Abstract
Low-altitude drones, which are unimpeded by traffic congestion or urban terrain, have become a critical asset in emergency rescue missions. To address the current lack of emergency rescue data, UAV aerial videos were collected to create an experimental dataset for action classification and localization annotation. A total of 5082 keyframes were labeled with 1–5 targets each, and 14,412 instances of data were prepared (including flight altitude and camera angles) for action classification and position annotation. To mitigate the challenges posed by high-resolution drone footage with excessive redundant information, we propose the SlowFast-Traffic (SF-T) framework, a spatio-temporal sequence-based algorithm for recognizing traffic accident rescue actions. For more efficient extraction of target–background correlation features, we introduce the Actor-Centric Relation Network (ACRN) module, which employs temporal max pooling to enhance the time-dimensional features of static backgrounds, significantly reducing redundancy-induced interference. Additionally, smaller ROI feature map outputs are adopted to boost computational speed. To tackle class imbalance in incident samples, we integrate a Class-Balanced Focal Loss (CB-Focal Loss) function, effectively resolving rare-action recognition in specific rescue scenarios. We replace the original Faster R-CNN with YOLOX-s to improve the target detection rate. On our proposed dataset, the SF-T model achieves a mean average precision (mAP) of 83.9%, which is 8.5% higher than that of the standard SlowFast architecture while maintaining a processing speed of 34.9 tasks/s. Both accuracy-related metrics and computational efficiency are substantially improved. The proposed method demonstrates strong robustness and real-time analysis capabilities for modern traffic rescue action recognition.
1. Introduction
As the modern road transportation system has rapidly developed, traffic accidents have become an important hidden danger that threaten public safety. They directly lead to a large number of casualties and significant property damage and are prone to causing secondary accidents due to the chaotic state of the scene, which further expands their dangerous consequences [1]. To reduce casualties from accidents, research in traffic rescue has evolved from manual rescue to mechanized rescue using mechanical equipment [2] such as hydraulic demolition tools, cranes, and trailers. This approach uses mechanical power to replace manpower for tasks such as demolition, lifting, and towing at accident scenes. This method can be used to quickly break through obstacles that are difficult to deal with manually, such as deformed metal structures, and reduce the risk of rescue personnel being exposed to dangerous environments. Thus, it enhances both rescue efficiency and safety. Although mechanical equipment has been introduced to enhance rescue efficiency, traditional rescue machinery often faces multiple dilemmas, particularly the “Three Interruptions” [3] (open circuits, disconnected networks, and power offs) and complex terrain. Open circuits are caused by earthquakes [4], mudslides, etc., resulting in highway and bridge damage or terrain obstruction that prevents rescue vehicles from reaching the scene. Disconnection in the network is mainly due to the destruction of communication base stations. In addition, power offs result in a paralysis of information transmission between the scene and the command center. Power outages cause communication equipment to malfunction and result in a lack of lighting on site, further complicating rescue efforts. Recently, intelligent unmanned equipment has also been applied in modern transportation scenarios and extended to transportation rescue. Low-altitude UAVs [5] have the advantage of not being constrained by the ground environment. They can quickly break through the “Three Interruptions” barrier by flying over collapsed roads and transmitting data through a satellite link when the network is broken. They can also utilize their own power supply in the event of a power outage. Additionally, they can operate continuously. UAVs have evolved from basic reconnaissance units into multifunctional platforms that integrate real-time image acquisition, environmental data modeling, and risk analysis [6]. Through infrared sensing, lidar, and other technologies, UAVs can provide key decision-making support for rescue commands in extreme scenarios, such as under the “Three Interruptions,” and promote the intelligent and unmanned evolution of traffic rescue.
With the rapid advancement and widespread adoption of unmanned systems in recent years, the advantages of drone-based data acquisition and analysis technologies in spatio-temporal intelligence have become increasingly prominent. Early-generation drones were constrained by limited payload capacity, performing only basic data collection tasks with low-quality outputs. However, modern drone technology has evolved to meet diverse rescue requirements, giving rise to specialized platforms such as fixed-wing drones [7], unmanned helicopters [8,9,10,11], and multi-rotor drones [12,13,14], each tailored for specific mission profiles. Furthermore, endurance capabilities have been significantly enhanced [15,16,17,18]. Advanced image recognition and data analysis algorithms now enable real-time processing of collected information [19,20]. Zhou [21] proposed a multi-scale feature fusion and enhancement network (MFFENet), which extracts the features of RGB and thermal images, respectively, through two encoders and conducts cross-modal fusion at different levels, effectively improving the performance of urban road scene analysis and performing especially well under complex lighting conditions. Multimodal feature extraction and real-time data processing and analysis can effectively support target detection at rescue sites and accurately assess on-site rescue conditions [22]. Zhong [23] systematically explains the difficulties and challenges of target detection in UAV aerial images. He reviews detection methods and optimization strategies based on deep learning and provides an overview of existing aerial image datasets and their characteristics. Tang [24] reviews the application of visual detection and navigation technology in electric UAVs for emergency rescue. He categorizes and summarizes typical disasters, analyzes the current state of UAV applications and key technologies, and discusses traditional and deep learning target detection algorithms and visual navigation technology.
However, the advancement of intelligent drone-based rescue platforms has been hindered by the scarcity of accident-related datasets, leading to relatively slow progress. To bridge this gap, our dataset provides high-quality annotated data specifically tailored for traffic rescue applications. It serves as both a reliable data foundation and a benchmark standard for developing intelligent models for understanding traffic rescue scenes and decision support systems. The rescue behavior in this paper refers to various types of actions (such as fire extinguishing, constructing roadblocks, and transporting materials) performed by rescue personnel at the scene of traffic accidents and disasters. For modern traffic accident and disaster scenes (such as highways, national and provincial roads, bridges, culverts, and tunnels), a large number of UAV aerial videos are collected, and image data are extracted for classification, positioning, and marking. The data include flight height, camera angle, and other information that can be effectively extracted from the rescue information in the traffic accident scene. The introduction of UAV airport, loading, control, and rescue operations is shown in Figure 1.

Figure 1.
Key equipment and behavior for unattended rescue in traffic situations.
In recent years, model architectures in deep learning have been continuously updated. Liu [25] proposed the Video Swin Transformer by extending the Swin Transformer from the spatial domain to the spatio-temporal domain. This was achieved by introducing a 3D shift window mechanism and a spatio-temporal locality induction bias. The Video Swin Transformer achieved advanced performance on the Kinetics-400, Kinetics-600, and Something-Something v2 video recognition benchmarks with a significantly reduced model size and pre-training data volume. Tong [26] proposed VideoMAE, inspired by ImageMAE, to efficiently pre-train videos using datasets such as Kinetics-400 and Something-Something V2. This is achieved by customizing the temporal pipe masking strategy and asymmetric codec architecture to utilize video temporal redundancy and correlation efficiently. Additionally, the data quality of self-supervised video pre-training is validated. We demonstrate the importance of data quality in self-supervised video pre-training and outperform previous state-of-the-art methods without additional data. Piergiovanni [27] proposed Tiny Video Networks (TVNs), which use evolutionary algorithms to automatically design efficient video architectures combined with lightweight modules for spatio-temporal dimensions (e.g., 1D/2D convolution and pooling). TVNs achieve better video quality than X3D on multiple datasets, such as Moments in Time and Charades, while maintaining real-time performance (under 20 ms on GPUs) and achieving better performance than state-of-the-art models, such as X3D and SlowFast, with significantly reduced model parameters and computation.
The SlowFast model, proposed by Facebook AI Research (FAIR) [28], is an efficient video action recognition model. We propose the SF-T framework to address the challenges of class imbalance and information redundancy in emergency rescue scenarios. By extracting spatio-temporal correlation features between dynamic targets and static scenes while temporally enhancing background information with compact ROI feature maps, our method achieves 8.5% higher accuracy than conventional SlowFast architectures and reaches 34.9 tasks per second in processing speed, ranking among the state of the art in comparable approaches.
In this paper, we release a high-quality Traffic Accident Rescue Behavior Dataset and propose the SF-T framework, which is trained and evaluated on our dataset with comprehensive comparisons to state-of-the-art methods. The objectives of the work presented in this paper can be summarized as follows.
- 1.
- We propose a novel high-quality annotated dataset specifically designed for complex traffic rescue scenarios under the “Three Disruptions”. This dataset not only covers common traffic accident scenarios but also systematically collects and annotates data for complex rescue environments under extreme disaster conditions. We provide multi-level fine-grained annotations for three critical rescue behaviors: emergency personnel rescue, specialized equipment operation, and comprehensive site management, including behavior types, temporal sequences, and spatial locations.
- 2.
- We propose a novel traffic accident rescue action recognition model that addresses the challenges of behavior identification in complex rescue scenarios by innovatively modeling the dynamic relationships between background context and rescue targets. We replaced the original Faster R-CNN with YOLOX-s to improve the target detection rate.
- 3.
- We validated our method on our proposed dataset for traffic rescue scenarios under the “Three Disruptions” and established it as the benchmark dataset.
