5 and 3 × 12 × 5), while its impact is negligible for 4 × 12 × 5. Indeed, allowing operation waiting expands the solution space to include promising solutions; however, as the instance size increases, this advantage is offset by the search inefficiency.
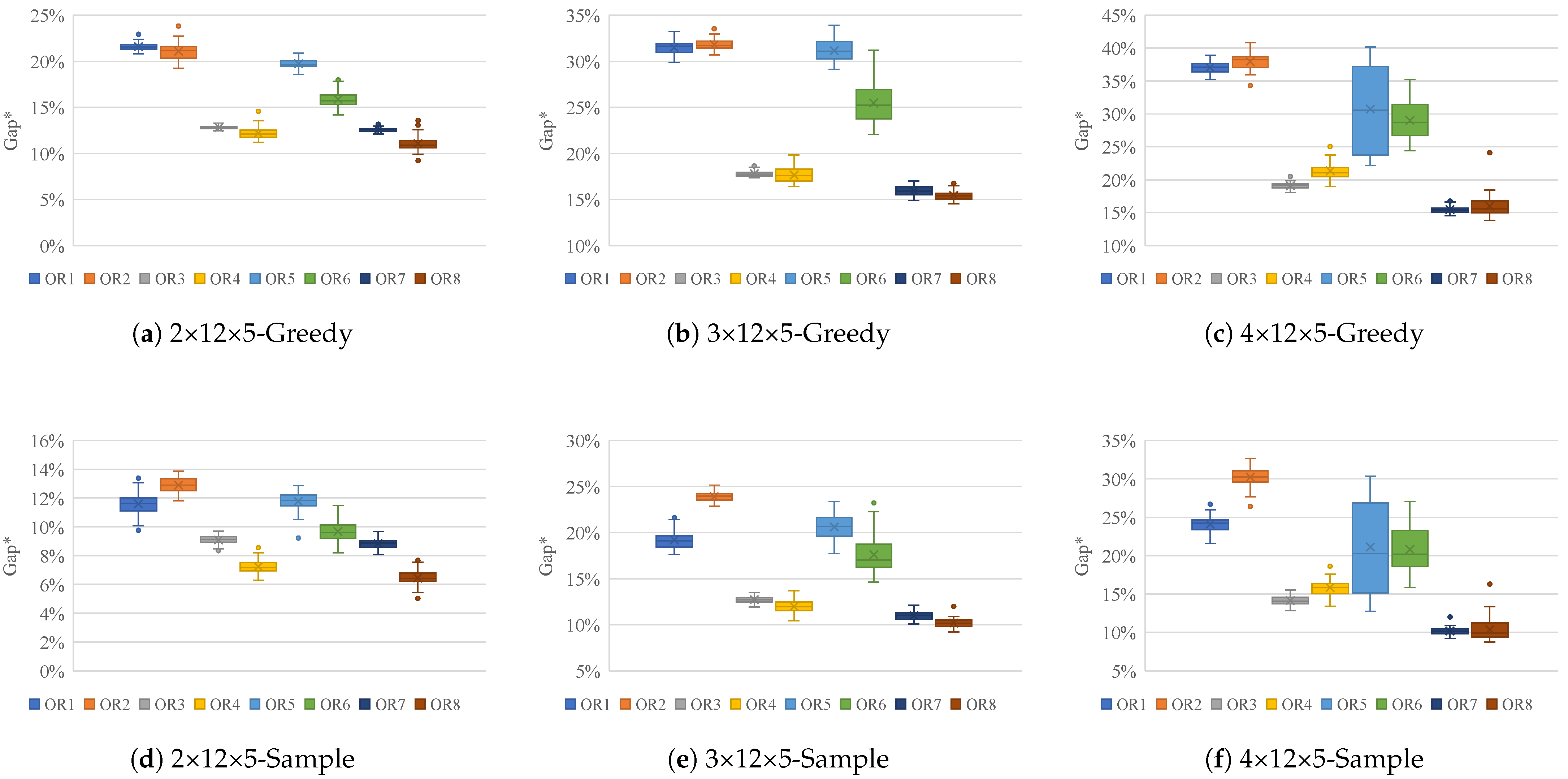
Figure 7 presents boxplots of the average relative gap for MGPPO. The labels OR1–OR8 correspond to the factor combinations listed in
Table 3, with each boxplot summarizing results from 1000 instances. Subfigures (a)–(c) in
Figure 7 illustrate the results under the greedy strategy, while (d)–(f) show the results under the sampling strategy. OR1 serves as the baseline configuration without any modifications to the mechanisms, whereas OR8 represents the complete configuration proposed in this paper. As shown, OR8—which incorporates all proposed components—consistently outperforms the other configurations across nearly all problem sizes and both strategies.
