
WRRT-DETR: Weather-Robust RT-DETR for Drone-View Object Detection in Adverse Weather


Abstract
1. Introduction
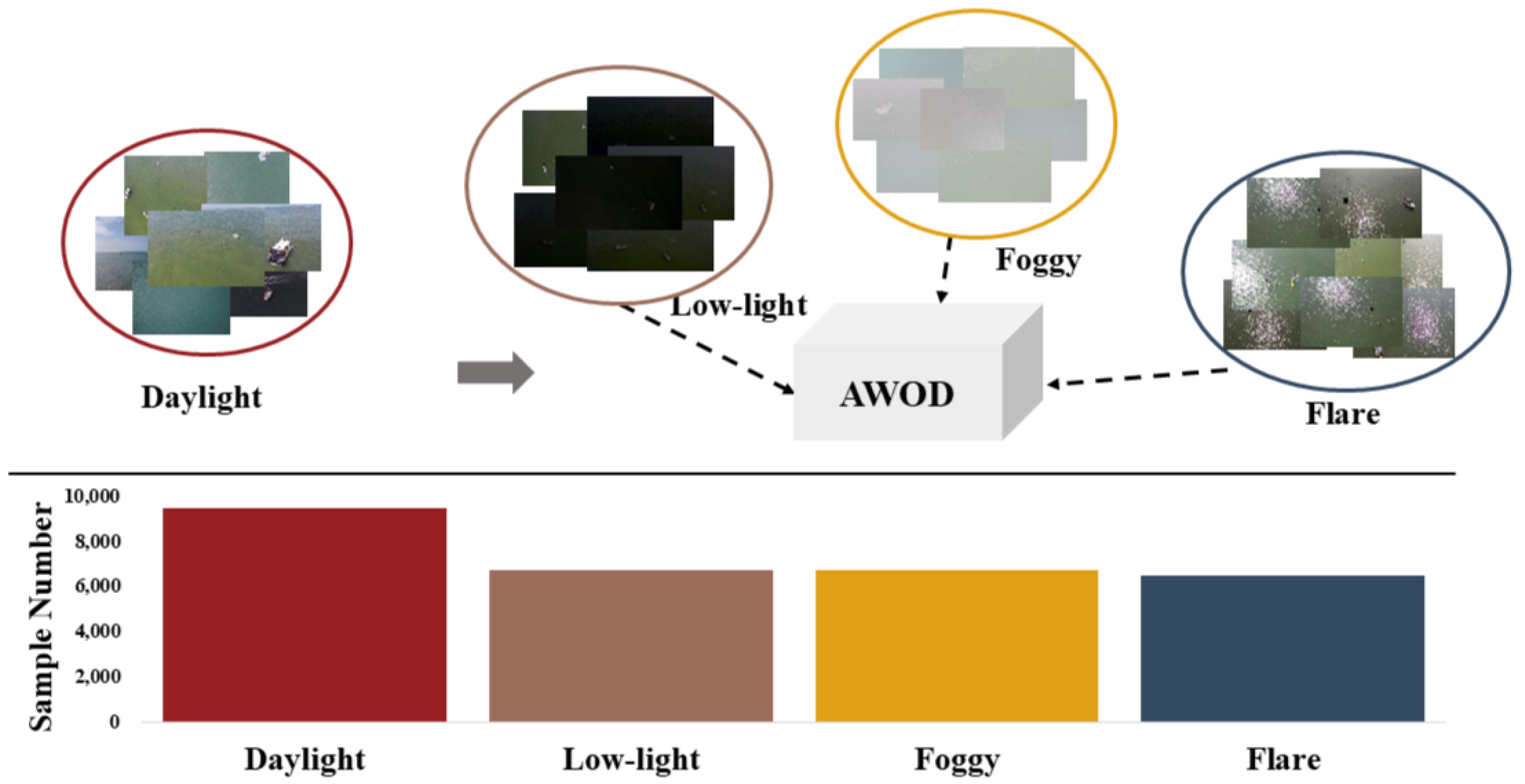
- Construction of the AWOD: The AWOD dataset is a large-scale dataset constructed from a UAV perspective aimed at solving object detection difficulties in adverse weather.
