

UAV-YOLO12: A Multi-Scale Road Segmentation Model for UAV Remote Sensing Imagery



Abstract
Highlights
- A UAV-oriented segmentation network (UAV-YOLOv12) is proposed, integrating SKNet and PConv to enhance spatial adaptability and feature selectivity.
- The model achieves high accuracy and generalization across four public aerial datasets, maintaining robust performance under occlusion and scale variation.
- The proposed method provides a practical and efficient solution for UAV-based road monitoring in real-world environments.
- It enables accurate extraction of small and occluded road structures, supporting real-time infrastructure assessment and smart city applications.
Abstract
1. Introduction
2. Methodology
2.1. Data Collection
2.1.1. UAV Detection
2.1.2. Data Preprocessing
- (1)
- Random cropping: Cropping to 512 × 512 patches from the original image with at least 80% area overlap with labeled masks.
- (2)
- Horizontal and vertical flipping: Each applied with a 50% probability.
- (3)
- Histogram equalization: Used to enhance contrast under low-light conditions.
- (4)
- Color jittering: Brightness, contrast, saturation, and hue were randomly adjusted within the range of ±15%.
- (5)
- Random rotation: Applied within ±10° range to simulate UAV yaw variability.
- (6)
- Gaussian blur: σ randomly selected between 0.1 and 1.0, applied with 30% probability to simulate motion blur.
2.1.3. Dataset Information
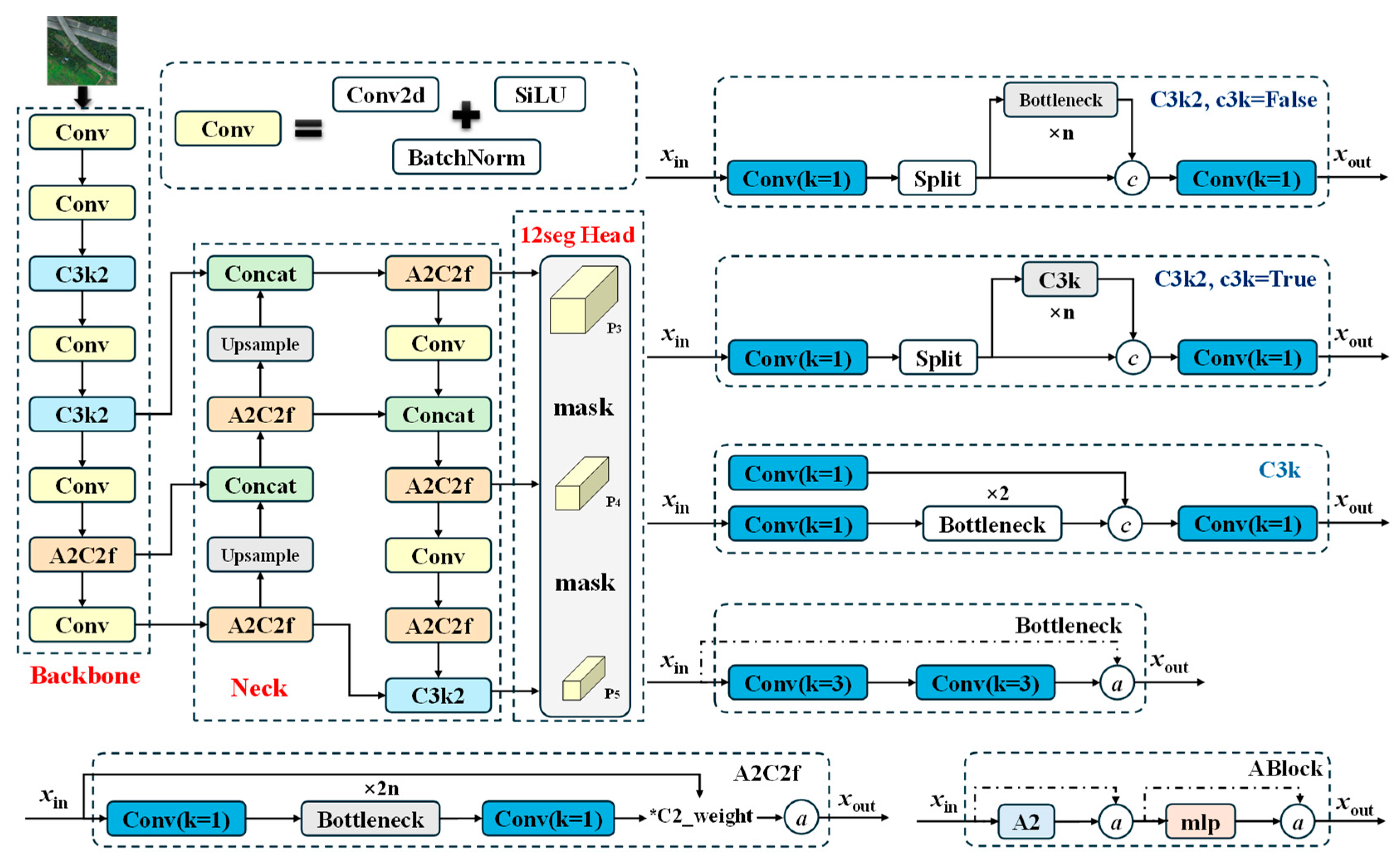
2.2. The Original YOLOv12
- Backbone: The backbone adopts an improved version of the Efficient Layer Aggregation Network (ELAN) architecture, known as R-ELAN. This design introduces block-level residual connections and feature scaling to address issues like gradient vanishing and training instability in deep networks. By improving feature reuse and aggregation across layers, R-ELAN can significantly strengthen the ability to represent multi-scale objects.
- Neck: The neck incorporates an Area Attention mechanism, which divides feature maps into horizontal and vertical regions to reduce the computational complexity of attention while preserving a large receptive field. In addition, YOLOv12 integrates FlashAttention, a high-efficiency memory access optimization for attention operations that accelerates inference speed. For multi-scale feature aggregation, the neck employs the A2C2f module, which facilitates effective fusion of semantic features at different scales, thereby improving detection performance for targets of varying sizes.
