1. Introduction
As a core component of future transportation systems, Intelligent Connected Vehicles (ICVs) are driving rapid advancements in onboard intelligent services, including advanced driver assistance systems, real-time route planning, and in-vehicle infotainment [
1]. While these services enhance driving safety and user experience, they also impose stringent computational demands on vehicles. Due to limited onboard computing resources and energy constraints, processing computation-intensive tasks locally often leads to severe computational overload and excessive power consumption, making it difficult to meet real-time requirements. Although offloading tasks to remote cloud servers presents a potential solution, the long-distance deployment of cloud infrastructure introduces significant transmission delays and backhaul energy consumption, particularly unsuitable for latency-sensitive vehicular applications [
2]. MEC technology, which brings computing and storage resources closer to the network edge, offers a promising alternative [
3]. In this context, UAV-assisted vehicular MEC systems leverage their high mobility, flexible coverage, and Line-of-Sight (LoS) communication advantages to provide on-demand edge services for high-speed vehicles, effectively addressing the limitations of traditional ground-based MEC infrastructure, such as high deployment costs and restricted coverage [
4].
In UAV-assisted vehicular MEC systems, content caching plays a crucial role in reducing service latency and improving user experience. Existing research primarily focuses on optimizing caching strategies based on content popularity or user mobility to maximize cache hit rates or minimize content delivery delays [
5,
6]. For instance, in [
7], Choi Y and Lim Y utilized deep reinforcement learning (DRL) to optimize edge caching in vehicular networks by predicting user mobility, aiming to minimize content delivery delays. However, most of these works consider content caching in isolation, overlooking the dependencies between computational service caching and task offloading decisions. For example, works like [
7] primarily focus on caching optimization, while studies such as [
8] by S Yu et al. concentrate on developing task offloading strategies for connected vehicles, often considering these aspects in isolation and thus overlooking their inherent dependencies [
9]. In practice, vehicles not only require access to content data but also rely on specific computational services for task execution [
10]. Successful task processing necessitates that edge nodes cache both the required service programs and relevant data, necessitating a co-optimization of caching and offloading strategies [
11,
12]. To address this, recent efforts, including [
13] by K Xue et al., have begun to explore co-optimization of task offloading and multi-cache placement in UAV-assisted MEC networks, recognizing the joint requirement for service programs and data. Similarly, Ref. [
14] by X Wang proposed a joint task offloading and resource allocation framework in medical vehicular networks, demonstrating the trend towards integrated solutions. Meanwhile, a common limitation in many existing task offloading studies, such as [
15] by M Hong et al., which focuses on energy-efficient data offloading in high-mobility vehicular MEC environments, is the implicit assumption that necessary services are always pre-deployed at edge nodes, thereby overlooking the critical impact of service availability on offloading feasibility. Such fragmented optimization approaches struggle to achieve optimal performance.
Furthermore, UAV flight trajectories directly influence communication quality, coverage range, and energy consumption, significantly affecting caching efficiency and offloading performance [
16]. For instance, in [
17], Bi X and Zhao L designed a two-layer edge intelligence framework for UAV-assisted vehicular networks, explicitly considering how UAV trajectories impact task offloading and computing capacity allocation. Moreover, studies like [
18] by F Shen et al. have focused on TD3-based trajectory optimization for energy consumption minimization in UAV-assisted MEC systems, and [
19] by E Pei et al. optimized resource and trajectory for UAV-assisted MEC communication, underscoring the direct link between UAV movement and system performance. Beyond these, recent works have also explored UAV trajectory optimization for specific objectives in diverse scenarios. For example, Ref. [
20] focused on ordered submodularity-based value maximization for UAV data collection in earthquake areas, while [
21] investigated reward maximization for disaster zone monitoring with heterogeneous UAVs. These studies highlight the critical role of UAV trajectory planning in achieving various system goals. Therefore, to fully exploit the potential of UAV-assisted vehicular MEC, a joint optimization of caching strategies, task offloading, and UAV trajectory planning is essential. Acknowledging this complexity, a holistic approach is warranted, necessitating a joint optimization of caching strategies, task offloading, and UAV trajectory planning. For example, Ref. [
4] by M Abdel-Basset et al. proposed an intelligent joint optimization of deployment (implying trajectory) and task scheduling for multi-UAV-assisted MEC systems, and [
22] by MF Dehkordi et al. explored efficient and sustainable task offloading in UAV-assisted MEC systems using meta deep reinforcement learning, implicitly integrating aspects of trajectory and resource management. This joint optimization problem exhibits high dynamism and complexity, involving discrete caching and offloading decisions alongside continuous trajectory variables. Traditional optimization methods, such as convex optimization or integer programming, face substantial challenges due to the non-convexity and high dimensionality of the problem, making real-time decision-making in dynamic environments difficult. For instance, while methods like those in [
23] by L Shao apply optimization techniques to UAV-assisted MEC systems for security and resource allocation, the inherent non-convexity and dynamic nature of jointly optimizing caching, offloading, and trajectory often render classical approaches computationally intractable for real-time scenarios.
DRL, leveraging its adaptability to dynamic environments and capability to handle high-dimensional decision spaces, provides a novel approach to solving such complex optimization problems. Multi-Agent DRL (MADRL) extends this capability further, making it suitable for collaborative optimization scenarios involving multiple UAVs and vehicles [
6]. Recent advancements have seen MADRL effectively applied to various aspects of UAV-aided MEC and resource management. For instance, Li et al. [
24,
25] extensively investigated the energy-efficient computation offloading problem in multi-UAV-assisted Internet of Things (IoT) networks over the Terahertz (THz) band. They jointly optimized UAV trajectories, user equipment (UE), local central processing unit (CPU) clock speeds, UAV–UE associations, time slot slicing, and UE offloading powers through a tailored MADRL solution, DSPAC-MN. Their work notably focused on maximizing energy efficiency in THz communications and ensuring safe UAV flights, even incorporating a more practical ITU-suggested building distribution model [
24] into their channel modeling.
However, existing MADRL methods still exhibit notable limitations when addressing joint optimization in vehicular networks: most studies focus on optimizing only one or two aspects among offloading [
26], caching [
27], and trajectory planning [
28], failing to achieve comprehensive joint optimization [
29], and widely used algorithms (such as Multi-Agent Deep Deterministic Policy Gradient (MADDPG) [
6], Deep Q-Learning Network (DQN) [
30], Actor Critic (AC) [
31], and Deep Deterministic Policy Gradient (DDPG) [
32]) suffer from training instability and hyperparameter sensitivity, limiting their effectiveness in complex vehicular environments. Particularly, in scenarios where task execution depends on cached services, existing algorithms struggle to manage multi-agent coordination and non-stationarity effectively.
To address the aforementioned challenges, particularly the fragmented optimization of existing approaches and the inherent instability of current MADRL algorithms in dynamic vehicular environments where task execution depends on cached services, this paper proposes a MADRL problem tailored for joint optimization in UAV-assisted vehicular networks. Unlike existing studies that often overlook the strong interdependencies or optimize only one or two aspects among offloading, caching, and trajectory planning, our problem achieves comprehensive joint optimization of content and service caching, computation offloading decisions, and UAV trajectories, explicitly accounting for task dependencies on cached services. We precisely model this highly dynamic and complex problem as a Dec-POMDP, which effectively captures system dynamics and multi-agent interactions. Furthermore, to overcome the training instability and hyperparameter sensitivity observed in widely used MADRL algorithms like MADDPG, we employ a MAPPO algorithm. This algorithm operates under a CTDE paradigm, balancing efficient learning with robust real-world deployment.
Table 1 summarizes and compares our contributions in the field of UAV-assisted MEC with the current state-of-the-art in this domain. The key contributions of this work include the following:
We propose a comprehensive joint optimization problem for UAV-assisted vehicular networks, precisely modeled as a Dec-POMDP to capture dynamic environments and complex agent interactions. The model thoroughly considers UAVs’ roles in service and content caching and vehicular computation offloading, while simultaneously accounting for cache hit rate, computation delay, and system energy consumption. To balance these conflicting metrics and ensure fairness, we innovatively introduce “system efficiency” as a holistic and unified performance indicator. This metric comprehensively considers cache hit rate, task computation latency, system energy consumption, and resource allocation fairness, and is balanced through appropriate weighting. The ultimate objective is to maximize overall system efficiency by jointly optimizing UAV caching strategies, vehicular computation offloading decisions, and UAV flight trajectories within the Dec-POMDP framework.
To address the complex Dec-POMDP model, we propose a MAPPO reinforcement learning algorithm. It efficiently solves the problem through innovative state space design and refined reward shaping mechanisms. The state space comprehensively includes UAV locations, caching states, vehicular service requests, network resource status, and real-time channel quality, providing agents with complete environmental awareness. Beyond positive rewards for service efficiency, the reward mechanism meticulously designs various penalty terms for exceeding UAV flight areas, excessive energy consumption, latency, and unfair resource allocation. These designs effectively constrain agent behavior, ensuring learning stability, accelerating convergence, and enabling optimal decisions in dynamic environments, significantly improving system performance.
