
Implications from Legacy Device Environments on the Conceptional Design of Machine Learning Models in Manufacturing



Abstract
1. Introduction
1.1. Problem Statement
1.2. Research Approach
- Sensors (and actuators) for process interaction;
- Connectivity for communication and automation;
- Data management for data accumulation and abstraction;
- Operational integration for business decisions.
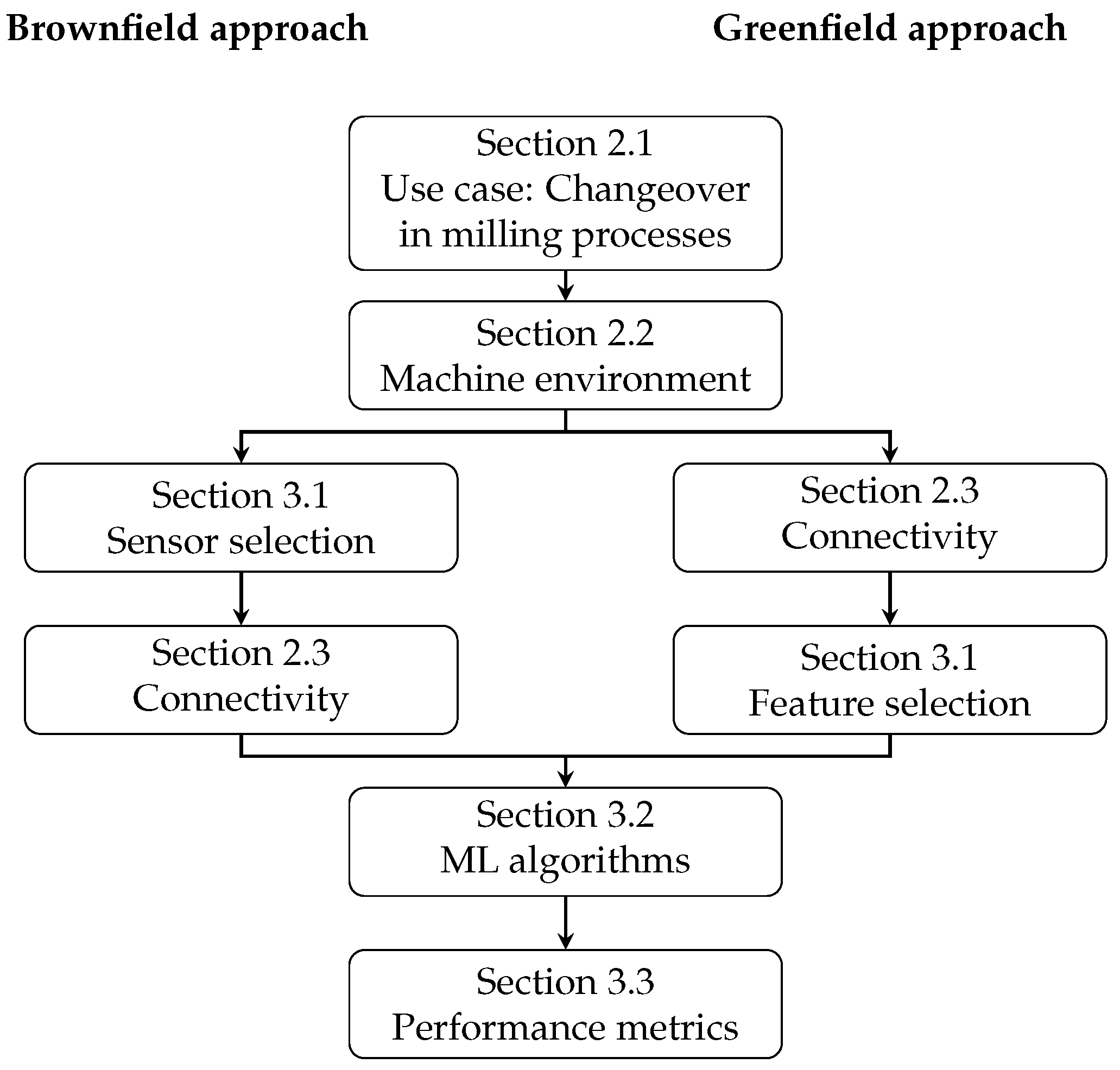
1.3. Article Structure
2. Materials
2.1. Use Case Description
2.2. Machine Environments
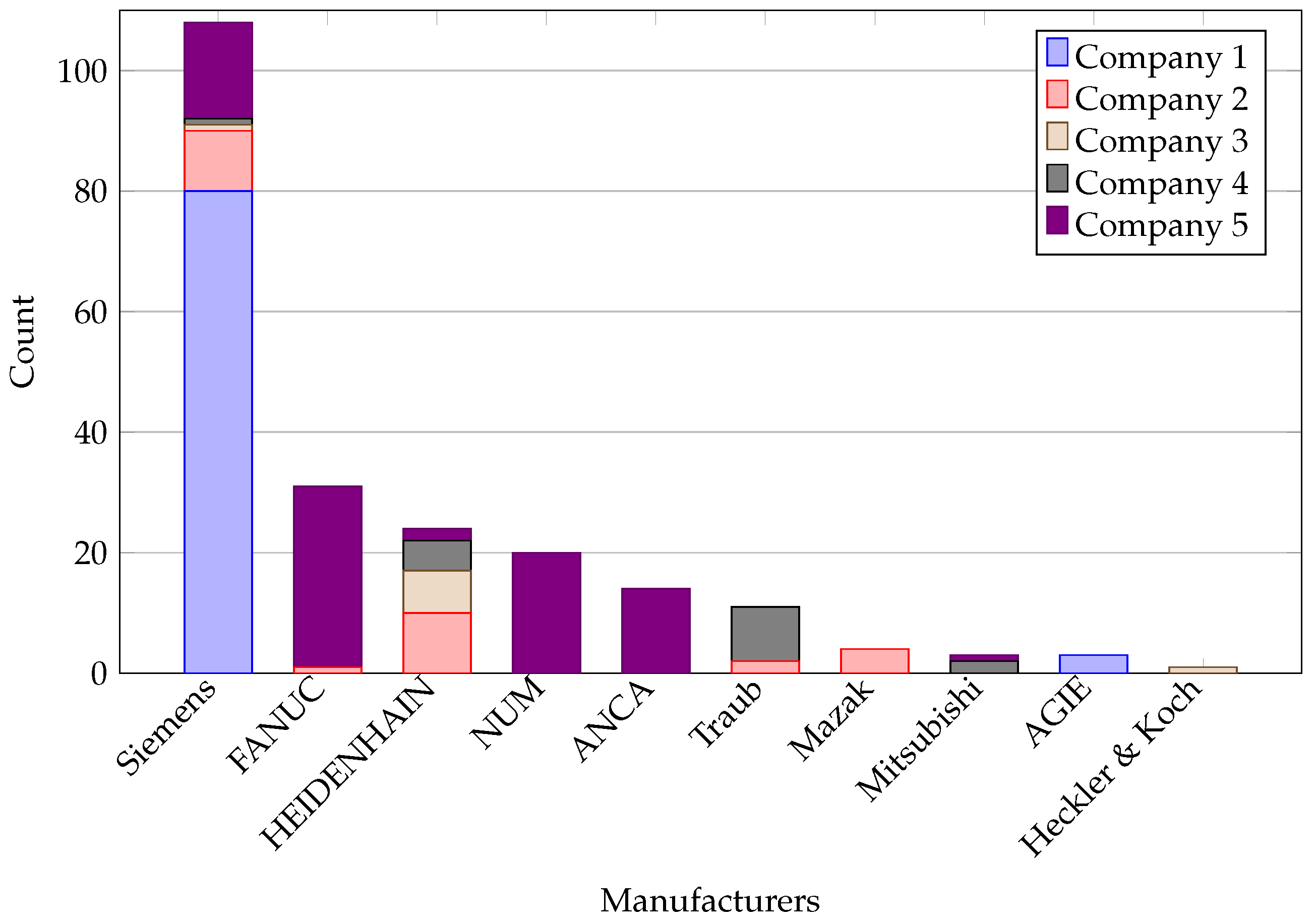
2.2.1. Siemens
2.2.2. FANUC
2.2.3. HEIDENHAIN
2.2.4. Used Machine Tools