- Head: The head includes multi-scale detection and segmentation. The YOLOv12 head comprises three parallel branches operating on feature maps P3, P4 and P5; each branch uses cascaded 1 × 1 and 3 × 3 convolutions (C3k2/C3k modules) and prediction layers to localize and classify small, medium, and large objects, respectively. Immediately following each detection branch, a lightweight segmentation subhead fuses multi-scale features via A2C2f blocks, upsampling and concatenations to produce a per-pixel mask at the corresponding resolution, sharpening object boundaries. By jointly learning detection and segmentation in an end-to-end architecture, this dual-task head delivers high precision and robust boundary accuracy across diverse object scales without compromising real-time inference speed.
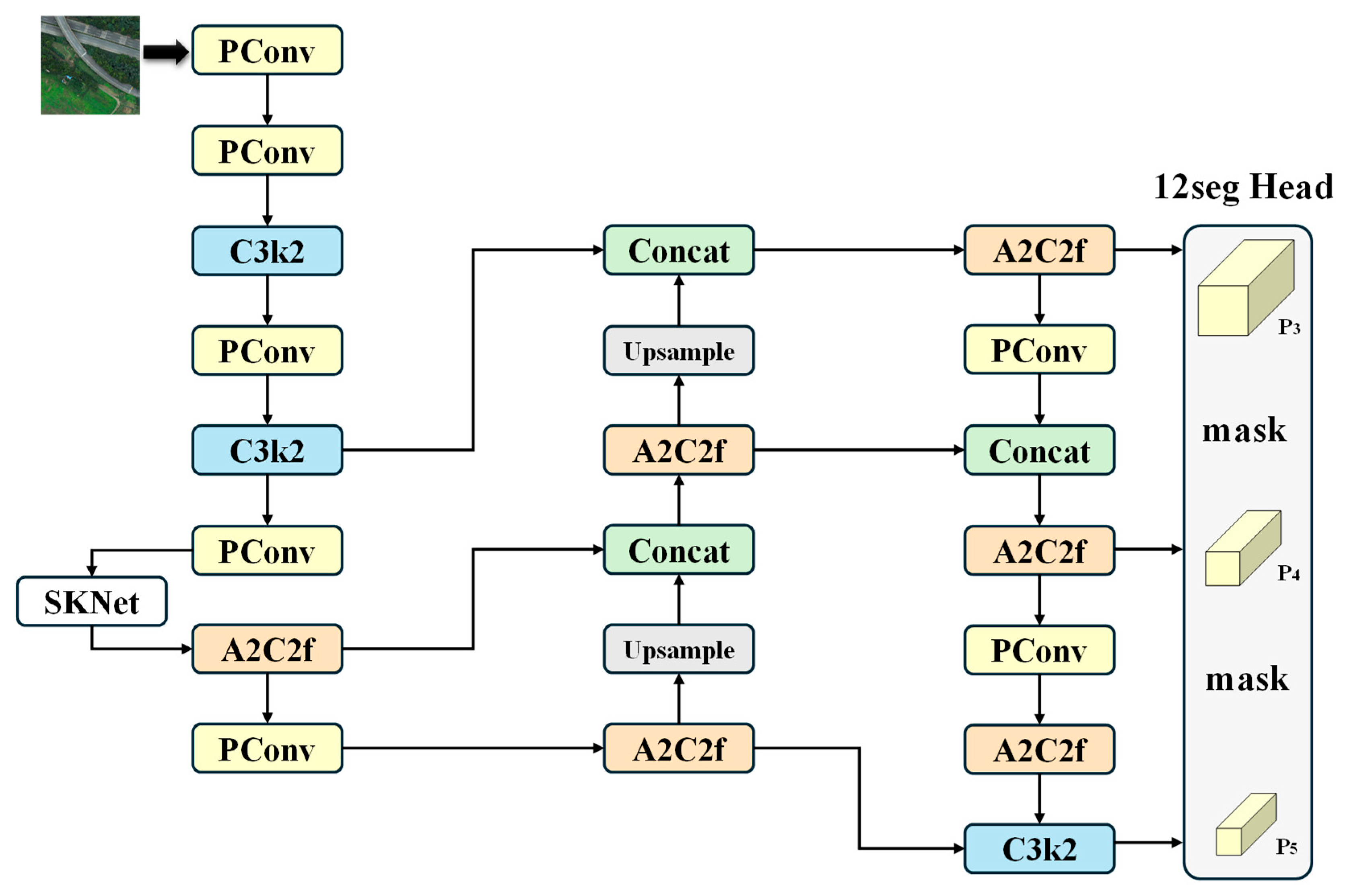
2.3. UAV-YOLOv12
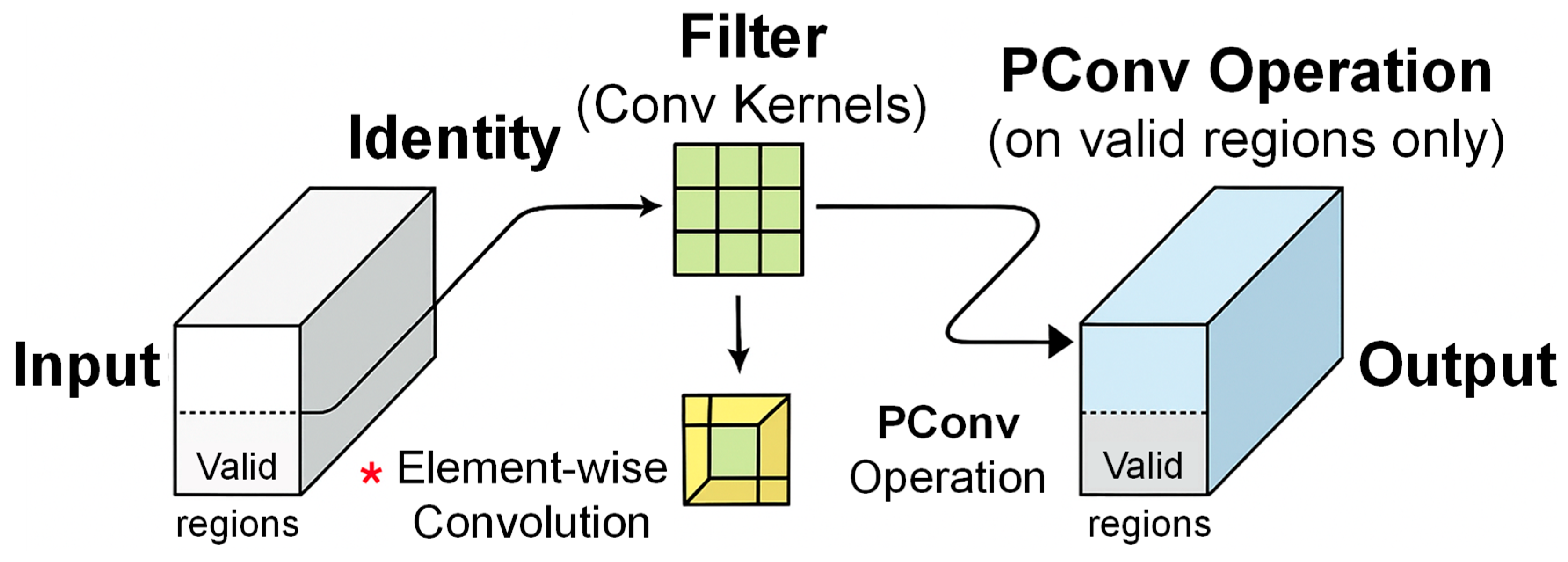
2.3.1. PConv
- It focuses only on regions that contain significant semantic content and automatically ignores low-information areas such as repetitive textures, vegetation, and lighting artifacts commonly found in UAV road scenes.
