
MASP: Scalable Graph-Based Planning Towards Multi-UAV Navigation

 , , , ,
, , , ,  and
and
Abstract
1. Introduction
- Proposing a hierarchical multi-UAV navigation planner, Multi-UAV Scalable Graph-based Planner (MASP), to decompose a large exploration space into multiple goal-conditioned subspaces, enhancing sample efficiency in a large exploration space.
- Representing drones and goals as graphs and applying an attention-based mechanism and a group division mechanism to ensure scalability to arbitrary numbers of drones and promote effective cooperation.
- Compared to planning-based competitors, enhancing task efficiency by over 19.12% in MPE with 50 drones and 27.92% in OmniDrones with 20 drones (referred to Section 5.5.1), and achieving at least a 47.87% enhancement across varying team sizes (referred to Section 5.5.2).
2. Related Work
2.1. Multi-UAV Navigation
2.2. Goal-Conditioned HRL
2.3. Graph Neural Networks
3. Problem Formulation
4. Methodology
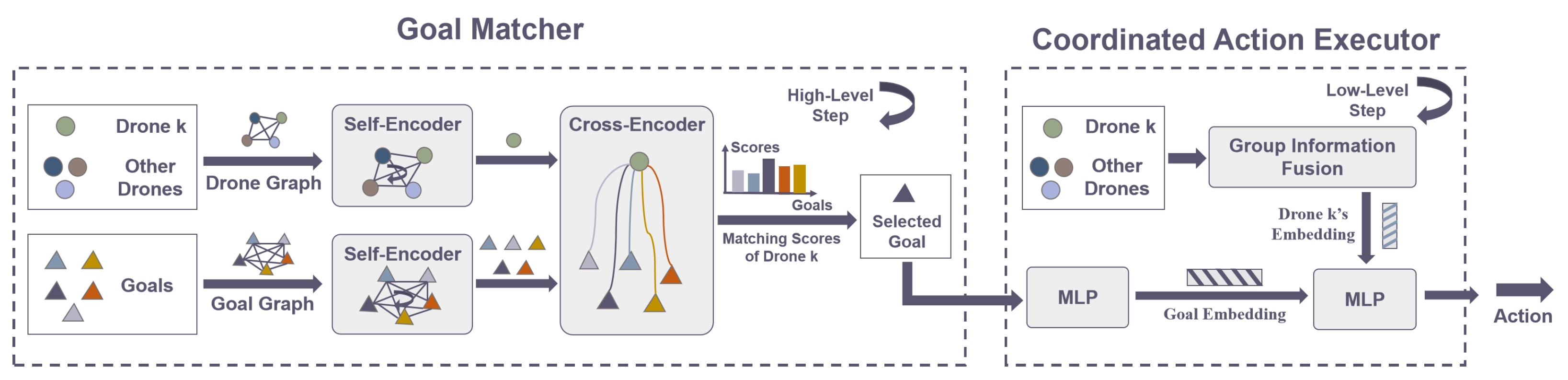
4.1. Overview
4.2. The High-Level Policy: Goal Matcher
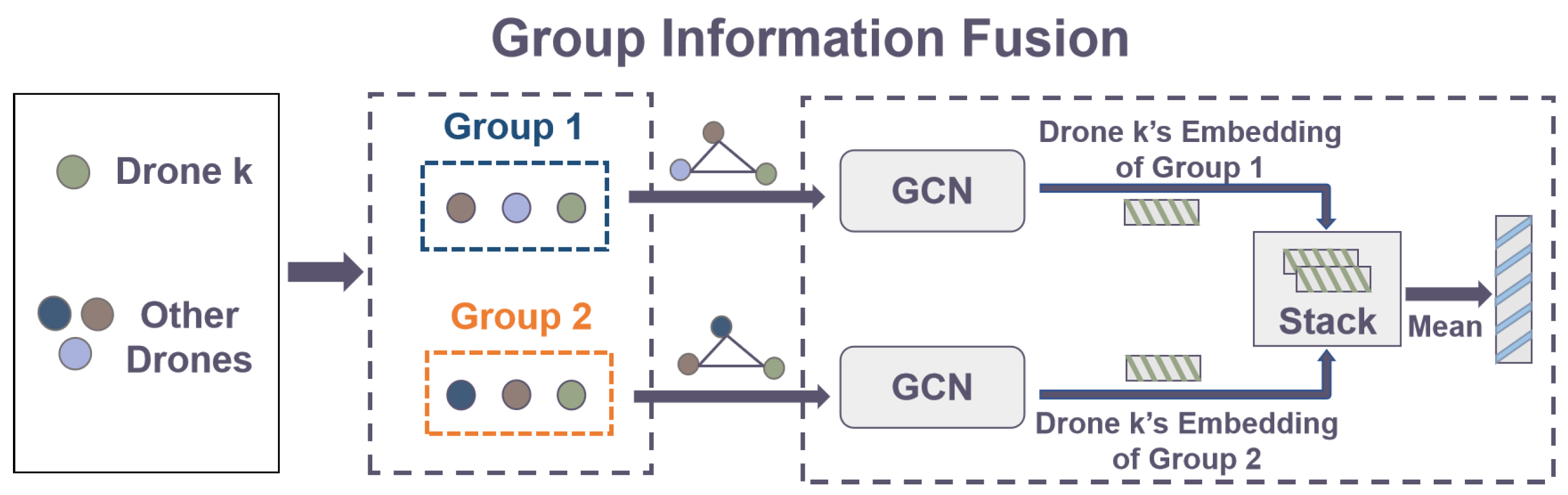
4.3. The Low-Level Policy: Coordinated Action Executor
- A complete bonus for successfully reaching the assigned goal, , which is 1 if agent k reaches its assigned goal, otherwise 0.