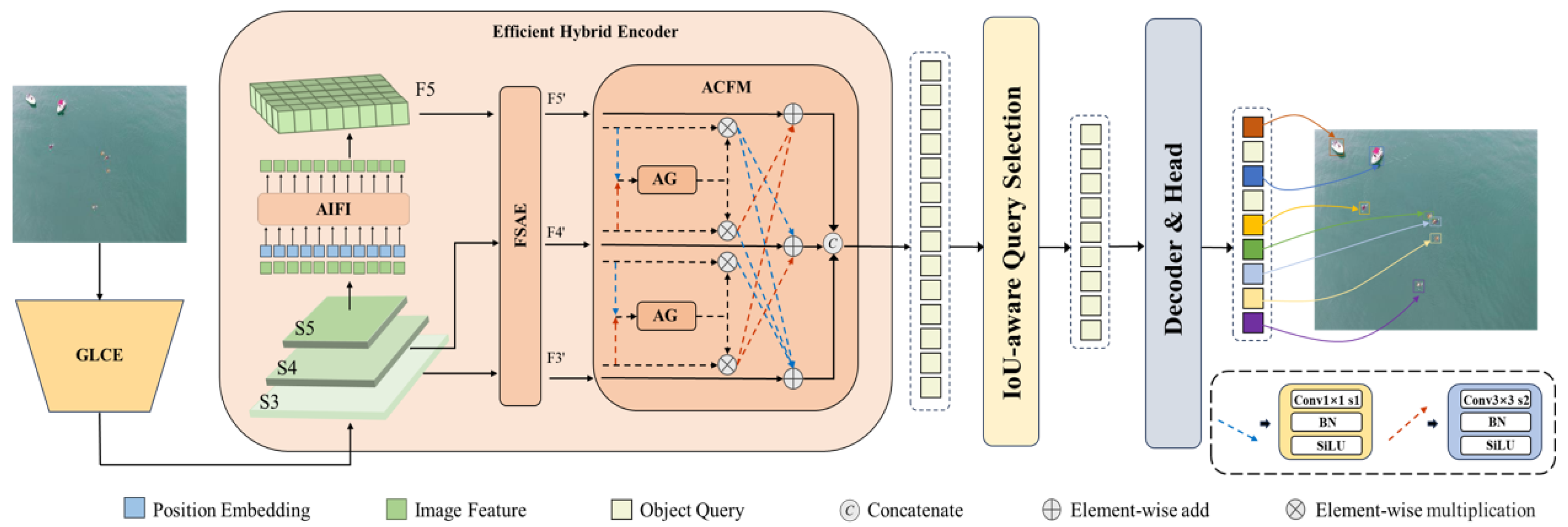
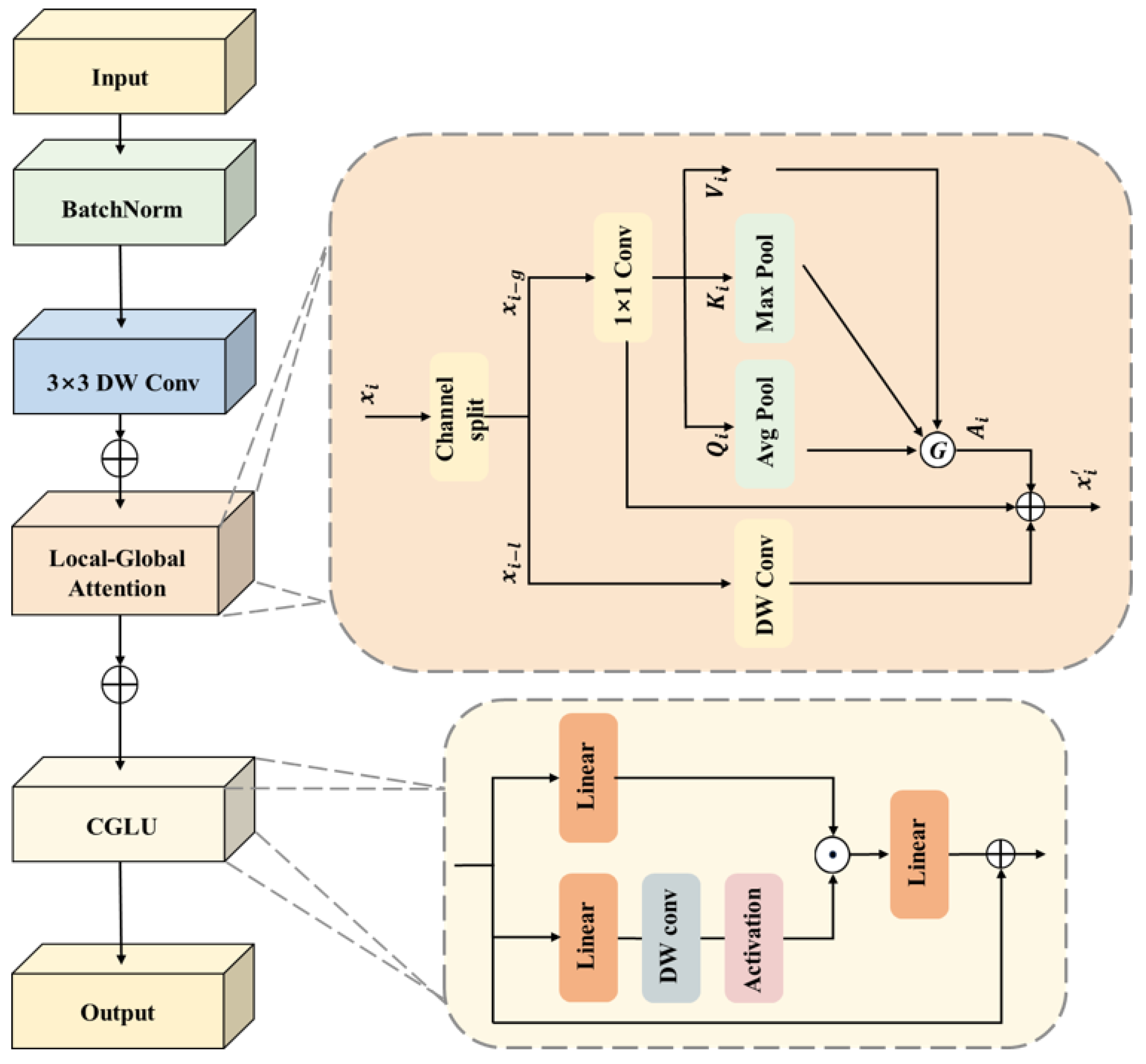
- The Gated global–local attention backbone network: The GCLE block integrates depthwise convolution, pooled transposed attention, and gated attention to efficiently fuse global and local information, enhancing object perception while reducing computational complexity and improving model robustness and detection accuracy in complex environments.
