

UAV-OVD: Open-Vocabulary Object Detection in UAV Imagery via Multi-Level Text-Guided Decoding



Abstract
1. Introduction
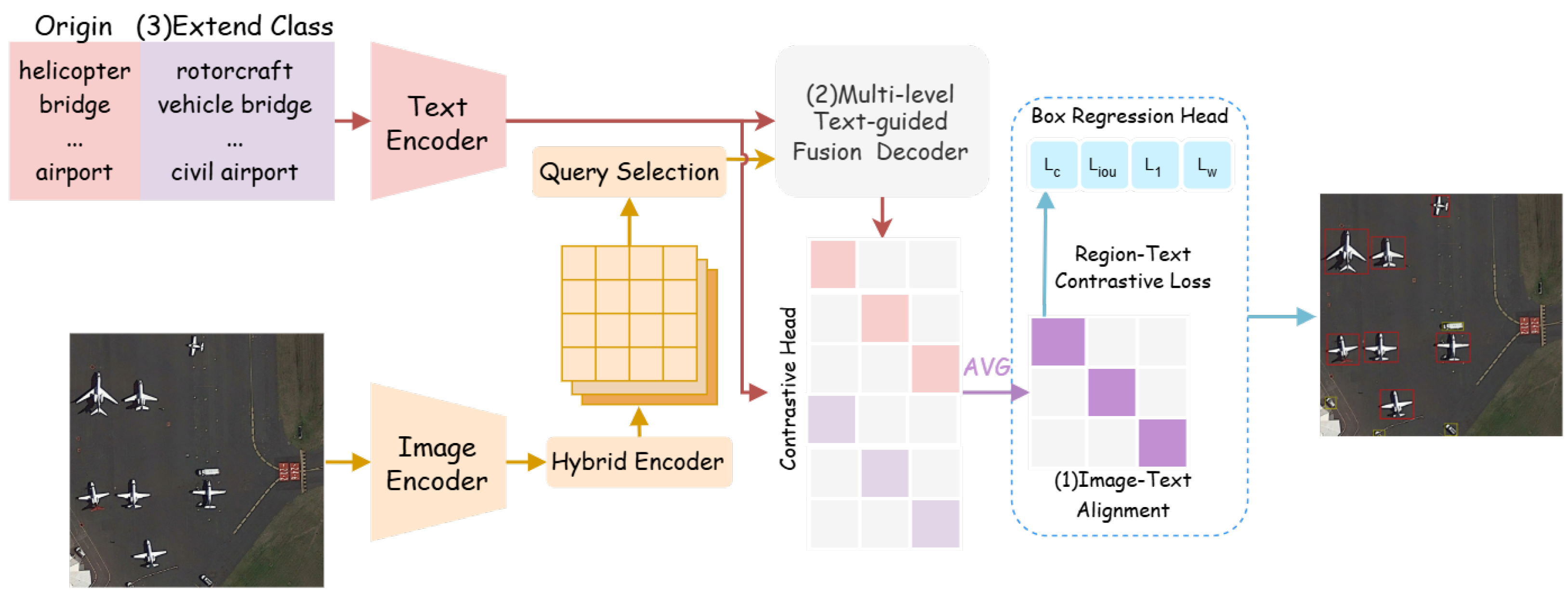
- We propose UAV-OVD, an efficient open-vocabulary detection framework tailored for aerial scenarios. By leveraging image–text alignment, UAV-OVD incorporates class-level semantic information and employs a region–text contrastive loss, enabling the model to recognize categories beyond predefined label sets with greater flexibility.
- We design a multi-level text-guided fusion decoder (MTFD) to address the challenges of small object sizes and complex backgrounds in aerial imagery. This module fuses multi-scale visual features with textual cues, enhancing the extraction of class-relevant representations and significantly improving the detection of small and visually ambiguous objects.
- We introduce a class extension strategy to improve the model’s linguistic generalization capabilities. By integrating manually curated synonyms into the training process, the model learns to associate diverse natural language expressions with target categories, enhancing its robustness in open-world scenarios.
2. Related Work
2.1. Object Detection
2.2. UAV Imagery Detection
2.3. Open Vocabulary Object Detection
3. Methods
- Training level: A region–text contrastive loss is introduced to replace conventional classification loss.
- Architectural level: A multi-level text-guided fusion decoder (MTFD) is designed to enhance feature fusion across scales.
- Data level: A synonym-based class extension strategy is applied to enrich textual supervision.
