1. Introduction
With the ongoing convergence of control, communication, and computing technologies, the cooperative control of multi-agent systems has garnered significant attention from researchers worldwide. Compared with single-agent systems, multi-agent systems offer a wide range of advantages, including the ability to handle more complex tasks, higher efficiency, improved fault tolerance, and inherent parallelism. Consequently, leveraging consensus theory in multi-agent cooperation to investigate formation reconfiguration, path planning, and obstacle avoidance has emerged as a vibrant and promising research domain.
Path-planning algorithms primarily address the challenge of enabling agents to navigate through environments containing obstacles by determining the shortest or most efficient path while avoiding collisions. Classic path-planning approaches include the A* algorithm [
1], Dijkstra’s algorithm [
2], rapidly exploring random trees [
3], ant colony optimization [
4], particle swarm optimization [
5], neural-network-based methods [
6], deep reinforcement learning [
7], and the artificial potential field method [
8], among others. Each of these approaches presents unique strengths and limitations. For instance, the A* algorithm utilizes a heuristic function to reduce inefficient searches but may still incur substantial computational overheads. ACO, known for its powerful global search capability [
9,
10], often suffers from slow convergence and high complexity. Dijkstra’s method exhaustively explores all paths, resulting in inefficiency. Neural-network- and DRL-based methods offer superior adaptability in complex environments but require massive datasets—often in the order of millions—to effectively learn optimal behaviors. Meanwhile, RRT generates paths by incrementally extending the nodes toward the target, but the resulting trajectories may lack smoothness and consistency.
The APF algorithm is widely adopted in robot path planning due to its simplicity, computational efficiency, and ease of implementation. However, its effectiveness is compromised by several well-known issues. First, when the target is far away, the attractive force becomes excessively strong, potentially leading agents to overshoot into obstacles. Second, in cluttered environments, agents can easily become trapped in local minima where the net force is zero. These issues make the goal unreachable in certain configurations. To overcome these drawbacks, a number of researchers have proposed improvements to the APF method. Song [
11] combined velocity obstacle algorithms with APF to create a hybrid field comprising repulsion and centrifugal components, enabling agents to bypass obstacles by modulating their velocity and direction. Chen [
12] redefined the attractive and repulsive force models and analyzed the motion characteristics to mitigate the local minima and goal-inaccessibility issues. Fedele [
13] introduced a novel spiral potential field that effectively eliminates zero resultant force zones during obstacle avoidance. Azzabi [
14] proposed an alternative repulsive field function that introduces a virtual escape force in the form of rotational dynamics to help agents exit local traps smoothly. Di [
15] and Lee [
16] adopted virtual targets to provide directional guidance when agents fall into local minima. Xu [
17] proposed the use of safety distances to prune unnecessary paths, thus reducing the path length and computation time. Wang [
18] added a tangential force between agents and obstacles to resolve oscillatory behaviors. However, such solutions still struggle with semi-enclosed obstacles. To this end, Yu [
19] introduced a transverse auxiliary field to break the equilibrium at the local minima, while Hao [
20] proposed a collision risk assessment mechanism to further enhance the robustness of APF-based obstacle avoidance. Zhang [
21] contributed enhancements including velocity repulsion fields and dynamic sub-goal generation to improve the safety, robustness, and escape capability from semi-enclosed regions. Zhang [
22] set up a virtual barrier to seal the semi-enclosed obstacle by making the intelligent body return to the original path after falling into a local minima and escaping the semi-enclosed obstacle through a tangent algorithm.
Simulated annealing (SA), a probabilistic optimization method inspired by the annealing process in metallurgy [
23], and its stochastic nature can generate some random paths to escape from the local minima when the intelligences fall into the local minima in the APF algorithm. Zhang [
24] applied SA-APF to path planning for soccer robots. Zhao [
25] introduced random sub-goals to guide agents away from traps. Luan [
26] used virtual targets to escape from U-shaped obstacle configurations. Yuan [
27] applied SA-APF in marine environments to enable surface vessel formations to avoid obstacles. However, the existing SA-based improvements often suffer from limitations such as unsmooth paths, failure to escape complex semi-enclosed regions, or inability to find valid exits due to the high stochasticity inherent in SA. In a multi-UAV distributed formation, the unsmooth or even cluttered paths generated by the leader escaping the local minima using the simulated annealing algorithm can cause the follower to follow, generating cluttered movements, so the simulated annealing algorithm must be improved to generate shorter and smoother paths to support the escape from the local minima in multi-UAV formations.
Most existing studies on the APF are limited to single-agent scenarios. For multi-agent formations, common coordination strategies include the leader–follower approach [
28], behavior-based methods [
29], and virtual structure frameworks [
30]. Among them, the leader–follower model is widely adopted due to its task-oriented structure, where a designated leader defines the target trajectory and the followers dynamically adjust their positions based on the leader’s state. Many scholars have applied the leader–follower model to distributed formation control models. Pereira [
31] proposed a distributed model predictive control algorithm under the leader–follower formation for spacecraft formation flight scenarios. Wang [
32] introduced a distributed saturation control strategy to realize the leader–follower’s multi-quadrotor formation. This method offers high adaptability and can be optimized for a variety of formation and path-following tasks.
To address the aforementioned limitations, this paper proposes a novel algorithm—deflected simulated annealing–adaptive artificial potential field (DSA-AAPF)—that combines an improved simulated annealing mechanism with an enhanced APF framework. The key contributions of this work are as follows:
(1) Under the distributed leader–follower formation control framework, we redefine the potential field formulation by drawing inspiration from momentum-based gradient descent methods. The resultant force applied to each UAV retains a portion of the previous moment’s force, thereby avoiding overshooting and reducing oscillations near obstacles. This results in smoother and safer UAV trajectories.
(2) A novel adaptive attractive gain function is introduced to dynamically regulate the UAVs’ velocities across different regions of the environment. Combined with a fast-converging control law, this mechanism improves the target convergence and prevents collisions near the goal.
(3) To handle semi-enclosed obstacles and local minima, we propose a directional deflection mechanism in the simulated annealing module. By continuously applying force vectors along a consistent rotational direction, UAVs can escape complex environments via arc-like paths.
(4) The effectiveness and practicality of the proposed algorithm are validated through comprehensive simulations in MATLAB (R2022b), demonstrating its advantages in terms of formation maintenance, dynamic reconfiguration, and robust obstacle avoidance.
Selected studies that have improved the APF algorithm in recent years [
19,
20,
21,
22] are compared with the main innovations of this paper’s algorithm, DSA-AAPF, as shown in
Table 1.
In this paper,
Section 2 presents the dynamical modeling of the leader–follower formation adopted in our multi-UAV system.
Section 3 introduces the fundamental principles of the traditional artificial potential field (APF) method, followed by detailed explanations of the proposed adaptive artificial potential field (AAPF) and its integration with the deflected simulated annealing (DSA) algorithm.
Section 4 conducts simulation experiments and analyses in four scenarios: oscillation test, formation reconfiguration, obstacle avoidance in complex environments, and escape from semi-enclosed obstacles. The results demonstrate the feasibility and effectiveness of the proposed DSA-AAPF method. Finally,
Section 5 summarizes the conclusions and discusses potential directions for future work.
3. Improved Artificial Potential Field Method
3.1. Fundamentals and Analysis of the Traditional Artificial Potential Field
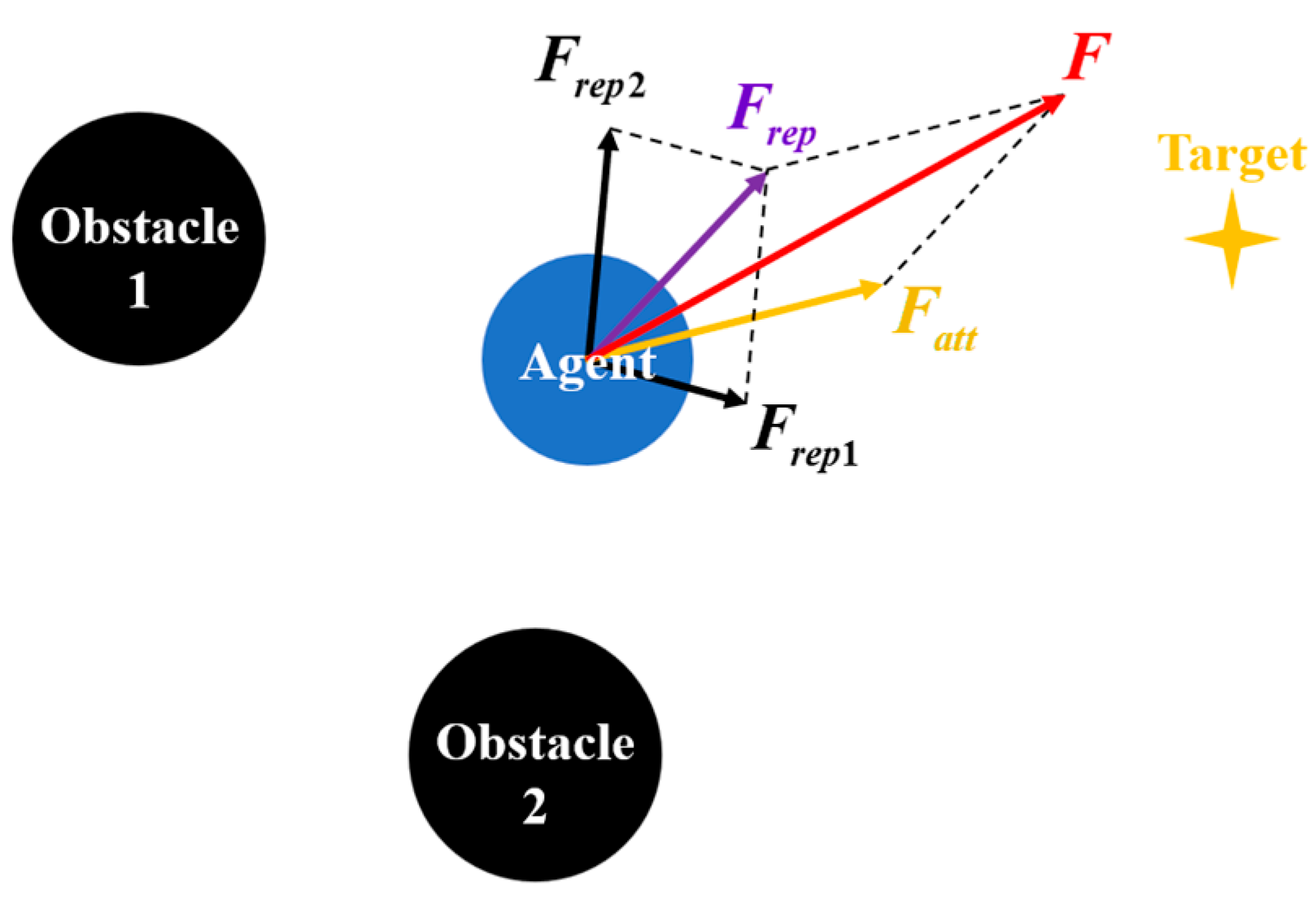
The artificial potential field (APF) method was first introduced by Khatib, incorporating the concept of potential fields from physics into path planning. The core idea is to model the UAV as a point mass moving within a virtual force field, where the field comprises an attractive potential generated by the target and a repulsive potential induced by the surrounding obstacles. The resultant force acts as the driving input for the UAV’s motion.
The potential field function in the APF method is defined as the sum of the attractive and repulsive potential fields, as expressed in Equation (4):
where
denotes the position vector of the mobile robot,
is the attractive potential field and
is the repulsive potential field, which are shown in Equations (5) and (6):
where
and
denote the attractive and repulsive gain coefficients, respectively;
represents the goal position, and
denotes the nearest point on the obstacle surface to the UAV. For circular obstacles, this point corresponds to the intersection of the line connecting the UAV and the obstacle center with the obstacle boundary. The terms
and
, respectively, denote the Euclidean distances of the UAV from the target point and the obstacle, and
defines the maximum influence radius of the obstacle. Beyond this radius, the repulsive force exerted by the obstacle on the UAV is zero.
The artificial force applied to the UAV is defined as the negative gradient of the total potential field, consisting of both attractive and repulsive components. The resultant force experienced by UAV
is expressed as:
where the attractive force
is:
and the repulsive
is:
When multiple obstacles are present in the environment, the total repulsive force acting on a UAV is the superposition of the repulsive forces exerted by each obstacle. Accordingly, the resultant force acting on UAV
is expressed as:
where
denotes the number of obstacles affecting the UAV.
An illustration of the force components under the APF framework is shown in
Figure 2.
Despite its simplicity and computational efficiency, the traditional APF method suffers from several significant drawbacks.
(1) The attractive force in the conventional APF is linearly proportional to the distance between the UAV and the target. As a result, when the UAV is far from the target, it may move too rapidly, potentially leading to excessive acceleration toward obstacles. This sudden proximity to obstacles can induce large repulsive forces, causing oscillations or even collisions. Conversely, when the UAV is close to the target, the attraction becomes too weak, and the UAV may fail to reach the goal.
(2) To better mimic physical realism, recent implementations often constrain the UAVs to moving a fixed step length in the direction of the resultant force. However, such an approach neglects the magnitude of the resultant force, leading to slow convergence and reduced efficiency. Moreover, the final positioning accuracy becomes dependent on the fixed step size, limiting the precision–speed tradeoff.
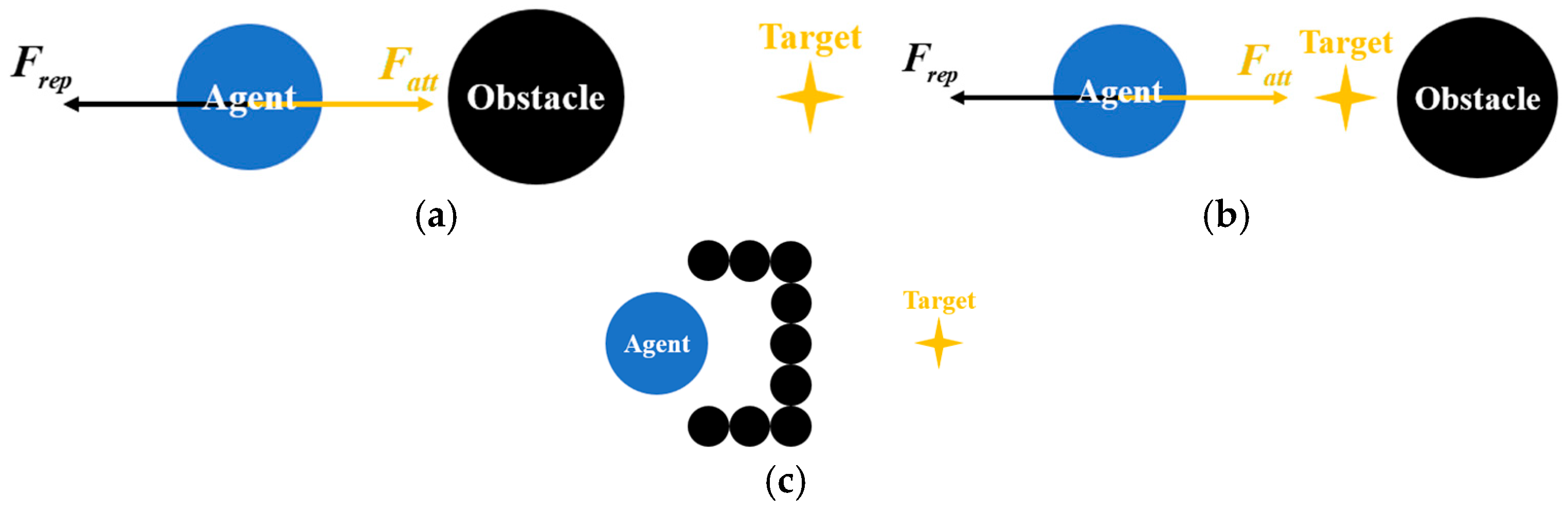
(3) The traditional APF framework is unable to handle local minima effectively. As illustrated in
Figure 3, three typical scenarios may trap the UAV. In cases 1 and 2, the attractive and repulsive forces are nearly equal in magnitude but opposite in direction, resulting in oscillatory behavior or stagnation. In case 3, the UAV is confined within a U-shaped obstacle configuration, where the repulsive field completely blocks the path toward the goal, leaving the UAV unable to escape.
