
Visual Point Cloud Map Construction and Matching Localization for Autonomous Vehicle


Abstract
1. Introduction
2. Related Work
2.1. Map Construction
2.2. Matching Localization in Prior Map
- The designed model of the visual point cloud map can extract features from complex raw data and provide enough data support for matching localization. By introducing the road network base, this model achieves effective regional segmentation, which can accelerate the data indexing speed of the matching localization process.
- A multi-sensors fusion map construction method is designed, which lies the enforced constraints of inverse external parameters. This method can autonomously build geographical high-precision visual point cloud maps.
- An improved iterative closest point matching method is proposed to reduce the impact of local convergence, which can effectively enhance the success rate of matching and localization accuracy.
- The proposed fusion localization strategy based on pose graph optimization can reduce the mismatch rate of point cloud matching, effectively constrain the drift error of odometry, and enhance vehicle localization accuracy.
3. System Overview
4. Visual Point Cloud Map Construction
4.1. Visual Point Cloud Map Model
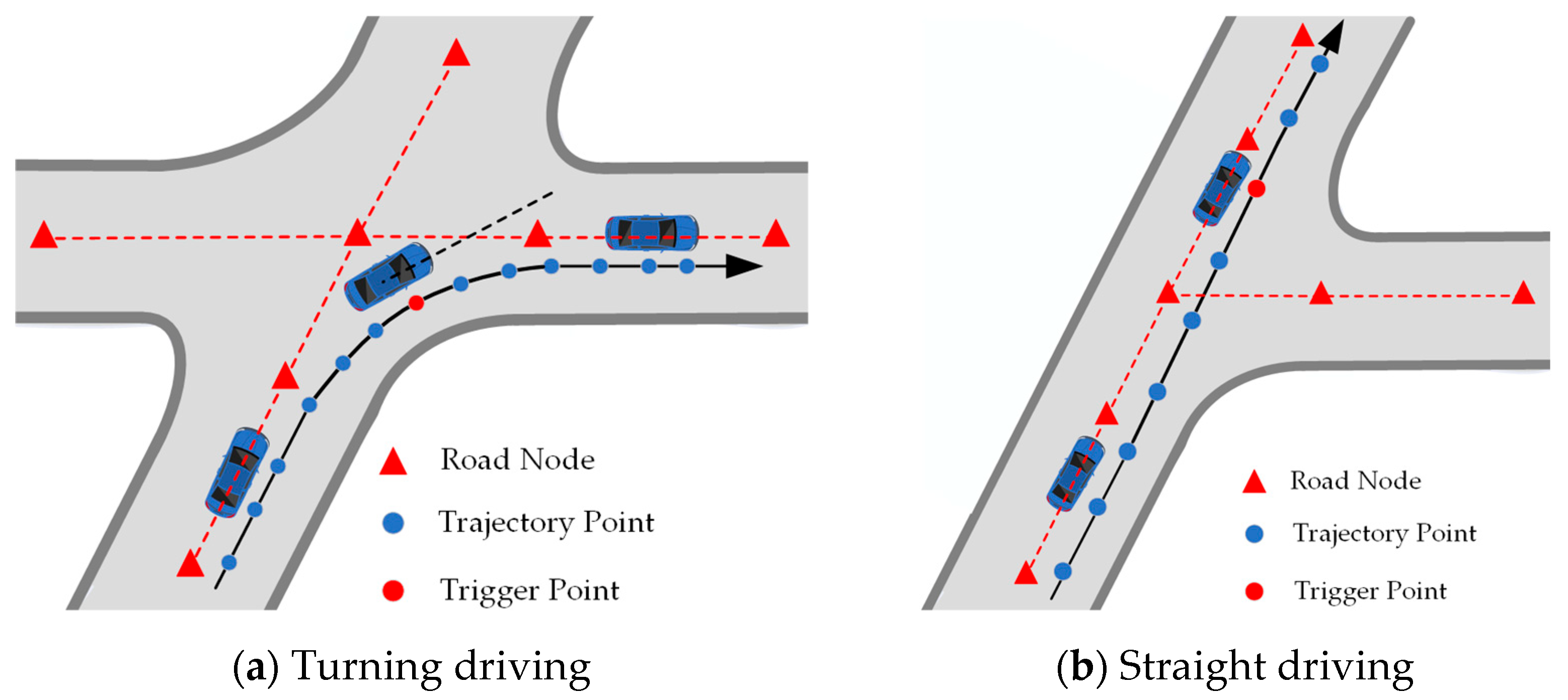
4.2. Road Network Base Construction
4.3. Point Cloud Map Construction
4.4. Overall Map Construction
5. Localization Under Prior VPCM Constraints
5.1. Visual Odometry
5.2. Adaptive Prior Map Segmentation
5.3. Localization by Geometric Matching
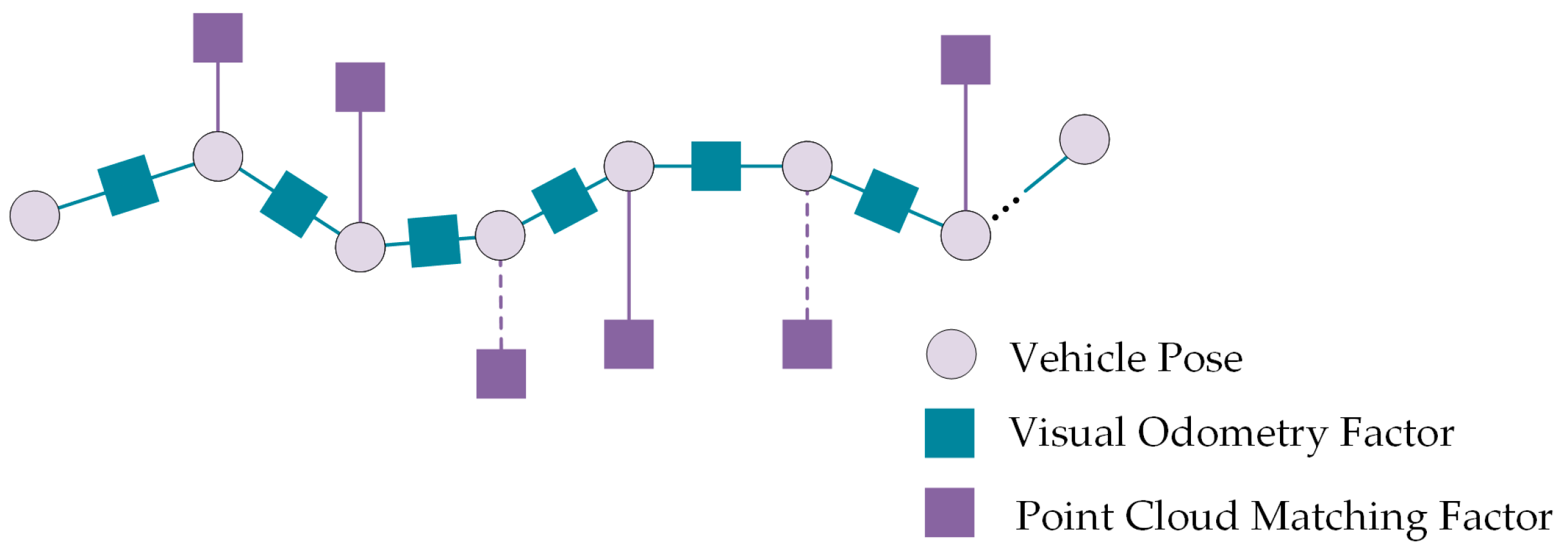
5.4. Localization Based on Pose Graph Optimization
- Visual Odometry Factor
- 2.