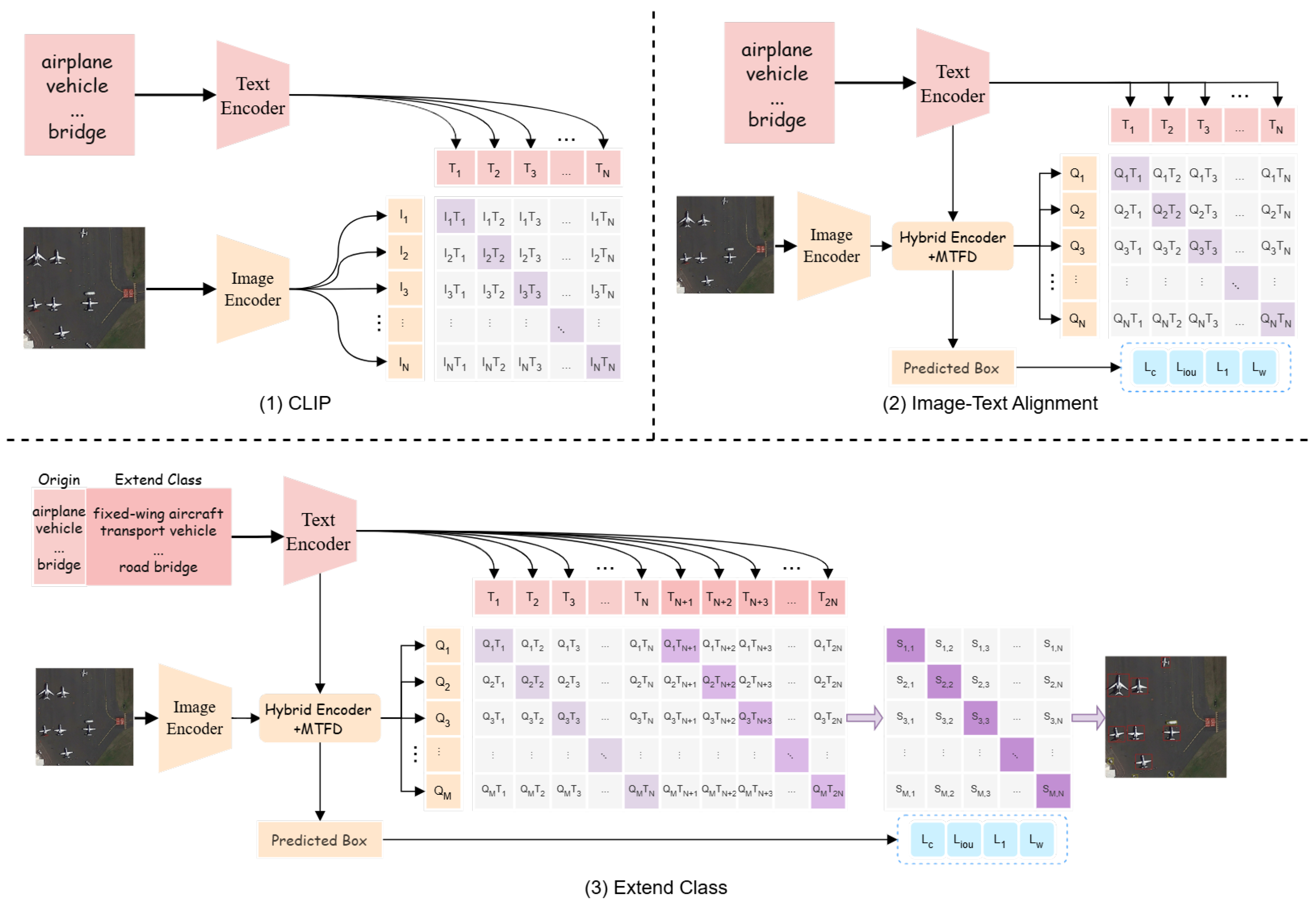
3.1. Image–Text Alignment
- Region–text contrastive loss In conventional object detectors such as RT-DETR [18], classification supervision is typically imposed through a categorical regression loss applied to the outputs of a classification head. Notably, RT-DETR [18] adopts the Varifocal Loss [42], which computes a soft classification loss that emphasizes high-quality predictions by weighting the classification confidence with the corresponding IoU scores. This design allows the detector to better capture both the correctness and the localization quality of object predictions.Building upon this foundation, we depart from the use of traditional category logits and instead adopt a more generalizable strategy based on semantic embeddings. Specifically, we leverage a CLIP-based architecture [19,20] to extract both visual and textual embeddings in a unified semantic space. Specifically, category labels are encoded using the CLIP text encoder to obtain dense semantic representations. For the visual stream, we adopt the ResNet-50 variant of the CLIP image encoder for its balance between performance and efficiency. To better adapt it to the detection setting, we remove the final AttnPool layer and extract multi-scale feature maps from the last three stages of the backbone. The resulting region-level visual features are then projected into the same embedding space as the text features through a lightweight linear projection, enabling effective region–text alignment for open-vocabulary object detection. To establish a shared visual-linguistic space, we introduce a contrastive head that projects both image regions and textual embeddings into comparable dimensions.As illustrated in Figure 2, given an aerial image and a list of category labels, we first encode each class label into a dense text embedding, denoted as , using the CLIP text encoder. The aerial image is passed through the CLIP-based visual encoder to extract multi-scale feature maps, which are subsequently flattened and processed to generate region-level object queries. From these, we select the top-K object queries based on confidence scores, denoted as . To measure the semantic similarity between visual and textual representations, we compute a similarity score between each object query and class embedding as follows:where denotes the cosine similarity between the visual query and the textual embedding. Following the default setting in [42], the region–text contrastive loss adopts the Varifocal Loss formulation as follows:where is the predicted similarity score between a region query and a text embedding and is defined as the IoU between the predicted box and its matched ground-truth box via Hungarian assignment.