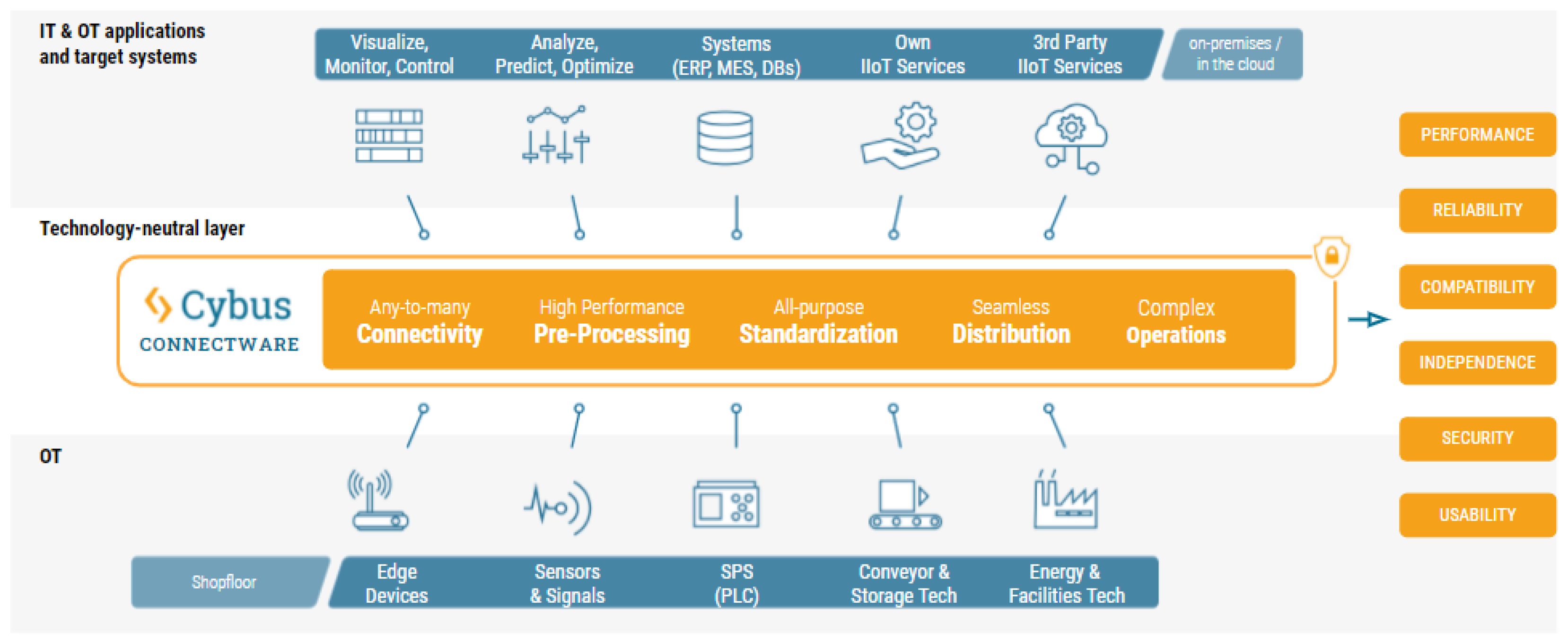
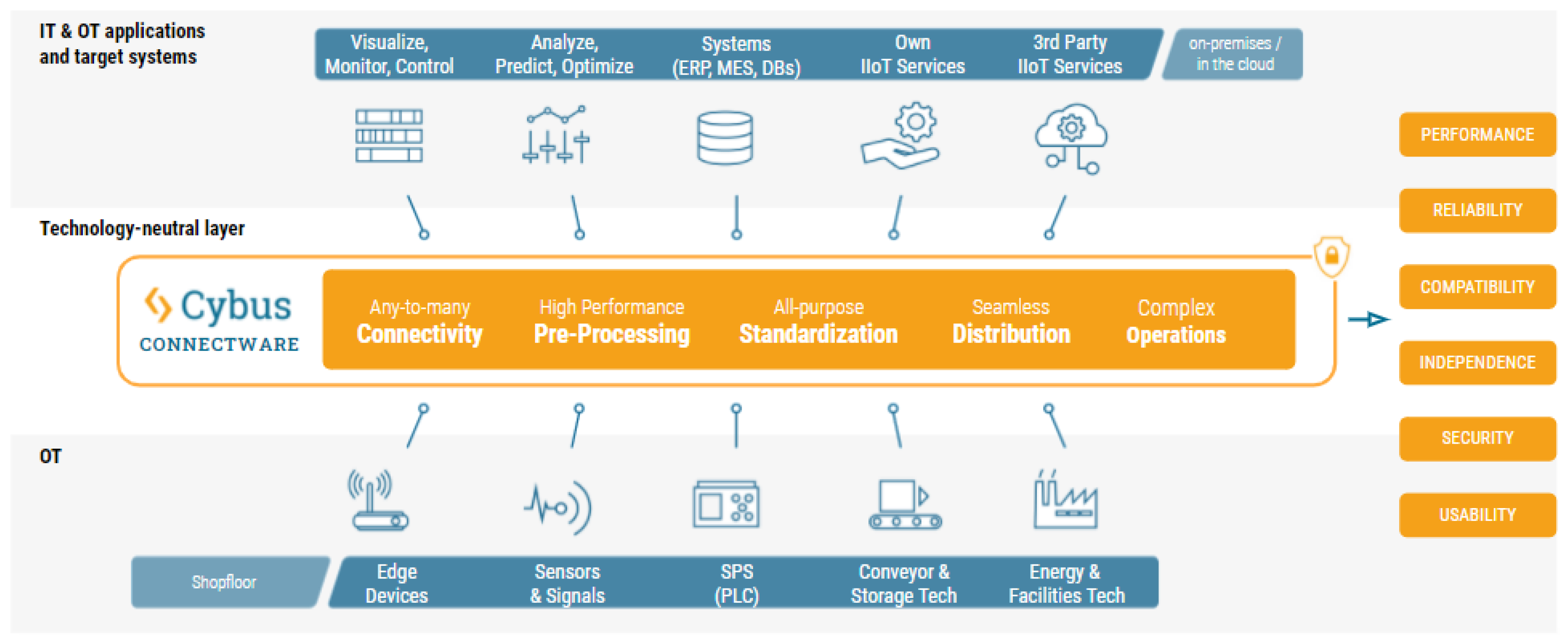
2.3. Connectivity
2.3.1. Brownfield Setup
2.3.2. Greenfield Setup
2.3.3. Combined Setup
3. Methods
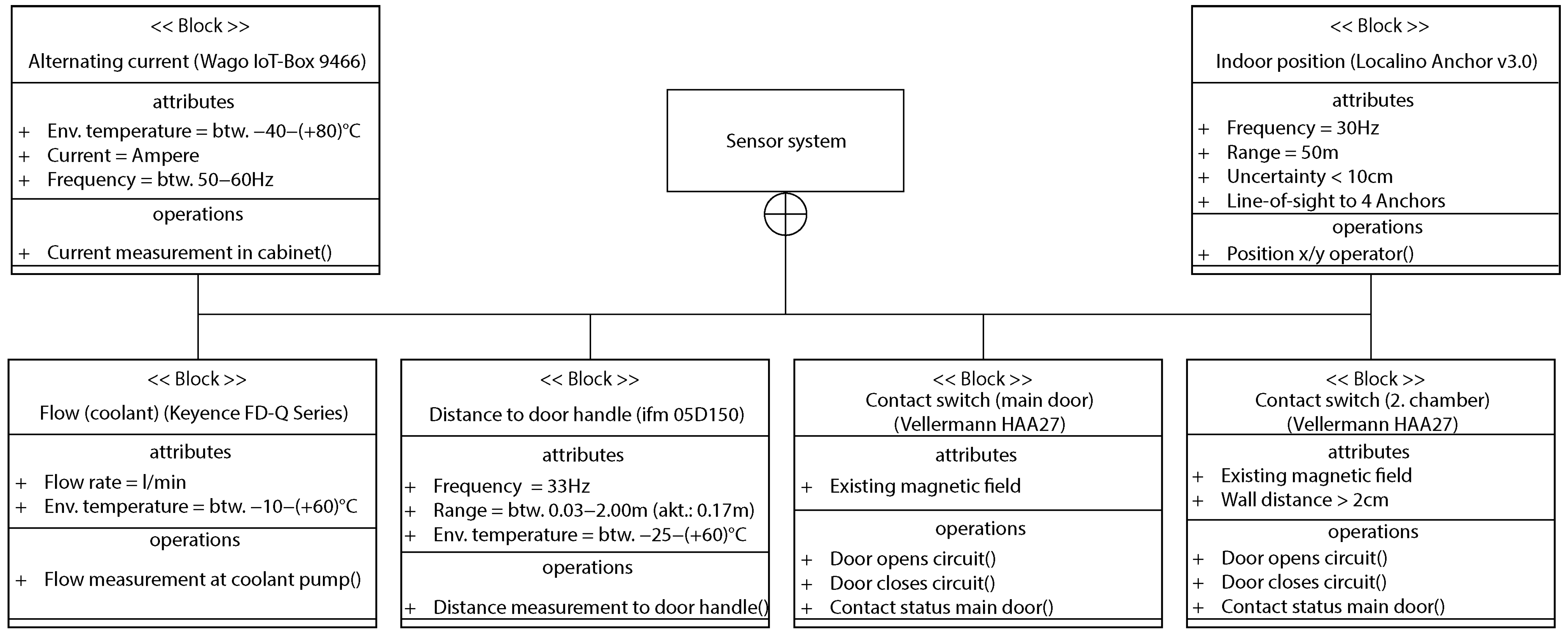
3.1. Sensor Selection Methods
- 1.
- Achieve an understanding of the optimization task (e.g., SIPOC, process map);
- 2.
- Understand the relations between the input and output variables (e.g., CE-Matrix, Ishikawa);
- 3.
- Prioritize the input variables (e.g., CE-Matrix);
- 4.
- Find a set of suited sensors for the measurand from these input variables (e.g., lists with measurement principles and sensor manuals);
- 5.
- Evaluate the sensors (e.g., MSA and uncertainty budget);
- 6.
- Conduct hypothesis tests for the most important inputs (e.g., data acquisition plan and statistical tests).
3.1.1. Brownfield Selection Methods
3.1.2. Greenfield Selection Methods
- 1.
- DoorStatus is a binary testing decision and can be checked with standardized methods;
- 2.
- DriveStatus, PocketTable, ProgramStatus, and OverrideFeed represent status information from the NC and are difficult to check;
- 3.
- FeedRate and SpindleSpeed are NC parameters for the milling process and can be checked with additional testing efforts (external testing equipment is necessary).
