
MultiDistiller: Efficient Multimodal 3D Detection via Knowledge Distillation for Drones and Autonomous Vehicles


Abstract
1. Introduction
2. Related Works
3. Method
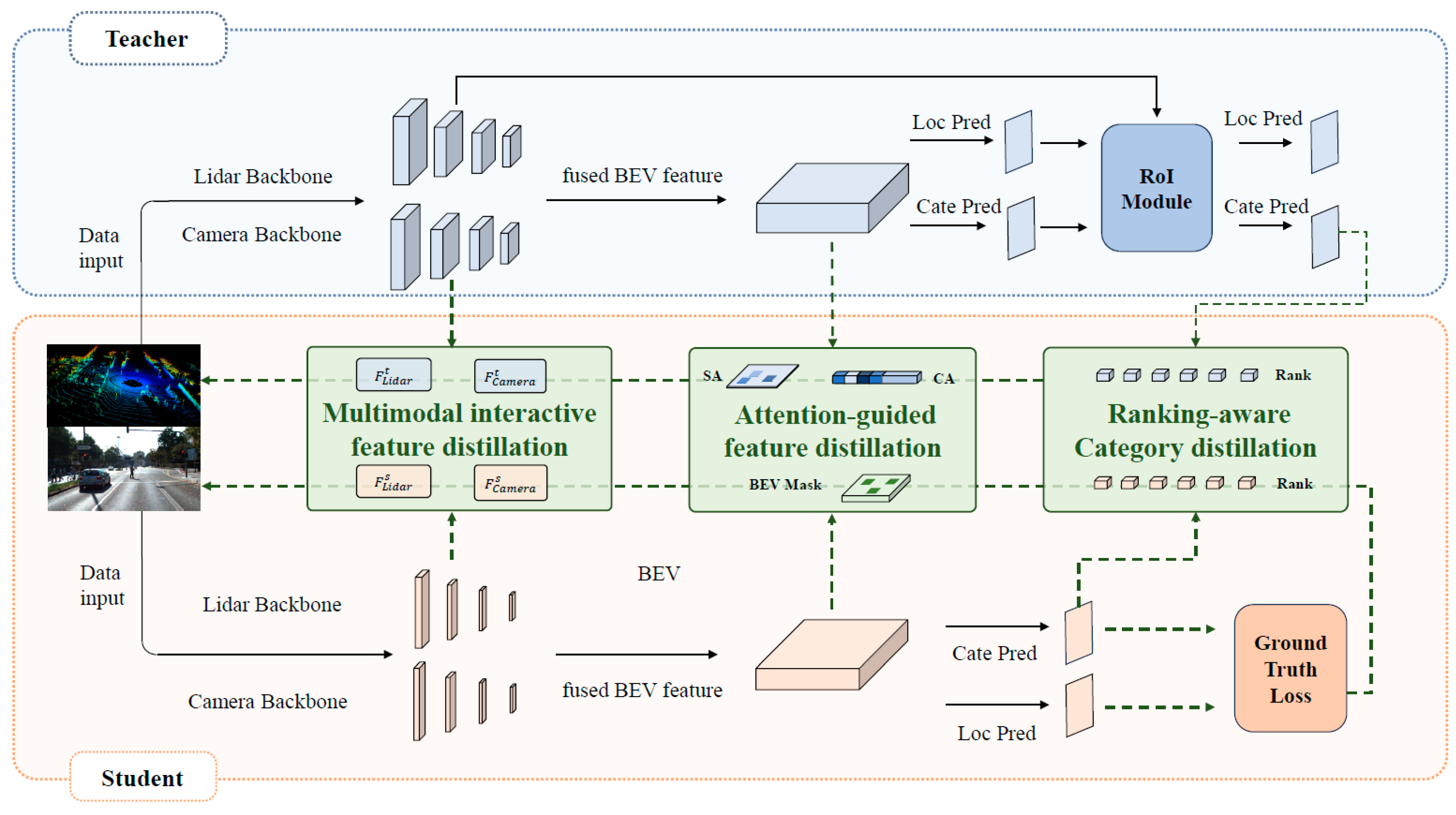
3.1. Overall Framework Description
3.2. Attention-Guided Feature Distillation
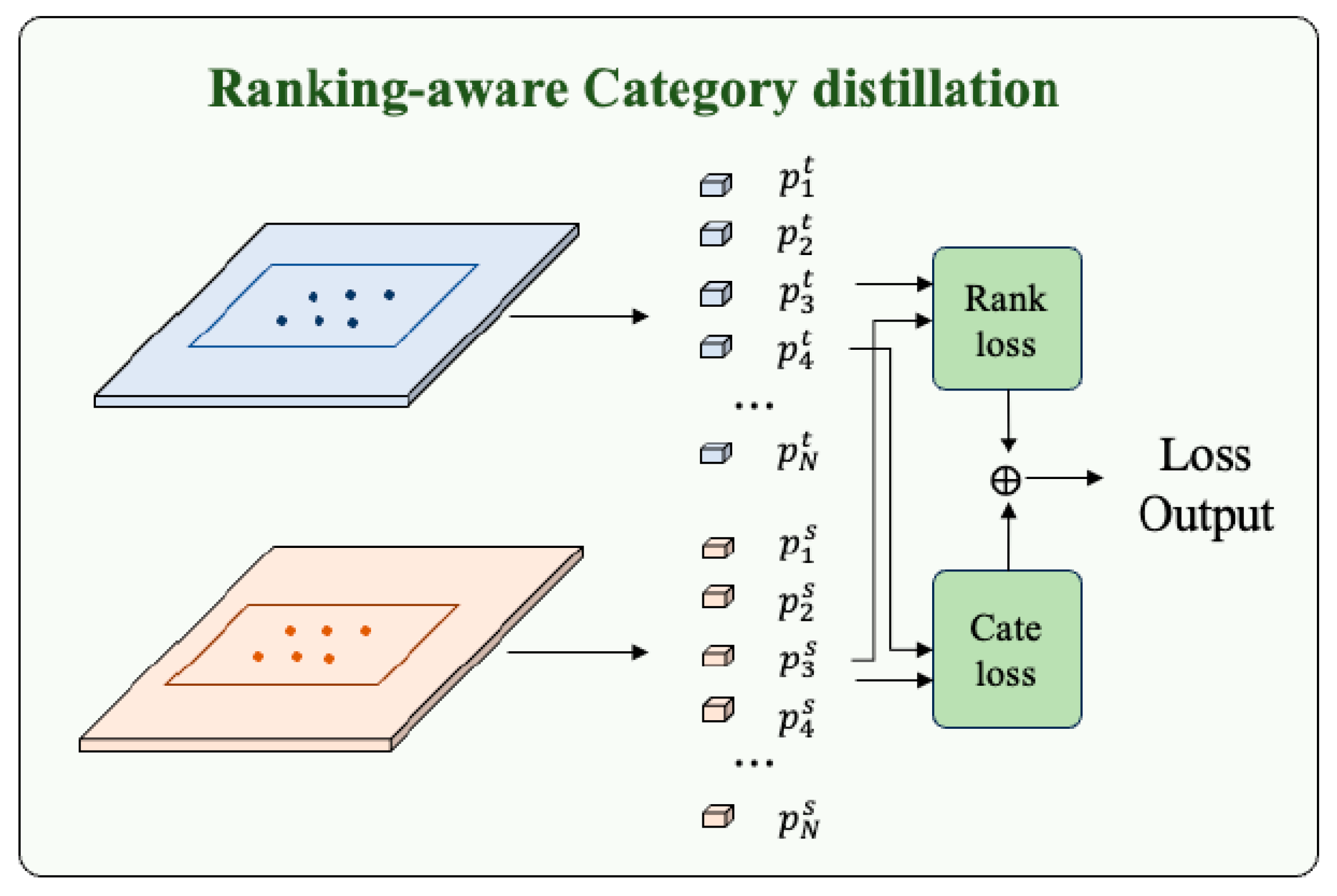
3.3. Ranking-Aware Class Distillation
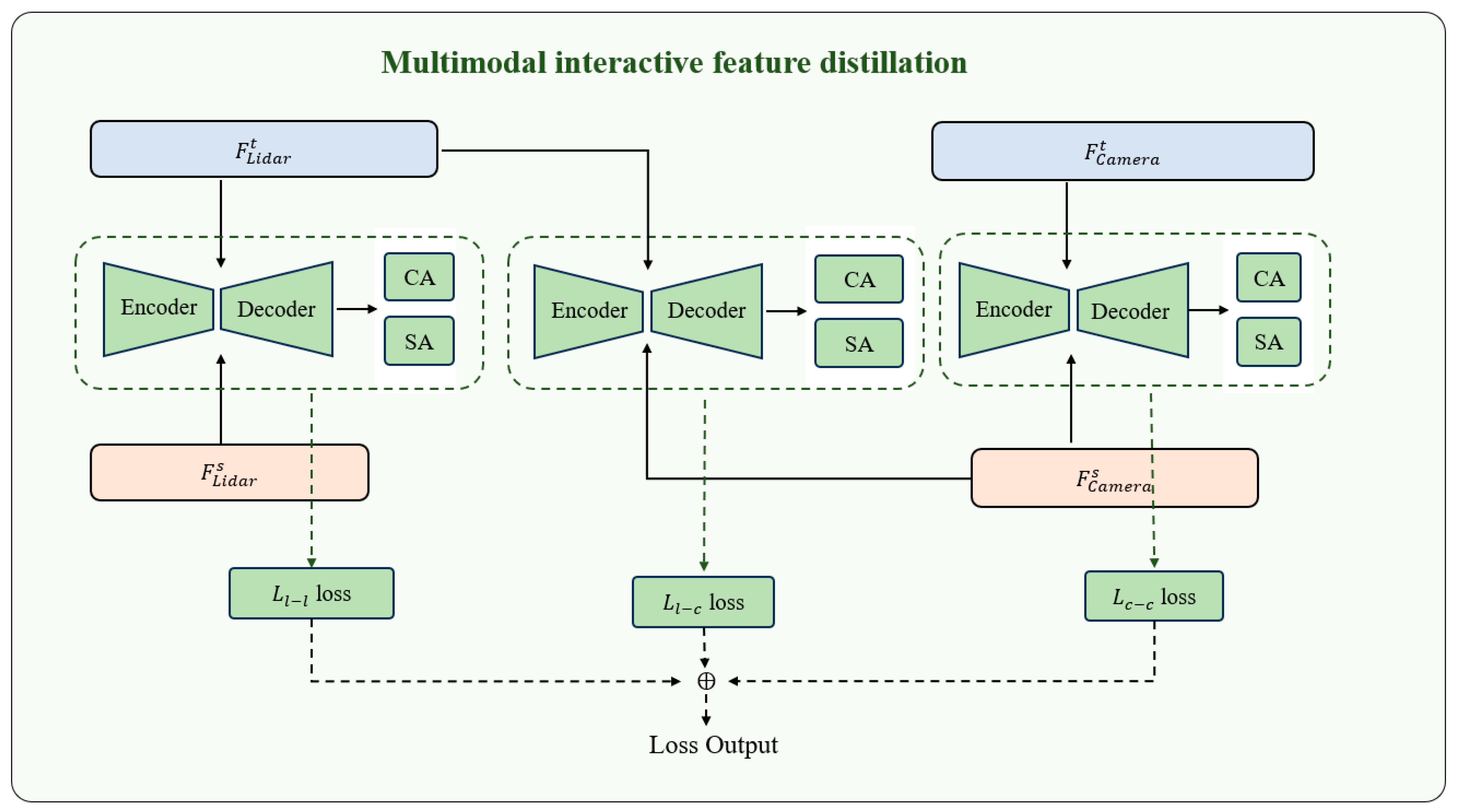
3.4. Interactive Feature Supervision Distillation
4. Experiment Result
4.1. Experiment Setting
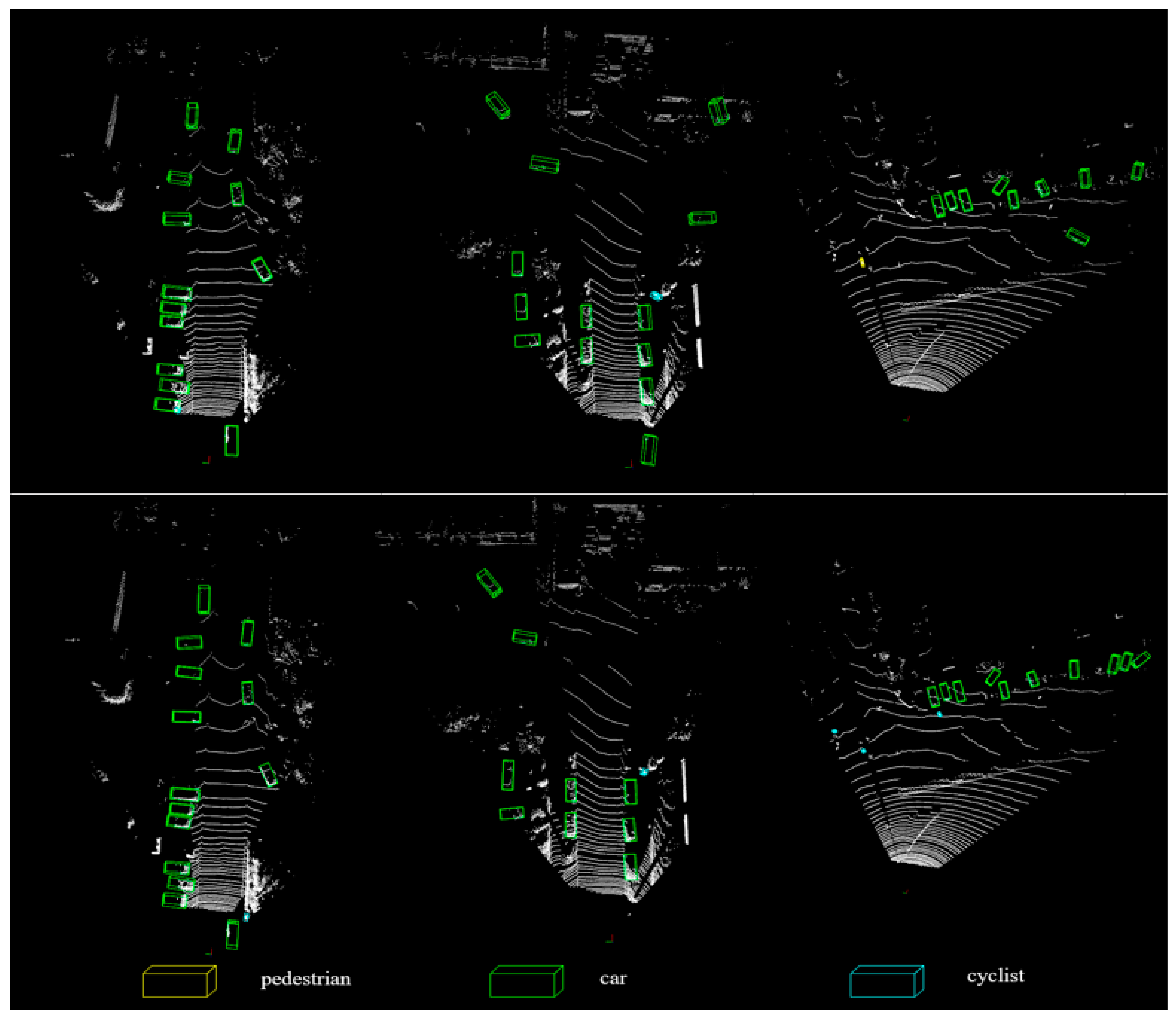
4.2. Experiment Result on KITTI
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D Object Detection for Autonomous Driving: A Comprehensive Survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Muzahid, A.A.M.; Han, H.; Zhang, Y.; Li, D.; Zhang, Y.; Jamshid, J.; Sohel, F. Deep learning for 3D object recognition: A survey. Neurocomputing 2024, 608, 128436. [Google Scholar] [CrossRef]
- Nagiub, A.S.; Fayez, M.; Khaled, H.; Ghoniemy, S. 3D Object Detection for Autonomous Driving: A Comprehensive Review. In Proceedings of the 2024 6th International Conference on Computing and Informatics (ICCI), New Cairo, Egypt, 6–7 March 2024; pp. 1–11. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 1080–1089. [Google Scholar]
- Zhang, L.; Dong, R.; Tai, H.-S.; Ma, K. PointDistiller: Structured Knowledge Distillation Towards Efficient and Compact 3D Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 21791–21801. [Google Scholar]