- IOU loss To accurately supervise the spatial alignment between predicted and ground-truth bounding boxes, we follow prior works [18,41] and adopt the IoU loss [43] as one of our localization objectives. Unlike smooth L1 loss [22] that treats box coordinates independently, IoU-based losses directly measure the overlap quality between two boxes, providing a more geometry-aware and task-relevant supervision signal. This loss encourages predicted boxes to match the ground truth not just in location but also in shape and scale.Given a predicted box and its assigned ground-truth box , the IoU loss is defined as:where denotes the area of a box and ∩, ∪ represent the intersection and union between the predicted and ground-truth boxes, respectively. A lower IoU loss corresponds to a higher degree of spatial alignment.
- L1 loss In addition to the IoU loss, we also incorporate the L1 loss to supervise the regression of bounding box coordinates. L1 loss is a commonly used objective in object detection tasks, offering a stable and straightforward optimization target. Similar to the IoU loss, we follow prior works [18,41] and apply it to directly minimize the difference between predicted and ground-truth box parameters.Given a predicted bounding box and a ground-truth box , the L1 loss is computed as:This formulation ensures that each coordinate of the predicted box is regressed toward the ground-truth value, contributing to precise localization in combination with the IoU-based supervision.
- Wasserstein loss Beyond the standard localization losses (i.e., IoU and L1), we introduce a Wasserstein loss [44] as a complementary objective to further enhance the model’s ability to capture the spatial distribution and geometric alignment of predicted bounding boxes. Unlike IoU and L1 losses, which focus on overlap and coordinate-wise differences, respectively, Wasserstein loss provides a more holistic measure of distance between box distributions in a metric space.This loss is inspired by the optimal transport theory and is designed to measure the “effort” required to transform one bounding box into another. Given two boxes and , we define the Wasserstein loss as:The first term captures the Euclidean distance between the centers of the predicted and ground-truth boxes, while the second term reflects the distance in size (width and height). This loss encourages predicted boxes not only to match the location but also to mimic the spatial extent of the ground truth, which is particularly beneficial in complex aerial scenes with high object variability.