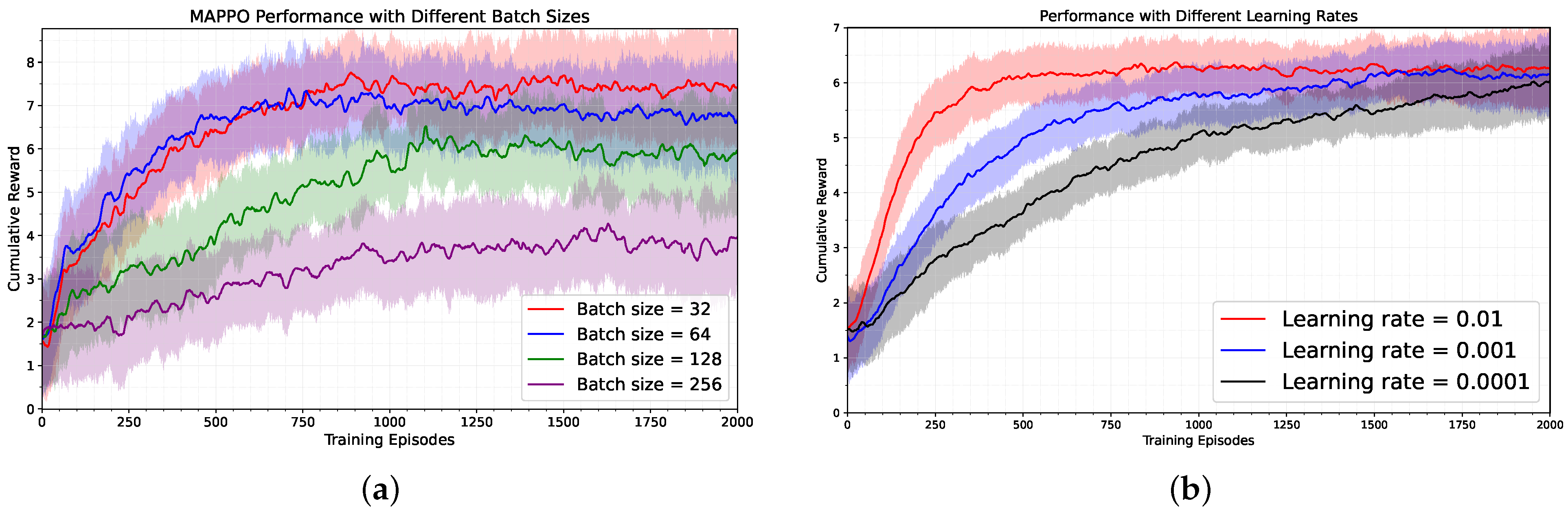
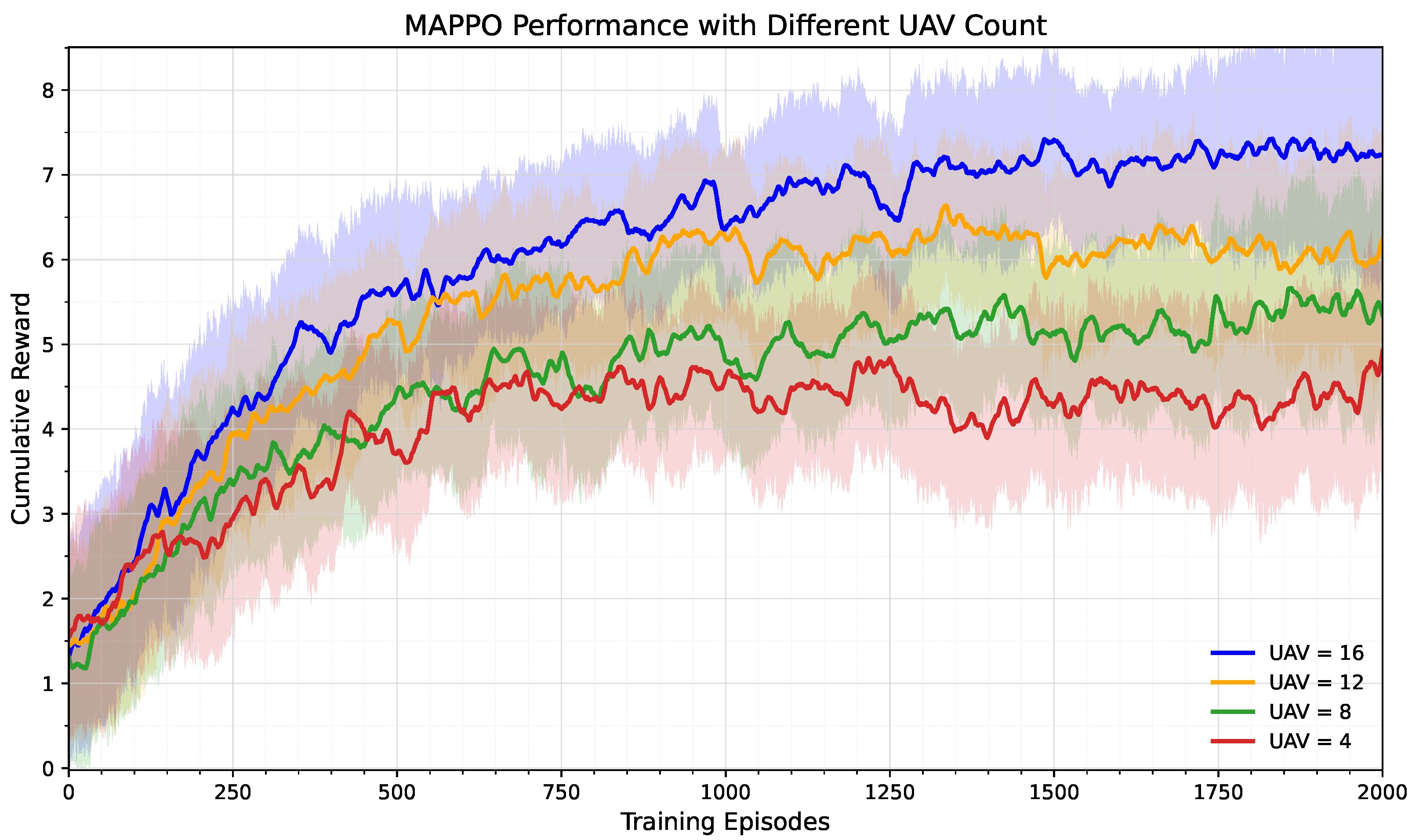
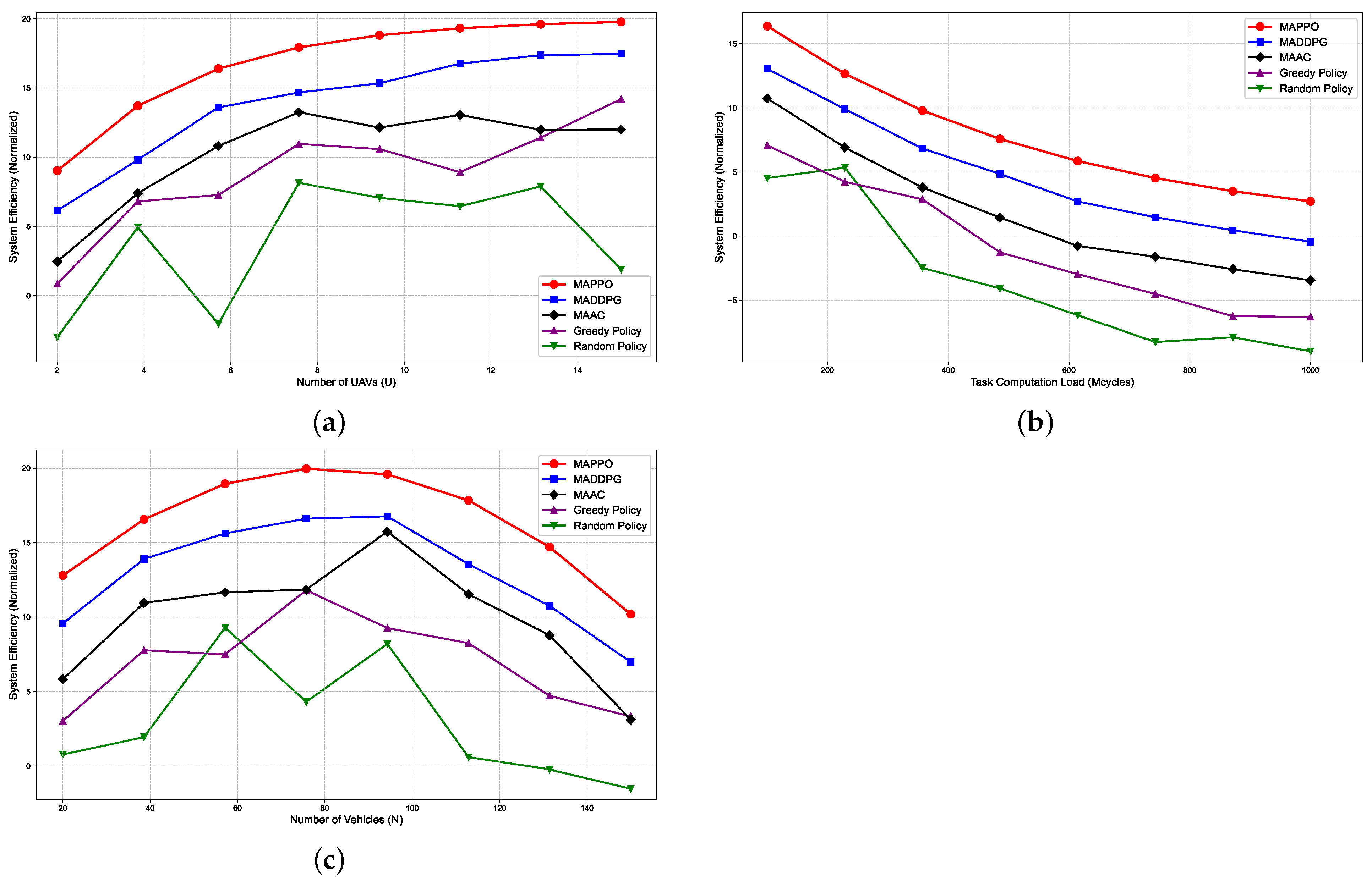
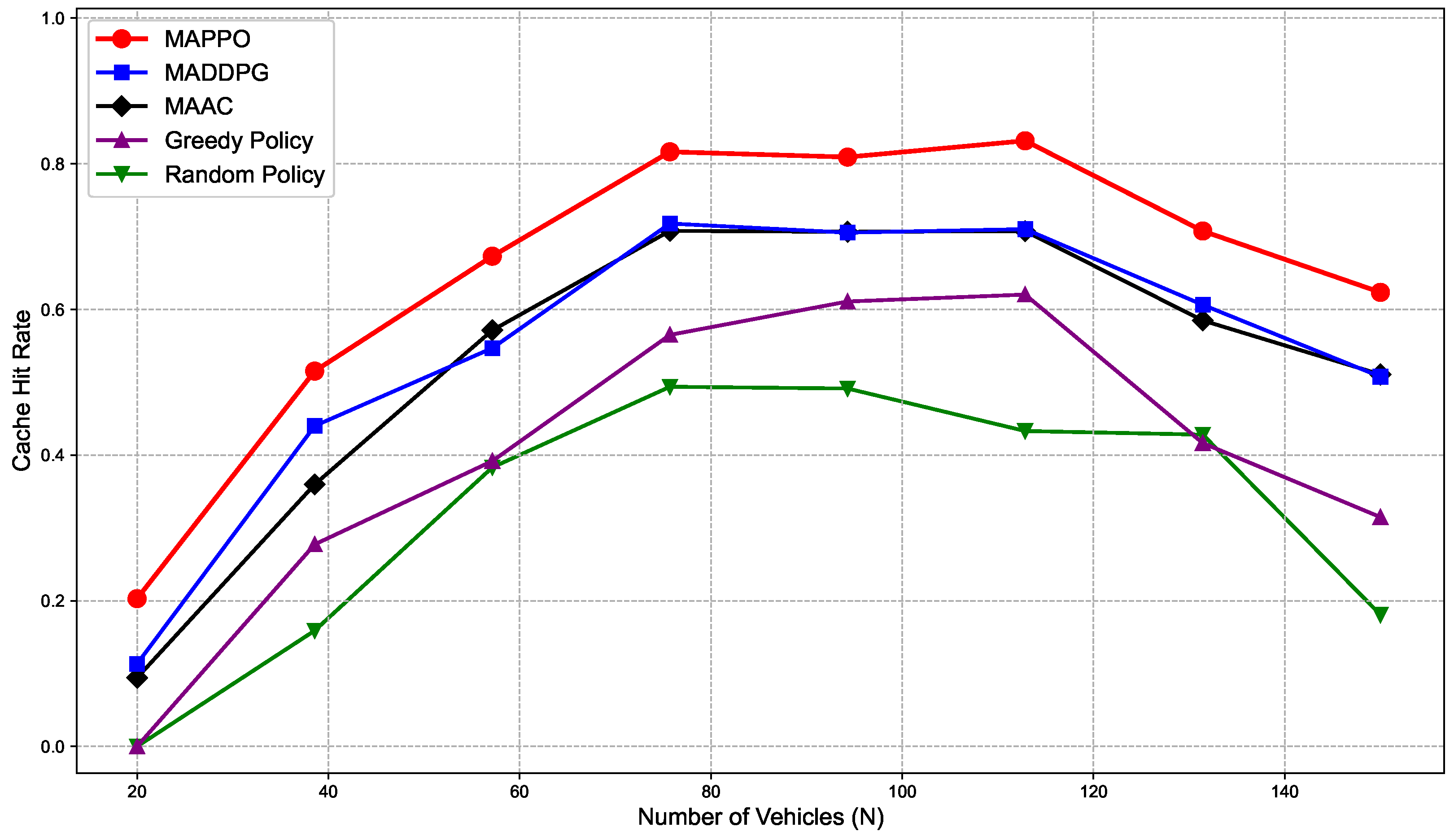
To comprehensively validate the effectiveness, robustness, and practical feasibility of the proposed joint optimization problem and reinforcement learning algorithm, extensive system simulations were conducted. The simulation results clearly demonstrate our method’s significant advantages in improving the service efficiency of UAV-assisted vehicular networks, specifically in reducing user task computation delay, decreasing overall system energy consumption, increasing content and service hit rates, and ensuring fair resource allocation. Comparative analysis across different network scenarios, vehicle densities, and UAV configurations further validates the crucial role of the innovative state space design and reward shaping mechanisms in training stability and algorithm convergence speed. These detailed results provide strong quantitative support for our solution’s practicality and superiority.
Table 1.
Comparison of our contributions to the state-of-the-art related literature.
Table 1.
Comparison of our contributions to the state-of-the-art related literature.