2. Materials and Methods
2.1. Data Acquisition
The experimental data were gathered at the North China Institute of Science and Technology (39.891° N, 117.359° E). In this study, traffic accident surveillance was conducted for a major transportation hub, with monitoring equipment strategically deployed at key locations in the surrounding area. Drones that are relatively close to the accident site quickly arrive at the scene after taking off from the airport and adopt differentiated data processing strategies for different network environments: At disaster and accident sites with good network conditions, unmanned aerial vehicles (UAVs) can capture MP4 format videos (with a resolution of 1920 × 1080 pixels) in real time. In this study, these videos were shot using a DJI M300 UAV equipped with a Fesi P3 disc and a Fesi IXM 120 medium-format aerial photography camera. Video data captured with the camera’s field of view (FOV) of 80° and effective pixel count (150 million) were sent back to the workstation for rapid processing through professional software. In areas with poor network conditions, edge computing devices were activated to conduct local preprocessing of data, and key frame images were sent back first to ensure the effective acquisition of information at the accident site. Both ISO and aperture were set to auto mode in order to ensure optimal data capture. The UAV was equipped with a gimbal and conducted data collection while hovering, avoiding the influence caused by the UAV’s own movement and vibration. The flight height was maintained at approximately 10 m above the ground at the accident site, a height which has been determined to provide a full view of the accident scene, including the location of the accident vehicle and the surrounding traffic congestion [20,22]. This height also allows for clear capture of key information, such as details of vehicle damage and the operations of rescue personnel. The flight operation was selected during the period when the rescue operation at the accident site was both tense and orderly, with rescue forces cooperating effectively. The weather conditions were predominantly sunny, cloudy, or overcast, with intermittent sunlight penetrating the clouds. Such light conditions created a complex yet relatively stable lighting environment, which provided a certain contrast for the photography and helped to highlight the contours and details of the accident scene.
As illustrated in Figure 2, the video frame dataset under consideration comprises a subset of footage that captures a variety of actions carried out by accident rescue workers. These include fundamental movements and rescue operations, such as running, squatting, firefighting, setting up roadblocks, and carrying supplies. The dataset also illustrates different levels of traffic accident damage, collision gestures, and the positioning of rescue vehicles. The considered dataset highlights the complex characteristics of the traffic accident scene. Furthermore, this dataset reflects challenging environmental factors, such as high vehicle density at the accident site, mutual occlusion, flame and smoke obstacles, and different lighting conditions. All of these pose significant challenges to the accuracy of subsequent model action recognition and the optimization strategies adopted.

Figure 2.
Examples of video frames from the dataset.
2.2. SlowFast Video Action Recognition Model
The model in question is able to decompose the video into two distinct streams, termed the Slow Path and the Fast Path, which are processed separately. The Slow Path operates at a low temporal resolution but high spatial resolution, capturing 2 frames per second to focus on extracting semantic information from the video. Conversely, the Fast Path captures dynamic information at a rate of 16 frames per second. The temporal axis is analyzed by the dual-path approach, which enables the capture of both short-term and long-term spatio-temporal information, leading to highly accurate video classification. The SlowFast model has become a popular choice in the field of video understanding due to its superior performance and efficient computational strategy. In comparison to traditional single-stream gesture recognition models, the SlowFast model attains an exceptional equilibrium between processing speed and recognition accuracy.
In comparison to other dual-stream video recognition architectures, the SlowFast model places particular emphasis on the joint modeling of long-term and short-term dynamic changes. The fast pathway processes raw data end-to-end without the need for optical flow computation, rendering it well suited for handling complex actions and scenarios involving alternating fast and slow motions.
SlowFast offers a variety of model sizes, such as SlowFast R50-4 × 16 and SlowFast R50-8 by 8, with the objective of adapting to the different computing resources and mission requirements. In this paper, the SlowFast-R50-8 × 8 model is selected as the base model, considering factors such as recognition accuracy and computational cost.
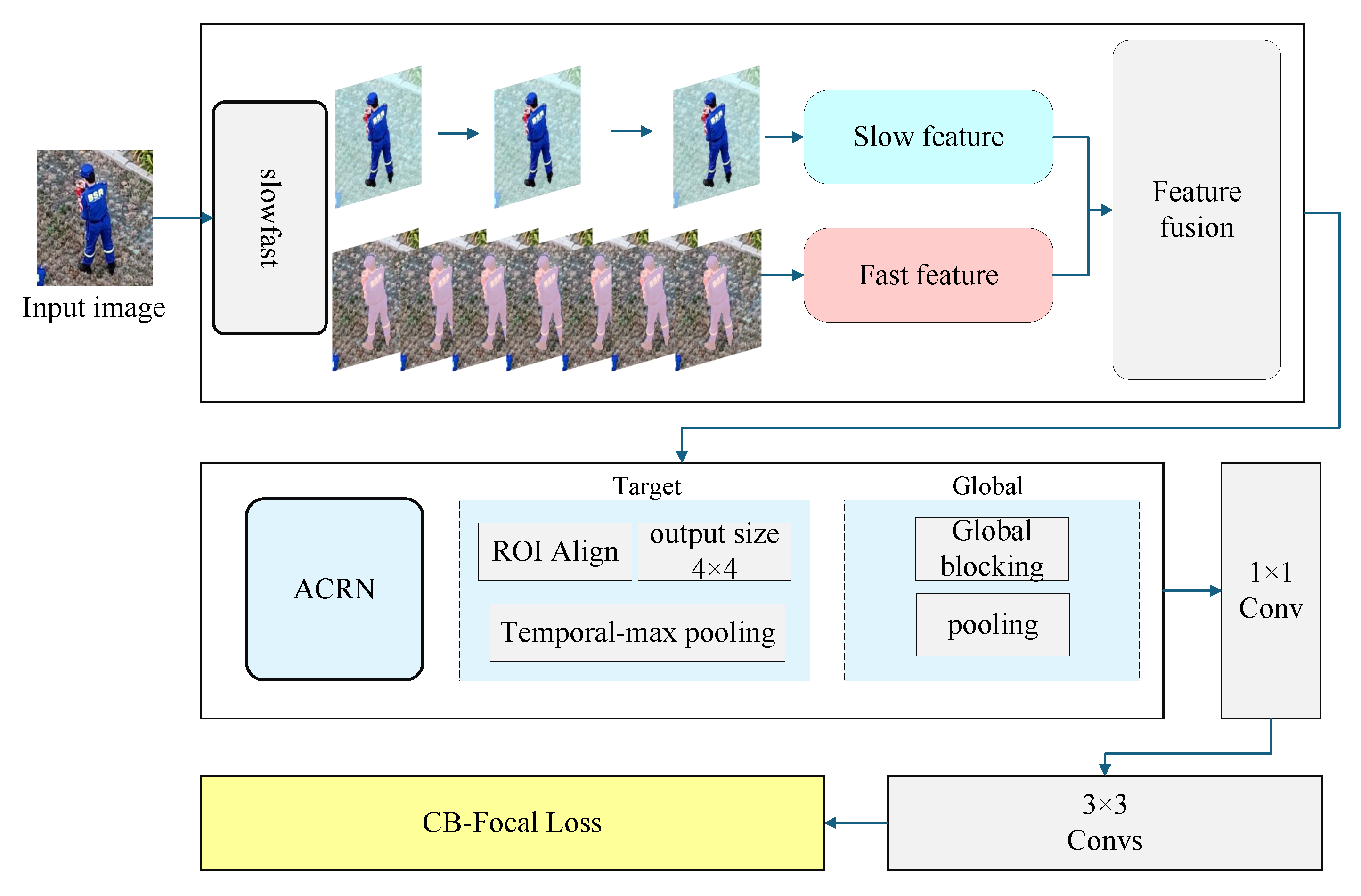
2.3. SF-T Traffic Accident Rescue Action Recognition Model
The SF-T model proposed in this paper makes several improvements on the standard SlowFast architecture. The original shared head is replaced by an ACRNHead (Actor-Centric Relation Network Head) [29]. The temporal maximum polling method [30] is incorporated to eliminate superfluous static background information in the temporal dimension. CB-Focal Loss has been employed to replace the original cross-entropy loss [31], with the aim of effectively reducing the class imbalance caused by the short duration of special rescue actions. The occurrence of rescue actions, which are typically confined to specific scenes (e.g., firefighting actions are usually only observed in scenes where fires are present), can lead to the occlusion of special rescue actions (e.g., smoke typically obscures the visibility of the fire scene), resulting in a paucity of qualified data samples and an undue influence of the discrepancy between difficult and easy samples on the discriminant ability of the model. The extraction parameters of the ROI head [32] were reduced to further optimize the performance. The main steps are as follows:
- 1.
- The feature maps of the Fast Path and the Slow Path processed by the SlowFast model are each input into the model.
- 2.
- The input image feature map is maximally pooled and globally pooled in terms of the time dimension.
- 3.
- The actor is then copied to calculate the features of the relation feature map, and 1 × 1 convolutions are applied.
- 4.
- Finally, 3 × 3 convolutions are applied to the relation feature map to calculate the information relations from the neighbors.
