
Deep Learning-Based Acoustic Recognition of UAVs in Complex Environments

 ,
,
Abstract
1. Introduction
- A UAV acoustic feature database is constructed using the feature extraction method;
- An improved lightweight ResNet10_CBAM model is proposed;
- Acoustic recognition of UAVs in complex (low signal-to-noise ratio and environments with varying levels of noise interference) environments is performed.
2. Proposed Method
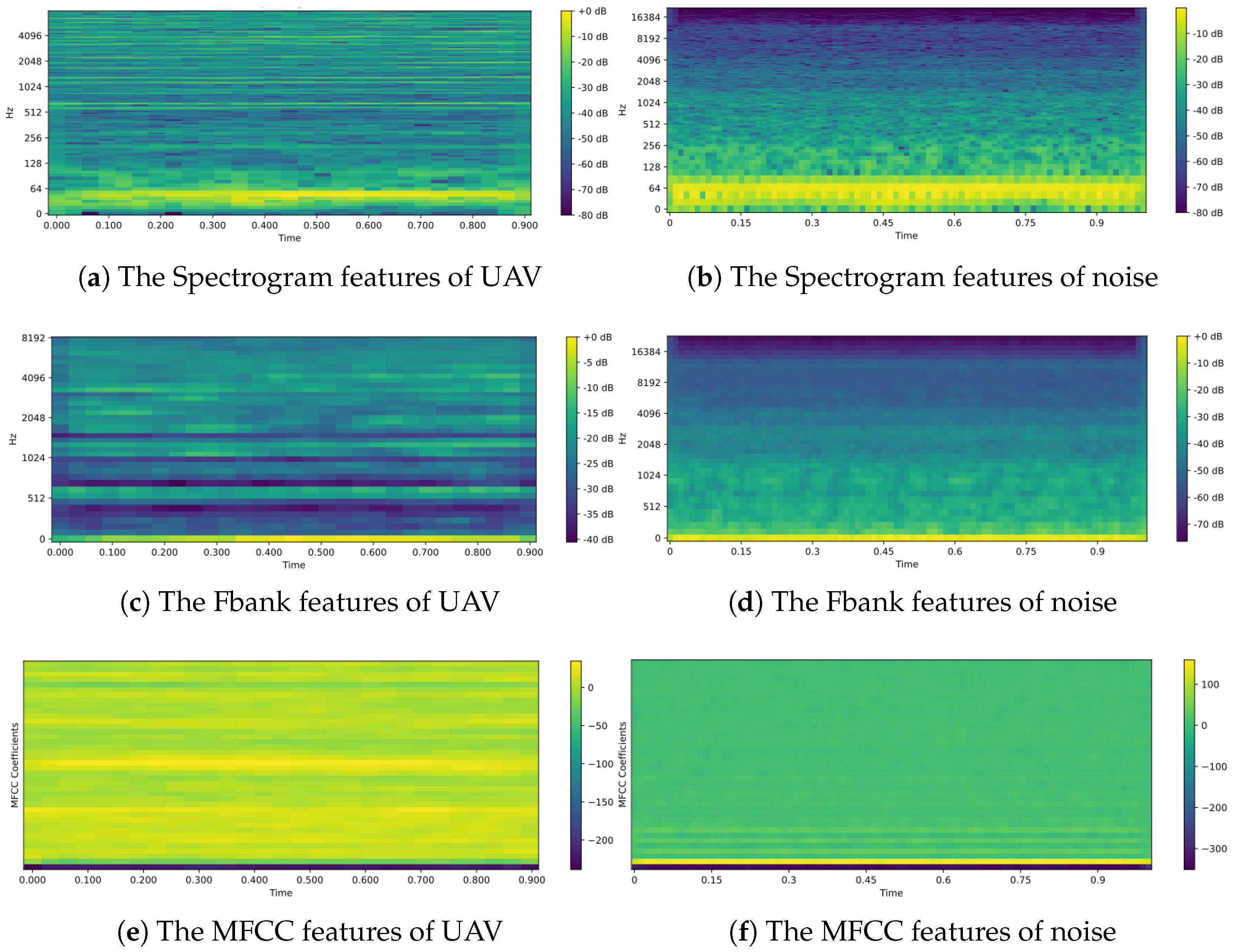
2.1. Features Extraction
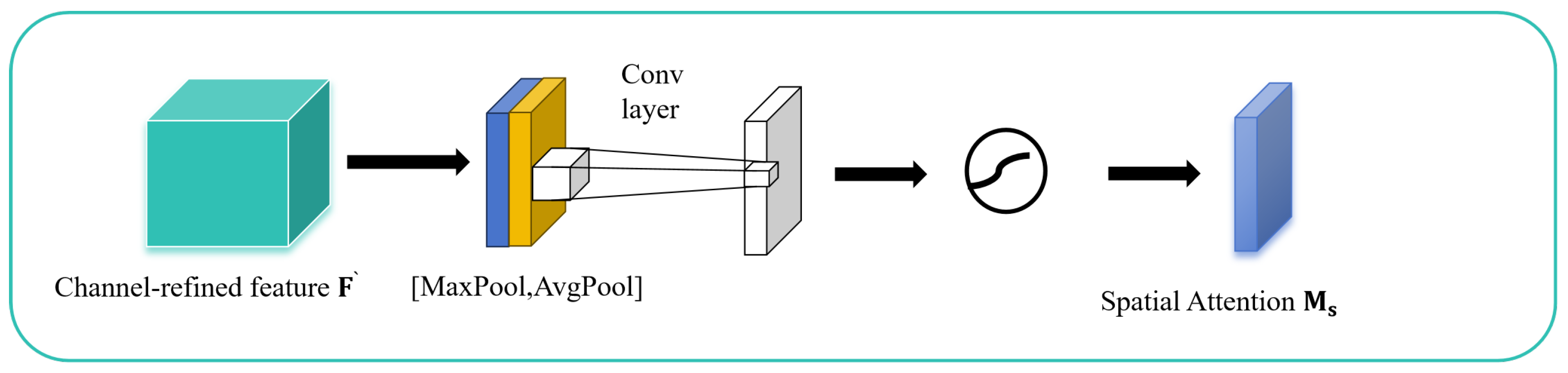
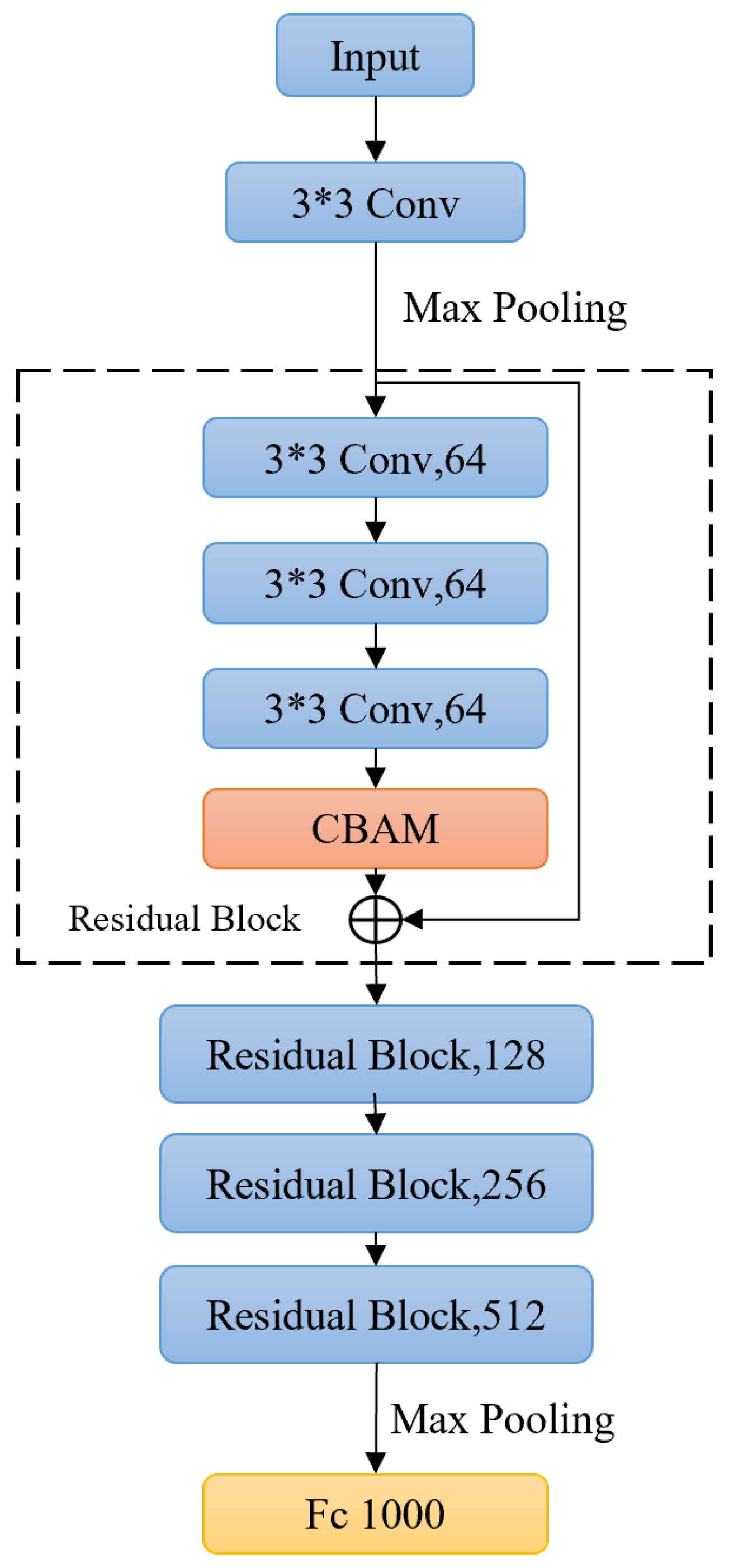
2.2. Deep Model Architecture
2.2.1. Models and Methods
2.2.2. Model Optimization
3. Experimental Setting and Results
3.1. Datasets
3.2. Experimental Details
3.3. Evaluation Index
3.4. The Experimental Result
3.4.1. The Experiment Result of Features Extraction
3.4.2. Experiment Results of Model Comparison
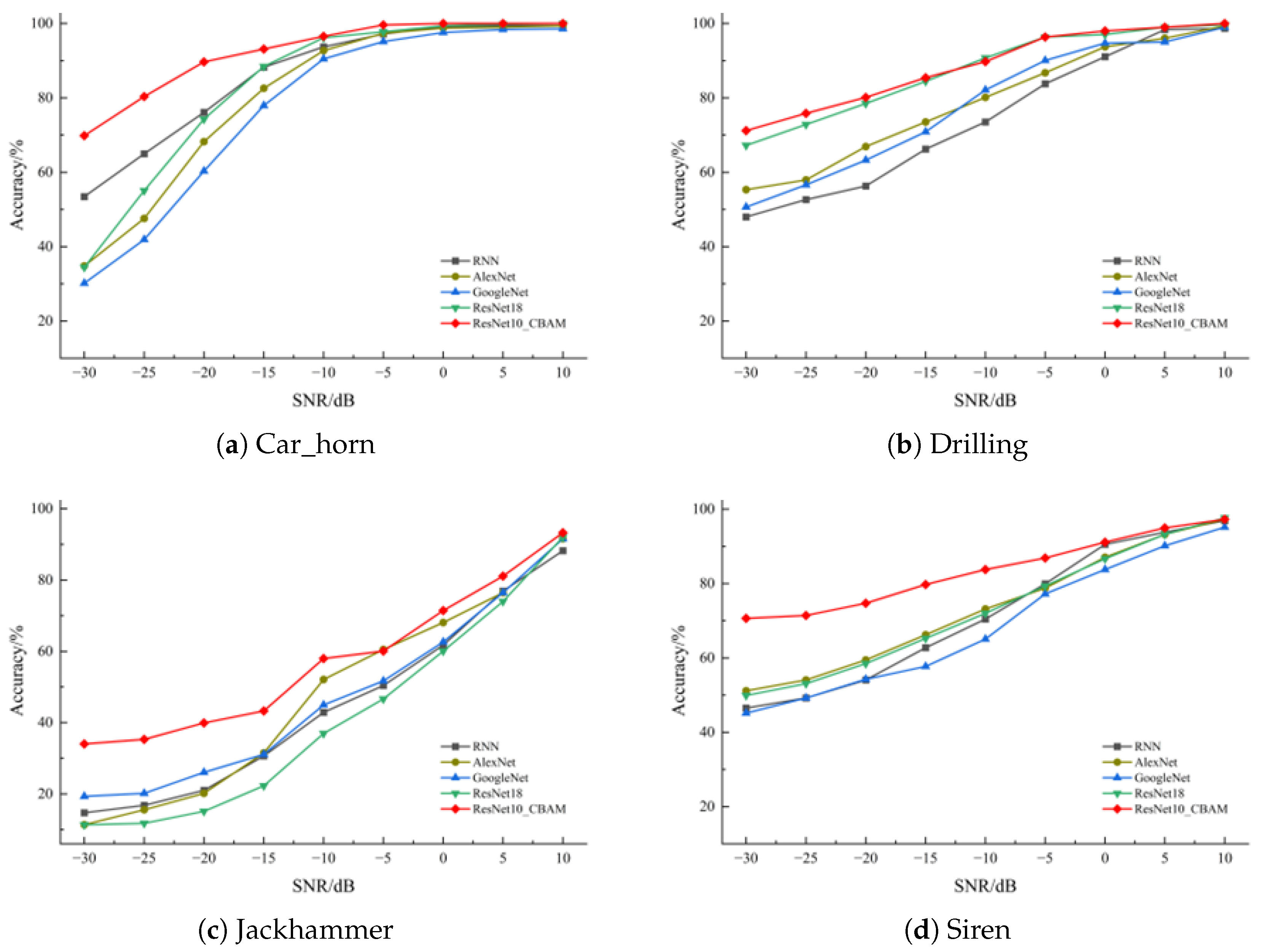
3.4.3. Experiment Results of Model Comparison in Different Environments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rejeb, A.; Abdollahi, A.; Rejeb, K.; Treiblmaier, H. Drones in Agriculture: A Review and Bibliometric Analysis. Comput. Electron. Agric. 2022, 198, 107017. [Google Scholar] [CrossRef]
- Misara, R.; Verma, D.; Mishra, N.; Rai, S.K.; Mishra, S. Twenty-Two Years of Precision Agriculture: A Bibliometric Review. Precis. Agric. 2022, 23, 2135–2158. [Google Scholar] [CrossRef]