- Since PConv operates only on activated subregions, it eliminates unnecessary computations, leading to lower memory usage and fewer parameters without sacrificing performance.
- The method is particularly effective in detecting object boundaries and structural defects in road targets, making it suitable for fine-grained tasks such as crack localization and edge delineation.
- PConv demonstrates more stable performance under challenging conditions, including occlusion, missing data, and heavy background noise, which are prevalent in UAV-based remote sensing imagery.
- By explicitly modeling valid spatial support, PConv enhances the interpretability of feature maps, enabling better visual analysis of the model’s attention regions during UAV-based road detection.
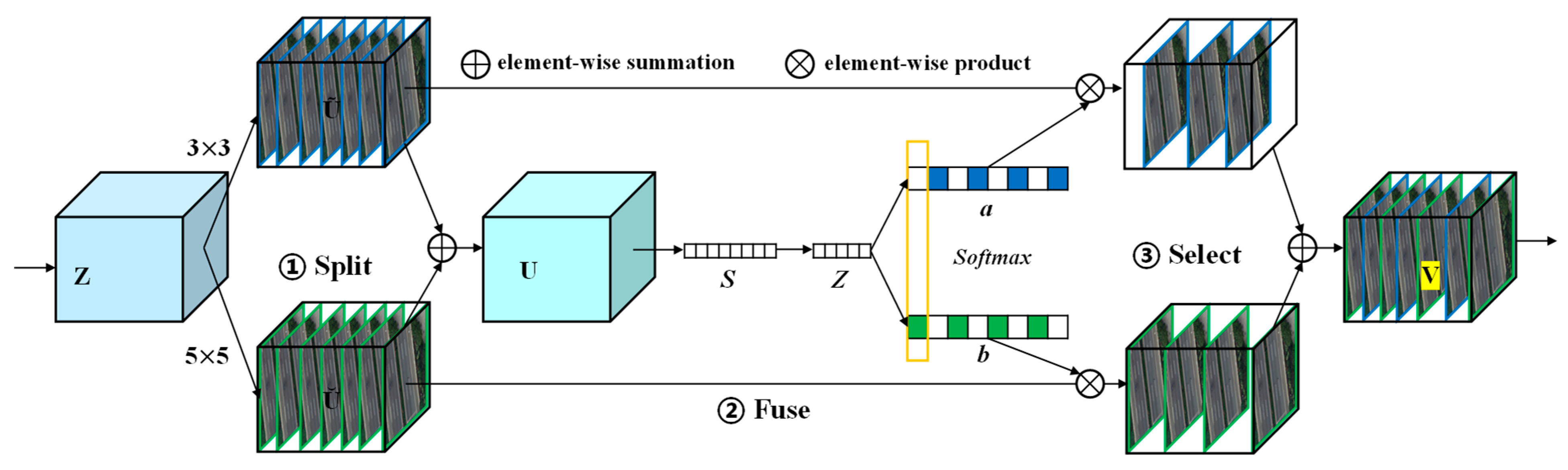
2.3.2. SKNet
- Split: The input feature map Z is simultaneously processed by two convolutional branches with different kernel sizes. One branch uses a standard 3 × 3 convolution, and the other applies a dilated 5 × 5 convolution with a dilation rate of 2. These two branches are designed to extract both local and broader contextual features, capturing multi-scale semantic information.