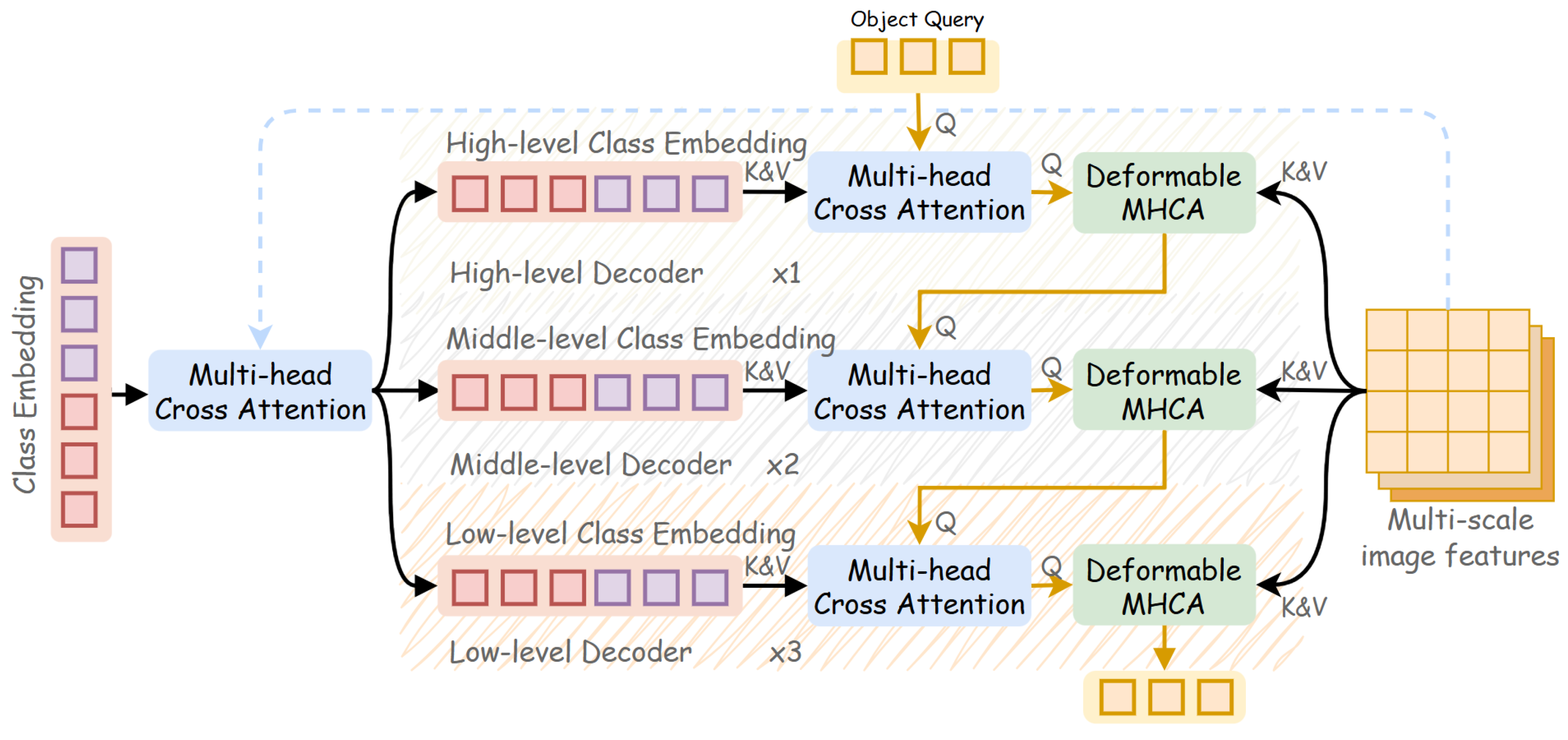
3.2. Multi-Level Text-Guided Fusion Decoder
- for
- for
- for
3.3. Extend Class
4. Results
4.1. Experimental Setup
- xView contains over 1 million object instances across 60 categories. The imagery is captured at a ground resolution of 0.3 m, offering significantly higher spatial detail compared to most public satellite datasets. It features a wide variety of small, rare, fine-grained, and multi-type objects with bounding box annotations, making it particularly suitable for UAV-based object detection tasks.
- DIOR is a large-scale benchmark dataset for object detection in optical remote sensing imagery. It consists of 23,463 images and 192,472 annotated object instances, covering 20 object categories. The dataset provides a rich diversity of scenes and object types that support evaluation of detection performance in more generalized aerial contexts.
