1. Introduction
Automated underwater vehicles (AUVs) play increasingly important roles in the exploitation of marine resources due to their high flexibility and autonomy. AUVs do not require a tether connection or inputs from an operator, enabling them to perform various complex underwater tasks in more challenging and harsh underwater environments [
1]. With the advancement of AUV technology, they can now accommodate larger payloads and operate for longer durations [
2]. These technological improvements have all driven the application of AUVs in marine resource development. To date, AUVs have been successfully applied in fields such as seabed mapping [
3], polar exploration [
4], marine biological research [
5], and karst exploration [
6].
To perform various complex underwater tasks, AUVs are typically equipped with multiple sensors including Inertial Navigation Systems (INSs), Doppler Velocity Logs (DVLs), and a Global Positioning System (GPS) [
7]. Underwater navigation poses a significant challenge for AUVs because radio signals rapidly attenuate underwater, preventing them from utilizing GPS for navigation [
8]. Additionally, Inertial Navigation Systems (INSs) cannot meet the long-term navigation requirements for AUV underwater operations due to accumulated errors.
Terrain-Aided Navigation (TAN) is an autonomous navigation method with no cumulative error that can effectively solve the underwater navigation problems faced by AUVs. TAN technology corrects the INS trajectory during navigation based on the measured terrain information to achieve accurate vehicle positioning. TAN can be divided into Terrain Matching Navigation (TMN) and the Simultaneous Localization and Mapping (SLAM) algorithms according to whether a prior terrain map is required [
9]. The SLAM algorithm can realize navigation and localization without a prior map. In contrast, the TMN algorithm can achieve navigation by comparing the measured terrain information with the terrain information from a prior terrain map to correct the INS data. Filter-based methods and correlation-based batch processing methods are the two most classic categories of TMN algorithm. In recent years, a series of emerging terrain matching methods based on deep learning technologies have also been developed [
10,
11].
On the basis of this classification, TMN can further be divided into filter-based methods and correlation-based batch processing methods depending on the way in which the algorithm is implemented.
Filter-based methods use a variation of Bayesian filtering for recursion to achieve real-time correction of the AUV’s position. Bayesian filtering variations include the extended Kalman Filter (EKF), Particle Filter (PF), and Point Mass Filter (PMF) [
12]. Among these, PF has been most widely studied due to its high precision. Zhou et al. [
13] proposed the Kullback–Leibler Distance Particle Filter (KLD-PF), which can adjust the particle number according to its distribution in real time, thereby enhancing the efficiency of the PF. Zhou et al. [
14] proposed the PF based on gradient fitting, which can select the appropriate distribution according to the terrain gradient characteristics and remove large gradient samples. Chai et al. [
15] proposed a TAN method based on cubature PFs (CPF) that improves the PF performance by improving the particle resampling mechanism. Yousuf et al. [
16] cascaded a fuzzy particle filter with the ESKF specifically to enhance the performance of TAN in highly nonlinear systems. Although the filter-based TAN method has excellent real-time and positioning accuracy, it often struggles to effectively correct when a large error occurs at a certain time. Therefore, how to improve the robustness of the algorithm has become a research focus of the filter TAN method. Liu et al. [
17] integrated fuzzy logic into the PF to enhance the navigation robustness. Ma et al. [
18] proposed a TAN method based on fuzzy theory that combined the grid PF and the contour PF to improve the effect of the PF in different terrains. The Rao–Blackwellized Particle Filter (RBPF) is an algorithm designed to address challenges in high-dimensional nonlinear problems. This enables adjustments of more physical quantities without compromising the real-time performance [
19,
20].
Numerous studies regarding the improvement and application of the RBPF algorithm have been conducted [
21,
22,
23]. Zhang et al. [
24] combined the maximum entropy criterion and adaptive filtering technology to improve the robustness of the algorithm based on the 3-D RBPF. Additionally, some studies have been conducted to correct the initial error in the PF algorithm [
25,
26,
27].
The robustness of the PF algorithm remains insufficient in self-similar terrains or fuzzy measurements.
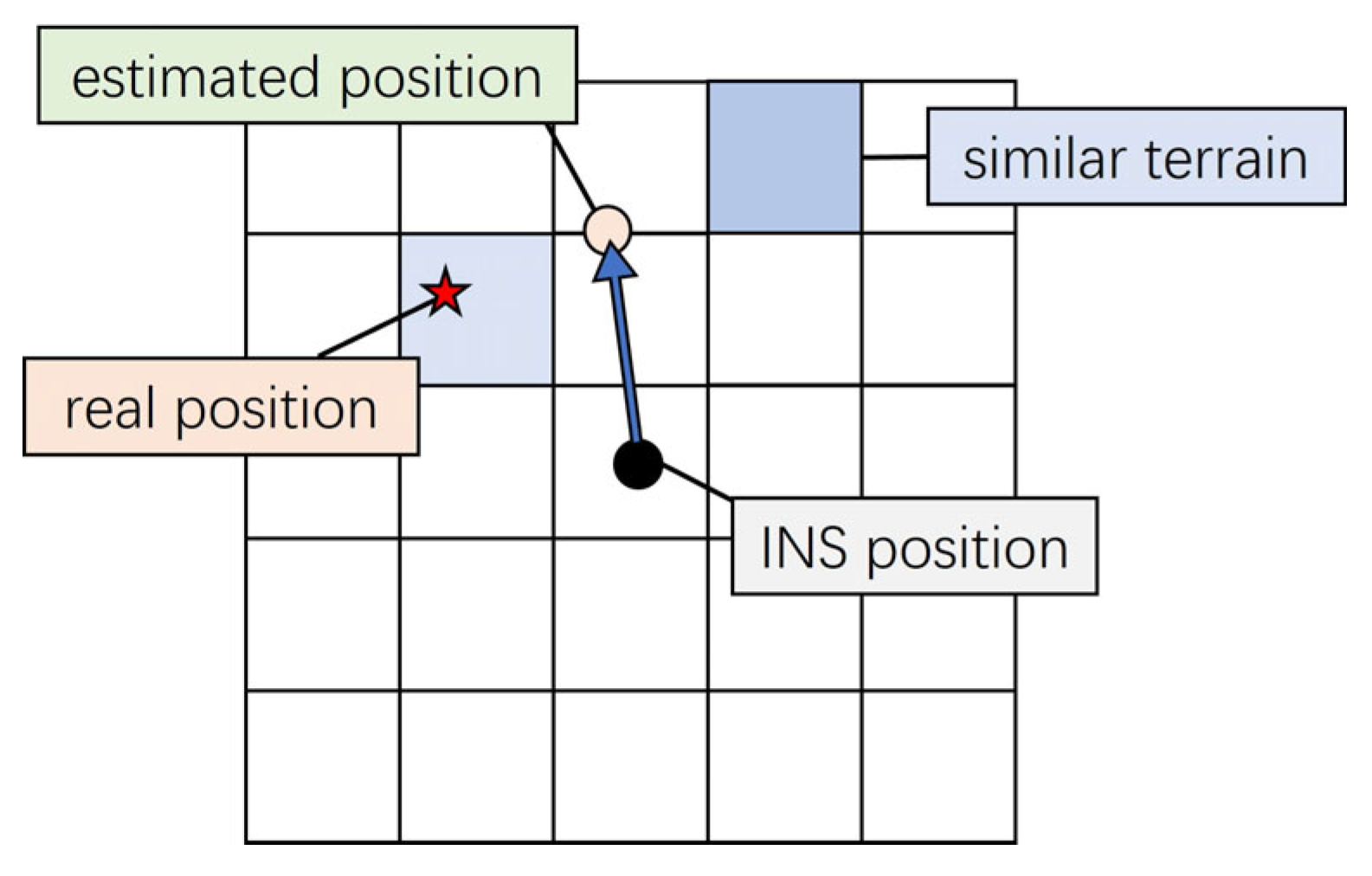
Figure 1 shows that when terrains with similar heights exist in the search area, the estimated position of the PF will be misled.