- Yang, J.; Shi, S.; Ding, R.; Wang, Z.; Qi, X. Towards efficient 3D object detection with knowledge distillation. In Proceedings of the Proceedings of the 36th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 28 November–9 December 2022; Curran Associates, Inc.: Red Hook, NY, USA, 2022; pp. 21300–21313. [Google Scholar]
- Zhang, H.; Liu, L.; Huang, Y.; Yang, Z.; Lei, X.; Wen, B. CaKDP: Category-Aware Knowledge Distillation and Pruning Framework for Lightweight 3D Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 15331–15341. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1201–1209. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3D Object Detection and Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11779–11788. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10526–10535. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries. In Proceedings of the 5th Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021. [Google Scholar]
- Philion, J.; Fidler, S. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 194–210. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4603–4611. [Google Scholar]
- Wu, X.; Peng, L.; Yang, H.; Xie, L.; Huang, C.; Deng, C.; Liu, H.; Cai, D. Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 5408–5417. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10386–10393. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. arXiv 2015, arXiv:1412.65550. [Google Scholar] [CrossRef]
- He, Z.; Dai, T.; Lu, J.; Jiang, Y.; Xia, S.-T. Fakd: Feature-Affinity Based Knowledge Distillation for Efficient Image Super-Resolution. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 518–522. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Hui, T.-W.; Loy, C.C. Inter-Region Affinity Distillation for Road Marking Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12483–12492. [Google Scholar]
- Guo, X.; Shi, S.; Wang, X.; Li, H. LIGA-Stereo: Learning LiDAR Geometry Aware Representations for Stereo-based 3D Detector. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3133–3143. [Google Scholar]
- Zhao, L.; Song, J.; Skinner, K.A. CRKD: Enhanced Camera-Radar Object Detection with Cross-Modality Knowledge Distillation. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 15470–15480. [Google Scholar]
- Huang, X.; Wu, H.; Li, X.; Fan, X.; Wen, C.; Wang, C. Sunshine to Rainstorm: Cross-Weather Knowledge Distillation for Robust 3D Object Detection. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, Vancouver, BC, Canada, 20–27 February 2024; Wooldridge, M.J., Dy, J.G., Natarajan, S., Eds.; AAAI Press: Washington, DC, USA, 2024; pp. 2409–2416. [Google Scholar]
- Cho, H.; Choi, J.; Baek, G.; Hwang, W. itKD: Interchange Transfer-based Knowledge Distillation for 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 13540–13549. [Google Scholar]
- Xiao, J.; Wu, Y.; Chen, Y.; Wang, S.; Wang, Z.; Ma, J. LSTFE-Net: Long Short-Term Feature Enhancement Network for Video Small Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14613–14622. [Google Scholar]