3.1.3. Combined Approach Selection Methods
3.2. Chosen Machine Learning Algorithms
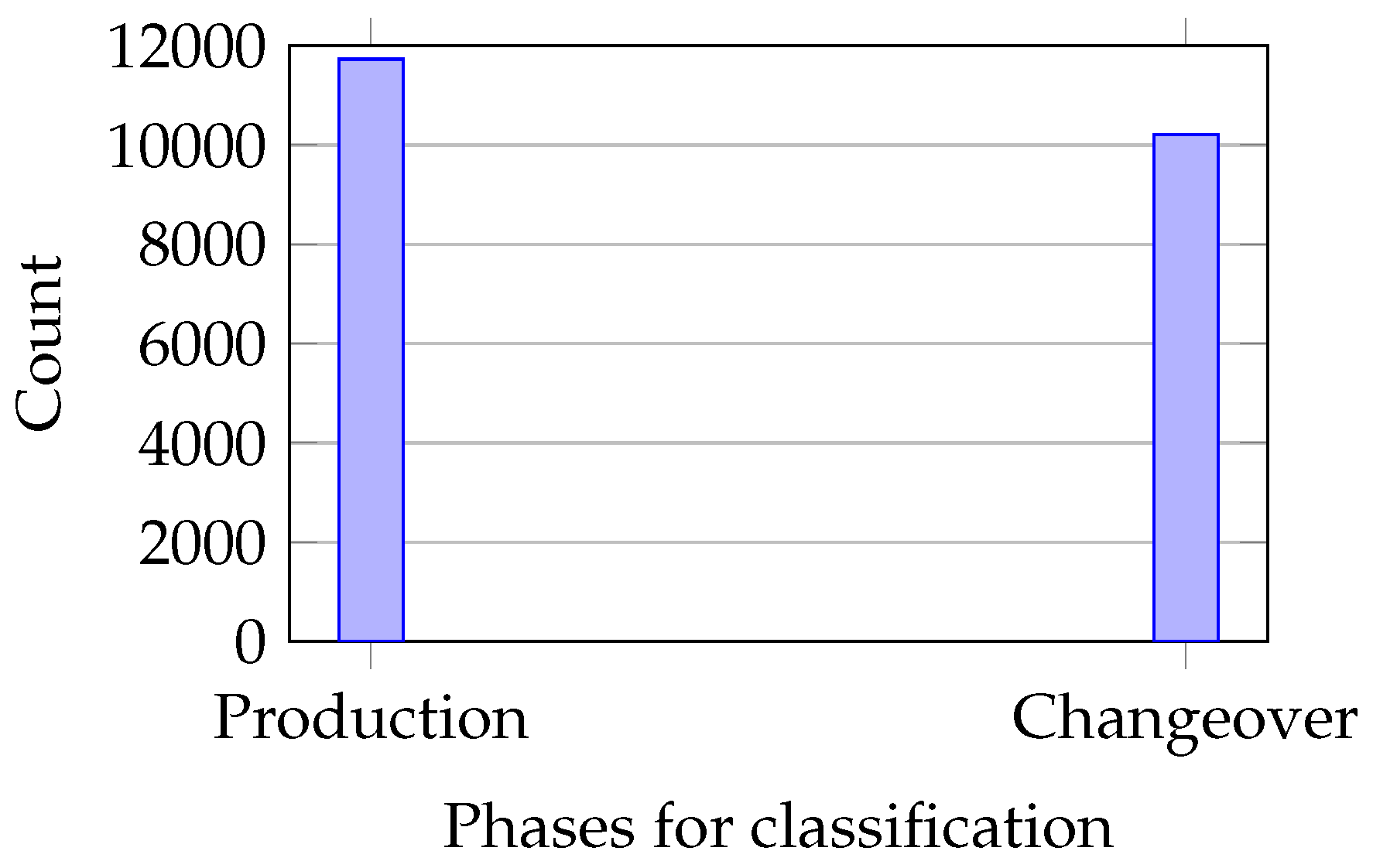
3.3. Performance Metrics
4. Results
4.1. General Findings from Implementation
4.1.1. Brownfield Findings
4.1.2. Greenfield Findings
4.1.3. Combined Approach Findings
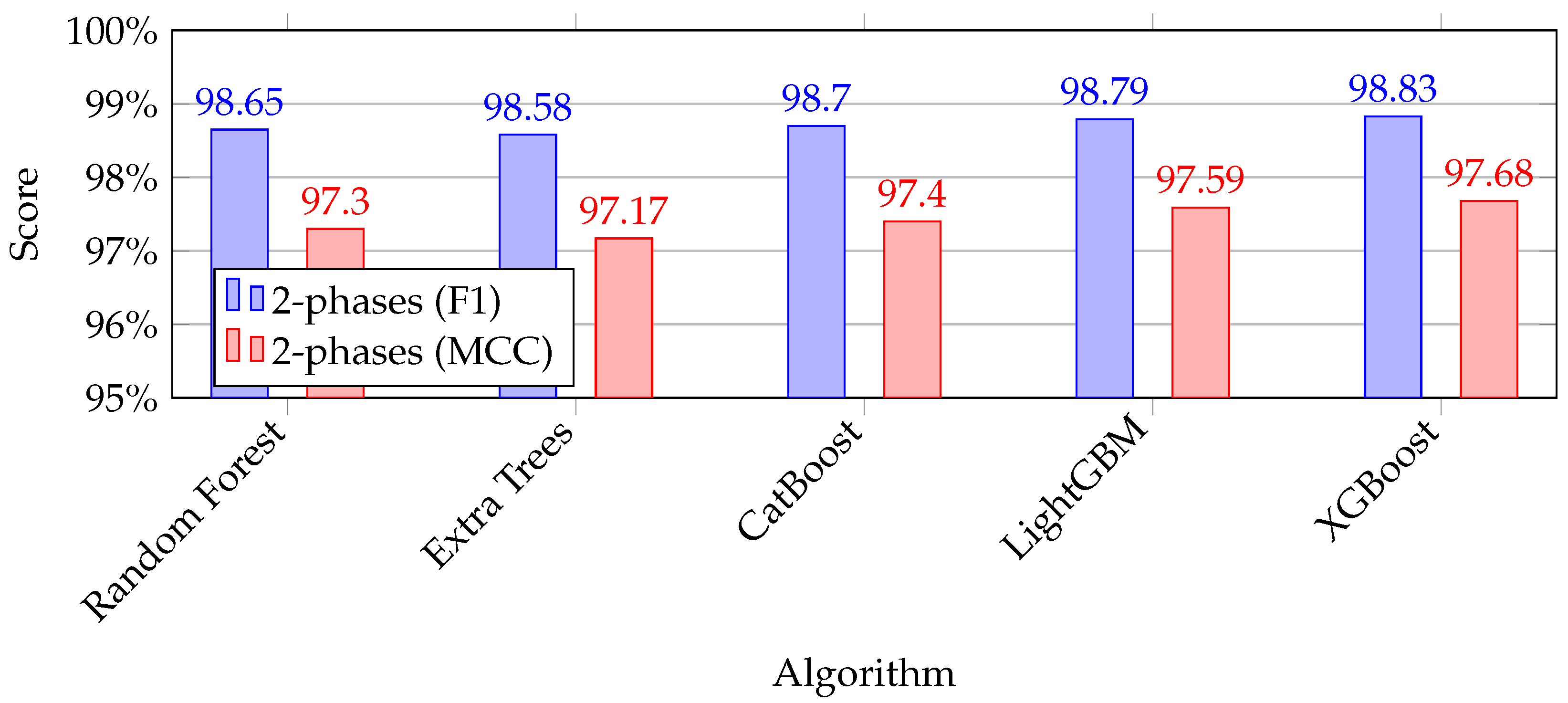
4.2. Performance Metrics Results
4.2.1. Brownfield Results
4.2.2. Combined Approach Results
4.2.3. Greenfield Results
5. Discussion
6. Conclusions and Further Research
6.1. Conclusions
6.2. Further Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CE-Matrix | cause-and-effect matrix |
| DNC | distributed numerical control |
| ERP | enterprise resource planning |
| PS | positioning system |
| IIoT | industrial Internet of Things |
| IT | information technology |
| LTE | long-term evolution |
| MCC | Matthews correlation coefficient |
| MES | manufacturing execution system |
| ML | machine learning |
| MQTT | message queuing telemetry transport |
| MSA | measurement system analysis |
| NC | numerical control |
| NUC | Next Unit of Computing |
| OBerA | Optimization of Processes and Machine Tools through Provision, Analysis and |
| Target/Actual Comparison of Production Data | |
| OT | operation technology |
| PCA | principal component analysis |
| PFI | permutation feature importance |
| PLC | programmable logic controller |
| OPC UA | Open Platform Communications Unified Architecture |
| SIPOC | supplier, input, process, output, customer diagram |
| SME | small and medium-sized enterprise |
| SQL | structured query language |
| SysML | systems modeling language |
| t-SNE | t-distributed stochastic neighbor embedding |
| umati | universal machine technology interface |
| VM | virtual machine |
| YAML | Yet Another Markup Language |
Appendix A. Hyperparameters of Algorithms
- Number of estimators (trees): 30;
- Bootstrap: False;
- Max. depth of tree: 30;
- Min. samples at leaf: 1;
- Min. samples to split: 2.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CatBoost | XGBoost |
|---|---|
| iterations: 260 | objective: binary:logistic |
| depth: 9 | colsample_bytree: 0.7 |
| loss_function: Logloss | learning_rate: 0.4 |
| random_strength: 0.7 | max_depth: 9 |
| eta: 0.3 | n_estimators: 170 |
| sampling_frequency: PerTree | reg_alpha: 0.005 |
| scale_pos_weight: 3.3 | |
| subsample: 0.9 |
References
- Europäische Kommission—Empfehlung der Kommission vom 6. Mai 2003 Betreffend die Definition der Kleinstunternehmen Sowie der Kleinen und Mittleren Unternehmen. 2003. Available online: https://eur-lex.europa.eu/legal-content/DE/TXT/PDF/?uri=CELEX:32003H0361&fro=DE (accessed on 29 July 2021).
- Säfsten, K.; Harlin, U.; Johansen, K.; Larsson, L.; Vult von Steyern, C.; Öhrwall Rönnbäck, A. Towards Resilient and Sustainable Production Systems: A Research Agenda. In SPS2022; IOS Press: Amsterdam, The Netherlands, 2022; pp. 768–780. [Google Scholar]
- Thornton, G.; Franz, M.; Edwards, D.; Pahlen, G.; Nathanail, P. The challenge of sustainability: Incentives for brownfield regeneration in Europe. Environ. Sci. Policy 2007, 10, 116–134. [Google Scholar] [CrossRef]