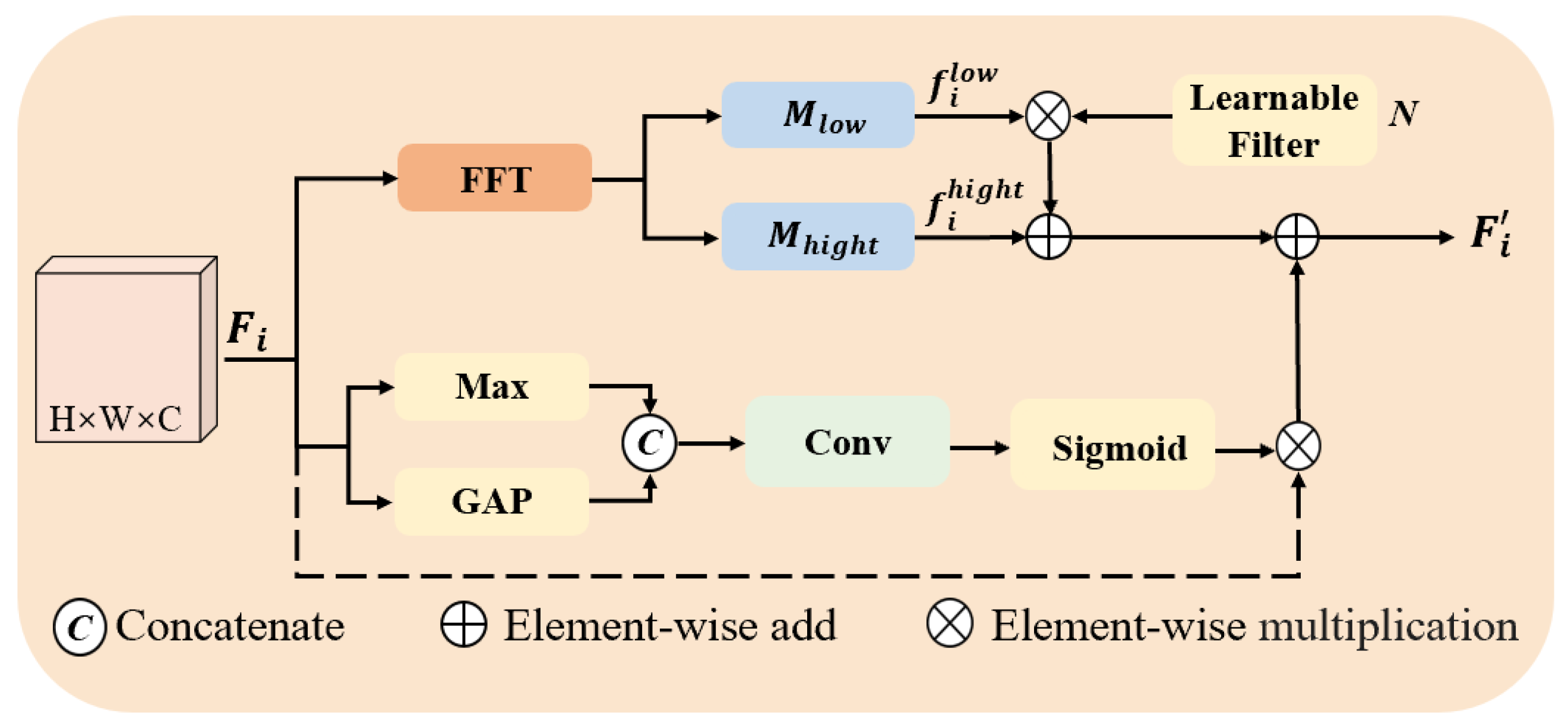
- Spatial–Frequency Augmented Enhancement (FSAE) module: By integrating frequency and spatial domain information, global frequency features compensate for the missing local spatial information, thereby strengthening the model’s capacity to detect occluded and low-contrast objects in complex environments.