- A distance penalty for task efficiency, , which is the negative L2 distance between agent k and its assigned goal.
- A collision penalty for collision avoidance, , computed based on the number of collisions at each time step.
4.4. Multi-UAV Scalable Graph-Based Planner Training
| Algorithm 1 Training Procedure of MASP |
|
5. Experiments
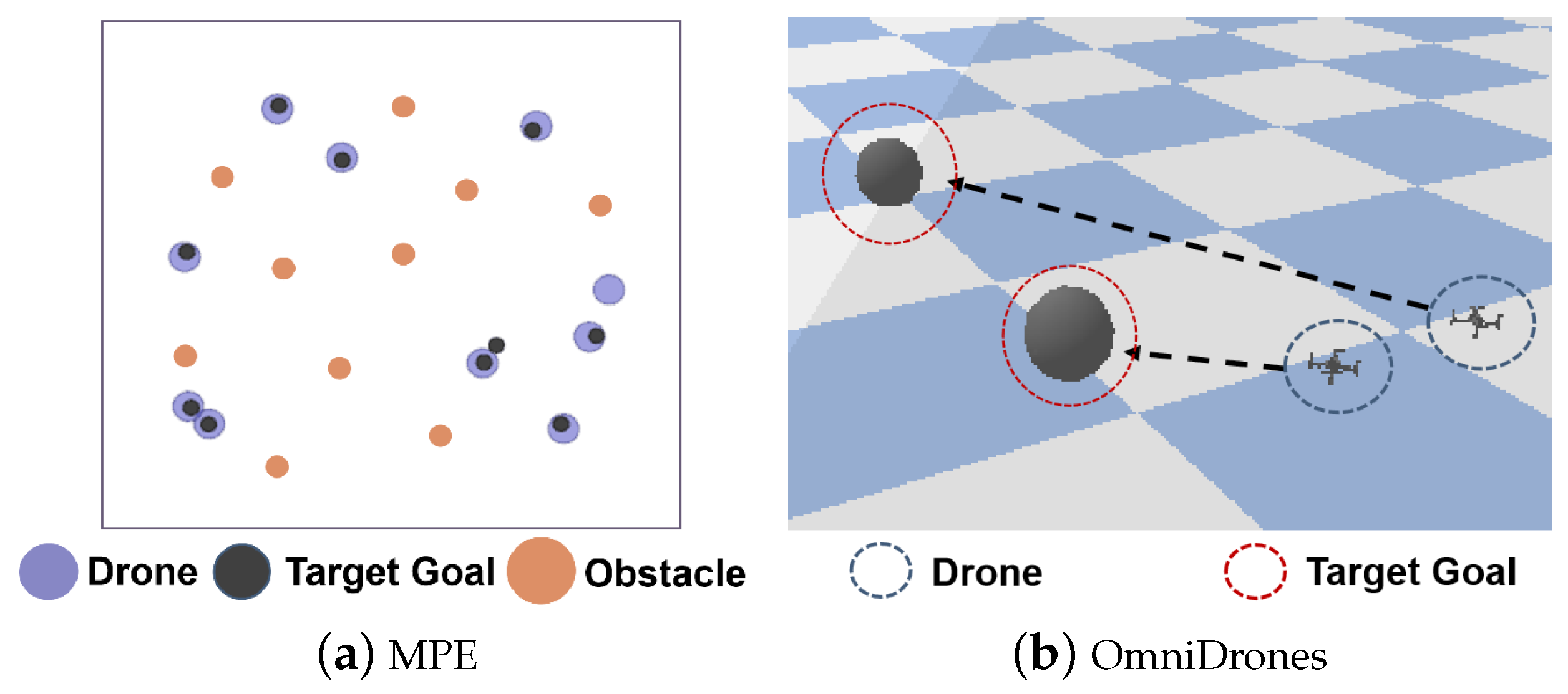
5.1. Testbeds
5.2. Implementation Details
5.3. Evaluation Metrics
- Success Rate (SR): This metric measures the average ratio of goals reached by the drones to the total goals per episode.
- Steps: This metric represents the average timesteps required to reach 100% Success Rate per episode.
- Collisions: This metric denotes the average number of collisions per step.
- Execution Time: This metric represents the time required for evaluation, measured in milliseconds (ms).
- Memory Usage: This metric represents the memory size required for evaluation, measured in Gigabyte (GB).
- Network Parameters: This metric refers to the number of network parameters needed for each RL-based method.
5.4. Baselines
- ORCA [7]: ORCA is an obstacle avoidance algorithm that excels in multi-UAV scenarios. It predicts the movements of surrounding obstacles and other drones, and then infers a collision-free velocity for each drone.
- Voronoi [9]: A Voronoi diagram comprises a set of continuous polygons, with a vertical bisector of lines connecting two adjacent points. By partitioning the map into Voronoi units, a safe path can be planned from the starting point to the destination.