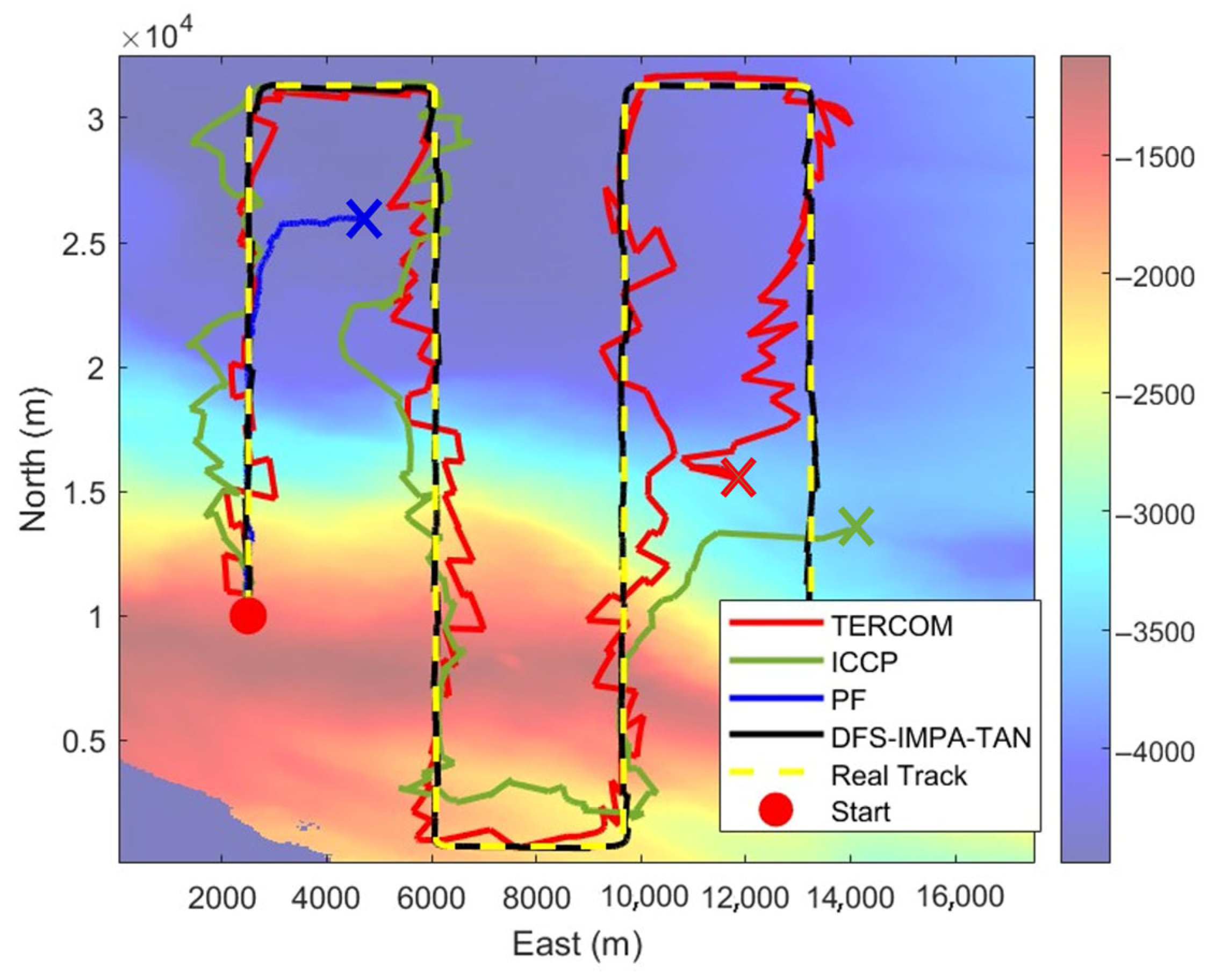
Correlation-based batch processing TAN methods are, to a certain extent, less susceptible to interference from small-scale similar terrains. These methods often allow the AUV to travel for a period of time for recording the positions of the AUV indicated by the INS and terrain height of the points on the trajectory and find the most similar trajectory from the Digital Terrain Map (DTM) based on the correlation metric to correct the INS navigation data. The Terrain Contour Matching (TERCOM) algorithm, Iterated Closest Contour Point (ICCP), and the Particle Swarm Optimization (PSO) algorithm are the common correlation-based batch processing TAN systems.
TERCOM is a simple and effective TAN algorithm. However, its inability to correct heading angle error limits the system’s precision [
28]. The ICCP algorithm finds the nearest reference point on the contour near the trajectory point and acquires the optimal transformation of the trajectory to the nearest reference point. Li et al. [
29] integrated the ICCP algorithm matching results with the KF to enhance navigation accuracy and stability. Wang et al. [
30] selected the paths of three data points in multi-beam data for parallel calculation to solve the problem of the large initial error divergence of the ICCP. Ding et al. [
31] first used the maximum likelihood estimation for coarse matching based on multi-beam data and then used the ICCP algorithm for fine matching based on single-beam data. Zhang et al. [
32] performed ICCP matching based on the terrain features obtained by the multi-beam data to address the issue of poor matching accuracy under large initial errors in the ICCP algorithm. The TAN method based on the PSO algorithm uses the parameters of the affine transformation model as optimization parameters to find the optimal transformation of the trajectory. Wang et al. [
33] combined artificial bee colonies (ABCs) with PSO for terrain-assisted navigation.
As navigation corrections are periodic, not real-time, current batch-processing TAN methods using correlation are inferior to the PF algorithm in real-time performance and accuracy. In terms of robustness, the divergence induced by mismatches has a significant impact on the navigation stability of correlation-based batch processing TAN methods.