To overcome these limitations, this study proposes an improved APF framework within the context of a distributed leader–follower formation. The potential field function is redefined, and a momentum-inspired smoothing technique is introduced into the force computation to mitigate oscillations and ensure smooth trajectories. An adaptive attractive gain function is also designed to regulate the UAV’s velocity across different phases of its motion. Furthermore, to enable rapid reformation and precise convergence after obstacle avoidance, a fast-converging consensus controller is incorporated into the formation framework. Finally, a modified simulated annealing mechanism is developed to allow the UAVs to escape the local minima, particularly within semi-enclosed environments.
3.2. Adaptive Artificial Potential Field
3.2.1. Redefinition of the Potential Field Function
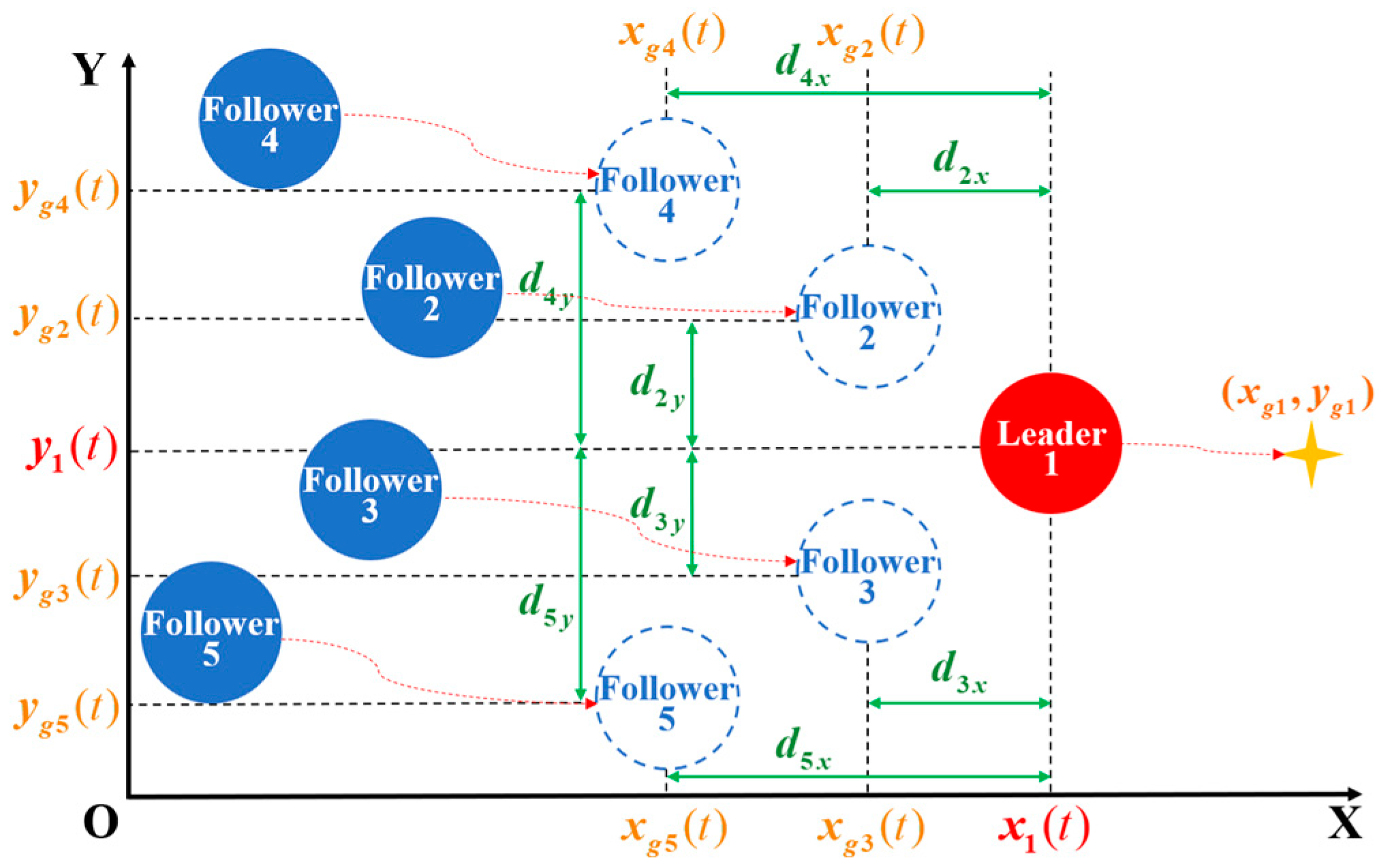
To improve upon the limitations of the classical APF, the potential field function is redefined in Equations (11) and (12) while retaining the basic structure as the sum of the attractive and repulsive components:
where
denotes the virtual target point of UAV
. For the leader UAV (UAV 1), the target
is fixed and predefined. The vector
represents the constant relative displacement between the leader and the follower in the desired formation. For the leader itself,
. The term
denotes the distance function between two points, and
is a small positive constant to ensure the target is always at the minimum of the potential field.
The corresponding attractive and repulsive force functions are defined as:
Specifically, the repulsive terms
and
are expressed as:
The resultant force in the AAPF retains the same form as the original APF expression shown in Equation (10).
3.2.2. Resultant Force Optimizes Momentum Smoothing
To address the issue of oscillations caused by abrupt repulsion near obstacles, a momentum-inspired smoothing mechanism is incorporated into the resultant force computation. Drawing on the momentum-based gradient descent, the current effective force is defined as a weighted combination of the current and previous timestep forces:
where
is the raw resultant force at time
, computed from Equations (10), (13), and (14);
is the effective force from the previous timestep; and
is a tunable coefficient controlling the momentum contribution.
Figure 4 illustrates the effect of the force smoothing, as defined in Equation (17). In
Figure 4a, which depicts the case without smoothing, the blue dashed circle, solid blue circle, and red dashed circle represent the positions of the UAV at three successive timesteps. At the intermediate timestep, the UAV approaches the obstacle too closely due to the strong attractive force. This results in a large repulsive reaction force from the obstacle, which sharply redirects the UAV and causes a sudden deviation from its intended path—leading to the position indicated by the red dashed circle.
In contrast,
Figure 4b demonstrates the scenario with force smoothing applied. Although the UAV reaches a similar position near the obstacle, the momentum-based adjustment prevents it from being forcefully repelled. As a result, the UAV maintains a smooth trajectory and navigates around the obstacle without abrupt direction changes.
3.2.3. Adaptive Attractive Gain Design
To address the limitations of the traditional artificial potential field—namely, that UAVs tend to move too quickly when far from the target due to excessive attractive forces (leading to potential collisions) and too slowly when approaching the target due to insufficient attraction (resulting in failure to reach the goal)—an adaptive attractive gain function
is proposed. The gain is defined in a piecewise manner to regulate the UAV’s motion across different phases of the trajectory, as shown in Equation (18):
where
is a constant baseline gain;
is a small positive constant introduced to prevent division by zero and to stabilize the numerical computation; and
,
and
are tunable constants that can be selected according to the performance requirements.
The three operational cases are illustrated in
Figure 5.
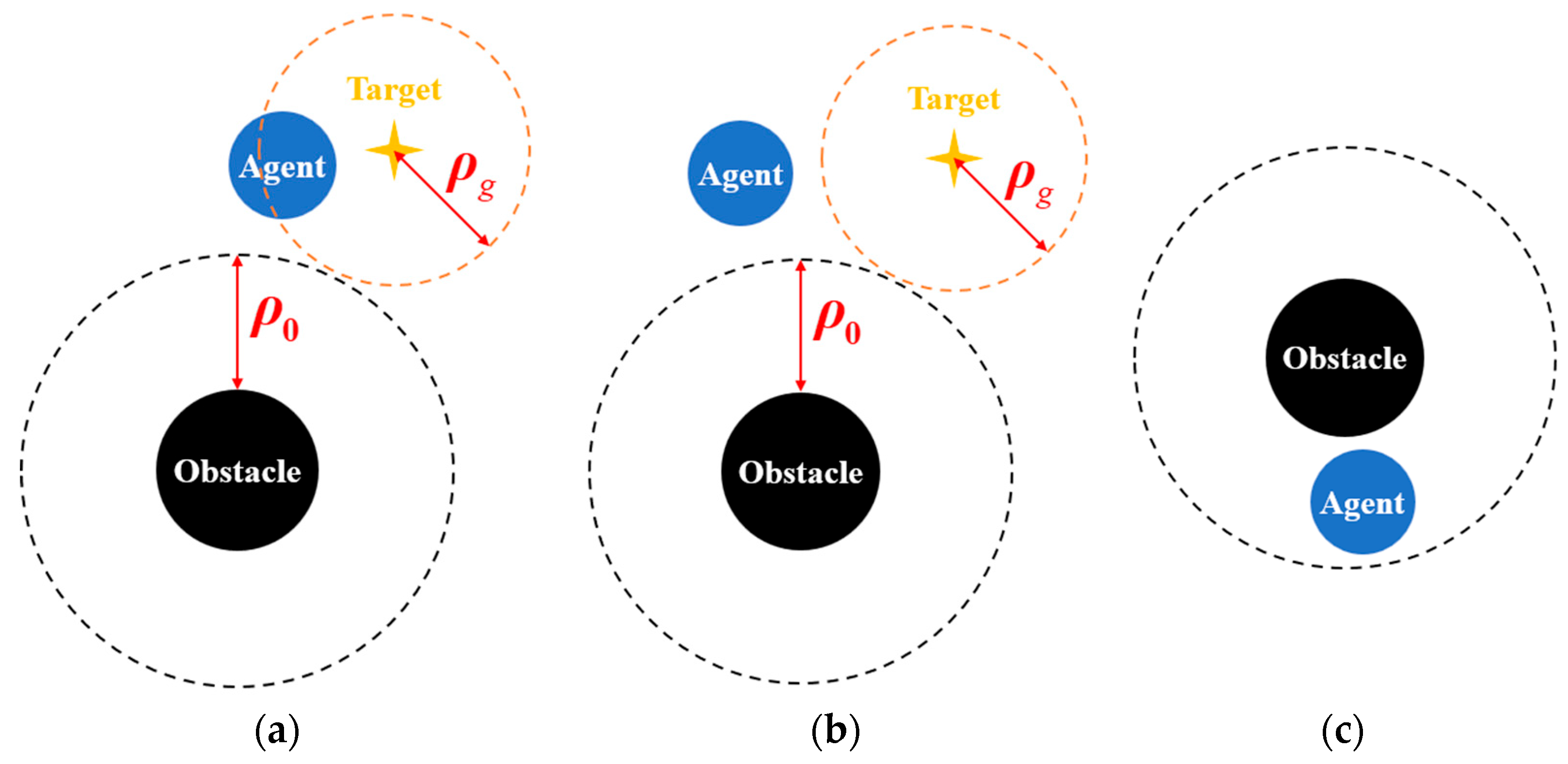
In
Figure 5a, when the UAV is not influenced by any obstacle and is within the specified proximity threshold
from the goal, the attractive gain is set to a moderate value
. This setting ensures that the UAV does not overshoot the target due to high speed while maintaining sufficient pull to prevent stagnation near the goal. In
Figure 5b, if the UAV is outside the goal proximity but still free from repulsive influence, the attractive gain is scaled inversely with respect to the distance to the goal using the adaptive attractive gain term
. A larger value of
amplifies the gain in this mid-range zone, accelerating the UAV’s movement toward the goal after obstacle avoidance, thereby shortening the convergence time. In
Figure 5c, when the UAV is within the repulsive influence of an obstacle, the attractive gain is held at
, promoting cautious and stable movement around the obstacle.
3.2.4. Control Law
The controller employed in this study is based on a consensus control framework proposed by Huang [
33], which supports different convergence performance requirements. The framework includes multiple control functions with fast convergence guarantees and proven stability. In this work, a set of nine control functions is selected from the original framework and applied to the AAPF-based formation structure. The simulation results in
Section 4 demonstrate that this controller, when integrated with the proposed formation control algorithm, enables rapid reconfiguration and accurate convergence after obstacle avoidance.
The control input for UAV
is defined as follows:
where
is a gain coefficient;
is a direction function determining the control orientation and stability; and
is a shaping function designed to meet performance criteria such as the convergence speed and robustness.
The vector denotes the smoothed resultant force at time .
3.3. Escape from Semi-Enclosed Obstacles Using DSA-AAPF
This subsection introduces an enhanced approach for escaping local minima by combining the deflected simulated annealing (DSA) algorithm with the adaptive artificial potential field (AAPF) framework. The discussion focuses primarily on scenarios involving semi-enclosed obstacles.
Simulated annealing (SA) is a Monte-Carlo-based probabilistic optimization algorithm used for approximating global optima. The algorithm consists of two nested loops: an outer loop in which the system temperature gradually decreases and an inner loop that probabilistically accepts new candidate solutions based on the metropolis criterion. The probability that a particle reaches equilibrium at a given temperature
is
, where
is the internal energy at temperature
,
represents the change in energy between states, and
is the Boltzmann constant. The metropolis acceptance rule is formally defined as:
where
is a candidate position at the next iteration;
is the current position of the UAV;
and
represent the internal energy (i.e., the potential field value) at these respective positions; and
denotes the current system temperature.
The temperature is updated iteratively according to a linear decay model as follows:
where
is a decay constant slightly less than one.
When applied to the AAPF-based path-planning framework, the variables in Equation (20) correspond to the following:
(1) : the UAV’s current position;
(2) : a randomly sampled candidate position nearby;
(3) : the potential energy at the current position;
(4) : the potential energy at the candidate position.