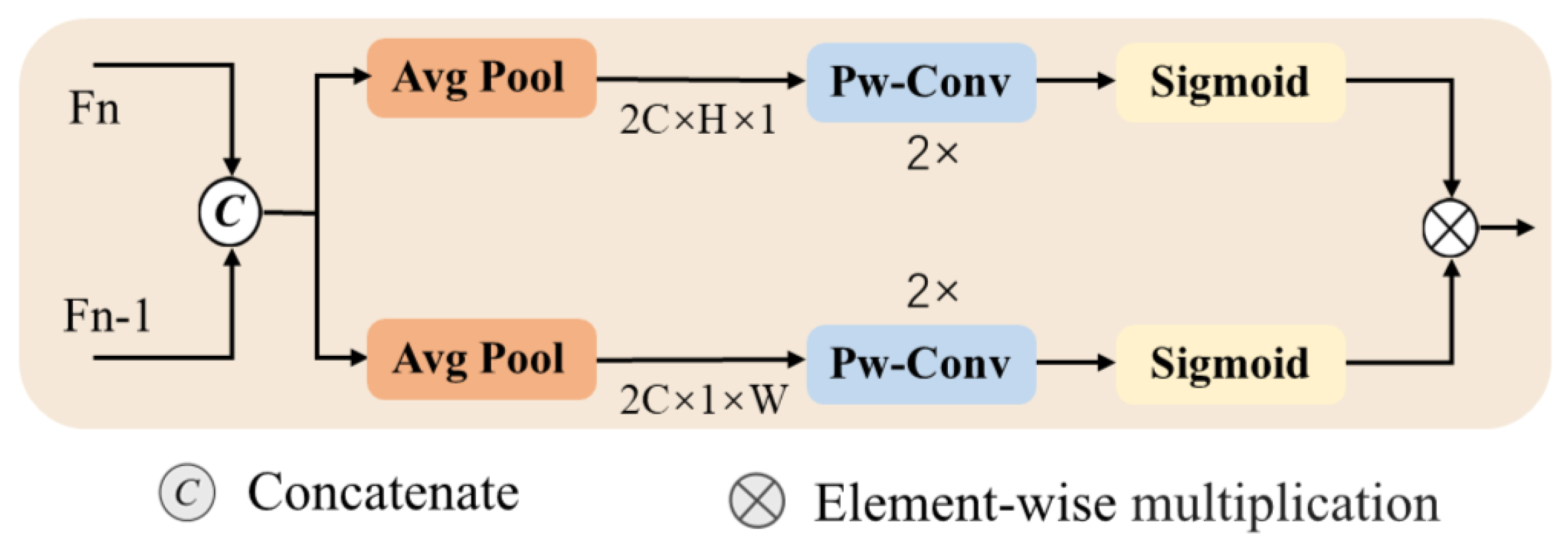
- Attention-Guided Cross-Fusion Module (ACFM): This is designed to aggregate features from different stages while assigning importance weights to them. This module effectively filters out redundant information and background interference, enhancing the model’s ability to represent object features in complex environments.
2. Related Work
2.1. Drone-View Datasets
2.2. Adverse Weather Object Detection
2.3. Drone-View Object Detection
3. AWOD Dataset
3.1. Dataset Introduction
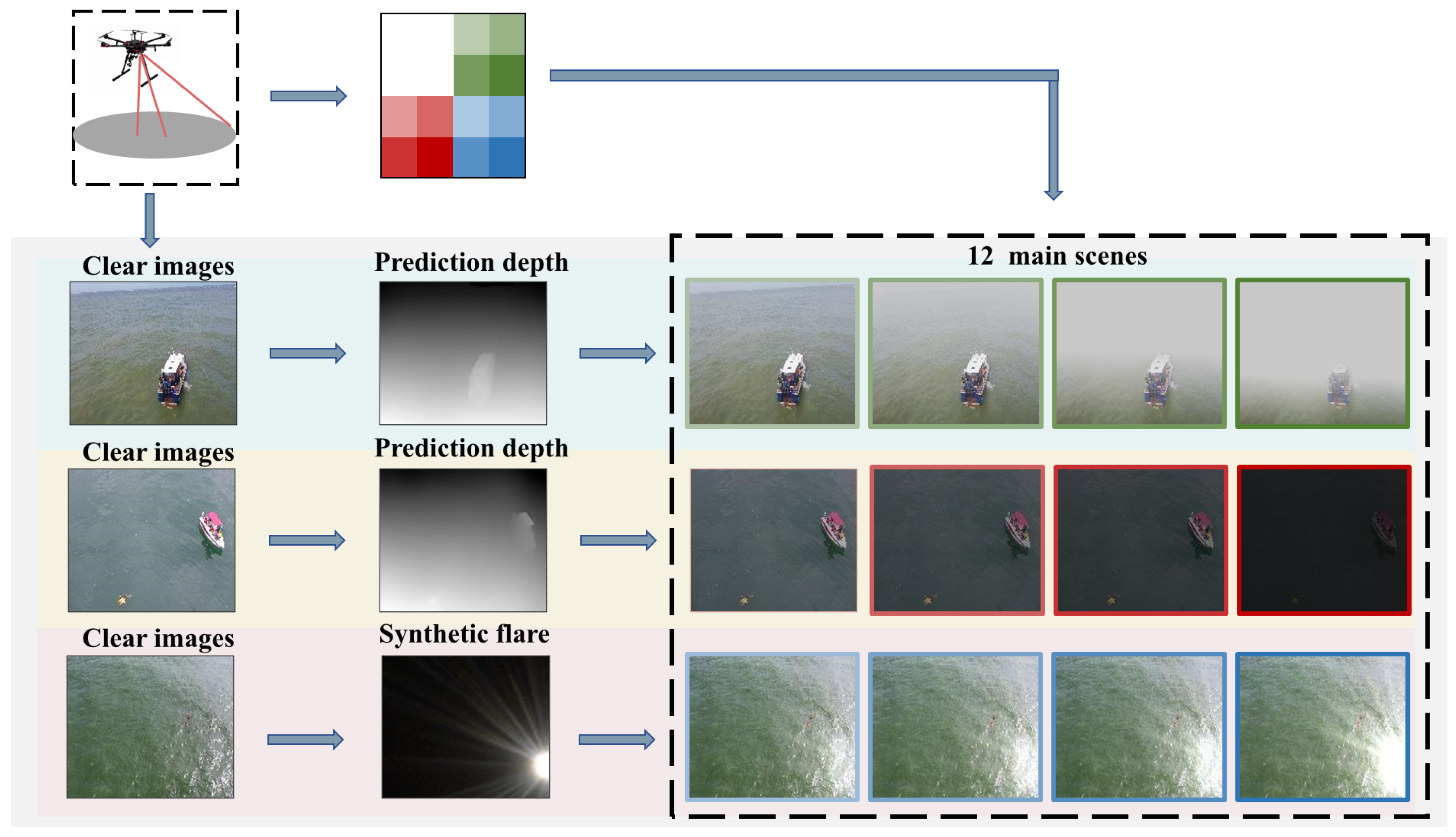
3.2. Synthetic Weather Degradation
3.3. Weather Degradation Ratio
4. Materials and Methods
4.1. The Gated Global–Local Attention Backbone Network
4.2. Frequency–Spatial Augmented Enhancement
4.3. Attention-Guided Cross-Fusion
5. Experiments and Discussion
5.1. Evaluation Metrics
5.2. Implementation Details
5.3. Performance of Detectors on AWOD
5.4. Ablation Experiments
5.5. Comparative Experiments
5.6. Robustness Analysis
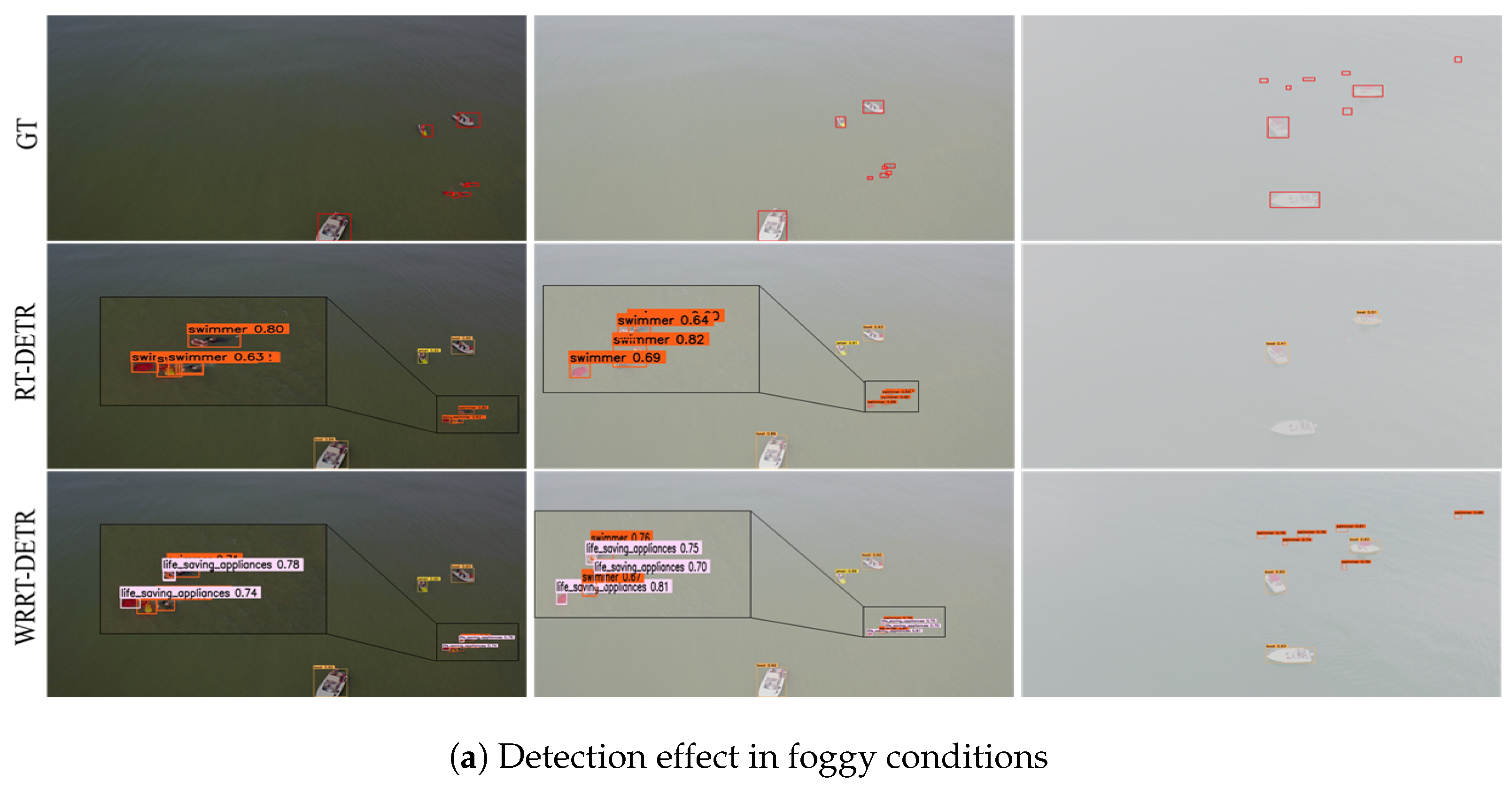
5.7. Visualization Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Wu, C.; Guo, W.; Zhang, T.; Li, W. CFANet: Efficient detection of UAV image based on cross-layer feature aggregation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608911. [Google Scholar] [CrossRef]
- Wang, K.; Fu, X.; Ge, C.; Cao, C.; Zha, Z.J. Towards generalized UAV object detection: A novel perspective from frequency domain disentanglement. Int. J. Comput. Vis. 2024, 132, 5410–5438. [Google Scholar] [CrossRef]
- Wang, K.; Fu, X.; Huang, Y.; Cao, C.; Shi, G.; Zha, Z.J. Generalized uav object detection via frequency domain disentanglement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1064–1073. [Google Scholar]
- Varga, L.A.; Kiefer, B.; Messmer, M.; Zell, A. Seadronessee: A maritime benchmark for detecting humans in open water. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2260–2270. [Google Scholar]
- Cafarelli, D.; Ciampi, L.; Vadicamo, L.; Gennaro, C.; Berton, A.; Paterni, M.; Benvenuti, C.; Passera, M.; Falchi, F. MOBDrone: A drone video dataset for man overboard rescue. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 633–644. [Google Scholar]
- Liu, D.; Zhang, J.; Qi, Y.; Wu, Y.; Zhang, Y. Tiny object detection in remote sensing images based on object reconstruction and multiple receptive field adaptive feature enhancement. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5616213. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. Unimix: Towards domain adaptive and generalizable lidar semantic segmentation in adverse weather. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 14781–14791. [Google Scholar]