TAN methods based on optimization algorithms hold great potential according to their principles. This is because the final transformation found by the ICCP is contained within the search space of optimization-based TAN method. This indicates that when the performance of the optimization algorithm is sufficiently strong, the optimization-based TAN method is always capable of finding a solution with the same or better fitness than the ICCP method.
However, TAN methods based on optimization algorithms often struggle to achieve stable navigation performance under the influence of the terrains with similar height. These terrains with similar height are categorized into similar terrain and local optimum terrain. Specifically, the height of similar terrains exhibits the same or higher measurement correlation compared to the actual terrain. This renders such terrain impossible to distinguish using any correlation-based methods. As illustrated in
Figure 2, when terrain height measurements fall at the lower bound of the error margin, point B matches the measurements better than the true terrain position. Local optimum terrain shows a slightly inferior correlation with measurements compared to the actual terrain. If the algorithm fails to explore the true terrain, this suboptimal solution may be selected, thereby disrupting the navigation process.
The concept of similar trajectories follows an analogous principle: they have superior comprehensive correlation across multiple points compared to the true trajectory. During terrain matching, there are typically a small number of similar trajectories and numerous local optimum trajectories. If the optimization algorithm inadequately explores the solution space, it may converge to a local optimum trajectory. Even if the algorithm finds the theoretical optimum, it cannot differentiate between similar trajectories and the true trajectory.
In response to the susceptibility of current TAN methods to self-similar terrains and fuzzy measurements, we propose a novel TAN framework based on an Improved Marine Predators Algorithm (IMPA) and Depth-First Search (DFS). This TAN framework outperforms various existing correlation-based batch processing TAN methods in navigation accuracy. In terms of navigation robustness, it is capable of self-correcting navigation divergence caused by self-similar terrains and fuzzy measurements, demonstrating exceptional adaptability. In this paper, our contributions are as follows:
(1) Existing optimization-based TAN methods are prone to being trapped in local optima, which often leads to mismatches during the navigation process. We attribute this issue to the insufficient performance of conventional intelligent optimization algorithms. To address this, we propose a novel Hunger Learning Algorithm using in the Marine Predators Algorithm (MPA) aiming to enhance information exchange among particles during the optimization process. Then, we apply the improved algorithm IMPA in the TAN framework. Simulation results demonstrate that the IMPA algorithm effectively avoids local optima and consistently locates the global optimum from the search areas. This significantly alleviates the issue of local optimum terrain interference encountered by optimization-based TAN methods. Furthermore, the matching results from the IMPA algorithm are integrated with a Kalman Filter (KF), enabling the system to operate in a real-time, periodically corrected mode. Based on this, IMPA-TAN provides higher navigation accuracy and stability for AUVs.
(2) Although the IMPA algorithm nearly eliminates the impact of local optima, it remains unable to distinguish self-similar terrains with a higher correlation due to terrain measurement errors during navigation. This adversely affects navigation accuracy and can even lead to divergence. To address this issue, this paper innovatively proposes a tree-structured framework based on Depth-First Search (DFS). During IMPA-TAN operation, this framework records all potential solutions within the bounds of measurement error. When subsequent navigation errors occur, it reverts to a previous navigation state and attempts alternative solutions for correction. Consequently, the proposed DFS-IMPA-TAN framework ensures stable navigation performance of the AUVs when encountering special conditions such as self-similar terrains and fuzzy measurements through node backtracking, which is difficult for other traditional TAN methods to achieve.
In this article, a novel TAN framework with strong robustness against self-similar terrains is proposed.
Section 2 introduces the MPA optimization algorithm and its improvement.
Section 3 introduces the IMPA-TAN and DFS-IMPA-TAN, including their principles and implementation details.
Section 4 presents the simulation tests and in-vehicle experiments that validate the algorithm performance. Finally,
Section 5 presents the conclusion.
3. The Proposed DFS-IMPA-TAN Navigation Framework
3.1. IMPA-TAN Algorithm
The IMPA-TAN system provides navigation and positioning for AUVs based on INS, terrain measurement units, and DEM. The INS incorporates three vertically oriented gyroscopes and accelerometers, whose processed outputs yield angular and velocity increments per unit time. This information is further processed to calculate the AUV’s position, velocity, and attitude. The terrain measurement unit includes depth sensors and sonar bathymetry equipment, with its output continuously transmitted to the IMPA-TAN system for terrain matching and height damping correction. DEM should be stored in the system for terrain matching, whose resolution and accuracy both impact the final navigation performance.
TAN utilizes terrain height information for navigation, making terrain features a critical factor determining the final navigation performance. Before applying terrain-aided navigation, it is necessary to analyze the terrain features in advance and identify navigation-suitable areas. During operation, the AUV’s route should be planned to steer clear of unsuitable areas as much as possible to ensure navigation accuracy.
The IMPA-TAN is a method that uses the IMPA algorithm to find the optimal affine transformation of the INS trajectory to correct the navigation error. The IMPA-TAN method comprises three primary phases: the acquisition phase, the optimization phase and the correction process.