| | [4] | [9] | [22] | [23] | [24] | [25] | [27] | [28] | [31] | [32] | Ours |
|---|
| UAV-Assisted Vehicle Networks | | | ✔ | ✔ | | | | | ✔ | ✔ | ✔ |
| Multi-UAV Cooperation | ✔ | ✔ | | | | | ✔ | ✔ | ✔ | ✔ | ✔ |
| Service Caching | | | ✔ | ✔ | | | | | ✔ | ✔ | ✔ |
| Content Caching | | | ✔ | ✔ | | | | | ✔ | ✔ | ✔ |
| Computation Offloading | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| UAV Trajectory Optimization | ✔ | ✔ | | | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| DRL-based Solution |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
The remainder of this paper is organized as follows:
Section 2 details the system model and problem formulation.
Section 3 presents the MAPPO-based joint optimization algorithm.
Section 4 evaluates performance through experiments, and
Section 5 concludes the paper and discusses future directions.
2. System Model and Problem Formulation
In this section, we first introduce the UAV-assisted Internet of Vehicles (IoV) system, followed by a detailed description of the system model, including the caching model, the computation model, and the communication model. Then, we propose a joint data caching and computation offloading optimization problem for UAV-assisted IoV. To quickly clarify some variables, we summarize the key symbols used in
Table 2.