The configuration of the enhanced SF-T model is illustrated in Figure 3.
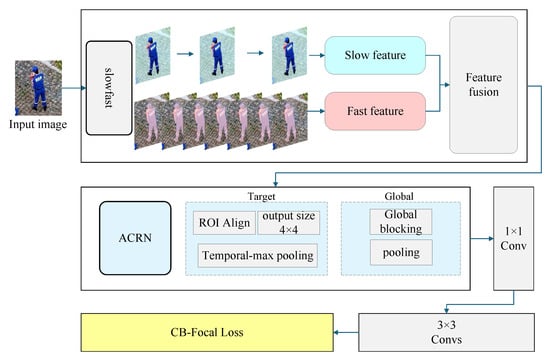
Figure 3.
SF-T model architecture diagram.
Furthermore, the detector was replaced with YOLOX-s, a modification that has been shown to enhance the efficiency of the system by increasing the speed of inference and detection while decreasing the memory footprint.
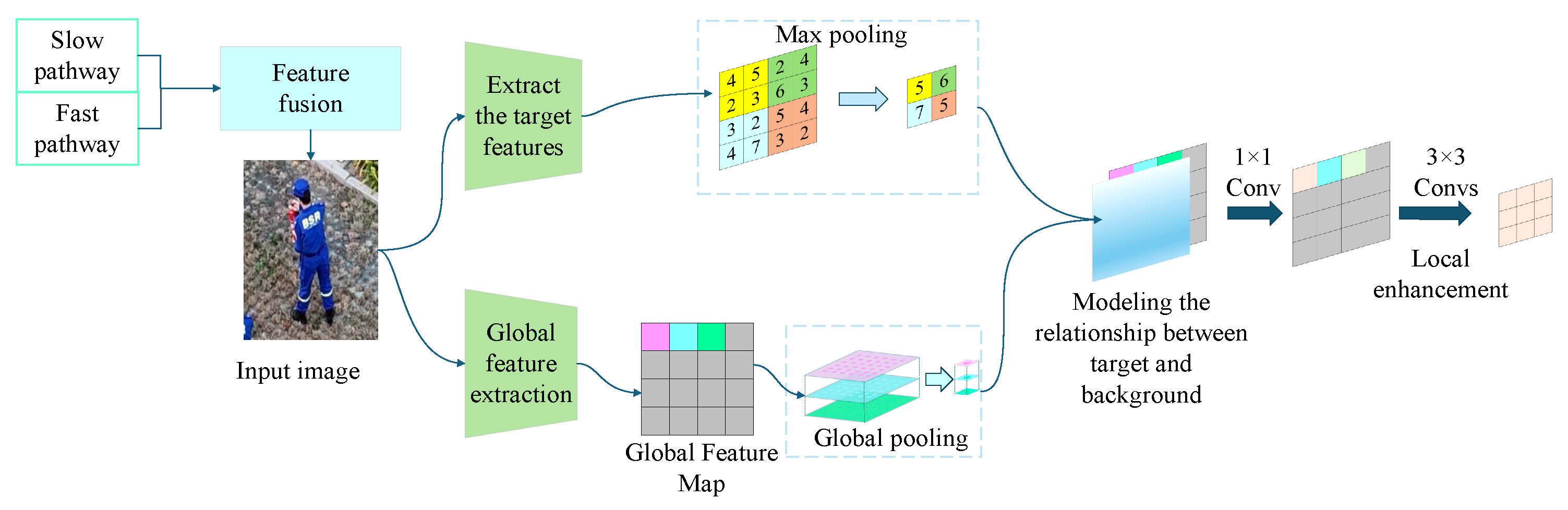
2.3.1. Spatio-Temporal Sequence Model for Feature Extraction of Relation Between Object and Background
In this article, ACRNHead [29] is introduced as a shared head to improve the performance of action classification by more accurately modeling the relationship between the object and the background. In the SF-T model, SingleRoIExtractor3D is utilized for the extraction of target features, while ACRN models the relationship features between the target and the background based on the background region features of time blocks. The discrimination accuracy of rescue actions in a short period of time and the temporal dynamic characteristics of the ROI are further improved by modeling the relationship between the target and the background. The max pooling method is employed in the SF-T model in the time dimension, thereby enabling the model to focus on the time step with the largest feature in the time dimension. This approach facilitates the capture of key action frames and the reduction in interference from irrelevant time information on action recognition.
ACRN extracts target features (ROI features), and max pooling is performed on the time dimension to obtain the most significant target features in time. The block side length = k × ROI side length, where the scaling factor k ∈ [0.4, 0.6], and 0.5 is generally selected, as shown in Equation (1).
The global feature map is divided into blocks (excluding the target ROI). Each background block is globally pooled, and all background blocks are spliced to obtain the context feature shown in Equations (2) and (3) [29].
Here, i represents the ith background block, is the feature of each background block, and is the background feature matrix. To model the target–background relationship, the ROI feature vector is copied h × w times to form a feature map consistent with the shape of the background feature, and the feature extraction and relationship calculation are carried out by 1 × 1 convolution, as shown in Equation (4) [29].
The relation features are enhanced by 3 × 3 convolutions to obtain local context information. The enhanced feature vectors are generated by feature fusion of target features and background features, and, finally, the action recognition task is completed, as shown in Equation (5) [29].
The essence is the golden section of target size and background features, combined with the four-fold subdivision mechanism of near-field region, the core interaction area around the target is spatially strengthened: the original background block is equally divided into a 2 × 2 grid, generating 4 sub-blocks, each with an area of 1/4 of the original block. By improving the spatial resolution to capture subtle dynamic features, the feature sampling density of the target’s near-field background is increased by 4 times.
The aerial perspective of UAVs encompasses a substantial amount of contextual data, including accident vehicles and additional road information. The assessment of traffic accident rescue operations is contingent upon the presence of objects and the characteristics of the surrounding environment. The ACRN module has been developed to convert global background feature information into a format that is useful for the model, thereby enabling it to construct the relationship between the target and the background. The improved ACRN module mainly consists of the following steps:
- 1.
- The input video frames are divided into two distinct pathways. The Slow Path operates at a lower frame rate to capture spatial semantic information, while the Fast Path operates at a higher frame rate to preserve temporal dynamic information. Notably, the number of channels in the Fast Path is only 1/8 of that in the Slow Path.
- 2.
- The two paths, respectively, extract features through 3D convolutional networks.
- 3.
- The feature maps of the Fast Path and the Slow Path processed by the SlowFast model are input into the model. The features extracted from the Fast Path are reduced in dimension through 1 × 1 × 1 convolution and then laterally connected to the corresponding layer of the Slow Path.
- 4.
- The input image feature map is maximally pooled and globally pooled in terms of the time dimension.
- 5.
- The actor is then copied to calculate the features of the relation feature map, and 1 × 1 convolutions are applied.
- 6.
- Finally, 3 × 3 convolutions are applied to the relation feature map to calculate the information relations from the neighbors.
This improvement in the model’s accuracy is illustrated in Figure 4, which shows the schematic diagram of the improved ACRN module.
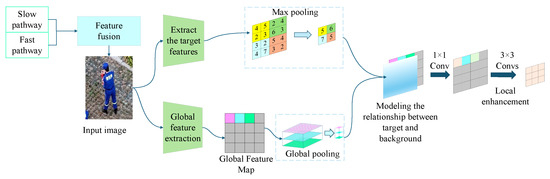
Figure 4.
Schematic diagram of the ACRN module.
2.3.2. Reduce the ROI Feature Map Output Size
In addition to the information pertaining to the traffic scene, the video captured from an unmanned aerial vehicle (UAV) generally comprises a substantial amount of superfluous data, including sky, dynamic illumination, and occlusion. Furthermore, the UAV typically operates within a communication environment characterized by limited bandwidth in the vicinity of the traffic accident scene. This paper proposes an approach to address these challenges by adjusting the ROI [32] feature extraction module within the standard SlowFast architecture, leveraging the high resolution of the UAV-captured video. Specifically, the output resolution (output_size) of the ROI feature map is adjusted. In the original design, the extracted features of each ROI are 8 × 8 3D feature maps, which are adjusted to 4 × 4 in this paper. This reduction in size is expected to decrease the computational complexity of the subsequent classification head. Despite the reduction in feature resolution, the input data retain a high resolution, and the feature map itself contains more detailed information, ensuring that the model can maintain high accuracy.
2.3.3. Loss Function Improvements
In the standard SlowFast architecture, the cross-entropy loss is utilized to quantify the discrepancy between the predicted probability distribution and the true distribution of the model. However, in multi-label video classification tasks, the sample class distribution is often imbalanced, particularly in scenes such as traffic accidents, where the class of some rescue actions is rarer than the common actions, or the duration is very short. To address this challenge, the Focal Loss is integrated into the SlowFast architecture [33]. This approach is tailored to address the challenges posed by class imbalance. Nevertheless, Focal Loss does not directly adjust the number of class samples, which can result in low recall for small sample categories. In the context of traffic accident rescue, the number of occurrences for certain categories is significantly imbalanced. When dealing with class imbalance, Focal Loss relies on the manually adjusted parameter and cannot dynamically adjust the weight according to the actual number of samples of the categories, which has certain limitations for action recognition in this scenario.