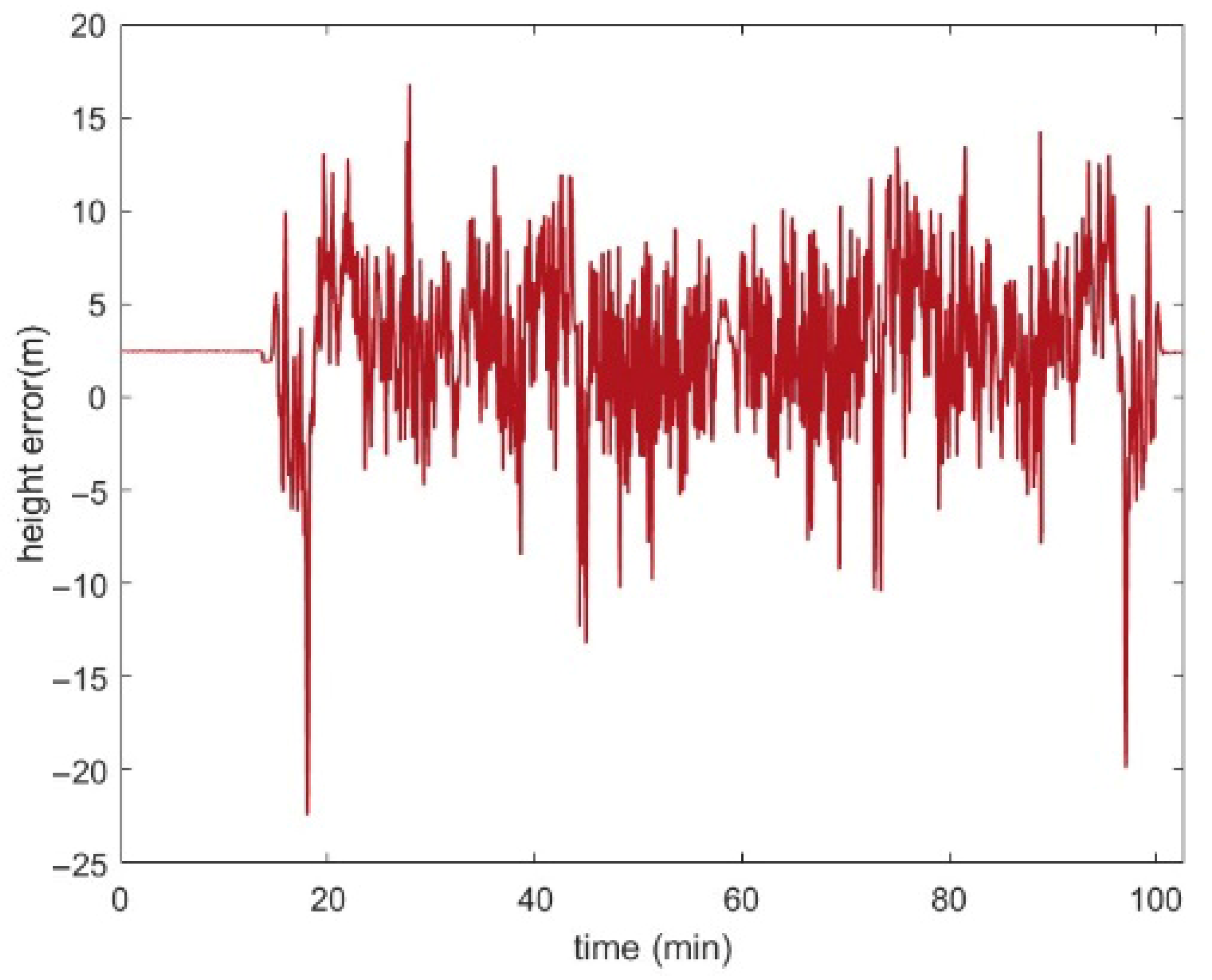
During the acquisition phase, the AUV performs the INS time update. Subsequently, it records the current position and measures terrain height at regular intervals based on the INS updates. After that, the system will correct navigation states based on multiple runs of the Kalman Filter (KF). These KF iterations share the same 15-dimensional state vector
, defined as follows:
where
,
, and
represent the east, north, and vertical attitude errors, respectively;
,
, and
represent the east, north, and vertical velocity errors, respectively;
,
, and
represent the longitude, latitude, and height errors, respectively;
,
, and
represent the east, north, and vertical gyroscope biases, respectively; and
,
, and
represent the east, north, and vertical accelerometer biases, respectively.
After each INS update, the system will perform an update of the state vector using a discretized KF. The system state equation is as follows:
where
represents the state vector at time
, and
is the discretized one-step state transition matrix from time
to
+1.
represents the equivalent process noise, with its covariance matrix being
. Following each acquisition of information from the terrain measurement unit of the AUV, the system first performs a measurement update of the KF based on the altitude to apply a dampening correction to the system. After completing the INS update and data collection of m data points, the system will enter the optimization phase.
After the acquisition phase, the system receives and saves the data from the IMU but pauses the INS time update. The INS update is resumed only after the optimization phase and correction process conclude, ensuring that subsequent updates proceed from the corrected navigation state.
The optimization phase is primarily based on the trajectory points and their corresponding terrain heights collected during the acquisition phase to optimize and solve. First, the system converts the coordinates of each trajectory point
into East–North–Up (ENU) coordinates
in meters to facilitate computation. It then seeks the optimal affine transformation for the INS-indicated trajectory, which maximizes the correlation between the transformed trajectory and the true terrain elevation. The expression for the affine transformation is as follows:
where
and
represent the position of the
-th point after the transformation;
and
record the position of the final point of the previous trajectory, or the starting point if it is the first match;
and
denote the position of the
-th point of the INS indicated trajectory; and
represent the scaling factor, rotation angle, and the translation distance in the
-direction and in the
-direction, which are the optimization parameters of the IMPA-TAN. The optimization fitness function is defined as follows:
where
represents the measured height of the
i-th point and
represents the map terrain height of the
i-th trajectory point after transformation.
After the optimization phase is completed, the system enters the correction phase. During this phase, the classical batch processing method directly corrects the position information based on the optimization results. However, there are two main problems: the first is that the update only adjusts the AUV’s position without correcting velocity and attitude information, which leading to errors in velocity and attitude that accumulate over time and causing trajectory deformation, thereby affecting subsequent data matching. The second is that the corrections are only made after a certain interval. This causes poor real-time performance.
To solve the problems of the IMPA-TAN in terms of error accumulation and real-time performance, we cascaded the position information of the optimal trajectory endpoint found by the IMPA algorithm with the INS update information using a KF filter. Both the velocity and attitude information could be corrected, and the real-time update was realized by outputting the INS information. In summary, the observation equation of KF is given as follows:
where
and
represent the observed values of longitude and latitude, respectively. These values are obtained by subtracting the converted trajectory endpoint from the AUV’s current position. The discrete observation equation of the system is given as follows:
where
represents the observation matrix at time t, with a value of
.
is the identity matrix of size
.
and
are zero matrices of corresponding sizes, respectively.
is the observation noise matrix, whose covariance matrix is
. The value of
relates to the navigation accuracy of the IMPA-TAN algorithm. In this system, it is set to
, where
denotes a diagonal matrix, 50 m is the estimated IMPA-TAN navigation accuracy, and
is the Earth’s equatorial radius.