- Testolina, P.; Barbato, F.; Michieli, U.; Giordani, M.; Zanuttigh, P.; Zorzi, M. Selma: Semantic large-scale multimodal acquisitions in variable weather, daytime and viewpoints. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7012–7024. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- van Lier, M.; van Leeuwen, M.; van Manen, B.; Kampmeijer, L.; Boehrer, N. Evaluation of Spatio-Temporal Small Object Detection in Real-World Adverse Weather Conditions. In Proceedings of the Winter Conference on Applications of Computer Vision, Tucson, AZ, USA, 26 February–6 March 2025; pp. 844–855. [Google Scholar]
- Gupta, H.; Kotlyar, O.; Andreasson, H.; Lilienthal, A.J. Robust object detection in challenging weather conditions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 7523–7532. [Google Scholar]
- Qi, Y.; Wang, D.; Xie, J.; Lu, K.; Wan, Y.; Fu, S. Birdseyeview: Aerial view dataset for object classification and detection. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1257–1265. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Qiu, Z.; Bai, H.; Chen, T. Special vehicle detection from UAV perspective via YOLO-GNS based deep learning network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Bakirci, M. Real-time vehicle detection using YOLOv8-nano for intelligent transportation systems. Trait. Signal 2024, 41, 1727–1740. [Google Scholar] [CrossRef]
- Hnewa, M.; Radha, H. Integrated multiscale domain adaptive YOLO. IEEE Trans. Image Process. 2023, 32, 1857–1867. [Google Scholar] [CrossRef]
- Lin, H.; Li, Y.; Fu, X.; Ding, X.; Huang, Y.; Paisley, J. Rain o’er me: Synthesizing real rain to derain with data distillation. IEEE Trans. Image Process. 2020, 29, 7668–7680. [Google Scholar] [CrossRef]
- Agyemang, S.A.; Shi, H.; Nie, X.; Asabere, N.Y. An integrated multi-scale context-aware network for efficient desnowing. Eng. Appl. Artif. Intell. 2025, 151, 110769. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, T.; Fu, X.; Yang, X.; Guo, X.; Dai, J.; Qiao, Y.; Hu, X. Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21747–21758. [Google Scholar]
- Özdenizci, O.; Legenstein, R. Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10346–10357. [Google Scholar] [CrossRef] [PubMed]
- Liang, D.; Li, L.; Wei, M.; Yang, S.; Zhang, L.; Yang, W.; Du, Y.; Zhou, H. Semantically contrastive learning for low-light image enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 1555–1563. [Google Scholar]
- Guo, X.; Hu, Q. Low-light image enhancement via breaking down the darkness. Int. J. Comput. Vis. 2023, 131, 48–66. [Google Scholar] [CrossRef]
- Qin, Q.; Chang, K.; Huang, M.; Li, G. DENet: Detection-driven enhancement network for object detection under adverse weather conditions. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 2813–2829. [Google Scholar]