- MAPPO [12]: MAPPO is a straightforward extension of PPO in the multi-agent setting, where each agent is equipped with a policy with a shared set of parameters. MAPPO is updated based on the aggregated trajectories from all drones. Additionally, an attention mechanism is applied to enhance the model’s performance.
- (H)MAPPO [12]: (H)MAPPO adopts a hierarchical framework, with the Hungarian algorithm as the high-level policy for goal assignment and MAPPO as the low-level policy for goal achievement.
- DARL1N [25]: DARL1N is under an independent decision-making setting for large-scale agent scenarios. It breaks the curse of dimensionality by restricting the agent interactions to one-hop neighborhoods. This method is extended to multi-UAV navigation tasks.
- HTAMP [38]: This is a hierarchical method for task and motion planning via reinforcement learning, integrating high-level task generation with low-level action execution.
- MAGE-X [14]: This is a hierarchical approach applied in multi-UAV navigation tasks. It first centrally allocates target goals to the drones at the beginning of the episode and then utilizes GNNs to construct a subgraph only with important neighbors for higher cooperation.
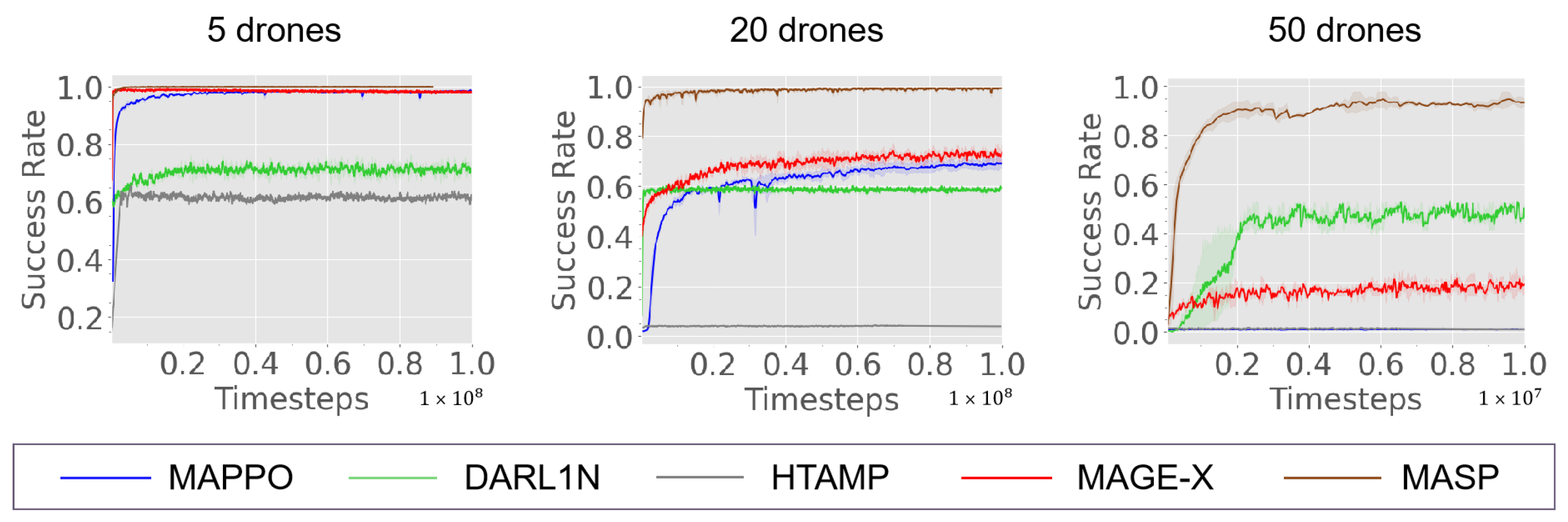
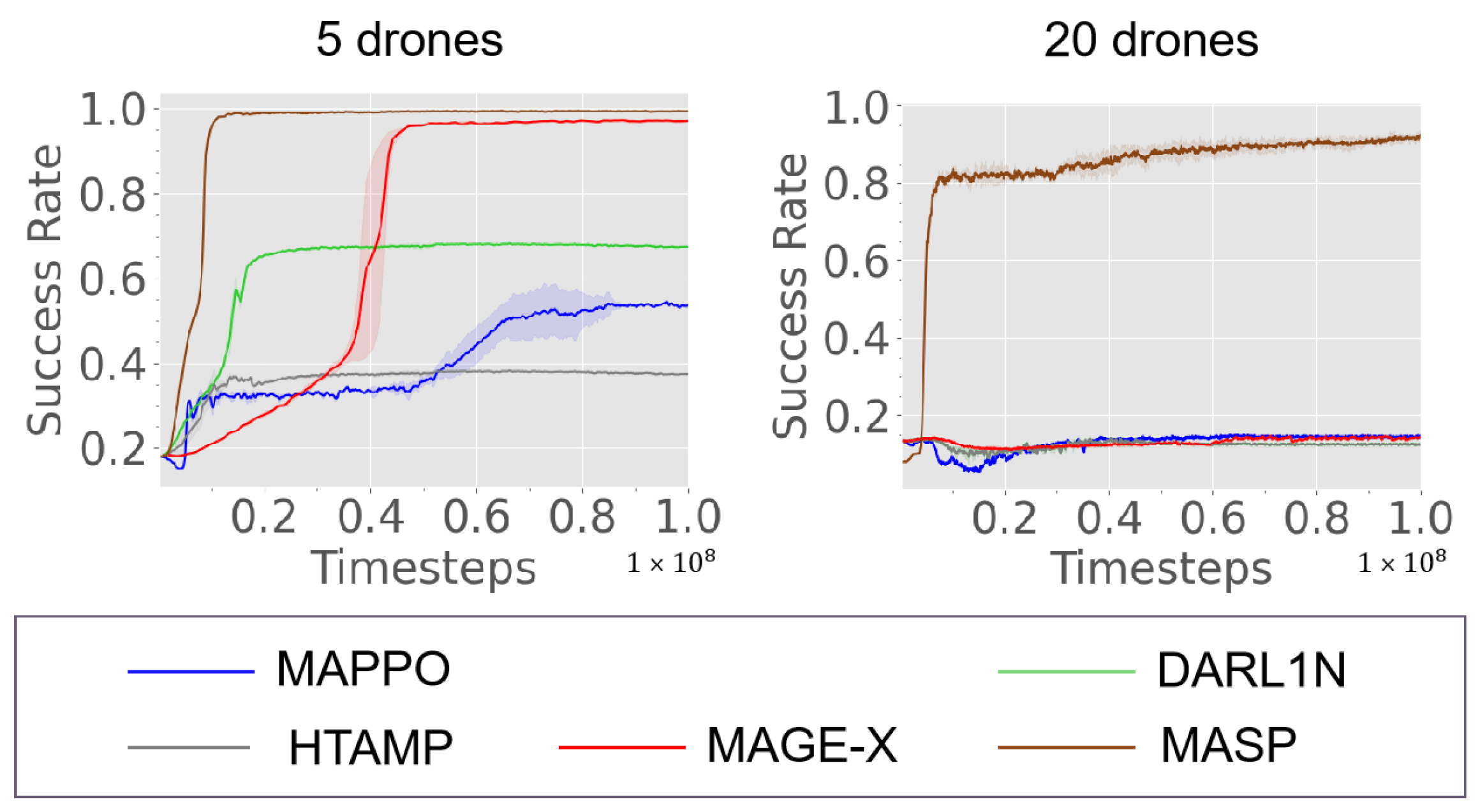
5.5. Main Results
5.5.1. Training with a Fixed Team Size
5.5.2. Varying Team Sizes Within an Episode
5.6. Robustness Evaluation in Noisy and Realistic Environments
5.7. Computational Cost
5.8. Sensitivity Analysis
5.9. Ablation Studies
- MASP w. RG: GM is replaced by random sampling, assigning each drone a random yet distinct goal.
- GM w.o. Graph: An MLP layer is adopted as an alternative to GM for assigning goals to drones at each high-level step. For drone k, the MLP layer takes in the concatenated position information of all drones and goals, with the position information of drone k listed first.
- CAE w.o. Graph: An MLP layer is employed as an alternative to CAE to capture the correlation between drones and goals. The input for drone k comprises the position of all drones and the assigned goal for drone k.
- MASP w. GraphSAGE: GM and Group Information Fusion module in CAE are replaced with GraphSAGE [54]. GraphSAGE generates embeddings by sampling and aggregating features from a node’s local neighborhood.
5.10. Strategies Analysis
6. Conclusions
7. Limitation
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September. 2018; pp. 370–386. [Google Scholar]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote. Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Menouar, H.; Guvenc, I.; Akkaya, K.; Uluagac, A.S.; Kadri, A.; Tuncer, A. UAV-enabled intelligent transportation systems for the smart city: Applications and challenges. IEEE Commun. Mag. 2017, 55, 22–28. [Google Scholar] [CrossRef]
- Maza, I.; Kondak, K.; Bernard, M.; Ollero, A. Multi-UAV cooperation and control for load transportation and deployment. In Proceedings of the Selected Papers from the 2nd International Symposium on UAVs, Reno, NE, USA, 8–10 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 417–449. [Google Scholar]