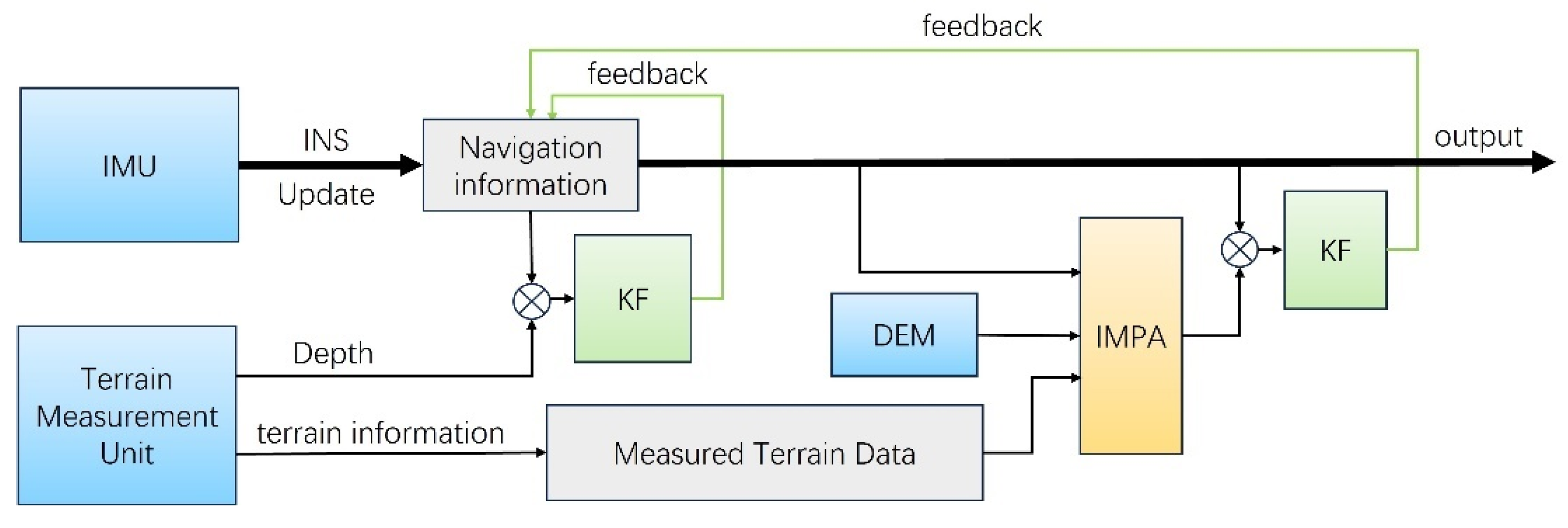
The IMPA-TAN algorithm complete flowchart is shown in
Figure 3. Firstly, the IMU output provides the basic navigation information of the AUV. When the terrain measurement unit takes a measurement, the system utilizes KF for damping correction by incorporating navigation information and depth data.
At the same time, the system also records the position and terrain height of the current point. After the system acquires a certain number of points, it will find out the most probable trajectory through the IMPA algorithm according to the information of these points and the Digital Elevation Model (DEM). After that, the framework inputs the matching result into the KF to make feedback corrections to the position, velocity, and attitude.
Additionally, it should be noted that the frequencies of the two KF updates and the navigation information output are all different. The navigation information output is accompanied by INS updates that have the highest frequency. The first KF update occurs after the terrain measurement unit output, whose frequency is medium. The second KF update is performed after a certain number of points are collected by the terrain measurement unit and its frequency is the lowest.
The KF effectively corrects the navigation information when optimization results are sufficiently accurate, thereby maintaining stable and effective navigation. However, it also further extends the impact of incorrect optimization results. This not only produces a large positional error, but also causes the velocity and attitude to deviate from their true values, leading to subsequent trajectory deformation. However, the existence of the terrain measurement error determines the existence of similar solutions. Even if the IMPA algorithm accurately finds the transformation with the minimum fitness every time, a similar solution with lower fitness can still interfere with the navigation results. To address the issue of erroneous updates, a novel model was introduced that effectively mitigated their effects and enhanced navigation stability.
3.2. DFS-IMPA-TAN Framework
To correct the effect of similar solutions during the execution of the IMPA-TAN method, the robust tree model was proposed.
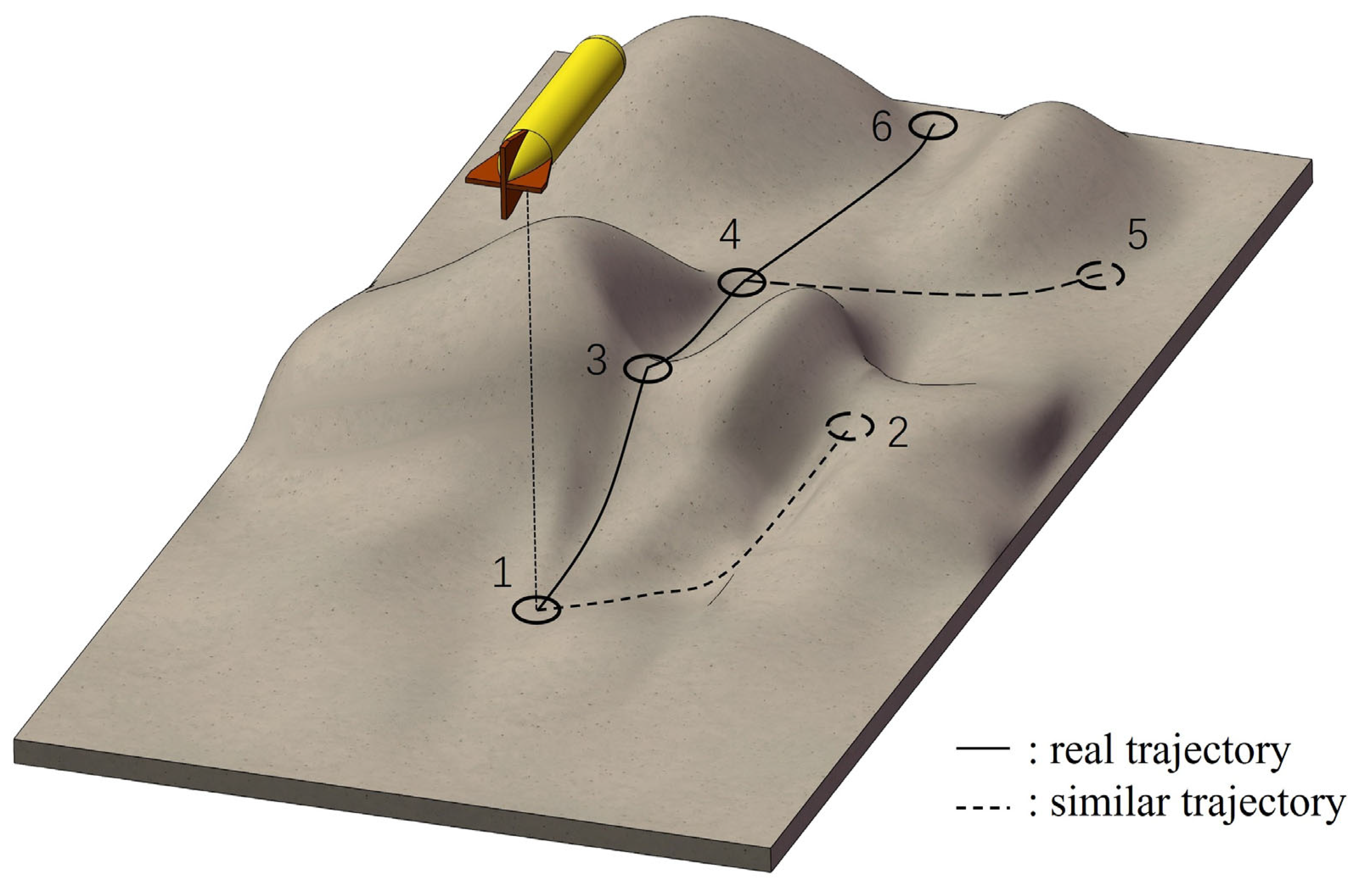
Figure 4 shows the schematic of this model. In the schematic diagram, the AUV travels along the trajectory ‘1-3-4-6’. There are two similar trajectories, ‘1–2’ and ‘4–5’, in the map, and their terrain information is very similar to the real trajectory. When the measurement error is slightly larger, these trajectories may exhibit lower fitness values than the true trajectory, potentially causing them to be incorrectly selected as optimal by the IMPA-TAN algorithm. The robust tree is constructed as a tree structure to store all possible update results. If a deviation is detected during later steps, the algorithm reverts to the parent node; otherwise, it continues to follow the optimal solution. It essentially builds and maintains a tree database based on a DFS. As shown in
Figure 4, if the first trajectory ‘1–2’ has lower fitness, the navigation updates, and the trajectory ‘1–3’ update results are simultaneously stored in the robust tree. During the second navigation update, if the deviation’s impact is minor and the IMPA algorithm successfully matches to trajectory ‘3–4’, the system continues to navigate. Conversely, if the deviation significantly affects the update and the IMPA algorithm is unable to identify a suitable affine transformation, the system returns to node 1. Subsequently, the system will access the node with the second lowest fitness, which stores the information for trajectories ‘1–3’, thereby continuing with accurate navigation updates.