- VPCM Matching Localization Factor
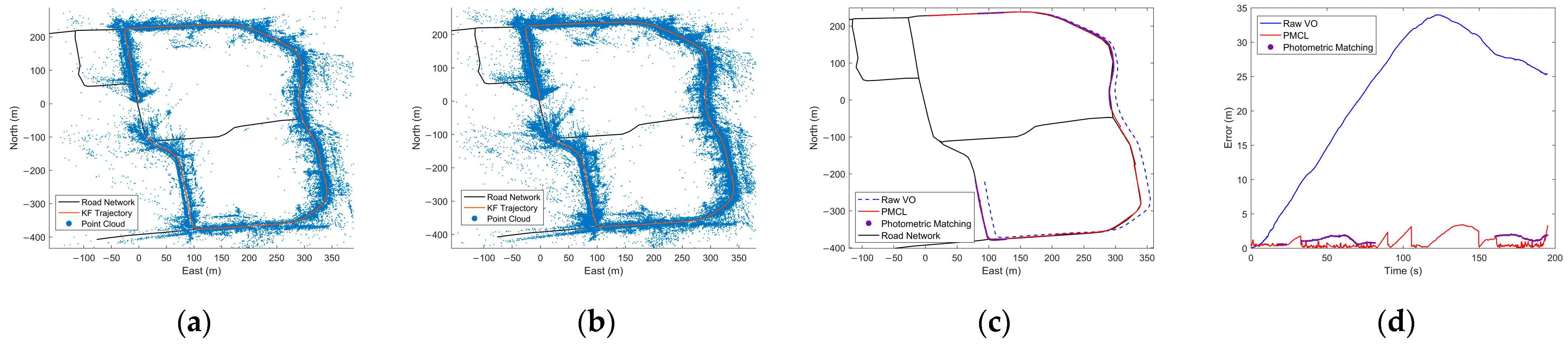
6. Experiment Results
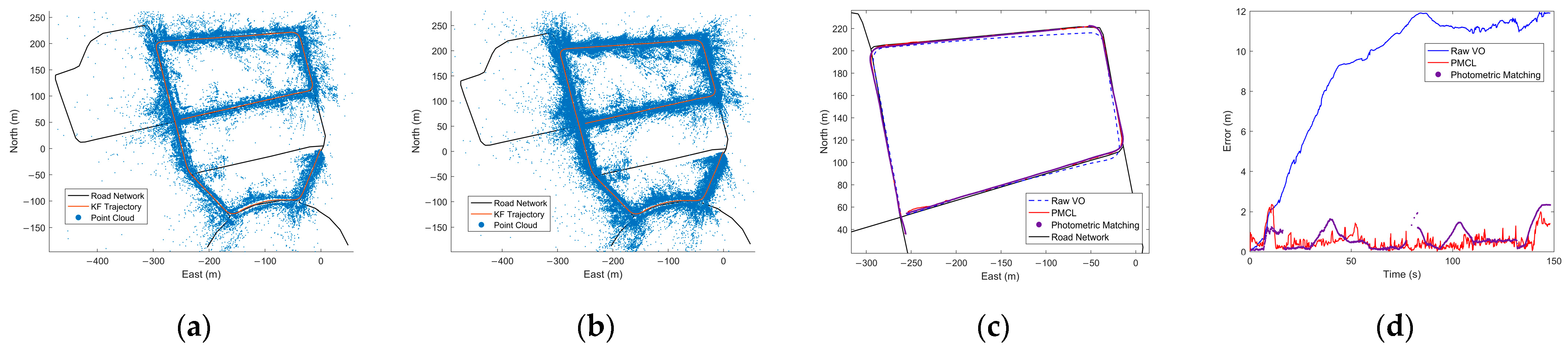
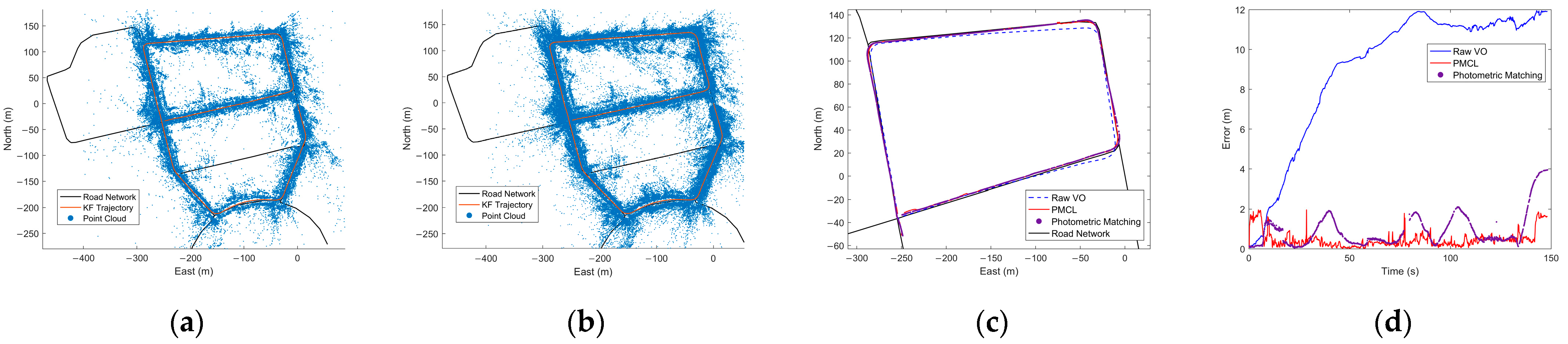
6.1. Map Construction Experiment on KITTI
6.2. Localization Experiment on KITTI
6.3. Localization Experiment in Different Scenarios
- 1.