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. Lsar: Multi-uav collaboration for search and rescue missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Scherer, J.; Yahyanejad, S.; Hayat, S.; Yanmaz, E.; Andre, T.; Khan, A.; Vukadinovic, V.; Bettstetter, C.; Hellwagner, H.; Rinner, B. An autonomous multi-UAV system for search and rescue. In Proceedings of the First Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Florence, Italy, 18 May 2015; pp. 33–38. [Google Scholar]
- Chang, X.; Wang, J.; Li, K.; Zhang, X.; Tang, Q. Research on multi-UAV autonomous obstacle avoidance algorithm integrating improved dynamic window approach and ORCA. Sci. Rep. 2025, 15, 14646. [Google Scholar] [CrossRef]
- Wang, L.; Huang, W.; Li, H.; Li, W.; Chen, J.; Wu, W. A review of collaborative trajectory planning for multiple unmanned aerial vehicles. Processes 2024, 12, 1272. [Google Scholar] [CrossRef]
- Dong, Q.; Xi, H.; Zhang, S.; Bi, Q.; Li, T.; Wang, Z.; Zhang, X. Fast and Communication-Efficient Multi-UAV Exploration Via Voronoi Partition on Dynamic Topological Graph. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 14063–14070. [Google Scholar]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed energy-efficient multi-UAV navigation for long-term communication coverage by deep reinforcement learning. IEEE Trans. Mob. Comput. 2019, 19, 1274–1285. [Google Scholar] [CrossRef]
- Xue, Y.; Chen, W. Multi-agent deep reinforcement learning for UAVs navigation in unknown complex environment. IEEE Trans. Intell. Veh. 2023, 9, 2290–2303. [Google Scholar] [CrossRef]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.; Wu, Y. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games. arXiv 2021, arXiv:2103.01955. [Google Scholar]
- Wen, M.; Kuba, J.G.; Lin, R.; Zhang, W.; Wen, Y.; Wang, J.; Yang, Y. Multi-Agent Reinforcement Learning is a Sequence Modeling Problem. arXiv 2022, arXiv:2205.14953. [Google Scholar]
- Yang, X.; Huang, S.; Sun, Y.; Yang, Y.; Yu, C.; Tu, W.W.; Yang, H.; Wang, Y. Learning Graph-Enhanced Commander-Executor for Multi-Agent Navigation. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, London, UK, 29 May–2 June 2023; pp. 1652–1660. [Google Scholar]
- Zhao, X.; Yang, R.; Zhong, L.; Hou, Z. Multi-UAV path planning and following based on multi-agent reinforcement learning. Drones 2024, 8, 18. [Google Scholar] [CrossRef]
- Hofstätter, S.; Zamani, H.; Mitra, B.; Craswell, N.; Hanbury, A. Local self-attention over long text for efficient document retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 2021–2024. [Google Scholar]
- Yu, C.; Yang, X.; Gao, J.; Yang, H.; Wang, Y.; Wu, Y. Learning efficient multi-agent cooperative visual exploration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 497–515. [Google Scholar]
- Yang, X.; Yang, Y.; Yu, C.; Chen, J.; Yu, J.; Ren, H.; Yang, H.; Wang, Y. Active neural topological mapping for multi-agent exploration. IEEE Robot. Autom. Lett. 2023, 9, 303–310. [Google Scholar] [CrossRef]
- Hu, S.; Zhu, F.; Chang, X.; Liang, X. UPDeT: Universal Multi-agent RL via Policy Decoupling with Transformers. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Xu, B.; Gao, F.; Yu, C.; Zhang, R.; Wu, Y.; Wang, Y. OmniDrones: An Efficient and Flexible Platform for Reinforcement Learning in Drone Control. arXiv 2023, arXiv:2309.12825. [Google Scholar] [CrossRef]