4.2. Evaluation Metrics
4.3. Ablation Experiment
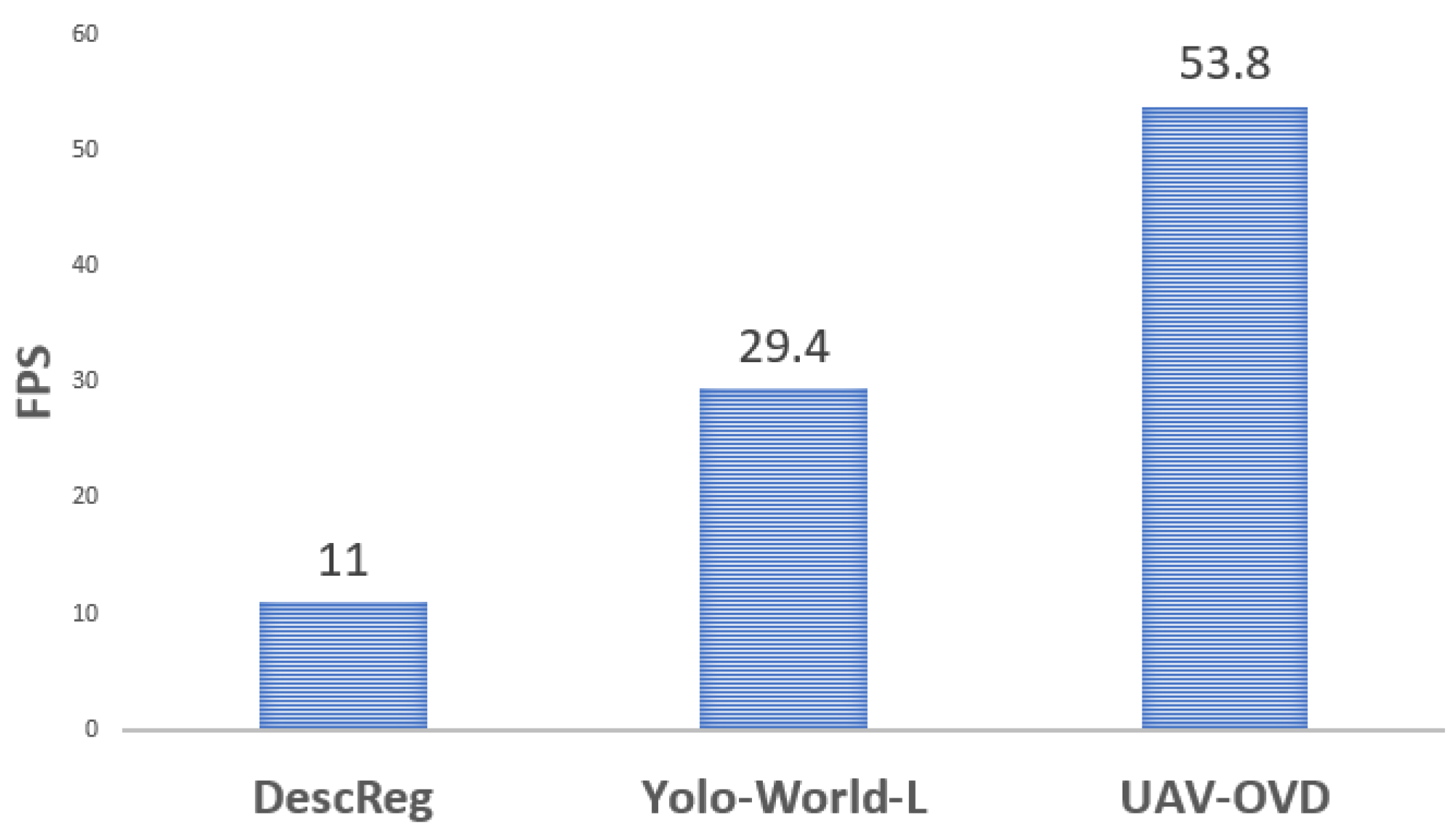
4.4. Comparison with the State of the Art
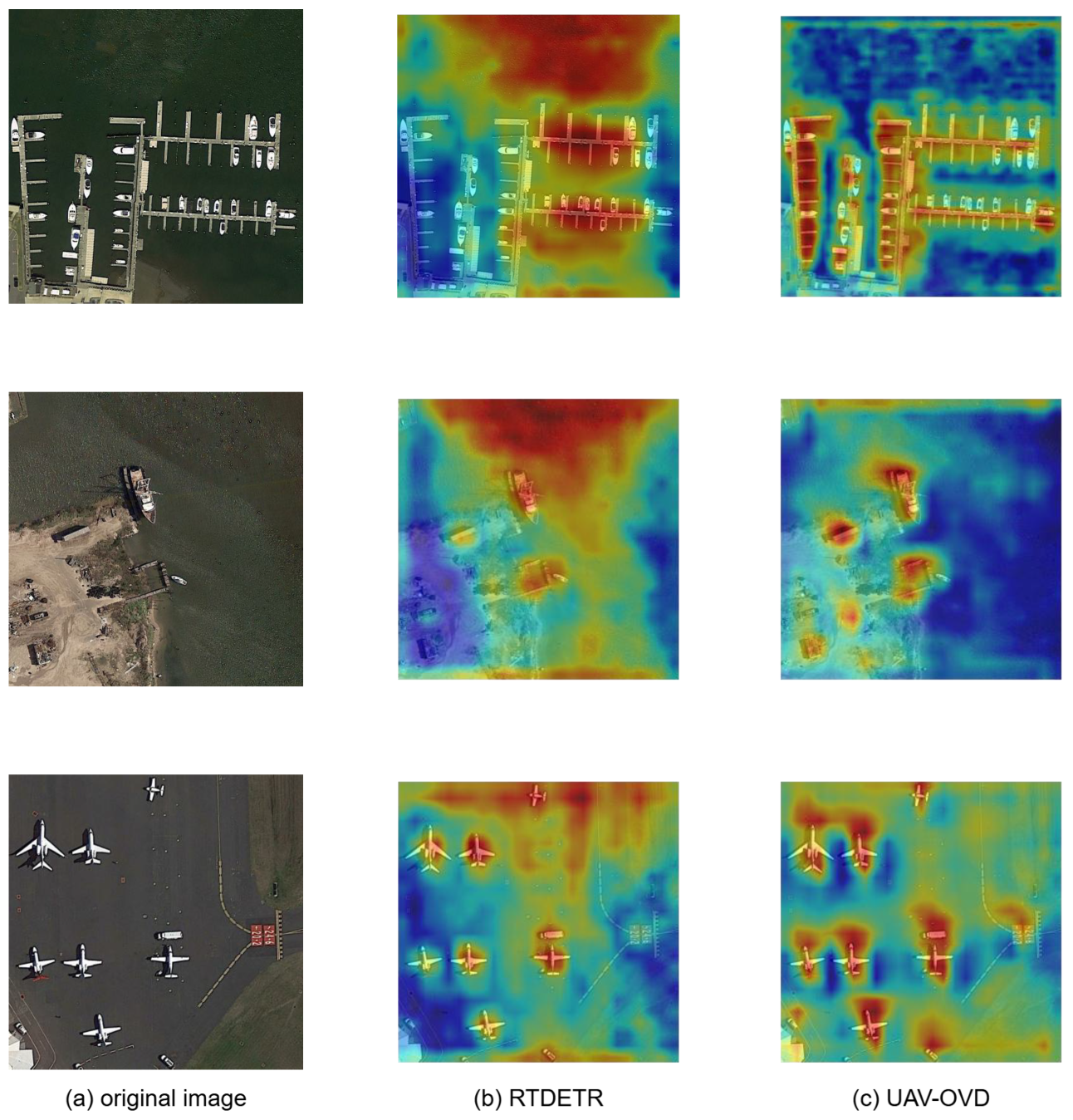
4.5. Visualization of Detections
5. Conclusions
6. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object detection in aerial images: A large-scale benchmark and challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7778–7796. [Google Scholar] [CrossRef]
- Sadgrove, E.J.; Falzon, G.; Miron, D.; Lamb, D.W. Real-time object detection in agricultural/remote environments using the multiple-expert colour feature extreme learning machine (MEC-ELM). Comput. Ind. 2018, 98, 183–191. [Google Scholar] [CrossRef]
- Sun, W.; Dai, L.; Zhang, X.; Chang, P.; He, X. RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring. Appl. Intell. 2022, 52, 8448–8463. [Google Scholar] [CrossRef]
- Dong, J.; Ota, K.; Dong, M. UAV-based real-time survivor detection system in post-disaster search and rescue operations. IEEE J. Miniaturization Air Space Syst. 2021, 2, 209–219. [Google Scholar] [CrossRef]
- Liu, H.; Yu, Y.; Liu, S.; Wang, W. A military object detection model of UAV reconnaissance image and feature visualization. Appl. Sci. 2022, 12, 12236. [Google Scholar] [CrossRef]
- Gu, X.; Lin, T.Y.; Kuo, W.; Cui, Y. Open-vocabulary object detection via vision and language knowledge distillation. arXiv 2021, arXiv:2104.13921. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Jiang, Q.; Li, C.; Yang, J.; Su, H.; et al. Grounding dino: Marrying dino with grounded pretraining for open-set object detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 38–55. [Google Scholar]