- Xiao, J.; Yao, Y.; Zhou, J.; Guo, H.; Yu, Q.; Wang, Y.-F. FDLR-Net: A feature decoupling and localization refinement network for object detection in remote sensing images. Expert Syst. Appl. 2023, 225, 120068. [Google Scholar] [CrossRef]
- Xiao, J.; Wang, S.; Zhou, J.; Zeng, Z.; Luo, M.; Chen, R. Revisiting the Learning Stage in Range View Representation for Autonomous Driving. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5702014. [Google Scholar] [CrossRef]
- Xiao, J.; Guo, H.; Zhou, J.; Zhao, T.; Yu, Q.; Chen, Y.; Wang, Z. Tiny object detection with context enhancement and feature purification. Expert Syst. Appl. 2023, 211, 118665. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and Global Knowledge Distillation for Detectors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 4633–4642. [Google Scholar]
- Li, G.; Li, X.; Wang, Y.; Zhang, S.; Wu, Y.; Liang, D. Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-Guided Feature Imitation. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; AAAI Press: Washington, DC, USA, 2022; pp. 1306–1313. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection From Point Cloud With Part-Aware and Part-Aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual Sparse Convolution for Multimodal 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 21653–21662. [Google Scholar]
- Dai, X.; Jiang, Z.; Wu, Z.; Bao, Y.; Wang, Z.; Liu, S.; Zhou, E. General Instance Distillation for Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7838–7847. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Model Size | KD | Car | Pedestrian | Cyclist | mAP | Up/Down1 | Up/Down2 | |
|---|---|---|---|---|---|---|---|---|---|
| Student | SECOND [12] | base | 82.49 | 53.98 | 67.41 | 67.96 | - | - | |
| CenterPoint [13] | base | 79.97 | 52.93 | 69.16 | 67.35 | - | - | ||
| Teacher | Voxel-RCNN [11] | base | 85.56 | 59.20 | 74.60 | 73.45 | - | - | |
| Student | SECOND [12] | base | 84.48 | 61.78 | 76.29 | 74.18 | |||
| S | 84.16 | 64.03 | 74.52 | 74.24 | |||||
| XS | 83.67 | 61.64 | 73.24 | 72.85 | |||||
| XXS | 80.33 | 54.76 | 67.41 | 67.50 | |||||
| CenterPoint [13] | base | 84.4 | 62.27 | 75.41 | 74.03 | ||||
| S | 83.72 | 60.39 | 74.76 | 72.96 | |||||
| XS | 81.71 | 62.04 | 73.08 | 72.28 | |||||
| XXS | 74.84 | 60.15 | 67.85 | 67.61 | |||||
| Teacher | PV-RCNN [15] | base | 85.50 | 59.21 | 73.13 | 72.61 | - | - | |
| Student | SECOND [12] | base | 84.59 | 60.28 | 75.41 | 73.43 | |||
| S | 83.88 | 60.76 | 72.9 | 72.51 | |||||
| XS | 83.33 | 61.57 | 72.29 | 72.40 | |||||
| XXS | 80.62 | 53.77 | 67.39 | 67.26 | |||||
| CenterPoint [13] | base | 84.68 | 58.66 | 71.72 | 71.69 | ||||
| S | 84.39 | 59.7 | 74.16 | 72.75 | |||||
| XS | 81.93 | 60.2 | 71.7 | 71.28 | |||||
| XXS | 75.35 | 58.92 | 68.26 | 67.51 | |||||
| Teacher | PartA2 [37] | base | 83.65 | 61.78 | 74.08 | 73.17 | - | - | |
| Student | SECOND [12] | base | 83.89 | 61.51 | 75.12 | 73.51 | |||