- Fuse: The outputs from the two branches are added elementwise to generate an intermediate feature map U, which is then globally average pooled to generate a channel descriptor S. This descriptor passes through two fully connected layers followed by a SoftMax activation to produce two channel-wise attention weights a and b, which represent the relative significance of each branch. The attention weights a and b enable the model to dynamically prioritize convolution outputs that best match the local structural context. This adaptive mechanism allows SKNet to enhance features relevant to road boundaries, particularly in cases with weak or missing edge cues.
- Select: The final output V is obtained by applying the weight a and b to the corresponding branch outputs and summing the weighted features. This process allows the network to emphasize the most informative receptive field for each spatial location based on the content of the input image.
2.3.3. Loss Function
- (1)
- The original YOLOv12 uses CIoU or DIoU loss to measure the discrepancy between predicted and ground-truth bounding boxes. In this work, we incorporate the more advanced SIoU (SCYLLA-IoU) loss. This method not only considers center distance, overlap area, and aspect ratio but also integrates angle and boundary direction information. This is particularly beneficial for scenarios involving slanted or curved structures, such as bent roads and oblique lane markings, significantly enhancing localization accuracy.
- (2)
- To address the class imbalance problem commonly found in UAV images, where small targets are underrepresented and background classes dominate, we adopt the Focal Loss mechanism. This adjusts the loss contribution of well-classified examples, reducing the impact of easy negatives and helping the model focus more on difficult and underrepresented classes.
- (3)
- To mitigate the imbalance between positive and negative samples during training, we introduce label smoothing to soften hard classification boundaries.
2.4. Evaluation Metrics
3. Results and Discussions
3.1. Abation Experiment Results
3.2. Experimental Results of Contrast Tests
3.2.1. Comparison of Detection Results with State-of-the-Art Models
3.2.2. Comparison of Detection Results of Different Labels
3.3. Generalization Performance Evaluation
4. Conclusions
- (1)
- The proposed UAV-YOLOv12 outperforms both traditional segmentation models (U-Net, DeepLabV3+) and the baseline YOLOv12 in all key metrics. It achieves F1-scores of 0.902 (road-H) and 0.825 (road-P), with IoUs up to 0.891 and 0.795, respectively.
- (2)
- The UAV-YOLOv12 still maintains high accuracy on multiple public datasets, including Massachusetts Roads and Drone Vehicle datasets, demonstrating strong generalization ability.