This paper further optimizes the shortcomings of Focal Loss, selects Class-Balanced Focal Loss [34], and introduces class frequency and adjustment factors to optimize CB-Focal Loss. The weights can be dynamically adjusted according to the number of samples in the category. The CB-Focal Loss reconstructs the gradient distribution through class frequency weighting and collaborates with the factor to expand the decision buffer domain for occlusion samples, essentially overcoming the static limitations of the traditional Focal Loss. Through Equation (6), the loss weights of rare categories (such as fire extinguishing actions) are automatically amplified to directly solve the problem of sample imbalance (such as the scarcity of fire scene samples). The factor (such as = 2) is retained, and higher weights are given to difficult samples of occluded scenes to improve the robustness of the model, as shown in Equation (6).
represents the dynamic calculation of class weights. denotes the moderating factor; the closer it is to 1, the stronger the weight amplification for the small sample category, which was set to 0.95 in this experiment. is the frequency of the category.
On the basis of dynamically adjusting the category weights, CB-Focal Loss retains the hard sample weight mechanism in Focal Loss, as shown in Equation (7).
denotes the true label of sample i in class j; denotes the prediction probability of sample i belonging to class j; denotes the adjustment factor, which is used to reduce the weight of easy-to-classify samples; and the generalized scene is generally set to a default value of 2. In this experiment, the difficult samples of the occluded scene are given a higher weight, which is set to 2.5.
By using the class frequency to adjust the loss contribution of each class, the weight of the few-shot class can be increased to reduce the model bias caused by class imbalance, improve the recognition accuracy of the few-shot class, and improve the overall accuracy of the model.
2.4. Experimental Platform
The Ubuntu 20.04 operating system is used to train and test the model in this paper. The software environment for model training includes Python 3.8, conda 4.5.11, CUDA 11.3, cuDNN 8.2.cd1, and the deep learning framework PyTorch 1.10.0+cu113. Table 1 gives some of the training parameter configurations used in this paper.

Table 1.
Experimental parameter configuration.
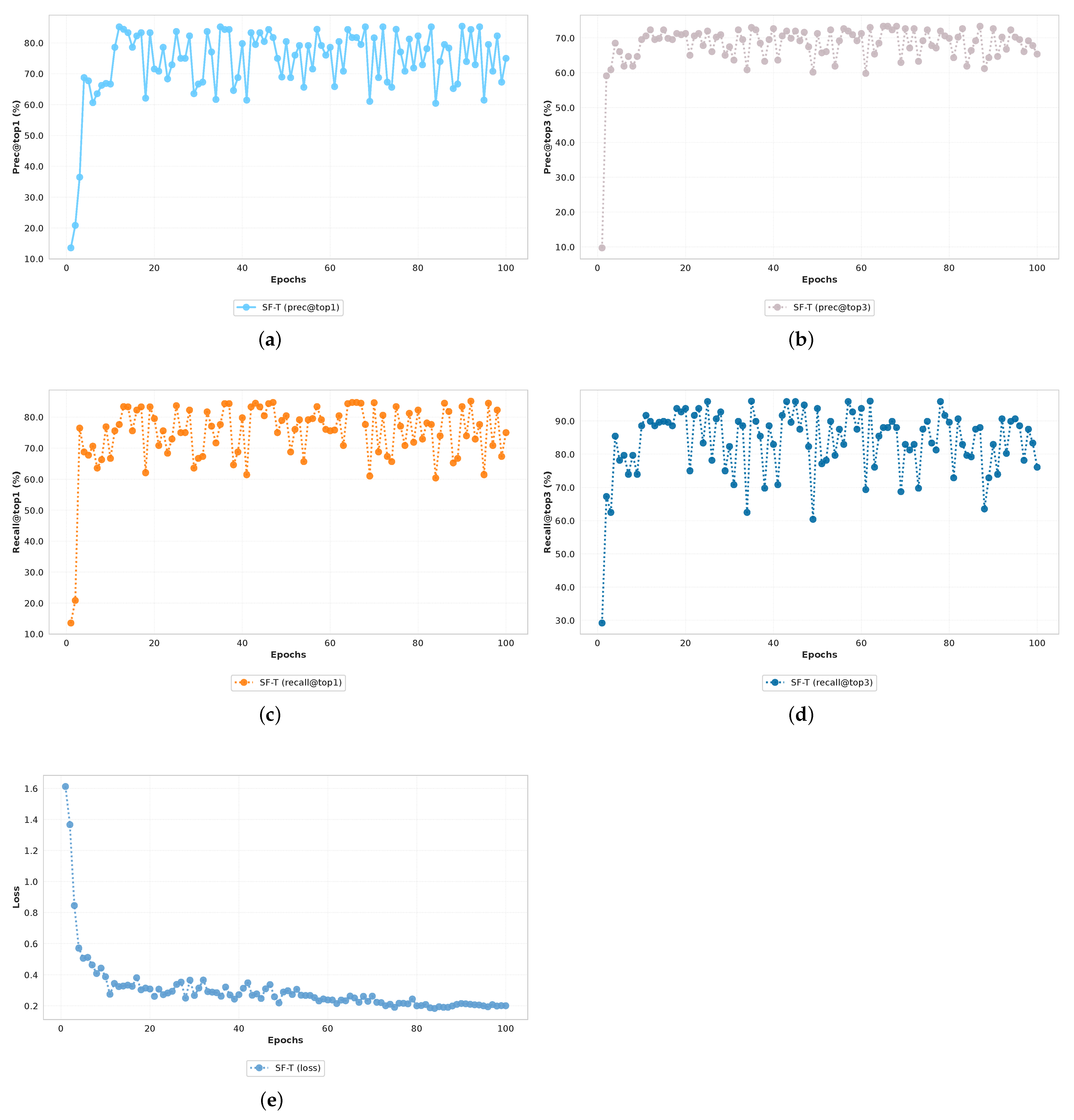
The SF-T model was trained over 100 epochs of 200 iterations each for a total of 20,000 iterations. We recorded the changes in the model’s precision, recall, and loss. Figure 5 shows the evolution of these indicators during the training process.
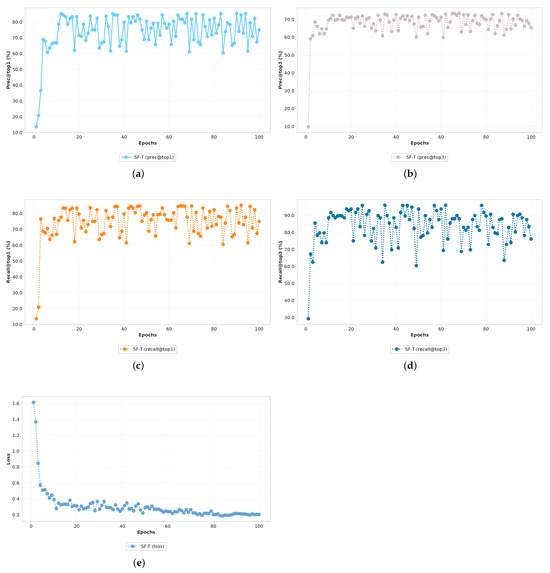
Figure 5.
Trend in training index. (a) precision top1; (b) precision top3; (c) recall top1; (d) recall top3; (e) loss.
As can be seen from the figure, the model rapidly improves its performance in the early stages of training, then gradually converges, and finally achieves high precision and recall on the verification set.
2.5. Evaluation Metrics
The performance of the traffic accident rescue action recognition model is evaluated in this paper using mean average precision (), precision, recall, and inference speed, as detailed in the following Equations (8)–(11):
In the object detection and evaluation system, average precision () is a metric used to quantify the precision of each category. The mean average precision () metric is a comprehensive evaluation of the model’s performance. The evaluation indicators are calculated based on the statistics of three types of basic data. The identification process involved the accurate classification of positive samples (), the erroneous identification of positive samples (), and the failure to identify positive samples (). Accuracy is defined as the ratio of true positives () to ( + ), and it is a measure of the reliability of test results. In the context of classification problems, recall rate is defined as the ratio of true positives () to ( + ), and it is a measure of the completeness of positive sample detection.
2.6. Detector Replacement and Parameterization
In the domain of action recognition systems, the identification of human subjects is paramount to the accurate recognition of spatio-temporal actions. Initially, Faster R-CNN is employed as the base detector. However, its adaptability to dense scenes and motion blur is found to be limited in practical applications. Consequently, we adopt YOLOX-S as an alternative detector. This is an efficient single-stage detector developed based on the YOLO series, and it achieves a better balance between accuracy and speed. The initial Faster R-CNN’s mAP@0.5 was 28.9%, with an actual inference speed of 23.5 tasks/s on the test set and a memory footprint of 3.2 GB. By contrast, yolox_s’s mAP@0.5 was 40.5%, with an actual inference speed of 34.9 tasks/s on the test set and a memory footprint of 1.8 GB. These results indicate that a superior balance can be achieved among recognition accuracy, speed, memory footprint, and other relevant metrics. Furthermore, notable enhancements have been observed in terms of memory consumption and other relevant aspects. The detector parameter settings are as follows: In order to enhance the recall rate, it is necessary to modify the detection confidence threshold to 0.3. The NMS threshold is set to 0.5 to accommodate partially overlapping targets.