4.3. Comparisons with Benchmark Algorithms
We compare MGPPO to four classic priority dispatching rules (PDRs) including First In First Out (FIFO), Most Operations Remaining (MOR), Shortest Processing Time (SPT), and Most Work Remaining (MWKR). These PDRs are combined with machine selection rules to address FJSP-JPC. The implementation details of these rules are provided as follows:
- 1.
First In First Out (FIFO): Select the candidate operation that is ready at the earliest time and assign it to the first available eligible machine.
- 2.
Most Operations Remaining (MOR): Select the candidate operation that has the highest number of remaining successor operations (cross-job), and assign it to a random machine that is immediately available.
- 3.
Shortest Processing Time (SPT): Select the combination with the shortest processing time.
- 4.
Most Work Remaining (MWKR): Select the candidate operation with the highest average remaining processing time of the remaining successor operations (cross-job), along with a random machine that is immediately available to process the operation.
We also adopted a state-of-the-art DRL algorithm named DANIEL [
23] as a benchmark, which was proposed for FJSP. We used the same training and validation parameters as in the original paper. Additionally, we compared the proposed method with a genetic algorithm introduced in [
9] with an encoding scheme tailored for FJSP-JPC. The genetic algorithm parameters were configured as follows: maximum iterations 100, population size 400, crossover rate 0.8, and mutation rate 0.1.
Table 4 presents the average makespan, Gap*, and computation time of these algorithms on 1000 different instances of specific sizes. For DRL methods, we employed two evaluation methods: greedy and sampling [
22]. The former generates a schedule based on the maximum action score, while the latter uses action sampling with (
22) to solve an instance 20 times and selects the best one as its result. This allows for utilizing more computational resources to improve the solution quality. Results of the DRL methods are averaged from 50 replications.
Gurobi and GA clearly deliver superior performance; however, their computational times are very long, especially for large instances. In contrast, although PDRs require shorter computational times, they exhibit poorer performance. DANIEL offers better performance than PDRs while maintaining a short runtime. The proposed algorithm outperforms both DANIEL and PDRs across all instances, achieving runtimes comparable to DANIEL. Furthermore, when employing the sampling strategy, the performance of MGPPO is significantly enhanced even with only 20 samples.
5. Discussion
The proposed DRL algorithm has proven to be a promising approach to FJSP-JPC. Its advantages stem from the tailored node features, the information diffusion mechanism, and the well-designed action space of MGPPO. The proposed method has no special requirements for the scale and structure in the instances. This means that even if changes occur in jobs and machines in the environment during the scheduling process, they will not affect the feasibility of the method. Theoretically, our method is not only applicable to FJSP-JPC, but also to the classical FJSP (where the predecessor job of each job is regarded as an empty set). In the future, experiments can be designed to validate the generality of this method.
Unlike methods such as Gurobi and GA, which generate the entire schedule at once, this approach makes incremental decisions based on the real-time status of the shop floor. As a result, even if the manufacturing process is disrupted by disturbances, the algorithm can respond flexibly. Moreover, the negligible decision time for each step makes the proposed algorithm highly applicable in dynamic environments, such as the modular flexible automotive assembly workshop, which is highly relevant to FJSP-JPC. Companies of this kind are frequently confronted with abrupt disruptions such as order changes or machine failures, and our method can effectively enhance production efficiency in such scenarios.
6. Conclusions
In this paper, we propose a deep reinforcement learning approach, named MGPPO, for solving FJSP-JPC. It employs a heterogeneous disjunctive graph to represent the shop floor status and utilizes a multi-head graph attention network to efficiently extract problem features. These features are then fed into an actor–critic framework, where the actor generates operation sequencing and machine assignment decisions simultaneously, while the critic evaluates the policy. The entire model is trained using the PPO algorithm.
Through experiments, we show that the proposed approach consistently outperforms traditional dispatching rules and a state-of-the-art DRL method. Key factors contributing to its performance include improved node features, cross-job information diffusion, and an enhanced action space.
In addition, our research for FJSP-JPC still has certain limitations, and future work can be carried out in the following aspects: first, the experiments in this paper consider no disturbance factors. In actual production environments, multi-source disturbances such as machine failures, order changes, and raw material shortages often intertwine, further increasing the solving difficulty of scheduling problems. Future work will focus on extending this approach to dynamic manufacturing environments with real-time disruptions and further enhancing its generalizability across various production scheduling problems.
Second, this paper only considers makespan as the optimization objective, without taking into account other practical production objectives such as equipment energy consumption, load balancing, and total tardiness. Future work can be expanded to multi-objective optimization by incorporating the diversified needs of intelligent manufacturing, designing weighted reward functions or Pareto front search mechanisms to balance indicators like production efficiency and sustainability.
Third, in the common scenarios of FJSP-JPC investigated in this paper (e.g., automotive assembly), companies typically face constraints on transportation resources and the collaborative scheduling of transportation and processing resources. Operations not only require a selection of processing machines but also match with available transportation equipment, as transportation delays may become production bottlenecks in actual manufacturing. Future work can develop problem models considering transportation resource constraints for further investigation.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}