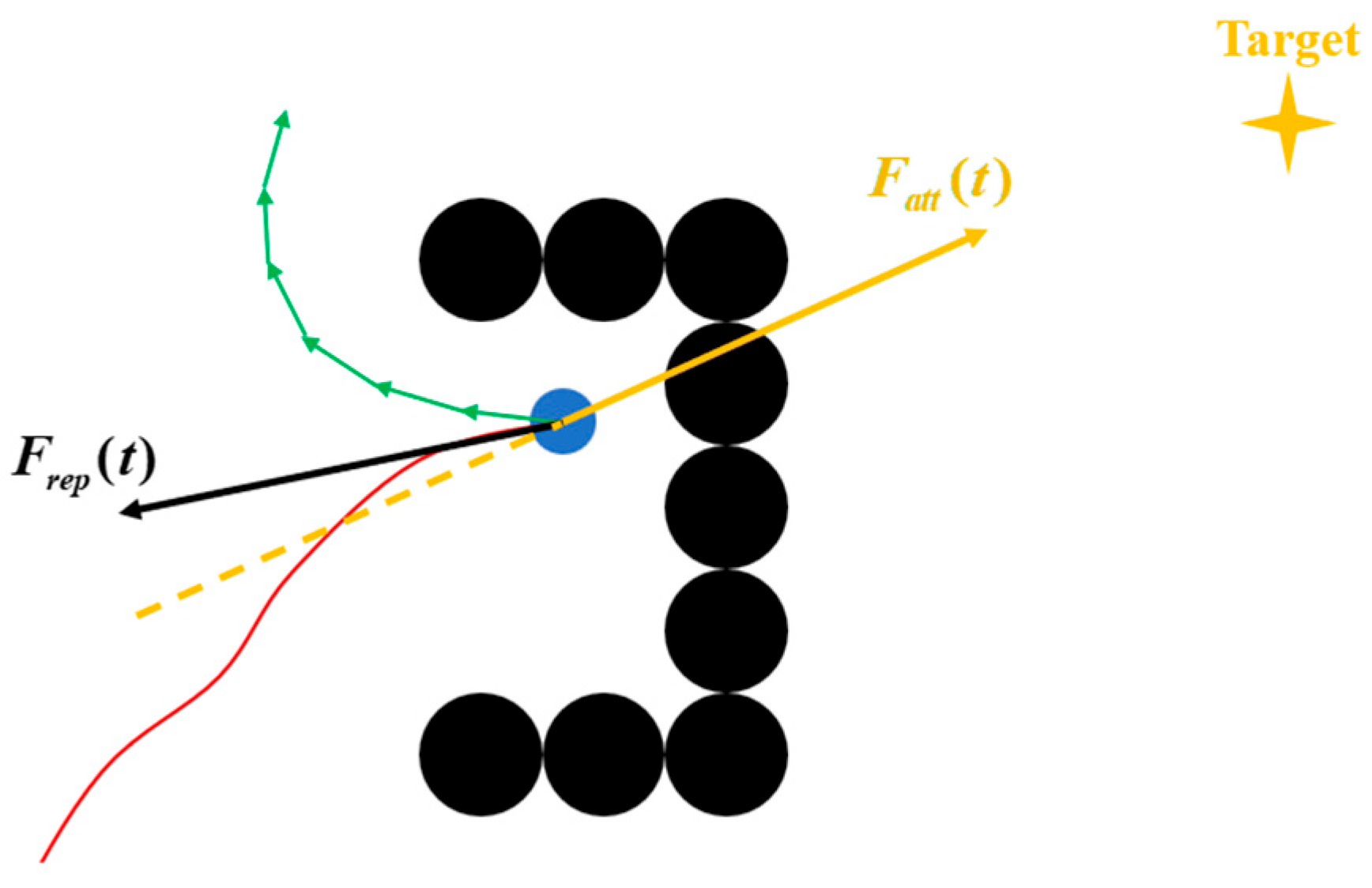
The key improvement proposed in this study lies in the method used to generate the candidate points , particularly in the context of escaping from semi-enclosed obstacles.
As illustrated in
Figure 6, the red solid line represents the trajectory previously traversed by the UAV, while the blue filled circle indicates the UAV’s current position. When the UAV becomes trapped in a local minimum within a semi-enclosed obstacle, a constant-magnitude force
is applied. This force is rotated by a random angle within a predefined range in a consistent direction over multiple iterations, generating an arc-like trajectory that enables the UAV to escape the enclosure.
To realize this escape mechanism, three key issues must be addressed.
(1) Directional Ambiguity
Within a semi-enclosed obstacle, there are typically two feasible escape directions. Choosing the correct direction significantly reduces the travel distance to the goal. As shown in
Figure 7, following the direction indicated by the green path yields a faster and more direct route to the goal compared to the orange path. Therefore, determining the optimal escape direction is critical.
(2) Parameter Design for Force and Rotation
The magnitude of the escape force and the rotational angle must be carefully selected. If the force is too weak or the rotation too large, the UAV may fail to exit the enclosure or collide with the obstacle boundary.
(3) Escape Condition Determination
A reliable method must be defined to determine when the UAV has successfully exited the semi-enclosed obstacle.
To address these challenges, the following strategy is proposed.
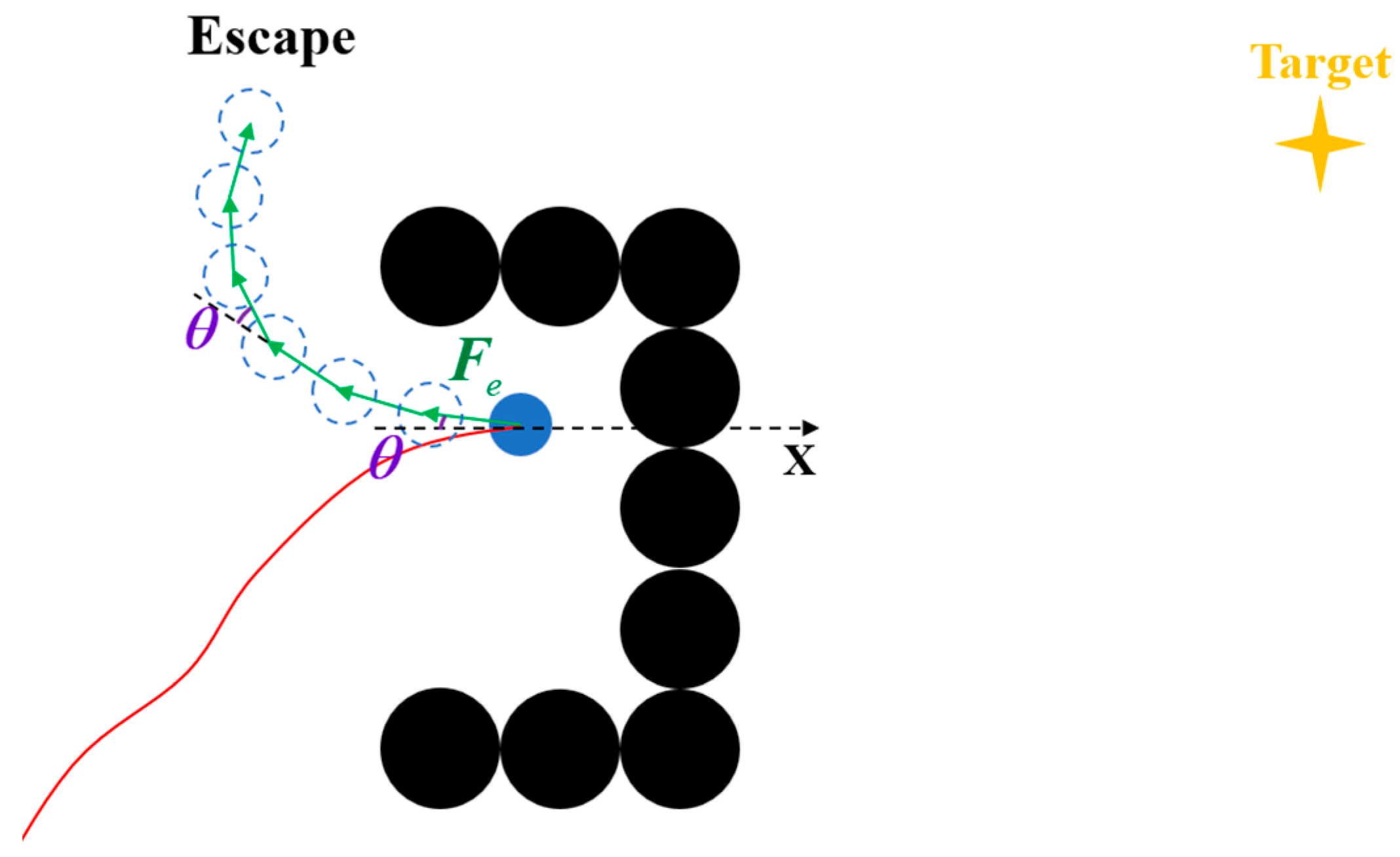
It is first noted that in real scenarios, it is rare for the attractive and repulsive forces to exactly cancel each other out in magnitude and direction. Instead, local minima usually occur when these forces are nearly equal and opposite, resulting in a net force that is too small to drive motion. When such a situation arises within a semi-enclosed obstacle, it is observed that eliminating the attraction component often leaves a repulsive force pointing outward—i.e., in a direction favorable for escape.
Additionally, since the goal is usually located outside the obstacle, the attractive force tends to bias the UAV toward that side. As a result, when the UAV enters the enclosure and becomes trapped, the repulsive force vector typically lies on the same side as the extension of the attractive force’s opposite direction. This relationship is illustrated in
Figure 8, where the optimal escape direction lies on the opposite side of the attractive force vector.
In the proposed algorithm, the escape direction is determined by identifying which side of the extended line opposite the attractive force the repulsive force lies on, as illustrated in
Figure 9. In this figure, the blue arrow represents the vector difference
. The angle
denotes the angle between the attractive force direction and the positive x-axis, while
represents the angle between the vector
and the positive x-axis.
If , the UAV should rotate in the clockwise direction.
If , the UAV should rotate counterclockwise.
Next, let denote the time at which the UAV enters a local minimum. The repulsive force experienced at this moment, , is defined as the initial value of the escape force , denoted as . The angle between and is denoted as , where . The value of angle is picked randomly in section (, where is a predefined constant.
The rotation matrix is defined as:
The escape force
at time
is then updated as:
As a result, this force is applied iteratively, rotating by at each step, maintained at a constant magnitude, until the UAV successfully escapes the semi-enclosed obstacle
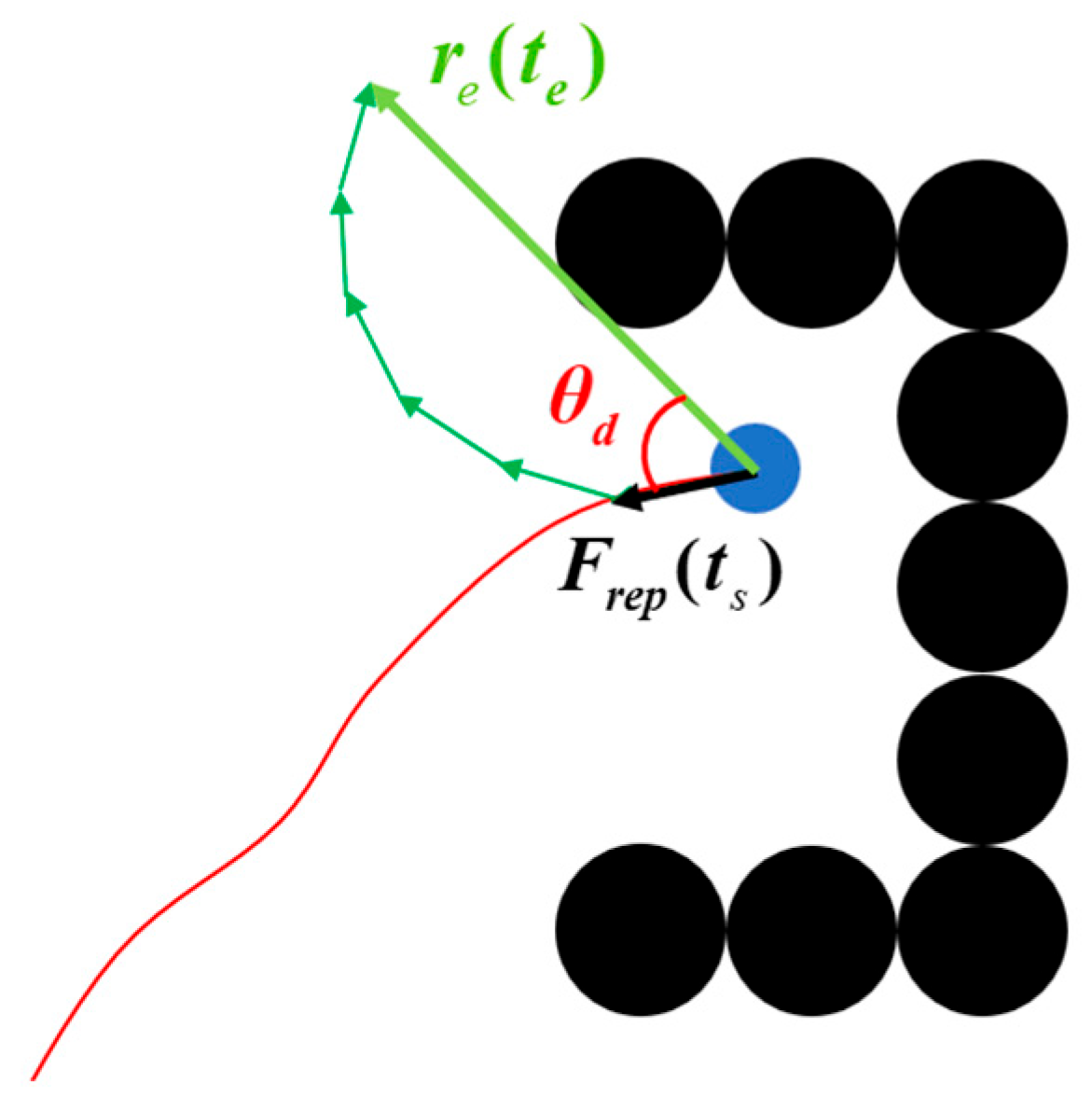
Let
denote the final iteration time of the simulated annealing loop. As illustrated in
Figure 10,
represents the displacement vector from the local minimum position to the UAV’s position at time
. The angle
denotes the angle between
and the initial escape force
, which is equivalent to
. In the algorithm, a threshold angle
is defined as a constant in
. If
, the UAV is considered to have successfully escaped from the semi-enclosed obstacle.