2.7. Experimental Setup
In this study, a new dataset was used to comprehensively and systematically verify the performance of SF-T. This dataset covers a wide range of rescue action samples and is capable of effectively simulating various complex scenarios. Consequently, a comprehensive training and testing process was conducted for all models involved in the comparison.
The experimental steps are outlined below:
- An ablation experiment is conducted to comprehensively investigate the internal optimization mechanism of the model. In this step, various improvements to the model are investigated, including different shared heads, feature map output sizes, parameter adjustment strategies, and loss function optimization. The impact of these mechanisms on the overall performance of the model is then evaluated by gradually changing them and observing the changes in model performance.
- A detailed comparison is provided between the SF-T and several mainstream spatio-temporal sequential behavior detection models that have emerged in recent years to provide a clear definition of the current position of the SF-T algorithm in the field. The detection speed and accuracy of these models are then compared and analyzed in detail when facing the traffic rescue motion target.
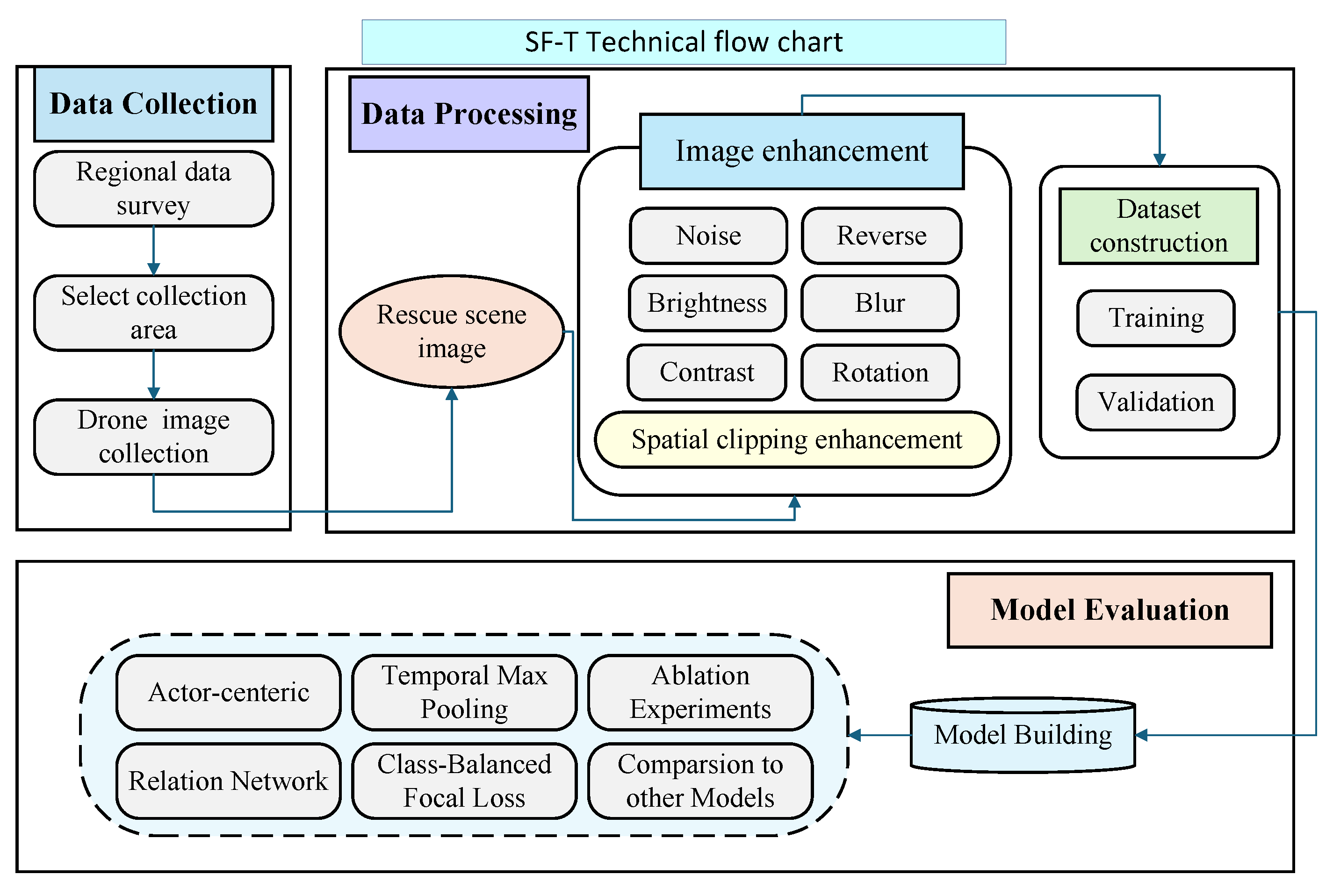
- The SF-T algorithm is deployed on two portable computing devices to further evaluate its performance in terms of model speed, and the final detection speed (in terms of inference speed (task/s)) is evaluated. The technical process of this study is shown in Figure 6.
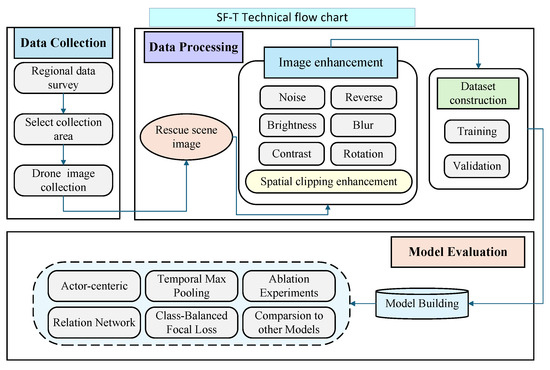 Figure 6. Technical flow chart.
Figure 6. Technical flow chart.
3. Experiments
3.1. Data Processing
In this article, a self-made dataset is used for model training and evaluation, with the original video data prepared according to the format of the AVA (Atomic Visual Action) dataset [35]. In order to meet the annotation requirements of the AVA dataset, all videos are cropped at fixed time intervals. The long video is uniformly divided into short videos with a duration of one minute and annotated at a frame rate of one frame per second for the purpose of action classification and localization. The annotation tool employed in this study utilizes Via (version 3) via_image_annotator to manually label objects, and the annotation information and the corresponding format data are saved in the relevant file according to the SlowFast object detection format.
It is acknowledged that the actual scene of UAV aerial photography and the scene of traffic accidents are characterized by greater occlusion and complexity in the background. In light of this, the present paper introduces random erasing data augmentation [36]. Within the context of video data, this approach emulates scenarios where the target is occluded and the background undergoes significant alterations. The primary objective of this methodology is to enhance the robustness of the model in the face of occlusion and background variations. When employed in conjunction with an enhanced data enhancement method based on the standard SlowFast architecture, it has been demonstrated to enhance the robustness and adaptability of the model, thereby mitigating the risk of overfitting to a certain extent. The efficacy of random erasing data augmentation is demonstrated in Figure 7.

Figure 7.
Effect of augmentation via random erasing data. Using this approach, 15% of the image area is erased, the aspect ratio ranges from 0.3 to 3, and the pixels of the image in the erased area are replaced with random values.
Subsequently, the representative UAV aerial videos of modern traffic rescue scenes collected for this experiment were compiled into a dataset. Five independently collected datasets of different scenes and viewpoints were reserved according to the number of scenes and targets as a test set, yielding a total of 300 keyframes. The remaining data were labeled on uniformly sampled key frames. The number of key frames was 5082, and each image contained 1–5 targets. Ultimately, 14,412 example data points were prepared, and the dataset and the labeled file were divided into a training set and a validation set at a ratio of 9:1.
3.2. Ablation Experiments
This paper presents the findings of an experimental study carried out on a dataset of rescue scenes from traffic accidents. The study involved the construction of a traffic accident rescue action recognition model, SF-T, based on the SlowFast algorithm. A comparison was made between the performance of the improved standard SlowFast and each module to evaluate the effectiveness of each modification. A represents the introduction of ACRNHead, B represents the use of max pooling and the reduction in ROI output size on the basis of A, C represents the use of the CB-Focal Loss function, and D represents the replacement of the Faster R-CNN detector with YOLOX-s. The sum of the test results of each model is shown in Table 2.
Table 2.
Results of ablation experiments.
The comparison of the effects of the original SlowFast baseline model, the SlowFast Improvement (without YOLOX-s detector replacement), and the SF-T is shown in Figure 8.

Figure 8.
Comparison of detection effects. (a) SlowFast base model; (b) SlowFast Improvement (without YOLOX-s detector replacement); (c) SF-T.