| S | 84.39 | 61.7 | 74.94 | 73.68 | |||||
| XS | 84.28 | 59.25 | 73.34 | 72.29 | |||||
| XXS | 78.82 | 54.42 | 67.36 | 66.87 | |||||
| CenterPoint [13] | base | 84.06 | 59.61 | 73.24 | 72.30 | ||||
| S | 83.85 | 59.62 | 74.46 | 72.64 | |||||
| XS | 81.18 | 60.86 | 73.67 | 71.90 | |||||
| XXS | 75.76 | 59.09 | 66.40 | 67.08 |
| Model | Size | Car | Pedestrians | Cyclist | |
|---|---|---|---|---|---|
| Tea | SFD [19] | base | 88.27 | 66.69 | 72.95 |
| Stu | Reduced SFD | S | 86.16 | 63.47 | 70.14 |
| +Vanilla KD [21] | S | 86.12 | 63.72 | 71.06 | |
| +GID [39] | S | 85.79 | 62.46 | 69.27 | |
| +SparseKD [8] | S | 87.11 | 65.29 | 71.15 | |
| +PointDistiller [7] | S | 86.84 | 64.12 | 70.74 | |
| +CaKDP [9] | S | 87.09 | 65.48 | 71.57 | |
| +Ours | S | 88.34 | 66.41 | 72.73 |
| Method | Car | Pedestrians | Cyclist | ||
|---|---|---|---|---|---|
| 86.16 | 63.47 | 70.14 | |||
| 87.14 | 64.51 | 71.07 | |||
| 86.87 | 64.37 | 70.86 | |||
| 86.94 | 65.14 | 71.24 | |||
| 87.49 | 65.25 | 70.97 | |||
| 87.74 | 65.75 | 71.94 | |||
| 87.19 | 65.83 | 71.48 | |||
| 88.34 | 66.41 | 72.73 | |||
| Model | Size | mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | |
|---|---|---|---|---|---|---|---|---|---|
| Tea | Transfusion [6] | base | 0.6388 | 0.2867 | 0.2555 | 0.2725 | 0.2624 | 0.1895 | 0.6927 |
| Stu | Reduced Transfusion | S | 0.6230 | 0.3290 | 0.2569 | 0.3124 | 0.2683 | 0.1921 | 0.6756 |
| Reduced Transfusion + Ours | S | 0.6387 | 0.2885 | 0.2564 | 0.2870 | 0.2638 | 0.1904 | 0.6907 |