- Sun, C.; Zhang, Y.; Ma, S. Dflm-yolo: A lightweight yolo model with multiscale feature fusion capabilities for open water aerial imagery. Drones 2024, 8, 400. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, Y.; Peng, L.; Sun, C.; Ding, L.; Zhu, Y. OWRT-DETR: A Novel Real-Time Transformer Network for Small Object Detection in Open Water Search and Rescue From UAV Aerial Imagery. IEEE Trans. Geosci. Remote. Sens. 2025, 63, 4205313. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tong, K.; Wu, Y. Small object detection using deep feature learning and feature fusion network. Eng. Appl. Artif. Intell. 2024, 132, 107931. [Google Scholar] [CrossRef]
- Zhu, Z.; Zheng, R.; Qi, G.; Li, S.; Li, Y.; Gao, X. Small object detection method based on global multi-level perception and dynamic region aggregation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10011–10022. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, H.; Zhao, Y. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 233–238. [Google Scholar]
- Nautiyal, R.; Deshmukh, M. Tiny Object Detection for Marine Search and Rescue with YOLOv8n-Tiny. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–7. [Google Scholar]
- Li, J.; Xu, R.; Ma, J.; Zou, Q.; Ma, J.; Yu, H. Domain adaptive object detection for autonomous driving under foggy weather. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 612–622. [Google Scholar]
- Marathe, A.; Ramanan, D.; Walambe, R.; Kotecha, K. Wedge: A multi-weather autonomous driving dataset built from generative vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3318–3327. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, Y.; Zhou, Z.; Zhao, J.; Wang, S.; Chen, X. Multiship speed measurement method based on machine vision and drone images. IEEE Trans. Instrum. Meas. 2023, 72, 2513112. [Google Scholar] [CrossRef]
- Li, R.; Cheong, L.F.; Tan, R.T. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1633–1642. [Google Scholar]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12504–12513. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12179–12188. [Google Scholar]
- Guo, T.; Li, S.; Zhou, Y.N.; Lu, W.D.; Yan, Y.; Wu, Y.A. Interspecies-chimera machine vision with polarimetry for real-time navigation and anti-glare pattern recognition. Nat. Commun. 2024, 15, 6731. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Liu, X.; Yang, H.; Wang, Z.; Wen, X.; He, X.; Qing, L.; Chen, H. Degradation Modeling for Restoration-enhanced Object Detection in Adverse Weather Scenes. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2384–2399. [Google Scholar] [CrossRef]