2.1. Network Model
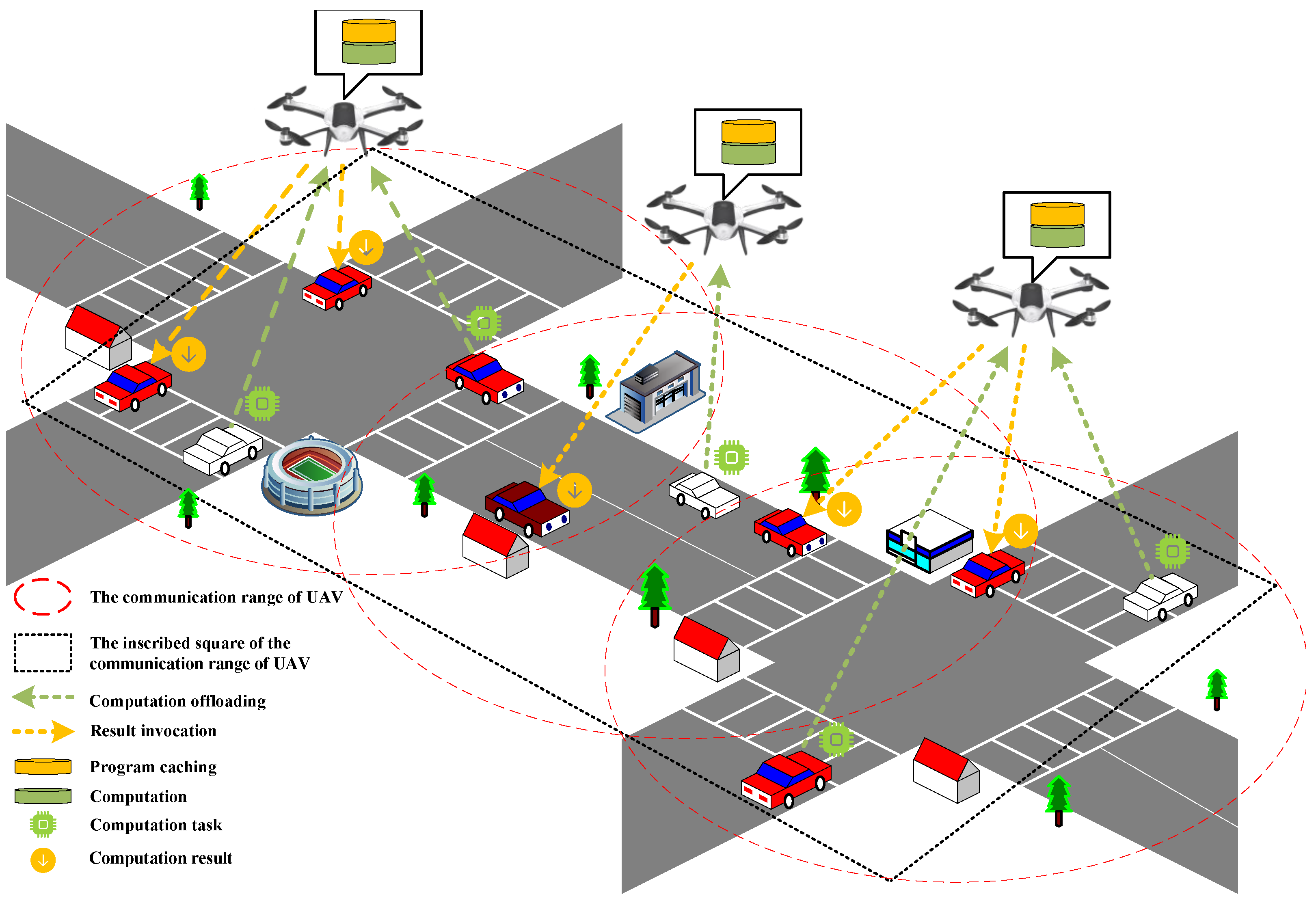
As shown in
Figure 1, we consider a multi-UAV-enabled MEC scenario for the IoV [
33]. UAVs can provide computing and caching services for vehicles on the ground. The set of UAVs and vehicles is represented as
and
, respectively. Since the take-off and landing times of UAVs are very short, and the energy consumption during these processes is minimal, we can ignore both the time and energy consumption involved in the UAVs’ takeoff and landing. For simplicity, it is assumed that the capacity of the wireless backhaul link from the BS to each UAV is equal to
.
In our paper, we adopt the 3D Cartesian coordinate system to represent the positions of UAVs and vehicles. We divide time transmitted from the vehicle to the UAV into a set of discrete time slots , and the size of each time slot is . Thus, the location of UAV u at time slot t is denoted as . The location of vehicle n at the time slot t is represented as . We assume that the velocity of the u-th UAV at time slot t is denoted by V and each vehicle n, , in the system generates multiple tasks during each time slot t, . For UAVs, they are independent and identically distributed, follow the homogeneous Poisson point process (PPP) with density , and are represented by set . This modeling choice indicates that the initial position of the UAV is randomly and uniformly distributed within the service area.
In the scenario studied in this paper, vehicles move along straight paths only, without considering turns or complex road conditions. This setup simplifies the vehicle motion model, allowing us to focus on the communication, computation, and caching scheduling problems during straight-line driving. This is a common simplification in initial studies before considering more complex mobility models [
34].
For the multi-UAV cooperative system architecture, we consider the following UAV location constraints to ensure proper system operation:
Safety Distance Constraint Between UAVs: The distance between each pair of UAVs
u and
v must be greater than or equal to the minimum safe distance dmin in all time slots:
where
and
denote the positions of UAV
u and UAV
v at the
t-th time slot, respectively. This constraint is essential for safety in multi-UAV systems [
35].
UAV Flight Altitude Constraint: Each UAV
u should maintain its altitude within the specified range:
These altitude limits are practical considerations for UAV deployment [
36].
As stated in [
24,
37], for a UAV with speed
V at time slot
t, the propulsion energy consumption within that time slot can be calculated as follows:
where
represents the rotor blade profile power of a UAV in a hovering state,
is the rotor blade induced power in hovering,
denotes the tip speed of the blades,
signifies the average rotor induced velocity during hover,
is the drag ratio experienced by the UAV,
represents air density,
s denotes the rotor disc solidity, and
A represents the blade disc area. The power consumption for the hovering state is
.
Therefore, the UAV’s propulsion consumption at the time slot
t is obtained by
This energy model is commonly used in UAV trajectory optimization studies [
38].
2.2. Caching Model
Let
and
denote the set of services and the set of contents, respectively. We use
and
to represent the size of service
d and content
k. Each UAV can cache some services that will be used by the associated vehicle to save the wireless backhaul time. Caching services at the edge is crucial for reducing latency in VEC systems [
39].
Let () be the binary decision variable indicating whether the UAV u caches program d (content k). () indicates that program d (content k) is cached by UAV u; otherwise, ().
Since the caching capacity of each UAV is limited, we have the following constraint:
where
is the total storage space of UAV
u. This constraint is standard in caching problems [
40].
2.3. Communication Model
In our work, we assume that the communication links between a vehicle and a UAV (V2U) are LoS. Due to that, the size of the processing result is in general much smaller than the size of the task, we ignore the transmission time of the downlink channel [
24,
25].
According to the Euclidean formula, the distance between vehicle
n and UAV
u at time slot
t is given by
We assume that the wireless channel from ground vehicles to the UAV is dominated by the LoS transmission link. It is noted that real-world scenarios, particularly in IoV, often utilize 3GPP Urban Macro (UMa) [
41,
42] or Urban Micro (UMi) [
43] environments. In this case, the channel remains unchanged within each fading block and is subject to distance-dependent power attenuation. Therefore, at the
t-th time slot, the channel power gain between the
n-th vehicle and the
u-th UAV can be formulated as
where
is the channel power gain at a reference distance
, and
is the path-loss exponent [
34].