- Tran, T.A.; Ruppert, T.; Eigner, G.; Abonyi, J. Retrofitting-based development of brownfield industry 4.0 and industry 5.0 solutions. IEEE Access 2022, 10, 64348–64374. [Google Scholar] [CrossRef]
- Etz, D.; Brantner, H.; Kastner, W. Smart manufacturing retrofit for Brownfield systems. Procedia Manuf. 2020, 42, 327–332. [Google Scholar] [CrossRef]
- Strauß, P.; Schmitz, M.; Wöstmann, R.; Deuse, J. Enabling of predictive maintenance in the brownfield through low-cost sensors, an IIoT-architecture and machine learning. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1474–1483. [Google Scholar]
- O’Donovan, P.; Gallagher, C.; Leahy, K.; O’Sullivan, D.T. A comparison of fog and cloud computing cyber-physical interfaces for Industry 4.0 real-time embedded machine learning engineering applications. Comput. Ind. 2019, 110, 12–35. [Google Scholar] [CrossRef]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef]
- Amershi, S.; Begel, A.; Bird, C.; DeLine, R.; Gall, H.; Kamar, E.; Nagappan, N.; Nushi, B.; Zimmermann, T. Software Engineering for Machine Learning: A Case Study. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Montreal, QC, Canada, 25–31 May 2019; pp. 291–300. [Google Scholar] [CrossRef]
- Axehill, J.W.; Herzog, E.; Tingström, J.; Bengtsson, M. From Brownfield to Greenfield Development – Understanding and Managing the Transition. INCOSE Int. Symp. 2021, 31, 832–847. [Google Scholar] [CrossRef]
- Klaeger, T.; Gottschall, S.; Oehm, L. Data Science on Industrial Data—Today’s Challenges in Brown Field Applications. Challenges 2021, 12, 2. [Google Scholar] [CrossRef]
- Runeson, P.; Host, M.; Rainer, A.; Regnell, B. Case Study Research in Software Engineering: Guidelines and Examples; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Miller, E.; Borysenko, V.; Heusinger, M.; Niedner, N.; Engelmann, B.; Schmitt, J. Enhanced Changeover Detection in Industry 4.0 Environments with Machine Learning. Sensors 2021, 21, 5896. [Google Scholar] [CrossRef]
- Hu, Z.; Gong, W.; Pedrycz, W.; Li, Y. Deep reinforcement learning assisted co-evolutionary differential evolution for constrained optimization. Swarm Evol. Comput. 2023, 83, 101387. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, H.; Wang, L. A pareto-based discrete jaya algorithm for multiobjective carbon-efficient distributed blocking flow shop scheduling problem. IEEE Trans. Ind. Inform. 2022, 19, 8588–8599. [Google Scholar] [CrossRef]
- Han, Y.; Peng, H.; Mei, C.; Cao, L.; Deng, C.; Wang, H.; Wu, Z. Multi-strategy multi-objective differential evolutionary algorithm with reinforcement learning. Knowl.-Based Syst. 2023, 277, 110801. [Google Scholar] [CrossRef]
- Engelmann, B.; Schmitt, S.; Miller, E.; Bräutigam, V.; Schmitt, J. Advances in Machine Learning Detecting Changeover Processes in Cyber Physical Production Systems. J. Manuf. Mater. Process. 2020, 4, 108. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Sauer, C.; Eichelberger, H.; Ahmadian, A.S.; Dewes, A.; Jürjens, J. Current Industry 4.0 Platforms—An Overview. IIP-Ecosphere Whitepaper, Leibniz Universität Hannover, Forschungszentrum L3S, Appelstraße 9a, 30167 Hannover, Germany, 2021. Available online: https://zenodo.org/records/4485756 (accessed on 14 January 2024).