- WZhang, Y.; Onda, Y.; Kato, H.; Feng, B.; Gomi, T. Understory Biomass Measurement in a Dense Plantation Forest Based on Drone-SfM Data by a Manual Low-Flying Drone under the Canopy. J. Environ. Manag. 2022, 312, 114862. [Google Scholar] [CrossRef]
- McKinney, M.; Wavrek, M.; Carr, E.; Jean-Philippe, S. Drone Remote Sensing in Urban Forest Management: A Case Study. SSRN Electron. J. 2022, 86, 127978. [Google Scholar] [CrossRef]
- Nooralishahi, P.; Ibarra-Castanedo, C.; Deane, S.; López, F.; Pant, S.; Genest, M.; Avdelidis, N.P.; Maldague, X.P.V. Drone-Based Non-Destructive Inspection of Industrial Sites: A Review and Case Studies. Drone 2021, 5, 106. [Google Scholar] [CrossRef]
- Hong, F.; Wu, G.; Luo, Q.; Huan, L.; Fang, X. Witold Pedrycz Logistics in the Sky: A Two-Phase Optimization Approach for the Drone Package Pickup and Delivery System. IEEE Trans. Intell. Transp. Syst. 2023, 24, 9175–9190. [Google Scholar] [CrossRef]
- Karaca, Y.; Cicek, M.; Tatli, O.; Sahin, A.; Pasli, S.; Beser, M.F.; Turedi, S. The Potential Use of Unmanned Aircraft Systems (Drones) in Mountain Search and Rescue Operations. Am. J. Emerg. Med. 2018, 36, 583–588. [Google Scholar] [CrossRef]
- Samadzadegan, F.; Dadrass Javan, F.; Ashtari Mahini, F.; Gholamshahi, M. Detection and Recognition of Drones Based on a Deep Convolutional Neural Network Using Visible Imagery. Aerospace 2022, 9, 31. [Google Scholar] [CrossRef]
- Liu, H.; Fan, K.; Ouyang, Q.; Li, N. Real-Time Small Drones Detection Based on Pruned YOLOv4. Sensors 2021, 21, 3374. [Google Scholar] [CrossRef] [PubMed]