The data transmission rate for offloading the task from vehicle
n to UAV
u can be calculated as:
where
is the spectrum bandwidth of the vehicle-to-UAV (V2U) communication channel,
is the transmission power of vehicle
n,
[
44], and
is the power of the white Gaussian noise. In this formula, we assume that all vehicles are connected to UAV
u using Orthogonal Frequency-Division Multiple Access (OFDMA), which is allocated by the spectrum resource. Thus, different V2U links do not interfere with each other, and the coverage areas of the UAVs do not overlap, eliminating interference between UAVs [
45]. Based on (
8), the transmission delay from vehicle
n to UAV
u is given by:
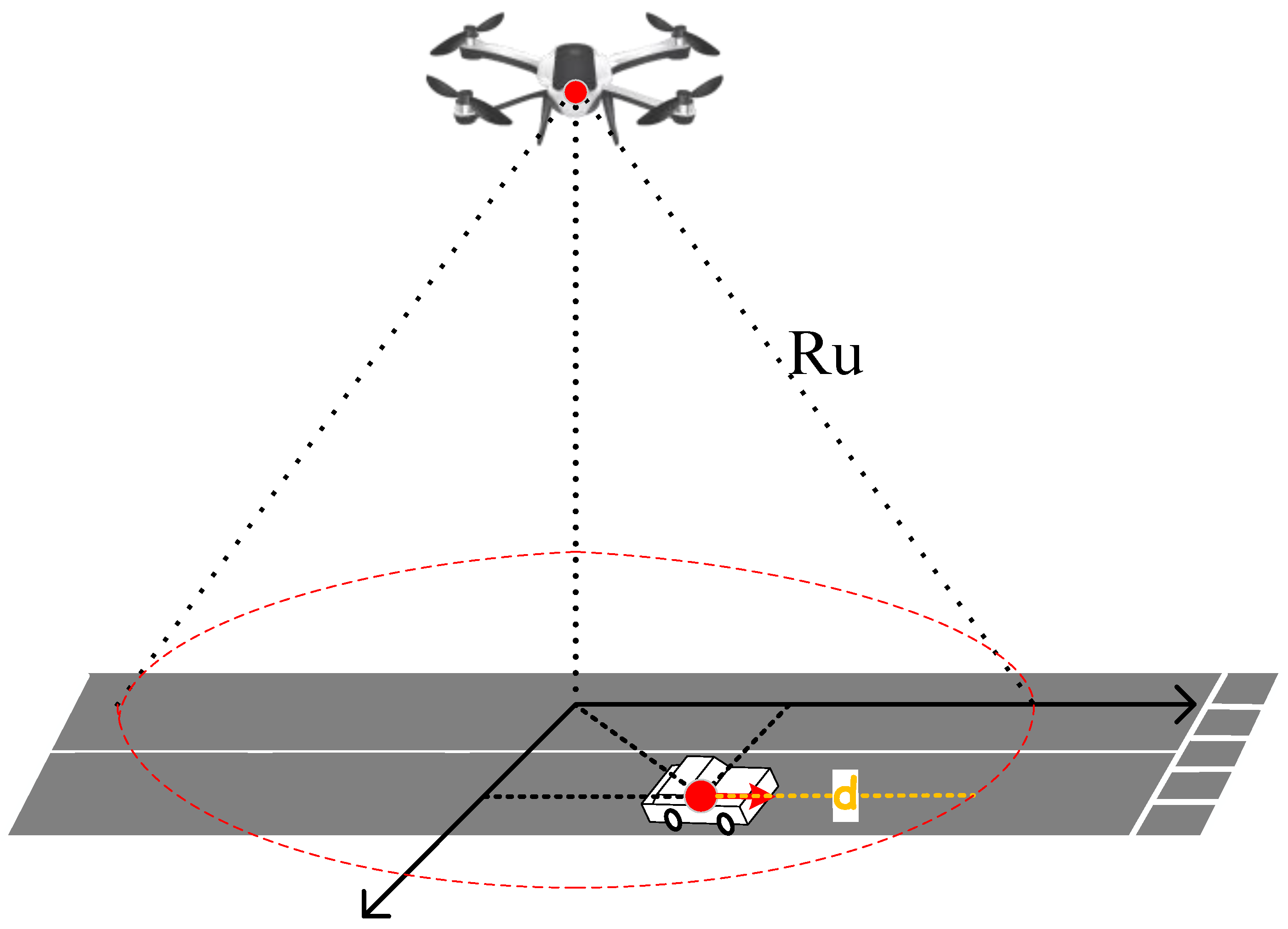
If a vehicle requests service from a UAV, the condition that must be satisfied is that the UAV is within the vehicle’s coverage range. This spatial condition is illustrated in
Figure 2, which shows the geometric relationship between the UAV and the vehicle. Whether the vehicle is within the UAV’s coverage range is represented by a binary 0–1 indicator
I, given by
where
represents the threshold of the communication rate.
2.4. Request Model
In this subsection, we consider
to represent the request generated by vehicle
n at time slot
t. We consider that
can either be a service request or a content request. By denoting
as the indicator of whether service
d (content
k) is requested by vehicle
n at time slot
t, we express the constraint on vehicle
n’s request as
where
denotes the indicator of the request type. If
,
is a service request. Otherwise,
is a content request [
46].
2.4.1. Content Request
When is a content request, i.e., . If vehicle n can download the requested content k from a specific UAV u, we consider that the request is satisfied. Meanwhile, vehicle n needs to be within the coverage of UAV u, i.e., and . Otherwise, is not satisfied.
2.4.2. Service Request
When is a service request, i.e., . To better show this request, we represent using a parameter tuple, given by , where represents the d-th service required for computing , represents the task data sizes (in bits), and represents the total number of instructions (in CPU cycles).
Vehicle n can choose to either compute it locally or offload it to the associated UAV that cached the service . We note that vehicle n can offload the computation tasks to UAV u when UAV u is accessible and deployed with the service, i.e., and .
We use
to represent whether the computation
is offloaded to UAV
u. Therefore, we have
Note that
indicates that task
is computed locally at vehicle
n at time slot
t. This models the binary offloading decision [
38].
For UAV
u, it can provide computation services to multiple vehicles satisfying the constraint on its computation capability, represented by the maximum number of services for UAVs, i.e.,
. So, we have the constraint
2.5. Performance Metrics
In this section, we will introduce the performance metrics used in this work. First, we define the UAV’s successful transmission probability and then calculate the content caching hit rate, which is defined as the ratio between the number of successfully responded content requests and the total number of content requests from all vehicles.
Let
represent the signal transmission power utilized by the UAVs, under the assumption that these UAVs share the spectrum resources with other UAVs, which results in interference from neighboring devices. When a user retrieves cached content from the UAV, the Signal-to-Interference-plus-Noise Ratio (SINR) can be formulated as
where
is the noise power, and
represents the Rayleigh channel gain from UAV
u to vehicle
n. The interference from other UAVs is represented as
The probability of successful transmission for vehicle
n to receive the requested content through U2V communication is defined as the likelihood that the Signal-to-Interference-plus-Noise Ratio (SINR) of the received signal surpasses the decoding threshold. This is mathematically expressed as
, where
denotes the probability of event
A [
47]. When vehicle
n successfully retrieves the desired content via U2V communication, the successful transmission probability can be derived as follows.
wherein step
is derived based on the formula
. The power gain
of a Rayleigh fading channel follows an exponential distribution. For an exponentially distributed random variable
X with rate parameter
, the probability
is given by
. In this context, we assume a unit mean for
, which implies
. Therefore, by letting
, the probability
is transformed to
.
represents the max communication distance between the UAV and vehicle and
is the probability density function (PDF) of the distance from the UAV to the requesting vehicle, expressed as
Let
, then the Laplace transform
of interference
is derived by using the properties of stochastic geometry as follows [
48].
Let
, then we have
where
. Then, by substituting (24) and (26) into (23), the expression for the successful transmission probability can be obtained as follows
Mathematically, the content cache hit ratio can be expressed as
This metric quantifies the effectiveness of the caching strategy [
49].
2.5.1. Local Computation
When
, tasks
will be computed locally at vehicle
n. The computation delay of task
is expressed as
where
is the total computation resource of vehicle
n. Local computation serves as a baseline option for task execution [
50].
2.5.2. UAV’s Computation
When
, tasks
will be offloaded to UAV
u. At each time slot
t, the UAV
u needs to process multiple tasks from vehicles within its coverage area simultaneously. However, due to the limited computation resources of UAVs, UAVs must efficiently allocate a portion of their computation resources to each task. Then, the computation delay of task
processed by UAV
u is expressed as
where
is the total computation resource of UAV
u. This delay depends on the UAV’s processing capacity [
38].
Employing the dynamic voltage and frequency scaling technique at the UAV, the energy consumption for computation at the u-th UAV at the time slot
t is
where
represents the computation energy efficiency coefficient related to the processor’s chip of the
u-th UAV [
51].
In addition to minimizing task latency and energy consumption, we also want to achieve fair task allocation among multiple UAVs to avoid situations where some UAVs are overloaded while others are underloaded. Jain’s Fairness Index (JFI) is commonly used to measure the fairness of resource allocation, so we include it in our optimization objective. JFI is a standard metric for evaluating fairness in resource allocation problems [
52].
is Jain’s fairness index, which is calculated as follows:
2.6. Problem Formulation
In this section, an optimization problem is formulated to minimize the maximum task latency among all vehicles, subject to the constraints of communication rate, UAV energy consumption, and memory capacity.
Based on (
9) and (
23), if the task
of vehicle
n is offloaded to UAV
u at time slot
t, its overall processing delay is given by:
Therefore, based on (
22) and (
26), at the time slot
t, the total delay of processing task
from vehicle
n is expressed by:
This combines the local and offloaded computation delays [
45].
Based on (
4) and (
24), the total energy consumption of the
u-th UAV at the time slot
t can be given as:
where
is the energy regulation factor balancing the magnitude disparity between computation and propulsion energy costs [
25].
We define the system efficiency for the system at time slot
t, denoted as
. This is a comprehensive metric designed to balance the content cache hit rate, task computation performance, system energy consumption, and resource allocation fairness. Its formula is as follows:
We jointly optimize the service placement decision , the content cache decision , the vehicle task offloading decision , and the locations of UAVs .
To sum up, the optimization problem can be formulated as:
where
and
are the weights for energy consumption and fairness, respectively.
C1 limits the total cached data size for UAV
u at time
t within its storage capacity
. C2 enforces binary offloading and caching decisions for
,
, and
. C3 restricts UAV
u’s total energy consumption to not exceed
. C4 ensures the minimum safe distance
between any two UAVs. Finally, C5 constrains UAV
u’s flight altitude between
and
. C6 limits the maximum number of tasks that can be processed by a single UAV
u at time slot
t to
[
53]. C7 ensures that for each vehicle
n, its task is offloaded to at most one UAV
u at any given time slot
t.