- E1: Impact of the camera perspective difference
- 2.
- E2: Impact of lighting changes at different time of the day
- 3.
- E3: Impact of environmental changes
6.4. Time Performance
7. Discussion
- (1)
- The evaluation of map accuracy primarily focuses on the precision of keyframes and the overall consistency of map points covering the roads. The precision of individual map points cannot be determined, making it difficult to discern whether localization errors primarily arise from potential errors in maps or from the matching method. In future work, the high-precision LiDAR can be introduced to assess the deviation levels of map points, further analyze the respective impacts of potential errors in maps and the matching method on localization accuracy.
- (2)
- In the real-world experiment E3, environmental changes resulted in sustained matching failures over a period of time, making it impossible to introduce real-time constraints. In extreme cases, when significant environmental changes occur and the map is not updated, the localization error may continuously diverge. Future work could consider integrating road-network-maps-assisted localization algorithms, enabling localization under multi-map joint constraints.
- (3)
- The VPCM constructed in this paper is situated in the ENU geographic coordinate system commonly used for vehicle localization. Within a regional range, the geographic coordinate system approximates a fixed geographic reference. However, the east and north directions can produce biases due to Earth’s curvature when applied to large cities. Future work could optimize the map model and global construction methods to enhance scalability to large city-scale maps.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, N.; Li, X.; Suo, Z.; Fan, J.; Wang, J.; Xie, D. Traversability Analysis and Path Planning for Autonomous Wheeled Vehicles on Rigid Terrains. Drones 2024, 8, 419. [Google Scholar] [CrossRef]
- Bai, S.; Lai, J.; Lyu, P.; Cen, Y.; Sun, X.; Wang, B. Performance enhancement of tightly coupled GNSS/IMU integration based on factor graph with robust TDCP loop closure. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2437–2449. [Google Scholar] [CrossRef]
- Lu, Y.; Ma, H.; Smart, E.; Yu, H. Real-time performance-focused localization techniques for autonomous vehicle: A review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6082–6100. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, J.; Sun, N. A review of collaborative air-ground robots research. J. Intell. Robot. Syst. 2022, 106, 60. [Google Scholar] [CrossRef]
- Renner, A.; Supic, L.; Danielescu, A.; Indiveri, G.; Frady, E.P.; Sommer, F.T.; Sandamirskaya, Y. Visual odometry with neuromorphic resonator networks. Nat. Mach. Intell. 2024, 6, 653–663. [Google Scholar] [CrossRef]
- Wang, G.; Wu, X.; Jiang, S.; Liu, Z.; Wang, H. Efficient 3d deep lidar odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5749–5765. [Google Scholar] [CrossRef] [PubMed]
- Lyu, Y.; Hua, L.; Wu, J.; Liang, X.; Zhao, C. Robust Radar Inertial Odometry in Dynamic 3D Environments. Drones 2024, 8, 197. [Google Scholar] [CrossRef]
- Wei, J.; Deng, H.; Wang, J.; Zhang, L. AFO-SLAM: An improved visual SLAM in dynamic scenes using acceleration of feature extraction and object detection. Meas. Sci. Technol. 2024, 35, 116304. [Google Scholar] [CrossRef]