- Martins Ezuma; Chethan Kumar Anjinappa; Vasilii Semkin; Ismail Guvenc Comparative Analysis of Radar-Cross-Section- Based UAV Recognition Techniques. IEEE Sens. J. 2022, 22, 17932–17949. [CrossRef]
- Kumar, P.; Idsøe, H.; Yakkati, R.R.; Kumar, A.; Zafar, M.; Yalavarthy, P.K. Linga Reddy Cenkeramaddi Localization and Activity Classification of Unmanned Aerial Vehicle Using MmWave FMCW Radars. IEEE Sens. J. 2021, 21, 16043–16053. [Google Scholar] [CrossRef]
- Xue, C.; Li, T.; Li, Y.; Ruan, Y.; Zhang, R.; Dobre, O.A. Radio-Frequency Identification for Drones with Nonstandard Waveforms Using Deep Learning. IEEE Trans. Instrum. Meas. 2023, 72, 5503713. [Google Scholar] [CrossRef]
- Mohammed, K.K.; El-Latif, E.I.A.; El-Sayad, N.E.; Darwish, A.; Hassanien, A.E. Radio Frequency Fingerprint-Based Drone Identification and Classification Using Mel Spectrograms and Pre-Trained YAMNet Neural. Internet Things 2023, 23, 100879. [Google Scholar] [CrossRef]
- Kümmritz, S. The Sound of Surveillance: Enhancing Machine Learning-Driven Drone Detection with Advanced Acoustic Augmentation. Drones 2024, 8, 105. [Google Scholar] [CrossRef]
- Aydın, İ.; Kızılay, E. Development of a New Light-Weight Convolutional Neural Network for Acoustic-Based Amateur Drone Detection. Appl. Acoust. 2022, 193, 108773. [Google Scholar] [CrossRef]
- Ding, R.; Yang, L.; Shan, Z.; Wang, Y.; Ren, H.; Liu, L.; Yu, L.; Liu, B. Drone Detection and Recognition Based on Fiber-Optic EFPI Acoustic Sensor and CNN-LSTM Network Model. IEEE Sens. J. 2024, 24, 28835–28843. [Google Scholar] [CrossRef]