- Ye, Z.; Wang, K.; Chen, Y.; Jiang, X.; Song, G. Multi-UAV navigation for partially observable communication coverage by graph reinforcement learning. IEEE Trans. Mob. Comput. 2022, 22, 4056–4069. [Google Scholar] [CrossRef]
- Causa, F.; Vetrella, A.R.; Fasano, G.; Accardo, D. Multi-UAV formation geometries for cooperative navigation in GNSS-challenging environments. In Proceedings of the 2018 IEEE/ION position, location and navigation symposium (PLANS), Monterey, CA, USA, 23–26 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 775–785. [Google Scholar]
- Li, Q.; Gama, F.; Ribeiro, A.; Prorok, A. Graph neural networks for decentralized multi-robot path planning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NE, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11785–11792. [Google Scholar]
- Wang, B.; Xie, J.; Atanasov, N. Darl1n: Distributed multi-agent reinforcement learning with one-hop neighbors. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 9003–9010. [Google Scholar]
- Wang, W.; Wang, L.; Wu, J.; Tao, X.; Wu, H. Oracle-guided deep reinforcement learning for large-scale multi-UAVs flocking and navigation. IEEE Trans. Veh. Technol. 2022, 71, 10280–10292. [Google Scholar] [CrossRef]
- Cheng, J.; Li, N.; Wang, B.; Bu, S.; Zhou, M. High-Sample-Efficient Multiagent Reinforcement Learning for Navigation and Collision Avoidance of UAV Swarms in Multitask Environments. IEEE Internet Things J. 2024, 11, 36420–36437. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Turpin, M.; Mohta, K.; Michael, N.; Kumar, V. Goal assignment and trajectory planning for large teams of interchangeable robots. Auton. Robot. 2014, 37, 401–415. [Google Scholar] [CrossRef]
- Wagner, G.; Choset, H. M*: A complete multirobot path planning algorithm with performance bounds. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3260–3267. [Google Scholar]
- Chen, D.; Qi, Q.; Fu, Q.; Wang, J.; Liao, J.; Han, Z. Transformer-based reinforcement learning for scalable multi-UAV area coverage. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10062–10077. [Google Scholar] [CrossRef]
- Wei, A.; Liang, J.; Lin, K.; Li, Z.; Zhao, R. DTPPO: Dual-Transformer Encoder-Based Proximal Policy Optimization for Multi-UAV Navigation in Unseen Complex Environments. arXiv 2024, arXiv:2410.15205. [Google Scholar]
- Ji, Y.; Li, Z.; Sun, Y.; Peng, X.B.; Levine, S.; Berseth, G.; Sreenath, K. Hierarchical reinforcement learning for precise soccer shooting skills using a quadrupedal robot. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1479–1486. [Google Scholar]
- Nasiriany, S.; Liu, H.; Zhu, Y. Augmenting reinforcement learning with behavior primitives for diverse manipulation tasks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7477–7484. [Google Scholar]
- Takubo, Y.; Chen, H.; Ho, K. Hierarchical reinforcement learning framework for stochastic spaceflight campaign design. J. Spacecr. Rocket. 2022, 59, 421–433. [Google Scholar] [CrossRef]
- Pope, A.P.; Ide, J.S.; Mićović, D.; Diaz, H.; Rosenbluth, D.; Ritholtz, L.; Twedt, J.C.; Walker, T.T.; Alcedo, K.; Javorsek, D. Hierarchical reinforcement learning for air-to-air combat. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 15–18 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 275–284. [Google Scholar]