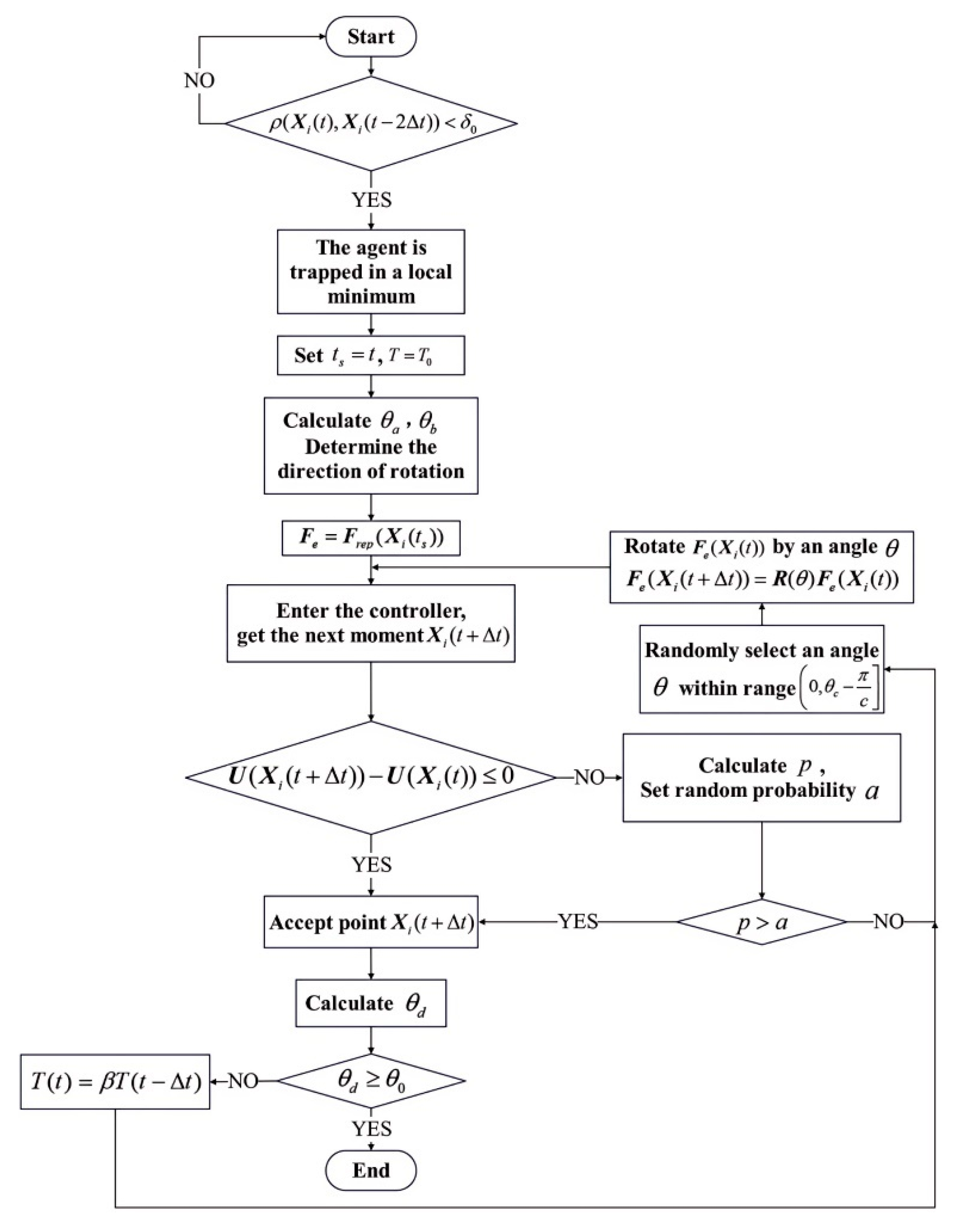
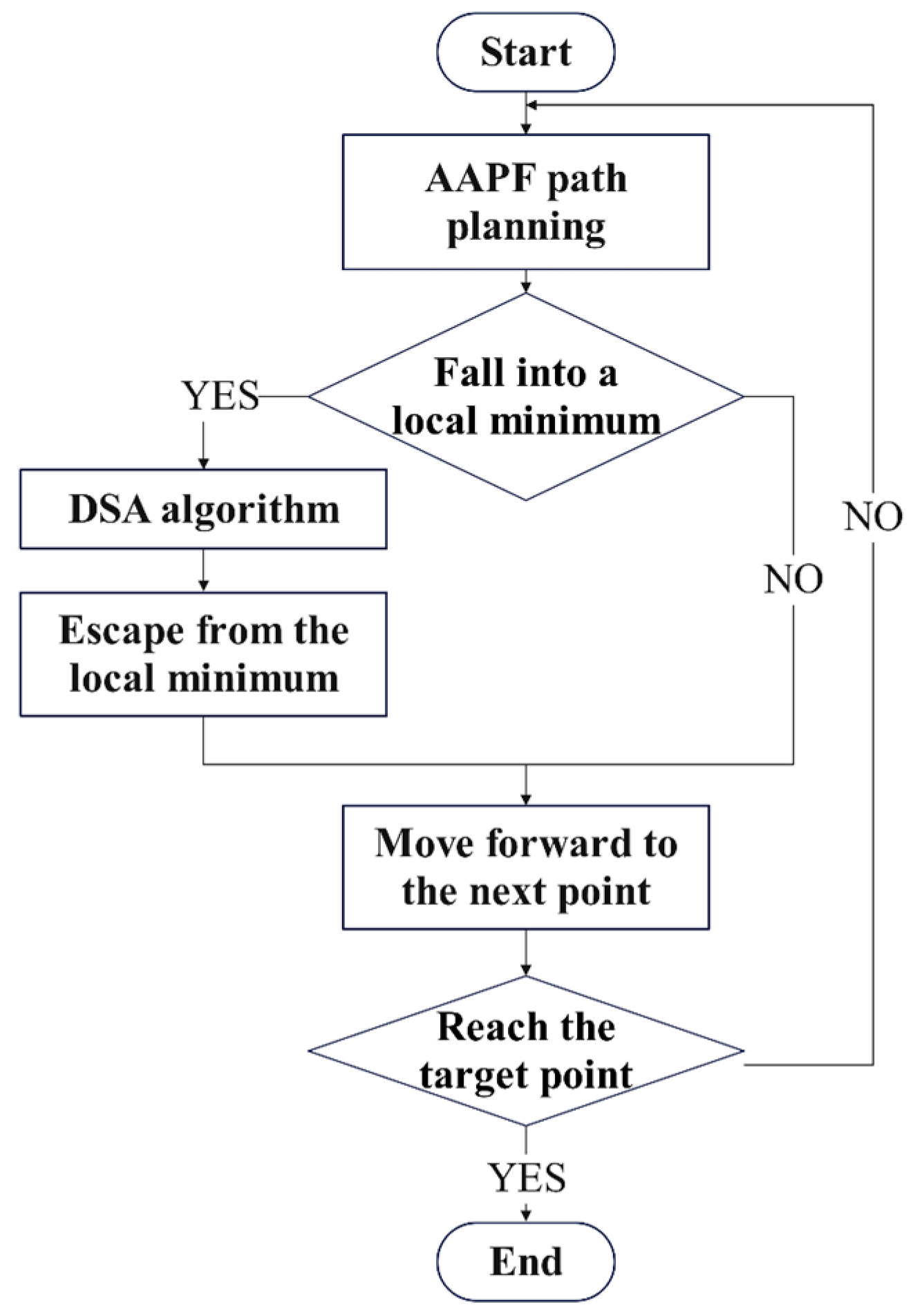
The complete procedure of the improved simulated annealing algorithm is summarized in
Figure 11. The flowchart of the whole DSA-AAPF algorithm is shown in
Figure 12.
4. Algorithm Simulations and Performance Evaluation
To validate the effectiveness of the proposed algorithm, a series of simulation experiments are conducted focusing on four core capabilities: (1) oscillatory testing of the resultant force optimization effects; (2) reformation of the multi-UAV formation after obstacle evasion; (3) obstacle avoidance when the environment is complicated; and (4) escaping from semi-enclosed obstacle environments. The controller functions employed are selected from nine function pairs proposed by Huang [
33], as listed in
Table 2. The performance metrics are evaluated based on the convergence speed and accuracy of each UAV along the
and
axes, ultimately identifying the most suitable controller configuration for the subsequent experiments.
The subsequent simulations are designed to assess the effectiveness of the formation navigation in environments with multiple complex obstacles, focusing on the avoidance performance and convergence efficiency. Finally, the capability of the formation to escape from semi-enclosed traps is tested to verify the robustness of the deflected simulated annealing–adaptive artificial potential field (DSA-AAPF) algorithm.
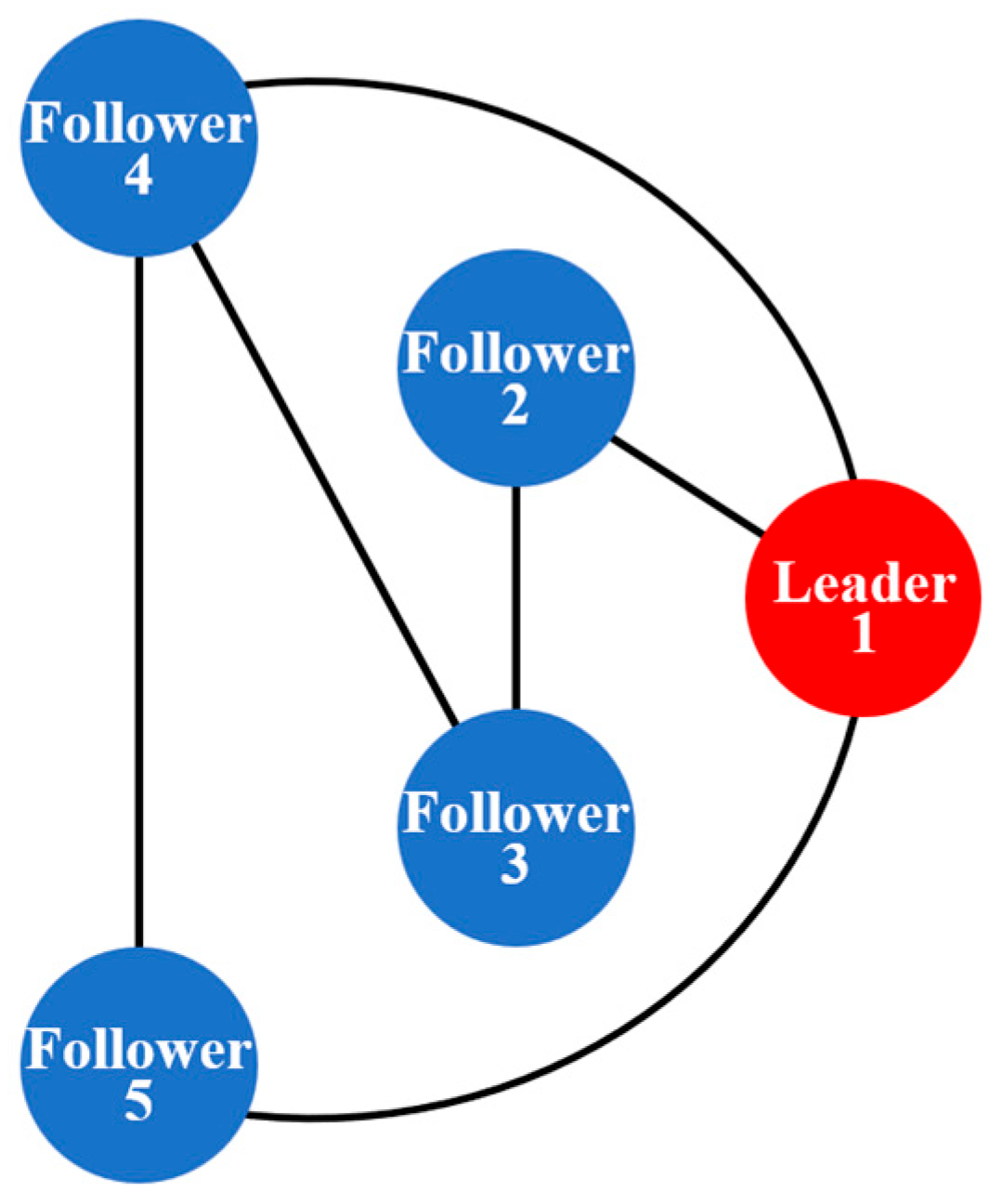
A formation composed of five UAVs is used for the evaluation, in which UAV 1 serves as the leader and the remaining four act as followers. The communication topology is modeled as an undirected graph, as shown in
Figure 13, where the adjacency matrix satisfies
, with all the other elements set to zero. The controller gain parameters are configured as follows:
,
,
,
,
, and the formation spacing vectors are defined as:
,
,
,
.
4.1. Oscillation Test
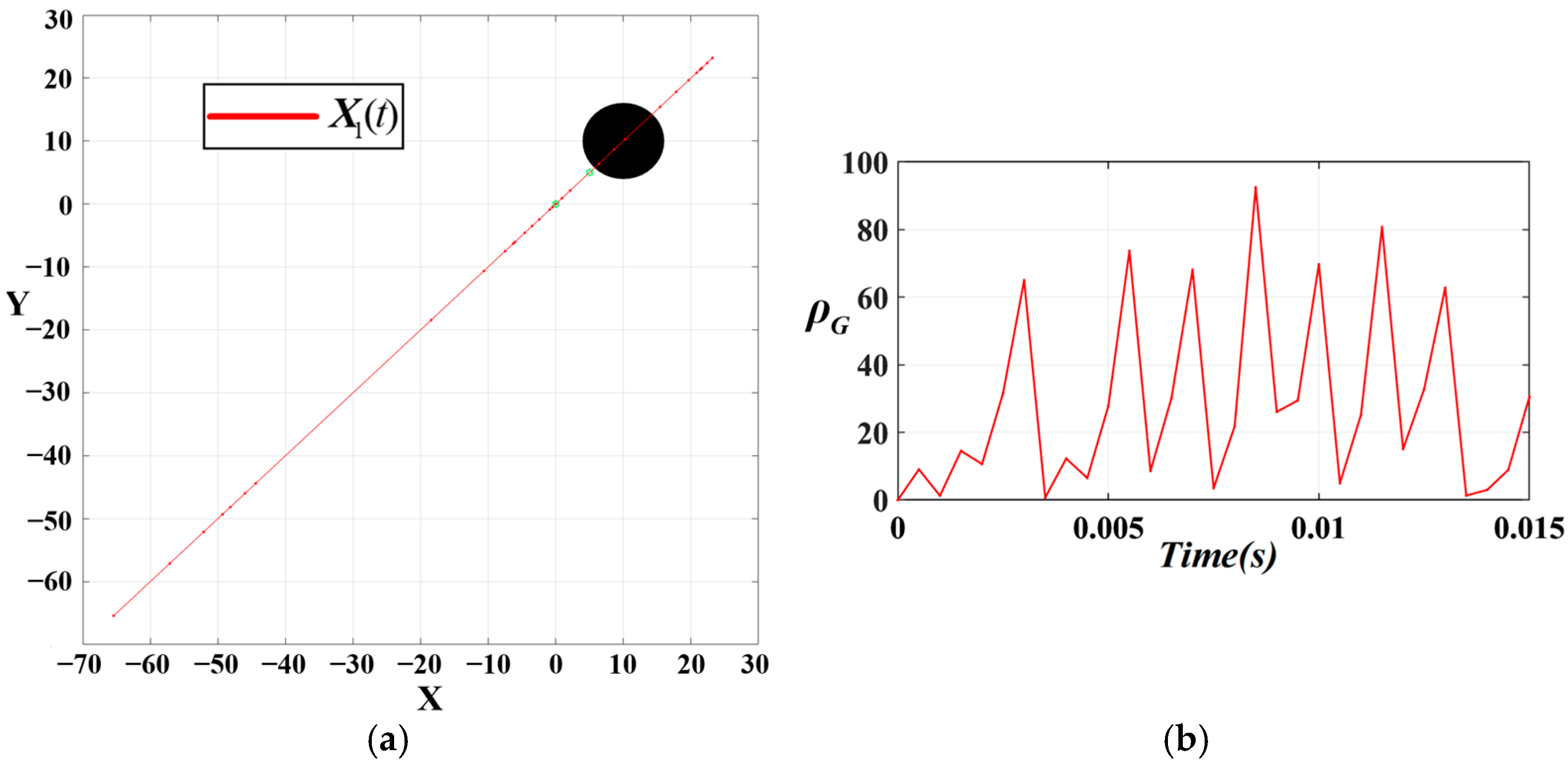
In order to obtain the scaling parameter in the resultant force optimization in Equation (17), we set the obstacles and target points very close to each other and three points co-linear with the starting point of the UAV to create an environment where the UAV would oscillate back and forth for the oscillation test. The magnitude of the scaling parameter is adjusted to observe the degree of suppression of the oscillations by the Equation (17) resultant force optimizes momentum smoothing in 0.015 . The distance of the UAV from the starting point is defined as .
Only one UAV is used in the test, with the starting point , the target point , and a circular obstacle centered at . The attractive gain is set as , and the repulsive gain as .
It is found experimentally that the best suppression of the oscillations is achieved when the scaling parameter is
. The simulated path diagram with the variation of
when
is shown in
Figure 14.