- Zhao, S.; Zhang, Z.; Schulter, S.; Zhao, L.; Vijay Kumar, B.; Stathopoulos, A.; Chandraker, M.; Metaxas, D.N. Exploiting unlabeled data with vision and language models for object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 159–175. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16901–16911. [Google Scholar]
- Wu, S.; Zhang, W.; Jin, S.; Liu, W.; Loy, C.C. Aligning bag of regions for open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 15254–15264. [Google Scholar]
- Li, J.; Zhang, J.; Li, J.; Li, G.; Liu, S.; Lin, L.; Li, G. Learning background prompts to discover implicit knowledge for open vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16678–16687. [Google Scholar]
- Zhong, Y.; Yang, J.; Zhang, P.; Li, C.; Codella, N.; Li, L.H.; Zhou, L.; Dai, X.; Yuan, L.; Li, Y.; et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16793–16803. [Google Scholar]
- Chen, F.; Zhang, H.; Yang, Z.; Chen, H.; Hu, K.; Savvides, M. Rtgen: Generating region-text pairs for open-vocabulary object detection. arXiv 2024, arXiv:2405.19854. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10965–10975. [Google Scholar]
- Zhang, H.; Zhang, P.; Hu, X.; Chen, Y.C.; Li, L.; Dai, X.; Wang, L.; Yuan, L.; Hwang, J.N.; Gao, J. Glipv2: Unifying localization and vision-language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36067–36080. [Google Scholar]
- Yao, L.; Han, J.; Liang, X.; Xu, D.; Zhang, W.; Li, Z.; Xu, H. Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 23497–23506. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Cherti, M.; Beaumont, R.; Wightman, R.; Wortsman, M.; Ilharco, G.; Gordon, C.; Schuhmann, C.; Schmidt, L.; Jitsev, J. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2818–2829. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Shehata, M.; Abo-Al-Ez, R.; Zaghlool, F.; Abou-Kreisha, M.T. Vehicles detection based on background modeling. arXiv 2019, arXiv:1901.04077. [Google Scholar]