3.3. Comparison with Other Models
In order to provide further validation of the effectiveness of the traffic accident rescue action recognition model, a comparison of the results with some spatio-temporal sequence detection models is warranted. These models include Slow Only [28], LFB [37], SlowFast [28], and VideoMAE [26]. In addition, a comparison of the results with an existing combination of SlowFast (SlowFast+X3D) [38], a recent state-of-the-art method (Video Swin Transformer) [25], and lightweight methods (Tiny Video Net) [27] is necessary to verify the comprehensive performance of SF-T.
In order to make a fair and rigorous performance comparison, we perform a comparison between the recent state-of-the-art spatio-temporal model Video Swin Transformer (Swin-T) and the lightweight representative Tiny Video Net (TVN) using a model pre-trained on our dataset in Kinetics-400 for fine-tuning (finetune). The following methodology was employed: both Swin-T and TVN were equipped with the official model weights that were pre-trained on the Kinetics-400 dataset, serving as the initialization. A comprehensive end-to-end fine-tuning of these models was conducted on the training set, employing an identical training protocol to SF-T (optimizer, learning rate scheduling, batch size, number of iterations, etc.). All model parameters could be updated during the fine-tuning process.
However, the performances of the fine-tuned Swin-T and TVN on the validation set did not reach their officially reported optimal levels on Kinetics-400 and were lower than that of the SF-T method proposed in this paper. Following this, we methodically examined the primary factors contributing to this phenomenon. A thorough examination revealed that the predominant factors contributing to this phenomenon were rooted in the fundamental discrepancies in the objectives of the tasks, as well as the adaptability of the model architectures.
Our dataset is a spatio-temporal behavior detection dataset. Its core aim is to detect the bounding boxes (box) of multiple actors on the key frames of the video and identify the specific actions (action) of each actor at this spatio-temporal position. This is essentially a composite “object detection + action classification” task. Kinetics pre-training learns global action patterns, while fine-tuning requires the learning of fine-grained actions of local subjects (people) at specific spatio-temporal points.
When dealing with the required dense spatio-temporal positioning and complex subject–action relationship reasoning, the potential of Swin-T may not have been fully exploited. TVN pursues ultimate lightweighting, and its design on kinetics prioritizes classification efficiency. The additional structure introduced to adapt to our detection tasks may not have sufficient capacity to fully learn complex spatio-temporal positioning patterns.
SF-T’s SlowFast-based dual-path design (whereby the Slow Path captures spatial semantics, while the Fast Path captures motion information) is architecturally better suited for spatio-temporal localization tasks. The ACRN module, which has been incorporated into the system, has been demonstrated to facilitate the identification of salient subjects and their behaviors in complex, dynamic scenarios, such as UAV traffic accident rescue, by means of explicitly modeling the subject–context relationship. The CB-Focal Loss has been optimized for the behavioral category imbalance problem that is prevalent in traffic rescue scenarios. The design decisions that were made have resulted in enhanced fitness and augmented optimization potential of SF-T on the specified dataset.
As shown in Table 3 and Figure 9, the average accuracy of SF-T on the validation set is higher than the average accuracy of Slow Only, LFB, SlowFast, SlowFast+X3D, VideoMAE, Swin-T, TVN, and YOLOv11 by 14.1%, 15.5%, 8.5%, 6.7%, 6.5%, 5.5%, 22.1%, and 2.7%, respectively. The retention rate on the test set is 82%. The effectiveness of the proposed model is demonstrated by its substantial improvement in accuracy-related performance metrics.
Table 3.
Model detection performance comparison.

Figure 9.
Detection results of different object detection models.
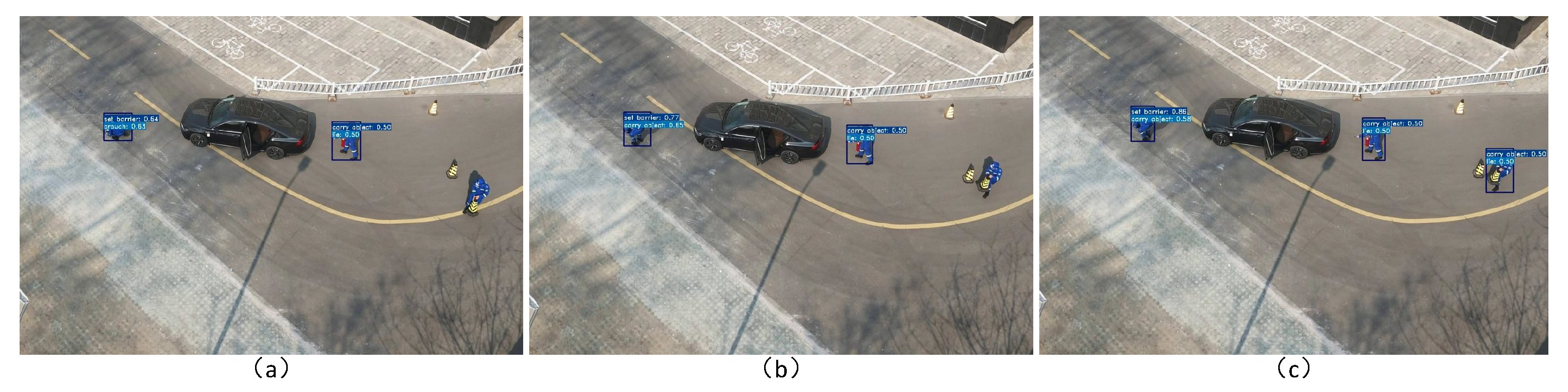
To further verify the advantages of SF-T, we supplement the comparison with YOLOv11 [39], the latest basic model in the field of object detection. It was adapted and adjusted to a composite task of “target detection + action classification”: the positioning module was retained to output the main bounding box, the classification head was replaced with the rescue action prediction layer, and the same training protocol as SF-T was used to fine-tune on the dataset. The results show that although the positioning accuracy of YOLOv11 is competitive, the action recognition accuracy is slightly lower than that of SF-T. The reason is that as a static detection model, YOLOv11 lacks the ability to model time series information, and it is difficult to capture the movement trend and spatio-temporal correlation dependent on rescue actions. The dual-path design of the SF-T and ACRN modules are naturally suitable for spatio-temporal positioning tasks and specially optimized for agent–action recognition in dynamic scenes, which is more suitable for the requirements of this task. A diagram comparing the effects of YOLOv11 and SF-T is shown in Figure 10.

Figure 10.
Comparison of the detection effects of YOLOv11 and SF-T: (a) setting barrier; (b) carrying object; (c) crouching; (d) extinguishing fire; (e) running; (f) vehicle extrication; (g) performing CPR; (h) lying.
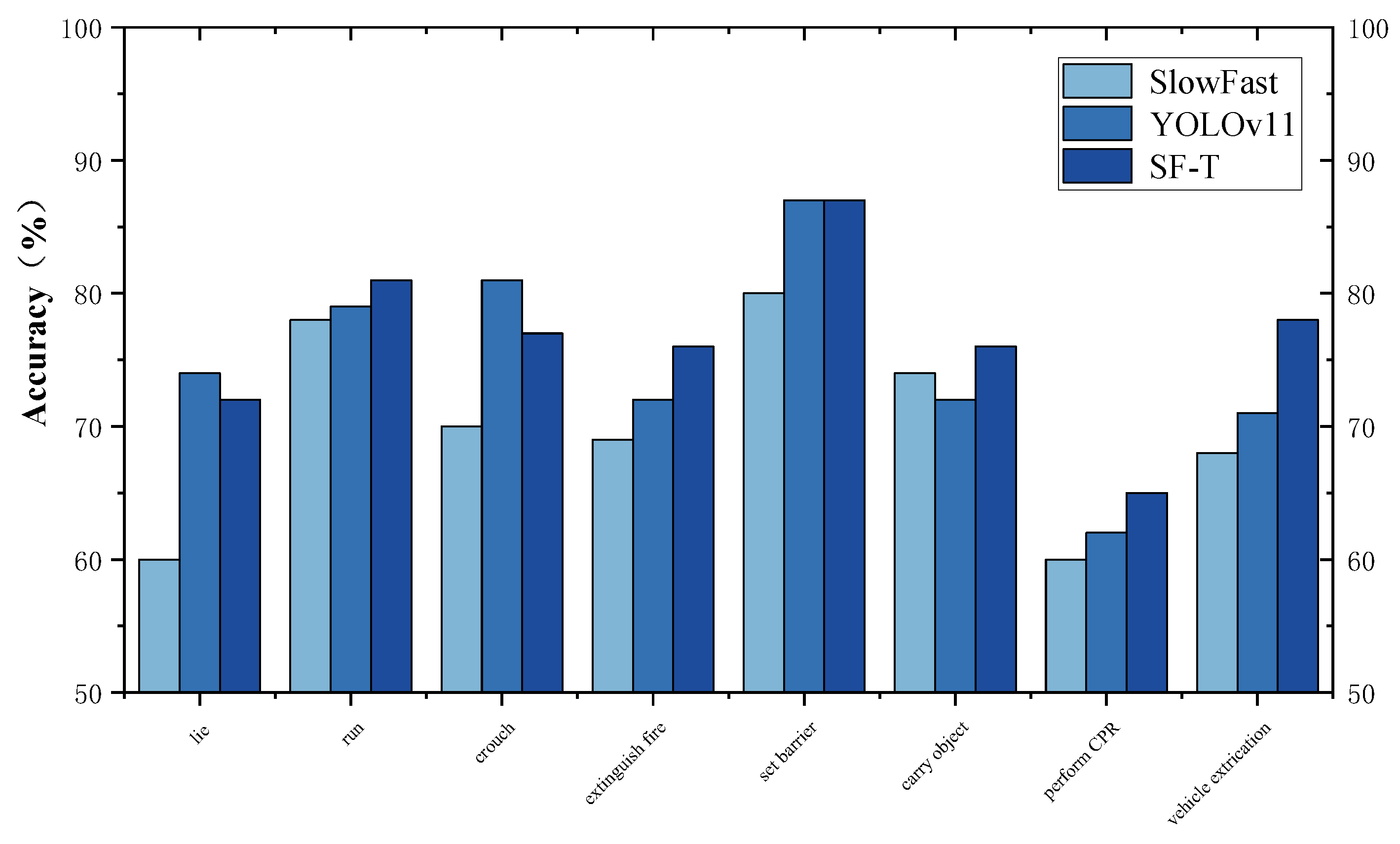
As illustrated in Figure 11, a comparison was conducted among the standard SlowFast model, YOLOv11, and the SF-T model in terms of their performance on the aerial photography dataset under identical conditions. The results indicate that the SF-T model outperforms the other two models in five out of eight categories, with one category showing equivalent performance to YOLOv11. Specifically, compared to the currently state-of-the-art YOLOv11 model, SF-T achieves a 7% higher mAP in detecting demolition actions and a 4% improvement in identifying fire extinguishing actions, particularly in complex scenarios where there is a strong interrelation between the target and its background. This improvement can be attributed to the SF-T model’s enhanced capability in jointly extracting and modeling both objects and their surrounding context. These experimental findings validate the effectiveness of the proposed approach.