3. MAPPO-Based Joint Caching and Computation Offloading Scheme
To effectively address the joint caching and computation offloading optimization problem, this paper adopts a Multi-Agent Deep Reinforcement Learning (MADRL) algorithm. Traditional optimization methods face significant challenges when dealing with complex Mixed-Integer Nonlinear Programming (MINLP) problems, such as high computational complexity, lack of real-time applicability, and sensitivity to model parameters. Deep reinforcement learning, on the other hand, can significantly reduce online computation through offline training and adapt to dynamic environments with uncertainty [
54]. Particularly for objectives that are difficult to model explicitly, such as minimizing system latency, MADRL enables efficient and robust optimization by learning the interactions and cooperation among multiple agents. To better implement the MADRL algorithm, we build it upon a Dec-POMDP framework, which will be described in detail below. Dec-POMDPs are suitable for modeling scenarios with multiple agents and partial observations [
55].
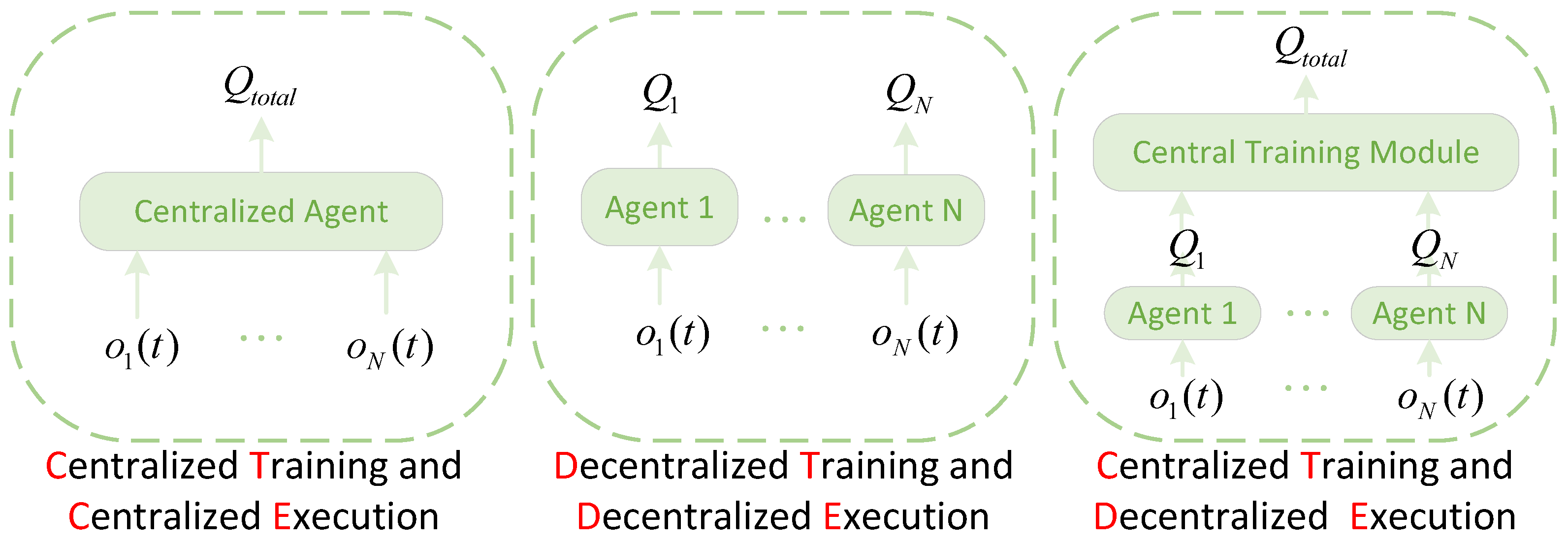
In Multi-Agent Reinforcement Learning (MADRL), various training and execution paradigms exist, as illustrated in
Figure 3. These paradigms primarily differ in whether agents share information or have a centralized coordinator during the training phase, and whether agents act independently or are controlled by a central entity during the execution phase. Common paradigms include: Centralized Training Centralized Execution (CTCE), Decentralized Training Decentralized Execution (DTDE), and CTDE, which combines the advantages of both training and execution. CTCE is suitable for scenarios with high agent cooperation and fully observable environments, but centralized execution has poor robustness and is difficult to scale to large-scale systems. DTDE emphasizes agent independence, resulting in simple and robust execution, but agents face a non-stationary environment during training, making it difficult to guarantee convergence and optimality. The CTDE paradigm allows the use of global information or centralized coordination during the training phase to stabilize the learning process, while in the execution phase, each agent makes decisions independently based on its local observations. This approach balances training efficiency with the flexibility and robustness of decentralized execution, making it particularly suitable for dynamic and partially observable distributed environments like vehicular networks.
3.1. Dec-POMDP Framework
Based on the MADRL algorithm introduced earlier, we build it upon a Dec-POMDP framework to address the joint caching and computation offloading optimization problem. This framework empowers individual agents (UAVs and vehicles) to make decentralized decisions in a dynamic IoV environment with partial state observability. Agents learn through interactions with the environment, adapting their actions to optimize collective behavior and maximize service efficiency, defined as the ratio of the cache hit rate to the total task processing delay.
The Dec-POMDP framework is formally defined as a tuple , where is the global state space; is the observation space; denotes the mapping from global state to observation ; is the action space; is the transition probability distribution of the global state transition : and ; is the instantaneous reward : ; and is the discount factor.
Assume that there is no global information exchange and each unit (UAV and vehicle) can only obtain its direct information. Then, we can obtain the state space, action space, and reward as follows.
The observation of UAV
u,
, contains the location of the UAV
u, the coverage range of the UAV
u, the remaining energy of the UAV
u, and the remaining caching space, i.e.,
where
,
, and
. Partial observations are typical in decentralized MADRL [
56].
The observation of vehicle
n,
, contains its location, i.e.,
Action Space (
): The action space of the UAV
u contains the cache decision of the UAV
u and the location of the UAV
u, i.e.,
where
denotes the caching decision vector of UAV
u, and
represents the location of UAV
u at time slot
t, and to satisfy the altitude constraint (
35), the vertical coordinate must obey
.
The action space of vehicle
n contains its offloading decision, i.e.,
where
.
Reward Function (): The reward function quantifies the immediate reward obtained by all agents after taking joint action a in state s. We aim to maximize the system efficiency, defined as below.
The service coefficient related reward
is defined as
The UAV energy consumption and minimum safe distance related reward
is defined as
The total energy consumption related reward
is the sum of these individual rewards across all UAVs
U.
The remaining caching space-related reward
is defined as
The total remaining caching space reward
is the sum of
over all UAVs
U.
The remaining computation core-related reward
is defined as
The total remaining cores reward
is the sum of
over all UAVs
U.
The fairness related reward is defined as
The overall reward function
at time slot
t is a composite value that combines the aforementioned components. It is defined as
where
,
,
, and
are positive weighting coefficients that balance the relative importance of UAV energy consumption, remaining cache capacity, available computation cores, and task allocation fairness in the overall optimization objective, respectively. These weights are hyperparameters tuned to achieve the desired trade-offs among the different performance metrics [
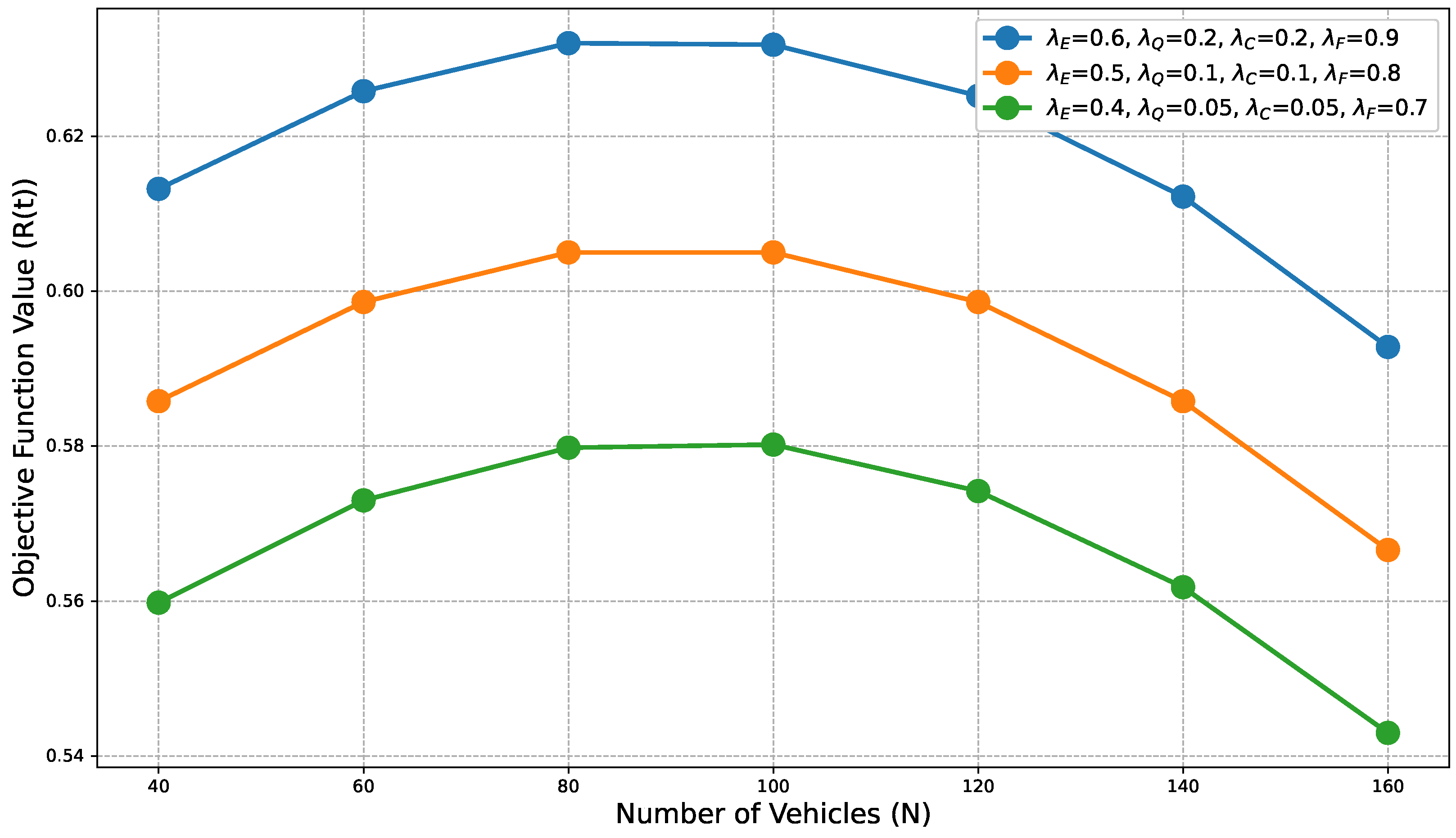
54].