- Wang, W.; Fan, K.; Ouyang, Q.; Yuan, Y. Acoustic UAV Detection Method Based on Blind Source Separation Framework. Appl. Acoust. 2022, 200, 109057. [Google Scholar] [CrossRef]
- Al-Emadi, S.; Al-Ali, A.; Al-Ali, A. Audio-Based Drone Detection and Identification Using Deep Learning Techniques with Dataset Enhancement through Generative Adversarial Networks. Sensors 2021, 21, 4953. [Google Scholar] [CrossRef]
- Wang, M.Y.; Chu, Z.; Ku, I.; Smith, E.C.; Matson, E.T. A 15-Category Audio Dataset for Drones and an Audio-Based UAV Classification Using Machine Learning. Int. J. Semant. Comput. 2023, 18, 257–272. [Google Scholar] [CrossRef]
- Diao, Y.; Zhang, Y.; Zhao, G.; Khamis, M. Drone Authentication via Acoustic Fingerprint; The University of Glasgow: Enlighten, UK, 2022; pp. 658–668. [Google Scholar] [CrossRef]
- Akbal, E.; Akbal, A.; Dogan, S.; Tuncer, T. An Automated Accurate Sound-Based Amateur Drone Detection Method Based on Skinny Pattern. Digit. Signal Process. 2023, 136, 104012. [Google Scholar] [CrossRef]
- Encinas, F.G.; Silva, L.A.; Mendes, A.S.; Gonzalez, G.V.; Reis, V.; Francisco, J. Singular Spectrum Analysis for Source Separation in Drone-Based Audio Recording. IEEE Access 2021, 9, 43444–43457. [Google Scholar] [CrossRef]
- Fang, J.; Li, Y.; Ji, P.N.; Wang, T. Drone Detection and Localization Using Enhanced Fiber-Optic Acoustic Sensor and Distributed Acoustic Sensing Technology. J. Light. Technol. 2022, 41, 822–831. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, Y.; Wang, L.; Li, J.; Wang, J.; Zhang, A.; Wang, S. Improved Method for Drone Sound Event Detection System Aiming at the Impact of Background Noise and Angle Deviation. Sens. Actuators A Phys. 2024, 377, 115676. [Google Scholar] [CrossRef]
- Ibrahim, O.A.; Sciancalepore, S.; Di Pietro, R. Noise2Weight: On Detecting Payload Weight from Drones Acoustic Emissions. Future Gener. Comput. Syst. 2022, 137, 319–333. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Schafer, R.W. Introduction to Digital Speech Processing. Found. Trends® Signal Process. 2007, 1, 1–194. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015, Boston, MA, USA, 7–12 June 2015; Volume 7, pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Al-Emadi, S. Saraalemadi/DroneAudioDataset. Available online: https://github.com/saraalemadi/DroneAudioDataset (accessed on 23 March 2025).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Origin/s | Enhance/s | Total/s |
|---|---|---|---|
| DJI Air 2S | 785 | ||
| DJI Mavic Air | 785 | 10,460 | |
| DJI Spark | 1045 | 14,407 | |
| Bebop | 666 | - | |
| Membo | 666 | - |
| SNR | Car_horn/s | Drilling/s | Jackhammer/s | Siren |
|---|---|---|---|---|
| −30–10 | 494 | 302 | 238 | 518 |
| Model | Accuracy/% | Precision/% | Recall/% | F1/% | Total Params |
|---|---|---|---|---|---|
| RNN | 92.65 | 90.37 | 90.05 | 90.21 | 258,179 |
| AlexNet | 90.34 | 90.60 | 89.63 | 90.11 | 3,988,164 |
| GoogleNet | 92.21 | 91.85 | 91.92 | 91.89 | 5,919,650 |
| ResNet18 | 93.32 | 92.94 | 93.34 | 93.14 | 11,350,514 |