- Chen, W.; Baojun, Z.; Linbo, T.; Boya, Z. Small vehicles detection based on UAV. J. Eng. 2019, 2019, 7894–7897. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Li, Z.; Yang, J.; Ma, X.; Chen, J.; Tang, X. Phsi-rtdetr: A lightweight infrared small target detection algorithm based on UAV aerial photography. Drones 2024, 8, 240. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ashraf, M.W.; Sultani, W.; Shah, M. Dogfight: Detecting drones from drones videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7067–7076. [Google Scholar]
- Zhao, Y.; Ju, Z.; Sun, T.; Dong, F.; Li, J.; Yang, R.; Fu, Q.; Lian, C.; Shan, P. Tgc-yolov5: An enhanced yolov5 drone detection model based on transformer, gam & ca attention mechanism. Drones 2023, 7, 446. [Google Scholar] [CrossRef]
- Bansal, A.; Sikka, K.; Sharma, G.; Chellappa, R.; Divakaran, A. Zero-shot object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Li, Y.; Guo, W.; Yang, X.; Liao, N.; He, D.; Zhou, J.; Yu, W. Toward open vocabulary aerial object detection with clip-activated student-teacher learning. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 431–448. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5356–5364. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, New York, NY, USA, 15–19 October 2016; MM’16. pp. 516–520. [Google Scholar] [CrossRef]
- Frogner, C.; Zhang, C.; Mobahi, H.; Araya, M.; Poggio, T.A. Learning with a Wasserstein loss. In Advances in Neural Information Processing Systems 28 (NIPS 2015); Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- OpenAI. GPT-4o Technical Report. 2024. Available online: https://openai.com/index/gpt-4o (accessed on 3 July 2025).