| Model | Size | Car | Pedestrians | Cyclist | |
|---|---|---|---|---|---|
| Tea | SFD | base | 88.27 | 66.69 | 72.95 |
| Stu | SFD | S | 88.53 | 66.72 | 73.10 |
| Tea | Voxel-RCNN | base | 85.56 | 59.20 | 74.60 |
| Stu | Voxel-RCNN | S | 85.76 | 60.14 | 74.87 |
| Tea | PV-RCNN | base | 85.50 | 59.21 | 73.13 |
| Stu | PV-RCNN | S | 85.61 | 59.33 | 73.48 |
| Tea | PartA2 | base | 83.65 | 61.78 | 74.08 |
| Stu | PartA2 | S | 83.72 | 61.94 | 74.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Tao, T.; Wu, W.; Zhang, Y.; Meng, X.; Yang, J. MultiDistiller: Efficient Multimodal 3D Detection via Knowledge Distillation for Drones and Autonomous Vehicles. Drones 2025, 9, 322. https://doi.org/10.3390/drones9050322
Yang B, Tao T, Wu W, Zhang Y, Meng X, Yang J. MultiDistiller: Efficient Multimodal 3D Detection via Knowledge Distillation for Drones and Autonomous Vehicles. Drones. 2025; 9(5):322. https://doi.org/10.3390/drones9050322
Chicago/Turabian StyleYang, Binghui, Tao Tao, Wenfei Wu, Yongjun Zhang, Xiuyuan Meng, and Jianfeng Yang. 2025. "MultiDistiller: Efficient Multimodal 3D Detection via Knowledge Distillation for Drones and Autonomous Vehicles" Drones 9, no. 5: 322. https://doi.org/10.3390/drones9050322
APA StyleYang, B., Tao, T., Wu, W., Zhang, Y., Meng, X., & Yang, J. (2025). MultiDistiller: Efficient Multimodal 3D Detection via Knowledge Distillation for Drones and Autonomous Vehicles. Drones, 9(5), 322. https://doi.org/10.3390/drones9050322