According to the principles of robust tree and IMPA-TAN, there are many trajectories that are close to the real trajectories or similar trajectories during the optimization process. If all those trajectories are included in the robust tree, the system will be overwhelmed by the amount of computation introduced.
The parameter of KF in the IMPA-TAN algorithm defines the estimated error range of the optimization algorithm. If the estimated error values in the and directions are both , navigation will not be greatly impacted when the IMPA-TAN optimization result lies within a rectangular region around the real position with dimensions determined by . According to this principle, the system will build robust trees by running IMPA twice.
The first IMPA is responsible for finding the global optimal transformation
and then solving for the endpoint coordinates of the transformed trajectory:
The second IMPA searches for all solutions with sufficiently low fitness during the optimization process. The specific solution process of the second IMPA is as follows: assuming the solution currently explored by IMPA is the
i-th solution, with corresponding affine transformation parameters
. Its fitness is first calculated according to Equations (19) and (20). Then, the following formula is used to determine whether the current solution satisfies the fitness condition:
where
denotes the fitness value of the
i-th solution, and
is the maximum tolerable fitness value in the robust tree. In this system, if the terrain elevation measurement error satisfies
, then
. Subsequently, for solutions satisfying the fitness condition, it is necessary to find the grid coordinates of their endpoints. Substituting
in Equation (23) in place of
yields the trajectory endpoint coordinates
. Following this, the grid coordinates corresponding to this solution are calculated as follows:
where
represents the obtained grid coordinates, and
denotes the function that truncates the fractional part. After determining the grid coordinates of the current solution, the storage status within the current grid cell is first checked. If the current solution’s grid does not contain any other solutions, the relevant information of the current solution will be recorded. Otherwise, the grid records the solution with the lower fitness value. After storing a new solution, nodes will be sorted by fitness value to prioritize lower-fitness solutions in subsequent exploration.
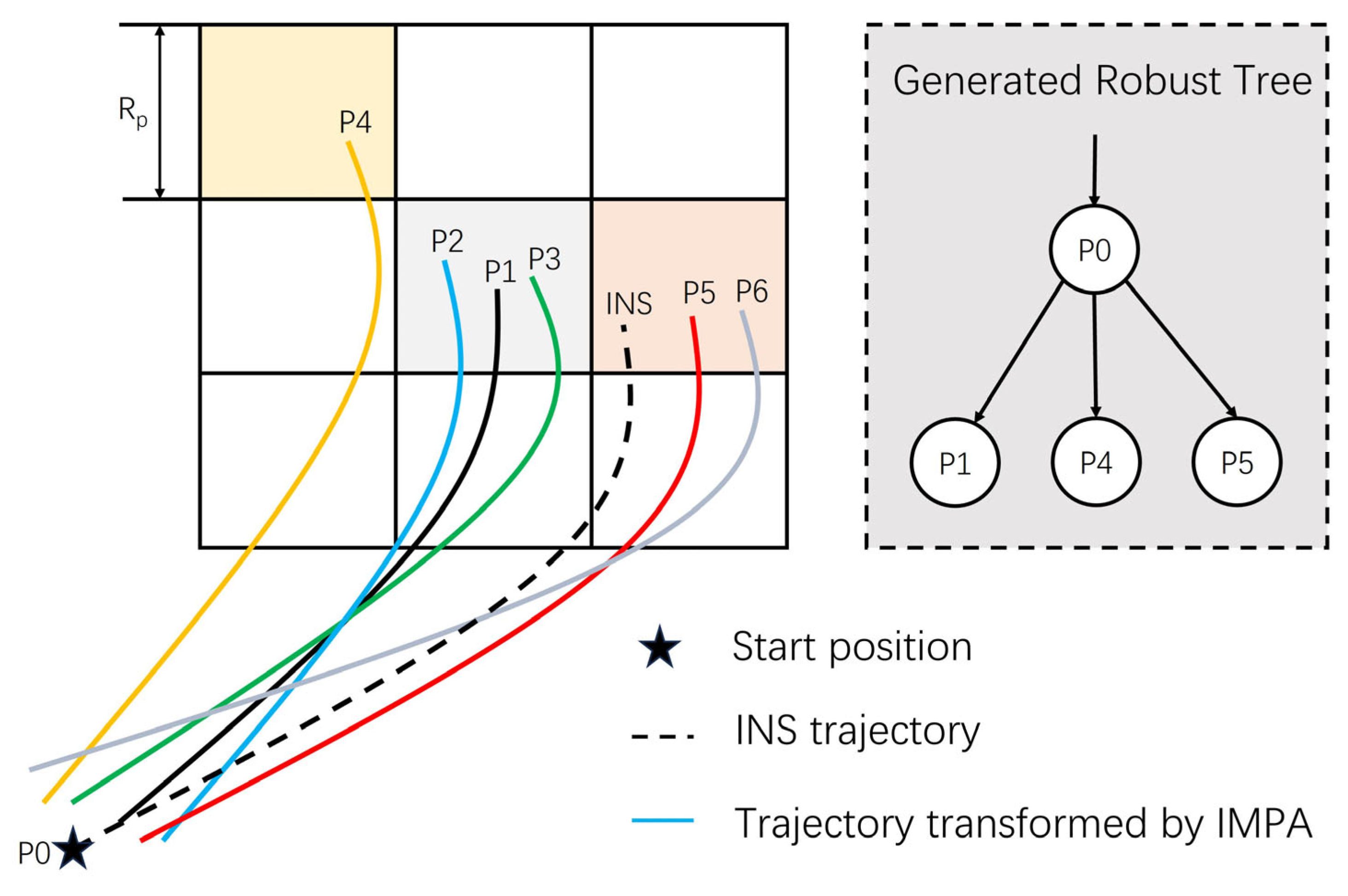
Figure 5 shows the schematic of robust tree construction where P1 to P6 are six possible trajectory transformations, and the index number corresponds to their fitness ranking. Based on the robust tree construction method, there are only three child nodes in this update. In addition, according to the principle of the robust tree, the end point of the true trajectory will be within the area covered by three nodes.