From
Figure 14, the UAV is displaced by a large distance due to the excessive gravitational force and then is too close to the obstacle to generate a large resistance and reverse the displacement by a large distance, with the variance of
reaching 741.5648, generating a very pronounced oscillation and even causing the path point to pass through the obstacle.
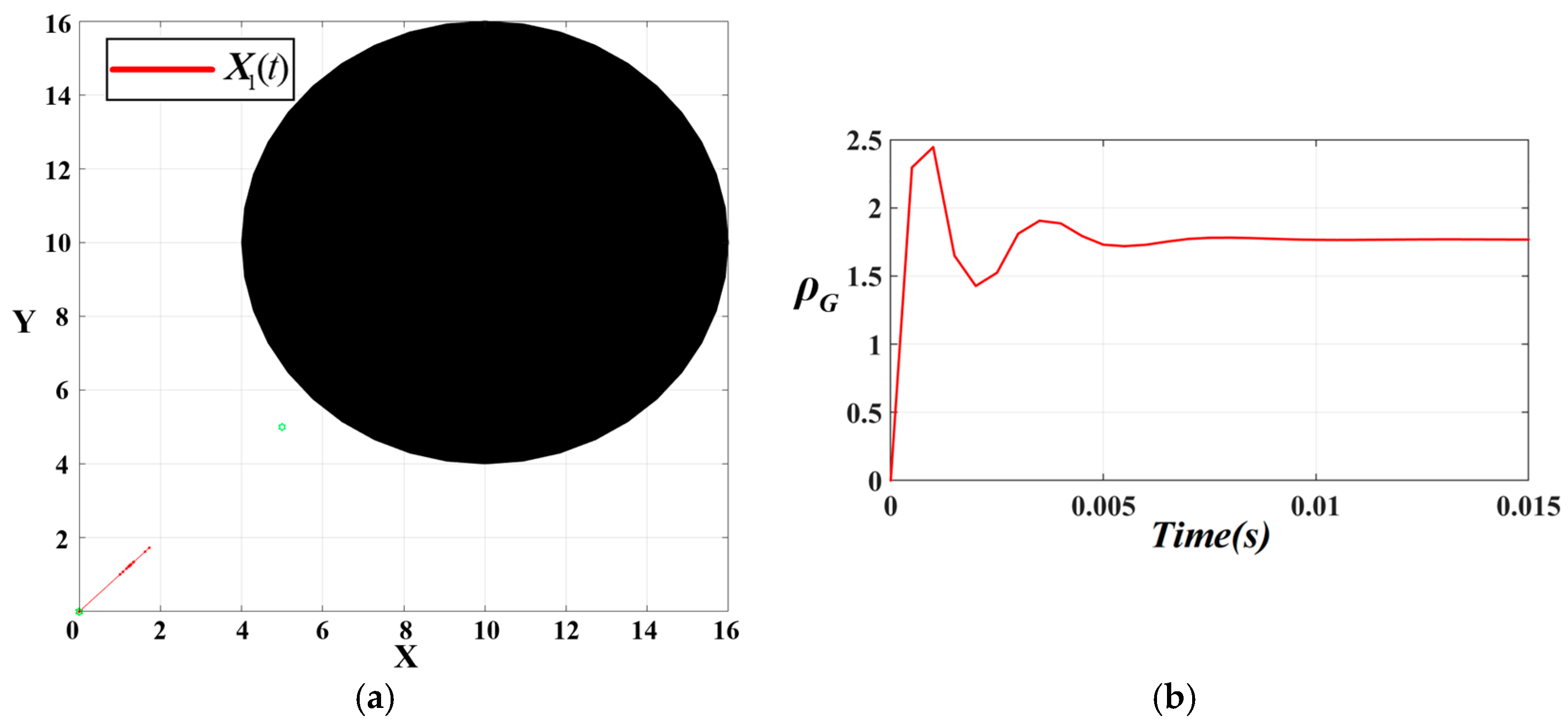
The simulated path diagram with the variation of
when the resultant force optimization is used and
is shown in
Figure 15.
From
Figure 15, the oscillation phenomenon of the UAV in
Figure 14 is very significantly suppressed, with a variance of only 0.1353. Under the same conditions, after the UAV is optimized with a resultant force of
, no very large oscillation occurs and the equilibrium is restored within 0.01
.
To summarize, for our subsequent experiments, we selected .
4.2. Formation Reconfiguration Test
To assess the system’s ability to maintain the formation structure during obstacle avoidance and reformation, the deviation between the UAV’s position and its target is quantified as . A circular obstacle is placed on the UAV’s trajectory to observe the response behavior. The attractive gain parameters are configured as , , and the adaptive gain factors , . The obstacle’s influence radius is set as . The initial positions are specified as ,, , , and . The leader’s destination is defined as , with a circular obstacle centered at . It is defined that when , to maintain the formation state, the error between the positions of all the followers and the formation target in the and directions must not exceed 0.1. Define time as the time it takes for a UAV formation to start avoiding obstacles from maintaining the formation state, leaving the formation state, bypassing the obstacles, and then resuming maintaining the formation state.
Given the structural similarity among the three configurations in each group (due to the identical potential functions), only one simulation formation trajectory per group is visualized.
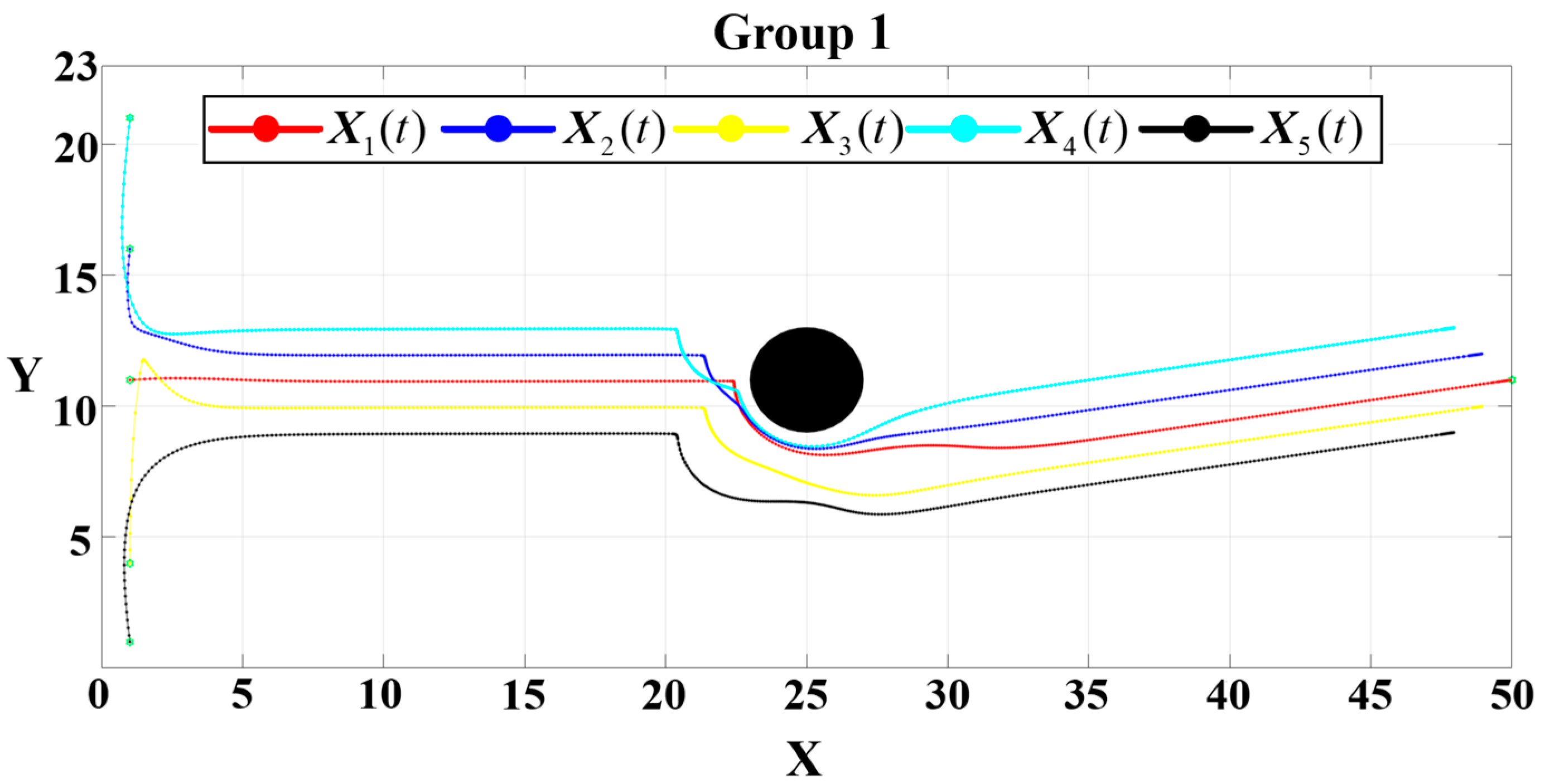
For Group 1, the attractive gain is set as
, and the repulsive gain as
. The corresponding trajectory of the formation reconfiguration and obstacle avoidance is depicted in
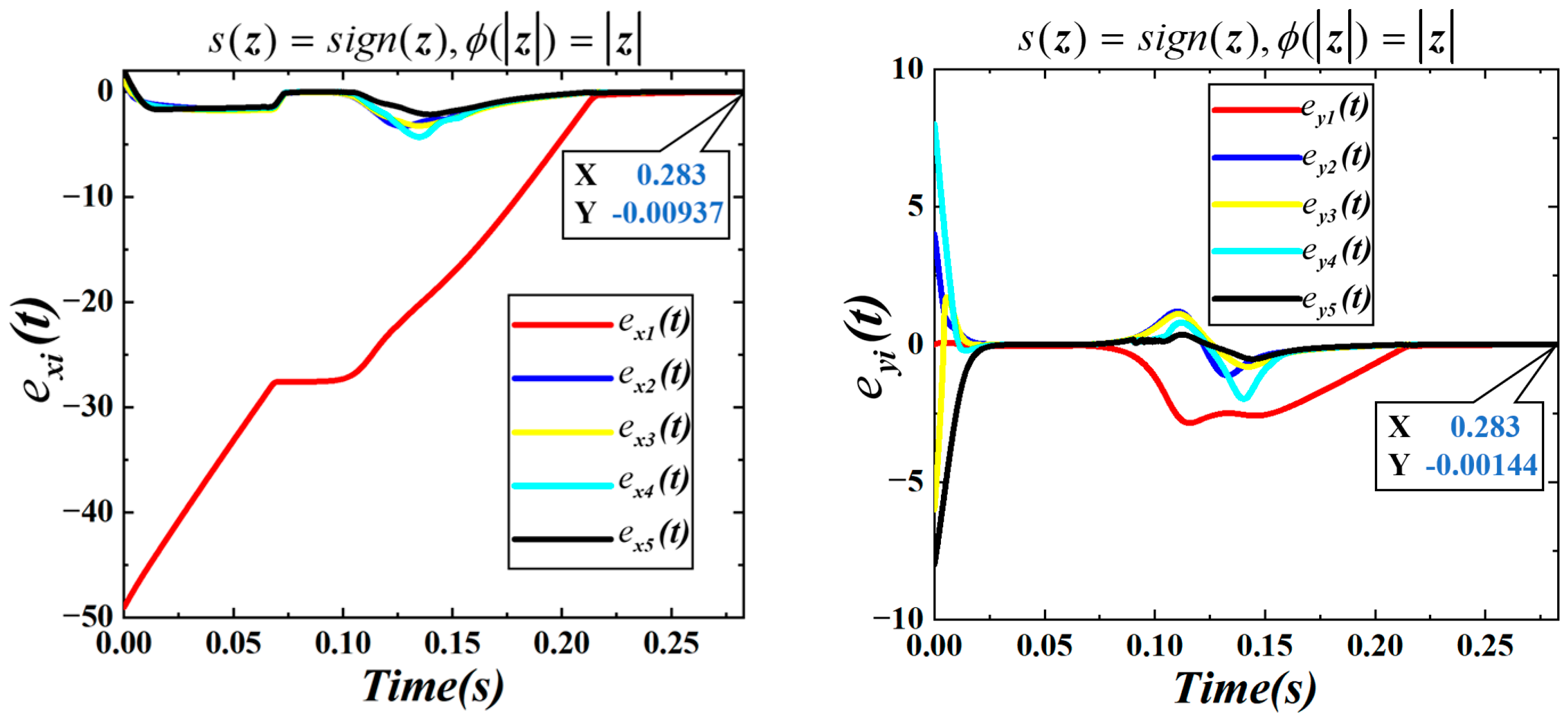
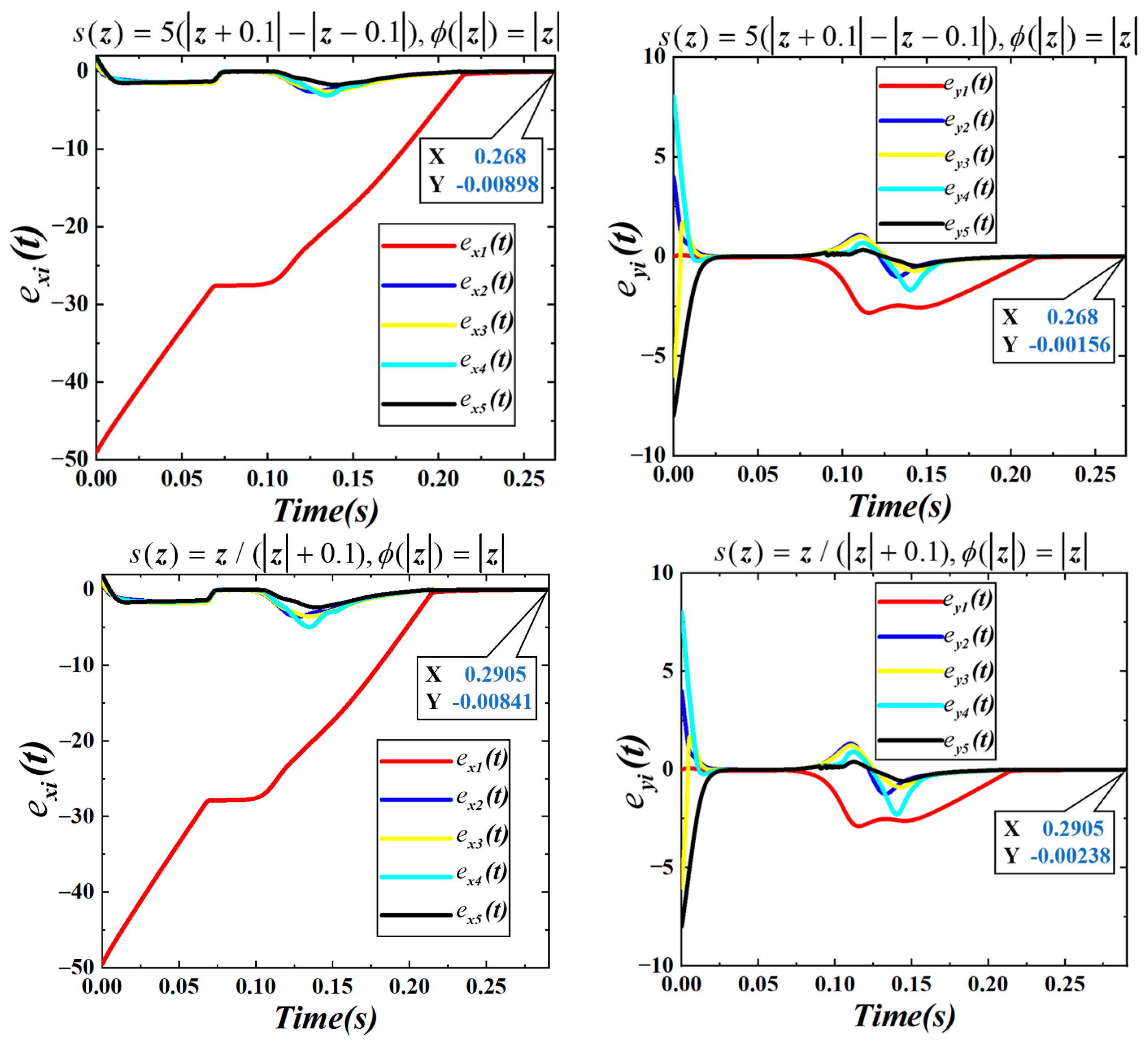
Figure 16, while the convergence dynamics in the
and
directions are illustrated in
Figure 17.