- Xu, C.; Ding, J.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Dynamic Coarse-To-Fine Learning for Oriented Tiny Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7318–7328. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Zhou, M.; Huang, J.; Yan, K.; Hong, D.; Jia, X.; Chanussot, J.; Li, C. A general spatial-frequency learning framework for multimodal image fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2024. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Xu, J.; Fan, X.; Jian, H.; Xu, C.; Bei, W.; Ge, Q.; Zhao, T. Yoloow: A spatial scale adaptive real-time object detection neural network for open water search and rescue from uav aerial imagery. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5623115. [Google Scholar] [CrossRef]
- Shen, H.; Lin, D.; Song, T. Object detection deployed on UAVs for oblique images by fusing IMU information. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6505305. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Instances | Object Size | ||
|---|---|---|---|---|
| Small | Medium | Large | ||
| Swimmer | 83,037 | 82,445 | 376 | 216 |
| Boat | 29,156 | 24,663 | 2495 | 1998 |
| Buoy | 9731 | 9689 | 42 | 0 |
| Jetski | 5219 | 4899 | 253 | 67 |
| Life_saving_appliances | 2068 | 2068 | 0 | 0 |
| Dataset | Object Class | Images | Adverse Weather |
|---|---|---|---|
| BirdsEyeView (2019) [12] | 6 | 5k | - |
| TinyPerson (2019) [13] | 2 | 2k | - |
| SeaDronesSee (2022) [4] | 6 | 10k | - |
| VisDrone (2022) [39] | 10 | 10k | - |
| ShipDataset (2023) [40] | 1 | 18k | - |
| AWOD (ours) | 6 | 20k | fog, low light, flares |
| Type | Version | Type | Value |
|---|---|---|---|
| GPU | RTX 4090 | Optimizer | AdamW |
| Python | 3.8.0 | Batch | 16 |
| Pytorch | 1.10.0 | Learning rate | |
| CUDA | 11.3 | Momentum | 0.9 |
| Epochs | Method | RTTS [15] | BDD-100K [16] | VisDrone2019 [14] | |||
|---|---|---|---|---|---|---|---|
| mAP50 | mAP50:95 | mAP50 | mAP50:95 | mAP50 | mAP50:95 | ||
| 0 | RT-DETR | 64.0 | 36.6 | 60.1 | 32.6 | 45.8 | 27.7 |
| WRRT-DETR | 66.4 | 37.6 | 62.7 | 33.9 | 49.5 | 29.2 | |
| 50 | RT-DETR | 65.6 | 37.1 | 60.8 | 32.9 | 47.9 | 28.4 |
| WRRT-DETR | 67.1 | 38.0 | 63.3 | 34.3 | 52.4 | 31.8 | |
| 100 | RT-DETR | 66.1 | 37.5 | 61.7 | 32.4 | 49.7 | 29.4 |
| WRRT-DETR | 67.5 | 38.3 | 63.8 | 34.7 | 54.8 | 32.4 | |
| GCLE | FSAE | ACFM | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|---|
| 84.9 | 76.8 | 76.9 | 42.3 | |||
| ✓ | 85.4 | 77.1 | 77.5 | 42.9 | ||
| ✓ | 86.4 | 77.8 | 78.4 | 64.3 | ||
| ✓ | 86.3 | 78.3 | 80.1 | 47.5 | ||
| ✓ | ✓ | 87.8 | 77.8 | 79.6 | 47.7 | |
| ✓ | ✓ | ✓ | 89.2 | 80.0 | 82.3 | 48.7 |
| Method | Easy (6500) | Normal (3100) | Difficult (8400) | Particularly (2000) | All (20,000) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP50 | mAP50:95 | mAP50 | mAP50:95 | mAP50 | mAP50:95 | mAP50 | mAP50:95 | mAP50 | mAP50:95 | |
| YOLOv9m [51] | 72.4 | 48.3 | 67.8 | 40.5 | 65.1 | 37.0 | 50.7 | 31.3 | 65.4 | 34.1 |
| YOLOv10m [52] | 72.7 | 49.2 | 67.3 | 40.8 | 65.9 | 37.2 | 51.3 | 32.9 | 65.6 | 35.3 |