- (3)
- In addition to architectural enhancements, UAV-YOLOv12 also maintains a real-time inference speed of 11.1 ms per image, supporting deployment on onboard UAV platforms.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, J.; Yoon, Y. Indicators development to support intelligent road infrastructure in urban cities. Transp. Policy 2021, 114, 252–265. [Google Scholar] [CrossRef]
- Ye, Z.; Wei, Y.; Yang, S.; Li, P.; Yang, F.; Yang, B.; Wang, L. IoT-enhanced smart road infrastructure systems for comprehensive real-time monitoring. Internet Things Cyber Phys. Syst. 2024, 4, 235–249. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, S.; Gu, X.; Dong, Q. Non-destructive testing and intelligent evaluation of road structural conditions using GPR and FWD. J. Traffic Transp. Eng. 2025, 12, 462–476. [Google Scholar] [CrossRef]
- Barbieri, D.M.; Lou, B. Instrumentation and testing for road condition monitoring—A state-of-the-art review. NDT E Int. 2024, 146, 103161. [Google Scholar] [CrossRef]
- Zhang, A.A.; Shang, J.; Li, B.; Hui, B.; Gong, H.; Li, L.; Zhan, Y.; Ai, C.; Niu, H.; Chu, X.; et al. Intelligent pavement condition survey: Overview of current researches and practices. J. Road Eng. 2024, 4, 257–281. [Google Scholar] [CrossRef]
- Xu, H.; Wang, L.; Han, W.; Yang, Y.; Li, J.; Lu, Y.; Li, J. A Survey on UAV Applications in Smart City Management: Challenges, Advances, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8982–9010. [Google Scholar] [CrossRef]
- Tilon, S.; Nex, F.; Vosselman, G.; Sevilla de la Llave, I.; Kerle, N. Towards Improved Unmanned Aerial Vehicle Edge Intelligence: A Road Infrastructure Monitoring Case Study. Remote. Sens. 2022, 14, 4008. [Google Scholar] [CrossRef]
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the Unmanned Aerial Vehicles (UAVs): A Comprehensive Review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Kujawski, A.; Dudek, T. Analysis and visualization of data obtained from camera mounted on unmanned aerial vehicle used in areas of urban transport. Sustain. Cities Soc. 2021, 72, 103004. [Google Scholar] [CrossRef]
- Biçici, S.; Zeybek, M. An approach for the automated extraction of road surface distress from a UAV-derived point cloud. Autom. Constr. 2021, 122, 103475. [Google Scholar] [CrossRef]
- Wang, M.; Wen, Y.; Wei, S.; Hu, J.; Yi, W.; Shi, J. SA-ISAR Imaging via Detail Enhancement Operator and Adaptive Threshold Sensing. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5205914. [Google Scholar] [CrossRef]
- Xiao, F.; Tong, L.; Luo, S. A Method for Road Network Extraction from High-Resolution SAR Imagery Using Direction Grouping and Curve Fitting. Remote Sens. 2019, 11, 2733. [Google Scholar] [CrossRef]
- Zeng, T.; Gao, Q.; Ding, Z.; Chen, J.; Li, G. Road Network Extraction from Low-Contrast SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 907–911. [Google Scholar] [CrossRef]
- Lin, H.; Hong, D.; Ge, S.; Luo, C.; Jiang, K.; Jin, H.; Wen, C. RS-MoE: A Vision–Language Model with Mixture of Experts for Remote Sensing Image Captioning and Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5614918. [Google Scholar] [CrossRef]
- Tuia, D.; Schindler, K.; Demir, B.; Zhu, X.X.; Kochupillai, M.; Džeroski, S.; van Rijn, J.N.; Hoos, H.H.; Frate, F.D.; Datcu, M.; et al. Artificial Intelligence to Advance Earth Observation: A review of models, recent trends, and pathways forward. IEEE Geosci. Remote Sens. Mag. 2024, 2–25. [Google Scholar] [CrossRef]