- Martins, A.; Lucas, J.; Costelha, H.; Neves, C. CNC Machines Integration in Smart Factories using OPC UA. J. Ind. Inf. Integr. 2023, 34, 100482. [Google Scholar] [CrossRef]
- Balduzzi, M.; Sortino, F.; Castello, F.; Pierguidi, L. An Empirical Evaluation of CNC Machines in Industry 4.0 (Short Paper). In Proceedings of the International Conference on Critical Information Infrastructures Security, Munich, Germany, 14–16 September 2022; Springer: Cham, Switzerland, 2022; pp. 56–62. [Google Scholar]
- Martins, A.; Lucas, J.; Costelha, H.; Neves, C. Developing an OPC UA server for CNC machines. Procedia Comput. Sci. 2021, 180, 561–570. [Google Scholar] [CrossRef]
- Ižol, P.; Grešová, Z.; Vrabel’, M.; Brindza, J.; Demko, M. The influence of tool path strategies for 3-and 5-axis milling on the accuracy and roughness of shaped surfaces. Mach. Technol. Mater. 2022, 16, 234–237. [Google Scholar]
- Wang, W.T.; Chang, C.H.; Sheng, R.N. The Study on the Implementation of Multi-Axis Cutting & Cyber-Physical System on Unity 3D Platform. In Proceedings of the 2019 IEEE 6th International Conference on Industrial Engineering and Applications (ICIEA), Tokyo, Japan, 12–15 April 2019; pp. 77–80. [Google Scholar]
- Trabesinger, S.; Butzerin, A.; Schall, D.; Pichler, R. Analysis of high frequency data of a machine tool via edge computing. Procedia Manuf. 2020, 45, 343–348. [Google Scholar] [CrossRef]
- Beşirova, C.; Akhtar, W.; Shahzad, A.; Üresin, U.; Çelikel, S.; İrican, M. Analysis of Machining Process with Data Collection Using Industrial Edge Computing. In Proceedings of the 11th International Congress on Machining, Istanbul, Turkey, 9–11 December 2021. [Google Scholar]
- Lutz, B.; Howell, P.; Regulin, D.; Engelmann, B.; Franke, J. Towards Material-Batch-Aware Tool Condition Monitoring. J. Manuf. Mater. Process. 2021, 5, 103. [Google Scholar] [CrossRef]
- Lima, F.; Massote, A.A.; Maia, R.F. IoT energy retrofit and the connection of legacy machines inside the industry 4.0 concept. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 5499–5504. [Google Scholar]
- Schmid, J.; Vallant, D.; Butzerin, A.; Brillinger, M.; Suschnigg, J.; Pichler, R.; Haas, F. Acquisition of machine tool data via the open source implementation open62541 for OPC-UA. Procedia CIRP 2021, 102, 303–307. [Google Scholar] [CrossRef]
- Martínez Ruedas, C.; Adame-Rodríguez, F.J.; Díaz-Cabrera, J.M. A Low-Cost’plug and Play’connectivity and Integration System for SINUMERIK CNC Machines to Join INDUSTRY 4.0. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4334474 (accessed on 14 January 2024).
- Siemens. Connecting Brownfield Facilities with Siemens MindSphere: Making any Factory a Smart Factory—Learn How to Get It Done. 2022. Available online: https://www.plm.automation.siemens.com/media/global/en/Brownfield%20Connectivity%20with%20MindSphere_tcm27-100928.pdf (accessed on 22 February 2022).
- Siemens. MindSphere Architecture. 2021. Available online: https://developer.mindsphere.io/concepts/concept-architecture.html (accessed on 6 December 2021).
- FANUC. MT-LINKi: The Easy Way to Monitor Your Production. 2021. Available online: https://www.fanuc.eu/~/media/files/pdf/products/cnc/flyers/mfl-02993-fa-mt-linki/mt-linki-flyer-en.pdf?la=de (accessed on 6 December 2021).
- FANUC. FANUC FOCAS Library for Easy Customisation of CNC’s. Available online: https://www.fanuc.eu/de/de/cnc/development-software/focas-development-libraries (accessed on 14 January 2022).
- FANUC. FANUC OPC Server. Available online: https://www.fanuc.eu/de/de/cnc/connectivity/opc-server (accessed on 14 January 2022).
- DR. JOHANNES HEIDENHAIN GmbH. Connected Machining. 2022. Available online: https://www.heidenhain.de/produkte/digitale-werkstatt/connected-machining (accessed on 13 January 2022).
- DR. JOHANNES HEIDENHAIN GmbH. Softwarelösungen. 2022. Available online: https://www.heidenhain.de/produkte/digitale-werkstatt/softwareloesungen (accessed on 13 January 2022).
- DR. JOHANNES HEIDENHAIN GmbH. Digitale Werkstatt. 2020. Available online: https://www.heidenhain.de/fileadmin/pdf/de/01_Produkte/Broschueren/BR_Digitale_Werkstatt_ID1329161_de_01.pdf (accessed on 14 January 2022).
- DR. JOHANNES HEIDENHAIN GmbH. Connected Machining—Individuelle Lösungen für das Digitale Auftragsmanagement in der Fertigung; Dr.-Johannes-Heidenhain-Straße: Traunreut, Germany, 2017. [Google Scholar]
- Uffelmann, J.; Wienzek, P.; Jahn, M. IO-Link—Band 1: Anwendung: Schlüsseltechnologie für Industrie 4.0; Number Bd. 1; Vulkan Verlag: Essen, Germany, 2020. [Google Scholar]
- Cybus. Overview. Available online: https://docs.cybus.io/latest/user/overview.html (accessed on 28 January 2022).
- Cybus. Cybus Journey. 2022. Available online: https://www.cybus.io/cybus-journey-de/ (accessed on 28 January 2022).
- Cybus. Connectivity Portfolio. 2022. Available online: https://www.cybus.io/connectivity-portfolio/ (accessed on 28 January 2022).
- Erichsen, J. Connectware Orchestration Using Ansible. 2022. Available online: https://www.cybus.io/learn/connectware-orchestration-using-ansible/ (accessed on 28 January 2022).