From the results shown in
Figure 16, the UAV formation maintains a compact structure during the initial phase of motion. Upon encountering the obstacle, the formation disperses to perform obstacle avoidance and subsequently reassembles into the predefined configuration before converging to the target destination.
As indicated in
Figure 17,
under the three controllers is 0.124
, 0.113
, and 0.132
, respectively, and the final distance to the target point converges to a very small value. The total completion times for the three configurations are approximately 0.283
, 0.268
, and 0.2905
, respectively.
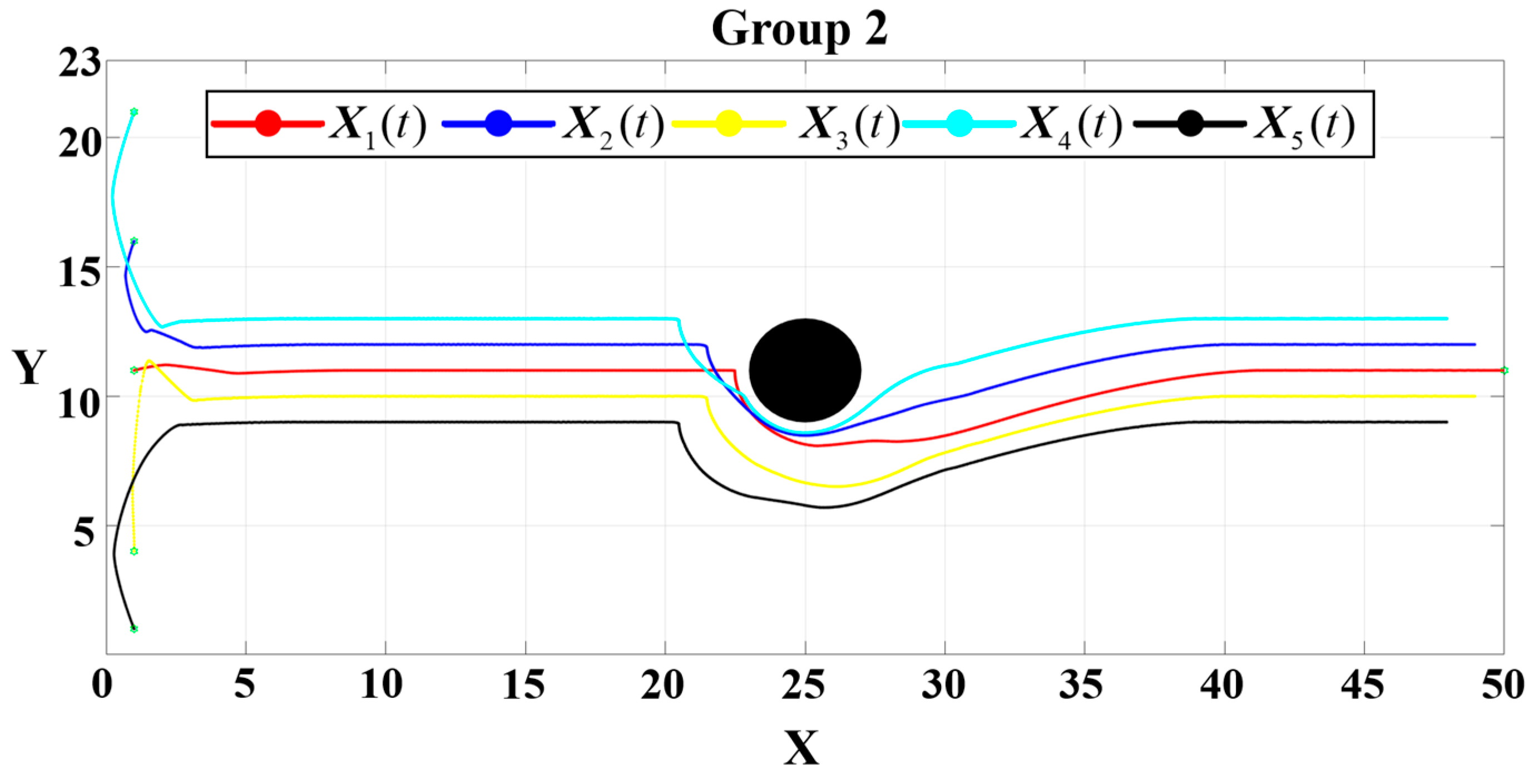
In the simulations for Group 2, the parameters are adjusted to
and
. The obstacle avoidance and reformation trajectory is presented in
Figure 18, while the convergence dynamics in the
and
directions are illustrated in
Figure 19.
The simulation reveals a stable reformation process similar to that of Group 1; however, the higher attractive gain caused a marginal increase in the oscillatory motion during avoidance. Despite this, the UAVs successfully completed the formation restoration with comparable convergence accuracy. under the three controllers is 0.324 , 0.286 , and 0.337 . The time required to complete the task for the three cases is approximately 0.885 , 0.864 , and 0.887 , respectively.
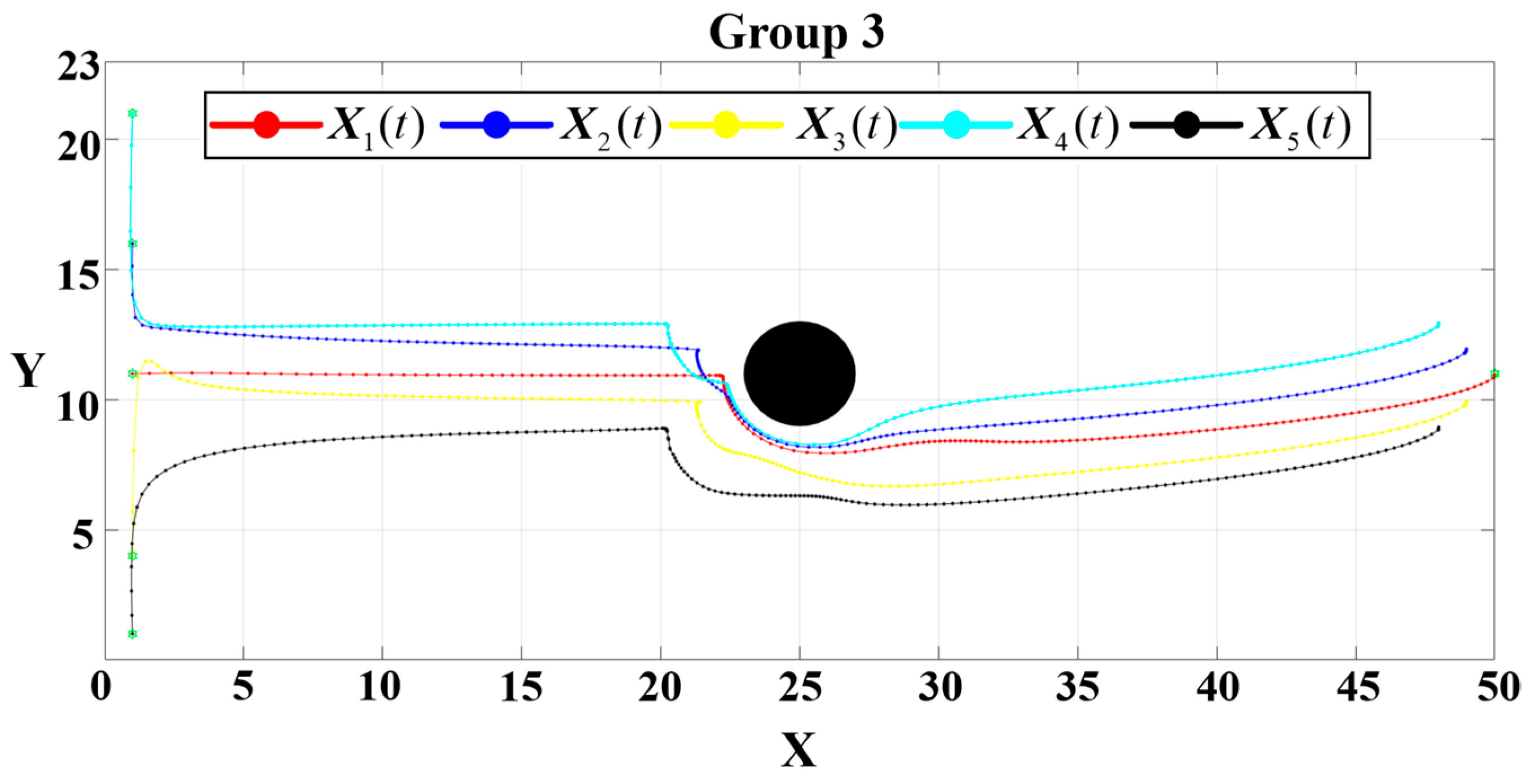
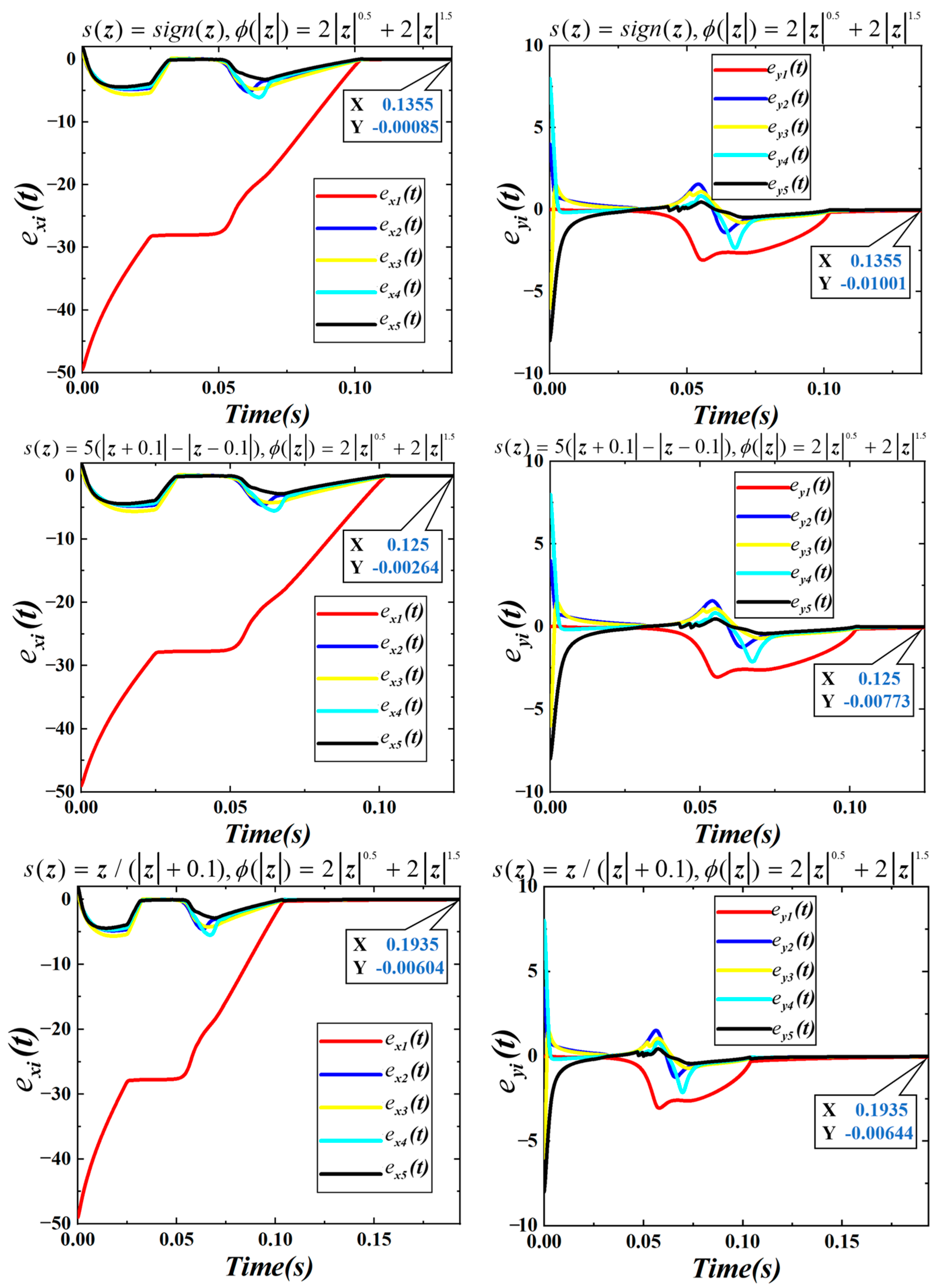
For Group 3, the gains are configured as
and
. The obstacle avoidance behavior is illustrated in
Figure 20, while the convergence dynamics in the
and
directions are illustrated in
Figure 21.
From
Figure 21,
under the three controllers is 0.064
, 0.052
, and 0.075
. Subsequently, the positional deviations from the target point converge to negligible values. The total completion times for the three scenarios are 0.1355
, 0.125
, and 0.1935
, respectively.
As summarized in
Table 3, while the configurations in Group 3 exhibit slightly inferior accuracy in the
direction compared to Groups 1 and 2, it demonstrates superior convergence accuracy in the
direction. Moreover, Group 3 consistently achieves faster reformation times and shorter total completion durations. Notably, the second configuration in Group 3 achieves the shortest overall completion time (0.125
) while maintaining a high level of accuracy. When compared with conventional methods, this approach demonstrates significant improvements in both speed and precision. Consequently, this configuration—defined by
and
—is selected for the subsequent simulations.