- Silva, L.A.; Leithardt, V.R.Q.; Batista, V.F.L.; González, G.V.; Santana, J.F.D.P. Automated Road Damage Detection Using UAV Images and Deep Learning Techniques. IEEE Access 2023, 11, 62918–62931. [Google Scholar] [CrossRef]
- Datta, S.; Durairaj, S. Review of Deep Learning Algorithms for Urban Remote Sensing Using Unmanned Aerial Vehicles (UAVs). Recent Adv. Comput. Sci. Commun. 2024, 17, 66–77. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Singh, P.P.; Garg, R.D. A two-stage framework for road extraction from high-resolution satellite images by using prominent features of impervious surfaces. Int. J. Remote Sens. 2014, 35, 8074–8107. [Google Scholar] [CrossRef]
- Khan, M.J.; Singh, P.P.; Pradhan, B.; Alamri, A.; Lee, C.W. Extraction of Roads Using the Archimedes Tuning Process with the Quantum Dilated Convolutional Neural Network. Sensors 2023, 23, 8783. [Google Scholar] [CrossRef]
- Zhao, W.; Li, M.; Wu, C.; Zhou, W.; Chu, G. Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network. Remote Sens. 2022, 14, 3996. [Google Scholar] [CrossRef]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Xiao, R.; Wang, Y.; Tao, C. Fine-Grained Road Scene Understanding from Aerial Images Based on Semisupervised Semantic Segmentation Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3001705. [Google Scholar] [CrossRef]
- Behera, T.K.; Bakshi, S.; Sa, P.K.; Nappi, M.; Castiglione, A.; Vijayakumar, P.; Gupta, B.B. The NITRDrone Dataset to Address the Challenges for Road Extraction from Aerial Images. J. Signal Process. Syst. 2023, 95, 197–209. [Google Scholar] [CrossRef]
- Sultonov, F.; Park, J.H.; Yun, S.; Lim, D.W.; Kang, J.M. Mixer U-Net: An Improved Automatic Road Extraction from UAV Imagery. Appl. Sci. 2022, 12, 1953. [Google Scholar] [CrossRef]
- Mahmud, M.N.; Osman, M.K.; Ismail, A.P.; Ahmad, F.; Ahmad, K.A.; Ibrahim, A. Road Image Segmentation using Unmanned Aerial Vehicle Images and DeepLab V3+ Semantic Segmentation Model. In Proceedings of the 2021 11th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–28 August 2021; pp. 176–181. [Google Scholar]
- Mahara, A.; Khan, M.R.K.; Deng, L.; Rishe, N.; Wang, W.; Sadjadi, S.M. Automated Road Extraction from Satellite Imagery Integrating Dense Depthwise Dilated Separable Spatial Pyramid Pooling with DeepLabV3+. Appl. Sci. 2025, 15, 1027. [Google Scholar] [CrossRef]
- Wei, X.; Li, Z.; Wang, Y. SED-YOLO based multi-scale attention for small object detection in remote sensing. Sci. Rep. 2025, 15, 3125. [Google Scholar] [CrossRef]
- Qiu, M.; Huang, L.; Tang, B.H. ASFF-YOLOv5: Multielement Detection Method for Road Traffic in UAV Images Based on Multiscale Feature Fusion. Remote Sens. 2022, 14, 3498. [Google Scholar] [CrossRef]
- Zhao, Z.; He, P. YOLO-U: Multi-task model for vehicle detection and road segmentation in UAV aerial imagery. Earth Sci. Inform. 2024, 17, 3253–3269. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K. Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning. Drones 2021, 5, 66. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, W.; Wang, D.; Cui, B.; Gu, X. Automatic extraction and 3D modeling of real road scenes using UAV imagery and deep learning semantic segmentation. Int. J. Digit. Earth 2024, 17, 2365970. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Ge, T.; Ning, B.; Xie, Y. YOLO-AFR: An Improved YOLOv12-Based Model for Accurate and Real-Time Dangerous Driving Behavior Detection. Appl. Sci. 2025, 15, 6090. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, S.; Gu, X.; Wang, D.; Dong, Q.; Cui, B. Intelligent Assessment of Pavement Structural Conditions: A Novel FeMViT Classification Network for GPR Images. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13511–13523. [Google Scholar] [CrossRef]