- Jung, J.H.; Cha, J.; Chung, J.Y.; Kim, T.I.; Seo, M.H.; Park, S.Y.; Yeo, J.Y.; Park, C.G. Monocular visual-inertial-wheel odometry using low-grade IMU in urban areas. IEEE Trans. Intell. Transp. Syst. 2020, 23, 925–938. [Google Scholar] [CrossRef]
- You, Z.; Liu, L.; Bethel, B.J.; Dong, C. Feature comparison of two mesoscale eddy datasets based on satellite altimeter data. Remote Sens. 2021, 14, 116. [Google Scholar] [CrossRef]
- Cheng, H.M.; Song, D. Graph-based proprioceptive localization using a discrete heading-length feature sequence matching approach. IEEE Trans. Robot. 2021, 37, 1268–1281. [Google Scholar] [CrossRef]
- Shi, Y.; Li, H. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17010–17020. [Google Scholar]
- Cai, Y.; Lu, Z.; Wang, H.; Chen, L.; Li, Y. A lightweight feature map creation method for intelligent vehicle localization in urban road environments. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Li, J.; Qin, H.; Wang, J.; Li, J. Openstreetmap-based autonomous navigation for the four wheel-legged robot via 3d-lidar and ccd camera. IEEE Trans. Ind. Electron. 2021, 69, 2708–2717. [Google Scholar] [CrossRef]
- Guo, S.; Rong, Z.; Wang, S.; Wu, Y. A LiDAR SLAM with PCA-based feature extraction and two-stage matching. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Gupta, A.; Fernando, X. Simultaneous localization and mapping (slam) and data fusion in unmanned aerial vehicles: Recent advances and challenges. Drones 2022, 6, 85. [Google Scholar] [CrossRef]
- Elaksher, A.; Ali, T.; Alharthy, A. A quantitative assessment of LiDAR data accuracy. Remote Sens. 2023, 15, 442. [Google Scholar] [CrossRef]
- Im, J.H.; Im, S.H.; Jee, G.I. Vertical corner feature based precise vehicle localization using 3D LIDAR in urban area. Sensors 2016, 16, 1268. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Shen, Y.; Lu, J.; Jiang, Q.; Xie, O.; Yang, Y.; Zhu, Q. DyStSLAM: An efficient stereo vision SLAM system in dynamic environment. Meas. Sci. Technol. 2022, 34, 025105. [Google Scholar] [CrossRef]
- Yabuuchi, K.; Wong, D.R.; Ishita, T.; Kitsukawa, Y.; Kato, S. Visual localization for autonomous driving using pre-built point cloud maps. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium, Nagoya, Japan, 11–17 July 2021; pp. 913–919. [Google Scholar]
- Zhou, G.; Yuan, H.; Zhu, S.; Huang, Z.; Fan, Y.; Zhong, X.; Du, R.; Gu, J. Visual Localization in a Prior 3D LiDAR Map Combining Points and Lines. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 6–10 December 2021; pp. 1198–1203. [Google Scholar]
- Dhoke, A.; Shankar, P. Exploring the Complexities of GPS Navigation: Addressing Challenges and Solutions in the Functionality of Google Maps. In Proceedings of the 2023 7th International Conference On Computing, Communication, Control And Automation (ICCUBEA), Pune, Maharashtra, India, 18–19 August 2023; pp. 1–6. [Google Scholar]
- Grinberger, A.Y.; Minghini, M.; Juhász, L.; Yeboah, G.; Mooney, P. OSM Science—The Academic Study of the OpenStreetMap Project, Data, Contributors, Community, and Applications. ISPRS Int. J. Geo-Inf. 2022, 11, 230. [Google Scholar] [CrossRef]
- Sun, H.; Xu, Z.; Yao, L.; Zhong, R.; Du, L.; Wu, H. Tunnel monitoring and measuring system using mobile laser scanning: Design and deployment. Remote Sens. 2020, 12, 730. [Google Scholar] [CrossRef]
- Chalvatzaras, A.; Pratikakis, I.; Amanatiadis, A.A. A survey on map-based localization techniques for autonomous vehicles. IEEE Trans. Intell. Veh. 2022, 8, 1574–1596. [Google Scholar] [CrossRef]