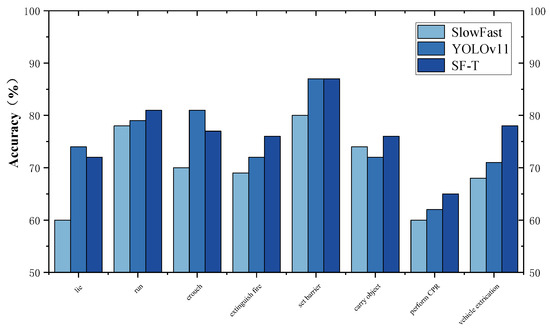
Figure 11.
Comparison of average accuracy rates in this dataset.
3.4. Performance of SF-T on Portable Computing Devices
To systematically analyze the practical effectiveness of the SF-T model in lightweight and resource-limited mobile or edge computing devices, the device shown in Table 4 above is taken as an object for inference evaluation: high-performance computing (HPC) systems, which are capable of executing complex and large-scale computing tasks. At the scene of traffic accidents, multi-source data can be integrated and analyzed, such as traffic recorder data and video data returned by equipment carried by rescue workers. The parallel computing of the algorithm enables the rapid identification of complex situations at the accident scene, with a processing speed of 34.9 task/s per second. In this study, a Lenovo Legion Y9000P laptop, a device frequently employed in mobile scenarios, is equipped with an Intel Core i9-14900 processor, 16 GB of memory, and an NVIDIA GeForce RTX 4060 independent video card, thus serving as a typical portable computing device. In the event of an accident, the device can function as both a real-time command center and a platform for the sharing of information, as well as providing remote expert guidance. The NVIDIA Jetson Nano development kit, designed for edge AI computing, boasts a small size and low power consumption, characteristics that make it well suited for use in embedded systems and edge computing scenarios. The kit is equipped with a quad-core Cortex-A57 central processing unit and a 128 core NVIDIA Maxwell graphics processing unit. This development kit is a highly representative edge device. Following the deployment of the kit, the UAV is capable of collecting and analyzing data from the accident scene in real time during flight, rapidly generating a comprehensive overview of the accident site and accurately identifying the location of key elements, including accident personnel, vehicles, and obstacles. Table 4 provides a synopsis of the primary hardware specifications of these devices. The software environment for model testing includes Python 3.11 and PyTorch 2.2.1 as the deep learning framework.
Table 4.
Device hardware details.
The model’s inference speed is 34.9 task/s. In the process of model speed testing, a random video data sample is selected from the dataset for evaluation. The inference speed (task/s) is utilized as the primary evaluation metric to assess the operational efficiency of the SF-T model across diverse devices. The results of this study are presented in Table 5 below.
Table 5.
Inference speed of different devices.
It is evident that high-performance computing (HPC) training platforms exhibit relatively high performance; however, the terminal devices employed in actual application scenarios are often constrained in terms of computing power configuration, memory space, and storage resources. In order to achieve the immediate processing and analysis of on-site data, it is necessary to adapt the lightweight model developed in this study to resource-constrained devices or platforms as much as possible.
4. Discussion
4.1. Analysis of Detection Errors
The experimental results show that the accuracy of SF-T does not reach more than 90%. There may be two explanations for this:
- 1.
- The lack of scene diversity and dynamic annotation accuracy of “roadblock” samples in the training data leads to insufficient learning of the model’s unique spatio-temporal features, and the feature fusion mechanism of the model fails to effectively distinguish the essential differences in behavioral purpose between “handling materials” and “roadblock.” This weakens the understanding of action semantics and eventually leads to misjudgment.
- 2.
- The fire extinguishing samples lack the typical characteristics that reflect the core nature of “spray extinguishing,” making it challenging to identify key visual markers—such as medium injection trajectory—within the simulation environment. Instead, these samples incorporate features associated with forceful holding and posture generation that resemble breaking or dismantling actions. Consequently, the model struggles to capture the behavioral logic of “fire alignment–virtual injection” in fire simulation scenarios. The feature fusion mechanism fails to distinguish between these two types of actions based on the inherent properties of the operation target. Furthermore, the video lacks distinct directional cues specific to fire simulation actions while containing numerous high-frequency frames resembling demolition behaviors. As a result, the model’s interpretation of action semantics is inclined toward categorizing fire-related actions as those superficially similar to breaking or dismantling.
The errors are displayed in Figure 12.

Figure 12.
Failure cases: (a) setting up barricades; (b) fire extinguishing.
4.2. Scene Impact Analysis
Recognizing rescue actions in the context of traffic accidents is a sophisticated visual task that requires the consideration of multiple occlusion factors that are prevalent in real-world scenarios. Specifically, in minor collision scenes where vehicle damage is minimal, the visibility of rescue personnel actions remains high. Conversely, in severe collision scenarios, vehicles suffer extensive damage, necessitating more intricate rescue operations. The similarity between different action categories increases, and the presence of debris or overturned vehicles significantly impairs the visibility of rescue personnel, leading to reduced model recognition accuracy. In fire scenes, the dynamic nature and high luminance of flames further complicate the definition of clear bounding boxes for rescue actions. Furthermore, the time dependence of actions in fire scenes is exacerbated by the presence of dense smoke, which not only diminishes overall image contrast but can also completely obscure rescue personnel or target vehicles, severely impacting model recognition accuracy.
In order to enhance the precision of detecting traffic accident scenes of varying severity, this paper proposes a data processing method that utilizes random erasing data augmentation. This approach incorporates a series of enhanced data to address the occlusion problem, thereby expanding the diversity of the model’s training samples and enhancing the algorithm’s robustness to occlusion. Concurrently, annotation optimization is conducted for occluded scenes, with partially occluded actions being distinctly labeled. The CB-Focal Loss function is introduced, which addresses the imbalance in the number of action samples (e.g., fire fighting) in occluded scenes, such as fire and smoke, to a certain extent, thereby enhancing the recognition accuracy of the model for rescue actions in extreme scenes. The model possesses a certain degree of optimization potential in the temporal dimension for dynamic occlusions such as fire and smoke, and a key frame selection module can be designed to dynamically capture the key information that remains unoccluded.