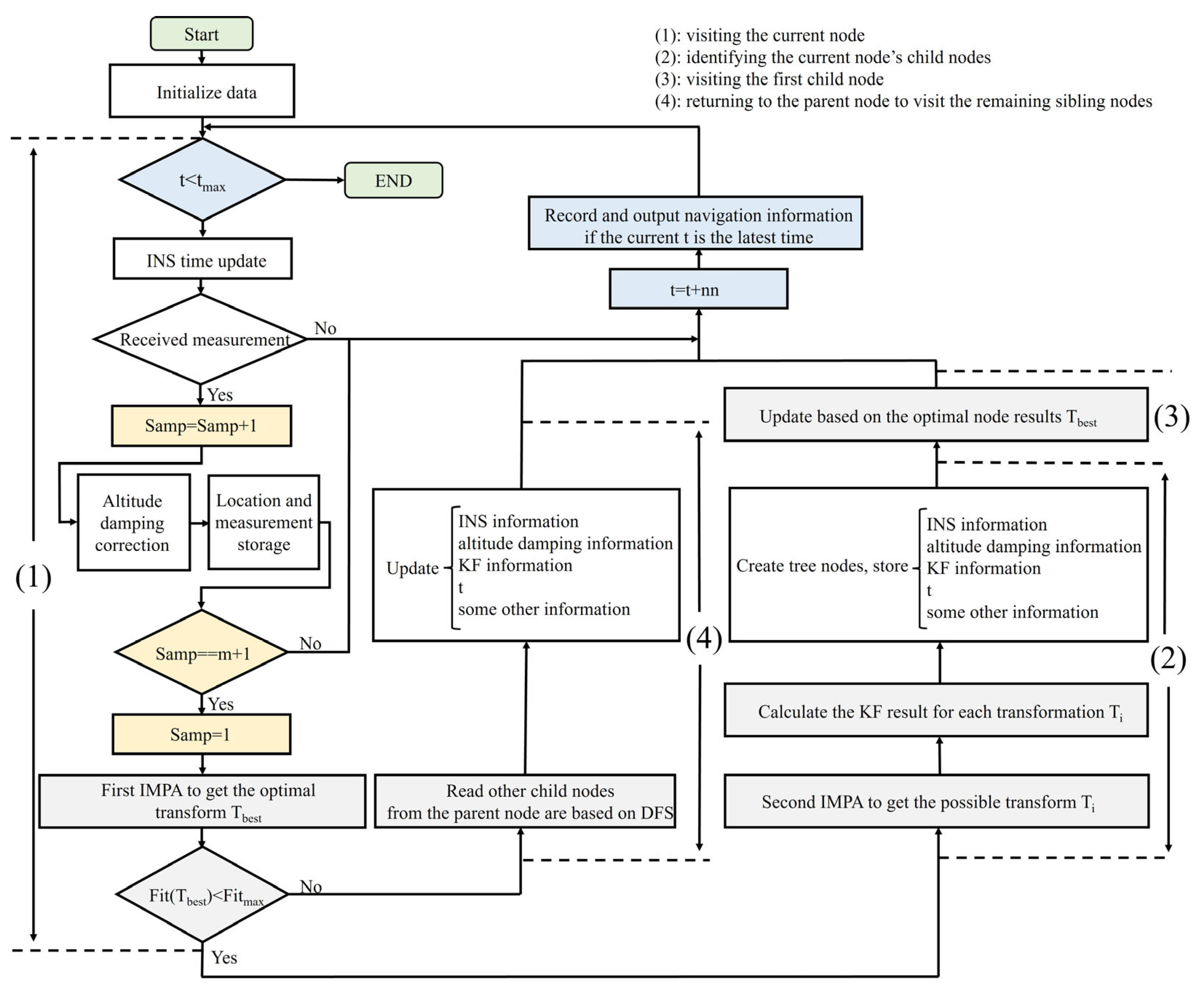
The primary flow of the DFS-IMPA-TAN framework is shown in
Figure 6. The loop’s body corresponds to four phases of DFS: visiting the current node, identifying the current node’s child nodes, visiting the first child node, and returning to the parent node to visit the remaining sibling nodes. Each phase is clearly labeled in the flowchart.
During the first phase of the DFS process, corresponding to the ‘visiting the current node’ step, the system performs a series of operations that include INS updates, altitude damping and the first IMPA optimization. is the navigation duration. In playback experiments, it is set to the final moment of navigation; while in actual applications, the loop only exits upon manual termination. The visit result of the node depends on the fitness of the first IMPA’s optimal solution. If the fitness is too high, the node is rejected.
The second and third stages correspond to ‘identifying the current node’s child nodes’ and ‘visiting the first child node’, respectively. During the second stage, the second IMPA is utilized to construct the robust tree. For each child node, the KF update results are calculated and stored along with time and other parameters. It is essential to ensure that all relevant parameters are recorded for reproducing the navigation state at any given time. The contents saved in the
i-th node are as follows:
where
INS represents variables related to inertial navigation;
KF denotes variables related to the Kalman Filter;
ALT signifies variables related to altitude damping;
is the endpoint of the node at the previous time step, and
t contains all the variables used for recording time.
During the third stage, the system inputs the parameters of the first child node into the system to continue updating.
The fourth corresponds to the ‘returning to the parent node to visit the remaining sibling nodes’ step. The system will revert to previous time nodes to perform updates and correct the prior erroneously updated results. Navigation information is output only when the current time t is the latest moment.
Finally, it is worth noting that the tree needs to be pruned during system operation to prevent excessive memory consumption by stored data. The method used in this framework only keeps the nodes of the newest 10-level tree in order to conserve computing and storage resources without affecting the performance of the robust tree.
In
Section 3, we designed the DFS-IMPA-TAN framework. Compared with traditional TAN algorithms, this framework can better deal with the problems of terrain with self-similar features or fuzzy measurements and maintains real-time, accurate, and stable navigation.