- Hafner, D.; Lee, K.H.; Fischer, I.; Abbeel, P. Deep hierarchical planning from pixels. Adv. Neural Inf. Process. Syst. 2022, 35, 26091–26104. [Google Scholar]
- Newaz, A.A.R.; Alam, T. Hierarchical Task and Motion Planning through Deep Reinforcement Learning. In Proceedings of the 2021 Fifth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 15–17 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 100–105. [Google Scholar]
- Cheng, Y.; Li, D.; Wong, W.E.; Zhao, M.; Mo, D. Multi-UAV collaborative path planning using hierarchical reinforcement learning and simulated annealing. Int. J. Perform. Eng. 2022, 18, 463. [Google Scholar]
- Yuan, Y.; Yang, J.; Yu, Z.L.; Cheng, Y.; Jiao, P.; Hua, L. Hierarchical goal-guided learning for the evasive maneuver of fixed-wing uavs based on deep reinforcement learning. J. Intell. Robot. Syst. 2023, 109, 43. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Liu, Y.; Zeng, K.; Wang, H.; Song, X.; Zhou, B. Content matters: A GNN-based model combined with text semantics for social network cascade prediction. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Virtual Event, 11–14 May 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 728–740. [Google Scholar]
- Zhang, S.; Liu, Y.; Xie, L. Molecular mechanics-driven graph neural network with multiplex graph for molecular structures. arXiv 2020, arXiv:2011.07457. [Google Scholar]
- Jiang, Z.; Chen, Y.; Wang, K.; Yang, B.; Song, G. A Graph-Based PPO Approach in Multi-UAV Navigation for Communication Coverage. Int. J. Comput. Commun. Control. 2023, 18, 5505. [Google Scholar] [CrossRef]
- Du, Y.; Qi, N.; Li, X.; Xiao, M.; Boulogeorgos, A.A.A.; Tsiftsis, T.A.; Wu, Q. Distributed multi-UAV trajectory planning for downlink transmission: A GNN-enhanced DRL approach. IEEE Wirel. Commun. Lett. 2024, 13, 3578–3582. [Google Scholar] [CrossRef]
- Zhao, B.; Huo, M.; Li, Z.; Yu, Z.; Qi, N. Graph-based multi-agent reinforcement learning for large-scale UAVs swarm system control. Aerosp. Sci. Technol. 2024, 150, 109166. [Google Scholar] [CrossRef]
- Wu, D.; Cao, Z.; Lin, X.; Shu, F.; Feng, Z. A Learning-based Cooperative Navigation Approach for Multi-UAV Systems Under Communication Coverage. IEEE Trans. Netw. Sci. Eng. 2024, 12, 763–773. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.Z.; Kaiser, L. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Gerkey, B.P.; Matarić, M.J. A formal analysis and taxonomy of task allocation in multi-robot systems. Int. J. Robot. Res. 2004, 23, 939–954. [Google Scholar] [CrossRef]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10076–10085. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Furrer, F.; Burri, M.; Achtelik, M.; Siegwart, R. Rotors—A modular gazebo mav simulator framework. In Robot Operating System (ROS) The Complete Reference (Volume 1); Springer: Berlin/Heidelberg, Germany, 2016; pp. 595–625. [Google Scholar]
- Kuffner, J.J.; LaValle, S.M. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065); IEEE: Piscataway, NJ, USA, 2000; Volume 2, pp. 995–1001. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How Attentive are Graph Attention Networks? In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022.