- Pittig, K. Installing Cybus Connectware on Kubernetes Clusters. 2022. Available online: https://www.cybus.io/learn/installing-cybus-connectware-on-kubernetes-clusters/ (accessed on 28 January 2022).
- Evans, J.; Schmeding, D. Service Basics. 2020. Available online: https://www.cybus.io/learn/service-basics/ (accessed on 28 January 2022).
- Gudenkauf, S.; Franke, J.; Behrens, J. Features of Event-Driven Message Queuing Architectures in Manufacturing: A Reference Model for Comparison; Gesellschaft für Informatik e.V.: Bonn, Germany, 2023. [Google Scholar]
- Reis, J.S.d.M.; Espuny, M.; Nunhes, T.V.; Sampaio, N.A.d.S.; Isaksson, R.; Campos, F.C.d.; Oliveira, O.J.d. Striding towards sustainability: A framework to overcome challenges and explore opportunities through industry 4.0. Sustainability 2021, 13, 5232. [Google Scholar] [CrossRef]
- Cybus. System Requirements. 2021. Available online: https://docs.cybus.io/latest/user/requirements.html (accessed on 29 December 2023).
- Kwak, Y.H.; Anbari, F.T. Benefits, obstacles, and future of six sigma approach. Technovation 2006, 26, 708–715. [Google Scholar] [CrossRef]
- Hassan, R.; Marimuthu, M.; Mahinderjit-Singh, M. Application of Six-Sigma for Process Improvement in Manufacturing Industries: A Case Study. Int. Bus. Manag. 2016, 10, 676–691. [Google Scholar]
- Melzer, A. Six Sigma—Kompakt und Praxisnah: Prozessverbesserung Effizient und Erfolgreich Implementieren; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2015. [Google Scholar]
- Joint Committee for Guides in Metrology. Evaluation of Measurement Data—Guide to the Expression of Uncertainty in Measurement. 2008. Available online: https://www.bipm.org/documents/20126/2071204/JCGM_100_2008_E.pdf/cb0ef43f-baa5-11cf-3f85-4dcd86f77bd6?version=1.10&t=1659082531978&download=true (accessed on 14 October 2022).
- Linß, G.; Zinner, C.; Dornig, S.; Sommer, S. Vergleich auf Praxistauglichkeit: QS-9000 (MSA), GUM UND VDA5: Prüfprozesse überprüft. QZ. Qualität und Zuverlässigkeit 2005, 50, 43–47. [Google Scholar]
- Knapp, W. Tolerance and uncertainty. WIT Trans. Eng. Sci. 1970, 34. [Google Scholar] [CrossRef]
- Alt, O. Modellbasierte Systementwicklung Mit SysML; Carl Hanser Verlag GmbH Co KG: Munich, Germany, 2012. [Google Scholar]
- Neuber, T.; Schmitt, A.M.; Engelmann, B.; Schmitt, J. Evaluation of the Influence of Machine Tools on the Accuracy of Indoor Positioning Systems. Sensors 2022, 22, 10015. [Google Scholar] [CrossRef] [PubMed]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, TAS, Australia, 4–8 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Akosa, J. Predictive accuracy: A misleading performance measure for highly imbalanced data. In Proceedings of the SAS Global Forum, Orlando, FL, USA, 2–5 April 2017; SAS Institute Inc.: Cary, NC, USA, 2017; Volume 12. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Cervantes, J.; Li, X.; Yu, W. Using genetic algorithm to improve classification accuracy on imbalanced data. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 2659–2664. [Google Scholar] [CrossRef]
- Cerrada, M.; Trujillo, L.; Hernández, D.E.; Correa Zevallos, H.A.; Macancela, J.C.; Cabrera, D.; Vinicio Sánchez, R. AutoML for Feature Selection and Model Tuning Applied to Fault Severity Diagnosis in Spur Gearboxes. Math. Comput. Appl. 2022, 27, 6. [Google Scholar] [CrossRef]







| Brownfield Approach | Combined Approach | Greenfield Approach | |
|---|---|---|---|
| Sensors | NC-external sensors | NC-external sensors NC-provided sensors | NC-provided sensors |
| Challenges | Heterogeneous data interface Sensor selection Perceived surveillance Exposure to environment | Heterogeneous data interface Sensor feature selection Perceived surveillance Exposure to environment NC manufacturer dependency Additional sensor data provisioning | NC manufacturer dependency Feature selection Additional sensor data provisioning |
| Benefits | Availability of sensors Application flexibility | Availability of sensors and features Application flexibility | Homogeneous data interface Availability of features |
| NC Manufacturer | Reported Interface Application | References |
|---|---|---|
| FANUC | Three-axis milling Five-axis micromachining, turning | [20] [21] |
| HEIDENHAIN | Three-axis milling Five-axis milling | [22,23] [17,21,23,24] |
| Siemens | Drilling Milling Milling, turning, laser cutting | [25,26] [26,27,28,29] [30] |