3.2. MAPPO-Based DRL Training Framework
The Dec-POMDP structure is realized through a multi-agent deep reinforcement learning (MADRL) methodology. Within this framework, each agent independently learns its operational policy aiming to maximize its expected cumulative return based on its own partial observations. Agents engage with the environment, carry out actions derived from their acquired policies, receive feedback in the form of rewards, and iteratively refine their strategies via a learning algorithm. This centralized learning approach facilitates the agents’ ability to adapt effectively to dynamic environmental shifts and to optimize their collective performance collaboratively. MAPPO is a popular on-policy MADRL algorithm known for its stability [
6].
The proposed MAPPO-based joint optimization strategy utilizes a CTDE paradigm, whose comprehensive diagram is depicted in
Figure 4. Under this paradigm, agents (comprising UAVs and vehicles) transmit their respective local observed data to a central training entity during the learning phase. This entity is tasked with aggregating observations and actions from all participating agents, calculating the global reward signal, and coordinating the policy adjustment process for the agents. Specifically, each agent possesses its distinct Actor network and Critic network. The Actor network generates potential action distributions based on the agent’s specific local observations, serving to guide agent behavior during the operational phase. The Critic network functions as a centralized value estimator that accepts the local observations of all agents (which are first processed by state encoders and multi-head attention modules) to evaluate the utility of the collective actions taken by the agents within the current global state, thereby supplying a value-based corrective signal for the Actor network’s training. State encoders are employed to transform raw observational inputs into condensed, low-dimensional feature representations, while multi-head attention mechanisms are utilized to capture the intricate interdependencies and interactive dynamics among agents, assisting the Critic network in forming a more precise assessment of the global state’s value. During the training period, the central module leverages comprehensive global information (like the positions, caching statuses, and task states of all agents) to train the Critic network; it then uses the advantage measure derived from the Critic network to direct the policy gradient updates of the individual, decentralized Actor networks. During the actual deployment phase, each agent relies solely on its local observations and its trained Actor network to make decisions, eliminating the need for centralized coordination, which boosts the system’s responsiveness and resilience. The detailed steps of the proposed MAPPO-based training framework are outlined in Algorithm 1.
Algorithm 1: MAPPO-based joint caching and computation offloading training framework |
|
We advocate employing the MAPPO algorithm to refine the policies within our established framework. In this setup, the actor network, parameterized by
, produces action choices guided by the policy
; this policy corresponds to the
v-th agent type and can be shared across agents of the same category. The critic network, parameterized by
, appraises the merit of these actions based on the received reward
and the state
[
55].
To facilitate implementation in distributed network environments, we adopt a framework involving centralized training and decentralized execution, as illustrated in
Figure 4. This architecture is designed to ensure robust overall system performance while preserving the decision-making autonomy of each individual agent. It is important to note that during the centralized training procedure, calculating rewards independently at each vehicle or UAV is challenging. Consequently, the involvement of a training hub is necessary; this hub centrally collects all observations and actions to compute the rewards. Concurrently, this training hub integrates the collected observations into a unified global state representation, which is then conveyed to the critic network associated with each agent. Subsequently, the critic network formulates the state–value function, formally defined as:
Here, signifies the expectation operator, represents the reward function for agent i belonging to the u-th agent type, serves as the reward discount factor, and denotes the collective policy employed by all agents.
As derived from (
52), the state–value function
is influenced by both the prevailing state
and the parameters
of the policy network
. Specifically, as the state
improves or becomes more favorable, the value
increases, signaling higher anticipated future returns. Similarly, when the policy
, characterized by parameters
, demonstrates enhanced performance, the value
also rises. If a policy
consistently achieves exceptional outcomes across all relevant states
within the same time step, the averaged value of the state–value function
is expected to be notably elevated. Consequently, we define the optimization objective for the actor network as:
This objective function is independent of the specific state and depends solely on the parameter set .
We modify the parameters
of the policy network using a gradient ascent approach, seeking to maximize the objective function. Let
indicate the current parameter values of the policy network; following a gradient ascent update step, the refined parameters
are obtained via:
where
is the learning rate for the actor network, and the gradient
can be expressed as:
Here,
is a coefficient that balances the trade-off between bias and variance in the estimation. The action–value function is defined as
, formulated as:
To effectively gauge the comparative advantage of a specific action and concurrently mitigate variance and bias during the learning phase, we employ generalized advantage estimation (GAE) as a substitute for the advantage function-like term appearing in (
53), in a manner that preserves generality. This approach bears resemblance to the use of surrogate objective functions and importance sampling techniques in conventional policy optimization methods. The policy gradient can thus be reformulated as:
where
.
Furthermore, to constrain the magnitude of policy updates and thereby preclude excessive optimization steps that could compromise stability [
57], we incorporate a clipping mechanism. The clip function serves to bind the ratio between the probabilities assigned by the new and old policies, ensuring that policy adjustments remain within an acceptable range. The definition of the clip function is given by:
Here,
acts as a regularization parameter. Drawing upon concepts from (
51), (
55), and (
56), we introduce
to represent the policy entropy of the state. Consequently, the objective function for the actor network, which now incorporates the clip function, can be formulated as:
In parallel, to update the critic network, which functions as a value estimator employed to evaluate the effectiveness of the actor network’s policies, we specify its loss function as:
Here,
denotes the approximation of the state–value function produced by the value network with parameters
, and
represents the estimated value of the subsequent state after the agent performs an action in the current state. Subsequently, we execute gradient descent to adjust the parameters
under the influence of the learning rate
, yielding the updated parameters:
3.3. Complexity Analysis
The computational complexity, associated with the MAPPO algorithm, primarily consists of two parts. On the one hand, the computational complexity generated by the
i-th layer of the MLP can be expressed as
, where
represents the number of neurons in the
i-th layer. Denoting the number of layers of one MLP as
I, we can calculate the computational complexity of an MLP as
. On the other hand, the complexity generated by the attention module can be expressed as
, in which
W denotes the length of feature values output from the state encoders [
54]. In our framework, the actor networks are composed of a single MLP, while the critic networks consist of one MLP for value output and two encoders designed for distinct agent types. Therefore, the computational complexity of the training algorithm for all Mte episodes is calculated as
3.4. Scalability Analysis and the Role of the Attention Mechanism
The multi-agent joint optimization strategy based on MAPPO proposed in this paper, under the CTDE paradigm, effectively enhances the algorithm’s scalability when dealing with high-dimensional observation and action spaces through a carefully designed neural network architecture. Specifically, a state encoder transforms high-dimensional raw local observations into compact feature representations, thereby reducing the input dimension for the core network. Building upon this, the centralized Critic network creatively integrates a multi-head attention mechanism, enabling it to dynamically focus on and selectively weight the most relevant and critical information within the observation space. This mechanism efficiently captures complex correlations and interaction dynamics between agents, as well as between agents and the environment. Regardless of changes in the number of agents in the system, it avoids the inefficiencies that traditional fully connected networks might suffer due to dimensionality explosion, significantly enhancing the algorithm’s learning efficiency and evaluation accuracy when dealing with increasing dimensions.