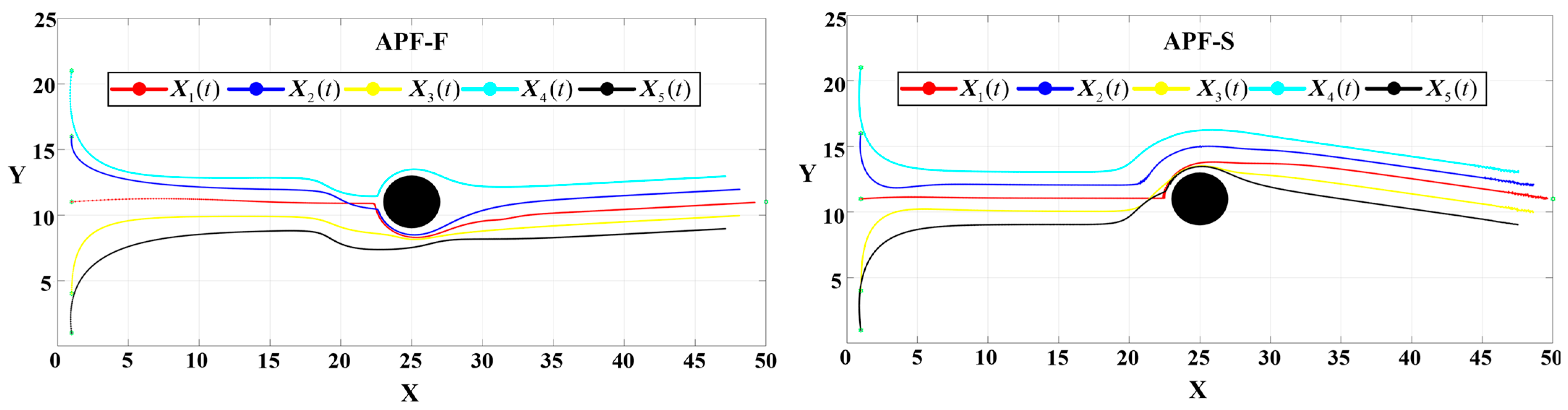
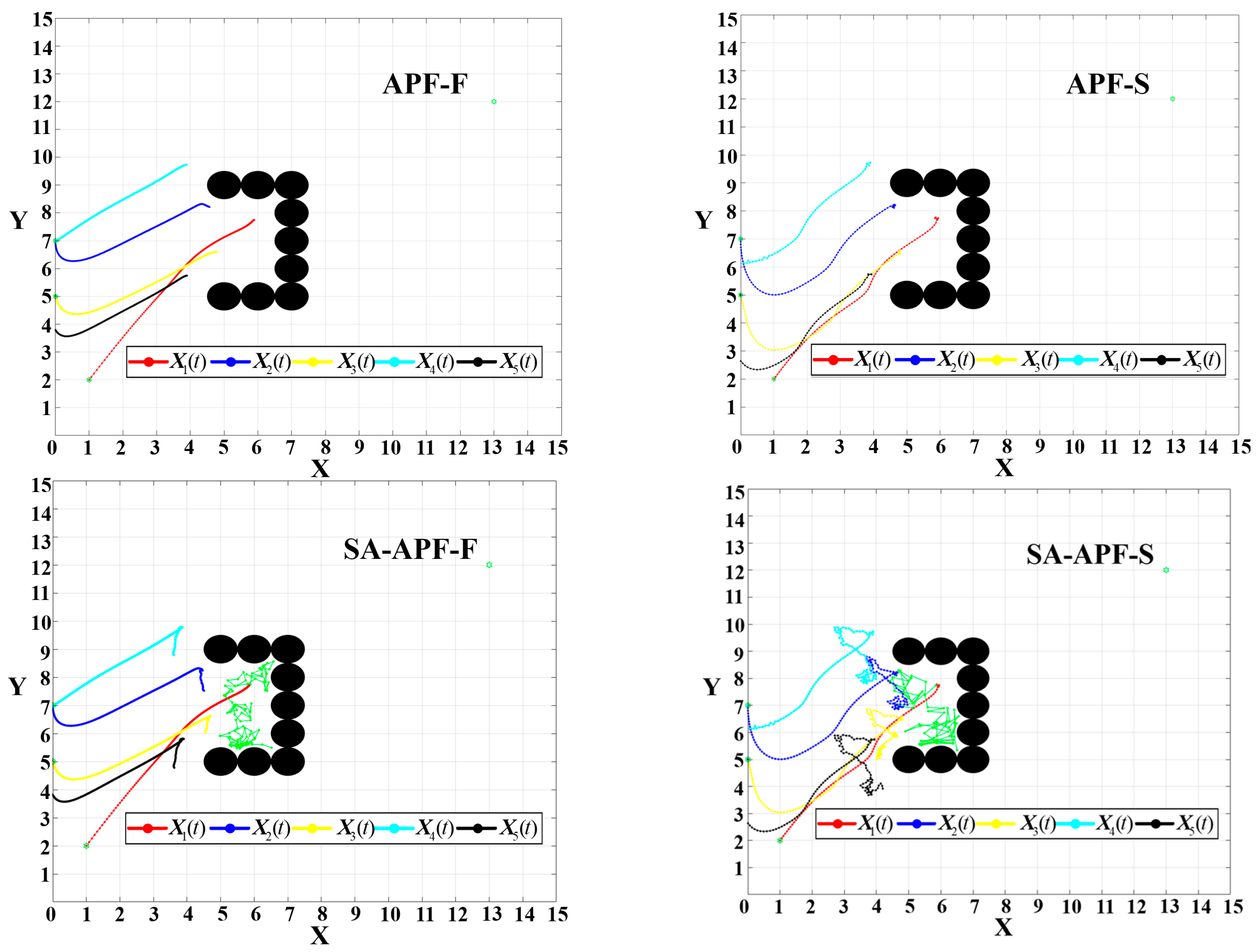
In order to evaluate the superiority of DSA-AAPF more intuitively, we next test the traditional APF algorithms in the same experimental environment as in the previous section for comparison. We categorize the traditional APF algorithms into the following two types depending on the UAV movement method.
(1) Movement with the resultant force as the control input (APF-F)
Instead of using the control rate, adaptive gain and control rate of the DSA-AAPF algorithm, only the resultant force is computed as a control input to move.
(2) Movement with a fixed step size in the direction of the resultant force (APF-S)
The difference from APF-F is that it does not move through the control input. Instead, it calculates the direction of the resultant force and then moves a fixed step in this direction, with a fixed step size of 0.1.
The gain of the control function used in the DSA-AAPF algorithm selected in the previous test is
and
. Since the gravitational force acting on APF-F is too small at this gain and it is almost impossible to move in the second half, we increase the gravitational gain by four times and use
and
. The simulated formation path diagram of APF-F and APF-S is shown in
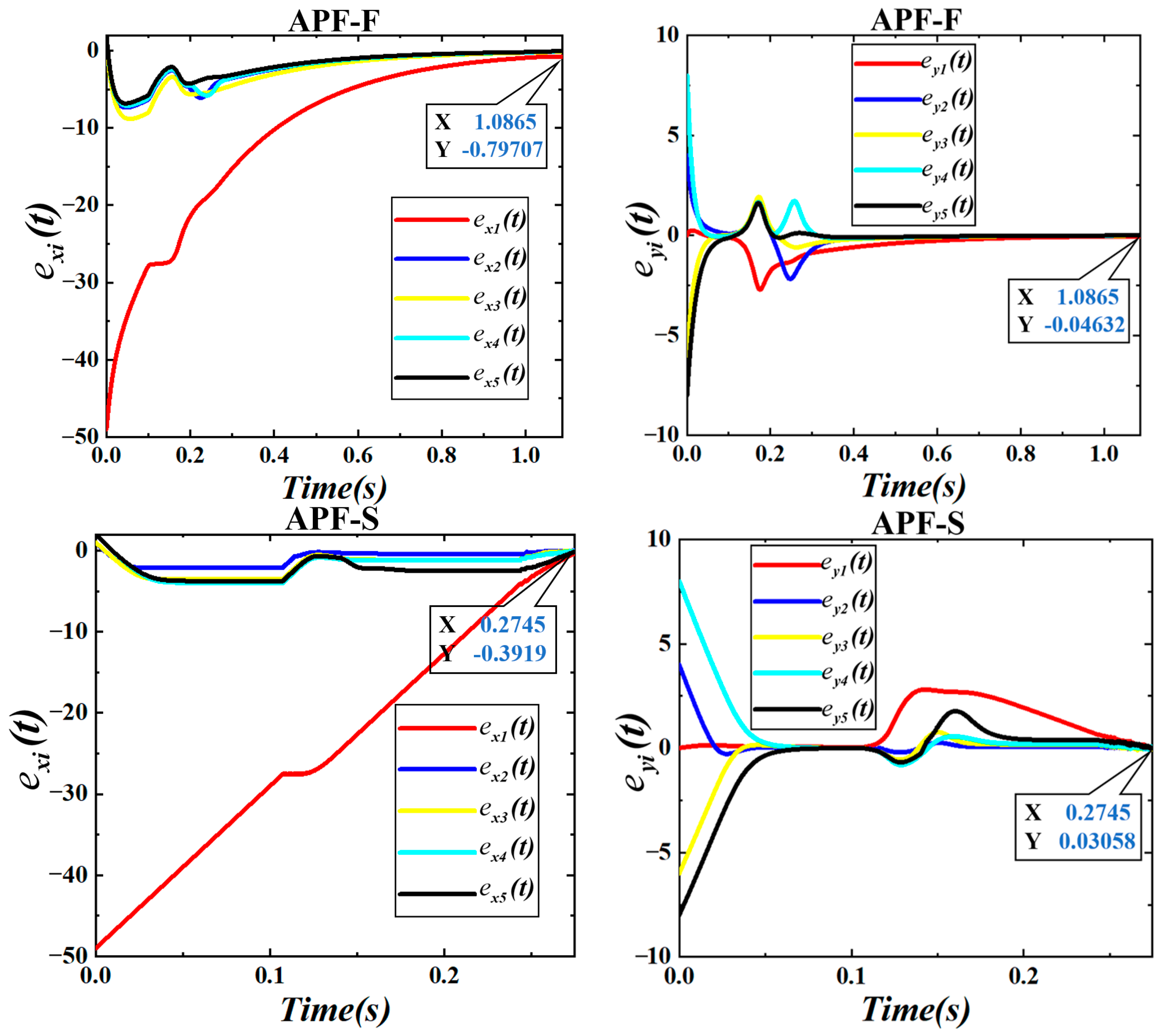
Figure 22. The convergence dynamics in the
and
directions are illustrated in
Figure 23.
From
Figure 22, for the APF-S algorithm, when the UAV moves near the obstacles, an oscillation phenomenon occurs, resulting in an unbalanced path. This is because the resistance near the obstacles is relatively large and varies greatly with the position. Moving in a fixed step size causes the resultant force direction to oscillate back and forth at a large angle, thereby causing the oscillation of the UAV. For the APF-S algorithm, the UAV also experiences an oscillation phenomenon when approaching the target point. This is because when approaching the target point, the gravitational force exerted by the navigator on the target point is too small, while in the distributed control, part of the gravitational force exerted by the follower on the navigator causes the direction of the resultant force acting on the navigator to not always point toward the target point, resulting in an oscillation change. These oscillation phenomena prove that the APF-S algorithm is not applicable to the formation control of multiple UAVs.
From
Figure 23, APF-F is unable to enter the formation holding state before encountering obstacles due to its too slow convergence speed. Moreover, when approaching the target point, the convergence speed drops rapidly because the gravitational force becomes smaller and smaller. Under the APF-S algorithm,
. The total time taken by the two methods is 1.0865
and 0.2745
, respectively, and eventually, they fail to converge to smaller values in the x direction, which are −0.79707 and −0.3919, respectively.
From
Table 4, DSA-AAPF far exceeds the traditional APF-F and APF-S algorithms in both the convergence speed and accuracy, and it can be well applied in multi-UAV formations.
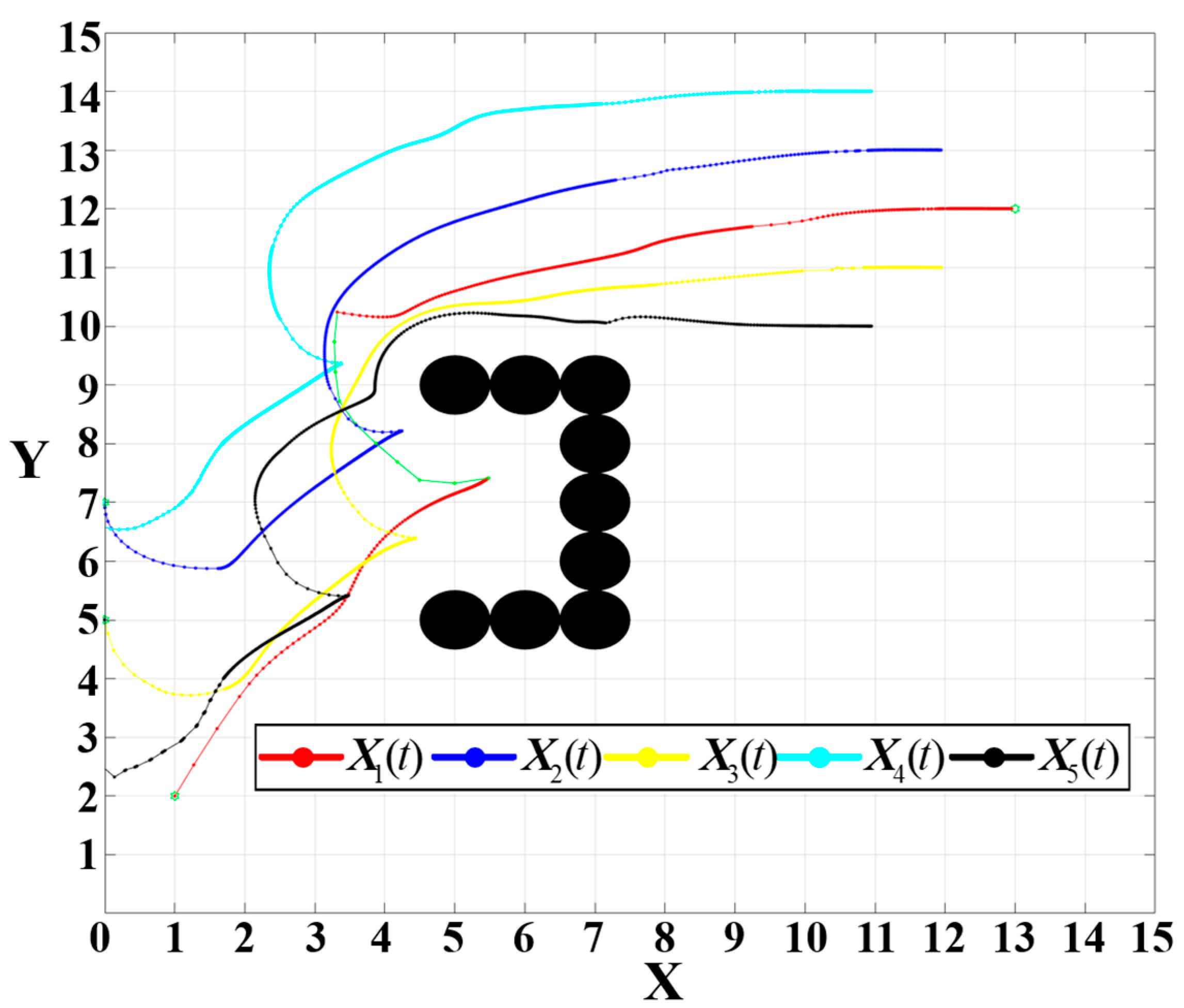
4.3. Obstacle Avoidance in Complex Environments
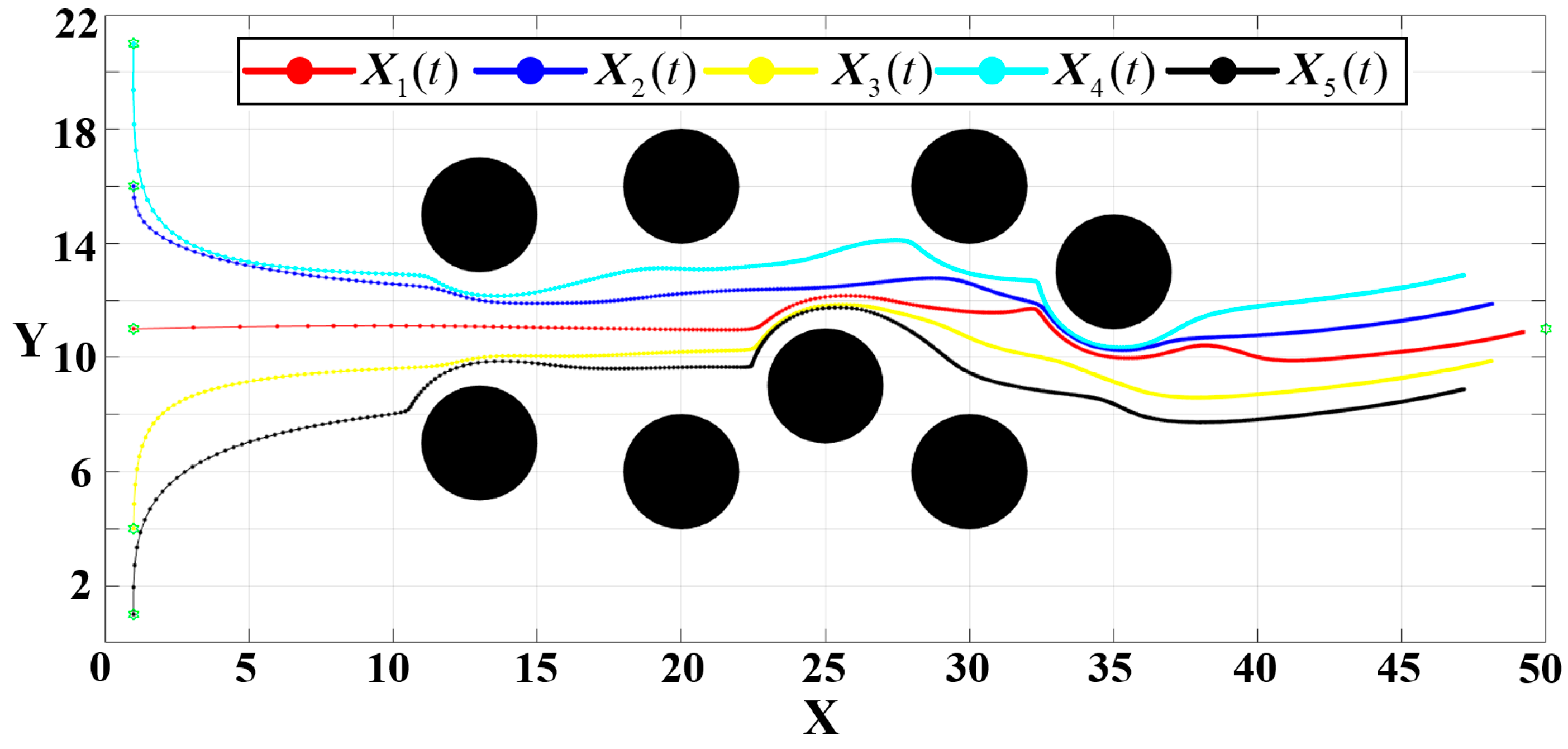
To evaluate the performance of the proposed algorithm in environments populated with multiple obstacles, a set of complex scenarios is designed. The attractive gain , the initial positions of the five UAVs, the target point for the leader, the obstacle radius, and the influence radius are all kept consistent with the previous experiments. The specific configuration is set as and .