| ResNet10_CBAM | 94.45 | 94.09 | 94.52 | 94.30 | 4,964,366 |
| SNR | RNN/% | AlexNet/% | GoogleNet/% | ResNet18/% | ResNet10_CBAM/% |
|---|---|---|---|---|---|
| 10 | 95.80 | 96.90 | 96.09 | 97.34 | 97.64 |
| 5 | 92.11 | 91.18 | 90.01 | 91.51 | 93.77 |
| 0 | 85.64 | 86.91 | 84.66 | 85.79 | 90.14 |
| −5 | 77.82 | 80.84 | 78.52 | 80.02 | 85.72 |
| −10 | 70.13 | 74.52 | 70.65 | 73.96 | 82.01 |
| −15 | 61.97 | 63.45 | 59.40 | 65.10 | 75.39 |
| −20 | 51.86 | 53.68 | 50.96 | 56.59 | 71.11 |
| −25 | 45.91 | 43.78 | 41.98 | 48.19 | 65.72 |
| −30 | 40.67 | 38.16 | 36.33 | 40.72 | 61.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Fan, K.; Chen, Y.; Xiong, L.; Ye, J.; Fan, A.; Zhang, H. Deep Learning-Based Acoustic Recognition of UAVs in Complex Environments. Drones 2025, 9, 389. https://doi.org/10.3390/drones9060389
Liu Z, Fan K, Chen Y, Xiong L, Ye J, Fan A, Zhang H. Deep Learning-Based Acoustic Recognition of UAVs in Complex Environments. Drones. 2025; 9(6):389. https://doi.org/10.3390/drones9060389
Chicago/Turabian StyleLiu, Zhongru, Kuangang Fan, Yuhang Chen, Lizhi Xiong, Jingzhen Ye, Aigen Fan, and Hengheng Zhang. 2025. "Deep Learning-Based Acoustic Recognition of UAVs in Complex Environments" Drones 9, no. 6: 389. https://doi.org/10.3390/drones9060389
APA StyleLiu, Z., Fan, K., Chen, Y., Xiong, L., Ye, J., Fan, A., & Zhang, H. (2025). Deep Learning-Based Acoustic Recognition of UAVs in Complex Environments. Drones, 9(6), 389. https://doi.org/10.3390/drones9060389