5. Conclusions
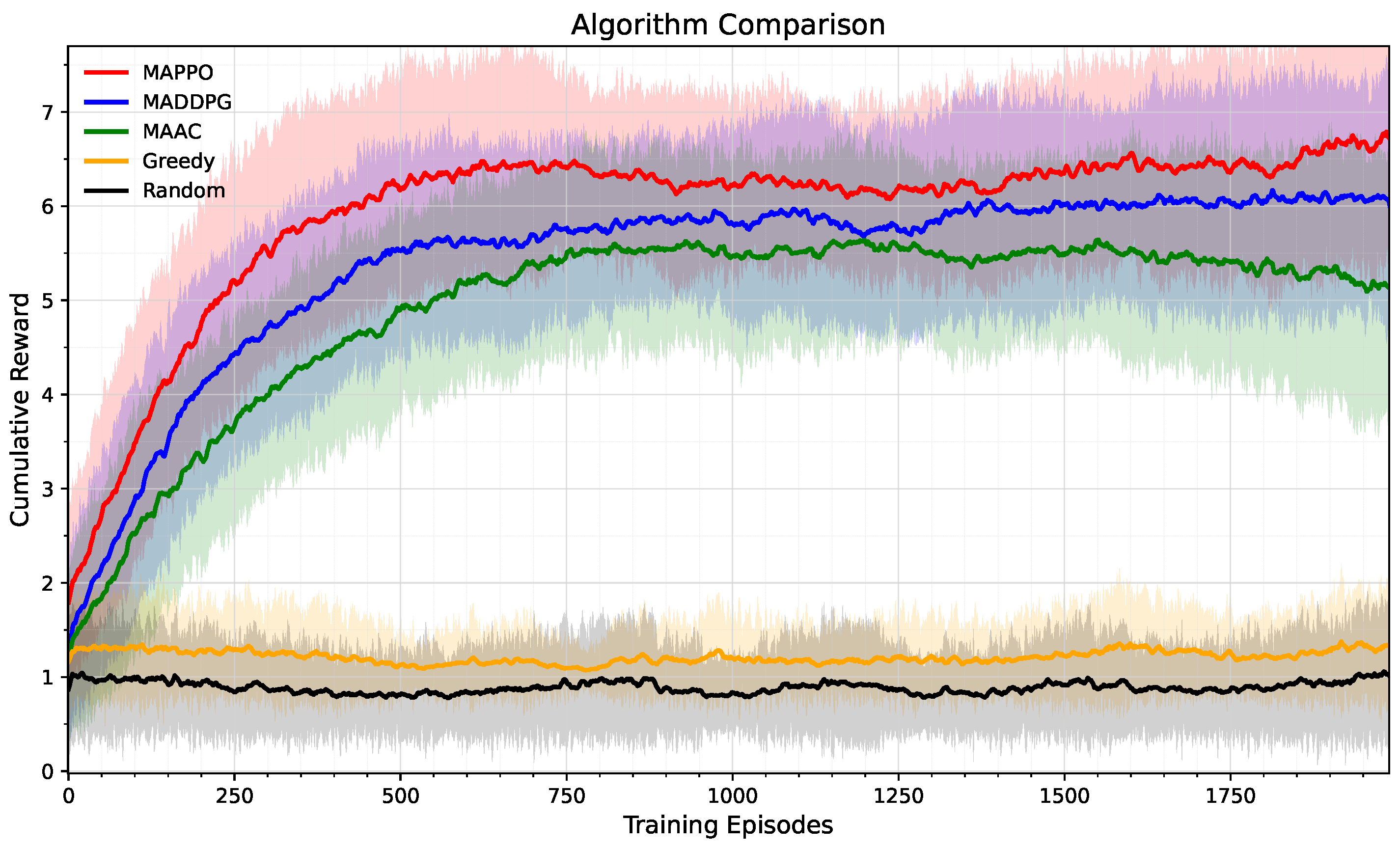
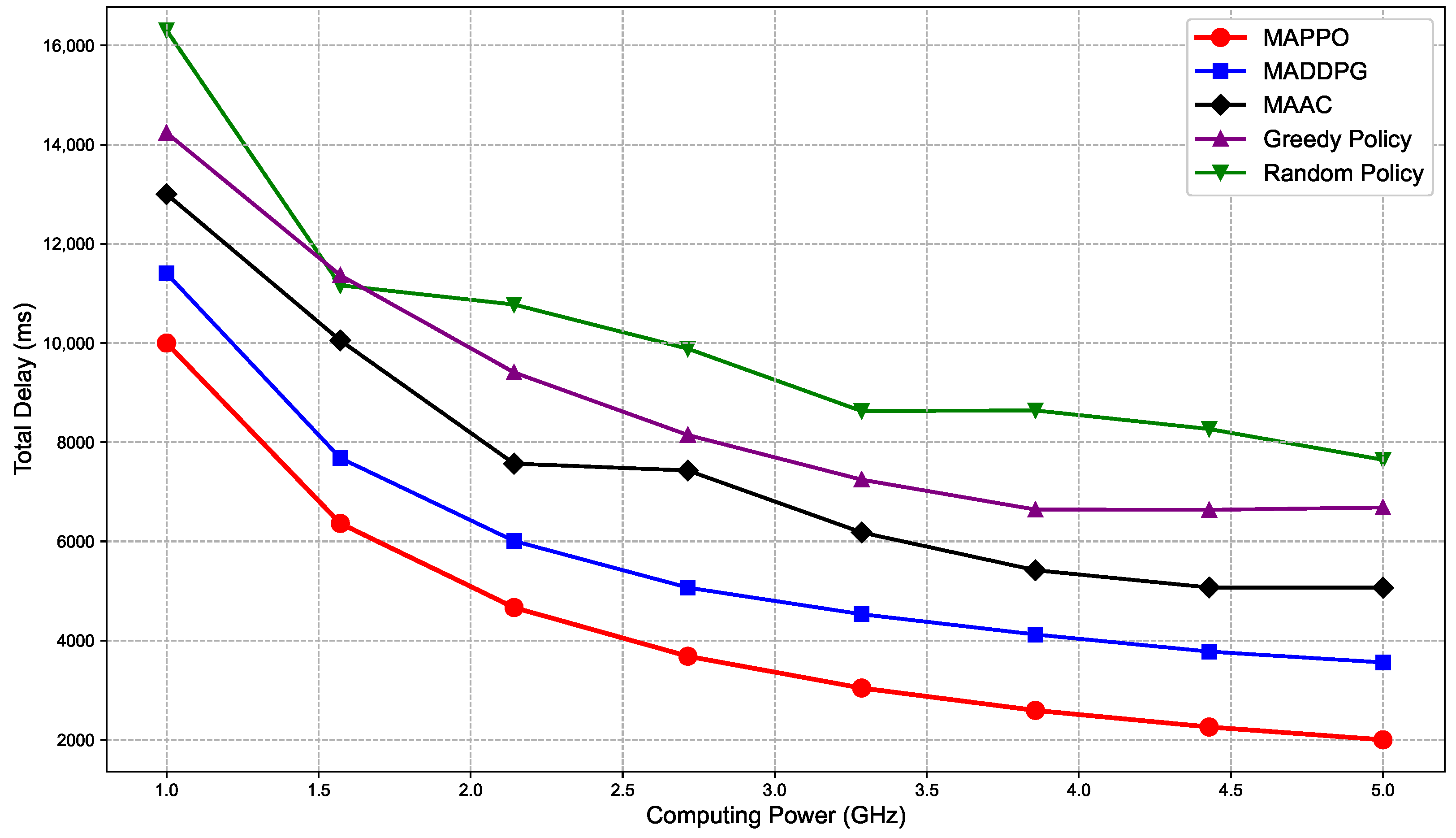
In this paper, we addressed the complex problem of jointly optimizing caching strategies, computation offloading, and UAV trajectories in dynamic UAV-assisted vehicular networks. Due to the problem’s coupled, distributed, and constrained nature, traditional optimization and existing multi-agent deep reinforcement learning (MARL) methods struggle with stability and convergence in such environments. To tackle this, we proposed a novel MARL framework by modeling the problem as a Dec-POMDP and developing a MAPPO algorithm that adheres to the CTDE paradigm. We innovatively introduce system efficiency as a unified performance metric, and with this as the primary optimization objective, we balance multiple performance indicators such as cache hit rate, task delay, energy consumption, and fairness. Extensive simulations demonstrated that our MAPPO-based approach outperforms baselines such as MADDPG, MAAC, Greedy, and Random, showing clear gains in cumulative rewards, cache hit rate, system efficiency, and task delay reduction, while effectively controlling UAV energy consumption. Sensitivity analysis across hyperparameters and system scales further confirmed its robustness. This work validates the potential of Dec-POMDP modeling and MAPPO enhanced by innovative state-space design and reward shaping mechanisms in solving dynamic, distributed resource management problems. Future directions include addressing realistic mobility patterns, large-scale scalability, and wireless interference, potentially incorporating predictive models to manage uncertainty.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}