- Liu, Q.; Cui, B.; Liu, Z. Air Quality Class Prediction Using Machine Learning Methods Based on Monitoring Data and Secondary Modeling. Atmosphere 2024, 15, 553. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto (Canada): Toronto, ON, Canada, 2013. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-quality instance segmentation for remote sensing imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-Based RGB-Infrared Cross-Modality Vehicle Detection Via Uncertainty-Aware Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Labeled | Road-H | Road-P | No Labeled | Total |
|---|---|---|---|---|---|
| Training set | 1038 | 1236 | 675 | 162 | 1200 |
| Validation set | 346 | 476 | 187 | 54 | 400 |
| Testing set | 346 | 523 | 221 | 54 | 400 |
| Models | P | R | F1 | IoU | Testing Time (ms) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | ||
| YOLOv12 | 0.831 | 0.758 | 0.832 | 0.723 | 0.831 | 0.740 | 0.833 | 0.647 | 8.3 |
| YOLOv12 1 | 0.853 | 0.795 | 0.834 | 0.784 | 0.843 | 0.789 | 0.849 | 0.705 | 9.5 |
| YOLOv12 2 | 0.868 | 0.807 | 0.837 | 0.779 | 0.852 | 0.793 | 0.851 | 0.723 | 9.8 |
| UAV-YOLOv12 | 0.913 | 0.845 | 0.891 | 0.805 | 0.902 | 0.825 | 0.891 | 0.795 | 11.1 |
| Models | P | R | F1 | IoU | Testing Time (ms) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | ||
| U-Net | 0.831 | 0.745 | 0.832 | 0.715 | 0.831 | 0.730 | 0.837 | 0.714 | 14.2 |
| DeepLabV3+ | 0.861 | 0.774 | 0.827 | 0.758 | 0.844 | 0.766 | 0.848 | 0.695 | 21.8 |
| Swin-UperNet | 0.863 | 0.785 | 0.829 | 0.768 | 0.846 | 0.776 | 0.845 | 0.701 | 29.7 |
| CMTFNet | 0.872 | 0.811 | 0.835 | 0.775 | 0.853 | 0.793 | 0.852 | 0.719 | 23.2 |
| YOLOV12 | 0.868 | 0.807 | 0.837 | 0.779 | 0.852 | 0.793 | 0.851 | 0.723 | 9.8 |
| UAV-YOLOv12 | 0.913 | 0.845 | 0.891 | 0.805 | 0.902 | 0.825 | 0.891 | 0.795 | 11.1 |
| Image | Labels | |||
|---|---|---|---|---|
| Road-H | Road-P | |||
| Input images |  |  |  |  |
| Output images |  |  |  |  |
| Models | P | R | F1 | IoU | F1 | IoU | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | Road-H | Road-P | |||
| Massachusetts Roads | 0.854 | 0.817 | 0.842 | 0.795 | 0.848 | 0.806 | 0.845 | 0.812 | 0.826 | 0.823 |
| UC Merced Land-Use Dataset | 0.843 | - | 0.837 | - | 0.840 | - | 0.842 | - | 0.84 | 0.842 |
| NWPU Dataset | 0.875 | - | 0.867 | - | 0.871 | - | 0.873 | - | 0.871 | 0.873 |
| Drone Vehicle Dataset | 0.873 | - | 0.886 | - | 0.879 | - | 0.881 | - | 0.879 | 0.881 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, B.; Liu, Z.; Yang, Q. UAV-YOLO12: A Multi-Scale Road Segmentation Model for UAV Remote Sensing Imagery. Drones 2025, 9, 533. https://doi.org/10.3390/drones9080533
Cui B, Liu Z, Yang Q. UAV-YOLO12: A Multi-Scale Road Segmentation Model for UAV Remote Sensing Imagery. Drones. 2025; 9(8):533. https://doi.org/10.3390/drones9080533
Chicago/Turabian StyleCui, Bingyan, Zhen Liu, and Qifeng Yang. 2025. "UAV-YOLO12: A Multi-Scale Road Segmentation Model for UAV Remote Sensing Imagery" Drones 9, no. 8: 533. https://doi.org/10.3390/drones9080533
APA StyleCui, B., Liu, Z., & Yang, Q. (2025). UAV-YOLO12: A Multi-Scale Road Segmentation Model for UAV Remote Sensing Imagery. Drones, 9(8), 533. https://doi.org/10.3390/drones9080533