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Na, H.; Moon, I.C. LAGMA: Latent goal-guided multi-agent reinforcement learning. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 37122–37140. [Google Scholar]
- Zhang, Q.; Zhang, H.; Xing, D.; Xu, B. Latent Landmark Graph for Efficient Exploration-exploitation Balance in Hierarchical Reinforcement Learning. In Machine Intelligence Research; Springer: Berlin/Heidelberg, Germany, 2025; pp. 1–22. [Google Scholar]
- Tan, D.M.S.; Ma, Y.; Liang, J.; Chng, Y.C.; Cao, Y.; Sartoretti, G. IR 2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 13245–13252. [Google Scholar]
- Alvarez, J.; Belbachir, A. Dynamic Position Estimation and Flocking Control in Multi-Robot Systems. In Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics, SCITEPRESS-Science and Technology Publications, Porto, Portugal, 18–20 November 2024; pp. 269–276. [Google Scholar]
- Deng, T.; Shen, G.; Xun, C.; Yuan, S.; Jin, T.; Shen, H.; Wang, Y.; Wang, J.; Wang, H.; Wang, D.; et al. MNE-SLAM: Multi-Agent Neural SLAM for Mobile Robots. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 1485–1494. [Google Scholar]
- Blumenkamp, J.; Morad, S.; Gielis, J.; Prorok, A. CoViS-Net: A Cooperative Visual Spatial Foundation Model for Multi-Robot Applications. In Proceedings of the 8th Annual Conference on Robot Learning, Munich, Germany, 6–9 November 2024. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agents | Metrics | (H)ORCA | (H)RRT* | (H)Voronoi | (H)MAPPO | MAPPO | DARL1N | HTAMP | MAGE-X | MASP |
|---|---|---|---|---|---|---|---|---|---|---|
| N = 5 | Steps↓ | 16.38(0.53) | 7.58(1.49) | 8.86(1.27) | 8.04(1.53) | 8.69(1.24) | ∖ | ∖ | 14.75(0.60) | 7.54(1.37) |
| SR↑ | 0.72(0.01) | 0.99(0.01) | 0.98(0.01) | 1.00(0.00) | 1.00(0.00) | 0.74(0.02) | 0.65(0.05) | 1.00(0.00) | 1.00(0.00) | |
| Collisions↓ | 0.57(0.03) | 3.41(0.14) | 3.44(0.25) | 0.42(0.02) | 1.32(0.38) | 2.80(0.53) | 1.63(0.43) | 0.45(0.02) | 0.47(0.01) | |
| N = 20 | Steps↓ | 34.28(3.22) | 26.86(2.27) | 28.72(2.68) | 27.43(2.49) | ∖ | ∖ | ∖ | ∖ | 24.41(2.66) |
| SR↑ | 0.95(0.03) | 0.99(0.01) | 1.00(0.00) | 1.00(0.00) | 0.71(0.02) | 0.62(0.03) | 0.05(0.01) | 0.75(0.02) | 1.00(0.00) | |
| Collisions↓ | 0.49(0.04) | 1.69(0.05) | 1.80(0.03) | 0.75(0.05) | 2.53(1.02) | 3.22(1.23) | 1.54(0.05) | 1.78(0.14) | 0.14(0.01) | |
| N = 50 | Steps↓ | 60.66(4.76) | 58.68(3.89) | 57.88(5.43) | 51.88(4.06) | ∖ | ∖ | ∖ | ∖ | 47.46(5.93) |
| SR↑ | 0.97(0.01) | 0.99(0.01) | 0.99(0.01) | 0.99(0.01) | 0.01(0.01) | 0.49(0.02) | 0.02(0.01) | 0.23(0.01) | 0.99(0.01) | |
| Collisions↓ | 0.30(0.02) | 1.39(0.14) | 1.31(0.42) | 0.42(0.75) | 0.78(0.26) | 1.14(0.34) | 1.35(0.21) | 1.69(0.37) | 0.23(0.01) |
| Agents | Metrics | (H)ORCA | (H)RRT* | (H)Voronoi | (H)MAPPO | MAPPO | DARL1N | HTAMP | MAGE-X | MASP |
|---|---|---|---|---|---|---|---|---|---|---|
| N = 5 | Steps↓ | 260.10(10.02) | 236.10(9.47) | 173.89(12.91) | 185.34(7.14) | ∖ | ∖ | ∖ | 231.26(19.32) | 138.35(13.57) |
| SR↑ | 0.98(0.03) | 0.97(0.01) | 0.99(0.02) | 1.00(0.00) | 0.50(0.09) | 0.68(0.02) | 0.32(0.08) | 0.99(0.01) | 1.00(0.00) | |
| Collisions↓ | 0.00(0.00) | 0.01(0.01) | 0.02(0.01) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) | 0.00(0.00) | |
| N = 20 | Steps↓ | 449.10(14.86) | 438.23(11.02) | 437.43(14.24) | 335.74(13.07) | ∖ | ∖ | ∖ | ∖ | 315.31(14.52) |
| SR↑ | 0.97(0.03) | 0.97(0.01) | 0.93(0.01) | 0.96(0.01) | 0.15(0.03) | 0.15(0.01) | 0.14(0.03) | 0.14(0.03) | 0.97(0.01) | |
| Collisions↓ | 0.01(0.03) | 0.03(0.03) | 0.01(0.03) | 0.01(0.01) | 0.03(0.02) | 0.05(0.01) | 0.04(0.02) | 0.08(0.02) | 0.01(0.01) |
| Agents | Metrics | (H)ORCA | (H)RRT* | (H)Voronoi | MASP |
|---|---|---|---|---|---|
| Steps↓ | 43.64(3.86) | 40.68(3.37) | 40.18(3.41) | 22.38(3.04) | |