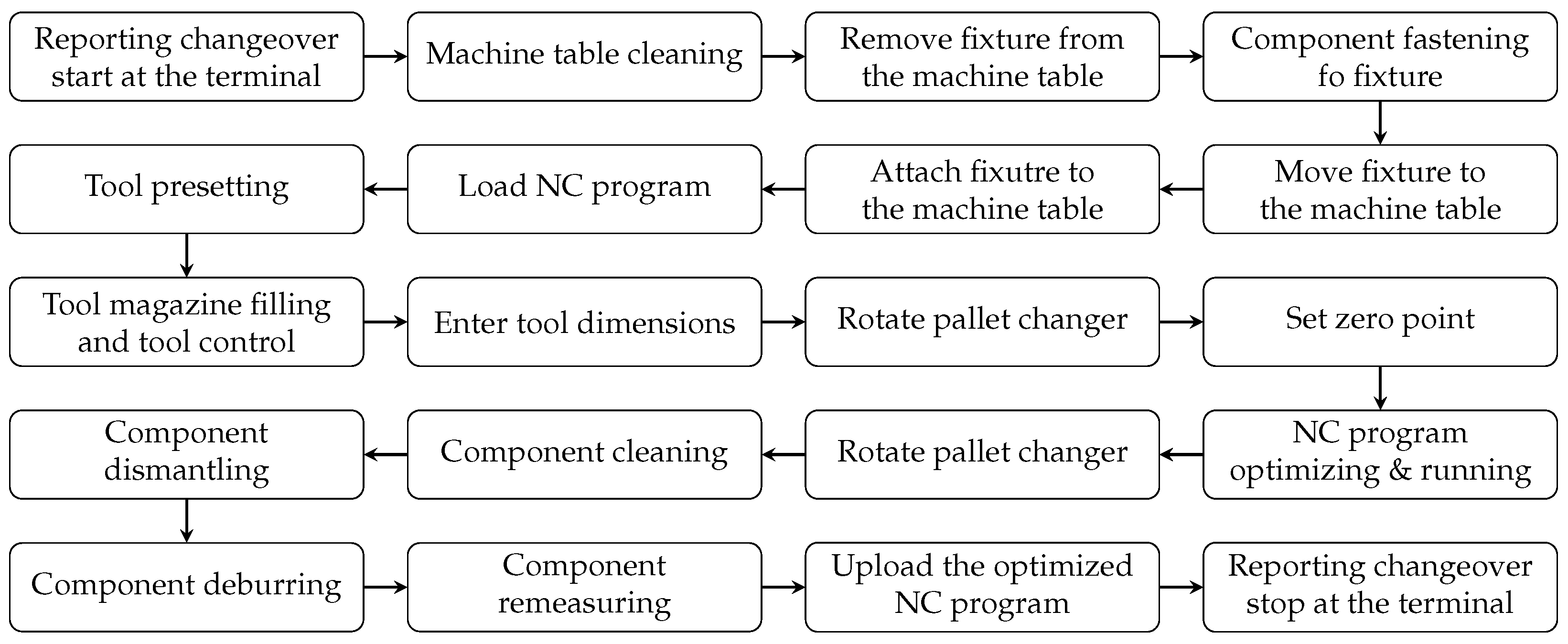
| Steps | Description | Factory Terminal | Distance to Door Handle (Tool Holder Cabinet) | Contact Switch (Second Chamber) | Contact Switch (Main Door) | Alternating Current | Flow (Coolant) | Indoor PS (x/y) |
|---|---|---|---|---|---|---|---|---|
| 1 | Reporting changeover start at the terminal | (1) | (9) | |||||
| 2 | Machine table cleaning | (2) | (9) | |||||
| 3 | Remove fixture from the machine table | (2) | (9) | |||||
| 4 | Component fastening to fixture | (9) | ||||||
| 5 | Move fixture to the machine table | (2) | (9) | |||||
| 6 | Attach fixture to the machine table | (2) | (9) | |||||
| 7 | NC program loading | (9) | ||||||
| 8 | Tool presetting | (9) | ||||||
| 9 | Tool magazine filling and tool control | (3) | (9) | |||||
| 10 | Enter tool dimensions | (9) | ||||||
| 11 | Rotate pallet changer | (4) | (4) | (6) | (9) | |||
| 12 | Zero point setting | (5) | (5) | (7) | ||||
| 13 | NC program optimizing and running | (5) | (5) | (7) | (8) | |||
| 14 | Rotate pallet changer | (4) | (4) | (6) | ||||
| 15 | Component cleaning | (9) | ||||||
| 16 | Component dismantling | (9) | ||||||
| 17 | Component deburring | (9) | ||||||
| 18 | Component remeasuring | (9) | ||||||
| 19 | Upoad the optimized NC program | (9) | ||||||
| 20 | Reporting changeover stop at the terminal | (1) | (9) |
| Sensor | Measurand |
|---|---|
| Distance | Distance to door handle (tool holder cabinet) |
| Flow | Flow (coolant) |
| Door status | Contact switch (main door) |
| Door status | Contact switch (second chamber) |
| Power consumption | Alternating current |
| Operator position | Indoor GPS position (x/y) |
| Initial Selection | Final Selection |
|---|---|
| CabinDoorLocks (Side, Front) | - |
| ChipCleaningGunStatus | - |
| CoolantFlow status | - |
| DNCMode | - |
| DoorStatuses (Main, Tooling) | DoorStatus (Tooling) |
| DriveStatus | DriveStatus |
| FeedRate | FeedRate |
| OverrideFeed | OverrideFeed |
| OverrideSpindle | - |
| PocketTable | PocketTable |
| ProgramChange | - |
| ProgramDetail | ProgramStatus |
| RapidTraverseKey | - |
| SpindleApproval | - |
| SpindleCleaning | - |
| SpindleSpeed | Spindle Speed |
| ToolNumber | ToolNumber |
| Sensors | Brownfield Approach | Combined Approach | ||
|---|---|---|---|---|
| Initial Selection | Final Selection | |||
| NC-external | Coolant flow | - | - | |
| Door contacts | - | - | ||
| Door handle distance | - | - | ||
| Indoor GPS (x, y) | Indoor GPS (x, y) | Indoor GPS (x, y) | ||
| Power consumption | Power consumption | - | ||
| NC-provided | Replacing | - | DoorStatuses | DoorStatus (Tooling) |
| (Main, Tooling) | ||||
| CoolantFlowStatus | - | |||
| New | - | CabinDoorLocks | - | |
| (Side, Front) | ||||
| ChipCleaning | - | |||
| GunStatus | ||||
| DNCMode | - | |||
| DriveStatus | DriveStatus | |||
| FeedRate | FeedRate | |||
| OverrideFeed | OverrideFeed | |||
| OverrideSpindle | - | |||
| PocketTable | PocketTable | |||
| ProgramChange | ProgramStatus | |||
| ProgramDetail | - | |||
| RapidTraverseKey | - | |||
| SpindleApproval | - | |||
| SpindleCleaning | - | |||
| SpindleSpeed | SpindleSpeed | |||
| ToolNumber | ToolNumber | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Engelmann, B.; Schmitt, A.-M.; Theilacker, L.; Schmitt, J. Implications from Legacy Device Environments on the Conceptional Design of Machine Learning Models in Manufacturing. J. Manuf. Mater. Process. 2024, 8, 15. https://doi.org/10.3390/jmmp8010015
Engelmann B, Schmitt A-M, Theilacker L, Schmitt J. Implications from Legacy Device Environments on the Conceptional Design of Machine Learning Models in Manufacturing. Journal of Manufacturing and Materials Processing. 2024; 8(1):15. https://doi.org/10.3390/jmmp8010015
Chicago/Turabian StyleEngelmann, Bastian, Anna-Maria Schmitt, Lukas Theilacker, and Jan Schmitt. 2024. "Implications from Legacy Device Environments on the Conceptional Design of Machine Learning Models in Manufacturing" Journal of Manufacturing and Materials Processing 8, no. 1: 15. https://doi.org/10.3390/jmmp8010015
APA StyleEngelmann, B., Schmitt, A.-M., Theilacker, L., & Schmitt, J. (2024). Implications from Legacy Device Environments on the Conceptional Design of Machine Learning Models in Manufacturing. Journal of Manufacturing and Materials Processing, 8(1), 15. https://doi.org/10.3390/jmmp8010015