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xView: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Zang, Z.; Lin, C.; Tang, C.; Wang, T.; Lv, J. Zero-Shot Aerial Object Detection with Visual Description Regularization. Proc. AAAI Conf. Artif. Intell. 2024, 38, 6926–6934. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8430–8439. [Google Scholar]
- Hudson, D.A.; Manning, C.D. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6700–6709. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2641–2649. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Huang, P.; Han, J.; Cheng, D.; Zhang, D. Robust Region Feature Synthesizer for Zero-Shot Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7612–7621. [Google Scholar] [CrossRef]
- Yan, C.; Chang, X.; Luo, M.; Liu, H.; Zhang, X.; Zheng, Q. Semantics-Guided Contrastive Network for Zero-Shot Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1530–1544. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MTFD | I-T Align | Extend Class | GZSD | ZSD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAPB | mAPN | mAPHM | RecallB | RecallN | RecallHM | mAP | Recall | |||
| 24.6 | 3.4 | 6.0 | 58.2 | 28.7 | 38.4 | 7.3 | 57.4 | |||
| ✓ | 28.6 | 3.6 | 6.2 | 59.1 | 23.2 | 33.2 | 9.6 | 62.3 | ||
| ✓ | ✓ | 26.6 | 3.7 | 6.4 | 58.0 | 27.0 | 36.7 | 10.3 | 64.3 | |
| ✓ | ✓ | ✓ | 29.7 | 8.0 | 12.5 | 61.3 | 32.0 | 42.1 | 9.9 | 67.3 |
| Method | Source | GZSD | ZSD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mAPB | mAPN | mAPHM | RecallB | RecallN | RecallHM | mAP | Recall | ||
| RRFS [58] | CVPR22 | 10.2 | 1.6 | 2.7 | 19.1 | 5.8 | 8.9 | 2.2 | 14.3 |
| ConstrastZSD [59] | TPAMI22 | 16.8 | 2.9 | 5.0 | 27.6 | 13.9 | 18.5 | 4.1 | 27.1 |
| DescReg [49] | AAAI24 | 17.1 | 5.8 | 8.7 | 28.0 | 12.8 | 17.6 | 8.3 | 43.0 |
| Yolo-World-M [10] | CVPR24 | 17.3 | 3.0 | 5.1 | 42.9 | 15.4 | 22.7 | 6.8 | 38.1 |
| Yolo-World-L [10] | CVPR24 | 18.5 | 3.3 | 5.6 | 41.4 | 15.2 | 22.2 | 7.9 | 37.1 |
| UAV-OVD (Ours) | – | 19.4 | 4.6 | 7.4 | 57.3 | 32.1 | 41.2 | 9.1 | 63.2 |
| Yolo-World-L [10] * | CVPR24 | 21.7 | 3.2 | 5.6 | 46.6 | 16.5 | 24.4 | 8.8 | 41.7 |
| UAV-OVD (Ours) * | – | 29.7 | 8.0 | 12.5 | 61.3 | 32.0 | 42.1 | 9.9 | 67.3 |
| Method | Source | GZSD | ZSD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mAPB | mAPN | mAPHM | RecallB | RecallN | RecallHM | mAP | Recall | ||
| RRFS [58] | CVPR22 | 41.9 | 2.8 | 5.2 | 60.0 | 19.9 | 29.9 | 9.7 | 19.8 |
| ConstrastZSD [59] | TPAMI22 | 51.4 | 3.9 | 7.2 | 69.2 | 25.9 | 37.7 | 8.7 | 22.3 |
| DescReg [49] | AAAI24 | 68.7 | 7.9 | 14.2 | 82.0 | 34.3 | 48.4 | 15.2 | 34.6 |
| Yolo-World-M [10] | CVPR24 | 78.4 | 12.0 | 20.8 | 90.6 | 37.2 | 52.7 | 23.4 | 38.9 |
| Yolo-World-L [10] | CVPR24 | 80.2 | 17.3 | 28.5 | 91.1 | 38.2 | 53.8 | 24.8 | 37.8 |
| UAV-OVD (Ours) | – | 77.9 | 17.2 | 28.1 | 93.1 | 67.3 | 78.1 | 32.6 | 81.1 |
| Yolo-World-L [10] * | CVPR24 | 78.5 | 3.1 | 5.9 | 91.5 | 18.6 | 30.9 | 6.7 | 20.6 |
| UAV-OVD (Ours) * | 76.6 | 2.8 | 5.3 | 91.8 | 55.6 | 69.2 | 14.3 | 72.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, L.; Wei, G.; Wang, Z.; Qi, Z.; Li, Y.; Zhang, H. UAV-OVD: Open-Vocabulary Object Detection in UAV Imagery via Multi-Level Text-Guided Decoding. Drones 2025, 9, 495. https://doi.org/10.3390/drones9070495
Tao L, Wei G, Wang Z, Qi Z, Li Y, Zhang H. UAV-OVD: Open-Vocabulary Object Detection in UAV Imagery via Multi-Level Text-Guided Decoding. Drones. 2025; 9(7):495. https://doi.org/10.3390/drones9070495
Chicago/Turabian StyleTao, Lijie, Guoting Wei, Zhuo Wang, Zhaoshuai Qi, Ying Li, and Haokui Zhang. 2025. "UAV-OVD: Open-Vocabulary Object Detection in UAV Imagery via Multi-Level Text-Guided Decoding" Drones 9, no. 7: 495. https://doi.org/10.3390/drones9070495
APA StyleTao, L., Wei, G., Wang, Z., Qi, Z., Li, Y., & Zhang, H. (2025). UAV-OVD: Open-Vocabulary Object Detection in UAV Imagery via Multi-Level Text-Guided Decoding. Drones, 9(7), 495. https://doi.org/10.3390/drones9070495