The formation trajectory in this complex obstacle environment is illustrated in
Figure 24, where each dot represents a discrete position of the UAV at a given timestep. The density of these path points serves as an indicator of the UAV’s velocity—denser points signify slower movement. The adaptive attractive gain function
defined in Equation (18) effectively modulates the UAV’s velocity throughout the trajectory. The UAVs accelerates when outside obstacle influence zones, decelerates upon entering obstacle-affected regions, and then accelerates again after bypassing the obstacles. Finally, as the UAVs approach the convergence radius
around the target point, they decelerate to ensure precise arrival.
The evolution of errors in both the
and
directions is presented in
Figure 25.
As shown in
Figure 25, the formation completes the entire avoidance and convergence process in just 0.131
. The final deviation from the target is 0.00251 in the
direction and −0.00768 in the
direction, respectively. These results demonstrate that the proposed algorithm enables the multi-UAV formation to navigate efficiently and accurately, even under complex multi-obstacle conditions.
To demonstrate the improvement of the fast convergence control rate, adaptive gravitational gain and resultant force optimizing the momentum smoothing proposed in this paper on the traditional APF-F, under the conditions of the obstacle avoidance experiment in the complex environment in this subsection, we conducted the ablation experiment in
Appendix A.
4.4. Test of Escaping Semi-Enclosed Obstacles
This subsection evaluates the formation’s ability to escape from semi-enclosed obstacle regions—a common cause of local minima in traditional potential field methods. The attractive gain parameters are set as follows: , , , , and .
The initial positions of the five UAVs are defined as , , , and , with the leader’s target point set as . The circular obstacle is defined with a radius of 0.5 and an influence range .
The simulated annealing parameters are defined as follows: initial temperature , attenuation coefficient , rotation constant and escape angle threshold .
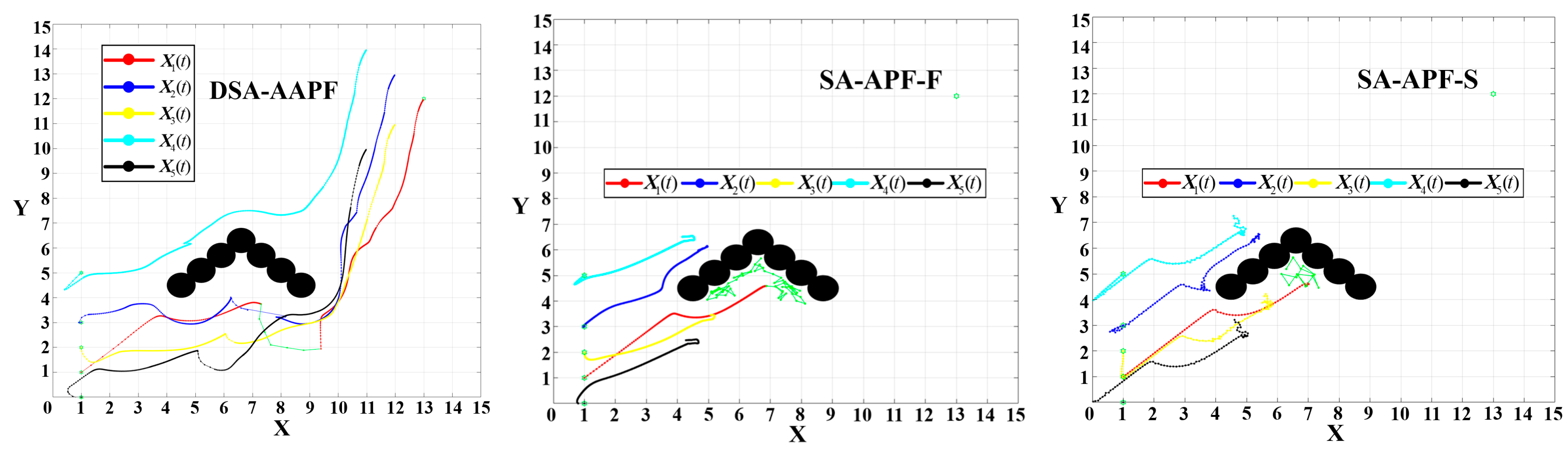
In the first test, the obstacle is modeled as a left-open semi-enclosed structure. The escape trajectory of the UAV formation is illustrated in
Figure 26.
As shown in
Figure 26, the green trajectory denotes the path of the leader (UAV 1) as it successfully escapes the semi-enclosed obstacle using the improved deflected simulated annealing mechanism. The escape path is short and efficient, with the total process completed in 0.355
.
The left-open semi-enclosed obstacle escape test is conducted using the traditional algorithms APF-F and APF-S, and SA-APF-F and SA-APF-S, with the addition of the traditional SA algorithm on their basis. The simulated path map is shown in
Figure 27.
From
Figure 27, APF-F and APF-S are completely incapable of escaping from the local minima. SA-APF-F and SA-APF-S are also almost unable to escape when facing local minima situations such as semi-enclosed obstacles. They randomly collide within the obstacles along very chaotic paths and disrupt the entire formation. It is indicated that none of these methods are applicable to the escape of multiple UAV formations from semi-enclosed obstacles.
To test the stability of the algorithm, we conducted a sensitivity analysis with a 10% change in the main control parameters, including
and
in Equation (18) and rotation constant
, to observe the change in the escape success rate. The results are shown in
Table 5 as follows.
From
Table 5, making small-scale changes to the main parameters has almost no impact on the success rate.
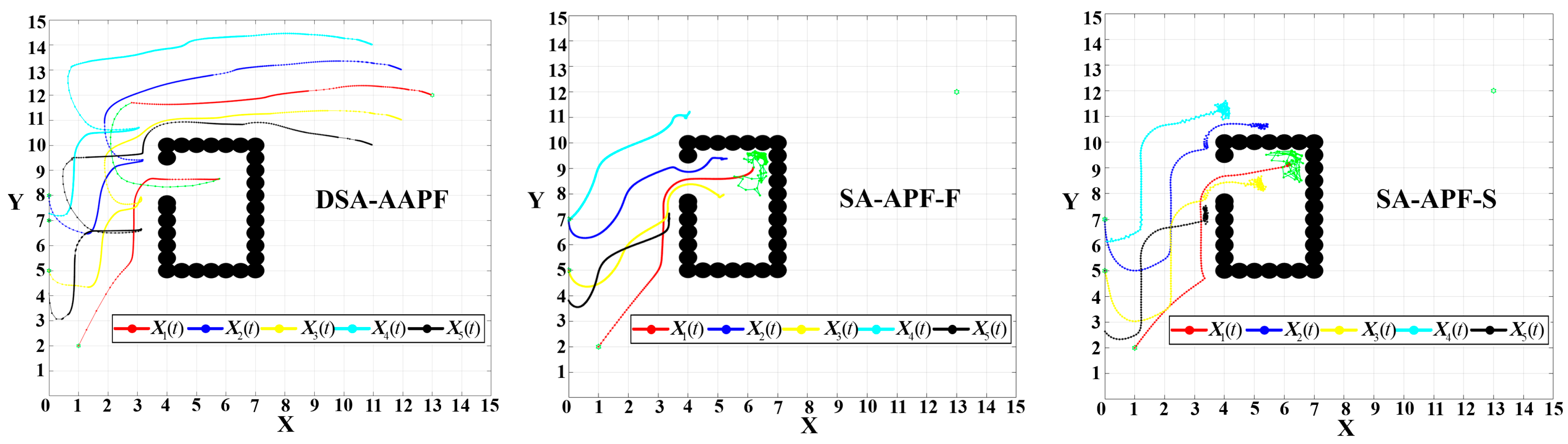
In the second test, the obstacle is configured as a bottom-open semi-enclosed structure. The initial positions of the UAVs remain unchanged. The final escape angle threshold is maintained at and all the other parameters are identical to those used in the previous test. The initial positions of the five UAVs are defined as , , , , and . A comparative experiment is conducted between DSA-AAPF and SA-APF-F and SA-APF-S.
The escape trajectory for this configuration is depicted in
Figure 28.
From
Figure 28, obviously, in the DSA-AAPF algorithm, the navigator successfully avoids the semi-closed obstacles that are open at the bottom and completes this process with a short and efficient path. The total execution time is 0.466
. The SA-APF-F and SA-APF-S algorithms still can hardly escape from the semi-enclosed obstacles with open bottoms, and the paths they attempt to escape via are very chaotic.
In the third experiment, the obstacle is expanded to leave only a small gap to verify the escape ability of DSA-AAPF in more complex situations, and comparative experiments are conducted simultaneously with SA-APF-F and SA-APF-S. The rotation constant
. The simulation path diagrams in the three cases are shown in
Figure 29.
From
Figure 29, the DSA-AAPF algorithm still allows the navigator to escape nearly fully enclosed obstacles via a shorter path, and the other two algorithms still cannot.
After a large number of experiments, we can draw the conclusions in
Table 6. DSA-AAPF has an extremely high success rate when encountering the above three obstacles, while APF-F and APF-S have no ability to escape the local minima. SA-APF-F and SA-APF-S have an extremely low probability of escape only when encountering local minima caused by relatively simple obstacles. They are ineffective when encountering complex obstacles, and the paths for attempting to escape the obstacles are very chaotic, making them not suitable for multi-UAV formations. To sum up, it is sufficient to prove that DSA-AAPF has higher superiority and robustness compared with several other traditional algorithms.
5. Conclusions
This paper proposes an enhanced deflected simulated annealing–adaptive artificial potential field (DSA-AAPF) algorithm to address the limitations inherent in traditional artificial potential field (APF) methods. The improved framework redefines the potential field functions and integrates the APF with a leader–follower distributed control strategy for multi-UAV formation tasks. To mitigate the oscillations caused by excessive velocity when the UAVs are far from the target and approach obstacles abruptly, a modified force computation model is introduced. This change retains a fraction of the previous timestep’s resultant force, thereby ensuring smoother UAV trajectories. To address the challenge of an inadequate attractive force near the target—leading to failure in terms of convergence—a novel adaptive attractive gain function is designed. This allows the UAVs to dynamically adjust their movement speed based on the proximity to obstacles and the goal, and it is supported by a controller with fast convergence characteristics, ensuring that the formation reaches the target both accurately and efficiently. Furthermore, to overcome the local minima problem typically caused by semi-enclosed obstacles, the simulated annealing algorithm is refined. The proposed method enables UAVs to escape these traps by applying a continuous deflection force that guides the UAV along an arc-like path. Comprehensive simulation experiments—including an oscillation test, formation reconfiguration, obstacle avoidance in cluttered environments, and escape from semi-enclosed obstacles—demonstrated the efficacy and robustness of the DSA-AAPF algorithm.
Three promising directions are identified for future research.
(1) Extension to 3D dynamic environments
The current study focuses solely on two-dimensional environments with static circular obstacles. A natural progression would involve extending the algorithm to operate in three-dimensional spaces, accounting for dynamic and irregularly shaped obstacles to enhance the real-world applicability. This extension requires integrating 3D kinematic models, such as Dubins paths or spline-based trajectories, to handle the UAV pitch and yaw dynamics, while incorporating velocity obstacles or reinforcement learning for dynamic collision avoidance. Additionally, signed distance fields (SDFs) or voxel grids could efficiently represent complex geometries, although the computational overhead remains a key challenge for real-time processing.
(2) Path optimization in semi-enclosed regions
While the improved deflected simulated annealing method effectively enables UAVs to escape from semi-enclosed obstacles, further investigation is warranted to identify the optimal escape trajectories that minimize the energy consumption and execution time. A hybrid optimization approach, combining gradient-based methods like sequential quadratic programming with metaheuristics, could refine the escape paths for efficiency. Additionally, formulating a multi-objective optimization problem that balances the energy expenditure (e.g., drag-induced losses) against the time delays would enhance the practicality, while topological tools such as homology analysis could help identify structurally optimal escape routes in cluttered environments.
(3) Real UAV swarm limitations
In this paper, Equation (1) simplifies the dynamic model of the UAV. It is necessary to further extend the algorithm to the three-dimensional space to use the six-degree-of-freedom dynamic model of the UAV, accounting for realistic aerodynamics and control surfaces. Furthermore, in real UAV swarms, the communication delays, packet losses, and limited energy budgets critically impact the formation control and collision avoidance. Future work should embed robust communication protocols, such as delay-tolerant networking (DTN) or consensus algorithms under intermittent connectivity, while integrating energy-aware path planning to extend the operational endurance under battery constraints. These considerations are essential for deploying the algorithm in real-world scenarios where imperfect communication and finite energy resources dominate the system performance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}