| SR↑ | 0.89(0.01) | 0.92(0.01) | 0.93(0.01) | 1.00(0.00) | |
| Collisions↓ | 0.18(0.02) | 0.72(0.14) | 0.86(0.13) | 0.16(0.03) | |
| Steps↓ | ∖ | 89.18(4.88) | 88.73(4.27) | 46.49(4.49) | |
| SR↑ | 0.86(0.01) | 0.91(0.01) | 0.91(0.02) | 1.00(0.00) | |
| Collisions↓ | 0.15(0.03) | 0.56(0.05) | 0.67(0.03) | 0.15(0.01) |
| Agents | Metrics | (H)ORCA | (H)RRT* | (H)Voronoi | MASP |
|---|---|---|---|---|---|
| Steps↓ | ∖ | ∖ | 490.35(15.63) | 426.73(18.50) | |
| SR↑ | 0.68(0.04) | 0.61(0.04) | 0.85(0.03) | 0.94(0.01) | |
| Collisions↓ | 0.00(0.00) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) |
| Agents | Metrics | (H)ORCA | (H)RRT* | (H)Voronoi | MASP |
|---|---|---|---|---|---|
| Steps↓ | 228.05(14.52) | 269.20(13.78) | 203.65(10.71) | 146.38(10.83) | |
| SR↑ | 0.94(0.02) | 0.87(0.03) | 0.93(0.02) | 0.98(0.02) | |
| Collisions↓ | 0.01(0.01) | 0.02(0.01) | 0.01(0.01) | 0.01(0.01) | |
| Steps↓ | 408.10(10.40) | 484.50(16.95) | 453.35(13.38) | 334.62(11.53) | |
| SR↑ | 0.98(0.02) | 0.92(0.02) | 0.91(0.03) | 0.96(0.01) | |
| Collisions↓ | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) | |
| Steps↓ | ∖ | ∖ | ∖ | 439.62(13.02) | |
| SR↑ | 0.75(0.02) | 0.57(0.02) | 0.85(0.02) | 0.90(0.01) | |
| Collisions↓ | 0.02(0.01) | 0.01(0.01) | 0.01(0.01) | 0.01(0.01) |
| Agents | Metrics | GM | CAE | MASP |
|---|---|---|---|---|
| N = 100 | Memory Usage↓ | 1.28 | 0.72 | 2 |
| Execution Time↓ | 11(1) | 7(1) | 18(2) |
| Methods | ORCA | RRT* | Voronoi | MAPPO | DARL1N | HTAMP | MAGE-X | MASP |
|---|---|---|---|---|---|---|---|---|
| Execution Time↓ | 39(6) | 456(10) | 44(5) | 13(4) | 16(3) | 14(3) | 20(5) | 14(2) |
| Agents | Metrics | 2 | 3 | 5 |
|---|---|---|---|---|
| N = 20 | Steps↓ | 28.85(2.12) | 24.41(2.66) | 23.78(2.35) |
| SR↑ | 1.00(0.00) | 1.00(0.00) | 1.00(0.00) | |
| Collisions↓ | 0.15(0.01) | 0.14(0.01) | 0.14(0.01) | |
| Network Parameters↓ | P | ~2P | ~5P |
| Agents | Metrics | 1 | 3 | 10 |
|---|---|---|---|---|
| N = 20 | Steps↓ | 24.23(2.11) | 24.41(2.66) | 29.59(2.43) |
| SR↑ | 1.00(0.00) | 1.00(0.00) | 1.00(0.00) | |
| Collisions↓ | 0.12(0.01) | 0.14(0.01) | 0.16(0.01) | |
| Execution Time↓ | 45(7) | 13(4) | 4(2) |
| Agents | Metrics | 8 | 32 | 64 |
|---|---|---|---|---|
| N = 20 | Steps↓ | 28.66(2.73) | 24.41(2.66) | 24.82(2.00) |
| SR↑ | 1.00(0.00) | 1.00(0.00) | 1.00(0.00) | |
| Collisions↓ | 0.18(0.01) | 0.14(0.01) | 0.13(0.01) | |
| Network Parameters↓ | P | ~4P | ~9P |
| Agents | Metrics | MASP w. RG | GM w.o. Graph | CAE w.o. Graph | MASP w. GraphSAGE | MASP w. GATv2 | MASP |
|---|---|---|---|---|---|---|---|
| N = 20 | Steps↓ | 35.91(2.73) | ∖ | 28.25(3.21) | 38.97(3.22) | 28.17(2.40) | 24.41(2.66) |
| SR↑ | 1.00(0.00) | 0.04(0.01) | 1.00(0.00) | 0.85(0.04) | 0.98(0.03) | 1.00(0.00) | |
| Collisions↓ | 0.25(0.02) | 3.32(0.02) | 0.17(0.01) | 1.26(0.03) | 0.83(0.02) | 0.14(0.01) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yang, X.; Yu, C.; Chen, J.; Ding, W.; Yang, H.; Wang, Y. MASP: Scalable Graph-Based Planning Towards Multi-UAV Navigation. Drones 2025, 9, 463. https://doi.org/10.3390/drones9070463
Yang X, Yang X, Yu C, Chen J, Ding W, Yang H, Wang Y. MASP: Scalable Graph-Based Planning Towards Multi-UAV Navigation. Drones. 2025; 9(7):463. https://doi.org/10.3390/drones9070463
Chicago/Turabian StyleYang, Xinyi, Xinting Yang, Chao Yu, Jiayu Chen, Wenbo Ding, Huazhong Yang, and Yu Wang. 2025. "MASP: Scalable Graph-Based Planning Towards Multi-UAV Navigation" Drones 9, no. 7: 463. https://doi.org/10.3390/drones9070463
APA StyleYang, X., Yang, X., Yu, C., Chen, J., Ding, W., Yang, H., & Wang, Y. (2025). MASP: Scalable Graph-Based Planning Towards Multi-UAV Navigation. Drones, 9(7), 463. https://doi.org/10.3390/drones9070463