5. Discussion
To enhance the robustness of underwater TAN, a TAN framework based on DFS and IMPA is proposed. On the one hand, IMPA possesses strong optimization capabilities, enabling it to identify the global optimum within the search space more, thereby achieving accurate terrain matching. On the other hand, the robust tree structure based on DFS endows the TAN framework with self-correcting capability against navigation divergence. This means the DFS-IMPA-TAN has stronger navigation robustness.
However, as DFS-IMPA-TAN is a batch-processing TAN method, it faces the following inherent limitations:
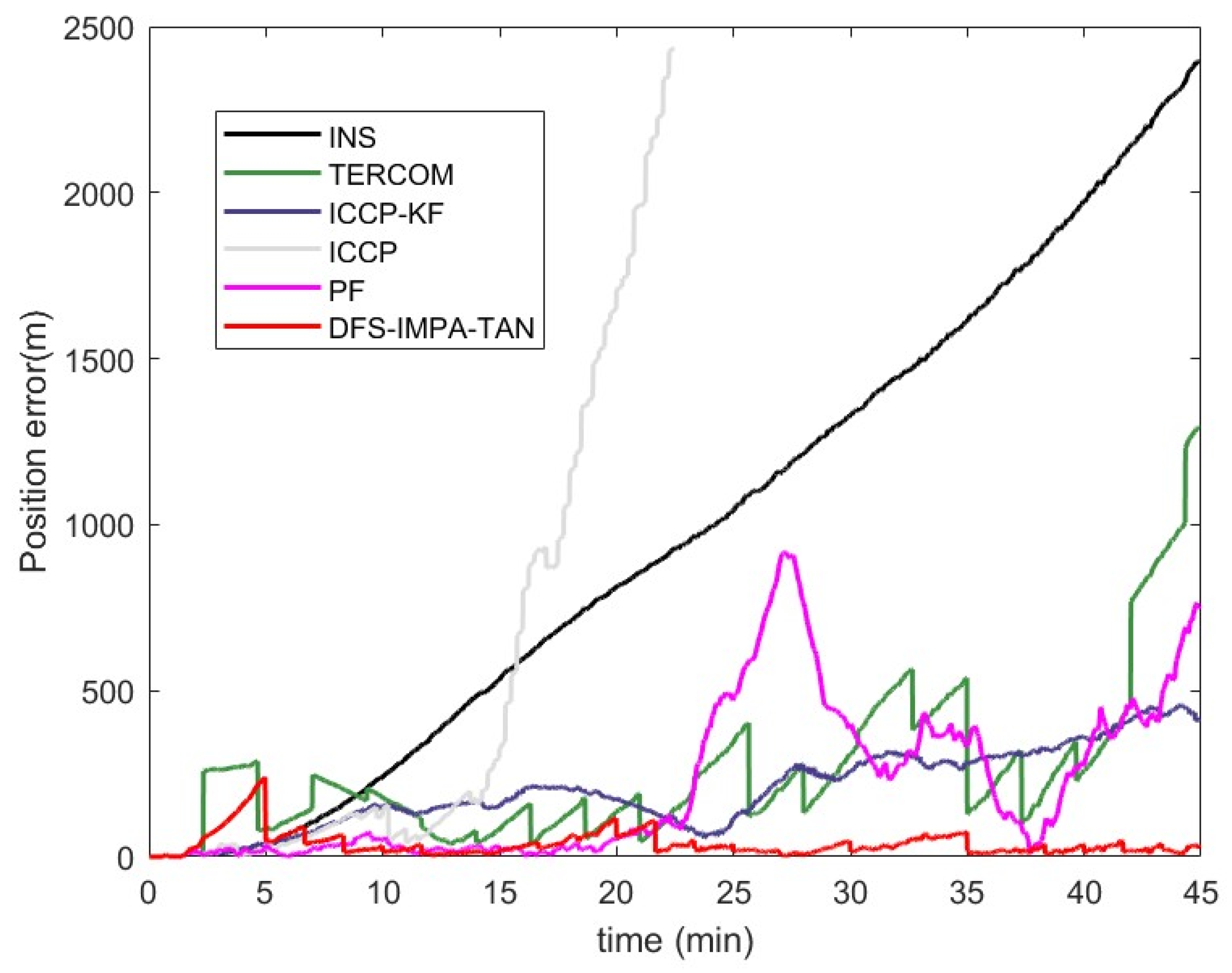
1. Batch-processing TAN methods utilize the terrain information of more trajectory points for navigation updates. While this makes batch-processing TAN methods have stronger robustness, their longer update intervals are accompanied by the accumulation of INS error. Consequently, the theoretical accuracy ceiling of these methods is lower than that of real-time updating TAN algorithms like the PF.
2. Batch-processing TAN methods achieve terrain matching by finding an affine transformation of the trajectory. However, when velocity/attitude errors are significant or the vehicle undergoes complex curvilinear motion, the INS-indicated trajectory may deviate substantially from the true path. In such situations, DFS-IMPA-TAN also fails to achieve accurate matching.
In summary, the stable navigation performance of DFS-IMPA-TAN enables AUVs to achieve reliable positioning across more diverse terrains. Though its accuracy ceiling may be lower than real-time updating algorithms, its stable output can serve as a valuable reference for methods like PF, potentially enhancing their robustness.
6. Conclusions
Robustness has been a key focus in underwater TAN for AUVs. This paper proposes a novel TAN framework. Given its divergence self-correction capability, this framework can maintain stable navigation performance even when encountering challenging conditions such as self-similar terrain features or measurement uncertainties. Experimental validation of the proposed navigation framework leads to the following conclusions:
(1) Compared to other common optimization methods in the TAN field, IMPA based on the Hunger learning algorithm demonstrates superior optimization performance and is rarely trapped in local optima when solving TAN optimization problems.
(2) IMPA-TAN can maintain stable navigation performance in most scenarios. The robust tree framework corrects occasional navigation divergence, further enhancing the framework’s navigational stability. The single matching time of the DFS-IMPA-TAN algorithm is significantly shorter than the matching cycle, ensuring continuous operation during mission execution.
(3) Due to its periodic correction rather than real-time correction mechanism, the DFS-IMPA-TAN method exhibits slightly lower navigation accuracy than PF under favorable conditions, though it surpasses other batch-processing TAN methods. However, in terms of robustness, DFS-IMPA-TAN operates effectively under more challenging terrains and larger measurement errors, and possesses divergence self-correction capability. Thus, it demonstrates stronger robustness compared to other algorithms.
In summary, DFS-IMPA-TAN is a robust TAN framework. This framework enables AUVs to operate effectively in more complex environments, thereby expanding the range of TAN applications. DFS-IMPA-TAN can provide AUVs with robust underwater navigation, enabling them to adapt to various complex and dynamic underwater environments.
Future research will focus on integrating its stable navigation output with high-precision methods such as PF to achieve navigation solutions with higher accuracy and enhanced robustness.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}