5. Conclusions
The aim of this paper is to address the issue of rescue action recognition in UAVs (unmanned aerial vehicles) in traffic accident rescue scenes. To this end, a large number of UAV aerial videos were collected from modern traffic accident and disaster-prone scenes (such as high-speed roads, national and provincial highways, bridges, culverts, and tunnels) to form an experimental dataset. The dataset has 5082 keyframes and 14,412 pieces of instance data that were prepared. The image data, incorporating flight height, camera angle of view, and other pertinent information, can be effectively extracted from traffic accident rescue information. Utilizing this comprehensive dataset, a traffic accident rescue action recognition model, designated SF-T, was developed for UAV aerial videos. The model utilizes the enhanced SlowFast framework, employing ACRNHead as a replacement for the conventional shared head. It extracts and models the features of the target and background, leveraging max pooling in the temporal dimension to enhance the model’s capacity for time-based information extraction. This enhances the discrimination accuracy of rescue actions that occur within a brief time frame. The CB-Focal Loss function dynamically balances the loss weight of each category, strengthens the model’s attention to the few-sample categories, and improves the model’s ability to discriminate class-imbalanced actions. The experimental results verify the effectiveness of each modification of the SF-T model, and the average accuracy is 83.9%. The proposed model reduces the output size of the ROI feature map and facilitates deployment on resource-constrained platforms. A comparison of the proposed model with the SlowFast standard architecture reveals a substantial enhancement in mAP by 8.5%. The speed of detecting actions at the same time increased to 34.9%. These results are more aligned with the demands of complex UAVs for efficient extraction of key information from traffic accidents. The evaluation of SF-T’s performance on diverse computing devices substantiates its relevance in real-time traffic rescue operations. The model requires further optimization to address dynamic occlusion and complex environmental conditions at rescue sites—such as night-time, adverse weather, and smoke. These improvements focus on three key areas: the fusion of multi-source data, the extraction of multimodal image features, and the recognition of rescue actions in complex scenarios. In conclusion, SF-T provides a more effective solution for traffic accident rescue action recognition in UAV aerial videos and provides effective support for UAV inspection and rescue applications in modern traffic scenes.
Author Contributions
Conceptualization, B.Y. and J.L.; methodology, J.L.; software, C.G.; validation, B.Y., T.L. and Y.T.; formal analysis, B.Z.; investigation, B.Z. and S.Z.; resources, B.Y.; data curation, J.L.; writing—original draft preparation, C.G.; writing—review and editing, C.G.; visualization, T.L.; supervision, Y.T.; project administration, S.Z.; funding acquisition, B.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by “the Central Government Guides Local Funds for Science and Technology Development” (No. 236Z0307G), “the Fundamental Research Funds for the Central Universities” (No. 3142021002, 3142023021), and Hebei Province higher education teaching reform research and practice project (No. 2025GJJG476).
Data Availability Statement
The data that support the findings of this study were derived from the following resources available in the public domain: https://github.com/you-chen0/T-AVA-Dataset (accessed on 10 June 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chunjiao, D.; Yujie, W.; Penghu, L. Multi-class traffic accident risk assessment based on interpretable random forest. J. Beijing Univ. Technol. 2025, 31, 1–10. [Google Scholar]
- Yang, L.; Chen, B.; Sun, J.; Liu, S. Research on scenario analysis of major and catastrophic maritime traffic accidents and configuration strategy of rescue equipment. J. Saf. Sci. Technol. 2023, 19, 172–177. [Google Scholar]
- Chen, L.; Li, W.; Lu, J.; Tian, Y. Exploration and Practice of Emergency on Command and Communication System Facing the Background of “Three Interruptions”. China Emerg. Rescue 2023, 2023, 54–58. [Google Scholar]
- Bai, X.; Yang, Z.; Luo, W.; Wang, J.; Tian, P.; Dai, Y. An Emergency Evaluation Approach to Road Disruption Risk Influenced by Earthquake-induced Landslide Using GIS and Multivariate Decision Tree. J. Seismol. Res. 2023, 46, 343–353. [Google Scholar]
- Zhang, J.; Chen, L.; Gao, Z.; Duo, Y. Low-Altitude Unmanned Aerial Vehicle Technology: Current Status and Prospects. Strateg. Study CAE 2025, 27, 73–85. [Google Scholar]
- Li, J.; Sun, J.; Jing, X.; Wang, Z.; Huang, X.; Tian, Q.; Man, X.; Zhang, W. Analysis on Unmanned Aerial Vehicle Photogrammetry Effect for Monitoring Slope Deformation Disaster Risk. Shandong Land Resour. 2024, 40, 61–66. [Google Scholar]
- Guo, J.; Luo, W.; Song, B.; Yu, F.R.; Du, X. Intelligence-sharing vehicular networks with mobile edge computing and spatiotemporal knowledge transfer. IEEE Netw. 2020, 34, 256–262. [Google Scholar] [CrossRef]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. A generic spatiotemporal scheduling for autonomous UAVs: A reinforcement learning-based approach. IEEE Open J. Veh. Technol. 2020, 1, 93–106. [Google Scholar] [CrossRef]
- Mirzaeinia, A.; Hassanalian, M.; Lee, K. Drones for borders surveillance: Autonomous battery maintenance station and replacement for multirotor drones. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0062. [Google Scholar] [CrossRef]
- Petrescu, R.V.; Aversa, R.; Akash, B.; Berto, F.; Apicella, A.; Petrescu, F.I. Unmanned helicopters. J. Aircr. Spacecr. Technol. 2017, 1, 241–248. [Google Scholar] [CrossRef]
- Nex, F.; Remondino, F. UAV for 3D mapping applications: A review. Appl. Geomat. 2014, 6, 1–15. [Google Scholar] [CrossRef]
- Toscano, F.; Fiorentino, C.; Capece, N.; Erra, U.; Travascia, D.; Scopa, A.; Drosos, M.; D’Antonio, P. Unmanned Aerial Vehicle for Precision Agriculture: A Review. IEEE Access 2024, 12, 69188–69205. [Google Scholar] [CrossRef]
- Fang, C.; Ding, X. A novel movement-based operation method for dual-arm rescue construction machinery. Robotica 2016, 34, 1090–1112. [Google Scholar] [CrossRef]
- Wang, T.; Yin, X.; Zhang, P.; Kou, Y.; Jiang, B. Road traffic injury and rescue system in China. Lancet 2015, 385, 1622. [Google Scholar] [CrossRef] [PubMed]
- Song, Z.; Ban, S.; Hu, D.; Xu, M.; Yuan, T.; Zheng, X.; Sun, H.; Zhou, S.; Tian, M.; Li, L. A Lightweight YOLO Model for Rice Panicle Detection in Fields Based on UAV Aerial Images. Drones 2024, 9, 1. [Google Scholar] [CrossRef]
- Zhang, P.; Wu, T.; Cao, R.; Li, Z.; Xu, J. UAV swarm resilience assessment considering load balancing. Front. Phys. 2022, 10, 821321. [Google Scholar] [CrossRef]
- Seguin, C.; Blaquière, G.; Loundou, A.; Michelet, P.; Markarian, T. Unmanned aerial vehicles (drones) to prevent drowning. Resuscitation 2018, 127, 63–67. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.Q.; Phang, S.K.; Ang, K.Z.; Wang, F.; Dong, X.; Ke, Y.; Lai, S.; Li, K.; Li, X.; Lin, F.; et al. Drones for cooperative search and rescue in post-disaster situation. In Proceedings of the 2015 IEEE 7th International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Siem Reap, CA, USA, 15–17 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 167–174. [Google Scholar] [CrossRef]
- Dominguez, M.H.; Nesmachnow, S.; Hernández-Vega, J.I. Planning a drone fleet using artificial intelligence for search and rescue missions. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cuzco, Peru, 15–18 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, X.; Zou, H.; Niu, W.; Song, Y.; He, W. An approach of traffic accident scene reconstruction using unmanned aerial vehicle photogrammetry. In Proceedings of the 2019 2nd International Conference on Sensors, Signal and Image Processing, Prague, Czech Republic, 8–10 October 2019; pp. 31–34. [Google Scholar] [CrossRef]
- Zhou, W.; Lin, X.; Lei, J.; Yu, L.; Hwang, J.N. MFFENet: Multiscale feature fusion and enhancement network for RGB—Thermal urban road scene parsing. IEEE Trans. Multimed. 2021, 24, 2526–2538. [Google Scholar] [CrossRef]
- Wang, J.Y.; Su, D.P.; Feng, P.; Liu, N.; Wang, J.B. Optimal Height of UAV in Covert Visible Light Communications. IEEE Commun. Lett. 2023, 27, 2682–2686. [Google Scholar] [CrossRef]
- Zhong, S.; Wang, L. Review of Research on Object Detection in UAV Aerial Images. Laser Optoelectron. Prog. 2025, 62, 71–89. [Google Scholar]
- Tang, P.; Li, J.; Sun, H. A review of electric UAV visual detection and navigation technologies for emergency rescue missions. Sustainability 2024, 16, 2105. [Google Scholar] [CrossRef]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 3202–3211. [Google Scholar] [CrossRef]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 10078–10093. [Google Scholar]
- Piergiovanni, A.; Angelova, A.; Ryoo, M.S. Tiny video networks. Appl. AI Lett. 2022, 3, e38. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Vondrick, C.; Murphy, K.; Sukthankar, R.; Schmid, C. Actor-centric relation network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 318–334. [Google Scholar] [CrossRef]
- Tang, T.N.; Kim, K.; Sohn, K. Temporalmaxer: Maximize temporal context with only max pooling for temporal action localization. arXiv 2023, arXiv:2303.09055. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar] [CrossRef]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar] [CrossRef]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018; pp. 6047–6056. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Number 07. pp. 13001–13008. [Google Scholar] [CrossRef]
- Wu, C.Y.; Feichtenhofer, C.; Fan, H.; He, K.; Krahenbuhl, P.; Girshick, R. Long-term feature banks for detailed video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 284–293. [Google Scholar] [CrossRef]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).