- Li, S.; Liu, S.; Zhao, Q.; Xia, Q. Quantized self-supervised local feature for real-time robot indirect VSLAM. IEEE ASME Trans. Mechatron. 2021, 27, 1414–1424. [Google Scholar] [CrossRef]
- Mo, J.; Islam, M.J.; Sattar, J. Fast direct stereo visual SLAM. IEEE Robot. Autom. Lett. 2021, 7, 778–785. [Google Scholar] [CrossRef]
- Daoud, H.A.; Md. Sabri, A.Q.; Loo, C.K.; Mansoor, A.M. SLAMM: Visual monocular SLAM with continuous mapping using multiple maps. PLoS ONE 2018, 13, e0195878. [Google Scholar] [CrossRef] [PubMed]
- Elvira, R.; Tardós, J.D.; Montiel, J.M. ORBSLAM-Atlas: A robust and accurate multi-map system. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 6253–6259. [Google Scholar]
- Wen, J.; Tang, J.; Liu, H.; Qian, C.; Fan, X. Real-time scan-to-map matching localization system based on lightweight pre-built occupancy high-definition map. Remote Sens. 2023, 15, 595. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.H. Autonomous vehicle localization without prior high-definition map. IEEE Trans. Robot. 2024, 40, 2888–2906. [Google Scholar] [CrossRef]
- Kim, Y.; Jeong, J.; Kim, A. Stereo camera localization in 3d lidar maps. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Zhang, C.; Zhao, H.; Wang, C.; Tang, X.; Yang, M. Cross-modal monocular localization in prior lidar maps utilizing semantic consistency. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 4004–4010. [Google Scholar]
- Ankenbauer, J.; Lusk, P.C.; Thomas, A.; How, J.P. Global localization in unstructured environments using semantic object maps built from various viewpoints. In Proceedings of the 2023 IEEE/RSJ international conference on intelligent robots and systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 1358–1365. [Google Scholar]
- Wang, Z.; Zhang, Z.; Kang, X. A Visual Odometry System for Autonomous Vehicles Based on Squared Planar Markers Map. In Proceedings of the 2023 IEEE International Conference on Unmanned Systems (ICUS), Hefei, China, 13–15 October 2023; pp. 311–316. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. Relocalization, global optimization and map merging for monocular visual-inertial SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1197–1204. [Google Scholar]
- Liang, S.; Zhang, Y.; Tian, R.; Zhu, D.; Yang, L.; Cao, Z. Semloc: Accurate and robust visual localization with semantic and structural constraints from prior maps. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4135–4141. [Google Scholar]
- Kascha, M.; Xin, K.; Zou, X.; Sturm, A.; Henze, R.; Heister, L.; Oezberk, S. Monocular Camera Localization for Automated Driving. In Proceedings of the 2023 29th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Queenstown, New Zealand, 15–17 November 2023; pp. 1–6. [Google Scholar]
- Churchill, W.; Newman, P. Experience-based navigation for long-term localisation. Int. J. Robot. Res. 2013, 32, 1645–1661. [Google Scholar] [CrossRef]
- Lin, X.; Wang, F.; Yang, B.; Zhang, W. Autonomous vehicle localization with prior visual point cloud map constraints in GNSS-challenged environments. Remote Sens. 2021, 13, 506. [Google Scholar] [CrossRef]
- Elsayed, H.; El-Mowafy, A.; Wang, K. Bounding of correlated double-differenced GNSS observation errors using NRTK for precise positioning of autonomous vehicles. Measurement 2023, 206, 112303. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Xu, S.; Sun, Y.; Zhao, K.; Fu, X.; Wang, S. Road-network-map-assisted vehicle positioning based on pose graph optimization. Sensors 2023, 23, 7581. [Google Scholar] [CrossRef] [PubMed]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of KFs | Number of MPs | Matching Number | Map Size (M) | Error (m) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [43] | SAMC | [43] | SAMC | [43] | SAMC | [43] | SAMC | [43] | [39] | SAMC | |