| YOLOv11m [53] | 73.1 | 50.6 | 68.4 | 41.4 | 66.6 | 37.5 | 51.8 | 33.8 | 66.9 | 36.1 |
| DINO [54] | 84.8 | 56.5 | 77.9 | 46.2 | 76.6 | 44.5 | 74.4 | 41.6 | 78.9 | 44.7 |
| DAB-DETR [55] | 85.4 | 54.3 | 76.1 | 43.9 | 73.1 | 43.0 | 71.3 | 39.4 | 76.3 | 40.7 |
| DN-DETR [56] | 84.9 | 54.8 | 76.7 | 44.3 | 73.2 | 42.8 | 70.8 | 39.1 | 74.9 | 39.9 |
| RT-DETR [48] | 85.5 | 55.8 | 77.4 | 45.8 | 75.8 | 44.1 | 74.2 | 41.6 | 76.9 | 43.3 |
| RT-DETR-R50 [48] | 86.1 | 56.9 | 78.8 | 46.8 | 76.3 | 44.5 | 74.7 | 41.8 | 77.7 | 45.8 |
| WRRT-DETR (ours) | 86.3 | 56.7 | 80.2 | 47.5 | 78.8 | 45.9 | 76.4 | 43.4 | 82.3 | 46.6 |
| Method | Params (M) | FLOPs (G) | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) | FPS (s) |
|---|---|---|---|---|---|---|---|
| TOOD [57] | 32.0 | 199.0 | 55.3 | 49.4 | 58.7 | 34.6 | 34.9 |
| YOLOv9m [51] | 25.3 | 102.3 | 69.8 | 62.0 | 65.4 | 34.1 | 100.1 |
| YOLOv10m [52] | 24.3 | 120.0 | 73.9 | 63.4 | 65.6 | 35.3 | 132.5 |
| YOLOv11m [53] | 25.1 | 67.7 | 76.2 | 63.5 | 66.9 | 36.1 | 143.7 |
| YOLO-OW [58] | 42.1 | 94.8 | 78.1 | 69.8 | 70.5 | 34.9 | 61.3 |
| UAV-YOLO [59] | 47.4 | 103.3 | 70.9 | 63.1 | 62.7 | 35.7 | 80.9 |
| RT-DETR [48] | 20.0 | 57.3 | 83.2 | 76.1 | 76.9 | 43.3 | 71.5 |
| RT-DETR-R50 [48] | 42.1 | 129.9 | 84.9 | 76.8 | 77.7 | 45.8 | 53.5 |
| WRRT-DETR (ours) | 20.2 | 58.6 | 86.7 | 79.5 | 82.3 | 46.6 | 66.4 |
| Class | RT-DETR | WRRT-DETR | ||||
|---|---|---|---|---|---|---|
| Foggy | Low-Light | Flare | Foggy | Low-Light | Flare | |
| All | 70.4 | 69.6 | 77.3 | 77.0 (+6.6) | 74.5 (+4.9) | 80.5 (+3.2) |
| Swimmer | 72.8 | 54.4 | 73.4 | 78.3 (+5.5) | 58.6 (+4.2) | 77.1 (+3.7) |
| Boat | 95.5 | 92.3 | 96.9 | 96.4 (+0.9) | 94.6 (+2.3) | 97.2 (+0.3) |
| Buoy | 74.8 | 61.4 | 75.9 | 79.0 (+4.2) | 68.4 (+7.0) | 81.8 (+5.9) |
| Jetski | 86.3 | 83.7 | 85.4 | 90.3 (+4.0) | 84.6 (+0.9) | 90.9 (+1.5) |
| Life_saving_appliances | 35.4 | 50.8 | 45.7 | 40.8 (+5.4) | 54.4 (+3.7) | 49.8 (+4.1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Jin, J.; Zhang, Y.; Sun, C. WRRT-DETR: Weather-Robust RT-DETR for Drone-View Object Detection in Adverse Weather. Drones 2025, 9, 369. https://doi.org/10.3390/drones9050369
Liu B, Jin J, Zhang Y, Sun C. WRRT-DETR: Weather-Robust RT-DETR for Drone-View Object Detection in Adverse Weather. Drones. 2025; 9(5):369. https://doi.org/10.3390/drones9050369
Chicago/Turabian StyleLiu, Bei, Jiangliang Jin, Yihong Zhang, and Chen Sun. 2025. "WRRT-DETR: Weather-Robust RT-DETR for Drone-View Object Detection in Adverse Weather" Drones 9, no. 5: 369. https://doi.org/10.3390/drones9050369
APA StyleLiu, B., Jin, J., Zhang, Y., & Sun, C. (2025). WRRT-DETR: Weather-Robust RT-DETR for Drone-View Object Detection in Adverse Weather. Drones, 9(5), 369. https://doi.org/10.3390/drones9050369