| 00 | 1418 | 4541 | 132,700 | 500,172 | 365.6 | 551.0 | 177.062 | 5.724 | 6.74 | 0.11 | 0.003 |
| 02 | 1740 | 4661 | 176,842 | 607,682 | 303.9 | 484.6 | 217.357 | 7.079 | 13.92 | 0.13 | 0.015 |
| 03 | 227 | 801 | 25,510 | 87,263 | 372.2 | 606.3 | 28.437 | 1.02 | 1.34 | 0.20 | 0.006 |
| 04 | 155 | 271 | 16,179 | 34,444 | 326.0 | 442.6 | 19.431 | 0.3935 | 0.71 | 0.23 | 0.006 |
| 05 | 724 | 2761 | 71,765 | 296,154 | 338.4 | 545.9 | 90.539 | 3.463 | 1.95 | 0.10 | 0.002 |
| 06 | 507 | 1101 | 39,980 | 123,572 | 344.6 | 447.0 | 63.456 | 1.444 | 1.64 | 0.12 | 0.002 |
| 07 | 255 | 1101 | 26,768 | 112,672 | 353.7 | 620.8 | 31.847 | 1.319 | 0.78 | 0.09 | 0.007 |
| 08 | 1203 | 4071 | 115,245 | 451,053 | 296.4 | 515.2 | 150.165 | 5.271 | 11.61 | 0.17 | 0.002 |
| 09 | 588 | 1591 | 56,668 | 196,518 | 293.4 | 473.0 | 73.374 | 2.291 | 5.60 | 0.11 | 0.002 |
| 10 | 328 | 1201 | 30,827 | 131,501 | 289.1 | 512.9 | 40.896 | 1.537 | 3.65 | 0.10 | 0.006 |
| Seq | [43] | [31] | [32] | [33] | [34] | [35] | [38] | [39] | [41] | PMCL |
|---|---|---|---|---|---|---|---|---|---|---|
| 00 | 6.8096 | 0.146 | 0.5796 | 0.1325 | 0.5765 | 5.1 | 0.3367 | 0.1547 | 1.27 | 0.1233 |
| 02 | 13.819 | 0.045 | 5.9826 | 0.2205 | — | 10.2 | 0.3596 | 0.206 | — | 0.2123 |
| 03 | 1.3971 | 0.032 | — | 0.2368 | — | — | 0.3869 | 0.2767 | — | 0.0963 |
| 04 | 0.6716 | 0.027 | 0.2837 | 0.4496 | — | — | — | 0.2512 | — | 0.0791 |
| 05 | 1.8757 | 0.044 | 0.7450 | 0.1462 | 0.4783 | — | 0.2498 | 0.1416 | 3.18 | 0.1176 |
| 06 | 1.6533 | 0.033 | 0.7481 | 0.3753 | 0.7412 | 6.8 | 0.1956 | 0.1528 | — | 0.0669 |
| 07 | 0.7387 | 0.042 | 0.1789 | 0.1305 | 0.6630 | 3.6 | 0.3392 | 0.1401 | — | 0.0738 |
| 08 | 11.374 | 0.056 | 1.5473 | 0.1440 | 1.2784 | — | 1.9745 | 0.2655 | — | 0.1304 |
| 09 | 5.7846 | 0.035 | 0.9876 | 0.1799 | 0.7168 | 11.4 | 0.4773 | 0.1773 | 1.94 | 0.1503 |
| 10 | 4.2495 | 0.027 | 0.6663 | 0.2398 | 0.5023 | — | 0.3749 | 0.1597 | — | 0.0954 |
| Error/Frame | 7.4686 | 0.0645 | 1.9880 | 0.1838 | 0.7596 | 7.7175 | 0.6432 | 0.1910 | — | 0.1363 |
| Map-Seq | Collection Time | Distance (m) | Loc-Seq |
|---|---|---|---|
| Campus-01 | 2024-04-16 10:52:20 | 1588.54 | Campus-02 |
| Campus-02 | 2024-07-17 11:01:27 | 1195.44 | —— |
| Campus-03 | 2024-07-17 11:24:16 | 1296.72 | Campus-05 |
| Campus-04 | 2024-07-17 16:38:58 | 1194.71 | Campus-05 |
| Campus-05 | 2024-07-17 16:44:45 | 776.475 | —— |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Zhao, K.; Sun, Y.; Fu, X.; Luo, K. Visual Point Cloud Map Construction and Matching Localization for Autonomous Vehicle. Drones 2025, 9, 511. https://doi.org/10.3390/drones9070511
Xu S, Zhao K, Sun Y, Fu X, Luo K. Visual Point Cloud Map Construction and Matching Localization for Autonomous Vehicle. Drones. 2025; 9(7):511. https://doi.org/10.3390/drones9070511
Chicago/Turabian StyleXu, Shuchen, Kedong Zhao, Yongrong Sun, Xiyu Fu, and Kang Luo. 2025. "Visual Point Cloud Map Construction and Matching Localization for Autonomous Vehicle" Drones 9, no. 7: 511. https://doi.org/10.3390/drones9070511
APA StyleXu, S., Zhao, K., Sun, Y., Fu, X., & Luo, K. (2025). Visual Point Cloud Map Construction and Matching Localization for Autonomous Vehicle. Drones, 9(7), 511. https://doi.org/10.3390/drones9070511